Embed Size (px)
Citation preview

Scheduling

Hadoop as batch processing system
• Hadoop was designed mainly for running large batch jobs such as web indexing and log mining.
• Users submitted jobs to a queue, and the cluster ran them in order.
• Soon, another use case became attractive:
– Sharing a MapReduce cluster between multiple users.

The benefits of sharing
• With all the data in one place, users can run queries that they may never have been able to execute otherwise, and
• Costs go down because system utilization is higher than building a separate Hadoop cluster for each group.
• However, sharing requires support from the Hadoopjob scheduler to
– provide guaranteed capacity to production jobs and
– good response time to interactive jobs while allocating resources fairly between users.

Approaches to Sharing• FIFO : In FIFO scheduling, a JobTracker pulls jobs from a work queue, oldest
job first. This schedule had no concept of the priority or size of the job
• Fair : Assign resources to jobs such that on average over time, each job gets an equal share of the available resources. The result is that jobs that require less time are able to access the CPU and finish intermixed with the execution of jobs that require more time to execute. This behavior allows for some interactivity among Hadoop jobs and permits greater responsiveness of the Hadoop cluster to the variety of job types submitted.
• Capacity : In capacity scheduling, instead of pools, several queues are created, each with a configurable number of map and reduce slots. Each queue is also assigned a guaranteed capacity (where the overall capacity of the cluster is the sum of each queue's capacity). Queues are monitored; if a queue is not consuming its allocated capacity, this excess capacity can be temporarily allocated to other queues.
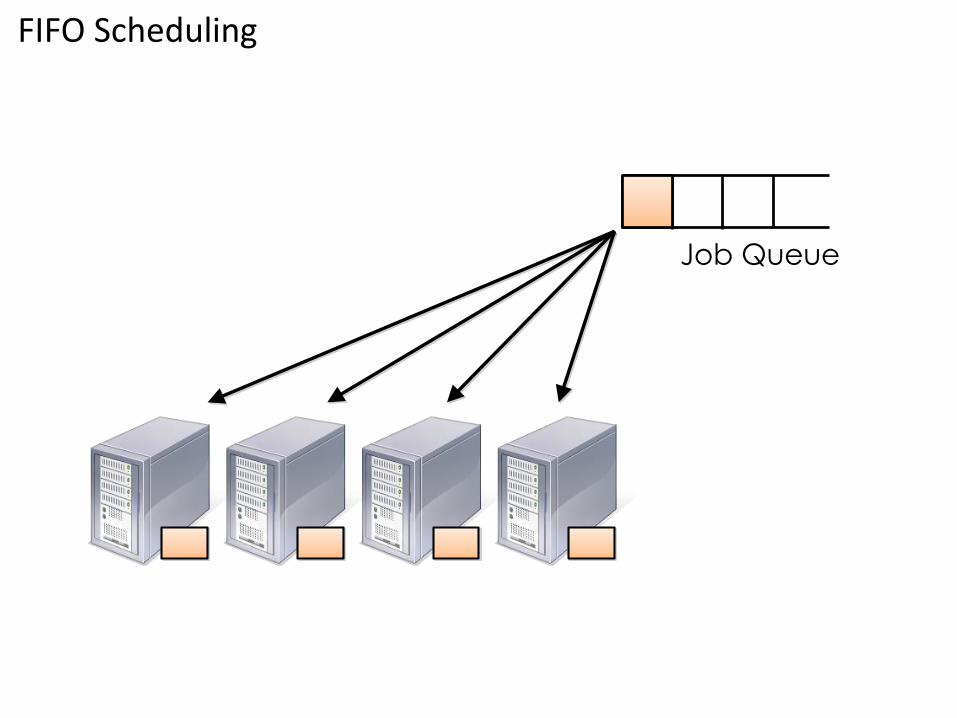
FIFO Scheduling
Job Queue
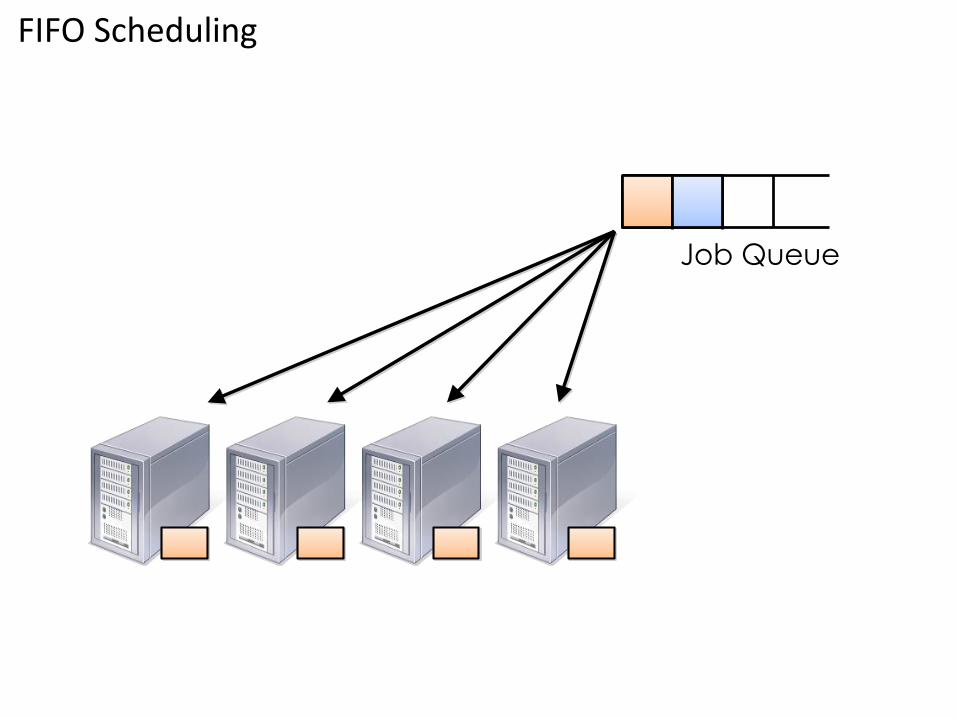
FIFO Scheduling
Job Queue
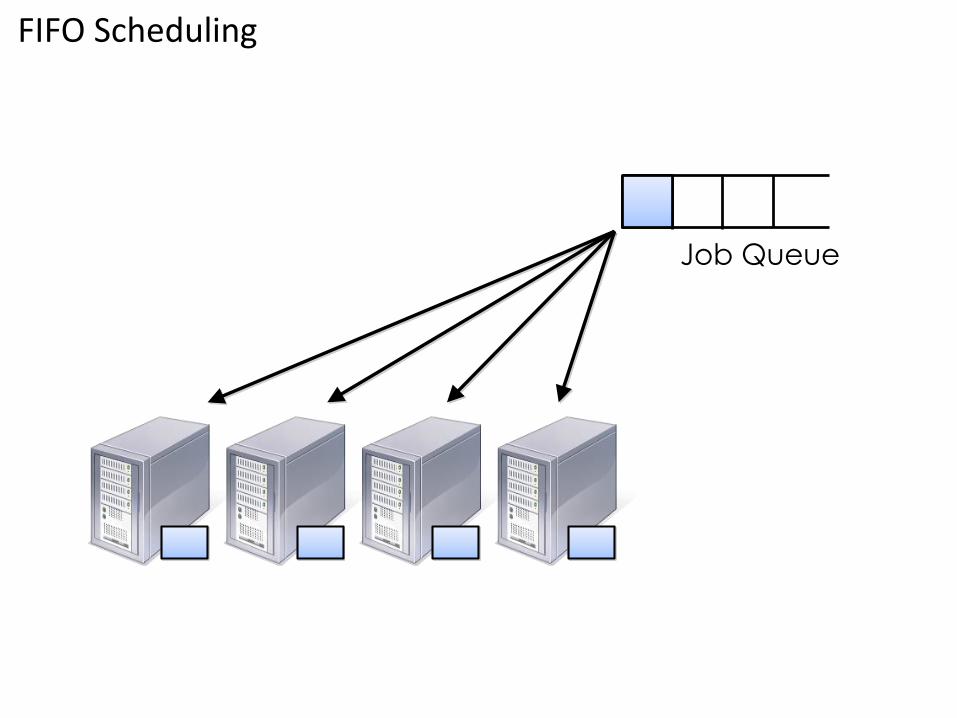
FIFO Scheduling
Job Queue

