Embed Size (px)
Citation preview

Eur Food Res Technol (2010) 231:985–998
DOI 10.1007/s00217-010-1353-0ORIGINAL PAPER
A method based on the ligation detection reaction–universal array (LDR–UA) for the detection and characterization of Listeria and Campylobacter strains
Andrea Lauri · Bianca Castiglioni · Marco Severgnini · Chiara Gorni · Paola Mariani
Received: 10 June 2010 / Revised: 4 August 2010 / Accepted: 12 August 2010 / Published online: 1 September 2010© Springer-Verlag 2010
Abstract Listeria and Campylobacter genera includesome of the most widely spread human pathogens acrossEurope and represent a serious health threat, especially tochildren, immunocompromised people and pregnantwomen. Both genera are frequently isolated from farm ani-mals and food; therefore, their rapid detection is importantfor food safety and to prevent disease outbreaks. A rapiddetection approach based on the combination of ligationdetection reaction and universal array (LDR–UA) wasdeveloped to reveal the presence of Listeria and Campylo-bacter pathogenic species and to identify the Division (I, IIand III) of L. monocytogenes isolates. The approach wastested Wrst on reference strains then on Weld isolates. TheLDR–UA approach showed high sensitivity and high speci-Wcity in reliably discriminate target sequences diVering inas little as one base pair, thus facilitating the discriminationof closely related strains.
Keywords Food safety · Diagnostics · Ligation detection reaction · Universal array · Listeria · Campylobacter
Introduction
The Listeria genus includes six species of Gram-positivebacilli: L. monocytogenes, which is considered the most
dangerous Listeria species; L. ivanovii and L. seeligeri, thathave been sporadically reported as causes of disease [1, 2];L. innocua, L. grayi and L. welshimeri, that do not result inclinical disease in humans [3]. L. monocytogenes is dividedinto three evolutionarily serotype lines: Division I (sero-types 1/2b, 3b, 4b, 4d, 4e and 7), Division II (serotypes1/2a, 1/2c, 3a, and 3c) and Division III (serotypes 4a and 4c)[4]. Most of the Listeria clinical isolates belong to DivisionI (about 85%) followed by Division II (15%). Listeria Divi-sion I isolates from food are also predominant with respectto Division II. Listeria Division III is rarely isolated fromboth food and clinical cases and has been reported to bepathogenic primarily to animals [5].
Campylobacter is a characteristic spiral-shaped micro-aerophilic Gram-negative bacterium and the genus includes18 species, 11 of which have been associated with humandiseases [6].
The European Food Safety Authority (EFSA) reportedthat in 2005 and 2007 Campylobacteriosis was the mostprevalent zoonotic disease in humans in the EuropeanUnion, with C. jejuni, C. coli, C. upsaliensis and C. lari thepredominant species [7, 8]. Listeria is also an importantcause of livestock-derived infections and in contrast toother pathogens (e.g. Salmonella), seems not to havedecreased in frequency over the last years [7, 9, 10]. Fur-thermore, Listeriosis is the zoonotic disease with the high-est death rate, estimated over 20% [10, 11].
Poultry is considered a major reservoir of both Campylo-bacter and Listeria, but other farm animals, such as diaryand beef cattle and pigs, and the derived products, consti-tute possible sources of infection. Additional sources ofinfection include Wsh products, water, fruits and vegetables[7, 9, 10, 12].
A quick and precise assay to detect contaminations andthe source of human infections would improve food safety
A. Lauri (&) · C. Gorni · P. MarianiPTP, via A. Einstein, 26900 Lodi, Italye-mail: [email protected]
B. CastiglioniIBBA-CNR, via A. Einstein, 26900 Lodi, Italy
M. SevergniniITB-CNR, via F.lli Cervi 93, 20090 Segrate, Milano, Italy
123

986 Eur Food Res Technol (2010) 231:985–998
and medical care. Indeed, fast and sensitive molecular tech-niques are increasingly implemented in routine diagnosistogether with traditional methods, which are based on cul-ture and biochemical protocols [13–15].
Among the molecular approaches, TaqMan PCR hasbeen increasingly used for diagnostic tests as it facilitatesthe rapid and accurate detection of pathogens. In contrast totraditional PCR, TaqMan PCR cuts oV unspeciWc ampliW-cations, thanks to Xuorescently labeled probes speciWc tothe ampliWed target DNA [16–18]. However, the simulta-neous detection of multiple diVerent bacterial species andthe discrimination of subspecies is diYcult and expensive.
The use of DNA microarrays oVers a higher throughputwith respect to PCR and facilitates the simultaneous detec-tion of thousands of species simultaneously, as many spe-ciWc probes can be printed as microspots on the arraysurface [19, 20].
Universal Arrays (UA) are microarrays carrying a seriesof 24–25-bp-long DNA sequences, the so-called Zip Codes,instead of speciWc probes. UAs have been successfully usedwith the ligation detection reaction (LDR) to reveal the pres-ence of DNA target sequences and sequence mismatcheswith a single-nucleotide resolution [21]. The LDR–UA tech-nology has been successfully applied to the detection ofmicroorganisms in diVerent environments [22–24].
Among the target DNA sequences used in molecularmethods for the detection of Listeria spp. are iap (present inall Listeria species; [25]) and hlyA (reported in hemolyticspecies only: L. monocytogenes, L. ivanovii, L. seeligeri;[26, 27]). Regarding Campylobacter spp., target DNAsequences for cadF (called oprF in C. lari and C. upsalien-sis; [28, 29]), cdtB [30] and the ribosomal 16S rRNA geneare commonly used. Besides the 16S rRNA gene, ubiqui-tously present in all bacteria [31], the other genes were cho-sen for their relationship with pathogenicity.
In the present study, the LDR–UA approach was used todevelop a test to simultaneously detect and discriminateCampylobacter spp. and Listeria spp. and Divisions. Thismolecular diagnostic test has the Xexibility of the PCRapproach, the throughput of microarrays, together with thehigh discrimination typical of the LDR.
Materials and methods
All reagents used in the procedures reported in this sectionwere purchased at Sigma-Aldrich (St. Louis, MO, USA), ifnot expressly indicated.
Bacteria strains
Bacteria strains are listed in Tables 1 and 2. They wereobtained from the Collection of the Institute Pasteur (Paris,
France, marked with CIP), from the German Collection ofMicroorganisms and Cell Cultures (Braunschweig,Germany, marked with DSM), from the American TypeCulture Collection (MD, USA, marked with ATCC) andfrom the Salmonella Genetic Stock Centre (Calgary, Canada,marked with SGSC). Field isolates, assessed by PCRaccording to the protocol of Persson and colleagues [31],were kindly provided by Istituto ZooproWlattico Sperimen-tale della Lombardia e dell’Emilia Romagna (IZSLER,Lodi, Italy). Bacteria strains were cultivated according tosupplier recommendations. SpeciWcally, L. monocytogeneswas grown on Columbia Agar and the other Listeria specieson Brain Heart Infusion at 37 °C for 24/48 h with shaking.Campylobacter spp. were grown for 24/48 h on SkirrowAgar in microaerophilic conditions crated using GENbagmicroaer (BioMérieux, France).
Choice of the target sequences
The DNA sequences of the chosen genes (hlyA, iap, cadF,cdtB and 16S rRNA gene) were downloaded from publicdatabases for Campylobacter, Listeria, and for other bacte-ria strains containing homologous genes. HlyA, iap, cadFand cdtB DNA sequences were obtained from NCBI dataset(http://www.ncbi.nlm.nih.gov/), whereas the 16S rRNA genesequences for all Campylobacteriaceae were down-loaded from the Ribosomal Database Project (RDP) website (http://rdp.cme.msu.edu/) [32].
In house re-sequencing was performed for all genes withthe primers listed in Table 3. Bacteria templates are listedin Tables 1 and 2.
Probe design
Sequences obtained by in house re-sequencing and frompublic databases were aligned by ClustalW (http://www.ebi.ac.uk/Tools/clustalw2/index.html). ARB software [33]was used to visualize the sequence alignments and to searchfor sequence polymorphisms.
In order to discriminate and avoid cross-reactivity withhighly similar sequences, probes (listed in Table 4) weredesigned to have the discriminating polymorphism(s) atthe 3� extremity of the discriminating probe (DP) (Fig. 1).The common probe (CP) was designed immediately adja-cent to the 3� end of the DP. Variable bases other than thetarget polymorphisms were masked using Inosine (I),which is an artiWcial base able to equally bind to all fournatural DNA bases. Both CP and DP calculated meltingtemperatures ranged between 65 and 67 °C. DP was mod-iWed at the 5� end with a Cy3 Xuorophore, while the CPwas modiWed at the 5� end with a phosphate and extendedat the 3� end with a cZip Code (reported in Table 4 and in[34]).
123

Eur Food Res Technol (2010) 231:985–998 987
Listeria and Campylobacter detection tool outline
The diagnostic test was created using 34 probe sets, 18 forCampylobacter and 16 for Listeria (Table 4).
