Embed Size (px)
Citation preview

Language and Speech 1 –28
© The Author(s) 2015Reprints and permissions:
sagepub.co.uk/journalsPermissions.navDOI: 10.1177/0023830914564452
las.sagepub.com
Language and Speech
Asking or Telling – Real-time Processing of Prosodically Distinguished Questions and Statements
Willemijn FL HeerenLeiden University Centre for Linguistics/Leiden Institute for Brain and Cognition, Leiden University, The Netherlands
Sarah A BibykDepartment of Brain and Cognitive Sciences, University of Rochester, USA
Christine GunlogsonDepartment of Linguistics, University of Rochester, USA
Michael K TanenhausDepartment of Brain and Cognitive Sciences, University of Rochester, USA
AbstractWe introduce a targeted language game approach using the visual world, eye-movement paradigm to assess when and how certain intonational contours affect the interpretation of utterances. We created a computer-based card game in which elliptical utterances such as “Got a candy” occurred with a nuclear contour most consistent with a yes–no question (H* H-H%) or a statement (L* L-L%). In Experiment 1 we explored how such contours are integrated online. In Experiment 2 we studied the expectations listeners have for how intonational contours signal intentions: do these reflect linguistic categories or rapid adaptation to the paradigm? Prosody had an immediate effect on interpretation, as indexed by the pattern and timing of fixations. Moreover, the association between different contours and intentions was quite robust in the absence of clear syntactic cues to sentence type, and was not due to rapid adaptation. Prosody had immediate effects on interpretation even though there was a construction-based bias to interpret “got a” as a question. Taken together, we believe this paradigm will provide further insights into how intonational contours and their phonetic realization interact with other cues to sentence type in online comprehension.
KeywordsComprehension of prosody, real-time language processing, intonation, boundary tones, phrase accents, nuclear contours
Corresponding author:Willemijn Heeren, Leiden University Centre for Linguistics/Leiden Institute for Brain and Cognition, Cleveringaplaats 1, 2311 BD Leiden, The Netherlands. Email: [email protected]
564452 LAS0010.1177/0023830914564452Language and SpeechHeeren et al.research-article2014
Original Article
at UNIV OF ROCHESTER LIBRARY on January 15, 2015las.sagepub.comDownloaded from

2 Language and Speech
1 Introduction
Most research on the real-time processing of intonation has focused on pitch accents and phrasal groupings (e.g., Dahan, Tanenhaus, & Chambers, 2002; Ito & Speer, 2008; Weber, Braun, & Crocker, 2006), with comparatively little attention being paid to the boundary tonal targets that are assumed to control the shape of that portion of the intonational contour following the nuclear pitch accent. The contribution of boundary movements to the interpretation of an utterance is distinct in kind from that of pitch accents. Whereas the placement of pitch accents functions in a relative way to structure content, highlighting some constituents over others, the overall tune, and especially the boundary-oriented portion, more typically plays a role in signalling different speech acts (e.g., questions versus statements) that operate over the utterance as a whole. Pitch accent structure has thus far lent itself more readily to modelling in terms of relationships between referential expres-sions in discourse, and hence to online measures such as visual world eye-tracking (Cooper, 1974; Tanenhaus, Spivey-Knowlton, Eberhard, & Sedivy, 1995).
In this paper we aim to extend the use of online measures to the study of intonational contours that contrast with respect to boundary targets as well as their nuclear pitch accents. To explore how such tunes are integrated online, along with other potential cues to intention, we created a “targeted language game” (Brown-Schmidt & Tanenhaus, 2008; Tanenhaus & Brown-Schmidt, 2008) that makes differences in fixation patterns contingent on the listener’s interpretation of an interlocutor’s utterance as either a question (asking about the listener’s own game cards) or a statement (provid-ing information about the interlocutor’s cards). We exploit the intuitive contrast between the utter-ance-final “rising” intonation often associated with questioning, and a corresponding “falling” (or level) contour more typically associated with stating. The paradigm thus allows us to study the expectations listeners have for how combinations of a pitch accent with boundary tones (also referred to as nuclear contours, see Gussenhoven, 2004, p. 296) may signal intentions.
We employ the widely used ToBI transcription system (Beckman & Ayers, 1993; Beckman & Hirschberg, 1999; Pierrehumbert, 1980), in which pitch accents, phrasal accents and boundary tones are represented as static tonal targets (High or Low). A minimal utterance tune in the ToBI system contains three tonal specifications, with each element either H(igh) or L(ow): the pitch accent (indicated by *, together with + in the case of complex pitch accents), an intermediate phrase accent (indicated by – or no symbol) and an intonational phrase boundary tone (notated with %). Pitch accents affiliate with stressed syllables, boundary tones align to the end of an intonational phrase (often involving utterance-final changes in the fundamental frequency, F0) and phrase accents are “edge tones with a secondary association to an ordinary tone-bearing unit” (Grice, Ladd, & Arvaniti, 2000, p. 180). The phrasal or boundary contour follows the nuclear pitch accent – that is, the last pitch accent of the phrase – spreading over any unstressed post-nuclear syllables. In this investigation we examine two tunes, (H*) L* L-L% (“falling”) and (H*) H* H-H% (“ris-ing”), which differ across their final three elements and exhibit a clear intuitive contrast. Note that the ToBI transcription system does not reify boundary movements, such as “rises” and “falls”, and we are not making a theoretical claim about the existence of such elements. Rather, we are simply classifying for convenience the L* L-L% sequence of tones as falling and the H* H-H% sequence as rising.
Despite the intuitive contrast, the association between questioning and H* H-H% (and asserting and L* L-L%) is far from straightforward, as noted by Pierrehumbert and Hirschberg (1990), among others. Syntactic sentence type, together with contextual factors, enters into the determina-tion of speech acts; rarely does the intonational contour alone suffice. For instance, while syntacti-cally interrogative polar questions (e.g., Is the server down?) often end with H-H%, a rising contour is not required for the utterance to function as a question, and L-L% does not routinely turn the
at UNIV OF ROCHESTER LIBRARY on January 15, 2015las.sagepub.comDownloaded from

Heeren et al. 3
interrogative into a statement. In fact, syntactic wh-questions often end with a fall rather than a rise (e.g., When did the server go down?). Similarly, while it is true that a syntactically declarative utterance with H-H% (e.g., The server’s down?) can (in an appropriate context) invite the listener to either confirm or deny the proposition, much as a syntactic interrogative does (e.g., Is the server down?), “declarative questions” are not fully interchangeable with their syntactically interrogative counterparts (see Bartels, 1997; Gunlogson, 2003, 2008). The high degree of variability in how rising and falling intonation is used in questions (even polar interrogatives) has in some cases led to the conclusion that intonation in fact provides no indication whatsoever of speech act type (Geluykens, 1988). There is also widespread documentation of rising declaratives not being used as questions (i.e., “Uptalk”) in a variety of dialects of English (e.g., Southern Californian English: McLemore, 1991; New Zealand English: Warren, 2005). The interpretation and realization of rises associated with questioning in the context of “Uptalk” raises an important set of issues beyond the scope of this article (for discussion see, e.g., Fletcher, Grabe, & Warren, 2005; Warren, 2005).
Following Pierrehumbert and Hirschberg (1990), we assume that intonational meaning is best understood as contributing in systematic ways to inferences about specific intentions, attitudes and speech acts, rather than representing such intentions, attitudes and acts directly. Thus, in many languages the complex interactions of intonation, sentence type and context can make it difficult to isolate and test specific hypotheses about each. This is especially challenging for phrase accents/boundary tones, because in many languages they typically co-occur with other differences in form, such as interrogative versus declarative syntactic structure, and discourse structural factors that (in theory at least) are available prior to the utterance-final material on which the phrase accents/boundary tones are realized.
In part because of this difficulty, temporal integration of whole tunes, in particular those with contrasting boundary components, in spoken language comprehension has –to our knowledge– received very little attention thus far. Online investigations on phrase accent/boundary tone pro-cessing are mostly restricted to spatial studies on the neural regions involved (e.g., Doherty, West, Dilley, Shattuck-Hufnagel, & Caplan, 2004; Fournier, Gussenhoven, Jensen, & Hagoort, 2010), with the exception of some recent work on the combination of contrastive pitch accents with con-tinuation rises (e.g., Kurumada, Brown, & Tanenhaus, 2012; Kurumada, Brown, Bibyk, Pontillo, & Tanenhaus, 2014a). There is, however, a substantial body of research investigating how phrase accents/boundary tones interact with comprehension using offline measures. These studies have shown that listeners are able to categorize level to falling versus rising utterance-final changes in F0 into statements versus yes–no questions, respectively, on the basis of intonation alone. Comparable results have been obtained for a number of different languages (e.g., Polish and American-English: Majewski & Blasdell, 1968; Swedish and American-English: Studdert-Kennedy & Hadding, 1973; German: Schneider & Lintfert, 2003; Dutch: Van Heuven & Haan, 2002). In addition, sentences may contain other phonetic cues to questions, such as declination, that is, the F0 trend over the course of an utterance (Thorsen, 1980; Van Heuven & Haan, 2002), and the realization of pitch accents earlier in the sentence (Petrone & Niebuhr, 2014; Van Heuven & Haan, 2002). In a study on Dutch, Van Heuven and Haan (2002) showed that the trend of the F0 baseline and the size of the object accent in subject–verb–object (SVO) sentences influenced lis-teners’ expectations about whether an utterance was a statement or a question. Both a slightly upward trend and a large object accent were interpreted as signalling a question, but both cues were overruled by information conveyed by the boundary tones. A similar interpretation of declination was reported by Thorsen (1980), who found that Danish listeners associated steeply falling sen-tence intonation with statements, and associated rising sentence intonation with questions. Pitch accents in the pre-nuclear region may also cue speech act types, as has been shown for Northern Standard German (Petrone & Niebuhr, 2014). In sum, listeners are sensitive to both local and
at UNIV OF ROCHESTER LIBRARY on January 15, 2015las.sagepub.comDownloaded from

