Embed Size (px)
Citation preview

Matching Fashion Products With LSH Image Similarity

Hi, I’m Eddie. @ejbell

We collect the world of fashion into a customisable
shopping experience.
3

What makes us different?
All data is scraped from retailers
500 spiders (scrapy), 9000 designers
Almost everything is automated
SEO, recommendation, classification, sales
This architecture comes with a few problems
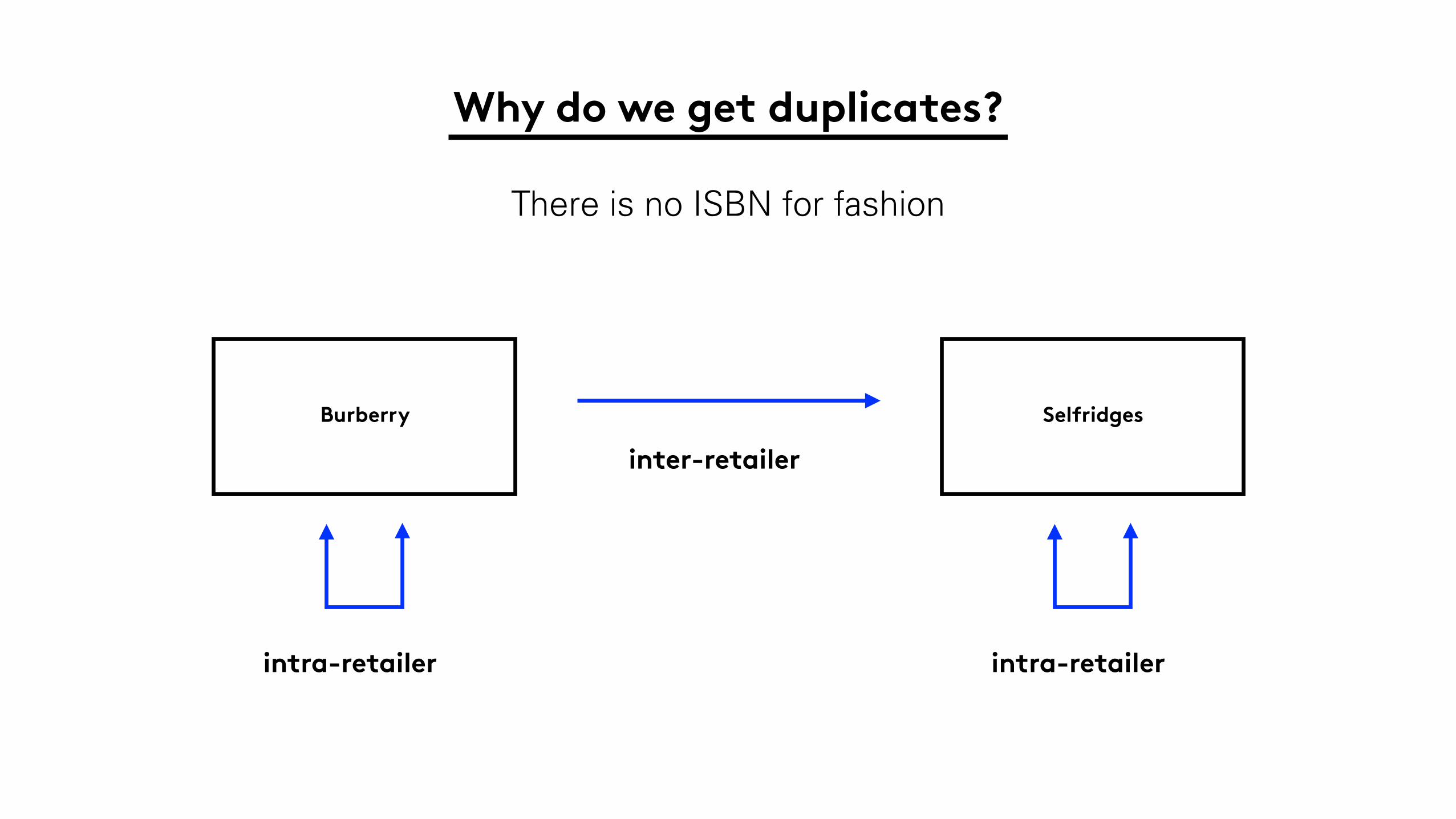
Why do we get duplicates?
There is no ISBN for fashion
Burberry Selfridges
inter-retailer
intra-retailer intra-retailer

How We Used to Find Duplicates
Lucene fuzzy string matching
Doesn’t really work
Yoox.com
3,000 products called “dress”
7,000 products called “shirt”

How We Detect Duplicates Now
BRISK image descriptors
Leutenegger, Chli and Siegwart
BRISK: Binary Robust Invariant Scalable Keypoints.
ICCV 2011: 2548-2555

BRISK octaves
How We Detect Duplicates Now

From Descriptors to Image Similarity
k-means
bag of words
1 x k

Architecture
Started in Storm/Java
Very painful
Ended up in Celery
Much nicer
Matching is done in elastic search.