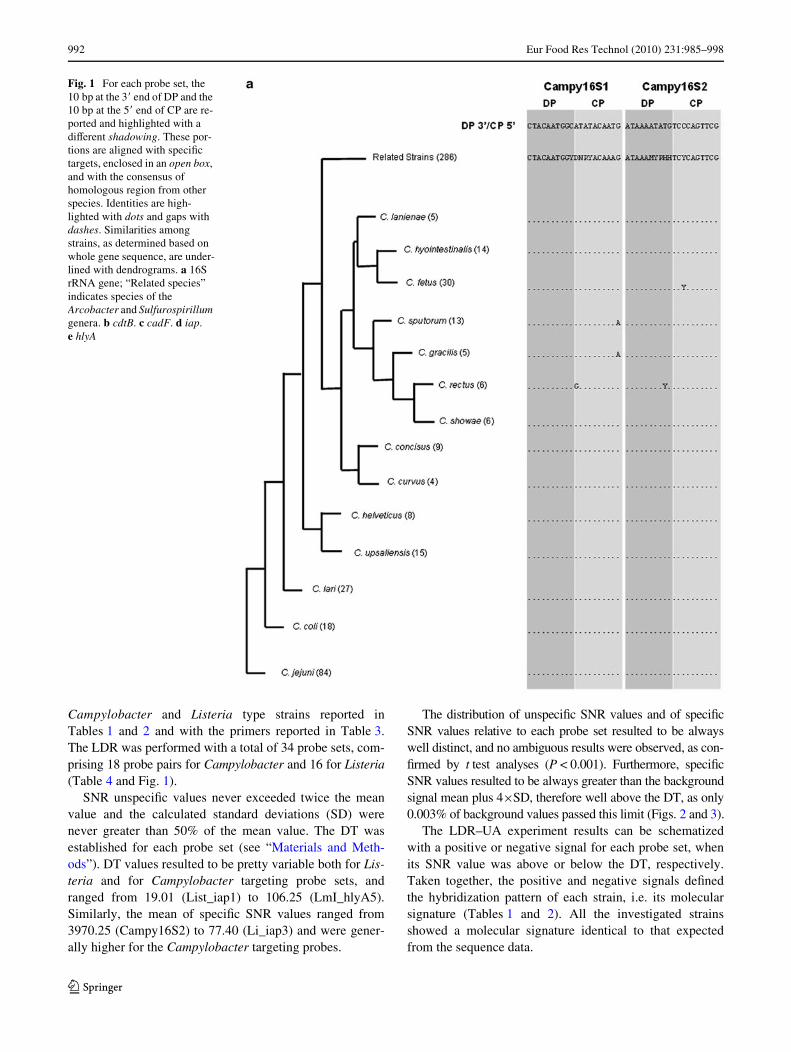
The identiWcation of Campylobacter species wasachieved through the detection of the 16S rRNA gene withprobes designed using the consensus sequence from 14Campylobacter species (C. lanienae, C. hyointestinalis,C. fetus, C. sputorum, C. graci, C. rectus, C. showae,
C. concisus, C. curvus, C. helveticus, C. upsaliensis, C. lari,C. coli, C. jejuni). These probes speciWcally recognizeCampylobacter but not other members of the Campylobact-eraceae family, such as Arcobacter and Sulfurospirillum(286 sequences considered) (Fig. 1a). The discrimination ofC. coli, C. jejuni, C. upsaliensis and C. lari was achievedwith 4 probe sets per species that discriminate polymor-phisms found within the cdtB and cadF genes (Table 4;Figs. 1b, c).
Table 1 Molecular signatures for each Listeria and Campylobacter strain are reported
Positive and negative calls are deWned as above or below DT and represented with a black or white box, respectively
Ls_h
lyA
1Li
_hly
A2
Lm_h
lyA
3Lm
_hly
A4
LmI_
hlyA
5Lm
II_hl
yA6
LmIII
_hly
A7
List
_iap
1Lg
_iap
2
Li_i
ap3
Ls_i
ap4
Lm_i
ap5
Lm_i
ap6
LmI_
iap7
LmII_
iap8
LmIII
_iap
9
Listeria monocytogenes - 1/2a ATCC BAA-679Listeria monocytogenes – 1/2a DSM 20600Listeria monocytogenes – 1/2a DSM 12464Listeria monocytogenes - 1/2b ATCC 51780Listeria monocytogenes – 1/2b CIP 105449Listeria monocytogenes – 1/2b CIP 55.143Listeria monocytogenes – 1/2c CIP 105448Listeria monocytogenes – 1/2c CIP 103573Listeria monocytogenes – 3a CIP 54.152Listeria monocytogenes – 3b CIP 78.35Listeria monocytogenes – 3c CIP 78.36Listeria monocytogenes – 4a CIP 105457Listeria monocytogenes - 4b ATCC 19115Listeria monocytogenes – 4b CIP 103322Listeria monocytogenes – 4b DSM 15675Listeria monocytogenes – 4c CIP 54.135Listeria monocytogenes – 4d CIP 105458Listeria monocytogenes – 4e CIP 105459Listeria monocytogenes – 7 CIP 78.43Listeria grayi DSM 20596Listeria grayi DSM 20601Listeria innocua ATCC BAA-680Listeria innocua – 6a DSM 20649Listeria ivanovii subsp. ivanovii DSM 20750Listeria ivanovii subsp. londoniensis DSM 12491Listeria seeligeri – 1/2b DSM 20751Listeria welshimeri DSM 15452Listeria welshimeri - 1/2b DSM 20650
Table 2 Molecular Signatures for each Listeria and Campylobacter strain are reported
Positive and negative calls are deWned as above or below DT and represented with a black or white box, respectively
DB number origin Cam
py16
S1C
ampy
16S2
CcC
adF1
CcC
adF2
CcC
dtB
1C
cCdt
B2
CjC
adF1
CjC
adF2
CjC
dtB
1C
jCdt
B2
ClC
adF1
ClC
adF2
ClC
dtB
1C
lCdt
B2
CuC
adF1
CuC
adF2
CuC
dtB
1C
uCdt
B2
C. jejuni CCUG6824 Human fecesC. jejuni CCUG8714 Human fecesC. jejuni CCUG10937 Human fecesC. jejuni CCUG10954 Human fecesC. jejuni CCUG11284 Bovine fecesC. jejuni CCUG25903 ChickenC. coli CCUG10969 Turkey fecesC. coli CCUG11283 Porcine fecesC. lari CCUG23947 Gull cloacal swabC. upsaliensis CCUG14913 Canine feces
Campylobacter 55 Field Isolate MilkCampylobacter 57 Field Isolate MilkCampylobacter 58 Field Isolate Bovine fecesCampylobacter 59 Field Isolate MilkCampylobacter 60 Field Isolate MilkCampylobacter 61 Field Isolate MilkCampylobacter 63 Field Isolate Milk
123

988 Eur Food Res Technol (2010) 231:985–998
The detection of Listeria was based on variations in iapand hlyA. All Listeria species detection was achieved withiap targeting probe sets. List_iap1 was designed to detect L.innocua, L. monocytogenes, L. ivanovii, L. seeligeri and L.welshimeri, and iap2 to detect L. grayii.
Further iap probe sets were designed to discriminate theListeria pathogenic species: L. ivanovii (Li_iap3), L. seeligeri(Ls_iap4) and L. monocytogenes (Lm_iap5 and Lm_iap6).The three L. monocytogenes subspecies Divisions were alsodiscerned with Lm_iap7 (Division I), Lm_iap8 (Division II)and Lm_iap9 (Division III) (Table 4 and Fig. 1d).
The same probe design scheme was used with hlyA as atarget sequence. Ls_hlyA1 and Li_hlyA2 were designed tospeciWcally recognize L. ivanovii and L. seeligeri, respec-tively. All L. monocytogenes serotypes were detected withLm_hlyA3 and Lm_hlyA4, whereas the Division attribu-tion relied on Lm_hlyA5 (Division I), Lm_hlyA6 (DivisionII) and Lm_hlyA7 (Division III) (Table 4 and Fig. 1e).
In total, with regard to the two target genes iap and hlyA,the presence of L. ivanovii and L. seeligeri was revealed bytwo speciWc probe sets each, whereas the predominantL. monocytogenes was detected by four probe sets and sixadditional probe sets classiWed the strain under investiga-tion in one of the Divisions.
As it is evident from the tool outline, the system wasconceived to provide redundant information. The detectionof a strain was therefore conWrmed at multiple levels:genus, species and, for L. monocytogenes, subspecies. Foreach level, more probe sets were designed providing identi-cal information. This “vertical” and “horizontal” redun-dancy was introduced to confer robustness and versatility tothe system (see “Discussion”).
