Embed Size (px)
Citation preview

Dr. Susan Wegner, Telekom Innovation Laboratories
25. Februar 2015, BITKOM Big Data Summit, Hanau
Future analytics – Fabrication of Synthetic Data
DATA NATIVES 2015, Dr. Susan Wegner, Telekom Innovation Laboratories

www.laboratories.telekom.com @T_Labs
ACCESS TO DATA IS STILL AN ISSUE
2
DUE TO DIFFERENT TECHNOLOGY AND DATA SOURCES
www.laboratories.telekom.com @T_Labs
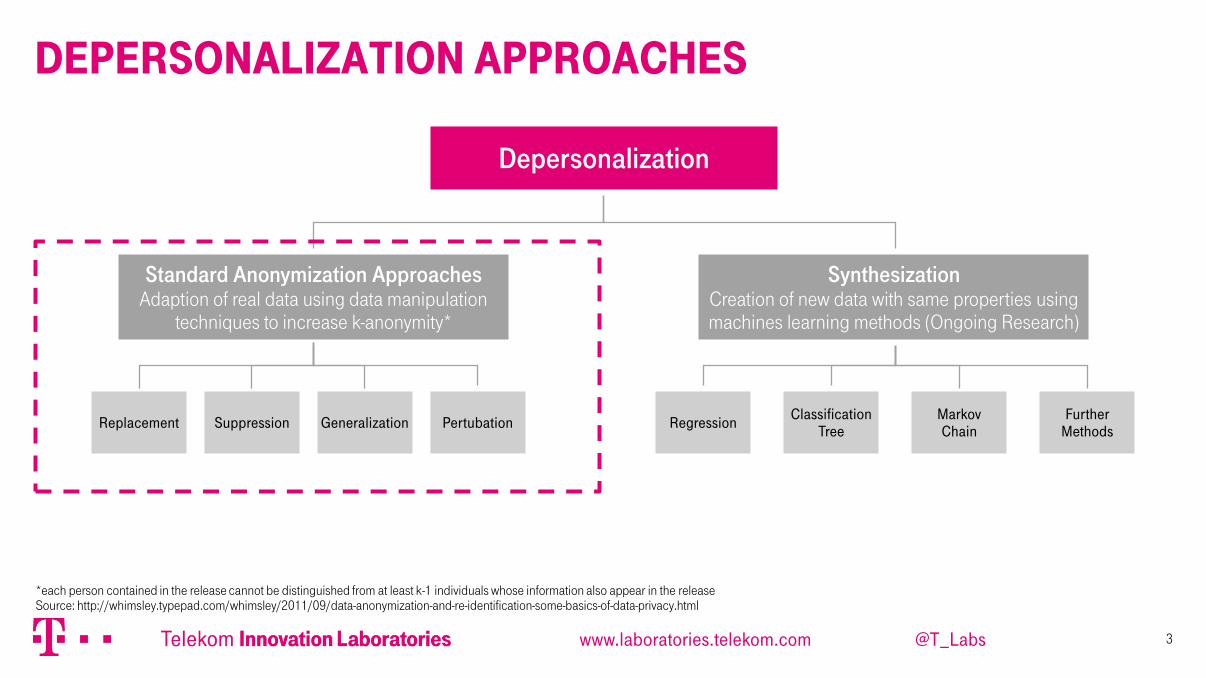
Depersonalization approaches
3
Depersonalization
Standard Anonymization Approaches Adaption of real data using data manipulation
techniques to increase k-anonymity*
Pertubation Regression Classification
Tree Generalization Suppression Replacement
Markov Chain
Further Methods
*each person contained in the release cannot be distinguished from at least k-1 individuals whose information also appear in the release Source: http://whimsley.typepad.com/whimsley/2011/09/data-anonymization-and-re-identification-some-basics-of-data-privacy.html
Synthesization Creation of new data with same properties using machines learning methods (Ongoing Research)

www.laboratories.telekom.com @T_Labs
Standard Anonymization Approaches A tradeoff between anonymity and usefulness
4
Tradeoff
Perfect Anonymity
Perfect Usefulness
It is not possible to create a perfectly anonymised dataset that is perfectly useful to researchers at the same time.