Hadoop default scheduler (FIFO)
– Problem: short jobs get stuck behind long ones
• Separate clusters
– Problem 1: poor utilization
– Problem 2: costly data replication
• Full replication across clusters nearly infeasible at Facebook/Yahoo! scale
• Partial replication prevents cross-dataset queries
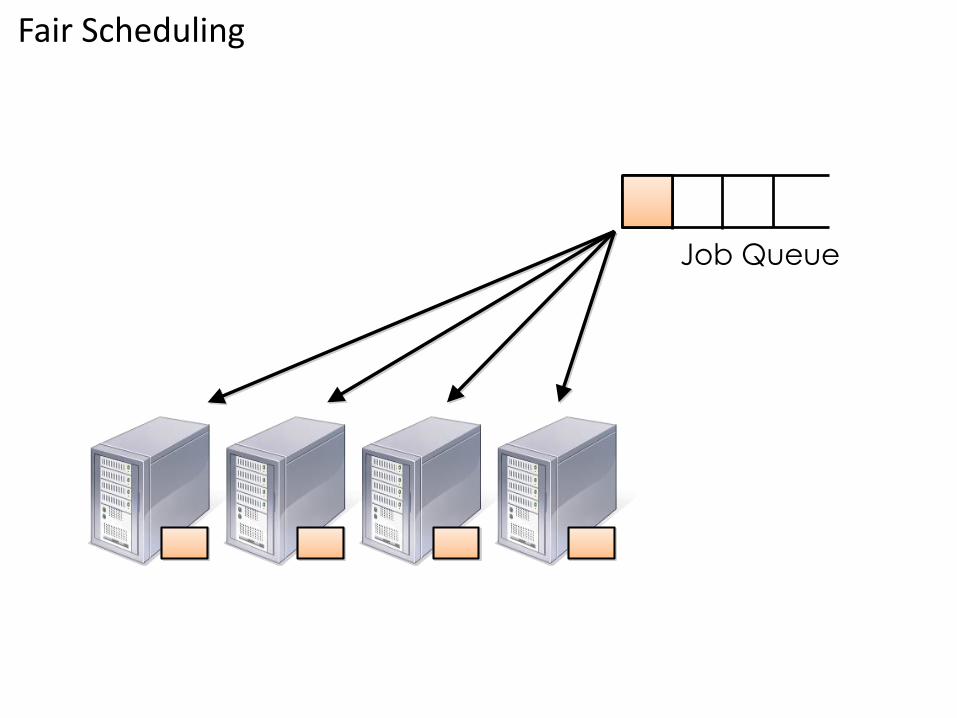
Fair Scheduling
Job Queue
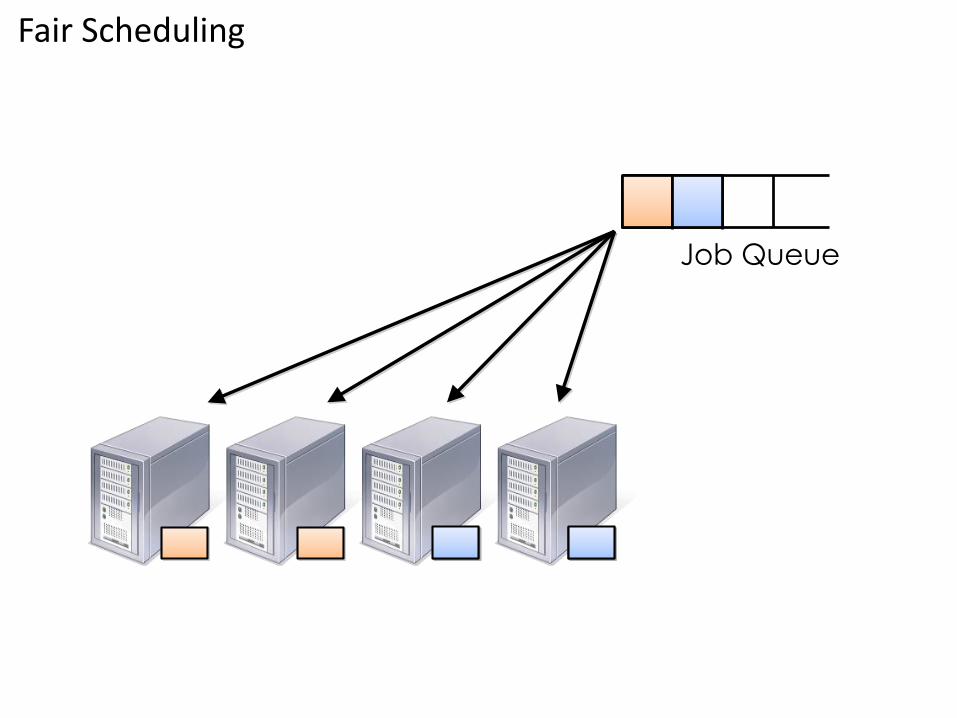
Fair Scheduling
Job Queue