Results

Results

Results

Results

Speed
We apply some filters but still lots of data
Could be doing 1,000,000+ comparisons per image
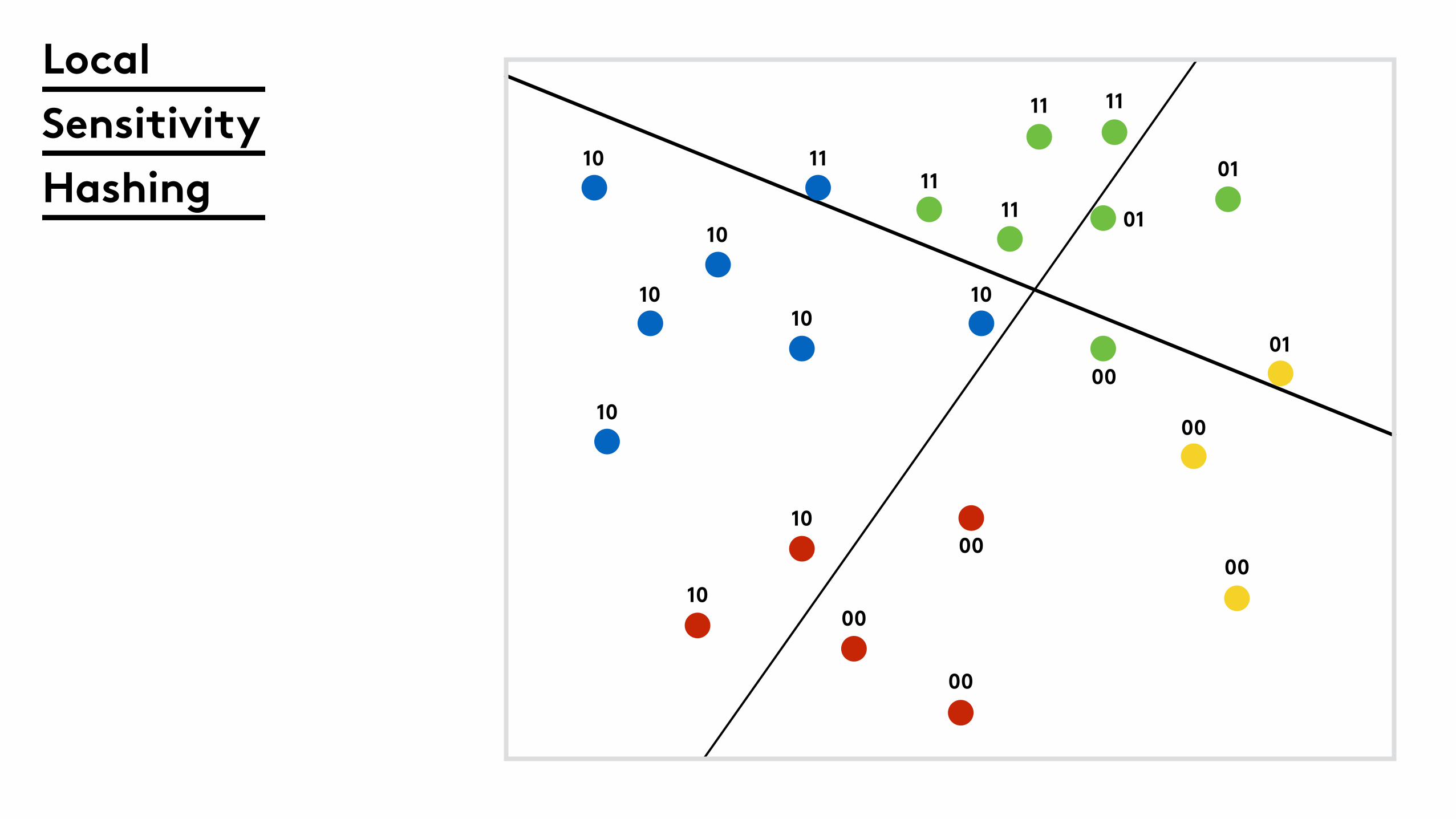
Speed it up with local sensitivity hashing
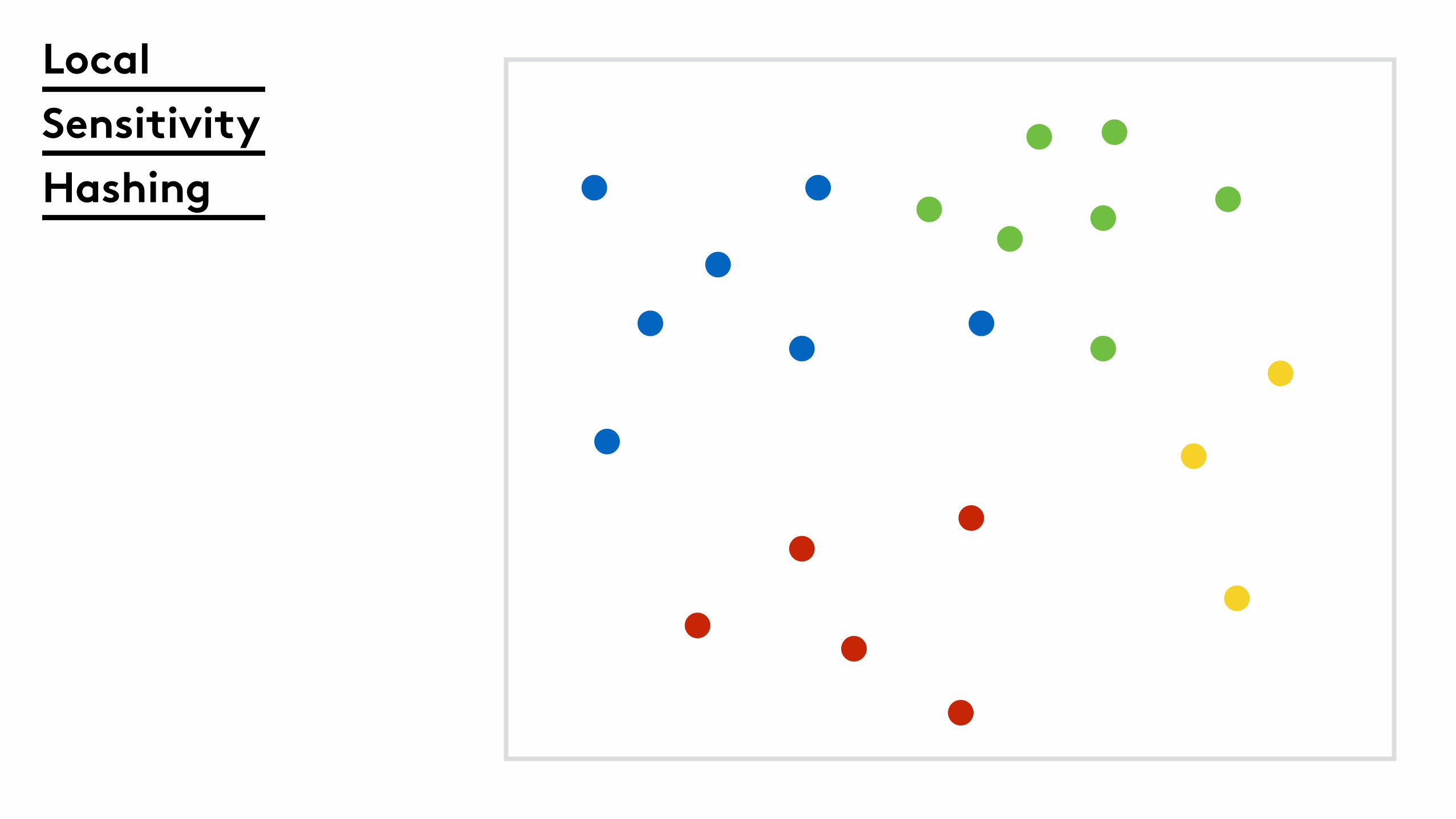
Local
Sensitivity
Hashing
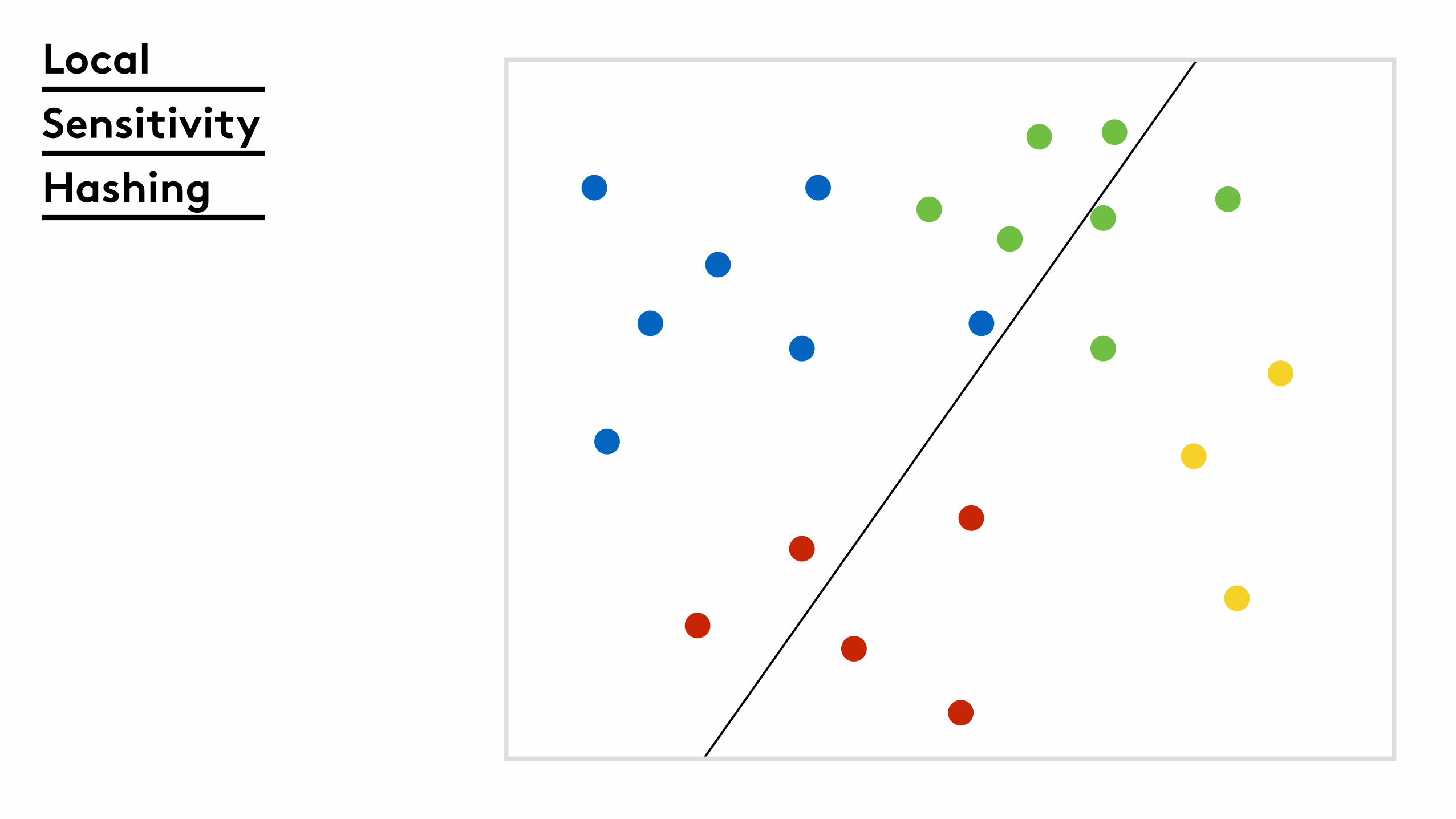
