Embed Size (px)
Citation preview

Migrating Database Content from SQL Server to SAP HANA
Applies to
HANA 1.0 SP06
Author: Weibin Yu
Company: SAP AG
Created on: November 2013

SAP Co-Innovation Lab http://coil.sap.com
© 2009 SAP AG 2
Table of Contents
Migrating Database Content from SQL Server to SAP HANA ............................................................................................. 1
1 Overview ...................................................................................................................................................................... 3
1.1 Purpose .............................................................................................................................................................. 3
1.2 Note for the audience ......................................................................................................................................... 3
1.3 About SAP HANA ............................................................................................................................................... 3
1.4 MS SQL System targeted ................................................................................................................................... 3
2 Database Schema Migration ........................................................................................................................................ 4
2.1 Mapping the MS SQL databases to SAP HANA Schema ................................................................................... 4
2.2 Migrate a MS SQL database to an SAP HANA schema ..................................................................................... 5
2.2.1 Obtaining a MS SQL table definition ................................................................................................................... 5 2.2.2. Data Types Mapping ...................................................................................................................................... 6
2.2.3. Database constraint and key conversion (primary and foreign key) ............................................................... 7
2.2.4. Database Index conversion ............................................................................................................................ 8
2.2.5. Table Creation ................................................................................................................................................... 8
2.3 Using SAP BusinessObjects Data Services for Database Schema Migration .................................................... 9
3 Data transfer to SAP HANA ......................................................................................................................................... 9
3.1 Create Repository and Data Store for MSSQL and SAP HANA. ...................................................................... 10 3.1.1 Create SQL SERVER and SAP ODBC connections. ................................................................................... 10
3.1.2. Create Data Store in the Data Services ....................................................................................................... 10
3.2 Creating the data migration project including batch job and data flow .............................................................. 11
3.3 Configure and execute batch job to complete data transferring ....................................................................... 12
4 MS SQL Server Stored Procedure migration ............................................................................................................. 13
4.1 The difference between SAP HANA and MS SQL procedures ......................................................................... 13
4.2 Procedure Migration Steps and samples .......................................................................................................... 14 4.2.1 Parameters (IN OUT) translation .................................................................................................................. 14
4.2.2 Procedure Body Conversion ........................................................................................................................ 16
5 Optimizing Procedures – Best Practices .................................................................................................................... 18
5.1 Temporary table in a store procedure ............................................................................................................... 18
5.2 Use the Cursor carefully ................................................................................................................................... 19
5.3 SQL Statement and calculation optimizaiton .................................................................................................... 20
5.4 SQL Statement and calculation optimization .................................................................................................... 20
5.5 Implicit Type Casting ........................................................................................................................................ 20
5.6 Join Statement optimization ............................................................................................................................. 21
6 HANA procedure troubleshooting .............................................................................................................................. 22
6.1 Debugging HANA procedures .......................................................................................................................... 22
6.2 Trace intermediate results in HANA procedures ............................................................................................... 23
Copyright............................................................................................................................................................................ 24

