Embed Size (px)
Citation preview




Úvod
Čo je proces?
Každý z nás má skúsenosť, že sa naše okolie mení. Od týchto zmien je odvodenéaj naše chápanie času. Človek sa však neuspokojuje s tým, že zmeny v jeho okolílen konštatuje, ale snaží sa poznať príčiny ich vzniku, predpovedať ich následky vbudúcnosti, ba dokonca ich ovplyvňovať. Človek najčastejšie registruje zmeny v jehookolí priamo, pomocou zmyslov. Tým informačne najbohatším zmyslom je zrak a vsúčasnosti vidíme veľké úsilie o spracovanie, prenos a uchovanie zrakových vnemovpomocou techniky. Autori tejto učebnice sa venujú druhému informačne bohatémuzmyslu - sluchu, resp. jednému jeho účelu, ktorým je hlasová komunikácia. Dnes savšak človek nezaujíma len o zmeny, ktoré sú priamo postrehnuteľné zmyslami. Sú tozmeny, ktorých rýchlosť je mimo dosahu našich zmyslov - sú pre ne príliš pomalé, alebopríliš rýchle, prípadne naše zmysly ich nie sú schopné vôbec prijímať. Vnímame ichlen sprostredkovane pomocou záznamových a meracích prístrojov. Všimol si niektoz vás, že erupcie na Slnku sa vyskytujú periodicky s periódou približne 13 rokov?Počul niekto lokačné signály netopierov, ktoré okolo vás preleteli? Dnes však predsa otýchto dejoch vieme, pretože človek zostrojil prístroje, schopné tieto zmeny indikovaťa zaznamenať. Dokonca zaznamenávame aj zmeny, ktoré spôsobuje človek svojoučinnosťou. Vieme, koľko pribudlo v minulom roku železa vyrobeného na Slovensku,koľko bolo vydaných kníh, koľko študentov sa zapísalo na vysokoškolské štúdium.Človeka zaujímajú zmeny najmä ekonomické, sociálne a kultúrne, hoci ich nevnímapriamo zmyslami. Určite ste si všimli, že uvádzame príklady len takých zmien, čovieme odmerať. Zmeny, ktoré nevieme kvantifikovať sú síce tiež dôležité (a možnonajdôležitejšie pre zachovanie ľudstva), predsa však nebudú obsahom tejto učebnice.Môžeme teda povedať, že predmetom tejto učebnice budú zmeny, pri ktorých viemepovedať, v akej sú súvislosti voči nejakej referenčnej periodicky sa opakujúcej zmene(napr. periodickej zmene atómov plynového amoniaku na vlnovej dĺžke 1,2599 cm),čiže hodín. Týmito hodinami vytvárame hodnotu času, v ktorom zmena nastala aakým číslom sa dá veľkosť zmeny ohodnotiť.
Okrem toho, že vnímame zmeny merateľných veličín, máme skúsenosť, že pri rov-nako vnímanej fyzikálnej veličine dochádza k rovnakým kauzálnym zmenám, napr.voda začne vrieť, alebo zamrzne. Preto zavedieme určitú referenčnú hodnotu nielenpre veľkosť zmeny, ale aj pre samotnú veľkosť veličiny (čo je samozrejme veľkosť jejzmeny od referenčnej hodnoty). Napr. Anders Celsius zaviedol ako referenčnú hod-notu teploty takú teplotu, pri ktorej zamŕza voda a na meranie zmeny teploty určil
i

ii
druhú referenčnú hodnotu - teplotu, pri ktorej voda vrie (všetko pri ďalších defino-vaných podmienkach pokusu). Dnes tieto hodnoty poznáme ako 0C a 100C. Inéspôsoby merania teploty zaviedli Fahrenheit a Réamour a aby to nebolo jednoduché,ďalší fyzici si zvolili ako referenčnú hodnotu tú najnižšiu teplotu, ktorá môže v prí-rode byť. Prečo si teda aj Vy nezvolíte svoju stupnicu pre vyjadrenie veľkosti teploty?Zrejme preto, že už nejaké máme a jednak preto, že okrem hodnoty teploty by stemuseli vysvetľovať aj Vašu stupnicu (nám Európanom stačia problémy ak nám pove-dia teplotu vo Fahrenheitoch). Pretože však budeme pracovať s rôznymi fyzikálnymiaj nefyzikálnymi veličinami a ich zmenami, bude vhodné, ak si neskôr povieme, akéspoločné zásady pre tvorbu systému merania dodržiavať, aby sme s hodnotami veli-činy mohli pracovať rovnako intuitívne, ako pracujeme so stupňom Celsia, metromalebo sekundou. Možno práve Vy budete potrebovať vytvoriť novú veličinu (zrejmenefyzikálnu) a navrhnúť spôsob merania jej veľkosti.
Ako sme uviedli, poznaniu príčin a následkov zmien okolo nás sa venuje veda dl-hodobo, preto je prirodzené, že sa špecializovala podľa prostredia, v ktorom sa tietozmeny dejú. Zmeny v prírode študuje najmä fyzika, chémia, biológia, máme vedy očloveku ako medicína alebo psychológia a máme tiež ekonomické a spoločenské vedy.Vašu pozornosť ako študentov technickej vysokej školy by sme radi sústredili na tech-nické vedy, ktoré upriamujú pozornosť aj na to, ako takéto zmeny riadiť alebo vytvá-rať pomocou umelo vytvorených zariadení (napr. počítačmi). Táto učebnica však vžiadnom prípade nechce konkurovať učebniciam fyziky, medicíny, ekonómie či progra-movaniu. Chce len upozorniť na to, že určité zákonitosti v zmenách sledovaného okoliamôžeme odvodiť len zo samotného záznamu veľkosti týchto zmien bez ohľadu na to,čo je príčinou ich vzniku. V tomto zmysle je táto učebnica pomocníkom pri štúdiufyziky, medicíny, atď., nie ich konkurentom, či dokonca náhradou. Je prirodzené, žeak budeme abstrahovať od príčiny vzniku zmien a budeme analyzovať len postupnosťzaznamenaných číselných hodnôt, tak hlavným pomocníkom pri tomto štúdiu budematematika. Pri výklade sme sa snažili o to, aby sme používali čo najjednoduchšiematematické nástroje. Najskôr sú použité len tie, s ktorými máte skúsenosti zo stred-nej školy a základného kurzu matematiky a až neskôr sú zovšeobecnené tak, aby stepochopili ako analýzu zmien v jednom prostredí možno bez podstatných zmien použiťaj v prostredí inom, napr. úplne novom.
Ako robiť analýzu procesov?
Predmetom skúmania tejto učebnice je súbor hodnôt niektorej merateľnej veličiny tak,ako boli zaznamenané v určitých časových okamihoch. Tento súbor hodnôt, spolu sozodpovedajúcimi časovými okamihmi budeme nazývať proces. Aby zreteľnejšie vy-nikli základné myšlienkové postupy pri analýze procesov, zameriame sa najmä nasúbory, ktoré obsahujú konečný počet nameraných hodnôt. Pozície nameraných hod-nôt procesu nie sú navzájom zameniteľné, pretože každá sa viaže k určitému časovémuokamžiku. Príklad na trojicu čísel, ktorých hodnoty sú viazané na pozíciu v záznamepoznáte - je to bod v priestore, ktorého poloha je daná tromi súradnicami. A vlast-nosti bodov v priestore poznáme nielen z osobnej skúsenosti pri pohybe v priestore,ale aj zo štúdia geometrie. Základnou myšlienkou tejto učebnice je použiť predstavy,

iii
ktoré máme o trojrozmernom priestore pri analýze procesov. Nič nám nebráni v tom,aby sme interpretovali časovú súradnicu procesu ako súradnicu bodu a aby sme si pro-ces s tromi zaznamenanými hodnotami predstavili ako bod v priestore. Pretože všakmálokedy potrebujeme poznať vlastnosti procesu len s tromi zaznamenanými hodno-tami, ako prvý krok zovšeobecnenia zavedieme viacrozmerný priestor. Len pre Vašupredstavu: 1 sekunda jednej stopy záznamu zvuku na Vašom CD nosiči obsahuje 44100 hodnôt o intenzite akustického tlaku snímaného dvomi mikrofónmi pri nahrávke.Takýto zvuk si potom môžeme predstaviť ako jeden bod v 44 100-rozmernom prie-store. Asi ťažko si takýto priestor predstavíme, ale všetko, čo budeme s týmto bodomrobiť sa nebude odlišovať od toho, čo robíme s bodom v trojrozmernom priestore.
Aby sme mohli posudzovať súvislosti medzi polohami bodov v priestore, zavediemepojem vektora ako objektu, ktorý má koniec v danom bode priestoru a začiatok v po-čiatku súradnicového systému, tj. v bode s nulovými súradnicami. Takáto predstavapomáha nielen vo fyzike, ale aj v geometrii umožňuje zaviesť pojem uhla medzi vek-tormi, veľkosť vektora, násobok vektora, súčet vektorov a podobne. Pojem vektora,resp. vektorového priestoru bude základným nástrojom pre analýzu procesov v tejtoučebnici. Podotknime ešte, že okrem konečnorozmernosti ohraničíme naše úvahy napriestory lineárne. Intuitívne si môžeme takýto priestor predstaviť ako priestor všaderovnako hustý, v ktorom platí priama úmera, tj. že súčet dvoch rovnakých vektorovje rovnaký, ako dvojnásobok tohto vektora. Samozrejme, že tieto pojmy vymedzímev učebnici presnejšie.
Ako nám však predstava o vlastnostiach bodov v priestore môže pomôcť pri po-znaní vlastností procesu? Proces, v ktorom medzi hodnotami neexistuje žiadna súvis-losť, zodpovedá bodu, ktorý sa s rovnakou možnosťou nachádza na hociktorom miestepriestoru. Ak však bude medzi hodnotami procesu určitá závislosť, zodpovedajúci bodbude ležať v blízkosti niektorej roviny, priamky, či dokonca bodu v priestore, medziktorými je rovnaký typ závislosti. A ak zistíme, že bod zodpovedajúci procesu leží vblízkosti určitej priamky so zadanými vlastnosťami, potom na približné určenie jehopolohy v priestore postačuje jediné číslo, ktoré určuje polohu najbližšieho bodu napriamke. Vo všeobecnosti sa dá povedať, že medzi hodnotami procesu sme našli určitúzákonitosť, ak na "akceptovateľný" popis procesu postačí podstatne menej čísel (pa-rametrov modelu zákonitosti), než je jeho zaznamenaných hodnôt. Napríklad ak byprocesom bol záznam 1 sekundy už spomínaného zvuku a za akceptovateľný by smepovažovali tento zvuk tak, ako by sme ho počuli cez mobilný telefón (GSM enhancedfull rate), tak potom na jeho popis miesto 44 100 hodnôt postačuje 940 čísel.
Našou metódou pri hľadaní zákonitostí v procese bude otáčanie priestoru tak,aby sme uvideli, k akej rovine, priamke, či bodu s vopred zadanými vlastnosťami saproces blíži. Zistime napríklad, či proces s tromi hodnotami nemá tú vlastnosť, ževšetky jeho hodnoty sú približne rovnaké. Aké miesto bodov vytvárajú v priestorebody, ktorých všetky tri súradnice sú rovnaké? Je to priamka (nazvime ju bázickou)prechádzajúca počiatkom súradnicového systému a zvierajúca s každou osou uhol 45.Ak chceme zistiť, či proces má uvedenú vlastnosť, pozrieme sa na priestor tak, abynám "prechádzala" bázická priamka cez sietnicu, takže ju uvidíme len ako "bázický"bod. Ak takto pozorovaná vzdialenosť medzi "bázickým" a analyzovaným bodom budemalá, má proces vlastnosť, že všetky jeho hodnoty sú približne rovnaké a analyzovanýproces môžeme približne nahradiť (aproximovať) procesom, ktorého všetky hodnoty

iv
sú rovnaké, tj. bodom, ktorý leží na bázickej priamke. Kde však na nej leží? Postačí, akzadáme jeho vzdialenosť od počiatku, prípadne jednu jeho súradnicu (pretože ostatnédve sú rovnaké). Poznanie základných vlastností vektorového priestoru umožní totočíslo vypočítať.
Pre koho je učebnica určená a čo obsahuje
Informatické fakulty na technických vysokých školách na Slovensku historicky vznikaliz katedier informatiky na elektrotechnických fakultách. V matematickej príprave štu-dentov je vďaka tomu dodnes venovaná dominantná pozornosť matematickej analýzeaj v prípade, že je možné riešiť úlohy viacerými spôsobmi. Typickým príkladom jenapríklad metóda lineárnej regresie. Metódy lineárnej algebry, pomocou ktorých sa dáregresia interpretovať ako priemet do podpriestoru, nie sú študentom na technickýchinformatických fakultách príliš známe. Lineárna regresia je častejšie odvodzovaná akooptimalizačná úloha a riešená metódami diferenciálneho počtu.
V tejto učebnici by sme chceli ukázať, že pomocou metód diskrétnej matematikyje možné priamo riešiť množstvo problémov, ktoré sa zatiaľ riešia metódami spojitejmatematiky, a až potom sa transformujú do diskrétnej formy, aby mohli byť imple-mentované na počítači. Výlučne diskrétnymi metódami síce nevyriešime všetky úlohy,ale aspoň časť z nich urobíme prístupnejšiu väčšiemu počtu študentov.
Učebnica je určená študentom posledného ročníka bakalárskeho štúdia alebo štu-dentom inžinierskeho stupňa štúdia informatiky na technických vysokých školách. Učitateľov sa predpokladá ovládanie látky zo základných matematických kurzov akosú lineárna algebra a pravdepodobnosť, prípadne základy diferenciálneho počtu. Tátoskladba prerekvizít by podľa predchádzajúcej úvahy nemala nutne obsahovať kalku-lus. Chceme však využiť súčasný stav vyučovania matematiky a v učebnici uvádzameniekoľko príkladov na odvodenie tej istej metódy nielen pomocou metód lineárnejalgebry ale aj pomocou metód diferenciálneho počtu, ktoré študenti poznajú.
Hlavným cieľom učebnice je ukázať študentom postup, ako vedomosti z matema-tiky získané v nižších ročníkoch možno použiť na popis metód a algoritmov, ktoré saskutočne využívajú v technickej praxi.
Prvá kapitola učebnice je motivačná a popisuje (aj keď nie úplne detailne), akodobré porozumenie matematickej podstaty technickej aplikácie umožňuje urobiť jejvylepšenia pri zmenených technologických podmienkach. Táto časť sa zaoberá rieše-ním jednoduchšieho problému, či proces má vopred zadanú vlastnosť, teda či jemuzodpovedajúci bod sa nachádza v blízkosti zadaného podpriestoru a ak áno, tak kto-rým procesom ho aproximovať.
Druhá kapitola je venovaná vektorovým priestorom a využitiu vektorov na mode-lovanie časových radov. Formálne definície a výpočty, ktoré študenti poznajú z ma-tematických predmetov, sú vysvetlené na elementárnych príkladoch. Týmto čitateľzíska vhľad do vlastností a pojmov, ktoré potom použije aj v priestoroch, v ktorýchsi už tieto objekty predstaviť nedokáže.
Tretia kapitola je venovaná lineárnej regresii a jej interpretácii ako priemetu vek-tora do podpriestoru menšej dimenzie.
V ďalších troch kapitolách sú popísané metódy a postupy využívané v informa-

v
tike, ktoré je možné popísať teoretickým aparátom z predchádzajúcich kapitol. Ide ometódy využívané pri prenose signálov digitálnymi sieťami, ako sú modulácia, kódo-vanie, kompresia, optimálny príjem. Ďalej je to metóda kĺzavých súčtov a diskrétnaFourierova transformácia.
Posledná kapitola učebnice rieši zložitejší problém: či viacero procesov má nejakúspoločnú vlastnosť a ak áno tak akú? V geometrickej interpretácii to znamená zistiť,či viacero bodov v priestore (predpokladajme, že sú viac než tri), leží v blízkosti ne-jakej roviny alebo priamky. Ak áno, tak ju nájdime tak, aby po nahradení pôvodnýchbodov bodmi tejto roviny či priamky sme sa dopustili najmenšej chyby. Samozrejmeúlohu rozšírime do viacrozmerného priestoru. My budeme v tejto učebnici predpokla-dať, že hodnoty procesu (súradnice bodu) sú náhodné, ale poznáme stupeň lineárnejzávislosti medzi nimi. To znamená, že budeme potrebovať základné vedomosti z teóriepravdepodobnosti.
Pre Vás, študentov informatiky, je poznanie metód analýzy procesov potrebnénielen preto, aby ste ich vedeli použiť vo vedách ktoré skúmajú príčiny zmien v ur-čitej oblasti, akými sú skôr spomínaná fyzika, ekonómia atď., ale aj preto, aby stetieto metódy naučili počítače, tj. aby ste ich boli schopní naprogramovať. Metódy,ktoré sú vysvetlené v tejto učebnici (založené na lineárnych priestoroch) nie sú tými,ktoré by boli pri analýze malého objemu dát lepšie, než by to urobil človek na základeskúseností. Dnes je však potrebné nepretržite analyzovať veľké množstvo procesov, ve-ľakrát v nepriaznivých podmienkach a s krátkou reakčnou dobou. Za týchto okolnostíje lepšie pri analýze procesov nahradiť človeka počítačom.
Veríme, že pochopenie princípov analýzy procesov pomocou jednoduchých lineár-nych modelov Vám pomôže prípadne aj neskôr, ak ich budete potrebovať aplikovaťv nových oblastiach, alebo ak s ich výsledkami už nebudete spokojní a siahnete ponelineárnych modeloch.
História učebnice
Štúdium matematických modelov fyzikálnych procesov patrí k základným krokompochopenia prenosu informácie. Preto vždy bolo súčasťou predmetu Teória oznamo-vania, ktorého hlavným predstaviteľom nielen v Žiline ale na Slovensku bol prof.Kroutl. V tom čase (1960 – 1977) to boli najmä spojité signály, ktoré boli nositeľominformácie v telefónnych systémoch, preto hlavným nástrojom na ich štúdium bolamatematická analýza. S príchodom digitálnych technológií sa digitalizuje prenos hlasua objavuje sa služba prenosu dát ako nový fenomén. Na Katedre technickej kyberne-tiky, ktorá bola predchodcom Fakulty riadenia a informatiky na Žilinskej univerzite saod školského roku 1979/80 začal učiť predmet Teória informácie a prenos dát. V rámcivyučovania tohto predmetu bol zvolený netradičný prístup k vyučovaniu modelova-nia informačných procesov založený na algebraických vlastnostiach signálov. Zatiaľčo klasický postup vyučovania sa sústredil na spojité signály a modely diskrétnychsignálov vyvodzoval z nich, algebraický prístup umožnil vysvetliť základné myšlienkymodelovania signálov na jednoduchých signáloch s diskrétnym časom a neskôr ichzovšeobecniť aj na signály so spojitým časom. Po založení Fakulty riadenia a infor-matiky a vzniku študijného odboru Informačné a riadiace systémy bol od šk. roku

vi
1993/94 vyučovaný povinný predmet Analýza procesov. Cieľom predmetu bolo naučiťštudentov tvoriť základné modely procesov z nameraných dát bez ohľadu na to, čodáta reprezentujú a aká je časová mierka. Preto mohol byť tento predmet spoločný prezamerania Aplikovaná informatika, Manažment aj pre zameranie Informačná a ria-diaca technika. Predmet tak vhodne dopĺňal špecializované predmety, v ktorých saštudent dozvedel, čo dáta reprezentujú a aké ďalšie poznatky o nich vieme. Text tejtoučebnice odzrkadľuje naše mnohoročné skúsenosti s vyučovaním predmetu Analýzaprocesov.

Obsah
Úvod i
1 Teoretické modely a ich využitie v technike 11.1 Počítačové spracovanie reči . . . . . . . . . . . . . . . . . . . . . . . . 11.2 Spracovanie signálu pre prenos . . . . . . . . . . . . . . . . . . . . . . 21.3 Výpočet koeficientov vektora v rôznych bázach . . . . . . . . . . . . . 41.4 Nekonečnorozmerné vektorové priestory . . . . . . . . . . . . . . . . . 71.5 Využitie pre IP telefóniu . . . . . . . . . . . . . . . . . . . . . . . . . 11
2 Procesy a dáta ako prvky vektorových priestorov 132.1 Vektorové priestory . . . . . . . . . . . . . . . . . . . . . . . . . . . . 132.2 Báza a dimenzia vektorového priestoru . . . . . . . . . . . . . . . . . 232.3 Súradnice vektora vzhľadom na bázu . . . . . . . . . . . . . . . . . . 262.4 Zmena bázy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 272.5 Skalárny súčin . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 302.6 Koeficienty vektora v ortogonálnej báze . . . . . . . . . . . . . . . . . 322.7 Norma vektora . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 332.8 Kolmý priemet vektora do podpriestoru . . . . . . . . . . . . . . . . . 362.9 Gramova-Schmidtova ortogonalizácia . . . . . . . . . . . . . . . . . . 38
3 Modely využívajúce závislosť hodnôt procesu od času 433.1 Vektor ako časová závislosť . . . . . . . . . . . . . . . . . . . . . . . . 433.2 Aproximácia vektora v podpriestore . . . . . . . . . . . . . . . . . . . 443.3 Metóda najmenších štvorcov . . . . . . . . . . . . . . . . . . . . . . . 473.4 Chyba aproximácie . . . . . . . . . . . . . . . . . . . . . . . . . . . . 483.5 Priamka rovnobežná s časovou osou, y = c . . . . . . . . . . . . . . . 503.6 Priamka prechádzajúca počiatkom, y = c · t . . . . . . . . . . . . . . . 523.7 Priamka neprechádzajúca počiatkom, y = c0 + c1 · t . . . . . . . . . . 533.8 Parabola, y = c0 + c1 · t+ c2 · t2 . . . . . . . . . . . . . . . . . . . . . 553.9 Lineárna regresia ako priemet do podpriestoru . . . . . . . . . . . . . 593.10 Všeobecný zápis lineárnej regresie . . . . . . . . . . . . . . . . . . . . 603.11 Koeficienty v neortogonálnej báze . . . . . . . . . . . . . . . . . . . . 673.12 Linearizácia nelineárnych úloh . . . . . . . . . . . . . . . . . . . . . . 71
vii

viii Obsah
4 Modely využívajúce súvislosti medzi hodnotami procesu 774.1 Modely kĺzavých súčtov . . . . . . . . . . . . . . . . . . . . . . . . . . 774.2 Všeobecná formulácia úlohy . . . . . . . . . . . . . . . . . . . . . . . 84
5 Periodické vlastnosti procesov 915.1 Periodické modely . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 915.2 Harmonická báza . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 985.3 Diskrétna Fourierova transformácia (DFT) . . . . . . . . . . . . . . . 1035.4 Priemet do podpriestoru určeného DFT . . . . . . . . . . . . . . . . . 1065.5 Walsh-Hadamardova báza . . . . . . . . . . . . . . . . . . . . . . . . 1195.6 Použitie Fourierovej transformácie v praxi . . . . . . . . . . . . . . . 123
6 Analýza viacrozmerných objektov 1256.1 Dôležité súradnice . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1266.2 Váhové koeficienty pre maximálny rozptyl . . . . . . . . . . . . . . . 1296.3 Analýza hlavných komponentov . . . . . . . . . . . . . . . . . . . . . 1366.4 Náhodné procesy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1456.5 Náhodné vektory . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1476.6 Karhunen Loevov rozklad . . . . . . . . . . . . . . . . . . . . . . . . . 152
7 Lineárne systémy 1597.1 Lineárny systém . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1607.2 Modulácia . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1617.3 Optimálny prijímač . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1627.4 Lineárne časovo invariantné transformácie . . . . . . . . . . . . . . . 1647.5 Spektrálny popis lineárnych, časovo invariantných transformácií . . . 1657.6 Gradientová metóda . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1677.7 Metóda adaptívneho hľadania koeficientov . . . . . . . . . . . . . . . 169
8 Diskrétne lineárne systémy 1718.1 Detekcia parity . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1718.2 Ochrana proti reverzii polarity . . . . . . . . . . . . . . . . . . . . . . 1738.3 Hammingov (7,4) kód . . . . . . . . . . . . . . . . . . . . . . . . . . . 1748.4 Konvolučné kódy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1798.5 Polynomiálne kódy . . . . . . . . . . . . . . . . . . . . . . . . . . . . 182
9 Modelovanie náhodnosti v procesoch 1879.1 Modelovanie lineárnej regresie . . . . . . . . . . . . . . . . . . . . . . 1889.2 Stacionárny proces . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1939.3 Využitie stacionarity na predikciu a interpoláciu . . . . . . . . . . . . 1959.4 Biely šum . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1999.5 MA(q) procesy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2009.6 AR(p) procesy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2039.7 Yule-Walkerove rovnice . . . . . . . . . . . . . . . . . . . . . . . . . . 2049.8 Durbin-Levinsonova rekurzia . . . . . . . . . . . . . . . . . . . . . . . 2069.9 Woldova dekompozícia . . . . . . . . . . . . . . . . . . . . . . . . . . 208

Obsah ix
10 Matematický softvér 21110.1 Matlab . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21210.2 R . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21610.3 Mathematica . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 221
Literatúra 225
Register 227

x Obsah

1 Teoretické modely a ich využitie v technike
Začnime citátom z knihy [20], v ktorej je milo popísaný rozdiel medzi vedou a techni-kou: "Technika je o vyrábaní vecí, bez toho, že by im človek musel rozumieť. Veda je oporozumení veciam bez toho, aby ich človek musel vyrábať." Cieľom tejto kapitoly nieje ponúknuť ucelenú teóriu, ale načrtnúť problém, ktorý bol riešený v spolupráci medzivedou a technikou. Na riešení konkrétnej úlohy si ukážeme, že je užitočné rozumieť ajmatematickému modelu, aj tomu, aké sú technické prostriedky, ktorými je model re-alizovaný. Strety medzi technickou a matematickou koncepciou pri riešení problémovvedú často k nedorozumeniam, prípadne zaznávaniu inžinierov matematikmi ("lebo súpovrchní") aj matematikov inžiniermi ("lebo dokazujú úplné samozrejmosti a navyševnucujú svoje dokazovanie aj ’normálnym’ ľuďom"). V už citovanej knihe nájdemeaj ďalšiu vetu: "Skutočná veda vznikla až vtedy, keď si ľudia uvedomili, že teória apokusy idú ruka v ruke a že táto kombinácia je účinný spôsob ako vyriešiť hromaduproblémov a objaviť zaujímavé nové problémy."
V tejto kapitole netreba všetkému rozumieť. Je to ilustratívna a motivačná kapi-tola a preto čitateľ nemusí hĺbať nad detailami. Tie budú vysvetlené v nasledujúcichkapitolách.
Nasledujúca ukážka ilustruje ako hlbšie matematické pochopenie už existujúcehoriešenia môže ukázať cestu novým technickým riešeniam. V situácii, keď sa zmeniapodmienky, je možné model upraviť. Budeme sa zaoberať počítačovým spracovanímreči, konkrétne IP (Internet Protocol) telefóniou. V klasickej telefónii je signál spraco-vaný tzv. A/D (analógovo/digitálnou) konverziou, pri ktorej sa z analógového signáluvytvorí digitálny, vhodný na prenos. Dá sa dokázať, že v súčasnosti používaný A/Dprevod je najlepší možný. Ale najlepší možný len pre telefóniu cez telefónne siete.Dátové siete (internet) používajú na prenos inú technológiu, pri ktorej vznikajú inéproblémy ako pri klasickej telefónii. Navrhneme nový spôsob A/D konverzie, pri kto-rom bude zabezpečená väčšia odolnosť prenášaného obsahu (v našom prípade rečovéhosignálu) voči stratám paketov, ktoré vznikajú pri prenose signálu IP sieťou. Tým sadosiahne vyššia kvalita prijatého telefónneho signálu.
1.1 Počítačové spracovanie reči
Počítačové spracovanie reči umožňuje hlasovú komunikáciu medzi dvoma ľuďmi po-mocou počítača alebo medzi počítačom a človekom. Podľa toho, ako počítač reč spra-cuje, rozlišujeme tri hlavné úlohy spracovania reči počítačom: rozpoznávanie, syntézua prenos reči sieťou.
Rozpoznávanie reči je proces, pri ktorom počítač identifikuje hovorené slová a re-aguje na ne. Teda na rovnaký hovorený podnet dostaneme od počítača vždy rovnakú
1

2 Kapitola 1. Teoretické modely a ich využitie v technike
odozvu, napríklad sa na monitore vypíše príslušný text. Iný výstup môže byť iden-tifikácia a verifikácia osôb, bližšie sa o rozpoznávaní reči dá dočítať napríklad v [12],[13].
Opačným spôsobom spracovania je syntéza reči, ktorá spočíva vo vytvorení zvu-kového prepisu textu, ktorý nebol vopred v počítači uložený. Pre syntézu sa používajúdva postupy: buď modelovanie vokálneho traktu človeka, alebo skladanie zvuku z vo-pred nahovorených rečových jednotiek. Teda zo súboru nahovorených foném (resp.difém) uložených v databáze sa poskladá slovo, ktoré zaznie z reproduktoru. Jedenz funkčných syntetizátorov vytvorených pre slovenský jazyk sa dá vyskúšať na inter-netovej adrese http://tts.kis.fri.uniza.sk. Tento syntetizátor vyvinula skupinapracovníkov a doktorandov katedry KIS FRI ŽU. Popis práce tohto syntetizátora avysvetlenie ako funguje je možné nájsť napríklad v článkoch [6], [15].
Prenos hlasu telefónnou sieťou používa principiálne inú technológiu, ako je prenoszdigitalizovaného hlasu cez dátové siete. Rozdiel je v spôsobe fungovania prenosovýchmechanizmov telefónnej siete a dátových sietí. Telefónna sieť funguje na princípeprepájania okruhov a dátové siete fungujú na princípe prepájania paketov. To zna-mená, že pre klasický telefónny hovor je vytvorený samostatný okruh po celú dobuhovoru. Pre hovor cez IP siete sú krátke segmenty reči balené do paketov a pre-nášané sieťou. Mechanizmus prepájania okruhov, používaný v telefónnych sieťach jeprispôsobený rovnomernému prenosu a dokáže mu garantovať požadovanú prenosovúkapacitu, rýchlosť a pravidelnosť doručovania. Tento spôsob fungovania telefónnychsietí je však podstatne drahší ako prenos reči po dátových sieťach. V dátových sie-ťach (napr. v sieti internet) je používaný princíp prepájania paketov. Pri prepájanípaketov je snaha čo najefektívnejšie využiť celkovú dostupnú prenosovú kapacitu. Nadruhej strane v dátových sieťach nie je garantovaný čas doručenia dát alebo ich maxi-málne meškanie. Je však zrejmá ekonomická výhodnosť prenosu telefónnych hovorovpo dátovej sieti, pretože užívateľ platí len za pripojenie k internetu, ale neplatí zadĺžku hovoru alebo za vzdialenosť, na ktorú je hovor prenášaný. Presnejšie informácieo prenose reči internetom nájde čitateľ napríklad v práci [16].
1.2 Spracovanie signálu pre prenos
Pre prenos od vysielača k prijímaču je potrebné zmeniť analógový rečový signál nadigitálny (A/D konverzia). V súčasnosti sa A/D konverzia pre klasickú aj IP telefóniurealizuje rovnakým spôsobom. V prvom kroku sa nasnímajú (odmerajú) hodnoty re-čového signálu vo vopred určených časových okamihoch. Čím sú tieto okamihy k sebebližšie, tým je signál popísaný presnejšie. Preto je jedným z parametrov určujúcichkvalitu zvuku vzorkovacia frekvencia, ktorá udáva ako často sa meria hodnota vstup-ného signálu. Pre telefóniu sa používa napríklad frekvencia 8 kHz, čo znamená, žeza 1 sekundu je odmeraných 8000 hodnôt signálu (vzoriek). Hudobné záznamy v CDkvalite používajú frekvenciu 44,1 kHz. Vzorkovanie signálu je znázornené na obrázku1.1.
Veľkosť intervalu medzi jednotlivými snímanými vzorkami určuje Shannonovavzorkovacia veta, ktorá hovorí, že vzorkovacia frekvencia má byť aspoň dvojnásob-kom najvyššej frekvencie obsiahnutej v signáli. Ľudské ucho počuje frekvencie od 20

1.2. Spracovanie signálu pre prenos 3
Obr. 1.1. Spracovanie signálu - vzorkovanie
Hz do 20 kHz, odtiaľ sa odvodilo vzorkovanie 44,1 kHz ako približne dvojnásoboknajvyššej frekvencie počuteľnej človekom. Pri nedodržaní pravidla o veľkosti vzorko-vacej frekvencie môže byť zrekonštruovaný signál úplne odlišný od vstupného signálu,ako vidíme na obrázku 1.2. Tento problém sa nazýva aliasing.
Obr. 1.2. Vznik aliasingu pri vzorkovaní s nesprávnou vzorkovacou frekvenciou
Namerané hodnoty signálu sú bodmi nespočítateľnej množiny, na ich vyjadrenieje však k dispozícii iba konečný počet čísel. Preto je potrebné hodnoty signálu v dru-hom kroku upraviť (zaokrúhliť) tak, aby množina hodnôt signálu mala len konečneveľa prvkov. Výsledné hodnoty sa nazývajú kvantovacie hladiny a čím je ich viac,tým presnejšie je signál zaznamenaný. Zvyčajne sa v telefónii používa na zakódovaniejednej hodnoty 8 binárnych čísel, presnejšie 255 hodnôt (hladín, úrovní), 128 so zna-mienkom "+", 128 so znamienkom "-", pričom 0 je v oboch skupinách. Zaokrúhľovaniev telefónii sa realizuje nerovnomerne, kvôli zachovaniu rovnakej relatívnej chyby preveľké aj malé hodnoty. Najjednoduchším nástrojom na nerovnomerné zaokrúhľovanieje odmerka na múku alebo na lieky, ktorá je pre malé množstvá úzka a pre väčšie šir-šia. V telefónii sa na nerovnomerné zaokrúhľovanie nepoužíva odmerka, ale realizujesa pomocou logaritmickej funkcie, ktorou zmeníme škálovanie úrovní (kvantovacíchhladín) signálu.
Posledným krokom spracovania pre prenos je kódovanie, teda prepis hodnoty sig-nálu do binárneho tvaru, jeho vyjadrenie pomocou núl a jednotiek. Pri klasickej te-

4 Kapitola 1. Teoretické modely a ich využitie v technike
lefónii sú potom tieto hodnoty prenášané cez okruh, ktorý je vytvorený počas celéhotelefónneho hovoru. Pri IP telefónii sú z digitálnych hodnôt tvorené rámce, ktoré súnásledne balené do paketov. V jednom pakete sú dáta zodpovedajúce 20 ms reči.Po prenose dátovými sieťami je z prenesených diskrétnych hodnôt f (k∆) vytvorenýanalógový (spojitý) signál ako súčet radu
f(t) =
∞∑k=−∞
f(k∆)sin(Ω(t− k∆)
)Ω(t− k∆)
kde Ω =π
∆(1.2.1)
Problémy v IP telefónii nastávajú v prípade, že niektoré z paketov nedorazia včas.Tento jav je spôsobený náhodným charakterom oneskorenia v sieti (chvenie), alebopoškodením paketu pri prenose. Chvenie (jitter) je spôsobené náhodným zaťaženímsiete a rôznymi cestami, ktorými pakety s dátami sieťou prechádzajú. Navyše, aj keďje možné detekovať poškodené pakety, nie je možné si vyžiadať ich opätovný prenos,pretože v tom čase už majú byť prehrávané telefonujúcemu účastníkovi. Rozklad donekonečného radu (1.2.1) sa na počesť jeho autora nazýva Shannonov rozklad a mô-žeme ho chápať aj ako rozklad signálu do bázy, pričom prenášané vzorky (dáta) súvlastne koeficienty tohto rozkladu. Čo to znamená rozklad signálu do bázy si vysvet-líme v nasledujúcej podkapitole.
1.3 Výpočet koeficientov vektora v rôznych bázach
V tomto odseku si na jednoduchých príkladoch ukážeme ako sa počítajú koeficientyrozkladu do bázy. Ako model, použijeme trojrozmerný Euklidov priestor, jednoduchšiepovedané: priestor vytvorený z usporiadaných trojíc reálnych čísel.
Bázou B = (b0, b1, b2) tohto priestoru nazveme systém vektorov, ktorý je úplný ajednoznačný. Teda každý vektor priestoru sa bude dať napísať ako lineárna kombináciavektorov bázy a navyše, bude sa to dať urobiť iba jediným spôsobom.
Bázami trojrozmerného Euklidovho priestoru môžu byť napríklad systémy:
B0 = ((1, 0, 0), (0, 1, 0), (0, 0, 1))
B1 = ((5, 0, 2), (0, 2, 0), (1/5, 0,−1/2))
B2 = ((1, 1, 0), (0, 1, 1), (1, 0, 1))
Rozložme teraz vektor f = (5, 4, 2) postupne do troch báz B0, B1, B2.Pod pojmom rozložiť vektor f do bázy B = (b0,b1,b2) rozumieme nájsť také koefi-cienty c0, c1, c2, pre ktoré platí
f = (5, 4, 2) = c0b0 + c1b1 + c2b2
V báze
B0 = ((1, 0, 0), (0, 1, 0), (0, 0, 1))

1.3. Výpočet koeficientov vektora v rôznych bázach 5
bude mať vektor f koeficienty rozkladu c0 = 5, c1 = 4, c2 = 2.Naozaj platí
f = (5, 4, 2) = 5 · (1, 0, 0) + 4 · (0, 1, 0) + 2 · (0, 0, 1)
Navyše sa koeficienty c0, c1, c2 dajú vypočítať aj podľa vzorca
ck =f ⊙ bk
bk ⊙ bk(1.3.1)
kde ⊙ značí skalárny súčin vektorov, napríklad
(5, 4, 2)⊙ (1, 0, 0) = 5.1 + 4.0 + 2.0 = 5
Teda
c0 =(5, 4, 2)⊙ b0
b0 ⊙ b0=
(5, 4, 2)⊙ (1, 0, 0)
(1, 0, 0)⊙ (1, 0, 0)=
5
1= 5
c1 =(5, 4, 2)⊙ (0, 1, 0)
(0, 1, 0)⊙ (0, 1, 0)=
4
1= 4
c2 =(5, 4, 2)⊙ (0, 0, 1)
(0, 0, 1)⊙ (0, 0, 1)=
2
1= 2
Rovnako v bázeB1 = ((5, 0, 2), (0, 2, 0), (1/5, 0,−1/2))
koeficienty c0, c1, c2 vektora f = (5, 4, 2) vypočítame podľa rovnakého vzorca ck =f ⊙ bk
bk ⊙ bk. Ich hodnoty budú tentokrát
c0 =(5, 4, 2)⊙ b0
b0 ⊙ b0=
(5, 4, 2)⊙ (5, 0, 2)
(5, 0, 2)⊙ (5, 0, 2)=
29
29= 1
c1 =(5, 4, 2)⊙ (0, 2, 0)
(0, 2, 0)⊙ (0, 2, 0)=
8
4= 2
c2 =(5, 4, 2)⊙ (1/5, 0,−1/2)
(1/5, 0,−1/2)⊙ (1/5, 0,−1/2)=
0
0.29= 0
Naozaj platí
f = (5, 4, 2) = 1 · (5, 0, 2) + 2 · (0, 2, 0) + 0 · (1/5, 0,−1/2)
V báze
B2 = ((1, 1, 0), (0, 1, 1), (1, 0, 1))

6 Kapitola 1. Teoretické modely a ich využitie v technike
už vzorec (1.3.1) pre výpočet koeficientov nefunguje. Koeficienty vypočítané podľavzorca ck = f⊙bk
bk⊙bkby totiž boli
c0 = (5,4,2)⊙b0
b0⊙b0= (5,4,2)⊙(1,1,0)
(1,1,0)⊙(1,1,0) =92 = 4.5
c1 = (5,4,2)⊙b1
b1⊙b1= (5,4,2)⊙(0,1,1)
(0,1,1)⊙(0,1,1) =62 = 3
c2 = (5,4,2)⊙b2
b2⊙b2= (5,4,2)⊙(1,0,1)
(1,0,1)⊙(1,0,1) =72 = 3.5
Teraz ale lineárnou kombináciou bázových vektorov s koeficientmi
c0 = 4.5 , c1 = 3 , c2 = 3.5
nedostaneme vektor f :
f = (5, 4, 2) = 4.5 · (1, 1, 0) + 3 · (0, 1, 1) + 3.5 · (1, 0, 1) = (8, 7.5, 6.5)
Odvoďme všeobecný vzorec pre výpočet koeficientov c0, c1, c2 vektora f v bázeB = (b0,b1,b2). Vyjadrenie vektora f v tejto báze je
f = c0b0 + c1b1 + c2b2 (1.3.2)
Vynásobme skalárne vzťah (1.3.2) postupne všetkými bázovými vektormi. Dostanemesystém
f ⊙ b0 = c0b0 ⊙ b0 + c1b1 ⊙ b0 + c2b2 ⊙ b0
f ⊙ b1 = c0b0 ⊙ b1 + c1b1 ⊙ b1 + c2b2 ⊙ b1
f ⊙ b2 = c0b0 ⊙ b2 + c1b1 ⊙ b2 + c2b2 ⊙ b2
(1.3.3)
Po dosadení jednotlivých vektorov a vypočítaní príslušných skalárnych súčinov dos-taneme systém troch rovníc o troch neznámych.
9 = c02 + c1 + c26 = c0 + c12 + c27 = c0 + c1 + c22
Po vyriešení dostaneme správne hodnoty koeficientov
c0 = 3.5 , c1 = 0.5 , c2 = 1.5
Naozaj platí
f = (5, 4, 2) = 3.5 · (1, 1, 0) + 0.5 · (0, 1, 1) + 1.5 · (1, 0, 1)
Zároveň vidíme, že pre bázy B0,B1 bol vzťah na výpočet jednoduchší preto, že vý-sledky súčinov bk ⊙ bl = 0 pre k = l. Takéto vektory, ktorých skalárny súčin je 0nazývame kolmé (ortogonálne) a bázy, ktoré spĺňajú túto podmienku sa nazývajúortogonálne bázy.

1.4. Nekonečnorozmerné vektorové priestory 7
Teda ortogonálna báza je taká, že skalárny súčin každých dvoch rôznych vektorovje rovný nule. V ortogonálnej báze sa koeficienty vektora f počítajú podľa vzorca
ck =f ⊙ bk
bk ⊙ bk
V neortogonálnej báze je potrebné vypočítať koeficienty vektora ako riešenie systémurovníc (1.3.3).
Vráťme sa k bázam
B0 = ((1, 0, 0), (0, 1, 0), (0, 0, 1))
B1 = ((5, 0, 2), (0, 2, 0), (1/5, 0,−1/2))
B2 = ((1, 1, 0), (0, 1, 1), (1, 0, 1))
Báza B0 sa nazýva jednotková báza a koeficienty vektora v nej ani netreba počítať,ale rovno použiť namerané hodnoty vektora.Bázy B0 a B1 sú ortogonálne bázy a koeficienty vektora v nich vypočítame rýchlopodľa jednoduchého vzorca (1.3.1).Báza B2 je neortogonálna báza a koeficienty vektora v nej vypočítame zložitejšie,riešením systému rovníc.
1.4 Nekonečnorozmerné vektorové priestory
Priestor rečových signálov tvoria spojité, hladké funkcie s ohraničenou energiou. Mô-žeme ich však tiež považovať za vektory, teda prvky nekonečnorozmerného vektoro-vého priestoru. Pri spracovaní reči sa najčastejšie používajú dva spôsoby rozkladu.Oba používajú ortogonálny systém bázových funkcií.
Pre rozpoznávanie a analýzu rečového signálu sa používa Fourierova transformácia.Fourierova (alebo tiež harmonická) báza pozostáva z funkcií
bn(t) = ejωnt
kde j je komplexná jednotka, ale známejší je asi tvar
bn(t) = cosωnt a an(t) = sinωnt
kde ωn = nω0 = n 2πT0
. Fourierovu bázu by sme mohli prirovnať k báze
B1 = ((5, 0, 2), (0, 2, 0), (1/5, 0,−1/2))
ktorá je ortogonálna, ale nevidno to na prvý pohľad. Podrobnejšie odvodenie bázy akoaj základy práce s komplexnými číslami sú obsahom kapitoly 5.1.1. Rozklad signáluf(t) do harmonickej bázy je
f(t) =
∞∑n=−∞
cnejnω0t

8 Kapitola 1. Teoretické modely a ich využitie v technike
a jeho koeficienty vypočítame podľa známeho vzorca rozkladu do ortogonálnej bázy:
cn =f (t)⊙ bn (t)
bn (t)⊙ bn (t)
Skalárny súčin je však v tomto priestore definovaný pomocou integrálu zo súčinuprvého vektora a vektora komplexne združeného k druhému vektoru:
f(t)⊙ g(t) =
T02∫
−T02
f(t) g(t)dt
Pretože platí(ejnω0t) = e−jnω0t
tak vzorec pre výpočet koeficientov má tvar
cn =f(t)⊙ bn(t)
bn(t)⊙ bn(t)=
T02∫
−T02
f(t)e−jnω0tdt
T02∫
−T02
ejnω0te−jnω0tdt
=1
T0
T02∫
−T02
f(t)e−jnω0tdt, T0 =2π
ω0
Hodnoty |cn| sú vlastne amplitúdy jednotlivých funkcií sínus a kosínus, z ktorých sasignál skladá. Ako príklad rečového signálu je na obrázku 1.3 časový priebeh slovaPYTAGORAS. Nasleduje vyjadrenie tohto slova vo Fourierovej (harmonickej) báze.
Obr. 1.3. Časový priebeh rečového signálu
Rozklad krátkeho úseku rečového signálu do Fourierovej bázy dáva koeficienty, ktorýchveľkosť je znázornená na obrázku 1.4. Tieto hodnoty sa nazývajú okamžité amplitú-dové spektrum signálu. Hodnoty okamžitého amplitúdového spektra sa počítajú prekrátky časový priebeh reči, ktorý sa z pôvodného signálu vyberie pomocou takzvanéhookna. Pri výpočte ďalších koeficientov spektra sa okno posúva len o malý úsek, a taksa okná prekrývajú. Niekedy sa hodnoty signálu v okne prenásobia váhovou funkciou,ktorá zabezpečí, že hodnoty na koncoch okna majú menší význam ako hodnoty v

1.4. Nekonečnorozmerné vektorové priestory 9
Obr. 1.4. Priebeh amplitúdového spektra pre jedno okno
strede okna.
Na obrázku 1.5 je niekoľko takýchto priebehov vedľa seba, pričom veľkosť koeficientovje teraz udávaná farbou. Je to amplitúdové spektrum signálu z obrázku 1.3. Presnej-šie je to amplitúdové Fourierove spektrum, lebo aj koeficienty v inej ako harmonickejbáze sa niekedy nazývajú spektrom, alebo zovšeobecneným spektrom signálu.
Obr. 1.5. Priebeh spektra pre jedno okno a pre celý signál
Na prenos rečového signálu telefónnou sieťou, presnejšie pre A/D konverziu sa používaShannonova transformácia. Shannonova báza pozostáva z funkcií
bn(t) =sin(Ω(t− n∆)
)Ω (t− n∆)
, kde Ω =π
∆

10 Kapitola 1. Teoretické modely a ich využitie v technike
Rozklad signálu f (t) do tejto bázy je
f (t) =∞∑
n=−∞cn
sin(Ω(t− n∆)
)Ω(t− n∆)
a jeho koeficienty vypočítame podľa známeho vzorca rozkladu do ortogonálnej bázy:
cn =f (t)⊙ bn (t)
bn (t)⊙ bn (t)
Skalárny súčin je aj v tomto priestore definovaný pomocou integrálu zo súčinu vekto-rov:
f(t)⊙ g(t) =
∫f(t)g(t)dt
a po vypočítaní koeficientov v Shannonovej báze zistíme, že sa vlastne rovnajú na-meraným vzorkám signálu
cn = f (n∆)
Takže dostávame situáciu analogickú so situáciou v prípade bázy
B0 = ((1, 0, 0), (0, 1, 0), (0, 0, 1))
kedy koeficienty rozkladu nepotrebujeme počítať, lebo sú okamžite známe.Príklad priebehu rečového signálu a jeho aproximácia pomocou jednej a siedmichShannonovych bázových funkcií je na obrázku 1.6.
Obr. 1.6. Signál vyjadrený v Shannonovej báze
Poznamenajme ešte, že aproximácia signálu pomocou konečného počtu bázových fun-kcií sa chová inak v prípade Fourierovej a inak v prípade Shannonovej bázy. V prípadeFourierovej bázy je chyba aproximácie rovnaká na celom časovom priebehu a s rastú-cim počtom členov sa chyba rovnomerne na celej osi zmenšuje. V prípade Shannonovejbázy je aproximácia najpresnejšia v strede časového intervalu, a zhoršuje sa smeromk jeho okrajom, alebo inak, s rastúcim počtom členov sa rozširuje interval, v ktoromje funkcia odhadnutá presne.Pokúsme sa teraz nájsť analógiu k báze
B2 = ((1, 1, 0), (0, 1, 1), (1, 0, 1))

1.5. Využitie pre IP telefóniu 11
Takáto báza, pretože nie je ortogonálna, bude mať koeficienty, ktorých výpočet budezložitejší. Bude mať aj však svoje výhody. Koeficienty v tejto báze môžu niesť aj in-formáciu o iných koeficientoch, ktoré umožnia rekonštrukciu koeficientov v stratenompakete. V prípade, že bázové funkcie budú mať tvar bn(t) = h (t− n∆), bude maťrozklad signálu tvar
f (t) =∞∑
n=−∞cnh (t− n∆) (1.4.1)
Pomocou teórie cyklostacionárnych náhodných procesov sa dá teoreticky dokázať, žepo prenose signálu rozloženého do tvaru (1.4.1), bude mať rekonštruovaný signál rov-naké, alebo lepšie hodnoty odstupu signálu od šumu než pri v súčasnosti používanomShannonovom rozklade. Teoretický výpočet bol urobený pre prípad straty paketov sprenášanými koeficientmi. Na obrázku 1.7 je príklad bázovej funkcie, pomocou ktorejsa naozaj dá urobiť rozklad reči do bázy.
Obr. 1.7. Bázová funkcia klobúk
1.5 Využitie pre IP telefóniu
Zrekonštruovaný signál na strane prijímača má byť ľudským uchom počuteľný rov-nako ako vyslaný signál. Nie je teda snahou, aby zrekonštruovaný signál bol čo najb-ližšie k pôvodnému v zmysle niektorej štandardnej metriky používanej pre vektorovýpriestor. Pre naše účely je potrebné, aby sa čo najmenej zmenili vlastnosti signálu,počuteľné pre ľudské ucho. Sluchom rozlišujeme amplitúdu a frekvenciu jednotlivýchsínusových a kosínusových funkcií, z ktorých sa zložený rečový signál skladá. Nepoču-jeme fázový posun, o ktorý sú tieto funkcie posunuté. Ľudské ucho slúži ako frekvenčnýanalyzátor zvukových signálov. Nervové vlákna dávajú mozgu informáciu o prítom-nosti jednotlivých funkcií sínus a kosínus v signáli. Mozog je informovaný o frekvencii,teda o hodnote n a amplitúde | cn| každej z nich. Fázový posun týchto funkcií všaknevníma. Na ilustráciu uvedieme dva rozdielne priebehy, ktoré ucho vníma rovnako.
Na obrázku 1.8 sú znázornené tri signály predstavujúce sínusové funkcie a zloženýsignál, ktorý vznikne ako ich súčet. Na obrázku 1.9 sú znázornené tri sínusové sig-nály, ktoré majú rovnakú frekvenciu a amplitúdu, ako prvé tri. Od prvej trojice salíšia iba o fázový posun jednej z funkcií. Zložený signál, ktorý vznikne ako súčet tejtotrojice má iný časový priebeh. Vnímanie ľudským uchom je rovnaké pri zloženomsignáli na obrázkoch 1.8 a 1.9. Tieto funkcie si blízke v metrike určenej počúvaním aj

12 Kapitola 1. Teoretické modely a ich využitie v technike
Obr. 1.8. Tri sínusové signály a zložený signál, ktorý vznikne ako ich súčet
Obr. 1.9: Tri sínusové signály s posunom a zložený signál, ktorý vznikne ako ich súčet
keď v iných (klasických) metrikách sú od seba vzdialené. Nebudeme preto porovnávaťpriebeh pôvodného a rekonštruovaného signálu, ale zvolíme iné metódy porovnáva-nia, konkrétne komplexný model, ktorý zahŕňa viacero parametrov, aby bolo ľudsképočúvanie modelované čo najlepšie. Jedným z parametrov v tomto modeli je odstupsignálu od šumu
SNR = 10 logNf
Ns
kde Nf je stredný výkon signálu a Ns je stredný výkon šumu. Hodnota podielu SNRje bezrozmerná veličina, ale zaviedli sa pre ňu jednotky, decibely [dB]. Logaritmickástupnica sa zavádza kvôli potrebe jemnejšieho škálovania v oblasti nižších frekvencií.Dôvodom tejto úpravy je analógia s ľudským uchom, kde sú tiež lepšie rozlišované niž-šie frekvencie. Definíciu a pekné príklady na výpočet SNR je možné nájsť v publikácii[25]. V práci [2] je popísané, že rozklad a následná rekonštrukcia reči v neštandard-nej báze vykazuje pri strate koeficientov lepší odstup signálu od šumu než klasickypoužívaný Shannonov rozklad.
Načrtnuté myšlienky ukazujú, že v podmienkach IP telefónie vznikajú principiálneiné technické problémy a ohraničenia, ako v klasickej telefónii. Hlbšie matematicképochopenie toho, ako funguje telefónia umožňuje využiť výhody jednej pri zavádzanídruhej a nechať priestor na modifikáciu toho, čo potrebné nie je. Navyše sme sa mohlipresvedčiť, že matematika je prostriedkom, ktorý pomáha napredovať technickýmriešeniam.