4 Language and Speech
global changes in the speaker’s fundamental frequency as cues to speech acts, when asked to judge (parts of) utterances offline. However, little is known about if and when these cues are used during online speech processing.
Research examining the time course with which listeners use phrase accents/boundary tones faces two methodological challenges. The first challenge, mentioned above, is to separate the effects of intonation from preceding syntactic information. We address that challenge here by using elliptical utterances (e.g., got a candy) that are syntactically and semantically compatible with an interpretation as either a declarative/statement or an interrogative/question, as detailed in the next section. In the absence of syntactic cues to speech act type, the tonal sequence has the potential to emerge as the primary cue influencing interpretation of a particular utterance as asking or telling.1
The second methodological challenge is to develop a paradigm that is sensitive to the time course of processing of the intonational tune as a whole, including boundary-aligned targets that do not necessarily coincide with particular syllables of lexical elements (thus differing from pitch-accented targets). This requires creating a situation where (a) there are different intentions that the listener might infer from the tonal sequence and (b) a real-time measure can be used to infer how the listener is mapping the sequences onto the candidate intentions. A body of recent research on pitch accents has used the visual world paradigm in which eye movements to objects or pictures in a visual display are monitored as the utterance unfolds (Cooper, 1974; Tanenhaus et al., 1995). This paradigm is useful for studying issues in pragmatics, because the language is interpreted with respect to a context and, when combined with a task, there is a goal structure in which intentions can be embedded. However, the visual world paradigm is inherently a referential paradigm; partici-pants begin to look at potential referents as early as 200 ms after relevant speech input that helps circumscribe the referential domain (Allopenna, Magnuson, & Tanenhaus, 1998; Chambers, Tanenhaus, Eberhard, Filip, & Carlson, 2002; Salverda, Kleinschmidt, & Tanenhaus, 2014). Studies examining pitch accents map fairly naturally onto referential tasks where the pitch accent can provide information that, if used, would bias the listener towards a particular referent. For example, in some studies (Dahan et al., 2002; Watson, Tanenhaus, & Gunlogson, 2008), the display contained pictures with names that began with the same syllable, so-called cohort competitors (e.g., “candle/candy” and “turtle/turkey”). Watson et al. (2008) found that the type of pitch accent on the first syllable of the temporarily ambiguous word biased interpretation towards a particular referent even when the segmental information was still consistent with both members of the cohort pair. Ito and Speer (2008; also see Weber et al., 2006) used multiple objects in the visual display of the same type but differentiated by colour or some other feature. These experiments evaluated whether a L+H* accent would bias a contrastive interpretation between two objects mentioned in succession (e.g., “blue ball, GREEN ball”). They found effects of L+H* during the colour adjec-tive, that is, before any segmental information from the noun was even heard. Thus, both types of studies show that information from pitch accents is rapidly integrated during reference resolution.
The post-nuclear shape of the contour, however, does not establish relationships between spe-cific referents in the discourse (such as a new, given or contrastive referent). Utilizing the visual world paradigm to assess processing of falling and rising contours requires developing a task that indirectly ties specific referents to the different speech acts signalled by H* H-H% (asking) and L* L-L% (telling). We addressed this challenge by creating a “targeted language game” (Brown-Schmidt, Gunlogson, & Tanenhaus, 2008; Brown-Schmidt & Tanenhaus, 2008; Tanenhaus & Brown-Schmidt, 2008) in which we could embed minimal pairs of utterances for which prosody was decisive in distinguishing between an intended statement and question. Crucially, the partici-pant’s actions, and thus eye movements, differed for statements and questions, providing an online measure of the processing of falling and rising contours. We hypothesized that the post-nuclear
at UNIV OF ROCHESTER LIBRARY on January 15, 2015las.sagepub.comDownloaded from

Heeren et al. 5
accent portion of the contour is interpreted as rapidly as pitch accents are. In Experiment 2, we studied the expectations listeners have for how rising and falling contours may signal intentions: do expectations reflect underlying linguistic categories or do they originate from rapid adaptation to the paradigm?
2 Experiment 1: Online processing of rising and falling tones
We developed a targeted language game in which the participant played a card game against a computer by means of a verbal interaction. The game was designed so that on critical trials only the prosody distinguished whether the computer was making a statement (signalled by L* L-L%) or asking a yes–no question (H* H-H%). We removed correlated syntactic cues by having the computer, on target trials, use elliptical sentences of the form “Got a <card category>”, which could be elliptical versions of either “I have got a <card category>.” or “Have you got a <card category>?”. By eliminating syntactic cues from the computer’s utterances and designing the game so that intended questions versus statements led to different actions on the part of the partici-pant (thus leading to different fixation patterns), together with holding constant the location of the nuclear accent, we were able to focus on listeners’ online processing of the shape of the nuclear contour, including post-nuclear movement. In the utterances used in the game, the nuclear pitch accent lands on the utterance-final word (the card category name).
2.1 Game design
The goal of the game was for the two opponents, the player and the computer, to discard cards from their (virtual) hands by pairing them with a match card, a face-up card in the middle of the com-puter screen (see Figure 1).
On the computer’s turn, the player would hear the computer either produce a statement to announce a match (when the computer had a playing card matching the match card, e.g., “Got a window.”) or produce a question to ask for a card (when the computer did not have a matching card,
Figure 1. On-screen game layout at the start. In the middle, the match card is shown. The player’s cards are the ones on the bottom, the computer’s cards the ones on the top. Playing cards are on the left; the stacks of blocking cards are on the right.
at UNIV OF ROCHESTER LIBRARY on January 15, 2015las.sagepub.comDownloaded from

6 Language and Speech
e.g., “Got a window?”). The computer’s utterances were pre-recorded by a female speaker (see Section 2.3 for details). The order of events during the game (question or statement, player or com-puter) was fully determined to meet the restrictions of (i) presenting each target trial exactly twice, and (ii) keeping the duration of the game to about 10 minutes, to maintain calibration and thus prevent track loss and/or drift. The game was programmed in MATLAB to follow this pre-deter-mined series of events; progress through this script was cued by the player’s clicks on particular on-screen locations.2 There were eight target trials each for questions and statements, and there also were filler questions and statements with a total of 11 computer-produced statements (fillers + targets), and 14 computer-produced questions (fillers + targets). There were four card categories, each represented by a black and white line drawing shown on the match, playing or blocking card. Two of the categories were monosyllabic words (shoe [ʃu:], wheel [wi:l]) and the other two were disyllabic words (candy [kændi], window [wındoʊ]). This feature will become important when we present analyses of the phonetic properties of the stimuli and of the eye movements. To foreshadow the issues, for the disyllabic words we can separate effects of the nuclear accent, which is aligned with the first syllable for “candy” and “window”, from the post-nuclear component of the contour – the phrase tone and the boundary tone, which would be aligned to the final syllable. For the monosyllabic words, however, the nuclear accent and post-nuclear component of the contour are realized on the same syllable.
The rules of the game are as follows. To improve clarity, we will refer to the example participant as “he” and the computer as “she”. At the beginning of the game the player and the computer each have four playing cards and a stack of blocking cards, the top one of which can be used to block the other’s matches. In Figure 1 the player’s cards are shown at the bottom and the computer’s cards are shown at the top. The player’s playing cards are the four cards on the bottom left and the computer’s playing cards are the four cards on the top left. The player’s stack of blocking cards is shown on the bottom right and the computer’s stack of blocking cards is shown on the top right. On his turn, the player checks his playing cards for a match with the match card, which is the card in the middle of the screen that faces up. In Figure 2(a) a possible match is shown, as the player’s hand contains a candy that can be paired with the candy match card in the middle of the screen.
If the player has a match, as in Figure 2(a), he has to announce the match (for instance by saying “I have a candy” or “I can make a match”), thus allowing the computer to see if she can block it. If a block is possible, which is the case when the block card is of the same category as the match card
Figure 2. Possible outcomes when the player checks for a match. (a) Match: the player has a candy card in his hand that matches the candy match card in the middle. (b) No match: the player does not have any card in his hand that matches the match card.
at UNIV OF ROCHESTER LIBRARY on January 15, 2015las.sagepub.comDownloaded from

Heeren et al. 7
in the middle, the computer will announce the block (e.g., “I am blocking you”) and the player is not allowed to discard the card from his hand. If the computer cannot block (e.g., “I can’t block”), the player discards the matching card from his hand. The player’s turn then continues, regardless of whether the player makes a match or the computer blocks the match. A new match card then appears in the center of the screen, and both the player’s and the computer’s blocking cards are updated. If the player does not have a matching playing card in his hand, as in Figure 2(b), he is obliged to ask the computer if she can make the match instead. If the computer has a matching card, she discards that card. If she does not have a matching card, the player receives a penalty card, an extra card in his hand. The computer then takes the next turn, regardless of whether the player receives a penalty card or the computer makes a match.
As an illustration of the dialogue between player and computer, example (1) presents a sequence of utterances taken from a game played by one of the subjects. It shows one turn by the computer (C) followed by the player’s (P) turn, and in the right-hand column the game event, as also exem-plified in Figures 2 and 3, is indicated.
(1)
Figure 3. Possible outcomes when the player checks for a block. (a) Block: the player’s blocking card is the same as the match card in the middle. (b) No block: the player’s blocking card is different from the match card.
Speaker Utterance Event
C “My turn.” “Got a candy.” Computer has a matchP “I can’t block.” Player cannot blockC “Do you have a shoe?” Computer does not have a matchP “No.” Player cannot match insteadC “Too bad.” “Your turn.” P “I have a wheel.” Player has a matchC “I’m blocking you.” Computer can blockP “I have a candy.” Player has a matchC “I can’t block.” Computer cannot blockP “Do you have a candy?” Player does not have a matchC “Yes.” Computer makes match instead
at UNIV OF ROCHESTER LIBRARY on January 15, 2015las.sagepub.comDownloaded from