SAP Co-Innovation Lab http://coil.sap.com
© 2009 SAP AG 3
1 Overview
1.1 Purpose
This Migration Guide is intended as a reading for anyone involved in migrating an SQL Server database to SAP HANA. This document will guide readers through the process of planning and executing the migration.
This guide also introduces hints for the procedures’ optimization and testing methods.
One can basically distinguish between four steps while migrating database content from MS SQL to SAP HANA: Database migration, Data migration, Procedure and Function Migration and Testing & Optimization (see the Figure 1 below).
Figure 1: Migration Steps Overview
1.2 Note for the audience
The reader is expected to be familiar with relational database concepts and particularly those of MS SQL Server. For a successful database migration, there should be a detailed understanding of the current MS SQL system, including its high- and low-level architecture, as well as the interaction between the client application and the MS SQL database.
1.3 About SAP HANA
The SAP In-Memory Appliance (SAP HANA) enables business departments to analyze business as it happens. Individuals can create very flexible analytic models based on real-time data originating from business systems.
This guide is based on SAP HANA 1.0 Revision 60. SAP HANA Server and SAP HANA Studio.
1.4 MS SQL System targeted
This Migration Guide can be applied to any type of MS SQL system. While it does not focus on a specific type of applications, workload or system design, the majority of MSSQL migration candidate systems are expected to be transactional systems.
SAP Co-Innovation Lab http://coil.sap.com
© 2009 SAP AG 4
2 Database Schema Migration
The first step is to migrate the database schema. The "database schema" refers to the physical data model: the definition of the database structure (tables, columns, indexes, views, data types etc.). This structure is typically expressed in SQL DDL (Data Definition Language), e.g. the 'create table' statements.
There are some differences between the HANA and MS SQL schema definitions.
In HANA, a "schema" is a central concept. It is a collection of database objects (tables, views, stored procedures, triggers etc.) owned by a particular user. A decision needs to be made as to how to map an SAP HANA schema to a MS SQL database; see section 4.5 for details.
MS SQL also has a command “create schema authorization” which creates a number of tables and views
plus associated permission settings as a transactional unit. This command is however rarely used in HANA and it is not used or discussed further in this Migration Guide.
In SAP HANA context, one can use the key word “set schema” to switch to the (logical) database (in MS SQL
context).
2.1 Mapping the MS SQL databases to SAP HANA Schema
SAP HANA uses the schema to collect all database objects like tables, views, procedures, triggers etc. The concept of a HANA Schema is a bit similar to the concept of a MS SQL Database, the comparison is as follows:
Object/Artifact SQL Server SAP HANA
Database collections
Databases Catalog
Database Databases/<database> Catalog/<schema>
Table/View Databases/<database>/Tables (views) Catalog/<schema>/Tables (views)
Procedure
Databases/<database>/Programmability/Stored Procedure
Catalog/<schema>/Procedures
Function Databases/<database>/Programmability/Functions
Catalog/<schema>/Functions
Triggers Databases/<database>/Programmability/Triggers
Catalog/<schema>/Triggers
Table 1: Terminology comparison
For the migration, the schema should be created in HANA according to the source MS SQL database. For example, if the source MS SQL database is db_sample, than one shall create the corresponding database schema in SAP HANA:
CREATE SCHEMA db_sample;
Once the schema db_sample is in place, all corresponding tables, views, procedures, triggers, functions should be created under the specified schema. The migration of the particular artifacts (tables, procedures etc.) will be discussed in the following chapters.
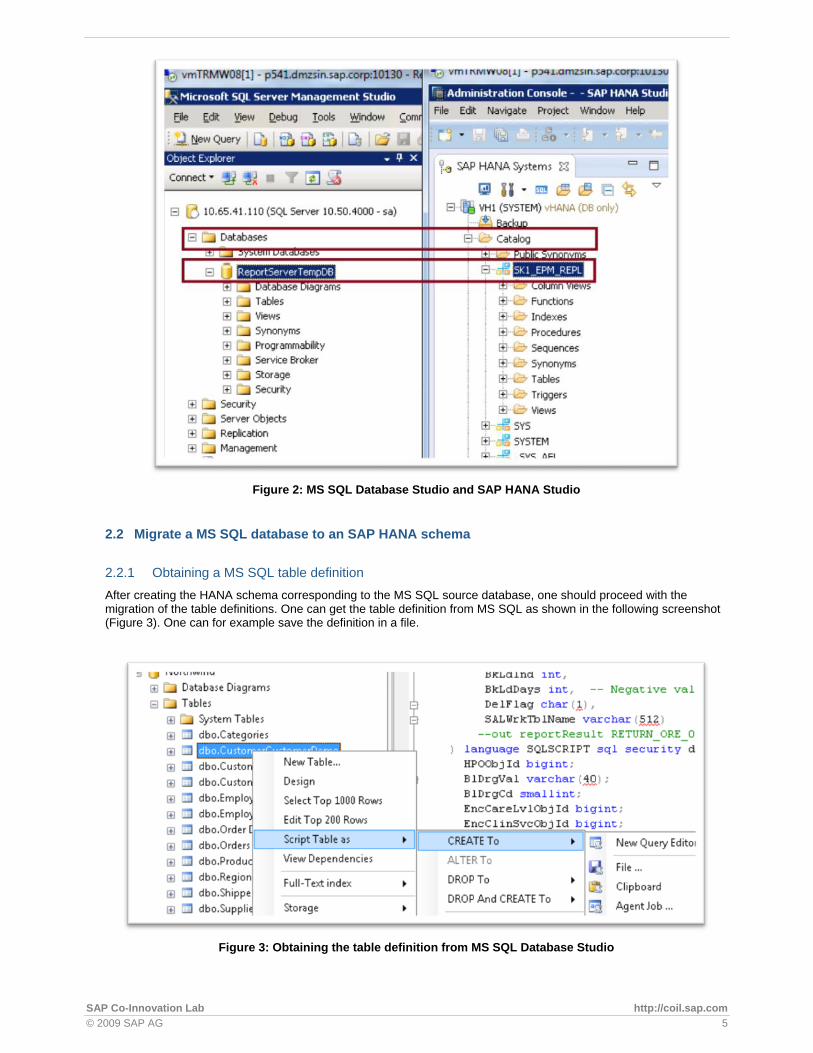
Figure 2 below captures some conceptual differences in the artifacts management between the HANA Studio and MS SQL Management Studio.
SAP Co-Innovation Lab http://coil.sap.com
© 2009 SAP AG 5
Figure 2: MS SQL Database Studio and SAP HANA Studio
2.2 Migrate a MS SQL database to an SAP HANA schema
2.2.1 Obtaining a MS SQL table definition
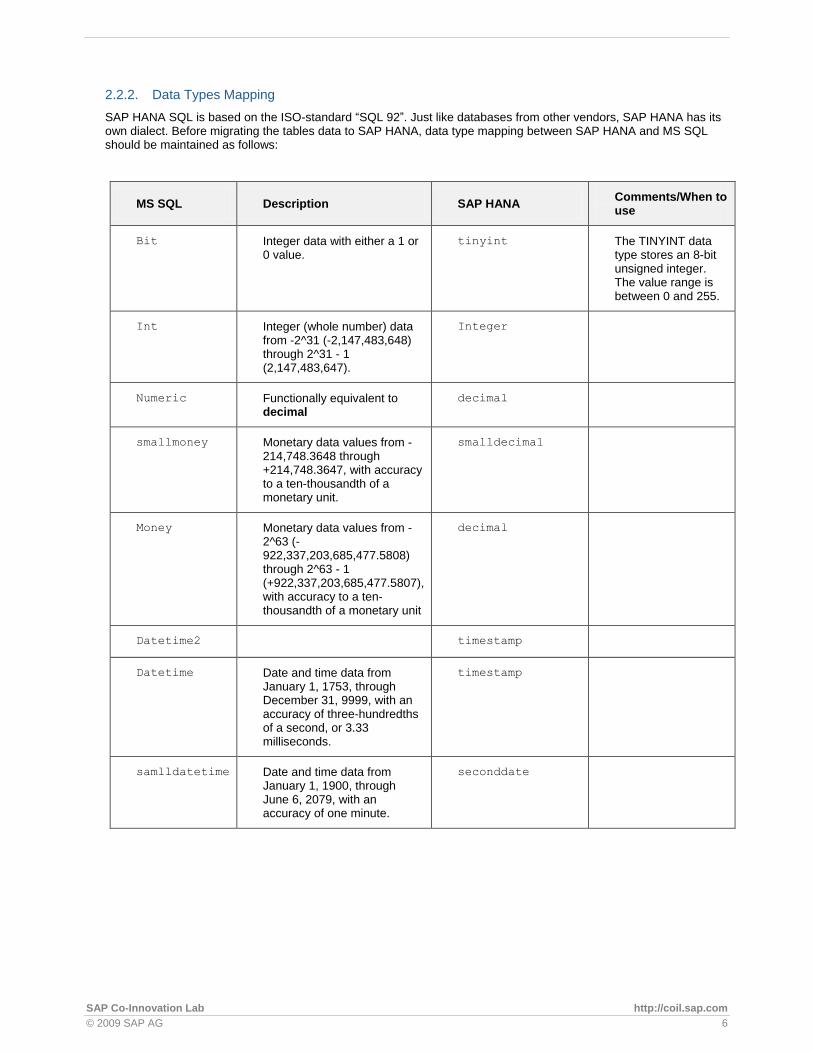
After creating the HANA schema corresponding to the MS SQL source database, one should proceed with the migration of the table definitions. One can get the table definition from MS SQL as shown in the following screenshot (Figure 3). One can for example save the definition in a file.
Figure 3: Obtaining the table definition from MS SQL Database Studio
SAP Co-Innovation Lab http://coil.sap.com
© 2009 SAP AG 6
2.2.2. Data Types Mapping
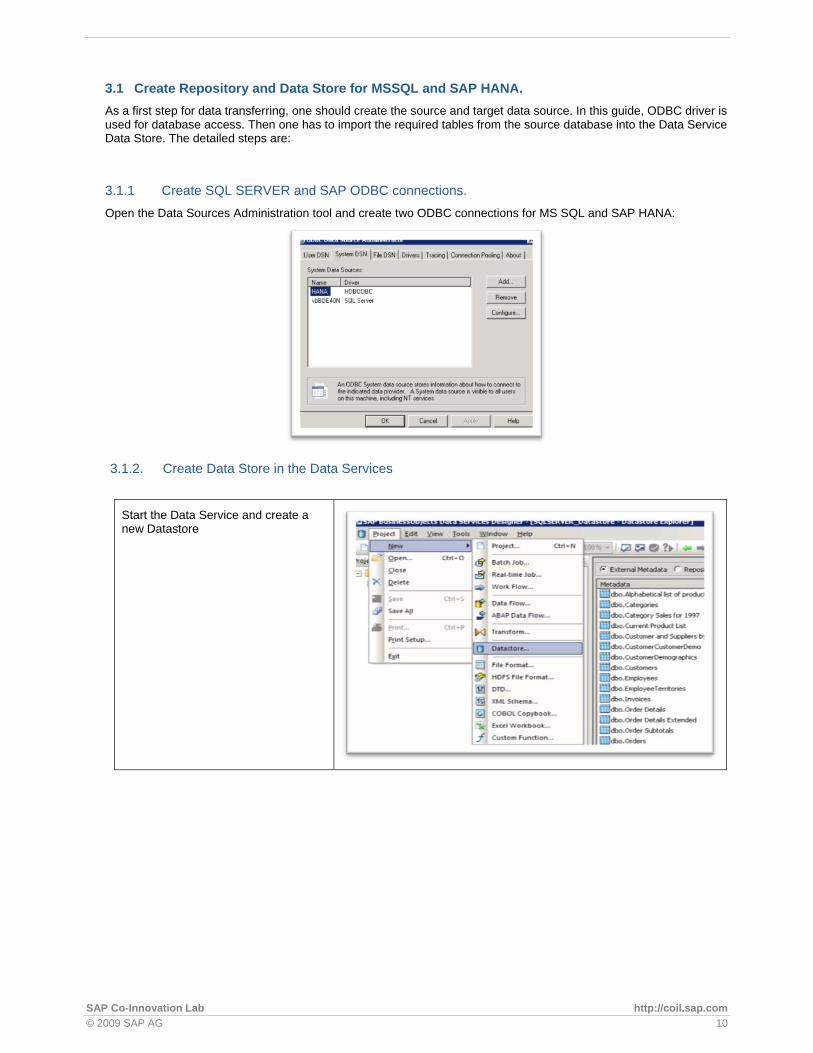
SAP HANA SQL is based on the ISO-standard “SQL 92”. Just like databases from other vendors, SAP HANA has its own dialect. Before migrating the tables data to SAP HANA, data type mapping between SAP HANA and MS SQL should be maintained as follows:
MS SQL Description SAP HANA Comments/When to use
Bit Integer data with either a 1 or 0 value.
tinyint The TINYINT data type stores an 8-bit unsigned integer. The value range is between 0 and 255.
Int Integer (whole number) data from -2^31 (-2,147,483,648) through 2^31 - 1 (2,147,483,647).
Integer
Numeric Functionally equivalent to decimal
decimal
smallmoney Monetary data values from -214,748.3648 through +214,748.3647, with accuracy to a ten-thousandth of a monetary unit.
smalldecimal
Money Monetary data values from -2^63 (-922,337,203,685,477.5808) through 2^63 - 1 (+922,337,203,685,477.5807), with accuracy to a ten-thousandth of a monetary unit
decimal
Datetime2 timestamp
Datetime Date and time data from January 1, 1753, through December 31, 9999, with an accuracy of three-hundredths of a second, or 3.33 milliseconds.
timestamp
samlldatetime Date and time data from January 1, 1900, through June 6, 2079, with an accuracy of one minute.
seconddate

