Embed Size (px)
Citation preview

Gunosy Inc.吉田 宏司
2017.4
Gunosy DM #1181.5 部分観測マルコフ決定過程と強化学習

2©Gunosy Inc.
この資料について
Gunosyデータマイニング研究会 #118 https://gunosy-dm.connpass.com/event/54124/の発表資料ですこれからの強化学習の1.5節についての内容です

3©Gunosy Inc.
1.5節でやること
前節までで扱っていたMDP(マルコフ決定過程 : Markov Decisioll Process)は、エージェントが状態を完全に観測可能であると仮定していた
しかし、実問題では、センサの性能不足やノイズなどから、状態の観測は不確実(部分的)となってしまう
● エージェントから見ると同一の状態でも、実際には異なった状態が存在するため、エージェントから見るとマルコフ性を仮定出来なくなる
本節では、この不確実性を考慮したPOMDP(部分観測マルコフ過程 : Patially Observable Markov Decisioll Process)における強化学習について学ぶ

4©Gunosy Inc.
Kaelbingらの部分観測マルコフ決定過程の定義● <S, A, T, R, Ω, O> の組
— S : 状態集合
— A : 行動集合
— T : 状態遷移関数(状態遷移確率を記述する関数)
● T(s, a, s’) = P(s’ | s, a)— R : 報酬集合
— Ω : 観測集合(エージェントの観測を要素にもつ有限な集合)
— O : 観測関数(エージェントの観測を記述する関数)
● O(s’, a, o) = P(o | a, s’)● o : sの部分的な観測
部分観測マルコフ決定過程の定義

5©Gunosy Inc.
野鳥の保護に対するPOMDPの適用可能性の検討● 状態 : 巣らしき場所に取りが住んでいるか・いないか
● 行動 : 調査活動を行うか・通常の行動を行うか
— 調査にはコストがかかる
— 通常の行動は利益が出るが、野鳥がいるのに通常の行動を取ると大きな不利益が出る
● 制約 : 観測を行っても、巣らしき場所に鳥がいるのかどうかは確実ではない
部分観測マルコフ決定過程の応用事例

6©Gunosy Inc.
環境に対するモデルの事前知識の利用有無の観点● 有 : モデルベースド
— モデル(状態遷移確率や観測関数)を推定してから、方策を学習する
● 無 : モデルフリー
— モデル推定なしに、方策を学習する
— Q-learning等
価値や方策を求めるタイミングの観点● オンライン
— 価値・方策を求めながら、その時点で得られた方策を実行していく
● オフライン
— 価値・方策を求めてから、得られた方策を実行していく
部分観測マルコフ決定過程下の強化学習の解法の分類

7©Gunosy Inc.
『信念状態とは、どの状態にいるかを表す確率を並べてつくる「状態」である.』● 信念 b は状態空間 S 上の確率分布
● b(s) ∈ [0,1] は環境が状態 s ∈ S にいる確率
信念状態

8©Gunosy Inc.
2つのドアのどちらかを開けるとトラがいて、ドアを開けるたびにトラは移動する● 状態
— s_l : 左のドアにトラがいる
— s_r : 右のドアにトラがいる
● 報酬
— ドアを開けて、トラがいると大きな負の報酬
— いないと正の報酬
● 行動
— left : 左のドアを開ける
— right : 右のドアを開ける
— listen : 音を聞く
信念状態の例Tiger

9©Gunosy Inc.
信念状態の例Tiger

10©Gunosy Inc.
belief update(信念状態の更新 )
信念状態 b は、POMDPの要素である、状態遷移関数 T 、観測関数 O を用いて更新できる
● 状態遷移関数 : T(s, a, s’) = P(s’ | s, a)● 観測関数 : O(s’, a, o) = P(o | a, s’)

11©Gunosy Inc.
信念状態 b を状態と考えれば、POMDPはMDPのように扱うことができるようになり、このMDPをbelief MDPと呼ぶ
● エージェントにとって信念は既知のため、belief MDPは部分観測ではなくなる
● <B, A, τ, r > の組
— B : 信念状態空間
— A : 行動集合
— T : 状態遷移関数
— R : 報酬関数
● 信念は無限に存在しうるので、belief MDPは連続状態空間上に存在する
— 計算が大変
belief MDP

