Embed Size (px)
Citation preview

О.Н. Лопатеева
Базы данных
Курс лекций

МИНИСТЕРСТВО ОБРАЗОВАНИЯ И НАУКИ РОССИЙСКОЙ ФЕДЕРАЦИИ
федеральное государственное бюджетное образовательное учреждение высшего образования
«Сибирский государственный университет науки и технологий имени академика М.Ф. Решетнева»
О.Н. Лопатеева
Базы данных

Раздел 1
ОСНОВЫ БАЗ ДАННЫХ
Лекция 1. Введение в базы данных Лекция 2. Система управления базами данных Лекция 3. Информационные системы в сетях

Лекция 1
ВВЕДЕНИЯ В БАЗЫ
Содержание 1.1. История развития баз данных 1.2. Файлы и файловые системы 1.2.1. Структура файлов 1.2.2. Именование файлов 1.2.3. Защита файлов 1.2.4. Режим многопользовательского доступа 1.2.5. Области применения файлов 1.3. Потребности информационных систем 1.4. Системы баз данных 1.5. Трехуровневая архитектура ANSI-SPARC 1.6. Независимость от данных 1.7. Процесс прохождения пользовательского запроса Связанные темы Система управления базами данных (см. лекцию 2). Информационные системы в сетях (см. лекцию 3). Модели данных (см. раздел 2). 1.1. История развития баз данных В истории вычислительной техники можно проследить развитие двух основных
областей ее использования. Первая область — применение вычислительной техники для выполнения численных расчетов, которые слишком долго или вообще невозможно производить вручную. Развитие этой области способствовало интенсификации методов численного решения сложных математических задач, появлению языков программирования, ориентированных на удобную запись численных алгоритмов, становлению обратной связи с разработчиками новых архитектур ЭВМ. Характерной особенностью данной области применения вычислительной техники является наличие сложных алгоритмов обработки, которые применяются к простым по структуре данным, объем которых сравнительно невелик.
Вторая область, которая непосредственно относится к нашей теме, — это использование средств вычислительной техники в автоматических или автоматизированных информационных системах. Информационная система представляет собой программно-аппаратный комплекс, обеспечивающий выполнение следующих функций:
• надежное хранение информации в памяти компьютера; • выполнение специфических для данного приложения преобразований
информации и вычислений; • предоставление пользователям удобного и легко осваиваемого интерфейса.

Обычно такие системы имеют дело с большими объемами информации, имеющей достаточно сложную структуру. Классическими примерами информационных систем являются банковские системы, автоматизированные системы управления предприятиями, системы резервирования авиационных или железнодорожных билетов, мест в гостиницах и т. д.
Вторая область использования вычислительной техники возникла несколько позже первой. Это связано с тем, что на заре вычислительной техники возможности компьютеров по хранению информации были очень ограниченными. Говорить о надежном и долговременном хранении информации можно только при наличии запоминающих устройств, сохраняющих информацию после выключения электрического питания. Оперативная (основная) память компьютеров этим свойством обычно не обладает. В первых компьютерах использовались два вида устройств внешней памяти — магнитные ленты и барабаны. Емкость магнитных лент была достаточно велика, но по своей физической природе они обеспечивали последовательный доступ к данным. Магнитные же барабаны (они ближе всего к современным магнитным дискам с фиксированными головками) давали возможность произвольного доступа к данным, но имели ограниченный объем хранимой информации.
Эти ограничения не являлись слишком существенными для чисто численных расчетов. Даже если программа должна обработать (или произвести) большой объем информации, при программировании можно продумать расположение этой информации во внешней памяти (например, на последовательной магнитной ленте), обеспечивающее эффективное выполнение этой программы. Однако в информационных системах совокупность взаимосвязанных информационных объектов фактически отражает модель объектов реального мира. А потребность пользователей в информации, адекватно отражающей состояние реальных объектов, требует сравнительно быстрой реакции системы на их запросы. И в этом случае наличие сравнительно медленных устройств хранения данных, к которым относятся магнитные ленты и барабаны, было недостаточным.
Можно предположить, что именно требования нечисловых приложений вызвали появление съемных магнитных дисков с подвижными головками, что явилось революцией в истории вычислительной техники. Эти устройства внешней памяти обладали существенно большей емкостью, чем магнитные барабаны, обеспечивали удовлетворительную скорость доступа к данным в режиме произвольной выборки, а возможность смены дискового пакета на устройстве позволяла иметь практически неограниченный архив данных.
С появлением магнитных дисков началась история систем управления данными во внешней памяти. До этого каждая прикладная программа, которой требовалось хранить данные во внешней памяти, сама определяла расположение каждой порции данных на магнитной ленте или барабане и выполняла обмены между оперативной памятью и устройствами внешней памяти с помощью программно-аппаратных средств низкого уровня (машинных команд или вызовов соответствующих программ операционной системы). Такой режим работы не позволяет или очень затрудняет поддержание на одном внешнем носителе нескольких архивов долговременно хранимой информации. Кроме того, каждой прикладной программе приходилось решать проблемы именования частей данных и структуризации данных во внешней памяти.

1.2. Файлы и файловые системы Историческим шагом явился переход к использованию централизованных систем
управления файлами. С точки зрения прикладной программы файл - это именованная область внешней памяти, в которую можно записывать и из которой можно считывать данные. Правила именования файлов, способ доступа к данным, хранящимся в файле, и структура этих данных зависят от конкретной системы управления файлами и, возможно, от типа файла. Система управления файлами берет на себя распределение внешней памяти, отображение имен файлов в соответствующие адреса во внешней памяти и обеспечение доступа к данным.
Первая развитая файловая система была разработана фирмой IBM для ее серии 360. К настоящему времени она очень устарела, и мы не будем рассматривать ее подробно. Заметим лишь, что в этой системе поддерживались как чисто последовательные, так и индексно-последовательные файлы, а реализация во многом опиралась на возможности только появившихся к этому времени контроллеров управления дисковыми устройствами. Если учесть к тому же, что понятие файла в OS/360 было выбрано как основное абстрактное понятие, которому соответствовал любой внешний объект, включая внешние устройства, то работать с файлами на уровне пользователя было очень неудобно. Требовался целый ряд громоздких и перегруженных деталями конструкций. Все это хорошо знакомо программистам среднего и старшего поколения, которые прошли через использование отечественных аналогов компьютеров IBM.
1.2.1. Структура файлов Дальше мы будем говорить о более современных организациях файловых систем.
Начнем со структур файлов. Прежде всего, практически во всех современных компьютерах основными устройствами внешней памяти являются магнитные диски с подвижными головками, и именно они служат для хранения файлов. Такие магнитные диски представляют собой пакеты магнитных пластин (поверхностей), между которыми на одном рычаге двигается пакет магнитных головок. Шаг движения пакета головок является дискретным, и каждому положению пакета головок логически соответствует цилиндр магнитного диска. На каждой поверхности цилиндр "высекает" дорожку, так что каждая поверхность содержит число дорожек, равное числу цилиндров. При разметке магнитного диска (специальном действии, предшествующем использованию диска) каждая дорожка размечается на одно и то же количество блоков таким образом, что в каждый блок можно записать по максимуму одно и то же число байтов. Таким образом, для произведения обмена с магнитным диском на уровне аппаратуры нужно указать номер цилиндра, номер поверхности, номер блока на соответствующей дорожке и число байтов, которое нужно записать или прочитать от начала этого блока.
Однако эта возможность обмениваться с магнитными дисками порциями меньше объема блока в настоящее время не используется в файловых системах. Это связано с двумя обстоятельствами. Во-первых, при выполнении обмена с диском аппаратура выполняет три основных действия: подвод головок к нужному цилиндру, поиск на дорожке нужного блока и собственно обмен с этим блоком. Из всех этих действий в среднем наибольшее время занимает первое. Поэтому существенный выигрыш в суммарном времени обмена за счет считывания или записывания только части блока получить практически невозможно. Во-вторых, для того, чтобы работать с частями блоков, файловая система должна обеспечить соответствующего размера буфера оперативной памяти, что существенно усложняет распределение оперативной памяти.
Поэтому во всех файловых системах явно или неявно выделяется некоторый базовый уровень, обеспечивающий работу с файлами, представляющими набор прямо адресуемых в адресном пространстве файла блоков. Размер этих логических блоков файла

совпадает или кратен размеру физического блока диска и обычно выбирается равным размеру страницы виртуальной памяти, поддерживаемой аппаратурой компьютера совместно с операционной системой.
В некоторых файловых системах базовый уровень доступен пользователю, но более часто прикрывается некоторым более высоким уровнем, стандартным для пользователей. Распространены два основных подхода. При первом подходе, свойственном, например, файловым системам операционных систем фирмы DEC RSX и VMS, пользователи представляют файл как последовательность записей. Каждая запись - это последовательность байтов постоянного или переменного размера. Записи можно читать или записывать последовательно или позиционировать файл на запись с указанным номером. Некоторые файловые системы позволяют структурировать записи на поля и объявлять некоторые поля ключами записи. В таких файловых системах можно потребовать выборку записи из файла по ее заданному ключу. Естественно, что в этом случае файловая система поддерживает в том же (или другом, служебном) базовом файле дополнительные, невидимые пользователю, служебные структуры данных. Распространенные способы организации ключевых файлов основываются на технике хеширования и B-деревьев (мы будем говорить об этих приемах более подробно в следующих лекциях). Существуют и многоключевые способы организации файлов.
Второй подход, ставший распространенным вместе с операционной системой UNIX, состоит в том, что любой файл представляется как последовательность байтов. Из файла можно прочитать указанное число байтов либо начиная с его начала, либо предварительно произведя его позиционирование на байт с указанным номером. Аналогично, можно записать указанное число байтов в конец файла, либо предварительно произведя позиционирование файла. Заметим, что тем не менее скрытым от пользователя, но существующим во всех разновидностях файловых систем ОС UNIX, является базовое блочное представление файла.
Конечно, для обоих подходов можно обеспечить набор преобразующих функций, приводящих представление файла к некоторому другому виду. Примером тому служит поддержание стандартной файловой среды системы программирования на языке Си в среде операционных систем фирмы DEC.
1.2.2. Именование файлов Остановимся коротко на способах именования файлов. Все современные файловые
системы поддерживают многоуровневое именование файлов за счет поддержания во внешней памяти дополнительных файлов со специальной структурой - каталогов. Каждый каталог содержит имена каталогов и/или файлов, содержащихся в данном каталоге. Таким образом, полное имя файла состоит из списка имен каталогов плюс имя файла в каталоге, непосредственно содержащем данный файл. Разница между способами именования файлов в разных файловых системах состоит в том, с чего начинается эта цепочка имен.
В этом отношении имеются два крайних варианта. Во многих системах управления файлами требуется, чтобы каждый архив файлов (полное дерево справочников) целиком располагался на одном дисковом пакете (или логическом диске, разделе физического дискового пакета, представляемом с помощью средств операционной системы как отдельный диск). В этом случае полное имя файла начинается с имени дискового устройства, на котором установлен соответствующий диск. Такой способ именования используется в файловых системах фирмы DEC, очень близко к этому находятся и файловые системы персональных компьютеров. Можно назвать эту организацию поддержанием изолированных файловых систем.
Другой крайний вариант был реализован в файловых системах операционной системы Multics. Эта система заслуживает отдельного большого разговора, в ней был реализован целый ряд оригинальных идей, но мы остановимся только на особенностях

организации архива файлов. В файловой системе Miltics пользователи представляли всю совокупность каталогов и файлов как единое дерево. Полное имя файла начиналось с имени корневого каталога, и пользователь не обязан был заботиться об установке на дисковое устройство каких-либо конкретных дисков. Сама система, выполняя поиск файла по его имени, запрашивала установку необходимых дисков. Такую файловую систему можно назвать полностью централизованной.
Конечно, во многом централизованные файловые системы удобнее изолированных: система управления файлами принимает на себя больше рутинной работы. Но в таких системах возникают существенные проблемы, если кому-то требуется перенести поддерево файловой системы на другую вычислительную установку. Компромиссное решение применено в файловых системах ОС UNIX. На базовом уровне в этих файловых системах поддерживаются изолированные архивы файлов. Один из этих архивов объявляется корневой файловой системой. После запуска системы можно "смонтировать" корневую файловую систему и ряд изолированных файловых систем в одну общую файловую систему. Технически это производится с помощью заведения в корневой файловой системе специальных пустых каталогов. Специальный системный вызов курьер ОС UNIX позволяет подключить к одному из этих пустых каталогов корневой каталог указанного архива файлов. После монтирования общей файловой системы именование файлов производится так же, как если бы она с самого начала была централизованной. Если учесть, что обычно монтирование файловой системы производится при раскрутке системы, то пользователи ОС UNIX обычно и не задумываются об исходном происхождении общей файловой системы.
1.2.3. Защита файлов Поскольку файловые системы являются общим хранилищем файлов,
принадлежащих, вообще говоря, разным пользователям, системы управления файлами должны обеспечивать авторизацию доступа к файлам. В общем виде подход состоит в том, что по отношению к каждому зарегистрированному пользователю данной вычислительной системы для каждого существующего файла указываются действия, которые разрешены или запрещены данному пользователю. Существовали попытки реализовать этот подход в полном объеме. Но это вызывало слишком большие накладные расходы как по хранению избыточной информации, так и по использованию этой информации для контроля правомочности доступа.
Поэтому в большинстве современных систем управления файлами применяется подход к защите файлов, впервые реализованный в ОС UNIX. В этой системе каждому зарегистрированному пользователю соответствует пара целочисленных идентификаторов: идентификатор группы, к которой относится этот пользователь, и его собственный идентификатор в группе. Соответственно, при каждом файле хранится полный идентификатор пользователя, который создал этот файл, и отмечается, какие действия с файлом может производить он сам, какие действия с файлом доступны для других пользователей той же группы, и что могут делать с файлом пользователи других групп. Эта информация очень компактна, при проверке требуется небольшое количество действий, и этот способ контроля доступа удовлетворителен в большинстве случаев.
1.2.4. Режим многопользовательского доступа Последнее, на чем мы остановимся в связи с файлами, - это способы их
использования в многопользовательской среде. Если операционная система поддерживает многопользовательский режим, вполне реальна ситуация, когда два или более пользователей одновременно пытаются работать с одним и тем же файлом. Если все эти пользователи собираются только читать файл, ничего страшного не произойдет. Но если

хотя бы один из них будет изменять файл, для корректной работы этой группы требуется взаимная синхронизация.
Исторически в файловых системах применялся следующий подход. В операции открытия файла (первой и обязательной операции, с которой должен начинаться сеанс работы с файлом) помимо прочих параметров указывался режим работы (чтение или изменение). Если к моменту выполнения этой операции от имени некоторой программы A файл уже находился в открытом состоянии от имени некоторой другой программы B (правильнее говорить "процесса", но мы не будем вдаваться в терминологические тонкости), причем существующий режим открытия был несовместимым с желаемым режимом (совместимы только режимы чтения), то в зависимости от особенностей системы программе A либо сообщалось о невозможности открытия файла в желаемом режиме, либо она блокировалась до тех пор, пока программа B не выполнит операцию закрытия файла.
Заметим, что в ранних версиях файловой системы ОС UNIX вообще не были реализованы какие бы то ни было средства синхронизации параллельного доступа к файлам. Операция открытия файла выполнялась всегда для любого существующего файла, если данный пользователь имел соответствующие права доступа. При совместной работе синхронизацию следовало производить вне файловой системы (и особых средств для этого ОС UNIX не предоставляла). В современных реализациях файловых систем ОС UNIX по желанию пользователя поддерживается синхронизация при открытии файлов. Кроме того, существует возможность синхронизации нескольких процессов, параллельно модифицирующих один и тот же файл. Для этого введен специальный механизм синхронизационных захватов диапазонов адресов открытого файла.
1.2.5. Области применения файлов После этого краткого экскурса в историю файловых систем рассмотрим возможные
области их применения. Прежде всего, конечно, файлы применяются для хранения текстовых данных: документов, текстов программ и т.д. Такие файлы обычно образуются и модифицируются с помощью различных текстовых редакторов. Структура текстовых файлов обычно очень проста: это либо последовательность записей, содержащих строки текста, либо последовательность байтов, среди которых встречаются специальные символы (например, символы конца строки).
Файлы с текстами программ используются как входные тексты компиляторов, которые в свою очередь формируют файлы, содержащие объектные модули. С точки зрения файловой системы, объектные файлы также обладают очень простой структурой - последовательность записей или байтов. Система программирования накладывает на эту структуру более сложную и специфичную для этой системы структуру объектного модуля. Подчеркнем, что логическая структура объектного модуля неизвестна файловой системе, эта структура поддерживается программами системы программирования.
Аналогично обстоит дело с файлами, формируемыми редакторами связей и содержащими образы выполняемых программ. Логическая структура таких файлов остается известной только редактору связей и загрузчику - программе операционной системы. Примерно такая же ситуация с файлами, содержащими графическую и звуковую информацию.
Одним словом, файловые системы обычно обеспечивают хранение слабо структурированной информации, оставляя дальнейшую структуризацию прикладным программам. В перечисленных выше случаях использования файлов это даже хорошо, потому что при разработке любой новой прикладной системы опираясь на простые, стандартные и сравнительно дешевые средства файловой системы можно реализовать те структуры хранения, которые наиболее естественно соответствуют специфике данной прикладной области.