SAP Co-Innovation Lab http://coil.sap.com
© 2009 SAP AG 7
2.2.3. Database constraint and key conversion (primary and foreign key)
When migrating the MS SQL database to an SAP HANA schema, we first need to get the MSSQL database definition including table definitions, procedures etc.
SQL Server Constraint Syntax SAP HANA Constraint Syntax
[ CONSTRAINT constraint_name ]
{ [ { PRIMARY KEY | UNIQUE }
[ CLUSTERED | NONCLUSTERED ]
{ ( column [ ASC | DESC ]
[ ,...n ] ) }
[ WITH FILLFACTOR = fillfactor ]
[ ON { filegroup | DEFAULT } ]
]
| FOREIGN KEY
[ ( column [ ,...n ] ) ]
REFERENCES ref_table
[ ( ref_column [ ,...n ] ) ]
[ ON DELETE { CASCADE | NO
ACTION } ]
[ ON UPDATE { CASCADE | NO
ACTION } ]
[ NOT FOR REPLICATION ]
| CHECK [ NOT FOR REPLICATION ]
( search_conditions )
}
CREATE [UNIQUE] [BTREE | CPBTREE] INDEX
<index_name> ON <table_name>
(<column_name_order_entry>[{,
<column_name_order_entry>}...])
[<global_index_order>]
Here are two constraint conversion examples (one for primary and one for foreign key):
SQL Server SAP HANA
Primary Key
ALTER TABLE t ADD CONSTRAINT prim_key
PRIMARY KEY (a, b);
CONSTRAINT [PKCL_HPerson] PRIMARY KEY
CLUSTERED
([ObjectID] ASC) WITH (PAD_INDEX =
OFF, STATISTICS_NORECOMPUTE = OFF,
IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS
= ON, ALLOW_PAGE_LOCKS = ON) ON
[PRIMARY]) ON [PRIMARY]
ALTER TABLE t ADD CONSTRAINT
prim_key PRIMARY KEY (a, b);
Foreign Key
ADD CONSTRAINT FK_ContactBacup_Contact
FOREIGN KEY (ContactID)
REFERENCES Person.Person
(BusinessEntityID)
ALTER TABLE tab1 ADD CONSTRAINT
foreign_key1 FOREIGN KEY (a)
REFERENCES ref_tab1 (c)

SAP Co-Innovation Lab http://coil.sap.com
© 2009 SAP AG 8
2.2.4. Database Index conversion
MS SQL Server Index Creation SAP HANA Index Creation
CREATE [ UNIQUE ] [ CLUSTERED | NONCLUSTERED
] INDEX index_name ON <object> ( column [
ASC | DESC ] [ ,...n ] )
[ INCLUDE ( column_name [ ,...n ] ) ]
[ WHERE <filter_predicate> ]
[ WITH ( <relational_index_option> [
,...n ] ) ]
[ ON { partition_scheme_name
( column_name )
| filegroup_name
| default
}
]
[ FILESTREAM_ON {
filestream_filegroup_name |
partition_scheme_name | "NULL" } ]
[ ; ]
CREATE [UNIQUE] [BTREE | CPBTREE] INDEX
<index_name> ON <table_name>
(<column_name_order_entry>[{,
<column_name_order_entry>}...])
[<global_index_order>]
Index conversion examples
MS SQL Server SAP HANA
CREATE UNIQUE CLUSTERED INDEX Idx1 ON
t1(c);
CREATE INDEX idx ON t(b);
2.2.5. Table Creation
MS SQL Server Table Creation SAP HANA Table Creation
CREATE TABLE [database_name.[owner].|
owner.] table_name
({<column_definition> | column_name AS
computed_column_expression |
<table_constraint> } [ ,...n ])
[ ON { filegroup | DEFAULT } ]
[ TEXTIMAGE_ON { filegroup |
DEFAULT } ]
CREATE [<table_type>] TABLE
<table_name> <table_contents_source>
[<logging_option>]
[<auto_merge_option>]
[<unload_priority_clause>]
[<schema_flexibility_option>]
[<partition_clause>]
[<location_clause>] | CREATE VIRTUAL
TABLE <table_name>
<remote_location_clause>

