Embed Size (px)
Citation preview

Thomas Pötter, Compris Technologies AG
Data Natives, Nov. 17, 2017

REST Call Versioning (1)1. Versioning through URI parameters or data inside the parameter objects
(recommended): http://host/serviceName?version=1
2. Accept header (recommended): You modify the accept header to specify the version, for example “Accept: application/vnd.serviceName.v2+json” Not perfect because harder to test: I can no longer just give someone a URL and say “Here, click this”, rather they have to carefully construct the request and configure the accept header appropriately.
Others (not recommended):
3. URL: You simply whack the API version into the URL, for example: https://host/serviceName/v2 URLs are not perfect as they should represent the entity; the entity I’m retrieving is an object, not a version of an object. Semantically, it’s not really correct but it’s easy to use!
4. Custom request header: You use the same URL as before but add a header such as “api-version: 2” Not perfect as it’s not really a semantic way of describing the resource: The HTTP spec gives us a means of requesting the nature we’d like the resource represented in by way of the accept header, why reproduce this?
5. Versioning through content negotiation: Versioning a single resource representation instead of versioning the entire API (less usable): curl -H “Accept: application/vnd.xml.service1+json; version=1”
http://host/serviceName

REST Call Versioning (2)1. URI parameter versioning:http://host/serviceName?version=1
2. Accept header:HTTP GET:https://host/serviceName
Accept: application/vnd.serviceName.v2+json
Source code annotation in C#.net:[VersionedRoute("serviceName/{account}", 2)]
[Route("serviceName/{account}")]
public IEnumerable<MyClass> GetV2(string param1)
3. URL versioning:HTTP GET:https://host/serviceName/v2
4. Custom request header:HTTP GET:https://host/serviceName
api-version: 2
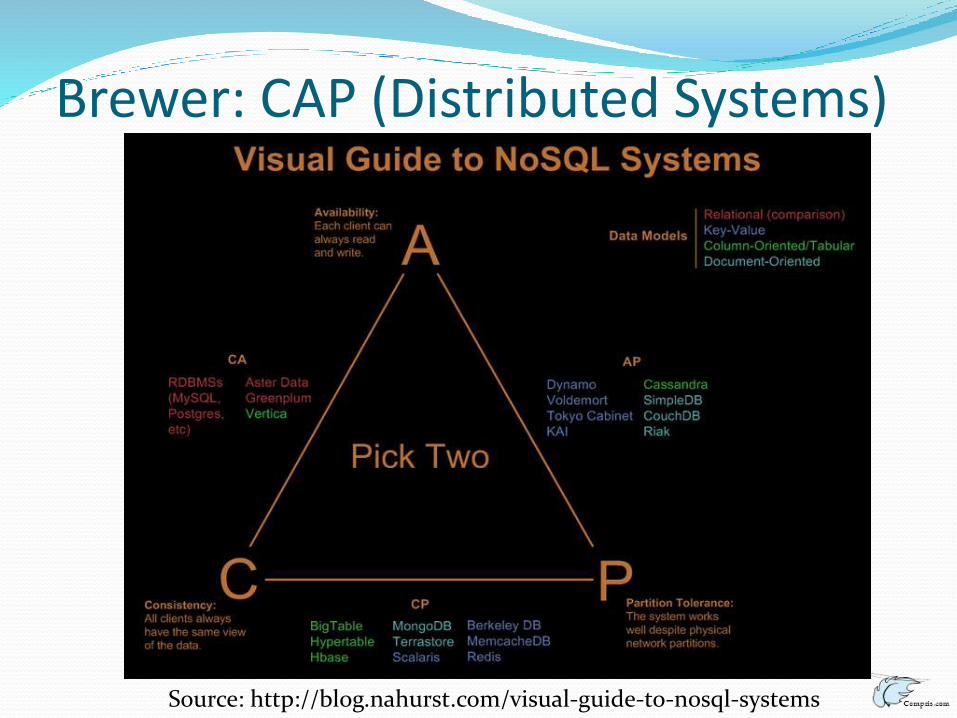
Brewer: CAP (Distributed Systems)
Source: http://blog.nahurst.com/visual-guide-to-nosql-systems
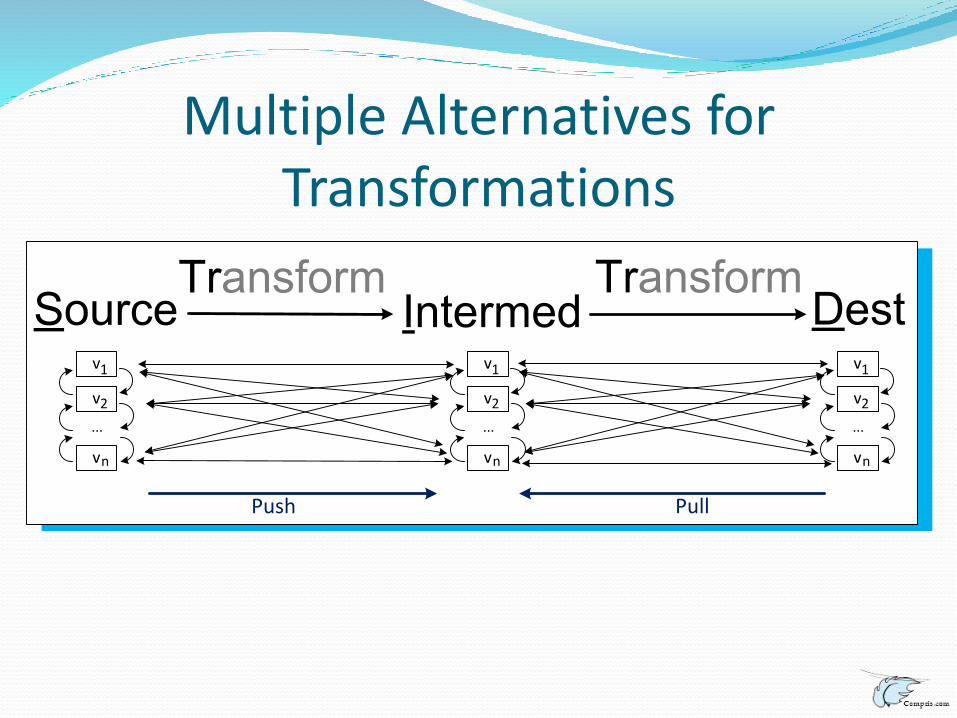
Multiple Alternatives for Transformations
v
v
vn
1
2
...
v
v
vn
1
2
...
v
v
vn
1
2
...
Push Pull