1.3. Потребности информационных систем Однако ситуация коренным образом отличается для упоминавшихся в начале
лекции информационных систем. Эти системы главным образом ориентированы на хранение, выбор и модификацию постоянно существующей информации. Структура информации зачастую очень сложна, и хотя структуры данных различны в разных информационных системах, между ними часто бывает много общего. На начальном этапе использования вычислительной техники для управления информацией проблемы структуризации данных решались индивидуально в каждой информационной системе. Производились необходимые надстройки над файловыми системами (библиотеки программ), подобно тому, как это делается в компиляторах, редакторах и т.д.
Но поскольку информационные системы требуют сложных структур данных, эти дополнительные индивидуальные средства управления данными являлись существенной частью информационных систем и практически повторялись от одной системы к другой. Стремление выделить и обобщить общую часть информационных систем, ответственную за управление сложно структурированными данными, явилось, на наш взгляд, первой побудительной причиной создания СУБД. Очень скоро стало понятно, что невозможно обойтись общей библиотекой программ, реализующей над стандартной базовой файловой системой более сложные методы хранения данных.
Покажем это на примере. Предположим, что мы хотим реализовать простую информационную систему, поддерживающую учет сотрудников некоторой организации. Система должна выполнять следующие действия: выдавать списки сотрудников по отделам, поддерживать возможность перевода сотрудника из одного отдела в другой, приема на работу новых сотрудников и увольнения работающих. Для каждого отдела должна поддерживаться возможность получения имени руководителя этого отдела, общей численности отдела, общей суммы выплаченной в последний раз зарплаты и т.д. Для каждого сотрудника должна поддерживаться возможность выдачи номера удостоверения по полному имени сотрудника, выдачи полного имени по номеру удостоверения, получения информации о текущем соответствии занимаемой должности сотрудника и о размере его зарплаты.
Предположим, что мы решили основывать эту информационную систему на файловой системе и пользоваться при этом одним файлом, расширив базовые возможности файловой системы за счет специальной библиотеки функций. Поскольку минимальной информационной единицей в нашем случае является сотрудник, естественно потребовать, чтобы в этом файле содержалась одна запись для каждого сотрудника. Какие поля должна содержать такая запись? Полное имя сотрудника (EmployeeName), номер его удостоверения (EmployeeID), информацию о его соответствии занимаемой должности (EmployeeJob), размер зарплаты (EmployeeSalary), номер отдела (EmployeeDepartment). Поскольку мы хотим ограничиться одним файлом, та же запись должна содержать имя руководителя отдела (DepartmentManager).
Функции нашей информационной системы требуют, чтобы обеспечивалась возможность многоключевого доступа к этому файлу по уникальным ключам (недублируемым в разных записях) EmployeeName и EmployeeID. Кроме того, должна обеспечиваться возможность выбора всех записей с общим значением EmployeeDepartment, то есть доступ по неуникальному ключу. Для того, чтобы получить численность отдела или общий размер зарплаты, каждый раз при выполнении такой функции информационная система должна будет выбрать все записи о сотрудниках отдела и посчитать соответствующие общие значения.
Таким образом мы видим, что даже для такой простой системы ее реализация на базе файловой системы, во-первых, требует создания достаточно сложной надстройки для многоключевого доступа к файлам, и, во-вторых, вызывает требование существенной

избыточности хранения (для каждого сотрудника одного отдела повторяется имя руководителя) и выполнение массовой выборки и вычислений для получения суммарной информации об отделах. Кроме того, если в ходе эксплуатации системы нам захочется, например, выдавать списки сотрудников, получающих заданную зарплату, то придется либо полностью просматривать файл, либо реструктуризовывать его, объявляя ключевым поле EmployeeSalary.
Первое, что приходит на ум, - это поддерживать два многоключевых файла: Employee и Department. Первый файл должен содержать поля EmployeeName, EmployeeID, EmployeeJob, EmployeeSalary и EmployeeDepartment, а второй - Department, DepartmentManager, DepartmentEmployeeSalary (общий размер зарплаты) и DepartmentCount (общее число сотрудников в отделе). Большинство неудобств, перечисленных в предыдущем абзаце, будут преодолены. Каждый из файлов будет содержать только недублируемую информацию, необходимости в динамических вычислениях суммарной информации не возникает. Но заметим, что при таком переходе наша информационная система должна обладать некоторыми новыми особенностями, сближающими ее с СУБД.
Прежде всего, система должна теперь знать, что она работает с двумя информационно связанными файлами (это шаг в сторону схемы базы данных), должна знать структуру и смысл каждого поля (например, что EmployeeDepartment в файле Employee и Department в файле Department означают одно и то же), а также понимать, что в ряде случаев изменение информации в одном файле должно автоматически вызывать модификацию во втором файле, чтобы их общее содержимое было согласованным. Например, если на работу принимается новый сотрудник, то необходимо добавить запись в файл Employee, а также соответствующим образом изменить поля DepartmentEmployeeSalary и DepartmentCount в записи файла Department, описывающей отдел этого сотрудника.
Понятие согласованности данных является ключевым понятием баз данных. Фактически, если информационная система (даже такая простая, как в нашем примере) поддерживает согласованное хранение информации в нескольких файлах, можно говорить о том, что она поддерживает базу данных. Если же некоторая вспомогательная система управления данными позволяет работать с несколькими файлами, обеспечивая их согласованность, можно назвать ее системой управления базами данных. Уже только требование поддержания согласованности данных в нескольких файлах не позволяет обойтись библиотекой функций: такая система должна иметь некоторые собственные данные (метаданные) и даже знания, определяющие целостность данных.
Но это еще не все, что обычно требуют от СУБД. Во-первых, даже в нашем примере неудобно реализовывать такие запросы как "выдать общую численность отдела, в котором работает Петр Иванович Сидоров". Было бы гораздо проще, если бы СУБД позволяла сформулировать такой запрос на близком пользователям языке. Такие языки называются языками запросов к базам данных. Например, на языке SQL наш запрос можно было бы выразить в форме:
SELECT DepartmentCount FROM Employee, Department WHERE EmployeeName = 'Петр Иванович Сидоров' AND EmployeeDepartment = Employee_Department Таким образом, при формулировании запроса СУБД позволит не задумываться о
том, как будет выполняться этот запрос. Среди ее метаданных будет содержаться информация о том, что поле EmployeeID является ключевым для файла Employee, а Department - для файла Department, и система сама воспользуется этим. Если же возникнет потребность в получении списка сотрудников, не соответствующих занимаемой должности, то достаточно предъявить системе запрос:
SELECT EmployeeName, EmployeeID

FROM Employee WHERE EmployeeJob = 'Программист' и система сама выполнит необходимый полный просмотр файла Employee,
поскольку поле EmployeeJob не является ключевым. Далее, представьте себе, что в нашей первоначальной реализации информационной
системы, основанной на использовании библиотек расширенных методов доступа к файлам, обрабатывается операция регистрации нового сотрудника. Следуя требованиям согласованного изменения файлов, информационная система вставила новую запись в файл Employee и собиралась модифицировать запись файла Department, но именно в этот момент произошло аварийное выключение питания. Очевидно, что после перезапуска системы ее база данных будет находиться в рассогласованном состоянии. Потребуется выяснить это (а для этого нужно явно проверить соответствие информации с файлах Employee и Department) и привести информацию в согласованное состояние. Настоящие СУБД берут такую работу на себя. Прикладная система не обязана заботиться о корректности состояния базы данных.
Наконец, представим себе, что мы хотим обеспечить параллельную (например, многотерминальную) работу с базой данных сотрудников. Если опираться только на использование файлов, то для обеспечения корректности на все время модификации любого из двух файлов доступ других пользователей к этому файлу будет блокирован (вспомните возможности файловых систем для синхронизации параллельного доступа). Таким образом, зачисление на работу Петра Ивановича Сидорова существенно затормозит получение информации о сотруднике Иване Сидоровиче Петрове, даже если они будут работать в разных отделах. Настоящие СУБД обеспечивают гораздо более тонкую синхронизацию параллельного доступа к данным.
Таким образом, СУБД решают множество проблем, которые затруднительно или вообще невозможно решить при использовании файловых систем. При этом существуют приложения, для которых вполне достаточно файлов; приложения, для которых необходимо решать, какой уровень работы с данными во внешней памяти для них требуется, и приложения, для которых безусловно нужны базы данных.
1.4. Системы баз данных Система баз данных (СБД) – компьютеризированная система для хранения
информации в БД. Компоненты СБД: I) Пользователи – делятся на четыре группы: 1) Администраторы: • администраторы данных – отвечают за управление данными, включая
планирование БД, разработку и сопровождение стандартов, бизнес правил (описывают основные характеристики данных с точки зрения организации) и деловых процедур, а также концептуальное и логическое проектирование БД;
• администраторы баз данных – отвечают за физическую реализацию БД, включая физическое проектирование, обеспечение безопасности и целостности данных, а также обеспечение максимальной производительности приложений и пользователей (более технический характер по сравнению с администратором данных);
Рис. 1.1. Компоненты СБД

2) Разработчики баз данных: • разработчики логической базы данных – занимаются идентификацией
данных, связей между данными и устанавливают ограничения, накладываемые на хранимые данные - (ответ на вопрос ЧТО?);
• разработчики физической базы данных – по готовой логической модели создают физическую реализацию (формирование таблиц, выбор структур хранения, методов доступа, мер защиты) – (ответ на вопрос КАК?).
3) Прикладные программисты – создание приложений предоставляющих пользователям необходимые функциональные возможности (действия над базой данных);
4) Пользователи (клиенты БД): • наивные пользователи – осуществляют доступ к БД через прикладные
программы; • опытные пользователи – могут осуществлять доступ к БД с использованием
языков запросов или создавать собственные прикладные программы; II) Прикладные программы – обеспечивают простой доступ к БД для
пользователей, реализуются с использованием языков программирования 3-го (процедурные языки - C, COBOL, Fortran, Ada, Pascal) или 4-го поколения (SQL, QBE). 4-е поколение (“4GL”) - непроцедурные языки, возможно генерирование прикладного приложения по параметрам, заданных пользователем, делятся на: языки представления информации (языки запросов или генераторы форм и отчетов); специализированные языки (электронных таблиц и БД); генераторы приложений для определения, вставки, обновления или извлечения сведений из БД; языки очень высокого уровня для генерации кода приложений.
III) Банк данных (БнД) — это система специальным образом организованных данных — баз данных, программных, технических, языковых, организационно-методических средств, предназначенных для обеспечения централизованного накопления и коллективного многоцелевого использования данных.
IV) База данных (БД) – совокупность логически связанных данных, хранящихся в компьютеризованной системе и отражающих некоторую предметную область человеческой деятельности. БД – единое, большое хранилище данных (набор интегрированных записей с самоописанием), содержит данные с минимальной долей избыточности, к которым может обращаться большое число пользователей. Описание данных называются системным каталогом или словарем данных, а сами элементы описания – метаданные (данные о данных) (обеспечивают независимость между программами и данными).
V) СУБД – система управления базами данных – программное обеспечение, с помощью которого пользователи могут определять, создавать и поддерживать БД, а также осуществлять к ней контролируемый доступ.
VI) Словарь данных (СД) представляет собой подсистему БнД, предназначенную для хранения информации о структурах данных, взаимосвязях файлов БД друг с другом, типах данных и форматах их представления, принадлежности данных пользователям, кодах защиты и разграничения доступа и т.п.
Функционально СД присутствует на всех БнД, но не всегда выполняющий эти функции компонент имеет именно такое название. Чаще всего функции СД выполняются СУБД и вызываются из основного меню системы или реализуются с помощью ее утилит.
Главные преимущества СБД – преодоление ограничений файловых систем (в основном из-за обеспечения централизованного управления данными).
1.5. Трехуровневая архитектура ANSI-SPARC Основная цель СУБД – показ пользователям данных в абстрактном представлении,
т.е. сокрытие от пользователей особенностей хранения и управления данными.

Попытки стандартизации терминологии и общей архитектуры СУБД предприняты в 1971 группой DBTG (DataBase Task Group). Был предложен двух уровневый подход к архитектуре СУБД, выработанный на основе системного представления): схема (уровень администратора) и подсхемы (уровень пользовательских представлений). В 1975 комитетом планирования стандартов и норм SPARC (Standarts Planning and Requeirements Committee) Национального института стандартизации США ANSI (American National Standard Institute) была предложена необходимость трехуровневого подхода. Эта модель не является стандартом, но представляет собой основу для понимания функциональных особенностей СУБД.
Цель трехуровневой архитектуры – отделение пользовательского представления базы данных от ее физического представления по ряду причин:
• каждый пользователь должен иметь возможность обращаться к данным, используя собственное представление о них (независимо от представлений других пользователей);
• взаимодействие пользователя с базой не должно зависеть от особенностей хранения данных в ней (например, индексирование, хеширование);
• администратор базы данных должен иметь возможность изменять структуру хранения данных в базе, не оказывая влияния на пользовательские представления;
• внутренняя структура БД не должна зависеть от изменений физических аспектов хранения информации (например, использование нового устройства хранения).
Архитектура ANSI-SPARC имеет три уровня: внешний, концептуальный и внутренний.
Рис. 1.2. Трехуровневая архитектура ANSI-SPARC
Внешний уровень – представление БД с точки зрения пользователей (для каждой
группы пользователей – описываются только необходимая часть БД). Т.е. каждый пользователь имеет свое представление о «реальном мире», и не видит лишние (с его точки зрения) данные. Кроме того, разные представления могут по-разному отображать одни и те же данные (например, дату). Также часть данных при этом может не храниться в БД (так называемые производные и вычисляемые данные), а получаться по мере надобности (например, возраст сотрудников), что не потребует лишних обновлений БД и уменьшит ее объем.
Концептуальный уровень – обобщающее представление БД (описывает, какие данные хранятся в БД, а также связи между ними). Это промежуточный уровень в архитектуре. Он содержит логическую структуру всей БД (с точки зрения администратора

базы данных), а именно: все сущности, их атрибуты и связи; накладываемые на данные ограничения; семантическая информация о данных; информация о мерах безопасности и поддержки целостности данных. Все внешние представления получаются из данных этого уровня, но этот уровень не содержит никаких сведений о методах хранения данных (например, может быть информация о длине полей их типе, названии, но нет данных об объеме в байтах и т.п.).
Внутренний уровень – физическое представление базы данных в компьютере (описывает, как информация хранится в БД). Описывает физическую реализацию, и предназначен для достижения оптимальной производительности и обеспечения экономного распределения дискового пространства (содержит описание структур данных и описание организации файлов). На этом уровне осуществляется взаимодействие СУБД с методами доступа операционной системы для работы с данными. Уровень содержит информацию о распределении дискового пространства, описание подробностей хранимых записей (реальная длина - байты), сведения о размещении записей, сжатии и шифровании данных.
Ниже внутреннего уровня находится физический уровень, который контролируется операционной системой (под руководством СУБД, причем разделение функций ОС и СУБД варьируется от системы к системе). Физический уровень использует только известные операционной системе элементы (например, указатели).
Общее описание БД принято называть схемой базы данных. Для каждого уровня архитектуры ANSI-SPARC существуют свои схемы. На внешнем уровне имеется несколько внешних схем или подсхем (для различных представлений данных пользователей). Для концептуального и внешнего уровня имеются соответственно концептуальная и внешняя схемы (для каждой БД существуют в единственном экземпляре). Концептуальная схема описывает все элементы данных, связи между ними, ограничения целостности и т.п. Внутренняя схема описывает определения хранимых записей , методов представления, описания полей данных, индексов и т.п.
СУБД отвечает за установление соответствия между этими схемами (проверка их непротиворечивости – например, чтобы можно было каждую внешнюю схему вывести на основе концептуальной схемы (на основе данных внутренней схемы), проверить соответствие имен и т.п.). Концептуальная схема связана с внутренней посредством концептуально-внутреннего отображения (для поиска фактической записи на физическом устройстве хранения, которая соответствует логической записи в концептуальной схеме с учетом ограничений). Каждая внешняя схема связана с концептуальной схемой с помощью внешне-концептуального отображения (отображение имен пользовательского представления на соответствующую часть концептуальной схемы). Например, пользователь хочет получить данные из БД, при этом его запрос преобразуется к виду принятому на концептуальном уровне (отображение внешний-концептуальный, например, изменение имен полей для получения логического описания), затем логическое описание отображается на внутренний уровень (отображение концептуальный-внутренний) для доступа к реальным данным, затем производится обратный процесс.
Следует различать описание БД и саму БД (описание БД (содержание БД) – схема базы данных, создается в процессе проектирования (редко), а сама БД (детализация) – информация содержащаяся в таблицах может меняться часто). Совокупность данных, хранящихся в БД на определенный момент времени – состояние БД (состояний может быть различное множество).
Основное назначение трехуровневой архитектуры – обеспечение независимости от данных (т.е. чтобы изменения на различных уровнях никак не влияли на другие уровни).
Принятое в архитектуре ANSI-SPARC двух уровневое отображение на практике снижает производительность системы, но при этом поддерживает более высокую независимость от данных (для повышения эффективности есть возможность прямого

отображения внешних схем на внутреннюю, но при изменениях внутренней схемы необходимо будет вносить изменения во внешние схемы и прикладные программы).
1.6. Независимость от данных Независимость от данных – основополагающий принцип построения СБД. В
соответствии с этим принципом, в системе должны поддерживаться раздельные представления данных для пользователя («логическое представление») и для системных механизмов среды хранения БД («физическое представление»). Такое разделение избавляет пользователя от необходимости знания принятого способа хранения БД и позволяет динамически в процессе эксплуатации системы оптимизировать способ хранения БД для обеспечения более высокой производительности системы и (или) более рационального использования ресурсов памяти.
Различают два типа независимости от данных: • логическая независимость от данных – защищенность внешних схем от
изменений, вносимых в концептуальную схему (добавление и удаление новых сущностей, атрибутов и связей должны осуществляться без изменений уже существующих внешних схем или изменения прикладных программ)
• физическая независимость от данных – защищенность концептуальной схемы от изменений, вносимых во внутреннюю схему (изменения в структурах хранения, модификация индексов и т.п. должны осуществляться без изменения концептуальной и внешней схем, пользователи могут заметить изменения только по изменению производительности).
1.7. Процесс прохождения пользовательского запроса Рисунок 1.3. иллюстрирует взаимодействие пользователя, СУБД и ОС при
обработке запроса на получение данных. Цифрами помечена последовательность взаимодействий:
Рис. 1.3. Схема прохождения запроса к БД
1. Пользователь посылает СУБД запрос на получение данных из БД. 2. Анализ прав пользователя и внешней модели данных, соответствующей
данному пользователю, подтверждает или запрещает доступ данного пользователя к запрошенным данным.
3. В случае запрета на доступ к данным СУБД сообщает пользователю об этом (стрелка 12) и прекращает дальнейший процесс обработки данных, в противном случае

СУБД определяет часть концептуальной модели, которая затрагивается запросом пользователя.
4. СУБД запрашивают информацию о части концептуальной модели. 5. СУБД получает информацию о запрошенной части концептуальной модели. 6. СУБД запрашивает информацию о местоположении данных на физическом
уровне (файлы или физические адреса). 7. В СУБД возвращается информация о местоположении данных в терминах
операционной системы. 8. СУБД вежливо просит операционную систему предоставить необходимые
данные, используя средства операционной системы. 9. Операционная система осуществляет перекачку информации из устройств
хранения и пересылает ее в системный буфер. 10. Операционная система оповещает СУБД об окончании пересылки. 11. СУБД выбирает из доставленной информации, находящейся в системном
буфере, только то, что нужно пользователю, и пересылает эти данные в рабочую область пользователя.
БМД — это База Метаданных, именно здесь и хранится вся информация об используемых структурах данных, логической организации данных, правах доступа пользователей и, наконец, физическом расположении данных. Для управления БМД существует специальное программное обеспечение администрирования баз данных, которое предназначено для корректного использования единого информационного пространства многими пользователями.
Всегда ли запрос проходит полный цикл? Конечно, нет. СУБД обладает достаточно развитым интеллектом, который позволяет ей не повторять бессмысленных действий. И поэтому, например, если этот же пользователь повторно обратится к СУБД с новым запросом, то для него уже не будут проверяться внешняя модель и права доступа, а если дальнейший анализ запроса покажет, что данные могут находиться в системном буфере, то СУБД осуществит только 11 и 12 шаги в обработке запроса.
Разумеется, механизм прохождения запроса в реальных СУБД гораздо сложнее, но и эта упрощенная схема показывает, насколько серьезными и сложными должны быть механизмы обработки запросов, поддерживаемые реальными СУБД.