SAP Co-Innovation Lab http://coil.sap.com
© 2009 SAP AG 9
Here is a table creation example:
MS SQL Server SAP HANA
CREATE column TABLE "XXXX"."phase" (
"OBJID" INTEGER CS_FIXED NOT NULL,
"ENTITYID" BIGINT CS_FIXED NOT
NULL,
............
............
PRIMARY KEY (
"OBJID","ENTITYID" ) )
CREATE column TABLE "XXXX"."phase" (
"OBJID" INTEGER CS_FIXED NOT NULL,
"ENTITYID" BIGINT CS_FIXED NOT
NULL,
............
............
PRIMARY KEY ( "OBJID","ENTITYID" )
)
2.3 Using SAP BusinessObjects Data Services for Database Schema Migration
SAP BusinessObjects Data Services is probably one of the most advanced ETL tools on the market. It is a standalone tool, supporting various database types, of which and in this case MS SQL and SAP HANA are of primal interest to us .
For more information on SAP BusinessObjects Data Services, please refer to http://scn.sap.com/community/data-services.
We found that using Data Services for the schema/database migration is very convenient, since it provides a natural integration with SAP HANA.
Prerequisites: the following needs to be installed on your client side for using Data Services:
ODBC Driver for SAP HANA (the latest version available, but at least version 1.0.60).
MSSQL ODBC driver.
Overview: You need to perform the following steps in order to migrate the schema (tables, indexes, views, constraint).
For details, please refer to chapter 3:
1. Create two data sources: MS_SQL and SAP HANA and load the table into the repository.
2. Create new project and batch job under the specified project.
3. Create the dataflow and drag the template table from HANA data source to create related query.
4. Run the job for initial data loading. The HANA table schema will be created.
3 Data transfer to SAP HANA
SAP Data Services and SAP Information Steward are part of the Enterprise Information Management suite of products that target the Information Management personas: the administrator, the designer and the subject matter experts in charge of data stewardship and data governance.
SAP Data Services delivers a single enterprise-class solution for data integration, data quality, data profiling and text data processing that:
Allows you to integrate, transform, improve, and deliver trusted data to critical business processes.
Provides development user interfaces, a metadata repository, a data connectivity layer, a run-time environment and a management console—enabling IT organizations to lower total cost of ownership and accelerate time to value.
SAP Co-Innovation Lab http://coil.sap.com
© 2009 SAP AG 10
3.1 Create Repository and Data Store for MSSQL and SAP HANA.
As a first step for data transferring, one should create the source and target data source. In this guide, ODBC driver is used for database access. Then one has to import the required tables from the source database into the Data Service Data Store. The detailed steps are:
3.1.1 Create SQL SERVER and SAP ODBC connections.
Open the Data Sources Administration tool and create two ODBC connections for MS SQL and SAP HANA:
3.1.2. Create Data Store in the Data Services
Start the Data Service and create a new Datastore
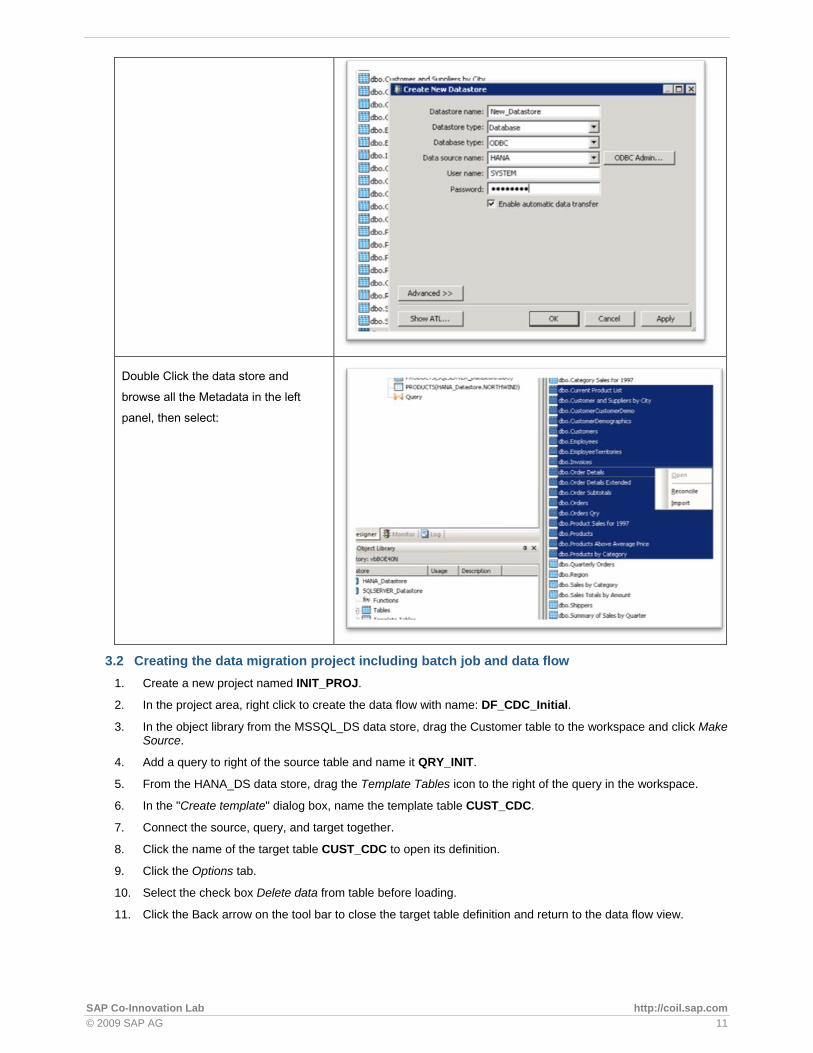
SAP Co-Innovation Lab http://coil.sap.com
© 2009 SAP AG 11
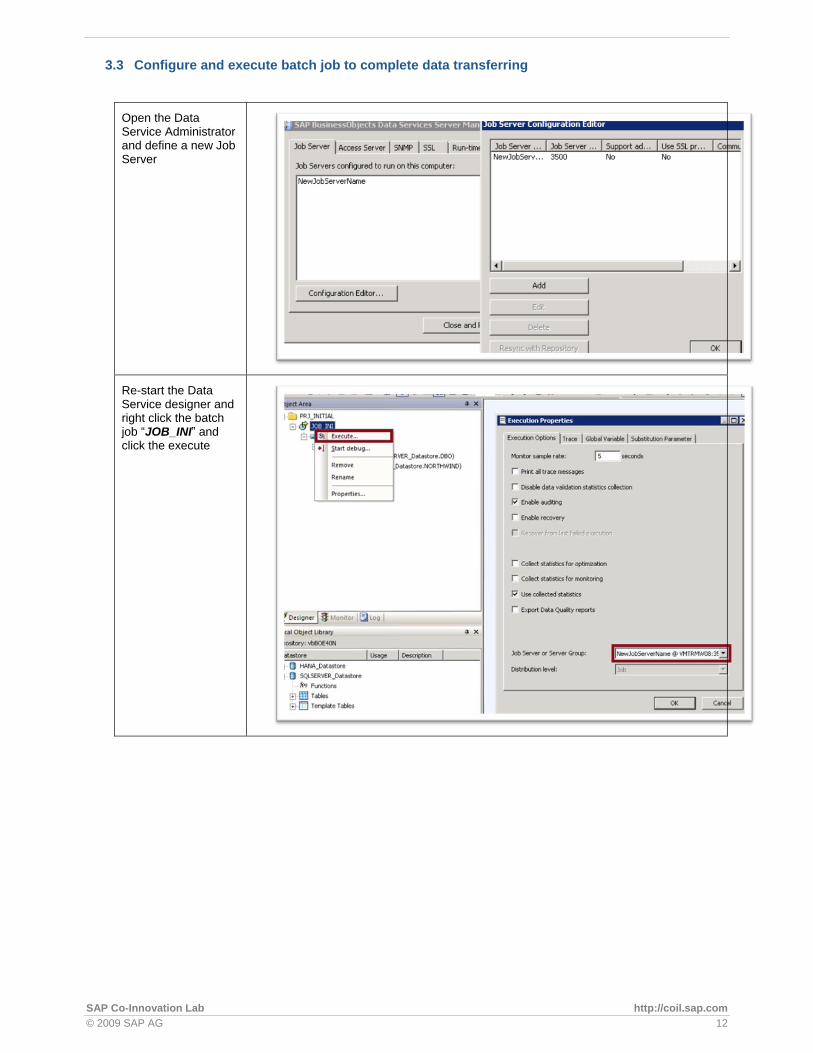
Double Click the data store and
browse all the Metadata in the left
panel, then select:
3.2 Creating the data migration project including batch job and data flow
1. Create a new project named INIT_PROJ.
2. In the project area, right click to create the data flow with name: DF_CDC_Initial.
3. In the object library from the MSSQL_DS data store, drag the Customer table to the workspace and click Make Source.
4. Add a query to right of the source table and name it QRY_INIT.
5. From the HANA_DS data store, drag the Template Tables icon to the right of the query in the workspace.
6. In the "Create template" dialog box, name the template table CUST_CDC.
7. Connect the source, query, and target together.
8. Click the name of the target table CUST_CDC to open its definition.
9. Click the Options tab.
10. Select the check box Delete data from table before loading.
11. Click the Back arrow on the tool bar to close the target table definition and return to the data flow view.
SAP Co-Innovation Lab http://coil.sap.com
© 2009 SAP AG 12
3.3 Configure and execute batch job to complete data transferring
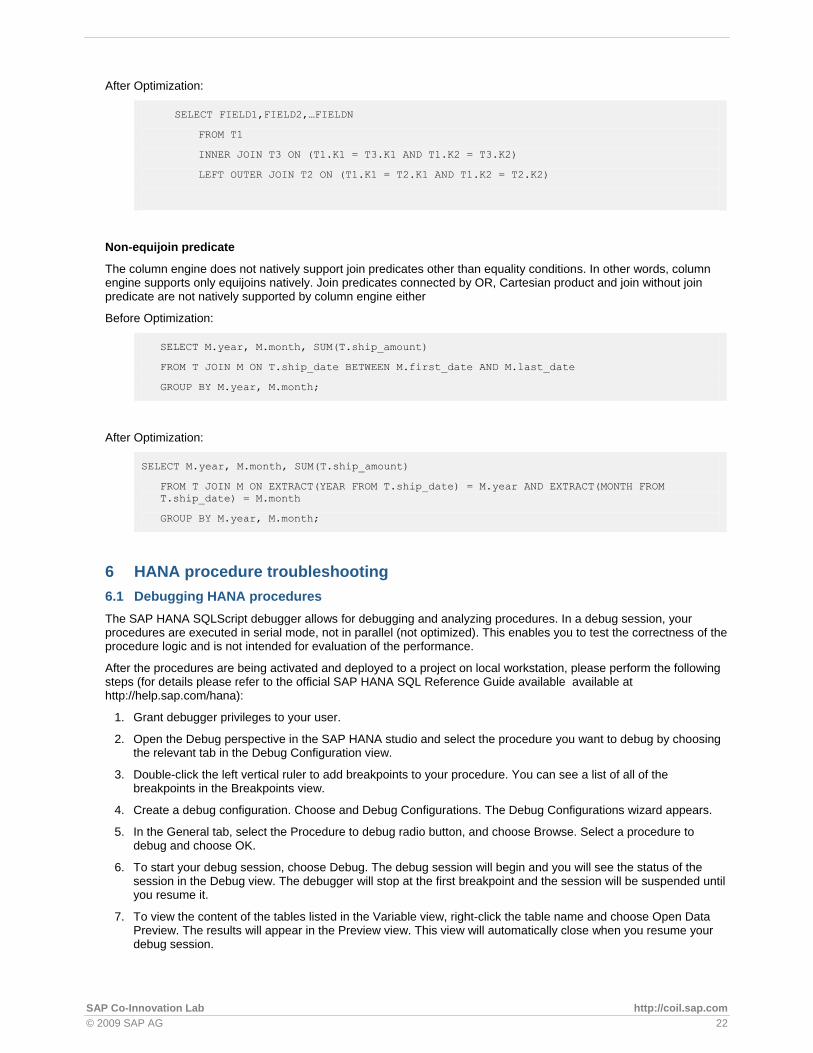
Open the Data Service Administrator and define a new Job Server
Re-start the Data Service designer and right click the batch job “JOB_INI” and click the execute