Formalization of Transformations
Source Intermed Dest
DataD
= TrI D
( TrIS(DataS))
n n n
DataSn
DataSn+1
DataSn+2
Source Data Format Evolution from version n to n+2:
DataI
= TrS I ( TrSS
(DataS
))
Transform Transform
Mathematically:
n+2n+2 nnBacktransform withpossible loss ofnew attributes
Multiple Possibilities:
DataI
= TrI I ( TrIS(Data
S))
n+2n+2 n+1n+1 n
n
n
DataI
= TrIS
(DataS
))n+2n+2 n+1n+1
a)
b)
c)
...
Custom transfor-mation to new in-termediate format
n

C(A/P)S Versioning Principle: Sacrifice
With Big Data, storing data redundantly or converting terabytes is an issue.
C(A/P)S Principle: Tradeoff between Code Amount – Availability/Performance –Storage: One needs to be sacrificed:
1. With each new version as storage format, all old data could be eagerly migrated to the latest version (active migration, perhaps partial service availability during migration and perhaps loss of attributes from old versions although they might be required for revision-safety: Low-Availability/Performance cost factor).
2. Migrate only those pieces of the data that are needed (lazily, e.g. on-access migration or when it’s foreseeable); however, then the large ORC/Parquet files cannot be fully migrated and thus not deleted before copying also the rest of the data away or before migrating it (also due to block size; high storage costs, medium programming costs with converter cascade from very old to the latest version: Storage cost factor).
3. Program converters from source into older (replay/late arrivals) and perhaps multiple versions of newer storage formats and out of these formats to potentially multiple versioned destination formats (Code Amount).