2 Procesy a dáta ako prvky vektorových priestorov
Pri spracovaní procesov je typickou úlohou rozložiť (analyzovať) daný proces alebosignál na dve alebo viacero zložiek. Je to prirodzený vedecký prístup. Geológa prihodnotení rudného ložiska zaujíma, koľko zlata, striebra, medi sa môže z danej horninyvydolovať. Nutricionistu zaujíma koľko, tuku, cukru, vitamínov a vlákniny je v jednejporcii obedu v MacDonalde. Delenie na zložky môže mať rôzne motivácie:
• môžeme rozkladať proces na zaujímavú a nezaujímavú časť,
• môžeme rozkladať proces na známu a neznámu časť,
• môžeme rozkladať proces na podstatnú a nepodstatnú časť,
• môžeme rozkladať proces aj na viacero častí, a na zvyšok.
Tento rozklad (analýza) sa väčšinou deje vo vektorovom priestore. Cieľom tejtokapitoly je vybudovať intuitívnu predstavu o vektoroch, a súvisiacich pojmoch:
• vektorový priestor,
• lineárna kombinácia vektorov,
• báza vektorového priestoru,
• veľkosť vektora,
• skalárny súčin.
2.1 Vektorové priestory
Začnime otázkou: "Čo je to vektor?" S týmto pojmom sme sa stretli v matematike ajfyzike a môžeme povedať, že v rôznych disciplínach sú slovom vektor popísané rôzneobjekty. Napríklad vo fyzike predstavuje vektor veličinu, ktorá má okrem veľkosti ajsmer. Tým sa líši od obyčajného čísla, ktoré má iba veľkosť. Príkladom vektora vofyzike je rýchlosť, ktorá má veľkosť a smer. Ďalším príkladom vektora je zrýchlenie.V matematike na strednej škole sme sa stretli s vektorom ako usporiadanou n-ticouprvkov, označovaných ako zložky vektora. Čo majú tieto príklady vektorov spoločné?
13

14 Kapitola 2. Procesy a dáta ako prvky vektorových priestorov
Sčitovanie a odčítanie vektorov
V prvom rade je to možnosť sčítania a odčítania. Povedzme, že normálne bežíte rých-losťou 20 kilometrov za hodinu. Ak vám fúka od chrbta vietor, tak dobehnete do cieľarýchlejšie. Ak zase do tváre, tak pomalšie. Vo všeobecnosti výsledný vektor rýchlostibežca je súčtom vektora jeho vlastnej rýchlosti a vektora rýchlosti vetra.
A ako sčitovať a odčitovať n-tice reálnych čísel? Po zložkách, teda
(4, 3, 7,−1) + (3, 4, 5, 6) = (4 + 3, 3 + 4, 7 + 5,−1 + 6) = (7, 7, 12, 5)
(4, 3, 7,−1)− (3, 4, 5, 6) = (4− 3, 3− 4, 7− 5,−1− 6) = (1,−1, 2,−7)
Násobenie vektora reálnym číslom
Povedzme, že dnes nie ste vo forme a podávate len 90 % normálneho fyzického výkonu.Ak normálne bežíte rýchlosťou 20 kilometrov za hodinu, tak dnes ste schopný utekaťlen 0.9 ·20 = 18 kilometrov za hodinu. Je teda prirodzené hovoriť o tom, že vynásobiteváš vektor rýchlosti reálnym číslom.
Násobenie n-tíc reálnym číslom sa znova vykoná po zložkách
3 · (2, 3, 4, 8) = (3 · 2, 3 · 3, 3 · 4, 3 · 8) = (6, 9, 12, 24)
podobne ako delenie nenulovým reálnym číslom
1
2· (2, 3, 4, 8) = (
1
2· 2, 1
2· 3, 1
2· 4, 1
2· 8) = (1,
3
2, 2, 4)
2.1.1 Všeobecná definícia
Keby sme chceli presne odpovedať na otázku v úvode, možno (trocha lišiacky) pove-dať, že vektor je prvok vektorového priestoru. Teraz ale treba povedať, čo je vektorovýpriestor. Vektorový priestor je štruktúra obsahujúca dve množiny prvkov. Prvá znich sú skaláre a tú druhú tvoria vektory. Prvky týchto dvoch množín možno na-vzájom kombinovať pomocou binárnych operácií
argumenty možné operácieskalár so skalárom sčítať, odčítať, násobiť, deliť nenulovým prvkomvektor s vektorom sčítať, odčítaťskalár s vektorom vynásobiť, vydeliť nenulovým skalárom
Tieto operácie musia spĺňať určité pravidlá (matematici ich nazývajú axiómy).
Komutatívnosť sčítania
Podobne ako pre reálne čísla platí 3 + 4 = 4 + 3 musí platiť aj pre ľubovoľné dvaskaláre a, b
a+ b = b+ a

2.1. Vektorové priestory 15
a pre ľubovoľné dva vektory u,v
u+ v = v + u
Ťažko si predstaviť, aký druh sčítania by nebol komutatívny. V matematike je tonaozaj veľmi zriedkavý jav, pretože matematici používajú sčítanie takmer výlučnena označenie komutatívnych operácií. V chémii však napríklad nie je jedno či doskúmavky najprv dáte kyselinu sírovú a potom prilejete vodu, alebo naopak do vodyprilejete kyselinu sírovú.
Asociatívnosť sčítania a násobenia
Pre ľubovoľné tri skaláre a, b, c musí platiť
(a+ b) + c = a+ (b+ c)
(a · b) · c = a · (b · c)
a podobne pre ľubovoľné tri vektory u,v,w musí platiť
(u+ v) +w = u+ (v +w)
Asociatívnosť operácií v matematike je ešte častejšia ako komutatívnosť. Avšak aso-ciatívnosť je porušená v praxi pri počítaní s reálnymi číslami v počítači. Napríklad(
1 + 3.2 · 1030)+ (−3.2 · 1030) = 1 +
(3.2 · 1030 + (−3.2 · 1030)
)Existencia neutrálnych prvkov
Existujú dva (rôzne) skaláre 0, 1 také, že pre ľubovoľný skalár platí
0 + a = a+ 0 = a
1 · a = a · 1 = a
1 · v = v
a nakoniec existuje nulový vektor 0 taký, že pre ľubovoľný vektor v
0+ v = v + 0 = v
0 · v = 0
Existencia inverzných prvkov
Pre ľubovoľný skalár a existuje prvok −a taký, že
a+ (−a) = 0
Podobne pre ľubovoľný vektor v existuje opačný vektor −v taký, že
v + (−v) = 0

16 Kapitola 2. Procesy a dáta ako prvky vektorových priestorov
Nakoniec pre ľubovoľný skalár a rôzny od 0 musí existovať inverzný prvok a−1 taký,že
a · a−1 = 1
Existencia inverzných prvkov pre binárne operácie je relatívne zriedkavý jav, napríkladoperácia zjednotenia množín má neutrálny prvok, ale nemá inverzný prvok. To istéplatí pre sčítanie celých čísel na mikroprocesore so saturovaním.
Distributívne zákony
Tieto zákony dávajú do súvisu sčítanie s násobením.Pre ľubovoľné skaláre a, b, c platí
(a+ b) · c = a · c+ b · c
Podobne pre ľubovoľné skaláre a, b a vektor v platí
(a+ b) · v = a · v + b · v
a takisto pre ľubovoľné vektory v,w a skalár a platí
a · (v +w) = a · v + a ·w
Komutatívnosť násobenia skalárov
Pre ľubovoľné dva skaláre a, b musí platiť
a · b = b · a
Toto pravidlo je celosvetovo prijaté, s výnimkou Francúzska. My ho budeme predpo-kladať v celej knižke.
Všimnite si, že žiadna z axióm sa nezmieňovala o delení. Je to preto, že delenie jedefinované pomocou násobenia a inverzného prvku. Teda podiel dvoch skalárov je
a
b= a · b−1
a
b· v = (a · b−1) · v = a · (b−1) · v
2.1.2 Príklady vektorových priestorov
Definícia vektorového priestoru sa môže zdať komplikovaná, spĺňa však úlohu zaviesťpojem, ktorý zastreší všetky doterajšie predstavy o vektoroch. Treba si uvedomiť, žetáto definícia plní ešte jednu úlohu a to, že vymedzuje aj iné, nové vektory, ktorénemusia byť vektormi tak, ako ich chápeme v geometrii, alebo vo fyzike. Môže to byťľubovoľný matematický objekt spĺňajúci axiómy vektorového priestoru. Napríkladpolynómy stupňa najviac n, alebo spojité funkcie. Samozrejme na to, aby polynómy,

2.1. Vektorové priestory 17
alebo funkcie mohli byť považované za vektory, musíme k uvedeným množinám objek-tov (vektorov) pridať operáciu sčítania, vymedziť množinu skalárov, operáciu násobe-nia skalárom a zabezpečiť platnosť všetkých axióm vektorového priestoru. V týchtovektorových priestoroch platia rovnaké tvrdenia a vety ako v priestoroch, ktoré bu-deme rozoberať podrobnejšie. Je len na vôli čitateľa, aké zovšeobecnenia si vyberiepre svoje potreby.
V ďalšom texte budeme pracovať s dvomi vektorovými priestormi V1,V2. Cieľombude ukázať, že vlastnosti, ktorým rozumieme v jednom priestore sa dajú zovšeobecniťa použiť v inom priestore. Zavedieme teraz dva vektorové priestory V1 a V2. Nechvektorový priestor V1, je tvorený posunutiami roviny, teda množinu vektorov V1tvoria skupiny úsečiek, ktoré majú rovnaký smer, veľkosť a sú vzájomne rovnobežné.Množinu skalárov F1 tvoria reálne čísla. Operácia + na množine V1 je definovaná preľubovoľné vektory v,u ∈ V1 nasledujúco v + u = z, výsledný vektor z má veľkosťa smer rovnaké ako uhlopriečka rovnobežníka so stranami v,u. Operácie + a · namnožine F1 = R sú definované obvyklým spôsobom. Násobenie vektora v číslom cje definované tak, že výsledný vektor má rovnaký smer ako v v prípade, že c > 0a opačný smer ak c < 0. Veľkosť výsledného vektora je |c|-násobok veľkosti vektorav. Nulový vektor je jednoducho bod a opačný vektor je vektor, ktorý má prehodenýpočiatočný a koncový bod.Vektorový priestor V2 je tvorený N -ticami reálnych čísel. Množinu skalárov F2
tvoria znovu reálne čísla. Operácia + na množine V2 je definovaná pre ľubovoľnévektory v = (v0, v1, . . . , vN−1),u = (u0, u1, . . . , uN−1) ∈ V2 nasledujúco: v + u = zje taký vektor, pre ktorý platí z = (z0, z1, . . . , zN−1) = (v0 + u0, v1 + u1, . . . , vN−1 +uN−1). Operácie + a · na množine skalárov F2 = R sú definované obvyklým spôsobom.
Príklad 2.1.1 Na obrázku 2.1 je znázornený postup pri geometrickom sčítaní dvochvektorov z priestoru V1.
Obr. 2.1. Súčet vektorov v a u
Príklad 2.1.2 Vektory na obrázku 2.1 môžeme chápať ako usporiadané dvojice. Naobrázku 2.2 skutočne vidíme, že geometrický súčet v priestore V1 môžeme nahradiťalgebraickým súčtom v priestore V2.
v + u = z
(2, 3) + (4, 1) = (6, 4)

18 Kapitola 2. Procesy a dáta ako prvky vektorových priestorov
Obr. 2.2. Súčet vektorov v = (2, 3) a u = (4, 1) je z = (6, 4)
Úloha 2.1.1 Overte, že V1 a V2 spĺňajú axiómy vektorového priestoru.
Úloha 2.1.2 Dokážte, že ak vektor z je súčtom vektorov (posunov) v a u v priestoreV1, tak zodpovedajúce vektory (usporiadané dvojice) v a u majú aj v priestore V2
súčet vektor z.
Príklad 2.1.3 Aká je veľkosť vektora c = (4, 3)?
Riešenie:Veľkosť vektora c na obrázku 2.3 sa dá vypočítať pomocou Pytagorovej vety c2 =a2 + b2. Teda
|c| =√a2 + b2 =
√42 + 32 =
√25 = 5
c
4
3
Obr. 2.3. Veľkosť vektora c=(4,3).
Príklad 2.1.4 Aká je veľkosť vektora d = (a, b, c)?
Riešenie:Veľkosť vektora d na obrázku 2.4 sa dá vypočítať pomocou dvojnásobného využitiaPytagorovej vety. Teda v trojrozmernom priestore bude veľkosť vektora
|d| =√a2 + u2 =
√a2 + (
√(b2 + c2))2 =
√a2 + b2 + c2
Úloha 2.1.3 Aká bude veľkosť vektora e v štvorrozmernom priestore?

2.1. Vektorové priestory 19
Obr. 2.4. Veľkosť vektora d pre hodnoty (a, b, c) = (3, 4, 5)
Úloha 2.1.4 Môžeme vzorec pre veľkosť vektora v priestore V1 použiť v priestore V2?Ako bude vyzerať vzorec pre veľkosť vektora, ktorý má N zložiek? Čo znamená rozmerpriestoru?
Okrem súčtu vektorov je vo vektorovom priestore daný aj ich rozdiel.Rozdiel vektorov w = v − u je súčet vektora v a opačného vektora k vektoru u.To je dobré si uvedomiť, kvôli geometrickej predstave rozdielu dvoch vektorov, ako jeto vidno na obrázku 2.5.
Obr. 2.5. Vektor w je rozdiel vektorov v a u
S pojmami veľkosť vektora a rozdiel dvoch vektorov je už možné riešiť úlohuako aproximovať jeden vektor iným vektorom a určiť chybu, ktorej sme sa pri tomdopustili.
Príklad 2.1.5 Ktorý z vektorov u, v na obrázku 2.6 lepšie nahradí vektor a?
Riešenie:V situácii, keď je potrebné vektor a nahradiť jedným z vektorov u alebo v, vyberiemeten vektor, ktorý lepšie aproximuje pôvodný vektor. Vektor v je k vektoru a podstatnebližšie, v sa viac podobá na a, než vektor u. Vyberieme vektor v, lebo veľkosť rozdieluv − a je menšia ako veľkosť rozdielu u− a.

20 Kapitola 2. Procesy a dáta ako prvky vektorových priestorov
Obr. 2.6. Aproximácia vektora a bližším z vektorov u, v
Príklad 2.1.6 Vektory z príkladu 2.1.5 môžeme zakresliť do roviny aj tak, že jednot-livé zložky vektora budú hodnoty nejakého procesu v časoch 1 a 2, ako je to na obrázku2.7. Takýmto spôsobom bude možné nakresliť aj viaczložkové vektory.
Obr. 2.7. Aproximácia 2-zložkového vektora a bližším z vektorov u, v
Úloha 2.1.5 Môže sa problém z príkladu 2.1.5 riešiť aj v priestore V7?Ktorý z vektorov u = (1, 4, 5, 2, 9, 3, 2), v = (4, 2, 1, 3, 5, 2, 3) je bližšie k vektoru a =(3, 5, 2, 1, 4, 4, 3)?
Úloha 2.1.6 Ako zakresliť vektor z priestoru V7? Je vidno z obrázku 2.8, ktorý zvektorov u alebo v lepšie aproximuje vektor a?
Na to, aby sme mohli presne odpovedať na otázky v predchádzajúcich úlohách, budepotrebné zaviesť (alebo zopakovať) ďalšie pojmy z lineárnej algebry.Nech c0, c1, . . . , cN−1 sú skaláry.Vektor v = c0 · v0 + c1 · v1 + · · · + cN−1 · vN−1 nazveme lineárnou kombináciouvektorov v0,v1, . . . ,vN−1.
Príklad 2.1.7 Vektor (2, 4, 1) je lineárnou kombináciou vektorov (1, 2, 4) a(0, 0, 1), lebo
(2, 4, 1) = 2 · (1, 2, 4)− 7 · (0, 0, 1)Rovnako vektory (−1,−2,−4), (0, 0, 0) aj (1, 2, 1) sú lineárnymi kombináciami vekto-rov (1, 2, 4) a (0, 0, 1), pretože
(−1,−2,−4) = −1 · (1, 2, 4) + 0 · (0, 0, 1)

2.1. Vektorové priestory 21
Obr. 2.8. Aproximácia 7-zložkového vektora a bližším z vektorov u, v
(0, 0, 0) = 0 · (1, 2, 4) + 0 · (0, 0, 1)
(1, 2, 1) = 1 · (1, 2, 4)− 3 · (0, 0, 1)
Úloha 2.1.7 Vyjadrite postupne vektor a = (2, 4) ako lineárnu kombináciu vektorovu, v a načrtnite príslušný obrázok.
• u = (1, 0), v = (0, 1)
• u = (2, 0), v = (0, 2)
• u = (1, 4), v = (4, 2)
• u = (1, 4), v = (2, 8)
Úloha 2.1.8 Vyjadrite postupne vektor a = (2, 4, 6) ako lineárnu kombináciu vekto-rov:
• u = (1, 0, 0), v = (0, 2, 3)
• u = (2, 0, 0), v = (0, 2, 4)
• u = (1, 0, 2), v = (0, 2, 0), w = (0, 0, 2)
Vektory v0,v1, . . . ,vN−1 sa nazývajú lineárne závislé, ak existuje vektor c taký,že platí
c0v0 + c1v1 + · · ·+ cN−1vN−1 = 0
c = (c0, c1, . . . , cN−1) = 0
Poznámka:Vektor c je nenulový, ak aspoň jedno z čísel c0, c1, . . . , cN−1 je rôzne od nuly.

22 Kapitola 2. Procesy a dáta ako prvky vektorových priestorov
Príklad 2.1.8 Vektory (2, 4, 8, 1), (1, 2, 4, 0) a (0, 0, 0, 1) sú lineárne závislé lebo
1 · (2, 4, 8, 1)− 2 · (1, 2, 4, 0)− 1 · (0, 0, 0, 1) = (0, 0, 0, 0) = 0
teda existuje nenulový vektor koeficientov c = (1,−2,−1) = (0, 0, 0) taký, že pomocouneho je možné urobiť lineárnu kombináciu, ktorá je rovná vektoru 0.
Úloha 2.1.9 Nakreslite
• dvojicu lineárne závislých vektorov u, v
• trojicu lineárne závislých vektorov u, v, w
• principiálne inú trojicu lineárne závislých vektorov u, v, w
Úloha 2.1.10 Doplňte na
• dvojicu lineárne závislých vektorov u = (1, 0), v =?
• dvojicu lineárne závislých vektorov u = (1, 1), v =?
• dvojicu lineárne závislých vektorov u = (1, 0, 1), v =?
• trojicu lineárne závislých vektorov u = (1, 0, 1),v = (1, 1, 1),w =?
• trojicu lineárne závislých vektorov u = (4, 2, 4),v = (2, 1, 2),w =?
Vektory v0,v1, . . . ,vN−1 sa nazývajú lineárne nezávislé, ak lineárna kom-binácia c0v0 + c1v1 + · · · + cN−1vN−1 je rovná nule iba pre nulový vektor c =(c0, c1, . . . , cN−1) = 0.
Príklad 2.1.9 Vektory (2, 4, 7, 1), (1, 2, 4, 0) a (0, 0, 0, 1) sú lineárne nezávislé leborovnica
c0 · (2, 4, 7, 1) + c1 · (1, 2, 4, 0) + c2 · (0, 0, 0, 1) = (0, 0, 0, 0)
pre neznámu c má iba jediné riešenie c = (0, 0, 0).
Úloha 2.1.11 Nakreslite
• dvojicu lineárne nezávislých vektorov u, v
• trojicu lineárne nezávislých vektorov u, v, w
• principiálne inú trojicu lineárne nezávislých vektorov u, v, w
Úloha 2.1.12 Doplňte na
• dvojicu lineárne nezávislých vektorov u = (1, 0), v =?
• dvojicu lineárne nezávislých vektorov u = (1, 1), v =?
• dvojicu lineárne nezávislých vektorov u = (1, 0, 1), v =?
• trojicu lineárne nezávislých vektorov u = (1, 0, 1),v = (1, 1, 1),w =?

2.2. Báza a dimenzia vektorového priestoru 23
• trojicu lineárne nezávislých vektorov u = (4, 2, 4),v = (2, 1, 2),w =?
Pri riešení úloh môže pomôcť nasledujúce tvrdenie (ktorého dôkaz čitateľ nájdev učebniciach lineárnej algebry alebo ho urobí sám). Pre lepšiu orientáciu v lineár-nej algebre odporúčame zopakovať vedomosti zo základného kurzu algebry napríkladpodľa [21], hlbšie uchopenie problematiky a teoretické zázemie nájde čitateľ v [26].
Tvrdenie 2.1.1 Vektory v0,v1, . . . ,vN−1 sú lineárne závislé, ak aspoň jeden z nichsa dá vyjadriť ako lineárna kombinácia ostatných vektorov.
2.2 Báza a dimenzia vektorového priestoru
Jedným z najdôležitejších pojmov, s ktorými v tejto knihe budeme pracovať je pojembázy. Bázou vektorového priestoru nazveme usporiadanú n-ticu vektorov B =(b0,b1, . . . ,bN−1) vektorového priestoru V práve vtedy, ak
• vektory b0,b1, . . . ,bN−1 sú lineárne nezávislé
• každý z vektorov priestoru V možno vyjadriť ako lineárnu kombináciu vek-torov tejto bázy, teda pre ľubovoľný vektor x ∈ V existujú také koeficientyc0, c1, . . . , cN−1 ∈ F , že platí
x = c0b0 + c1b1 + · · ·+ cN−1bN−1
Poznámka:Hovoríme, že systém bázových vektorov je nezávislý (lineárna nezávislosť vektorovbázy) a úplný (všetky vektory sa dajú vyjadriť ako lineárna kombinácia vektorovbázy).
Nezávislosť systému zabezpečí, že dostaneme jednoznačný rozklad (a súčasne naj-menší počet vektorov v lineárnej kombinácii). Vďaka úplnosti systému, môžeme dobázy rozložiť ľubovoľný vektor priestoru V.
Príklad 2.2.1 Systém vektorov B = ((2, 5), (−1, 3)) je bázou vektorového priestoruV2 všetkých dvojzložkových vektorov.
Riešenie:Skutočne, ľubovoľný vektor v = (v0, v1) sa dá napísať ako lineárna kombinácia vek-torov (2, 5) a (−1, 3)
(v0, v1) = c0(2, 5) + c1(−1, 3)Táto vektorová rovnica vedie na lineárnu sústavu rovníc
v0 = c02 + c1(−1)v1 = c05 + c13
Riešením tejto sústavy (s neznámymi c0, c1 a parametrami v0, v1) sú
c0 =3v0 + v1
11
c1 =−5v0 + 2v1
11

24 Kapitola 2. Procesy a dáta ako prvky vektorových priestorov
Skutočne platí, že
c0 · (2, 5) + c1 · (−1, 3) =3v0 + v1
11· (2, 5) + −5v0 + 2v1
11· (−1, 3) =
=
(6v0 + 2v1
11,15v0 + 5v1
11
)+
(5v0 − 2v1
11,−15v0 + 6v1
11
)=
(11v011
,11v111
)= (v0, v1)
Úloha 2.2.1 Zistite, či nasledujúce systémy vektorov tvoria bázu nejakého vektoro-vého priestoru V:
• B0 = ((1, 0), (1, 1))
• B1 = ((1, 0, 1), (1, 1, 0))
• B2 = ((1, 0, 1), (1, 1, 0), (2, 2, 1)
• B3 = ((1, 0), (1, 1), (2, 3))
• B4 = ((1, 0, 1), (1, 1, 0), (0, 0, 1), (1, 0, 0))
• B5 = ((51, 14, 76, 22), (1, 1, 0, 4), (3, 0, 0, 1))
• B6 = ((34, 42, 50), (61, 19, 30), (0, 0, 0))
Tvrdenie 2.2.1 Všetky bázy vektorového priestoru V majú rovnaký počet prvkov.
Predchádzajúce tvrdenie umožňuje zaviesť pojem dimenzie priestoru.Dimenzia vektorového priestoru V je počet prvkov bázy tohto priestoru.Poznámka:Ak má vektorový priestor dimenziu N, nazýva sa N-rozmerný vektorový priestor,značíme dim(V) = N .Prvky bázy nazývame bázové vektory, alebo vektory bázy.
Príklad 2.2.2 Koľko rozmerný je vektorový priestor V, pozostávajúci zo všetkýchtrojzložkových vektorov (v0, v1, v2)?
Riešenie:Vektory môžeme napísať ako lineárnu kombináciu
(v0, v1, v2) = v0 · (1, 0, 0) + v1 · (0, 1, 0) + v2 · (0, 0, 1)
Systém troch vektorov E = ((1, 0, 0), (0, 1, 0), (0, 0, 1)) tvorí bázu (presnejšie jednu zmnohých báz) priestoru V. Že je to naozaj báza ukážeme tak, že overíme úplnosťa lineárnu nezávislosť systému E . Vektorový priestor V, ktorého báza má tri prvky(vektory), je trojrozmerný.
V príklade 2.2.2 sme ukázali úplne jasné tvrdenie, že trojzložkové vektory tvoriatrojrozmerný vektorový priestor. Dôležitejší než výsledok úlohy je však postup, ktorýneskôr použijeme pri určovaní rozmeru v zložitejších priestoroch.

2.2. Báza a dimenzia vektorového priestoru 25
Tvrdenie 2.2.2 Každá množina N lineárne nezávislých vektorov patriacich do N -rozmerného vektorového priestoru V tvorí bázu vektorového priestoru V.
Vektorový priestor P je vektorovým podpriestorom vektorového priestoru V,ak pre každý vektor z P platí:
v ∈ P⇒ v ∈ V
Príklad 2.2.3 Objekty "priamka", "rovina", "priestor" v geometrickom chápaní môžubyť vektorovými priestormi.
• Objekt "priamka" je jednorozmerným vektorovým podpriestorom dvojrozmer-ného vektorového priestoru "rovina".
• Objekt "rovina" je dvojrozmerným vektorovým podpriestorom trojrozmernéhovektorového priestoru "priestor".
• Objekt "priamka" je jednorozmerným vektorovým podpriestorom trojrozmer-ného vektorového priestoru "priestor".
Tvrdenie 2.2.3 Množina všetkých lineárnych kombinácií vektorovv0,v1, . . . ,vM−1 ∈ VN tvorí vektorový podpriestor VM priestoru VN .
VM = c0v0 + c1v1 + · · ·+ cM−1vM−1; c0, c1, . . . , cM−1 ∈ F
Hovoríme, že vektory v0,v1, . . . ,vM−1 generujú podpriestor VM , značíme
VM = [v0,v1, . . . ,vM−1]
Príklad 2.2.4 Príklady systémov vektorov, ktoré generujú vektorové priestory.
• S1 = ((1, 0, 0), (0, 1, 0), (0, 0, 1)) generuje trojrozmerný vektorový priestor
• S2 = ((1, 0, 0), (0, 1, 0)) generuje dvojrozmerný vektorový podpriestor trojroz-merného vektorového priestoru
• S3 = ((1, 1, 0), (2, 2, 0)) generuje jednorozmerný vektorový podpriestor trojroz-merného vektorového priestoru
Úloha 2.2.2 Zistite, koľkorozmerný vektorový podpriestor generujú vektory
• B1 = ((1, 0, 0, 0), (2, 0, 1, 0), (0, 0, 0, 1))
• B2 = ((4, 4, 3, 3), (2, 2, 1, 1), (0, 0, 1, 1))
O podpriestory akého priestoru ide?
Úloha 2.2.3 Ako súvisí rozmer priestoru generovaného systémom vektorov B s hod-nosťou matice B, ktorej riadky sú jednotlivé vektory systému B?
Jednotkovou bázou E vektorového priestoru VN , nazveme bázu
E = (e1, e2, . . . , eN )
kde ek = (0, . . . , 1, . . . , 0) je vektor, ktorý má všetky zložky 0, len na k-tom miestemá 1.

26 Kapitola 2. Procesy a dáta ako prvky vektorových priestorov
2.3 Súradnice vektora vzhľadom na bázu
Tvrdenie 2.3.1 Každý vektor v vektorového priestoru V možno jednoznačne vyjadriťako lineárnu kombináciu bázových vektorov
v =N−1∑k=0
ckbk
Koeficienty c0, c1, . . . , cN−1 rozkladu vektora do bázy nazývame súradnice vektorav vzhľadom na bázu B.Píšeme
v = (c0, c1, . . . , cN−1)B
Ak bázu v zápise neoznačíme, budú to súradnice v jednotkovej báze E :
v = (v0, v1, . . . , vN−1)
v = (v0, v1, . . . , vN−1)E
Tvrdenie 2.3.2 k-tu súradnicu vektora v vypočítame ako skalárny súčin vektoraek = (0, . . . , 1, . . . , 0) a vektora v = (v0, v1, . . . , vN−1):
vk = (v, ek) = ((v0, v1, . . . , vN−1), (0, . . . , 1, . . . , 0))
Matica patriaca k báze B, je matica B, ktorej riadky sú vektory bázy B.
B =
b0
b1
...bN−1
=
b00 b01 . . . b0N−1
b10 b11 . . . b1N−1
...bN−10 bN−11 . . . bN−1N−1
Poznámka:Ak vektor v = (v0, v1, . . . , vN−1) má vzhľadom na bázu B súradnice c0, c1, . . . ažcN−1, potom platí:
v = (v0, v1, . . . , vN−1)E
v = (c0, c1, . . . , cN−1)B =N−1∑k=0
ckbk = c ·B (2.3.1)
Príklad 2.3.1 Aké sú súradnice vektora v = (−2, 11) v báze B = ((1, 2), (−1, 1))?
Riešenie:K báze B = ((1, 2), (−1, 1)) patrí matica B.
B =
(b0
b1
)=
(1 2−1 1
)Vyriešime sústavu rovníc
v = (3, 5)B

2.4. Zmena bázy 27
a dostaneme, že súradnice vektora v = (−2, 11) v báze B sú c0 = 3, c1 = 5.Naozaj platí
v = (−2, 11)v = (3, 5)B = c0b0 + c1b1 = 3 · (1, 2) + 5 · (−1, 1)
V maticovom tvare
v = (−2, 11) = (3, 5) ·(
1 2−1 1
)= c ·B
Úloha 2.3.1 Ako bude vyzerať rovnica ( 2.3.1) v prípade jednorozmernej bázy B?
2.4 Zmena bázy
Pri analyzovaní procesu sa na dáta pozeráme rôznym spôsobom. Jednou z metódanalýzy je chápať proces ako vektor a zmena pohľadu na dáta je vlastne zmena bázya v nej vyjadrené súradnice procesu. Zmenou bázy zabezpečíme zmenu pohľadu nadáta ako sme to využili v kapitole 1.
Zmenou bázy B na bázu B⋆ rozumieme prechod od súradníc v báze B k súradniciamv báze B⋆:
v = (c0, c1, . . . , cN−1)Bv = (c⋆0, c
⋆1, . . . , c
⋆N−1)B⋆
v =
N−1∑k=0
ck · bk = c ·B
v =
N−1∑k=0
c⋆kb⋆k = c⋆ ·B⋆
Z rovnostiv = c ·B = c⋆ ·B⋆ (2.4.1)
dostávamec⋆ = c ·B · (B⋆)−1 (2.4.2)
Poznámka:Pre stĺpcový vektor v a maticu B prislúchajúcu báze, tvorenú stĺpcovými vektormi
B =(b0 b1 . . . bN−1
)=
b00 b10 . . . bN−1,0
b01 b11 . . . bN−1,1
...b0N−1 b1N−1 . . . bN−1,N−1

28 Kapitola 2. Procesy a dáta ako prvky vektorových priestorov
vzťahy (2.3.1), (2.4.1) a (2.4.2) majú tvar
vB =
c0c1...
cN−1
v =
N−1∑k=0
ckbk = B · c
v = B · c = B⋆ · c⋆
c⋆ = (B⋆)−1 ·B · c
Súradnice procesu vzhľadom na bázu E nazývame namerané hodnoty procesu.Súradnice procesu vzhľadom na danú bázu B nazývame spektrum procesu vzhľa-dom na bázu B.
Príklad 2.4.1 Nech vektor v má v bázeB = (b0, b1, b2) = ((−2, 1,−5), (1, 2, 0), (−2, 1, 1)) koeficienty c = (1, 4, 3). TedavB = (1, 4, 3).Aké koeficienty bude mať vektor v v bázeB⋆ = (b⋆
0, b⋆1, b
⋆2) = ((2, 1, 0), (1, 1, 0), (1, 1, 1))?
Riešenie:Označme si dané a hľadané súradnice
vB = (c0, c1, c2)
vB⋆ = (c⋆0, c⋆1, c
⋆2)
v = (c0, c1, c2)B = (c⋆0, c⋆1, c
⋆2)B
⋆
v = (1, 4, 3)
−2 1 −51 2 0−2 1 1
= (c⋆0, c⋆1, c
⋆2)
2 1 01 1 01 1 1
(c⋆0, c⋆1, c
⋆2) = (1, 4, 3)
−2 1 −51 2 0−2 1 1
2 1 01 1 01 1 1
−1
(c⋆0, c⋆1, c
⋆2) = (−4, 12,−2)
1 −1 0−1 2 00 −1 1
= (−16, 30,−2)
SkutočnevB = (1, 4, 3)
vB⋆ = (−16, 30,−2)

2.4. Zmena bázy 29
Lepšie však bude vypočítať najskôr súčin matíc B (B⋆)−1, pretože matica
Bpr = B (B⋆)−1
je maticou prechodu od bázy B k báze B⋆.
(c⋆0, c⋆1, c
⋆2) = (1, 4, 3)
−3 9 −5−1 3 0−3 3 1
= (−16, 30,−2)
Úloha 2.4.1 Bez výpočtu odhadnite súčin vektora (−16, 30,−2) a matice B⋆ z prí-kladu 2.4.1.
Príklad 2.4.2 Zmena škály na súradnicových osiach grafu je vlastne jednoduchá zmenabázy. Napríklad vektor vE = (8, 6) v jednotkovej báze E má v báze B = ((2, 0), (0, 2))súradnice vB = (4, 3).
Úloha 2.4.2 Zistite, kde sa používa logaritmické škálovanie a vysvetlite, prečo je vý-hodné ho použiť.
Úloha 2.4.3 Vyhľadajte na internete dáta, ktoré tvoria 100 hodnôt nejakého procesuv závislosti od času. Tieto dáta tvoria 100-zložkový vektor. Je to vektor 100 rozmernéhovektorového priestoru. Vektor vykreslite a napíšte k nemu stručný popis, teda v akýchčasových intervaloch sa dáta merali a čo boli namerané hodnoty. Namerané hodnotysú súradnice procesu vzhľadom na jednotkovú bázu E. Zmeňte vektory bázy (napríkladdesaťnásobne zväčšite ich dĺžku). Ako sa zmenia koeficienty procesu vzhľadom na tútobázu oproti pôvodným nameraným hodnotám?
1.6.2005 19.7.2005 8.9.20050
2
4
6
8
10
12
Obr. 2.9. Počty koncertov ako proces
Príklad 2.4.3 100 zložkový vektor môžu tvoriť napríklad počty koncertov , ktoré sauskutočnili v Bratislave v dobe od 1. júna do 8. októbra 2005, čo je presne 100 dní.

30 Kapitola 2. Procesy a dáta ako prvky vektorových priestorov
2.5 Skalárny súčin
Spomedzi vektorových priestorov sa v aplikáciách najčastejšie používajú vektorovépriestory so skalárnym súčinom. V geometrii bol skalárny súčin definovaný ako skalár,ktorý vznikne ako výsledok binárnej operácie medzi dvoma vektormi. Predpis preskalárny súčin dvoch vektorov v rovine je
v ⊙ u = |v| · |u| · cosφ (2.5.1)
kde φ je uhol, ktorý zvierajú vektory v,u.
v
u
ϕ
Obr. 2.10. Uhol vektorov v a u
Príklad 2.5.1 Vezmime si vektory v = (1, 1),u = (2, 0). Pre tieto dva vektory jeľahké určiť, že zvierajú uhol 45, pozri obr. 2.11. Preto ich skalárny súčin sa vypočítaako
(1, 1)⊙ (2, 0) = |(1, 1)| · |(2, 0)| · cos(45) =√2 · 2 ·
√2
2= 2
Jednoduchší spôsob výpočtu je
(1, 1)⊙ (2, 0) = 1 · 2 + 1 · 0 = 2
v=45
u
oϕx
y
Obr. 2.11. Uhol vektorov v = (1, 1),u = (2, 0)
Úloha 2.5.1 Zistite, prečo oba spôsoby výpočtu v príklade 2.5.1 dávajú rovnaký vý-sledok.
Úloha 2.5.2 Nakreslite v rovine aspoň tri rôzne dvojice vektorov, ktorých skalárnysúčin je rovný nule.

2.5. Skalárny súčin 31
Vo vektorovom priestore V je teda možné okrem sčítania vektorov definovať ďalšiuoperáciu nazývanú skalárny súčin. Zovšeobecnením geometrického skalárneho súčinuje skalárny súčin dvoch vektorov vo vektorovom priestore. Definujeme ho tak, abyv konkrétnom vektorovom priestore z príkladu 2.5.1 platil predpis (2.5.1). Zmenaoznačenia skalárneho súčinu v tomto texte zo spôsobu v ⊙ u na spôsob ⟨u,v⟩ jezámerná, treba si uvedomiť, že nasledujúca definícia je zovšeobecnením pôvodnéhopojmu.Skalárny súčin vo vektorovom priestore V = ((V,+), (F,+, ·)) je zobrazenie⟨ , ⟩ : V × V → F , pre ktoré platí:
⟨v,v⟩ ≥ 0,navyše ⟨v,v⟩ = 0⇔ v = 0 pozitívnosť⟨v,u⟩ = ⟨u,v⟩ symetria⟨u+ h,v⟩ = ⟨u,v⟩+ ⟨h,v⟩ bilinearita⟨k v,u⟩ = k ⟨v,u⟩
(2.5.2)
Skalárny súčin nie je súčasťou definície vektorového priestoru. V tejto učebnicivšak budeme uvažovať iba priestory so skalárnym súčinom. Konečnorozmerný reálnyvektorový priestor so skalárnym súčinom sa nazýva Euklidov vektorový priestor.
Úloha 2.5.3 Dokážte, že súčin vektorov N-rozmerného Euklidovho vektorového prie-storu V z príkladu 2.1.1 definovaný ako
⟨v,u⟩ =N−1∑k=0
vk · uk
je naozaj skalárny súčin.
Vektory v,u nazveme navzájom kolmé (ortogonálne) práve vtedy, ak je ich skalárnysúčin rovný 0.
v⊥u⇔ ⟨v,u⟩ = 0
Bázu vektorového priestoru nazveme ortogonálnou bázou práve vtedy, ak sú každédva navzájom rôzne vektory bázy na seba kolmé:
B = (b0,b1, . . . ,bN−1); ⟨bi,bj⟩ = 0 pre i = j
Príklad 2.5.2 Báza
• B1 = ((1, 1, 0), (1,−1, 0), (0, 0, 3)) je ortogonálna
• B2 = ((1, 1, 0), (1,−1, 1), (0, 3, 3)) nie je ortogonálna
Úloha 2.5.4 Dokážte, že ortogonálny systém nenulových vektorov je lineárne nezá-vislý.
Úloha 2.5.5 Nájdite príklad použitia neortogonálnej bázy (napr. v deskriptívnej geomet-rii).

32 Kapitola 2. Procesy a dáta ako prvky vektorových priestorov
2.6 Koeficienty vektora v ortogonálnej báze
V odseku 2.4 sme riešili úlohu, ako vypočítať koeficienty v novej báze, ak poznámekoeficienty v pôvodnej. Ilustráciu takéhoto výpočtu koeficientov nájdeme aj v kapitole1.3. Nasledujúce tvrdenie dáva návod, ako koeficienty vypočítať pomocou skalárnehosúčinu. Riešime úlohu, ako z nameraných hodnôt procesu vypočítať koeficienty vortogonálnej báze B.
v = (v0, v1, . . . , vN−1)E
v = (c0, c1, . . . , cN−1)B
c0 =?, c1 =?, . . . , cN−1 =?
Tvrdenie 2.6.1 Nech je vo vektorovom priestore daná ortogonálna báza B, potomkoeficienty ľubovoľného vektora v = (v0, v1, . . . , vN−1)E sa v báze B dajú vypočítaťpodľa vzorca
ci =⟨v,bi⟩⟨bi,bi⟩
(2.6.1)
Dôkaz:Vypočítajme skalárny súčin s jednotlivými bázovými vektormi:
⟨v,bi⟩ =
⟨N−1∑k=0
ckbk,bi
⟩=
N−1∑k=0
⟨ckbk,bi⟩ =N−1∑k=0
ck⟨bk,bi⟩ = ci⟨bi,bi⟩
odtiaľci =
⟨v,bi⟩⟨bi,bi⟩
Príklad 2.6.1 Aké koeficienty má vektor vE = (1, 4, 2) v bázeB = (b0,b1,b2) = ((−2, 1,−5), (1, 2, 0), (−2, 1, 1))?
Riešenie:Najskôr jednoduchým výpočtom overíme, že báza B je ortogonálna.Skutočne, skalárny súčin každej dvojice vektorov bázy je 0.
⟨b0,b1⟩ = (−2, 1,−5) ⊙ (1, 2, 0) = 0⟨b0,b2⟩ = (−2, 1,−5) ⊙ (−2, 1, 1) = 0⟨b1,b2⟩ = (1, 2, 0) ⊙ (−2, 1, 1) = 0
Báza je ortogonálna a preto môžeme použiť vzorec (2.6.1), podľa ktorého
c0 =⟨v,b0⟩⟨b0,b0⟩
= − 8
30
c1 =⟨v,b1⟩⟨b1,b1⟩
=9
5
c2 =⟨v,b2⟩⟨b2,b2⟩
=4
6

2.7. Norma vektora 33
Skutočne
c0 · b0 + c1 · b1 + c2 · b2 = − 8
30· (−2, 1,−5) + 9
5· (1, 2, 0) + 4
6· (−2, 1, 1) = (1, 4, 2)
Úloha 2.6.1 Je možné vypočítať koeficienty vektora pomocou skalárneho súčinu (akov príklade 2.6.1) aj v prípade, že báza nie je ortogonálna?
Úloha 2.6.2 Navrhnite spôsob, ako pomocou skalárneho súčinu vektor
v = (c0, c1, . . . , cN−1)B
s koeficientmi v ortogonálnej báze B vyjadriť ako vektor
v = (c⋆0, c⋆1, . . . , c
⋆N−1)B⋆
v inej ortogonálnej báze B⋆.
2.7 Norma vektora
Teraz už môžeme presne zaviesť pojem veľkosť vektora, ktorý sme zatiaľ zaviedli lenintuitívne v geometrickom modeli. Vo vektorovom priestore so skalárnym súčinommôže byť veľkosť (norma) vektora definovaná nasledujúco:
||v|| =√⟨v,v⟩
Poznámka:V Euklidovom vektorovom priestore môže byť skalárny súčin definovaný ako ⟨v,u⟩ =N−1∑k=0
vk · uk. Norma odvodená od tohto skalárneho súčinu má tvar
||v|| =√⟨v,v⟩ =
√√√√N−1∑k=0
v2k
Vo vektorovom priestore môžu byť vzdialenosti definované aj iným spôsobom a normynemusia byť odvodené od skalárneho súčinu.
Príklad 2.7.1 Aká je norma (veľkosť) vektora u = (1, 4, 5, 2, 9, 3, 2)?Po dosadení do vzorca dostaneme
||v|| =√⟨v,v⟩ =
√√√√N−1∑k=0
v2k =√12 + 42 + 52 + 22 + 92 + 32 + 22 = 11.83
Úloha 2.7.1 Zistite, čo znamená slovo ortonormálny. Nájdite dva ortonormálne vek-tory.

34 Kapitola 2. Procesy a dáta ako prvky vektorových priestorov
Nasledujúca veta je tvrdenie známe z geometrie, ktorého pravdivosť je možné do-kázať aj vo všeobecnom vektorovom priestore. Stačí ak je v tomto priestore definovanýskalárny súčin.
Tvrdenie 2.7.1 (Pytagorova veta)Vo vektorovom priestore so skalárnym súčinom pre každé dva ortogonálne vektory v,u platí:
||v + u||2 = ||v||2 + ||u||2
Dôkaz:Dosadíme súčet vektorov u+ v do definície normy:
||v + u||2 = ⟨v + u,v + u⟩ = ⟨v,v⟩+ ⟨v,u⟩+ ⟨u,v⟩+ ⟨u,u⟩ == ⟨v,v⟩+ 0 + 0 + ⟨u,u⟩ = ||v||2 + ||u||2
Úloha 2.7.2 Dokážte, že Pytagorova veta platí aj pre rozdiel kolmých vektorov. Vovektorovom priestore so skalárnym súčinom, pre každé dva ortogonálne vektory v, uplatí:
||v − u||2 = ||v||2 + ||u||2
Úloha 2.7.3 Platí aj nasledujúce tvrdenie?Vo vektorovom priestore so skalárnym súčinom, pre každé dva ortogonálne vektory
v, u platí:||v + u||2 = ||v − u||2
O aké geometrické tvrdenie ide?
Vo vektorovom priestore so skalárnym súčinom môžeme definovaťvzdialenosť dvoch vektorov ako veľkosť rozdielového vektora.
d (v,u) = ||v − u|| (2.7.1)
Tvrdenie 2.7.2 (Vlastnosti metriky) Dá sa ukázať, že vzdialenosť (metrika) de-finovaná vzťahom (2.7.1) má nasledujúce vlastnosti:
d (v,u) ≥ 0, pričom d (v,u) = 0⇔ v = u pozitívnosťd (v,u) = d (u,v) symetriad (v,u) ≤ d (v,h) + d (h,u) trojuholníková nerovnosť
(2.7.2)
Existujú metriky, ktoré nie sú odvodené od skalárneho súčinu. Na to, aby bola binárnaoperácia (definovaná na dvojiciach vektorov, taká, že jej výsledkom je kladné reálnečíslo) metrika, stačí aby spĺňala vlastnosti (2.7.2).
Špeciálna metrika, odvodená od skalárneho súčinu ⟨v,u⟩ =N−1∑k=0
vk ·uk, ktorá má tvar
d (v,u) = ||v − u|| =√⟨v − u,v − u⟩ =
√√√√N−1∑k=0
(vk − uk)2 (2.7.3)
sa nazýva Euklidova metrika.

2.7. Norma vektora 35
Príklad 2.7.2 V zmysle Euklidovej metriky (2.7.3) sa problém z úlohy 2.1.5 môžeriešiť ako hľadanie vektora s menšou vzdialenosťou.
Riešenie:Ktorý z vektorov u = (1, 4, 5, 2, 9, 3, 2), v = (4, 2, 1, 3, 5, 2, 3) je bližšie k vektorua = (3, 5, 2, 1, 4, 4, 3)?K vektoru a je bližšie vektor v, pretože
||a− v|| = 4.47 < ||a− u|| = 6.48
Euklidova metrika sa používa napríklad pri rozpoznávaní reči. Jednotlivým hlás-
kam sú priradené vektory. Ak sa nameraný zvuk nelíši svojimi hodnotami od vektoraniektorej hlásky viac ako je vopred daná, empiricky zistená tolerancia, tak ho môžemepovažovať za túto hlásku.
Metrika, ktorá nie je odvodená od skalárneho súčinu je napríklad Hammingovametrika. Používa sa pri kódovaní pomocou vektorov zložených z 0 a 1, kde sa meraniepomocou Euklidovej metriky ukázalo ako nevhodné. Hammingova vzdialenosť jepočet jednotiek v súčte kódových slov modulo dva:
1011101010 + 0011001001 = 1000100011
Hammingova metrika sa používa napríklad pri samoopravných kódoch.
Úloha 2.7.4 Dokážte, že Hammingova vzdialenosť je skutočne metrika.
Úloha 2.7.5 Zistite ako je definovaná Mahalanobisova metrika a kde sa používa.

36 Kapitola 2. Procesy a dáta ako prvky vektorových priestorov
2.8 Kolmý priemet vektora do podpriestoru
Riešme v Euklidovom vektorovom priestore úlohu nájsť na x-ovej osi taký vektor v,ktorý dostaneme ako obraz pôvodného vektora v pri kolmom premietaní. To znamená,že vektory v− v a v budú na seba kolmé. Na obrázku 2.12 je zobrazená geometrickápredstava kolmého priemetu vektora v na os x. Neskôr v tvrdení 3.2.1 ukážeme, žeje naozaj pravda to, čo vidno na obrázku, že vektor v − v je najkratší zo všetkýchvektorov v − y, kde y leží na x-ovej osi.
v
x
y
v~
v-v~
Obr. 2.12. Vektor v − v je kolmý na v (na priemet vektora v na os x)
Príklad 2.8.1 Ku vektoru v = (3, 2) nájdite na x-ovej osi taký vektor v, že vektoryv − v a v budú na seba kolmé.
Riešenie:Najprv si povedzme, aké vektory budú ležať na osi x. Budú to všetky násobky vektorab = (1, 0), ale napríklad aj vektorov (2, 0) alebo (−3.7, 0). Os x je vlastne jednoroz-merný vektorový podpriestor dvojrozmerného vektorového priestoru. Vektor ležiacina osi x bude mať preto tvar
v = c · b = c · (1, 0) = (c, 0)
Pretože v − v a v majú byť na seba kolmé, musí platiť, že ich skalárny súčin buderovný 0.
⟨v − v, v⟩ = 0
To nastane práve vtedy, keď⟨v − v,b⟩ = 0
Teda riešime rovnicu⟨v − c · b,b⟩ = 0
Odtiaľ s využitím vlastností skalárneho súčinu dostaneme
⟨v,b⟩ − c · ⟨b,b⟩ = 0⟨v,b⟩ = c · ⟨b,b⟩

2.8. Kolmý priemet vektora do podpriestoru 37
c =⟨v,b⟩⟨b,b⟩
=⟨(3, 2), (1, 0)⟩⟨(1, 0), (1, 0)⟩
=3
1= 3
Teda hľadaný priemet vektora (3, 2) na os x bude vektor
v = c · b = c · (1, 0) = (3, 0)
Nech je daný N -rozmerný vektorový priestor VN so skalárnym súčinom a jeho
M -rozmerný vektorový podpriestor VM , teda 0 < M ≤ N .Nech B = (b0,b1, . . . ,bM−1) je báza podpriestoru VM .Priemet vektora v ∈ VN do podpriestoru VM je vektor v, ktorý leží v podpriestoreVM , pričom vektor v − v je kolmý na každý vektor podpriestoru VM .
Tvrdenie 2.8.1 Koeficienty vektora v ∈ VM , ktorý je kolmým priemetom vektora vdo M -rozmerného priestoru VM s ortogonálnou bázouB = (b0,b1, . . . ,bM−1), vypočítame nasledujúco:
ck =⟨v,bk⟩⟨bk,bk⟩
pre k = 0, 1, . . . ,M − 1 (2.8.1)
Dôkaz:Pretože vektor v− v musí byť kolmý na podpriestor VM , bude kolmý na každý prvokbázy VM . Platí
⟨v − v,bk⟩ = 0 pre k = 0, 1, . . . ,M − 1
v ∈ VM , preto
⟨v − v,bk⟩ = ⟨v −N−1∑i=0
cibi,bk⟩ = 0 pre k = 0, 1, . . . ,M − 1
⟨v,bk⟩ −N−1∑i=0
ci⟨bi,bk⟩ = 0
⟨v,bk⟩ = ck⟨bk,bk⟩ pretože ⟨bi,bk⟩ = 0 pre i = k
ck =⟨v,bk⟩⟨bk,bk⟩
Keďže v− v je kolmý na bázové vektory, je kolmý na ich akúkoľvek lineárnu kombi-náciu, a teda na celý podpriestor VM .
Príklad 2.8.2 Aký je priemet vektora v = (2, 4, 8, 1) do vektorového podpriestorugenerovaného bázou B = (b0,b1), kde
b0 = (1, 2, 4, 0),b1 = (8, 0,−2, 1)?

38 Kapitola 2. Procesy a dáta ako prvky vektorových priestorov
Riešenie:Priemet vektora v = (2, 4, 8, 1) do podpriestoru generovaného bázouB = (b0,b1), kde b0 = (1, 2, 4, 0),b1 = (8, 0,−2, 1), je vektor v so súradnicami
v = (2, 0.02)Bv = (2.16, 4, 7.96, 0.02)E
Pretože báza B je ortogonálna, koeficienty rozkladu sa vypočítajú zo vzorca (2.8.1).
c0 =⟨(2, 4, 8, 1), (1, 2, 4, 0)⟩⟨(1, 2, 4, 0), (1, 2, 4, 0)⟩
=42
21= 2
c1 =⟨(2, 4, 8, 1), (8, 0,−2, 1)⟩⟨(8, 0,−2, 1), (8, 0,−2, 1)⟩
=1
69= 0.02
2.9 Gramova-Schmidtova ortogonalizácia
Keď chceme z danej známej bázy B = (b0,b1, . . . ,bN−1) priestoru V vyrobiť ortogo-nálnu bázu B′ = (b′
0,b′1, . . . ,b
′N−1), môžeme použiť nasledujúci postup:
1. Vyberieme jeden z vektorov bázy B a označíme ho ako vektor b′0 bázy B′:
b′0 = b0.
2. Nájdeme vektor b′1 taký, že b′
1⊥b′0 a leží v rovine (podpriestore) určenej vek-
tormi b′0,b1. Túto požiadavku spĺňa vektor b′
1 = b1 − b1, kde b1 je kolmýpriemet vektora b1 na priamku určenú vektorom b′
0.
3. Nájdeme vektor b′2 taký, že b′
2⊥b′0, b′
2⊥b′1 a leží v podpriestore určenom vek-
tormi b′0,b
′1,b2. Túto požiadavku spĺňa vektor b′
2 = b2 − b2, kde b2 je kolmýpriemet vektora b2 do podpriestoru určeného vektormi b′
0,b′1.
4. Krok 3 opakujeme, až kým v báze B′ nie je N vektorov.
Úloha 2.9.1 Napíšte kroky 2 a 3 z algoritmu Gram-Schmidtovej ortogonalizácie akojeden indukčný krok, v ktorom všeobecne vyjadríte vektor b′
n pomocou vektorovb′0,b
′1, . . . ,b
′n−1 a bn.
Úloha 2.9.2 Čo sa stane, ak systém vektorov B, z ktorého chceme vyrobiť ortogonálnubázu B′ pomocou Gram-Schmidtovej ortogonalizácie, nie je ortogonálny? Aký výsledokdá Gram-Schmidtov algoritmus?
Úloha 2.9.3 Nájdite ortogonálnu bázu vektorového priestoru určeného bázou
B = ((1, 2, 3, 4, 5, 6), (3, 4, 2, 1, 3, 4), (5, 4, 1, 0, 1, 2),
(1, 3, 4, 5, 6, 1), (2, 3, 4, 5, 1, 2), (1, 2, 3, 4, 2, 1)).
Dá sa úloha riešiť bez počítača?

2.9. Gramova-Schmidtova ortogonalizácia 39
Príklad 2.9.1 Ortogonalizujte pomocou Gram-Schmidtovej ortogonalizácie bázu B =((1, 1, 1), (0, 1, 2), (0, 1, 4)).
Riešenie:Pôvodná báza je
B = (b0,b1,b2) = ((1, 1, 1), (0, 1, 2), (0, 1, 4))
Ako prvý vektor bázy sme vybrali vektor b′0 = (1, 1, 1).
Druhý vektor bázy b′1 bude rovný kolmému priemetu b1 na vektor b′
0 a vypočítameho zo vzťahu ⟨b1 − cb′
0,b′0⟩ = 0, pričom b′
1 = b1 − cb′0. Po vypočítaní koeficientu c
nám vyjde b′1 = (−1, 0, 1).
Analogicky bude tretí vektor novej bázy b′2 rovný kolmému priemetu b2 do roviny
určenej vektormi b′0 a b′
1. Vypočítame ho zo vzťahu b′2 = b2 − c0b
′0 − c1b
′1 kde
koeficienty c0 a c1 dostaneme vyriešením sústavy
⟨b2 − c0b′0 − c1b′
1,b′0⟩ = 0 (2.9.1)
⟨b2 − c0b′0 − c1b′
1,b′1⟩ = 0 (2.9.2)
Dostaneme výsledok b′2 = ( 13 ,−
23 ,
13 ). Ortogonálna báza, ktorú dostaneme Gram-
Schmidtovou ortogonalizáciou je báza
B′ = (b′0,b
′1,b
′2) =
((1, 1, 1), (−1, 0, 1),
(1
3,−2
3,1
3
))Neskôr ukážeme užitočnosť takto vytvorenej ortogonálnej bázy B′. Teraz len pozna-menáme, že vektory bázy B′ majú nasledujúce vlastnosti:
• prvý vektor b′0 = (1, 1, 1) predstavuje konštantnú zložku procesu,
• vektor b′1 = (−1, 0, 1) predstavuje lineárnu zložku procesu,
• vektor b′2 = ( 13 ,−
23 ,
13 ) predstavuje kvadratickú (parabolickú) zložku procesu.
Navyše vektor b′1 predstavuje lineárny nárast bez konštantnej zložky a
vektor b′2 predstavuje kvadratický priebeh bez konštantnej a bez lineárnej zložky.
Vektory b′0,b
′1,b
′2 sú vykreslené na obrázku 2.13.
Príklad 2.9.2 Nájdite konštantnú, lineárnu a kvadratickú zložku vektorov v = (3, 6, 2)a u = (0, 2, 7).
Riešenie:V trojrozmernom vektorovom priestore bude konštantný priebeh predstavovať vektor
b′0 = (1, 1, 1)
lineárny nárast bude predstavovať vektor
b′1 = (−1, 0, 1)

40 Kapitola 2. Procesy a dáta ako prvky vektorových priestorov
Obr. 2.13: Ortogonálne vektory b′0,b
′1,b
′2, ktoré predstavujú očistený konštantný,
lineárny a kvadratický priebeh
a kvadratický priebeh bude predstavovať vektor
b′2 =
(1
3,−2
3,1
3
)Tieto vektory sú na seba kolmé, preto môžeme podľa vzorca (2.8.1) vypočítať koefi-cienty vektora v = (3, 6, 2):
c0 =11
3, c1 = −1
2, c2 = −7
2
Vidíme, že platí
(3, 6, 2) =11
3· (1, 1, 1)− 1
2· (−1, 0, 1)− 7
2·(1
3,−2
3,1
3
)Pre vektor u = (0, 2, 7) sú koeficienty
d0 = 3, d1 = 3.5, d2 = 1.5
(0, 2, 7) = 3 · (1, 1, 1) + 3.5 · (−1, 0, 1) + 1.5 ·(1
3,−2
3,1
3
)Navyše z obrázkov 2.14 a 2.15 vidíme, ako dobre jednotlivé vektory b′
0,b′1,b
′2 apro-
ximujú každý z pôvodných vektorov v a u.
Príklad 2.9.3 Nájdite ortogonálnu bázu B′ = (b′0,b
′1) vektorového podpriestoru U
priestoru V, ak viete, že U = [(1, 2, 0,−1), (1, 1, 3, 0)].

2.9. Gramova-Schmidtova ortogonalizácia 41
Obr. 2.14. Vektor v = (3, 6, 2) a príspevky vektorov b′0,b
′1,b
′2
Obr. 2.15. Vektor u = (0, 2, 7) a príspevky vektorov b′0,b
′1,b
′2

42 Kapitola 2. Procesy a dáta ako prvky vektorových priestorov
Riešenie:Vektory (1, 2, 0,−1), (1, 1, 3, 0) sú lineárne nezávislé, ale nie sú ortogonálne, lebo ichskalárny súčin je 3 a nie 0.Keby sme úlohu riešili tak, že vyberieme dva kolmé vektory,napr. (1, 2, 0,−1), (1, 0, 0, 1), dostaneme síce ortogonálnu bázu dvojrozmerného pod-priestoru, ale nie podpriestoru U generovaného vektormi b0 = (1, 2, 0,−1),b1 =(1, 1, 3, 0).Napríklad vektor (1, 1, 3, 0) sa nedá napísať ako lineárna kombinácia vektorov(1, 2, 0,−1), (1, 0, 0, 1).Pri báze, ktorú dostaneme Gram-Schmidtovou ortogonalizáciou však je zaručené, žeje bázou toho istého podpriestoru ako báza, z ktorej bola odvodená:
Ako prvý zoberieme do bázy prvý vektor b′0 = (1, 2, 0,−1).
Druhý vektor b′1, dostaneme ako rozdiel vektora b1 a jeho kolmého priemetu na
vektor b′0, ktoré oba ležia v podpriestore U, teda aj vektor b′
1 bude ležať v podpriestoreU.
b′1 = b1 − b1 = b1 − c · b′
0 , kde c =⟨b1,b
′0⟩
⟨b′0,b
′0⟩
Riešením príkladu je báza B′ = (b′0,b
′1), kde
b′0 = (1, 2, 0,−1)
b′1 = (1, 1, 3, 0)− b1 = (1, 1, 3, 0)− 0.5 · (1, 2, 0,−1) =
= (1, 1, 3, 0)− (0.5, 1, 0,−0.5) = (0.5, 0, 3, 0.5)
Z postupu vidíme, že vektor (0.5, 0, 3, 0.5) ortogonálnej bázy, sme dostali ako lineárnukombináciu vektorov pôvodnej bázy.
Úloha 2.9.4 Nájdite ortogonálnu bázu B′ = (b′0,b
′1,b
′2,b
′3) vektorového podpriestoru
U priestoru V, ak viete, žeU = [(1, 2, 3, 4, 5, 6), (3, 4, 2, 1, 3, 4), (5, 4, 1, 0, 1, 2), (1, 3, 4, 5, 6, 1)].