SAP Co-Innovation Lab http://coil.sap.com
© 2009 SAP AG 13
Job execution logs
4 MS SQL Server Stored Procedure migration
4.1 The difference between SAP HANA and MS SQL procedures
HANA is similar to MS SQL in many aspects. It is a block-structured, imperative language, and all variables have to be declared. Assignments, loops, conditionals are similar. Here is an exemplar grammar comparison:
SAP HANA MS SQL
CREATE PROCEDURE <proc_name>
[(<parameter_clause>)] [LANGUAGE <lang>]
[SQL SECURITY <mode>] [DEFAULT SCHEMA
<default_schema_name>] [READS SQL DATA
[WITH RESULT VIEW <view_name>]] AS
<local_scalar_variables> BEGIN
[SEQUENTIAL EXECUTION] <procedure_body>
ENDSyntax
CREATE { PROC | PROCEDURE } [schema_name.]
procedure_name [ ; number ]
[ { @parameter [ type_schema_name. ]
data_type }
[ VARYING ] [ = default ] [ OUT |
OUTPUT | [READONLY]
] [ ,...n ]
[ WITH <procedure_option> [ ,...n ] ]
[ FOR REPLICATION ]
AS { [ BEGIN ] sql_statement [;] [ ...n ]
[ END ] }
The main differences one should keep in mind when porting from PL/SQL to PL/pgSQL are:
Parameter clause
Variable declaration
Key statements migration (for example IFor FOR Statements)
Cursor creation and calling
SQL function mapping between SAP HANA and MS SQL
In the following chapter we will describe the migration procedure in detail.