Polymerase chain reaction (PCR)
Each PCR was performed in a separate tube with 20 ng ofgenomic bacterial DNA (extraction with Gentra kit,
QIAGEN, Hilden, Germany). The primers used are listed inTable 3. PCR conditions were as follows: 4 mM MgCl2, 1UTaq DNA Polymerase (Invitrogen, Carlsbad, California,USA), 1£ reaction buVer, 0.2 �M of each primer, 0.2 mMof each dNTP in a total volume of 20 �L. PCR mix was Wrstdenatured 5� at 94 °C, then cycles of 1� at 94 °C, 1� at 56 °Cand 1� at 72 °C were repeated 40 times. The reaction endedwith 10� at 72 °C extension. Ten microliters of PCR prod-uct was loaded onto a 2% EtBr agarose gel to check thepresence and quality of the ampliWcation product. PCRproducts were puriWed by GenElute PCR Clean-Up Kit(Sigma, Steinheim, Germany), eluted in 50 �L of water andquantiWed with a NanoDrop spectrophotometer.
Universal array (UA) preparation
Phenylen-diisothiocyanate (PDITC) activated chitosanglass slides were used as surfaces [35]. Microarrays wereprepared as described [36], using a MicroGrid II Compact(Biorobotics, UK) contact pin spotter, equipped with Sili-con Microarray pins (Parallel Synthesis Technologies,Santa Clara, CA, USA). Thirty-six Zip Codes wereassigned for the recognition of the target DNA sites. Zip 66and Zip 63 were used as hybridization control and ligationcontrol, respectively. Eight subarrays per slide were posi-tioned such to be hybridized independently with a multi-chamber hybridization system. Each subarray containedfour replicates of each Zip Code distributed according tothe deposition scheme previously reported [36].
Ligation detection reaction (LDR) and universal array hybridization
The LDR was carried out in a volume of 20 �L. The reactionmix included the following: 1 unit of Pfu Ligase (Stratagene,La Jolla, California, USA), 2 �L of 10£ buVer, 50 ng ofeach puriWed PCR product and CP and DP probes to the
Table 3 Primers used in this study
Gene Primer name
Primer sequence Literature
Listeria
iap LisF ATGAATATGAAAAAAGCAACKATC Volokhov et al [20]
LisR ACATARATIGAAGAAGAAGAWARATTATTCCA
hlyA IsoF GTTAATGAACCTACAAGHCCTTCC Volokhov et al [20]
IsoR AACCGTTCTCCACCATTCCCA
Campylobacter
cdtB AL114 GGCACTTGGAATTTGCAAGGCTCAT This study
AL117 GCATCATTTCCTATGCGAATTCCTATAATAGGTC
cadF AL119 GATAACAATGTAAAATTTGAAATCACTCC This study
AL120 AATTTGATCTCTAGTTTCAAGTCTTAAAGC
16S 16S-F GGAGGCAGCAGTAGGGAATA Persson et al. [31]
16S-R TGACGGGCGGTGAGTACAAG
123
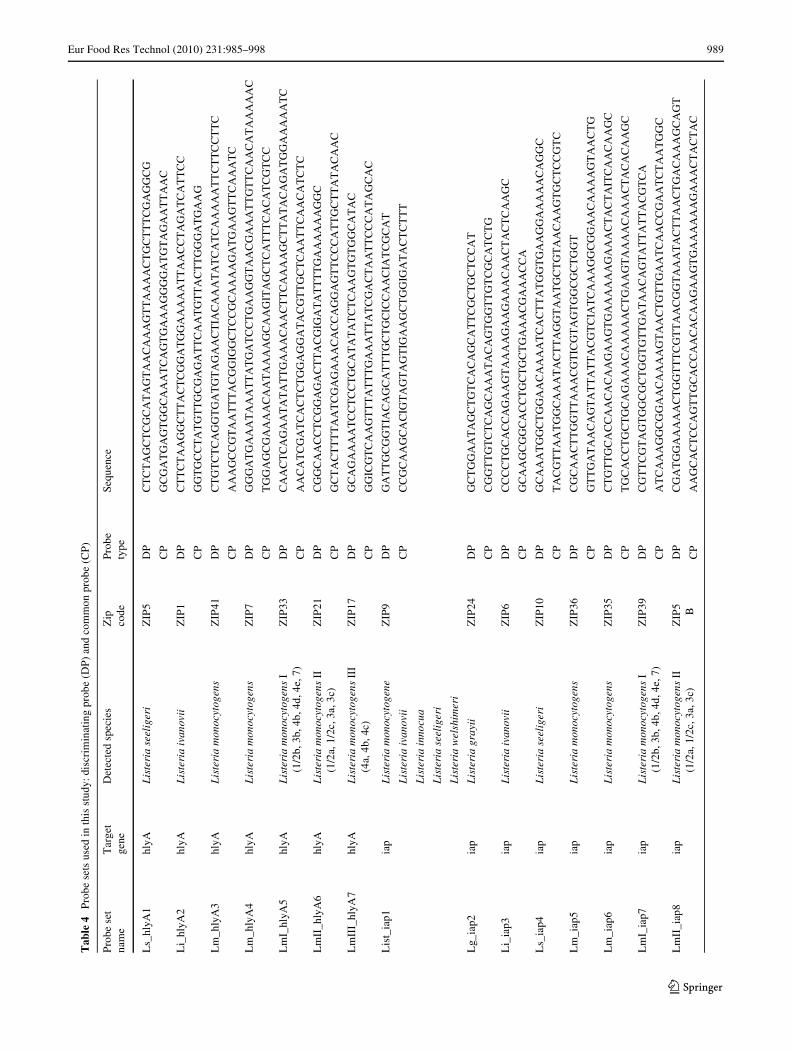
Eur Food Res Technol (2010) 231:985–998 989
Tab
le4
Prob
e se
ts u
sed
in th
is s
tudy
: dis
crim
inat
ing
prob
e (D
P) a
nd c
omm
on p
robe
(C
P)
Pro
be s
et
nam
eT
arge
t ge
neD
etec
ted
spec
ies
Zip
co
dePr
obe
type
Sequ
ence
Ls_
hlyA
1hl
yAL
iste
ria
seel
iger
iZ
IP5
DP
CT
CT
AG
CT
CG
CA
TA
GT
AA
CA
AA
GT
TA
AA
AC
TG
CT
TT
CG
AG
GC
G
CP
GC
GA
TG
AG
TG
GC
AA
AT
CA
GT
GA
AA
GG
GG
AT
GT
AG
AA
TT
AA
C
Li_
hlyA
2hl
yAL
iste
ria
ivan
ovii
ZIP
1D
PC
TT
CT
AA
GG
CT
TA
CT
CG
GA
TG
GA
AA
AA
TT
AA
CC
TA
GA
TC
AT
TC
C
CP
GG
TG
CC
TA
TG
TT
GC
GA
GA
TT
CA
AT
GT
TA
CT
TG
GG
AT
GA
AG
Lm
_hly
A3
hlyA
Lis
teri
a m
onoc
ytog
ens
ZIP
41D
PC
TG
TC
TC
AG
GT
GA
TG
TA
GA
AC
TIA
CA
AA
TA
TC
AT
CA
AA
AA
TT
CT
TC
CT
TC
CP
AA
AG
CC
GT
AA
TT
TA
CG
GIG
GC
TC
CG
CA
AA
AG
AT
GA
AG
TT
CA
AA
TC
Lm
_hly
A4
hlyA
Lis
teri
a m
onoc
ytog
ens
ZIP
7D
PG
GG
AT
GA
AA
TA
AA
TT
AT
GA
TC
CT
GA
AG
GT
AA
CG
AA
AT
TG
TT
CA
AC
AT
AA
AA
AC
CP
TG
GA
GC
GA
AA
AC
AA
TA
AA
AG
CA
AG
ITA
GC
TC
AT
TT
CA
CA
TC
GT
CC
Lm
I_hl
yA5
hlyA
Lis
teri
a m
onoc
ytog
ens
I (1
/2b,
3b,
4b,
4d,
4e,
7)
ZIP
33D
PC
AA
CT
CA
GA
AT
AT
AT
TG
AA
AC
AA
CT
TC
AA
AA
GC
TT
AT
AC
AG
AT
GG
AA
AA
AT
C
CP
AA
CA
TC
GA
TC
AC
TC
TG
GA
GG
AT
AC
GT
TG
CT
CA
AT
TC
AA
CA
TC
TC
Lm
II_h
lyA
6hl
yAL
iste
ria
mon
ocyt
ogen
s II
(1
/2a,
1/2
c, 3
a, 3
c)Z
IP21
DP
CG
GC
AA
CC
TC
GG
AG
AC
TT
AC
GIG
AT
AT
TT
TG
AA
AA
AA
GG
C
CP
GC
TA
CT
TT
TA
AT
CG
AG
AA
AC
AC
CA
GG
AG
TT
CC
CA
TT
GC
TT
AT
AC
AA
C
Lm
III_
hlyA
7hl
yAL
iste
ria
mon
ocyt
ogen
s II
I (4
a, 4
b, 4
c)Z
IP17
DP
GC
AG
AA
AA
TC
CT
CC
TG
CA
TA
TA
TC
TC
AA
GT
GT
GG
CA
TA
C
CP
GG
ICG
TC
AA
GT
TT
AT
TT
GA
AA
TT
AT
CG
AC
TA
AT
TC
CC
AT
AG
CA
C
Lis
t_ia
p1ia
pL
iste
ria
mon
ocyt
ogen
eZ
IP9
DP
GA
TT
GC
GG
TIA
CA
GC
AT
TT
GC
TG
CIC
CA
AC
IAT
CG
CA
T
Lis
teri
a iv
anov
iiC
PC
CG
CA
AG
CA