Лекция 2 СИСТЕМЫ УПРАВЛЕНИЯ БАЗАМИ ДАННЫХ Содержание 2.1. История развития СУБД (становление и поколения) 2.2. Основные функции СУБД 2.2.1 Непосредственное управление данными во внешней памяти 2.2.2. Управление буферами оперативной памяти 2.2.3. Управление транзакциями 2.2.4. Журнализация 2.2.5. Поддержка языков БД 2.3. Типовая организация СУБД 2.4. Компоненты СУБД 2.5. Архитектура многопользовательских СУБД 2.6. Преимущества и недостатки СУБД 2.7. Способы разработки и выполнения приложений Связанные темы Введение в базы данных (см. лекцию 1). Реляционная модель данных (см. лекцию 5). Структурированный язык запросов SQL (см. раздел 3). Физическая модель данных (см. раздел 4). Использование баз данных (см. раздел 5). Разработка приложений БД (см. раздел 6). СУБД (DBMS) – программное обеспечение, с помощью которого пользователи
могут определять, создавать и поддерживать БД, а также осуществлять к ней контролируемый доступ. Фактически – прослойка между БД и пользователем (прикладной программой) для скрытия особенностей хранения и управления данными (абстрагирование).
Примечание. На протяжении курса изучения баз данных мы будем изучать работу с реляционной
СУБД Microsoft SQL Server 2008 (MS SQL Server). В лекции 17 (Современные СУБД) будут подробно описаны такие СУБД, как Oracle, MySQL, PostgeSQL, FireBird.
2.1. История развития СУБД (становление и поколения) СУБД выросли из файловых систем. Примерное начало становления СУБД – 60-е
годы 20 века (нет данных о разработках других стран (СССР, Европа)): • для управления данными американского проекта Apollo в начале 60-х
создано программное обеспечение GUAM (North American Aviation (теперь Rockwell International)), в середине 60-х на базе GUAM создана первая коммерческая СУБД IMS (Information Management System) (NAA + IBM) – носители магнитная лента, иерархическая структура данных (подходило для управления иерархией частей проекта (компоненты → узлы → детали));
• в середине 60-х фирма General Electric создала систему IDS (Integrated Data Store) – сетевая СУБД (более сложные взаимосвязи, чем у иерархических СУБД, попытка создания стандарта баз данных).
Формирование стандартов БД – в 1965 на конференции CODASYL (Conference on Data System Languages) создана группа List Processing Task Force, переименованная в 1967

в DBTG (Data Base Task Group) – предложен стандарт в отчетах 1969, 1971 на сетевые БД (логическая организация данных + язык управления данными) – стандарт не одобрен ANSI, но на его основе разработано большое число систем (CODASYL или DBTG-систем).
DBTG-системы + системы на основе иерархического подхода – СУБД первого поколения (будут рассмотрены при изучении иерархической и сетевой модели данных), имеют ряд недостатков:
• для выполнения простых запросов требуют написания достаточно сложных программ;
• независимость от данных реализована в минимальной степени; • отсутствие теоретических основ для описания (только технические
стандарты). В 1970 опубликована работа (E.F. Codd, IBM) о реляционной модели данных,
устраняющей недостатки иерархической и сетевой моделей. На базе этой модели появилось множество экспериментальных СУБД. Первые коммерческие реляционные СУБД – конец 70-х – начало 80-х (экспериментальная СУБД System R (IBM, Сан-Хосе, Калифорния) – создана для проверки реляционной модели, в ходе проекта создан язык SQL; СУБД DB2 (IBM); Oracle (Oracle Corporation)). Реляционные СУБД относятся к СУБД второго поколения.
Реляционная модель также имеет ряд недостатков, один из них – ограниченные возможности моделирования. Наиболее значимые работы по устранению этого недостатка реляционной модели (в области семантического моделирования данных – исследований о способах представления смыслового значения, о модели более точно описывающей реальный мир):
• 1976, Чен предложил модель «сущность-связь» (ER-модель) – технология проектирования баз данных (будем рассматривать);
• Кодд предложил расширенные версии реляционной модели (RM/T (1979) и RM/V2 (1990)).
В связи с возрастанием сложности приложений БД появились новые системы: объектно-ориентированные СУБД (OODBMS) и объектно-реляционные СУБД (ORDBMS). Они представляют собой СУБД третьего поколения, однако структура этих моделей пока еще определена не окончательно (не совсем ясна).
2.2. Основные функции СУБД Для СУБД характерно наличие следующих функций и служб (сервисов) (первые
восемь - Эдгар Кодд, 1982): Примечание.
Эдгар Франк «Тед» Кодд (англ. Edgar Frank Codd; 23 августа 1923 — 18 апреля 2003) — британский учёный, работы которого заложили основы теории реляционных баз данных.
• СУБД должна предоставлять пользователям возможность сохранять, изменять и обновлять данные в БД (основная функция СУБД, способ реализации этой функции должен скрывать от пользователя детали физической реализации системы (абстрагирование));
• СУБД должна иметь доступный конечным пользователям каталог, в котором хранится описание элементов данных (т.н. системный каталог – хранилище информации, описывающей данные БД (метаданных): имена, типы и размеры элементов данных; имена связей; накладываемые на данные ограничения поддержки целостности; имена санкционированных пользователей; описание схем архитектуры БД; статистические данные (счетчики событий)); преимущества использования системного каталога: централизованный контроль доступа к данным; определение смысла данных для

понимания их предназначения; упрощается определение владельца данных или прав доступа к ним; облегчается протоколирование изменений БД; последствия изменений могут быть определены до их внесения в БД (усиление безопасности и целостности данных);
• СУБД должна иметь механизм, который гарантирует выполнение либо всех операций обновления данной транзакции, либо ни одной из них (транзакция – набор действий выполняемых пользователем (прикладной программой) с целью доступа или изменения БД (при этом в БД вносится сразу несколько изменений); если во время внесения изменений происходит сбой (например, вносимые данные вызывают нарушение целостности данных), то все изменения должны быть отменены (возвращение в непротиворечивое состояние БД));
• СУБД должна иметь механизм, который гарантирует корректное обновление БД при параллельном выполнении операций обновления многими пользователями (этот вопрос связан с поддержкой транзакций);
• СУБД должна предоставлять средства восстановления БД на случай ее повреждения или разрушения (этот вопрос связан с поддержкой транзакций);
• СУБД должна иметь механизм, гарантирующий возможность доступа к БД только санкционированных пользователей (скрытие части ненужных данных и защита от любого несанкционированного доступа);
• СУБД должна обладать способностью к интеграции с коммуникационным программным обеспечением (для поддержки связи с пользователями);
• СУБД должна обладать инструментами контроля за тем, чтобы данные и их изменения соответствовали заданным правилам (целостность БД – корректность и непротиворечивость хранимых данных, один из типов защиты БД; целостность выражается в виде ограничений или правил сохранения непротиворечивости данных (если есть противоречия – изменения не вносятся в БД));
• СУБД должна обладать инструментами поддержки независимости программ от фактической структуры БД (независимость достигается за счет реализации механизма поддержки представлений (Архитектура ANSI-SPARC), однако достичь полной логической независимости от данных очень сложно, т.к. обычно система легко адаптируется к добавлению нового объекта (атрибута, связи и т.п.), но не к их удалению (в некоторых системах вообще запрещено вносить изменения в существующие компоненты логической схемы));
• СУБД должна предоставлять некоторый набор различных вспомогательных служб (в основном для эффективного администрирования БД: импорт данных, мониторинг, стратегический анализ, реорганизация индексов, сборка мусора и перераспределение памяти).
Более точно, к числу функций СУБД принято относить следующие: 2.2.1. Непосредственное управление данными во внешней памяти Эта функция включает обеспечение необходимых структур внешней памяти как
для хранения данных, непосредственно входящих в БД, так и для служебных целей, например, для убыстрения доступа к данным в некоторых случаях (обычно для этого используются индексы). В некоторых реализациях СУБД активно используются возможности существующих файловых систем, в других работа производится вплоть до уровня устройств внешней памяти. Но подчеркнем, что в развитых СУБД пользователи в любом случае не обязаны знать, использует ли СУБД файловую систему, и если использует, то как организованы файлы. В частности, СУБД поддерживает собственную систему именования объектов БД.
2.2.2. Управление буферами оперативной памяти

СУБД обычно работают с БД значительного размера; по крайней мере этот размер
обычно существенно больше доступного объема оперативной памяти. Понятно, что если при обращении к любому элементу данных будет производиться обмен с внешней памятью, то вся система будет работать со скоростью устройства внешней памяти. Практически единственным способом реального увеличения этой скорости является буферизация данных в оперативной памяти. При этом, даже если операционная система производит общесистемную буферизацию (как в случае ОС UNIX), этого недостаточно для целей СУБД, которая располагает гораздо большей информацией о полезности буферизации той или иной части БД. Поэтому в развитых СУБД поддерживается собственный набор буферов оперативной памяти с собственной дисциплиной замены буферов.
Заметим, что существует отдельное направление СУБД, которое ориентировано на постоянное присутствие в оперативной памяти всей БД. Это направление основывается на предположении, что в будущем объем оперативной памяти компьютеров будет настолько велик, что позволит не беспокоиться о буферизации. Пока эти работы находятся в стадии исследований.
2.2.3. Управление транзакциями Транзакция - это последовательность операций над БД, рассматриваемых СУБД
как единое целое. Либо транзакция успешно выполняется, и СУБД фиксирует (COMMIT) изменения БД, произведенные этой транзакцией, во внешней памяти, либо ни одно из этих изменений никак не отражается на состоянии БД. Понятие транзакции необходимо для поддержания логической целостности БД. Если вспомнить наш пример информационной системы с файлами Employee и Department, то единственным способом не нарушить целостность БД при выполнении операции приема на работу нового сотрудника является объединение элементарных операций над файлами Employee и Department в одну транзакцию. Таким образом, поддержание механизма транзакций является обязательным условием даже однопользовательских СУБД (если, конечно, такая система заслуживает названия СУБД). Но понятие транзакции гораздо более важно в многопользовательских СУБД.
То свойство, что каждая транзакция начинается при целостном состоянии БД и оставляет это состояние целостным после своего завершения, делает очень удобным использование понятия транзакции как единицы активности пользователя по отношению к БД. При соответствующем управлении параллельно выполняющимися транзакциями со стороны СУБД каждый из пользователей может в принципе ощущать себя единственным пользователем СУБД (на самом деле, это несколько идеализированное представление, поскольку в некоторых случаях пользователи многопользовательских СУБД могут ощутить присутствие своих коллег).
С управлением транзакциями в многопользовательской СУБД связаны важные понятия сериализации транзакций и сериального плана выполнения смеси транзакций. Под сериализаций параллельно выполняющихся транзакций понимается такой порядок планирования их работы, при котором суммарный эффект смеси транзакций эквивалентен эффекту их некоторого последовательного выполнения. Сериальный план выполнения смеси транзакций - это такой план, который приводит к сериализации транзакций. Понятно, что если удается добиться действительно сериального выполнения смеси транзакций, то для каждого пользователя, по инициативе которого образована транзакция, присутствие других транзакций будет незаметно (если не считать некоторого замедления работы по сравнению с однопользовательским режимом).
Существует несколько базовых алгоритмов сериализации транзакций. В централизованных СУБД наиболее распространены алгоритмы, основанные на

синхронизационных захватах объектов БД. При использовании любого алгоритма сериализации возможны ситуации конфликтов между двумя или более транзакциями по доступу к объектам БД. В этом случае для поддержания сериализации необходимо выполнить откат (ликвидировать все изменения, произведенные в БД) одной или более транзакций. Это один из случаев, когда пользователь многопользовательской СУБД может реально (и достаточно неприятно) ощутить присутствие в системе транзакций других пользователей.
2.2.4. Журнализация Одним из основных требований к СУБД является надежность хранения данных во
внешней памяти. Под надежностью хранения понимается то, что СУБД должна быть в состоянии восстановить последнее согласованное состояние БД после любого аппаратного или программного сбоя. Обычно рассматриваются два возможных вида аппаратных сбоев: так называемые мягкие сбои, которые можно трактовать как внезапную остановку работы компьютера (например, аварийное выключение питания), и жесткие сбои, характеризуемые потерей информации на носителях внешней памяти. Примерами программных сбоев могут быть: аварийное завершение работы СУБД (по причине ошибки в программе или в результате некоторого аппаратного сбоя) или аварийное завершение пользовательской программы, в результате чего некоторая транзакция остается незавершенной. Первую ситуацию можно рассматривать как особый вид мягкого аппаратного сбоя; при возникновении последней требуется ликвидировать последствия только одной транзакции.
Понятно, что в любом случае для восстановления БД нужно располагать некоторой дополнительной информацией. Другими словами, поддержание надежности хранения данных в БД требует избыточности хранения данных, причем та часть данных, которая используется для восстановления, должна храниться особо надежно. Наиболее распространенным методом поддержания такой избыточной информации является ведение журнала изменений БД.
Журнал - это особая часть БД, недоступная пользователям СУБД и поддерживаемая с особой тщательностью (иногда поддерживаются две копии журнала, располагаемые на разных физических дисках), в которую поступают записи обо всех изменениях основной части БД. В разных СУБД изменения БД журнализуются на разных уровнях: иногда запись в журнале соответствует некоторой логической операции изменения БД (например, операции удаления строки из таблицы реляционной БД), иногда - минимальной внутренней операции модификации страницы внешней памяти; в некоторых системах одновременно используются оба подхода.
Во всех случаях придерживаются стратегии "упреждающей" записи в журнал (так называемого протокола Write Ahead Log - WAL). Грубо говоря, эта стратегия заключается в том, что запись об изменении любого объекта БД должна попасть во внешнюю память журнала раньше, чем измененный объект попадет во внешнюю память основной части БД. Известно, что если в СУБД корректно соблюдается протокол WAL, то с помощью журнала можно решить все проблемы восстановления БД после любого сбоя.
Самая простая ситуация восстановления - индивидуальный откат транзакции. Строго говоря, для этого не требуется общесистемный журнал изменений БД. Достаточно для каждой транзакции поддерживать локальный журнал операций модификации БД, выполненных в этой транзакции, и производить откат транзакции путем выполнения обратных операций, следуя от конца локального журнала. В некоторых СУБД так и делают, но в большинстве систем локальные журналы не поддерживают, а индивидуальный откат транзакции выполняют по общесистемному журналу, для чего все записи от одной транзакции связывают обратным списком (от конца к началу).

При мягком сбое во внешней памяти основной части БД могут находиться объекты, модифицированные транзакциями, не закончившимися к моменту сбоя, и могут отсутствовать объекты, модифицированные транзакциями, которые к моменту сбоя успешно завершились (по причине использования буферов оперативной памяти, содержимое которых при мягком сбое пропадает). При соблюдении протокола WAL во внешней памяти журнала должны гарантированно находиться записи, относящиеся к операциям модификации обоих видов объектов. Целью процесса восстановления после мягкого сбоя является состояние внешней памяти основной части БД, которое возникло бы при фиксации во внешней памяти изменений всех завершившихся транзакций и которое не содержало бы никаких следов незаконченных транзакций. Для того, чтобы этого добиться, сначала производят откат незавершенных транзакций (undo), а потом повторно воспроизводят (redo) те операции завершенных транзакций, результаты которых не отображены во внешней памяти. Этот процесс содержит много тонкостей, связанных с общей организацией управления буферами и журналом. Более подробно мы рассмотрим это в соответствующей лекции.
Для восстановления БД после жесткого сбоя используют журнал и архивную копию БД. Грубо говоря, архивная копия - это полная копия БД к моменту начала заполнения журнала (имеется много вариантов более гибкой трактовки смысла архивной копии). Конечно, для нормального восстановления БД после жесткого сбоя необходимо, чтобы журнал не пропал. Как уже отмечалось, к сохранности журнала во внешней памяти в СУБД предъявляются особо повышенные требования. Тогда восстановление БД состоит в том, что исходя из архивной копии по журналу воспроизводится работа всех транзакций, которые закончились к моменту сбоя. В принципе, можно даже воспроизвести работу незавершенных транзакций и продолжить их работу после завершения восстановления. Однако в реальных системах это обычно не делается, поскольку процесс восстановления после жесткого сбоя является достаточно длительным.
2.2.5. Поддержка языков БД Для работы с базами данных используются специальные языки, в целом
называемые языками баз данных. В ранних СУБД поддерживалось несколько специализированных по своим функциям языков. Чаще всего выделялись два языка - язык определения схемы БД (SDL - Schema Definition Language) и язык манипулирования данными (DML - Data Manipulation Language). SDL служил главным образом для определения логической структуры БД, т.е. той структуры БД, какой она представляется пользователям. DML содержал набор операторов манипулирования данными, т.е. операторов, позволяющих заносить данные в БД, удалять, модифицировать или выбирать существующие данные. Мы рассмотрим более подробно языки ранних СУБД в следующей лекции.
В современных СУБД обычно поддерживается единый интегрированный язык, содержащий все необходимые средства для работы с БД, начиная от ее создания, и обеспечивающий базовый пользовательский интерфейс с базами данных. Стандартным языком наиболее распространенных в настоящее время реляционных СУБД является язык SQL (Structured Query Language). В нескольких лекциях этого курса язык SQL будет рассматриваться достаточно подробно, а пока мы перечислим основные функции реляционной СУБД, поддерживаемые на "языковом" уровне (т.е. функции, поддерживаемые при реализации интерфейса SQL).
Прежде всего, язык SQL сочетает средства SDL и DML, т.е. позволяет определять схему реляционной БД и манипулировать данными. При этом именование объектов БД (для реляционной БД - именование таблиц и их столбцов) поддерживается на языковом уровне в том смысле, что компилятор языка SQL производит преобразование имен объектов в их внутренние идентификаторы на основании специально поддерживаемых