How to store/employ the data model versions used and the relevant converters: High programming costs, mitigatable through converter cascades or code generation; complex version and release management: Wages as cost factor.
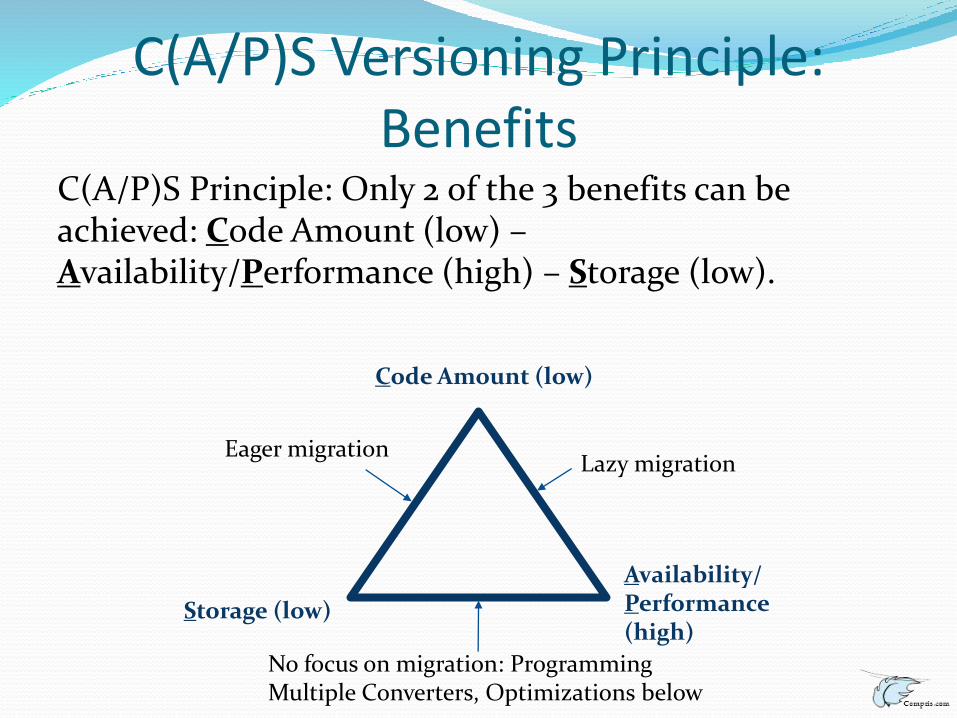
C(A/P)S Versioning Principle: Benefits
C(A/P)S Principle: Only 2 of the 3 benefits can be achieved: Code Amount (low) –Availability/Performance (high) – Storage (low).
Code Amount (low)
Availability/ Performance (high)
Storage (low)
Lazy migrationEager migration
No focus on migration: Programming Multiple Converters, Optimizations below
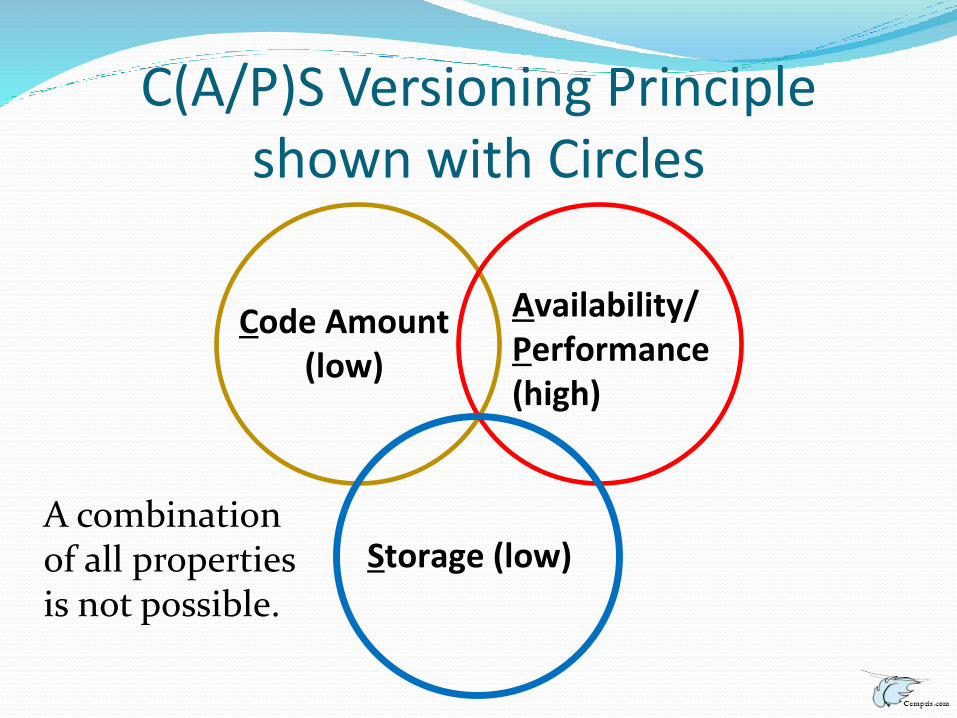
C(A/P)S Versioning Principleshown with Circles
A combination of all properties is not possible.

Avro-Tree Textual alternative to graphical data mapping tools.
https://github.com/jayflo/avro-map can generate a flattened tree data structure out of any Avro structure:
[{type: 'record',name: 'A',fields: [ {name: 'A1', type: 'string'},
{name: 'A2', type: 'int'} ]},
[// 0{path: '', type: 'record', ref:
schema[0], parent: undefined},// 1{path: 'A1', type: 'string', ref:
{type: 'string'}, parent: flattened[0]},
// 2{path: 'A2', type: 'int', ref: {type:
'int'}, parent: flattened[0]}]
This flattened structure can be used for (programmatically) easily detecting and analyzing the differences in Avro models and for code generation.

Questions?
Understood?
Comprendes?
verstanden.de
compris.com


![SGX-SSD: A Policy-based Versioning SSD with Intel SGX · Existing Solution: Versioning SSD[BVSSD, Systor12], [Project Almanac, Eurosys19] §Versioning SSD implements versioning system](https://img.pdfslide.net/doc/110x75/60ae19522c0a8f54c27ad581/sgx-ssd-a-policy-based-versioning-ssd-with-intel-sgx-existing-solution-versioning.jpg)


