Local
Sensitivity
Hashing
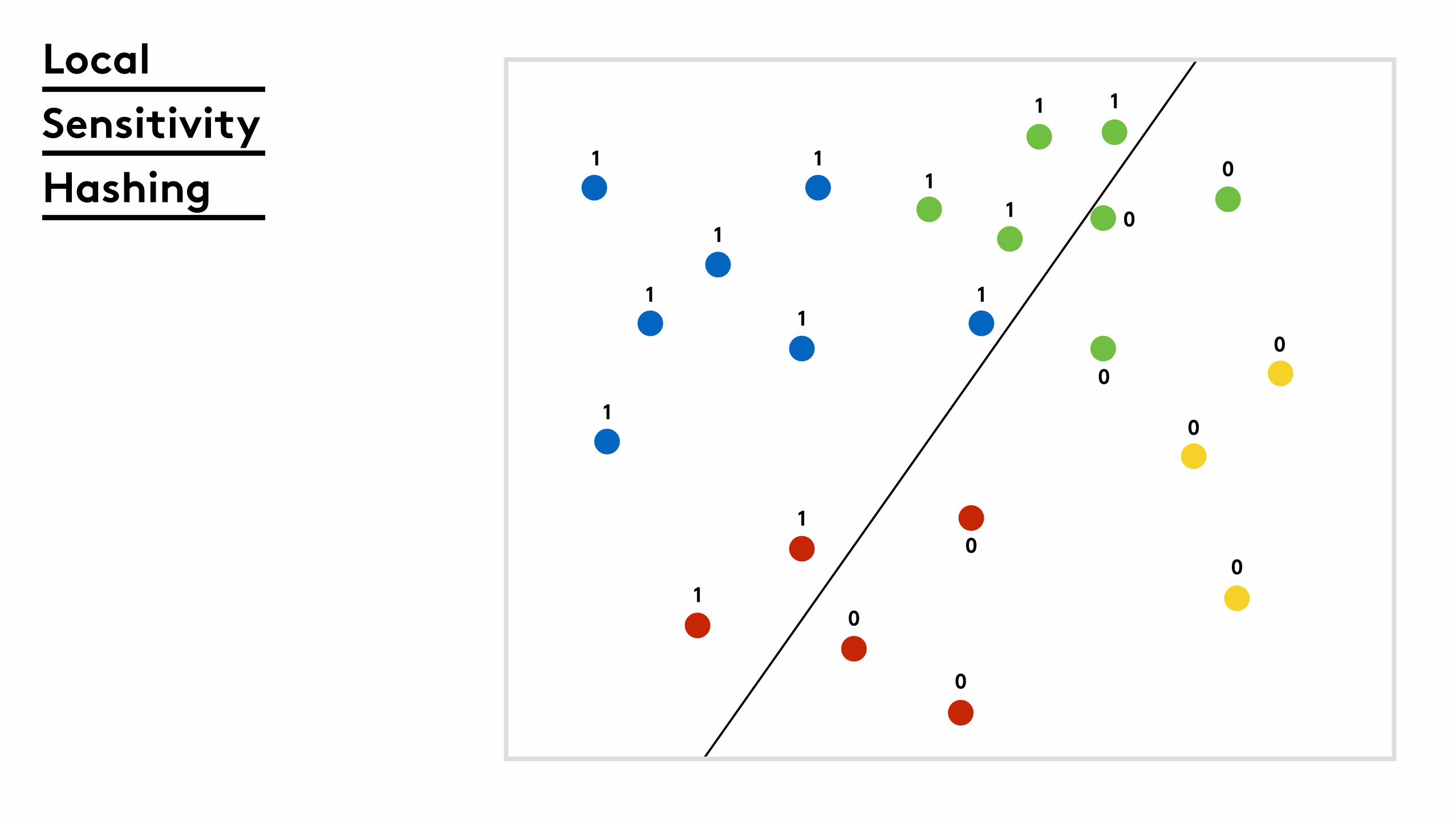
Local
Sensitivity
Hashing
1
1
1
1 1
11
11
1 1
0
0
0
0
0
0
0
1
1
0
0
Local
Sensitivity
Hashing
10
10
10
10 11
1010
1111
11 11
01
00
01
00
01
00
00
00
10
10
00
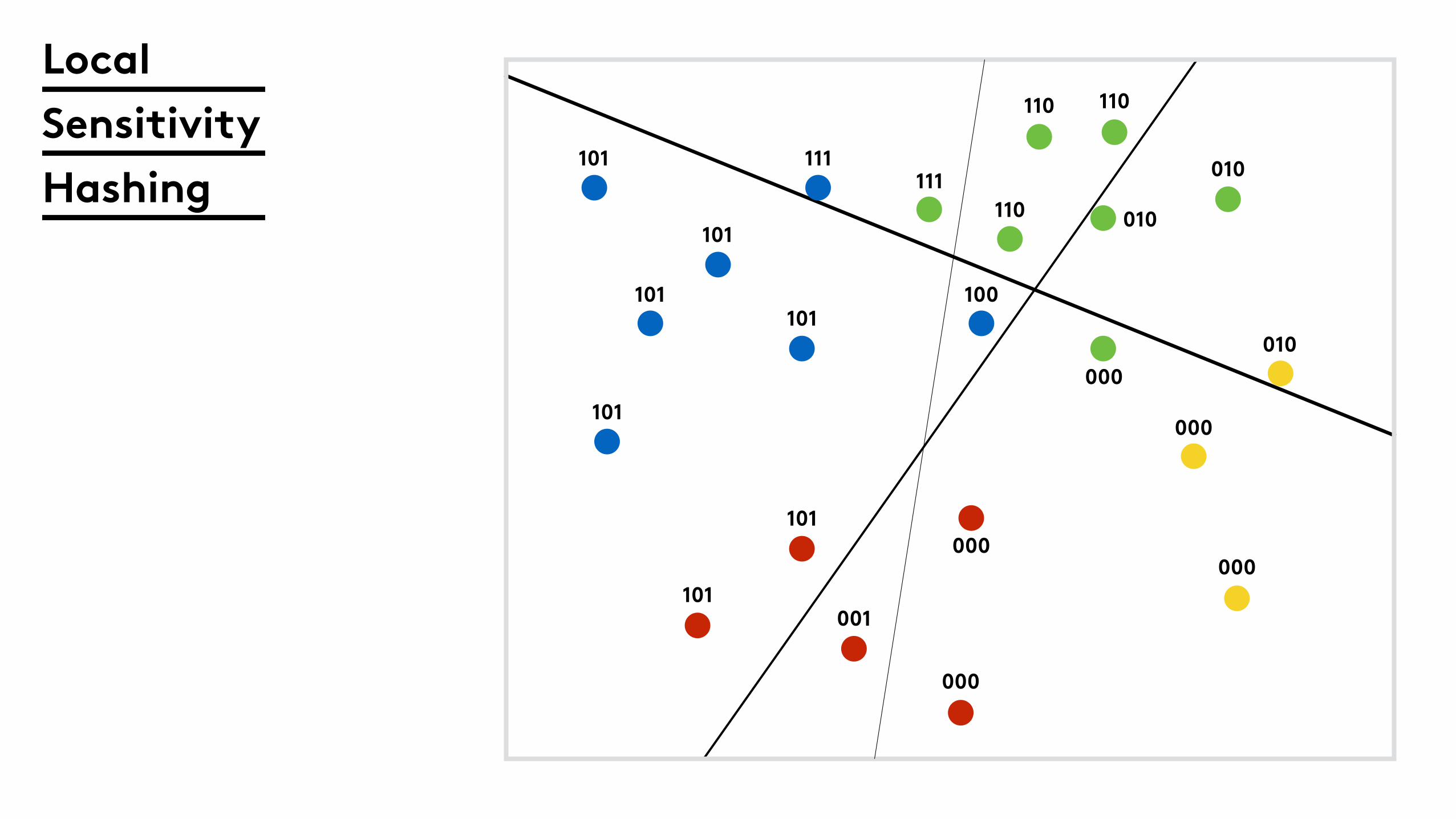
Local
Sensitivity
Hashing
101
101
101
101 111