служебных таблиц-каталогов. Внутренняя часть СУБД (ядро) вообще не работает с именами таблиц и их столбцов.
Язык SQL содержит специальные средства определения ограничений целостности БД. Опять же, ограничения целостности хранятся в специальных таблицах-каталогах, и обеспечение контроля целостности БД производится на языковом уровне, т.е. при компиляции операторов модификации БД компилятор SQL на основании имеющихся в БД ограничений целостности генерирует соответствующий программный код.
Специальные операторы языка SQL позволяют определять так называемые представления БД, фактически являющиеся хранимыми в БД запросами (результатом любого запроса к реляционной БД является таблица) с именованными столбцами. Для пользователя представление является такой же таблицей, как любая базовая таблица, хранимая в БД, но с помощью представлений можно ограничить или наоборот расширить видимость БД для конкретного пользователя. Поддержание представлений производится также на языковом уровне.
Наконец, авторизация доступа к объектам БД производится также на основе специального набора операторов SQL. Идея состоит в том, что для выполнения операторов SQL разного вида пользователь должен обладать различными полномочиями. Пользователь, создавший таблицу БД, обладает полным набором полномочий для работы с этой таблицей. В число этих полномочий входит полномочие на передачу всех или части полномочий другим пользователям, включая полномочие на передачу полномочий. Полномочия пользователей описываются в специальных таблицах-каталогах, контроль полномочий поддерживается на языковом уровне.
Более точное описание возможных реализаций этих функций на основе языка SQL будет приведено в лекциях, посвященных языку SQL и его реализации.
2.3. Типовая организация СУБД Естественно, организация типичной СУБД и состав ее компонентов соответствует
рассмотренному нами набору функций. Напомним, что мы выделили следующие основные функции СУБД:
• управление данными во внешней памяти; • управление буферами оперативной памяти; • управление транзакциями; • журнализация и восстановление БД после сбоев; • поддержание языков БД. Логически в современной реляционной СУБД можно выделить наиболее
внутреннюю часть - ядро СУБД (часто его называют Data Base Engine), компилятор языка БД (обычно SQL), подсистему поддержки времени выполнения, набор утилит. В некоторых системах эти части выделяются явно, в других - нет, но логически такое разделение можно провести во всех СУБД.
Ядро СУБД отвечает за управление данными во внешней памяти, управление буферами оперативной памяти, управление транзакциями и журнализацию. Соответственно, можно выделить такие компоненты ядра (по крайней мере, логически, хотя в некоторых системах эти компоненты выделяются явно), как менеджер данных, менеджер буферов, менеджер транзакций и менеджер журнала. Как можно было понять из первой части этой лекции, функции этих компонентов взаимосвязаны, и для обеспечения корректной работы СУБД все эти компоненты должны взаимодействовать по тщательно продуманным и проверенным протоколам. Ядро СУБД обладает собственным интерфейсом, не доступным пользователям напрямую и используемым в программах, производимых компилятором SQL (или в подсистеме поддержки выполнения таких
программ) и утилитах БД. Ядро СУБД является основной резидентной частью СУБД. При использовании архитектуры "клиент-сервер" ядро является основной составляющей серверной части системы.
Основной функцией компилятора языка БД является компиляция операторов языка БД в некоторую выполняемую программу. Основной проблемой реляционных СУБД является то, что языки этих систем (а это, как правило, SQL) являются непроцедурными, т.е. в операторе такого языка специфицируется некоторое действие над БД, но эта спецификация не является процедурой, а лишь описывает в некоторой форме условия совершения желаемого действия (вспомните примеры из первой лекции). Поэтому компилятор должен решить, каким образом выполнять оператор языка прежде, чем произвести программу. Применяются достаточно сложные методы оптимизации операторов, которые мы подробно рассмотрим в следующих лекциях. Результатом компиляции является выполняемая программа, представляемая в некоторых системах в машинных кодах, но более часто в выполняемом внутреннем машинно-независимом коде. В последнем случае реальное выполнение оператора производится с привлечением подсистемы поддержки времени выполнения, представляющей собой, по сути дела, интерпретатор этого внутреннего языка.
Наконец, в отдельные утилиты БД обычно выделяют такие процедуры, которые слишком накладно выполнять с использованием языка БД, например, загрузка и выгрузка БД, сбор статистики, глобальная проверка целостности БД и т.д. Утилиты программируются с использованием интерфейса ядра СУБД, а иногда даже с проникновением внутрь ядра.
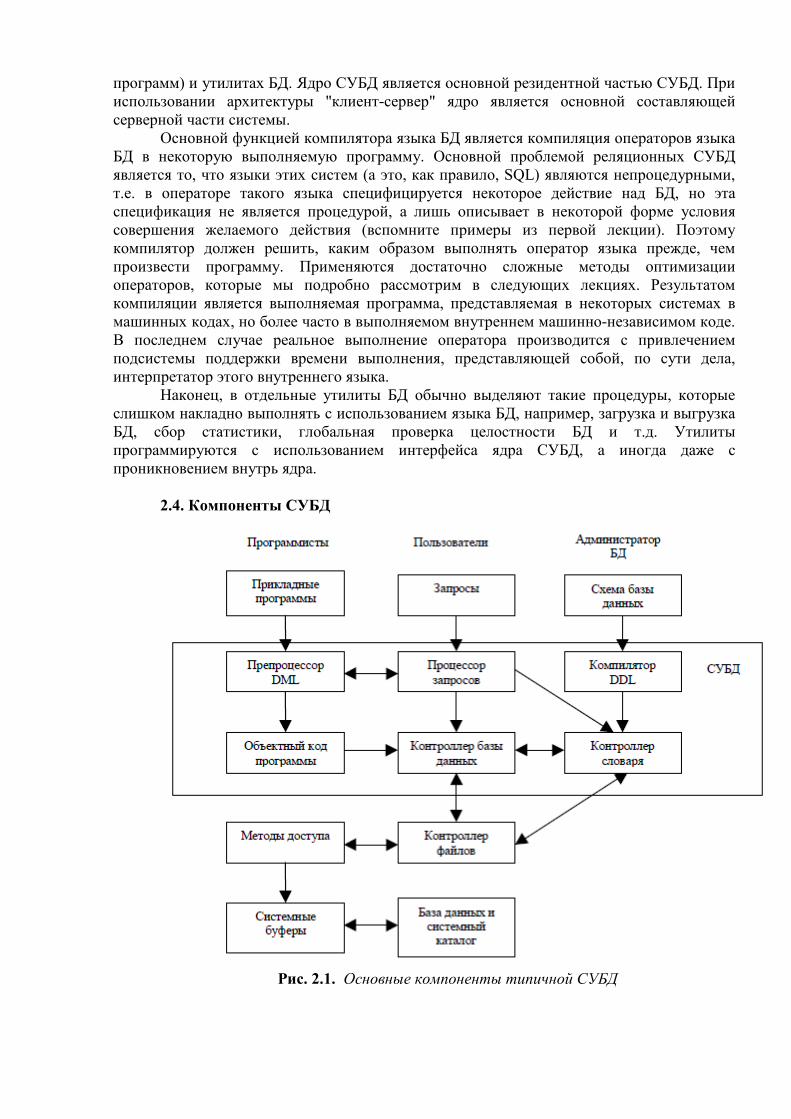
2.4. Компоненты СУБД
Рис. 2.1. Основные компоненты типичной СУБД

СУБД состоит из программных компонентов (модулей), каждый модуль выполняет одну специфическую операцию (часть операций может поддерживаться операционной системой, но только базовые и контролируемые СУБД (как надстройкой над ОС)).
Компоненты типичной СУБД: • процессор запросов – основной компонент СУБД – преобразует запросы в
последовательность низкоуровневых инструкций для контроллера базы данных; • контроллер базы данных – принимает запросы, проверяет внешние и
концептуальные схемы для определения тех концептуальных записей, которые необходимы для выполнения запроса, в него входят обычно следующие основные компоненты: контроль прав доступа, процессор команд, средства контроля целостности, оптимизатор запросов, контроллер транзакций, планировщик, контроллер восстановления, контроллер буферов (память-диск);
• контроллер файлов – манипулирует файлами БД (создает и поддерживает список структур и индексов, определенных во внутренней схеме, но не управляет вводом-выводом данных непосредственно, а лишь передает запросы соответствующим методам доступа, которые обмениваются данными между системными буферами и диском);
• препроцессор языка DML – преобразует внедренные в прикладные программы DML-операторы в вызовы стандартных функций базового языка (взаимодействуя с процессором запросов); DML (Data Manipulation Language) – язык, содержащий набор операторов для поддержки основных операций манипулирования содержащимися в базе данными (вставки, модификации, извлечения и удаления данных); DML может быть двух типов: процедурный – указывает, как можно получить результат оператора DML (обычно оперирует данными по одной записи), непроцедурный – описывает, какой результат будет получен (обычно оперирует наборами записей - SQL);
• компилятор языка DDL – преобразует DDL-команды в набор таблиц, содержащих метаданные (сохраняются в системном каталоге и частично в заголовках файлов с данными); DDL (Data Definition Language) - описательный язык, который позволяет описывать сущности (объекты), необходимые для работы некоторого приложения, а также связи, имеющиеся между различными сущностями (теоретически, в архитектуре ANSI-SPARC, можно выделить языки DDL для каждой схемы, но на практике есть один, позволяющий задавать спецификации как минимум для внешней и концептуальной схем);
• контроллер словаря – управляет доступом к системному каталогу и обеспечивает работу с ним (почти все компоненты СУБД имеют доступ к системному каталогу).
2.5. Архитектура многопользовательских СУБД Эффективность функционирования информационной системы (ИС) во многом
зависит от ее архитектуры. В настоящее время перспективной является архитектура клиент-сервер. В достаточно распространенном варианте она предполагает наличие компьютерной сети и распределенной базы данных, включающей корпоративную базу данных (КБД) и персональные базы данных (ПБД). КБД размещается на компьютере-сервере. ПБД размещается на компьютерах сотрудников подразделений, являющихся клиентами корпоративной базы данных.
Сервером определенного ресурса в компьютерной сети называется компьютер (программа), управляющий этим ресурсом, клиентом - компьютер (программа), использующий данный ресурс. В качестве ресурса компьютерной сети могут выступать, к примеру, базы данных, файловые системы, службы печати, почтовые службы. Тип сервера определяется видом ресурса, которым он управляет. Например, если управляемым ресурсом является база данных, то соответствующий сервер называется сервером базы данных.

Различают следующие архитектуры (по мере развития): 1) Телеобработка В данном случае используется один компьютер, соединенный с терминалами
пользователей (терминал – неинтеллектуальное устройство, предназначенное только для ввода-отображения информации), пользователь через терминал обращается к пользовательскому приложению, а то в свою очередь – к СУБД, затем результат идет в обратном порядке к пользователю. В последнее время наблюдается тенденция к децентрализации и замене дорогих мейнфреймов сетями персональных компьютеров (более эффективно).
2) Файловый сервер Обработка данных распределена в сети (обычно – в локальной вычислительной
сети (ЛВС)). Пользовательские приложения и сама СУБД размещены и функционируют на рабочих станциях и обращаются к файловому серверу только при необходимости доступа к данным (нужным файлам).
Недостатки: • большой объем сетевого трафика; • необходимость в наличии СУБД на каждой рабочей станции; • управление параллельностью, восстановлением и целостностью данных
усложняется (доступ к данным от нескольких экземпляров СУБД). 3) Технология «клиент/сервер». Существует единая двухуровневая система,
состоящая из клиентского процесса (толстый (интеллектуальный) клиент) (запрос некоторого ресурса) и серверного процесса (предоставление некоторого ресурса). Процессы совсем необязательно должны быть размещены на одном компьютере (обычно сервер располагается на одном узле ЛВС, а клиенты – на других узлах).
Клиент управляет пользовательским интерфейсом и логикой приложения (рабочая станция с пользовательским приложением): принимает от пользователя запрос, проверяет синтаксис и генерирует запрос к базе данных, передает сообщение серверу, ожидает поступление ответа и форматирует полученные данные для показа пользователю.
Сервер принимает и обрабатывает запросы к базе данных (включая проверку полномочий клиента, обеспечение требований целостности, поддержку системного каталога, поддержку параллельного доступа, выполнение запроса и обновление данных), а затем передает полученные результаты обработки обратно клиенту.
Преимущества технологии «клиент/сервер»: • более широкий доступ к существующим базам данных; • повышение производительности системы (по сравнению с выше
перечисленными подходами); • снижение стоимости аппаратного обеспечения (серверная машина – более
мощная, чем клиентские); • снижение сетевого трафика (по сети идут только необходимые данные); • повышается уровень непротиворечивости данных (проверка целостности
данных выполняется централизованно на сервере, а не у клиентов). • Расширение двухуровневой технологии «клиент/сервер» - переход к
трехуровневой структуре (эффективна в Internet): • тонкий (неинтеллектуальный) клиент – управление только
пользовательским интерфейсом (например, web browser); • средний уровень (клиент) – управление логикой пользовательского
приложения; • сервер базы данных.
Примечание. Более подробное изучение этой темы будет представлено в Лекции 13.
(Распределенная обработка данных).

2.6. Преимущества и недостатки СУБД Преимущества СУБД: • контроль за избыточностью данных (вводится контролируемая
избыточность – хранятся только те данные, что необходимы для описания модели, теперь все данные хранятся централизованно);
• непротиворечивость данных (легче отслеживать возникновение противоречивых состояний в БД, чем в файлах разбросанных по отделам, кроме того, меньше избыточность данных (см. выше));
• больше полезной информации при том же объеме хранимых данных (т.к. в БД хранится вся информация, а не только данные одного отдела (как в файловых системах), то возможно использование совместных данных для анализа некоторых ситуаций и подготовке отчетов);
• совместное использование данных (фактически учет и ведение данных на новом уровне – не для себя одного (отдела), а в многопользовательском режиме – вся организация (больший объем данных для сотрудника));
• поддержка целостности данных (корректность и непротиворечивость хранимых данных – в одном месте легче настраивать, проверять и изменять);
• повышенная безопасность (несмотря на то, что централизованные данные более уязвимы, чем распределенные, в интегрированной системе проще выработать систему безопасности (прав доступа к данным) и заставить ее работать);
• применение стандартов (установка требуемых форматов данных для обмена, отчетов, обновления и правил доступа);
• повышение эффективности с ростом масштабов системы (снижение затрат на создание прикладных программ (т.к. приложения работают с одним источником данных (доступ упрощен), перенос бюджета в область обновления оборудования без потерь в обновлении прикладных программ);
• возможность нахождения компромисса для противоречивых требований (потребности одних пользователей (отделов) могут противоречить потребностям другим пользователей (отделов), имея общий взгляд на всю структуру БД, администратор базы данных может контролировать такие противоречия и оперативно их устранять (обычно производительность отдается важным приложениям за счет менее важных));
• повышение доступности данных и их готовности к работе (т.е. устраняется время на распространение общих данных по отделам, данные становятся доступными сразу по их внесении в БД);
• улучшение показателей производительности (в СУБД программист освобожден от реализации стандартных действий (т.к. такие функции уже созданы и оптимизированы), поэтому его время используется более продуктивно));
• упрощение сопровождения системы за счет независимости от данных (т.к. в СУБД описания данных отделены от приложений, поэтому приложения защищены от изменений в описании данных, что упрощает обслуживание и сопровождение приложений);
• улучшенное управление параллельностью (в файловых системах при одновременной записи в файл возможна потеря данных или их целостности, СУБД позволяет вести параллельный доступ к БД);
• развитые службы резервного копирования и восстановления (в файловых системах резервное копирование должен делать пользователь, в СУБД – данные лежат централизованно, и данные операции поддерживаются автоматически (программно и аппаратно)).
Недостатки СУБД:

• сложность и размер (при проектировании БД, разработчики должны хорошо представлять функциональные возможности СУБД, непонимание может приводить к неудачным результатам проектирования, более сложные СУБД занимают значительный объем дискового пространства (при равных качествах кода);
• стоимость СУБД и дополнительные затраты на аппаратное обеспечение (чем больше возможностей у СУБД (и число пользователей БД при равной производительности), тем выше ее стоимость, стоимость ее сопровождения и аппаратных затрат);
• затраты на преобразование (при переносе БД с одной СУБД на другую важную роль представляют не только затраты на аппаратные и программные средства, но и затраты на перенос данных, переучивание специалистов, запуск новой системы (т.е. правильный выбор СУБД – тонкая вещь));
• производительность (т.к. приложения файловых систем оптимизируются каждое к конкретному случаю, то их производительность может быть очень высока, СУБД же предназначена для решения общих задач и соответственно «притормаживать»);
• серьезные последствия при выходе системы из строя (централизация повышает уязвимость системы, выход из строя компонента СУБД – прекращение работы организации).
2.7. Способы разработки и выполнения приложений Современные СУБД позволяют решать широкий круг задач по работе с базами
данных без разработки приложения. Тем не менее, есть случаи, когда целесообразно разработать приложение. Например, если требуется автоматизация манипуляций с данными, терминальный интерфейс СУБД недостаточно развит, либо имеющиеся в СУБД стандартный функции по обработке информации не устраивают пользователя. Для разработки приложений СУБД должна иметь программный интерфейс, основу которого составляют функции и/или процедуры соответствующего языка программирования.
Существующие СУБД поддерживают следующие технологии (и их комбинации) разработки приложений:
• ручное кодирование программ (Clipper, FoxPro, Paradox, C++…); • создание текстов приложений с помощью генераторов (Visual FoxPro,
С++Builder, Borland Delphi…); • автоматическая генерация готового приложения методами визуального
программирования (Delphi, Access, С++Builder, Borland Delphi, Visual Basic, C# Visual Studio, Java…).
При ручном кодировании программисты вручную набирают текст программ приложений, после чего выполняют их отладку.
Использование генераторов упрощает разработку приложений, поскольку при этом можно получить программный код без ручного набора. Генераторы приложений облегчают разработку основных элементов приложений (меню, экранных форм, запросов и т.), но зачастую не могут полностью исключить ручное кодирование.
Средства визуального программирования приложений являются дальнейшим развитием идеи использования генераторов приложений. Приложение при этом строится из готовых “строительных блоков” с помощью удобной интегрированной среды. При необходимости разработчик легко может вставить в приложение свой код. Интегрированная среда, как правило, представляем мощное средство создания, отладки и модификации приложений. Использование средств визуального программирования позволяет в кротчайшие сроки создавать более надежные, привлекательные и эффективные приложения по сравнению с приложениями, полученными первыми двумя способами.

Разработанное приложение обычно состоит из одного или нескольких файлов операционной системы.
Если основным файлом приложения является исполняемый файл, то это приложение, скорее всего, является независимым приложением, которое выполняется автономно от среды СУБД. Получение независимого приложения на практике осуществляется путем компиляции исходных текстов программ, полученных различными способами: путем набора текста вручную, а также полученных с помощью генератора приложения или среды визуального программирования.
Во многих случаях приложение не может исполняться без среды СУБД. Выполнение приложения состоит в том, что СУБД анализирует содержимое файлов приложения и автоматически строит необходимые машинные коды. Другими словами, приложение выполняется методом интерпретации.
Существуют системы, использующие промежуточный вариант между компиляцией и интерпретацией – так называемую псевдокомпиляцию. В таких системах исходная программа путем компиляции преобразуется в промежуточный код (псевдокод) и записывается на диск. В этом виде ее в некоторых системах разрешается даже редактировать, но главная цель псевдокомпиляции – преобразовать программу к виду, ускоряющему процесс ее интерпретации. Такой прием широко применялся в СУБД, работающих под управлением DOS, например, FoxBase+ и Paradox 4.0/ for DOS.
В СУБД, работающих под управлением Windows, псевдокод чаще используют для того, чтобы запретить модифицировать приложение. Это полезно для защиты от случайной или преднамеренной порчи работающей программы. Например, такой прием применен в СУБД Paradox for Windows, где допускается разработанные экранные формы и отчеты преобразовывать в соответствующие объекты, не поддающиеся редактированию.
Достоинством применения независимых приложений является то, что время выполнения машинной программы обычно меньше, чем при интерпретации. Такие приложения целесообразно использовать на слабых машинах и в случае установки систем “под ключ”, когда необходимо закрыть приложение от доработок со стороны пользователей.
Важным достоинством применения интерпретируемых приложений является легкость их модификации. Если готовая программа подвергается частым изменениям, то для их внесения нужна инструментальная система, т.е. СУБД или аналогичная среда. Для интерпретируемых приложений такой инструмент всегда под рукой, что очень удобно.
Другим серьезным достоинством систем с интерпретацией является то, что хорошие СУБД обычно имеют мощные средства контроля целостности данных и защиты от несанкционированного доступа, чего не скажешь о системах компилирующего типа. В последних упомянутые функции приходится программировать вручную, либо оставлять на совести администраторов.
При выборе средств для разработки приложения следует учитывать три основных фактора: ресурсы компьютера, особенности приложения (потребности в модификации функций программы, время на разработку, необходимость контроля доступа и поддержание целостности информации) и цель разработки (отчуждаемый программный продукт или система автоматизации своей повседневной деятельности).
Для пользователя, имеющего современный компьютер и планирующего создать несложное приложение, по всей видимости, больше подойдет СУБД интерпретирующего типа. Напомним, что такие системы достаточно мощны, имеют высокоуровневые средства для разработки и отладки, позволяют быстро выполнить разработку и обеспечивают удобное сопровождение и модификацию приложения.
При использовании компьютера со слабыми характеристиками лучше остановить свой выбор на системе со средствами разработки независимых приложений. Разница в выполнении независимого приложения и выполнения приложения в режиме интерпретации колеблется в пределах миллисекунд в пользу независимого приложения. В

то же время разница во времени подготовки приложения к его использованию обычно составляет величины порядка минуты – часы в пользу систем с интерпретацией.

