Embed Size (px)
Citation preview

Milan – July 13 2016
Introduction to Distributed Computing Engines for
Data ProcessingSimone Robutti
Machine Learning Engineer at Radicalbit@SimoneRobutti

What is a Distributed Computing System
It’s the solution to the problem where your RAM is too small and your data are too big and/or too CPU-intensive to be processed on a single machine.

What is a Distributed Computing System
Solution: a huge, monolithic mainframe.

What is a Distributed Computing System
Solution: a huge, monolithic mainframe.

What is a Distributed Computing System
Solution: do your job on a cluster.

Distributed vs Parallel
Parallel: execute identical tasks (with different data or parameters).
Parallel Distributed: do this on multiple machines.
Distributed: split a big task into smaller tasks and execute them on multiple machines

What is a Distributed Computing System
Goal: the programmer should write its programs easily and efficiently without caring about distribution.
Issues: a cluster is complex and conceptually very far from a local environment.

HadoopWhat: the first OSS distributed computing engine.
When: 2006 (work began).
Where: Google. Why: Google had a lot of data (for that time) to process. They built a solution. Eventually it became a series of papers and got implemented as OSS.
How: HDFS (distributed file system), MapReduce (computational abstraction), YARN (resource and cluster manager).
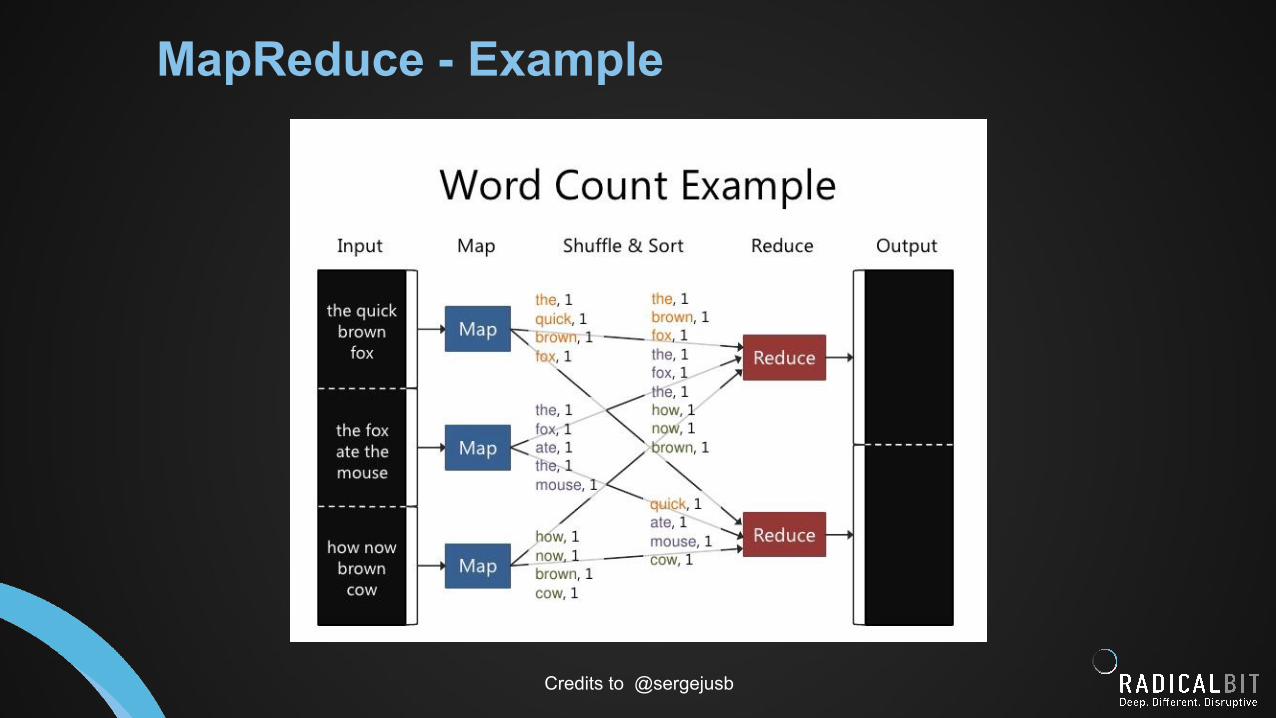
MapReduce - Example
Credits to @sergejusb

Hadoop TodayCommon in many enterprise environments.
Still good enough for many batch processing use cases.
HDFS and Yarn widely used by other processing engines.
i.e.:
● Log analysis● Clickstream analysis● Text processing

SparkWhat: a more generic distributed processing engine for batch and streaming alike.
When: 2014 (1.0 Release).
Where: Berkeley + Databricks. Why: They aimed for faster and more general processing with better abstractions on top.
How: InMemory computing, DAG, RDD, polyglot functional API, libraries out-of-the-box .