3 Modely využívajúce závislosť hodnôt procesuod času
3.1 Vektor ako časová závislosť
V tejto kapitole budeme často pojem vektor zamieňať pojmom proces. Dôvodom je, žeteoretické výsledky o vektorových priestoroch, ktoré sme zopakovali v predchádzajúcejkapitole budeme používať pri vyšetrovaní vlastností (analyzovaní) procesov závislýchod času. Takéto procesy sa niekedy nazývajú časové rady.
Aby sme si lepšie uvedomili, že objektom nášho skúmania je proces, ktorého hod-noty sú merané postupne, v po sebe nasledujúcich časoch, označíme proces nasledu-júco:
f = (f(t0), f(t1), . . . , f(tN−1))
To znamená, že proces f chápeme na jednej strane ako vektor, na druhej strane akofunkciu času v okamihoch t0, t1, . . . , tN−1. Časové okamihy môžeme tiež považovať zavektor
t = (t0, t1, . . . , tN−1)
Časy môžeme označiť ich poradovým číslom aj keď intervaly medzi nimi nemusia byťrovnaké, tj. ekvidištančné.Potom vektor f môžeme zapísať ako
f = (f0, f1, . . . , fN−1)
Základnou úlohou v tejto kapitole bude nájsť v procese nejakú závislosť od času amodelovať proces pomocou tejto časovej funkcie.Najjednoduchším modelom bude konštantná funkcia.
Príklad 3.1.1 Nech f0, f1, f2 sú vektory tvaru:
f0 = (c0, c0, . . . , c0)f1 = (c1, c1, . . . , c1)f2 = (c2, c2, . . . , c2)
Zistite, koľkorozmerný je priestor, ktorý určujú tieto vektory.
Riešenie:Ľubovoľný vektor fn spomedzi vektorov f0, f1, f2 môžeme vyjadriť ako:
fn = cn · b0 = cn · (1, 1, . . . , 1) = (cn, . . . , cn)
fn = (cn)B
43

44 Kapitola 3. Modely využívajúce závislosť hodnôt procesu od času
Vidíme, že každý z vektorov fn sa dá napísať ako násobok vektora b0, a teda ide ojednorozmerný podpriestor generovaný bázou
B = (b0) = ((1, 1, . . . , 1))
V príklade 3.1.1 boli zadané vektory, z ktorých každý sa dal vyjadriť v tvare c ·(1, 1, . . . , 1). To znamená, že všetky tieto vektory ležia v podpriestore generovanomvektorom (1, 1, . . . , 1). Keď si tento podpriestor predstavíme ako priebeh procesu včase, dostávame konštantný priebeh.Funkcia času zodpovedajúca tomuto modelu je f(tk) = c. Na obrázku 3.1 sú trivektory, ktoré ležia v podpriestore V generovanom vektorom (1, 1, . . . , 1), s hodnotamic0 = 3, c1 = 1.2, c2 = −2.
0 2 4 6 8 10
−2
0
1.2
3
f0=3*b0
f2= −2*b0
f1=1.2*b0
Obr. 3.1. Násobky vektora (1, 1, . . . , 1)
Konštanty c0 = 3, c1 = 1.2, c2 = −2 a vektor (1, 1, . . . , 1) úplne popisujú procesyf0, f1, f2. Teda na popis týchto vektorov stačí omnoho menší počet hodnôt (bitov).
Nie každý vektor sa dá vyjadriť ako násobok vektora (1, 1, . . . , 1). Keď sa budemesnažiť popísať menším počtom hodnôt iné vektory, dopustíme sa chyby. Nevyjadrímepresne pôvodný vektor, ale len jeho aproximáciu. V nasledujúcom odseku ukážeme,ako zabezpečiť, aby sme sa dopustili čo najmenšej chyby.
3.2 Aproximácia vektora v podpriestore
V tomto odseku riešime úlohu ako v podpriestore U nájsť vektor y, ktorý leží v U anajlepšie aproximuje zadaný vektor v.Hovoríme, že vektor y ležiaci v podpriestore U sa najviac podobá na proces v(alebo vektor y je najbližšie k vektoru v, vektor y aproximuje vektor v), práve vtedy,

3.2. Aproximácia vektora v podpriestore 45
ak vzdialenosť medzi týmito vektormi je minimálna:
d = minf∈Ud (f ,y)
Jednou z metód ako úlohu riešiť je použitie diferenciálneho počtu, ako ukazuje nasle-dujúci príklad.
Príklad 3.2.1 Nájdite vektor y ležiaci na osi x, taký, že je najlepšou aproximáciouvektora v = (4, 2).
Riešenie:Vektory na osi x sú násobky vektora b = (1, 0), teda majú tvar (c, 0), kde c je ľubo-voľné reálne číslo.Najbližšie k vektoru v = (4, 2) bude ten z vektorov (c, 0), ktorý minimalizuje vzdia-lenosť medzi nimi
d (v,y)→ min
d ((4, 2), (c, 0))→ min
V Euklidovom vektorovom priestore budeme minimalizovať vzdialenosť√(4− c)2 + (2− 0)2
Hľadáme bod c, v ktorom funkcia√(4− c)2 + (2− 0)2 dosiahne minimum.
Stačí ak nájdeme minimum funkcie g(c) = (4−c)2+(2−0)2, nakoľko druhá odmocninaje na príslušnej oblasti rastúca funkcia.
g′(c) = 2 · (4− c)(−1), g′′(c) = 2
Odtiaľ dostávame, že c = 4 je stacionárny bod a kladná druhá derivácia zabezpečí,že je to minimum.Teda najbližšie k vektoru v = (4, 2) je na osi x vektor y = (4, 0).
Tento výsledok sa dal dosiahnuť intuitívne. Rovnakým spôsobom teraz môžetevyriešiť nasledujúcu úlohu.
Úloha 3.2.1 Nájdite vektor y, ležiaci v podpriestore generovanom vektoromb = (1, 1, 1, 1, 1) taký, že je najlepšou aproximáciou vektora v = (4, 2, 3, 2, 3).
Metóda, ktorú sme použili v príklade 3.2.1 sa značne skomplikuje, keď bude pod-priestor, v ktorom aproximáciu hľadáme, viacrozmerný. Namiesto extrému funkciejednej premennej bude potrebné nájsť minimum funkcie viac premenných, čo môžebyť náročná úloha.
Príklad 3.2.2 Nech je proces f zadaný 100 hodnotami. Ako tento proces popíšemelen tromi hodnotami c0, c1, c2?
Riešenie:Proces f vyjadríme vo vektorovom priestore, ktorého báza je B = (b0,b1,b2) ac0, c1, c2 sú koeficienty v báze B.
f = (f0, f1, . . . , f100) = c0b0 + c1b1 + c2b2

46 Kapitola 3. Modely využívajúce závislosť hodnôt procesu od času
Vektor f je vyjadrený v trojrozmernom vektorovom priestore určenom bázou B.Niektoré 100 zložkové vektory naozaj možno napísať ako lineárnu kombináciu vektorovz B. Nie vždy je to však možné. Vtedy sa snažíme nájsť v priestore určenom bázou Btaký vektor f , ktorý je najbližší k vektoru f .
Existuje však aj iná metóda, vychádzajúca z geometrického pravidla, že kolmá vzdia-lenosť je najkratšia, alebo, že odvesna v pravouhlom trojuholníku je vždy kratšiaako prepona (ako vidno na obrázku 3.2). V nasledujúcom tvrdení je dokázané, žev Euklidovom vektorovom priestore je k vektoru f , spomedzi všetkých vektorov vpodpriestore, najbližšie jeho kolmý priemet do tohto podpriestoru.
Tvrdenie 3.2.1 Nech V je N -rozmerný vektorový priestor a U je jeho M -rozmernývektorový podpriestor.Nech f ∈ V. Spomedzi vektorov y ∈ U bude najbližší k vektoru f jeho kolmý priemetdo podpriestoru U, teda vektor f ∈ U, taký, že f − f je kolmý na všetky vektory U.
Dôkaz:Nech y je ľubovoľný vektor patriaci do U, potom vektor y− f tiež patrí do U. Vektorf − f je kolmý na každý vektor z U, teda aj na vektor y− f . Podľa Pytagorovej vetypre kolmé vektory f − f a y − f platí
||(f − f)− (y − f)||2 = ||f − f ||2 + ||y − f ||2
||f − y||2 = ||f − f ||2 + ||y − f ||2
d (f ,y) = d (f , f) + d (y, f)
Pretože vzdialenosť je nezáporná, d (y, f) ≥ 0, platí
d (f ,y) ≥ d (f , f)
Vektor y bol ľubovoľný, preto platí, že d (f , f) je minimálna.
Obr. 3.2. Najbližší k vektoru f spomedzi vektorov y ∈ U je vektor f
Príklad 3.2.3 Nájdite v podpriestore U = [(1, 0, 2), (−2, 1, 1)] vektor, ktorý je najb-ližšie k vektoru f = (1, 2, 3).

3.3. Metóda najmenších štvorcov 47
Riešenie:Najbližšie k vektoru f = (1, 2, 3) bude vektor f , pre ktorý platí
f = c0 · (1, 0, 2) + c1 · (−2, 1, 1)
(f − f)⊥ (1, 0, 2)
(f − f)⊥ (−2, 1, 1)
Podmienky môžeme upraviť na tvar
f = c0 · (1, 0, 2) + c1 · (−2, 1, 1)
⟨f − f , (1, 0, 2)⟩ = 0
⟨f − f , (−2, 1, 1)⟩ = 0
Odtiaľ po dosadení za f
⟨(1, 2, 3), (1, 0, 2)⟩ = c0 · ⟨(1, 0, 2), (1, 0, 2)⟩+ c1 · ⟨(−2, 1, 1), (1, 0, 2)⟩
⟨(1, 2, 3), (−2, 1, 1)⟩ = c0 · ⟨(1, 0, 2), (−2, 1, 1)⟩+ c1 · ⟨(−2, 1, 1), (−2, 1, 1)⟩
Teda platí7 = c0 · 5 + c1 · 0
3 = c0 · 0 + c1 · 6
Nakoniecf =
7
5· (1, 0, 2) + 3
6· (−2, 1, 1) = (0.4, 0.5, 3.3)
Úloha 3.2.2 Nájdite v podpriestore U = [(1, 0, 2), (−2, 1, 1)] vektor, ktorý je najbližšiek vektoru f = (−5, 2, 0).
3.3 Metóda najmenších štvorcov
Pomerne známou metódou na výpočet krivky, ktorá čo najlepšie aproximuje dáta, jemetóda najmenších štvorcov. Úloha je zvyčajne formulovaná pre priamku a riešenámetódami diferenciálneho počtu. Aj v tomto prípade však môžeme úlohu previesť dojazyka vektorových priestorov. Minimalizáciou vzdialenosti medzi vektorom Euklido-veho vektorového priestoru f a jeho priemetom f do podpriestoru dostaneme metódunajmenších štvorcov. Na obrázku 3.3 je zobrazený priemet do podpriestoru, ktorýurčuje priamku y = a+ b · t.Nech:
f = (f0, f1, . . . , fN−1), f = (f0, f1, . . . , fN−1)
Potomd (f , f) = ||f − f || =
√⟨f − f , f − f⟩ =

48 Kapitola 3. Modely využívajúce závislosť hodnôt procesu od času
=
√(f0 − f0)2 + · · ·+ (fN−1 − fN−1)2 =
√√√√N−1∑k=0
(fk − fk)2 → min
d (f , f)2 =
N−1∑k=0
(fk − fk)2 → min
Obr. 3.3. Dáta aproximované priamkou
3.4 Chyba aproximácie
Pri aproximácii procesu nejakým iným procesom je dôležité vedieť, akej chyby smesa pri odhade dopustili. Pokiaľ poznáme oba procesy, pôvodný aj jeho odhad, viemepresne povedať aká je chyba odhadu.Nech f = (f0, f1, . . . , fN−1)E je proces vyjadrený v jednotkovej báze N -rozmernéhovektorového priestoru. Hodnotu ||f ||2 = (d(f ,0))
2 nazveme energia procesu f .
Nech f je aproximácia procesu f v podpriestore určenom bázou B. Vektor e =(e0, e1, . . . , eN−1) = f − f nazveme chybový proces.Vzdialenosť
d (f , f) =
√√√√N−1∑k=0
(fk − fk)2 =
√√√√N−1∑k=0
e2k = ||e||
nazveme veľkosť chybového procesu.
f = (c0, c1, . . . , cM−1)Bf = (f0, f1, . . . , fN−1)Ee = (e0, e1, . . . , eN−1)E
d2(f , f) =N−1∑k=0
e2k

3.4. Chyba aproximácie 49
Hodnota ||e||2 je energia chybového procesu.
Obr. 3.4: Pôvodný proces, jeho priemet do dvojrozmerného podpriestoru, chybovýproces (proces po odstránení lineárneho trendu)
Príklad 3.4.1 Nech aproximácia časti procesu y = (1, 3, 4, 3, 5, 6, 7, 4, 6, 8) z obrázku3.4 je približne proces
y = (1.23, 2.04, 2.85, 3.67, 4.48, 5.29, 6.11, 6.92, 7.73, 8.54)
Aká je veľkosť chyby?
Riešenie:Chybový proces je proces
e = (−0.23, 0.96, 1.15,−0.67, 0.52, 0.71, 0.89,−2.92,−1.73,−0.54)
Veľkosť chybového procesu je ||e|| = 4.0154 a jeho energia je ||e||2 = 16.1234.
Úloha 3.4.1 Nájdite dva procesy, ktoré majú rovnakú veľkosť chyby, ale rôzne chybovéprocesy.
Tvrdenie 3.4.1 Ak sú dva procesy na seba kolmé, potom energia súčtového procesusa rovná súčtu energií jednotlivých procesov.
Dôkaz:Upravíme výraz pre energiu súčtu procesov:
||f + g||2 = ⟨f + g, f + g⟩ = ⟨f , f + g⟩+ ⟨g, f + g⟩= ⟨f , f⟩+ ⟨f ,g⟩+ ⟨g, f⟩+ ⟨g,g⟩ = ⟨f , f⟩+ 0 + 0 + ⟨g,g⟩ = ||f ||2 + ||g||2
Toto tvrdenie je vlastne inak formulovaná Pytagorova veta.

50 Kapitola 3. Modely využívajúce závislosť hodnôt procesu od času
Predchádzajúce tvrdenie v tvare
||f ||2 = ||f + e||2 = ||f ||2 + ||e||2
hovorí o tom, že priemet do podpriestoru má menšiu energiu ako pôvodný proces.Tento fakt sa využíva napríklad pri kompresných metódach.
Zopakujme, že úlohou v tejto kapitole je nájsť v procese nejakú závislosť od časua modelovať proces pomocou tejto časovej funkcie. Modely, ktorými budeme priebehprocesu vyjadrovať, budú lineárne vzhľadom na neznáme koeficienty. Metóda, ktorá knameraným dátam nájde spomedzi všetkých lineárnych kombinácií nejakých konkrét-nych funkcií tú najlepšiu v zmysle Euklidovej metriky, sa nazýva lineárna regresia.Nasledujú jednotlivé úlohy lineárnej regresie rozdelené podľa tvaru regresnej krivky.
3.5 Priamka rovnobežná s časovou osou, y = c
Je daný proces f = (f0, f1, . . . , fN−1) popísaný N hodnotami, ktoré nadobudol včasoch t0, t1, . . . , tN−1 (tieto časy sú zadané a nemusia byť ekvidištančné). Riešmeúlohu popísať tento proces jednou hodnotou, ktorá určí také umiestnenie priamkyrovnobežnej s časovou osou, že priamka namerané dáta popisuje najlepšie, viď obrázok3.5.
Obr. 3.5. Priamky, rovnobežné s časovou osou
Príklad 3.5.1 Chceme teda vyjadriť proces f = (f0, f1, . . . , fN−1) ako násobok vek-tora b = (1, 1, . . . , 1). Všetky násobky vektora b tvoria jednorozmerný vektorový pod-priestor N -rozmerného vektorového priestoru, z ktorého je vektor f . Podľa tvrdenia3.2.1, je najbližšie k vektoru f spomedzi všetkých vektorov tvaru c · b taký vektorf = c · b, ktorý je kolmým priemetom vektora f do podpriestoru s bázou tvorenouvektorom b.
f = (f0, f1, . . . , fN−1)E f = (c)B f = (c, c, . . . , c)E

3.5. Priamka rovnobežná s časovou osou, y = c 51
f = c · b, kde b = (1, 1, . . . , 1)
c =⟨f ,b⟩⟨b,b⟩
=⟨(f0, f1, . . . , fN−1), (1, 1, . . . , 1)⟩⟨(1, 1, . . . , 1), (1, 1, . . . , 1)⟩
=
N−1∑k=0
fk
N=
1
N
N−1∑k=0
fk
Hodnota, ktorú sme dostali, je aritmetický priemer všetkých hodnôt procesu f . Uvede-ným modelom sú dobre popísané procesy, ktorých hodnoty sú približne rovnaké.
Na internetovej stránke http://www.adis-computers.sk sme našli štatistiku náv-števnosti stránky za posledných 100 dní. Ide o počet unikátnych IP adries denne.Namerané hodnoty procesu sú
f = (20, 34, 20, 35, 24, 16, 34, 29, 28, 27, 25, 20, 22, 28, 34, 33, 30, 32, 27, 20,
36, 31, 33, 39, 30, 24, 33, 28, 43, 33, 30, 27, 22, 25, 29, 26, 28, 29, 24, 8 ,
14, 30, 28, 21, 20, 31, 9 , 28, 31, 18, 29, 33, 30, 20, 21, 26, 28, 33, 27, 28,
15, 29, 32, 36, 33, 43, 24, 21, 25, 33, 40, 30, 31, 31, 17, 27, 24, 33, 26, 24,
23, 22, 14, 26, 38, 27, 27, 30, 13, 17, 25, 31, 30, 31, 26, 14, 20, 26, 32, 30)
Aproximujte tento proces procesom s konštantným priebehom.
Riešenie:Konštantnú zložku procesu vyjadríme ako
f = c · b = c · (1, 1, . . . , 1) kde c =⟨f ,b⟩⟨b,b⟩
c =1
100
99∑k=0
fk = 26.97
Priebeh procesu a jeho aproximácia konštantným procesom sú zobrazené na obrázku3.6.
Obr. 3.6. Návštevnosť internetovej stránky a jej aproximácia konštantou

52 Kapitola 3. Modely využívajúce závislosť hodnôt procesu od času
3.6 Priamka prechádzajúca počiatkom, y = c · t
Ak hodnoty procesu rastú lineárne a priamka lineárnej závislosti prechádza počiat-kom, bude mať proces f hodnoty fk = c ·tk. Príklady takýchto priamok sú na obrázku3.7.
Obr. 3.7. Sklon priamky y = c · t závisí od koeficientu c
Teda proces s nameranými hodnotami
f = (f0, f1, . . . , fN−1)E ,
ktoré nadobudol v časoch t0, t1, . . . , tN−1, popíšeme jednou hodnotou c
f = (f0, f1, . . . , fN−1)E = (c · t0, c · t1, . . . , c · tN−1) = c(t0, t1, . . . , tN−1)
f = c · b = (c · t0, c · t1, . . . , c · tN−1)
Ku procesu f hľadáme taký proces f , pre ktorý platí
d (f , f)→ min
Nahradíme proces f = c · b, pretože jeho hodnoty ležia na priamke:
d (f , c · b)→ min
Na vypočítanie koeficientu c použijeme podmienku (f − c · b)⊥b. Podmienka orto-gonálnosti vyjadrená pomocou skalárneho súčinu má tvar:
⟨f − c · b,b⟩ = 0
Využijeme vlastnosti skalárneho súčinu a dostaneme
⟨(f0 − c · t0, f1 − c · t1, . . . , fN−1 − c · tN−1), (t0, t1, . . . , tN−1)⟩ = 0
c =⟨f ,b⟩⟨b,b⟩
=
N−1∑k=0
fk · tk
N−1∑k=0
t2k

3.7. Priamka neprechádzajúca počiatkom, y = c0 + c1 · t 53
Príklad 3.6.1 Na internete sme našli históriu vývoja devízových rezerv Národnejbanky Slovenska za obdobie od 29. 1. 1993 do 28. 2. 2001. Sledované hodnoty sa za-pisovali a sledovali vždy k poslednému pracovnému dňu v danom mesiaci. Nameranéhodnoty procesu sú v miliónoch USD:
f = ( 197, 176, 184, 175, 256, 243, 336, 386, 567, 538, 508, 450, 401, 382,
475, 534, 610, 689, 1125, 1294, 1464, 1565, 1598, 1745, 17411813, 1969,
2022, 2186, 2622, 2630, 2708, 2813, 2873, 3046, 3418, 3307, 3398, 3459,
3407, 3355, 3377, 3504, 3677, 3655, 3602, 3595, 3473, 3434, 3472, 3453,
3347, 2974, 3019, 3010, 3181, 3151, 3411, 3446, 3285, 3161, 3202, 3143,
3349, 3723, 3790, 3770, 3622, 3110, 2987, 2939, 2923, 2860, 2910, 2814,
2732, 2515, 2953, 2864, 2805, 2935, 2952, 2869, 3425, 3444, 3564, 3699,
4198, 4085, 4037, 3988, 4433, 4214, 3994, 4024, 4101, 3973, 3971, 3890,
4074)
Aproximujte tento proces procesom s lineárnym nárastom s jedným parametrom.
Riešenie:Lineárny nárast procesu vyjadríme pomocou jedného koeficientu ako
f = c · b = c · (0, 1, 2, . . . , 99) kde c =⟨f ,b⟩⟨b,b⟩
c =
99∑k=0
k · fk99∑k=0
k2= 49.0672
Priebeh procesu a jeho aproximácia lineárnym procesom s jedným parametrom súzobrazené na obrázku 3.8.
Úloha 3.6.1 Vyhľadajte na internete stav devízových rezerv NBS k dnešnému dá-tumu a porovnajte túto hodnotu s odhadom, ktorý urobíte pomocou modelu z príkladu3.6.1.
3.7 Priamka neprechádzajúca počiatkom,y = c0 + c1 · t
Ak hodnoty procesu rastú lineárne a priamka lineárnej závislosti neprechádza počiat-kom, bude mať proces f hodnoty fk = c0 + c1 · tk. Predpokladáme, že proces s name-ranými hodnotami f = (f0, f1, . . . , fN−1), ktoré nadobudol v časoch t0, t1, . . . , tN−1,ležia približne na priamke, ktorá neprechádza počiatkom.Budeme ich aproximovať hodnotami
f = (f0, f1, . . . , fN−1) = (c0 + c1 · t0, c0 + c1 · t1, . . . , c0 + c1 · tN−1)

54 Kapitola 3. Modely využívajúce závislosť hodnôt procesu od času
Obr. 3.8. Devízové rezervy NBS a ich aproximácia priamkou s jedným parametrom
fk = c0 + c1 · tkf = (c0, c1)Bf = c0(1, 1, . . . , 1) + c1(t0, t1, . . . , tN−1)E =
= (c0 + c1 · t0, c0 + c1 · t1, . . . , c0 + c1 · tN−1) = c0 · b0 + c1 · b1
kde bázaB = (b0,b1), kdeb0 = (1, 1, . . . , 1),b1 = (t0, t1, . . . , tN−1)
Procesy b0 a b1 nie sú na seba kolmé. Hľadáme proces f , ktorý leží v podpriestore Uurčenom bázou B a je najbližší k procesu f . Ukázali sme, že to bude proces f , pre ktorýplatí, že f− f bude kolmý na U. To znamená, že bude kolmý na každý proces z U, tedaaj na každý proces bázy B = (b0,b1). Teda proces f = c0b0 + c1b1 a f − f ⊥U.Vychádzame zo vzťahov f − f ⊥b0 a f − f ⊥b1.Upravíme:
⟨f − f ,b0⟩ = 0 ; ⟨f − f ,b1⟩ = 0
⟨f − c0 · b0 − c1 · b1,b0⟩ = 0⟨f − c0 · b0 − c1 · b1,b1⟩ = 0
⟨f ,b0⟩ − ⟨c0b0,b0⟩ − ⟨c1b1,b0⟩ = 0⟨f ,b1⟩ − ⟨c0b0,b1⟩ − ⟨c1b1,b1⟩ = 0
⟨f ,b0⟩ − c0⟨b0,b0⟩ − c1⟨b1,b0⟩ = 0⟨f ,b1⟩ − c0⟨b0,b1⟩ − c1⟨b1,b1⟩ = 0
c0⟨b0,b0⟩+ c1⟨b1,b0⟩ = ⟨f ,b0⟩c0⟨b0,b1⟩+ c1⟨b1,b1⟩ = ⟨f ,b1⟩
Dostaneme sústavu dvoch lineárnych rovníc o dvoch neznámych.
c0 ·N + c1 ·N−1∑k=0
tk =N−1∑k=0
fk
c0 ·N−1∑k=0
tk + c1 ·N−1∑k=0
t2k =N−1∑k=0
fk · tk

3.8. Parabola, y = c0 + c1 · t + c2 · t2 55
Riešením tejto sústavy budú koeficienty procesu f v báze B = (b0,b1).
Príklad 3.7.1 Aproximujte proces z príkladu 3.6.1 procesom s lineárnym nárastom sdvomi parametrami.
Riešenie:Lineárny nárast procesu vyjadríme pomocou dvoch koeficientov ako
f = c0 · b0 + c1 · b1 = c0 · (1, 1, . . . , 1) + c1 · (0, 1, 2, . . . , 99)
Koeficienty c0, c1 vypočítame ako riešenie sústavy rovníc
100 · c0 + c1 ·99∑k=0
k =99∑k=0
fk
c0 ·99∑k=0
k + c1 ·99∑k=0
k2 =99∑k=0
fk · k
100 · c0 + 4950 · c1 = 2647734950 · c0 + 328350 · c1 = 16111220
Riešením tejto sústavy sú koeficienty c0 = 862.61, c1 = 36.06.Priebeh procesu a jeho aproximácia lineárnym procesom s dvomi parametrami sú
zobrazené na obrázku 3.9.
Obr. 3.9. Devízové rezervy NBS a ich aproximácia priamkou s dvomi parametrami
Úloha 3.7.1 Stav devízových rezerv NBS k dnešnému dátumu porovnajte s odhadom,ktorý urobíte pomocou modelu z príkladu 3.7.1.Chyba tohto odhadu bude zrejme men-šia, ako chyba odhadu z úlohy 3.6.1.
3.8 Parabola, y = c0 + c1 · t+ c2 · t2
Bežne sa stáva, že hodnoty procesu nemajú lineárny trend, ale niekedy rastú a inokedyzase klesajú. Niekedy je vhodné takéto hodnoty aproximovať kvadratickou krivkou, na-zývanou aj parabola. V takomto prípade bude mať proces f hodnoty fk = c0+c1 ·tk+

56 Kapitola 3. Modely využívajúce závislosť hodnôt procesu od času
c1·t2k. Predpokladáme teda, že proces s nameranými hodnotami f = (f0, f1, . . . , fN−1),ktoré nadobudol v časoch t0, t1, . . . , tN−1, ležia približne na parabole. Táto parabolavo všeobecnosti nemusí prechádzať počiatkom.Budeme ich aproximovať hodnotami
f = (f0, f1, . . . , fN−1) kde dosadíme fk = c0 + c1 · tk + c2 · t2k= (c0 + c1 · t0 + c2 · t20, c0 + c1 · t1 + c2 · t21, . . . , c0 + c1 · tN−1 + c2 · t2N−1)
fB = (c0, c1, c2)
fE = c0(1, 1, . . . , 1) + c1(t0, t1, . . . , tN−1) + c2(t20, t
21, . . . , t
2N−1) =
= (c0 + c1 · t0 + c2 · t20, c0 + c1 · t1 + c2 · t21, . . . , c0 + c1 · tN−1 + c2 · t2N−1)
= c0 · b0 + c1 · b1 + c2 · b2
kde báza B = (b0,b1,b2), pozostáva z vektorov
b0 = (1, 1, . . . , 1),
b1 = (t0, t1, . . . , tN−1),
b2 = (t20, t21, . . . , t
2N−1).
Procesy b0,b1 a b2 nie sú na seba kolmé. Hľadáme proces f , ktorý leží v podpriestoreU určenom bázou B a je najbližší k procesu f . Ukázali sme, že to bude proces f , prektorý platí, že f − f bude kolmý na U. To znamená, že bude kolmý na každý procesz U, teda aj na každý proces bázy B = (b0,b1,b2). Teda proces f = c0b0 + c1b1 +c2b2 a f − f ⊥U.Vychádzame zo vzťahov f − f ⊥b0, f − f ⊥b1 a f − f ⊥b2.Upravíme:
⟨f − f ,b0⟩ = 0 ; ⟨f − f ,b1⟩ = 0 ; ⟨f − f ,b2⟩ = 0
⟨f − c0 · b0 − c1 · b1 − c2 · b2,b0⟩ = 0⟨f − c0 · b0 − c1 · b1 − c2 · b2,b1⟩ = 0⟨f − c0 · b0 − c1 · b1 − c2 · b2,b2⟩ = 0
⟨f ,b0⟩ − ⟨c0b0,b0⟩ − ⟨c1b1,b0⟩ − ⟨c2b2,b0⟩ = 0⟨f ,b1⟩ − ⟨c0b0,b1⟩ − ⟨c1b1,b1⟩ − ⟨c2b2,b1⟩ = 0⟨f ,b2⟩ − ⟨c0b0,b2⟩ − ⟨c1b1,b2⟩ − ⟨c2b2,b2⟩ = 0
⟨f ,b0⟩ − c0⟨b0,b0⟩ − c1⟨b1,b0⟩ − c2⟨b2,b0⟩ = 0⟨f ,b1⟩ − c0⟨b0,b1⟩ − c1⟨b1,b1⟩ − c2⟨b2,b1⟩ = 0⟨f ,b2⟩ − c0⟨b0,b2⟩ − c1⟨b1,b2⟩ − c2⟨b2,b2⟩ = 0
c0⟨b0,b0⟩+ c1⟨b1,b0⟩+ c2⟨b2,b0⟩ = ⟨f ,b0⟩c0⟨b0,b1⟩+ c1⟨b1,b1⟩+ c2⟨b2,b1⟩ = ⟨f ,b1⟩c0⟨b0,b2⟩+ c1⟨b1,b2⟩+ c2⟨b2,b2⟩ = ⟨f ,b2⟩

3.8. Parabola, y = c0 + c1 · t + c2 · t2 57
Dostaneme sústavu troch lineárnych rovníc o troch neznámych
c0 ·N + c1 ·N−1∑k=0
tk + c2 ·N−1∑k=0
t2k =N−1∑k=0
fk
c0 ·N−1∑k=0
tk + c1 ·N−1∑k=0
t2k + c2 ·N−1∑k=0
t3k =N−1∑k=0
fk · tk
c0 ·N−1∑k=0
t2k + c1 ·N−1∑k=0
t3k + c2 ·N−1∑k=0
t4k =N−1∑k=0
fk · t2k
Riešením tejto sústavy budú koeficienty procesu f v báze B = (b0,b1,b2).
Príklad 3.8.1 Na internete sa dá sledovať vývoj hodnôt akciového indexu Dow JonesIndustrial Average. Vývoj hodnôt počas turbulentného vývoja po páde americkej bankyLehman Brothers zaznamenal prudký pokles nasledovaný miernejším rastom. Počasobdobia od 1. 7. 2008 do 1. 8. 2009 sme sledovali týždenné hodnoty indexu:
f = ( 11288, 11100, 11496, 11370, 11326, 11734, 11659, 11628, 11543,
11220, 11421, 11388, 11143, 10325, 8451, 8852, 8378, 9325, 8943,
8497, 8046, 8829, 8635, 8629, 8579, 8515, 8515, 9034, 8599, 8281,
8077, 8000, 8280, 7850, 7365, 7062, 6626, 7223, 7278, 7776, 8017,
8083, 8131, 8076, 8212, 8574, 8268, 8277, 8500, 8763, 8799, 8539,
8438, 8280, 8146, 8743, 9093, 9171, 9370)
Aproximujte tento proces procesom s kvadratickou krivkou s tromi parametrami.
Riešenie:Kvadratický trend tohto procesu sa dá odhadnúť už z grafického znázornenia na ob-rázku 3.10. Parabolické správanie procesu vyjadríme pomocou troch koeficientov ako
f = c0 · b0 + c1 · b1 + c2 · b2
= c0 · (1, 1, . . . , 1) + c1 · (0, 1, 2, 3, . . . , 58) + c2 · (0, 1, 4, 9, . . . , 582)
Koeficienty c0, c1, c2 vypočítame ako riešenie sústavy rovníc
c0 · 59 + c1 ·58∑k=0
k + c2 ·58∑k=0
k2 =58∑k=0
fk
c0 ·58∑k=0
k + c1 ·58∑k=0
k2 + c2 ·58∑k=0
k3 =N−1∑k=0
fk · k
c0 ·58∑k=0
k2 + c1 ·58∑k=0
k3 + c2 ·58∑k=0
k4 =58∑k=0
fk · k2
c0 · 59 + c1 · 1722 + c2 · 66729 = 533663c0 · 1722 + c1 · 66729 + c2 · 2927521 = 14524784c066729 + c12927521 + c2136994637 = 560982049
Riešením tejto sústavy sú koeficienty c0 = 14657.7, c1 = −431.942, c2 = 6.188.Priebeh procesu a jeho aproximácia kvadratickým procesom s tromi parametrami súzobrazené na obrázku 3.10.

58 Kapitola 3. Modely využívajúce závislosť hodnôt procesu od času
Obr. 3.10: Vývoj akciového indexu Dow Jones Industrial Average v období od1. 7. 2008 do 1. 8. 2009 a jeho aproximácia parabolou s tromi parametrami
Úloha 3.8.1 Pokiaľ by sme sledovali vývoj hodnôt indexu DJIA od začiatku minuléhostoročia, na obrázku 3.11 vidno, že trend by nebol ani lineárny ani kvadratický. V 5-ročných intervaloch by sme namerali tieto hodnoty, začínajúce v roku 1900 a končiacev roku 2000:
f = ( 66.61, 70.39, 98.34, 54.63, 108.76, 121.25, 244.2, 102.76,
151.43, 153.58, 198.89, 388.2, 630.24, 869.78, 809.2, 717.85, 867.15,
1198.87, 2810.15, 3838.24, 11357.51)
Aproximujte tento proces procesom s exponenciálnou krivkou y = c0 ec1·t s dvoma
parametrami c0 a c1.
Obr. 3.11: Vývoj akciového indexu Dow Jones Industrial Average v období od roku1900 do 2000 v 5-ročných intervaloch

3.9. Lineárna regresia ako priemet do podpriestoru 59
3.9 Lineárna regresia ako priemet do podpriestoru
Nech fE = (f0, f1, . . . , fN−1) je proces vyjadrený v jednotkovej báze N -rozmernéhovektorového priestoru. Tento proces aproximujeme procesmi menejrozmerného vek-torového podpriestoru U podobne, ako sme to robili v predchádzajúcich úlohách.Nasledujú príklady priemetu procesu f v podpriestoroch generovaných bázami:
• Jednorozmerný podpriestor generovaný bázou
B1 = (b) = ((1, 1, . . . , 1)).
Priemety do tohto podpriestoru majú tvar:
fE = (c, c, . . . , c)
fB1 = (c)
• Dvojrozmerný podpriestor generovaný bázou
B2 = (b0,b1) = ((1, 1, . . . , 1), (t0, t1, . . . , tN−1)).
Priemety do tohto podpriestoru majú tvar:
fE = (c0 + c1 · t0, c0 + c1 · t1, . . . , c0 + c1 · tN−1)
fB2 = (c0, c1)
• M-rozmerný podpriestor generovaný bázou
B3 = ((1, 1, . . . , 1), . . . , (tM−10 , tM−1
1 , . . . , tM−1N−1 )).
Priemety do tohto podpriestoru majú tvar:
fE = (c0 + c1t0 + c2 · t20 + . . . cM−1 · tM−10 ,
c0 + c1t1 + c2 · t21 + · · ·+ cM−1 · tM−11 ,
. . .
c0 + c1tN−1 + c2 · t2N−1 + . . . cM−1 · tM−1N−1 )
fB3 = (c0, c1, . . . , cM−1)
• M-rozmerný podpriestor generovaný bázou
B4 = ((φ0(t0), . . . , φ0(tN−1)), . . . , (φM−1(t0), . . . , φM−1(tN−1))).
Priemety do tohto podpriestoru majú tvar:
fE =(c0 · φ0(t0) + c1 · φ1(t0) + c2 · φ2(t0) + · · ·+ cM−1 · φM−1(t0),
c0 · φ0(t1) + c1 · φ1(t1) + c2 · φ2(t1) + · · ·+ cM−1 · φM−1(t1),
. . .
c0 · φ0(tN−1) + c1 · φ1(tN−1) + · · ·+ cM−1φM−1(tN−1))
=
(M−1∑n=0
cn · φn(t0), . . . ,
M−1∑n=0
cn · φn(tk), . . . ,
M−1∑n=0
cn · φn(tN−1)
)fB4 =(c0, c1, . . . , cM−1)

60 Kapitola 3. Modely využívajúce závislosť hodnôt procesu od času
Úloha 3.9.1 Nájdite v literatúre alebo na internete návod, ako riešiť úlohu lineárnejregresie pomocou diferenciálneho počtu funkcie viac premenných. Vyriešte pomocoutohto návodu úlohu z príkladu 3.7.1.
Úloha 3.9.2 Porovnajte riešenie rovnakej úlohy v aspoň troch rôznych softvéroch.Zistite, ktorý urobí najmenšiu a ktorý najväčšiu chybu odhadu.
3.10 Všeobecný zápis lineárnej regresie
Všeobecne sa snažíme proces f nahradiť procesom f vyjadreným v báze b0,b1, . . . ,bM−1
f =M−1∑n=0
cnbn
pričomb0 = (φ0(t0), φ0(t1), . . . , φ0(tk), . . . , φ0(tN−1))
b1 = (φ1(t0), φ1(t1), . . . , φ1(tk), . . . , φ1(tN−1))
...
bM−1 = (φM−1(t0), φM−1(t1), . . . , φM−1(tk), . . . , φM−1(tN−1))
Teda proces f je lineárnou kombináciou procesov b0,b1, . . . ,bM−1 a proces f − fje kolmý na všetky bázické procesy. Kolmosť môžeme vyjadriť pomocou skalárnehosúčinu:
(f − f)⊥bm pre m = 0, 1, . . .M − 1
⟨f − f ,bm⟩ = 0
⟨f ,bm⟩ = ⟨f ,bm⟩
Dosadíme:
⟨f ,bm⟩ =
⟨M−1∑n=0
cn · bn,bm
⟩Upravíme:
⟨f ,bm⟩ =M−1∑n=0
cn · ⟨bn,bm⟩ pre m = 0, 1, . . .M − 1
N−1∑k=0
fkφm(tk) =M−1∑n=0
cn ·N−1∑k=0
φn(tk)φm(tk) pre m = 0, 1, . . .M − 1
Príklad 3.10.1 V časoch 0, 1, 3, 4 nadobudol proces f hodnoty 7, 3, 5, 7. Zistite, ktoráz nasledujúcich funkcií (modelov) najlepšie vyjadruje priebeh procesu a aká bude pri-bližná hodnota procesu v časoch 2 a 5.
a) φ(t) = c

3.10. Všeobecný zápis lineárnej regresie 61
b) φ(t) = c · t
c) φ(t) = c · t2
d) φ(t) = c0 + c1 · t
e) φ(t) = c0 · t+ c1 · t2
f) φ(t) = c0 + c1 · et
Riešenie:
a) Pre model φ(t) = c, teda pre konštatný priebeh zvolíme bázu
B = ((1, 1, 1, 1))
Proces f odhadneme procesom f = (c)B = (c, c, c, c)E .Predpokladáme teda, že odhad má tvar f = c·b a hodnotu c vypočítame úpravouvzťahu
⟨f − f ,b⟩ = 0
Využitím vlastností skalárneho súčinu dostaneme
⟨f ,b⟩ = ⟨f ,b⟩
⟨f ,b⟩ = c · ⟨b,b⟩
Preto platí
c =⟨f ,b⟩⟨b,b⟩
=22
4= 5.5
Proces f = (7, 3, 5, 7) odhadneme (priblížime, aproximujeme) procesom f =(5.5, 5.5, 5.5, 5.5). Chyba tohto odhadu (chybový vektor) je
e = f − f = (1.5,−2.5,−0.5, 1.5)
Veľkosť tejto chyby je
∥e∥ = ∥f − f∥ =√(1.5)2 + (−2.5)2 + (−0.5)2 + (1.5)2 = 3.3166
V čase 2 bude odhadnutá hodnota procesu rovná 5.5 (interpolácia).V čase 5 bude odhadnutá hodnota procesu rovná 5.5 (extrapolácia).
φ(tk) = c, φ(2) = 5.5, φ(5) = 5.5

62 Kapitola 3. Modely využívajúce závislosť hodnôt procesu od času
Obr. 3.12. Aproximácia procesu priamkou φ(tk) = 5.5
b) Pre model φ(t) = c · t, teda pre lineárny nárast, zvolíme jednorozmernú bázu.Bázový vektor má zložky c · t0, c · t1, c · t2, c · t3, ktoré zodpovedajú hodnotámφ(tk) = c · tk v časoch t0, t1, t2, t3. Pre jednoduchosť zvolíme c = 1 a dostanemebázu
B1 = ((0, 1, 3, 4))
Proces f odhadneme procesom f = (c)B1, f = (0, c, 3 · c, 4 · c)E .Hodnotu c vypočítame ako v predchádzajúcej časti zo vzťahu
⟨f ,b⟩ = c · ⟨b,b⟩
Preto platí
c =⟨f ,b⟩⟨b,b⟩
=46
26= 1.77
Proces f = (7, 3, 5, 7) odhadneme (priblížime, aproximujeme) procesom f =(0, 1.77, 5.31, 7.08). Chyba tohto odhadu (chybový vektor) je
e1 = f − f = (7, 1.23,−0.31,−0.08)
Veľkosť tejto chyby je
∥e1∥ = ∥f − f∥ =√(7)2 + (1.23)2 + (−0.31)2 + (−0.08)2 = 7.11
Veľkosť chyby ukazuje, že táto aproximácia je horšia ako v predchádzajúcommodeli. Dôvodom, že chyba je veľká je, že v tomto modeli musí regresná priamkac · tk prechádzať bodom (0, 0), ktorý predstavuje v čase 0 hodnotu procesu 0.Tento bod je ďaleko od skutočnej hodnoty f(0) = 7 procesu v bode 0. Príslušnéregresné priamky sú na obrázkoch 3.12 a 3.13. V časoch 2 a 5 budú odhadnutéhodnoty procesu rovné 3.54 a 8.85.
φ(tk) = c · tk, φ(2) = 1.77 · 2 = 3.54, φ(5) = 1.77 · 5 = 8.85

3.10. Všeobecný zápis lineárnej regresie 63
Obr. 3.13. Aproximácia procesu priamkou φ(tk) = 1.77tk
c) Pre model φ(tk) = c · t2k, teda pre kvadratický priebeh zvolíme bázu, ktorejprvky sú štvorzložkové vektory. Jednotlivé zložky vektorov zodpovedajú modeluv časoch t0, t1, t2, t3. Teda zložky vektorov majú postupne hodnoty c · t20, c · t21, c ·t22, c · t23. Pre jednoduchosť zvolíme c = 1 a dostaneme bázu
B2 = ((0, 1, 9, 16))
Proces f odhadneme procesom f = (c)B2, f = (0, c, 9 · c, 16 · c)E .Hodnotu c vypočítame ako
c =⟨f ,b⟩⟨b,b⟩
= 0.47
Proces f = (7, 3, 5, 7) odhadneme procesom f = (0, 0.47, 4.26, 7.57). Chyba tohtoodhadu je
e2 = f − f = (7, 2.53, 0.74,−0.57)
Veľkosť tejto chyby je
∥e2∥ = ∥f − f∥ =√(7)2 + (2.53)2 + (0.74)2 + (−0.57)2 = 7.5007
Veľkosť chyby ukazuje, že táto aproximácia je lepšia ako v predchádzajúcommodeli. Chyba je ale stále veľká, pretože v tomto modeli musí regresná krivkac · t2k prechádzať bodom (0, 0), ktorý predstavuje v čase 0 hodnotu procesu 0.Tento bod je ďaleko od skutočnej hodnoty (=7) procesu v bode 0. Regresnákrivka pre tento model (parabola) je na obrázku 3.14.
V časoch 2 a 5 budú odhadnuté hodnoty procesu rovné 1.89 a 11.83.
φ(tk) = c · t2k, φ(2) = 0.47 · 22 = 1.89, φ(5) = 0.47 · 52 = 11.83

64 Kapitola 3. Modely využívajúce závislosť hodnôt procesu od času
Obr. 3.14. Aproximácia procesu regresnou krivkou φ(tk) = 0.4734 · t2k
d) Pre model φ(tk) = c0 + c1 · tk, teda pre lineárny nárast s konštantnou zložkouzvolíme bázu, ktorej prvky sú štvorzložkové vektory. Jednotlivé zložky vektorovzodpovedajú modelu v časoch t0, t1, t2, t3. Teda zložky vektorov majú postupnehodnotyc0 + c1 · t0, c0 + c1 · t1, c0 + c1 · t2, c0 + c1 · t3. Pre jednoduchosť zvolímenajprv c0 = 1, c1 = 0, potom c0 = 0, c1 = 1 a dostaneme bázu
B3 = ((1, 1, 1, 1), (0, 1, 3, 4))
Proces f odhadneme procesom
f = (c0, c1)B3f = (c0, c0, c0, c0)E + (0, c1, 3 · c1, 4 · c1)E
Teda f = c0 · b0 + c1 · b1. Hodnoty c0 a c1 vypočítame úpravou vzťahov
⟨f − f ,b0⟩ = 0
⟨f − f ,b1⟩ = 0
⟨f ,b0⟩ = (c0 · b0 + c1 · b1,b0⟩
⟨f ,b1⟩ = (c0 · b0 + c1 · b1,b1⟩
Preto sú c0 a c1 riešeniami sústavy
⟨f ,b0⟩ = c0 · ⟨b0,b0⟩+ c1 · ⟨b1,b0⟩
⟨f ,b1⟩ = c0 · ⟨b0,b1⟩+ c1 · ⟨b1,b1⟩
22 = 4c0 + 8c1, 46 = 8c0 + 26c1
c0 = 5.1, c1 = 0.2

3.10. Všeobecný zápis lineárnej regresie 65
Proces f = (7, 3, 5, 7) odhadneme (priblížime, aproximujeme) procesom f =(5.1, 5.3, 5.7, 5.9). Chyba tohto odhadu (chybový vektor) je
e3 = f − f = (1.9,−2.3,−0.7, 1.1)
Veľkosť tejto chyby je
∥e3∥ = ∥f − f∥ = 3.2558
Toto je zatiaľ najlepšia aproximácia. Príslušná regresná priamka je na obrázku3.15.
Obr. 3.15. Aproximácia procesu priamkou φ(tk) = 5.1 + 0.2 · tk
V časoch 2 a 5 budú odhadnuté hodnoty procesu rovné 5.5 a 6.1.
φ(tk) = c0 + c1 · tk, φ(2) = 5.5, φ(5) = 6.1
e) Predtým ako budeme rozoberať model φ(tk) = c0 · tk + c1 · t2k, zamyslime sa,či vôbec má šancu byť "dobrý" model, teda či jeho chyba bude nízka. Ak siuvedomíme, že aj tu bude musieť regresná krivka prechádzať bodom (0, 0), takhneď vidno, že veľkosť chyby bude aspoň 7, teda model bude opäť dosť nepresný.Pre model φ(tk) = c0 · tk + c1 · t2k zvolíme bázu, ktorej prvky sú štvorzložkovévektory. Jednotlivé zložky vektorov zodpovedajú modelu v časoch t0, t1, t2, t3.Teda zložky vektorov majú postupne hodnoty c0 · t0 + c1 · t20, c0 · t1 + c1 · t21, c0 ·t2+c1 · t22, c0 · t3+c1 · t23. Pre jednoduchosť zvolíme najprv c0 = 1, c1 = 0, potomc0 = 0, c1 = 1 a dostaneme bázu
B4 = ((0, 1, 3, 4), (0, 1, 9, 16))
Proces f odhadneme procesom
f = (c0, c1)B4fE = (0, c0, 3 · c0, 4 · c0) + (0, c1, 9 · c1, 16 · c1)

66 Kapitola 3. Modely využívajúce závislosť hodnôt procesu od času
Teda f = c0 · b0 + c1 · b1. Hodnoty c0 a c1 vypočítame riešením sústavy
46 = 26c0 + 92c1, 160 = 92c0 + 338c1
c0 = 2.56, c1 = −0.22
Proces f = (7, 3, 5, 7) aproximujeme procesom f = (0, 2.33, 5.67, 6.67).
Chyba tohto odhadu (chybový vektor) je
e4 = f − f = (7, 0.67,−0.67, 0.33)
Veľkosť tejto chyby je ∥e4∥ = ∥f − f∥ = 7.0711.Príslušná regresná krivka je na obrázku 3.16.
Obr. 3.16. Aproximácia procesu krivkou φ(tk) = 2.56 · tk − 0.22 · t2k
V časoch 2 a 5 budú odhadnuté hodnoty procesu rovné 4.22 a 7.22.
φ(tk) = c0 · tk + c1 · t2k, φ(2) = 2.56 · 2− 0.22 · 22 = 4.22,
φ(5) = 2.56 · 5− 0.22 · 52 = 7.22
f) Pre model φ(tk) = c0 + c1 etk zvolíme bázu, ktorej prvky sú štvorzložkové vek-
tory. Jednotlivé zložky vektorov zodpovedajú modelu v časoch t0, t1, t2, t3. Tedazložky vektorov majú postupne hodnoty c0+c1 ·et0 , c0+c1 ·et1 , c0+c1 ·et2 , c0+c1 ·et3 . Pre jednoduchosť zvolíme najprv c0 = 1, c1 = 0, potom c0 = 0, c1 = 1a dostaneme bázu
B5 = ((1, 1, 1, 1), (1, 2.72, 20.09, 54.6))
Proces f odhadneme procesom
f = (c0, c1)B5f = (c0, c0, c0, c0)E + (e0 ·c1, e1 ·c1, e3 ·c1, e4 ·c1)E

3.11. Koeficienty v neortogonálnej báze 67
Teda f = c0 · b0 + c1 · b1. Hodnoty c0 a c1 vypočítame riešením sústavy
22 = 4c0 + 78.4c1, 497.77 = 78.4c0 + 3392.8c1
c0 = 4.8, c1 = 0.04
Proces f = (7, 3, 5, 7) aproximujeme procesom
f = (4.83, 4.89, 5.51, 6.75).
Chyba tohto odhadu (chybový vektor) je
e5 = f − f = (2.17,−1.9,−0.51, 0.24)
Veľkosť tejto chyby je ∥e5∥ = ∥f − f∥ = 2.94.Príslušná regresná krivka je na obrázku 3.17.
Obr. 3.17. Aproximácia procesu krivkou φ(tk) = 4.8 + 0.04 etk
V časoch 2 a 5 budú odhadnuté hodnoty procesu rovné 5.06 a 10.11.φ(2) = 4.8 + 0.04 · e2 = 5.06, φ(5) = 4.8 + 0.04 · e5 = 10.11
Najlepší odhad spomedzi uvedených modelov dáva funkcia φ(tk) = c0+c1 etk . Veľkosť
chyby v tomto prípade je 2.94.
Úloha 3.10.1 Navrhnite funkciu s dvomi parametrami c0 a c1, ktorá odhadne procesz príkladu 3.10.1 lepšie, než modely navrhnuté v príklade.
3.11 Koeficienty v neortogonálnej báze
Koeficienty priemetu procesu do bázy sú rôzne v závislosti od bázy. Pre jeden vektordostávame rôzne jeho vyjadrenia v rôznych bázach.
f = c0b0 + c1b1 + · · ·+ cnbn = c′0b′0 + c′1b
′1 + · · ·+ c′nb
′n

68 Kapitola 3. Modely využívajúce závislosť hodnôt procesu od času
Ak bázové vektory predstavujú časové vyjadrenie funkcie, ktorou je proces modelo-vaný, je možné vypočítané koeficienty použiť na vyjadrenie funkcie, ktorou procesaproximujeme:
φ(tk) = c0φ0(tk) + c1φ1(tk) + · · ·+ cnφn(tk) (3.11.1)
Výpočet koeficientov ck vyžaduje riešiť sústavu rovníc. V prípade, že bázu najprvortogonalizujeme, stačí na výpočet každého z koeficientov jeden vzorec.
c′k =⟨f ,b′
k⟩⟨b′
k,b′k⟩
Preto sa niekedy neortogonálna báza (vyjadrujúca časový priebeh) najskôr ortogona-lizuje. Výpočet koeficientov ortogonálnej bázy bude jednoduchší, ale koeficienty c′k sanedajú použiť ako koeficienty funkcie φ(tk). V nasledujúcom príklade ukážeme, akosa zo známych koeficientov ortogonálnej bázy dajú vypočítať koeficienty pôvodnejneortogonálnej bázy.
Príklad 3.11.1 Aproximujte proces z príkladu 3.6.1, resp. príkladu 3.7.1, procesom slineárnym nárastom s dvomi parametrami. Bázu najprv ortogonalizujte, potom vypo-čítajte koeficienty v ortogonálnej báze a nakoniec z týchto koeficientov odvoďte koefi-cienty funkcie
φ(tk) = c0 + c1 · tk
Riešenie:Lineárny nárast procesu vyjadríme pomocou dvoch koeficientov ako
f = c0 · b0 + c1 · b1 = c0 · (1, 1, . . . , 1) + c1 · (0, 1, 2, . . . , 99)
Zodpovedajúca neortogonálna báza je
B = (b0,b1) = ((1, 1, . . . , 1), (0, 1, 2, . . . , 99))
Ortogonálnu bázu B′ dostaneme Gram-Schmidtovou ortogonalizáciou bázy B.
b′0 = b0
b′1 = b1 − b1 = b1 − k · b0 = b1 − 49.5 · b0
Koeficienty c′0, c′1 v báze B′ vypočítame zo vzorcov
c′0 =⟨f ,b′
0⟩⟨b′
0,b′0⟩
= 2647.7
c′1 =⟨f ,b′
1⟩⟨b′
1 · b′1⟩
= 36.06
Koeficienty c0 a c1 dostaneme zo vzťahu
f = c0 · b0 + c1 · b1 = c′0 · b′0 + c′1 · b′
1 = 2647.7 · b0 + 36.06 · (b1 − 49.5 · b0) =

3.11. Koeficienty v neortogonálnej báze 69
= (2647.7− 1.7851) · b0 + 36.06 · b1 = 862.61 · b0 + 36.06 · b1
Odtiaľ dostávame c0 = 862.61 a c1 = 36.06, a teda vyjadrenie procesu ako funkciečasu bude
φ(tk) = 862.61 + 36.06 · tkVýslednú aproximáciu vidíme na obrázku 3.18. Rovnaký výsledok sme dostali aj v prí-klade 3.7.1, keď sme koeficienty c0 a c1 hľadali riešením sústavy rovníc.
Obr. 3.18: Aproximácia dát priamkou φ(tk) = 862.61+36.06·tk, vektor b′0 reprezentuje
konštantný trend a vektor b′1 reprezentuje lineárny nárast
Príklad 3.11.2 Nech je proces f aproximovaný pomocou časovej funkcie
φ(tk) = c0φ0(tk) + c1φ1(tk) + c2φ2(tk)
Jednotlivé funkcie φ0(tk), φ1(tk), φ2(tk) sú vyjadrené procesmi pôvodnej bázy
B = (b0,b1,b2)
Vyjadrenie v pôvodnej báze je
f = c0b0 + c1b1 + c2b2
Z bázy B je Gram-Schmidtovou ortogonalizáciou vytvorená ortogonálna báza:
B′ = (b′0,b
′1,b
′2)
Vyjadrite zo známych koeficientov c′0, c′1, c
′2 procesu v ortogonálnej báze, koeficienty
v pôvodnej, neortogonálnej báze.

70 Kapitola 3. Modely využívajúce závislosť hodnôt procesu od času
Riešenie:Priemet procesu f do podpriestoru s ortogonálnou bázou vyjadruje vzťah:
f = c′0b′0 + c′1b
′1 + c′2b
′2
Vyjadríme vektory ortogonálnej bázy pomocou vektorov pôvodnej bázy.Potom pôvodné bázické vektory nahradíme jednotlivými funkciami, čím dosta-
neme funkciu, ktorá aproximuje proces.Postup ako vyjadriť vektory ortogonálnej bázy pomocou vektorov pôvodnej bázy
je možné vyvodiť z postupu ortogonalizácie.Je zrejmé, že b0 = b′
0.V postupe ortogonalizácie sme použili
b′1 = b1 − k · b′
0 = b1 − k · b0 , kde k =⟨b1,b0⟩⟨b0,b0⟩
b′2 = b2 − k0 · b0 − k1b′
1 , kde k0 =⟨b2,b0⟩⟨b0,b0⟩
a k1 =⟨b2,b
′1⟩
⟨b′1,b
′1⟩
Vo vzťahu pre b′2 je síce použité b′
1, ktoré je ale vyjadrené vyššie.Čiže
b′2 = b2 − k0 · b0 − k1(b1 − kb0) = b2 − k1b1 − (k0 − k1 · k)b0
Napríklad funkciay = a · tk + b · t2k + c · t3k
by pomocou koeficientov c′0, c′1, c
′2 vypočítaných v ortogonálnej báze vyzerala nasle-
dujúco
f(tk) = c′0 · tk + c′1 · (t2k − ktk) + c′2 · (t3k − k1 · t2k − (k0 − k1k) · tk)
Príklad 3.11.3 Je daný proces f = (2, 4, 5, 13). Vytvorte pre funkciuφ(tk) = c0+c1 ·tk+c2 ln tk bázu B zodpovedajúcu časom t = (1, 2, 3, 4). Ortogonalizujtepomocou Gram-Schmidtovej metódy bázu B. Vyjadrite koeficienty c′0, c′1, c′2 procesu f =(2, 4, 5, 13) v ortogonálnej báze B′. Pomocou koeficientov c′0, c′1, c′2 vyjadrite koeficientyc0, c1, c2, ktoré je možné použiť na vyjadrenie funkcie φ(tk) = c0 + c1 · tk + c2 ln tk.
Riešenie:
B = ((1, 1, 1, 1), (1, 2, 3, 4), (0, 0.69, 1.1, 1.39))
B′ = (b′0,b
′1,b
′2), b
′0 = (1, 1, 1, 1)
b′1 = b1 − k · b0, kde k =
⟨b1,b′0⟩
⟨b′0,b
′0⟩
= 2.5
b′1 = (1, 2, 3, 4)− 2.5 · (1, 1, 1, 1) = (−1.5,−0.5, 0.5, 1.5)

3.12. Linearizácia nelineárnych úloh 71
b′2 = b2 − k0 · b′
0 − k1 · b′1, kde k0 =
⟨b2,b′0⟩
⟨b′0,b
′0⟩
= 0.8 a k1 =⟨b2,b
′1⟩
⟨b′1,b
′1⟩
= 0.46
b′2 = (0, 0.69, 1.1, 1.39)− 0.8 · (1, 1, 1, 1)− 0.46 · (−1.5,−0.5, 0.5, 1.5) =
= (−0.11, 0.13, 0.08,−0.09)Koeficienty odhadu f = (2.3, 2.69, 6.74, 12.28) procesu f = (2, 4, 5, 13) v ortogonálnejbáze B′ sú
c′0 = 6, c′1 = 3.4, c′2 = −12.7Dosaďme do vyjadrenia procesu pôvodné bázové vektory.
f = c′0 ·b′0+c
′1 ·b′
1+c′2 ·b′
2 = c′0 ·b0+c′1 ·(b1−k ·b0)+c
′2 ·(b2−k0 ·b0−k1 ·(b1−k ·b0)
= (c′0 − c′1 · k − c′2 · k0 + c′2 · k1 · k)b0 + (c′1 − c′2 · k1)b1 + c′2 · b2
Platí zároveňf = c0 · b0 + c1 · b1 + c2 · b2
A odtiaľ dostávame
c0 = c′0 − c′1 · k − c′2 · k0 + c′2 · k1 · k = −6.9, c1 = c′1 − c′2 · k1 = 9.2, c2 = c′2 = −12.7
Odhad procesu f je daný funkciou φ(tk) = c0 + c1 · tk + c2 ln tk s koeficientmi c0 =−6.9, c1 = 9.2, c2 = −12.7. Regresná krivka na odhad procesu je na obrázku 3.19.
3.12 Linearizácia nelineárnych úloh
Metódou lineárnej regresie nevyriešime napríklad
φ(tk) = tc0k ln(c1 · tk + c2)
lebo tento vzťah sa nedá vyjadriť ako lineárna kombinácia bázických vektorov s ko-eficientmi c0, c1, c2.Iná je situácia napríklad pre
φ(tk) = c0 · e−c1·tk
ktorú vieme linearizovať tak, že výraz logaritmujeme
lnφ(tk) = (ln c0)− c1 · tk
Substitúciou lnφ(tk) = φ⋆(tk) dostaneme φ⋆(tk) = −c1 · tk + ln c0.Teda ak sa dá φ(tk) prepísať na tvar
φ⋆(tk) =M−1∑n=0
cn · φn(tk)

72 Kapitola 3. Modely využívajúce závislosť hodnôt procesu od času
Obr. 3.19. Aproximácia procesu krivkou φ(tk) = −6.9 + 9.2 · tk − 12.7 ln tk
môžeme pôvodnú úlohu riešiť ako úlohu lineárnej regresie.Hovoríme, že nelineárnu úlohu môžeme linearizovať.Poznámka:Na prevod nelineárnej úlohy na úlohu lineárnej regresie sa môže použiť napríklad lo-garitmus, arcsin, prevrátená hodnota...
Príklad 3.12.1 Nech sú v časoch t = (1, 2, 3, 4) namerané hodnoty procesu f =(9, 5, 3, 2). Nelineárnu úlohu aproximovať proces f pomocou funkcie
φ(tk) =c0 · tkc1 + tk
prerobte na úlohu lineárnej regresie.
Riešenie:Použijeme prevrátenú hodnotu nelineárnej funkcie φ(tk) a dostaneme lineárnu fun-kciu:
φ⋆(tk) =1
φ(tk)=c1 + tkc0 · tk
(3.12.1)
Rovnakú úpravu urobíme s hodnotami procesu f = (9, 5, 3, 2) a dostaneme f⋆ =(0.11, 0.2, 0.33, 0.5).

3.12. Linearizácia nelineárnych úloh 73
Úpravami vzťahu (3.12.1) dostaneme úlohu lineárnej regresie
φ⋆(tk) =c1
c0 · tk+
tkc0 · tk
=c1
c0 · tk+
1
c0
f⋆ = d0 · b0 + d1 · b1
kde
d0 =c1c0, d1 =
1
c0, b0 = (
1
t0,1
t1,1
t2,1
t3) = (1,
1
2,1
3,1
4), b1 = (1, 1, 1, 1)
Koeficienty d0, d1 sú riešením sústavy rovníc:
⟨f⋆,b0⟩ = d0 · ⟨b0,b0⟩+ d1 · ⟨b1,b0⟩⟨f⋆,b1⟩ = d0 · ⟨b0,b1⟩+ d1 · ⟨b1,b1⟩
0.45 = d0 · 1.42 + d1 · 2.081.14 = d0 · 2.08 + d1 · 4
d0 = 0.44, d1 = 0.51
f⋆ = −0.44 · b0 + 0.51 · b1 = (0.08, 0.3, 0.37, 0.41)
Treba si uvedomiť, že lineárnu regresiu sme robili v pokrivenej, transformovanej ob-lasti. Odhadovaný vektor f⋆ aj jeho aproximácia f⋆ sa nachádzajú v inom priestoreako pôvodné hodnoty procesu, viď obrázok 3.20.
Odhad pôvodného procesu dostaneme po spätnej transformácii procesu f⋆ na pro-ces f , viď obrázok 3.21.
f =1
f⋆= (13.26, 3.39, 2.71, 2.47)
Iný postup, ktorý môžeme použiť je vypočítať najskôr hodnoty koeficientov c0, c1využitím vzťahov
d0 =c1c0, d1 =
1
c0.
−0.44 =c1c0, 0.51 =
1
c0
c1 = −0.86, c0 = 1.95
Poznámka:Je potrebné si uvedomiť, že po linearizácii úlohy už nehľadáme najbližší vektor vmetrike pôvodného priestoru. Veľkosť chyby aproximácie bude minimálna iba v zme-nenej metrike nového priestoru (po transformácii) a nebude vyjadrená v hodnotáchpôvodného priestoru.

