Embed Size (px)
Citation preview

1
Tree and Graph Processing On Hadoop
Ted Malaska

2
Schedule
• Intro• Overview of Hadoop and Eco-System• Summarize Tree Rooting• MR Overview/Implementation Options• Hbase Overview/Implementation Options• Giraph Overview/Implementation Options• Spark Overview/Implementation Options• Summery• Quesitons

3
Intro
• Hi there

4
Overview of Hadoop and Eco-System
Search
NoSqlMachine LearningLFPRTQStreamingIngestionBatch
HDFS
Security and Access Controls
Auditing and Monitoring
Map
Red
uce
Pig
Cru
nch
Hiv
e
Gir
aph
Sqo
op
Flu
me
Kafk
a
Sto
rm
Spar
k St
ream
ing
Spar
k
Imp
ala
Mah
ou
t
Ory
x
R Pyt
ho
n S
trea
min
g
SAS
HB
ase
Acc
um
ulo
NFS
Sear
ch S
olR

5
In Scope for Tonight
Search
NoSqlMachine LearningLFPRTQStreamingIngestionBatch
HDFS
Security and Access Controls
Auditing and Monitoring
Map
Red
uce
Pig
Cru
nch
Hiv
e
Gir
aph
Sqo
op
Flu
me
Kafk
a
Sto
rm
Spar
k St
ream
ing
Spar
k
Imp
ala
Mah
ou
t
Ory
x
R Pyt
ho
n S
trea
min
g
SAS
HB
ase
Acc
um
ulo
NFS
Sear
ch S
olR

6
Summarize Tree Rooting
• Basic Tree
0
1 1
22
2
2
3
33
True Root
Leafs
Branches
Vertex
Edge
Depth

7
Summarize Tree Rooting
• More Complex Tree
0
11
22 2
2
3
32
Circular Link
Multiple Parents

8
Summarize Tree Rooting
• Merging Trees• Borderline True Graph Problem
0
11
22 2
2
3
32
0
0
Multi RootedVertex
True RootTrue Root

9
Summarize Tree Rooting
• Know your data

10
Basic Storage Format
• <NodeID>|<EdgeID>
• Example• 101• 101|201• 101|202• 201• 202|301• 301

11
Preprocessing
• Terming Data• Nodes and edges have data• Data has weight• Normally linkage information is under 10% of true data size
• Organize Data by Partitioning

12
Basic Solution
• Step 1: Identify Roots• Echo to all edges• Vertexes with that receive no echoes are roots• Root the root
• Step 2: Walk the tree• Echo from last newly rooted Vertex to all edges• If vertex is not already rooted then root it.
• 101• 101|201• 101|202• 201• 202|301• 301
• 101|R:101• 101|201|R:101• 101|202|R:101• 201|R:Null• 202|301|R:Null• 301|R:Null
• 101|R:101• 101|201|R:101• 101|202|R:101• 201|R:101• 202|301|R:101• 301|R:Null
• 101|R:101• 101|201|R:101• 101|202|R:101• 201|R:101• 202|301|R:101• 301|R:101

13
Map Reduce
• Massive parallel processing on Hadoop• Based on the Google 2004 MapReduce white paper• Able to process PBs of data

14
Map Reduce
Data Blocks
Data Blocks
Data Blocks
Mapper
Mapper
Mapper
Sort & Shuffle
Sort & Shuffle
Sort & Shuffle
Mapper
Mapper
Data Blocks
Data Blocks

15
Map Reduce
• Self Joins• Always dumping two output:
• Newly Rooted• Still Un-Rooted
All Data
Un-Rooted
Newly Rooted
Un-Rooted
Newly Rooted
Old Rooted 0
MR - Stage0
Root Identifying
MR – Stage1
Rooting
Un-Rooted
Newly Rooted
Old Rooted 0
MR – Stage2
Rooting
Old Rooted 1