8 Language and Speech
Given the design of the game, we expected that upon hearing a question, the player would look at his playing cards (left bottom) to see whether he had a match (see Figures 2(a) and (b)), and upon hearing a statement, the player would look at his blocking card (right bottom) see whether he could block the computer’s match (see Figures 3(a) and (b)). Crucially, the participant’s actions, and thus eye movements, would differ for statements and questions, providing a measure of the online pro-cessing of rising and falling intonation.
The center of the match card was placed equidistant to the center of the mean size of the playing card set and the center of the blocking card. Because the game was fully determined, card set sizes at each stage of the game were known and could be used to compute these optimal distances. After each successful match or blocked match, the player’s playing and blocking cards were again cov-ered, in order to make it more difficult for players to remember the cards in their hand. Therefore, we expected players to visually attend to their cards before making a response. The player’s cards were revealed by having the player click a button labelled “S” for “show”, which was visible on screen below the appropriate set of cards. The computer’s cards were covered at all times so that the player would not be able to see the computer’s hand.
2.2 Participants
Sixteen adult, native speakers of American-English with normal or corrected-to-normal vision and self-reported normal hearing participated. They were recruited from the student population of the University of Rochester, NY, USA. All gave informed consent, and were paid for their efforts.
2.3 Materials
The computer’s utterances were pre-recorded, including eight target sentences (four statements/four questions) and nine fillers (three statements/six questions). The pre-recorded target and filler utterances are available as supplementary materials. (Available at: http://las.sagepub.com/) Filler utterances were used to introduce syntactic variation into the computer’s speech (e.g., “Do you have a candy?”). The computer’s utterance set also included utterances to keep track of turns dur-ing the game (e.g., “It’s your/my turn.”), to respond to the player’s questions for a match (e.g., “Yes.” or “No, sorry.”) and to block the player’s match (e.g., “I’m blocking you.”). The recordings took place in a sound-treated booth using an Audio-technica ATM75 head-worn microphone and a Marantz PMD 670 solid state recorder (mono at 32 kHz, 16 bits). The speaker (SB) was a 23-year-old female native speaker of American-English. She was instructed to produce intonational con-tours that she felt were natural given the context of the game, but to try to keep the contours within a condition (i.e., question versus statement) consistent across utterances.
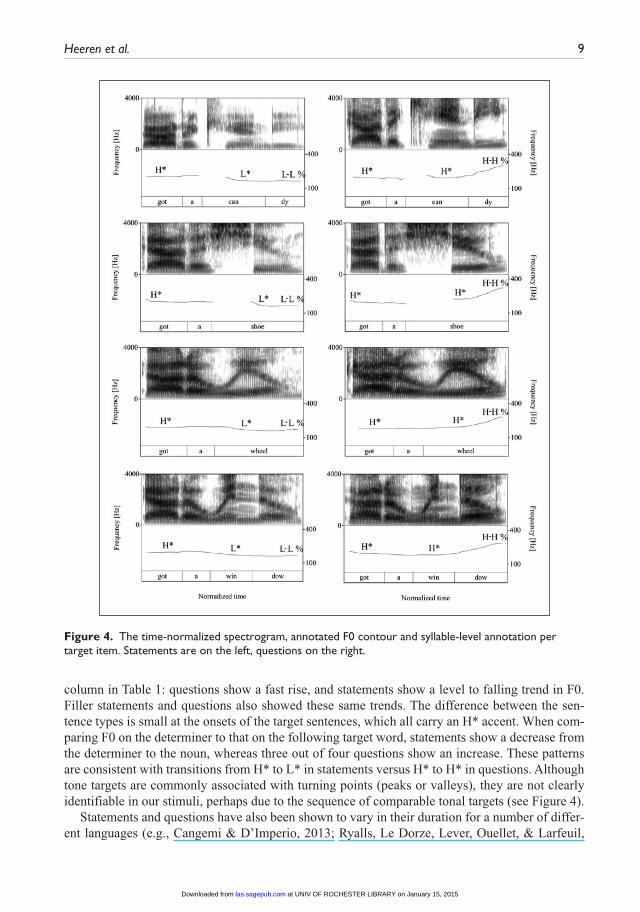
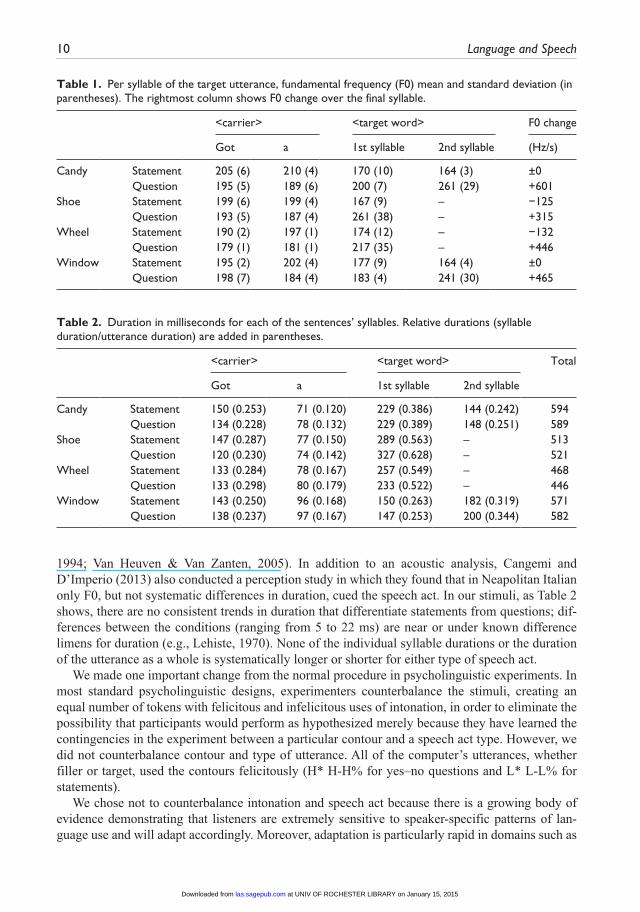
Phonetic details on each of the target utterances are shown in Figure 4. The ToBI annotations were provided by a trained independent labeller. Note that sentence onsets were consistently pro-duced with an H* accent on got, but that nuclear contours differed between the speech acts (H* H-H% in questions and L* L-L% in statements). These contours were realized consistently within each speech act. Using Praat (Boersma, 2001), absolute duration (in ms) and mean fundamental frequency (F0, in hertz) were measured per syllable, for each of the target sentences. Results are given in Table 1 (F0 and its standard deviation) and Table 2 (absolute and relative duration).
Previous research has found that the entire F0 contour can cue different speech acts, not just the nuclear portion (e.g., Petrone & Niebuhr, 2014; Van Heuven & Haan, 2002). Table 1 shows that there are indeed differences between the F0 trajectories in target statements and questions, and these differences are also visually represented in Figure 4. The most obvious difference in F0 is found over the target word, and especially on the final syllable, as can be seen from the rightmost
at UNIV OF ROCHESTER LIBRARY on January 15, 2015las.sagepub.comDownloaded from
Heeren et al. 9
column in Table 1: questions show a fast rise, and statements show a level to falling trend in F0. Filler statements and questions also showed these same trends. The difference between the sen-tence types is small at the onsets of the target sentences, which all carry an H* accent. When com-paring F0 on the determiner to that on the following target word, statements show a decrease from the determiner to the noun, whereas three out of four questions show an increase. These patterns are consistent with transitions from H* to L* in statements versus H* to H* in questions. Although tone targets are commonly associated with turning points (peaks or valleys), they are not clearly identifiable in our stimuli, perhaps due to the sequence of comparable tonal targets (see Figure 4).
Statements and questions have also been shown to vary in their duration for a number of differ-ent languages (e.g., Cangemi & D’Imperio, 2013; Ryalls, Le Dorze, Lever, Ouellet, & Larfeuil,
Figure 4. The time-normalized spectrogram, annotated F0 contour and syllable-level annotation per target item. Statements are on the left, questions on the right.
at UNIV OF ROCHESTER LIBRARY on January 15, 2015las.sagepub.comDownloaded from
10 Language and Speech
1994; Van Heuven & Van Zanten, 2005). In addition to an acoustic analysis, Cangemi and D’Imperio (2013) also conducted a perception study in which they found that in Neapolitan Italian only F0, but not systematic differences in duration, cued the speech act. In our stimuli, as Table 2 shows, there are no consistent trends in duration that differentiate statements from questions; dif-ferences between the conditions (ranging from 5 to 22 ms) are near or under known difference limens for duration (e.g., Lehiste, 1970). None of the individual syllable durations or the duration of the utterance as a whole is systematically longer or shorter for either type of speech act.
We made one important change from the normal procedure in psycholinguistic experiments. In most standard psycholinguistic designs, experimenters counterbalance the stimuli, creating an equal number of tokens with felicitous and infelicitous uses of intonation, in order to eliminate the possibility that participants would perform as hypothesized merely because they have learned the contingencies in the experiment between a particular contour and a speech act type. However, we did not counterbalance contour and type of utterance. All of the computer’s utterances, whether filler or target, used the contours felicitously (H* H-H% for yes–no questions and L* L-L% for statements).
We chose not to counterbalance intonation and speech act because there is a growing body of evidence demonstrating that listeners are extremely sensitive to speaker-specific patterns of lan-guage use and will adapt accordingly. Moreover, adaptation is particularly rapid in domains such as
Table 1. Per syllable of the target utterance, fundamental frequency (F0) mean and standard deviation (in parentheses). The rightmost column shows F0 change over the final syllable.
<carrier> <target word> F0 change
Got a 1st syllable 2nd syllable (Hz/s)
Candy Statement 205 (6) 210 (4) 170 (10) 164 (3) ±0 Question 195 (5) 189 (6) 200 (7) 261 (29) +601Shoe Statement 199 (6) 199 (4) 167 (9) – −125 Question 193 (5) 187 (4) 261 (38) – +315Wheel Statement 190 (2) 197 (1) 174 (12) – −132 Question 179 (1) 181 (1) 217 (35) – +446Window Statement 195 (2) 202 (4) 177 (9) 164 (4) ±0 Question 198 (7) 184 (4) 183 (4) 241 (30) +465
Table 2. Duration in milliseconds for each of the sentences’ syllables. Relative durations (syllable duration/utterance duration) are added in parentheses.
<carrier> <target word> Total
Got a 1st syllable 2nd syllable
Candy Statement 150 (0.253) 71 (0.120) 229 (0.386) 144 (0.242) 594 Question 134 (0.228) 78 (0.132) 229 (0.389) 148 (0.251) 589Shoe Statement 147 (0.287) 77 (0.150) 289 (0.563) – 513 Question 120 (0.230) 74 (0.142) 327 (0.628) – 521Wheel Statement 133 (0.284) 78 (0.167) 257 (0.549) – 468 Question 133 (0.298) 80 (0.179) 233 (0.522) – 446Window Statement 143 (0.250) 96 (0.168) 150 (0.263) 182 (0.319) 571 Question 138 (0.237) 97 (0.167) 147 (0.253) 200 (0.344) 582
at UNIV OF ROCHESTER LIBRARY on January 15, 2015las.sagepub.comDownloaded from

Heeren et al. 11
prosody and pragmatics, where there is considerable variability among speakers. When infelicitous utterances are included, listeners quickly learn to ignore the cue that makes the utterance infelici-tous. For example, when faced with a speaker who overuses pre-nominal adjectives, listeners will no longer use the presence of the adjective to predict an upcoming contrast between two objects (e.g., tall versus short cup; Grodner & Sedivy, 2011). Similarly, listeners generally interpret the sentence “It looks like a zebra” to mean The speaker thinks it’s a zebra when the noun is focused, but to mean You might think it’s a zebra, but it isn’t when the verb is focused (Kurumada et al., 2012, 2014a). However, when exposure trials are included in which the speaker sometimes uses prosody infelicitously (e.g., a few trials in which verb-focus prosody is used with the “it is” interpretation and noun-focus prosody with the “it isn’t” interpretation), or when the speaker uses contrastive focus infelicitously in another construction (Kurumada, Brown, Bibyk, Pontillo & Tanenhaus, 2014b) participants quickly begin to place less weight on that prosodic dimension. Therefore, in experimen-tal research investigating aspects of prosody that map onto intentions, such as the present study, it is important to avoid the infelicitous use of prosody, and to adopt other ways of assessing alternative explanations based on possible task-specific contingencies.
Thus for Experiment 1 the computer only used rising and falling intonation felicitously to signal its intentions. Experiment 2 subsequently addressed the contingency concern by reversing the use of the mapping between the intonation and the speech act, that is, using a H* H-H% contour for a statement and a L* L-L% contour for a question. If the results of Experiment 1 were solely due to participants having learned within-experiment contingencies, then we should observe the opposite pattern of results in Experiment 2.
2.4 Procedure
Participants were given both written and oral instructions. During testing, the verbal interaction was recorded using a Realistic 33-984A Highball dynamic unidirectional table microphone placed between the computer speakers and the player, so that it would register both interlocutors. Eye movements were recorded using a head-mounted ASL eye-tracker, sampling at 60 Hz, and a Sony DSR-30 digital video recorder, with Sony 184 DVCAM digital videotapes. Before the actual test started, the participant played a practice game that contained all possible game situations (making a match, being asked for a match, blocking the computer’s move, being blocked). Calibration of the eye-tracker was checked at regular intervals throughout the test game. Calibration checks always occurred before a new turn for the participant, but never before the computer’s turn. The entire session of instruction–calibration–practice–experiment lasted 30–45 minutes.
The order of events (question or statement, player or computer’s turn) during the game was fully determined, but the order for the card items (candy, shoe, etc.) was rotated and balanced over four lists. For target utterances, the wave file started 1400 ms after the match card had changed. For filler items, the preceding silence was variable, but the shortest delay was 1200 ms. This variability was introduced to increase the naturalness of the computer’s utterances; a human player would not respond at completely regular intervals. The pre-recorded computer utterances were played to the participants at a comfortable listening level over computer speakers. The use of pre-recorded speech allowed for control over the natural speech presented to listeners while also allowing for the possibility of using manipulated speech in future work.
2.5 Results and discussion
The 33 ms video frames were coded manually from the onset of a target utterance until the partici-pant’s verbal response, which was a variant of “I can(’t) match” or “I can(’t) block”. We coded for
at UNIV OF ROCHESTER LIBRARY on January 15, 2015las.sagepub.comDownloaded from