Раздел 2 МОДЕЛИ ДАННЫХ Лекция 4. Модели данных. Логическая модель данных Лекция 5. Реляционная модель данных Лекция 6. Базисные средства манипулирования реляционными данными Лекция 7. Концептуальные модели данных. Проектирование реляционных
БД Лекция 8. Средства автоматизации проектирования

Лекция 4 МОДЕЛИ ДАННЫХ. ЛОГИЧЕСКАЯ МОДЕЛЬ ДАННЫХ Содержание 4.1. Определение и классификация моделей данных 4.2. Логическая модель данных 4.2.1. Теоретико-графовые модели данных 4.2.1.1. Системы, основанные на инвентарных списках 4.2.1.1.1. Структуры данных 4.2.1.1.2. Манипулирование данными 4.2.1.1.3. Ограничение целостности 4.2.1.2. Иерархическая модель данных. Структура данных 4.2.1.2.1. Язык описания данных 4.2.1.2.2. Манипулирование данными 4.2.1.2.3. Операторы поиска 4.2.1.2.4. Операторы поиска данных с возможностью модификации 4.2.1.2.5. Операторы модификации 4.2.1.2.6. Ограничение целостности 4.2.1.3. Сетевая модель данных. Структуры данных 4.2.1.3.1. Язык описания данных 4.2.1.3.2. Манипулирование данными 4.2.1.3.3. Ограничение целостности 4.2.1.4. Достоинства и недостатки 4.2.2. Реляционная модель данных 4.2.3. Постреляционная модель данных 4.2.4. Многомерная модель данных 4.2.5. Объектно-ориентированная модель данных Связанные темы Введение в базы данных (см. лекцию 1). Реляционная модель данных (см. лекцию 5). Концептуальные модели данных. Проектирование реляционных БД (см.
лекция 7) Использование баз данных (см. раздел 5). Развитие БД (см. раздел 7). 4.1. Определение и классификация моделей данных Модель данных является представлением «реального мира» (т.е. реальных
объектов и событий, и связей между ними), это некоторая абстракция, в которой остаются только те части реального мира, которые важны для разработчиков БД, а все второстепенные – игнорируются.
Цель построения модели данных – представление данных в понятном виде, который легко можно применить при проектировании БД (модель должна точно и недвусмысленно описывать части реального мира в таком виде, который позволяет разработчикам и пользователям (заказчикам) БД обмениваться мнениями при разработке и поддержке БД).
Модель данных включает в себя следующие части: • структурная часть – набор правил, по которым может быть построена БД;

• управляющая часть – определяет типы допустимых операций с данными (обновление и извлечение данных, изменение структуры);
• ограничения поддержки целостности данных (необязательная часть). Модели данных можно разделить на три категории: 1) концептуальные (объектные) модели данных – описание данных высокого
уровня (уровня объектов): модель типа «сущность-связь» или ER-модель (Entity-Relationship), объектно-ориентированная модель (состояние + поведение объектов), функциональная модель;
2) логические модели данных (модели данных на основе записей) – БД состоит из логических записей фиксированного формата: систем, основанные на инвертированных списках, сетевая модель данных (network), иерархическая модель данных (hierarchical) и реляционная модель данных (relational) (хотя и не в такой степени, как две предыдущие – табличный подход (как в представлении данных для пользователя, так и в обработке (декларативный подход (какие данные надо извлечь), а не навигационный (по одной записи))) и неявные связи между записями – ближе к объектным моделям);
3) физические модели данных – описывают, как данные хранятся в компьютере (информация о структуре записей, порядке расположения записей и путях доступа к ним): обобщающая модель (unifying), модель памяти кадров (frame memory).
Для отображения ANSI-SPARC архитектуры существует три модели данных: • внешняя модель данных (предметная область пользователей), • концептуальная модель данных (логическое представление о данных), • внутренняя модель данных (представление концептуальной модели
средствами конкретной СУБД). Первые две категории моделей данных используются для описания
концептуального и внешнего уровней, а последняя – для внутреннего уровня.
Рис. 4.1. Классификация моделей данных

В соответствии с рассмотренной ранее трехуровневой архитектурой мы
сталкиваемся с понятием модели данных по отношению к каждому уровню. И действительно, физическая модель данных оперирует категориями, касающимися организации внешней памяти и структур хранения, используемых в данной операционной среде. В настоящий момент в качестве физических моделей используются различные методы размещения данных, основанные на файловых структурах: это организация файлов прямого и последовательного доступа, индексных файлов и инвертированных файлов, файлов, использующих различные методы хеширования, взаимосвязанных файлов. Кроме того, современные СУБД широко используют страничную организацию данных. Физические модели данных, основанные на страничной организации, являются наиболее перспективными.
Наибольший интерес вызывают модели данных, используемые на концептуальном уровне. По отношению к ним внешние модели называются подсхемами и используют те же абстрактные категории, что и концептуальные модели данных.
Кроме трех рассмотренных уровней абстракции при проектировании БД существует еще один уровень, предшествующий им. Модель этого уровня должна выражать информацию о предметной области в виде, независимом от используемой СУБД. Эти модели называются концептуальные, или семантическими, и отражают в естественной и удобной для разработчиков и других пользователей форме информационно-логический уровень абстрагирования, связанный с фиксацией и описанием объектов предметной области, их свойств и их взаимосвязей.
Концептуальные модели данных используются на ранних стадиях проектирования для описания структур данных в процессе разработки приложения, а логические модели уже поддерживаются конкретной СУБД.
Документальные модели данных соответствуют представлению о слабоструктурированной информации, ориентированной в основном на свободные форматы документов, текстов на естественном языке.
Модели, основанные на языках разметки документов, связаны прежде всего со стандартным общим языком разметки — SGML (Standart Generalised Markup Language), который был утвержден ISO в качестве стандарта еще в 80-х годах.
Этот язык предназначен для создания других языков разметки, он определяет допустимый набор тегов (ссылок), их атрибуты и внутреннюю структуру документа. Контроль за правильностью использования тегов осуществляется при помощи специального набора правил, называемых DTD-описаниями, которые используются программой клиента при разборе документа. Для каждого класса документов определяется свой набор правил, описывающих грамматику соответствующего языка разметки. С помощью SGML можно описывать структурированные данные, организовывать информацию, содержащуюся в документах, представлять эту информацию в некотором стандартизованном формате. Но ввиду некоторой своей сложности SGML использовался в основном для описания синтаксиса других языков (наиболее известным из которых является HTML), и немногие приложения работали с SGML-документами напрямую.
Гораздо более простой и удобный, чем SGML, язык HTML позволяет определять оформление элементов документа и имеет некий ограниченный набор инструкций — тегов, при помощи которых осуществляется процесс разметки. Инструкции HTML в первую очередь предназначены для управления процессом вывода содержимого документа на экране программы-клиента и определяют этим самым способ представления документа, но не его структуру. В качестве элемента гипертекстовой базы данных, описываемой HTML, используется текстовый файл, который может легко передаваться по сети с использованием протокола HTTP. Эта особенность, а также то, что HTML является открытым стандартом и огромное количество пользователей имеет возможность

применять возможности этого языка для оформления своих документов, безусловно, повлияли на рост популярности HTML и сделали его сегодня главным механизмом представления информации в Интернете.
Однако HTML сегодня уже не удовлетворяет в полной мере требованиям, предъявляемым современными разработчиками к языкам подобного рода. И ему на смену был предложен новый язык гипертекстовой разметки, мощный, гибкий и, одновременно с этим, удобный язык XML. В чем же заключаются его достоинства?
XML (Extensible Markup Language) — это язык разметки, описывающий целый класс объектов данных, называемых XML-документами. Он используется в качестве средства для описания грамматики других языков и контроля за правильностью составления документов. То есть сам по себе XML не содержит никаких тегов, предназначенных для разметки, он просто определяет порядок их создания.
Тезаурусные модели основаны на принципе организации словарей, содержат определенные языковые конструкции и принципы их взаимодействия в заданной грамматике. Эти модели эффективно используются в системах-переводчиках, особенно многоязыковых переводчиках. Принцип хранения информации в этих системах и подчиняется тезаурусным моделям.
Дескрипторные модели — самые простые из документальных моделей, они широко использовались на ранних стадиях использования документальных баз данных. В этих моделях каждому документу соответствовал дескриптор — описатель. Этот дескриптор имел жесткую структуру и описывал документ в соответствии с теми характеристиками, которые требуются для работы с документами в разрабатываемой документальной БД. Например, для БД, содержащей описание патентов, дескриптор содержал название области, к которой относился патент, номер патента, дату выдачи патента и еще ряд ключевых параметров, которые заполнялись для каждого патента. Обработка информации в таких базах данных велась исключительно по дескрипторам, то есть по тем параметрам, которые характеризовали патент, а не по самому тексту патента.
4.2. Логическая модель данных Прежде, чем перейти к детальному и последовательному изучению реляционных
систем БД, остановимся коротко на ранних (дореляционных) СУБД. В этом есть смысл по трем причинам: во-первых, эти системы исторически предшествовали реляционным, и для правильного понимания причин повсеместного перехода к реляционным системам нужно знать хотя бы что-нибудь про их предшественников; во-вторых, внутренняя организация реляционных систем во многом основана на использовании методов ранних систем; в-третьих, некоторое знание в области ранних систем будет полезно для понимания путей развития постреляционных СУБД.
Заметим, что в этой лекции мы ограничиваемся рассмотрением только общих подходов к организации трех типов ранних систем, а именно, систем, основанных на инвертированных списках, иерархических и сетевых систем управления базами данных. Мы не будем касаться особенностей каких-либо конкретных систем; это привело бы к изложению многих технических деталей, которые, хотя и интересны, находятся несколько в стороне от основной цели нашего курса. Детали можно найти в рекомендованной литературе.
Начнем с некоторых наиболее общих характеристик ранних систем: • Эти системы активно использовались в течение многих лет, дольше, чем
используется какая-либо из реляционных СУБД. На самом деле некоторые из ранних систем используются даже в наше время, накоплены громадные базы данных, и одной из актуальных проблем информационных систем является использование этих систем совместно с современными системами.

• Все ранние системы не основывались на каких-либо абстрактных моделях. Как мы упоминали, понятие модели данных фактически вошло в обиход специалистов в области БД только вместе с реляционным подходом. Абстрактные представления ранних систем появились позже на основе анализа и выявления общих признаков у различных конкретных систем.
• В ранних системах доступ к БД производился на уровне записей. Пользователи этих систем осуществляли явную навигацию в БД, используя языки программирования, расширенные функциями СУБД. Интерактивный доступ к БД поддерживался только путем создания соответствующих прикладных программ с собственным интерфейсом.
• Можно считать, что уровень средств ранних СУБД соотносится с уровнем файловых систем примерно так же, как уровень языка Кобол соотносится с уровнем языка Ассемблера. Заметим, что при таком взгляде уровень реляционных систем соответствует уровню языков Ада или APL.
• Навигационная природа ранних систем и доступ к данным на уровне записей заставляли пользователя самого производить всю оптимизацию доступа к БД, без какой-либо поддержки системы.
• После появления реляционных систем большинство ранних систем было оснащено "реляционными" интерфейсами. Однако в большинстве случаев это не сделало их по-настоящему реляционными системами, поскольку оставалась возможность манипулировать данными в естественном для них режиме.
4.2.1. Теоретико-графовые модели данных Как уже упоминалось ранее, эти модели отражают совокупность объектов
реального мира в виде графа взаимосвязанных информационных объектов. В зависимости от типа графа выделяют системы, основанные на инвертированных списках, иерархическую или сетевую модели. Исторически эти модели появились раньше, и в настоящий момент они используются реже, чем более современная реляционная модель данных. Однако до сих пор существуют системы, работающие на основе этих моделей, а одна из концепций развития объектно-ориентированных баз данных предполагает объединение принципов сетевой модели с концепцией реляционной.
4.2.1.1. Системы, основанные на инвентарных списках К числу наиболее известных и типичных представителей таких систем относятся
Datacom/DB компании Applied Data Research, Inc. (ADR), ориентированная на использование на машинах основного класса фирмы IBM, и Adabas компании Software AG.
Организация доступа к данным на основе инвертированных списков используется практически во всех современных реляционных СУБД, но в этих системах пользователи не имеют непосредственного доступа к инвертированным спискам (индексам). Кстати, когда мы будем рассматривать внутренние интерфейсы реляционных СУБД, вы увидите, что они очень близки к пользовательским интерфейсам систем, основанных на инвертированных списках.
4.2.1.1.1. Структуры данных База данных, организованная с помощью инвертированных списков, похожа на
реляционную БД, но с тем отличием, что хранимые таблицы и пути доступа к ним видны пользователям. При этом:

• Строки таблиц упорядочены системой в некоторой физической последовательности.
• Физическая упорядоченность строк всех таблиц может определяться и для всей БД (так делается, например, в Datacom/DB).
• Для каждой таблицы можно определить произвольное число ключей поиска, для которых строятся индексы. Эти индексы автоматически поддерживаются системой, но явно видны пользователям.
4.2.1.1.2. Манипулирование данными Поддерживаются два класса операторов: • Операторы, устанавливающие адрес записи, среди которых: • прямые поисковые операторы (например, найти первую запись таблицы по
некоторому пути доступа); • операторы, находящие запись в терминах относительной позиции от
предыдущей записи по некоторому пути доступа; • Операторы над адресуемыми записями. Типичный набор операторов: • LOCATE FIRST - найти первую запись таблицы T в физическом порядке;
возвращает адрес записи; • LOCATE FIRST WITH SEARCH KEY EQUAL - найти первую запись
таблицы T с заданным значением ключа поиска K; возвращает адрес записи; • LOCATE NEXT - найти первую запись, следующую за записью с заданным
адресом в заданном пути доступа; возвращает адрес записи; • LOCATE NEXT WITH SEARCH KEY EQUAL - найти следующую запись
таблицы T в порядке пути поиска с заданным значением K; должно быть соответствие между используемым способом сканирования и ключом K; возвращает адрес записи;
• LOCATE FIRST WITH SEARCH KEY GREATER - найти первую запись таблицы T в порядке ключа поиска K со значением ключевого поля, большим заданного значения K; возвращает адрес записи;
• RETRIVE - выбрать запись с указанным адресом; • UPDATE - обновить запись с указанным адресом; • DELETE - удалить запись с указанным адресом; • STORE - включить запись в указанную таблицу; операция генерирует адрес
записи. 4.2.1.1.3. Ограничение целостности Общие правила определения целостности БД отсутствуют. В некоторых системах
поддерживаются ограничения уникальности значений некоторых полей, но в основном все возлагается на прикладную программу.
4.2.1.2. Иерархическая модель данных. Структура данных Иерархическая модель данных является наиболее простой среди всех логических
моделей. Исторически она появилась первой среди всех логических моделей: именно эту модель поддерживает первая из зарегистрированных промышленных СУБД IMS фирмы IBM.
Появление иерархической модели связано с тем, что в реальном мире очень многие связи соответствуют иерархии, когда один объект выступает как родительский, а с ним может быть связано множество подчиненных объектов. Иерархия проста и естественна в отображении взаимосвязи между классами объектов.

Основными информационными единицами в иерархической модели являются: база данных (БД), сегмент и поле. Поле данных определяется как минимальная, неделимая единица данных, доступная пользователю с помощью СУБД. Например, если в задачах требуется печатать в документах адрес клиента, но не требуется дополнительного анализа полного адреса, то есть города, улицы, дома, квартиры, то мы можем принять весь адрес за элемент данных, и он будет храниться полностью, а пользователь сможет получить его только как полную строку символов из БД. Если же в наших задачах существует анализ частей, составляющих адрес, например города, где расположен клиент, то нам необходимо выделить город как отдельный элемент данных, только в этом случае пользователь может получить к нему доступ и выполнить, например, запрос на поиск всех клиентов, которые проживают в конкретном городе, например в Париже. Однако если пользователю понадобится и полный адрес клиента, то остальную информацию по адресу также необходимо хранить в отдельном поле, которое может быть названо, например, Сокращенный адрес. В этом случае для каждого клиента в БД хранится как Город, так и Сокращенный адрес.
Сегмент в терминологии Американской Ассоциации по базам данных DBTG (Data Base Task Group) называется записью, при этом в рамках иерархической модели определяются два понятия: тип сегмента или тип записи и экземпляр сегмента или экземпляр записи.
Тип сегмента — это поименованная совокупность типов элементов данных, в него входящих. Экземпляр сегмента образуется из конкретных значений полей или элементов данных, в него входящих. Каждый тип сегмента в рамках иерархической модели образует некоторый набор однородных записей. Для возможности различия отдельных записей в данном наборе каждый тип сегмента должен иметь ключ или набор ключевых атрибутов (полей, элементов данных). Ключом называется набор элементов данных, однозначно идентифицирующих экземпляр сегмента. Например, рассматривая тип сегмента, описывающий сотрудника организации, мы должны выделить те характеристики сотрудника, которые могут его однозначно идентифицировать в рамках БД предприятия. Если предположить, что на предприятии могут работать однофамильцы, то, вероятно, наиболее надежным будет идентифицировать сотрудника по его табельному номеру. Однако если мы будем строить БД, содержащую описание множества граждан, например нашей страны, то, скорее всего, нам придется в качестве ключа выбрать совокупность полей, отражающих его паспортные данные.
В иерархической модели сегменты объединяются в ориентированный древовидный граф. При этом полагают, что направленные ребра графа отражают иерархические связи между сегментами: каждому экземпляру сегмента, стоящему выше по иерархии и соединенному с данным типом сегмента, соответствует несколько (множество) экземпляров данного (подчиненного) типа сегмента. Тип сегмента, находящийся на более высоком уровне иерархии, называется логически исходным по отношению к типам сегментов, соединенным с данным направленными иерархическими ребрами, которые в свою очередь называются логически подчиненными по отношению к этому типу сегмента. Иногда исходные сегменты называют сегментами-предками, а подчиненные сегменты называют сегментами-потомками.
Рис. 4.2. Пример иерархических связей между сегментами
На концептуальном уровне определяется понятие схемы БД в терминологии
иерархической модели.