16
Map Reduce
• Great for large batch operations• No memory limit• Not good at iterations

17
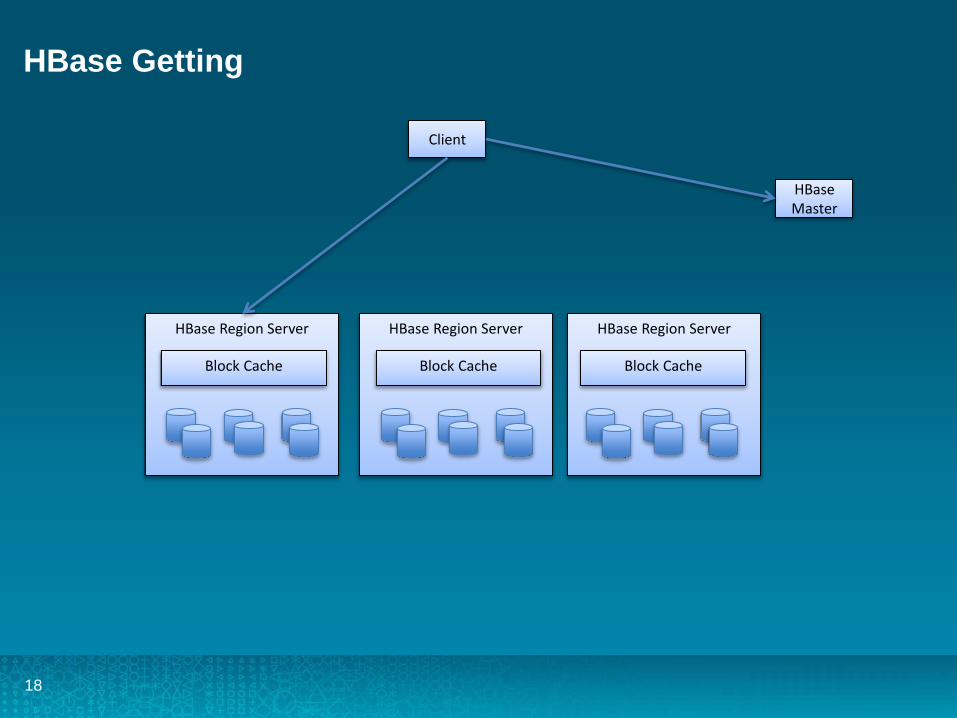
HBase
• Largest and Most used NoSql Implementation in the World• Based on the Google 2006 BigTable white paper• Imagine it like a giant HashMap with keys and values• Handles 100k of operations a second on even a small 10 node cluster
18
HBase Getting
Client
HBase Master
HBase Region Server HBase Region Server HBase Region Server
Block Cache Block Cache Block Cache

19
HBase Putting
Client
HBase Master
HBase Region Server HBase Region Server HBase Region Server
WAL
MemStore
HFi
le
HFi
le
HFi
le
WAL
MemStore
WAL
MemStore

20
HBase
• Good for graph traversing• Bad for large batch processing
• Scan rate about 8x slower then HDFS• Good for end of a long tail

