Embed Size (px)
Citation preview

Towards Modelling Language Innovation Acceptance in Online Social Networks
24th November 2015Daniel Kershaw – [email protected]

Daniel KershawComputer Science BSc – Lancaster University – 2009
Digital Innovation MRes – Highwire – Lancaster University – 2010
PhD Candidate – 2010 – Now
Supervisors Dr. Matthew Rowe – School of Computing and Communication (SCC)
Dr. Patrick Stacey – Management Science (LUMS)
Research Area:Social Computing
Big Data / Big Data Systems
Who Am I

“Language, never forget, is more like fashion than science, and matters of usage, spelling, and pronunciation tend to wander around like hemlines”
- Bill Bryson, The Mother Tongue: English and How It Got That Way

Language is in constant change
Online communication adds extra pressure though the merging of time and space
– Awesomesauce
– Bants
– beer o’clock
– brain fart
– Brexit
– bruh
Language is Contently Changing

State of the Art - Detection Of Innovation
Three studies
1. Looking for term “this mean”/“is defined as”
2. Using know heuristics of blends to detect origins
3. Detecting changes in semantic orientation or words
Cook, P., & Stevenson, S. (2007)Cook, P., & Stevenson, S. (2010)

State of the Art - Diffusion
Identify words that exist in small time frame
Model diffusion using monri-carlo simulations
Showed existence of wave and gravity diffusion models.
Does not detect local community innovations
Eisenstein, J., O'Connor, B., Smith, N. A., & Xing, E. P. (2012, October)
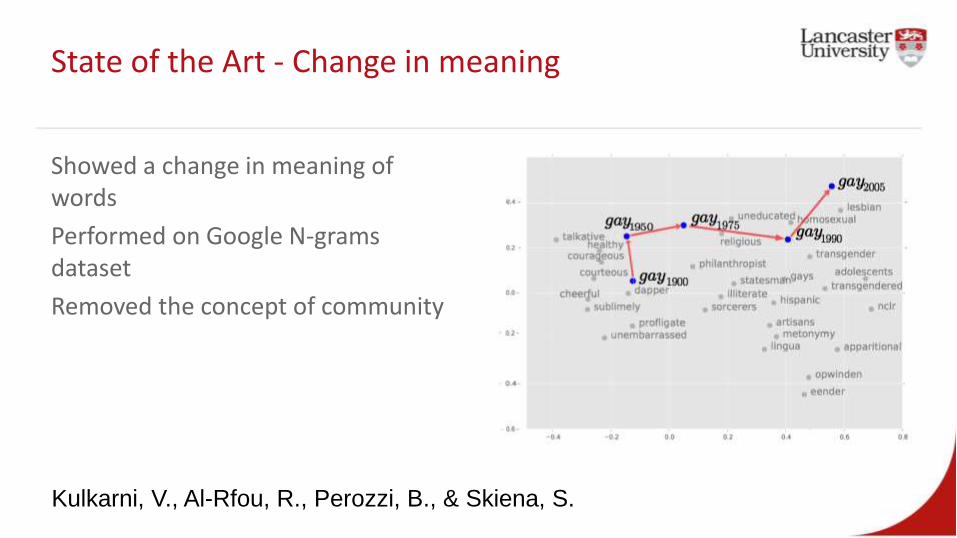
State of the Art - Change in meaning
Showed a change in meaning of words
Performed on Google N-grams dataset
Removed the concept of community
Kulkarni, V., Al-Rfou, R., Perozzi, B., & Skiena, S.

State of the Art - User Language Change
Change in language as a tool to predict users leaving social network
Initially language conforms to the group
Before they level the language bears away from the language of the group
Danescu-Niculescu-Mizil C, West R, Jurafsky D, Leskovec J, Potts C

1. Word innovation acceptance models through computation means
2. Identification of local and global acceptance
3. Multiple network analysis
4. Large Corpus Analysis
Contribution

Metcalf’s Fudge
Frequency of the word
Unobtrusiveness of the rod
Diversity of users and situations
Generation of other forms and meanings
Endurance of the concept
Grounded Models
Barnhart’s Vfrgt
(V) Number of forms
(F) Frequency of word
(R) Number of sources
(G) Number of genera
(T) Time Span of Word
Linguists and lexicographers aim to understand language Developed heuristics to aid the decision to include words in dictionaries

The Data
Twitter Reddit
Users 3,108,844 ≈25,000,000
Posts 73,528,954 ≈500,000,000
Communities 3046 121,373
Words (n > 200) 373,217 2,712,629
Time Periods 283 days 880 days
Data gathered from the June 2015 Reddit Data Release https://goo.gl/j116ML

Data Groupings
Group by Time
Day of year
Geo Location for Twitter
UK -> North West -> LA -> LA1
Subreddit for Reddit
Reddit -> meta interest group -> subreddit

Variation in Frequency
Assess changed in raw frequency and user frequency over time
Diversity in Form
Assess users adoption of varying forms e.g. additions of ing
Diversity in Meaning
Over time can we see a convergence in meaning of the word
Measures

