Embed Size (px)
Citation preview

1
1
FIRST LAST
TITLE
Welcome Message
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Curabitur elementum posuere pretium. Quisque nibh dolor, dignissim ac dignissim ut, luctus ac urna. Aliquam aliquet non massa quis tincidunt. Mauris ullamcorper justo tristique dui posuere tincidunt. In nec lacus laoreet orci varius
imperdiet sit. Lorem ipsum dolor sit amet, consectetur adipiscing elit. Curabitur elementum posuere pretium. Quisque nibh dolor, dignissim ac dignissim ut, luctus ac urna. Aliquam aliquet non massa quis tincidunt. Mauris ullamcorper justo tristique dui posuere tincidunt. In nec lacus
laoreet orci varius imperdiet sit. In nec lacus laoreet orci varius imperdiet sit. Lorem ipsum dolor sit amet, consectetur adipiscing elit.
Welcome message goes here
Named entity recognition and disambiguation using an iterative
graph processing system
Julien Gonçalves

2
2
Julien Gonçalves
VP research and partner at Reportlinker
Working on semantic technologies since 2004
@rlk_jgo
fr.linkedin.com/pub/julien-gonçalves/2/557/a21

3
3
Who is Reportlinker?
ReportLinker is a technology company focused on providing actionable information from global market research and data, to Marketers, Analysts, Researchers and knowledge workers in the enterprise.
4000 recurring clients around the world (HonneyWell, 3M, …)
A 10M€ Company
40 Employees with 50% engineers and semantic specialists

4
4
What is ReportLinker?
Reportlinker finds, filters and organizes the latest industry data

5
5
Find, Filter and Organize
30 million new documents analyzed / month
Document discovery NLP Search Engine
1 billion url verified / month
3 million documents available as relevant
Each part of the workflow is scalable

6
6
Natural Language Processing
Text preprocessingConverting
PDF/DOC/PTT format to Text.
Lexical analysisParsing words and
sentences
Morphology analysis
Chapter/Table/Figure detection using the
morphology of the original document
Semantic analysis
Using a thesaurus with 3.5 millions
ontologies (industry,
geography, topic)
Storage
Structured, annoted, sliced:
ready to be searchable
Data relevance
Scoring each type of data by relevance
(statistics, analysis, …)

7
7
Semantic Analysis
Industry
Geography
Topic
A Data Lexical Platform using a thesaurus with 3 dimensions
350 industries, 3000 sub-industries
world regions, countries, main cities
Ontologies about industrial economics (production, exportation, …)

8
8
Semantic Analysis
Industry
Controlled vocabulary helps to find the right meaning of a term
Agribusiness
Food
Fruit and Vegetable
Fruit
apple banana
One term can be used for several meanings (ex: “apple” as fruit or company).
The proximity with other concept in the thesaurus helps to find the right meaning when found in the same section of text.

9
Semantic Analysis
How can we find, normalize and classify the company names mentioned in our
reports ?

10
Semantic Analysis : Company
Very simple approach: Use a database of company names as ontology
FAIL ! This approach did not work at all
We bought and used a database with 2 000 000 company names
Too many company names existing as common name (ex: “Post Office”, “Table”, …)
To avoid the noise, we need to match more context in order to be sure of the right meaning of a concept.

11
Semantic Analysis : Company
Millions of companies exist around the world
Company context changes very often (acquisisions, new activities, ...)
Hundreds of companies can have the same name
To be able to disambiguate, we need additional context for each company concept.

12
Our approach
STEP 1Hypotheses
STEP 2
Inferences
STEP 3
Analysis & Classification
To create our own database of company names with additional context for disambiguation.
To exploit our content (110 millions documents) to discover and identify company names, people, products.
To use an inference engine to build a relational graph with verified concepts and contexts.
To use this new base of verified companies, enriched with contexts, to find the right companies in our content.

13
Step 1: Hypotheses
For each document analysed, we extract several “hypotheses” (unverified facts) using text mining rules
Identification of a concept (the probability that its a company, person, product, …)
We mainly have 3 types of hypotheses:
Relation between 2 concepts (context proximity between 2 concepts in the document)
Proximity between a concept and an industry/country (context proximity with an other dimension in the document)

14
Step 1: Hypotheses
In march 2010, Toto inc. acquired Thingso corp., the new CEO Kevin Sherpa wants to be present in China to sell the new Xbrid3.
Example
“Kevin Sherpa” is guessed as a person name (NER rules).
“Toto inc.” and “Thingso corp.” are guessed as company (using NER rules). More the pattern is “safe”, more the hypothese is strong.
“China” is a country (Ontology).
“Xbrid3” is an unidentified named entity (NER rules).

15
Step 1: Hypotheses
Toto inc.
Label Context Industry / Geography
Toto inc. Thingso corp. (C) / Kevin Sherpa (P) / Xbrid3 China
Thingso corp. Toto inc. (C) / Kevin Sherpa (P) / Xbrid3 China
Thingso corp.
Kevin Sherpa Xbrid3

16
Step 1: Hypotheses
To validate these hypotheses we need to find more facts verifying the same hypotheses.
Data volume is one of the key elements of this approach
We mine billions of sentences from economic reports and 3 million news update every month.
Each hypothese brings new information and new contexts around a company concept.
More an hypothese is verified with several sources, more chance it has to become a verified fact.