74 Kapitola 3. Modely využívajúce závislosť hodnôt procesu od času
Obr. 3.20. Aproximácia procesu regresnou krivkou φ⋆(tk) =d0
tk+ d1
Obr. 3.21. Aproximácia procesu krivkou φ(tk) = c0·tkc1+tk

3.12. Linearizácia nelineárnych úloh 75
Príklad 3.12.2 V príklade 3.12.1 je minimalizovaná veľkosť chyby aproximácie f⋆
procesu f⋆. Veľkosť chyby v transformovanom priestore je
∥e⋆∥ = ∥f⋆ − f⋆∥ = 0.14
Veľkosť chyby nelineárnej aproximácie f procesu f v pôvodnom priestore je
∥e∥ = ∥f − f∥ = 4.58
Zistite, či veľkosť chyby v pôvodnom priestore je minimálna, alebo či sa dajú nájsťkoeficienty c0 a c1 také, že chyba aproximácie procesu krivkou
φ(tk) =c0 · tkc1 + tk
bude menšia ako 4.58.
Riešenie:Hľadanými koeficientmi sú napríklad koeficienty c0 = 2.2 a c1 = −0.7. Pomocoutýchto koeficientov dostaneme vektor
f = φ(t) =c0 · tc1 + t
= (7.33, 3.38, 2.87, 2.67)
Veľkosť chyby odhadu je v tomto prípade:
∥e∥ = ∥f − f∥ = 2.42
Dosiahli sme chybu, ktorá je menšia, než akú sme dosiahli metódou linearizácienelineárnej úlohy. Naša metóda však spočívala iba v náhodnom hľadaní. Takým hľa-daním sa dokonca dajú nájsť koeficienty c0 a c1, pre ktoré je veľkosť chyby menšianež 1.54. Vyskúšajte to!

76 Kapitola 3. Modely využívajúce závislosť hodnôt procesu od času

4 Modely využívajúce súvislosti medzi hodnotamiprocesu
4.1 Modely kĺzavých súčtov
V predchádzajúcej kapitole sme zisťovali, ako sa v procese prejaví časová závislosť.Jednotlivé modely predstavovali explicitné funkcie času, ktoré aproximovali proces.Ako dobre sme proces aproximovali sa dalo zistiť podľa veľkosti chyby, teda veľ-kosti rozdielu pôvodného procesu a jeho aproximácie. Našou úlohou bolo nájsť tvara parametre funkcie času tak, aby chyba aproximácie pomocou tejto funkcie bolaminimálna.
V tejto kapitole nebudeme sledovať závislosť procesu od času, ale súvislosť hodnôtprocesu medzi sebou navzájom. Riešime otázku ako súvisia jednotlivé hodnoty pro-cesu. Súvislosť medzi hodnotami procesu by mohla byť ovplyvnená tým, že hodnotyprocesu by boli merané v nepravidelných časoch. Aby sme zamedzili tomuto vplyvu,budeme v tejto kapitole predpokladať, že hodnoty procesu sú merané v ekvidištanč-ných časoch a dĺžka časového intervalu bude 1. V nasledujúcom texte budeme hodnotyf(tk) značiť iba ako fk.
Motivačnou úlohou tejto kapitoly je interpolácia procesu. Pod interpoláciourozumieme vyhladenie nameraných hodnôt tak, že ich nahradíme vhodnou krivkou adopočítame chýbajúce hodnoty pomocou vyjadrenia tejto krivky ako funkcie času. Vtejto kapitole sa však nebudeme zaoberať vyjadrením procesu ako explicitnej funkciečasu. Našou úlohou bude nájsť súvislosť medzi koeficientmi a vyjadriť chýbajúcuhodnotu pomocou ostatných hodnôt.
Nech sú namerané hodnoty f0, f1, . . . , fk−1, fk+1, . . . , fN−1 procesu f , ako to vi-díme na obrázku 4.1.
Chceme odhadnúť hodnotu fk, ktorá nie je nameraná. Predpokladáme, že hodnotyfk−1,fk a fk+1 sa príliš nelíšia. V jednoduchších modeloch, keď nezisťujeme nič o tomako hodnoty medzi sebou súvisia, sa hodnota fk vypočíta ako aritmetický priemersusedných hodnôt:
fk =fk−1 + fk+1
2
Priebeh procesu s chýbajúcou hodnotou a jeho aproximácia procesom, v ktoromsa použije na výpočet aritmetický priemer dvoch susedných hodnôt, sú zobrazené naobrázku 4.2. Na obrázku je prerušovanou čiarou znázornený aj chybový proces, ktorývypočítame ako rozdiel pôvodného a odhadnutého procesu.
∥e1∥ = ∥f − f∥ =√∑
j =k
(fj − fj)2
77

78 Kapitola 4.Modely využívajúce súvislosti medzi hodnotami procesu
Obr. 4.1. Priebeh procesu s chýbajúcou hodnotou
Veľkosť chyby je v tomto prípade 7.77, odhadnutú hodnotu fk sme pri výpočte chybynepoužili.
Obr. 4.2: Priebeh procesu, jeho aproximácia pomocou aritmetického priemeru a chy-bový vektor
Pokúsime sa teraz úlohu vyriešiť všeobecnejšie. Budeme hľadať také hodnotyc0, c1, pre ktoré proces f , so zložkami
fk = c0fk−1 + c1fk+1
bude najlepšie aproximovať pôvodný proces f .

4.1. Modely kĺzavých súčtov 79
Vektorový zápis:f = c0b0 + c1b1
kdef =(f0, f1, . . . , fk−1, ∗, fk+1, . . . , fN−1)
b0 =(∗, f0, . . . , fk−2, fk−1, ∗, . . . , fN−2)
b1 =(f1, f2, . . . , ∗, fk+1, fk+2, . . . , ∗)
To nastane vtedy, keď||f − f || → min
odtiaľ(f − f)⊥b0 a (f − f)⊥b1
a teda⟨f − f ,b0⟩ = 0 a ⟨f − f ,b1⟩ = 0
⟨f − c0 · b0 − c1 · b1,b0⟩ = 0⟨f − c0 · b0 − c1 · b1,b1⟩ = 0
⟨f ,b0⟩ − ⟨c0b0,b0⟩ − ⟨c1b1,b0⟩ = 0⟨f ,b1⟩ − ⟨c0b0,b1⟩ − ⟨c1b1,b1⟩ = 0
⟨f ,b0⟩ − c0⟨b0,b0⟩ − c1⟨b1,b0⟩ = 0⟨f ,b1⟩ − c0⟨b0,b1⟩ − c1⟨b1,b1⟩ = 0
c0⟨b0,b0⟩+ c1⟨b1,b0⟩ = ⟨f ,b0⟩c0⟨b0,b1⟩+ c1⟨b1,b1⟩ = ⟨f ,b1⟩
Dostaneme sústavu dvoch lineárnych rovníc o dvoch neznámych
c0 ·
(k−1∑j=0
f2j +N−2∑
j=k+1
f2j
)+ c1 ·
(k−3∑j=0
fj · fj+2 + fk−1 · fk+1 +N−3∑
j=k+1
fj · fj+2
)=
N−1∑j=1,j =k,j =k+1
fj · fj−1
c0 ·
(k−3∑j=0
fj · fj+2 + fk−1 · fk+1 +N−3∑
j=k+1
fj · fj+2
)+ c1 ·
(k−1∑j=1
f2j +N−1∑
j=k+1
f2j
)=
N−2∑j=0,j =k,j =k−1
fj · fj+1
(4.1.1)
Riešením tejto sústavy budú koeficienty procesu f v báze B = b0,b1. Prie-beh procesu s chýbajúcou hodnotou a jeho aproximácia procesom, ktorý použije navýpočet priemet do podpriestoru pomocou dvoch susedných hodnôt, sú zobrazenéna obrázku 4.3. Na obrázku je prerušovanou čiarou znázornený aj chybový proces,ktorého veľkosť je teraz menej ako v predošlom prípade, ||e2|| = 7.69.

80 Kapitola 4.Modely využívajúce súvislosti medzi hodnotami procesu
Obr. 4.3: Priebeh procesu, jeho aproximácia pomocou priemetu do podpriestoru achybový vektor
Hviezdičky na začiatku a na konci bázových procesov môžeme nahradiť hodno-tami podľa povahy procesu, alebo pri výpočte skalárneho súčinu vynechať príslušnúhodnotu vo všetkých vektoroch. Rovnako vynecháme vo všetkých procesoch súradnicezodpovedajúce chýbajúcej hodnote fk.
Metóda získania koeficientov c0, c1 spočíva v hľadaní takého riešenia sústavy (4.1.1),pri ktorom chyba aproximácie pôvodného procesu f procesom f bude minimálna.Koeficienty, ktoré minimalizujú veľkosť chyby sa môžu počítať pomocou diferenciál-neho počtu rovnako dobre ako metódou priemetu do podpriestoru. Uvedený postupsa nazýva metóda kĺzavých súčtov.
Aritmetický alebo vážený priemer sa používa aj pri známej hodnote fk. V prípade,že chceme proces vyhladiť, riešime úlohu filtrácie procesu. Predpokladajme, ženamerané hodnoty sú
f0, f1, . . . , fk−1, fk, fk+1, . . . , fN−1
ale hodnota fk je výrazne odlišná a chceme ju prispôsobiť ostatným hodnotám. Takátosituácia nastane napríklad keď chceme odstrániť šum na zvukovom zázname. Najjed-noduchší postup bude, ak hodnotu fk nahradíme aritmetickým priemerom susednýchhodnôt:
fk =fk−1 + fk+1
2To môžeme napísať aj ako
fk =1
2fk−1 +
1
2fk+1
Všeobecnejší zápis a presnejší výsledok dostaneme, ak namiesto koeficientov 12 pou-
žijeme vhodné koeficienty c0 a c1.
fk = c0 · fk−1 + c1 · fk+1

4.1. Modely kĺzavých súčtov 81
Úloha je, ako zvoliť c0, c1, aby sa filtrovaný proces, čo najviac podobal na pôvodnýproces f . Nový proces bude mať súradnice
f = (c0, c1)B
v báze B, ktorú treba vhodne zvoliť. Pôjde teda o priemet do dvojrozmerného vekto-rového priestoru, určeného bázou B. Príklad procesu a jeho filtrácie je na obrázku 4.4
Obr. 4.4: Vyhladené dáta pomocou metódy kĺzavých súčtov, pôvodné dáta sú označené* a vyhladené sú označené o, použitý je model fk = c0fk−1 + c1fk+1
Príklad 4.1.1 Interpolácia a filtrácia sa používa napríklad aj pri úprave obrázkov.Pri digitálnom prenose čiernobielych obrázkov môžu okrem iných vzniknúť tieto dvadruhy zašumenia:
1. Pre niektoré pixely nedostaneme informáciu o hodnote intenzity sivej farby, pri-čom vieme, pre ktoré pixely táto informácia chýba.
2. To isté čo predtým, len nevieme, ktorým pixelom informácia chýba, prípadnektoré pixely obsahujú chybnú informáciu.
Na obr. 4.5 vidíme (a) originálny obrázok a (b) obrázok zašumený. Veľkosť obrázka je256×256 pixelov a pre každý pixel je odtieň sivej reprezentovaný prirodzeným číslommedzi 0 a 255. Použite metódu kĺzavých súčtov pri rekonštrukcii obrázka.
Riešenie:Obrázok si reprezentujeme ako maticu B. V prípade, že poznáme polohu šumu, tj.súradnice bielych bodov (sx, sy), môžeme pre chýbajúce hodnoty priradiť aritmetickýpriemer susedných bodov, a teda používame interpoláciu
M(sx, sy) =1
4
(M(sx − 1, sy) +M(sx + 1, sy) +M(sx, sy − 1) +M(sx, sy + 1)
)

82 Kapitola 4.Modely využívajúce súvislosti medzi hodnotami procesu
Takto zrekonštruovaný obrázok je znázornený na obr. 4.5 (c). Vidíme, že obrázoksa podarilo zrekonštruovať veľmi dobre. Horší výsledok sa ale dá očakávať, keď po-lohu chýbajúcich bodov nepoznáme. Tu už musíme priemerovať všetky pixely, a tedaprebehne filtrácia procesu.
Pre lepší výsledok budeme priemerovať 9 pixelov vo štvorci 3x3 okolo jednéhobodu
M(p, s) =1
9
(M(p− 1, s− 1) +M(p− 1, s) +M(p− 1, s+ 1)
+M(p, s− 1) +M(p, s) +M(p, s+ 1)
+M(p+ 1, s− 1) +M(p+ 1, s) +M(p+ 1, s+ 1))
pre všetky p = 0, . . . , 255 a s = 0, . . . , 255.Výsledok je zobrazený na obr. 4.5 (d). Vidíme, že rekonštrukcia má stále príliš
jasné škvrny v miestach pôvodného šumu. Preto upravíme náš filtrovací proces abudeme priemerovať 25 pixelov vo štvorci 5x5 okolo daného bodu.
Výsledok na obr. 4.5 (e) sa mierne zlepší.Ďalším zväčšením štvorca na 7x7 získame už príliš rozmazný obrázok, viď obr. 4.5
(f).
(a) pôvodný obrázok (b) obrázok so šumom (c) interpolácia
(d) filtrácia 3× 3 (e) filtrácia 5× 5 (f) filtrácia 7× 7
Obr. 4.5: Benchmarkový obrázok dievčiny (Lena), ktorý sme filtrovali metódou kĺza-vých súčtov

4.1. Modely kĺzavých súčtov 83
(a) pôvodný obrázok (b) obrázok so šumom (c) interpolácia
(d) filtrácia 3× 3 (e) filtrácia 5× 5 (f) filtrácia 7× 7
Obr. 4.6. Bežný obrázok psa (Dena) a jeho filtrácia
Poznámky:
• Pri obrázkoch (d) a (e) vidno, že sú mierne rozmazané. Je to dôsledok toho, žehodnoty boli priemerované. V mieste prechodu medzi dvoma farbami by malbyť ostrý skok, avšak filtráciou sme tento skok zhladili.
• Obrázok (e) je rozmazanejší ako obrázok (d), pretože sme používali väčšiu časťobrázka na priemerovanie.
• Znalosť polohy šumu sa ukázala ako veľká výhoda. Nielenže sme priemerovali lenv miestach šumu - a teda sme ostrosť obrázka mimo zašumených miest nestratili- ale zároveň sme chybu neposúvali do vedľajších pixelov. Bohužiaľ informáciao polohe šumu je známa len zriedka.
• Ak porovnáme obr. 4.5 a obr. 4.6 vidíme, že obrázok psa sa ťažšie rekonštruoval.Buď sme mali nedostatočne odstránený šum, alebo bol výsledný obrázok prílišrozmazaný. Je to preto, lebo originálny obrázok psa obsahuje menej súvislýchplôch, kde sa farba príliš nemení. Zvieracia srsť obsahuje veľa skokov vo farbe.
Ďalej budeme riešiť úlohu extrapolácie procesu. Predpokladajme, že nameranéhodnoty procesu f sú f0, f1, . . . , fk−1. Chceme odhadnúť (predpovedať) ďalšiu hod-

84 Kapitola 4.Modely využívajúce súvislosti medzi hodnotami procesu
notu fk, ktorú odhadujeme pomocou M predchádzajúcich hodnôt:
fk =
M∑j=1
cj · fk−j
Príklad 4.1.2 Ako bude vyzerať prediktor prvého rádu pre úlohu kĺzavých súčtov?
Riešenie:Ak M = 1, dostaneme fk = c · fk−1.Namerané sú hodnoty pôvodného procesu f = (f0, f1, . . . , fk, . . . , fN−1), nový procesbude mať hodnoty
f = (∗, c f0, c f1, . . . , c fk, . . . , c fN−2)
Báza B = b0 bude obsahovať jediný vektor
b0 = (∗, f0, f1, . . . , fk, . . . , fN−2),
pričom prvú zložku vektora b0 zanedbáme (hodnotu "*" nahradíme hodnotou 0).
c =⟨f ,b0⟩⟨b0,b0⟩
=⟨(f0, f1, . . . , fk, . . . , fN−1⟩, (0, f0, f1, . . . , fk, . . . , fN−2)⟩⟨(0, f0, f1, . . . , fk, . . . , fN−2)(0, f0, f1, . . . , fk, . . . , fN−2)⟩
c =
N−1∑k=0
fk · fk−1
N−1∑k=0
f2k−1
To bol prediktor, ktorý používa jednu hodnotu. Nazývame ho tiež prediktor prvéhorádu.
Úloha 4.1.1 Odvoďte vzorec pre prediktor, ktorý používa tri hodnoty, teda prediktortretieho rádu. Tieto hodnoty môžu byť tri posledné prechádzajúce hodnoty. Ale keď na-príklad sledujeme vývoj peňažného kurzu, je lepšie brať do úvahy predošlý deň, predošlýtýždeň a predošlý mesiac.
Porovnajte účinnosť navrhovaných modelov na nejakých reálnych dátach.
4.2 Všeobecná formulácia úlohy
Vo všeobecnosti riešime úlohu lineárnej regresie pre model
φ(tk) =
M∑j=1
cj · fj (4.2.1)
V tomto modeli na rozdiel od klasickej úlohy lineárnej regresie v tvare φ(tk) =M∑j=1
cj · φj(tk) nie sú dopredu určené regresné funkcie φj(tk). Namiesto nich sú ako

4.2. Všeobecná formulácia úlohy 85
báza použité známe (namerané) hodnoty procesu fj v nejakých určených časovýchokamihoch.
Predpokladáme, že hodnoty sú merané v pravidelných intervaloch, preto pre rie-šenie úloh kĺzavých súčtov je dôležité dodržať podmienku ekvidištančnosti časovýchokamihov, v ktorých sa merajú hodnoty procesu.
tj+1 = tj +∆ t, j = 1, 2, . . . , N
Predchádzajúcu podmienku môžeme normalizovať a dostávame postupnosť časovýchokamihov:
t1 = 1, tj+1 = tj + 1, j = 1, 2, . . . , N − 1
Podľa vzájomného vzťahu hodnôt k a M vo vyjadrení modelu (4.2.1) budeme riešiťúlohy:
k > M, extrapolácia1 < k < M, interpolácia1 ≤ k ≤M, filtrácia
Extrapolácia znamená odhadnúť nasledujúcu (budúcu) hodnotu procesu, ak po-známe jednu, alebo niekoľko predchádzajúcich hodnôt.Interpolácia znamená odhadnúť chýbajúcu hodnotu ak sú známe hodnoty pred a potejto neznámej hodnote.Filtrácia znamená nahradenie nameranej hodnoty procesu inou, takou, ktorá lepšiezodpovedá ostatným hodnotám procesu.Schématický náčrt týchto postupov je na obrázku 4.7
f0
f1
f2
f3f4
f5=?
0 1 2 3 54
f0
f1
f2=?
f3f4
0 1 2 3 4
f0
f1
f2=?
f3f4
0 1 2 3 4
f2
Obr. 4.7. Extrapolácia, interpolácia a filtrácia procesu
Extrapolácia (predikcia)
Slovo extrapolácia pochádza z latinského extrapolatus a druhá časť slova znamenávyleštiť, vyčistiť, predpona extra tu znamená dopredu, alebo mimo oblasť známych

86 Kapitola 4.Modely využívajúce súvislosti medzi hodnotami procesu
hodnôt. Rieši sa úloha odhadnúť hodnotu procesu v nasledujúcom časovom okamihu,preto sa táto metóda nazýva aj predikcia. V úlohe sa odhaduje hodnota procesupomocou vzťahu:
fk+1 =M−1∑j=0
cj · fk−j (4.2.2)
Uvažujme napríklad M = 2.
fk+1 = c0 · fk + c1 · fk−1 (4.2.3)
f = (f0, f1, f2, . . . , fN−1)
f = (0, 0, c0 · f1 + c1 · f0, c0 · f2 + c1 · f1, . . . , c0 · fN−1−1 + c1 · fN−1−2)
f = c0 · (0, 0, f1, f2, . . . , fN−1−1) + c1 · (0, 0, f0, f1, . . . , fN−1−2)
b0 = (0, 0, f1, f2, . . . , fN−1−1)b1 = (0, 0, f0, f1, . . . , fN−1−2)
d (f , f)→ min; d (c0 · b0 + c1 · b1, f)→ min
f − (c0 · b0 + c1 · b1)⊥bi; i = 0, 1⟨f − c0 · b0 − c1 · b1,bi⟩ = 0; i = 0, 1
i = 0 :⟨(0, 0, f2 − c0f1 − c1f0, . . . , fN−1 − c0fN−1−1 − c1fN−1−2),(0, 0, f1, . . . , fN−1−1)⟩ = 0i = 1 :⟨(0, 0, f2 − c0f1 − c1f0, . . . , fN−1 − c0fN−1−1 − c1fN−1−2),(0, 0, f0, . . . , fN−1−2)⟩ = 0
i = 0 :N−1∑k=2
(fk − c0fk−1 − c1fk−2) fk−1 = 0
i = 1 :N−1∑k=2
(fk − c0fk−1 − c1fk−2) fk−2 = 0
c0N−1∑k=2
f2k−1 + c1N−1∑k=2
fk−2fk−1 =N−1∑k=2
fkfk−1
c0N−1∑k=2
fk−1fk−2 + c1N−1∑k=2
f2k−2 =N−1∑k=2
fkfk−2
Koeficienty c0 a c1, ktoré sú riešením poslednej sústavy rovníc, použijeme vo vzťahu(4.2.3) na odhad nasledujúcej hodnoty procesu.

4.2. Všeobecná formulácia úlohy 87
Vráťme sa k všeobecnému tvaru (4.2.2) úlohy extrapolácie, v ktorej najprv procesf odhadneme procesom f a potom využijeme koeficienty tohto odhadu na výpočetďalších hodnôt procesu.
fk+1 =
M−1∑j=0
cj · fk−j
f =(f0, . . . fM−1, fM , . . . fk, . . . fN−1)
f =
(0, . . . 0,M−1∑j=0
cj · fM−1−j . . .M−1∑j=0
cj · fk−1−j . . .M−1∑j=0
cj · fN−2−j)
Príslušná báza bude mať tvarmiesto: 0 1 . . . M − 1 M . . . k . . . N − 1
b0 = ( 0, 0 . . . 0, fM−1, . . . fk−1 . . . fN−2)b1 = ( 0, 0 . . . 0, fM−2, . . . fk−2 . . . fN−3)...bn = ( 0, 0 . . . 0, fM−n−1, . . . fk−n−1 . . . fN−n−2)...
bM−1 = ( 0, 0 . . . 0, f0, . . . fk−M−2 . . . fN−M−1)
Vzdialenosť medzi f a f je minimálna, ak platí
⟨f − f ,bn⟩ = 0, ∀n = 0, 1, . . . ,M − 1
Po dosadení vektorov f , f a bn dostaneme⟨(f0, f1, . . . , fM−1, fM −
M−1∑j=0
cj · fM−1−j , . . . , fk −M−1∑j=0
cj · fk−1−j , . . . ,
fN−1 −M−1∑j=0
cj · fN−2−j), (0, 0, . . . , 0, fM−n−1, . . . , fk−n−1, . . . , fN−n−2)
⟩= 0
N−1∑k=M
fk −M−1∑j=0
cj · fk−1−j
· fk−1−n = 0
Po roznásobení zátvorky a zámene súm dostávame vzorec na výpočet koeficientov preúlohu extrapolácie.
M−1∑j=0
cj ·N−1∑k=M
fk−1−j · fk−1−n =
N−1∑k=M
fkfk−1−n n = 0, 1, . . . ,M − 1 (4.2.4)
Postup, ktorý využíva vzťah (4.2.4) sa nazýva aj lineárne prediktívne kódovanie apríslušné koeficienty sa označujú ako LPC koeficienty.

88 Kapitola 4.Modely využívajúce súvislosti medzi hodnotami procesu
Interpolácia a filtrácia
Slovo interpolácia pochádza z latinského interpolatus a druhá časť slova znamenávyleštiť, vyčistiť, predpona inter tu znamená dnu, alebo v oblasti známych hodnôt.Rieši sa úloha odhadnúť neznámu hodnotu, alebo nahradiť známu, ale nevyhovujúcuhodnotu procesu v časovom okamihu, ktorý sa nachádza medzi nameranými dátami.V úlohe filtrácie sa odhaduje hodnota procesu pomocou vzťahu:
fk = c0 · fk +
M∑j=1
(cj · fk−j + c−j · fk+j) (4.2.5)
V úlohe interpolácie sa odhaduje hodnota procesu pomocou vzťahu:
fk =
M∑j=1
(cj · fk−j + c−j · fk+j) (4.2.6)
Uvažujme napríklad M = 1.
fk = c1 · fk−1 + c−1 · fk+1 (4.2.7)
f = (f0, f1, f2, . . . , fN−1)
f = (0, c1 · f0 + c−1 · f2, c1 · f1 + c−1 · f3, . . . , c1 · fN−3 + c−1 · fN−1, 0)
f = c1 · (0, f0, f1, . . . , fN−3, 0) + c−1 · (0, f2, f3, . . . , fN−1, 0)
b1 = (0, f0, f1, . . . , fN−3, 0)b−1 = (0, f2, f3, . . . , fN−1, 0)
d (f , f)→ min; d (c1 · b1 + c−1 · b−1, f)→ min
f − (c1 · b1 + c−1 · b−1)⊥bi; i = −1, 1⟨f − c1 · b1 − c−1 · b−1,bi⟩ = 0; i = −1, 1
i = 1 :⟨(f0, f1 − c1f0 − c−1f2, . . . , fN−2 − c1fN−3 − c−1fN−1, fN−1),(0, f0, . . . , fN−3, 0)⟩ = 0i = −1 :⟨(f0, f1 − c1f0 − c−1f2, . . . , fN−2 − c1fN−3 − c−1fN−1, fN−1),(0, f2, . . . , fN−1, 0)⟩ = 0
i = 1 :N−2∑k=1
(fk − c1fk−1 + c−1fk+1) fk−1 = 0
i = −1 :N−2∑k=1
(fk − c1fk−1 + c−1fk+1) fk+1 = 0
c1N−2∑k=1
f2k−1 + c−1
N−2∑k=1
fk−1 · fk+1 =N−2∑k=1
fk · fk−1
c1N−2∑k=1
fk−1 · fk+1 + c−1
N−2∑k=1
f2k+1 =N−2∑k=1
fk · fk+1

4.2. Všeobecná formulácia úlohy 89
Koeficienty c1 a c−1, ktoré sú riešením poslednej sústavy rovníc, použijeme vo vzťahu(4.2.7) na odhad chýbajúcej, alebo chybnej hodnoty procesu.
Vráťme sa k všeobecnému tvaru (4.2.6) úlohy interpolácie, v ktorej najprv procesf odhadneme procesom f a potom využijeme koeficienty tohto odhadu na výpočetchýbajúcich hodnôt procesu.
fk =M∑j=1
(cj · fk−j + c−j · fk+j) =M∑
j=−M ; j =0
cj · fk−j
V nasledujúcich úvahách budeme uvažovať c0 = 0.
f =(f0, . . . , fM−1, fM , . . . , fk, . . . , fN−1−M , fN−1−M+1, . . . , fN−1)
f =
(0, . . . , 0︸ ︷︷ ︸M
,M∑
j=−M
cj · fM−j , . . . ,M∑
j=−M
cj · fk−j , . . . ,M∑
j=−M
cj · fN−1−M−j , 0, . . . , 0︸ ︷︷ ︸M
)
Príslušná báza bude mať tvar
miesto: 0 . . . M − 1 M, . . . N − 1−M N −M N − 1
b1 = ( 0, . . . 0, fM−1, . . . fN−M−2, 0, . . . , 0)b−1 = ( 0, . . . 0, fM+1, . . . fN−M , 0, . . . , 0)...bn = ( 0, . . . 0, fM−n, . . . fN−1−M−n, 0, . . . , 0)...bM = ( 0, . . . 0, f0, . . . fN−1−2M , 0, . . . , 0)b−M = ( 0, . . . 0, f2M , . . . fN−1, 0, . . . , 0)
Vzdialenosť medzi f a f je minimálna ak platí
⟨f − f ,bn⟩ = 0, ∀n = −M, . . . ,M
Po dosadení vektorov f , f a bn dostaneme(f0, . . . , fM−1︸ ︷︷ ︸M
, fM −M∑
j=−M
cj · fM−j , . . . , fN−1−M −M∑
j=−M
cj · fN−1−M−j ,
fN−M , fN−M+1, . . . , fN−1︸ ︷︷ ︸M
), (0, . . . , 0︸ ︷︷ ︸M
, fM−n, . . . , fN−1−M−n, 0, . . . , 0︸ ︷︷ ︸M
)
= 0
N−1−M∑k=M
fk − M∑j=−M
cj · fk−j
fk−n = 0

90 Kapitola 4.Modely využívajúce súvislosti medzi hodnotami procesu
Po roznásobení zátvorky a zámene súm dostávame vzorec na výpočet koeficientov preúlohu interpolácie.
M∑j=−M
cj ·N−1−M∑k=M
fk−j · fk−n =N−1−M∑k=M
fkfk−n (4.2.8)
kde n = −M, . . . ,M, n = 0Koeficienty vypočítané riešením sústavy (4.2.8) sa využijú vo vzorci (4.2.6) na inter-poláciu, alebo filtráciu procesu f .
Úloha 4.2.1 Navrhnite postup, ako použiť metódu kĺzavých súčtov v prípade, že in-tervaly, v ktorých sú hodnoty procesu namerané, nie sú ekvidištančné.

5 Periodické vlastnosti procesov
5.1 Periodické modely
V prípade, že sa v modeli pre zovšeobecnenú lineárnu regresiu (3.11.1) použijú akofunkcie φn(tk) niektoré z funkcií sínus, alebo kosínus, budú analyzované periodickévlastnosti tohto procesu.
φ(tk) = c0φ0(tk) + c1φ1(tk) + · · ·+ cnφN−1(tk)
Príkladom modelu lineárnej regresie, ktorou je možné aproximovať proces s približneperiodickým priebehom, je funkcia:
φ(tk) = c0 · sin(ω0 tk) + c1 · cos(ω1 tk)
Hodnoty ω0 a ω1 zvolíme vopred podľa periód, ktoré sa v procese vyskytujú.Pomocou postupov z predchádzajúcej kapitoly potom vypočítame koeficienty c0 a c1,ktoré určujú najlepšiu aproximáciu procesu pomocou krivky takéhoto tvaru.
Príklad 5.1.1 Aproximujte proces f = (12,−1,−6,−2,−10,−13, 1, 5, 2, 10) regres-nou krivkou tvaru φ(tk) = c0 · sin(ω0 tk) + c1 · cos(ω1 tk).
Riešenie:Metódou lineárnej regresie vypočítame koeficienty c0 a c1, ktoré sú najlepšie pri ap-roximácii funkciou φ(tk). Hodnoty ω0 a ω1 treba zvoliť vopred, pretože sú vo vnútrifunkcií sínus a kosínus a nie je možné na ich výpočet použiť lineárne metódy, nie jemožné ich exaktne vypočítať. Na obrázkoch 5.1, 5.2 a 5.3 sú vykreslené aproximáciepri intuitívne odhadnutých hodnotách ω0 a ω1. Veľkosti chýb odhadu sú postupne∥e1∥ = 20.85, ∥e2∥ = 14.89 a ∥e3∥ = 10.7.
Z obrázkov aj z výpočtu veľkosti chyby vidíme, že koeficienty ω0 a ω1 podstatneovplyvňujú tvar funkcie φ(tk), a teda aj úspešnosť, s akou je proces f aproximovaný.
Lepšiu aproximáciu by sme mohli dostať, keby sme okrem parametrov ω0 a ω1,ktoré ovplyvňujú dĺžku periódy, zaviedli ďalšie dva parametre α0 a α1, ktoré budúovplyvňovať miesto, kde funkcie sínus a kosínus prechádzajú nulou. Týmito paramet-rami posunieme obe funkcie po časovej osi. Na obrázku 5.4 je vykreslená aproximáciapri intuitívne odhadnutých hodnotách ω0, ω1, α0 a α1. Veľkosť chyby odhadu je vtomto prípade ∥e4∥ = 7.3.
Dá sa dosiahnuť aj omnoho lepšia aproximácia, s veľkosťou chyby ∥e5∥ = 1, aletento výsledok uvedieme až po vybudovaní potrebného matematického aparátu vpríklade 5.4.3.
91

92 Kapitola 5. Periodické vlastnosti procesov
Obr. 5.1. Aproximácia procesu f krivkou φ(tk) = c0 · sin(1 tk) + c1 · cos(1 tk)
Obr. 5.2. Aproximácia procesu f krivkou φ(tk) = c0 · sin(1 tk) + c1 · cos(2 tk)
Obr. 5.3. Aproximácia procesu f krivkou φ(tk) = c0 · sin(0.5 tk) + c1 · cos(2 tk)

5.1. Periodické modely 93
Obr. 5.4: Aproximácia procesu f krivkou φ(tk) = c0 · sin(0.5 tk−0.39)+ c1 · cos(2 tk−0.19)
Úloha 5.1.1 S pomocou výpočtovej techniky nájdite také hodnoty parametrov ω0, ω1,α0 a α1 pre funkciu
φ(tk) = c0 · sin(ω0 tk + α0) + c1 · cos(ω1 tk + α1)
aby veľkosť chyby odhadu ∥e∥ < 7.
Problém, ktorý bol riešený v príklade 5.1.1, však môžeme formulovať aj inýmspôsobom. Metódou lineárnej regresie vypočítame koeficienty procesu v báze, ktorápozostáva z veľkého počtu kosínusových priebehov, pričom každý z týchto priebehovmá inú periódu. Na obrázku 5.5 sú zobrazené tri takéto funkcie s rôznou periódou ajamplitúdou.
Obr. 5.5. Funkcie kosínus s rôznymi periódami a rôznymi amplitúdami
Podľa toho, aké veľké budú koeficienty pri jednotlivých funkciách sa dá určiť,ktoré sú viac a ktoré menej významné periódy procesu. Báza, ktorá sa na vydeľovanie

94 Kapitola 5. Periodické vlastnosti procesov
periodických trendov z procesu používa, sa nazýva harmonická báza a takáto zmenabázy sa nazýva aj diskrétna Fourierova transformácia.
Riešime úlohu aproximovať proces ako lineárnu kombináciu funkcií kosínus. Am-plitúdy a fázy (= max. výška a posun) týchto funkcií sa vypočítajú ako koeficientyrozkladu procesu do harmonickej bázy.
Odhad f procesu f vyjadríme v takom podpriestore S pôvodného priestoru, ktorýbude generovaný bázovými vektormi s najväčšími koeficientmi v rozklade procesu f .Rozmer podpriestoru S určíme podľa požiadaviek v zadaní problému. Na ilustráciutejto myšlienky uvedieme príklad o výbere troch vektorov z jednotkovej bázy vekto-rového priestoru.
Príklad 5.1.2 Rozložme vektor f = (1, 13, 4, 2, 17, 3, 2, 3) do jednotkovej bázy. Vy-berme z bázy tri bázové vektory, tak, že v priemet do podpriestoru určeného týmitovektormi bude najlepšie vyjadrovať pôvodný vektor.
Vidíme, že takými vektormi budú vektory
e4 = (0, 0, 0, 0, 1, 0, 0, 0), e1 = (0, 1, 0, 0, 0, 0, 0, 0), e2 = (0, 0, 1, 0, 0, 0, 0, 0)
Priemet vektora f do podpriestoru určeného bázovými vektormi e4, e1 a e2 je vektorf = (0, 13, 4, 0, 17, 0, 0, 0), ktorý je najlepšou aproximáciou vektora f spomedzi všet-kých trojrozmerných podpriestorov určených trojprvkovou bázou B3 ⊂ E . Teda naj-lepšie bude zobrať do trojrozmernej bázy vektory s najväčšími koeficientmi c1 = 13,c2 = 4 a c4 = 17. Na obrázku 5.6 je použitá báza B3 = e1, e2, e4, teda báza snajväčšími koeficientmi. Na obrázku 5.7 je použitá báza B3 = e0, e3, e6, teda bázas najmenšími koeficientmi.
Obr. 5.6: Aproximácia (dobrá) procesu f v podpriestore s bázou z vektorov s najväč-šími koeficientmi
Úloha 5.1.2 V príklade 5.1.2 je ukázané, že najbližší vektor k vektoru f (v podpries-tore generovanom trojrozmernou bázou, ktorá je podmnožinou bázy B celého prie-storu), je vektor f , ktorého koeficienty sú tri najväčšie z koeficientov v báze B. Do

5.1. Periodické modely 95
Obr. 5.7: Aproximácia (zlá) procesu f v podpriestore s bázou z vektorov s najmenšímikoeficientmi
bázy B3 sú vybrané bázové vektory zodpovedajúce týmto trom najväčším koeficientom.Nájdite takú bázu štvorrozmerného priestoru, v ktorom týmto postupom nenájdemenajlepší trojrozmerný podpriestor. Teda vektor f s najväčšími koeficientmi nebudenajlepšou aproximáciou spomedzi všetkých priemetov do všetkých podpriestorov gene-rovaných bázami B3 ⊂ B.
Úloha 5.1.3 Akú podmienku musí spĺňať báza, aby bolo možné použiť postup z prí-kladu 5.1.2?
Rovnaký princíp ako v príklade 5.1.2 použijeme aj pri výbere významných koeficien-tov pri rozklade do harmonickej bázy. Čím väčšia bude absolútna hodnota koeficienturozkladu vektora f do bázy, tým lepšie bude daný bázový vektor (vynásobený prísluš-ným koeficientom) aproximovať vektor f . Že je to naozaj pravda dokážeme tak, že vodseku 5.4 ukážeme, že veľkosť chyby odhadu f je pri tomto postupe najmenšia.
5.1.1 Skalárny súčin v komplexnom obore
Aj v tejto kapitole budeme analyzovať procesy, ktorých hodnoty sú reálne čísla. Na ichspracovanie však budeme potrebovať komplexné čísla a komplexné vektory. Preto te-raz vysvetlíme matematický aparát potrebný na spracovanie vektorov s komplexnýmihodnotami.
Komplexné číslo je číslo, ktoré má okrem reálnej zložky navyše zložku imaginárnu,teda je popísané dvomi hodnotami. Geometricky môžeme čísla znázorniť na priamke(napr. prirodzené, celé, reálne), na znázornenie komplexných čísel je potrebný väčšírozmer, teda rovina. Na obrázku 5.8 je znázornená Gaussova rovina, na ktorej jevyznačený bod zodpovedajúci komplexnému číslu
z = 5 + j 3 = 5.83 (cos(0.54) + j sin(0.54)) = 5.83 e0.54 j
Číslo j vo vyjadrení komplexného čísla sa nazýva komplexná jednotka. Jeho naj-významnejšia vlastnosť je, že na rozdiel od reálnych čísel, je jeho druhá mocnina číslo

96 Kapitola 5. Periodické vlastnosti procesov
Obr. 5.8. Komplexné číslo z = 5 + j 3
záporné.j2 = −1
Každé komplexné číslo z môžeme zapísať v algebraickom, geometrickom, goniomet-rickom alebo exponenciálnom tvare:
• Algebraický tvar je súčetz = a+ j b
kde a je reálna zložka a b je imaginárna zložka komplexného čísla z.
Rez = a, Imz = b
• Geometrický tvar je usporiadaná dvojica (a, b), ktorá udáva súradnice kom-plexného čísla v Gaussovej rovine, pričom prvá zložka udáva hodnotu reálnejčasti (os x) a druhá zložka udáva hodnotu imaginárnej časti (os y)
z = (a, b)
• Goniometrický tvar je vyjadrenie komplexného čísla pomocou jeho veľkosti|z| a uhla α. V Gaussovej rovine je hodnota |z| rovná vzdialenosti bodu z = (a, b)od bodu o = (0, 0), a uhol α je uhol, ktorý zviera úsečka oz s kladnou reálnoupolosou (kladnou polosou x).
z = |z| · (cos(α) + j sin(α)) ; kde |z| =√a2 + b2,
tan(α) =b
a⇒ α = arctan
(b
a
)cosα =
a
|z|, sinα =
b
|z|, α ∈ (−π
2,π
2)
• Exponenciálny tvar používa rovnako ako goniometrický tvar veľkosť |z| auhol α.
z = |z| · ej α kde |z| =√a2 + b2, α = arctan
(b
a
)

5.1. Periodické modely 97
Operáciu sčítania je najjednoduchšie vykonať (s najnižšími nárokmi na pamäť počí-tača) vtedy, keď sú komplexné čísla v algebraickom tvare.
z1 + z2 = (a1 + j b1) + (a2 + j b2) = (a1 + a2) + j (b1 + b2)
Operáciu násobenia je najjednoduchšie vykonať, keď sú komplexné čísla v goniomet-rickom, alebo exponenciálnom tvare.
z1 · z2 = |z1| · (cos(α1) + j sin(α1)) · |z2| · (cos(α2) + j sin(α2)) =
= |z1||z2| · (cos(α1) cos(α2) + j sin(α1) cos(α2) + j cos(α1) sin(α2)+
+ j sin(α1) j sin(α2)) = |z1||z2| · (cos(α1) cos(α2)− sin(α1) sin(α2))+
+ j (sin(α1) cos(α2) + cos(α1) sin(α2)) = |z1||z2| · (cos(α1 + α2) + j sin(α1 + α2))
respektívez1 · z2 = |z1| · ej α1 ·|z2| · ej α2 = |z1| · |z2| ej (α1+α2)
Komplexne združené číslo k číslu z = a+ j b = |z| · ej α nazveme číslo
z = a− j b = |z| · e− j α
Definujeme skalárny súčin vektorov, ktorých hodnoty môžu byť aj komplexné čísla.Urobíme to tak, aby zúženie tejto definície na reálne vektory bolo skalárnym súčinompodľa definície v odseku 2.5.Skalárny súčin je zobrazenie: ⟨ , ⟩ : V × V → F , pre ktoré:
⟨f , f⟩ ≥ 0,navyše ⟨f , f⟩ = 0⇔ f = 0 pozitívnosť⟨f ,g⟩ = ⟨g, f⟩ symetria⟨g + h, f⟩ = ⟨g, f⟩+ ⟨h, f⟩⟨k f ,g⟩ = k · ⟨f ,g⟩ bilinearita
Predchádzajúca definícia dáva viacero možností ako definovať skalárny súčin v kon-krétnom vektorovom priestore. My budeme pracovať s vektorovým priestorom, kto-rého prvkami budú usporiadané N -tice komplexných čísel a skalárny súčin pre ľubo-voľné dva komplexné vektory f ,g bude:
f = (f0, f1, . . . , fN−1), g = (g0, g1, . . . , gN−1) kde fi, gi ∈ C
Potom skalárny súčin f a g je
⟨f ,g⟩ =N−1∑k=0
fkgk, kde gk je číslo komplexne združené ku gk
Úloha 5.1.4 Dokážte, že takto definovaný súčin, je naozaj skalárny súčin. Teda súsplnené vlastnosti uvedené v definícii skalárneho súčinu.
Úloha 5.1.5 Vynásobte dve komplexné čísla v algebraickom tvare.
Úloha 5.1.6 Sčítajte dve komplexné čísla v goniometrickom, resp. exponenciálnomtvare.
Úloha 5.1.7 Zvoľte si dve komplexné čísla v a w. Do Gaussovej roviny zakreslitesúčet aj súčin týchto komplexných čísel.

98 Kapitola 5. Periodické vlastnosti procesov
5.2 Harmonická báza
Na analýzu periodických vlastností v procese budeme používať harmonickú bázu,ktorá bude reprezentovať postupne periódy dĺžky N , N/2, N/3 až po najkratšiuperiódu dĺžky N/(N − 1). Všeobecný tvar n-tého vektora harmonickej bázy HN vN -rozmernom vektorovom priestore je
hn =(. . . , ej
2πN n·(k−1), ej
2πN n·k, . . .
)kde n = 0, 1, . . . , N − 1 (5.2.1)
Jednotlivé vektory N -prvkovej harmonickej bázy majú tvar:
h0 = (1, 1, . . . , 1)
h1 =(1, ej
2πN , ej
2πN 2, . . . , ej
2πN k, . . . , ej
2πN (N−1)
)h2 =
(1, ej
2πN 2, ej
2πN 2·2, . . . , ej
2πN 2·k, . . . , ej
2πN 2·(N−1)
)...hn =
(1, ej
2πN n, ej
2πN n·2, . . . , ej
2πN n·k, . . . , ej
2πN n·(N−1)
)...hN−1 =
(1, ej
2πN (N−1), ej
2πN (N−1)·2, . . . , ej
2πN (N−1)·k, . . . , ej
2πN (N−1)·(N−1)
)Príklad 5.2.1 Nakreslite hodnoty komponentov vektorov harmonickej bázy H6 dokomplexnej roviny a potom nakreslite imaginárnu zložku každého bázového vektoraako sínusový priebeh.
Riešenie:Na obrázku 5.9 sú na jednotkovej kružnici nakreslené jednotlivé hodnotya, b, c, d, e, f , ktoré sú zložkami vektorov harmonickej bázy H6. Ak vykreslíme proces,ktorého hodnoty budú iba imaginárne zložky bázových vektorov, dostaneme sínusovépriebehy. Na obrázku 5.9 je vykreslený sínusový priebeh zodpovedajúci vektoru h1.Pre hodnoty a, b, c, d, e, f platí, že b = f a c = e.
Obr. 5.9. Komplexné čísla a, b, c, d, e, f sú zložky vektora harmonickej bázy H6
Navyše uhol αc zodpovedajúci komplexnému číslu c je dvojnásobný v porovnaní suhlom αb, ktorý zodpovedá komplexnému číslu b.

5.2. Harmonická báza 99
Harmonické bázové vektory 6-rozmerného vektorového priestoru majú teda tvar
h0 = ( 1, 1, 1, 1, 1, 1)
h1 = ( 1, b, c, −1, c, b)h2 = ( 1, c, c, 1, c, c)h3 = ( 1, −1, 1, −1, 1, −1)h4 = ( 1, c, c, 1, c, c)
h5 = ( 1, b, c, −1, c, b)
Vektory h1 a h5 sú komplexne združené. Rovnako sú komplexne združené vektoryh2 a h4. Priebehy, ktoré zodpovedajú komplexne združeným vektorom h1 a h5 sú naobrázku 5.10.
Obr. 5.10: Sínusové priebehy, zodpovedajúce komplexne združeným bázovým vekto-rom h1 a h5 bázy H6
Ako vidno na obrázku 5.10 priebehy, ktoré zodpovedajú komplexne združeným vek-torom, môžu byť interpretované ako priebehy s rôzne dlhými periódami, ale aj akopriebehy s rovnakou periódou a fázovým posunom o hodnotu π.
Tvrdenie 5.2.1 Pre vektory harmonickej bázy HN platí, že
hn = hN−n (5.2.2)
Dôkaz:Vyjadrime k-tu zložku vektora hn:
hn(k) = ej2πN n·k
Vyjadrime k-tu zložku vektora hN−n:
hN−n(k) = ej2πN (N−n)·k = ej
2πN N ·k · ej 2π
N (−n)·k = ej 2π·k︸ ︷︷ ︸=1+j 0
· e− j 2πN n·k = hn(k)
Teda naozaj platí vzťah (5.2.2).

100 Kapitola 5. Periodické vlastnosti procesov
Príklad 5.2.2 Aký priebeh má proces, ktorého hodnoty sú imaginárne zložky vektoraharmonickej bázy?Vykreslite hodnoty tohto procesu v časoch t = (0, 1, . . . , N − 1).
Riešenie:Harmonická báza HN reprezentuje N -zložkové procesy s rôzne veľkými periódami.Harmonická báza N -rozmerného vektorového priestoru má N prvkov. Každý z bá-zových vektorov možno interpretovať ako niekoľko obehov po jednotkovej kružnici,respektíve bude reprezentovať niekoľko periód funkcie sínus, ktoré môžeme vykresliťv závislosti od času v intervale ⟨0, N − 1⟩. Jednotlivé zložky bázových vektorov súkomplexné čísla, ktoré ležia na jednotkovej kružnici a dve susedné spomedzi týchtokomplexných čísel sa líšia o uhol 2π
N ako vidno na obrázku 5.11, kde je vykreslený sínu-sový priebeh zodpovedajúci vektoru h1 harmonickej bázy HN . Vektor h0 predstavuje
Obr. 5.11. Zložky vektora h1 harmonickej bázy HN
konštantnú zložku, respektíve priamku rovnobežnú s osou x.Vektor h1 predstavuje jeden obeh po jednotkovej kružnici, respektíve jednu celú
periódu funkcie sínus v intervale ⟨0, N − 1⟩.Vektor h2 predstavuje dva obehy po jednotkovej kružnici, respektíve dve peri-
ódy funkcie sínus v intervale ⟨0, N − 1⟩. Pritom "rýchlosť", akou obehne jednotkovúkružnicu, bude dvojnásobná oproti "rýchlosti"obehu v prípade vektora h1.
Vektor hn predstavuje n obehov po jednotkovej kružnici, respektíve n periód fun-kcie sínus v intervale ⟨0, N − 1⟩. Okrem dĺžky periódy môže byť periodické chovanie procesu popísané frekvenciou.Frekvencia je počet obehov (periód), ktoré sa vykonajú za jednotku času, v našomprípade počas celého priebehu procesu. Základnou frekvenciou pre harmonickú bázuje jeden obeh za N časových intervalov, teda
∆f =1
N
Jednotky, v ktorých sa meria frekvencia, môžu byť napr.[s−1],[rok−1
].
Frekvenciou pre n-tý bázový vektor hn je frekvencia
fn = n∆f =n
N
a znamená to, že n-tý bázový vektor je reprezentovaný n periódami počas celéhosvojho priebehu.

5.2. Harmonická báza 101
Na obrázku 5.12 je zobrazená súvislosť medzi časovými intervalmi ∆t medzi jed-notlivými hodnotami procesu a intervalmi ∆f medzi frekvenciami procesu.
∆f =1
N∆t
Obr. 5.12: Súvislosť medzi časovým priebehom procesu f = (f0, f1, . . . , fN−1) a frek-venciami
Vektory harmonickej bázy reprezentujú rôzne dlhé periódy, resp. frekvencie zastú-pené v procese. Pre n = 1 je to jedna perióda (jeden obeh), pre n = 2 sú to 2 periódy(obehy), ale pre n = N − 1 je to jedna perióda, pre n = N − 2 sú to dve periódy akoto vidno na obrázku 5.10.
Tvrdenie 5.2.2 Najvyššia frekvencia (resp. najkratšia perióda) zastúpená v harmo-nickej báze N -rozmerného priestoru je perióda vektora hn , kde n = N
2 (resp. celáčasť N
2 ak je N nepárne).
Tvrdenie 5.2.2 je možné formulovať aj opačne. Ak chceme dobre popísať diskrétnyproces, treba interval ∆t v ktorom meriame hodnoty procesu (vzorkovací interval)zvoliť tak, aby jeho prevrátená hodnota bola aspoň dvojnásobkom maximálnej frek-vencie procesu. Teda aby platil vzťah:
1
∆t≥ 2 · fMax
Toto tvrdenie sa nazýva aj Shannon Koteľnikova veta.
Úloha 5.2.1 Nájdite na internete, alebo v literatúre presné znenie Shannon Koteľni-kovej vety a vysvetlite ho.
Na začiatku tejto kapitoly sme zaviedli pojem harmonická báza, ale zatiaľ sme ne-dokázali, že skutočne ide o bázu. Na to, aby množina N vektorov tvorila bázu N -rozmerného vektorového priestoru, musia byť tieto vektory lineárne nezávislé.
Tvrdenie 5.2.3 Harmonické procesy (vektory) definované vzťahom (5.2.1) tvoria or-togonálnu bázu nejakého N -rozmerného vektorového priestoru.Norma každého z vektorov hn je rovná N .
Dôkaz:Najprv dokážeme, že vektory harmonickej bázy hn, kde n = 0, 1, . . . , N−1 sú na seba

102 Kapitola 5. Periodické vlastnosti procesov
kolmé a potom, že kolmé vektory sú lineárne nezávislé.Počítajme skalárny súčin vektorov hn a hm:
⟨hn,hm⟩ =
0 ak je n = mN ak je n = m
n = m
⟨hn,hm⟩ = ⟨hm,hm)⟩ =N−1∑k=0
bk · bk =N−1∑k=0
ej2πN n·k ·ej 2π
N n·k =
=N−1∑k=0
ej2πN n·k ·e− j 2π
N n·k =N−1∑k=0
1 = N
n = m
⟨hn,hm⟩ =N−1∑k=0
ej2πN n·k ·ej 2π
N m·k =N−1∑k=0
ej2πN (n−m)·k, kde n−m = 0
Označme
S =N−1∑k=0
ej2πN (n−m)·k pre n−m = 0 (5.2.3)
Potrebujeme ukázať, že S = 0.Komplexné čísla ej
2πN (n−m)·k, pre k = 0, 1, . . . , N − 1 ležia na jednotkovej kružnici
ako vidíme na obrázku 5.13.
Obr. 5.13. Komplexné čísla ej2πN (n−m)·k, pre k = 0, 1, . . . , N − 1
Keď vynásobíme rovnicu (5.2.3) číslom ej2πN (n−m) = 0, dostaneme komplexné čísla,
ktorých umiestnenie je na jednotkovej kružnici, len každé číslo je posunuté o uhol2πN (n − m) oproti svojej predchádzajúcej pozícii, preto je na mieste iného čísla (pokružnici vľavo). Umiestnenie čísel je teda rovnaké ako na obrázku 5.13, preto platí
S · ej 2πN (n−m) = S
Pretože sme násobili nenulovým číslom, musí byť S = 0, aby posledná rovnosť platila.Teda naozaj pre n = m je (hn,hm) = 0 a platí, že vektory hn,hm sú na seba kolmé.Podľa nasledujúcej lemy sú aj lineárne nezávislé.
Lema 5.2.1 Ak sú dva vektory na seba kolmé, potom sú lineárne nezávislé.

5.3. Diskrétna Fourierova transformácia (DFT) 103
Dôkaz:Predpokladáme
⟨f ,g⟩ = 0
hľadáme riešenie rovnicec1 · f + c2 · g = 0
celú rovnicu vynásobíme skalárne vektorom f . Dostaneme
⟨c1 · f + c2 · g, f⟩ = ⟨0, f⟩
po úpraváchc1⟨f , f⟩+ c2⟨g, f⟩ = 0
c1⟨f , f⟩+ 0 = 0
posledná rovnosť nastane, len keď c1 = 0. Podobne
⟨c1 · f + c2 · g,g⟩ = ⟨0,g⟩
c1⟨f ,g⟩+ c2⟨g,g⟩ = 0
0 + c2⟨g,g⟩ = 0
a zase rovnosť nastane, len keď c2 = 0.Teda riešenie rovnice
c1 · f + c2 · g = 0
je jediné a to c1 = 0 a c2 = 0, čo je vlastne podmienka nezávislosti, ktorú sme malidokázať. Ukázali sme, že harmonická báza má niekoľko užitočných vlastností.
• hn⊥hm pre n = m
• ⟨hm,hm⟩ = N
• hn = hN−n
5.3 Diskrétna Fourierova transformácia (DFT)
Nech je daný procesf = (f0, f1, . . . , fN−1)
Tento proces je vyjadrený v jednotkovej báze N -rozmerného vektorového priestoru.Hodnoty procesu v jednotkovej báze E sú namerané hodnoty procesu.Vyjadrime teraz tento proces v tom istom N -rozmernom vektorovom priestore, kto-rého báza bude určená harmonickými vektormi tvaru
hn =(. . . , ej
2πN n·k, . . .
)kde n = 0, 1, . . . , N − 1
Z priebehu procesu môžeme pomocou rozkladu do harmonickej bázy určiť, ktoré zperiód v harmonickej báze sú v danom procese zastúpené výraznejšie, teda ktoré majúv rozklade do harmonickej bázy väčšie koeficienty. Hovoríme, že pomocou harmonickejbázy môžeme analyzovať periodické chovanie sa procesu.

104 Kapitola 5. Periodické vlastnosti procesov
Príklad 5.3.1 Nájdite na internete príklady konkrétnych procesov, ktoré majú vý-raznú niektorú periódu.
Riešenie:Príkladom je záznam predaja Coca-coly, má periódu približne 1 rok, výskyt slnečnýchškvŕn, ktorý má periódu cca 13 rokov, ekonomické procesy, ktoré majú periódy rok,mesiac, deň, (sezónne trendy), procesy popisujúce priebeh niektorých samohlások vľudskej reči majú periódu cca 5 milisekúnd. Harmonická báza je bázou N -rozmerného vektorového priestoru, preto riešime úlohuzmeny bázy (jednotkovej, f je časový priebeh procesu) v tom istom N -rozmernompriestore. Koeficienty procesu f v ortogonálnej harmonickej báze vypočítame pomo-cou vzorca pre výpočet koeficientov v ortogonálnej báze, tak ako sme ich odvodili vkapitole o lineárnej regresii.
cn =⟨f ,hn⟩⟨hn,hn⟩
=1
N
N−1∑k=0
fk e− j 2πN n·k (5.3.1)
Vyjadrenie procesu pomocou týchto koeficientov je
f =N−1∑n=0
cnhn tj. fk =N−1∑n=0
cn · ej2πN n·k (5.3.2)
Vzťah (5.3.1) nazývame spätná diskrétna Fourierova transformácia.Vzťah (5.3.2) nazývame diskrétna Fourierova transformácia a budeme ju ozna-čovať ako DFT.
f = (c0, c1, . . . , cN−1)H
Vektor koeficientov c sa nazýva spektrum procesu v harmonickej báze, často aj lenspektrum procesu.
c = (c0, c1, . . . , cN−1)
Vektor absolútnych hodnôt ca = (c0, |c1|, . . . , |cN−1|) spektra procesu nazývame am-plitúdové spektrum procesu.Vektor α = (α0, α1, . . . , αN−1) uhlov αk spektra procesu, kde ck = |ck| ej αk nazývamefázové spektrum procesu.Poznámka:Koeficient c0 má vždy reálnu hodnotu. V amplitúdovom spektre môže ako jediný na-dobudnúť aj zápornú hodnotu. Zodpovedajúci uhol fázového spektra α0 má hodnotu0. Koeficient c0 je koeficient bázového vektora h0 =
(. . . , ej
2πN 0·k, . . .
)= (1, 1, . . . , 1).
Príslušný výpočet je
c0 =⟨f ,h0⟩⟨h0,h0⟩
=
N−1∑k=1
fk
N−1∑k=1
1
=1
N
N−1∑k=1
fk
Posledný vzťah je aritmetický priemer hodnôt procesu f , preto je koeficient c0 nazý-vaný stredná hodnota procesu.