12©Gunosy Inc.
モデルベースドな手法 = 状態信念空間上のMDPのモデルが分かっているとして、行動価値や方策を求める手法
● 以下について紹介する
— belief MDP上の価値関数の表現
— exact value iteration(価値関数を求める厳密解法)
— Point-Based Value Iteration(PBVI、価値反復の近似解法)
— Point-Based Policy Iteration(PBPI、方策反復の近似解法、省略されてる)
モデルベースドな手法

13©Gunosy Inc.
belief MDP上の価値関数の表現
価値反復法 = 繰り返し計算でベルマン最適方程式の解を求める手法● 式(1.5.5) : 状態価値関数に関するベルマン最適方程式
● 式(1.5.6) : 価値反復法で行うバックアップという操作
● 式(1.5.7), (1.5.8) : belief MDP版

14©Gunosy Inc.
belief MDP上の価値関数の表現(αベクトルを使用)
価値関数 V(s) は、信念状態 b(s) と s の価値関数を表す α ベクトルの線形和で表される(ことが知られている)
● (直感的には)信念状態空間の中央付近は、エージェントが状態観測が上手くいっていない状況なので、適切な行動選択ができず、価値関数は低くなり、下に凸となる

15©Gunosy Inc.
(よく分かっていない)αベクトル数が指数的に増えてしまう● 「直感的には、現在知っている深さ k 以下の行動決定木に対応する α ベクトルをも
とにして、新しい根ノードを組み合わせることで深さ k+1 の行動決定木に対応する α ベクトルのすべてを生成するプロセスと捉えることができる」
exact value iteration(価値関数の厳密解法)
16©Gunosy Inc.
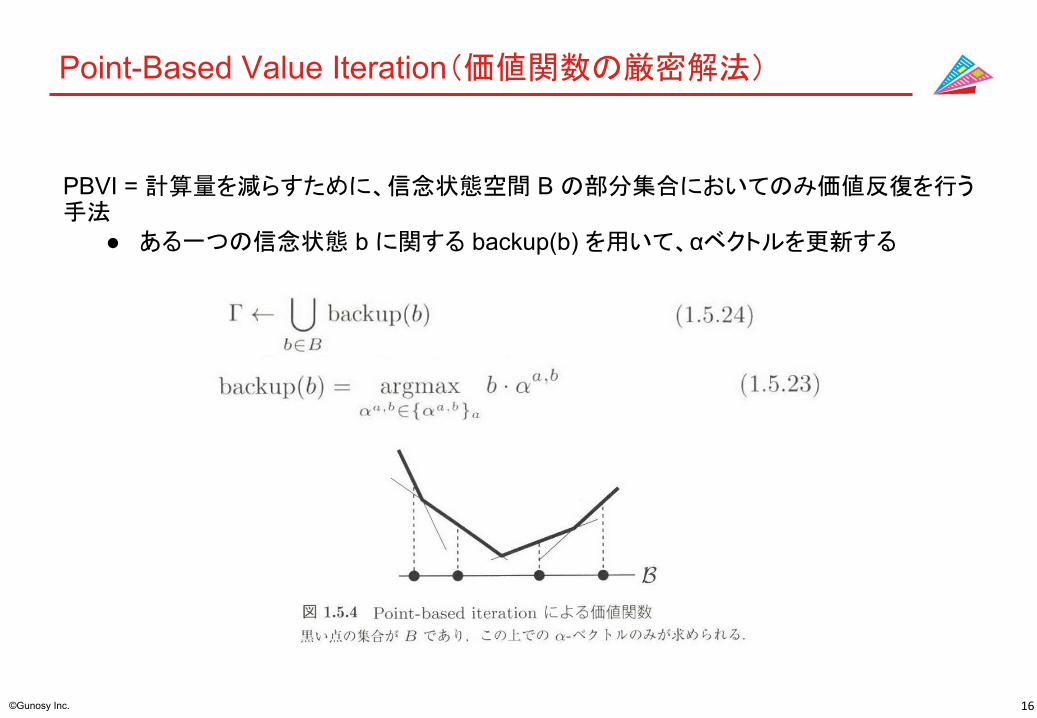
Point-Based Value Iteration(価値関数の厳密解法)
PBVI = 計算量を減らすために、信念状態空間 B の部分集合においてのみ価値反復を行う手法
● ある一つの信念状態 b に関する backup(b) を用いて、αベクトルを更新する

17©Gunosy Inc.
強化学習とは?(What is Reinforcement Learning?)強化学習 その4部分観測マルコフ決定過程 - Wikipedia
参考文献





