Fair Scheduler Basics
• Group jobs into “pools”
• Assign each pool a guaranteed minimum share
• Divide excess capacity evenly between pools

Pools
• Determined from a configurable job property
– Default in 0.20: user.name (one pool per user)
• Pools have properties:
– Minimum map slots
– Minimum reduce slots
– Limit on # of running jobs
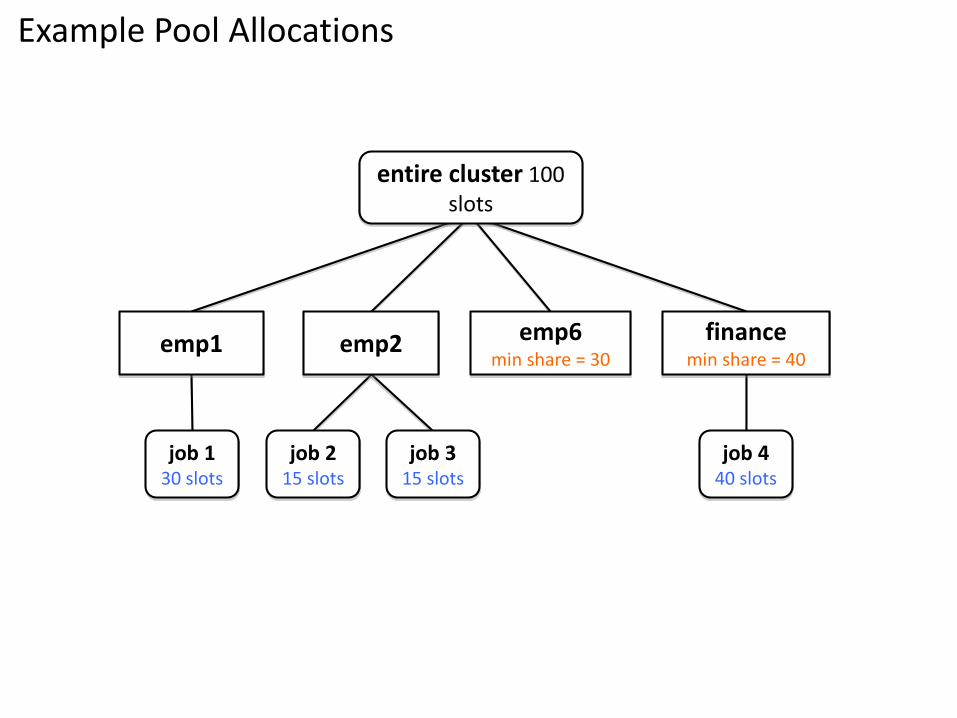
Example Pool Allocations
entire cluster 100 slots
emp1 emp2 financemin share = 40
emp6min share = 30
job 215 slots
job 315 slots
job 130 slots
job 440 slots