• BNC (British National Corpus) – Gold standard of English
• Filter out:
– Hash tags
– URLs
– Punctuation
– Emoticons / Emoji
• Light Normalization:
– soooooooo -> soo
What is an Innovation
Twitter Reddit
# innovation (N > 200)
62,141 373,217

• Normalized word count
– Per time period
– Per community
• Normalized user word count
– Per time period
– Per community
Variation in Frequency

Assess the prefix and suffix addition of an innovation
List of prefix and suffixes from the OED
– apple -> apples
– hero -> antihero
Diversity in Form

Diversity in Meaning
Looking for innovations that have not been seen before
No solidified meaning within existing systems e.g. WordNet

Looking for innovations that have not been seen before
No solidified meaning within existing systems e.g. WordNet
Learns the embedding of words within a corpus using word2vec
Developed by Google in 2009
Uses documents to train neural net
Diversity in Meaning - word2vec

User the data grouping; time and location
Train w2v model each split of data e.g. London, week1
Query model with each innovation against model (top 100 synonyms) e.g. fleek
Compute similarity between each region in a time period for an innovation e.g. week 1 fleek
Diversity in Meaning

Looking for statistically significant growth or decay of an innovation
Presume language change happens in a monotonic fashion
Fit Spearman's rank to each time series
X value is days since start of data
Y value is normalized frequency of word
Value range -1 to 1
Sampling the Data

Sampling the Data
Class statistically significate change as above and bellow the 95% confidence interval.

The Tools

Some Processing Later

Variation in Frequency

Variation in Frequency – Samples
Twitter Reddit

Variation in Frequency - Reddit

Variation in Frequency – User vs. Frequency
TwitterReddit

Variation in Frequency – User vs. Frequency

Variation in Frequency - Community
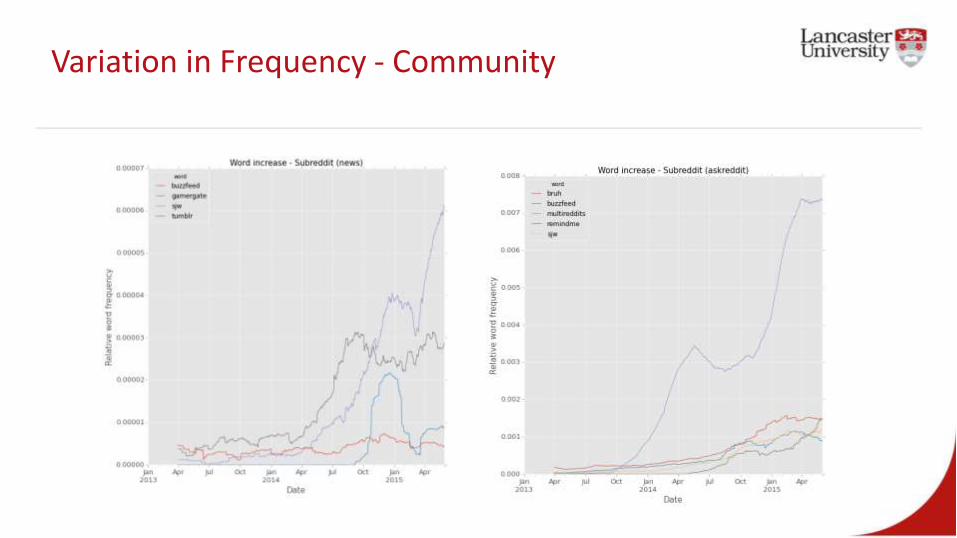
Variation in Frequency - Community

Diversity in Form

Variation in Form

Diversity in Form - Reddit

Diversity in Form - Reddit

• Mistaken Clustering:
– jkt – (Just Keep Thinking)
– Lijkt – (Dutch word for ‘You appear’)
Issues
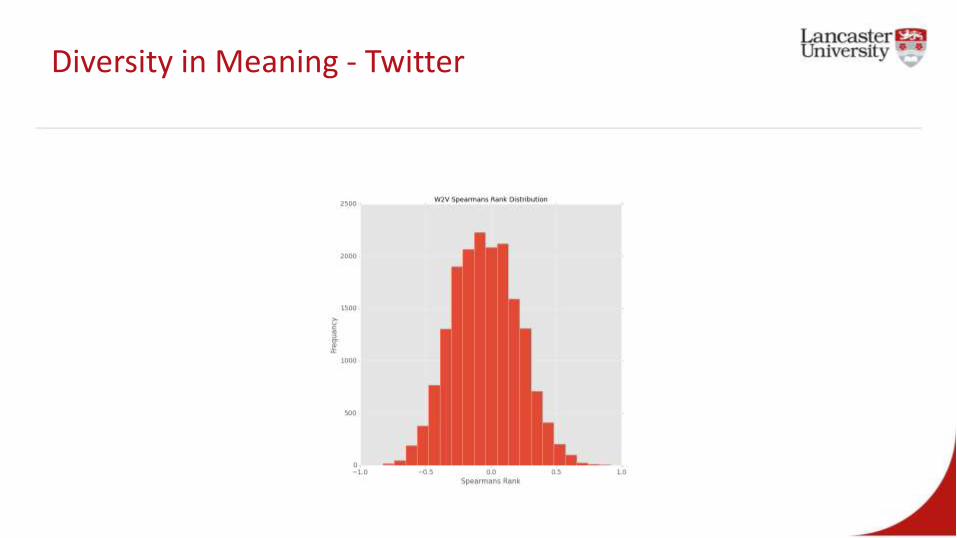
Diversity in Meaning - Twitter