12 Language and Speech
five locations: (1) the playing cards; (2) the match card; (3) the blocking card; (4) other on-screen locations; and (5) track loss. Saccade-initial frames were counted as fixations to the landing site. Out of a total of 256 trials (16 subjects × 16 targets), only six trials were misinterpreted by the participants (2%: three statements, three questions). Misinterpretation was defined as clicking to reveal cards at the wrong side of the screen, that is, trying to match when a block was called for and vice versa. These trials were excluded from the analyses.
In order to examine the effects of the falling and rising contours on fixations, we had to make decisions about how to align analysis windows with the speech and how long to make the analysis windows. Because the stimuli did not contain turning points, we aligned the analysis windows to the offset of the target word. Salverda et al. (2014) have recently established that 200 ms is a con-servative estimate of the earliest linguistically mediated saccades in an action-based visual world study. The longest second syllable in a disyllabic word was 200 ms (“window” with a rising con-tour). Therefore for the disyllabic words, an analysis window that ends at offset should capture fixations that are triggered by the nuclear accent (and arguably, the phrase accent) before phonetic realization of the boundary tone, which falls on the second syllable. The shortest final syllable for any word is 144 ms (“candy” with a falling contour). If information about the boundary tone was not available until late in the vowel, we might not see the earliest effects on fixations until about 150–200 ms after the syllable offset. Therefore, we decided upon a window size of 300 ms.3 In order to equate the sample size across the pre-offset and post-offset windows, we analysed a pre-offset window of −300–0 ms and post-offset window of 0–300 ms.
As explained above, for the disyllabic words we can plausibly separate the effects of the nuclear accent from boundary tone. However, for the monosyllabic words the nuclear accent, the phrase accent and the boundary tone all fall on the same syllable. In order to be conservative, we will refer to the post-offset window as capturing the effects of the rise and fall, without making stronger claims about which components of the contour are triggering the effects. However, based on the results of separate analyses for the monosyllabic and disyllabic stimuli, we will draw some tenta-tive conclusions about the effects of the phrase accents/boundary tones.
Over the pre-offset and post-offset analysis windows, fixation proportions to playing cards and the blocking card for each of the conditions were averaged per participant. To compare looking pat-terns between conditions, the ratio between looks to the playing card and looks to the sum of playing cards and blocking card was computed, and compared between H* H-H% and L* L-L% targets (see also Dahan & Tanenhaus, 2005) using Wilcoxon signed ranks tests for paired samples.
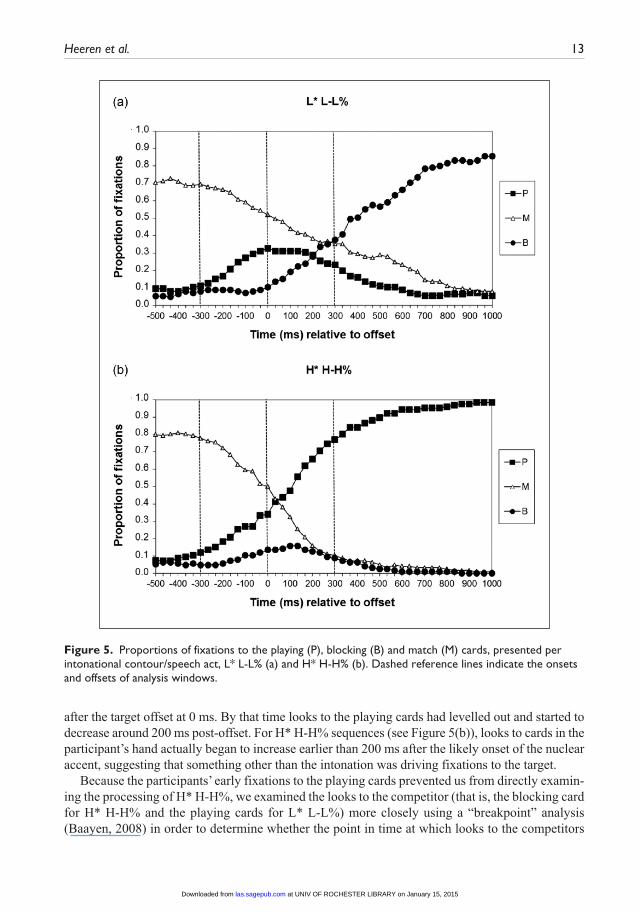
The proportions of fixations to the different coding categories are presented separately by con-tour in Figure 5. In general, participants first looked at the match card and next shifted gaze to the on-screen regions that contained the playing cards or the blocking card.4 In the pre-offset region −300–0 ms, no significant difference in fixation proportions to playing versus blocking cards was found between the conditions, (Z = −0.094, p = 0.925). A sub analysis of only the disyllabic stimuli also revealed no significant difference in fixation proportions between the playing and blocking cards (Z = −0.178, p = 0.859). Based on this analysis, we can tentatively conclude that the nuclear accent by itself, and perhaps the nuclear accent in conjunction with the phrase accent, is not suffi-cient to affect the interpretation of the utterance as a question or an assertion prior to the boundary tone. The absence of an effect for the combined stimuli also suggests that there is no noticeable effect of any of the preceding prosodic information. Notice that participants, regardless of condi-tion, looked more at their playing cards than their blocking card (Z = −2.355, p = 0.019). We will return to a discussion of this bias later in this section.
In the post-offset window from 0 to +300 ms, a significant difference was found between fixation proportions following a L* L-L% compared to a H* H-H% sequence, (Z = −2.999, p = 0.003). For L* L-L% sequences (see Figure 5(a)), looks to the blocking card began to increase about 200 ms
at UNIV OF ROCHESTER LIBRARY on January 15, 2015las.sagepub.comDownloaded from
Heeren et al. 13
after the target offset at 0 ms. By that time looks to the playing cards had levelled out and started to decrease around 200 ms post-offset. For H* H-H% sequences (see Figure 5(b)), looks to cards in the participant’s hand actually began to increase earlier than 200 ms after the likely onset of the nuclear accent, suggesting that something other than the intonation was driving fixations to the target.
Because the participants’ early fixations to the playing cards prevented us from directly examin-ing the processing of H* H-H%, we examined the looks to the competitor (that is, the blocking card for H* H-H% and the playing cards for L* L-L%) more closely using a “breakpoint” analysis (Baayen, 2008) in order to determine whether the point in time at which looks to the competitors
Figure 5. Proportions of fixations to the playing (P), blocking (B) and match (M) cards, presented per intonational contour/speech act, L* L-L% (a) and H* H-H% (b). Dashed reference lines indicate the onsets and offsets of analysis windows.
at UNIV OF ROCHESTER LIBRARY on January 15, 2015las.sagepub.comDownloaded from

14 Language and Speech
were influenced by the different contours was comparable across both conditions. This analysis looks for a breakpoint, or turning point, in a linear relation between the dependent variable (fixa-tions) and the independent variable (time relative to utterance offset) by fitting two regression lines, one to the interval before a possible breakpoint and one to the interval after that breakpoint. This procedure is repeated for all possible breakpoints in a region of interest, and finally the best breakpoint/model is selected.
The chosen region of interest was the interval during which information from the post-nuclear contour would become available, specifically from −100 ms until +400 ms relative to the offset of the utterance. This interval was divided into two windows, and looks to the competitor were mod-elled as a function of the interaction of time with time window using a logistic mixed-effects model.5 Firstly, we determined that the breakpoint was justified in both conditions by choosing an arbitrary location for the breakpoint (200 ms) and by then comparing a model that contained just the simple effect of time (along with random intercepts and slopes for time by participants) to a model that contained the interaction of time and time window (along with random intercepts and slopes for the time by time window interaction by participants). In both conditions a chi-square test determined that the model with the interaction of time by time window accounted for significantly more of the variance than the model with only time: H* H-H% χ2(4) = 60.337, p < 0.001, and L* L-L% χ2(4) = 121.68, p < 0.001. Thus, including a breakpoint in both conditions is justified. The optimal breakpoint was then determined by fitting a model for each possible division of the region of interest into two time windows (shifting the breakpoint in 33-ms steps at a time), and then select-ing the model with the lowest Bayesian Information Criterion (Schwarz, 1978).
For looks to the competitor in the case of H* H-H% sequences (i.e., to the blocking card), the optimal breakpoint was found at +233 ms, and for looks to the competitor in the case of L* L-L% sequences (i.e., to the playing cards), the optimal breakpoint was found at +200 ms. This means that for both H* H-H% and L* L-L% trials, fixations to the competitor dropped off around 200 ms after boundary tone offset. Although there was a bias to fixate the target early with H* H-H%, the competitors reveal a similar time course for the influence of both L* L-L% and H* H-H% on processing.
Why should there be an early bias for looking at the playing cards? We can see two possible explanations for this bias. The first is that the bias is due to a game-based strategy, perhaps reflect-ing the player’s need to be aware of his hand once a new match card appears. Recall that all cards in a player’s hand were covered at the beginning of a turn, so that players could not actually see the card categories in their hand. The number of cards in their hand, however, might still be considered useful information as it tells players how close they are to potentially winning the game. A related game-based explanation is that players might prefer to look at their hand because it contained more cards than the blocking card.
The second explanation is that the bias could be syntactic or constructional in nature; the phrase “got a” might favor a question interpretation over a statement one. Comments made by some of the participants after the experiment suggested this bias as a plausible explanation. In the following sections we evaluate these two types of explanations.
2.5.1 Testing the game-based bias. If the early bias for listeners to look at the cards in their hand is game based, then the same bias should also be observed in the fillers, and especially in the declara-tive fillers. Recall that these filler utterances had early syntactic disambiguation of their intended speech act due to the presence or absence of subject-auxiliary inversion.
For each of the 16 participants, all fillers were coded in the same way as explained in Section 2.5. There were three declarative fillers of the form “I’ve got a <card category>.”, and six inter-rogative fillers of the form “Do you have a <card category>?”. Both filler types were roughly of
at UNIV OF ROCHESTER LIBRARY on January 15, 2015las.sagepub.comDownloaded from
Heeren et al. 15
comparable length, with declaratives varying in duration between 601 and 768 ms, and interroga-tives varying between 630 and 770 ms. Intonational contours in the fillers showed a steep rise in questions and a flat to falling trend in statements. None of the 144 filler trials (16 participants × 9 trials) were misinterpreted.
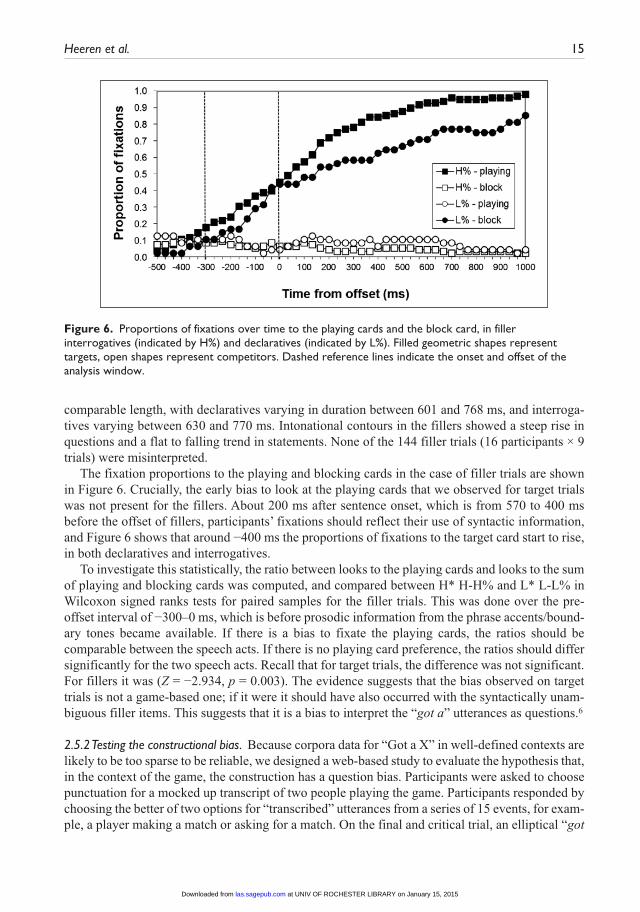
The fixation proportions to the playing and blocking cards in the case of filler trials are shown in Figure 6. Crucially, the early bias to look at the playing cards that we observed for target trials was not present for the fillers. About 200 ms after sentence onset, which is from 570 to 400 ms before the offset of fillers, participants’ fixations should reflect their use of syntactic information, and Figure 6 shows that around −400 ms the proportions of fixations to the target card start to rise, in both declaratives and interrogatives.
To investigate this statistically, the ratio between looks to the playing cards and looks to the sum of playing and blocking cards was computed, and compared between H* H-H% and L* L-L% in Wilcoxon signed ranks tests for paired samples for the filler trials. This was done over the pre-offset interval of −300–0 ms, which is before prosodic information from the phrase accents/bound-ary tones became available. If there is a bias to fixate the playing cards, the ratios should be comparable between the speech acts. If there is no playing card preference, the ratios should differ significantly for the two speech acts. Recall that for target trials, the difference was not significant. For fillers it was (Z = −2.934, p = 0.003). The evidence suggests that the bias observed on target trials is not a game-based one; if it were it should have also occurred with the syntactically unam-biguous filler items. This suggests that it is a bias to interpret the “got a” utterances as questions.6
2.5.2 Testing the constructional bias. Because corpora data for “Got a X” in well-defined contexts are likely to be too sparse to be reliable, we designed a web-based study to evaluate the hypothesis that, in the context of the game, the construction has a question bias. Participants were asked to choose punctuation for a mocked up transcript of two people playing the game. Participants responded by choosing the better of two options for “transcribed” utterances from a series of 15 events, for exam-ple, a player making a match or asking for a match. On the final and critical trial, an elliptical “got
Figure 6. Proportions of fixations over time to the playing cards and the block card, in filler interrogatives (indicated by H%) and declaratives (indicated by L%). Filled geometric shapes represent targets, open shapes represent competitors. Dashed reference lines indicate the onset and offset of the analysis window.
at UNIV OF ROCHESTER LIBRARY on January 15, 2015las.sagepub.comDownloaded from