Scheduling Algorithm
• Split each pool’s min share among its jobs
• Split each pool’s total share among its jobs
• When a slot needs to be assigned:
– If there is any job below its min share, schedule it
– Else schedule the job that we’ve been most unfair to (based on “deficit”)
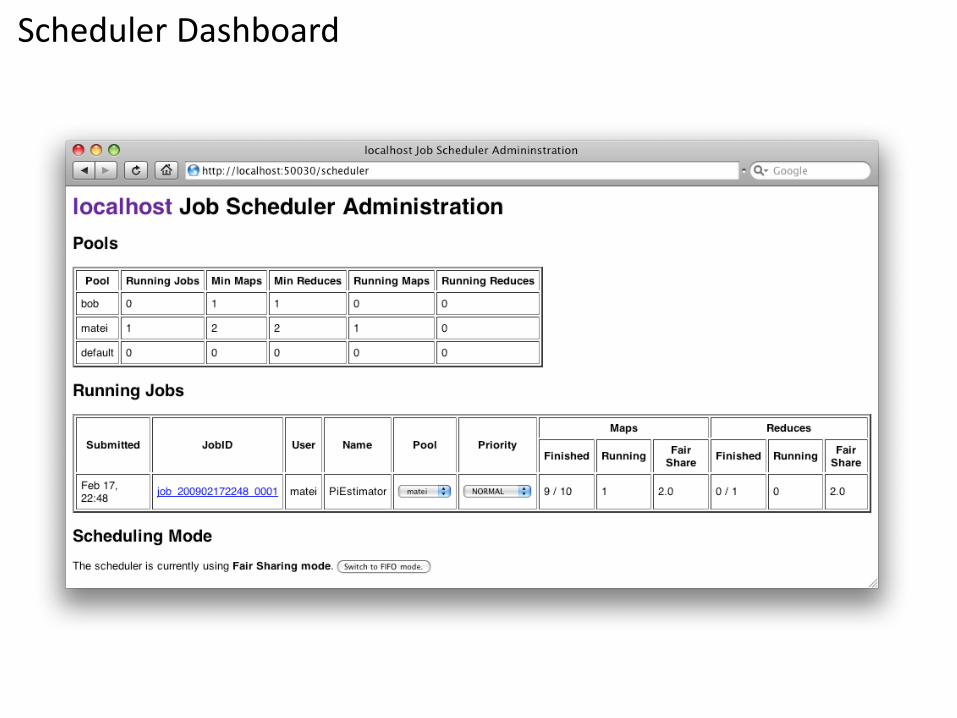
Scheduler Dashboard
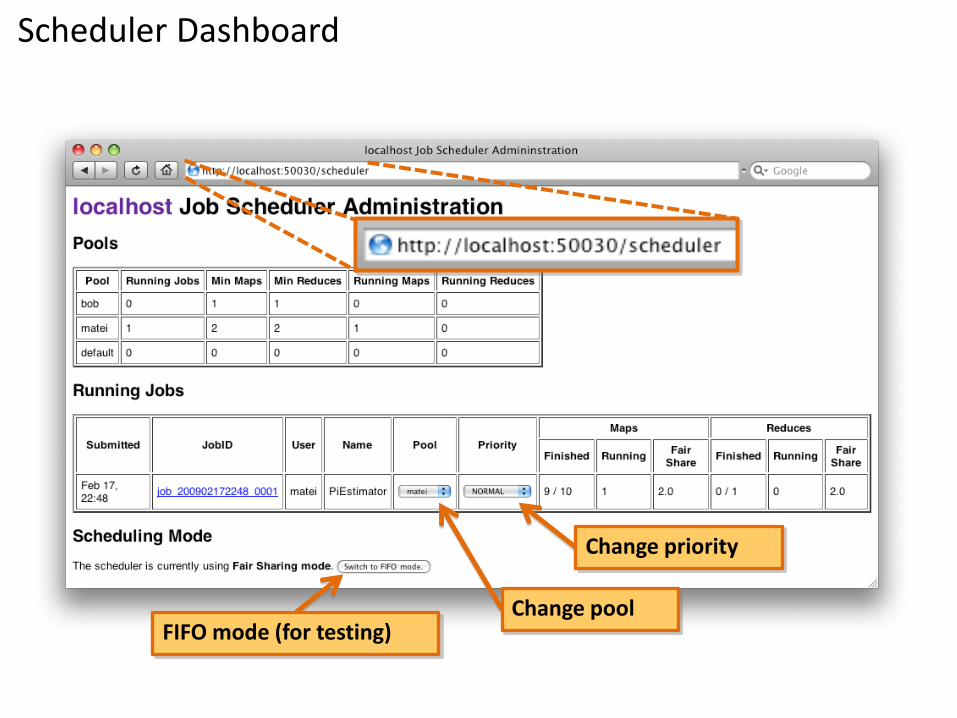
Scheduler Dashboard
Change priority
Change poolFIFO mode (for testing)