Схема иерархической БД представляет собой совокупность отдельных деревьев, каждое дерево в рамках модели называется физической базой данных. Каждая физическая БД удовлетворяет следующим иерархическим ограничениям:
• в каждой физической БД существует один корневой сегмент, то есть сегмент, у которого нет логически исходного (родительского) типа сегмента;
• каждый логически исходный сегмент может быть связан с произвольным числом логически подчиненных сегментов;
• каждый логически подчиненный сегмент может быть связан только с одним логически исходным (родительским ) сегментом.
Очень важно понимать различие между сегментом и типом сегмента — оно такое же, как между типом переменной и самой переменной: сегмент является экземпляром типа сегмента. Например, у нас может быть тип сегмента Группа (Номер, Староста) и сегменты этого типа, такие как (4305, Петров Ф. И.) или (383, Кустова Т. С).
Между экземплярами сегментов также существуют иерархические связи.
Рассмотрим, например, иерархический граф, представленный на рис. 4.3.
Рис. 4.3. Пример структуры иерархического дерева
Каждый тип сегмента может иметь множество соответствующих ему экземпляров.
Между экземплярами сегментов также существуют иерархические связи. На рис. 4.4 представлены 2 экземпляра иерархического дерева соответствующей
структуры.
Рис. 4.4. Пример двух экземпляров данного дерева
Экземпляры-потомки одного типа, связанные с одним экземпляром сегмента-
предка, называют "близнецами". Так, для нашего примера экземпляры b1, b2 и b3 являются "близнецами", но экземпляр b4 подчинен другому экземпляру родительского сегмента, и он не является "близнецом" по отношению к экземплярам b1, b2 и b3. Набор всех экземпляров сегментов, подчиненных одному экземпляру корневого сегмента, называется физической записью. Количество экземпляров-потомков может быть разным для разных экземпляров родительских сегментов, поэтому в общем случае физические записи имеют разную длину. Так, используя принцип линейной записи иерархических графов, пример на рис. 4.4 можно представить в виде двух записей:

а1 b1 b2 b3 c1 d1 d2 e1
a2 b4 b5 c2 c3 d3 d4 e2 e3 e4
Запись 1 Запись 2 Как видно из нашего примера, физические записи в иерархической модели
различаются по длине и структуре. 4.2.1.2.1. Язык описания данных В рамках иерархической модели выделяют языковые средства описания данных
(DDL, Data Definition Language) и средства манипулирования данными (DML, Data Manipulation Language).
Каждая физическая база описывается набором операторов, определяющих как ее логическую структуру, так и структуру хранения БД. Описание начинается с оператора DBD (Data Base Definition):
DBD Name = < имя БД>, ACCESS = < способ доступа> Способ доступа определяет способ организации взаимосвязи физических записей.
Определено 5 способов доступа: HSAM — hierarchical sequential access method (иерархически последовательный метод), HISAM — hierarchical index sequential access method (иерархически индексно-последовательный метод), HDAM — hierarchical direct access method (иерархически прямой метод), HIDAM — hierarchical index direct access method (иерархически индексно-прямой метод), INDEX — индексный метод.
Далее идет описание наборов данных, предназначенных для хранения БД: DATA SET DD1 = < имя оператора, определяющего хранимый набор данных>, DEVICE =< устройство хранения БД>, [OVFLW = < имя области переполнения>] Так как физические записи имеют разную длину, то при модификации данных
запись может увеличиться и превысит исходную длину записи до модификации. В этом случае при определенных методах хранения может понадобиться дополнительное пространство хранения, где и будут размещены дополнительные данные. Это пространство и называется областью переполнения.
После описания всей физической БД идет описание типов сегментов, ее составляющих, в соответствии с иерархией. Описание сегментов всегда начинается с описания корневого сегмента. Общая схема описания типа сегмента такова:
SEGM NAME = < имя сегмента>, BYTES =< размер в байтах>, FREQ = <средняя частота реализаций сегмента под одним исходным> PARENT = <имя родительского сегмента> Параметр FREQ определяет среднее количество экземпляров данного сегмента,
связанных с одним экземпляром родительского сегмента. Для корневого сегмента это число возможных экземпляров корневого сегмента.
Для корневого сегмента параметр PARENT равен 0 (нулю). Далее для каждого сегмента дается описание полей : FIELD NAME = {(<имя поля> [, SEQ],{U | M}) | <имя поля> }, START = < номер байта, с которого начинается значения поля >, BYTES = <размер поля в байтах>, TYPE = {X | P | C} Признак SEQ — задается для ключевого поля, если экземпляры данного сегмента
физически упорядочены в соответствии со значениями данного поля.

Параметр U задается, если значения ключевого поля уникальны для всех экземпляров данного сегмента, M — в противном случае. Если поле является ключевым, то его описание задается в круглых скобках, в противном случае имя поля задается без скобок. Параметр TYPE определяет тип данных. Для ранних иерархических моделей были определены только три типа данных: X — шестнадцатеричный, P —упакованный десятичный, C — символьный.
Заканчивается описание схемы вызовом процедуры генерации: • DBDGEN — указывает на конец последовательности управляющих
операторов описания БД; • FINISH — устанавливает ненулевой код завершения при обнаружении
ошибки; • END — конец. В системе может быть несколько физических БД (ФБД), но каждая из них
описывается отдельно своим DBD и ей присваивается уникальное имя. Каждая ФБД содержит только один корневой сегмент. Совокупность ФБД образует концептуальную модель данных.
Внешние модели При работе с иерархической моделью каждая программа, пользователь или
приложение определяет свою внешнюю модель. Внешняя модель представляет собой совокупность поддеревьев для физических баз данных, с которыми работает данный пользователь. Каждый подграф внешней модели в обязательном порядке должен содержать корневой тип сегмента соответствующей физической базы данных концептуальной модели.
Представление внешней модели называется логической базой данных и определяется совокупностью блоков связи данного приложения с физическими БД, входящими в концептуальную схему БД. Блок связи — PCB, program communication block — описывает связь с одной физической БД по следующим правилам:
DBD NAME = < имя логической БД (подсхемы)> , ACCESS = LOGICAL DATA SET = LOGICAL. SEGM NAME = <имя сегмента в подсхеме>, PARENT =<имя родительского сегмента в подсхеме>, SOURCE =(Имя соответствующего сегмента ФБД, имя ФБД) ... DBDGEN FINISH END Совокупность блоков PCB образует полное внешнее представление данного
приложения, называемое "блоком спецификации программ" (PSB, program specification block ).
Рассмотрим пример иерархической БД. Наша организация занимается производством и продажей компьютеров, в рамках
производства мы комплектуем компьютеры из готовых деталей по индивидуальным заказам. У нас существует несколько базовых моделей, которые мы продаем без предварительных заказов по наличию на складе. В организации существуют несколько филиалов (рис. 4.5) и несколько складов, на которых хранятся комплектующие. Нам необходимо вести учет продаваемой продукции.

Рис. 4.5. Физическая БД "Филиалы"
Какие задачи нам надо решать в ходе разработки приложения? • При приеме заказа мы должны выяснить, какую модель заказывает заказчик:
типичную или индивидуальную комплектацию. • Если заказывается типичная модель, то выясняется, какая модель и есть ли
она в наличии, если модель есть, то надо уменьшить количество компьютеров данной модели в данном филиале на покупаемое количество. На этом будем считать заказ выполненным, однако при оформлении заказа может потребоваться задание полной спецификации покупаемого изделия.
• Если заказывается индивидуальная модель, то требуется описать весь состав новой модели.
Для того чтобы можно было бы принимать заказы на индивидуальные модели, нам понадобится информация о наличии конкретных деталей на складе, в этом случае нам необходимо второе дерево — Склады (см. рис. 4.6).
Рис. 4.6. Физическая модель "Склады"
4.2.1.2.2. Манипулирование данными Для доступа к базе данных у пользователя должна быть сформирована специальная
среда окружения, поддерживающая в явном виде имеющиеся навигационные операции. Для этого в ней должны храниться:

• шаблоны всех записей логических баз данных, доступных пользователю; • указатели на текущий экземпляр сегмента данного типа — для всех типов
сегментов. Язык манипулирования данными в иерархической модели поддерживает в явном
виде навигационные операции. Эти операции связаны с перемещением указателя, который определяет текущий экземпляр конкретного сегмента.
Все операторы в языке манипулирования данными можно разделить на 3 группы. Первую группу составляют операторы поиска данных.
4.2.1.2.3. Операторы поиска Синтаксис: GET UNIQUE <имя сегмента> WHERE <список поиска>; список поиска состоит из последовательности условий вида: <имя сегмента>.<имя поля>ОС <constant или имя другого поля данного сегмента
или имя переменной>; ОС — операция сравнения; условия могут быть соединены логическими операциями И и ИЛИ { & , }. Назначение: Получить единственное значение. Пример: Найти типовую модель стоимостью не более $600, которая существует не менее
чем в 10 экземплярах. GET UNIQUE ТИПОВЫЕ МОДЕЛИ WHERE ТиповыеМодели.Стоимость <= $600
AND ТиповыеМодели.Количество на складе >= 10 Данная команда всегда ищет с начала БД и останавливается, найдя первый
экземпляр сегмента, удовлетворяющий условиям поиска. Синтаксис: GET NEXT <имя сегмента> WHERE <список аргументов поиска> Назначение: Получить следующий экземпляр сегмента для тех же условий. Пример: Напечатать полный список заказов стоимостью не менее $500. GET UNIQUE ИНДИВИДУАЛЬНЫЕ МОДЕЛИ WHERE ИндивидуальныеМодели.Стоимость >= $500 WHILE NOT FAIL (пока не конец поиска) DO PRINT № заказа, Стоимость, Количество GET NEXT ИНДИВИДУАЛЬНЫЕ МОДЕЛИ END Синтаксис: GET NEXT <имя сегмента> WITHIN PARENT [ where <дополн.условия>] Назначение: Получить следующий для того же исходного. Пример: Получить перечень винчестеров, имеющихся на складе номер 1, в количестве не
менее 10 с объемом 10 Гбайт. GET UNIQUE СКЛАД WHERE Склад.Номер = 1 GET NEXT ИЗДЕЛИЕ WITHIN PARENT WHERE Изделие.Наименование = ‘Винчестер’

GET NEXT ХАРАКТЕРИСТИКИ WITHIN PARENT WHERE ХАРАКТЕРИСТИКИ.Параметр = 10 AND ХАРАКТЕРИСТИКИ.Единицы Измерения = Гб AND ХАРАКТЕРИСТИКИ.Величина > 10 WHILE NOT FAIL (пока поиск не завершен) DO GET NEXT WITHIN PARENT END 4.2.1.2.4. Операторы поиска данных с возможностью модификации 1. Найти и удержать единственный экземпляр сегмента. Эта операция подобна
первой операции поиска GET UNIQUE, единственным отличием этой операции является то, что после выполнения этой операции над найденным экземпляром сегмента допустимы операции модификации (изменения) данных.
Синтаксис: GET HOLD UNIQUE <имя сегмента> WHERE <список поиска> 2. Найти и удержать следующий с теми же условиями поиска. Аналогично
операции 4 эта операция дублирует вторую операции поиска GET NEXT с возможностью выполнения последующей модификации данных.
Синтаксис: GET HOLD NEXT [WHERE дополнительные условия>] 3. Получить и удержать следующий для того же родителя. Эта операция
является аналогом операции поиска 3, но разрешает выполнение операций модификации данных после себя.
Синтаксис: GET HOLD NEXT WITHIN PARENT [ where <дополн.условия>] 4.2.1.2.5. Операторы модификации 1) Удалить Это первая из трех операций модификации. Синтаксис: DELETE Эта команда не имеет параметров. Почему? Потому что операции модификации
действуют на экземпляр сегмента, найденный командами поиска с удержанием. А он всегда единственный текущий найденный и удерживаемый для модификации экземпляр конкретного сегмента. Поэтому при выполнении команды удаления будет удален именно этот экземпляр сегмента.
2) Обновить Синтаксис: UPDATE Как же происходит обновление, если мы и в этой команде не задаем никаких
параметров. СУБД берет данные из рабочей области пользователя, где в шаблонах записей соответствующих внутренних переменных находятся значения полей каждого сегмента внешней модели, с которой работает данный пользователь. Именно этими значениями и обновляется текущий экземпляр сегмента. Значит, перед тем как выполнить операции модификации UPDATE, необходимо присвоить соответствующим переменным новые значения.
3) Ввести новый экземпляр сегмента. INSERT <имя сегмента>

Эта команда позволяет ввести новый экземпляр сегмента, имя которого определено в параметре команды. Если мы вводим данные в сегмент, который является подчиненным некоторому родительскому экземпляру сегмента, то он будет внесен в БД и физически подключен к тому экземпляру родительского сегмента, который в данный момент является текущим.
Как видим, набор операций поиска и манипулирования данными в иерархической БД невелик, но он вполне достаточен для получения доступа к любому экземпляру любого сегмента БД. Однако следует отметить, что способ доступа, который применяется в данной модели, связан с последовательным перемещением от одного экземпляра сегмента к другому. Такой способ напоминает движение летательного аппарата или корабля по заданным координатам и называется навигационным.
4.2.1.2.6. Ограничение целостности Автоматически поддерживается целостность ссылок между предками и потомками.
Основное правило: никакой потомок не может существовать без своего родителя. Заметим, что аналогичное поддержание целостности по ссылкам между записями, не входящими в одну иерархию, не поддерживается.
В иерархических системах поддерживалась некоторая форма представлений БД на основе ограничения иерархии.
4.2.1.3. Сетевая модель данных. Структуры данных Стандарт сетевой модели впервые был определен в 1975 году организацией
CODASYL (Conference of Data System Languages), которая определила базовые понятия модели и формальный язык описания.
• Базовыми объектами модели являются: • элемент данных; • агрегат данных; • запись; • набор данных. Элемент данных — то же, что и в иерархической модели, то есть минимальная
информационная единица, доступная пользователю с использованием СУБД. Агрегат данных соответствует следующему уровню обобщения в модели. В модели
определены агрегаты двух типов: агрегат типа вектор и агрегат типа повторяющаяся группа.
Агрегат данных имеет имя, и в системе допустимо обращение к агрегату по имени. Агрегат типа вектор соответствует линейному набору элементов данных. Например, агрегат Адрес может быть представлен следующим образом:
Адрес
ород лица ом к
вартира Агрегат типа повторяющаяся группа соответствует совокупности векторов данных.
Например, агрегат Зарплата соответствует типу повторяющаяся группа с числом повторений 12.
Зарплата
есяц С
умма
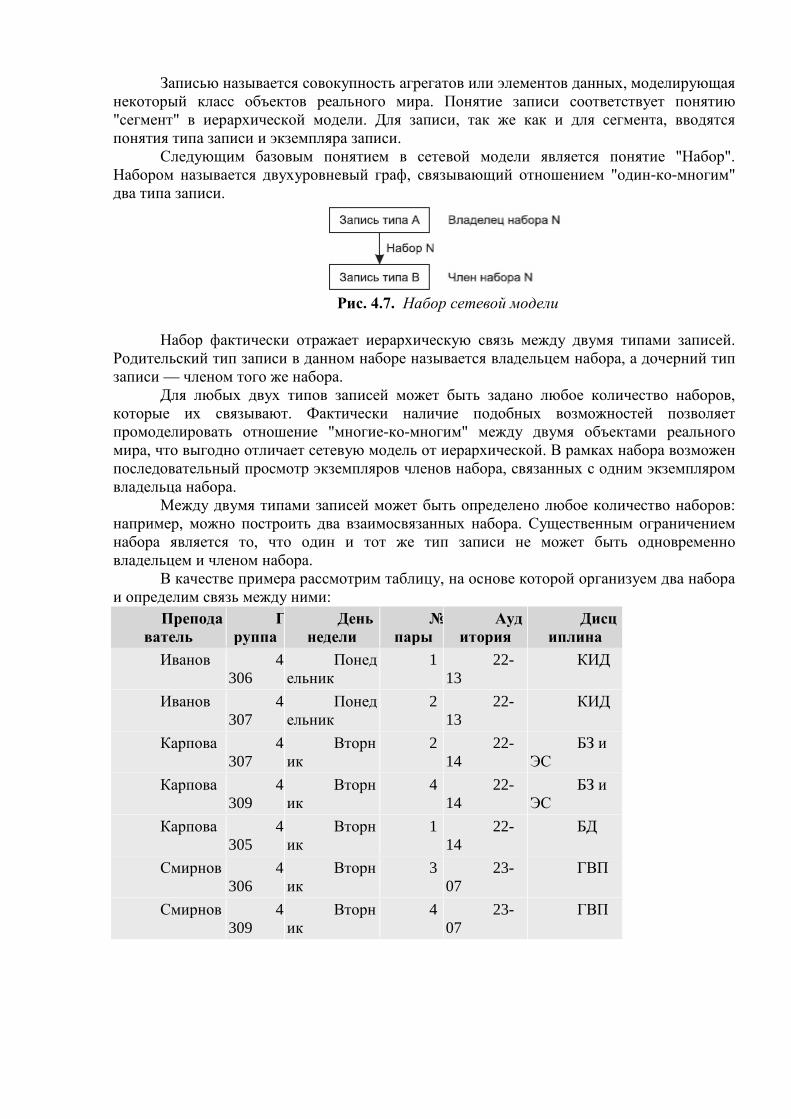
Записью называется совокупность агрегатов или элементов данных, моделирующая некоторый класс объектов реального мира. Понятие записи соответствует понятию "сегмент" в иерархической модели. Для записи, так же как и для сегмента, вводятся понятия типа записи и экземпляра записи.
Следующим базовым понятием в сетевой модели является понятие "Набор". Набором называется двухуровневый граф, связывающий отношением "один-ко-многим" два типа записи.
Рис. 4.7. Набор сетевой модели
Набор фактически отражает иерархическую связь между двумя типами записей.
Родительский тип записи в данном наборе называется владельцем набора, а дочерний тип записи — членом того же набора.
Для любых двух типов записей может быть задано любое количество наборов, которые их связывают. Фактически наличие подобных возможностей позволяет промоделировать отношение "многие-ко-многим" между двумя объектами реального мира, что выгодно отличает сетевую модель от иерархической. В рамках набора возможен последовательный просмотр экземпляров членов набора, связанных с одним экземпляром владельца набора.
Между двумя типами записей может быть определено любое количество наборов: например, можно построить два взаимосвязанных набора. Существенным ограничением набора является то, что один и тот же тип записи не может быть одновременно владельцем и членом набора.
В качестве примера рассмотрим таблицу, на основе которой организуем два набора и определим связь между ними:
Преподаватель
Группа
День недели
№ пары
Аудитория
Дисциплина
Иванов 4306
Понедельник
1 22-13
КИД
Иванов 4307
Понедельник
2 22-13
КИД
Карпова 4307
Вторник
2 22-14
БЗ и ЭС
Карпова 4309
Вторник
4 22-14
БЗ и ЭС
Карпова 4305
Вторник
1 22-14
БД
Смирнов 4306
Вторник
3 23-07
ГВП
Смирнов 4309
Вторник
4 23-07
ГВП