5.3. Diskrétna Fourierova transformácia (DFT) 105
Úloha 5.3.1 Ak by sme v amplitúdovom spektre požadovali kladnú hodnotu zápornéhokoeficientu c0, zmenila by sa jeho fáza α0. Akú hodnotu by mala táto fáza?
Tvrdenie 5.3.1 Pre spektrálne koeficienty procesu podobne ako pre vektory harmo-nickej bázy platí, že
cn = cN−n
Dôkaz:
cn =⟨f ,hn⟩⟨hn,hn⟩
=1
N
N−1∑k=0
fk e− j 2πN nk
cN−n =⟨f ,hN−n⟩
⟨hN−n,hN−n⟩=
1
N
N−1∑k=0
fk e− j 2πN (N−n) k =
=1
N
N−1∑k=0
fk e− j 2πN N k e− j 2π
N (−n) k =1
N
N−1∑k=0
fk ej2πN nk =
1
N
N−1∑k=0
fk e− j 2πN nk
Tvrdenie 5.3.2 Pre amplitúdové spektrum procesu platí |cn| = |cN−n|.
Dôkaz:Podľa tvrdenia 5.3.1 platí cn = cN−n.
|cn| =√(Recn)2 + (Imcn)2 =
√(Recn)2 + (−Imcn)2 = |cn|
Amplitúdové spektrum je symetrické (podľa osi) tak, ako to vidno na obrázku 5.14.
Obr. 5.14. Amplitúdové spektrum je osovo symetrické (okrem hodnoty c0)
Tvrdenie 5.3.3 Pre fázové spektrum procesu platí αn = −αN−n
Dôkaz:Podľa tvrdenia 5.3.1 platí cn = cN−n. Odtiaľ už priamo vyplýva
αn = −αN−n

106 Kapitola 5. Periodické vlastnosti procesov
Obr. 5.15. Fázové spektrum je bodovo symetrické (okrem hodnoty α0)
Fázové spektrum je symetrické (podľa stredu) tak, ako to vidno na obrázku 5.15. Pomocou spektrálnych koeficientov je možné vypočítať veľkosť procesu tak, ako touvádza nasledujúce tvrdenie.
Tvrdenie 5.3.4 (Veľkosť procesu) Je daný proces f s nameranými hodnotami f =(f0, f1, . . . , fN−1), nech jeho spektrum v harmonickej báze je c = (c0, c1, . . . , cN−1).Potom platí
∥f∥2 = N ·N−1∑n=0
|cn|2
Dôkaz:Dosaďme za f jeho rozklad do harmonickej bázy.
∥f∥2 = (f , f) =
(N−1∑n=0
cnhn,N−1∑m=0
cmhm
)=
N−1∑n=0
N−1∑m=0
cn · cm (hn,hm)︸ ︷︷ ︸=0 (pre n=m)
=
=
N−1∑n=0
|cn|2 (hn,hn) = N ·N−1∑n=0
|cn|2
Vlastnosti z tvrdení 5.3.1, 5.3.2 a 5.3.3 znamenajú, že na presné určenie spektraprocesu (= koeficientov procesu v harmonickej báze) stačí vypočítať polovicu koefi-cientov. Ostatné je možné určiť, pretože sú komplexne združené k už vypočítanýmkoeficientom. V každom z koeficientov sú však uložené dve informácie o bázovomvektore. Jeho amplitúda a posun. V nasledujúcej kapitole uvedieme, ako analyzovaťproces pomocou jeho koeficientov v harmonickej báze.
5.4 Priemet do podpriestoru určeného DFT
Úlohy, ktoré môžeme riešiť pomocou harmonickej bázy procesu, sú napríklad:
• odhaľovanie periodických vlastností procesu (periodických trendov)

5.4. Priemet do podpriestoru určeného DFT 107
• filtrácia procesu
Úloha 5.4.1 Spomedzi všetkých M -rozmerných vektorových podpriestorov, generova-ných vektormi harmonickej bázy N -rozmerného vektorového priestoru, nájdite taký, vktorom bude proces f najlepšie aproximovaný.
Označme HN harmonickú bázu N -rozmerného vektorového priestoru a HM jej M -prvkovú podmnožinu.
HM ⊂ HN
Proces f môžeme presne vyjadriť v báze HN a v báze E :
f = (f0, f1, . . . , fN−1)E = (c0, c1, . . . , cN−1)HN
Priemet procesu f do podpriestoru generovaného bázou HM označíme f :
f = (c0, c1, . . . , cN−1)HN
pričom M hodnôt spomedzi ck bude rovných pôvodným koeficientom ck a N −Mkoeficientov ck bude rovných nule. Nule budú rovné tie koeficienty, pre ktoré budevzdialenosť d (f , f) minimálna. Chceme, aby ||f − f || → min.To nastane vtedy, keď
||f − f ||2 → min
Pre priemet f platí(f − f)⊥f
Podľa Pytagorovej vety||f ||2 = ||f ||2 + ||f − f ||2
||f − f ||2 = ||f ||2 − ||f ||2 = (f , f)− (f , f) =
= N
N−1∑n=0
|cn|2 −NN−1∑n=0
|cn|2 = N
N−1∑n=0
(|cn|2 − |cn|2)→ min
Hodnota N∑N−1
n=0 (|cn|2 − |cn|2) bude minimálna, ak do bázy vyberieme tie bázovéfunkcie hn, pre ktoré sú absolútne hodnoty koeficientov |cn| čo najväčšie.Hodnota normy rozdielu ||f−f ||2 bude potom najmenšia spomedzi všetkých priemetovdo podpriestorov pozostávajúcich z rovnakého počtu vektorov harmonickej bázy.
Vektory harmonickej bázy majú komplexné hodnoty, rovnako koeficienty sú kom-plexné čísla. Vo všeobecnosti môže byť ich lineárna kombinácia vektor s hodnotami,ktoré nie sú reálne čísla. Ukážeme, že môžeme vybrať vektory z harmonickej bázya im zodpovedajúce koeficienty tak, aby ich lineárna kombinácia bol reálny vektor.Ukázali sme už, že pre vektory a koeficienty harmonickej bázy platí
hn = hN−n a cn = cN−n
Tvrdenie 5.4.1 Súčet cnhn + cN−nhN−n je reálny a navyše platí
cnhn + cN−nhN−n = 2Imcn cos(2π
Nnt)− 2Recn sin(
2π
Nnt) (5.4.1)

108 Kapitola 5. Periodické vlastnosti procesov
Dôkaz:Vypočítajme k-tu zložku vektora cnhn + cN−nhN−n:
(cnhn + cN−nhN−n)k = (cnhn + cnhn)k =
= (Recn+ j Imcn) · ej2πN n·k +(Recn − j Imcn) · e− j 2π
N n·k =
= (Recn+ j Imcn) · (cos(2π
Nn · k) + j sin(
2π
Nn · k))+
+(Recn − j Imcn) · (cos(−2π
Nn · k) + j sin(−2π
Nn · k)) =
= 2Recn cos(2π
Nn · k)− 2Imcn sin(
2π
Nn · k)
Odvodená rovnosť je vlastne k-ta zložka vzťahu (5.4.1). Poznámka:Riešili sme úlohu nájsť priemet procesu do podpriestoru HM , ktorý obsahuje vopreddaný počet vektorov M . V skutočnosti sa to dá iba v prípade, že M je také číslo(podľa potreby párne, alebo nepárne), že sa do bázy dá spolu s vektorom hn zobraťaj vektor hN−n, ktorý je s ním komplexne združený. Iba vtedy dostaneme ako súčetreálny vektor.
Úloha 5.4.2 V N -rozmernom priestore, kde N = 8 chceme urobiť priemet do M -rozmerného podpriestoru generovaného vektormi harmonickej bázy. Určite, aké hod-noty môže mať číslo M .
Príklad 5.4.1 Hodnoty procesu f v časoch t = (0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11) sú f =(1, 2, 4, 2, 5, 6, 3, 5, 7, 4, 6, 8). Analyzujte tento proces pomocou Fourierovej transformá-cie a nájdite dominantnú periódu tohto procesu.
Z procesu odstránime lineárnu časovú závislosť reprezentovanú funkciou
φ(tk) = c0 + c1 · tk
ako priemet 12-rozmerného vektora f do dvojrozmerného vektorového priestoru gene-rovaného bázou B2 = b0,b1, kde
b0 = (1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1),
b1 = (0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11).
Proces, ktorý ostal po odčítaní lineárneho trendu je na obrázku 5.16. Má hodnoty
g = (− 0.82,−0.29, 1.23,−1.23, 1.29, 1.82,− 1.65,−0.12, 1.40,−2.07,−0.54, 0.99)
Spektrum procesu g v harmonickej báze jec = (0,−0.09− 0.22 j, 0.03 + 0.1 j, 0.24 + 0.01 j,−0.72 + 0.37 j, 0.06 + 0.02 j, 0.15,0.06− 0.02 j,−0.72− 0.37 j, 0.24− 0.01 j, 0.03− 0.1 j,−0.09 + 0.22 j).

5.4. Priemet do podpriestoru určeného DFT 109
Obr. 5.16: Pôvodný proces f , jeho priemet do dvojrozmerného podpriestoru f , procesg je proces f po odstránení lineárneho trendu
Obr. 5.17. Amplitúdové spektrum procesu g

110 Kapitola 5. Periodické vlastnosti procesov
Amplitúdové spektrum procesu g je|c| = (0, 0.23, 0.1, 0.24, 0.81, 0.06, 0.15, 0.06, 0.81, 0.24, 0.1, 0.23).
Ak proces g vyjadríme v harmonickej báze, dostaneme presne hodnoty procesu:
g = c0h0 + c1h1 + c2h2 + c3h3 + c4h4 + c5h5 + c6h6 + · · ·+ c10h10 + c11h11
0 2 4 6 8 10 11
0
Obr. 5.18: Hodnoty procesu g a lineárna kombinácia všetkých vektorov harmonickejbázy, vykreslená ako spojitá funkcia času
Ak proces g odhadneme pomocou priemetu do dvojrozmerného podpriestoru, do-stávame postupne aproximácie zobrazené v obrázkoch 5.19–5.21:
0 2 4 6 8 10 11
0
−2 0 2 4 6 8 10 11
0
Obr. 5.19: Hodnoty procesu g a lineárna kombinácia vektorov h1,h11 (chyba 4.21);lineárna kombinácia vektorov h2,h10 (chyba 4.34)
Vidíme, že spomedzi jedno až dvojrozmerných vektorových priestorov je proces gnajlepšie aproximovaný v priestore generovanom bázou B2 = h4,h8. Perióda, ktorúmajú bázové funkcie h4,h8 je teda dominantnou periódou procesu g.Dominantná perióda zodpovedá dominantnej frekvencii 4
N s uhlom ω = 2πN 4 = 2π
12 4 =2π12 4 = 2π
3 . Dĺžka periódy je potom 2πω , čo zodpovedá N
4 = 3 hodnotám procesu g.Porovnajme ešte súčet c5h5 + c7h7 so súčinom c6h6. Na obrázku 5.22 vidíme, že
hoci |c5| = 0.1527 je viac ako dvojnásobok hodnoty |c6| = 0.0626, ich príspevky majútakmer rovnakú amplitúdu.

5.4. Priemet do podpriestoru určeného DFT 111
0 2 4 6 8 10 11
0
0 2 4 6 8 10 11
0
Obr. 5.20: Hodnoty procesu g a lineárna kombinácia vektorov h3,h9 (chyba 4.21) alineárna kombinácia vektorov h4,h8 (chyba 1.81)
0 2 4 6 8 10 11
0
0 2 4 6 8 10 11
0
Obr. 5.21: Hodnoty procesu g a lineárna kombinácia vektorov h5,h7 (chyba 4.35);násobok vektora h6 (chyba 4.33)
0 2 4 6 8 10 11
0
Obr. 5.22: Hodnoty procesu g, lineárna kombinácia vektorov b5, b7 a násobok vektorab6

112 Kapitola 5. Periodické vlastnosti procesov
Pri hľadaní najväčšej z hodnôt amplitúdového spektra budeme s ostatnými hodno-tami amplitúdového spektra porovnávať polovičnú hodnotu |cN
2|, teda budeme hľadať
najväčšiu spomedzi hodnôt
|c0|, |c1|, . . . |cN2 −1|,
1
2|cN
2|, |cN
2 +1|, . . . |cN−1|
Tvrdenie 5.4.2Nech má proces f = (f0, f1, . . . , fN−1) spektrum c = (c0, c1, . . . , cN−1). Potom tentoproces môžeme vyjadriť ako lineárnu kombináciu vektorov harmonickej bázy HN .
f =
N−1∑n=0
cn · hn (5.4.2)
Modelom tohto rozkladu je funkcia, ktorá je lineárnou kombináciou funkcií sínus akosínus. Hodnota ⌊N2 ⌋ je dolná celá časť podielu N
2 a časy tk = k.
φ(k) = c0 +
⌊N2 ⌋∑
n=1
(2Recn cos
(2π n
Nk
)− 2 Imcn sin
(2π n
Nk
))(5.4.3)
Funkcia φ(k) sa dá vyjadriť aj ako lineárna kombinácia funkcií kosínus, posunutýcho fázu určenú fázovým spektrom.
φ(k) = c0 +
⌊N2 ⌋∑
n=1
2|cn| cos(2π n
Nk + αn
)(5.4.4)
Dôkaz:Vzťah (5.4.2) je vlastne spätná Fourierova transformácia.Vzťah (5.4.3) vznikne dosadením rovnosti (5.4.1) pre fk = φ(k) do vzťahu (5.4.2).Úpravou vzťahu (5.4.3) dostaneme vzťah (5.4.4).
φ(k) = c0 +
⌊N2 ⌋∑
n=1
(2Recn cos
(2π n
Nk
)− 2 Imcn sin
(2π n
Nk
))=
= c0 +
⌊N2 ⌋∑
n=1
2Recn|cn|
Recn
cosαn︷ ︸︸ ︷Recn|cn|
cos
(2π n
Nk
)−
−2 Imcn|cn|
ImcnImcn|cn|︸ ︷︷ ︸sinαn
sin
(2π n
Nk
) =

5.4. Priemet do podpriestoru určeného DFT 113
= c0 +
⌊N2 ⌋∑
n=1
2 |cn|(cosαn cos
(2π n
Nk
)− sinαn sin
(2π n
Nk
))=
= c0 +
⌊N2 ⌋∑
n=1
2|cn| cos(2π n
Nk + αn
)V poslednom kroku sme použili goniometrický súčtový vzorec:
cosα · cosβ − sinα · sinβ = cos(α+ β)
Úloha 5.4.3 Navrhnite tvar vzorcov pre diskrétnu Fourierovu transformáciu pre pro-ces f = (f0, f1, . . . , fN−1), ktorého hodnoty sú namerané v ekvidištančných časovýchintervaloch
t = (t0, t1, . . . , tN−1) = (t0, t0 +∆t, . . . , t0 + (N − 1)∆t)
Úloha 5.4.4 Navrhnite tvar vzorcov pre diskrétnu Fourierovu transformáciu pre pro-ces f = (f0, f1, . . . , fN−1), ktorého hodnoty sú namerané v neekvidištančných časovýchintervaloch
t = (t0, t1, . . . , tN−1)
Príklad 5.4.2 Proces f = (1,−2, 4, 2,−4, 0, 1,−1, 1, 2) aproximujte postupne v zväč-šujúcich sa podpriestoroch Sn určených podmnožinami harmonickej bázy 10-rozmernéhovektorového priestoru.
Riešenie:Vypočítajme spektrum procesu f v harmonickej báze H10.
c = (0.4, 0.47− 0.04 j,−0.48− 0.1 j,−0.32 + 1.21 j, 0.53− 0.06 j,
0.2, 0.53 + 0.06 j,−0.32− 1.21 j,−0.48 + 0.1 j, 0.47 + 0.04 j)
Amplitúdové spektrum procesu f je
ca = (|c0|, |c1|, . . . , |c9|) = (0.4, 0.47, 0.49, 1.25, 0.53, 0.2, 0.53, 1.25, 0.49, 0.47)
Fázové spektrum procesu f je
α = (α0, α1, . . . , α9) = (0,−0.09,−2.95, 1.83,−0.11, 0, 0.11,−1.83, 2.95, 0.09)
Do bázy vyberieme vektory ktoré zodpovedajú najväčším hodnotám amplitúdovéhospektra, teda postupne hodnotám |c3|, |c4|, |c2|, |c1|, |c0| a |c5|.
Na obrázku 5.23 je aproximácia procesu f procesom f1 ∈ S1, ktorý je generovanýbázou B1 = h3,h7. Veľkosť chyby odhadu je e1 = ∥f − f1∥ = 4.1.
Na obrázku 5.24 je aproximácia procesu f procesom f2 ∈ S2, ktorý je generovanýbázou B2 = h3,h7,h4,h6. Veľkosť chyby odhadu je e2 = ∥f − f2∥ = 3.34.

114 Kapitola 5. Periodické vlastnosti procesov
0 1 2 3 4 5 6 7 8 9
−4
−3
−2
−1
0
1
2
3
4
Obr. 5.23. Aproximácia procesu f krivkou φ1(tk) = 2.5 cos (1.89 tk + 1.83)
0 1 2 3 4 5 6 7 8 9
−4
−3
−2
−1
0
1
2
3
4
Obr. 5.24: Aproximácia procesu f krivkou φ2(tk) = 2.5 cos (1.89tk + 1.83) +1.06 cos (2.51tk − 0.11)

5.4. Priemet do podpriestoru určeného DFT 115
0 1 2 3 4 5 6 7 8 9−4
−3
−2
−1
0
1
2
3
4
5
Obr. 5.25: Aproximácia procesu f krivkou φ3(tk) = 2.5 cos (1.89tk + 1.83) +1.06 cos (2.51 · tk − 0.11) + 0.98 cos (1.26 tk − 2.95)
0 1 2 3 4 5 6 7 8 9−5
−4
−3
−2
−1
0
1
2
3
4
5
Obr. 5.26: Aproximácia procesu f krivkou φ4(tk) = 2.5 cos (1.89tk + 1.83) +1.06 cos (2.51 · tk − 0.11) + 0.98 cos (1.26 tk − 2.95) + 0.93 cos (0.63 tk − 0.09)

116 Kapitola 5. Periodické vlastnosti procesov
Na obrázku 5.25 je aproximácia procesu f procesom f3 ∈ S3, ktorý je generovanýbázou B3 = h3,h7,h4,h6,h2,h8. Veľkosť chyby odhadu je e3 = ∥f − f3∥ = 2.53.
Na obrázku 5.26 je aproximácia procesu f procesom f4 ∈ S4, ktorý je generovanýbázou B4 = h3,h7,h4,h6,h2,h8,h1,h9. Veľkosť chyby odhadu je e4 = ∥f − f4∥ =1.41.
Na obrázku 5.27 je aproximácia procesu f procesom f5 ∈ S5, ktorý je generovanýbázou B5 = h3,h7,h4,h6,h2,h8,h1,h9,h0. Veľkosť chyby odhadu je e5 = ∥f −f5∥ = 0.63.
0 1 2 3 4 5 6 7 8 9
−4
−3
−2
−1
0
1
2
3
4
Obr. 5.27: Aproximácia procesu f krivkou φ5(tk) = 2.5 cos (1.89tk + 1.83) +1.06 cos (2.51 · tk − 0.11) + 0.98 cos (1.26 tk − 2.95) + 0.93 cos (0.63 tk − 0.09) + 0.4
Na obrázku 5.28 je aproximácia procesu f procesom f6 ∈ S6, ktorý je generovanýbázou B6 = h3,h7,h4,h6,h2,h8,h1,h9,h0,h5. Veľkosť chyby odhadu je e6 = ∥f −f6∥ = 0.
Posledná aproximácia f6 ∈ S6 je vektorom pôvodného 10-rozmerného priestoru,preto f6 = f a chyba aproximácie je 0.
Príklad 5.4.3 Aproximujte proces f = (12,−1,−6,−2,−10,−13, 1, 5, 2, 10) z prí-kladu 5.1.1 regresnou krivkou tvaru φ(tk) = c0tk+α0)+ c1cos(ω1 tk+α1). Pri riešenípoužite riešení použite diskrétnu Fourierovu transformáciu.
Riešenie:Vypočítajme spektrum procesu f v harmonickej báze H10.
c = (c0, c1, . . . , c9) = (−0.2, 3.74 + 2.72 j,−0.02 + 0.06 j, 2.51 + 1.21 j,
− 0.13− 0.1 j,0,−0.13 + 0.1 j, 2.51− 1.21 j,−0.02− 0.06 j, 3.74− 2.72 j)
Amplitúdové spektrum procesu f je
ca = (|c0|, |c1|, . . . , |c9|) = (−0.2, 4.62, 0.06, 2.79, 0.16, 0, 0.16, 2.79, 0.06, 4.62)

5.4. Priemet do podpriestoru určeného DFT 117
0 1 2 3 4 5 6 7 8 9−4
−3
−2
−1
0
1
2
3
4
5
6
Obr. 5.28: Aproximácia procesu f krivkou φ6(tk) = 2.5 cos (1.89tk + 1.83) +1.06 cos (2.51 · tk − 0.11) + 0.98 cos (1.26 tk − 2.95) + 0.93 cos (0.63 tk − 0.09) + 0.4 +0.2 cos (3.14 tk)
Fázové spektrum procesu f je
α = (α0, α1, . . . , α9) = (0, 0.63, 1.88, 0.45,−2.51, 0, 2.51,−0.45,−1.88,−0.63)
Do bázy vyberieme vektory s najväčšími hodnotami amplitúdového spektra, teda h1,h9, h3 a h7.
f = c1 · h1 + c9 · h9 + c3 · h3 + c7 · h7 = (12.5,−1,−5.5,−2,−10,−12.5, 1, 5.5, 2, 10)
Chyba odhadu je∥f − f∥ = 1
Zodpovedajúca funkcia času je
φ(tk) = 2 · |c1| cos(2π 1
10tk + α1
)+ 2 · |c3| cos
(2π 3
10tk + α3
)=
= 9.24 cos (0.63 tk + 0.63) + 5.58 cos (1.89 tk + 0.45)
Odhad je súčtom dvoch funkcií kosínus, ktoré sú zobrazené na obrázku 5.29. Odhadje zobrazený na nasledujúcom obrázku 5.30.
Jednu z funkcií kosínus prerobíme na funkciu sínus posunutím o fázu π2 .
Výsledná funkcia má tvar
φ(tk) = 9.24 sin(0.63 · tk + 0.63 +
π
2
)+ 5.58 cos (1.89 tk + 0.45) =
9.24 sin (0.63 tk + 0.22) + 5.58 cos (1.89 tk + 0.45)
Chyba odhadu je ∥e5∥ = 1.
Úloha 5.4.5 Popíšte čo znamená slovo "diskrétna" v pojme diskrétna Fourierovatransformácia. (Okrem diskrétnej Fourierovej transformácie je používaná ešte spojitáFourierova transformácia.)

118 Kapitola 5. Periodické vlastnosti procesov
0 1 2 3 4 5 6 7 8 9
0
Obr. 5.29: Aproximácia procesu f krivkou φ1(tk) = 9.24 cos (0.63 tk + 0.22) a φ2(tk) =5.58 cos (1.89 tk + 0.45)
0 1 2 3 4 5 6 7 8 9
0
Obr. 5.30: Aproximácia procesu f krivkou φ(tk) = 9.24 sin (0.63 tk + 0.22) +5.58 cos (1.89 tk + 0.45)

5.5. Walsh-Hadamardova báza 119
5.5 Walsh-Hadamardova báza
Fourierova báza nie je jediná báza, ktorou sa dajú popísať periodické vlastnosti pro-cesu. Inou diskrétnou bázou, ktorá popisuje periodické chovanie procesu je napríkladWalsh-Hadamardova báza. Táto báza je zložená len z vektorov, ktorých hodnotysú 1 alebo -1.
Návod na generovanie Walsh-Hadamardovej bázy je nasledujúci.Vytvoríme n-tú Hadamardovu maticu podľa predpisu:
H0 = (1)
H2n =
H2n−1 H2n−1
H2n−1 −H2n−1
(5.5.1)
Riadky Hadamardovej matice H2n sú vektory Walsh-Hadamardovej bázy 2n-rozmernéhopriestoru.
Príklad 5.5.1 Vyjadrite Hadamardove matice H0, H2, H4 a H8.
Riešenie:Podľa predpisu (5.5.1) budú Hadamardove matice postupne
H0 = (1) H2 =
1 1
1 −1
H4 =
1 1 1 1
1 −1 1 −1
1 1 −1 −1
1 −1 −1 1
H8 =
1 1 1 1 1 1 1 1
1 −1 1 −1 1 −1 1 −1
1 1 −1 −1 1 1 −1 −1
1 −1 −1 1 1 −1 −1 1
1 1 1 1 −1 −1 −1 −1
1 −1 1 −1 −1 1 −1 1
1 1 −1 −1 −1 −1 1 1
1 −1 −1 1 −1 1 1 −1

120 Kapitola 5. Periodické vlastnosti procesov
Úloha 5.5.1 Napíšte desiaty riadok Hadamardovej matice H16.
Úloha 5.5.2 Dokážte, že Walsh-Hadamardova báza 8-rozmerného vektorového prie-storu je ortogonálna a každý jej vektor má veľkosť
√8.
Vektor koeficientov c sa nazýva spektrum procesu vo Walsh-Hadamardovej báze.
c = (c0, c1, . . . , cN−1)
Vektor absolútnych hodnôt ca = (|c0|, |c1|, . . . , |cN−1|) spektra procesu sa nazývaamplitúdové spektrum procesu.
Úloha 5.5.3 Spomedzi všetkých M -rozmerných podpriestorov, generovaných vektormiWalsh-Hadamardovej bázy, najlepšia aproximácia pôvodného procesu bude v podpries-tore, v ktorom sa nachádzajú vektory s najväčšími hodnotami amplitúdového spektrapôvodného procesu. Dokážte toto tvrdenie.
Príklad 5.5.2 Napíšte Walsh-Hadamardovu bázu 8-rozmerného vektorového priestorua vyjadrite v tejto báze koeficienty procesu
f = (12,−1,−6,−2,−10,−13, 1, 5)
Čo najlepšie aproximujte proces f v trojrozmernom podpriestore 8-rozmerného eukli-dovského priestoru generovaného vektormi Walsh-Hadamardovej bázy.
Riešenie:
W8 = (1, 1, 1, 1, 1, 1, 1, 1), (1,−1, 1,−1, 1,−1, 1,−1),(1, 1,−1,−1, 1, 1,−1,−1), (1,−1,−1, 1, 1,−1,−1, 1),(1, 1, 1, 1,−1,−1,−1,−1), (1,−1, 1,−1,−1, 1,−1, 1),(1, 1,−1,−1,−1,−1, 1, 1), (1,−1,−1, 1,−1, 1, 1,−1)
Spektrum procesu f v báze W8 je
c = (−1.75, 1,−1.25, 3, 2.5, 1.25, 6, 1.25)
Najlepšou aproximáciou procesu f v jednorozmernom podpriestore generovanom vek-torom Walsh-Hadamardovej bázy je vektor
c6 wh6 = 6 (1, 1,−1,−1,−1,−1, 1, 1) = (6, 6,−6,−6,−6,−6, 6, 6)
Veľkosť chyby tejto aproximácie je ∥e6∥ = 13.86 a pôvodný vektor a jeho aproximáciasú znázornené na obrázku 5.31
Najlepšou aproximáciou procesu f v dvojrozmernom podpriestore generovanomdvomi vektormi Walsh-Hadamardovej bázy je vektor
c3 wh3 + c6 wh6 =3 (1,−1,−1, 1, 1,−1,−1, 1) + 6 (1, 1,−1,−1,−1,−1, 1, 1) ==(9, 3,−9,−3,−3,−9, 3, 9)

5.5. Walsh-Hadamardova báza 121
0 1 2 3 4 5 6 7−15
−5
0
5
15
Obr. 5.31: Aproximácia procesu f v jednorozmernom podpriestore, procesom c6 wh6
0 1 2 3 4 5 6 7−15
−5
0
5
15
Obr. 5.32: Aproximácia procesu f v dvojrozmernom podpriestore procesom c6 wh6 +c3 wh3 a vektor c3 wh3

122 Kapitola 5. Periodické vlastnosti procesov
Veľkosť chyby tejto aproximácie je ∥e36∥ = 10.96 a pôvodný vektor a jeho aproximáciasú znázornené na obrázku 5.32
Najlepšou aproximáciou procesu f v trojrozmernom podpriestore generovanomtromi vektormi Walsh-Hadamardovej bázy je vektor
c3 wh3 + c4 wh4 + c6 wh6 =3 (1,−1,−1, 1, 1,−1,−1, 1)++2.5 (1, 1, 1, 1,−1,−1,−1,−1)++6 (1, 1,−1,−1,−1,−1, 1, 1)+=(11.5, 5.5,−6.5,−0.5,−5.5,−11.5, 0.5, 6.5)
Veľkosť chyby tejto aproximácie je ∥e346∥ = 8.37 a pôvodný vektor a jeho aproximáciasú znázornené na obrázku 5.33
0 1 2 3 4 5 6 7−15
−10
−5
0
5
10
15
Obr. 5.33: Aproximácia procesu f v trojrozmernom podpriestore procesom c6 wh6 +c3 wh3 + c4 wh4 a vektor c4 wh4

5.6. Použitie Fourierovej transformácie v praxi 123
Poznámka:Metódou priemetu vektora do podpriestoru sme riešili tri úlohy: lineárnu regresiu,kĺzavý priemer a diskrétnu Fourierovu transformáciu. Ku základnej myšlienke prie-metu sa v rôznych metódach menil spôsob výberu bázy vhodného podpriestoru.
• Lineárna regresia:Časová zákonitosť; prekladanie procesu analytickou funkciou.Hodnota v čase súvisí s hodnotami v iných časoch (je splnená podmienka li-nearity). Báza priestoru, do ktorého robíme projekciu, je tvorená vektormi, kto-rých zložky sú funkciami času.
• Kĺzavý priemer:Hodnotu procesu v čase vypočítame z hodnôt tohto procesu v "susedných časoch".Báza priestoru, do ktorého robíme projekciu, je tvorená vektormi, ktoré dosta-neme posunutím hodnôt pôvodného vektora.
• Diskrétna Fourierova transformácia alebo Walsh-Hadamardova transformácia:Harmonická aj Walsh-Hadamardova báza sú dopredu dané a podpriestor vybe-rieme až po spočítaní koeficientov v tejto báze. Vyberieme tie bázové vektory,ktorých koeficienty majú najväčšiu absolútnu hodnotu.
5.6 Použitie Fourierovej transformácie v praxi
Diskrétna Fourierova transformácia našla široké použitie v praxi. Pri spracovaní obra-zu sa používa jej variant, diskrétna kosínusová transformácia, pri kompresii formátuJPEG. V spracovaní zvuku je Fourierova transformácia štandardným nástrojom priodhade spektra zvuku, čo je nevyhnutný krok pri jeho digitálnom spracovaní ako ajnapríklad pri rozpoznávaní reči.
Dôležitým problémom pri praktickom použití Fourierovej transformácie je jej rýchlyvýpočet. Fourierova transformácia spočíva v podstate vo vynásobení vektora fixnouštvorcovou maticou n×n. Takýto výpočet vo všeobecnosti nemožno spraviť podstatnerýchlejšie než s pomocou n2 operácií.
Cooley a Tukey [5] prišli na to, ako rýchlo počítať Fourierovu transformáciu vprípade, že n je presná mocnina 2 (napríklad 256). V tomto prípade na výpočet stačílen ∼ n log n operácií. Tento algoritmus sa nazýva Fast Fourier Transform (FFT), abol známy už aj Gaussovi.
V súčasnosti poznáme veľa druhov Fourierovych transformácií [24], [7], a sú známeaj rýchle algoritmy, keď n je prvočíslo [14]. Najnovšie prebieha výskum algoritmov,ktoré počítajú Fourierovu transformáciu signálov s malým počtom nenulových spek-trálnych koeficientov [9].

124 Kapitola 5. Periodické vlastnosti procesov

6 Analýza viacrozmerných objektov
V tejto kapitole si ukážeme metódy, ktoré sa používajú na analýzu štruktúry mnoho-rozmerných dát. Ako jednoduchý príklad použitia môžeme uviesť charakterové kvízy včasopisoch. V nich je séria 10-30 otázok s rôzne obodovanými hodnoteniami. Po zodpo-vedaní kvízu a sčítaní bodov získate hodnotenie nejakej ľudskej vlastnosti, napríkladkreativity, impulzívnosti, rozhodnosti a podobne. V tomto prípade ide o zobrazenievektora odpovedí r na číselné hodnotenie pomocou váhového vektora w
hodnotenie charakteristiky = w · r
V iných prípadoch analýzy viacrozmerných dát nám jedno číselné hodnotenie ne-postačuje. Aby sme pochopili štruktúru dát, môžeme sa pokúsiť vypočítať dve hod-notenia
hodnotenie prvej charakteristiky = w1 · rhodnotenie druhej charakteristiky = w2 · r
a nakresliť si rozloženie týchto charakteristík do dvojrozmerného obrázka, ktorý uka-zuje dvojrozmerný náhľad do vysoko rozmerných dát.
hodnotenie1
hodn
oten
ie2
fonémaaaaodcliysh
Obr. 6.1. Zobrazenie spektier anglických foném pomocou dvoch lineárnych funkcií
125

126 Kapitola 6. Analýza viacrozmerných objektov
Znižovanie dimenzií sa často používa pri rozdelení dát na skupiny, ako je to po-trebné napríklad pri rozpoznávaní reči. Príklad takého zníženia dimenzií pomocoulineárnych funkcií je znázornený na obrázku 6.1. Pomocou tohto zobrazenia do rovinyzískavame intuíciu o tom, ako sú vektory rozložené vo vysokorozmernom priestore,ktorý si nevieme predstaviť.
6.1 Dôležité súradnice
Úloha, ktorou sa budeme zaoberať je zjednodušenie popisu skupiny viacrozmernýchdátových vektorov tým spôsobom, že sa urobí ich lineárna transformácia. Touto trans-formáciou získame informáciu o tých súradniciach, v ktorých sa vektory najviac líšia.Na ilustráciu načrtnutej myšlienky uvedieme nasledujúci príklad.
Príklad 6.1.1 Zákazník si chce vybrať spomedzi 3 mobilných telefónov. Parametre,podľa ktorých sa rozhoduje sú cena, výdrž baterky, veľkosť pamäte a váha mobilu.Hodnoty parametrov pre jednotlivé mobily sú v tabuľke 6.1.
cena baterka pamäť váhaM1 3700 81 400 40M2 3700 82 200 20M3 3700 81 500 50
Tab. 6.1. Cena, výdrž baterky, pamäť a váha troch mobilných telefónov
Zákazník sa chce rozhodnúť pre kúpu telefónu len podľa jedného parametra. Ktorý zparametrov si má pre svoje rozhodovanie vybrať?
Riešenie:Riešenie úlohy vidno už z prvého pohľadu na tabuľku. Na cene nezáleží, pretože sa vnej telefóny nelíšia. Podobne je to s výdržou baterky, tu sú síce rozdiely, ale sú veľmimalé. Podľa prvých dvoch parametrov sa rozhodnúť nedá. Tretí a štvrtý parameteruž majú telefóny rozdielne. Stačí však uvažovať iba jeden z nich, lebo druhý je jehonásobkom. Na rozlíšenie medzi telefónmi stačí zákazníkovi uvažovať napríklad váhumobilu (posledný parameter).
V príklade 6.1.1 sme riešili úlohu nájsť také premenné, ktoré najlepšie odlíšiaviacrozmerné dáta. Našli sme zjednodušenie, ktoré nám umožní zoradiť jednotlivéviacrozmerné dáta podľa jedného parametra.
V nasledujúcom príklade ukážeme ako sa dajú zmeniť viacrozmerné dáta na pre-hľadnejšie.
Príklad 6.1.2 Referenti študijného oddelenia vysokej školy sa rozhodli urobiť rebrí-ček úspešnosti študentov bakalárskeho stupňa. Ako kritérium si zvolili body za známkyzískané počas štúdia, ktoré sú uvedené v tabuľke 6.2. Najlepšie je hodnotenie 5, naj-horšie je hodnotenie 1.Ako usporiadať študentov podľa študijných výsledkov?

6.1. Dôležité súradnice 127
P1 P2 P3 P4 P5 P6 P7 P8 P9
S1 1 2 3 4 5 3 2 4 1S2 3 2 3 2 3 2 3 4 1S3 1 1 2 3 2 3 1 1 2S4 2 1 4 4 4 3 2 1 2S5 3 1 3 2 1 1 1 3 1S6 2 1 2 5 4 2 2 5 2S7 1 2 4 3 4 2 2 4 1S8 2 2 1 5 2 2 2 5 4S9 2 2 2 3 2 2 1 1 1S10 2 1 2 3 1 3 2 5 5S11 1 2 2 4 3 2 4 3 4
Tab. 6.2. Body 11 študentov z 9 predmetov
Riešenie:Riešenie úlohy už nie je také evidentné ako v predchádzajúcom prípade. Načrtnutiegrafov výsledkov jednotlivých študentov neurobí úlohu prehľadnejšou, ako to vidnona obrázku 6.2.
Zo školskej praxe samozrejme každý vie, že školské výsledky možno sumarizovaťaj jediným číslom, ich aritmetickým priemerom. Hodnotenie reprezentované aritme-tickým priemerom bude prehľadnejšie a študentov môžeme jednoducho usporiadať.Nevýhodou tohto postupu je, že aritmetický priemer nevypovedá o úspešnosti štu-denta príliš presne. V našom prípade sú aritmetické priemery jednotlivých študentovčasto zhodné, ako vidíme v tabuľke 6.3.
S1 S2 S3 S4 S5 S6 S7 S8 S9 S10 S11
2.27 2.09 1.45 2.09 1.45 2.27 2.09 2.27 1.45 2.27 2.27
Tab. 6.3. Priemerné hodnotenie 11 študentov
Aritmetickým priemerom sme teda dosiahli rozdelenie študentov na 3 skupiny
A1 = S3, S5, S9, A2 = S2, S4, S7 A3 = S1, S6, S8, S10, S11
Študentov z jednotlivých skupín A1, A2, A3 už nedokážeme rozlíšiť. Zo skúsenostivšak vieme, že rovnaký priemerný výsledok môžu dosiahnuť aj veľmi rozdielne úspešníštudenti, respektíve študenti pri rôznom pracovnom výkone.
Predstavme si, že potrebujeme podstatne jemnejšie usporiadanie študentov podľaich výsledkov. S riešením nám znovu pomôže bežná prax na vysokých školách, kdesa na ohodnotenie výsledkov štúdia používa takzvaný vážený priemer, ktorým zvý-šime význam náročnejších predmetov a potlačíme jednoduchšie predmety, ktoré odštudenta vyžadujú menej učenia sa. Predpokladajme, že úlohu riešime na technickejVŠ a z rozloženia úspešnosti v jednotlivých predmetoch vidíme, že predmet P2 je

128 Kapitola 6. Analýza viacrozmerných objektov
1 2 3 4 5 6 7 8 9
1
2
3
4
5
Obr. 6.2. Hodnotenie znázornené graficky
zrejme matematika a predmet P4 je telesná výchova. Študijné oddelenie teda zvýšiváhu predmetu P2 tak, že výsledky tohto predmetu vynásobí dvomi a zníži váhu pred-metu P4 tak, že výsledky tohto predmetu vydelí dvomi. Po takejto úprave je možnérozlíšiť študentov presnejšie, ako vidíme v tabuľke 6.4.
S1 S2 S3 S4 S5 S6 S7 S8 S9 S10 S11
2.78 2.67 1.72 2.44 1.78 2.61 2.61 2.72 1.83 2.72 2.78
Tab. 6.4. Vážené priemerné hodnotenie 11 študentov
Váženým aritmetickým priemerom sme dosiahli rozloženie študentov podľa prospechuna 8 skupín
A1 = S3, A2 = S5, A3 = S9, A4 = S4, A5 = S6, S7,
A6 = S2, A7 = S8, S10, A8 = S1, S11
Študentov z jednotlivých skupín A5, A7 a A8 nedokážeme rozlíšiť, ale študenti súusporiadaní lepšie ako v predchádzajúcom prípade.
Znovu, ale prehovorí skúsenosť zo škôl, že váha predmetu sa môže zmeniť (skúšaprísnejší učiteľ), alebo nezodpovedá náročnosti predmetu. Skúsme preto len zo zná-mych výsledkov, bez toho, aby sme vedeli o aké predmety ide, určiť také váhy jed-notlivým predmetom, že rozlíšenie študentov pomocou váženého priemeru bude čonajlepšie. Táto úloha bude témou nasledujúcej podkapitoly.

6.2. Váhové koeficienty pre maximálny rozptyl 129
6.2 Váhové koeficienty pre maximálny rozptyl
Ukázali sme, že v prípade analýzy viacrozmerných dát, môžu byť niektoré súradniceviac a niektoré menej významné. Vhodnou lineárnou kombináciou môžeme z maticedát získať sadu čísel, ktoré popisujú jednotlivé riadky matice. Tieto čísla sú dostatočnerozptýlené na to, aby sa dali pôvodné dáta od seba navzájom dobre odlíšiť.
Ukážeme ako pre dáta z príkladu 6.1.1 rozdeliť váhy medzi jednotlivé parametretelefónu tak, aby výsledné lineárne kombinácie mali čo najväčší rozptyl. Predpokla-dáme, že dáta, ktoré ideme spracovávať, sú prvkami matice M. Každý jej riadok súparametre jedného mobilného telefónu.Vektor w = (w1, w2, w3, w4) je vektor, ktorého zložky sú váhy jednotlivých paramet-rov.
Chceme, aby vektor MwT mal, čo najväčší rozptyl, teda aby sa vážené priemeryjednotlivých telefónov od seba čo najviac líšili.
MwT =
3700 81 400 403700 82 200 203700 81 500 50
wT =
3700 81 400 403700 82 200 203700 81 500 50
w1
w2
w3
w4
=
3700w1 + 81w2 + 400w3 + 40w4
3700w1 + 82w2 + 200w3 + 20w4
3700w1 + 81w2 + 500w3 + 50w4
Úloha 6.2.1 Maximalizovať rozptyl budeme tak, že budeme maximalizovať súčet vzdia-leností všetkých hodnôt od priemernej hodnoty. Pre pohodlnejšie výpočty budeme akovzdialenosť používať druhú mocninu rozdielu.
Ukážte, že rovnaký rozptyl ako vektor MwT má vektor M wT , v ktorom maticuM dostaneme z matice M tak, že od každého stĺpca odčítame jeho aritmetický priemer.
M =
0 −0.3 33.3 3.30 0.7 −166.7 −16.70 −0.3 133.3 13.3
Príklad 6.2.1 Ukážte, že aritmetický priemer každého stĺpca matice M je 0.
Riešenie:Tvrdenie vyplýva priamo z konštrukcie matice M. Súčet jedného stĺpca matice M jevlastne N -násobok jeho aritmetického priemeru. Matica M vznikne z M tak, že odkaždého prvku v stĺpci odpočítame aritmetický priemer celého stĺpca, spolu N -krát.Súčet jedného stĺpca matice M preto je:
N × aritmetický priemer−N × aritmetický priemer = 0
Preto priemer každého stĺpca bude 0. Hľadáme také w, ktoré bude maximalizovať rozptyl vektora MwT od jeho priemernejhodnoty, resp. vektora M wT od hodnoty 0.

130 Kapitola 6. Analýza viacrozmerných objektov
M wT =
0w1 − 0.3w2 + 33.3w3 + 3.3w4
0w10.67w2 − 166.67w3 − 16.67w4
0w1 − 0.33w2 + 133.33w3 + 13.33w4
Rozptyl ROZ vektora MwT okolo hodnoty 0 je
ROZ = (−0.3w2 + 33.3w3 + 3.3w4 − 0)2 + (0.67w2 − 166.67w3 − 16.67w4 − 0)2+
+(−0.33w2 + 133.33w3 + 13.33w4 − 0)2
Maticovo môžeme rozptyl ROZ zapísať ako:
ROZ = wMT M wT = (−0.3w2 + 33.3w3 + 3.3w4)2
+(0.67w2 − 166.67w3 − 16.67w4)2 + (−0.33w2 + 133.33w3 + 13.33w4)
2 (6.2.1)
Úloha 6.2.2 Ako vzdialenosť sme použili
∥v − u∥2 = (v0 − u0)2 + (v1 − u1)2 + · · ·+ (vN−1 − uN−1)2
Ukážte, že táto hodnota bude maximálna vtedy, keď bude maximálna hodnota
∥v − u∥ =√(v0 − u0)2 + (v1 − u1)2 + · · ·+ (vN−1 − uN−1)2
Vidíme, že výraz (6.2.1) dosiahne tým väčšiu hodnotu, čím je väčší vektor w, pretomusíme určiť nejakú ďalšiu podmienku, aby sme mohli hľadať maximum. Pretože vnašej úlohe vektor w reprezentoval váhové koeficienty, budeme predpokladať, že veľ-kosť tohto vektora je 1.Riešime teda úlohu, nájsť spomedzi všetkých vektorov w dĺžky 1 taký, ktorý maxi-malizuje výraz (6.2.1).
wMT M wT → max za podmienky ∥w∥ = 1
Túto úlohu môžeme riešiť metódami matematickej analýzy. Je to úloha nájsť via-zaný extrém funkcie. Riešenie pomocou Lagrangeových multiplikátorov vedie na hľa-danie extrému funkcie viac premenných tvaru
f(w) = wMT M wT − λ(wwT − 1)
Hodnoty, pre ktoré táto funkcia dosiahne maximum, musia spĺňať podmienky prestacionárne body funkcie:
∂f
∂w= 2MT M wT − 2λwT = 0
∂f
∂λ= −wwT + 1 = 0
Úpravami dostaneme rovnicu pre neznámy parameter λ a neznámy vektor w, prektorý má byť ∥w∥ = 1.

6.2. Váhové koeficienty pre maximálny rozptyl 131
MT M wT = λ wT (6.2.2)
Hľadáme taký vektor wT , že jeho vynásobenie maticou sa dá nahradiť vynáso-bením jedným číslom. Takýto vektor sa nazýva vlastný vektor matice a λ sa nazývavlastné číslo tejto matice.
Vzťah (6.2.2) môžeme zapísať v maticovom tvare:(MT M − λE
)wT = O (6.2.3)
Riešením rovnice (6.2.3) je napríklad vektor w = (0, 0, . . . , 0). Takéto riešenie alenemôžeme použiť ako váhový vektor. Hľadáme preto nenulové riešenie rovnice (6.2.3).Teda chceme, aby táto rovnica mala aspoň jedno nenulové riešenie. To nastane ibavtedy, ak matica MT M − λE bude singulárna, a teda determinant matice bude 0.
det(MT M − λE
)= 0 (6.2.4)
V našom príklade s mobilnými telefónmi dostaneme úpravami rovnice (6.2.4) rov-nicu pre neznámu hodnotu λ:
det
0− λ 0 0 00 1− λ −167 −170 −167 46667− λ 46670 −17 4667 467− λ
= 0
Vlastné čísla λ1, λ2, λ3, λ4 sú riešením rovnice
(−λ)[(1− λ)(46667− λ)(467− λ) + (−17)(−167)(4667) + (−167)(4667)(−17)
−(−17)(46667− λ)(−17)− (1− λ)(4667)(4667)− (−167)(−167)(467− λ)]= 0
Riešenia sú približne
λ1 = 0, λ2 = 0.03, λ3 = 0.64, λ4 = 47134.3
V nasledujúcej úprave nahradíme násobenie maticou násobením vlastným číslom,dosadíme wwT = ∥w∥2 = 1 a upravíme funkciu f(w):
f(w) = wMT M wT − λ(wwT − 1) = w(λ)2 wT − λ(wwT − 1) = (λ)2
Túto úvahu urobíme neskôr presnejšie, aj teraz však intuitívne vidíme, že maxi-málny rozptyl dosiahneme pre najväčšie vlastné číslo λ = 47134 a jemu zodpovedajúcivlastný vektor, ktorý vypočítame ako riešenie rovnice (6.2.3) pre konkrétnu hodnotuλ.
Vlastný vektor, zodpovedajúci vlastnému číslu λ = 47134 je vektorw = (0,−0.0036, 0.995, 0.0995). Pre najväčší rozptyl lineárnych kombinácií treba po-užiť v prípade mobilného telefónu váhové koeficienty
w1 = 0, w2 = −0.0036, w3 = 0.995, w4 = 0.0995

132 Kapitola 6. Analýza viacrozmerných objektov
cena baterka pamäť váha vážený priemerM1 3700 81 400 40 401.7M2 3700 82 200 20 200.7M3 3700 81 500 50 502.2
Tab. 6.5. Cena, pamäť, výdrž baterky, váha troch mobilných telefónov
Keby sme chceli telefóny odlíšiť iba podľa jediného parametra, bol by to tretí pa-rameter (pamäť telefónu). S týmto parametrom dosiahneme najväčšie odlíšenie medzitelefónmi.
Poznámka:Z riešenia príkladu o mobilných telefónoch je zrejmé, že najvýraznejší rozptyl dosiah-neme, keď dáme vysokú váhu tým premenným, ktoré majú veľký rozptyl a vysokéčíselné hodnoty. Ak sú číselné parametre v rôznych jednotkách, ich interpretácia môžebyť skreslená.
Lepšie výsledky dá uvedená metóda v prípade, že všetky parametre budú maťrovnaký rozsah hodnôt. Takáto situácia nastane v príklade so známkami (príklad6.1.2) .
Príklad 6.2.2 Nájdite váhové koeficienty pre najväčší rozptyl. Použite dáta z príkladu6.1.2, v ktorom sú popísané známky 11 študentov z 9 predmetov.
Riešenie:Podobne ako v predchádzajúcej úlohe vytvoríme z dát maticu nameraných hodnôt.
M =
1 2 3 4 5 3 2 4 13 2 3 2 3 2 3 4 11 1 2 3 2 3 1 1 22 1 4 4 4 3 2 1 23 1 3 2 1 1 1 3 12 1 2 5 4 2 2 5 21 2 4 3 4 2 2 4 12 2 1 5 2 2 2 5 42 2 2 3 2 2 1 1 12 1 2 3 1 3 2 5 51 2 2 4 3 2 4 3 4

6.2. Váhové koeficienty pre maximálny rozptyl 133
Z centrovanej matice M vytvoríme súčin matíc MTM:
5.64 −0.91 0.27 −3.09 −4.36 −2.45 −1 1.55 −1.64−0.91 2.73 −0.82 0.27 2.09 −0.64 2 1.36 −1.090.27 −0.82 8.55 −4.18 4.27 1.09 0 −1.91 −5.27−3.09 0.27 −4.18 10.73 5.91 1.64 2 4.64 6.09−4.36 2.09 4.27 5.91 17.64 2.55 4 1.55 −7.64−2.45 −0.64 1.09 1.64 2.55 4.18 0 −1.82 2.45−1 2 0 2 4 0 8 5 51.55 1.36 −1.91 4.64 1.55 −1.82 5 26.18 8.45−1.64 −1.09 −5.27 6.09 −7.64 2.45 5 8.45 21.64
Nájdeme vlastné čísla matice MT M:
λ1 = 0, λ2 = 0.1, λ3 = 0.17, λ4 = 0.37, λ5 = 0.66, λ6 = 0.94, λ7 = 1.8,
λ8 = 2.69, λ9 = 3.81
Nájdeme vlastný vektor zodpovedajúci najväčšiemu vlastnému číslu λ:
w = (−0.02, 0.02,−0.21, 0.28,−0.09, 0.01, 0.22, 0.66, 0.62)
Váhy jednotlivých vyučovacích predmetov, použiteľné pre vážený priemer s najväčšímrozptylom sú:
w1 = −0.02, w2 = 0.02, w3 = −0.21, w4 = 0.28, w5 = −0.09, w6 = 0.01,
w7 = 0.22, w8 = 0.66, w9 = 0.62
Vážené priemery jednotlivých riadkov matice M , resp. priemery známok pre jednot-livých študentov sú
3.8, 3.58, 2.4, 2.28, 2.63, 5.6, 3.39, 7.25, 1.76, 6.98, 5.82,
V tabuľke 6.6 je popísaný prospech študentov pomocou aritmetického priemeru (stĺpec
"priem"), váženého priemeru s odhadnutými váhami (stĺpec "vp1") a váženého prie-meru s vypočítanými váhami (stĺpec "vp2"). Výpočet váženého priemeru pomocouvlastného vektora rozptylovej matice zabezpečí nielen najväčší rozptyl, ale aj vyššiuváhu tých hodnôt, ktoré majú väčší rozptyl. Konkrétne v tomto príklade to znamená,že ak majú všetci študenti dobrú známku z telesnej výchovy, tak vo váženom prie-mere vystupuje telesná výchova s nízkym váhovým koeficientom. Naopak, ak sú zinformatiky dobré aj zlé známky, tak informatika bude mať vysoký váhový koeficient.A nakoniec, ak sú z matematiky iba zlé známky, tak matematika bude mať nízkyváhový koeficient.
Pri konkrétnom spracovaní dát treba uvážiť všetky výhody aj nevýhody použitiatejto metódy. V každom prípade však touto metódou môžeme zistiť, ktoré parametresú pre rozlíšenie dát významné a ktoré menej významné.