Additional Features
• Weights for unequal sharing:
– Job weights based on priority (each level = 2x)
– Job weights based on size
– Pool weights
• Limits for # of running jobs:
– Per user
– Per pool

Installing the Fair Scheduler
• Build it:
–ant package
• Place it on the classpath:
–cp build/contrib/fairscheduler/*.jar lib

Configuration Files
• Hadoop config (conf/mapred-site.xml)
– Contains scheduler options, pointer to pools file
• Pools file (pools.xml)
– Contains min share allocations and limits on pools
– Reloaded every 15 seconds at runtime

Minimal hadoop-site.xml
<property>
<name>mapred.jobtracker.taskScheduler</name>
<value>org.apache.hadoop.mapred.FairScheduler</value>
</property>
<property>
<name>mapred.fairscheduler.allocation.file</name>
<value>/path/to/pools.xml</value>
</property>

Minimal pools.xml
<?xml version="1.0"?>
<allocations>
</allocations>

Configuring a Pool
<?xml version="1.0"?>
<allocations>
<pool name=“emp4">
<minMaps>10</minMaps>
<minReduces>5</minReduces>
</pool>
</allocations>

Setting Running Job Limits<?xml version="1.0"?>
<allocations>
<pool name=“emp4">
<minMaps>10</minMaps>
<minReduces>5</minReduces>
<maxRunningJobs>3</maxRunningJobs>
</pool>
<user name=“emp1">
<maxRunningJobs>1</maxRunningJobs>
</user>
</allocations>

Default Per-User Running Job Limit
<?xml version="1.0"?>
<allocations>
<pool name=“emp4">
<minMaps>10</minMaps>
<minReduces>5</minReduces>
<maxRunningJobs>3</maxRunningJobs>
</pool>
<user name=“emp1">
<maxRunningJobs>1</maxRunningJobs>
</user>
<userMaxJobsDefault>10</userMaxJobsDefault>
</allocations>

Other Parameters
mapred.fairscheduler.assignmultiple:
• Assign a map and a reduce on each heartbeat; improves ramp-up speed and throughput; recommendation: set to true

Other Parameters
mapred.fairscheduler.poolnameproperty:
• Which JobConf property sets what pool a job is in
- Default: user.name (one pool per user)
- Can make up your own, e.g. “pool.name”, and pass in JobConf with conf.set(“pool.name”, “mypool”)

Useful Setting<property>
<name>mapred.fairscheduler.poolnameproperty</name>
<value>pool.name</value>
</property>
<property>
<name>pool.name</name>
<value>${user.name}</value>
</property>
Make pool.name default to user.name