Pro: 100% Data Privacy
Con: Data Loss and distortions can compromise conclusions
Pro: A maximum of data based insights is possible Con: Disclosure of individuals is possible
Decreasing Intensity of Anonymization
www.laboratories.telekom.com @T_Labs
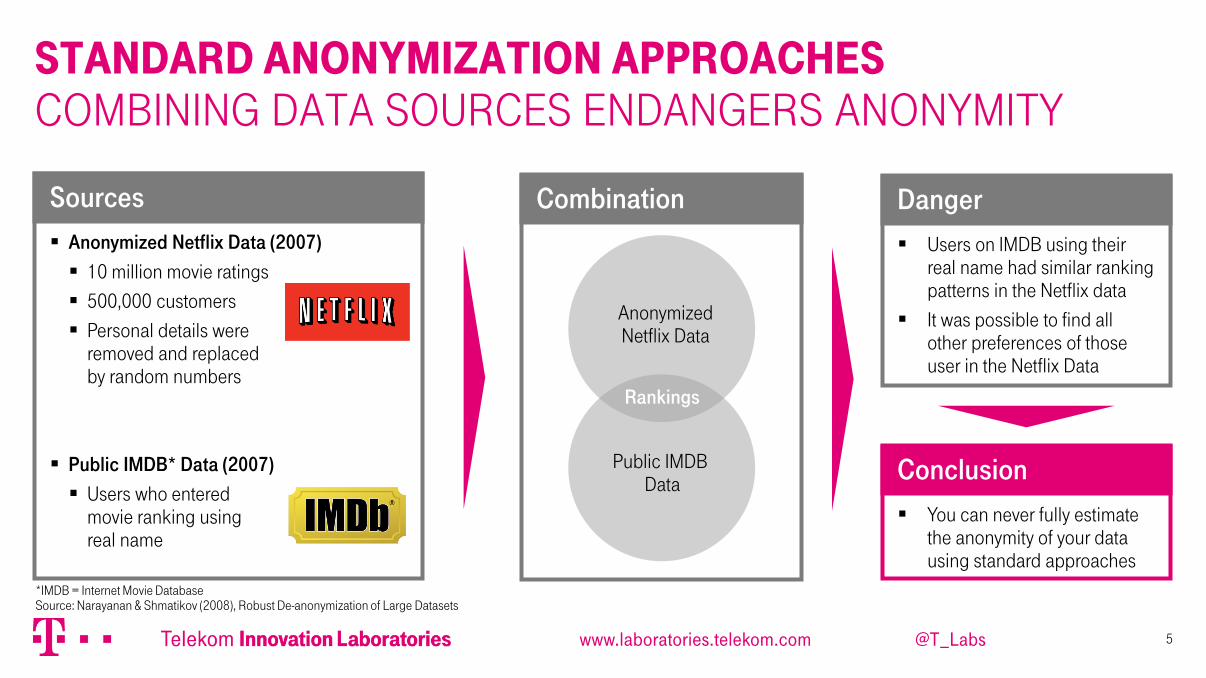
Standard Anonymization Approaches Combining data sources endangers anonymity
5
Anonymized Netflix Data (2007)
10 million movie ratings
500,000 customers
Personal details were removed and replaced by random numbers
Public IMDB* Data (2007)
Users who entered movie ranking using real name
Sources Combination
Rankings
Anonymized Netflix Data
Public IMDB Data
Users on IMDB using their real name had similar ranking patterns in the Netflix data
It was possible to find all other preferences of those user in the Netflix Data
Danger
You can never fully estimate the anonymity of your data using standard approaches
Conclusion
*IMDB = Internet Movie Database Source: Narayanan & Shmatikov (2008), Robust De-anonymization of Large Datasets
www.laboratories.telekom.com @T_Labs
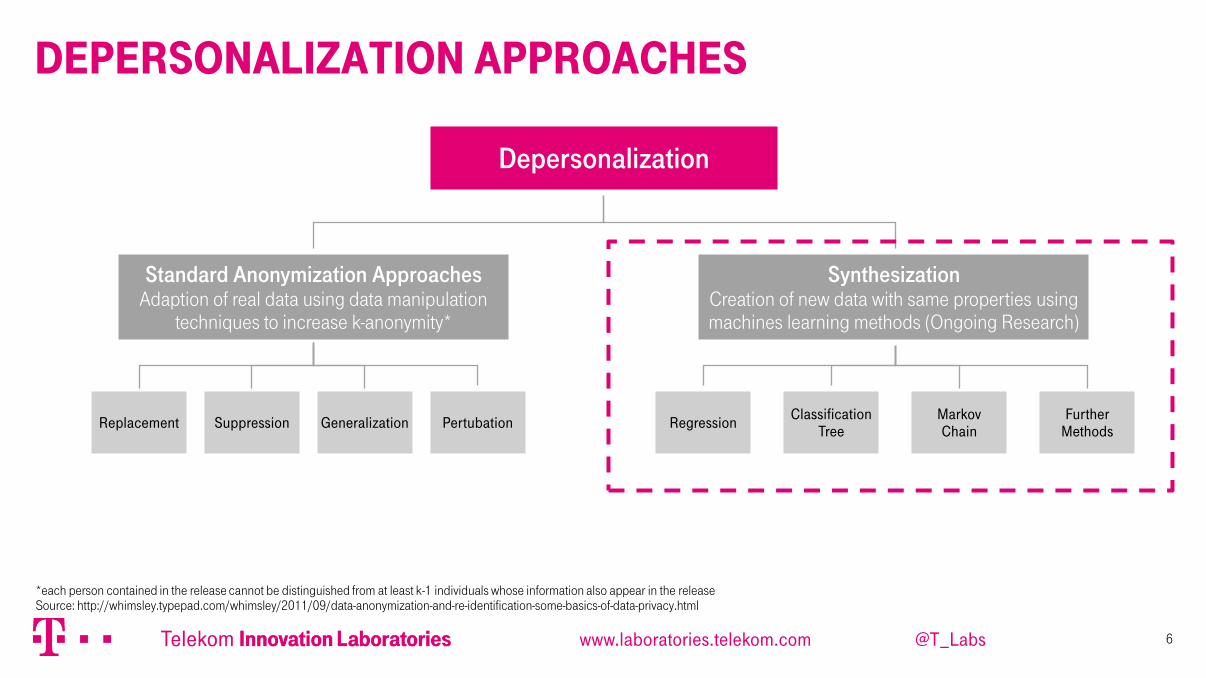
Depersonalization Approaches
6
Depersonalization
Standard Anonymization Approaches Adaption of real data using data manipulation
techniques to increase k-anonymity*
Pertubation Regression Classification
Tree Generalization Suppression Replacement
Markov Chain
Further Methods
Synthesization Creation of new data with same properties using machines learning methods (Ongoing Research)
*each person contained in the release cannot be distinguished from at least k-1 individuals whose information also appear in the release Source: http://whimsley.typepad.com/whimsley/2011/09/data-anonymization-and-re-identification-some-basics-of-data-privacy.html

www.laboratories.telekom.com @T_Labs
synthetic data to overcome privacy issues
7

www.laboratories.telekom.com @T_Labs
ADVANTAGES & DISADVANTAGES OF TECHNIQUES
8
Rendering anonymous means the modification of personal data so that the information concerning personal or material circumstances can no longer be attributed to an identified or identifiable individual.
Anonymization
Actual data is used to develop patterns in which the characteristics of this actual data are largely retained. These patterns are then used to generate new data, which no longer has any reference to an individual in the actual data. Synthetic data makes it possible, for the first time, to use data that was previously unavailable.