134 Kapitola 6. Analýza viacrozmerných objektov
Ukázali sme, ako vybrať váhové koeficienty tak, aby vážený priemer jednotlivýchskupín dát mal čo najväčší rozptyl. Zároveň sme však videli, že v prípade rôznychrozsahov jednotlivých parametrov, budú mať väčšiu váhu tie parametre, ktoré súzadané v jednotkách s väčšími hodnotami. Ak uvedieme váhu v gramoch dosiahnemeväčší rozptyl, než keď tú istú váhu uvedieme v kilogramoch.
Z uvedeného dôvodu je zrejmé, že metóda hľadania váhových koeficientov pre naj-väčší rozptyl bude dávať rozumné výsledky v tom prípade, keď budú mať rôzne para-metre rovnaký rozsah hodnôt. To je dôvod, prečo metóda dáva realistickejšie výsledkyv príklade o školskom prospechu (6.1.2). V príklade o mobilných telefónoch (6.1.2)bola parametrom "cena" a "výdrž baterky" telefónu priradená váha 0. V prípade cenyto bolo opodstatnené, nakoľko sa telefóny v cene nelíšili. V prípade parametra "výdržbaterky" by sme dostali podstatne väčší váhový koeficient, keby bol tento parameterzadaný v sekundách namiesto v minútach.
Príklad 6.2.3 Pri kúpe auta si zákazník zostavil tabuľku s hodnotením 14 paramet-rov pre 5 rôznych áut. V tabuľke si vyznačil mieru svojej spokojnosti s jednotlivýmiparametrami auta bodmi od 0 po 10.Určte váhy jednotlivých parametrov a vypočítajte vážený priemer pre mieru spokojnostipre jednotlivé autá. Ktoré z áut má pri takomto výpočte najvyššie hodnotenie?
Riešenie:K matici M predstavujúcej dáta zostrojíme centrovanú maticu M.Nájdeme vlastné čísla matice MT M. Sú to postupne čísla:
λ0 = 0, λ1 = 0, . . . , λ10 = 0, λ11 = 58, λ12 = 103.79,
λ13 = 140.18, λ14 = 200.82
K najväčšiemu vlastnému číslu λ = 200.82 prislúcha vlastný vektor
w = (0.13, 0.56, 0.23, 0.24,−0.31,−0.26, 0.32, 0.03, 0.33, 0.25, 0.18, 0.03,−0.12, 0.27)
Keď tento vektor použijeme ako váhový vektor pre hodnotenie parametrov, dostanemeiné poradie, než pri poradí áut podľa aritmetického priemeru. Z hodnôt v tabuľke 6.8vidíme, že ak usporiadame autá podľa vážených priemerov, najlepšie hodnotené jeauto a4 a najhoršie auto a3. Pri hodnotení podľa aritmetického priemeru je rovnakonajlepšie hodnotené auto a4 ale najhoršie hodnotené je auto a1.
Pri riešení príkladu 6.2.3 sme vypočítali, že matica má iba 4 nenulové vlastné čísla. Vďalšom odseku ukážeme, ako vypočítať ďalšie vektory w2,w3, . . . , ktoré budú tvoriťspolu s vektorom w = w1 ortogonálnu bázu. Na veľmi presnú aproximáciu pôvodnýchdát stačí malý počet vektorov tejto bázy. Na vyjadrenie sa používajú iba tie vektory,ktoré zodpovedajú nenulovým vlastným číslam matice MTM, pričom M je maticapôvodných hodnôt.
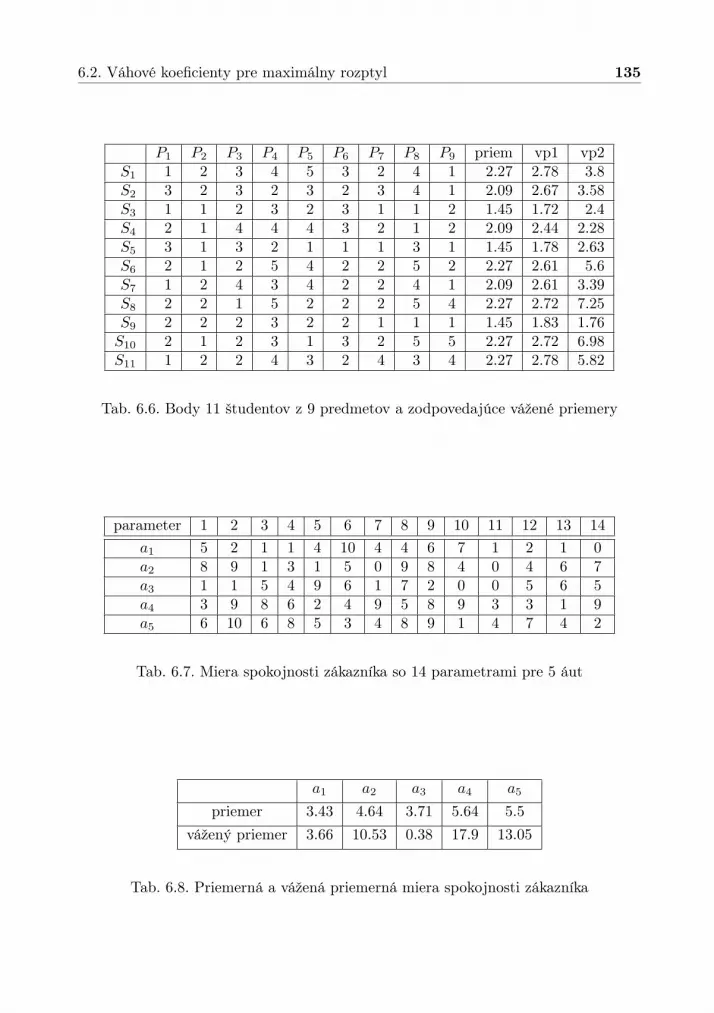
6.2. Váhové koeficienty pre maximálny rozptyl 135
P1 P2 P3 P4 P5 P6 P7 P8 P9 priem vp1 vp2S1 1 2 3 4 5 3 2 4 1 2.27 2.78 3.8S2 3 2 3 2 3 2 3 4 1 2.09 2.67 3.58S3 1 1 2 3 2 3 1 1 2 1.45 1.72 2.4S4 2 1 4 4 4 3 2 1 2 2.09 2.44 2.28S5 3 1 3 2 1 1 1 3 1 1.45 1.78 2.63S6 2 1 2 5 4 2 2 5 2 2.27 2.61 5.6S7 1 2 4 3 4 2 2 4 1 2.09 2.61 3.39S8 2 2 1 5 2 2 2 5 4 2.27 2.72 7.25S9 2 2 2 3 2 2 1 1 1 1.45 1.83 1.76S10 2 1 2 3 1 3 2 5 5 2.27 2.72 6.98S11 1 2 2 4 3 2 4 3 4 2.27 2.78 5.82
Tab. 6.6. Body 11 študentov z 9 predmetov a zodpovedajúce vážené priemery
parameter 1 2 3 4 5 6 7 8 9 10 11 12 13 14
a1 5 2 1 1 4 10 4 4 6 7 1 2 1 0a2 8 9 1 3 1 5 0 9 8 4 0 4 6 7a3 1 1 5 4 9 6 1 7 2 0 0 5 6 5a4 3 9 8 6 2 4 9 5 8 9 3 3 1 9a5 6 10 6 8 5 3 4 8 9 1 4 7 4 2
Tab. 6.7. Miera spokojnosti zákazníka so 14 parametrami pre 5 áut
a1 a2 a3 a4 a5
priemer 3.43 4.64 3.71 5.64 5.5vážený priemer 3.66 10.53 0.38 17.9 13.05
Tab. 6.8. Priemerná a vážená priemerná miera spokojnosti zákazníka

136 Kapitola 6. Analýza viacrozmerných objektov
6.3 Analýza hlavných komponentov
S úlohou riešenou v predchádzajúcej kapitole súvisí metóda, ktorá sa nazýva ana-lýza hlavných komponentov (PCA). Túto metódu uviedol Angličan Karl Pearson vroku 1901. Rieši úlohu vyjadriť maticu nameraných hodnôt v inej báze. Táto bázabude taká, aby na dobrú aproximáciu stačil menší počet súradníc. V predchádzajú-com odseku sme ukázali, že maximálny rozptyl dosiahne taká lineárna kombinácianameraných hodnôt, v ktorej sú ako koeficienty použité zložky vlastného vektora,prislúchajúceho najväčšiemu vlastnému číslu matice
R = MTM
Uvedená lineárna kombinácia obsahuje najväčšie množstvo neurčitosti, a teda aj in-formácie o nameraných hodnotách. Váhový vektor z predchádzajúcej úlohy môžemechápať aj ako bázový vektor. Násobky tohto vektora sú najlepšou aproximáciou spo-medzi všetkých jednorozmerných aproximácií pôvodných dát. Preto sa táto lineárnakombinácia nazýva prvým hlavným komponentom. Ak prvý hlavný komponent zdát odstránime, znovu môžeme riešiť rovnakú úlohu. Riešením bude druhé najväč-šie vlastné číslo a jemu prislúchajúci vlastný vektor. Priemet pôvodných vektorov dopodpriestoru generovaného vlastným vektorom s druhým najväčším vlastným číslomsa nazýva druhý hlavný komponent.
Uvedený výsledok nie je samozrejmý, ani triviálny. Na jeho odvodenie sa využijenasledujúce tvrdenie.
Tvrdenie 6.3.1 Vlastné čísla ľubovoľnej matice, ktorá sa dá vyjadriť v tvare ATA súreálne čísla väčšie alebo rovné 0. Vlastné vektory, ktoré prislúchajú týmto vlastnýmčíslam, tvoria ortogonálny systém vektorov (ktorý sa dá upraviť na ortonormálny).
Celý postup PCA spočíva v niekoľkých krokoch, v ktorých sa spracuje maticanameraných hodnôt
M =
v1
v2
...vm
Rozmer matice M je m × n, matica obsahuje dáta pre m objektov, každý s n para-metrami.
• z matice M vytvoríme centrovanú maticu M tak, že od každého stĺpca maticeodčítame jeho aritmetický priemer
• vytvoríme maticu R = MTM, ktorej rozmer je n× n
• nájdeme vlastné čísla λk a vlastné vektory wk matice R
• zoradíme vlastné čísla podľa veľkosti a označíme tak, aby platilo
λ1 ≥ λ2 ≥ · · · ≥ λn

6.3. Analýza hlavných komponentov 137
• zodpovedajúce vlastné vektory označíme w1,w2, . . . ,wn
dá sa overiť, že tieto vektory sú ortogonálne
• riadky matice M označíme ako vektory v1,v
2, . . . ,v
m
• najpresnejšia aproximácia vektorov v1,v
2, . . . ,v
m spomedzi všetkých jednoroz-
merných podpriestorov bude v podpriestore generovanom vektorom w1
• najpresnejšia aproximácia vektorov v1,v
2, . . . ,v
m spomedzi všetkých dvojroz-
merných podpriestorov bude v podpriestore generovanom vektormi w1,w2
• najpresnejšia aproximácia vektorov v1,v
2, . . . ,v
m spomedzi všetkých
k-rozmerných podpriestorov bude v podpriestore generovanom vektormiw1,w2, . . . ,wk
• vypočítame koeficienty vektorov v1, v
2, . . . , v
m v ortogonálnej báze
w1,w2, . . . ,wk ako koeficienty priemetov vektorov v na jednotlivé vektory tejtobázy, teda podľa vzorcov
v = c1 ·w1 + c2 ·w2 + · · ·+ ck ·wk
cj =⟨v,wj⟩⟨wj ,wj⟩
• aproximáciu pôvodných vektorov v1,v2, . . . ,vm dostaneme tak, že ku vektoromv1,v
2, . . . ,v
m pripočítame aritmetické priemery jednotlivých stĺpcov matice M
Metódu PCA odvodíme neskôr, zatiaľ ju iba ilustrujeme na úlohe zmenšenia počtukoeficientov potrebných na vyjadrenie sedemrozmerných vektorov.
Príklad 6.3.1 Číslice na digitálnych hodinkách sú tvorené siedmimi čiarkami, ktorébuď svietia, alebo nesvietia. Na určenie, o akú číslicu ide, použijeme 7 hodnôt. Hodnota0 znamená, že príslušná čiarka nesvieti, hodnota 1 znamená, že príslušná čiarka svieti.Nájdite pomocou metódy PCA hlavné komponenty tak, aby bolo možné určiť každú zdigitálnych číslic pomocou menšieho počtu koeficientov než 7.
Riešenie:Vyobrazenia číslic na digitálnych hodinkách, tak ako ich budeme v úlohe používať súna obrázku 6.3. V každej číslici sú niektoré z čiarok zasvietené, iné nie. Hrubá čiarana obrázku znamená zasvietenú čiarku a bude jej priradená hodnota 1. Tenká čiaraznamená, že príslušné miesto je nezasvietené a bude mu priradená hodnota 0.
Obr. 6.3. Vyobrazenia číslic 0, 1, 2, 3, 4, 5, 6, 7, 8, 9

138 Kapitola 6. Analýza viacrozmerných objektov
Na obrázku 6.4 sú pozície jednotlivých čiarok označené číslami.
1
2
34
5
67
Obr. 6.4. Čísla 1, 2, 3, 4, 5, 6, 7 označujú pozíciu čiarky v digitálnom čísle
Jednotlivé číslice budú reprezentované vektormi, ktorých súradnice sú hodnoty 0,alebo 1 na zodpovedajúcich miestach.
v0 = (1, 1, 1, 1, 1, 1, 0)
v1 = (0, 1, 1, 0, 0, 0, 0)
v2 = (1, 0, 1, 1, 0, 1, 1)
v3 = (1, 1, 1, 1, 0, 0, 1)
v4 = (0, 1, 1, 0, 1, 0, 1)
v5 = (1, 1, 0, 1, 1, 0, 1)
v6 = (1, 1, 0, 1, 1, 1, 1)
v7 = (0, 1, 1, 1, 0, 0, 0)
v8 = (1, 1, 1, 1, 1, 1, 1)
v9 = (0, 1, 1, 1, 1, 0, 1)
Matica M reprezentujúca namerané dáta, v našom prípade vektory v0, . . . ,v9 mátvar:
M =
1 1 1 1 1 1 00 1 1 0 0 0 01 0 1 1 0 1 11 1 1 1 0 0 10 1 1 0 1 0 11 1 0 1 1 0 11 1 0 1 1 1 10 1 1 1 0 0 01 1 1 1 1 1 10 1 1 1 1 0 1
Vypočítame aritmetický priemer každého stĺpca matice. Dostaneme vektor aritmetic-kých priemerov m.
m = (0.6, 0.9, 0.8, 0.7, 0.6, 0.4, 0.7)

6.3. Analýza hlavných komponentov 139
Z matice M vypočítame centrovanú maticu M = M−m.
M =
0.4 0.1 0.2 0.3 0.4 0.6 −0.7−0.6 0.1 0.2 −0.7 −0.6 −0.4 −0.70.4 −0.9 0.2 0.3 −0.6 0.6 0.30.4 0.1 0.2 0.3 −0.6 −0.4 0.3−0.6 0.1 0.2 −0.7 0.4 −0.4 0.30.4 0.1 −0.8 0.3 0.4 −0.4 0.30.4 0.1 −0.8 −0.7 0.4 0.6 0.3−0.6 0.1 0.2 0.3 −0.6 −0.4 −0.70.4 0.1 0.2 0.3 0.4 0.6 0.3−0.6 0.1 0.2 0.3 0.4 −0.4 0.3
Vypočítame maticu R = MTM.
R =
0.27 −0.04 −0.09 0.09 0.04 0.18 0.09−0.04 0.1 −0.02 −0.03 0.07 −0.07 −0.03−0.09 −0.02 0.18 0.04 −0.09 −0.02 −0.070.09 −0.03 0.04 0.23 −0.02 0.02 0.010.04 0.07 −0.09 −0.02 0.27 0.07 0.090.18 −0.07 −0.02 0.02 0.07 0.27 0.020.09 −0.03 −0.07 0.01 0.09 0.02 0.23
Nájdeme všetky vlastné čísla matice R a zoradíme ich podľa veľkosti.
λ1 = 0.57, λ2 = 0.37, λ3 = 0.22, λ4 = 0.19, λ5 = 0.14, λ6 = 0.05, λ7 = 0.01
K vlastným číslam vypočítame zodpovedajúce vlastné vektory.
w1 = ( 0.6, −0.09, −0.29, 0.15, 0.36, 0.52, 0.35)w2 = ( −0.27, 0.32, −0.36, −0.46, 0.59, −0.28, 0.25)w3 = ( 0.05, 0.02, −0.04, 0.6, −0.05, −0.59, 0.53)w4 = ( 0.11, −0.35, −0.27, −0.53, −0.57, −0.09, 0.43)w5 = ( −0.36, −0.3, 0.64, −0.08, 0.23, 0.26, 0.49)w6 = ( 0.49, 0.62, 0.51, −0.27, −0.13, −0.1, 0.15)w7 = ( 0.43, −0.55, 0.23, −0.2, 0.36, −0.48, −0.27)
(Presvedčíme sa, že vektory w1,w2, . . . ,w7 sú ortogonálne.)Vypočítame súradnice vektorov v
0, v1, v
2, v
3, v
4, v
5, v
6, v
7, v
8, v
9, v ortogonálnej báze
w1,w2, . . . ,w7 ako koeficienty priemetov vektorov v do tejto bázy, teda podľa vzorca
v = c1 ·w1 + c2 ·w2 + · · ·+ c7 ·w7
cj =⟨v,wj⟩⟨wj ,wj⟩
, j = 1, . . . , 7
V prípade, že do bázy zoberieme iba prvý vlastný vektor, vyjadríme vektory akonásobky vektora w1 = (0.6, −0.09, −0.29, 0.15, 0.36, 0.52, 0.35), a tak dostanemenajpresnejší jednorozmerný odhad centrovaných vektorov v
0, . . . ,v9.
v0 = c01 ·w1, kde c01 =
⟨v0,w1⟩
⟨w1,w1⟩=⟨v
0,w1⟩1
= 0.43

140 Kapitola 6. Analýza viacrozmerných objektov
v0 = (0.26, −0.04, −0.12, 0.06, 0.15, 0.22, 0.15)
Po pripočítaní vektora stredných hodnôt dostaneme odhad pôvodného vektora v0,reprezentujúceho digitálnu číslicu "0".
v0 = v0 +m = (0.86, 0.86, 0.68, 0.76, 0.75, 0.62, 0.85)
Pre ostatné vektory rovnakým spôsobom dostaneme hodnoty:
v1 = (−0.12, 1.01, 1.15, 0.52, 0.17, −0.22, 0.27)v2 = (0.91, 0.85, 0.65, 0.78, 0.78, 0.67, 0.88)
v3 = (0.54, 0.9, 0.83, 0.69, 0.57, 0.35, 0.67)
v4 = (0.3, 0.95, 0.94, 0.63, 0.42, 0.15, 0.53)
v5 = (0.93, 0.85, 0.64, 0.78, 0.8, 0.69, 0.9)
v6 = (1.15, 0.81, 0.53, 0.84, 0.93, 0.87, 1.02)
v7 = (−0.04, 1, 1.1, 0.54, 0.22, −0.14, 0.33)v8 = (1.07, 0.83, 0.57, 0.82, 0.88, 0.8, 0.98)
v9 = (0.4, 0.93, 0.9, 0.65, 0.48, 0.22, 0.58)
Tým je úloha priemetu do podpriestoru určeného prvým vlastným vektorom ukon-čená. Každá číslica je v tomto podpriestore určená jediným koeficientom. Keby smechceli odhadnuté digitálne číslice zakresliť podobne ako na obrázku 6.3, museli by smepoužiť odtiene sivej farby.
Teraz urobíme zjednodušenie a hodnoty zaokrúhlime a až potom zakreslíme. OznačmeMw1 maticu zaokrúhlených hodnôt, predstavujúcich priemet na prvý vlastný vektor.
Mw1 =
1 1 1 1 1 1 10 1 1 1 0 0 01 1 1 1 1 1 11 1 1 1 1 0 10 1 1 1 0 0 11 1 1 1 1 1 11 1 1 1 1 1 10 1 1 1 0 0 01 1 1 1 1 1 10 1 1 1 0 0 1
Vyobrazenia číslic, predstavujúce prvý hlavný komponent, sú na obrázku 6.5. Táto
aproximácia je dosť nepresná, správne zakreslené sú len 2 čísla z 10, úspešnosť je 20%.V prípade, že do bázy zoberieme prvé dva vlastné vektory, vyjadríme vektory ako
lineárnu kombináciu vektorov w1 a w2. Dostaneme najpresnejší dvojrozmerný odhadcentrovaných vektorov v
0, . . . ,v9.
v0 = c01 ·w1 + c02 ·w2, kde c01 =
⟨v0,w1⟩
⟨w1,w1⟩= 0.43
c02 =⟨v
0,w2⟩⟨w2,w2⟩
= −1.2

6.3. Analýza hlavných komponentov 141
Obr. 6.5. Vyobrazenia číslic 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 ako prvý hlavný komponent
v0 = (0.36, −0.16, 0.02, 0.25, −0.07, 0.33, 0.05)
Po pripočítaní vektora stredných hodnôt dostaneme odhad pôvodného vektora v0,reprezentujúceho digitálnu číslicu "0".
v0 = v0 +m = (0.96, 0.74, 0.82, 0.95, 0.52, 0.73, 0.75)
Pre ostatné vektory rovnakým spôsobom dostaneme hodnoty v1, . . . , v9. Vypočítanéhodnoty zaokrúhlime a potom zakreslíme.
Označme Mw1,w2 maticu zaokrúhlených hodnôt, predstavujúcich priemet do pod-priestoru určeného prvými dvomi vlastnými vektormi.
Mw1,w2 =
1 1 1 1 1 1 10 1 1 1 0 0 01 1 1 1 0 1 11 1 1 1 0 0 10 1 1 0 1 0 11 1 0 1 1 1 11 1 0 1 1 1 10 1 1 1 0 0 01 1 1 1 1 1 10 1 1 0 1 0 1
Vyobrazenia číslic, vyjadrených ako lineárna kombinácia prvých dvoch vlastných
vektorov sú na obrázku 6.6. Táto aproximácia je trochu presnejšia, správne zakresle-ných je 5 čísel z 10, úspešnosť je 50%.
Obr. 6.6: Vyobrazenia číslic 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 ako lineárna kombinácia prvýchdvoch vlastných vektorov
Matica zaokrúhlených hodnôt, predstavujúcich priemet do podpriestoru určenéhovektormi w1, w2 a w3 je matica Mw1,w2,w3 . Táto matica sa od matice pôvodných

142 Kapitola 6. Analýza viacrozmerných objektov
dát líši len na jedinom mieste.
Mw1,,w2,w3 =
1 1 1 1 1 1 00 1 1 0 0 0 01 1 1 1 0 1 11 1 1 1 0 0 10 1 1 0 1 0 11 1 0 1 1 0 11 1 0 1 1 1 10 1 1 1 0 0 01 1 1 1 1 1 10 1 1 1 1 0 1
Vyobrazenia číslic, vyjadrených ako lineárna kombinácia vektorov w1, w2 a w3 sú
na obrázku 6.7. Táto aproximácia je znovu presnejšia, správne zakreslených je 9 číselz 10, úspešnosť je 90%.
Obr. 6.7: Vyobrazenia číslic 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 ako lineárna kombinácia w1, w2 aw3
Matica zaokrúhlených hodnôt, predstavujúcich priemet do podpriestoru určenéhovektormi vektorov w1, w2, w3 a w4 je zhodná s maticou pôvodných hodnôt M.
Vyobrazenia číslic, vyjadrených ako lineárna kombinácia štyroch vlastných vekto-rov sú na obrázku 6.8. Táto aproximácia je zhodná s pôvodným obrázkom 6.3.
Obr. 6.8: Vyobrazenia číslic 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 ako lineárna kombinácia vektorovw1, w2, w3 a w4
To znamená, že je postačujúce vyjadriť vektory v0, . . . ,v9 pomocou 4 koeficientovv báze tvorenej z prvých štyroch vlastných vektorov w1, w2, w3 a w4.
Príklad 6.3.2 Vyjadrite v báze vytvorenej z prvých štyroch vlastných vektorov z prí-kladu 6.3.1 vektory
f1 = (0, 1, 1, 0, 1, 1, 0)
f2 = (0, 0, 1, 0, 0, 1, 1)
f3 = (1, 0, 0, 1, 0, 0, 1)
Je báza z príkladu 6.3.1 vhodná na ich reprezentáciu?

6.3. Analýza hlavných komponentov 143
Riešenie:Vektorom f1, f2, f3 zodpovedajú vyobrazenia, ktoré sú na obrázku 6.9.
Obr. 6.9. Vyobrazenia vektorov f1, f2, f3
Použijeme výpočty z príkladu 6.3.1. Vektor stredných hodnôt bude znovu vektor
m = (0.6, 0.9, 0.8, 0.7, 0.6, 0.4, 0.7)
Vypočítame koeficienty priemetov centrovaných vektorov f1 , f2 , f
3 do podpries-
toru generovaného vektormi w1, w2, w3 a w4.
f1 = c11 ·w1 + c12 ·w2 + c13 ·w3 + c14 ·w4
= (−0.39, 0.24, 0.13, −0.74, 0.35, 0.47, −0.83)
f2 = c21 ·w1 + c22 ·w2 + c23 ·w3 + c24 ·w4
= (0.02, −0.43, −0.05, −0.8, −0.8, 0.25, −0.08)
f3 = c31 ·w1 + c32 ·w2 + c33 ·w3 + c34 ·w4
= (0.41, −0.46, −0.21, 0.14, −0.69, −0.19, 0.73)
Po pripočítaní vektora m a zaokrúhlení hodnôt na celé čísla dostávame odhadyvektorov f1, f2, f3.
f1 = (0, 1, 1, 0, 1, 1, 0)
f2 = (1, 0, 1, 0, 0, 1, 1)
f3 = (1, 0, 1, 1, 0, 0, 1)
Na rozdiel od predchádzajúceho príkladu, v tomto prípade aproximácia v štvor-rozmernom podpriestore nie je taká presná, ako vidíme na obrázku 6.10. Dôvodom je,že vlastné vektory boli vytvorené k matici R zostavenej pre číslice, teda pre vektoryrôzne od f1, f2, f3. Chyba však nebola príliš veľká. V jednom prípade chyba nena-stala, v dvoch prípadoch bola chyba na jednom mieste. Navyše chyby spôsobili, že saaproximované obrazce viac podobajú na číslice, než pôvodné vektory.
Úloha 6.3.1 Zopakujte postup z príkladu 6.3.2 pre rôzne vektory f . Nájdite taký vek-tor f , ktorý bude najviac odlišný od svojho priemetu do 4-rozmerného podpriestorugenerovaného vektormi w1, w2, w3 a w4 z príkladu 6.3.1. Pridajte vektor f do maticeM pôvodných hodnôt (použite maticu M z príkladu 6.3.1). Vypočítajte vlastné vek-tory pre takto vytvorenú maticu. Zistite, koľko koeficientov stačí na presné vyjadrenievšetkých digitálnych číslic a vektora f .

144 Kapitola 6. Analýza viacrozmerných objektov
Obr. 6.10. Vyobrazenia vektorov f1, f2, f3
Úloha 6.3.2 Vyjadrite písmená slovenskej abecedy ako obrázky vytvorené z čiernycha bielych štvorčekov v sieti veľkosti 5×5. Každé písmeno sa dá vyjadriť ako 25−zložkovývektor, ktorého zložky sú čísla 0 a 1. Nájdite pomocou metódy PCA bázu so 6 vek-tormi, v ktorej budú jednotlivé písmená najlepšie aproximované (spomedzi všetkých6−rozmerných podpriestorov 25–rozmerného priestoru).
Metódy, ktoré sme uviedli v tejto kapitole, spočívajú vo vyjadrení viacrozmerných dátako lineárnych kombinácií vlastných vektorov matice R = MTM, ktorú vypočítamez matice nameraných hodnôt M. Namiesto nameraných hodnôt matice M môžemeuvažovať o všetkých možných hodnotách a ich teoretických pravdepodobnostiach. Vtom prípade nahradíme maticu dát náhodným procesom. Analýze náhodných proce-sov sa budeme venovať v ďalšej podkapitole.

6.4. Náhodné procesy 145
6.4 Náhodné procesy
Analýza hlavných komponentov je metóda, ktorá pracuje s konkrétnymi dátami. Vteoretickom modeli dáta nahradíme hodnotami odhadnutými pomocou pravdepodob-nosti výskytu týchto hodnôt. Teoretická metóda zodpovedajúca PCA sa nazýva Kar-hunen Loevova transformácia. Na odvodenie tejto metódy sú potrebné pojmy a tvrde-nia z teórie pravdepodobnosti a náhodných procesov, ktoré tu uvedieme bez dôkazov.
6.4.1 Pojmy a tvrdenia z teórie pravdepodobnosti
V teórii pravdepodobnosti je vybudovaný aparát, ktorý prevádza reálne udalosti doreči čísel, množín, ďalších matematických objektov a vzťahov medzi nimi. Nameranéhodnoty sú reprezentované teoretickými hodnotami, sú predpovedané pravdepodob-nosti uskutočnenia jednotlivých udalostí pri opakovaní pokusu s rovnakými vstupnýmihodnotami. Ak pri rovnakých vstupných podmienkach nastane vždy rovnaký výstup,ide o deterministický pokus. Ak pri rovnakých vstupných podmienkach môžu nastaťrôzne výsledky, ide o náhodný pokus.
Najjednoduchší model na popis náhodného pokusu pozostáva z množiny elemen-tárnych udalostí Ω a pravdepodobnostnej funkcie P : Ω → R, ktorá každej udalostiω ∈ Ω priradí pravdepodobnosť tejto udalosti P (ω) ∈ ⟨0, 1⟩. Vo všeobecnosti súnáhodné udalosti vyjadrené ako podmnožiny A ⊆ Ω, teda množiny elementárnychudalostí.
Pravdepodobnostnú funkciu môžeme prirodzene rozšíriť na všetky náhodné uda-losti nasledovným spôsobom:
P (A) =∑ω∈A
P (ω).
Dvojicu (Ω, P ) nazývame pravdepodobnostný priestor.
Pre náhodnú udalosť A ⊆ Ω definujeme opačnú udalosť A ako udalosť, ktorázodpovedá doplnku množiny A do množiny Ω.
Tvrdenie 6.4.1 (Vlastnosti pravdepodobnosti) Nech A, B sú náhodné udalostia nech P (A) a P (B) sú pravdepodobnosti týchto udalostí, potom
P (∅) = 0, P (Ω) = 1
0 ≤ P (A) ≤ 1
akA ∩B = ∅, potomP (A ∪B) = P (A) + P (B)
P (A) = 1− P (A)ak je množinaA podmnožinou množinyB potomP (A) ≤ P (B)
Príklad 6.4.1 Pri náhodnom pokuse spočívajúcom v hádzaní kockou môžeme za ná-hodnú udalosť považovať to, že padne párne číslo. Množina reprezentujúca túto udalosťje A = 2, 4, 6. Predpokladajme, že všetky elementárne udalosti ω ∈ 1, 2, 3, 4, 5, 6

146 Kapitola 6. Analýza viacrozmerných objektov
majú rovnakú pravdepodobnosť uskutočnenia P (ω) = 16 .
Pre pravdepodobnosť hodenia párneho čísla bude
P (A) =∑ω∈A
P (ω) =3
6=
1
2
Náhodná premenná je zobrazenie X : Ω → R, ktoré každej elementárnej uda-losti ω priradí reálnu hodnotu X(ω).
Ku náhodnej premennej X a ku podmnožine reálnych čísel S ⊆ R označíme
X−1(S) = ω ∈ Ω; X(ω) ∈ S
vzor množiny S v zobrazení X. Týmto spôsobom môžeme pravdepodobnosť udalostiX(ω), ktorá sa zobrazí do množiny S definovať vzťahom
P (X ∈ S) = P (X−1(S))
Ak je množinou S interval tvaru (−∞, x) kde x ∈ R, dostaneme funkciu F : R→ Rdanú predpisom
F (x) = P (X < x)
nazývanú distribučná funkcia náhodnej premennej X. Podobne pre interval (a, b⟩bude P (a < X ≤ b) atď. (Reálna hodnota a môže byť interpretovaná ako interval⟨a, a⟩.)Distribučná funkcia náhodnej premennej vyjadruje všetky dôležité vlastnosti tejtopremennej. Podľa tejto úvahy, náhodné premenné s rovnakou distribučnou funkciouzvyknú byť považované za rovnaké. Hustota náhodnej premennej X je definovanáako derivácia jej distribučnej funkcie
φ(x) = F ′(x)
Na jednoduchší popis náhodnej premennej sa používajú číselné charakteristikynáhodnej premennej. Najdôležitejšie, ktoré budeme používať, sú stredná hodnota,disperzia, pre dve náhodné premenné budeme používať kovarianciu a koeficient ko-relácie.Pre zjednodušenie označme Ω = ω1, . . . , ωM a položme P (ωk) = pk pre k =1, . . . ,M . Čísla xk nazveme hodnoty náhodnej premennej X. Podobne pre náhodnúpremennú X položme X(ωk) = xk. Týmto spôsobom bude náhodná premenná X re-prezentovaná M -rozmerným vektorom (x1, . . . , xM ) ∈ RM .Nech xk ∈ X(Ω) sú hodnoty náhodnej premennej a pk ich pravdepodobnosti. Stred-nou hodnotou náhodnej premennej X nazveme číslo
E(X) =∑xk∈X
xk · pk
Disperziou náhodnej premennej X nazveme číslo
D(X) = E[(X− E(X))2
]=∑xk∈X
x2k · pk −
(∑xk∈X
xk · pk
)2

6.5. Náhodné vektory 147
Kovariancia dvoch náhodných premenných X,Y je definovaná ako
cov(X,Y) = E(X− E(X))(Y− E(Y)) = E(XY)− E(X)E(Y)
Korelačný koeficient dvoch náhodných premenných X,Y je definovaný ako
ρ(X,Y) =cov(X,Y)
(X− E(X)) (Y− E(Y))=
=E(X− E(X))(Y− E(Y))√
D(X)√D(Y)
=E(XY)− E(X)E(Y)√
D(X)D(Y)
Dve náhodné premenné X,Y nazveme nekorelované, ak platí
ρ(X,Y) = 0 alebo cov(X,Y) = 0.
6.5 Náhodné vektory
Procesy, ktorým sme sa venovali v predchádzajúcich kapitolách, boli deterministicképrocesy. V deterministickom procese je pre každý časový okamih tk určená jedináhodnota fk.
f = (f0, f1, . . . , fN−1)
V tejto kapitole budeme vyšetrovať vlastnosti náhodných procesov.V náhodnom procese je každému časovému okamihu tk priradená náhodná pre-menná X(tk) = Xtk = Xk. Táto náhodná premenná je funkcia Xk : Ω → R. Obvyklesa označuje f(ω, tk) = Xtk(ω) = Xk(ω) a náhodný proces má potom tvar
f = (X0(ω),X1(ω), . . . ,XN−1(ω)) = (f(ω, t0), f(ω, t1), . . . , f(ω, tN−1))
Je to N -rozmerný vektor závislý od náhodnej udalosti ω ∈ Ω.Náhodný proces popisuje náhodné udalosti tak, že výsledku ω0 ∈ Ω náhodného
pokusu priradí funkciu času fω(tk), táto funkcia je jedna realizácia náhodnéhoprocesu:
fω(tk) = f(ω0, tk), k = 0, 1, . . . , N − 1
Všetky realizácie náhodného procesu v nejakom fixnom čase tk = t∗, teda rez ná-hodného procesu v čase, tvorí náhodnú premennú:
f(ω, tk = t∗) = ft∗(ω), ω ∈ S
Náhodný proces môžeme chápať ako vektor, ktorého zložky sú náhodné premenné:
f(ω, tk) = (f(ω, t0), f(ω, t1), . . . , f(ω, tN−1))
Distribučnou funkciou náhodného procesu nazveme funkciu
F : RN → R
F (x0, x1, . . . , xN−1) = P (f(ω, t0) < x0, f(ω, t1) < x1, . . . , f(ω, tN−1) < xN−1)

148 Kapitola 6. Analýza viacrozmerných objektov
Hovoríme, že dva náhodné procesy sa rovnajú ak sa rovnajú ich distribučné funkcie.Ak existujú parciálne derivácie distribučnej funkcie podľa všetkých premenných, mô-žeme zaviesť pojem hustoty náhodného procesu.Hustotou náhodného procesu nazveme funkciu N premenných
φ(x0, x1, . . . , xN−1) = F ′(x0, x1, . . . , xN−1) =
(∂F
∂x0,∂F
∂x1, . . . ,
∂F
∂xN−1
)Ak je známa distribučná funkcia náhodného procesu, je proces jednoznačne popísaný,poznáme ho celý. Takýto popis je však komplikovaný a preto často stačí, ak je známadvojrozmerná distribučná funkcia procesu:
F (xi, xj) = P (f(ω, i) < xi, f(ω, j) < xj), xi, xj ∈ R i, j ∈ 0, 1, . . . , N − 1
Popisom procesov, pri ktorom sa používa iba dvojrozmerná distribučná funkcia, sazaoberá korelačná teória.Základné charakteristiky, ktoré sme uviedli pre náhodnú premennú sú stredná hod-nota, disperzia, kovariancia. Tieto pojmy zavedieme aj pre náhodné procesy:Strednou hodnotou náhodného procesu nazveme deterministický vektor
m = (m0,m1, . . . ,mN−1), kde mk = E (f(ω, k)) , k = 0, 1, . . . , N − 1
Disperziou náhodného procesu nazveme deterministický vektor
d = (d0, d1, . . . , dN−1), kde dk = E(f2(ω, k)
)−m2
k k = 0, 1, . . . , N − 1
Kovariančnou maticou náhodného procesu nazveme maticu
C = [cij ], kde cij = E((f(ω, i)−mi) (f(ω, j)−mj)
)Na určenie strednej hodnoty a disperzie stačí použiť jednorozmernú distribučnú fun-kciu. Na určenie kovariančnej matice je potrebná dvojrozmerná distribučná funkcia.Centrovaným náhodným procesom sa nazýva proces, ktorého stredná hodnotaje rovná nule. Ak nie je proces f(ω, t) centrovaný, stačí odčítať jeho strednú hodnotua dostaneme centrovaný proces f(ω, t)
f(ω, t) = f(ω, t)−m
f(ω, t) = (f(ω, 0)−m0, f(ω, 1)−m1, . . . , f(ω,N − 1)−mN−1)
Kvôli zjednodušeniu a bez ujmy na všeobecnosti budeme v ďaľšom texte študovať lencentrované náhodné procesy.
Tvrdenie 6.5.1 Pre centrovaný náhodný proces majú korelačná a kovariančná ma-tica rovnaký tvar
C = [cij ] = R = [rij ] =[E(f(ω, i) f(ω, j)
)]kde i, j = 0, 1, . . . , N − 1
Tvrdenie 6.5.2 Pre prvky korelačnej matice a pre prvky kovariančnej matice platí
rij = rji, cij = cji
Úloha 6.5.1 Ak je proces popísaný strednou hodnotou, disperziou a korelačnou ma-ticou, môžeme ho rovnako dobre popísať len dvomi z týchto charakteristík. Ktorými aprečo?

6.5. Náhodné vektory 149
6.5.1 Priestor náhodných vektorov
Definujme N-rozmerný vektorový priestor náhodných vektorov. Prvkami sú vektory,ktorých jednotlivé zložky sú náhodné premenné:
f = (f(ω, 0), f(ω, 1), . . . , f(ω, k), . . . , f(ω,N − 1))
Skaláry v tomto priestore môžu byť buď reálne čísla, alebo reálne náhodné premenné.Súčtom dvoch nezávislých náhodných vektorov f a g nazveme vektor z, ktoréhohustotu dostaneme ako konvolúciu hustôt vektorov f a g.
z = f + g
z má hustotu φz(y) =
∫x∈RN
φf (y − x)φg(x)dx
Opačným vektorom k vektoru
f = (f(ω, 0), f(ω, 1), . . . , f(ω,N − 1))
je vektor−f = (−f(ω, 0),−f(ω, 1), . . . ,−f(ω,N − 1))
Neutrálnym prvkom vektorového priestoru je nulový náhodný vektor
0 = (0, 0, . . . , 0)
Súčin vektora so skalárom je definovaný
c · f = (c · f(ω, 0), c · f(ω, 1), . . . , c · f(ω,N − 1))
Bez ujmy na všeobecnosti budeme v ďalšom texte uvažovať iba centrované náhodnéprocesy. Skalárny súčin môžeme definovať viacerými spôsobmi, výsledok môže byťnáhodný, alebo nenáhodný.
Uvažujme najprv vektorový priestor, v ktorom je definovaný nenáhodný skalár.Skalárny súčin dvoch náhodných vektorov je skalár vektorového priestoru, tedanenáhodné číslo.
⟨f ,g⟩ = E
(N−1∑n=0
f(ω, n)g(ω, n)
)Dva náhodné vektory nazveme ortogonálne, ak je ich skalárny súčin rovný 0:
f⊥g ⇔ ⟨f ,g⟩ = 0
Veľkosť náhodného vektora definujeme:
||f || =√⟨f , f⟩

150 Kapitola 6. Analýza viacrozmerných objektov
Vzdialenosť dvoch náhodných vektorov definujeme:
d (f ,g) = ||f − g|| =√⟨f − g, f − g⟩
Rovnosť dvoch náhodných vektorov definujeme:
f = g ⇔ ||f − g|| = 0
V inom vektorovom priestore môžeme definovať skalár, ktorý je náhodná premenná.Skalárny súčin dvoch náhodných vektorov je skalár vektorového priestoru, tedanáhodná premenná:
⟨f ,g⟩ =N−1∑k=0
f(ω, k)g(ω, k)
V tomto prietore sú dva náhodné vektory ortogonálne, ak je ich skalárny súčin rovnýnáhodnej premennej so strednou hodnotou 0:
f⊥g ⇔ E⟨f ,g⟩ = 0
Veľkosť náhodného vektora definujeme:
||f || =√E⟨f , f⟩
Vzdialenosť dvoch náhodných vektorov definujeme:
d (f ,g) = ||f − g|| =√E⟨f − g, f − g⟩
Rovnosť dvoch náhodných vektorov definujeme:
f = g ⇔ ||f − g|| = 0
6.5.2 Vlastnosti priestorov s náhodnými vektormi
Tvrdenie 6.5.3 Pre náhodné vektory platí Pytagorova veta.
Dôkaz:Nech sú f a g navzájom kolmé náhodné vektory, potom
||f + g||2 = E
(N−1∑n=0
(f(ω, n) + g(ω, n))(f(ω, n) + g(ω, n))
)=
= E
(N−1∑n=0
f(ω, n)f(ω, n)
)+ E
(N−1∑n=0
g(ω, n)g(ω, n)
)= ||f ||2 + ||g||2
Teda platí
E
(N−1∑n=0
|f(ω, n) + g(ω, n)|2)
= E
(N−1∑n=0
|f(ω, n)|2)
+ E
(N−1∑n=0
|g(ω, n)|2)
To znamená, že stredná energia súčtu dvoch navzájom kolmých procesov sa rovnásúčtu stredných energií týchto procesov Podmienku kolmosti môžeme nahradiť podmienkou nekorelovanosti.

6.5. Náhodné vektory 151
Tvrdenie 6.5.4 Stredná energia súčtu dvoch navzájom nekorelovaných procesov sarovná súčtu stredných energií týchto procesov.
Systém vektorov B = bn, n = 0, 1, . . . , N − 1 s N prvkami tvaru
bn = (bn(ω, 0), bn(ω, 1), . . . , bn(ω,N − 1))
nazveme bázou vektorového priestoru náhodných procesov, ak sa každý náhodnýproces f vektorového priestoru dá jednoznačne napísať ako lineárna kombinácia vek-torov bázy:
f =
N−1∑n=0
cnbn
Tvrdenie 6.5.5 Ak pre každé dva vektory bn,bm n = m bázy B, platí, že sú ortogo-nálne
E(bn,bm) = 0
potom sú aj nekorelované a pre koeficienty cn rozkladu f =N−1∑n=0
cnbn platí:
a) v prípade, že skaláry sú deterministické (reálne, alebo komplexné čísla)
cn =⟨f ,bn⟩⟨bn,bn⟩
=
E
(N−1∑k=0
f(ω, k)bn(ω, k)
)E
(N−1∑k=0
|bn(ω, k)|2) n = 0, 1, . . . , N − 1
b) v prípade, že skaláry sú náhodné (reálne, alebo komplexné náhodné premenné)
cn(ω) =⟨f ,bn⟩⟨bn,bn⟩
=
N−1∑k=0
f(ω, k)bn(ω, k)
N−1∑k=0
|bn(ω, k)|2n = 0, 1, . . . , N − 1
V prípade, že vo vektorovom priestore sú skaláry náhodné čísla, tak sa dá ukázať,že ortogonálnu bázu môžeme nahradiť deterministickou bázou. Výhodou rozkladu dodeterministickej bázy je, že do rovnakej bázy je možné rozložiť nielen proces, ale ajkaždú jeho realizáciu.
Tvrdenie 6.5.6 (Brown (1970)) Vzdialenosť medzi procesom f a jeho rozkladomdo deterministickej bázy sa rovná nule práve vtedy, ak je táto báza ortogonálna.
d (f ,
N−1∑n=0
cn(ω) · bn) = 0
Ak je daná ortogonálna báza tvorená deterministickými vektormi. Ak zoberiemeku vektorom tejto bázy náhodnú amplitúdu, vznikne náhodný proces.

152 Kapitola 6. Analýza viacrozmerných objektov
6.6 Karhunen Loevov rozklad
Príklad 6.6.1 Uvažujme proces, ktorý vznikne ako výsledok opakovaného hodu min-cou. Ak padne hlava, hodnota procesu bude 0, ak padne znak, hodnota procesu bude1. Na obrázku 6.11 vidíme 50 hodnôt takéhoto procesu. Žiadnou z doteraz uvedených
0 10 20 30 40 50
0
1
Obr. 6.11. hod mincou: znak 1, hlava 0
metód analýzy procesov nevieme odhadnúť ďalšiu hodnotu tohto procesu, pretože medzihodnotami procesu nie je žiadna súvislosť a hodnoty nezávisia od času.
Zopakujme si postup pri analýze procesu f :
• Odstránenie časovej závislosti (všetky druhy lineárnej regresie, vrátane aproxi-mácie pomocou harmonickej bázy)
f(k) =
M−1∑n=0
cnφn(k) pre k = 0, 1, . . . , N − 1
Dostaneme proces g = f − f .
• Odstránenie súvislosti medzi hodnotami (modely kĺzavých súčtov)
g(tk) =L−1∑n=0
dng(k − n) pre k = 0, 1, . . . , N − 1
Dostaneme proces z = g − g.
Proces z by pri dobre urobenej analýze mal mať charakter podobný ako proces zpríkladu 6.6.1, v ktorom sa nedá predpovedať žiadna hodnota. Ak sme ako prediktorpoužili model využívajúci jednu predchádzajúcu hodnotu
fk+1 = c · fk
Koeficient c vypočítame pomocou vzorca c = ⟨z,b⟩⟨b,b⟩ . Ak je hodnota c = 0, tak bola
predikcia urobená dobre. Hodnotu c môžeme považovať za koeficient korelácie medzinasledujúcimi hodnotami. Ak je c = 0, tak hodnoty sú nekorelované. Ak je dobre

6.6. Karhunen Loevov rozklad 153
odhadnutá časová zložka, tak aritmetický priemer hodnôt procesu je rovný nule. Poodstránení časovej závislosti a súvislosti medzi hodnotami ostáva ešte jedna zákoni-tosť, a to štatistická. Táto zákonitosť sa v príklade 6.6.1 prejaví tak, že pri veľkompočte pokusov padne rovnako veľa 0 a 1.
Ak hodnoty procesu nezávisia od času, tak nemusíme popisovať na časovej osi,ale môžeme výsledky pokusu nanášať v jednom čase. V príklade s mincou dostaneme7-krát hodnotu 1 a 13-krát hodnotu 0. Dostali sme vlastne 20 realizácií náhodnejpremennej. Ak by ostala v procese z nejaká periodická časová závislosť, naskladámena seba časové periódy, ktoré proces vykazuje a dostaneme náhodný vektor. Tentobudeme analyzovať ako náhodný proces.
Tvrdenie 6.6.1 (Karhunen Loevov rozklad) Nech f je centrovaný náhodný vek-tor z vektorového priestoru s náhodným skalárom. Potom existuje jeho rozklad dodeterministickej bázy B = bn, n = 0, 1, . . . , N − 1:
f =N−1∑n=0
cn(ω)bn
taký, že každé pre n = m sú vektory bn,bm na seba kolmé. Navyše sú koeficientycn(ω), cm(ω) pre n = m nekorelované.Bázové vektory bn sú vlastné vektory kovariančnej matice procesu f , ktoré zodpovedajúvlastným hodnotám λn. Pre λn platí
λn = ||bn||2E(|cn(ω)|2
)= ||bn||2σ2
n
Dôkaz:Nech je proces rozložený do bázy podľa tvrdenia vety:
f =
N−1∑n=0
cn(ω)bn
a nech platí ⟨bn,bm⟩ = 0 a nech cn(ω), cm(ω) sú nekorelované.Vypočítame energiu n-tého bázického vektora bn a označíme σ2
n disperziu náhodnéhoskalára cn(ω).
(bn,bn) = ||bn||2 =
N−1∑k=0
|bn(k)|2 (6.6.1)
Z predpokladu nekorelovanosti cn(ω), cm(ω) dostaneme
E(cn(ω) · cm(ω)
)=
0 pre n = mσ2n pre n = m
(6.6.2)
Koeficienty cn(ω) procesu f vzhľadom na ortogonálnu deterministickú bázu vypočí-tame:
cn(ω) =⟨f ,bn⟩⟨bn,bn⟩
=1
||bn||2N−1∑k=0
f(ω, k)bn(k), n = 0, . . . , N − 1

154 Kapitola 6. Analýza viacrozmerných objektov
Číslo komplexne združené ku cm(ω) je
cm(ω) =1
||bm||2N−1∑k=0
f(ω, k) bm(k) m = 0, . . . , N − 1
Ak dosadíme cn(ω), cm(ω) do vzťahu (6.6.2) dostaneme
E(cn(ω) · cm(ω)
)= E
(1
||bn||2N−1∑k=0
f(ω, k)bn(k)1
||bm||2N−1∑k=0
f(ω, k)bm(k)
)
=
0 pre n = mσ2n pre n = m
Po ďalších úpravách dostaneme
1
||bn||2||bm||2N−1∑k=0
N−1∑l=0
E(f(ω, k)f(ω, l)
)bn(k) bm(l) =
0 pre n = mσ2n pre n = m
1
||bn||2 ||bm||2N−1∑k=0
bn(k)N−1∑l=0
rkl bm(l) =
0 pre n = mσ2n pre n = m
nakoniec
N−1∑k=0
bn(k)N−1∑l=0
rklbm(l) =
0 pre n = mσ2n ||bn||2 ||bm||2 pre n = m
(6.6.3)
pre n = m je pravá strana rovná 0, teda ostávajú len n = m, pričom platí
||bn||2 =N−1∑k=0
|bn(k)|2 =N−1∑k=0
bn(k)bn(k)
poslednú rovnosť rozšírime výrazom ||bn||2 σ2n, dostaneme
||bn||2 ||bn||2 σ2n =
N−1∑k=0
bn(k)||bn||2σ2nbn(k)
porovnaním poslednej rovnosti s (6.6.3) pre n = m dostaneme
N−1∑k=0
bn(k)N−1∑l=0
rkl bn(l) =N−1∑k=0
bn(k) ||bn||2 σ2n bn(k) (6.6.4)
Rovnosť (6.6.4) je splnená napríklad pre také bn a σ2n, pre ktoré platí
N−1∑l=0
rkl bn(l) = ||bn||2 σ2n bn(k)

6.6. Karhunen Loevov rozklad 155
označme λn = ||bn||2 σ2n
N−1∑l=0
rklbn(l) = λn bn(k)
alebo ak bn = (bn(0), bn(1), . . . , bn(N − 1)) a R = [rk,l]
Rbn = λn bn
Pre nekorelované cn(ω) dostaneme, že bázické vektory bn budú vlastné vektory ko-variančnej matice R náhodného procesu f .Vlastné čísla λn kovariančnej matice R určujú strednú energiu n-tej zložky cn(ω)bn
rozkladu náhodného procesu f .
λn = ||bn||2 σ2n = ⟨bn, bn⟩E
(|cn (ω)|2
)Ak zoradíme vlastné vektory podľa veľkosti vlastných čísel, ktoré im prislúchajú
λ0 ≥ λ1 ≥ · · · ≥ λN−1
najlepšou projekciou do M -rozmerného podpriestoru bude proces
f =M−1∑n=0
cn(ω)bn
a chyba aproximácie bude
||f − f ||2 =
N−1∑n=M
λn
Nekorelovanosť koeficientov cn(ω) zabezpečuje, že pre zadané M < N má odhad vKarhunen-Loevovej báze najmenšiu chybu.
Príklad 6.6.2 V tabuľke 6.9 sú váhy piatich novorodencov a váhy týchto detí v deňich prvých narodenín. Nech je náhodný vektor f(ω) modelom pre dáta, predstavujúce
dieťa váha pri narodení váha v 1. rokuD1 3 11D2 2.96 9D3 3.2 10D4 3.6 12D5 3.65 11.3
Tab. 6.9. Váha piatich detí pri narodení a v 1. roku
váhy detí pri narodení (prvá zložka vektora) a v deň prvých narodenín (druhá zložkavektora). Nájdite ortogonálnu bázu, v ktorej náhodný vektor f bude mať nekorelovanékoeficienty c0(ω), c1(ω).

156 Kapitola 6. Analýza viacrozmerných objektov
Riešenie:
Jednotlivé realizácie náhodného procesu f(ω) sú reprezentované maticou M.
M =
3 11
2.96 93.2 103.6 123.65 11.3
Vektory, reprezentujúce jednotlivé realizácie sú zakreslené na obrázku 6.12.
0 5
0
12
Obr. 6.12. Vektory zodpovedajúce matici M
Riadky centrovanej matice M sú zakreslené ako vektory na obrázku 6.13.Na obrázku 6.14 je zakreslená priamka predstavujúca bázový vektor v smere naj-
väčšieho rozptylu náhodného vektora f(ω).Na obrázku 6.15 je okrem prvej bázovej priamky nakreslená aj druhá bázová
priamka, ktorá je na prvú kolmá. Náhodná premenná c1(ω) predstavuje koeficientpriemetu vektora f(ω) na túto priamku. Koeficient c1(ω) je nekorelovaný s koeficien-tom c0(ω).

6.6. Karhunen Loevov rozklad 157
−1.5 0 1.5−2
0
2
Obr. 6.13. Vektory zodpovedajúce matici M
−1.5 0 1.5−2
0
2
Obr. 6.14. Smer najväčšieho rozptylu náhodného vektora f(ω)

158 Kapitola 6. Analýza viacrozmerných objektov
−2 −1.5 −1 −0.5 0 0.5 1 1.5 2−2
−1.5
−1
−0.5
0
0.5
1
1.5
2
Obr. 6.15: Dva kolmé smery, v ktorých má náhodný vektor f(ω) nekorelované koefi-cienty

7 Lineárne systémy
Začneme malým experimentom, ktorým ukážeme ako navzájom interagujú kĺzavésúčty a diskrétna Fourierova transformácia. Zoberme N = 2000 náhodne vybranýchreálnych čísel f1, . . . , f2000. Toto bude náš proces f . Takýto proces sa nazýva šumom.(Ak sme navyše vybrali fi navzájom nezávisle, tak sa f nazýva bielym šumom).
Naň aplikujeme kĺzavý súčet gk = fk+fk+1
2 a vytvoríme proces
g = (g1, . . . , g1999, 0)
Potom si vykreslíme ich amplitúdové spektrum, ako je to ukázané na obrázku 7.1.Na obrázku vidno, že spektrum pôvodného procesu je náhodné pre všetky Fourierove
0 200 400 600 800 1000
−30
−20
−10
010
20
Fourierové koeficienty
Am
plitú
dové
spe
ktru
m
Obr. 7.1: Amplitúdové spektrum procesu f (čierne krúžky) a amplitúdové spektrumprocesu g (červená čiara)
koeficienty. Avšak po aplikácii kĺzavého súčtu je vidno jasný trend. Pre nízke frekvenciespektrum je takmer nezmenené, zatiaľ čo vysoké frekvencie sú silno tlmené. Toto
159

160 Kapitola 7. Lineárne systémy
zaujímavé správanie sa využíva napríklad pri tvorbe ekvalizérov do HiFi systémov.Cieľom tejto kapitoly je pochopiť správanie podobných transformácií.
7.1 Lineárny systém
Transformácia jedného procesu na druhý sa nazýva (prenosovým) systémom. SystémT je schématicky znázornený na obrázku 7.2.
f g = T(f)Systém T
Obr. 7.2. Vstup a výstup zo systému T
Systém T sa nazýva lineárnym systémom, ak sa správa lineárne, tj.
T (f + g) = T (f) + T (g)T (c · f) = cT (f)
T (c1 · f1 + c2 · f2) = c1T (f1) + c2T (f2)T (c1 · f1 + c2 · f2 + . . .+ ck · fk) = c1T (f1) + c2T (f2) + . . .+ ckT (fk)
Kĺzavý súčet gk =fk + fk+1
2je typický príklad lineárneho systému.
Úloha 7.1.1 Ktoré z už uvedených vlastností spĺňajú systémy
• T1(f1, f2, f3) = (f1, f2, f3),
• T2(f1, f2, f3) = (f1 − f2, f2 − f3),
• T3(f1, f2, f3) =(√f1f2,
√f22 + f23
)?
Ak je proces lineárny, tak na jeho popis stačí odozva na jednotkové procesy (vek-tory). Odozva systému na jednotkový proces en sa nazýva impulzná charakteris-tika systému T . Označenie δn = T (en).Teda platí
f = T (N−1∑k=0
fkek) =N−1∑k=0
fkT (ek) =N−1∑k=0
fkδk
Príklad 7.1.1 Prenosový systém (lineárna transformácia) T , je úplne popísaný svo-jou odozvou na jednotkové impulzy:
δ0 = T (e0) =(1
2,1
2, 0
),
δ1 = T (e1) = (0, 1,−1),
δ2 = T (e2) =(−1
2, 0,
1
2
)

7.2. Modulácia 161
Proces f = (1, 2,−1) sa prenosovým systémom zobrazí na:
f = T (f) = T (1 · e0 + 2 · e1 − 1 · e2) = 1 · T (e0) + 2 · T (e1)− 1 · T (e2) =
= 1 · δ1 + 2 · δ1 − 1 · δ2 =
(1,
5
2,−5
2
)
7.2 Modulácia
V snahe čo najlepšie využiť kapacitu prenosového prostredia, používa sa pri prenosedát mechanizmus, ktorý dovoľuje tým istým kanálom prenášať rôzne dáta. Tento me-chanizmus sa nazýva modulácia a spočíva vo vtlačení určitého príznaku prenášanýmdátam tak, aby sa po prenose dali tieto dáta od seba bezpečne oddeliť, demodulovať.
Modulácia teda spočíva v transformácii procesu do tvaru, ktorý dovoľuje prenos.Matematický princíp, ktorý využíva modulácia, je vnorenie procesu do nadpriestoru.Jednotlivé hodnoty, ktoré chceme preniesť, prevedieme na vektory nadpriestoru tak,že ich vynásobíme bázovými vektormi patriacimi nejakej báze vektorového priestoru.Vynásobené vektory sčítame a takto skonštruovaný vektor (proces) prenesieme spo-ločným komunikačným prostredím. Po prenose, na strane prijímača proces demodulu-jeme tak, že urobíme jeho priemety do jednorozmerných podpriestorov generovanýchjednotlivými bázovými vektormi. Schéma postupu pri modulácii a demodulácii je na-kreslená na obrázku 7.3.
Obr. 7.3. Schématický náčrt princípu modulácie a demodulácie
Príklad 7.2.1 Na vstupe A je jedna hodnota z množiny 0, 1. Na vstupe B je jednahodnota z množiny 0, 1. Popíšte a zakreslite priebeh modulácie a demodulácie týchtohodnôt pomocou jednotkovej bázy dvojrozmerného vektorového priestoru.
Riešenie:Hodnotu cA z množiny 0, 1 na vstupe A vynásobíme vektorom (1, 0). Nech je tátohodnota 1.Hodnotu z cB množiny 0, 1 na vstupe B vynásobíme vektorom (0, 1). Nech je táto

162 Kapitola 7. Lineárne systémy
hodnota 0.Vektory sčítame a cez spoločné komunikačné prostredie prenesieme niektorý z vekto-rov (0, 0), (1, 0), (0, 1), (1, 1), v našom prípade to bude vektor (1,0).Demodulátor na strane prijímača potom urobí priemet preneseného vektora do dvochpodpriestorov. Do podpriestoru generovaného vektorom (1, 0) pre výstup A a do pod-priestoru generovaného vektorom (0, 1) pre výstup B.
cA =⟨(1, 0), (1, 0)⟩⟨(1, 0), (1, 0)⟩
= 1
cB =⟨(1, 0), (0, 1)⟩⟨(0, 1), (0, 1)⟩
= 0
Schéma postupu pri modulácii a demodulácii je nakreslená na obrázku 7.4.
Obr. 7.4. Schématický náčrt modulácie a demodulácie pre dve vstupné hodnoty
Úloha 7.2.1 Pri prenose dvoch hodnôt z množiny 0, 1, tak ako je popísaná v prí-klade 7.2.1, je komunikačným prostredím prenášaný dvojzložkový vektor. Aký je vlastnevýznam modulácie, keď namiesto dvoch hodnôt 1 a 0 je prenášaný vektor (1, 0)? Ne-stačilo by len povedať, že prvá zložka vektora bude hodnota zo vstupu A a druhá zložkavektora bude hodnota zo vstupu B? Vymyslite nejaké zdôvodnenie!
7.3 Optimálny prijímač
V úlohe modulácie sme riešili technickú úlohu ako cez jedno komunikačné prostredieprenášať naraz väčší počet správ. Teraz budeme riešiť úlohu, ako upraviť dáta preprenos tak, aby aj v prípade porúch počas prenosu, boli tieto na strane prijímačasprávne zrekonštruované. V tejto úlohe predpokladáme, že počas prenosu kanálombudú dáta náhodne zmenené. K prenášaným dátam sa pridá šum.
Na vstupe kanála dáta upravíme tak, aby na výstupe bolo možné správne iden-tifikovať, čo bolo vyslané. Úprava na vstupe bude spočívať vo vnorení hodnôt donadpriestoru tak, aby boli v tomto nadpriestore jednotlivé prenášané prvky od sebadostatočne vzdialené. Aj po prenose potom bude možné zistiť, čo bolo vyslané. Vy-sielanú hodnotu vynásobíme bázovým vektorom. Počas prenosu sa proces zašumí. Poprenose urobíme priemet procesu do podpriestoru generovaného bázovým vektorom.Priemet porovnáme s množinou prípustných výsledkov a vyberieme najbližší z nich.

7.3. Optimálny prijímač 163
Príklad 7.3.1 Na vstupe kanála je jedna hodnota z množiny 0, 1. Popíšte a zakres-lite spracovanie a optimálny príjem pomocou vektora (1, 1, 1).
Riešenie:Hodnotu c z množiny 0, 1 na vstupe vynásobíme vektorom b = (1, 1, 1). Ak je tátohodnota 1, budeme prenášať vektor f = 1 ·b = (1, 1, 1), ak je táto hodnota 0, budemeprenášať vektor f = 0 · b = (0, 0, 0).Vektor prenesieme cez komunikačný kanál, kde naň pôsobí šum a preto dostanemeniektorý z vektorov
(0, 0, 0), (1, 0, 0), (0, 1, 0), (1, 1, 0), (0, 0, 1), (1, 0, 1), (0, 1, 1), (1, 1, 1)
Nech to v našom prípade bude vektor f ′ = (1, 0, 1).Optimálny prijímač potom urobí priemet preneseného vektora do podpriestoru gene-rovaného vektorom b = (1, 1, 1).Koeficient priemetu f ′ vektora f ′ je
c =⟨f ′,b⟩⟨b,b⟩
=⟨(1, 0, 1), (1, 1, 1)⟩⟨(1, 1, 1), (1, 1, 1)⟩
= 0.67
Porovnajme teraz výsledný priemet f ′ = (0.67, 0.67, 0.67) s dvomi prípustnými mož-nosťami vyslaného procesu. Mohol to byť f0 = (1, 1, 1) alebo f1 = (0, 0, 0).
∥f ′ − f0∥ = ∥(−0.33,−0.33,−0.33)∥ =√
(−0.33)2 + (−0.33)2 + (−0.33)2
= 0.58
∥f ′ − f1∥ = ∥(0.67, 0.67, 0.67)∥ =√0.672 + 0.672 + 0.672 = 1.16
Porovnaním veľkosti odchýliek ∥f ′ − f0∥ a ∥f ′ − f1∥ usúdime, že pravdepodobne bolvyslaný vektor f0, a teda pôvodná vyslaná hodnota bola 1. Schéma použitia takéhotooptimálneho prijímača je nakreslená na obrázku 7.5.
kanál c=<f',b>
<b,b>
f'=(1,0,1)f=(1,1,1)
šum
0,1
f =(1,1,1)
f =(0,0,0)
0
1
b=(1,1,1)
||f -c.b||0
||f -c.b||1min 1
Obr. 7.5. Schéma práce optimálneho prijímača
Úloha 7.3.1 Navrhnite optimálny prijímač pre prenos 8 rôznych hodnôt. Koľko roz-merný vektorový priestor treba použiť?

164 Kapitola 7. Lineárne systémy
Poznámka:Optimálny prijímač a samoopravné kódy sú dve technológie, ktoré využívajú rovnakýprincíp vnorenia vektora, predstavujúceho prenášané slovo, do nadpriestoru. Komu-nikačným prostredím sú potom prenášané vektory, ktorých vzájomná vzdialenosť jedostatočne veľká na to, aby ich bolo možné aj po chybnom prenose správne vyhod-notiť. To znamená nahradiť najbližšími vektormi pôvodného priestoru. Optimálnyprijímač a samoopravné kódy teda používajú rovnaký princíp v rôznych vektorovýchpriestoroch, s rôznymi metrikami.
7.4 Lineárne časovo invariantné transformácie
Významnou skupinou lineárnych transformácií (systémov) sú transformácie časovoinvariantné (niekedy nazývané aj stacionárne transformácie), teda transformácie,ktoré nemenia svoje charakteristiky v čase.Presnejšie, odozva na vstup posunutý v čase, je výstup posunutý v čase:
T (e0) = (a0, a1, . . . , aN−1); ek = e0+k ⇒
T (ek) = T (e0+k) = (a0+k, a1+k, . . . , aN−1+k) = (ak, ak+1, . . . , ak−1)
Teda v e0, resp. v T (e0) robíme kruhový posun, preto na úplný popis časovo inva-riantnej transformácie stačí, ak poznáme hodnotu T (e0).
Príklad:Nech impulzná odozva na jednotkový impulz e0 = (1, 0, 0, 0) je
r = T (e0) = (1, 1,−1/2, 0)
Aká bude odpoveď lineárneho časovo invariantného systému (transformácie, popísanejodozvou r na vstupný proces f = (1, 2,−1, 3)?
e0 = (1, 0, 0, 0), T (e0) = (1, 1,−1/2, 0)
e1 = (0, 1, 0, 0), T (e1) = (0, 1, 1,−1/2)e2 = (0, 0, 1, 0), T (e2) = (−1/2, 0, 1, 1)e3 = (0, 0, 0, 1), T (e3) = (1,−1/2, 0, 1)
T (f) = T (1, 2,−1, 3) =1 · (1, 1,−1/2, 0)+ 2 · (0, 1, 1,−1/2)− 1 · (−1/2, 0, 1, 1)+ 3 · (1,−1/2, 0, 1)
=(9/2, 3/2, 1/2, 1)
Vyjadríme si teraz vzorce pre koeficienty f = T (f). Ak impulzná odozva na jednotkovýimpulz e0 je proces r
T (e0) = r = (r0, . . . , rn−1) (7.4.1)

7.5. Spektrálny popis lineárnych, časovo invariantných transformácií 165
tak pre prvú zložku f0 vektora f dostaneme:
f0 =r0f0 + r1f−1 + r2f−2 + · · ·+ rN−1f−N+1
=r0f0 + r1fN−1 + · · ·+ rN−1f1
a všeobecne
fk =
N−1∑n=0
fn rk−n (7.4.2)
Posledný výraz nazývame konvolúciou vektorov f , r
f = f ∗ r
Poznámka (model kĺzavého súčtu):
fk =M−1∑n=0
cnfk−n
Vidíme, že vzťah (7.4.2) sa podobá predchádajúcemu vzťahu. Rozdiel je iba v tom,že pri modeli kĺzavého súčtu sú nenulové hodnoty cn len pre n ≤ M − 1 (ostatné cnsú rovné nule).
7.5 Spektrálny popis lineárnych, časovo invariantnýchtransformácií
Ukázali sme, že ak T je lineárna, časovo invariantná transformácia, tak na popis tejtotransformácie stačí tzv. impulzná charakteristika.Pôvodný proces je definovaný nameranými hodnotami:
f = (f0, f1, . . . , fN−1)E
Jeho spektrálny popis je daný
f =N−1∑k=0
ckbk = (c0, c1, . . . , cN−1)B
Proces f ′ na výstupe lineárnej transformácie (systému) je popísaný
f ′ =N−1∑k=0
c′kb′k = (c′0, c
′1, . . . , c
′N−1)B′
Predpokladajme, že báza B aj B′ sú obe ortogonálne. Teda platí
⟨bn,bm⟩ = 0, pre n = m a takisto⟨b′
n,b′m⟩ = 0, pre n = m.