16 Language and Speech
a” sentence was presented, for the first time, and could be given either statement or question punc-tuation. We created two counterbalanced lists to control for the material that intervened between when players had last seen a non-elliptical question or statement prior to the critical trial.7 In the first version of the transcript the critical trial was as follows: I do now its my turn again got a candy, with the following two responses available:
a. I do! Now it’s my turn again. Got a candy.b. I do! Now it’s my turn again. Got a candy?
In the second version of the transcript the critical trial was got a candy, with the following two responses available:
a. Got a candy.b. Got a candy?
The responses differed slightly to accommodate the fact that the conversation proceeds differently depending on when the last question or statement occurred. Critically, however, the only difference in punctuation between response (a) and response (b) in both versions was whether “got a candy” ended with a full stop or a question mark. Both versions of the full survey are provided in the appendix.
Using the online crowd-sourcing service Amazon’s Mechanical Turk, 223 Human Intelligence Tasks (HITs) were posted for (self-reported) American-English participants (providing us with 200 unique participants). We collected 100 HITs for each version of the transcript, with the order of the answers for the critical trial counterbalanced across participants (50 saw the questions option first, and the other 50 saw the statement option first). Participants were paid for their efforts.
Over 90% percent of the subjects (185/200) selected the question option, (b) in the above exam-ples. An exact binomial test (success = 185, n = 200) determined that the probability of selecting the question option was significantly different from the null hypothesis of 0.5 (95% CI 0.88–0.96, p < 0.001). This evidence supports the hypothesis that the early preference to fixate the playing cards is due to a bias to interpret “got a” as a question.
2.6 Preliminary conclusion
Rising and falling intonation was processed quickly, and a strong association between H* H-H% and a question interpretation, and L* L-L% and a statement interpretation, was observed, with participants making very few errors. We found no direct evidence for an effect of the nuclear accent on speech act processing, but given the nature of our stimuli we cannot rule out the possibility that the nuclear accent also contributed. We also observed an early preference for looking at the playing cards regardless of intonation. This bias was likely caused by a preference to interpret “got a” as a question, but this early preference was rapidly overridden by information from the intonation. Given the strong constructional bias it is striking that information from the intonational contour had such an immediate effect. The rapidity with which the intonation was used, and the fact that participants had little uncertainty, suggests that listeners expect rising and falling intonation to provide reliable information that they can use to map utterances onto intentions.
In order to draw firm conclusions about the use of rising and falling intonation, however, it is important to address the possibility that the results simply reflect participants having learned the contingencies between the intonational contours and speech act types that were specific to this experiment. Recall that in Experiment 1 the computer only produced felicitous examples. Therefore,
at UNIV OF ROCHESTER LIBRARY on January 15, 2015las.sagepub.comDownloaded from

Heeren et al. 17
participants could have been developing a strategy based on the computer’s particular (and highly consistent) use of intonation rather than using pre-existing knowledge about the phonetic imple-mentation of English intonation. Experiment 2 was conducted to address this concern.
3 Experiment 2: Linguistic processing or rapid adaptation?
In Experiment 1 the computer always used H* H-H% when asking a question and L* L-L% when making a statement. But how do we know that we were not simply measuring rapid adaptation to the contingencies embedded in Experiment 1, rather than linguistic processing that takes into account expectations based on typical usage, for example, an experiment-independent prior, modu-lated by the adaptation that occurs with any exposure to linguistic input? If participants were simply learning to associate rising and falling intonation with particular actions based solely on the statis-tics of the experiment, then they should also quickly learn the opposite association of a rising intona-tion signalling a statement and a falling intonation signalling a question. Given the large amount of variability in terms of how rising and falling intonation is used to signal intentions, it is a viable concern that participants might have no prior expectations about how the computer will signal her questions and statements and would therefore rapidly adapt to whatever intonation-to-meaning mapping she used. To address this issue, we created a control condition of the game where prosody was reversed: target and filler questions were realized with L* L-L%, and target and filler statements were realized with H* H-H%, thus creating the same statistics for learning as in Experiment 1.
3.1 Participants
Sixteen adult, native American-English participants with self-reported normal hearing and normal or corrected-to-normal vision were recruited from the student population of the University of Rochester, NY, USA. All gave informed consent, and were paid for their efforts.
3.2 Materials
Fillers and targets were created with the H* H-H% sequence used for statements and L* L-L% for questions. As the phrase structure did not differ between the different speech acts in target utter-ances, these utterances were left unchanged. We achieved the reversed pairing of intonational con-tours and intentions by playing the original question utterance when the interaction required a statement and the original statement utterance when the interaction required a question. To exchange the prosody in the filler questions and statements (“Do you have a X” and “I’ve got a Y”) hybrid utterances were created using cross-splicing. Wave files from original statements were cut between “I’ve got a” and card category “Y”, and wave files from original questions were cut between “Do you have a” and card category “X”. Hybrids were created by adding the card category “Y” from a filler statement (containing the falling contour) onto a filler question “Do you have a”, and the other way around. In this way, H* H-H% occurred in declaratives, and L* L-L% in interrogatives. This exchange was made within card categories to preserve co-articulatory cues, effectively exchanging the nuclear contours in the fillers and thus their phonetic characteristics between speech acts expressed on the same word, that is, shoe, candy, window or wheel. Minor adjustments in the splic-ing were made as needed until the authors were satisfied with the naturalness of the stimuli.
3.3 Procedure
The procedure was the same as in Experiment 1.
at UNIV OF ROCHESTER LIBRARY on January 15, 2015las.sagepub.comDownloaded from