Issues with Fair Scheduler
– Fine-grained sharing at level of map & reduce tasks
– Predictable response times and user isolation
• Problem: data locality– For efficiency, must run tasks near their input data
– Strictly following any job queuing policy hurts locality: job picked by policy may not have data on free nodes
• Solution: delay scheduling– Relax queuing policy for limited time to achieve locality
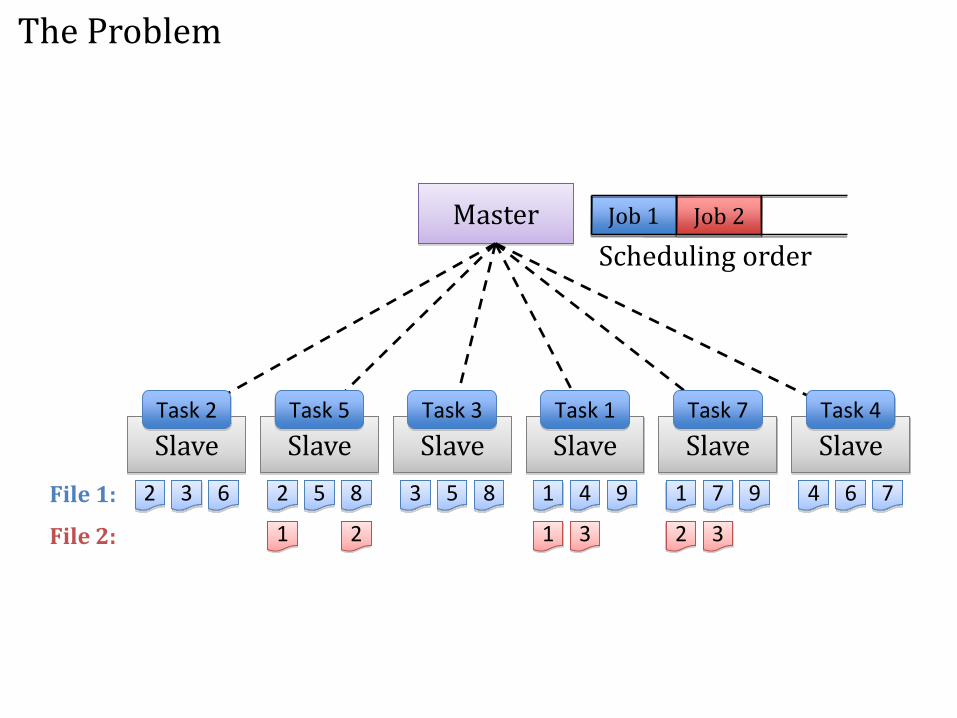
The Problem
Job 2Master Job 1
Scheduling order
Slave Slave Slave SlaveSlave Slave
42
1 1 22 33
95 33 6756 9 48 782 1 1
Task 2 Task 5 Task 3 Task 1 Task 7 Task 4
File 1:
File 2:
The Problem
Job 1Master Job 2
Scheduling order
Slave Slave Slave SlaveSlave Slave
42
1 22 3
95 33 6756 9 48 782 1 1
Task 2 Task 5 Task 3 Task 1
File 1:
File 2:
Task 1 Task 7Task 2 Task 4Task 3
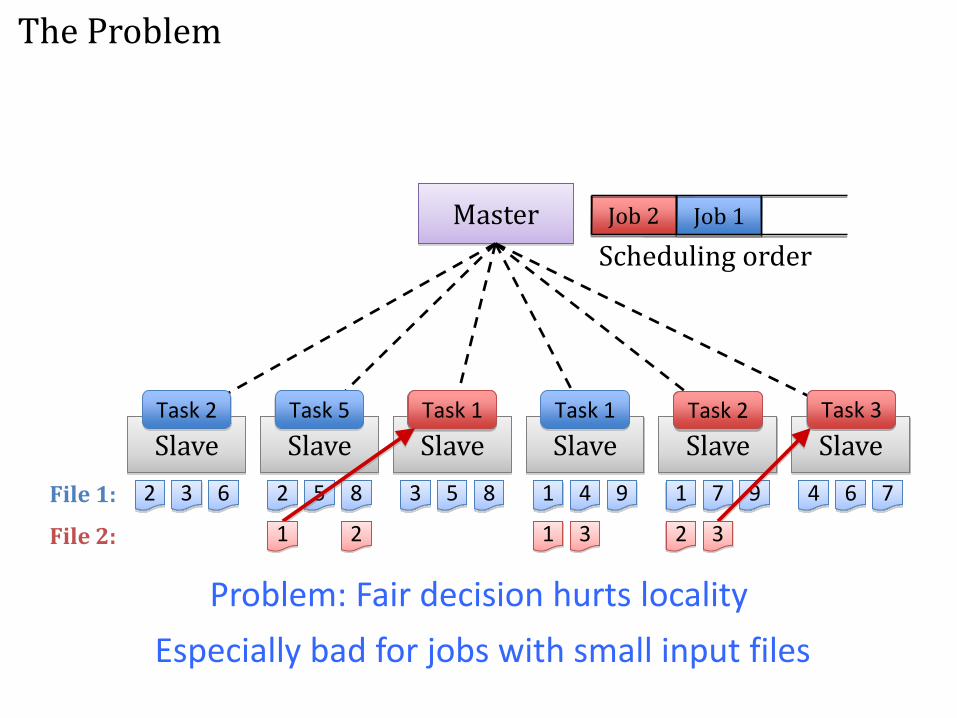
Problem: Fair decision hurts locality
Especially bad for jobs with small input files
1 3