CIG
TA
GT
AG
TIG
AA
GC
TG
GIG
AT
AC
TC
TT
T
Lis
teri
a in
nocu
a
Lis
teri
a se
elig
eri
Lis
teri
a w
elsh
imer
i
Lg_
iap2
iap
Lis
teri
a gr
ayii
ZIP
24D
PG
CT
GG
AA
TA
GC
TG
TC
AC
AG
CA
TT
CG
CT
GC
TC
CA
T
CP
CG
GT
TG
TC
TC
AG
CA
AA
TA
CA
GT
GG
TT
GT
CG
CA
TC
TG
Li_
iap3
iap
Lis
teri
a iv
anov
iiZ
IP6
DP
CC
CC
TG
CA
CC
AG
AA
GT
AA
AA
GA
AG
AA
AC
AA
CT
AC
TC
AA
GC
CP
GC
AA
GC
GG
CA
CC
TG
CT
GC
TG
AA
AC
GA
AA
CC
A
Ls_
iap4
iap
Lis
teri
a se
elig
eri
ZIP
10D
PG
CA
AA
TG
GC
TG
GA
AC
AA
AA
TC
AC
TT
AT
GG
TG
AA
GG
AA
AA
AC
AG
GC
CP
TA
CG
TT
AA
TG
GC
AA
AT
AC
TT
AG
GT
AA
TG
CT
GT
AA
CA
AG
TG
CT
CC
GT
C
Lm
_iap
5ia
pL
iste
ria
mon
ocyt
ogen
sZ
IP36
DP
CG
CA
AC
TT
GG
TT
AA
AC
GT
ICG
TA
GT
GG
CG
CT
GG
T
CP
GT
TG
AT
AA
CA
GT
AT
TA
TT
AC
GT
CIA
TC
AA
AG
GC
GG
AA
CA
AA
AG
TA
AC
TG
Lm
_iap
6ia
pL
iste
ria
mon
ocyt
ogen
sZ
IP35
DP
CT
GT
TG
CA
CC
AA
CA
CA
AG
AA
GT
GA
AA
AA
AG
AA
AC
TA
CT
AIT
CA
AC
AA
GC
CP
TG
CA
CC
TG
CT
GC
AG
AA
AC
AA
AA
AC
TG
AA
GT
AA
AA
CA
AA
CT
AC
AC
AA
GC
Lm
I_ia
p7ia
pL
iste
ria
mon
ocyt
ogen
s I
(1/2
b, 3
b, 4
b, 4
d, 4
e, 7
)Z
IP39
DP
CG
TT
CG
TA
GT
GG
CG
CT
GG
TG
TT
GA
TA
AC
AG
TA
TT
AT
TA
CG
TC
A
CP
AT
CA
AA
GG
CG
GA
AC
AA
AA
GT
AA
CT
GT
TG
AA
TC
AA
CC
GA
AT
CT
AA
TG
GC
Lm
II_i
ap8
iap
Lis
teri
a m
onoc
ytog
ens
II
(1/2
a, 1
/2c,
3a,
3c)
ZIP
5 BD
PC
GA
TG
GA
AA
AA
CT
GG
TT
TC
GT
TA
AC
GG
TA
AA
TA
CT
TA
AC
TG
AC
AA
AG
CA
GT
CP
AA
GC
AC
TC
CA
GT
TG
CA
CC
AA
CA
CA
AG
AA
GT
GA
AA
AA
AG
AA
AC
TA
CT
AC
123

990 Eur Food Res Technol (2010) 231:985–998
Tab
le4
cont
inue
d
Pro
be s
et
nam
eT
arge
t ge
neD
etec
ted
spec
ies
Zip
cod
ePr
obe
type
Seq
uenc
e
Lm
III_
iap9
iap
Lis
teri
a m
onoc
ytog
ens
III
(4a,
4b,
4c)
ZIP
12D
PG
TA
CC
GG
GT
CA
AA
AA
TT
AC
AA
GT
GA
CT
GA
AG
TA
AA
TG
AG
GT
CG
CT
AA
CP
AA
CA
GA
AA
AA
CA
AG
AG
AA
AT
CT
GT
TA
GC
GC
AA
CT
TG
GC
TA
AA
CG
TC
C
Cam
py16
S116
SA
ll C
ampy
loba
cter
sp
ecie
sZ
IP28
DP
CC
CA
GG
GC
GA
CA
CA
CG
TG
CT
AC
AA
TG
GC
CP
AT
AT
AC
AA
TG
AG
AC
GC
AA
TA
CC
GC
GA
GG
TG
GA
GC
Cam
py16
S216
SA
ll C
ampy
loba
cter
sp
ecie
sZ
IP16
DP
GA
GA
CG
CA
AT
AC
CG
CG
AG
GT
GG
AG
CA
AA
TC
TA
TA
AA
AT
AT
G
CP
TC
CC
AG
TT
CG
GA
TT
GT
TC
TC
TG
CA
AC
TC
GA
GA
GC
CjC
adF
1C
adF
C. j
ejun
iZ
IP8
DP
GT
GG
AG
GA
TA
TG
AG
GA
TT
TT
TC
AA
AT
GC
TG
CT
TA
TG
AT
AA
TA
AA
AG
CG
GT
CP
GG
AT
TT
GG
AC
AT
TA
TG
GC
GC
GG
GT
GT
AA
AA
TT
CC
GT
C
CjC
adF
2C
adF
C. j
ejun
iZ
IP1B
DP
GG
GT
TA
GA
GC
AT
TA
TT
CT
GA
TG
TT
AA
AT
AT
AC
AA
AT
AC
AA
AT
AA
AA
CT
AC
AG
AT
AT
TA
CA
CP
AG
AA
CT
TA
TT
TG
AG
TG
CT
AT
TA
AA
GG
TA
TT
GA
TG
TA
GG
TG
AG
CcC
adF
1C
adF
C. c
oli
ZIP
23D
PC
TG
GT
GIG
GG
AT
AT
GA
GG
AT
TT
TT
CT
AA
AG
GC
GC
TT
TT
GA
TA
AT
AA
AA
GT
CP
GG
AG
GA
TT
TG
GC
CA
TT
AT
GG
AG
CA
GG
TT
TA
AA
AT
TT
CG
C
CcC
adF
2C
adF
C. c
oli
ZIP
20D
PG
AC
TA
GG
GT
AT
CA
TT
TT
GA
TG
AT
TT
TT
GG
CT
TG
AT
CA
AT
TA
GA
AC
TA
GG
TT
TA
GA
A
CP
CA
TT
AC
TC
GG
AT
GT
AA
AA
TA
TA
CA
AA
TT
CT
AC
TC
TT
AC
CA
CC
G
ClC
adF
1C
adF
C. l
ari
ZIP
29D
PC
AC
TC
CA
AC
CT
TT
AA
CT
AC
AC
AA
CC
CC
AG
AA
GG
AA
AT
TT
AG
AT
CT
TA
AA
AA
TT
AT
A
CP
GT
GG
AG
TG
GG
AT
TG
AG
AT
TT
GG
CT
AT
CA
TT
AT
GA
TG
AT
TT
AT
GG
ClC
adF
2C
adF
C. l
ari
ZIP
38D
PG
AG
TA
TT
TA
AG
TC
AT
GG
AG
CT
TA
TG
AA
AA
TA
AA
AG
CA
GC
AT
GT
TT
GC
TC
AA
CP
TA
TG
GT
GC
AG
GT
TT
GA
AG
TT
TG
CA
CT
TG
GG
GA
AG
AT
TT
GG
CuC
adF
1C
adF
C. u
psal
iens
isZ
IP18
DP
GT
TT
TA
AT
AA
AT
TT
GA
GG
GA
AA
TT
TA
GA
CC
TT
GA
TG
AT
AG
GG
CA
GC
C
CP
CC
TG
GT
GT
GA
GA
CT
TG
GC
TA
TC
AT
TT
TG
AT
GA
TT
TT
TG
GC
CuC
adF
2C
adF
C. u
psal
iens
isZ
IP25
BD
PG
TG
CG
AT
TA
AG
GG
CA
TT
GA
TG
TA
GG
TG
AA
AG
CT
TT
TA
CT
TT
TA
T
CP
GG
TT
TA
GC
TG
GT
GG
AG
GT
TA
TG
AA
AG
AT
TT
TC
TA
AC
GA
GC
AG
CjC
dtB
1C
dtB
C. j
ejun
iZ
IP19
DP
GC
AA
AC
CC
CT
TA
GA
TA
TC
TT
AA
TG
AT
AC
AA
GA
AG
CA
GIA
AC
TT
TA
CC
AA
GA
CP
AC
AG
CC
AC
TC
CA
AC
AG
GA
CG
CC
AT
GT
GC
AA
C
CjC
dtB
2C
dtB
C. j
ejun
iZ
IP22
DP
GG
CA
CT
TG
GA
AT
TT
GC
AA
GG
CT
CA
TC
CG
CA
GC
CA
CA
CP
GA
AA
GC
AA
AT
GG
AG
TG
TT
AG
IGT
AA
GA
CA
AC
TT
GT
AA
GT
GG
AG
C
ClC
dtB
1C
dtB
C. l
ari
ZIP
15D
PG
GC
TC
AT
CA
GC
TT
CT
AC
TG
AA
AG
TA
AG
TG
GA
AT
AT
TA
GT
AT
AA
GA
CA
AC
TT
G
CP
TA
AC
TG
GT
GC
TA
AT
CC
TA
TG
GA
TA
TT
TT
GG
CT
GT
TC
AA
GA
AG
C
ClC
dtB
2C
dtB
C. l
ari
ZIP
34D
PG
TA
TG
AA
TG
GA
AT
TT
GG
GC
TC
AT
CA
AG
TC
GT
CC
AA
AT
TC
AG
TT
TA
TA
TA
TA
CT
AC
CP
TC
AA
GA
GT
TG
AT
GT
TG
GG
GC
AA
AT
CG
CG
TA
AA
TA
TG
GC
CcC
dtB