Synthetization
www.laboratories.telekom.com @T_Labs
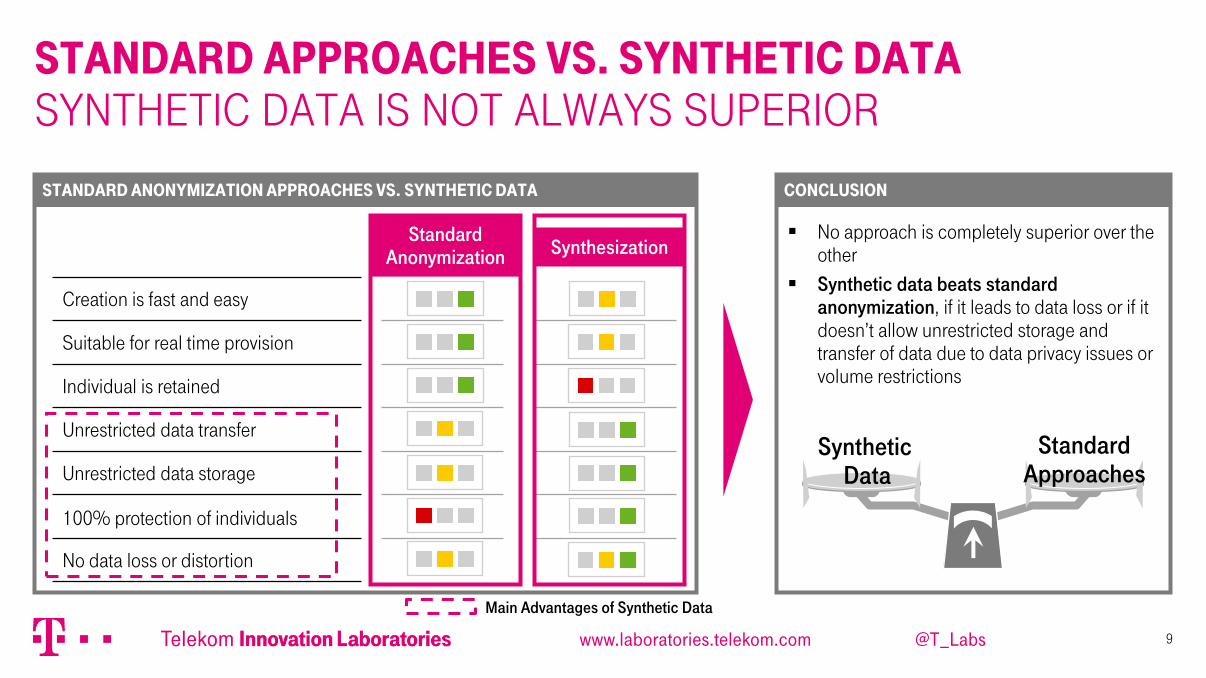
Standard Anonymization Approaches vs. Synthetic Data
Standard Approaches vs. Synthetic Data Synthetic data is not always superior
9
Creation is fast and easy
Suitable for real time provision
Individual is retained
Unrestricted data transfer
Unrestricted data storage
100% protection of individuals
No data loss or distortion
Standard Anonymization Synthesization
No approach is completely superior over the other
Synthetic data beats standard anonymization, if it leads to data loss or if it doesn’t allow unrestricted storage and transfer of data due to data privacy issues or volume restrictions
Conclusion
Main Advantages of Synthetic Data
Synthetic Data
Standard Approaches
www.laboratories.telekom.com @T_Labs
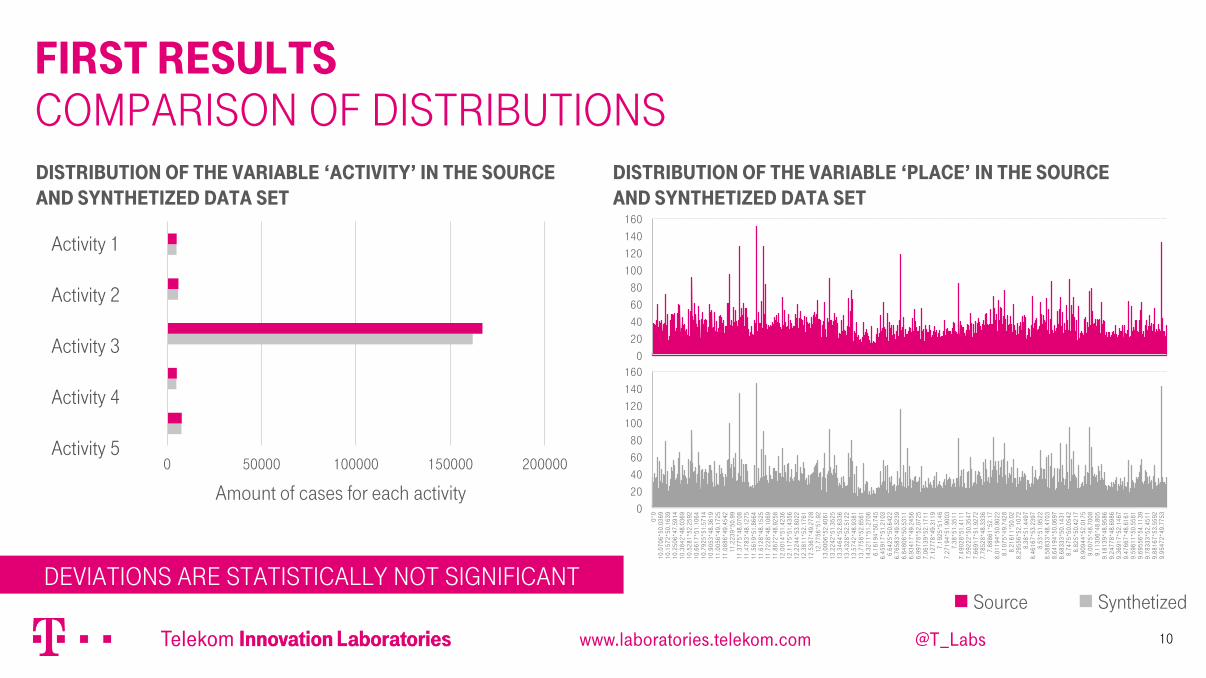
First results Comparison of Distributions