21
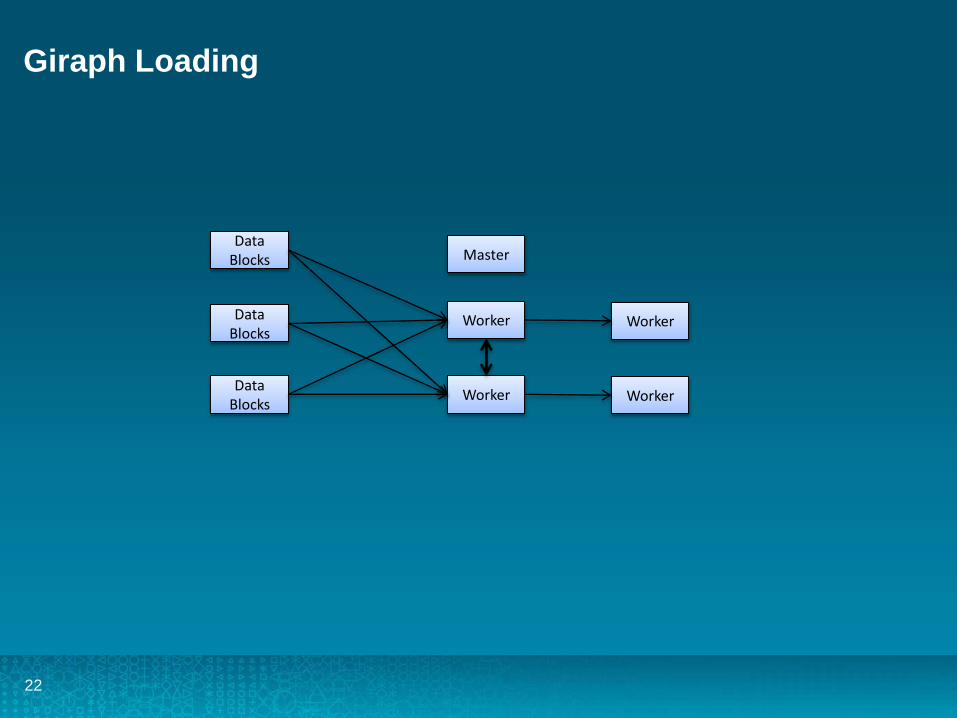
Giraph
• System built for Large Batch Graph Processing • Based on Pregel 2009 white paper• Hardened by LinkedIn and FaceBook• Recorded to handle up to a Trillion edges
22
Giraph Loading
Data Blocks
Data Blocks
Data Blocks
Worker
Worker
Worker
Worker
Master
Co
mm
un
icat
ion
23
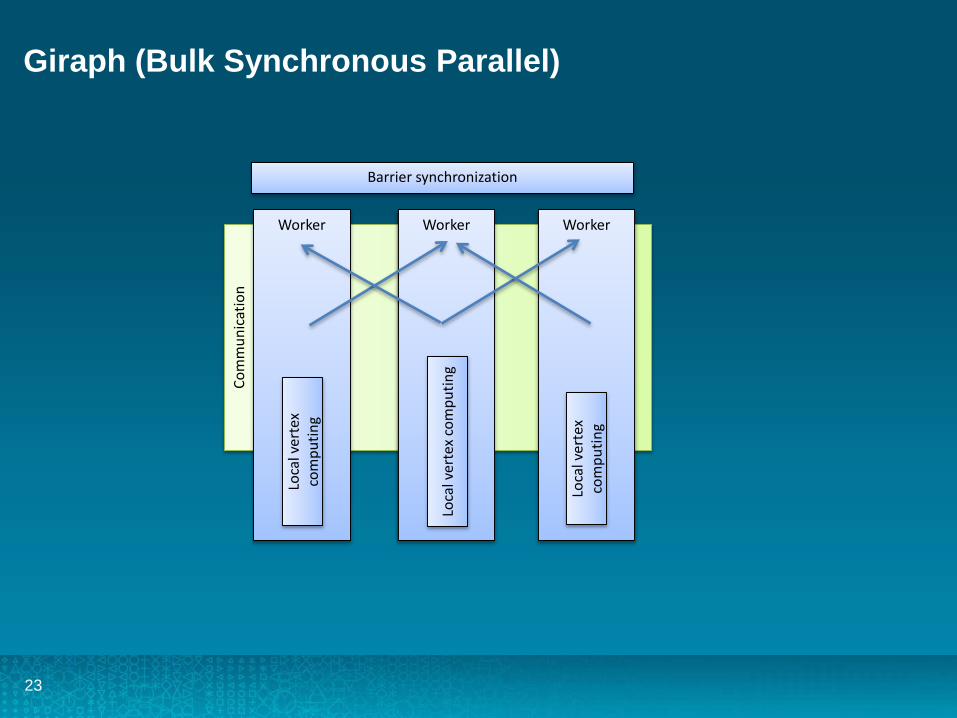
Giraph (Bulk Synchronous Parallel)
Worker Worker Worker
Loca
l ver
tex
com
pu
tin
g
Barrier synchronization
Loca
l ve
rtex
co
mp
uti
ng
Loca
l ver
tex
com
pu
tin
g

24
Giraph
• Most mature bulk graph processing out there• Of all the solutions, most graph focused

25
Spark
• At Berkeley around 2011 some asked is we could do better then MR• Take advantage of lower cost memory• Building on everything before

26
Spark
WorkerDag Scheduler
(Like a queue planner
Spark Worker
RDD Objects
Task Threads
Block Manager
Rdd1.join(rdd2).groupBy(…).filter(…)
Task Scheduler
Threads
Block Manager
ClusterManager

27
Spark
• Implementations• Onion MR approach with Basic Spark• Pregel approach with Bagel or GraphX
• Bagel is a Façade over Generic Spark Functionality• GraphX is an effort extend to Spark
• Less code• Learning curve • Its Raw will be changing a lot in the next year