SAP Co-Innovation Lab http://coil.sap.com
© 2009 SAP AG 14
4.2 Procedure Migration Steps and samples
4.2.1 Parameters (IN OUT) translation
HANA Procedure parameters are marked using the keywords IN/OUT/INOUT. Input and output parameters must be explicitly typed (i.e. no un-typed tables are supported). MS SQL Parameter name by using the “at” sign (@) as the first character. But in HANA, @ is an illegal character, which should be removed. The data type mapping is already described in one of the previous chapters.
HANA expects that the output parameters are explicitly declared.
HANA procedures can be defined in SQL, L and R Language. The default is SQL.
SAP HANA MS SQL
IN Parameters create procedure
"XXX".Sample
( in id bigint,
…….
create procedure
[XXX].[Sample]
@id int,
......
OUT Parameters create procedure
"XXX".Sample
( in id bigint,
out reportResult
RETURN_RESULT
…….
Scalar Type in id bigint,
…….
@id int,
Table Type out reportResult
RETURN_RESULT
Language create procedure
"XXXX".Sample
( .......
) language SQLSCRIPT
sql security definer
as
Limitation:
HANA Input parameter cannot be assigned a value
HANA Input parameter cannot set a default value

SAP Co-Innovation Lab http://coil.sap.com
© 2009 SAP AG 15
Migration Example:
MS SQL SAP HANA
CREATE PROCEDURE
HumanResources.uspGetEmployees2
@LastName nvarchar(50) = N'D%',
@FirstName nvarchar(50) = N'%'
AS
SELECT FirstName, LastName,
Department
FROM
HumanResources.vEmployeeDepartmentHistory
WHERE FirstName LIKE @FirstName
AND LastName LIKE @LastName;
GO
CREATE PROCEDURE
HumanResources.uspGetEmployees2
In LastName nvarchar(50),
FirstName nvarchar(50),
Out reust RETURN_RESULT
AS
……
Parameter name by using the “at” sign (@) as the first character. But in HANA, @ is an illegal character, which should be removed. The data type mapping is already described in one of the previous chapters.
Enter the procedure body, the variables should be declared. In MS SQL this is done by using the key word “declare”. In HANA this is not required.
MSSQL procedure variables accept a default value. HANA does not.
In HANA, the input parameters cannot be pre-assigned with a value in the procedure body. Define another variable to retrieve an input parameter and change the value if needed.
SAP HANA MS SQL
Var declaration create procedure
"XXX".Sample
( in id bigint,...)
create procedure "XXX".Sample
( @id int,
Varible grammar in id bigint,
...
DECLARE @id, ...
Default Value @id = 1,
...

SAP Co-Innovation Lab http://coil.sap.com
© 2009 SAP AG 16
4.2.2 Procedure Body Conversion
Basic Statements Migration
HANA assignment of a value to a variable or row/record field is written as: identifier := expression. In
MS SQL the syntax is: Set identifier = expression;
The result of a SELECT command yielding multiple columns (but only one row) can be assigned to a record
variable:
SAP HANA MS SQL
SELECT INTO target
select_expressions FROM
…
SELECT field1[, field2[, …]] INTO newtable [IN
externaldatabase] FROM source
For the single column scenario, the statement is the same, but for the one scalar type, the difference is:
SAP HANA MS SQL
SELECT FIELD1 INTO EXPRESSION FROM ...
SELECT EXPRESSION = FIELD1 FROM ...
Sometimes and while executing an expression or a Query without result (???) it is desirable to evaluate an expression or a query but discard the result. To do this in Hana Studio, use the statement: EXECUTE 'UPDATE tbl SET ' or EXECUTE 'SELECT FIELD1 INTO EXPRESSION’
Dynamic SQL statement execution example:
SAP HANA MS SQL
Assignment in id bigint ... @id int
Select into SELECT FIELD1 INTO EXPRESSION FROM ...
SELECT EXPRESSION = FIELD1 FROM ...
EXECUTE v_string := 'GRANT ' ||
:v_role1 || ' TO ' ||
:v_user;
EXEC :v_string;
...
SET @cmd = 'SELECT * FROM ' +
@MyTable
EXEC(@cmd)

SAP Co-Innovation Lab http://coil.sap.com
© 2009 SAP AG 17
Control Structure Migration
- Conditionals
SAP HANA MS SQL
IF boolean-expression
THEN
statements
ELSE
statements
END IF;
IF Boolean_expression
{ sql_statement | statement_block }
[ ELSE
{ sql_statement | statement_block } ]
- Loop
SAP HANA MS SQL
<proc_loop> ::= LOOP
<trigger_stmt_list> END LOOP ;
WHILE <condition> DO
<trigger_stmt_list> END WHILE ;
FOR <column_name> IN [<reverse>]
<expression> .. <expression> DO
<trigger_stmt_list> END FOR ;
WHILE Boolean_expression
{ sql_statement | statement_block |
BREAK | CONTINUE }
- Exception and Error message
SAP HANA MS SQL
<signal_value> ::= <signal_name> |
<sql_error_code>
<signal_name> ::=
<identifier>
<sql_error_code> ::=
<unsigned_integer>
THROW [ { error_number | @local_variable
},
{ message
| @local_variable },
{ state | @local_variable } ]
Cursors Migration
- Declaring a cursor
SAP HANA MS SQL
CURSOR <cursor_name> [(
proc_cursor_param_list )]
FOR <select_stmt> Cursor
definition.
<proc_open> ::= OPEN <cursor_name>
[proc_open_param_list] <proc_fetch> ::= FETCH
<cursor_name> INTO <column_name_list>
<proc_close> ::= CLOSE <cursor_name>
- Opening cursors
<proc_open> ::= OPEN <cursor_name> [proc_open_param_list]
<proc_fetch> ::= FETCH <cursor_name> INTO <column_name_list>
<proc_close> ::= CLOSE <cursor_name>

SAP Co-Innovation Lab http://coil.sap.com
© 2009 SAP AG 18
- Using Cursors
SAP HANA MS SQL
Cursor CURSOR cur FOR
SELECT field
FROM tbl
…..
FOR crow AS cur DO
…..
DECLARE cur CURSOR FOR
SELECT field FROM tbl1;
OPEN cur;
FETCH NEXT FROM cur;
WHILE @@FETCH_STATUS = 0
Migration of used built-in functions between HANA and SQL Server.
SQL Server SAP HANA Description
Isnull Ifnull Judge the value whether is null or not
CONVERT() ADD_DAYS() Add days based on the input parameter
5 Optimizing Procedures – Best Practices
5.1 Temporary table in a store procedure
The local temporary tables were used to store the intermediate result for performance improvement. For example:
create table #Sample (ID int);
insert into #Sample
select id from enc where id <> 7;
In SAP HANA, one should avoid inserting large volume data into a temporary table in the procedure. The table variant can be used to replace the temp table insert statement as follows:
create local temporary table #Sample (ID int);
var_#Sample = select * from #Sample
var_#Sample = select id from enc where id <> 7;