0 50000 100000 150000 200000
AIF/MOC
AIF/MTC
AIF/Upd ate Location
IuCS MOC
IuCS MTC
Deviations are statistically not significant
Distribution of the variable ‘Place’ in the source And synthetized data set
0
20
40
60
80
100
120
140
160
0*0
1
0.0
70
6*5
0.0
369
1
0.1
57
2*5
0.1
639
1
0.2
50
6*4
7.5
914
1
0.3
84
2*4
8.0
369
1
0.5
28
1*5
2.2
592
1
0.6
61
7*5
1.1
064
1
0.7
92
5*5
1.5
714
1
0.9
05
3*4
8.3
619
1
1.0
05
6*4
9.1
725
1
1.0
88
6*4
9.4
542
1
1.2
23
9*5
0.9
9
11
.37
75
*48
.07
08
11
.47
83
*48
.12
75
11
.56
19
*51
.86
64
11
.61
28
*48
.15
25
11
.72
28
*48
.10
69
11
.86
72
*48
.92
58
12
.00
14
*51
.42
36
12
.11
75
*51
.43
56
12
.22
44
*53
.80
22
12
.38
11
*52
.17
61
12
.53
67
*49
.27
28
12
.77
56
*51
.92
1
3.0
00
6*5
2.4
061
1
3.2
24
2*5
1.3
525
1
3.3
46
4*5
2.6
336
1
3.4
32
8*5
2.5
122
1
3.5
74
2*4
8.9
381
1
3.7
75
8*5
2.8
561
1
4.3
21
1*5
1.2
706
6
.16
19
4*5
0.7
45
6
.45
91
7*5
1.2
103
6
.64
25
*50.