Resilient Distributed DatasetRDDs hide the underlying distribution of data with a functional API
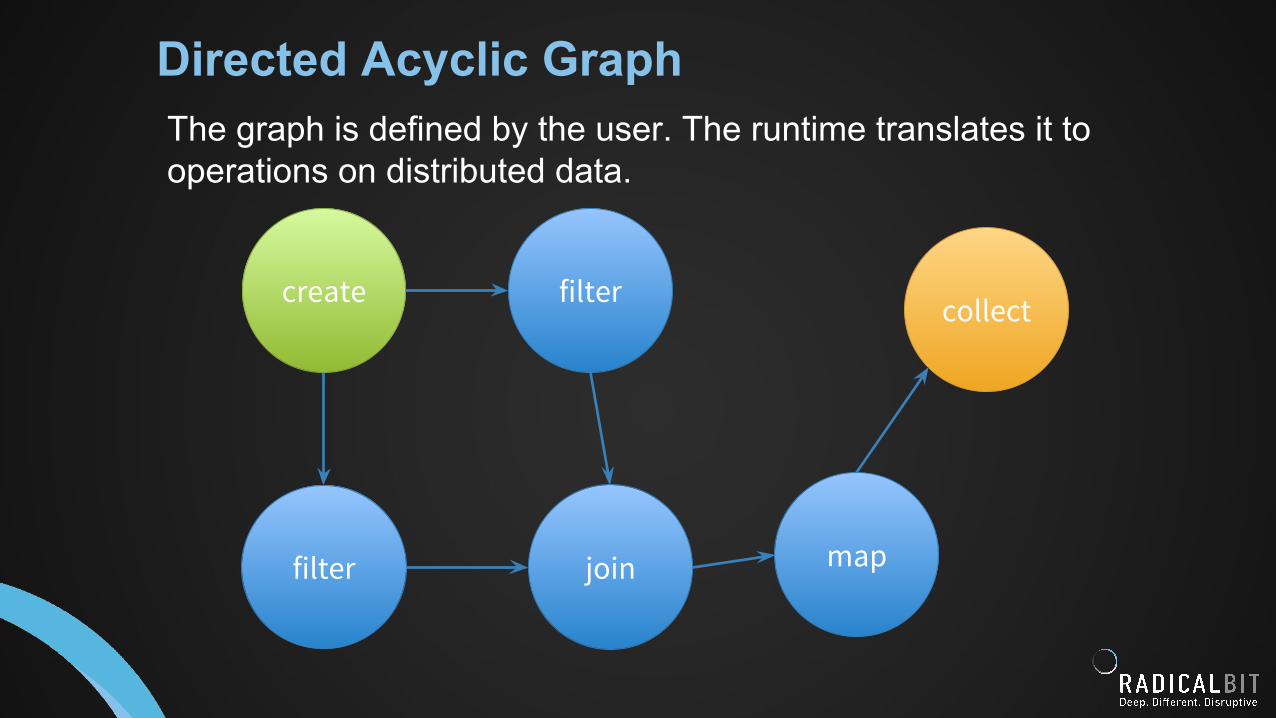
Directed Acyclic GraphThe graph is defined by the user. The runtime translates it to operations on distributed data.
create filter
filter join
collect
map

Spark TodayThe hot topic everyone talks about.
Just entered the phase of maturity, with an already huge and fast-growing ecosystem of libraries, integrations and tools.
Widely used as the go-to solution for Big Data (and not-so-Big) use cases.
I.e.:
● Recommending systems● Fraud Detection● Attack-Detection● Near-Real time decision-heavy solutions

FlinkWhat: a streaming first (with batch on top), low latency distributed processing engine.
When: 2016 (1.0 Release).
Where: German Research Foundation + dataArtisans. Why: a faster and flexible computational model that could guarantee low latency, high-throughput and fault-tolerance all at the same time.
How: streaming-first approach, checkpointing, lazy symbolic computation, powerful optimizations.

Flink TodayPerceived as an alternative to Spark. Gaining traction for specific use-cases (real-time streaming) but performs well on most generic uses cases.
Solid runtime and optimization; API and ecosystem still young.
Many big companies already adopted it for fast-data applications.
I.e.:
● Real-time precise analytics (counting)● Real-time model evaluation● Online Learning solutions

Alternative solutions
● Apache Storm/Heron● Apache Samza● Apache GearPump● Apache Apex

Following next
"The Barclays Data Science Hackathon: Building Retail Recommender Systems based on Customer Shopping Behaviour" by Gianmario Spacagna, Senior Data Scientist @ Pirelli
"Data intensive applications with Apache Flink" by Simone Robutti, Machine Learning Engineer @ Radicalbit





