SAP Co-Innovation Lab http://coil.sap.com
© 2009 SAP AG 19
5.2 Use the Cursor carefully
We can either use an embedded SELECT in the INSERT statement, or we can put the result of a single SELECT with
COUNT into a local scalar variable. With using a cursor the system cannot exploit the parallel execution and certain
optimizations. For example:
Before the optimization:
CREATE PROCEDURE get_item_nr_per_prod(IN year varchar(4))
LANGUAGE SQLSCRIPT AS
CURSOR cur FOR
SELECT h.created_at
FROM SK1_EPM_REPL.snwd_po h, SK1_EPM_REPL.snwd_po_i i
WHERE i.parent_key = h.node_key;
nr INT := 0;
BEGIN
FOR crow AS cur DO
IF crow.created_at >= to_decimal(:year||'0101000000') AND
crow.created_at <= to_decimal((:year+1)||'0101000000') THEN
nr := nr + 1;
END IF;
END FOR;
INSERT INTO some_result_tbl (year,number) values (:year,:nr);
END;
After the optimization:
CREATE PROCEDURE get_item_nr_per_prod(IN year varchar(4))
LANGUAGE SQLSCRIPT AS
nr INT := 0;
BEGIN
SELECT count(h.created_at) into nr INT
FROM SK1_EPM_REPL.snwd_po h, SK1_EPM_REPL.snwd_po_i i
WHERE i.parent_key = h.node_key
AND crow.created_at >= to_decimal(:year||'0101000000')
AND crow.created_at <= to_decimal((:year+1)||'0101000000');
INSERT INTO some_result_tbl (year,number) values (:year,:nr);
END;

SAP Co-Innovation Lab http://coil.sap.com
© 2009 SAP AG 20
5.3 SQL Statement and calculation optimizaiton
Hint: Avoid using SELECT * if not absolutely necessary!
Use SELECT [the fields needed] instead of SELECT * if you do not need to populate all the fields.
Before Optimization:
SELECT * FROM T1;
After Optimization:
SELECT FIELD1,FIELD2 FROM T1;
5.4 SQL Statement and calculation optimization
Avoid “switching” between the column and the row engine: if a calculation that is not supported by the column engine is used, the operation based on the calculation is executed on the row engine which can lead to large intermediate result transfer between column engine and row engine
Before Optimization:
SELECT * FROM T WHERE TO_DATE(date_string, 'YYYYMMDD') = CURRENT_DATE;
After Optimization:
SELECT * FROM T WHERE TO_DATE(date_string) = CURRENT_DATE;
5.5 Implicit Type Casting
System can generate type castings implicitly even if the user didn't explicitly wrote a type casting operation. For
example, if there is a comparison between a VARCHAR value and a DATE value, system generates implicit type
casting operation that casts the VARCHAR value into a DATE value. Implicit type casting is done from lower
precedence type to higher precedence type. You can find type precedence rule in the documentation for data types.
Before Optimization:
SELECT * FROM T WHERE date_string < CURRENT_DATE;
After Optimization:
SELECT * FROM T WHERE date_string < TO_CHAR(CURRENT_DATE, 'YYYYMMDD');

SAP Co-Innovation Lab http://coil.sap.com
© 2009 SAP AG 21
5.6 Join Statement optimization
Hint: Use CE_UNION_ALL instead of UNION ALL.
CE_UNION_ALL has better performance than UNION ALL. Try to separate the whole union statement into
independent pieces and use CE_UNION_ALL to merge the parts.
Before Optimization:
SELECT FIELD1,FIELD2…FIELDN FROM (...)AS T1
UNION ALL SELECT FIELD1,FIELD2…FIELDN FROM (...) AS T2
After Optimization:
T1 = SELECT FIELD1,FIELD2…FIELDN FROM (...)AS T1;
T2 = SELECT FIELD1,FIELD2…FIELDN FROM (...) AS T2;
T3 = CE_UNION_ALL(:T1,:T2);
Hint: Join sequence – put tables at same business level adjacent.
If there are a lot of tables to be joined together in a big SQL statement, try to put tables at the same business level to be adjacent, which may bring better performance based on the execution plan
Before Optimization:
SELECT A1.ERDAT,A1.AUDAT
FROM VBAK AS A1
INNER JOIN VBAP AS B1 ON (A1.MANDT = B1.MANDT AND A1.VBELN =
B1.VBELN)
INNER JOIN VBUK AS A2 ON (A1.MANDT = A2.MANDT AND A1.VBELN =
A2.VBELN)
INNER JOIN VBUP AS B2 ON (B1.MANDT = B2.MANDT AND B1.VBELN = B2.VBELN
AND B1.POSNR = B2.POSNR)
After Optimization:
SELECT A1.ERDAT,A1.AUDAT
FROM VBAK AS A1
INNER JOIN VBUK AS A2 ON (A1.MANDT = A2.MANDT AND A1.VBELN =
A2.VBELN)
INNER JOIN VBAP AS B1 ON (A1.MANDT = B1.MANDT AND A1.VBELN =
B1.VBELN)
INNER JOIN VBUP AS B2 ON (B1.MANDT = B2.MANDT AND B1.VBELN = B2.VBELN
AND B1.POSNR = B2.POSNR)
Hint: Put left outer join after inner join
Before Optimization:
SELECT FIELD1,FIELD2,…FIELDN
FROM T1
LEFT OUTER JOIN T2 ON (T1.K1 = T2.K1 AND T1.K2 = T2.K2)
INNER JOIN T3 ON (T1.K1 = T3.K1 AND T1.K2 = T3.K2)
SAP Co-Innovation Lab http://coil.sap.com
© 2009 SAP AG 22
After Optimization:
SELECT FIELD1,FIELD2,…FIELDN
FROM T1
INNER JOIN T3 ON (T1.K1 = T3.K1 AND T1.K2 = T3.K2)
LEFT OUTER JOIN T2 ON (T1.K1 = T2.K1 AND T1.K2 = T2.K2)
Non-equijoin predicate
The column engine does not natively support join predicates other than equality conditions. In other words, column engine supports only equijoins natively. Join predicates connected by OR, Cartesian product and join without join predicate are not natively supported by column engine either
Before Optimization:
SELECT M.year, M.month, SUM(T.ship_amount)
FROM T JOIN M ON T.ship_date BETWEEN M.first_date AND M.last_date
GROUP BY M.year, M.month;
After Optimization:
SELECT M.year, M.month, SUM(T.ship_amount)
FROM T JOIN M ON EXTRACT(YEAR FROM T.ship_date) = M.year AND EXTRACT(MONTH FROM
T.ship_date) = M.month
GROUP BY M.year, M.month;
6 HANA procedure troubleshooting
6.1 Debugging HANA procedures
The SAP HANA SQLScript debugger allows for debugging and analyzing procedures. In a debug session, your procedures are executed in serial mode, not in parallel (not optimized). This enables you to test the correctness of the procedure logic and is not intended for evaluation of the performance.
After the procedures are being activated and deployed to a project on local workstation, please perform the following steps (for details please refer to the official SAP HANA SQL Reference Guide available available at http://help.sap.com/hana):
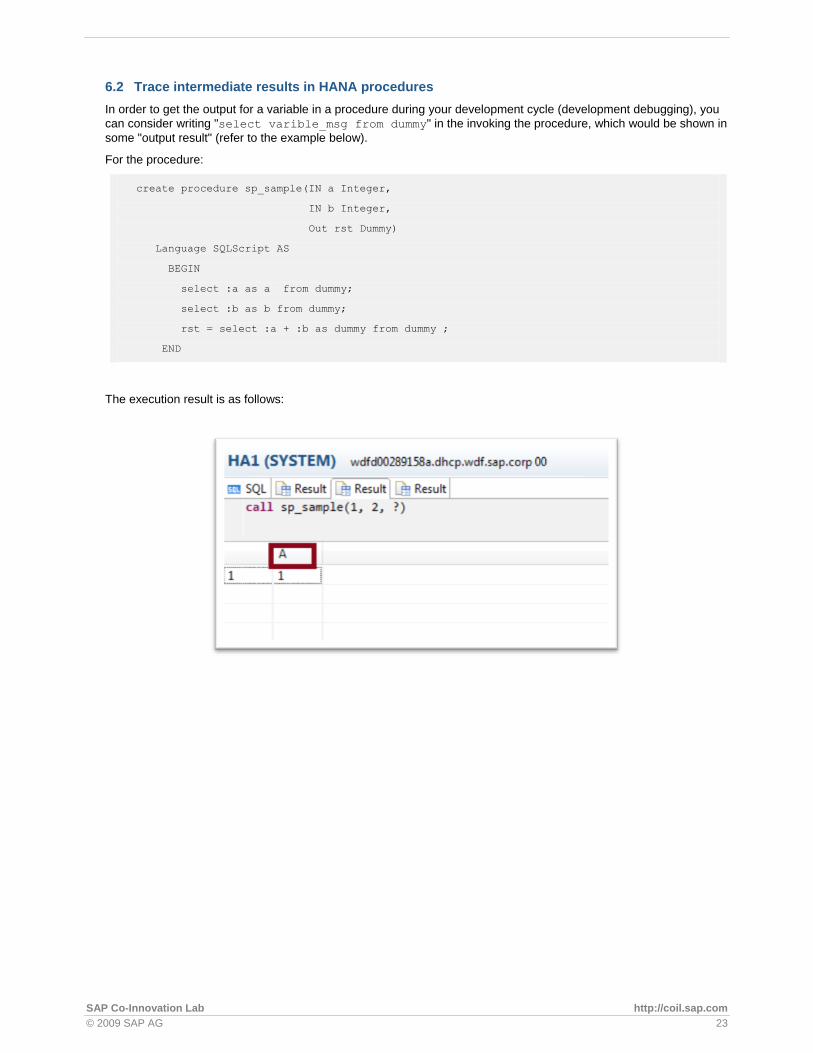
1. Grant debugger privileges to your user.
2. Open the Debug perspective in the SAP HANA studio and select the procedure you want to debug by choosing the relevant tab in the Debug Configuration view.
3. Double-click the left vertical ruler to add breakpoints to your procedure. You can see a list of all of the breakpoints in the Breakpoints view.
4. Create a debug configuration. Choose and Debug Configurations. The Debug Configurations wizard appears.
5. In the General tab, select the Procedure to debug radio button, and choose Browse. Select a procedure to debug and choose OK.
6. To start your debug session, choose Debug. The debug session will begin and you will see the status of the session in the Debug view. The debugger will stop at the first breakpoint and the session will be suspended until you resume it.
7. To view the content of the tables listed in the Variable view, right-click the table name and choose Open Data Preview. The results will appear in the Preview view. This view will automatically close when you resume your debug session.
SAP Co-Innovation Lab http://coil.sap.com
© 2009 SAP AG 23
6.2 Trace intermediate results in HANA procedures
In order to get the output for a variable in a procedure during your development cycle (development debugging), you
can consider writing "select varible_msg from dummy" in the invoking the procedure, which would be shown in
some "output result" (refer to the example below).
For the procedure:
create procedure sp_sample(IN a Integer,
IN b Integer,
Out rst Dummy)
Language SQLScript AS
BEGIN
select :a as a from dummy;
select :b as b from dummy;
rst = select :a + :b as dummy from dummy ;
END
The execution result is as follows:

SAP Co-Innovation Lab http://coil.sap.com
© 2009 SAP AG 24
Copyright
© Copyright 2013 SAP AG. All rights reserved.
No part of this publication may be reproduced or transmitted in any form or for any purpose without the express permission of SAP AG. The information contained herein may be changed without prior notice.
Some software products marketed by SAP AG and its distributors contain proprietary software components of other software vendors.
Microsoft, Windows, Excel, Outlook, and PowerPoint are registered trademarks of Microsoft Corporation.
IBM, DB2, DB2 Universal Database, System i, System i5, System p, System p5, System x, System z, System z10, System z9, z10, z9, iSeries, pSeries, xSeries, zSeries, eServer, z/VM, z/OS, i5/OS, S/390, OS/390, OS/400, AS/400, S/390 Parallel Enterprise Server, PowerVM, Power Architecture, POWER6+, POWER6, POWER5+, POWER5, POWER, OpenPower, PowerPC, BatchPipes, BladeCenter, System Storage, GPFS, HACMP, RETAIN, DB2 Connect, RACF, Redbooks, OS/2, Parallel Sysplex, MVS/ESA, AIX, Intelligent Miner, WebSphere, Netfinity, Tivoli and Informix are trademarks or registered trademarks of IBM Corporation.
Linux is the registered trademark of Linus Torvalds in the U.S. and other countries.
Adobe, the Adobe logo, Acrobat, PostScript, and Reader are either trademarks or registered trademarks of Adobe Systems Incorporated in the United States and/or other countries.
Oracle is a registered trademark of Oracle Corporation.
UNIX, X/Open, OSF/1, and Motif are registered trademarks of the Open Group.
Citrix, ICA, Program Neighborhood, MetaFrame, WinFrame, VideoFrame, and MultiWin are trademarks or registered trademarks of Citrix Systems, Inc.
HTML, XML, XHTML and W3C are trademarks or registered trademarks of W3C®, World Wide Web Consortium, Massachusetts Institute of Technology.
Java is a registered trademark of Sun Microsystems, Inc.
JavaScript is a registered trademark of Sun Microsystems, Inc., used under license for technology invented and implemented by Netscape.
SAP, R/3, SAP NetWeaver, Duet, PartnerEdge, ByDesign, SAP Business ByDesign, and other SAP products and services mentioned herein as well as their respective logos are trademarks or registered trademarks of SAP AG in Germany and other countries.
Business Objects and the Business Objects logo, BusinessObjects, Crystal Reports, Crystal Decisions, Web Intelligence, Xcelsius, and other Business Objects products and services mentioned herein as well as their respective logos are trademarks or registered trademarks of Business Objects S.A. in the United States and in other countries. Business Objects is an SAP company.
All other product and service names mentioned are the trademarks of their respective companies. Data contained in this document serves informational purposes only. National product specifications may vary.
These materials are subject to change without notice. These materials are provided by SAP AG and its affiliated companies ("SAP Group") for informational purposes only, without representation or warranty of any kind, and SAP Group shall not be liable for errors or omissions with respect to the materials. The only warranties for SAP Group products and services are those that are set forth in the express warranty statements accompanying such products and services, if any. Nothing herein should be construed as constituting an additional warranty.





























