Embed Size (px)
Citation preview

LiCord: Language Independent Content Word Finder
Md-Mizanur Rahoman, Tetsuya Nasukawa, Hiroshi Kanayama &Ryutaro Ichise
April 18, 2016

Background
currently 100s of languages are available, only few of them can beautomatically mined because of low or no NLP-resources availability
creating NLP-resources for all languages is not feasible
Content Words finding system for languages can be consideredbasic NLP-resource
Rahoman et.al., | LiCord | 2

Content Word
definition: Content Words [ref: American Heritage Dictionary]
are nouns, most verbs, adjectives, and adverbs that refer to someobject, action, or characteristiccarry independent meaningare usually open i.e, new words can be added
example: “NO8DO” is the official motto of Seville.
usage: Content Words can be used
(new) topic identificationdocument summarizingquestion answering etc.
Rahoman et.al., | LiCord | 3

Problem & Possible Solution
problemContent Words finding requires language dependent NLP-resource
language parserparallel corpora etc.
NLP-resource developing for all language is costly and “not feasible”
possible solution
morphological features of text segment can classify whether a segmentis Content Word
machine learning model can classify text segment into Content Wordbig text corpus can generate balanced morphological features for suchtext segments
Rahoman et.al., | LiCord | 4

System Framework
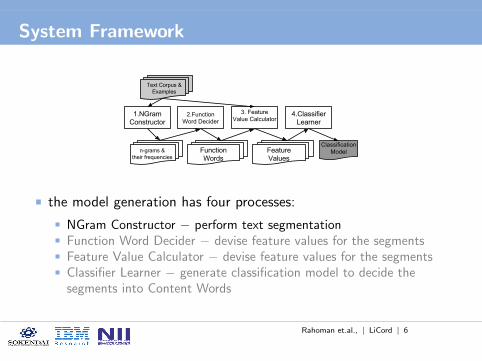
the model generation has four processes:
NGram Constructor − perform text segmentationFunction Word Decider − devise feature values for the segmentsFeature Value Calculator − devise feature values for the segmentsClassifier Learner − generate classification model to decide thesegments into Content Words
Rahoman et.al., | LiCord | 5
System Framework
the model generation has four processes:
NGram Constructor − perform text segmentationFunction Word Decider − devise feature values for the segmentsFeature Value Calculator − devise feature values for the segmentsClassifier Learner − generate classification model to decide thesegments into Content Words
Rahoman et.al., | LiCord | 6

1.NGram Constructor
segment text and construct variable token (length) n-grams
calculate n-gram frequencies
Table: Variable length n-grams and their frequencies for an exemplarycorpus T- = “Japan is an Asian country. Japan is a peaceful country”.
n-grams and frequencies over the T-
size 1 n-gram {[Japan−2], [is−2], [an−1], ..., }(/uni-gram) [country−2], [a−1], ... }size 2 n-gram {[Japan is−2], [is an−1], ..., }(/bi-gram) [Asian country−1], ...}size 3 n-gram {[Japan is an−1], [is an Asian−1], }(/tri-gram) [an Asian country−1], ... }
Rahoman et.al., | LiCord | 7

System Framework
the model generation has four processes:
NGram Constructor − perform text segmentationFunction Word Decider − devise feature values for the segmentsFeature Value Calculator − devise feature values for the segmentsClassifier Learner − generate classification model to decide thesegments into Content Words
Rahoman et.al., | LiCord | 8

2.Function Word Decider
Function Wordsexpress grammatical relationships with other wordshave little lexical meaning or have ambiguous meaningare frequent n-grams over a text documentexample: “the”, “in”, “in spite of” etc.
decide bypick a threshold number of frequent n-gramsmap frequent n-grams with available translation of known FunctionWords
use threshold only, if translation service is not available
n-gram # of token frq frq%the 1 3124631 67.60in 1 1774988 38.40... ... ... ...
united states 2 43698 0.94... ... ... ...
Rahoman et.al., | LiCord | 9

System Framework
the model generation has four processes:
NGram Constructor − perform text segmentationFunction Word Decider − devise feature values for the segmentsFeature Value Calculator − devise feature values for the segmentsClassifier Learner − generate classification model to decide thesegments into Content Words
Rahoman et.al., | LiCord | 10

3.Feature Value Calculator
select fifteen different morphological features of text & calculatetheir values for n-grams over a big corpus
where the n-grams appear i.e., begining/mid/end part of the sentenceshow frequent the n-grams appear in a corpushow the n-grams get added with Function Words, punctuationetc.
Rahoman et.al., | LiCord | 11