101100
111110
110 110
010
000
010
000
010
000
000
000
001
101
101
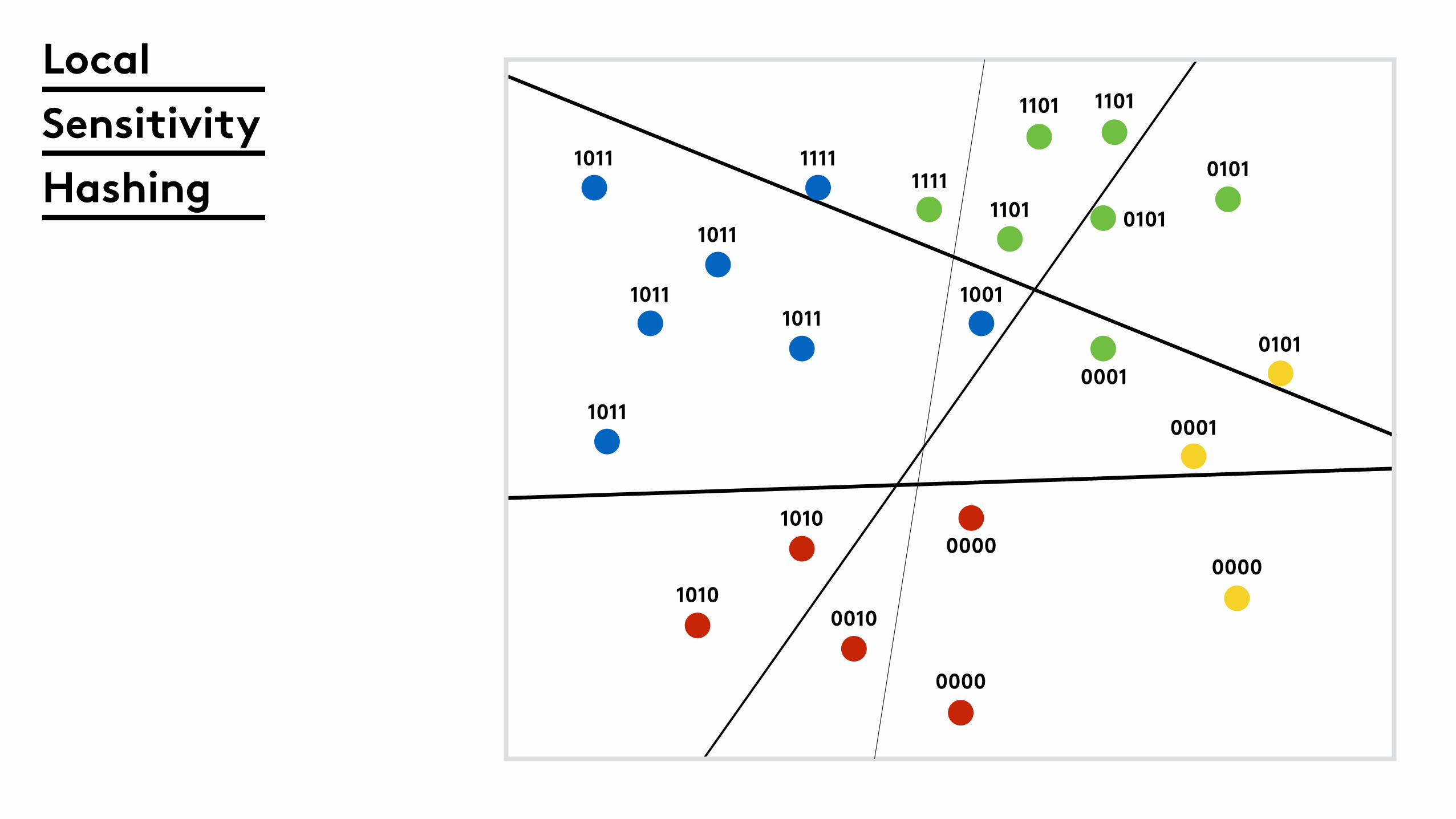
Local
Sensitivity
Hashing
1011
1011
1011
1011 1111
10111001
11111101
1101 1101
0101
0001
0101
0001
0101
0000
0000
0000
0010
1010
1010
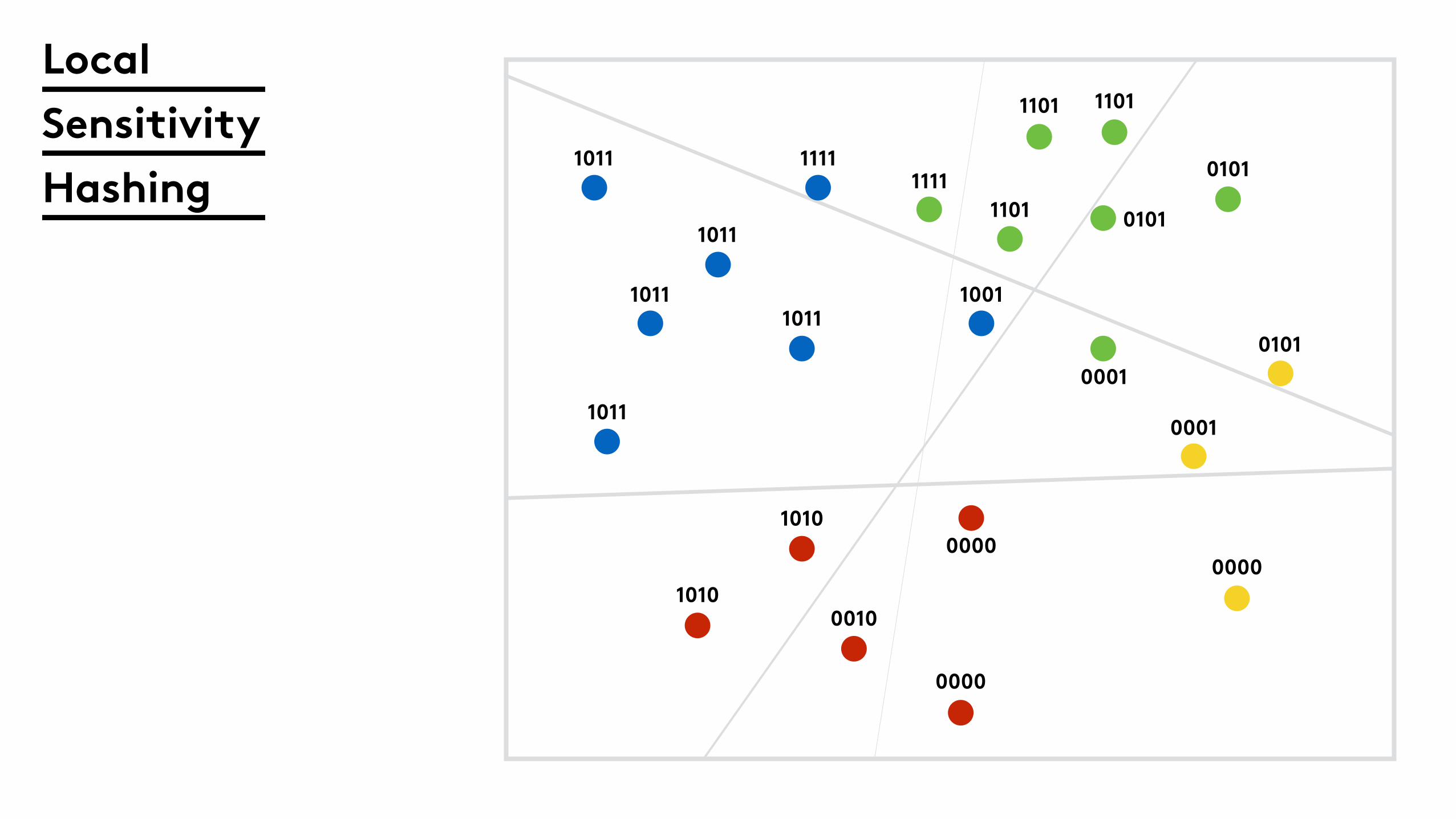
Local
Sensitivity
Hashing
1011
1011