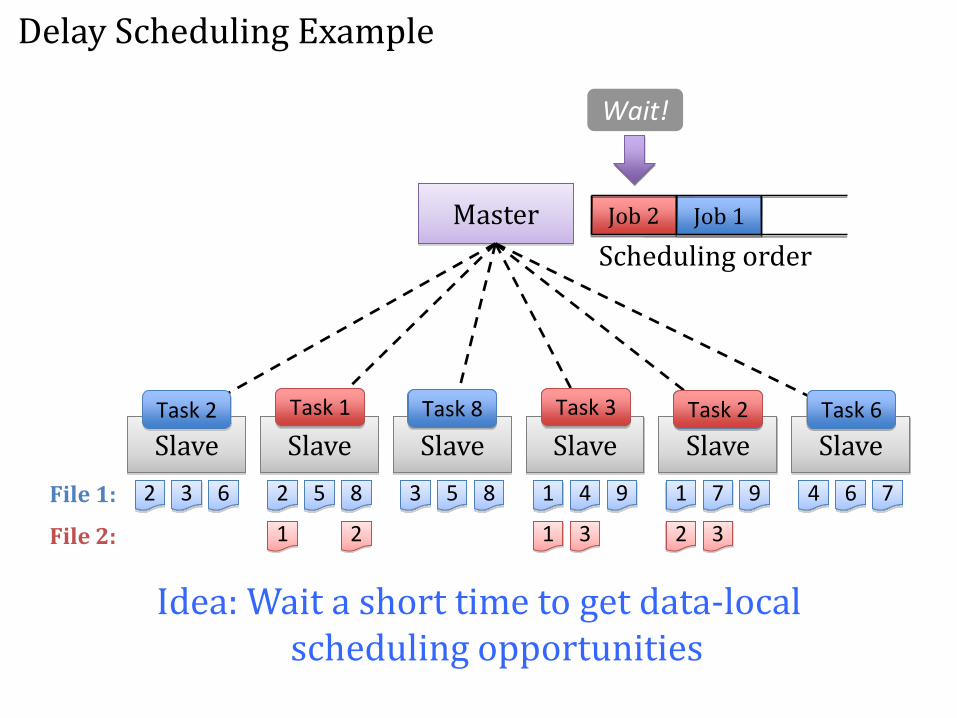
Solution: Delay Scheduling
• Relax queuing policy to make jobs wait for a limited time if they cannot launch local tasks
• Result: Very short wait time (1-5s) is enough to get nearly 100% locality
Delay Scheduling Example
Job 1Master Job 2
Scheduling order
Slave Slave Slave SlaveSlave Slave
42
1 1 22 33
95 33 6756 9 48 782 1 1
Task 2 Task 3
File 1:
File 2:
Task 8 Task 7Task 2 Task 4Task 6
Idea: Wait a short time to get data-local scheduling opportunities
Task 5Task 1 Task 1Task 3
Wait!

Delay Scheduling Details
• Scan jobs in order given by queuing policy, picking first that is permitted to launch a task
• Jobs must wait before being permitted to launch non-local tasks– If wait < T1, only allow node-local tasks
– If T1 < wait < T2, also allow rack-local
– If wait > T2, also allow off-rack
• Increase a job’s time waited when it is skipped

Capacity Scheduler
• Organizes jobs into queues
• Queue shares as %’s of cluster
• FIFO scheduling within each queue
• Supports preemption
• Queues are monitored; if a queue is not consuming its allocated capacity, this excess capacity can be temporarily allocated to other queues.

End of session
Day – 1: Scheduling







![Microsoft - USENIX...Hadoop MR, Centralized sched. MR 2003 2008 2013 2019 Scope, Centralized sched. Scope [eurosys07, vldb08] Hydra MR YARN Tez Spark +multi-framework +security +scheduler](https://img.pdfslide.net/doc/110x75/60540662d4892268c6428704/microsoft-usenix-hadoop-mr-centralized-sched-mr-2003-2008-2013-2019-scope.jpg)





