18 Language and Speech
3.4 Results and discussion
The eye movements were coded as in Experiment 1. As opposed to 2% of misinterpretations in Experiment 1 (6 out of 256 target trials), participants together misinterpreted 176 out of 256 target trials (69%). Over the first eight target trials participants misinterpreted 94 out of 128 (73%) and this number fell to 82 out of 128 (64%) for the second half of the experiment. This suggests that some learning took place in the course of the experiment. Specifically, participants showed improvement on the statement trials with H* H-H%, initially interpreting the H* H-H% as signal-ling a question, but later learning to associate it with a statement. Comparable learning was not found for the questions signalled by L* L-L%, most likely because some participants correctly interpreted the first three target questions as questions (i.e., by clicking on the playing cards) despite the L* L-L% contour. One explanation for this behaviour is participants’ preference to interpret “got a” as signalling a question as opposed to a statement, as shown earlier through the Amazon Mechanical Turk survey.
We confirmed this pattern of results with a mixed-effects logistic regression. We first re-coded trial number to reflect the relative position of each target trial within its own category (i.e., question trial 1, question trial 2, statement trial 3, etc.). Recall that the order of moves in the game was pre-determined and identical for all participants; thus, trial number and intonational sequence are highly correlated and cannot justifiably be used together in a regression analysis. It should be noted, however, that the general pattern of results does not change whether this correlation is pre-sent or removed by re-coding the trial number; nor does it change if the trial number is re-coded in a different manner, such as centering over the raw trial number within condition. Therefore we only report results from the best-fit model, which included the simple effects of trial and condition, the interaction, random intercepts and random slopes by trial. We found a significant interaction between trial number and intonation condition (β = 0.23019, z = 2.943, p < 0.01). As the trial num-ber increased, participants were more likely to answer correctly, but only for the statements with the H* H-H% contour.8
The eye-movement analysis was split into trials that were correctly interpreted (according to the reversed prosody set-up) and trials that were misinterpreted. Results were aligned at the end of the target utterance, as in Experiment 1, meaning that zero (0) corresponded to the end of the utterance as well as to roughly 200 ms after boundary tone onset. As before, the windows of interest were set to −300–0 ms (pre-offset) and 0–300 ms (post-offset). The ratio between looks to the playing card and looks to the sum of playing cards and blocking card was computed, and compared between H* H-H% and L* L-L% targets in Wilcoxon signed ranks tests for paired samples.
In Figure 7 the results are shown for the misinterpreted trials, which form the majority. Even though recorded questions (H* H-H%) were now intended as statements, and the other way around, participants responded to H* H-H% as if being asked for a match, and to L* L-L% as if being told of an impending match.
The fixation patterns are strikingly similar to the results from Experiment 1. This was confirmed in the statistical analysis, revealing different fixation patterns for questions and statements once the information about the nuclear contour becomes available (Z = −3.18, p = 0.001). Before that, that is for the −300–0 ms time window, the fixation patterns do not differ significantly between the conditions (Z = −1.424, p = 0.15).
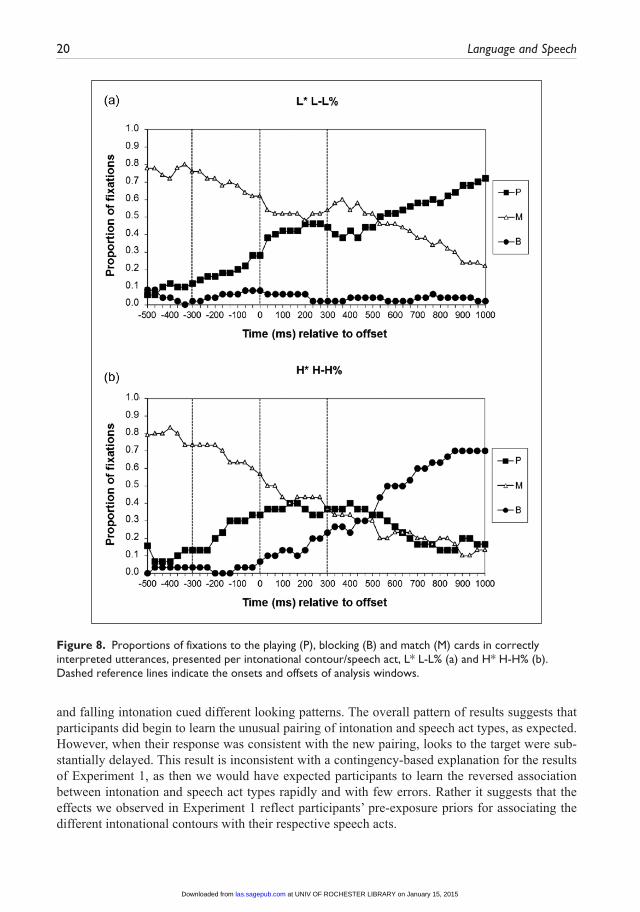
In Figure 8 results are shown for the trials that were correctly interpreted within the context of the pairing of intonation and speech act type in Experiment 2. These are the trials in which partici-pants treated H* H-H% as signalling a statement and L* L-L% as signalling a question. The results on trials where falling and rising contours were correctly interpreted show an asymmetry between L* L-L% and H* H-H% contours. The use of L* L-L% to signal a question does not seem to slow down looks to the playing cards. As we have seen earlier, participants have a tendency to fixate the
at UNIV OF ROCHESTER LIBRARY on January 15, 2015las.sagepub.comDownloaded from
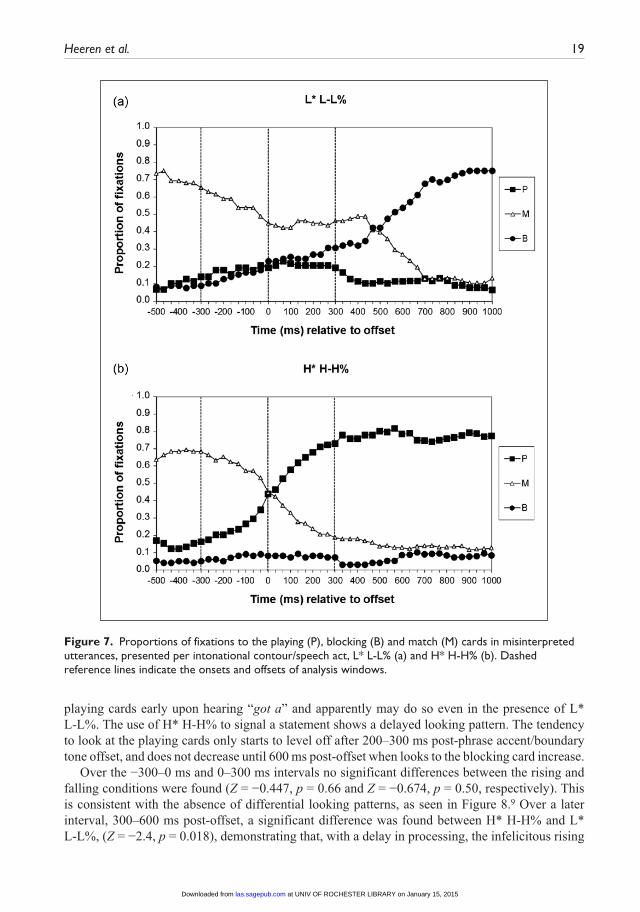
Heeren et al. 19
playing cards early upon hearing “got a” and apparently may do so even in the presence of L* L-L%. The use of H* H-H% to signal a statement shows a delayed looking pattern. The tendency to look at the playing cards only starts to level off after 200–300 ms post-phrase accent/boundary tone offset, and does not decrease until 600 ms post-offset when looks to the blocking card increase.
Over the −300–0 ms and 0–300 ms intervals no significant differences between the rising and falling conditions were found (Z = −0.447, p = 0.66 and Z = −0.674, p = 0.50, respectively). This is consistent with the absence of differential looking patterns, as seen in Figure 8.9 Over a later interval, 300–600 ms post-offset, a significant difference was found between H* H-H% and L* L-L%, (Z = −2.4, p = 0.018), demonstrating that, with a delay in processing, the infelicitous rising
Figure 7. Proportions of fixations to the playing (P), blocking (B) and match (M) cards in misinterpreted utterances, presented per intonational contour/speech act, L* L-L% (a) and H* H-H% (b). Dashed reference lines indicate the onsets and offsets of analysis windows.
at UNIV OF ROCHESTER LIBRARY on January 15, 2015las.sagepub.comDownloaded from
20 Language and Speech
and falling intonation cued different looking patterns. The overall pattern of results suggests that participants did begin to learn the unusual pairing of intonation and speech act types, as expected. However, when their response was consistent with the new pairing, looks to the target were sub-stantially delayed. This result is inconsistent with a contingency-based explanation for the results of Experiment 1, as then we would have expected participants to learn the reversed association between intonation and speech act types rapidly and with few errors. Rather it suggests that the effects we observed in Experiment 1 reflect participants’ pre-exposure priors for associating the different intonational contours with their respective speech acts.
Figure 8. Proportions of fixations to the playing (P), blocking (B) and match (M) cards in correctly interpreted utterances, presented per intonational contour/speech act, L* L-L% (a) and H* H-H% (b). Dashed reference lines indicate the onsets and offsets of analysis windows.
at UNIV OF ROCHESTER LIBRARY on January 15, 2015las.sagepub.comDownloaded from

Heeren et al. 21
4 General discussion and conclusion
We studied the online processing of rising and falling intonation through a targeted language game in which we could naturally embed minimal pairs of utterances for which intonation was decisive in distinguishing between an intended statement and intended question. Listeners’ looking patterns were closely time-locked to the target word’s final syllable, that is, the syllable containing the phrase accent/boundary tone sequence. Before the end of the target word, intonation influenced interpretation, thus guiding the listener’s response. Although it is difficult to tease apart the relative contributions from the nuclear pitch accent and the phrase accent/boundary tone sequence due to their close proximity to each other on the final word, our analyses suggest that in this particular case participants were waiting until the end of the utterance in order to interpret the computer’s intended meaning. In future work with this experimental paradigm it should be possible to con-struct materials to examine how different combinations of pitch accents and phrase accent/bound-ary tone sequences affect the processing of questions and statements.
We also demonstrated that listeners take into account additional, non-intonational cues to speech act type when processing a sentence. Listeners initially preferentially interpret “got a” sentences as questions. However, this early bias was immediately overridden by intonational information, which is consistent with Van Heuven and Haan (2002)’s finding that the intonational contour post-nuclear accent overrides earlier estimations of the utterances’ speech act, in their case projected by declination and the object accent.
In addition, we demonstrated that the listeners’ preference to interpret L* L-L% to signal a state-ment and H* H-H% to interpret a question is not based simply on rapid adaptation to the environ-ment of our targeted language game; it is based on listeners’ expectations of how rising and falling intonation should be phonetically realized to signal different intentions. Listeners can learn an alternative prosody, specifically the exact reversal with H* H-H% signalling a statement and L* L-L% signalling a yes–no question, but the learning is protracted and the delayed fixation patterns reveal that this learning takes a great deal of effort. Even towards the end of Experiment 2, when many participants had learned the novel prosody, eye-movements for correct responses still showed initial confusion with delayed fixations on the target. Therefore, we can conclude that people rap-idly use rising and falling intonation, while ruling out a probability-matching explanation.
In fact, we might ask why probability learning is so weak in the reversed condition. The weak learning, evidenced by delayed fixations and high error rates, seemingly goes against earlier stud-ies, demonstrating fast adaptation and learning. In their native language, listeners can rapidly adapt to new listening situations, such as new speakers (e.g., Nygaard & Pisoni, 1998; Smith & Hawkins, 2012), accented speech (e.g., Maye, Aslin, & Tanenhaus, 2008) and non-native speakers (e.g., Bradlow & Bent, 2008; Clarke & Garrett, 2004). For example, Clarke and Garrett (2004) reported that as little as one minute of exposure to Spanish-accented English was sufficient to bring an ini-tially reduced processing speed back to normal. (This was measured through reaction times to a visually presented probe word either matching or mismatching the auditory sentence it followed, not through online monitoring of speech processing.)
There are two potential reasons for the difference. Firstly, an increase in comprehension time when the prosody is reversed (as reflected in the delayed fixations) may have slowed learning. Comparable delayed effects of incongruent prosody have been reported at the lexical (Cutler & Clifton, 1984; Slowiaczek, 1990) and phrasal levels (Tyler & Warren, 1987). The intonational manipulation that we introduced was marked, but not coupled with any other evidence that the speech might require perceptual adaptation on the part of the listeners, such as the vowel shifts found in accented speech or any non-native segmental and suprasegmental mispronunciations.
at UNIV OF ROCHESTER LIBRARY on January 15, 2015las.sagepub.comDownloaded from