1C
dtB
C. c
oli
ZIP
31D
PG
CT
GC
AA
CT
GA
AA
GC
AA
AT
GG
AA
TG
TT
AG
TA
TA
AG
AC
AA
CT
CA
TA
AC
C
CP
GG
TG
CA
AA
TC
CT
AT
GG
AT
GT
TT
TA
GC
TG
TT
CA
AG
AA
GC
GG
123

Eur Food Res Technol (2010) 231:985–998 991
Wnal concentration of 50 nM each. The oligo-mix alsocontained a discriminating probe and a common probe spe-ciWc for the synthetic oligonucleotide used as ligation control(5�-AGC CGC GAA CAC CAC GAT CGA CCG GCGCGC GCA GCT GCA GCT TGC TCA TG-3�). The mix wasWrst denatured for 10� at 94 °C, followed by 30� at 94 °C and4� at 65 °C, repeated for 30 cycles. Then, 45 �L of hybridiza-tion buVer (1.10 M NaCl, 0.11 M sodium citrate, 7 �gsalmon sperm DNA) was added to the reaction, denatured at94 °C for 3� and immediately hybridized on UA at 65 °C for2 h. The UA was then washed at 65 °C in SSC 2£ (0.3 MNaCl, 0.03 M Sodium Citrate) and 0.1% SDS for 5�, in SSC2£ for 5�, in SSC 1£ for 5� and in SSC 0.5£ for 5�.
Array scanning, data acquisition and processing
Hybridized UAs were scanned by the laser scanner ScanAr-ray LITE (Perkin Elmer, Waltham, Massachusetts, USA).Images were acquired avoiding saturation and then ana-lyzed with the QuantArray software (Packard BioChipTechnologies, Billerica, USA) to quantify the signal/noiseratio (SNR). SNR is deWned as the ratio of the spot meanintensity to the Xuorescence from an area immediately out-side that represents the local background. For each experi-ment, the median SNR value of the four spot replicates ofeach Zip Code (and therefore of each probe set) was con-sidered. The median value is here referred to as speciWcSNR or unspeciWc SNR, depending on whether it was regis-tered in the presence of the probe set–speciWc target or onlyof the closest unspeciWc targets, respectively. For speciWcSNRs, at least 2 experiments were carried out per probe set.
The mean of unspeciWc SNRs (at least from 3 experi-ments) plus 3 times their standard deviation (SD) deWnedthe detection threshold (DT). For instance, to deWne the DTof probe sets targeting L. monocytogenes I (LmI_hlyA5 andLmI_iap7), experiments were carried out on the closestunspeciWc target (L. monocytogenes II and III). For theother Listeria and Campylobacter species, experimentswere performed on the other species belonging to the samegenus and, for Campylobacter 16S rRNA gene targetingprobes (Campy16S1 and Campy16S2), with no DNA.
Assuming the unspeciWc SNR values follow a NormalDistribution, only 0.1% of these values passed the DT.Therefore, values above this threshold are distinct frombackground with 99.9% conWdence.
Results
Implementation of the tool on type strains
The LDR–UA-based assay was tested on PCR productsobtained from genomic DNA extracted from theT
able
4co
ntin
ued
CPs
wer
e ex
tend
ed a
t the
3�
end
wit
h cZ
ip C
ode
sequ
ence
s [3
4]
Prob
e se
t na
me
Tar
get
gene
Det
ecte
d sp
ecie
sZ
ip
code
Prob
e ty
peSe
quen
ce
CcC
dtB
2C
dtB
C. c
oli
ZIP
11B
DP
CA
TA
TG
GA
AT
TT
AG
GC
TC
TG
TA
TC
AA
GA
CC
TA
GC
TC
TG
TT
TA
TA
TA
TA
TT
AT
TC
TA
GA
GT
G
CP
GA
TG
TA
GG
AG
CA
AA
TC
GT
GT
GA
AT
TT
AG
CT
AT
CG
TT
AG
CA
GA
G
CuC
dtB
1C
dtB
C. u
psal
iens
isZ
IP4
DP
TG
AT
GT
GG
GA
GC
AA
AC
CG
CG
TIA
AT
TT
AG
CC
AT
AG
TT
AG
CP
TC
GC
GT
TC
AA
GC
TG
AT
GA
AG
TC
TT
TG
TT
TT
AC
CT
CC
TC
C
CuC
dtB
2C
dtB
C. u
psal
iens
isZ
IP23
BD
PG
CA
AG
AA
GC
AG
GC
GT
TT
TIC
CA
AA
TT
CG
GC
AA
TG
AT
G
CP
AC
AG
GT
AG
AA
TG
GT
GC
AG
CC
CG
GIG
GC
123
992 Eur Food Res Technol (2010) 231:985–998
Campylobacter and Listeria type strains reported inTables 1 and 2 and with the primers reported in Table 3.The LDR was performed with a total of 34 probe sets, com-prising 18 probe pairs for Campylobacter and 16 for Listeria(Table 4 and Fig. 1).
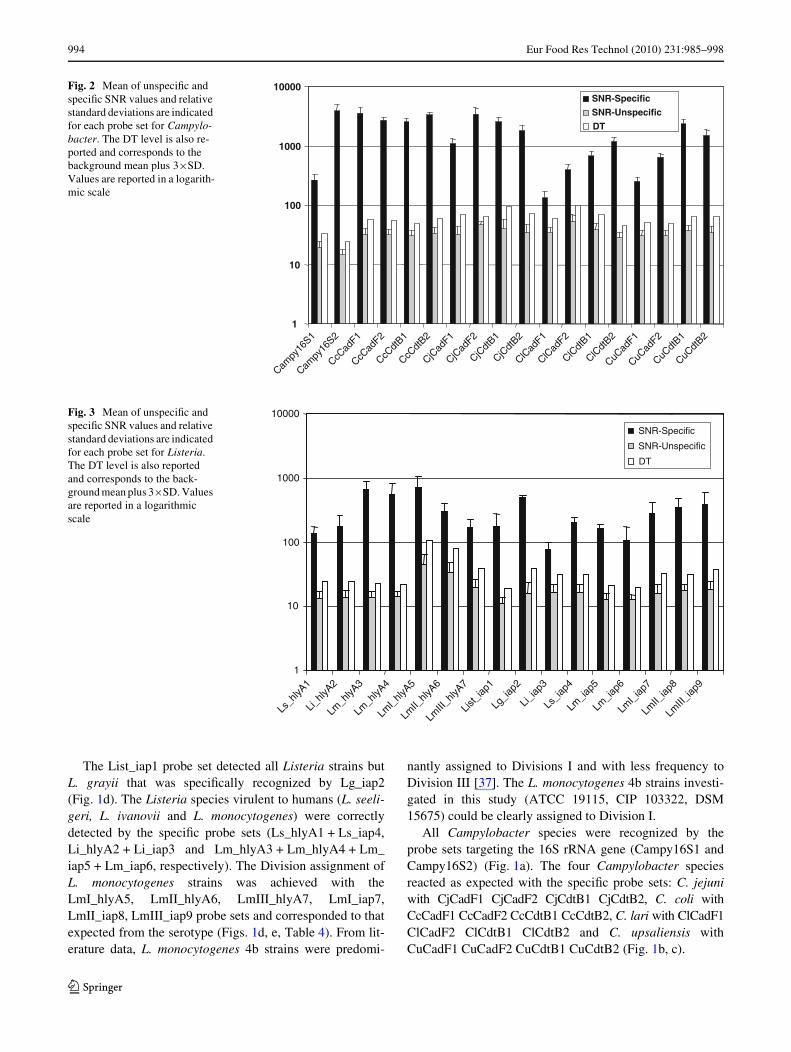
SNR unspeciWc values never exceeded twice the meanvalue and the calculated standard deviations (SD) werenever greater than 50% of the mean value. The DT wasestablished for each probe set (see “Materials and Meth-ods”). DT values resulted to be pretty variable both for Lis-teria and for Campylobacter targeting probe sets, andranged from 19.01 (List_iap1) to 106.25 (LmI_hlyA5).Similarly, the mean of speciWc SNR values ranged from3970.25 (Campy16S2) to 77.40 (Li_iap3) and were gener-ally higher for the Campylobacter targeting probes.