Diversity in Meaning - Twitter

Diversity in Meaning – Twitter (Ebola)

• Susceptible to excessive usage of a word
• Solution could be:
– Smoothing of data
– Sampling to give equal representation of word
Diversity in Meaning

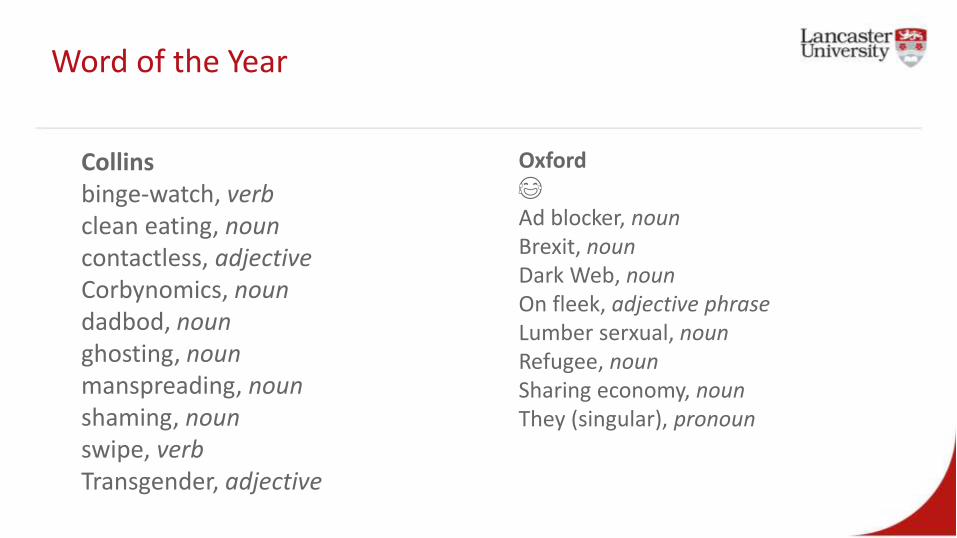
Word of the Year
Collinsbinge-watch, verbclean eating, nouncontactless, adjectiveCorbynomics, noundadbod, nounghosting, nounmanspreading, nounshaming, nounswipe, verbTransgender, adjective
Oxford😂
Ad blocker, nounBrexit, nounDark Web, nounOn fleek, adjective phraseLumber serxual, nounRefugee, nounSharing economy, nounThey (singular), pronoun

Word of the Year

Word of the Year

Word of the Year

Word of the Year


You can say a lot with Emojis

Word of the Year - Emoji

• Is language dependent on community structure
– Modeling Social Reinforcement and Homophile
– Again modeling on multiple levels and across different networks
• Is diffusion effected by the form of network e.g. geographical Twitter or crosposting on Reddit
• Who are the most influential in language innovation and adoption
– Fitting of general threshold models to predict when people adopt a term
– How to perform this at scale
Where next

Thank You
Any Questions

Eisenstein, J., O'Connor, B., Smith, N. A., & Xing, E. P. (2012, October). Mapping the geographical diffusion of new words. arXiv.org.
Eisenstein, J., O'Connor, B., Smith, N. A., & Xing, E. P. (2014). Diffusion of Lexical Change in Social Media. PLoS ONE, 9(11), e113114. http://doi.org/10.1371/journal.pone.0113114
Goldberg, Y., & Levy, O. (2014, February 15). word2vec Explained: deriving Mikolov et al.'s negative-sampling word-embedding method.
Metcalf, A. A. (2004). Predicting New Words. Houghton Mifflin Harcourt.
Barnhart, D. K. (2007). A Calculus for New Words, 28(1), 132–138. http://doi.org/10.1353/dic.2007.0009
References

Kulkarni, V., Al-Rfou, R., Perozzi, B., & Skiena, S. (2014, November 12). Statistically Significant Detection of Linguistic Change. arXiv.org. PeerJ Inc. http://doi.org/10.7717/peerj.68/table-1
Danescu-Niculescu-Mizil, C., West, R., Jurafsky, D., Leskovec, J., & Potts, C. (2013). No country for old members: user lifecycle and linguistic change in online communities (pp. 307–318). International World Wide Web Conferences Steering Committee.
Cook, P., Han, B., & Baldwin, T. (n.d.). Statistical Methods for Identifying Local Dialectal Terms from GPS-Tagged Documents.
Cook, P., & Stevenson, S. (2007). Automagically inferring the source words of lexical blends. Presented at the Proceedings of the Tenth Conference of the ….
References





























