Embed Size (px)
Citation preview

Data Science Tech

“Data Science is the extraction of knowledge from data using mathematics, statistics, computer science, machine learning, pattern recognition, predictive analysis, etc.”
- Wikipedia
“Information is not knowledge”- Einstein

- DIKW- Apache Spark- YARN- RDDs- Apache Hive- HDFS- Parquet- Niometrics
- Columnar DB- DBMS- HBase- OLAP- OLTP

DIKW Hierarchy

- signals, symbols, raw facts- first-line products of observation- unorganized
Data
0101 1101 1011 1001 0101 1101 1011 1001 0101 1101 1011 10010110 0001 1010 1111 0101 1101 1011 1001 0101 1101 1011 1001

Information
- inferred from data- answers interrogative questions- data that is now useful through organization
and structuring

Knowledge
- knowledge is subjective- many consider it as applied information- synthesis of multiple information- contextualized consolidated information

Wisdom
- an appreciation of the why- knowing the right things to do- very immaterial


Apache Spark
- fast engine for large-scale data processing- support for Python, Scala, Java- SparkSQL, MLlib, GraphX, Streaming


YARN
- Yet Another Resource Negotiator- resource management for computing
resources in a cluster- can be seen as a distributed operating
system- separates resource management from
Hadoop data processing layer

Apache Hive
- data warehouse infrastructure- provides data querying, analysis, and
aggregation- developed initially by Facebook

Resilient Distributed Databases (RDDs)
- fault-tolerant database management system used for cluster computing
- done by chunking data across multiple nodes and racks for redundancy
- a common feature in cluster computing

HDFS
- Hadoop Distributed File System- Runs with RDDs in managing a fault-tolerant
file system- Java based and spans clusters of
commodity servers


HBase
- Distributed non-relational database- modelled after Google’s BigTable- runs on top of HDFS- fault-tolerance on sparse and large data- supports compression, in-memory filtering
and operations

Parquet
- Columnar file format- stores data in columns instead of rows as in
traditional relational databases- for efficient compression and encoding- more aligned for OLAP

Columnar Database
- Stores tables as sections of columns - advantageous for data warehousing- more efficient for computations over large
numbers of rows with similar column items- more aligned for OLAP

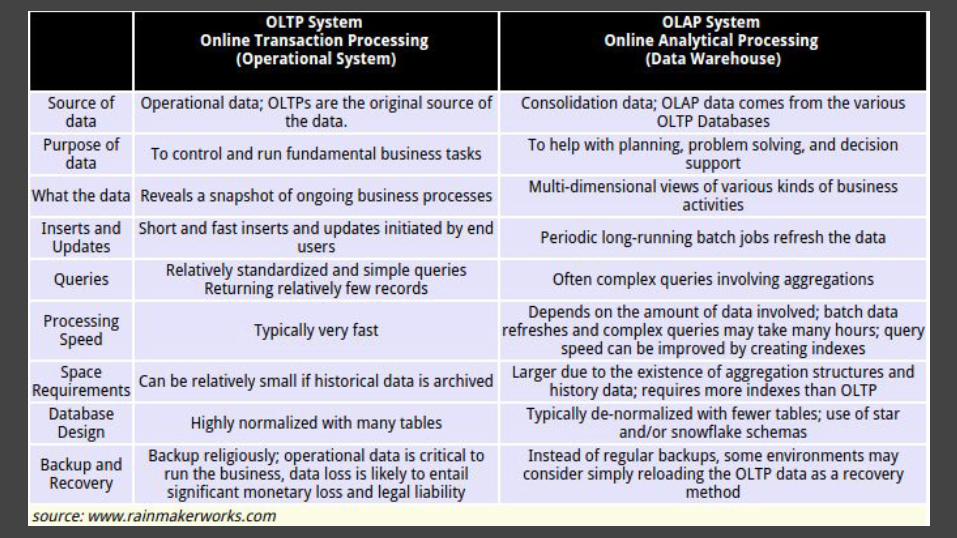
Online Transaction Processing (OLTP)
- Information processes that facilitate transactions
- data entry and retrieval- provide data for data warehousing- emphasis on fast simple single querying,- ACID, and multi-access- involve operational business processes

Online Analytical Processing (OLAP)
- low transactional volume- complex queries with aggregation- OLAP uses data from OLTP systems- queries involve traversing massive quantities
of data- involves business intelligence/data science
activities


Thank You





