The distribution of unspeciWc SNR values and of speciWcSNR values relative to each probe set resulted to be alwayswell distinct, and no ambiguous results were observed, as con-Wrmed by t test analyses (P < 0.001). Furthermore, speciWcSNR values resulted to be always greater than the backgroundsignal mean plus 4£SD, therefore well above the DT, as only0.003% of background values passed this limit (Figs. 2 and 3).
The LDR–UA experiment results can be schematizedwith a positive or negative signal for each probe set, whenits SNR value was above or below the DT, respectively.Taken together, the positive and negative signals deWnedthe hybridization pattern of each strain, i.e. its molecularsignature (Tables 1 and 2). All the investigated strainsshowed a molecular signature identical to that expectedfrom the sequence data.
Fig. 1 For each probe set, the 10 bp at the 3� end of DP and the 10 bp at the 5� end of CP are re-ported and highlighted with a diVerent shadowing. These por-tions are aligned with speciWc targets, enclosed in an open box, and with the consensus of homologous region from other species. Identities are high-lighted with dots and gaps with dashes. Similarities among strains, as determined based on whole gene sequence, are under-lined with dendrograms. a 16S rRNA gene; “Related species” indicates species of the Arcobacter and Sulfurospirillum genera. b cdtB. c cadF. d iap. e hlyA
123

Eur Food Res Technol (2010) 231:985–998 993
Fig. 1 continued
123
994 Eur Food Res Technol (2010) 231:985–998
The List_iap1 probe set detected all Listeria strains butL. grayii that was speciWcally recognized by Lg_iap2(Fig. 1d). The Listeria species virulent to humans (L. seeli-geri, L. ivanovii and L. monocytogenes) were correctlydetected by the speciWc probe sets (Ls_hlyA1 + Ls_iap4,Li_hlyA2 + Li_iap3 and Lm_hlyA3 + Lm_hlyA4 + Lm_iap5 + Lm_iap6, respectively). The Division assignment ofL. monocytogenes strains was achieved with theLmI_hlyA5, LmII_hlyA6, LmIII_hlyA7, LmI_iap7,LmII_iap8, LmIII_iap9 probe sets and corresponded to thatexpected from the serotype (Figs. 1d, e, Table 4). From lit-erature data, L. monocytogenes 4b strains were predomi-
nantly assigned to Divisions I and with less frequency toDivision III [37]. The L. monocytogenes 4b strains investi-gated in this study (ATCC 19115, CIP 103322, DSM15675) could be clearly assigned to Division I.
All Campylobacter species were recognized by theprobe sets targeting the 16S rRNA gene (Campy16S1 andCampy16S2) (Fig. 1a). The four Campylobacter speciesreacted as expected with the speciWc probe sets: C. jejuniwith CjCadF1 CjCadF2 CjCdtB1 CjCdtB2, C. coli withCcCadF1 CcCadF2 CcCdtB1 CcCdtB2, C. lari with ClCadF1ClCadF2 ClCdtB1 ClCdtB2 and C. upsaliensis withCuCadF1 CuCadF2 CuCdtB1 CuCdtB2 (Fig. 1b, c).
Fig. 2 Mean of unspeciWc and speciWc SNR values and relative standard deviations are indicated for each probe set for Campylo-bacter. The DT level is also re-ported and corresponds to the background mean plus 3£SD. Values are reported in a logarith-mic scale
1
10
100
1000
10000
Campy
16S1
Campy
16S2
CcCad
F1
CcCad
F2
CcCdt
B1
CcCdt
B2
CjCad
F1
CjCad
F2
CjCdt
B1
CjCdt
B2
ClCad
F1
ClCad
F2
ClCdt
B1
ClCdt
B2
CuCad
F1
CuCad
F2
CuCdt
B1
CuCdt
B2
SNR-Specific
SNR-Unspecific
DT
Fig. 3 Mean of unspeciWc and speciWc SNR values and relative standard deviations are indicated for each probe set for Listeria. The DT level is also reported and corresponds to the back-ground mean plus 3£SD. Values are reported in a logarithmic scale
1
10
100
1000
10000
Ls_h
lyA1
Li_hly
A2
Lm_h
lyA3
Lm_h
lyA4
LmI_
hlyA5
LmII_
hlyA6
LmIII
_hlyA
7
List_
iap1
Lg_ia
p2
Li_iap
3
Ls_ia
p4
Lm_ia
p5
Lm_ia
p6
LmI_
iap7
LmII_
iap8
LmIII
_iap9
SNR-Specific
SNR-Unspecific
DT
123

Eur Food Res Technol (2010) 231:985–998 995
Implementation of the tool on Weld isolates
The tool was tested on seven Campylobacter Weld isolatesfrom bovine feces and milk. These samples were foundpositive for the presence of C. jejuni by a routine PCR test[31], whereas primers speciWc to C. coli, also included inthe test, did not give positive result (not shown).
LDR–UA tests conducted on these samples conWrmedthe presence of C. jejuni as all were positive for C. jejuni-speciWc probe sets (CjCadF1, CjCadF2, CjCdtB1,CjCdtB2) (Table 2). One sample (Campylobacter 55) wasalso positive for all C. coli-speciWc probe sets (CcCadF1,CcCadF2, CcCdtB1, CcCdtB2), for CuCdtB1, and CuCdtB2,but not CuCadF1 and CuCadF2, speciWcally targetingC. upsaliensis. Positive calls were unequivocally above theDT level, as they exceeded this limit about twofold(CuCdtB1 and CuCdtB2), about Wvefold (CcCadF1 andCcCadF2) and about sixfold (CcCdtB1 and CcCdtB2).
The coexistence of diVerent species in the sampleCampylobacter 55 was conWrmed by sequencing thePCR product used as LDR target. The sequence chro-matogram clearly showed overlapping peaks in corre-spondence to the three species divergent bases, rulingout the possibility of probe cross-reactivity or of unspeciWchybridization.
Only one probe set (Campy16S1) failed to react withthree Campylobacter isolates (Campylobacter 55, 59, 63).However, the assignment of these isolates to this genus wasconWrmed by the second 16S rRNA gene targeting probeset (Campy16S2) that was positive in all samples.
SNR values from negative spots were always lower thanthe unspeciWc mean plus 1£SD and therefore well belowthe DT, set at 3£SD plus the mean.
Discussion
Listeria and Campylobacter are among the most diVusedfoodborne pathogens in Europe. Several are the infectionsources and concern all kinds of food from poultry, pork,beef to diary products. Contaminated water can spread bac-teria into Wsh cultures or vegetable cultivations.
The rapid detection of Campylobacter and Listeriacontamination is therefore important for food safety and toprevent outbreaks. The precise determination of the con-taminating species is also crucial, as both genera includestrains that are not a threat to human health and if notdistinguished from the pathogenic strains can create falsepositive detections and alarm.
To meet the need of a reliable and robust detection ofthese two genera, the LDR–UA technology was success-fully implemented in a new diagnostic tool.
Probe performance
Probe sets used in this study were designed to couple hightarget speciWcity to strain secure detection.
The DT, independently calculated for each probe set,allowed positive/negative calls with 99.9% conWdence.Within each probe set data, the unspeciWc SNR values, deW-ned on the basis of experiments conducted on unspeciWc tar-gets, showed to be contained within a short range (mean plus/minus 50%). On the other hand, diVerences among DTs weremore relevant. This could be due to the variation of the meanvalues rather than of the SD values, and therefore seemed todepend on the probe sequences rather than on random factors.These data conWrmed the need to set DTs independently foreach probe set, so to distinguish real signals from artifacts.
SNRs registered in the presence of speciWc targets wereabove the thresholds and clearly distinct from those consid-ered as background, both in experiments conducted onknown Listeria and Campylobacter strains and in blindtests performed on Campylobacter spp., as the lowest valuewas still higher than mean plus 4£SD. Nevertheless, set-ting the DT at this level is dangerous as the possibility thatspeciWc signals fall below this limit is not negligible. Thisis especially true for those probe sets with a low speciWcSNR mean such as Li_iap3 or ClCadF1 (Figs. 2 and 3).