17
Step 2: Inferences
An inference engine verifies all the hypotheses around each concept in order to keep only the verified facts
C1
C2
P2
P1
From millions/billions of sub-graphs (each scope of context), we obtain 1 final consolidated graph composed of only thousands of sub-graphs.

18
Step 2: Inferences
Apache Giraph is an iterative graph processing system built for high scalability.
Giraph implements the Pregel model and other features that makes it easy to use graph computation.
Giraph loads all the graph in-memory, computation is very quick.
Giraph is highly scalable.

19
Step 2: Inferences
Graph reduction continues until we can’t reduce the graph anymore
Toto Inc. #1
Kevin SherpaThingso corp.Xbrid3
Toto Inc. #2
Kevin SherpaDavid RegoXbrid3
Toto Inc. #3
Thingso corp.David RegoXbrid ProjectNeko Ltd.
Toto Inc. #4
Kevin SherpaXbrid ProjectNeko Ltd.
China ChinaUS
China
Toto Inc. #1 Kevin SherpaDavid RegoThingso corp.Xbrid3
China
Toto Inc. #2
Xbrid ProjectKevin SherpaXbrid3
ChinaUS
Toto Inc. #1
Xbrid ProjectKevin SherpaDavid RegoThingso corp.Neko Ltd.
Iteration 1
Iteration 2
David RegoThingso corp.Neko Ltd.
ChinaUS

20
Step 2: Inferences
The final graph is filtered to obtain a base of verified companies
Only the best context is kept for each company name (context frequently related to the company)
Special iterations are processed to normalize company names having very close names (ex: “Google France” and “Google Fr”).

21
Step 3: Semantic Analysis
Company Name
Name to Match / Alias Contexts Industry / Geography
Toto inc. Toto inc.Toto incorporatedToto
Xbrid ProjectKevin SherpaXbrid3David RegoThingso corp.Neko Ltd....
ChinaUS
Apple inc. Apple inc.Apple incorporatedApple
Tim CookiPhoneiPadSteve Jobs...
USWorld
More a company name is “common”, the more it will need a better diversity of context to be verified (common noun, several company with the same names, high frequency in the corpus)

22
Step 3: Semantic Analysis
Kevin Sherpa said “Toto forecasts to double its revenue in China selling the new Xbrid3.”
1) “Toto” is a possible name to match, normalized as “Toto inc.”
2) “Toto” is found in this text, we load all the contextual terms terlated to this concept in order to disambiguate and select the right concept.
3) Contextual terms are found, “Toto” is classified as “Toto inc.” in this text.
23
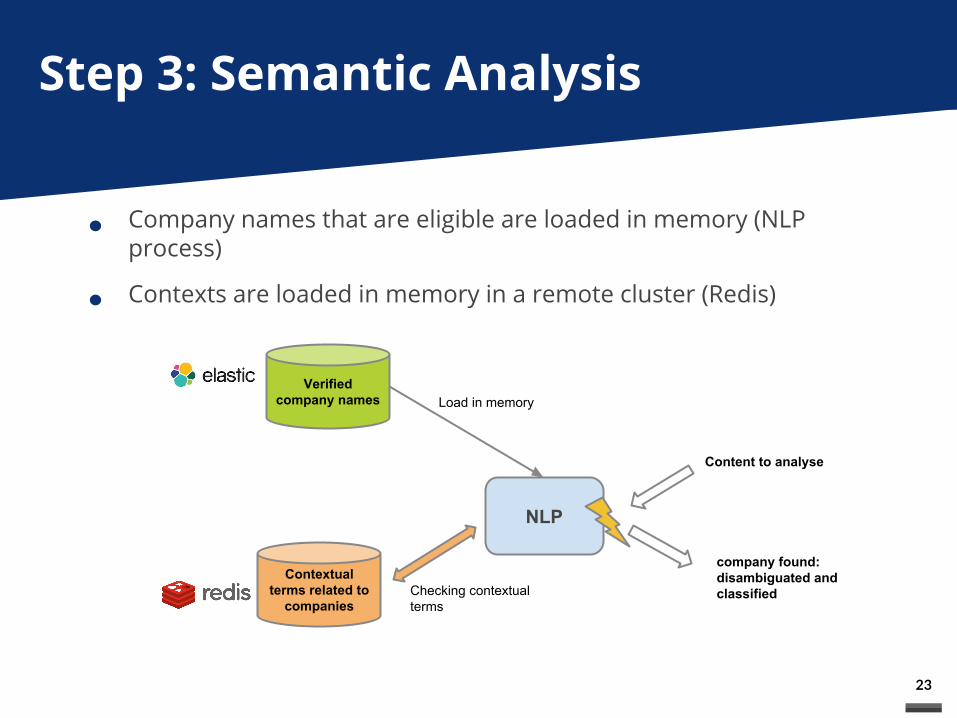
Step 3: Semantic Analysis
Contextual terms related to
companies
Verified company names
NLP
Content to analyse
Load in memory
Checking contextual terms
company found: disambiguated and classified
Company names that are eligible are loaded in memory (NLP process)
Contexts are loaded in memory in a remote cluster (Redis)

24
Beta version: Statistics
400 million hypotheses
2 million documents analysed
graph nodes: 27 milliongraph edges: 380 million
> 400 000 companies verified, enriched with contexts

25
Conclusion
Using Big Data analytics we found a very good approach to discover, disambiguate and normalise company names. This solution works because we succeed in resolving 3 main issues:
Data volume
Pattern detection to discover hypotheses (NER rules)
Optimized algorithms for the inference engine

26
QUESTIONS ?





