22 Language and Speech
Moreover, rather than inducing shifts in category boundaries, which has repeatedly been demon-strated for segmental contrasts (e.g., Norris, McQueen, & Cutler, 2003), listeners were asked to entirely re-label the categories themselves. These factors might have prevented faster learning.
Secondly, the remapping of rising and falling intonation may be extremely difficult (as sug-gested by the high error rates (69%) that were observed) because it is highly unnatural. A rise in intonation has been claimed to be strongly associated with interrogativity across languages, a phe-nomenon captured by the frequency code (Ohala, 1983), which claims that the correlation between larynx size, body size and F0 is used to express power relations (e.g., higher frequencies correlate with smaller sizes, which correlate with “submissiveness” and, consequently, “uncertainty” and “questioning”). Thus, we would expect more errors on statements than on questions, because it is more confusing for the listener to process a statement ending in a high tone than a question ending in a low one. In Dutch, for instance, the more syntactic cues (such as wh-words or inversion) an interrogative contains, the less likely it is that the speaker will produce high boundaries (Van Heuven & Haan, 2002). Comparable results have been reported for several dialects of British English (Grabe, 2002). Thus, whereas questions may still sound acceptable without a H-H%-ending (even in the case of declarative polar questions, see Englert, 2010), statements with a H-H% may require more evidence that the listener should expect the speaker to produce a large number of rising declaratives (such as if the speaker is a known Uptalker). Quoting Ladd (2008, p. 103), it seems to be the case that Pierrehumbert (1980) captured this asymmetry by suggesting that “The L% boundary tone … can best be described as indicating not a final fall but merely the absence of final rise”. Indeed, a closer examination of our error rates in Experiment 2 showed that more mis-interpretations were found on statements (98/128 = 77%) than questions (78/128 = 61%). Infelicitous use of phrase accents/boundary tones violates the strong association between phonetic realization and meaning, an association that according to the frequency code may in fact have a biological background.
Although the phonological and phonetic analyses revealed some potential early prosodic cues as to speech act, we did not find evidence that listeners used these cues to anticipate the intended speech act type. One explanation is that our relatively short carrier sentence did not contain suffi-cient cues to allow listeners to develop and use these cues to create real-time expectations. In ear-lier work, which targeted the role of declination in speech processing, sentences were generally longer, and in a gating task the effect of declination was not observed until listeners heard the object in sentences of the type subject–auxiliary verb–object–verb (Van Heuven & Haan, 2002). Also, durational differences in declarative sentences pronounced as either question or statement were only found for longer SVO sentences (Van Heuven & Van Zanten, 2005; but see Ryalls et al., 1994). These results are in line with the assumption that the short utterances used in the present study may not have provided sufficient early prosodic information. A second explanation is that, knowing that the phrase accent/boundary tone sequence is decisive over cues such as declination in speech act perception (e.g., a high tone signalling a question may even occur after declination consistent with a statement), early prosodic cues to speech act are judged as unreliable information and are therefore ignored. Speakers regularly turn their apparent statements into questions at the last minute, for example, by adding a question tag such as isn’t it or only a final rising pitch move-ment, H-H%, on the last syllable. It is possible that with longer utterances and larger differences, listeners might use this information. However, given the strength and reliability of intonational information, it seems plausible that listeners would down-weight a weaker, less reliable cue. The fact that we did observe effects of constructional bias makes it unlikely that our methods were too insensitive to reveal probabilistic use of other intonational cues to speech act type. We cannot, however, rule out the possibility that the constructional bias was strong enough to mask other early prosodic effects, especially because these cues occurred relatively close to the end of the utterance. A different lexical choice, on the other hand, might not induce the constructional bias.
at UNIV OF ROCHESTER LIBRARY on January 15, 2015las.sagepub.comDownloaded from

Heeren et al. 23
This study was –to our knowledge– one of the first to tap into the time course of the processing of nuclear contours (pitch accents in combination with phrase accents and boundary tones) rather than focusing solely on the contribution of the pitch accent. In addition, variations on this “got a” game paradigm (which can also be used with two naïve participants) should prove to be a powerful tool for further research into the role of prosody in speech act and speaker intention processing, while also allowing researchers to ask more detailed questions about information integration and (phonetic) cue trading with carefully controlled stimuli.
One obvious extension of this work would be to vary the verb used in the game to see if different biases arise in terms of whether the elliptical sentences are preferably interpreted as questions or statements (e.g., using have a or need a), and how this interacts with prosodic cues. If different verbs produce different biases in terms of whether they are preferably interpreted as a statement or a question, these biases would be reflected in the resulting fixation patterns, providing insights into how that information is integrated with the prosodic information provided by the nuclear accent and the phrase accents/boundary tones.
There are also a number of issues pertaining to the relationship between the speaker’s intentions (question versus statement) and the actual acoustic realization of her intonation that could be addressed with this paradigm. For example, one could ask whether having an alignment point in the intonation contour impacts when listeners launch saccades to the target. The “falling” contour H* L-L% and the “rising” contour L* H-H% both exhibit turning points at the nuclear accent (a peak with H* and a valley with L*). One might predict that fixations should be time-locked relative to the turning point – the earliest point at which listeners should have information about the upcom-ing phrase accent and boundary tone – and that varying the location of the turning point may cor-respondingly impact the timing of the target fixations. One could also investigate the relative importance of the nuclear accent and the phrase accent plus boundary by comparing H* H-H% to L* H-H% or H* H-H% to H* L-L%.
We also expect that introducing variability into how the computer produces the falling and ris-ing contours will affect how quickly (and well) listeners are able to adapt to the computer’s speech. Intonational contours that are more ambiguous between rising and falling should still require learn-ing on the part of the participants, but may be ultimately better learned than the complete reversal of rising and falling contours like in Experiment 2. The amount of variability in the intonation of the computer’s productions should also affect how quickly and how well listeners are able to adapt. A speaker who produces highly consistent contours may induce faster learning compared to a speaker who has a large amount of variability in her rising and falling contours.
In conclusion, rising and falling contours had an immediate effect on interpretation, as indexed by the pattern and timing of fixations. The association between intonation and different intentions was quite robust in the absence of clear cues to sentence type, and was not due to rapid adaptation. There was an immediate effect on interpretation, even though there was a construction-based bias to interpret “got a” as a question. Taken together, we believe this paradigm will provide further insights into how rising and falling intonation and their phonetic realizations interact with other cues to sentence type in online comprehension.
Acknowledgements
The authors would like to thank Esteban Buz, Judith Degen, Joyce McDonough, Dave Kleinschmidt, Harm Melief, Anne Pier Salverda, Shari Speer and Dana Subik.
Funding
This work was supported by the Netherlands Organisation for Scientific Research (NWO) [grant number VENI 275-75-008] and the National Institutes of Health [grant numbers HD073890 and HD27206].
at UNIV OF ROCHESTER LIBRARY on January 15, 2015las.sagepub.comDownloaded from

24 Language and Speech
Notes
1. We thank a reviewer for pointing out that some languages – Italian for one – lack this sort of systematic syntactic contrast between polar interrogative and declarative sentences, and therefore would provide a good testing ground for further exploration.
2. To recover from a possible player error in interpretation, the computer had utterances to deal with misun-derstandings, for example, “No, I’VE got it” or “No, do YOU have a candy?”. These were used in 6 out of 256 trials (details in Section 2.5).
3. We also conducted analyses using 200 ms windows. The results of the statistical tests were similar.4. In Figure 5 there appears to be a bit more uncertainty in the fall than the rise condition, as reflected by
differences in the asymptotes. This is consistent with a constructional bias. Moreover, in the L* L-L% condition there happened to initially be more looks to other locations than in the H* H-H% condition, which in the latter condition resulted in a slightly higher proportion of early looks to the match card.
5. We are using a logistic model because our dependent variable is binary (the fixations are “on” or “off” the competitor); however, the intercept and slope the model produces are still linear in log odds space and therefore can still be evaluated using a breakpoint analysis.
6. Note that for both the “gotta” stimuli and the filler stimuli, the asymptote for looks to the playing cards for rises (questions) has a higher asymptote than looks to the blocking card for the falls (assertions). This difference arises because there are more fixations occurring late in the trial to the “other” category for the assertions. While we do not have a principled explanation for why this might be the case, this difference does not affect any of the conclusions we are drawing.
7. We thank a reviewer for pointing out this potential issue, as originally we ran only one version of the transcript where the critical trial was preceded by a question filler.
8. Although we took steps to eliminate the correlation between trial number and condition, all predictors still showed some amount of collinearity (<0.3), perhaps due to the small amount of data per condition per participant. We believe the collinearity does not compromise our findings, since the coefficients were qualitatively similar in magnitude and direction across all combinations of fixed and random effects, even in models lacking the interaction term where collinearity was well below the 0.2 threshold.
9. Note that due to the low numbers of correct interpretations the data set available for analysis was rela-tively small, which in principle may have contributed to the absence of measurable effects.
References
Allopenna, P. D., Magnuson, J. S., & Tanenhaus, M. K. (1998). Tracking the time course of spoken word recognition using eye movements: evidence for continuous mapping models. Journal of Memory and Language, 38, 419–439.
Baayen, R. H. (2008). Analyzing linguistic data. A practical introduction to statistics using R. Cambridge, UK: Cambridge University Press.
Bartels, C. (1997). Towards a compositional interpretation of English statement and question intonation. PhD dissertation, University of Massachusetts Amherst.
Beckman, M., & Hirschberg, J. (1999). The ToBI annotation conventions. Columbus: The Ohio State University. Retrieved from http://www.ling.ohio-state.edu/~tobi/ame_tobi/annotation_conventions.html.
Beckman, M. E., & Ayers, G. M. (1993). Guidelines for ToBI labeling. Retrieved from http://www.ling.ohio-state.edu/research/phonetics/E_ToBI/
Boersma, P. (2001). Praat, a system for doing phonetics by computer. Glot International, 5, 341–345.Bradlow, A. R., & Bent, T. (2008). Perceptual adaptation to non-native speech. Cognition, 106, 707–729.Brown-Schmidt, S., Gunlogson, C., & Tanenhaus, M. K. (2008). Addressees distinguish shared from private
information when interpreting questions during interactive conversation. Cognition, 107, 1122–1134.Brown-Schmidt, S., & Tanenhaus, M. K. (2008). Real-time investigation of referential domains in unscripted
conversation: A targeted language game approach. Cognitive Science, 32, 643–684.Cangemi, F., & D’Imperio, M. (2013). Tempo and the perception of sentence modality. Laboratory
Phonology, 4, 191–219.
at UNIV OF ROCHESTER LIBRARY on January 15, 2015las.sagepub.comDownloaded from