166 Kapitola 7. Lineárne systémy
Pre koeficienty c′n dostaneme
c′n =⟨f ′,b′
n⟩⟨b′
n,b′n⟩
=⟨T (f),b′
n⟩⟨b′
n,b′n⟩
=
⟨T (N−1∑k=0
ckbk),b′n⟩
⟨b′n,b
′n⟩
=
N−1∑k=0
ck⟨T (bk),b′n⟩
⟨b′n,b
′n⟩
=N−1∑k=0
ckFnk
Čísla Fnk tvoria štvorcovú maticu F a charakterizujú transformovaný proces f ′ vspektrálnej oblasti.
c′T= FcT
Nech teraz bázy B a B′ sú rovnaké, teda
b′n = bn
Platí (bn,bm) = 0, pre n = m a naviac nech platí (T (bn),bm) = 0, pre n = m.Dostávame
c′n =N−1∑k=0
ckFnk = Fnncn
Vektor F = (F0, F1, . . . , FN−1), (kde použijeme označenie Fn = Fnn) nazývame spek-trálny prenos lineárneho systému.
Príklad 7.5.1 Vypočítajme spektrálny prenos lineárneho časovo invariantného sys-tému s impulznou odozvou r = (1/2, 1/2, 0, . . .) na priestore rozmeru N = 1000.Musíme vybrať vhodnú ortogonálnu bázu bn. Jednotková báza nie je vhodná, pretožeodozva systému nedodržuje ortogonálnosť vektorov
⟨T (e0), e1⟩ = ⟨(1/2, 1, 2, 0, . . . , 0), (0, 1, 0, . . . , 0)⟩ = 1/2
Vhodná je harmonická báza.
⟨T (hm),hn⟩ = ⟨T(ej
2πN m, ej
2πN 2m, . . .
),hn⟩
= ⟨(0.5ej
2πN m + 0.5ej
2πN 2m, 0.5ej
2πN 2m + 0.5ej
2πN 3m, . . .
),hn⟩
= ⟨0.5hm + 0.5ej2πN mhm,hn⟩
= (0.5 + 0.5ej2πN m)⟨hm,hn⟩
Na obrázku 7.6 je ukázaná veľkosť jednotlivých koeficientov Fn. Tento výsledok vysvet-ľuje tlmenie vyšších frekvencií, ktoré bolo vidno v úvode kapitoly na obrázku 7.1.

7.6. Gradientová metóda 167
0 200 400 600 800 1000
0.0
0.2
0.4
0.6
0.8
1.0
n
Fn
Obr. 7.6: Spektrálny prenos lineárneho časovo invariantného systému s odozvou(1/2, 1/2, 0, . . .)
Ak na vstupe lineárneho, časovo invariantného systému je harmonický proces, takaj na výstupe je harmonický proces (je to jediný proces s touto vlastnosťou):
b′n = bn = (1, e−j 2π
N n, . . . , e−j 2πN n·k, . . . , e−j 2π
N n·(N−1))
T (bn) = (Fn1, Fne−j 2π
N n, . . . , Fne−j 2π
N n·k, . . . , Fne−j 2π
N n·(N−1))
c′n = Fncn = |Fn|ejφncn
Na to, aby sme zistili F = (F0, F1, . . . , FN−1), dávame na vstup postupne všetky vek-tory harmonickej bázy.
Pomocou spektrálneho popisu teda vieme určiť časový priebeh výstupného pro-cesu:
f −→T −→ f ′
DFT ↓ ↑ DFT−1
c −→cnFn→ c′
7.6 Gradientová metóda
Gradientová metóda slúži na hľadanie minima alebo maxima. Začneme najjednoduch-ším prípadom, keď hľadáme minimum funkciu iba jedného argumentu f(x), ktorá jeznázornená na obrázku 7.7. Povedzme, že začíname v bode x1. Keďže funkcia v blíz-kosti x1 klesá, v hľadaní minima je najlepšie pokračovať doprava. Ak by sme všakzačali v bode x3, v ktorého okolí funkcia rastie, najlepšie je pokračovať doľava. To, či

168 Kapitola 7. Lineárne systémy
x x x1 2 3
f(x)
Obr. 7.7. Hľadanie minima funkcie
funkcia rastie, alebo klesá sa dá určiť z derivácie, ktorá vyjadruje sklon dotyčnice kugrafu funkcie f(x)
hodnota f ′(x)
> 0 funkcia rastie, a teda hľadaj vľavo< 0 funkcia klesá, a teda hľadaj vpravo
Príčina, prečo hrá určujúcu úlohu derivácia je, že v blízkosti bodu x platí približnáaproximácia
f(x+∆x) ≈ f(x) + f ′(x)∆x
V prípade funkcie dvoch premenných f(x1, x2) pri hľadaní minima už nemáme navýber len dva smery, ale nekonečne veľa smerov. Keby sme boli na kopci, a hľadámenajnižší bod, prirodzené je vybrať sa najstrmším smerom. Ako však určiť najstrmšísmer v prípade funkcie? Použitím Taylorovho rozvoja funkcie a predpokladu, že fun-kcia je približne lineárna v bode, z ktorého sa plánujeme pohnúť, dostávame
f(x1 +∆x1, x2 +∆x2) ≈ f(x1, x2) +∂f
∂x1∆x1 +
∂f
∂x2∆x2,
alebo inak povedané, prírastok funkcie je (približne) lineárnym systémom smeru po-hybu
f(x1 +∆x1, x2 +∆x2)− f(x1, x2) ≈∂f
∂x1∆x1 +
∂f
∂x2∆x2
=( ∂f∂x1
,∂f
∂x2
)·(∆x1,∆x2)
=
∣∣∣∣∣∣∣∣( ∂f∂x1 , ∂f∂x2)∣∣∣∣∣∣∣∣ ||(∆x1,∆x2)|| cosα,
kde α je uhol medzi gradientom
grad f :=( ∂f∂x1
,∂f
∂x2
)

7.7. Metóda adaptívneho hľadania koeficientov 169
a vektorom smeru, ktorý má zložky (∆x1,∆x2). Pri hľadaní minima je zjavne naj-lepšie, aby cosα = −1, a teda vybrali sme sa smerom opačným ku gradientu (vtedyje uhol π). Takže ďalší bod hľadania bude
x′ = x− s · grad f
kde veľkosť kroku s sa môže vybrať na základe experimentálneho testovania.Naopak pri hľadaní maxima je najlepšie, aby cosα = 1, a teda vybrali sa v smere
gradientu x′ = x+ s · grad f .
7.7 Metóda adaptívneho hľadania koeficientov
Príklad 7.7.1 Aplikujte gradientovú metódu na hľadanie optimálnych koeficientovg0, g1 pre predikčný model procesu f
fk = akfk−1 + bkfk−2.
Riešenie:Budeme postupne meniť koeficienty ak, bk tak, aby sme zmenšili chybu, ktorej smesa dopustili. Chyba
e2k = (fk − fk)2,
ktorej sa dopustíme je funkciou dvoch premenných e2k = E(ak, bk). Menšiu chybudosiahneme, keď zmeníme ak, bk pomocou gradientovej metódy. Gradient je vektor,ktorý má smer najvyššieho nárastu funkcie e2k = E(ak, bk), v závislosti od hodnôt ak,bk.
(ak+1, bk+1) = (ak, bk)− s grad e2k
grad e2k = (∂e2k∂ak
,∂e2k∂bk
)
Pre funkciu E, ktorá je konvexná sa týmto spôsobom dostaneme k minimu.Dostávame:
∂e2k∂ak
=∂
∂ak(fk − fk)2 =
∂
∂ak(fk − (akfk−1 + bkfk−2))
2 =
= 2(fk − (akfk−1 + bkfk−1))(−fk−1) = −2ekfk−1
Nasledujúce a0 teda položíme (podľa gk+1 = gk − s · grad e2k)
ak+1 := ak + 2s ekfk−1
Podobne:∂e2k∂bk
=∂
∂bk(fk − fk)2 =
∂
∂bk(fk − (akfk−1 + bkfk−2))
2 =
= 2(fk − (akfk−1 + bkfk−2))(−fk−2) = −2ekfk−2

170 Kapitola 7. Lineárne systémy
Nasledujúce bk+1 teda položíme
bk+1 := bk + 2s ekfk−2
Celkovo teda dostávame
(ak+1, bk+1) = (ak, bk) + s · ek(fk−1, fk−2)
Tento postup hľadania optimálneho predikčného modelu je špeciálnym prípadom
filtra najmenších stredných štvorcov objaveného B. Widrowom a T. Hoffom [23].

8 Diskrétne lineárne systémy
V informatike, sieťových, mobilných či rádiových komunikáciach sa stretávame so sys-témami, kde procesy pozostávajú z núl a jednotiek. Systémy, ktoré spracúvajú takétoprocesy nazveme diskrétnymi. Takéto systémy sa používajú napríklad na kompresiudigitálnych dát. Vstupom do systému môže byť binárny súbor alebo nejaký tok dát(povedzme zvuková nahrávka, alebo videosignál z kamery). Výstupom sú tiež binárnedáta, ale vhodne skomprimované, aby sa ušetrilo miesto.
Takpovediac opačný prístup má kódovanie. Pri kódovaní sa vstupné digitálne dátanejakým spôsobom zakódujú a objem dát väčšinou vzrastie. Kódovanie slúži buď naochranu dát pred rušivými vplyvmi na komunikačné kanály, alebo na ochranu dátpred neautorizovaným prístupom (šifrovanie).
Dekóder D
zakódované dáta fvstupné dáta d
Kóder K
dáta d'
rušivé prvky
pozmenené dáta f'
výstupné
Pri kódovaní sa často používajú lineárne systémy, ako si teraz ukážeme.
8.1 Detekcia parity
Pri reprezentácii dát v počítači sa používajú N -tice núl a jednotiek. Jednu takútoN -ticu nazveme slovo. Na najjednoduchšie zabezpečenie, ktoré umožňuje detekovaniechyby, sa používa zabezpečenie paritou. Spočíva v pridaní jedného bitu ku každémuprenášanému slovu tak, aby celkový počet jednotiek v zabezpečenom slove bol párny.Po prenesení sieťou sa v prenesenom slove spočítajú jednotky. Ak je ich počet nepárny,pri prenose určite nastala chyba.
Príklad 8.1.1 Urobte matematický model, ktorý popisuje zabezpečenie paritou akotransformáciu vektora do nadpriestoru.
171

172 Kapitola 8. Diskrétne lineárne systémy
Riešenie:Úlohu vysvetlíme na slovách, ktoré budú pozostávať z N znakov (0 alebo 1). TietoN -tice tvoria vektorový priestor S so skalármi 0 a 1. Operácie sčítania a násobeniaskalárov 0 a 1 sú definované ako sčítanie a násobenie modulo 2, (tabuľka 8.1).⊕
2 0 10 0 11 1 0
⊗2 0 1
0 0 01 0 1
Tab. 8.1. Tabuľky sčítania a násobenia modulo 2
Súčet vektorov f = (f0, f1, . . . , fN−1) a g = (g0, g1, . . . , gN−1) v priestore S je defino-vaný predpisom f + g = (f0 ⊕2 g0, f1 ⊕2 g1, . . . , fN−1 ⊕2 gN−1).Vektor f = (f0, f1, . . . , fN−1) patriaci do N -rozmerného vektorového priestoru S mô-žeme zapísať ako lineárnu kombináciu vektorov jednotkovej bázy
E = (1, 0, 0, 0, . . . , 0), (0, 1, 0, 0, . . . , 0), . . . , (0, 0, 0, 0, . . . , 1)
f = f0(1, 0, 0, 0, . . . , 0) + f1(0, 1, 0, 0, . . . , 0) + · · ·+ fN−1(0, 0, 0, 0, . . . , 1)
Vytvorme zabezpečený vektor f⋆ ako prvok N + 1-rozmerného vektorového priestoruS⋆. Bude to vektor f⋆ = (f0, f1, . . . , fN−1, z), kde z je podľa parity číslo 0 alebo 1.Ľubovoľná lineárna kombinácia dvoch zabezpečených kódových slov je zase zabez-pečené kódové slovo. Preto zabezpečené kódové slová tvoria N -rozmerný vektorovýpodpriestor K vektorového priestoru S⋆(N + 1-rozmerného).
Bázou podpriestoru K, ktorý pozostáva zo slov kódu (=zabezpečených slov) jemnožina
BK = (1, 0, 0, 0, . . . , 0, 1), (0, 1, 0, 0, . . . , 0, 1), . . . , (0, 0, 0, 0, . . . , 1, 1)
Ak vektor
f⋆ = f0(1, 0, 0, 0, . . . , 0, 1) + f1(0, 1, 0, 0, . . . , 0, 1) + · · ·+ fN−1(0, 0, 0, 0, . . . , 1, 1)
po prenose sieťou nie je prvkom podpriestoru K, tak hovoríme, že bola detekovanáchyba.Príklad prenášaného slova a jeho zabezpečenia je na obrázku 8.1.
0 1 1 0 1 0 0 0 1 1 1
kódované slovo
paritný bit
Obr. 8.1. Zabezpečenie slova paritou
Na obrázku 8.2 vidíme príklad poškodeného slova, teda slova, ktoré nepatrí do pod-priestoru kódových slov K.

8.2. Ochrana proti reverzii polarity 173
0 1 1 0 1 0 0 0 0 1 1
poškodené kódové slovo
poškodený bit
Obr. 8.2. Detekcia chyby pri zabezpečení paritou
Úloha 8.1.1 Navrhnite spôsob, ako zistiť, že zvolený vektor f⋆, ktorý je prvkom N+1-rozmerného vektorového priestoru S⋆ je vektorom podpriestoru K všetkých zabezpeče-ných kódových slov. Pri riešení sa môže využiť skutočnosť, že vektor v⋆ = (1, 1, . . . , 1)je kolmý na všetky vektory podpriestoru K.
Pri zabezpečení paritou je možné detekovať chybu, ale nie je to zaručené. Chybanebude zistená, ak sa zmenia 2, alebo párny počet bitov. Po detekovaní chyby jepotrebné poškodené slovo preniesť znovu, pretože táto metóda nedáva odpoveď nato, ktorý bit bol poškodený.
8.2 Ochrana proti reverzii polarity
Pri komunikáciach sa môže stať, že sa zmení fáza vstupu. To spôsobí, že nuly ajednotky sa navzájom vymenia. Toto je vcelku katastrofická chyba, pretože všetkyvstupné bity sú nesprávne. Existuje však jednoduchý a spoľahlivý spôsob ochrany.
Povedzme, že na vstupe príde dátový vektor (d1, d2, . . . , dn). Kódovací systémpošle na výstup vektor pozostávajúci z čiastkových súčtov
(f1, f2, . . .) := (0, d1, d1 + d2, , d1 + d2 + d3 + . . .)
Tieto čiastkové súčty sa dajú počítať aj rekurzívne vzorcami
f1 := 0
f2 := f1 + d1
f3 := f2 + d2
. . .
Schématicky sa takýto výpočet dá znázorniť schémou ako na obrázku 8.3. Tento kodérmá jednobitové pamäťové miesto P , kde si ukladá čiastkové súčty ft. Tie sú potomposielané spolu s novým vstupom do sčítačky, ktorá svoj výstup posiela aj do pamäteP , aj do výstupného kanála.
Dekodér funguje tak, že sa prijaté dáta postupne diferencujú. Keďže fi+1 = fi+di,vzájomné rozdiely fi+1 − fi nám dajú bity di, ak nedôjde k zmene polarity. Zmenapolarity však znamená, že ku všetkým bitom sa pripočíta 1, a teda zmena polaritynezmení výsledok dekódovania.

174 Kapitola 8. Diskrétne lineárne systémy
P
d tf t
+
Obr. 8.3. Kodér na opravu reverzie polarity
Príklad 8.2.1 Povedzme, že sme zakódovali postupnosť d = (1, 1, 0, 1, 1). Kodér vyšlepostupnosť
f = (0, 1, 1 + 1, 1 + 1 + 0, 1 + 1 + 0 + 1,+1 + 1 + 0 + 1 + 1) = (0, 1, 0, 0, 1, 0).
Ak prišla nezmenená, tak diferencovaním získame
(1− 0, 0− 1, 0− 0, 1− 0, 0− 1) = (1, 1, 0, 1, 1).
Ak došlo k reverzii polarity, tak dekodér prijal vektor (1, 0, 1, 1, 0, 1). Diferencovanímdostane
(0− 1, 1− 0, 1− 1, 0− 1, 1− 0) = (1, 1, 0, 1, 1).
Dekodér teda v obidvoch prípadoch vráti správne dáta.
8.3 Hammingov (7,4) kód
Hamming popísal tento kód vo svojom článku v roku 1950 [8], ktorým otvoril výskumkódovacej teórie. Tento kód funguje tak, že pridáva ku každej štvorici bitov 3 bitynavyše (odtiaľ pochádza jeho pomenovanie, sedem zakódovaných bitov zo štyrochdátových bitov). Oproti paritnému kódovaniu je tento kód schopný detekovať nielenjednu chybu, ale aj dve chyby. Navyše, ak nastala chyba iba v jednom bite, tak jeschopný určiť, ktorý bit to bol a opraviť ho. Takýto kód sa nazýva samoopravný.
Kodér funguje tak, že vstupný vektor zľava vynásobí maticou G, kde
G =
1 1 0 11 0 1 11 0 0 00 1 1 10 1 0 00 0 1 00 0 0 1
.
Všimnime si, že 3, 5, 6 a 7 riadok obsahujú iba jednu jednotku, a teda zakódovanývektor f má na pozíciach 3, 5, 6 a 7 pôvodné bity.

8.3. Hammingov (7,4) kód 175
Príklad 8.3.1 Zakódujme vektor d = (1, 1, 0, 1). Tento vektor vynásobíme maticouG a dostaneme
G · d =
1 1 0 11 0 1 11 0 0 00 1 1 10 1 0 00 0 1 00 0 0 1
1101
=
3212101
=
1010101
← d1
← d2← d3← d4
Hammingovho kód sa dá použiť dvoma spôsobmi.
• (Samoopravný kód) Ak je pravdepodobnosť chýb jednotlivých bitov nezávislá,potom je omnoho pravdepodobnejšie, že nastane nanajvýš jedna chyba, ako to,že nastanú dve alebo viac chýb. Hammingov kód sa dá použiť na detekciu jednejchyby a opraviť ju.
• (Detekčný kód) Niekedy je takmer rovnako pravdepodobné, že nastane jednaalebo dve chyby vedľa seba. Toto je typicky prípad pre výstup z konvolučnýchkódov, ktoré budú definované v ďalšej časti kapitoly. Vtedy sa Hammingov kódpoužíva na detekciu chyby prenosu.
8.3.1 Samoopravný kód
Prvým krokom pri dekódovaní je výpočet vektora nazývaného syndrómový vektor.Tieto syndrómy sa vypočítajú ako súčin matice H s prijatým vektorom f ′.
H :=
1 0 1 0 1 0 10 1 1 0 0 1 10 0 0 1 1 1 1
Ak dostaneme nulový vektor, tak nenastala žiadna chyba. Ak nám vyjde nenulovývektor, tak chyba nastala v bite, ktorého pozíciu kóduje výsledné dvojkové číslo.
Príklad 8.3.2 Pokračujeme v príklade 8.3.1. Povedzme, že nastala chyba v 6 bite adostali sme na vstup do dekodéra vektor f = (1, 0, 1, 0, 1, 1, 1). Vynásobením maticou

176 Kapitola 8. Diskrétne lineárne systémy
H dostaneme
H · f =
1 0 1 0 1 0 10 1 1 0 0 1 10 0 0 1 1 1 1
1010111
=
433
=
011
Keďže sme dostali nenulový syndróm, nastala chyba na mieste 1102 = 6. Keď tútochybu opravíme, dostaneme vektor f ′ = (1, 0, 1, 0, 1, 0, 1), o ktorom už ľahko overíme,že syndrómy Hf ′ sú rovné 0. Pôvodné dáta nájdeme na 3., 5., 6. a 7. mieste oprave-ného slova, a teda dekódovaný výstup je (1, 1, 0, 1).
Na prvý pohľad sa môže zdať neuveriteľné, ako niekto mohol prísť na takétomatice. Ukážeme si teraz, že matica H je daná jednoznačne, a matica G sa dá tiežľahko vybrať. Zhrňme si najprv požiadavky na tieto matice
P1 Kódovanie je dané vzorcom f = Gd,
P2 Ak nenastala chyba, musia byť syndrómy Hf rovné 0,
P3 Ak ani jeden bit nebol zmenený, musíme byť schopní dekódovať pôvodné dáta,
P4 Ak práve jeden bit bol pri prenose zmenený, jeho pozícia v dvojkovej sústave jerovná Hf .
Tieto štyri požiadavky zjavne stačia na to, aby kód bol odolný voči jednej možnejchybe.
Najprv si ukážeme, ako je skonštruovaná matica H. Ak budeme kódovať nulovývektor d, tak podľa P1 dostaneme nulový vektor f = 0. Ak nastane chyba na i-tommieste, tak sme neprijali 0 ale vektor ei, a podľa P4 dostávame
Hei = číslo i v dvojkovej sústave.
Lenže podľa pravidiel na násobenie matíc, výraz na ľavej strane je rovný i-temu stĺpcumatice H. Preto matica H musí mať v i-tom stĺpci zapísané i v dvojkovej sústave, čoaj má. Takže matica H je jednoznačne určená.
12 102 112 1002 1012 1102 1112↓ ↓ ↓ ↓ ↓ ↓ ↓1 0 1 0 1 0 1
prvky H→ 0 1 1 0 0 1 10 0 0 1 1 1 1

8.3. Hammingov (7,4) kód 177
Teraz si ukážeme, ako prísť na maticu G. Z vlastnosti P2 dostávame pre bezchybneprijatý vektor f = Gd
0 = Hf = H(Gd) = (HG)d.
Toto musí platiť pre všetky vektory, a teda aj pre jednotkové vektory ei. Teda musíplatiť
0 = (HG)ei ← výsledkom násobenia je i-ty stĺpec HG,
a teda každý stĺpec HG je nulový a preto HG musí byť nulová matica. Toto jezaujímavý fakt, ale ešte sme sa nezaoberali vlastnosťou P3. Tú môžeme dosiahnuťnapríklad tak, že všetky pôvodné bity d sa objavia vo vektore f . Povedzme si na-príklad, že budú na 1., 2., 3. a 4. mieste vektora f . To zaručia aj matice vyzerajúcenasledovne:
G′ =
1 0 0 00 1 0 00 0 1 00 0 0 1. . . .. . . .. . . .
, G′′ =
0 1 0 01 0 0 00 0 1 00 0 0 1. . . .. . . .. . . .
kde na mieste bodiek môže byť alebo 0 alebo 1. Teraz určíme hodnoty bodiek prematicu G′. Treba zabezpečiť rovnosť HG′ = 0. Ak si označíme bodky neznámymig51, . . . , g74 dostávame
HG′ =
1 0 1 0 1 0 10 1 1 0 0 1 10 0 0 1 1 1 1
1 0 0 00 1 0 00 0 1 00 0 0 1g51 g52 g53 g54g61 g62 g63 g64g71 g72 g73 g74
=
0 0 0 00 0 0 00 0 0 0
Toto si môžeme prepísať ako sústavu 12 rovníc o 12 neznámych. Napíšme si prvé trirovnice zodpovedajúce násobeniu prvým stĺpcom matice G′.
1 + g51 + g71 = 0
g61 + g71 = 0
g51 + g61 + g71 = 0
Z druhej rovnice dostávame g61 = −g71 = g71, keďže v dvojkovej sústave násobenie −1nemení prvky. Z tretej rovnice dostávame g51 + 2g61 = 0, a teda g51 = 0. Dosadenímdo prvej rovnice dostávame g71 = 1, a teda aj g61 = 1.
Úloha 8.3.1 Dopočítajte všetky prvky matice G′. Na aký vektor nám táto maticazakóduje vektor (1, 1, 0, 1) ?
Úloha 8.3.2 Dopočítajte všetky prvky matice G′′. Na aký vektor nám táto maticazakóduje vektor (1, 1, 0, 1) ?

178 Kapitola 8. Diskrétne lineárne systémy
8.3.2 Detekčný kód
Hammingov kód je na rozdiel od paritného kódu schopný detekovať aj dve chyby ato tým, že syndrómový vektor bude nenulový.
Príklad 8.3.3 Povedzme, že sme namiesto vektora f = (1, 0, 1, 0, 1, 0, 1) prijali vek-tor f ′ = (1, 1, 1, 0, 1, 1, 1), ktorý sa od neho líši v dvoch bitoch (na 2. a 6. mieste).Vypočítame syndróm
Hf ′ =
1 0 1 0 1 0 10 1 1 0 0 1 10 0 0 1 1 1 1
1110111
=
001
Keďže nám vyšiel nenulový syndróm, dostávame, že pri prenose nastala chyba alebo vjednom bite alebo v dvoch bitoch.
Všimnime si, že tieto dva prípady nemožno rozlíšiť. Zakódovaním vektora (1, 1, 1, 1)totiž dostaneme
1 1 0 11 0 1 11 0 0 00 1 1 10 1 0 00 0 1 00 0 0 1
1111
=
1111111
,
ktorý sa tiež líši od f ′ iba na jednom mieste. Preto nie sme schopní chybný vektordekódovať a rozlíšiť, či na vstupe bol vektor (1, 1, 0, 1) a nastali chyby v dvoch bitoch,alebo na vstupe bol vektor (1, 1, 1, 1) a nastala chyba v jednom bite. Sme schopní ibaurčiť, že pri prenose nastala nejaká chyba, podobne ako pri paritnom kóde.
Ak nastala chyba na i-tom mieste, tak po vynásobení H dostaneme
H(f + ei) = Hf +Hei = 0 +Hei = si
kde si je dvojkovo zapísaná pozícia i.Ak nastali chyby na i-tom a j-tom mieste tak po vynásobení prijatého vektora
maticou H dostaneme
H(f + ei + ej) = 0 + si + sj = si + sj
a si = sj a tak ich súčet v dvojkovej sústave nemôže byť nula.Všimnime si, že linearita výpočtu syndrómov bola kľúčová na dokázanie schop-
nosti detekcie dvoch chýb. Ďalej si treba uvedomiť, že schopnosť detekcie chyby boladaná tým, že ľubovoľné dve rôzne kódové slová sa líšili aspoň v 3 bitoch. Počet

8.4. Konvolučné kódy 179
rozdielnych bitov sa nazýva aj Hammingova vzdialenosť dvoch slov. Hammingov(7,4) kód funguje ako detekčný kód pre 1 alebo 2 bitové chyby preto, lebo minimálnaHammingova vzdialenosť medzi dvoma rôznymi kódovými slovami je aspoň 3.
Úloha 8.3.3 Koľko chybových bitov bude schopný detekovať kód, ktorý má minimálnuvzdialenosť medzi rôznymi kódovými slovami rovnú 5? Skúste navrhnúť lineárny kód,ktorý má minimálnu Hammingovu vzdialenosť aspoň 5.
8.4 Konvolučné kódy
Konvolučný kodér pozostáva z binárnych sčítačiek a pamäťových registrov, podobneako kodér z kapitoly 8.1. Na rozdiel od blokových kódov, tento kodér spracuje ľubo-voľne dlhý reťazec bitov.
Na obrázku 8.4 je znázornený príklad obvodu konvolučného kodéra. Ak si označíme
R S
+
d t
f
f
2t
2t-1
++
Obr. 8.4. Nerekurzívny konvolučný kodér s dvoma pamäťovými bitmi R,S.
Rt a St hodnoty pamäťových registrov R a S v čase t, tak zo schémy vyplývajúrovnosti:
Rt = dt−1
St = Rt−1 = dt−2
f2t = St + (dt +Rt) = dt−2 + dt−1 + dt
f2t−1 = St + dt = dt−2 + dt
(8.4.1)
Z týchto rovníc vidno, že konvolučný kodér je diskrétny lineárny systém.V Exceli, alebo inom tabuľkovom procesore si môžeme na základe rovníc (8.4.1)
pripraviť aj tabuľku rôznych stavov v závislosti od vstupných bitov dt:
Kódovanie
Rovnice (8.4.1) umožňujú ľahko naprogramovať kodér. Pre lepšie pochopenie činnostikonvolučného kodéra je však lepšie popísať ho pomocou prechodového diagramu, ktorýznázorňuje zmenu stavu pamäťových registrov.Na ľavej strane sú znázornené zakódované bity f pre každú možnosť vstupného bitu dt.Podobne pre každý stav na pravej strane Rt+1St+1 sú znázornené dve možnosti páru

180 Kapitola 8. Diskrétne lineárne systémy
vstup registre registre výstupdt−2 dt−1 dt Rt St Rt+1 St+1 f2t f2t−1
0 0 0 0 0 0 0 0 00 0 1 0 0 1 0 1 10 1 0 1 0 0 1 1 00 1 1 1 0 1 1 0 11 0 0 0 1 0 0 1 11 0 1 0 1 1 0 0 01 1 0 1 1 0 1 0 11 1 1 1 1 1 1 1 0
Tab. 8.2. Výpočtová tabuľka pre konvolučný kodér z obrázka 8.4
00
01
10
11
00
01
10
11
0,00
1,11
0,11
1,00
0,01
1,10
0,10
1,01
0,00
0,11
0,01
0,10
1,11
1,00
1,10
1,01
R Stt R t+1t+1d,f d,fS
Obr. 8.5. Prechodový diagram konvolučného kodéra z obrázka 8.4
bitov, ktoré kodér vyslal, a bit, ktorý prijal, aby sa dostal do tohto stavu. Všimnimesi, že bitové páry f pri každom stave, či už na ľavej strane, alebo na pravej stranesa odlišujú. To je v súlade s predpokladom, že kodér zakóduje dve rôzne postupnostid,d′ do dvoch rôznych postupností f , f ′ (za predpokladu, že počiatočné registre boliv rovnakom stave).
Ilustrujme si teraz použitie tohto prechodového diagramu na kódovanie postup-nosti bitov d = (0, 1, 0). Budeme predpokladať, že na začiatku boli registre R a Svynulované. Stavy, ktorými postupne prejde kodér sú znázornené na obrázku 8.6.Tento obrázok sa nazýva trellis.
Dekódovanie
Na dekódovanie sa najčastejšie používa Viterbiho algoritmus. Ten sa snaží nájsť takúpostupnosť zmien stavov kodéra, ktorá zodpovedá najmenšiemu počtu chýb. Pri dekó-dovaní sa pre každý stav pamätá jedna postupnosť, ktorá má najmenší počet bitovýchzmien od prijatých dát. Začne sa od počiatočného stavu (R,S) = (0, 0) a postupne

8.4. Konvolučné kódy 181
00
01
10
11
00
01
10
11
00
01
10
11
00
01
10
11
00 11 01Výstupný vektor f
Obr. 8.6: Postupnosť stavov (R,S), ktorými kodér prejde pri kódovaní vektora (0, 1, 0)
sa rozoberú stavy kodéra po každom prijatom písmene, pričom sa pre každý stavvypočíta najmenší možný počet chýb na to, aby sa kodér dostal do daného stavu.Vyhráva koncový stav s najmenším počtom chýb. Toto je znázornené na obrázku 8.7pre prijatú postupnosť f = (01 10 10).
0 1
1
2
3
2
1
3
3
3
2
01 10Prijaté dáta
10
1
1
1
1
2
0
1
1
2
2
1
1
0
2
Obr. 8.7. Vypočítané minimálne počty chýb pre každý stav v trellise.
Úloha 8.4.1 Pozrite si schému konvolučného kodéra na obrázku 8.8. Napíšte vzorcepre správanie tohto kodéra a nakreslite príslušný prechodový diagram. Použite Viter-biho dekódovací algoritmus na dekódovanie nasledujúcich postupností bitov
• 01,
• 01 10,

182 Kapitola 8. Diskrétne lineárne systémy
• 01 10 11,
• 01 10 11 11.
U V+
d t f
f
2t
2t+1
d t
+ +
=
Obr. 8.8. Rekurzívny konvolučný kodér s dvoma pamäťovými bitmi U, V
Použitie
Kombinácie konvolučných kódov so samoopravnými kódmi sú považované za vysokospoľahlivé a používajú sa v rôznych komunikačných aplikáciách, ako je napríkladdigitálna televízia. Dvojice konvolučných kódov sa používajú vo vysoko efektívnychturbo kódoch.
8.5 Polynomiálne kódy
Iným príkladom kódu je cyklický kód, ktorého názov sa odvodzuje od vlastnosticyklického opakovania sa zvyškov po delení generujúcim polynómom.
Myšlienku zabezpečenia delením dohodnutým deliteľom môžeme ukázať na delenícelými číslami. Dohodnime sa napríklad, že na zabezpečenie čísla 124 pre prenos jepotrebné ho upraviť na číslo, ktoré bude deliteľné číslom 7.
124 : 7 = 17 (zvyšok 5) (8.5.1)
Upravíme číslo 124:124− 5 = 119
Číslo 119 už bude deliteľné bezo zvyšku. Toto číslo prenesieme sieťou. Ak po prenosebude na strane prijímača číslo deliteľné 7, prenos bol bezchybný a vieme, že prenesenéčíslo 119 bolo skutočne aj vyslané. Problémom ostáva, že 119 nie je pôvodné číslo 124.Ako 119 mohli byť vyslané aj čísla 120, 121, 122, 123 alebo 125. Pri tomto kódovanínastala zmena pôvodného slova a preto sa nedozvieme, presne aké slovo bolo vyslané.Také kódy, pri ktorých sa pôvodné slovo zmení, sa nazývajú nesystematické kódy.
Kódy, pri ktorých sa ku pôvodnému slovu iba pridá zabezpečovacia časť (blok), sanazývajú blokové kódy.

8.5. Polynomiálne kódy 183
Ak chceme zabezpečiť číslo 124 tak, aby sme ho neporušili, pripíšeme zaň ešte jednucifru 124x. Číslo x bude také, aby bolo číslo 124x deliteľné siedmimi.
124x : 7 = 1246 : 7 = 178 zvyšok 0 (8.5.2)
Číslo x = 6 nájdeme tak, že za 124 pripíšeme 9, potom vydelíme 1249 : 7 = 178zvyšok 3. Nakoniec odpočítame 1249 − 3 a dostaneme zabezpečené slovo 1246. Totočíslo je skutočne deliteľné číslom 7 bezo zvyšku.
Úloha 8.5.1 Fungoval by tento postup kódovania, ak by sme pripisovali
• cifru 2,
• cifru 8?
Ukážkou blokového kódu je cyklický kód z nasledujúceho príkladu, ktorý sa v praxinaozaj používa.
Príklad 8.5.1 (Cyklický kód s generujúcim polynómom, CRC)Nech slovo, ktoré má byť zakódované je pätica pozostávajúca z núl a jednotiek, naprí-klad 11011. Za toto slovo pridáme nejaký počet binárnych číslic (v tomto prípade sú točíslice 001) tak, aby polynóm, reprezentovaný celým zabezpečeným slovom bol deliteľnýnejakým vopred dohodnutým generujúcim polynómom, napríklad q(x) = x3 + x + 1.Zabezpečené slovo je na obrázku 8.9.
prenášané slovočíslicenavyše
Obr. 8.9. Blokový kód, ktorý zabezpečí slovo 11011 blokom 001
Zabezpečené slovo bude polynóm s koeficientmi 1, 1, 0, 1, 1, 0, 0, 1 pri jednotlivýchmocninách x, konkrétne
1 · x7 + 1 · x6 + 0 · x5 + 1 · x4 + 1 · x3 + 0 · x2 + 0 · x1 + 1 · x0 = x7 + x6 + x4 + x3 + 1
Sčítanie a delenie polynómov definujeme tak, aby koeficienty polynómov boli vždy zmnožiny 0, 1. Pri súčte polynómov budú koeficienty pri zodpovedajúcich mocnináchsúčtom modulo 2. Pri algoritme delenia rovnako použijeme násobenie a sčítanie mo-dulo 2.Pre uvedené polynómy potom naozaj platí(
x7 + x6 + x4 + x3 + 1):(x3 + x+ 1
)= x3 + x2 + x+ 1 (zvyšok 0)
Ako sa vypočítajú hodnoty 001 v zabezpečovacom bloku? Ako sa detekuje chyba v pre-nesenom slove?

184 Kapitola 8. Diskrétne lineárne systémy
Riešenie:Prenášanému slovu 11011 zodpovedá polynóm
f(x) = 1 · x4 + 1 · x3 + 0 · x2 + 1 · x1 + 1 · x0 = x4 + x3 + x+ 1
Podobne ako pri príklade s celými číslami 8.5.1, zistíme zvyšok po delení vopred ur-čeným generujúcim polynómom q(x) = x3 + x+ 1. Tento zvyšok potom odpočítame,aby zabezpečený polynóm bol deliteľný polynómom q(x) bezo zvyšku. Prepis do tvarupolynómu navyše umožňuje oddeliť informačnú a zabezpečovaciu časť kódového slova.Vynásobením polynómu f(x) polynómom xk dostaneme polynóm f~(x), ktorý budemať nulové koeficienty pri mocninách x0, x1, . . . , xk−1 a koeficienty pri vyšších moc-ninách budú zodpovedať koeficientom polynómu f(x).
f~(x) = 1 · xk+4 + 1 · xk+3 + 0 · xk+2 + 1 · xk+1 + 1 · xk+0
Zodpovedajúce slovo polynómu f~(x) je 11011 00 . . . 0︸ ︷︷ ︸k
.
Hodnota k v polynóme xk závisí od veľkosti zvyškov po delení generujúcim polynó-mom. V prípade polynómu q(x) = x3 + x+ 1 sú zvyšky po delení
polynóm slovo0 0001 001x 010x+ 1 011x2 100x2 + x 110x2 + x+ 1 111
Z tvaru všetkých zvyškov vidíme, že na zabezpečenie stačia tri miesta. Preto polynómf(x) = x4 + x3 + x+ 1 (teda slovo 11011) vynásobíme x3.Po vynásobení dostaneme polynóm
f~(x) = x7 + x6 + x4 + x3
Zodpovedajúce slovo k polynómu f~(x) je 11011000.Tento polynóm však nie je deliteľný bezo zvyšku generujúcim polynómom q(x) =x3 + x + 1. Aby sme zistili, aké hodnoty má mať zabezpečovací blok, napodobnimepostup podľa výpočtu (8.5.2).(
x7 + x6 + x4 + x3):(x3 + x+ 1
)= x4 + x3 + x2 + x+ 1 (zvyšok 1)
Zvyšok 1 po delení generujúcim polynómom odpočítame (odpočítať binárne číslo mo-dulo 2 znamená pripočítať toto číslo) od polynómu f~(x) a dostaneme zabezpečenýpolynóm f⋆(x).
f⋆(x) = f~(x)− 1 = f~(x)⊕2 1 = x7 + x6 + x4 + x3 + 1

8.5. Polynomiálne kódy 185
Polynóm f⋆(x) je skutočne bezo zvyšku deliteľný generujúcim polynómom q(x) =x3+x+1 a navyše, jeho binárny zápis má informačnú časť oddelenú od zabezpečovacejčasti.
Kódové slovo bude obsahovať chybu, ak polynóm f⋆(x), prislúchajúci tomutoslovu, nie je deliteľný generujúcim polynómom q(x) = x3 + x+ 1.
Úloha 8.5.2 Dokážte, že pre ľubovoľné polynómy f(x), q(x) (z priestoru polynómovako v príklade 8.5.1), polynóm z(x) (zvyšok po delení f(x) : q(x)) a číslo k (ktoréudáva stupeň polynómu q(x)) platí:
q(x) je deliteľom polynómu f(x) · xk + z(x)
Úloha 8.5.3 Ako by sa zmenil algoritmus zabezpečovania slova generujúcim polynó-mom, keby sa na konci slova nepridalo k núl, ale k jednotiek?
Úloha 8.5.4 Pri CRC kódovaní je potrebné deliť polynómy zodpovedajúce kódovýmslovám. Slová pozostávajú z 0 a 1, preto by mohli byť považované za zápisy čísel vdvojkovej sústave. Je možné delenie polynómu polynómom nahradiť podielom číselv dvojkovej sústave, ktoré robí kalkulačka? Ak áno, vysvetlite prečo, ak nie, nájditepríklad, v ktorom nebude výsledok pri týchto spôsoboch delenia rovnaký.
Úloha 8.5.5 Aké slová sa skrývajú za skratkou CRC?
Príklad 8.5.2 Urobte matematický model, ktorý popisuje cyklický kód s generujúcimpolynómom ako transformáciu vektora do nadpriestoru.
Riešenie:Použijeme slová a generujúci polynóm ako v príklade 8.5.1. Naďalej budeme používaťsúčin a súčet modulo 2. Slová sú prvky vektorového priestoru S5 všetkých 5-zložkovýchvektorov zložených z 0 a 1. Tieto slová chceme preniesť nejakým prostredím a predtýmzakódovať tak, aby boli deliteľné generujúcim polynómom. Bázu B5 priestoru S5tvoria vektory
e0 = (1, 0, 0, 0, 0) e1 = (0, 1, 0, 0, 0) e2 = (0, 0, 1, 0, 0)
e3 = (0, 0, 0, 1, 0) e4 = (0, 0, 0, 0, 1)
Každý vektor f ∈ S5 možno napísať ako lineárnu kombináciu vektorov bázy B. Na-príklad
f = (1, 1, 0, 1, 1) == 1 · (1, 0, 0, 0, 0) + 1 · (0, 1, 0, 0, 0) + 0 · (0, 0, 1, 0, 0) + 1 · (0, 0, 0, 1, 0)++0 · (0, 0, 0, 0, 1) = 1 · e0 + 1 · e1 + 0 · e2 + 1 · e3 + 1 · e4
Vektorový priestor vnoríme ako podpriestor S do vektorového priestoru S8. Bázou Bvektorového podpriestoru S budú 8 zložkové vektory, ktoré budú rozšírením vektorovbázy B5 a budú zodpovedať polynómom, ktoré sú deliteľné generujúcim polynómomq(x) = x3 + x+ 1.
b0 = (1, 0, 0, 0, 0, 0, 0, 1) b1 = (0, 1, 0, 0, 0, 1, 0, 1) b2 = (0, 0, 1, 0, 0, 1, 1, 1)

186 Kapitola 8. Diskrétne lineárne systémy
b3 = (0, 0, 0, 1, 0, 1, 1, 0) b4 = (0, 0, 0, 0, 1, 0, 1, 1)
Zabezpečiť vektor f = (1, 1, 0, 1, 1) cyklickým kódom znamená vyjadriť ho v bázeB, teda
f⋆ = 1 · b0 + 1 · b1 + 0 · b2 + 1 · b3 + 1 · b4 = (1, 1, 0, 1, 1, 0, 0, 1)
Vektoru (1, 1, 0, 1, 1, 0, 0, 1) zodpovedá polynóm x7 + x6 + x4 + x3 + 1, ktorý jenaozaj bezo zvyšku deliteľný polynómom generujúcim polynómom q(x) = x3+x+1.
V prípade, že pri prenose komunikačným prostredím, teda transformácii vektoraf na vektor f ′ nastane chyba a výsledný polynóm nebude deliteľný polynómom q(x),tak vektor f ′ /∈ S.
Úloha 8.5.6 Ukážte, že ak sú dva polynómy deliteľné polynómom q(x), tak aj každáich lineárna kombinácia je deliteľná polynómom q(x).

9 Modelovanie náhodnosti v procesoch
Pozrime sa na dva grafy na obrázku 9.1, na ktorých sú zobrazené namerané dáta spolus regresnou priamkou. Ak by študent, vedec, lekár, ekonóm, inžinier či klimatológ
2 4 6 8 10
510
1520
2 4 6 8 10
510
1520
Obr. 9.1. Ideálny a reálny proces
tvrdil, že reálne namerané dáta sú z ľavého obrázka, je pravdepodobné, že nehovorípravdu. Prakticky namerané dáta sa takmer nikdy nesprávajú ideálne.
V predchádzajúcich kapitolách sme sa preto venovali hľadaniu procesov, ktoré v is-tom zmysle zachycujú dôležité črty procesov. Typická úloha bola nájsť " zjednodušený"proces f , ktorý najlepšie aproximuje daný proces f :
• v lineárnej regresii sme hľadali lineárnu priamku (alebo krivku), ktorá najlepšieaproximuje proces
• pomocou Fourierovej transformácie sme hľadali periodické vlastnosti procesu
• pomocou Karhunen-Loevovej transformácie sme hľadali dôležité smery v ná-hodných dátach
V tejto kapitole obrátime otázku a skúsime vytvoriť model, z ktorého prichádzajúnamerané dáta. Hlavnou myšlienkou je pridanie náhodnosti, avšak ako presne ju pri-dať si vyžaduje vhodný pohľad na problém.
187

188 Kapitola 9.Modelovanie náhodnosti v procesoch
9.1 Modelovanie lineárnej regresie
Povedzme, že sme dostali dáta vo forme dvoch vektorov x = (x1, . . . , xm) a y =(y1, . . . , ym). Predpokladajme, že medzi yi a xi existuje lineárna závislosť
yi = axi + b
Ak však hodnoty yi nie sú úplne presne rovné axi + b, do meraní sa premietla nejakáchyba. Toto si uvedomil už začiatkom 19. storočia nemecký matematik K. F. Gauss,ktorý robil geodetické merania. Ten navrhol, že táto chyba je reálna náhodná pre-menná, ktorú označíme ϵ, a teda v skutočnosti presne platí:
yi = axi + b+ ϵi, (9.1.1)
kde ϵi sú hodnoty náhodnej premennej ϵ.Ak náhodná premenná ϵ má nenulovú strednú hodnotu µ = 0, tak chyby v dátach
sa nazývajú systematické. Ak napríklad tachometer na aute ukazuje od 0 do 7 kmviac než je skutočná rýchlosť, tak meria rýchlosť so systematickou chybou. To sa dánapraviť tým, že od dát yi odpočítame µ = E(ϵ), a potom už chyby majú strednúhodnotu 0 a prestaneme robiť systematickú chybu.
Keď je známe pravdepodobnostné rozdelenie p(x) chýb ϵ, tak sa koeficienty a ab dajú vypočítať metódou, ktorú štatistici nazývajú metódou maximálnej vierhod-nosti (ML metóda z anglického Maximum likelihood). Metóda maximalizuje viero-hodnostnú funkciu modelu, ktorá je definovaná vzorcom
V (y|x; a, b) =m∏i=1
p(ϵi) =
m∏i=1
p(yi − axi − b).
Ukážeme si jej použitie v nasledujúcom príklade.
Príklad 9.1.1 Predpokladajme, že sme namerali nejaké dáta: Našou úlohou je nájsť
xi 1 2 3 4 5 6 7 8 9 10yi 3.52 5.53 7.7 10.4 11.6 13.9 16.2 18.9 20.9 23.5
pomocou metódy maximálnej vierohodnosti model y = ax + b, ktorý má najväčsiuvierohodnosť. Na to však musíme spraviť predpoklad o pravdepodobnostnom rozdeleníchýb ϵ. Úlohu budeme riešiť pre tri rôzne rozdelenia, aby sme si ukázali, že výsledokzávisí od toho, ako sú chyby rozdelené.
• normálne rozdelenie s pravdepodobnostnou funkciou p(x) = 1√2πe−x2/2
• Laplacovo rozdelenie s pravdepodobnostnou funciou p(x) = 12e
−|x|
• Cauchyho rozdelenie s pravdepodobnostnou funciou p(x) = 1π(x2+1)
Priebeh týchto funkcií je zobrazený na obrázku 9.2. Na obrázkoch 9.3, 9.4 a 9.5 jezobrazená veľkosť vierohodnosti pre rôzne hodnoty a, b. Čím bledšia oblasť, tým väčšia

9.1. Modelovanie lineárnej regresie 189
-3 -2 -1 1 2 3
0.1
0.2
0.3
0.4
0.5
Obr. 9.2. Grafy funkcií normálneho, Laplaceovho a Cauchyho rozdelenia
0.0 0.5 1.0 1.5 2.0 2.5 3.0
-5
0
5
10
Obr. 9.3. Veľkosť funkcie vierohodnostnosti pre Gaussovo (normálne) rozdelenie

190 Kapitola 9.Modelovanie náhodnosti v procesoch
0.0 0.5 1.0 1.5 2.0 2.5 3.0
-5
0
5
10
Obr. 9.4. Veľkosť funkcie vierohodnostnosti pre Laplacovo rozdelenie
0.0 0.5 1.0 1.5 2.0 2.5 3.0
-5
0
5
10
Obr. 9.5. Veľkosť funkcie vierohodnostnosti pre Cauchyho rozdelenie

9.1. Modelovanie lineárnej regresie 191
vierohodnosť modelu. V prípade Cauchyho rozdelenia je poloha maxima najzreteľnej-šia.
Na určenie presnej hodnoty, kde sa nachádza maximum vierohodnosti, použijemematematický softvér alebo gradientovú metódu z kapitoly 7.6, ktorý nám zistí tietohodnoty.
(a, b) = (2.20067, 1.11133) v prípade normálneho rozdelenia(a, b) = (2.20286, 1.13066) v prípade Laplaceovho rozdelenia(a, b) = (2.20022, 1.1191) v prípade Cauchyho rozdelenia
Vidíme, že výsledky sú podobné, čo sa dá vysvetliť tým, že pravdepodobnostné funkciepre chyby ϵi mali veľmi podobný tvar.
Keby sme vypočítali regresnú priamku y = ax + b pre dáta z predchádzajúcehopríkladu, vyšlo by nám (a, b) = (2, 20067; 1, 11133) teda presne ten istý výsledokako dáva ML metóda pre normálne rozdelenie. Toto nie je náhoda, pretože platínasledujúca veta.
Veta 9.1.1 Predpokladajme, že až na chyby ϵi platí lineárna závislosť medzi procesomf a procesmi bi, t.j
f = a1b1 + . . .+ anbn +
chyby︷ ︸︸ ︷(ϵ1, . . . , ϵm)
Ak chyby ϵi majú Gaussovské (normálne) rozdelenie so strednou hodnotou 0 a disper-ziou σ2, tak ML metóda dáva rovnaké výsledky ako metóda najmenších štvorcov.
Dôkaz:Nech je daný vektor f = (f1, . . . , fm), ku ktorému chceme nájsť koeficienty a1, . . . , anlineárnej kombinácie vektorov a1b1 + . . . + anbn pomocou ML metódy. Rozpíšme sivektory bi po zložkách
b1 =(b11, . . . , bm1)
. . .
bn =(b1n, . . . , bmn)
Podľa predpokladu ϵi, zložky rozdielu f−a1b1− . . . anbn, sú z normálneho rozdelenias pravdepodobnostnou funkciou p(x) = 1√
2πσ2e−x2/2σ2
. Toto sa značí ϵi ∼ N(0, σ2).Teraz ideme maximalizovať vierohodnostnú funkciu
V (f |bi; a1, . . . , an) =m∏i=1
p(ϵi).
Avšak bude šikovnejšie maximalizovať jej logaritmus namiesto samotnej funcie. Tonezmení miesto maxima, pretože logaritmus je rastúca funkcia. Pre logaritmus vier-

192 Kapitola 9.Modelovanie náhodnosti v procesoch
hodnostnej funkcie máme nasledujúce vyjadrenie:
log V (f |bi; a1, . . . , an) = log
m∏i=1
p(ϵi)
= logm∏i=1
1√2πσ2
e−ϵ2i/2σ2
=
( m∑i=1
log( 1√
2πσ2
))+
m∑i=1
log e−ϵ2i/2σ2
= −m2log(2πσ2)− 1
2σ2
m∑i=1
ϵ2i
Prvý člen nezávisí od výberu koeficientov lineárnej kombinácie a1, . . . , an a druhý simôžeme napísať
m∑i=1
ϵ2i =m∑i=1
(fi − a1bk1 − . . . anbkn)2
= ||f − a1b1 − . . .− anbn||2
Táto suma je najmenšia, ak lineárna kombinácia vektorov a1b1+. . .+anbn je najbliž-šia k f , a teda metóda najmenších štvorcov dáva ten istý výsledok, ako ML v prípadegaussovského rozdelenia chýb.
Zaujímavým faktom je, že výsledok ML metódy nezávisí od rozptylu gaussovskéhorozdelenia, ale len od toho, že má strednú hodnotu 0.K výpočtu rozptylu chyby môžeme pristúpiť dvoma rôznymi spôsobmi.
Základom prvého je vzorec σ2 = E(X2), ktorý platí pre náhodnú premennú s prie-merom 0. Keďže predpokladáme, že ϵi sú gaussovsky rozdelené so strednou hodnotou0, na odhad σ2 môžeme použiť vzorec
odhad σ2 =1
m− 1
∑ϵ2i =
1
m− 1||f − a1b1 − . . .− anbn||2.
Druhý spôsob spočíva v maximalizácii vierohodnosti ako funkcie rozptylu. Spočí-tajme deriváciu vierohodnosti podľa σ
∂ log V (f |bi; a1, . . . , ak)
∂σ=
∂
∂σ
(−m
2log(2πσ2)− 1
2σ2
m∑i=1
ϵ2i
)
= −m2
4πσ
2πσ2+
1
σ3
m∑i=1
ϵ2i
= −mσ
+1
σ3||f − a1b1 − . . .− anbn||2.
Maximálna vierohodnosť bude v tom bode, kde derivácia je rovná 0, tj.
0 = −mσ
+1
σ3||f − a1b1 − . . .− anbn||2

9.2. Stacionárny proces 193
odkiaľ
ML odhad σ2 =1
m||f − a1b1 − . . .− anbn||2
Vidíme, že ML odhad sa pre malé hodnoty m (počet pozorovaní) mierne líši od prvéhoodhadu, avšak so zväčšujúcim sa počtom dát sa tieto odhady k sebe približujú.
Ako môžeme využiť túto informáciu o rozptyle? Povedzme, že sa snažíme iden-tifikovať odľahlé hodnoty, ktoré majú podozrivo vysokú chybu. Čebyševova vetanapríklad hovorí, že aspoň 8/9 ≈ 89% hodnôt leží nanajvýš vo vzdialenosti 3σ odstrednej hodnoty. O normálnom rozdelení vieme silnejšie tvrdenie, že viac ako 95%pozorovaní leží nanajvýš vo vzdialenosti 2σ od očakávanej hodnoty. Vediac hodnotuσ môžeme posúdiť, či dané meranie je odľahlé.
Úloha 9.1.1 Zistite, či meranie (x, y) = (5.5, 11) leží vo vzdialenosti viac než 3σ predáta z príkladu 9.1.1.
9.2 Stacionárny proces
Analýza procesov často odhalí deterministickú črtu procesu, či už lineárny trend,alebo nenulový priemerný trend, alebo periodické správanie. Zvyšok procesu má veľminedeterministické, zdanlivo náhodné správanie. Na štúdium a modelovanie nedeter-ministických procesov sa používa teória stacionárnych procesov [3], [4]. Táto teóriasa rozvinula v súvislosti so štúdium geofyzikálnych javov, no našla široké uplatnenieaj v ekonómii pri modelovaní trhu cenných papierov a ekonomiky, ale aj v technike ato najmä v spracovaní zvuku a rozpoznávaní reči.
Porovnajte dva grafy procesov zobrazených na obrázku 9.6.Obidva procesy súnáhodné procesy. Spoločné majú to, že ani jeden nemá nejaký lineárny trend, ktorýmby sa odďaloval od 0. Avšak vidíme, že ten dolu sa "mení" podstatne menej. Akokeby predchádzajúca hodnota mala veľký vplyv na nasledujúcu hodnotu. Toto jetypické napríklad pre hodnoty komodít a akcií na burzách. Cena z predošlého dňa jepodstatným faktorom pre určenie dnešnej obchodnej ceny.
Teraz si tieto vlastnosti sformalizujeme definíciou stacionárneho procesu.Stacionárny proces je náhodný proces s nasledujúcimi vlastnosťami
• stredná hodnota sa nemení v čase a je konečná:
E(Xs) = E(Xt)
pre všetky časy s, t
• kovarianca medzi rozdeleniami procesu v rôznych časoch je konečná, a závisí lenod rozdielu časov, tj.
Cov(Xs, Xt) = Cov(Xs+d, Xt+d)

194 Kapitola 9.Modelovanie náhodnosti v procesoch
0 50 100 150 200
−3
−2
−1
01
2
0 50 100 150 200
−5
05
10
Obr. 9.6. Dve realizácie náhodných stacionárnych procesov

9.3. Využitie stacionarity na predikciu a interpoláciu 195
Keďže kovariancia závisí iba od vzdialenosti |s−t|, môžeme definovať autokovariančnúfunkciu
g(h) = Cov(Xs, Xs+h)
Špeciálne, pre s = t dostávame, že disperzia v každom čase je rovnaké konečné číslog(0) = σ2.
Zoberme si napríklad hladinu Dunaja. Toto nie je stacionárny proces, pretože vjarných mesiacoch býva v priemere viacej vody, ako v zimných. Avšak ak meriamelen hladinu Dunaja 1. januára v jednotlivých rokoch, tak toto už je pravdepodobnedobrý príklad na stacionárny proces.
Ako ďalší príklad si zoberme cenu akcie. Keďže fiškálna politika centrálnej bankyje udržiavať mierny rast, ceny v priemere mierne rastú o niekoľko percent ročne.Preto ani cena akcie nie je stacionárny proces. Aby sme mohli hovoriť o stacionárnomprocese, museli by sme ceny v jednotlivých rokoch upraviť o infláciu.
Ak má stacionárny proces nenulovú strednú hodnotu µ, tj. E(Xt) = µ pre každýčas t, tak odčítaním tejto strednej hodnoty dostaneme centrovaný stacionárny procesXt − µ, pričom vzájomné kovariancie sa nezmenia.
Pre stacionárny proces je dôležitou charakteristikou jeho autokorelačná funkcia
r(h) =Cov(Xs, Xs+h)√
Cov(Xs, Xs) · Cov(Xs+h, Xs+h)
=Cov(Xs, Xs+h)
Cov(Xs, Xs)
Autokorelačná funkcia nadobúda hodnoty od −1 do 1, pričom r(0) je vždy 1.Na obrázku 9.7 je znázornená autokorelačná funkcia nahrávky hovorenej reči. Vi-
díme, že tento zvuk má vysokú autokoreláciu pre h = 400. Keďže zvuk bol vzorkovanýna frekvencii 44100 Hz, môžeme z toho usúdiť, že je takmer periodický s frekvenciou44100/400 ≈ 110 Hz.
Väčšina štatistických softvérov má funkciu na vykreslenie autokorelačnej funkcie.Typicky sú zobrazené aj dve vodorovné čiary, ktoré ukazujú hranice, medzi ktorýmihodnoty autokorelácií sú štatisticky zanedbateľné. Hodnoty v týchto medziach mô-žeme považovať za nulové.
9.3 Využitie stacionarity na predikciu a interpoláciu
Hlavné použitie predpokladov o stacionárnosti je v predpovedi ďalších hodnôt pro-cesu. Typický príklad takejto predpovede je, že poznáme niekoľko posledných hodnôtprocesu a chcem predpovedať ďalšiu hodnotu. Napríklad, ak poznáme poslednýchpäť hodnôt Xt−5, Xt−4, Xt−3, Xt−2, Xt−1, bude nás zaujímať, či neexistuje lineárnakombinácia
a5Xt−5 + a4Xt−4 + a3Xt−3 + a2Xt−2 + a1Xt−1,
ktorá by čo najpresnejšie predpovedala hodnotu Xt procesu v čase t. Takáto lineárnakombinácia sa nazýva aj lineárny prediktor.