System Framework
the model generation has four processes:
NGram Constructor − perform text segmentationFunction Word Decider − devise feature values for the segmentsFeature Value Calculator − devise feature values for the segmentsClassifier Learner − generate classification model to decide thesegments into Content Words
Rahoman et.al., | LiCord | 12

4.Classifier Learner (1/2)
construct frequency-range-wise classification models
Reason
consume a large amount of time, if all n-grams are used as trainingexampledoes not represent entire dataset, if randomly pickedassume same frequency n-grams shares same kind of morphologicalfeatures (over the corpus)
Rahoman et.al., | LiCord | 13

4.Classifier Learner (2/2)
construct frequency-range-wise classification models
Method
collect range-based n-grams
X(i,j) = {x | x ∈ N ∧ i ≤ frq(x) ≤ j}N = all n-grams in corpus, x = n-gramselect threshold number of n-grams as training n-grams for each rangecalculate features for each range-wise selected n-gramslearn classification model for each range training n-grams
Rahoman et.al., | LiCord | 14

Experiment
check whether LiCord can identify Content Words languageindependently
analyzed language − English, Vietnamese, and Indonesianused training resource − Wikipedia Pages & Wikipedia Titles
+ve: when n-gram (text segment) exists on Wikipedia Title.E.g., Seville, official motto etc.-ve: otherwise.E.g.“NO8DO” is, is the etc.
classification algorithm − Support Vector Machine and C4.5(tree-based algorithm)
Rahoman et.al., | LiCord | 15
Language Independent Content Word Finding (1/2)
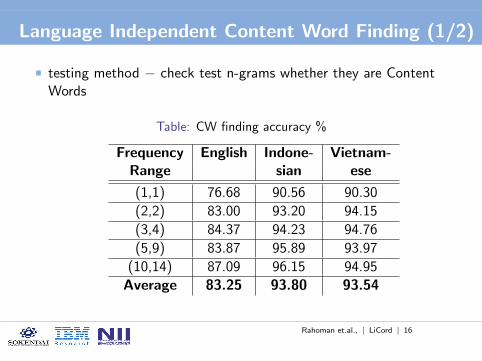
testing method − check test n-grams whether they are ContentWords
Table: CW finding accuracy %
Frequency English Indone- Vietnam-Range sian ese
(1,1) 76.68 90.56 90.30
(2,2) 83.00 93.20 94.15
(3,4) 84.37 94.23 94.76
(5,9) 83.87 95.89 93.97
(10,14) 87.09 96.15 94.95
Average 83.25 93.80 93.54
Rahoman et.al., | LiCord | 16

Language Independent Content Word Finding (2/2)
Newly discovered Content Words finding accuracy %
Frequency English Indone- Vietnam-Range sian ese
(1,1) 27.90 11.34 10.63
(2,2) 45.00 18.54 25.00
(3,4) 52.11 24.45 27.56
(5,9) 50.34 25.56 30.88
(10,14) 61.90 29.89 35.13
Average 47.45 21.95 22.50
finding − checking of a large number of sentences for their specificmorphological features over a big corpus can generate machinelearning model to find Content Words
Rahoman et.al., | LiCord | 17

Conclusion
language independent way Content Word finding a requirement incurrent days’ text mining
we propose a supervised Machine Learning technique to classifytext segments to Content Words
experiment results show proposed methods can serve as a ContentWord finder
Rahoman et.al., | LiCord | 18

Experiment 1 (1/2)
purpose − whether LiCord can identify NEs (Named Entities), andact like sentence parser
identifying NEs − executed for some test sentences, compared withWikifier and Spotlight
Table: Comparison for LiCordwith Wikifier
Recall
Wikifier 33.33%LiCord 90.47%
Table: Comparison for LiCordwith Spotlight
Recall
Spotlight 83.33%LiCord 91.66%
Rahoman et.al., | LiCord | 20

Experiment 1 (2/2)
acting as parser − executed for some test sentences, compared withStanford parser for Content Words
Table: Comparison for LiCord with Parser
Language Recall
English 92.30%
finding − checking of a large number of sentences for their specificmorphological features over a big corpus can support wordsegmenting
Rahoman et.al., | LiCord | 21

![Language-Independent Aspect-Oriented Programming · Language-Independent Aspect-Oriented Programming ... [Programming Languages]: ... same is true of development tools for which current](https://img.pdfslide.net/doc/110x75/5b141f007f8b9a257c8b67e9/language-independent-aspect-oriented-programming-language-independent-aspect-oriented.jpg)




