The 16S targeting probe sets (Campy16S1 andCampy16S2) were experimentally tested on C. jejuni, C.coli, C. lari and C. upsaliensis, even though they could vir-tually detect many other Campylobacter spp., as the probetarget sequence is conserved. Only the detection of C. rec-tus, a species possibly related to dental disease [38], mightbe diYcult because of variations in probe portions particu-larly sensitive to mismatches, i.e. the 5 bp at the 3� end ofDP and the 5 bp at the 5� end of CP [39]. SpeciWcally, C.rectus presents mismatches in the last base at the 5� of theCampy16S1 CP and in the second last position from the 3�
end of the Campy16S2 DP. Similarly, the Campy16S2probe set might not work on all C. fetus strains, as the C inthe third position from the 5� end of the CP was found to bereplaced by a T in 4/30 strains. Nevertheless, in case ofCampy16S2 malfunctioning on C. fetus, the detection ofthis species would be assured by the informatively redun-dant Campy16S1 probe set (Fig. 1a).
Although not experimentally tested, the cross-reaction ofCampy16S1 and Campy16S2 probe sets and any speciesnot belonging to the Campylobacter genus is to be excludedbecause of the poor homology between the probes and thetarget sequences. In fact, the Arcobacter genus that showedthe highest homology to Campylobacter has at least onemismatch positioned at the 3� end of the DP. All the otherspecies have more mismatches in the 5 bp at the 3� end ofDP and at the 5� end of CP and beyond (Fig. 1a).
123

996 Eur Food Res Technol (2010) 231:985–998
Although no probe sets returned ambiguous results, theSNR mean values were pretty variable for both Campylo-bacter and Listeria. DiVerences could not be correlatedwith probe features such as diVerent annealing tempera-tures, GC content, presence of Inosines or predicted sec-ondary structures. An explanation, though, to the diVerentprobe performance could be given by a nonobvious combi-nation of these factors.
LDR–UA tool performance
The aim of the work here described was to develop a diag-nostic tool that can quickly and precisely detect Campylo-bacter and Listeria spp., even in the presence ofconcomitant strains. The LDR–UA technology was chosenfor its great sensitivity and discriminating power thataccompany its customizability and Xexibility. The LDR–UA experiments could be carried out in one working day,thus conWrming its rapidity compared to traditional meth-ods [36, 40].
The implementation of 34 probe sets allowed the detec-tion of all Listeria and Campylobacter strains and the iden-tiWcation of the species pathogenic to humans.
For L. monocytogenes, by far the most dangerous andfrequently isolated in clinical cases among Listeria species,the determination of the Division was also possible. In caseof outbreaks, this would be of great help in L. monocytoge-nes contamination tracking and for epidemiological studies.Moreover, as the three Divisions have separated evolution-ary history, host adaptation and clinical symptoms, theDivision determination could be of great help to understandthe pathogenic potential of an isolate [41]. For L. monocyt-ogenes 4b, the mere determination of the strain serotype,achieved with immunochemical methods, does not indicatethe Division it belongs to, as 4b serotypes are split in Divi-sions I and III. So far, molecular PCR-based tests contrib-uted to the Division determination [42].
The detection of Listeria harmless species, such as L.innocua, that occupy ecological niches similar to L. mono-cytogenes, is of great consequence as it indicates a Listeriafavorable environment, thus the potential presence also ofL. monocytogenes [43].
The possibility to customize the pathogen detectionassay, simply by preparing the speciWc probe mix, gives theLDR–UA system great Xexibility and allows adapting theexperiment outline to any situation, for instance, decidingwhich speciWc pathogens to detect or what resolution isneeded. This oVers a solution to the intrinsic rigidity oftraditional diagnostic microarrays, with probes printeddirectly onto the chip, as in this case the tool customizationrequires the preparation of brand new microarray slideseach time.
The LDR–UA method here outlined has advantages alsoover the TaqMan PCR approach. First, to be equally infor-mative, the TaqMan approach must implement at least 34probes, with clear drawbacks in terms of handiness, as mul-tiplexing in one or few reactions is obviously diYcult. Sec-ondly, with the LDR–UA, a single base mismatch issuYcient to prevent the ligation reaction, conferring to thetool the highest discrimination power of single-nucleotidepolymorphisms (SNPs). The same performance is reachedin TaqMan experiments only with two diVerently markedcompeting probes per SNP, with a consequent costs raise.
The LDR–UA couples the ampliWcation power typical ofPCR to the throughput described for microarrays. In termsof sensitivity, the LDR–UA approach performs better thaneach of these two techniques because it adds, on top of thePCR exponential ampliWcation, the linear ampliWcation ofthe LDR. The hybridization of UA with LDR products per-formed with less that 1 ng of target DNA still gave a clearsignal ([36] and data not shown), thus making this diagnos-tic system suitable for the detection of very small amountsof bacteria. In order to increase reliability, the strain detec-tion was organized in multiple levels: genus, species and,for L. monocytogenes, Divisions. The positive signal fromeach species or Division-speciWc probe set was conWrmedby the signal from probe sets with broader speciWcity. Ateach level, more probe sets targeted diVerent PCR productsrepresenting the same pathogen, thus providing soundinformation about the presence of a speciWc genus, speciesand Division. The redundant detection of one strain confersrobustness to the system and reliability to the output.
The suitability of the tool for routine diagnostics on Weldisolates was conWrmed by the output of a parallel diagnostictest based on PCR (data not shown). Moreover, the LDR–UA assay resulted more sensitive and informative wherethe presence of more Campylobacter species was detected(e.g. isolate Campylobacter 55; Table 2). However, it can-not be ruled out that the routine PCR method failed todetect these additional species because of their low concen-tration in the sample. The absence of positive calls for thecadF targeting probes (CcCadF1 and CcCadF2) might bedue to a too low concentration of the bacteria and the con-sequent impossibility to detect, at this concentration, theless eYciently ampliWable cadF gene. Alternatively, thisstrain might really lack the cadF gene and be not virulent.In a similar fashion, for three strains (Campylobacter 55, 59and 63) only one 16S rRNA gene targeting probe set(Campy16S2) gave signal above background, whereas thesignal from Campy16S1 was below the DT. These casesproved that the choice of implementing more target genesper species/strain and more probe sets for the same targetgene was appropriate, since it allowed the successful detec-tion of species that would have been otherwise missed.
123

Eur Food Res Technol (2010) 231:985–998 997
The next step will be the validation of the tool directlyon Weld samples (food and specimens). The bacteria enrich-ment and the PCR ampliWcation protocols, tested andapplied to the routine PCR-based detection [31] and withthe Campylobacter-speciWc primers used in this study (pre-liminary data not shown), can be easily implemented in theLDR–UA approach.
The LDR–UA technique, here described with its appli-cation to the detection of Campylobacter and Listeria, con-Wrmed high performances. Moreover, with respect to othertechniques (TaqMan, microarray) the LDR–UA can behighly competitive and cost eVective and is a perfect solu-tion for the routine simultaneous detection of 15–40 targets[40].
Acknowledgments We are particularly thankful to Dr. Mario Luiniand Dr. Valentina Benedetti from IZSLER, Lodi, Italy, for providingWeld isolates, for sharing PCR results on Campylobacter Weld isolates,for help in Campylobacter cultivation, for critical reading of the man-uscript and for fruitful discussion.