Рис. 4.8. Два набора и связь между ними
Экземпляров набора Ведет занятия будет 3 (по числу преподавателей), экземпляров
набора Занимается у будет 4 (по числу групп). На рис. 4.9 представлены взаимосвязи экземпляров данных наборов.
Рис. 4.9. Пример взаимосвязи экземпляров двух наборов
Среди всех наборов выделяют специальный тип набора, называемый
"Сингулярным набором", владельцем которого формально определена вся система. Сингулярный набор изображается в виде входящей стрелки, которая имеет собственно имя набора и имя члена набора, но у которой не определен тип записи "Владелец набора". Например, сингулярный набор М.
Сингулярные наборы позволяют обеспечить доступ к экземплярам отдельных
типов данных, поэтому если в задаче алгоритм обработки информации предполагает обеспечение произвольного доступа к некоторому типу записи, то для поддержки этой возможности необходимо ввести соответствующий сингулярный набор.
В общем случае сетевая база данных представляет совокупность взаимосвязанных наборов, которые образуют на концептуальном уровне некоторый граф.
4.2.1.3.1. Язык описания данных Язык описания данных в сетевой модели имеет несколько разделов: • описание базы данных — области размещения; • описания записей — элементов и агрегатов (каждого в отдельности); • описания наборов (каждого в отдельности). SCHEMA IS <Имя БД>. AREA NAME IS <Имя физической области>. RECORD NAME IS <Имя записи (уникальное)> Для каждой записи определяется способ размещения экземпляров записи данного
типа: LOCATION MODE IS {DIRECT (напрямую) | CALC <Имя программы> USING <[Список пер.>] DUPLICATE ARE [NOT] ALLOWED VIA <Имя набора> SET (рядом с записями владельца) SYSTEM (решать будет система)}

Каждый тип записи должен быть приписан к некоторой физической области размещения:
WITHIN <Имя области размещения> AREA После описания записи в целом идет описание внутренней структуры: <Имя уровня> <Имя данного> <Шаблон> <Тип> Номер уровня определяет уровень вложенности при описании элементов и
агрегатов данных. Первый уровень — сама запись. Поэтому элементы или агрегаты данных имеют уровень начиная со второго. Если данное соответствует агрегату, то любая его составляющая добавляет один уровень вложенности.
Если агрегат является вектором, то он описывается как <Номер уровня> <Имя агрегата>.<Номер уровня> <Имя 1-й сост.> а если — повторяющейся группой, то следующим образом: <Номер уровня> <Имя агрегата>.OCCURS <N> TIMES где N — среднее количество элементов в группе. Описание набора и порядка включения членов в него выглядит следующим
образом: SET NAME IS <Имя набора>; OWNER IS (<Имя владельца> | SYSTEM). Далее указывается порядок включения новых экземпляров члена данного набора в
экземпляр набора: ORDER PERMANENT INSERTION IS {SORTED | NEXT | PREV | LAST | FIRST} После этого описывается член набора с указанием способа включения и способа
исключения экземпляра — члена набора из экземпляра набора. MEMBER IS <Имя члена набора> {AUTOMATIC | MANUAL} {MANDATORY | OPTIONAL} KEY IS (ACCENDING | DESCENDING) <Имя элемента данных> При автоматическом включении каждый новый экземпляр члена набора
автоматически попадает в текущий экземпляр набора в соответствии с заданным ранее порядком включения. При ручном способе экземпляр члена набора сначала попадает в БД, а только потом командой CONNECT может быть включен в конкретный экземпляр набора.
Если задан способ исключения MANDATORY, то экземпляр записи, исключаемый из набора, автоматически исключается и из базы данных. Иначе просто разрываются связи.
Внешняя модель при сетевой организации данных поддерживается путем описания части общего связного графа.
4.2.1.3.2. Манипулирование данными Все операции манипулирования данными в сетевой модели делятся на
навигационные операции и операции модификации. Навигационные операции осуществляют перемещение по БД путем прохождения
по связям, которые поддерживаются в схеме БД. В этом случае результатом является новый единичный объект, который получает статус текущего объекта.
Операции модификации осуществляют как добавление новых экземпляров отдельных типов записей, так и экземпляров новых наборов, удаление экземпляров записей и наборов, модификацию отдельных составляющих внутри конкретных экземпляров записей. Средства модификации данных сведены в табл. 3.1:
Таблица 3.1. Операторы манипулирования данными в сетевой модели Опера Назначение

ция READ
Y Обеспечение доступа данного процесса или пользователя к БД (сходна
по смыслу с операцией открытия файла) FINISH Окончание работы с БД FIND Группа операций, устанавливающих указатель найденного объекта на
текущий объект GET Передача найденного объекта в рабочую область. Допустима только
после FIND STORE Помещение в БД записи, сформированной в рабочей области CONN
ECT Включение текущей записи в текущий экземпляр набора
DISCONNECT
Исключение текущей записи из текущего экземпляра набора
MODIFY
Обновление текущей записи данными из рабочей области пользователя
ERASE Удаление экземпляра текущей записи В рабочей области пользователя хранятся шаблоны записей, программные
переменные и три типа указателей текущего состояния: • текущая запись процесса (код или ключ последней записи, с которой
работала данная программа); • текущая запись типа записи (для каждого типа записи ключ последней
записи, с которой работала программа); • текущая запись типа набор (для каждого набора с владельцем T1 и членом
T2 указывается, T1 или T2 были последней обрабатываемой записью). На рис. 4.10 представлена концептуальная модель торгово-посреднической
организации.
Рис. 4.10. Схема БД "Торговая фирма"
При необходимости возможно описание элементов данных, которые не
принадлежат непосредственно данной записи, но при ее обработке часто используются.

Для этого используется тип VIRTUAL с обязательным указанием источника данного элемента данных.
RECORD Цены 02 Цена TYPE REAL 02 Товар VIRTUAL SOURCE IS Товары.НаименованиеТовара OF OWNER OF Товар-Цены SET Наиболее интересна операция поиска (FIND), так как именно она отражает суть
навигационных методов, применяемых в сетевой модели. Всего существует семь типов операций поиска:
• По ключу (запись должна быть описана через CALC USING ...): • FIND <Имя записи> • RECORD BY CALC KEY <Имя параметра> • Последовательный просмотр записей данного типа: • FIND DUPLICATE <Имя записи> • RECORD BY CALC KEY • Найти владельца текущего экземпляра набора: • FIND OWNER OF CURRENT <Имя набора> SET • Последовательный просмотр записей—членов текущего экземпляра набора: • FIND (FIRST | NEXT) <Имя записи> • RECORD IN CURRENT <Имя набора> • SET • Просмотр записей—членов экземпляра набора, специфицированных рядом
полей: • FIND [DUPLICATE] <Имя записи> • RECORD IN CURRENT <Имя набора> • SET USING <Список полей> • Сделать текущей записью процесса текущий экземпляр набора: • FIND CURRENT OF <Имя набора> SET • Установить текущую запись процесса: • FIND CURRENT OF <Имя записи> RECORD Например, алгоритм и программа печати заказов, сделанных Петровым, будут
выглядеть так:

Рис. 4.11. Алгоритм и программа печати заказов
4.2.1.3.3. Ограничение целостности В принципе их поддержание не требуется, но иногда требуют целостности по
ссылкам (как в иерархической модели). 4.2.1.4. Достоинства и недостатки Сильные места ранних СУБД: • Развитые средства управления данными во внешней памяти на низком
уровне; • Возможность построения вручную эффективных прикладных систем; • Возможность экономии памяти за счет разделения подобъектов (в сетевых
системах). Недостатки: • Слишком сложно пользоваться; • Фактически необходимы знания о физической организации; • Прикладные системы зависят от этой организации; • Их логика перегружена деталями организации доступа к БД. 4.2.2. Реляционная модель данных Реляционная модель данных предложена сотрудником фирмы IBM Эдгаром
Коддом и основывается на понятии отношение (relation). Отношение представляет собой множество элементов, называемых кортежами.
Подробно теоретическая основа реляционной модели данных рассматривается в

следующем разделе. Наглядной формой представления отношения является привычная для человеческого восприятия двумерная таблица.
Таблица имеет строки (записи) и столбцы (колонки). Каждая строка таблицы имеет одинаковую структуру и состоит из полей. Строкам таблицы соответствуют кортежи, а столбцам — атрибуты отношения.
С помощью одной таблицы удобно описывать простейший вид связей между данными, а именно: деление одного объекта (явления, сущности, системы и проч.), информация о котором хранится в таблице, на множество подобъектов, каждому из которых соответствует строка или запись таблицы. При этом каждый из подобъектов имеет одинаковую структуру или свойства, описываемые соответствующими значениями полей записей. Например, таблица может содержать сведения о группе обучаемых, о каждом из которых известны следующие характеристики: фамилия, имя и отчество, пол, возраст и образование. Поскольку в рамках одной таблицы не удается описать более сложные логические структуры данных из предметной области, применяют связывание таблиц.
Физическое размещение данных в реляционных базах на внешних носителях легко осуществляется с помощью обычных файлов.
Достоинство реляционной модели данных заключается в простоте, понятности и удобстве физической реализации на ЭВМ. Именно простота и понятность для пользователя явились основной причиной их широкого использования. Проблемы же эффективности обработки данных этого типа оказались технически вполне разрешимыми.
Основными недостатками реляционной модели являются следую-щие: отсутствие стандартных средств идентификации отдельных записей и сложность описания иерархических и сетевых связей.
Примерами зарубежных реляционных СУБД для ПЭВМ являются следующие: dBaseIII Plus и dBase IY (фирма Ashton-Tate), DB2 (IBM), R:BASE (Microrim), FoxPro ранних версий и FoxBase (Fox Software), Paradox и dBASE for Windows (Borland), FoxPro более поздних версий, Visual FoxPro и Access (Microsoft), MS SQL Server, Clarion (Clarion Software), Ingres (ASK Computer Systems) и Oracle (Oracle).
К отечественным СУБД реляционного типа относятся системы: ПАЛЬМА (ИК АН УССР), а также система НуТесh (МИФИ).
Заметим, что последние версии реляционных СУБД имеют некоторые свойства объектно-ориентированных систем. Такие СУБД часто называют объектно-реляционными. Примером такой системы можно считать продукты Oracle 8.х. Системы предыдущих версий вплоть до Oracle 7.х считаются «чисто» реляционными.
4.2.3. Постреляционная модель данных Классическая реляционная модель предполагает неделимость данных, хранящихся
в полях записей таблиц. Это означает, что информация в таблице представляется в первой нормальной форме (подраздел 5.2). Существует ряд случаев, когда это ограничение мешает эффективной реализации приложений.
Постреляционная модель данных представляет собой расширенную реляционную модель, снимающую ограничение неделимости данных, хранящихся в записях таблиц. Постреляциоциая модель данных допускает многозначные поля — поля, значения которых состоят из подзначений. Набор значений многозначных полей считается самостоятельной таблицей, встроенной в основную таблицу.
На рис. 4.12 на примере информации о накладных и товарах для сравнения приведено представление одних и тех же данных с помощью реляционной (а) и постреляционной (б) моделей. Таблица INVOICES (накладные) содержит данные о номерах накладных (INVNO) и номерах покупателей (CUSTNO). В таблице JNVO ICE. ITEMS (накладные-товары) содержатся данные о каждой из накладных: номер накладной
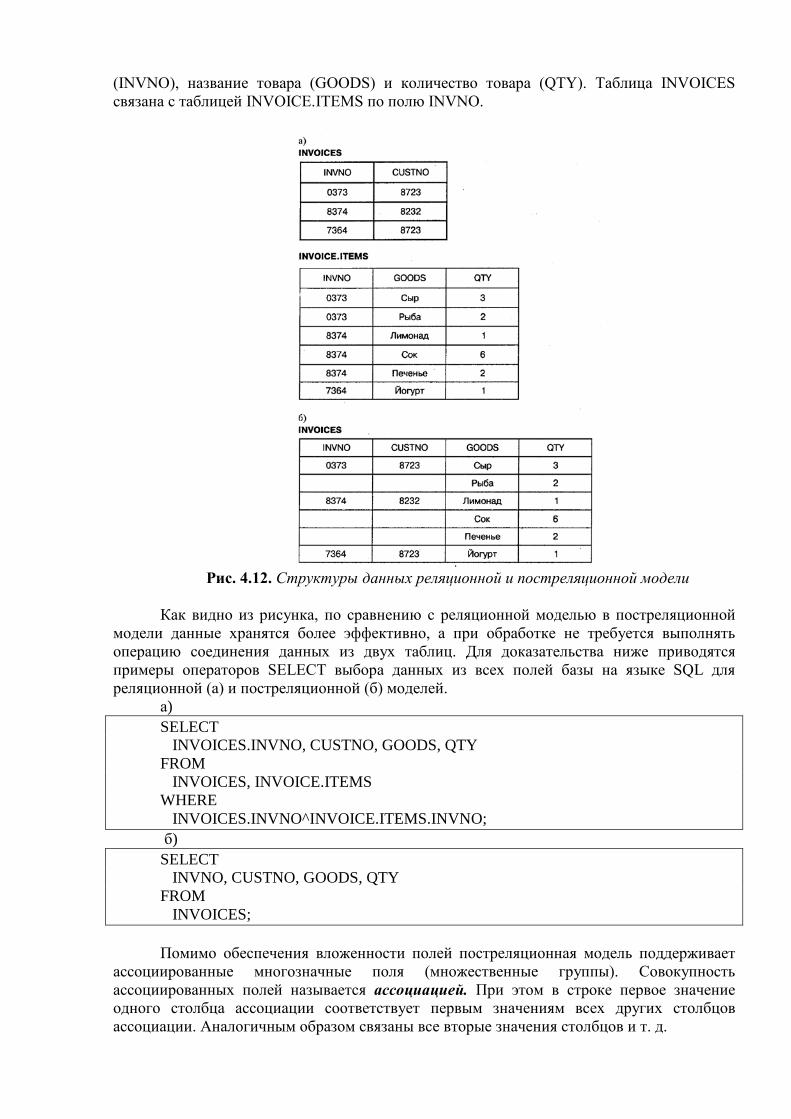
(INVNO), название товара (GOODS) и количество товара (QTY). Таблица INVOICES связана с таблицей INVOICE.ITEMS по полю INVNO.
Рис. 4.12. Структуры данных реляционной и постреляционной модели
Как видно из рисунка, по сравнению с реляционной моделью в постреляционной
модели данные хранятся более эффективно, а при обработке не требуется выполнять операцию соединения данных из двух таблиц. Для доказательства ниже приводятся примеры операторов SELECT выбора данных из всех полей базы на языке SQL для реляционной (а) и постреляционной (б) моделей.
а) SELECT INVOICES.INVNO, CUSTNO, GOODS, QTY FROM INVOICES, INVOICE.ITEMS WHERE INVOICES.INVNO^INVOICE.ITEMS.INVNO; б) SELECT INVNO, CUSTNO, GOODS, QTY FROM INVOICES; Помимо обеспечения вложенности полей постреляционная модель поддерживает
ассоциированные многозначные поля (множественные группы). Совокупность ассоциированных полей называется ассоциацией. При этом в строке первое значение одного столбца ассоциации соответствует первым значениям всех других столбцов ассоциации. Аналогичным образом связаны все вторые значения столбцов и т. д.

На длину полей и количество полей в записях таблицы не накладывается требование постоянства. Это означает, что структура данных и таблиц имеют большую гибкость.
Поскольку постреляционная модель допускает хранение в таблицах ненормализованных данных, возникает проблема обеспечения целостности и непротиворечивости данных. Эта проблема решается включением в СУБД механизмов, подобных хранимым процедурам в клиент-серверных системах.
Для описания функций контроля значений в полях имеется возможность создавать процедуры (коды конверсии и коды корреляции), автоматически вызываемые до или после обращения к данным. Коды корреляции выполняются сразу после чтения данных, перед их обработкой. Коды конверсии, наоборот, выполняются после обработки данных.
Достоинством постреляционной модели является возможность представления совокупности связанных реляционных таблиц одной постреляционной таблицей. Это обеспечивает высокую наглядность представления информации и повышение эффективности ее обработки.
Недостатком постреляционной модели является сложность решения проблемы обеспечения целостности и непротиворечивости хранимых данных.
Рассмотренная нами постреляционная модель данных поддерживается СУБД uniVers. К числу других СУБД, основанных на постреляционной модели данных, относятся также системы Bubba и Dasdb.
4.2.4. Многомерная модель данных Многомерный подход к представлению данных в базе появился практически
одновременно с реляционным, но реально работающих многомерных СУБД (МСУБД) до настоящего времени было очень мало. С середины 90-х годов интерес к ним стал приобретать массовый характер.
Толчком послужила в 1993 году программная статья одного из основоположников реляционного подхода Э. Кодда. В ней сформулированы 12 основных требований к системам класса OLAP (OnLine Analytical Processing — оперативная аналитическая обработка), важнейшие из которых связаны с возможностями концептуального представления и обработки многомерных данных. Многомерные системы позволяют оперативно обрабатывать информацию для проведения анализа и принятия решения. В развитии концепций И С можно выделить следующие два направления:
• системы оперативной (транзакционной) обработки; • системы аналитической обработки (системы поддержки принятия решений). Реляционные СУБД предназначались для информационных систем оперативной
обработки информации и в этой области были весьма эффективны. В системах аналитической обработки они показали себя несколько неповоротливыми и недостаточно гибкими. Более эффективными здесь оказываются многомерные СУБД (М СУ БД).
Многомерные СУБД являются узкоспециализированными СУБД, предназначенными для интерактивной аналитической обработки информации. Раскроем основные понятия, используемые в этих СУБД: агрегируемость, историчность и прогнозируемость данных.
Агрегируемость данных означает рассмотрение информации на различных уровнях ее обобщения. В информационных системах степень детальности представления информации для пользователя зависит от его уровня: аналитик, пользователь-оператор, управляющий, руководитель.
Историчность данных предполагает обеспечение высокого уровня статичности (неизменности) собственно данных и их взаимосвязей, а также обязательность привязки данных ко времени.
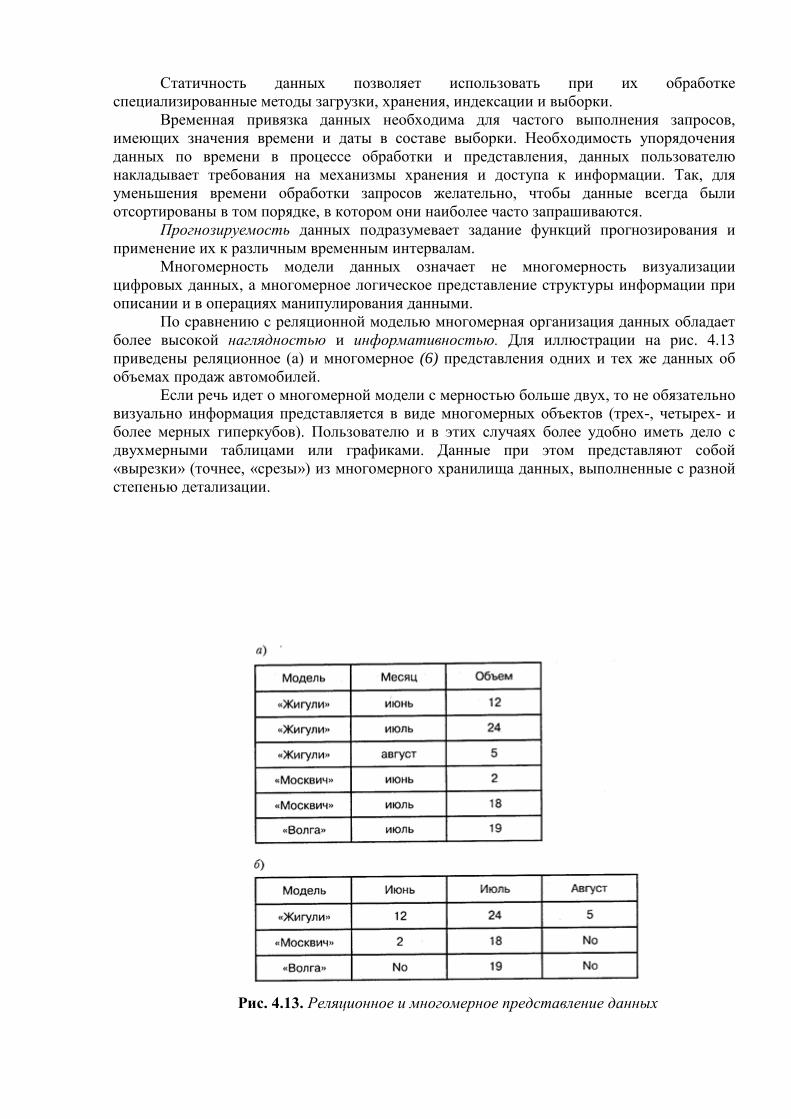
Статичность данных позволяет использовать при их обработке специализированные методы загрузки, хранения, индексации и выборки.
Временная привязка данных необходима для частого выполнения запросов, имеющих значения времени и даты в составе выборки. Необходимость упорядочения данных по времени в процессе обработки и представления, данных пользователю накладывает требования на механизмы хранения и доступа к информации. Так, для уменьшения времени обработки запросов желательно, чтобы данные всегда были отсортированы в том порядке, в котором они наиболее часто запрашиваются.
Прогнозируемость данных подразумевает задание функций прогнозирования и применение их к различным временным интервалам.
Многомерность модели данных означает не многомерность визуализации цифровых данных, а многомерное логическое представление структуры информации при описании и в операциях манипулирования данными.
По сравнению с реляционной моделью многомерная организация данных обладает более высокой наглядностью и информативностью. Для иллюстрации на рис. 4.13 приведены реляционное (а) и многомерное (6) представления одних и тех же данных об объемах продаж автомобилей.
Если речь идет о многомерной модели с мерностью больше двух, то не обязательно визуально информация представляется в виде многомерных объектов (трех-, четырех- и более мерных гиперкубов). Пользователю и в этих случаях более удобно иметь дело с двухмерными таблицами или графиками. Данные при этом представляют собой «вырезки» (точнее, «срезы») из многомерного хранилища данных, выполненные с разной степенью детализации.
Рис. 4.13. Реляционное и многомерное представление данных