196 Kapitola 9.Modelovanie náhodnosti v procesoch
0 100 200 300 400 500
−0.
50.
00.
51.
0
h
auto
kore
láci
a
Obr. 9.7. Autokorelačná funkcia hovorenej samohlásky
Príklad 9.3.1 Predpokladajme, že priemerná denná teplota počas januára v Breznesa správa ako centrovaný stacionárny proces Tt. Našou úlohou je odhadnúť teplotudnes, ak vieme, že včerajšia teplota bola Tt−1. Ak by včerajšia teplota bola nulová, jeprirodzené odhadnúť aj dnešnú teplotu nulou. Ak však včerajšia teplota bola povedzmenad nulou, dá sa očakávať, že aj dnešná teplota bude nad nulou, napriek tomu, žedlhodobý teplotný priemer je nula. Preto sa budeme pozerať na odhady dnešnej teplotyv tvare Tt = k · Tt−1. Vhodnosť odhadu budeme merať očakávanou chybou
E((Tt − Tt)2
)= E
((Tt − kTt−1)
2)
= E(T 2t − 2kTtTt−1 + k2T 2
t−1)
= E(T 2t )− 2kCov(Tt, Tt−1) + k2E(T 2
t−1)
pretože E(Tt) = E(Tt−1) = 0.
Vidíme, že veľkosť chyby je kvadratickou funkciou v závislosti od k. Derivovaním náj-deme miesto lokálneho minima
∂E(Tt − Tt)2
∂k= −2Cov(Tt, Tt−1) + 2kE(T 2
t−1)
a tým aj vzorec pre najlepší odhad
Tt = kTt−1 =Cov(Tt, Tt−1)
E(T 2t−1)
Tt−1

9.3. Využitie stacionarity na predikciu a interpoláciu 197
a keďže rozptyl Tt je v každom čase rovnaký
Tt =Cov(Tt, Tt−1)√E(T 2
t−1)E(T 2t ))
Tt−1
inými slovami
Tt =(autokorelačný koeficient r(1) procesu Tt
)· Tt−1
Úloha 9.3.1 22. januára bola v Brezne teplota −5 stupňov. Na základe predchádza-júceho príkladu odhadnite, aká teplota bola v Brezne 23. januára, ak viete, že
a) disperzia E(T 2t ) = 17 a autokorelácia r(1) = 0.6,
b) disperzia E(T 2t ) = 15 a kovariancia Cov(Tt, Tt−1) = 10.
Príklad 9.3.2 Predpokladajme, že výmenný kurz dolára voči euru má dlhodobý prie-mer 1.5 a odchýlka od tohto priemeru je centrovaný stacionárny proces, ktorý si ozna-číme Kt, tj. platí vzorec
kurz v deň t = 1.5 +Kt.
Ukážme, si aký vplyv má autokorelácia na predikciu. Našou úlohou je odhadnúť kurzD hodnotou D, s ktorým dnes budeme vymieňať doláre s eurami za predpokladu, ževieme včerajší výmenný kurz V . Tri príklady takých odhadov sú
• odhad odvodený od včerajšieho kurzu D1 = V ,
• odhad odvodený od dlhodobého priemeru D2 = 1.5,
• odhad, ktorý je priemerom predošlých dvoch odhadov D3 = 12 (V + 1.5).
Samozrejme, tieto tri odhady nie sú jediné možné. Obmedzíme sa len na lineárneodhady typu D = a + bV , ktoré zahŕňajú všetky tri už uvedené prípady. Kritériomkvality odhadu bude priemerná veľkosť chyby E(D − D)2.
Dosadíme
E((D − D)2
)= E(D2 − 2DD + D2)
= E(D2)− 2E(D · (a+ bV )) + E((a+ bV ))2)
= E(D2)− 2aE(D)− 2bE(D · V ) + a2 + 2abE(V ) + b2E(V 2)
Z definície stacionárneho procesu vyplýva, že E(D) = E(V ) = 1.5, a teda
E((D − D)2
)= E(D2)− 3a− 2bE(D · V ) + a2 + 3ab+ b2E(V 2)
Táto hodnota bude minimalizovaná, keď gradient bude nulový, tj.
E(D − D)2
∂a= −3 + 2a+ 3b = 0
E(D − D)2
∂b= −2E(D · V ) + 3a+ 2bE(V 2) = 0

198 Kapitola 9.Modelovanie náhodnosti v procesoch
Odtiaľ
a =1
2(3− 3b)
−2Cov(D,V ) +3
2(3− 3b) + 2bE(V 2) = 0
b =2E(D · V )− 9/2
2E(V 2)− 9/2
Dostali sme síce výsledok, ale výsledné vzorce nám veľa neobjasňujú. To sa zmení, akvýpočet mierne modifikujeme. Budeme hľadať odhad v tvare
D′ = 1.5 + c+ d(V − 1.5) = 1.5 + c+ dKt−1
Odhad v takomto tvare dosadíme do vzorca pre chybu
E(D − D′)2 = E((1.5 +Kt −
(1.5 + c+ dKt−1
))2)
= E((Kt − c− dKt−1)2)
= E(K2t ) + c2 + d2E(K2
t−1)
− 2cE(Kt)− 2cdE(Kt−1)− 2dE(KtKt−1)
a keďže Kt je centrovaný stacionárny proces, dostávame
E(D − D′)2 = E(K2t ) + c2 + d2E(K2
t−1)− 2dCov(Kt,Kt−1)
Minimum nastáva v bode, v ktorom je gradient nulový, a teda sú splnené rovnice
E(D − D′)2
∂c= 2c = 0
E(D − D′)2
∂d= 2dE(K2
t−1)− 2Cov(Kt,Kt−1) = 0
Odtiaľ dostaneme c = 0 a
d =Cov(Kt,Kt−1)
E(K2t−1)
=Cov(Kt,Kt−1)√E(K2
t−1)E(K2t ),
a teda d je korelácia medzi nasledujúcimi hodnotami stacionárneho procesu Kt, tj.prvá hodnota autokorelačnej funkcie.
Úloha 9.3.2 Včerajší výmenný kurz dolára k euru bol 1.7. Vypočítajte autokoreláciur(1), hodnoty a, b, c, d a predpovede D, D′ dnešného podľa predchádzajúceho príkladuv nasledujúcich prípadoch:
a) E(K2t ) = 3, Cov(Kt,Kt−1) = 0.9,
b) E(K2t ) = 5, Cov(Kt,Kt−1) = 1.5,

9.4. Biely šum 199
c) E(K2t ) = 5, Cov(Kt,Kt−1) = 4.5.
Poďme na záver vyriešiť problém interpolácie pre stacionárny proces. Nech Pt
je stacionárny proces, o ktorom budeme predpokladať, že je centrovaný . Budemesa snažiť odhadnúť hodnotu v čase t, ak sú známe hodnoty v časoch t − 1 a t + 1.Budeme hľadať koeficienty a, b tak, aby lineárny prediktor Pa,b = aPt−1 + bPt+1 bolčo najpresnejší, tj. aby chyba
E((Pt − Pa,b)2)
bola čo najmenšia. Dosadíme a upravíme
E((Pt−aPt−1 − bPt+1)2) = E(P 2
t ) + E(a2P 2t−1) + E(b2P 2
t+1)
− 2E(Pt · aPt−1)− 2E(Pt · bPt+1) + 2E(aPt−1 · bPt+1)
= (1 + a2 + b2)E(P 2t )− 2(a+ b)Cov(Pt, Pt+1) + 2abCov(Pt−1, Pt+1)
= E(P 2t )
((1 + a2 + b2)− 2(a+ b) r(1) + 2ab r(2)
)Minimum nastáva v bode, kde gradient funkcie vo veľkých zátvorkách je nulový, tj.ak
2a− 2r(1) + 2br(2) = 0
2b− 2r(1) + 2ar(2) = 0(9.3.1)
čo je sústava lineárnych rovníc pre koeficienty a, b v závislosti od autokorelačnýchkoeficientov r(1), r(2). Vidíme teda, že predikcia a interpolácia sú dobre riešiteľnépre stacionárne procesy, a najdôležitejšími údajmi pre návrh lineárnych prediktorovsú autokorelačné koeficienty.
9.4 Biely šum
V modelovaní javov sa v praxi často robí predpoklad o stacionárnosti procesu. Akosme si ukázali v predchádzajúcej kapitole, tento predpoklad umožňuje nájsť dobrélineárne prediktory ďalších hodnôt procesu. Toto však mnohokrát nestačí. Pri dopa-dových štúdiách sa napríklad musí určiť, či pravdepodobnosť opakujúcich sa dažďov,ktoré by viedli k povodniam, je viac než raz za 200 rokov. Alebo je cieľom určiť, akáje pravdepodobnosť, že cena zlata, alebo inej suroviny, ostane nad určitou hladinoupočas obdobia výroby nejakého produktu. Preto je dôležité byť schopný simulovaťstacionárne procesy, tj. v počítači vyprodukovať mnohé realizácie jedného stacionár-neho procesu. Najzákladnejší stacionárny proces, ktorý sa používa, je proces bielehošumu.
Stacionárny proces Zt nazveme bielym šumom, ak je centrovaný, a jeho hodnotysú v rôznych časoch navzájom lineárne nekorelované. Inakšie povedané E(Zt) = 0, aautokorelačná funkcia procesu Zt je okrem hodnoty v bode 0 všade nulová
r(h) =
0 ak h = 0
1 ak h = 0

200 Kapitola 9.Modelovanie náhodnosti v procesoch
Podobne jeho autokovariančná funkcia závisí od iba od jedného parametra σ2
g(t− s) = Cov(Zt, Zs) =
0 ak s = t
σ2 ak s = t
čo sa niekedy značí pomocou hranatých zátvoriek takto
g(t− s) = Cov(Zt, Zs) = σ2[s = t]. (9.4.1)
Dohoda je taká, že hodnota výrazu v zátvorkách je 1, ak je výraz pravdivý. Ak výrazje nepravdivý, hodnota výrazu je nula.
Ako príklad bieleho šumu si môžeme uviesť hladinu Dunaja meranú v ročnýchintervaloch. Keby sme chceli simulovať biely šum, stačí zobrať postupnosť náhodnevygenerovaných čísel. Ak sme použili dobrý generátor náhodných čísel, tak výslednýproces je bielym šumom.
To, že je proces Zt bielym šumom sa značí Zt ∼WN(0, σ2), vyjadrujúc, že strednáhodnota je 0, a disperzia v každom čase t je σ2.
9.5 MA(q) procesy
Teraz si predstavíme novú triedu stacionárnych procesov. Na rozdiel od bieleho šumu,tieto procesy môžu mať nenulovú autokoreláciu medzi náhodnými premennými Xt aXt+1. Názov týchto procesov je skratka z anglického pojmu moving average, tj. kĺzavýpriemer. Najjednoduchším príkladom MA(q) procesu je MA(1) proces. Ten vzniknez bieleho šumu aplikovaním metódy kĺzavých súčtov. Konkrétne, proces Xt je MA(1)proces, ak existuje proces bieleho šumu Zt ∼WN(0, σ2) taký, že platí
Xt = Zt + aZt−1,
kde a je reálna konštanta nezávisiaca od času t. Ľahko sa overí, že tento proces jecentrovaný
E(Xt) = E(Zt + aZt−1) = E(Zt) + aE(Zt−1) = 0
Ďalej vypočítame kovariančnú funkciu medzi rozdeleniami procesu v rovnakom čase
Cov(Xt, Xt) = Cov(Zt + aZt−1, Zt + aZt−1)
= Cov((Zt + aZt−1) · (Zt + aZt−1)
)= Cov(Z2
t + 2aZtZt−1 + a2Z2t−1)
= Cov(Zt, Zt) + 2aCov(Zt, Zt−1) + a2Cov(Zt−1, Zt−1)
= σ2 + 2a · 0 + a2σ2 = σ2(1 + a2)
Podobne spravíme výpočet pre časy vzdialené o 1:
Cov(Xt+1, Xt) = Cov(Zt+1 + aZt, Zt + aZt−1)
= Cov(Zt+1, Zt) + aCov(Zt+1, Zt−1)
+ aCov(Zt, Zt) + a2Cov(Zt, Zt−1)

9.5. MA(q) procesy 201
čo môžeme zjednodušiť využijúc (9.4.1)
Cov(Xt+1, Xt) = σ2([t+ 1 = t] + a[t+ 1 = t− 1] + a[t = t] + a2[t = t− 1]
)= 0 + 0 + aσ2 + 0 = aσ2
Ak počítame kovarianciu distribúcií vzdialených o čas d > 1, tak dostaneme výrazypodobné predchádzajúcemu prípadu
Cov(Xt+d, Xt) = Cov(Zt+d + aZt+d−1, Zt + aZt−1)
= Cov(Zt+d, Zt) + aCov(Zt+d, Zt−1)
+ aCov(Zt+d−1, Zt) + a2Cov(Zt+d−1, Zt−1)
= σ2([t+ d = t] + a[t+ d = t− 1]
+ a[t+ d− 1 = t] + a2[t+ d− 1 = t− 1])
Prvý výraz v zátvorke je nenulový iba keď d = 0, druhý keď d = −1, tretí keď d = 1a posledný keď d = 0. Preto pre d > 1 dostávame
Cov(Xt+d, Xt) = 0
Tieto výpočty ukazujú, že MA(1) proces je stacionárny proces. Z uvedených vý-počtov odvodíme vzorce pre autokovariančnú funkciu.
g(h) =
σ2(1 + a2) ak h = 0
σ2a ak h = ±10 ak |h| > 1
Pre autokorelačnú funkciu platí vzťah
r(h) =
1 ak h = 0a
1 + a2ak h = ±1
0 ak |h| > 1
Úloha 9.5.1 Nakreslite graf r(1) v závislosti od parametra a. Ukážte, že pre prvúautokoreláciu r(1) MA(1) procesu platí − 1
2 ≤ r(1) ≤12 .
Všeobecný MA(q) proces vznikne aplikáciou kĺzavého súčtu s q členmi na bielyšum.
Xt = Zt + a1Zt−1 + . . .+ aq−1Zt−q+1
Dá sa ukázať, že autokorelačná funkcia r(h) je nulová, ak h > q. Tento fakt sa využívapri modelovaní procesu. Rád modelu q sa vyberá tak, aby zahrnul všetky zjavnenenulové korelácie.

202 Kapitola 9.Modelovanie náhodnosti v procesoch
0 5 10 15 20 25 30
0.0
0.2
0.4
0.6
0.8
1.0
Lag
AC
FSeries arima.sim(list(ma = c(0.3, 0.9)), 1000)
Obr. 9.8. Autokorelačná funkcia realizácie procesu Xt = Zt + 0.3Zt−1 + 0.9Zt−2.
Príklad 9.5.1 Nech Xt je MA(2) proces daný vzorcom Xt = Zt +0.3Zt−1 +0.9Zt−2
a Zt ∼ WN(0, 1). Takýto proces môžeme nasimulovať v programe R, a vykresliť jehoautokorelačnú funkciu, ako vidno na obrázku 9.8. Keďže ide o MA(2) proces, iba au-tokorelácie r(1) a r(2) sú nenulové.
Úloha 9.5.2 Nech MA(1) proces je daný vzorcom Xt = Zt+3Zt−1, a Zt ∼WN(0, 1).Vygenerujte realizáciu (f1, . . . , f1000) tohto procesu o dĺžke 1000 vzoriek.
• (predikcia) Nájdite koeficienty a, b, také, aby lineárna kombinácia vektorov
a(f1, . . . , f998) + b(f2, . . . , f999)
bola čo najbližšie k vektoru (f3, . . . , f1000).
• (interpolácia) Nájdite koeficienty a, b, také, aby lineárna kombinácia vektorov
a(f1, . . . , f998) + b(f3, . . . , f1000)
bola čo najbližšie k vektoru (f2, . . . , f999).
Zopakujte obidve úlohy pre realizáciu procesu o dĺžke 10000. Skúste teoreticky zdôvod-niť výsledky.

9.6. AR(p) procesy 203
9.6 AR(p) procesy
Skratka AR pochádza z pomenovania autoregressive. Najjednoduchším príkladom jeAR(1) proces, ktorý spĺňa rovnicu
Xt = bXt−1 + Zt, kde Zt ∼WN(0, σ2)
pričom sa robia dva predpoklady:
• b je konštanta v absolútnej hodnote menšia ako 1, tj. |b| < 1,
• Xs pre s < t nie je korelované s Zt.
Všimnite si podobnosť s prípadom lineárnej regresie (9.1.1). Spočítajme autokova-riančnú funkciu g(h) pre h ≥ 1.
g(1) = Cov(Xt+1, Xt) = Cov((bXt + Zt+1), Xt
)= bCov(Xt, Xt) + Cov(Xt, Zt+1) = bg(0)
pretože druhý člen je podľa druhého predpokladu nulový. Ďalej
g(d) = Cov(Xt+dXt)
= Cov((bXt+d−1 + Zt+d), Xt
)= bCov(Xt+d−1, Xt) + Cov(Zt+d, Xt)
= bg(d− 1), pre d > 1
Z týchto rovníc dostávame autokorelačnú funkciu AR(1) procesu
r(h) =g(h)
g(0)= bh
Úloha 9.6.1 Spočítajte autokovariáciu g(0) = E(X2t ) pre AR(1) proces v závislosti
od b a σ2.
Simulácia AR(p) procesov je o čosi zložitejšia, než simulácia MA(q) procesov.Keďže sme spravili predpoklad |b| < 1, AR(1) sa dá vyjadriť ako nekonečný súčet,ktorého členy veľmi rýchlo konvergujú.
Xt = Zt + bZt−1 + b2Zt−2 + . . .
Táto vlastnosť procesu, sa nazýva kauzalita. Znamená, že hodnoty procesu sa dajúvyjadriť z predošlých hodnôt bieleho šumu.
Úloha 9.6.2 Nech AR(1) proces je daný vzorcom Xt − 0.3Xt−1 = Zt, a Zt ∼WN(0, 1). Vygenerujte realizáciu (f1, . . . , f1000) tohto procesu o dĺžke 1000 vzoriek.
• (predikcia) Nájdite koeficienty a, b, také, aby lineárna kombinácia vektorov
a(f1, . . . , f998) + b(f2, . . . , f999)
bola čo najbližšie k vektoru (f3, . . . , f1000).

204 Kapitola 9.Modelovanie náhodnosti v procesoch
• (interpolácia) Nájdite koeficienty a, b, také, aby lineárna kombinácia vektorov
a(f1, . . . , f998) + b(f3, . . . , f1000)
bola čo najbližšie k vektoru (f2, . . . , f999).
Zopakujte úlohu pre realizáciu procesu o dĺžke 10000. Porovnajte s výsledkom úlohy9.5.2. Skúste teoreticky zdôvodniť výsledky.
Vo všeobecnosti AR(p) proces je proces, ktorý spĺňa rovnicu
Xt − b1Xt−1 − . . .− bpXt−p = Zt, kde Zt ∼WN(0, σ2),
pričom Zt nie je korelované s Xs pre s < t, a všetky (aj komplexné riešenia) rovnice
zp − b1zp−1 − . . .− bp = 0
sú v absolútnej hodnote menšie ako 1.AR(p) procesy, na rozdiel od MA(q) procesov, majú nekonečne veľa nenulových
autokorelácií. Ak sa snažíme namodelovať AR model na danú realizáciu procesu, nedása určiť vhodné p z grafu autokorelačnej funkcie. Náhradou je zobrazenie čiastkovejautokorelácie (angl. partial autocorrelation, alebo partial ACF), ktorá vykresľuje ko-reláciu procesu s procesom, z ktorého bola odstránená najbližšia lineárna kombináciapredchádzajúcich členov. Rád modelu je určíme z posledného významne nenulovéhočlena čiastkovej autokorelačnej funkcie (viď obrázok 9.9).
9.7 Yule-Walkerove rovnice
Autoregresné modely sú populárne, pretože sú ľahšie vypočítateľné oproti MA mode-lom. Teraz si ukážeme jeden zo spôsobov, ako odhadnúť AR model z dát. Povedzme,že chceme namodelovať AR(3) model. Pre hodnoty AR(3) modelu platia vzorce:
Xt+1 = b1Xt + b2Xt−1 + b3Xt−2 + Zt+1
Xt+2 = b1Xt+1 + b2Xt + b3Xt−1 + Zt+2
Xt+3 = b1Xt+2 + b2Xt+1 + b3Xt + Zt+3
Vynásobíme si tieto vzorce Xt, a zoberieme strednú hodnotu. Dostaneme sústavurovníc
E(Xt ·Xt+1) = E(b1X2t ) + E(Xt · b2Xt−1) + E(Xt · b3Xt−2) + E(Xt · Zt+1)
E(Xt ·Xt+2) = E(Xt · b1Xt+1) + E(b2X2t ) + E(Xt · b3Xt−1) + E(Xt · Zt+2)
E(Xt ·Xt+3) = E(Xt · b1Xt+2) + E(Xt · b2Xt+1) + E(b3X2t ) + E(Xt · Zt+3)
Keďže Xt je centrovaný proces, E(Xs · Xt) je autokovariancia g(s − t), a poslednéčleny sú rovné nule, pretože Xt nie je korelované s nasledujúcimi hodnotami procesuZ. Preto dostávame sústavu rovníc nazývanou Yule-Walkerovou:
g(1) = g(0)b1 + g(1)b2 + g(2)b3
g(2) = g(1)b1 + g(0)b2 + g(1)b3
g(3) = g(2)b1 + g(1)b2 + g(0)b3
Tieto rovnice sa dajú použiť dvojakým spôsobom.

9.7. Yule-Walkerove rovnice 205
0 10 20 30 40
0.0
0.1
0.2
0.3
0.4
0.5
0.6
Lag
Par
tial A
CF
Series arima.sim(list(ar = c(0.6, 0.1)), 20000)
Obr. 9.9: Graf čiastkovej autokorelácie simulácie procesu Xt−0.6Xt−1−0.1Xt−2 = Zt

206 Kapitola 9.Modelovanie náhodnosti v procesoch
• Prvý spôsob použitia je, keď hľadáme koeficienty procesu aproximujúce danúrealizáciu procesu. V tom prípade vypočítame odhad autokorelácií, a dosadímeich do Yule-Walkerových rovníc.
• Ak sú dané koeficienty bi procesu, tak sa z nich dajú vypočítať hodnoty auto-korelačnej funkcie tohto procesu.
Príklad 9.7.1 Vypočítajte prvé tri hodnoty autokorelačnej funkcie pre autoregresnýAR(2) proces s rovnicou Xt − 0.6Xt−1 − 0.1Xt−2 = Zt.
Riešenie:V tomto prípade Yule-Walkerove rovnice vyzerajú takto
g(1) = 0.6g(0) + 0.1g(1)
g(2) = 0.6g(1) + 0.1g(0)
Vydelíme obe rovnice g0 a dostaneme
r(1) = 0, 6 + 0, 1r(1)
r(2) = 0, 6r(1) + 0, 1
Odtiaľ vyplýva r(1) = 2/3 a r(2) = 0, 5 a triviálne samozrejme r(0) = 1.
9.8 Durbin-Levinsonova rekurzia
Gaussova eliminačná metóda sústavu p rovníc o p neznámych vyrieši v rádovo p3
krokoch. Avšak zvláštny tvar sústavy Yule-Walkerových rovníc ju umožňuje vyriešiťrýchlejšie Durbin-Levinsonovou rekurziou. Táto metóda je aplikovateľná, keď maticasústavy lineárnych rovníc je toeplitzovská, tj. ak má matica rovnaké prvky na každejdiagonále vedúcej zo severozápadu na juhovýchod.
Matica sústavy Yule-Walkerových rovníc je nielen Toeplitzovská, ale navyše ajsymetrická. Konkrétne, Yule-Walkerove rovnice majú tvar
g(1)g(2)
...g(p)
=
g(0) g(1) . . . g(p− 1)g(1) g(0) . . . g(p− 2)
......
. . .g(p− 1) g(p− 2) . . . g(0)
b1b2...bp
Príklad 9.8.1 Vyriešme sústavu
g(1) = g(0)b1 + g(1)b2 + g(2)b3
g(2) = g(1)b1 + g(0)b2 + g(1)b3
g(3) = g(2)b1 + g(1)b2 + g(0)b3
Predpokladajme, že sme vyriešili jednoduchšiu sústavu s dvoma neznámymi x1, x2,ktorá vznikne vynechaním tretej rovnice a tretej neznámej.
g(1) = g(0)x1 + g(1)x2
g(2) = g(1)x1 + g(0)x2

9.8. Durbin-Levinsonova rekurzia 207
Všimnime si, že(g(0) g(1)g(1) g(0)
)(x2x1
)=
(g(0)x2 + g(1)x1g(1)x2 + g(0)x2
)=
(g(2)g(1)
)Preto z prvých dvoch rovníc dostávame(
b1b2
)=
(x1x2
)− b3
(x2x1
)Ostáva určiť len b3 a to dostaneme dosadením do poslednej rovnice:
g(3) = (g(2) g(1))
(b1b2
)+ g(0)b3
= (g(2) g(1))[(x1
x2
)− b3
(x2x1
)]+g(0)b3
Vo všeobecnosti Durbin-Levinsonov algoritmus definuje postupnosť vektorov zväč-šujúcej sa dĺžky
(b11)
(b21, b22)
(b31, b32, b33)
...
nasledujúcimi rekurzívnymi vzťahmi
b11 =g(1)
g(0), v0 = g(0)
bnn =1
vn−1
(g(n)−
n−1∑j=1
bn−1,j g(n− j))
bn1...
bn,n−1
=
bn−1,1
...bn−1,n−1
− bnnbn−1,n−1
...bn−1,1
vn = vn−1[1− bnn]2
Premenné v tomto algoritme majú nasledujúcu interpretáciu (pre každé n = 1, 2, . . .):
• vektor (bn1, . . . , bnn) je riešením Yule-Walkerove rovnice n-teho rádu, a tedapredstavuje najlepší AR(n) model pre dané autokovariancie,
• vn je disperzia procesu bieleho šumu pre AR(n) model,
• bnn je hodnota čiastkovej autokorelačnej funkcie.

208 Kapitola 9.Modelovanie náhodnosti v procesoch
Príklad 9.8.2 Predpokladajme, že proces Xt má nasledujúce autokovariancie:
g(0) = 2.1626356 g(1) = 1.1658003
g(2) = 0.8775780 g(3) = 0.7894288
Počiatočný krok Durbin-Levinsonovej rekurzie definuje
b11 =g(1)
g(0)= 0.5390646 v1 = v0(1− b211) = 1.534194
V ďalšej iterácii dostávame
b22 =1
v1
(g(2)− b11g(1)
)= 0.2484740 v2 = v1(1− b222) = 1.493737,
(b21) = (b11)− b22(b11) = 0.4515264
Konečne v treťom kroku dostávame
b33 =1
v2
(g(3)− b21g(2)− b22g(1)
)= 0.1364805
v3 = v2(1− b233) = 1.465913(b31b32
)=
(b21b22
)− b33
(b22b21
)=
(0.42936350.1007645
)Z týchto výpočtov vyplýva, že daný proces môžeme modelovať týmito spôsobmi:
• AR(1) procesom Xt = 0.5390646Xt−1 + Zt, kde Zt ∼WN(0, 1.534194)
• AR(2) procesom Xt = 0.4515264Xt−1+0.2484740Xt−2+Zt, kde Zt ∼WN(0, 1.493737)
• AR(3) procesom Xt = 0.4293635Xt−1 +0.1007645Xt−2 +0.1364805Xt−3 +Zt,kde Zt ∼WN(0, 1.465913).
Úloha 9.8.1 Nájdite AR(4) model z Yule-Walkerových rovníc pre predošlý príklad,ak viete, že g(4) = −0.01218353.
Úloha 9.8.2 Naprogramujte Durbin-Levinsovon algoritmus, a overte správnosť hod-nôt z príkladu 9.8.2 a úlohy 9.8.1.
9.9 Woldova dekompozícia
Modely stacionárnych procesov AR(p) a MA(q) dokážu namodelovať širokú škálu ná-hodných procesov. Vyvstáva otázka, či existujú iné stacionárne náhodné procesy, ktorésa takýmito modelmi nedajú vystihnúť. Začneme ukážkou jedného takého procesu.
Nech A,B sú nekorelované náhodné premenné so strednou hodnotou 0, a varian-ciou σ2. Definujme proces Yt = A cos(ωt) + B sin(ωt). Hoci tento proces je náhodný,

9.9. Woldova dekompozícia 209
má zaujímavú vlastnosť. Keď vieme dve jeho po sebe idúce hodnoty, vieme určiťvšetky nasledujúce, pretože platí
Yn = (2 cosω)Yn−1 − Yn−2.
Takýto proces sa nazýva deterministicky predikovateľný. Všeobecne, ak sa hodnotyprocesu dajú presne (lineárne) predpovedať na základe predošlých hodnôt, tak tentonazveme deterministicky predikovateľný.
Úloha 9.9.1 Vypočítajte autokovariačnú a autokorelačnú funkciu procesu Yt.
Woldova dekompzícia hovorí, že ľubovoľný nedeterministický stacionárny procesXt sa dá rozložiť na súčet
Xt =
∞∑j=0
ψjZt−j + Vt,
kde
1. b0 = 1 a∑∞
j=0 ψ2j <∞,
2. Zt ∼WN(0, σ2),
3. Cov(Zs, Vt) = 0 pre všetky časy s, t,
4. Vt je deterministicky predikovateľný proces.
Prvá zložka vo Woldovom rozklade, tj.∑∞
j=0 ψjZt−j sa nazýva aj MA(∞) procesom,keďže je zjavným zovšeobecnením MA(q) procesov z konečných na nekonečné kĺzavésúčty.
Woldova dekompozícia sa dá interpretovať tak, že MA(q) modely dokážu dobreaproximovať ľubovoľný stacionárny proces, ktorý nemá deterministicky predikova-teľnú zložku. V praxi sa osvedčilo použitie zovšeobecnených ARMA(p, q) modelov.V týchto modeloch proces Xt spĺňa rovnicu
Xt − b1Xt−1 − . . .− bpXt−p = Zt + a1Zt−1 + . . .+ aqZt−q
Väčšina štatistických softvérov dokáže nájsť najvhodnejší ARMA model na základeštatistických kritérií, ako je napríklad Akaikeho kritérium.

210 Kapitola 9.Modelovanie náhodnosti v procesoch
AR(p) procesy MA(q) procesy
ARMA(p,q) procesy
MA(∞) procesy
stacionárne procesydeterministické
procesy
Obr. 9.10. Vzťah medzi kategóriami procesov

10 Matematický softvér
V súčasnosti sú programy Matlab, R a Mathematica najpoužívanejšie softvéry vovedeckej i technickej praxi. V tomto apendixe si ukážeme použitie týchto programovna nasledujúce úlohy:
1. výpočet veľkosti lineárnej kombinácie dvoch vektorov,
2. riešenie sústavy lineárnych rovníc (riešiteľnej ale aj neriešiteľnej),
3. výpočet lineárnej regresie pomocou lineárnej a kvadratickej funkcie,
4. výpočet PCA
5. simulácia MA(1) procesu, tj. procesu, ktorý vznikne aplikáciou kĺzavých súčtovna biely šum a výpočet autokorelačnej funkcie výsledného procesu.
Pre tretiu úlohu predpokladáme, že dáta, ktoré chceme namodelovať, sú uložené vASCII súbore data.txt, v takzvanom CSV (comma separated values) formáte:
x , y2 . 6 , 4 . 84 . 1 , 2 . 48 . 2 , 31 0 . 3 , 7 . 213 . 3 , 1 0 . 914 . 4 , 1 2 . 416 ,15 .820 .6 ,3023 ,34 .424 . 9 , 4 3 . 6
Tento formát je podporovaný najväčšou škálou softvérov, a tak je uprednostňovanýnapríklad aj pred excelovskými súbormi. Excel, ale aj iné softvéry, má možnosť expor-tovať dáta do tohto formátu. Treba si však dať pozor na lokalizáciu. Niektoré lokali-zácie (vrátane slovenskej) používajú čiarku v úlohe desatinnej čiarky a používajú inýsymbol, napríklad bodkočiarku, namiesto čiarky na oddeľovanie dát v riadkoch.
211

212 Kapitola 10.Matematický softvér
10.1 Matlab
Matlab je softvér, ktorý je veľmi populárny medzi inžiniermi. Vydáva ho firma Mat-hWorks, ale existujú aj voľne šíriteľné (open-source) programy Octave (www.gnu.org/software/octave) a SciLab (www.scilab.org), ktoré používajú rovnakú syntax akoMatlab. Má veľmi dobrú podporu na prácu s vektormi, maticami a takisto sa ľahkorozširuje pomocou C knižníc.
10.1.1 Základná práca s vektormi
Skúsme vypočítať veľkosť lineárnej kombinácie 3v1 + 2v2 vektorov v1 = (3,−1, 4) av2 = (1, 1, 0). Výsledok týchto príkazov možno vidieť na nasledujúcom obrázku
Všimnime si, že Matlab vypisuje všetky medzivýsledky. Ak príkazy ukončíme bod-kočiarkou, tieto medzivýsledky nie sú zobrazované. Posledný výpočet sa dal spraviťaj týmito alternatívnymi príkazmi
• sqrt(v3 * v3’)
• sqrt(sum(v3 .* v3))
• norm(v3)
10.1.2 Riešenie sústavy rovníc
Ak má sústava riešenie, stačí vynásobiť ľavú stranu inverznou maticou.

10.1. Matlab 213
A = [1 0 1 ;0 1 1 ;1 1 0 ] ;
y = [ 3 ; 4 ; 5 ] ;x = inv (A) ∗ y
Ak sústava nemá riešenie, používa sa operátor delenia maticou.
A = [1 0 1 ;0 1 1 ;1 1 0 ;1 1 1 ]
y = [ 3 ; 4 ; 5 ; 1 3 ] ;x = A \ y
10.1.3 Metóda najmenších štvorcov
Na načítanie dát môžeme použiť príkaz textread, ktorý načíta dáta do dvoch stĺp-cových vektorov x,y.
[ x , y]= text read ( ’ data . txt ’ , ’%f ,% f ’ , ’ h e ad e r l i n e s ’ , 1)plot (x , y , ’ o ’ )
Výsledkom je obrázok 10.1.3.
0 5 10 15 20 250
5
10
15
20
25
30
35
40
45
Obr. 10.1. Vykreslenie nameraných hodnôt
Na výpočet regresie môžeme použiť funkciu polyfit, ktorá nájde najlepšiu apro-ximáciu polynómom daného stupňa.
p1 = polyf it (x , y , 1 )plot (x , y , ’ o ’ , x , polyval (p1 , x ) , ’− ’ )
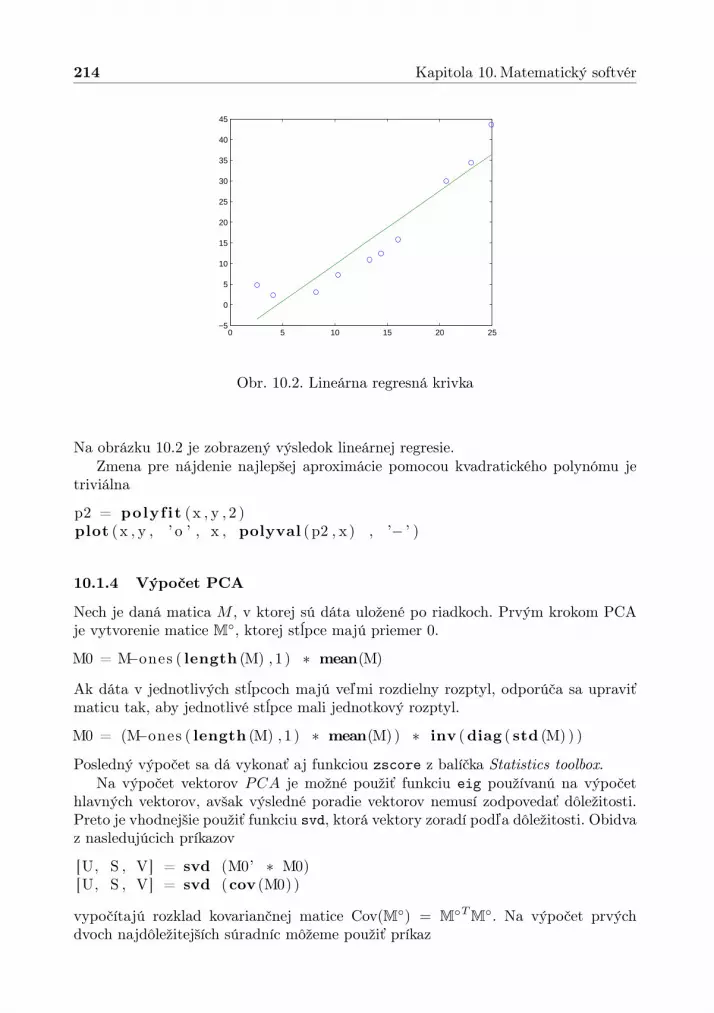
214 Kapitola 10.Matematický softvér
0 5 10 15 20 25−5
0
5
10
15
20
25
30
35
40
45
Obr. 10.2. Lineárna regresná krivka
Na obrázku 10.2 je zobrazený výsledok lineárnej regresie.Zmena pre nájdenie najlepšej aproximácie pomocou kvadratického polynómu je
triviálna
p2 = polyf it (x , y , 2 )plot (x , y , ’ o ’ , x , polyval ( p2 , x ) , ’− ’ )
10.1.4 Výpočet PCA
Nech je daná matica M , v ktorej sú dáta uložené po riadkoch. Prvým krokom PCAje vytvorenie matice M, ktorej stĺpce majú priemer 0.
M0 = M−ones ( length (M) , 1 ) ∗ mean(M)
Ak dáta v jednotlivých stĺpcoch majú veľmi rozdielny rozptyl, odporúča sa upraviťmaticu tak, aby jednotlivé stĺpce mali jednotkový rozptyl.
M0 = (M−ones ( length (M) , 1 ) ∗ mean(M) ) ∗ inv (diag ( std (M) ) )
Posledný výpočet sa dá vykonať aj funkciou zscore z balíčka Statistics toolbox.Na výpočet vektorov PCA je možné použiť funkciu eig používanú na výpočet
hlavných vektorov, avšak výsledné poradie vektorov nemusí zodpovedať dôležitosti.Preto je vhodnejšie použiť funkciu svd, ktorá vektory zoradí podľa dôležitosti. Obidvaz nasledujúcich príkazov
[U, S , V] = svd (M0’ ∗ M0)[U, S , V] = svd (cov (M0) )
vypočítajú rozklad kovariančnej matice Cov(M) = MTM. Na výpočet prvýchdvoch najdôležitejších súradníc môžeme použiť príkaz

10.1. Matlab 215
M0 ∗ V( : , 1 : 2 )
Alternatívne možno použiť funkciu princomp z balíčka Statistics toolbox. Matlab mátiež funkciu biplot umožňujúcu názorné vykreslenie dát v súradniciach danými pr-vými dvoma hlavnými komponentmi.
10.1.5 Autokorelácia MA(1) procesu.
Vygenerujme si 1001 výberov z bieleho šumu, ktorý vygenerujeme pomocou gaussov-ského rozdelenia N(0, 1).
bielySum = randn (1 , 1001 ) ;maProces = bielySum (1 : 1000 ) + 0 .5 ∗ bielySum ( 2 : 1 0 0 1 ) ;for i = 0 :50
kovMatica = cov ( maProces (1:(1000− i ) ) , . . .maProces ( ( i +1) : 1000 ) ) ;
autoKore lac ia ( i + 1) = kovMatica (1 , 2 ) / . . .sqrt ( kovMatica (1 , 1 ) ∗ kovMatica ( 2 , 2 ) ) ;
endplot ( 0 : 5 0 , autoKore lac ia , ’ x ’ )
Výsledkom je graf, ktorý je na obrázku 10.3. Je to prvých 51 autokorelácií danejrealizácie procesu.
0 10 20 30 40 50−0.2
0
0.2
0.4
0.6
0.8
1
1.2
Obr. 10.3. Prvých 51 autokorelácií danej realizácie procesu

216 Kapitola 10.Matematický softvér
10.2 R
R je open-source softvér (www.r-project.org) používaný najmä štatistikmi. Má opoznanie menej pohodlné značenie pre prácu s vektormi a maticami, no na druhejstrane je silnejší v pravdepodobnosti, štatistike a tvorbe názorných obrázkov vyjad-rujúcich štatistické charakteristiky dát.
10.2.1 Základná práca s vektormi
Skúsme vypočítať veľkosť lineárnej kombinácie 3v1 + 2v2 vektorov v1 = (3,−1, 4) av2 = (1, 1, 0). Výsledok týchto príkazov možno vidieť na nasledujúcom obrázku:
Všimnime si, že na tvorbu vektorov sa používa funkcia c(), ktorá spája svoje ar-gumenty. Na rozdiel od Matlabu vektory nie sú matice a treba použiť funkcie matrix,as.matrix, ak s nimi chceme pracovať ako s maticami. Program R, znova na rozdiel odMatlabu, vypisuje iba tie medzivýsledky, ktoré sa nepriradia do nejakej premennej.Ak sme zabudli priradiť výsledok výpočtu, nájdeme ho v preddefinovanej premen-nej .Last.value. Veľa funkcionality programu R je v knižniciach, ako napríklad ajnorm() funkcia, ktorá sa nachádza v knižnici Matrix. Ak ju chceme využiť, musímepríslušnú knižnicu najprv načítať pomocou príkazu library(Matrix), alebo použiťcelý názov funkcie Matrix::norm.
l ibrary ( Matrix )v1 = c (3 , −1, 4)v2 = c (1 , 1 , 0)

10.2. R 217
v3 = 3∗v1 + 2∗v2norm (as . matrix ( v3 ) , "F" )
10.2.2 Riešenie sústavy rovníc
Ak má sústava riešenie, môžeme použiť funkciu solve().
A = matrix (c (1 , 0 , 1 ,0 , 1 , 1 ,1 , 1 , 0 ) , nrow = 3)
y = matrix ( c (3 , 4 , 5 ) , ncol = 1)x = solve (A, y )
Ak sústava nemá riešenie, používa sa funkcia qr.solve().
A = matrix ( c (1 , 0 , 1 ,0 , 1 , 1 ,1 , 1 , 0 ,1 , 1 , 1 ) , nrow = 4)
y = c (3 , 4 , 5 , 1 3 ) ;x = qr . solve (A, y )
10.2.3 Metóda najmenších štvorcov
Na načítanie dát môžeme použiť príkaz read.csv, ktorý načíta dáta do dvoch stĺp-cových vektorov x,y.
data1 = read . csv ( ’ data . txt ’ )plot ( y ~ x , data = data1 )
Výsledkom je obrázok 10.4.
Na výpočet lineárnej regresie sa používa funkcia lm.
model1 = lm( y ~ x , data = data1 )plot ( y ~ x , data = data1 )abline ( model1 )
Na obrázku 10.5 je zobrazený výsledok lineárnej regresie.
Zmena pre nájdenie najlepšej aproximácie pomocou kvadratického polynómu je tri-viálna
model2 = lm ( y ~ x + I ( x^2) , data = data1 )plot ( y ~ x , data = data1 )l ines ( data1$x , predict ( model2 ) )

218 Kapitola 10.Matematický softvér
5 10 15 20 25
1020
3040
x
y
Obr. 10.4. Načítanie dát v R
5 10 15 20 25
1020
3040
x
y
Obr. 10.5. Lineárna regresia v R

10.2. R 219
10.2.4 Výpočet PCA
Nech je daná maticaM , v ktorej sú dáta uložené po riadkoch. Na rozklad matice podľasingulárnych hodnôt sa používa funkcia svd. Avšak PCA môžeme spraviť priamo, bezpoužitia tejto funkcie jedným z nasledujúcich príkazov
pcaData = prcomp (M)pcaData = prcomp (M, scale = TRUE)
Prvý z príkazov sa používa, keď rozptyl jednotlivých premenných je približne rovnaký.Ak tento predpoklad nie je splnený, odporúča sa použiť druhý príkaz, ktorý zodpovedáhľadaniu vlastných vektorov korelačnej matice. Výsledkom je objekt (štruktúra) snasledujúcimi zložkami:
• pcaData$sdev rozptyly hlavných komponentov (tj. druhé odmocniny vlastnýchčísel kovariančnej (v druhom príkaze korelačnej) matice)
• pcaData$rotation matica, ktorej stĺpce sú vlastné vektory
• pcaData$x dáta v transformovaných súradniciach
• pcaData$center stredné hodnoty premenných
• pcaData$scale rozpyly premenných
Táto štruktúra sa dá názorne vykresliť pomocou funkcie biplot(pcaData). Krátkysumár sa dá zobraziť zavolaním summary(pcaData).
10.2.5 Autokorelácia MA(1) procesu
Pri tejto úlohe sa ukáže silná podpora pre pravdepodobnostné a štatistické výpočty.Táto úloha sa dá vykonať v R dvoma riadkami.
maProces = arima . sim ( l i s t (ma = 0 . 5 ) , 1001)plot ( a c f ( maProces ) )
Na porovnanie s Matlabom a Mathematicou si ukážme, ako sa táto simulácia dá urobiťbez použitia funkcií arima.sim a acf.
bielySum = rnorm ( 1 001 ) ;maProces = bielySum [−1001] + 0 .5 ∗ bielySum [ −1 ] ;autoKore lac ia = rep (0 , 51 )for ( i in 0 : 50 )
autoKore lac ia [ i + 1 ] = cov ( maProces [1 :(1000− i ) ] ,maProces [ ( i +1 ) : 1 000 ] ) ;
plot ( 0 : 5 0 , autoKore lac ia )
Na nasledujúcom obrázku sú grafy autokorelačných funkcií vypočítané aj prvým ajdruhým prístupom.

220 Kapitola 10.Matematický softvér
0 5 10 15 20 25 30
0.0
0.2
0.4
0.6
0.8
1.0
Lag
AC
F
Series maProces
0 10 20 30 40 50
0.0
0.2
0.4
0.6
0.8
1.0
1.2
0:50
auto
Kor
elac
ia

10.3. Mathematica 221
10.3 Mathematica
Mathematica je komerčný softvér určený predovšetkým pre výskumníkov. Vydávaho firma Wolfram Research, ktorá stojí aj za portálom Wolfram Alpha. Tento portálumožňuje aj laikom zadať netriviálne otázky, a v pozadí softvér Mathematica vypočítaodpovede.
10.3.1 Základná práca s vektormi
Skúsme vypočítať veľkosť lineárnej kombinácie 3v1 + 2v2 vektorov v1 = (3,−1, 4) av2 = (1, 1, 0). Výsledok týchto príkazov možno vidieť na nasledujúcom obrázku
Podobne ako Matlab, Mathematica vypisuje všetky medzivýsledky, ktoré sa ne-končia bodkočiarkou. Odlišnosťou softvéru Mathematica je, že dokáže počítať presnévýsledky, a tak občas treba použiť funkciu N[], aby sme ich skonvertovali na reálnečíslo s desatinnou čiarkou.
10.3.2 Riešenie sústavy rovníc
Ak má sústava riešenie, môžeme použiť funkciu LinearSolve[].

222 Kapitola 10.Matematický softvér
LinearSolve [ 1 ,0 ,1 ,0 ,1 ,1 ,1 ,1 ,0 ,3 , 4 , 5 ]
Ak sústava nemá riešenie, treba použiť funkciu LeastSquares.
LeastSquares [ 1 ,0 ,1 ,0 ,1 ,1 ,1 ,1 ,0 ,1 ,1 ,1 ,3 , 4 , 5 , 13 ]
10.3.3 Metóda najmenších štvorcov
Na načítanie dát môžeme použiť príkaz Import, ktorý načíta dáta do premennejdata1, nasledovaný funkciou Drop, aby sme odstránili prvý riadok, ktorý obsahujenázvy stĺpcov.
data1 = Import [ "data . txt " , "CSV" ]data2 = Drop [ data1 , 1 ]ListPlot [ data2 ]
Výsledkom je nasledujúci obrázok.
10 15 20 25
20
30
40
Na výpočet regresie môžeme použiť funkciu LinearModelFit, ktorá nájde najlep-šiu aproximáciu polynómom daného stupňa.
model = LinearModelFit [ data2 , x , x ]Show [ ListPlot [ data2 ] , Plot [ model [ " BestFit " ] , x , 0 , 3 0 ] ]

10.3. Mathematica 223
5 10 15 20 25 30
10
20
30
40
Tu je zobrazený výsledok lineárnej regresie.Aby sme našli najlepšiu parabolu, treba použiť funkciu Fit.
parabola = Fit [ data2 , 1 , x , x^2 , x ]Show [ ListPlot [ data2 ] , Plot [ parabola , x , 0 , 3 0 ] ]
5 10 15 20 25 30
5
10
15
20
25
30
35
10.3.4 Výpočet PCA
Nech je daná matica M , v ktorej sú dáta uložené po riadkoch. Na rozklad maticepodľa singulárnych hodnôt sa používa funkcia SingularValueDecomposition. AvšakPCA môžeme spraviť bez použitia tejto funkcie jedným z nasledujúcich príkazov:
pcaData = PrincipalComponents (M, Method−>Covariance )pcaData = PrincipalComponents (M, Method−>Cor r e l a t i on )

224 Kapitola 10.Matematický softvér
Prvý z príkazov sa používa, keď rozptyl jednotlivých premenných je približne rovnaký.Ak tento predpoklad nie je splnený, odporúča sa použiť druhý príkaz, ktorý zodpovedáhľadaniu vlastných vektorov korelačnej matice.
Výsledkom je zoznam vektorov zoradený klesajúco podľa dôležitosti.
10.3.5 Autokorelácia MA(1) procesu
Vygenerujme si 1001 výberov z bieleho šumu, ktorý vygenerujeme pomocou Gaus-sovho rozdelenia N(0, 1).
bielySum = RandomVariate [ NormalDistr ibut ion [ ] , 1 0 0 1 ] ;maProces = bielySum [ [ Range [ 1 , 1 0 0 0 ] ] ]
+ 0 .5∗ bielySum [ [ Range [ 2 , 1 0 0 1 ] ] ] ;autoKore lac ia = Table [ i , 0 , i , 0 , 5 0 ] ;For [ i = 0 , i <= 50 , i++,
autoKore lac ia [ [ i + 1 , 2 ] ] =Cor r e l a t i on [ maProces [ [ Range [ 1 , 1000 − i ] ] ] ,maProces [ [ Range [ i + 1 , 1 0 0 0 ] ] ] ] ] ;
ListPlot [ autoKore lac ia , PlotRange −> Full ,PlotStyle −> Di r e c t i v e [Red, PointSize [Medium ] ] ]
Výsledkom je graf prvých 51 autokorelácií danej realizácie procesu.
10 20 30 40 50
0.2
0.4
0.6
0.8
1.0

Literatúra
[1] AXLER, S.: Linear Algebra Done Right, Second Edition 1991, Springer-Verlag,New-York, Berlin, Heidelberg, ISBN 0-387-98259-0
[2] BOROŇ, J.: Kvalita reči pre IP telefóniu pri rozklade do rôznych báz, diplomovápráca, Fakulta riadenia a informatiky, Žilinská univerzita 2007
[3] BROCKWELL P.J., DAVIS R. A.: Introduction to Time Series and Forecasting,2nd ed. (Springer texts in statistics) 2002
[4] BROCKWELL P.J., DAVIS R. A.: Time series: Theory and Methods, Springertexts in statistics, 1987
[5] COOLEY J.W., TUKEY J.W.: An algorithm for machine calculation of complexFourier series, Math. Comp. 19 (1965), 297–301
[6] ČÁKY, P., KLIMO, M., MIHÁLIK, I., MLADŠÍK, R.: Text-to-speech for Slovaklanguage, Text, speech and dialogue, 2004, Brno, Czech Republic, Springer 2004,ISBN 3-540-23049-1
[7] FRIGO M., JOHNSON S. G.: The Fastest Fourier Transform in the West, MITtechnical report MIT-LCS-TR-728, 1997
[8] HAMMING R.W.: Error detecting and error correcting codes, Syst. Tech. J.,29, (1950), 147–160
[9] HASSANIEH H., INDYK P., KATABI D., PRICE E.: Nearly optimal sparseFourier transform, http://arxiv.org/abs/1201.2501
[10] KLARNER, D.A.: The Mathematical Gardner, Wadsworth International Bel-mont, California 1981
[11] KLIMO, M., BACHRATÁ, K.: Mathematical education reform for ICT Stu-dents, ICETA 2008
[12] KUBA, M.: Úvod do problematiky rozpoznávania reči, TKR - QUO VADIS?,Žilina 2001 , ISBN 80-7100-826-5
[13] KUBA, M.: Rozpoznávanie rečových signálov z malého počtu akustických po-zorovaní pomocou skrytých Markovových modelov, (dizertačná práca), školiteľ:Martin Vaculík. – Žilinská univerzita 2006
225

226 Literatúra
[14] RADER, C.: Discrete Fourier transforms when the number of data samples isprime, IEEE Proc. 56, (1968), 1107–1108
[15] MIHÁLIK I., ŠKVAREK O., ČÁKY P., JANDÁK V.: Spracovanie textu pre re-čový syntetizátor a jazyk SSML, INFOTRANS 2007, Vydavateľstvo: UniverzitaPardubice 2007, Pardubice, Česká republika. ISBN 978-80-7194-989-3
[16] KLIMO, M., KOVÁČIKOVÁ, T.: Voice over Packet, module No 12 of the lineb-reak eEDUSER, No /02/B/F/PP/142256 Košice: Elfa 2005, ISBN 80-89066-99-2
[17] KOVÁČIKOVÁ T., SEGEČ P.: IP telephony for an interactive communicationwithin e-Learning, In: ICETA 2003: Košice, Slovak Republic: Košice: Elfa 2003
[18] KRŠÁK, E.: Elektronický podpis, Zborník prednášok na medzinárodnú konfe-renciu Systémová integrácia 2001, SSSI Žilina 2001, ISBN 80-7100-880-X
[19] PAPOULIS, A.: Probability, Random Variables, and Stochastic Processes, Po-lytechnic Institute of New York, McGraw-Hill, Inc., New York, Toronto London1991
[20] PRATCHETT T., STEWART I., COHEN J.: Věda Na Zeměploše, Talpress,ISBN: 80-7197-243-6, EAN: 9788071972433, The Science of Discworld 2004
[21] PALÚCH, S., STANKOVIANSKA, I.: Algebra a jej inžinierske aplikácie, EDIS2008, Žilina
[22] WALTER, J.: Stochastické modely v ekonómii, SNTL Praha 1970
[23] WIDROW, B., MC COOL, J.M., LARIMORE, M.G., JOHNSON, C.R., jr.:Stationary and nonstationary learning characteristics of the LMS adaptive filter,Proceedings of the IEEE, 64, 8, (1976), 1151–1162
[24] WINOGRAD S.: On computing the discrete Fourier transform, Mathematicsof Computation, 32, 141, (1978), 175-199
[25] ZIMMERMANN, J.: Spektrografická a škálografická analýza akustického rečo-vého signálu, Náuka, Prešov, 2002, ISBN 80-89038-22-0
[26] ZLATOŠ, P.: Lineárna algebra a geometria Lineárna algebra a geometria, Cestaz troch rozmerov s presahmi do príbuzných odborov, Marenčin PT 2011, ISBN978-80-8114-111-9

Register
AR(p) proces, 204AR(1) proces, 203–204
autokorelačná funkcia, 195autokovariančná funkcia, 195
bázaWalsh-Hadamardova, 119
báza vektorového priestoru, 23jednotková, 25ortogonálna, 31zmena bázy, 27
biely šum, 199–200
chybový proces, 48energia, 49veľkosť, 48
cyklický kód, 182
diskrétna Fourierova transformácia, 94,104
spätná, 104distribučná funkcia, 146Durbin-Levinsonov algoritmus, 206–208
extrapolácia procesu, 83
filtrácia procesu, 80
generujúci polynóm, 185Gramova-Schmidtova ortogonalizácia, 38–
42
Hammingova vzdialenosť, 35, 179harmonická báza, 94
impulzná charakteristika systému, 160interpolácia procesu, 77
kódyblokové, 182nesystematické, 182
konvolúcia, 165korelačný koeficient, 147kovariancia, 147
lineárna kombinácia, 20lineárna regresia, 50–71, 188–193
výpočet v Mathematice, 222výpočet v Matlabe, 213výpočet v R, 217
lineárny prediktor, 195lineárny systém, 160
MA(q) proces, 201MA(1) proces, 200–202
simulácia v Mathematice, 224simulácia v Matlabe, 215simulácia v R, 219
Mathematica, 221–224matica patriaca báze, 26Matlab, 212metóda
kĺzavých súčtov, 80najmenších štvorcov, 47–48
ML metóda, 188modulácia, 161
odľahlá hodnota, 193
PCA, 136–137priemet vektora, 37proces
deterministický, 147energia, 48náhodný, 147
227

228 Register
realizácia, 147Pytagorova veta, 34, 49, 150
R, 216–219
súradnice vektora, 26sústava lineárnych rovníc
riešenie v Mathematice, 221riešenie v Matlabe, 212riešenie v R, 217
skalár, 14skalárny súčin, 31, 97spektrum
amplitúdové, 104fázové, 104
spektrum procesu, 28, 104stacionárny proces, 193
centrovaný, 195stredná hodnota, 146
transformácie časovo invariantné, 164
vektor, 14syndrómový, 175veľkosť vektora, 33
vektorový priestor, 13–17dimenzia, 24Euklidov, 31podpriestor vektorového priestoru,
25príklady, 16–18
vektorybázové,bázy, 24generujúce podpriestor, 25kolmé, 31lineárne nezávislé, 22lineárne závislé, 21vzdialenosť vektorov, 34
vierohodnosť, 188
Yule-Walkerove rovnice, 204

Ondrej Šuch, PhD., prof. Ing. Martin Klimo, PhD.,
Dr. Ivan Cimrák, doc. RNDr. Katarína Bachratá, PhD.
ANALÝZA PROCESOV LINEÁRNYMI METÓDAMI
Vydala Žilinská univerzita v Žiline, Univerzitná 8215/1, 010 26 Žilina
v edičnom rade VYSOKOŠKOLSKÉ UČEBNICE
Vedecký redaktor prof. RNDr. Ivo Čáp, CSc.
Zodp. red. PhDr. Katarína Šimánková
Tech. red. Mária Závodská
Návrh obálky Mgr. Veronika Hucíková
Vytlačilo EDIS-vydavateľstvo Žilinskej univerzity v auguste 2012
ako svoju 3380. publikáciu
228 strán, 139 obrázkov, AH 12,04, VH 12,53
prvé vydanie, náklad 100 výtlačkov
ISBN 978-80-554-0556-8
www.edis.uniza.sk





