642
2
6.7
65
83
*49
.32
39
6.8
48
06
*50
.53
11
6.9
34
17
*49
.24
56
6.9
97
78
*52
.07
25
7.0
61
39
*52
.17
11
7.1
27
78
*49
.31
19
7.1
92
5*5
1.4
6
7.2
71
94
*51
.90
03
7.3
8*5
1.3
511
7
.49
02
8*5
1.4
111
7
.59
22
2*50
.35
47
7.6
69
17
*51
.92
72
7.7
85
28
*48
.33
36
7.8
88
61
*52
.17
8
.01
19
4*5
0.9
022
8
.10
75
*49.
742
8
8.2
16
11
*50
.02
8
.29
55
6*5
2.1
072
8
.38
*51
.449
7
8.4
61
67
*53
.23
97
8.5
3*5
1.9
522
8
.58
83
3*4
8.4
703
8
.64
19
4*5
0.0
697
8
.68
33
3*5
0.1
431
8
.74
75
*50.
054
2
8.8
25
*50
.42
17
8.9
09
44
*52
.01
75
9.0
07
5*4
8.7
008
9
.11
30
6*4
8.8
05
9
.18
13
9*4
8.9
586
9
.24
77
8*4
8.6
986
9
.36
91
7*5
2.1
467
9
.47
66
7*4
8.6
161
9
.59
61
1*5
0.5
581
9
.69
55
6*54
.11
39
9.7
83
33
*52
.45
11
9.8
81
67
*53
.55
92
9.9
54
72
*49
.77
53
0
20
40
60
80
100
120
140
160
0*0
1
0.0
70
6*5
0.0
369
1
0.1
57
2*5
0.1
639
1
0.2
50
6*4
7.5
914
1
0.3
84
2*4
8.0
369
1
0.5
28
1*5
2.2
592
1
0.6
61
7*5
1.1
064
1
0.7
92
5*5
1.5
714
1
0.9
05
3*4
8.3
619
1
1.0
05
6*4
9.1
725
1
1.0
88
6*4
9.4
542
1
1.2
23
9*5
0.9
9
11
.37
75
*48
.07
08
11
.47
83
*48
.12
75
11
.56
19
*51
.86
64
11
.61
28
*48
.15
25
11
.72
28
*48
.10
69
11
.86
72
*48
.92
58
12
.00
14
*51
.42
36
12
.11
75
*51
.43
56
12
.22
44
*53
.80
22
12
.38
11
*52
.17
61
12
.53
67
*49
.27
28
12
.77
56
*51
.92
1
3.0
00
6*5
2.4
061
1
3.2
24
2*5
1.3
525
1
3.3
46
4*5
2.6
336
1
3.4
32
8*5
2.5
122
1
3.5
74
2*4
8.9
381
1
3.7
75
8*5
2.8
561
1
4.3
21
1*5
1.2
706
6
.16
19
4*5
0.7
45
6
.45
91
7*5
1.2
103
6
.64
25
*50.
642
2
6.7
65
83
*49
.32
39
6.8
48
06
*50
.53
11
6.9
34
17
*49
.24
56
6.9
97
78
*52
.07
25
7.0
61
39
*52
.17
11
7.1
27
78
*49
.31
19
7.1
92
5*5
1.4
6
7.2
71
94
*51
.90
03
7.3
8*5
1.3
511
7
.49
02
8*5
1.4
111
7
.59
22
2*50
.35
47
7.6
69
17
*51
.92
72
7.7
85
28
*48
.33
36
7.8
88
61
*52
.17
8
.01
19
4*5
0.9
022
8
.10
75
*49.
742
8
8.2
16
11
*50
.02
8
.29
55
6*5
2.1
072
8
.38
*51
.449
7
8.4
61
67
*53
.23
97
8.5
3*5
1.9
522
8
.58
83
3*4
8.4
703
8
.64
19
4*5
0.0
697
8
.68
33
3*5
0.1
431
8
.74
75
*50.