Heeren et al. 25
Chambers, C. G., Tanenhaus, M. K., Eberhard, K. M., Filip, H., & Carlson, G. N. (2002). Circumscribing referential domains during real-time comprehension. Journal of Memory and Language, 47, 30–49.
Clarke, C. M., & Garrett, M. F. (2004). Rapid adaptation to foreign-accented English. Journal of the Acoustical Society of America, 166, 3647–3658.
Cooper, R. M. (1974). The control of eye fixation by the meaning of spoken language: A new methodol-ogy for the real-time investigation of speech perception, memory, and language processing. Cognitive Psychology, 6, 84–107.
Cutler, A., & Clifton, C. (1984). The use of prosodic information in word recognition. In H. Bouma & D. G. Bouwhuis (Eds.), Attention and performance X: Control of language processes (pp. 183–196). London, UK: Erlbaum.
Dahan, D., & Tanenhaus, M. K. (2005). Looking at the rope when looking for the snake: Conceptually medi-ated eye movements during spoken-word recognition. Psychonomic Bulletin & Review, 12, 453–459.
Dahan, D., Tanenhaus, M. K., & Chambers, C. G. (2002). Accent and reference resolution in spoken-language comprehension. Journal of Memory and Language, 47, 292–314.
Doherty, C. P., West, W. C., Dilley, L. C., Shattuck-Hufnagel, S., & Caplan, D. (2004). Question/statement judgments: An fMRI study of intonation processing. Human Brain Mapping, 23, 85–98.
Englert, C. (2010). Questions and responses in Dutch conversations. Journal of Pragmatics, 42, 2666–2684.Fletcher, J., Grabe, E., & Warren, P. (2005). Intonational variation in four dialects of English: The high rising
tone. In S.-A. Jun (Ed.), Prosodic typology: The phonology of intonation and phrasing (pp. 390–409). Oxford, UK: Oxford University Press.
Fournier, R., Gussenhoven, C., Jensen, O., & Hagoort, P. (2010). Lateralization of tonal and intonational pitch processing: an MEG study. Brain Research, 1328, 79–88.
Geluykens, R. (1988). On the myth of rising intonation in polar questions. Journal of Pragmatics, 12, 467–485.
Grabe, E. (2002). Variation adds to prosodic typology. In B. B. I. Marlien (Ed.), Proceedings of Speech Prosody 2002 (pp. 127–132). Aix-en-Provence, France: Laboratoire Parole et Langage.
Grice, M., Ladd, D. R., & Arvaniti, A. (2000). On the place of phrase accent in intonational phonology. Phonology, 17, 143–185.
Grodner, D., & Sedivy, J. (2011). The effect of speaker-specific information on pragmatic inferences. In N. Pearlmutter & E. Gibson (Eds.), The processing and acquisition of reference. Cambridge, MA: MIT Press.
Gunlogson, C. (2003). True to form: Rising and falling declaratives as questions in English. New York, NY: Routledge.
Gunlogson, C. (2008). A question of commitment. Belgian Journal of Linguistics, 22, 101–136.Gussenhoven, C. (2004). The phonology of tone and intonation. Cambridge, UK: Cambridge University Press.Ito, K., & Speer, S. R. (2008). Anticipatory effects of intonation: eye movements during instructed visual
search. Journal of Memory and Language, 58, 542–573.Kurumada, C., Brown, M., Bibyk, S., Pontillo, D. P., & Tanenhaus, M. K. (2014a). Is it or isn’t it: Listeners
make rapid use of prosody to infer speaker meanings. Cognition, 133, 335–342.Kurumada, C., Brown, M., Bibyk, S., Pontillo, D., & Tanenhaus, M. K. (2014b). Rapid adaptation in online
pragmatic interpretation of contrastive prosody. In Proceedings of the 37th Annual Meeting of the Cognitive Science Society.
Kurumada, C., Brown, M., & Tanenhaus, M. K. (2012). Pragmatic interpretation of contrastive prosody; It looks like speech adaptation. In N. Miyake, D. Peebles, & R. P. Cooper (Eds.), Proceedings of the 34th Annual Conference of the Cognitive Science Society (pp. 647–652). Austin, TX: Cognitive Science Society.
Ladd, D. R. (2008). Intonational phonology. Cambridge, UK: Cambridge University Press.Lehiste, I. (1970). Suprasegmentals. Cambridge, MA: MIT Press.Majewski, W., & Blasdell, R. (1968). Influence of fundamental frequency cues on the perception of some
synthetic intonation contours. Journal of the Acoustical Society of America, 45, 450–457.Maye, J., Aslin, R. N., & Tanenhaus, M. K. (2008). The weckud wetch of the wast: Lexical adaptation to a
novel accent. Cognitive Science, 32, 543–562.
at UNIV OF ROCHESTER LIBRARY on January 15, 2015las.sagepub.comDownloaded from

26 Language and Speech
McLemore, C. (1991). The pragmatic interpretation of English intonation: Sorority speech. Doctoral Dissertation, University of Texas at Austin.
Norris, D., McQueen, J. M., & Cutler, A. (2003). Perceptual learning in speech. Cognitive Psychology, 47, 204–238.
Nygaard, L. C., & Pisoni, D. B. (1998). Talker-specific learning in speech perception. Perception and Psychophysics, 60, 355–376.
Ohala, J. J. (1983). Cross-language use of pitch: An ethological view. Phonetica, 40, 1–18.Petrone, C., & Niebuhr, O. (2014). On the intonation of German intonation questions: The role of the prenu-
clear region. Language and Speech, 57, 108–146.Pierrehumbert, J., & Hirschberg, J. (1990). The meaning of intonational contours in the interpretation of
discourse. In P. Cohen, J. Morgan, & M. Pollack (Eds.), Intentions in communication (pp. 271–311). Cambridge, MA: MIT Press.
Pierrehumbert, J. B. (1980). The phonology and phonetics of English intonation. Ph.D. Dissertation, Massachusetts Institute of Technology.
Ryalls, J., Le Dorze, G., Lever, N., Ouellet, L., & Larfeuil, C. (1994). The effects of age and sex on speech intonation and duration for matched statements and questions in French. Journal of the Acoustical Society of America, 95, 2274–2276.
Salverda, A. P., Kleinschmidt, D., & Tanenhaus, M. K. (2014). Immediate effects of co-articulatory informa-tion in spoken word recognition. Journal of Memory and Language, 71, 145–163.
Schneider, K., & Linfert, B. (2003). Categorical perception of boundary tones in German. In M. Solé, D. Recasens, & J. Romero (Eds.), Proceedings of 15th International Congress of Phonetic Sciences (pp. 631–634), Barcelona.
Schwarz, G. (1978). Estimating the dimension of a model. Annals of Statistics, 6, 461–464.Slowiaczek, L. M. (1990). Effects of lexical stress in auditory word recognition. Language and Speech, 33,
47–68.Smith, R., & Hawkins, S. (2012). Production and perception of speaker-specific phonetic detail at word
boundaries. Journal of Phonetics, 40, 213–233.Studdert-Kennedy, M., & Hadding, K. (1973). Auditory and linguistic processes in the perception of intona-
tion contours. Language and Speech, 16, 293–313.Tanenhaus, M. K., & Brown-Schmidt, S. (2008). Language processing in the natural world. Philosophical
Transactions of the Royal Society B: Biological Sciences, 363, 1105–1122.Tanenhaus, M. K., Spivey-Knowlton, M. J., Eberhard, K. M., & Sedivy, J. C. (1995). Integration of visual and
linguistic information in spoken language comprehension. Science, 268, 1632–1634.Thorsen, N. G. (1980). A study of the perception of sentence intonation—Evidence from Danish. Journal of
the Acoustical Society of America, 67, 1014–1030.Tyler, L., & Warren, P. (1987). Local and global structure in spoken language comprehension. Journal of
Memory and Language, 26, 638–657.Van Heuven, V. J., & Haan, J. (2002). Temporal development of interrogativity cues in Dutch. In C.
Gussenhoven & N. Warner (Eds.), Laboratory phonology 7 (pp. 61–86). Berlin, Germany: Mouton de Gruyter.
Van Heuven, V. J., & Van Zanten, E. (2005). Speech rate as a secondary prosodic characteristic of polarity questions in three languages. Speech Communication, 47, 87–99.
Warren, P. (2005). Patterns of late rising in New Zealand English: Intonational variation or intonational change? Language Variation and Change, 17, 209–230.
Watson, D. G., Tanenhaus, M. K., & Gunlogson, C. A. (2008). Interpreting pitch accents in online compre-hension: H* vs. L+H*. Cognitive Science, 32, 1232–1244.
Weber, A., Braun, B., & Crocker, M. W. (2006). Finding referents in time: Eye-tracking evidence for the role of contrastive accents. Language and Speech, 49, 367–392.
at UNIV OF ROCHESTER LIBRARY on January 15, 2015las.sagepub.comDownloaded from

Heeren et al. 27
Appendix – Amazon Mechanical Turk survey
(The survey instructions were identical across the two versions, as was the early simulated dialogue between the two players. The **** indicate where differences between the two ver-sions begin).
INSTRUCTIONS: You will be reading a transcript of an interaction between two people as they play a card game similar to ‘Go Fish.’ In this game the two players are trying to be the first to get rid of all of their playing cards by making pairs with a ‘match card’ that appears between them. Aside from making matches, they can also ‘block’ a match made by their opponent using a special card called the ‘blocking card.’ They also have the option to ask their opponent to make a match if none of their own playing cards match the match card. There are four types of cards: windows, wheels, candies, and shoes.
You will see parts of a transcript that will be lacking any form of punctuation. Your task for each section of the transcript is to choose between two options which you think is the best punctuation for the sentence(s).
(BEGINNING VERSIONS 1 AND 2)
1: its my turn first Ive got a windowa. It’s my turn first I’ve got a window.b. It’s my turn first. I’ve got a window.
2: I cant block youa. I cant block you.b. I can’t block you.
1: sweet ok Ive also got a shoea. Sweet! Ok, I’ve also got a shoe.b. Sweet, ok, I’ve also got a shoe.
2: now I can blocka. Now, I can block.b. Now I can block.
1: shoot I dont have a match do you have a candya. Shoot. I don’t have a match. Do you have a candy?b. Shoot. I dont have a match. Do you have a candy.
2: yes I do my turn another candy can you make a matcha. Yes I do. My turn. Another candy. Can you make a match?b. Yes, I do. My turn. Another candy? Can you make a match?
1: no sorry my turn again I have a wheela. No, sorry. My turn again. I have a wheel.b. No, sorry, my turn again. I have a wheel.
2: cant blocka. Can’t block.b. Cant block.
1: and no match have you got a shoea. And no match, have you got a shoe?b. And no match. Have you got a shoe?
2: nope my turn now yes wheela. Nope. My turn now. Yes! Wheel!b. Nope, my turn now. Yes, wheel!
at UNIV OF ROCHESTER LIBRARY on January 15, 2015las.sagepub.comDownloaded from

28 Language and Speech
1: I’m blocking the matcha. I’m blocking the match.b. Im blocking the match.
(CONTINUATION VERSION 1)
****2: no ha but theres another wheela. No! Ha, but there’s another wheel.b. No, ha, but there’s another wheel.
1: alright go aheada. Alright go ahead.b. Alright, go ahead.
2: shoot do you have a shoea. Shoot, do you have a shoe?b. Shoot! Do you have a shoe?
1: I do now its my turn again got a candya. I do! Now it’s my turn again. Got a candy.b. I do! Now it’s my turn again. Got a candy?
(CONTINUATION VERSION 2)
****2: shoot do you have a shoea. Shoot, do you have a shoe?b. Shoot! Do you have a shoe?
1: I do now its my turn again Ive got a wheela. I do! Now it’s my turn again. I’ve got a wheel.b. I do, now it’s my turn again. I’ve got a wheel.
2: alright go aheada. Alright go ahead.b. Alright, go ahead.
1: got a candya. Got a candy.b. Got a candy?
at UNIV OF ROCHESTER LIBRARY on January 15, 2015las.sagepub.comDownloaded from





