1011
1011 1111
10111001
11111101
1101 1101
0101
0001
0101
0001
0101
0000
0000
0000
0010
1010
1010
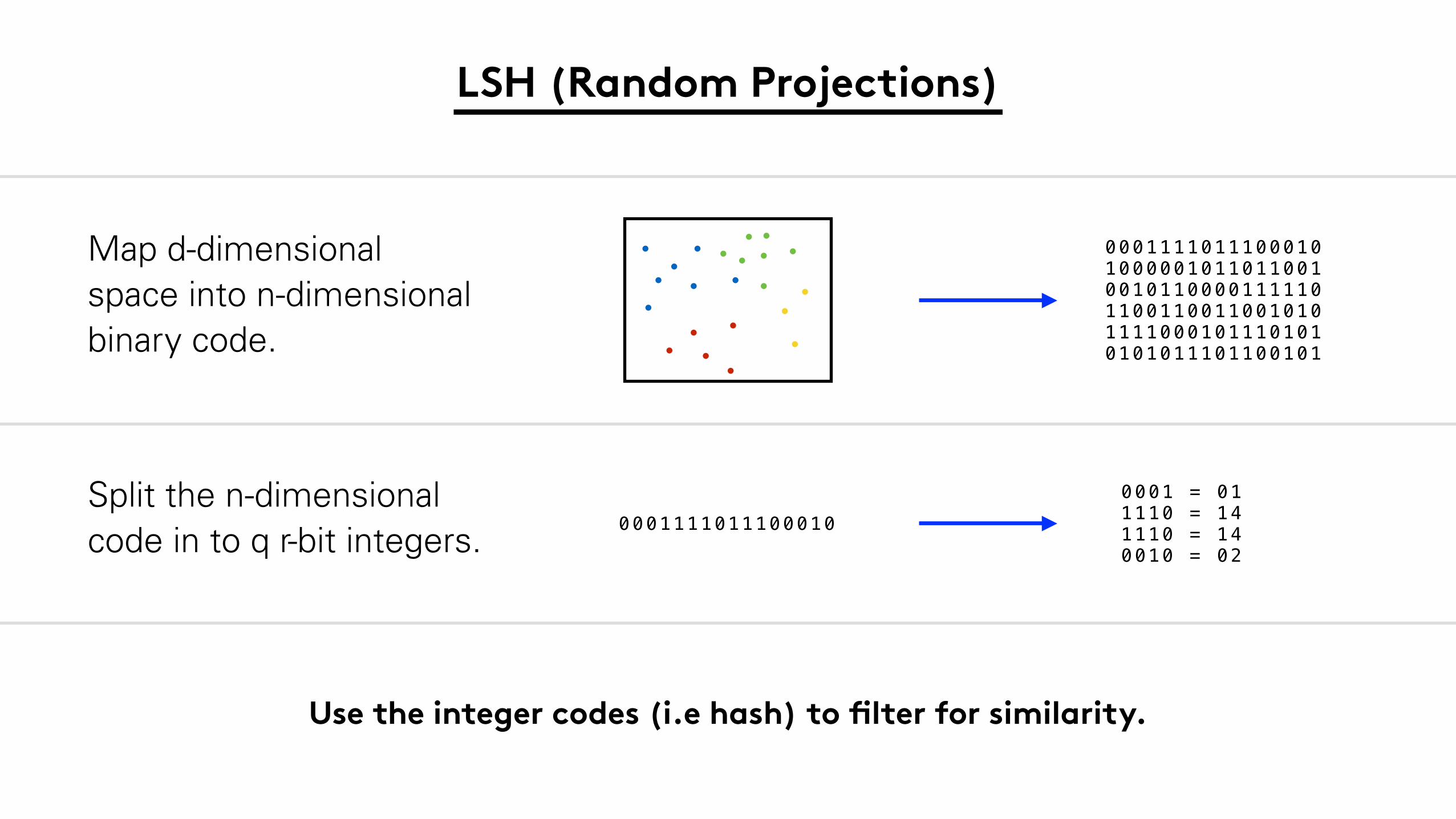
LSH (Random Projections)
Split the n-dimensional
code in to q r-bit integers.0001111011100010
0001 = 01 1110 = 14 1110 = 14 0010 = 02
Map d-dimensional
space into n-dimensional
binary code.
0001111011100010 1000001011011001 0010110000111110 1100110011001010 1111000101110101 0101011101100101
Use the integer codes (i.e hash) to filter for similarity.

Parameters
The Johnson-Lindestrauss lemma states that
For a n×m matrix we can project into…
d = O(log n)
… dimensions and still preserve distance.

Performance
…?!

Other “useful” applications

Color Variants

Matching Sets

Outfits

Model Faces

What’s Next
Reverse image search
This works! We tried during a hackathon
Similiar textual features
i.e. word embeddings
Dual image / text vector embeddings

thank you @ejbell






![Ranking Preserving Hashing for Fast Similarity Search · tags). Locality-Sensitive Hashing (LSH) [Datar et al., 2004] ... ing results, very limited work explores the ranking accuracy,](https://img.pdfslide.net/doc/110x75/5ff37e8bd20cdb25fe395569/ranking-preserving-hashing-for-fast-similarity-search-tags-locality-sensitive.jpg)






