054
2
8.8
25
*50
.42
17
8.9
09
44
*52
.01
75
9.0
07
5*4
8.7
008
9
.11
30
6*4
8.8
05
9
.18
13
9*4
8.9
586
9
.24
77
8*4
8.6
986
9
.36
91
7*5
2.1
467
9
.47
66
7*4
8.6
161
9
.59
61
1*5
0.5
581
9
.69
55
6*54
.11
39
9.7
83
33
*52
.45
11
9.8
81
67
*53
.55
92
9.9
54
72
*49
.77
53
Distribution of the variable ‘activity’ in the source And synthetized data set
Source Synthetized
Amount of cases for each activity
Activity 1 Activity 2 Activity 3 Activity 4 Activity 5
10

www.laboratories.telekom.com @T_Labs
Why Synthetic data?
The Solution/USP:
Synthetic data have nearly the same quality as the original.
They cannot be traced back to their origin.
100% compliant with Data Privacy
Patents pending (disruptive technology).
It can be stored in any way and transferred to other.
This makes new services, including individualized services, possible.
11

BACKUP
www.laboratories.telekom.com @T_Labs
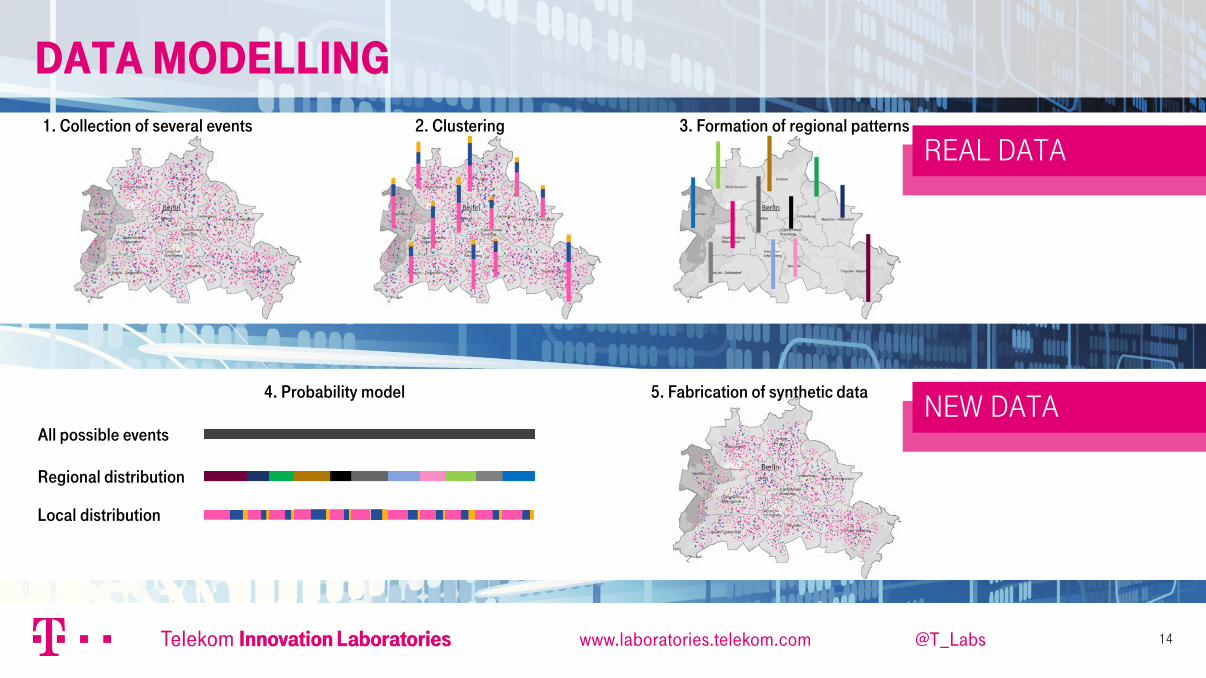
Data modelling
14
Real Data
New Data
1. Collection of several events 2. Clustering 3. Formation of regional patterns
4. Probability model 5. Fabrication of synthetic data
All possible events
Regional distribution
Local distribution
www.laboratories.telekom.com @T_Labs
Future Analytics – exemplary application
15

www.laboratories.telekom.com @T_Labs
Vision – include everything in one picture
100% Compliant with Data Privacy
16






