References
1. McLauchlin J, Mitchell RT, Smerdon WJ, Jewell K (2004) Listeriamonocytogenes and listeriosis: a review of hazard characterisation foruse in microbiological risk assessment of foods. Int J Food Micro-biol 92:15–33
2. Rocourt J, Schrettenbrunner A, Hof H, Espaze EP (1987) Un nou-velle espèce du genre Listeria: Listeria seeligeri. Pathol Biol35:1075–1080
3. Vazquez-Boland JA, Kuhn M, Berche P, Chakraborty T, Domin-guez-Bernal G, Goebel W, Gonzalez-Zorn B, Wehland J, Kreft J(2001) Listeria pathogenesis and molecular virulence determi-nants. Clin Microbiol Rev 14:584–640
4. Rasmussen OF, Skouboe P, Dons L, Rossen L, Olsen JE (1995)Listeria monocytogenes exists in at least three evolutionary lines:evidence from Xagellin, invasive associated protein and listerioly-sin O genes. Microbiology 141(Pt 9):2053–2061
5. Jinneman KC, Hill WE (2001) Listeria monocytogenes lineagegroup classiWcation by MAMA-PCR of the listeriolysin gene. CurrMicrobiol 43:129–133
6. Humphrey T, O’Brien S, Madsen M (2007) Campylobacters aszoonotic pathogens: a food production perspective. Int J FoodMicrobiol 117:237–257
7. EFSA (2009) The community summary report on trends andsources of zoonoses and zoonotic agents in the European Union in2007. EFSA J
8. Moore JE, Corcoran D, Dooley JS, Fanning S, Lucey B, MatsudaM, McDowell DA, Megraud F, Millar BC, O’Mahony R, O’Rior-dan L, O’Rourke M, Rao JR, Rooney PJ, Sails A, Whyte P (2005)Campylobacter. Vet Res 36:351–382
9. EFSA (2005) Trends and sources of zoonoses, zoonotic agents andantimicrobial resistance in the European Union in 2004. EFSA J
10. EFSA (2006) The community summary report on trends andsources of zoonoses, zoonotic agents, antimicrobial resistance andfoodborne outbreaks in the European Union in 2005. EFSA J
11. Adak GK, Long SM, O’Brien SJ (2002) Trends in indigenousfoodborne disease and deaths, England and Wales: 1992 to 2000.Gut 51:832–841
12. Smith KE, Stenzel SA, Bender JB, Wagstrom E, Soderlund D,Leano FT, Taylor CM, Belle-Isle PA, Danila R (2004) Outbreaks
of enteric infections caused by multiple pathogens associated withcalves at a farm day camp. Pediatr Infect Dis J 23:1098–1104
13. Lawson AJ, ShaW MS, Pathak K, Stanley J (1998) Detection ofcampylobacter in gastroenteritis: comparison of direct PCR assayof faecal samples with selective culture. Epidemiol Infect121:547–553
14. Roy S, Sen CK (2006) cDNA microarray screening in food safety.Toxicology 221:128–133
15. Wiedmann M (2002) Subtyping of bacterial foodborne pathogens.Nutr Rev 60:201–208
16. Best EL, Fox AJ, Frost JA, Bolton FJ (2005) Real-time single-nucleotide polymorphism proWling using Taqman technology forrapid recognition of Campylobacter jejuni clonal complexes.J Med Microbiol 54:919–925
17. Logan JM, Edwards KJ, Saunders NA, Stanley J (2001) RapididentiWcation of Campylobacter spp. by melting peak analysis ofbiprobes in real-time PCR. J Clin Microbiol 39:2227–2232
18. Rantsiou K, Alessandria V, Urso R, Dolci P, Cocolin L (2008)Detection, quantiWcation and vitality of Listeria monocytogenes infood as determined by quantitative PCR. Int J Food Microbiol121:99–105
19. Volokhov D, Chizhikov V, Chumakov K, Rasooly A (2003)Microarray-based identiWcation of thermophilic Campylobacterjejuni, C. coli, C. lari, and C. upsaliensis. J Clin Microbiol41:4071–4080
20. Volokhov D, Rasooly A, Chumakov K, Chizhikov V (2002) Iden-tiWcation of Listeria species by microarray-based assay. J ClinMicrobiol 40:4720–4728
21. Gerry NP, Witowski NE, Day J, Hammer RP, Barany G, Barany F(1999) Universal DNA microarray method for multiplex detectionof low abundance point mutations. J Mol Biol 292:251–262
22. Candela M, Consolandi C, Severgnini M, Biagi E, Castiglioni B,Vitali B, De Bellis G, Brigidi P (2010) High taxonomic level Wn-gerprint of the human intestinal microbiota by ligase detectionreaction-universal array approach. BMC Microbiol 10:116
23. Delrio-Lafreniere SA, Browning MK, McGlennen RC (2004)Low-density addressable array for the detection and typing of thehuman papillomavirus. Diagn Microbiol Infect Dis 48:23–31
24. Rantala A, Rizzi E, Castiglioni B, De Bellis G, Sivonen K (2008)IdentiWcation of hepatotoxin-producing cyanobacteria by DNA-chip. Environ Microbiol 10:653–664
25. Liu D (2006) IdentiWcation, subtyping and virulence determina-tion of Listeria monocytogenes, an important foodborne pathogen.J Med Microbiol 55:645–659
26. Bilir Ormanci FS, Erol I, Ayaz ND, Iseri O, Sariguzel D (2008)Immunomagnetic separation and PCR detection of Listeria mono-cytogenes in turkey meat and antibiotic resistance of the isolates.Br Poult Sci 49:560–565
27. Lehner A, Loncarevic S, Wagner M, Kreike J, Brandl E (1999) Arapid diVerentiation of Listeria monocytogenes by use of PCR-SSCPin the listeriolysin O (hlyA) locus. J Microb Met 34:165–171
28. Konkel ME, Gray SA, Kim BJ, Garvis SG, Yoon J (1999) Identi-Wcation of the enteropathogens Campylobacter jejuni andCampylobacter coli based on the cadF virulence gene and its product.J Clin Microbiol 37:510–517
29. Rozynek E, Dzierzanowska-Fangrat K, Jozwiak P, Popowski J,Korsak D, Dzierzanowska D (2005) Prevalence of potential viru-lence markers in Polish Campylobacter jejuni and Campylobactercoli isolates obtained from hospitalized children and from chickencarcasses. J Med Microbiol 54:615–619
30. Thorsness JL, Sherwood JS, Danzeisen GT, Doetkott C, LogueCM (2008) Baseline Campylobacter prevalence at a new turkeyproduction facility in North Dakota. J Food Prot 71:2295–2300
31. Persson S, Olsen KE (2005) Multiplex PCR for identiWcation ofCampylobacter coli and Campylobacter jejuni from pure culturesand directly on stool samples. J Med Microbiol 54:1043–1047
123

998 Eur Food Res Technol (2010) 231:985–998
32. Cole JR, Wang Q, Cardenas E, Fish J, Chai B, Farris RJ,Kulam-Syed-Mohideen AS, McGarrell DM, Marsh T, Garrity GM,Tiedje JM (2009) The ribosomal database project: improved align-ments and new tools for rRNA analysis. Nucleic Acids Res 37:D141–D145
33. Ludwig W, Strunk O, Westram R, Richter L, Meier H, Kumar Y,Buchner A, Lai T, Steppi S, Jobb G, Forster W, Brettske I, GerberS, Ginhart AW, Gross O, Grumann S, Hermann S, Jost R, KonigA, Liss T, Lussmann R, May M, NonhoV B, Reichel B, StrehlowR, Stamatakis A, Stuckmann N, Vilbig A, Lenke M, Ludwig T,Bode A, Schleifer KH (2004) ARB: a software environment for se-quence data. Nucleic Acids Res 32:1363–1371
34. Chen J, Iannone MA, Li MS, Taylor JD, Rivers P, Nelsen AJ,Slentz-Kesler KA, Roses A, Weiner MP (2000) A microsphere-based assay for multiplexed single nucleotide polymorphism anal-ysis using single base chain extension. Genome Res 10:549–557
35. Consolandi C, Severgnini M, Castiglioni B, Bordoni R, Frosini A,Battaglia C, Rossi Bernardi L, Bellis GD (2006) A structuredchitosan-based platform for biomolecule attachment to solid sur-faces: application to DNA microarray preparation. BioconjugChem 17:371–377
36. Castiglioni B, Rizzi E, Frosini A, Sivonen K, Rajaniemi P,Rantala A, Mugnai MA, Ventura S, Wilmotte A, Boutte C,Grubisic S, Balthasart P, Consolandi C, Bordoni R, Mezzelani A,Battaglia C, De Bellis G (2004) Development of a universalmicroarray based on the ligation detection reaction and 16S rrnagene polymorphism to target diversity of cyanobacteria. ApplEnviron Microbiol 70:7161–7172
37. Borucki MK, Call DR (2003) Listeria monocytogenes serotypeidentiWcation by PCR. J Clin Microbiol 41:5537–5540
38. Mahlen SD, Clarridge JE 3rd (2009) Oral abscess caused by Cam-pylobacter rectus: case report and literature review. J Clin Micro-biol 47:848–851
39. Szemes M, Bonants P, de Weerdt M, Baner J, Landegren U,Schoen CD (2005) Diagnostic application of padlock probes–mul-tiplex detection of plant pathogens using universal microarrays.Nucleic Acids Res 33:e70
40. Cremonesi P, Pisoni G, Severgnini M, Consolandi C, Moroni P,Raschetti M, Castiglioni B (2009) Pathogen detection in milk sam-ples by ligation detection reaction-mediated universal array meth-od. J Dairy Sci 92:3027–3039
41. Wiedmann M, Bruce JL, Keating C, Johnson AE, McDonough PL,Batt CA (1997) Ribotypes and virulence gene polymorphisms sug-gest three distinct Listeria monocytogenes lineages with diVer-ences in pathogenic potential. Infect Immun 65:2707–2716
42. Liu D, Lawrence ML, Gorski L, Mandrell RE, Ainsworth AJ,Austin FW (2006) Listeria monocytogenes serotype 4b strainsbelonging to lineages I and III possess distinct molecular features.J Clin Microbiol 44:214–217
43. Rodriguez-Lazaro D, Hernandez M, Scortti M, Esteve T,Vazquez-Boland JA, Pla M (2004) Quantitative detection of Liste-ria monocytogenes and Listeria innocua by real-time PCR: assess-ment of hly, iap, and lin02483 targets and AmpliFluor technology.Appl Environ Microbiol 70:1366–1377
123





