Рассмотрим основные понятия многомерных моделей данных, к числу которых относятся измерение и ячейка.
Измерение (Dimension) — это множество однотипных данных, образующих одну из граней гиперкуба. Примерами наиболее часто используемых временных измерений являются Дни, Месяцы, Кварталы и Годы. В качестве географических измерений широко употребляются Города, Районы, Регионы и Страны. В многомерной модели данных измерения играют роль индексов, служащих для идентификации конкретных значений в ячейках гиперкуба.
Ячейка (Cell) или показатель — это поле, значение которого однозначно определяется фиксированным набором измерений. Тип поля чаще всего определен как цифровой. В зависимости от того, как формируются значения некоторой ячейки, обычно она может быть переменной, (значения изменяются и могут быть загружены из внешнего источника данных или сформированы программно) либо формулой (значения, подобно формульным ячейкам электронных таблиц, вычисляются по заранее заданным формулам).
В примере на рис. 4.13б каждое значение ячейки Объем продаж однозначно определяется комбинацией временного измерения (Месяц продаж) и модели автомобиля. На практике зачастую требуется большее количество измерений. Пример трехмерной модели данных приведен на рис. 4.14.
В существующих МСУБД используются два основных варианта (схемы) организации данных: гиперкубическая и поликубическая.
Рис. 4.14. Пример трехмерной модели
В поликубической схеме предполагается, что в БД может быть определено несколько гиперкубов с различной размерностью и с различными измерениями в качестве граней. Примером системы, поддерживающей поликубический вариант БД, является сервер Oracle Express Server.
В случае гиперкубической схемы предполагается, что все показатели определяются одним и тем же набором измерений. Это означает, что при наличии нескольких гиперкубов БД все они имеют одинаковую размерность и совпадающие измерения,

Очевидно, в некоторых случаях информация в БД может быть избыточной (если требовать обязательное заполнение ячеек).
В случае многомерной модели данных применяется ряд специальных операций, к которым относятся: формирование «среза», «вращение», агрегация и детализация.
«Срез» (Slice) представляет собой подмножество гиперкуба, полученное в результате фиксации одного или нескольких измерений. Формирование «срезов» выполняется для ограничения используемых пользователем значений, так как все значения гиперкуба практически никогда одновременно не используются. Например, если ограничить значения измерения Модель автомобиля в гиперкубе (рис. 4.14) маркой «Жигули», то получится двухмерная таблица продаж этой марки автомобиля различными менеджерами по годам.
Операция «вращение» (Rotate) применяется при двухмерном представлении данных. Суть ее заключается в изменении порядка измерений при визуальном представлении данных. Так, «вращение» двумерной таблицы, показанной на рис. 4.13б, приведет к изменению ее вида таким образом, что по оси Х будет марка автомобиля, а по оси Y — время.
Операцию «вращение» можно обобщить и на многомерный случай, если под ней понимать процедуру изменения порядка следования измерений. В простейшем случае, например, это может быть взаимная перестановка двух произвольных измерений.
Операции «агрегация» (Drill Up) и «детализация» (Drill Down) означают соответственно переход к более общему и к более детальному представлению информации пользователю из гиперкуба.
Для иллюстрации смысла операции «агрегация» предположим, что у нас имеется гиперкуб, в котором помимо измерений гиперкуба, приведенного на рис. 4.14, имеются еще измерения: Подразделение, Регион, Фирма, Страна. Заметим, что в этом случае в гиперкубе существует иерархия (снизу вверх) отношений между измерениями: Менеджер, Подразделение, Регион, Фирма, Страна.
Пусть в описанном гиперкубе определено, насколько успешно в 1995 году менеджер Петров продавал автомобили «Жигули» и «Волга». Тогда, поднимаясь на уровень выше по иерархии, с помощью операции «агрегация» можно выяснить, как выглядит соотношение продаж этих же моделей на уровне подразделения, где работает Петров.
Основным достоинством многомерной модели данных является удобство и эффективность аналитической обработки больших объемов данных, связанных со временем. При организации обработки аналогичных данных на основе реляционной модели происходит нелинейный рост трудоемкости операций в зависимости от размерности БД и существенное увеличение затрат оперативной памяти на индексацию.
Недостатком многомерной модели данных является ее громоздкость для простейших задач обычной оперативной обработки информации.
Примерами систем, поддерживающими многомерные модели данных, являются Essbase (Arbor Software), Media Multi-matrix (Speedware), Oracle Express Server (Oracle) и Cache (InterSystems). Некоторые программные продукты, например Media/ MR (Speedware), позволяют одновременно работать с многомерными и с реляционными БД. В СУБД Cache, в которой внутренней моделью данных является многомерная модель, реализованы три способа доступа к данным: прямой (на уровне узлов многомерных массивов), объектный и реляционный.
4.2.5. Объектно-ориентированная модель данных В объектно-ориентированной модели при представлении данных имеется
возможность идентифицировать отдельные записи базы. Между записями базы данных и функциями их обработки устанавливаются взаимосвязи с помощью механизмов,

подобных соответствующим средствам в объектно-ориентированных языках программирования.
Стандартизованная объектно-ориентированной модель описана в рекомендациях стандарта ODMG-93 (Object Database Management Group — группа управления объектно-ориентированными базами данных). Реализовать в полном объеме рекомендации ODMG-93 пока не удается. Для иллюстрации ключевых идей рассмотрим несколько упрощенную модель объектно-ориентированной БД.
Структура объектно-ориентированной БД графически представима в виде дерева, узлами которого являются объекты. Свойства объектов описываются некоторым стандартным типом (например, строковым — string) или типом, конструируемым пользователем (определяется как class).
Значением свойства типа string является строка символов. Значение свойства типа class есть объект, являющийся экземпляром соответствующего класса. Каждый объект-экземпляр класса считается потомком объекта, в котором он определен как свойство. Объект-экземпляр класса принадлежит своему классу и имеет одного родителя. Родовые отношения в БД образуют связную иерархию объектов.
Пример логической структуры объектно-ориентированной БД библиотечного дела приведен на рис. 4.15.
Здесь объект типа БИБЛИОТЕКА является родительским для объектов-экземпляров классов АБОНЕНТ, КАТАЛОГ и ВЫДАЧА. Различные объекты типа КНИГА могут иметь одного или разных родителей. Объекты типа КНИГА, имеющие одного и того же родителя, должны различаться, по крайней мере, инвентарным номером (уникален для каждого экземпляра книги), но имеют одинаковые значения свойств isbn, удк, название и автор.
Рис. 4.15. Логическая структура БД библиотечного дела
Логическая структура объектно-ориентированной БД внешне похожа на структуру
иерархической БД. Основное отличие между ними состоит в методах манипулирования данными.
Для выполнения действий над данными в рассматриваемой модели БД применяются логические операции, усиленные объектно-ориентированными механизмами

инкапсуляции, наследования и полиморфизма. Ограниченно могут применяться операции, подобные командам SQL (например, для создания БД).
Создание и модификация БД сопровождается автоматическим формированием и последующей корректировкой индексов (индексных таблиц), содержащих информацию для быстрого поиска данных.
Рассмотрим кратко понятия инкапсуляции, наследования и полиморфизма применительно к объектно-ориентированной модели БД.
Инкапсуляция ограничивает область видимости имени свойства пределами того объекта, в котором оно определено. Так, если в объект типа КАТАЛОГ добавить свойство, задающее телефон автора книги и имеющее название телефон, то мы получим одноименные свойства у объектов АБОНЕНТ и КАТАЛОГ. Смысл такого свойства будет определяться тем объектом, в который оно инкапсулировано.
Наследование, наоборот, распространяет область видимости свойства на всех потомков объекта. Так, всем объектам типа КНИГА, являющимся потомками объекта типа КАТАЛОГ, можно приписать свойства объекта-родителя: isbn, удк, название и автор. Если необходимо расширить действие механизма наследования на объекты, не являющиеся непосредственными родственниками (например, между двумя потомками одного родителя), то в их общем предке определяется абстрактное свойство типа abs. Так, определение абстрактных свойств билет и номер в объекте БИБЛИОТЕКА приводит к наследованию этих свойств всеми дочерними объектами АБОНЕНТ, КНИГА и ВЫДАЧА. Не случайно, поэтому значения свойства билет классов АБОНЕНТ и ВЫДАЧА, показанных на рисунке, будут одинаковыми- 00015.
Полиморфизм в объектно-ориентированных языках программирования означает способность одного и того же программного кода работать с разнотипными данными. Другими словами, он означает допустимость в объектах разных типов иметь методы (процедуры или функции) с одинаковыми именами. Во время выполнения объектной программы одни и те же методы оперируют с разными объектами в зависимости от типа аргумента. Применительно к нашей объектно-ориентированной БД полиморфизм означает, что объекты класса КНИГА, имеющие разных родителей из класса КАТАЛОГ, могут иметь разный набор свойств. Следовательно, программы работы с объектами класса КНИГА могут содержать полиморфный код.
Поиск в объектно-ориентированной БД состоит в выяснении сходства между объектом, задаваемым пользователем, и объектами, хранящимися в БД. Определяемый пользователем объект, называемый объектом-целью (свойство объекта имеет тип goal), в общем случае может представлять собой подмножество всей хранимой в БД иерархии объектов. Объект-цель, а также результат выполнения запроса могут храниться в самой базе. Пример запроса о номерах читательских билетов и именах абонентов, получавших в библиотеке хотя бы одну книгу, показан на рис. 4.16.

Рис. 4.16. Фрагмент БД с объектом-целью
Основным достоинством объектно-ориентированной модели данных в сравнении с реляционной является возможность отображения информации о сложных взаимосвязях объектов. Объектно-ориентированная модель данных позволяет идентифицировать отдельную запись базы данных и определять функции их обработки.
Недостатками объектно-ориентированной модели являются высокая понятийная сложность, неудобство обработки данных и низкая скорость выполнения запросов.
В 90-е годы существовали экспериментальные прототипы объектно-ориентированных систем управления базами данных. В настоящее время такие системы получили широкое распространение, в частности, к ним относятся следующие СУБД: РОЕТ (РОЕТ Software), Jasmine (Computer Associates), Versant (Versant Technologies), 02 (Ardent Software), ODB-Jupiter (научно-производственный центр "Интеллект Плюс"), а также Iris, Orion и Postgres.

Лекция 5 РЕЛЯЦИОННАЯ МОДЕЛЬ ДАННЫХ Содержание 5.1. Реляционные объекты данных (структура) 5.1.1. Тип данных 5.1.2. Домен 5.1.3. Отношения. Свойства отношений 5.1.4. Представление 5.1.5. Индексирование 5.2. Связывание таблиц. Целостность реляционных данных 5.2.1. Потенциальные ключи 5.2.2. Внешние ключи 5.2.3. Целостность сущности и ссылок 5.2.4. NULL-значения 5.2.5. Третье средство обеспечения общей целостности в реляционной
модели 5.3. Реляционные базы данных в Microsoft SQL Server 2008 5.3.1 СУБД Microsoft SQL Server 2008 5.3.2. Microsoft SQL Server Manager 5.3.3. Типы данных в MS SQL Server 2008 5.3.4. Базы данных в MS SQL Server 2008 5.3.4.1. Создание базы данных 5.3.4.2. Создание таблиц 5.3.4.3. Ключи и индексы 5.3.4.3.1. Первичный ключ 5.3.4.3.2. Индексы и ключи 5.3.4.4. Схемы баз данных. Ссылочная целостность 5.3.4.5. Занесение и редактирование данных таблицы Связанные темы Модели данных. Логическая модель данных (см. лекцию 3). Базисные средства манипулирования реляционными данными (см. лекцию
6). Концептуальные модели данных. Проектирование реляционных БД (см.
лекцию 7). Физическая модель данных (см. раздел 4). Современные СУБД (см. лекцию 17). Структурированный язык запросов SQL (см. раздел 3). Базы данных, построенные на реляционной модели в настоящее время, наиболее
востребованы. Популярность реляционной модели связана, прежде всего, с однородностью структурной организации данных.
Реляционная модель была предложена Э.Ф. Коддом (E.F. Codd, IBM, математик) в 1970 в статье «Реляционная модель данных для больших совместно используемых банков данных» - поворотный пункт в истории развития СБД (однако еще раньше была предложена модель основанная на множествах (Childs, 1968)).
Реляционная модель – формальная теория данных, основанная на некоторых положениях математики (теории множеств и предикативной логике). Кодд впервые

осознал, что математические дисциплины можно использовать, чтобы внести в область управления базами данных строгие принципы и точность (в то время не было устоявшихся терминов (однозначных определений) в этой области).
Идеи лежащие в основе реляционной модели и развитие ее оказали влияние на: • обеспечение более высокой независимости от данных (чем в более ранних
моделях данных); • расширение языков управления данными (за счет включения операций над
множествами) • решение ряда вопросов семантики, проблем непротиворечивости и
избыточности данных; • развитие других областей (искусственного интеллекта, обработки
естественных языков, разработки аппаратных систем). Наиболее значительные исследования реляционной модели были проведены в
рамках трех проектов: • «System R» (конец 1970-х, г. Сан-Хосе, Калифорния, лаборатория IBM
(руководитель проекта Astrahan)) – прототип истинной реляционной СУБД (был создан для проверки практичности реляционной модели), в ходе выполнения проекта получена информация о проблемах управления параллельностью, оптимизации запросов, управления транзакциями, обеспечения безопасности и целостности данных, восстановления, влияния человеческого фактора и разработки пользовательского интерфейса; проект стимулировал создание языка структурированных запросов (SQL) и ряда коммерческих СУБД (DB/2, ORACLE);
• «INGRES» (конец 1970-х, Калифорнийский университет, г. Беркли), практически те же цели разработки, получена академическая версия и коммерческие продукты;
• «Peterlee Relational Test Vehicle» (1976, г. Петерли, Великобритания, научный центр IBM) – более теоретический проект, основные цели – решение задач оптимизации и обработки запросов, а также функциональные расширения системы.
Коммерческие системы на основе реляционной модели начали появляться в начале 1980-х (на сегодня - более нескольких сотен типов, хотя они и не удовлетворяют точному определению реляционной модели данных – нет необходимости следовать теории только «ради теории», главное назначение теории обеспечить базу для построения систем, практичных на 100%, кроме того некоторые вопросы реляционной теории до сих пор спорны). Также, многие нереляционные системы обеспечиваются реляционным пользовательским интерфейсом (независимым от базовой модели СУБД).
Были предложены некоторые расширения реляционной модели данных, предназначенные для наиболее полного и точного выражения смысла данных (Codd, 1979 и 1990), для поддержки объектно-ориентированных понятий (Stonebraker и Rowe, 1986), а также для поддержки дедуктивных возможностей (Gardarin и Valduriez, 1989).
Реляционная модель связана с тремя аспектами данных: структурой (представлением данных в БД), целостностью (ключи) и обработкой (операторы обработки данных). Для всех этих частей существуют свои специальные термины.
5.1. Реляционные объекты данных (структура) Реляционная модель данных основана на математическом понятии отношения
(relation), физическим представлением которого является таблица. Все данные (описания объектов) в реляционной БД пользователь воспринимает как набор таблиц (множество отношений).
Краткое (неформальное, т.е. нестрогое) описание терминов: • отношение – плоская таблица; • кортеж – строка таблицы (не включая заголовок);

• кардинальное число – количество строк таблицы (без заголовка); • атрибут – столбец таблицы (или поле строки); • степень – количество столбцов таблицы; • первичный ключ – уникальный идентификатор для таблицы; • домен – общая совокупность допустимых значений. Формальное описание терминов (теория) приведено ниже.
Рис. 5.1. Реляционные объекты данных (отношение S)
5.1.1 . Тип данных Понятие тип данных в реляционной модели данных полностью адекватно понятию
типа данных в языках программирования. Обычно в современных реляционных БД допускается хранение символьных, числовых данных, битовых строк, специализированных числовых данных (таких как "деньги"), а также специальных "темпоральных" данных (дата, время, временной интервал). Достаточно активно развивается подход к расширению возможностей реляционных систем абстрактными типами данных (соответствующими возможностями обладают, например, системы семейства Ingres/Postgres).
Примечание. Более подробно используемые типы данных Microsoft SQL Server 2008 будут
рассмотрены в пункте 3 (Базы данных в MS SQL Server 2008) этой лекции. 5.1.2. Домен Домен – именованное множество скалярных значений (скаляр – наименьшая
(атомарная) семантическая единица данных (например, «номер детали»)) одного типа (например, в домене «города» будут представлены все возможные названия городов, которыми может оперировать модель).
Значения атрибута (атрибутов) выбираются из множества значений домена, при этом каждый атрибут должен быть определен на единственном домене (т.е. в любой момент времени набор значений атрибута (в отношении) является некоторым подмножеством множества значений его домена, также в любой момент времени в домене могут существовать такие значения, которые не являются значениями ни одного из атрибутов, соответствующих этому домену).
Значение доменов в реляционной модели: • домены позволяют централизованно определять смысл и источник значений,
которые могут получать атрибуты (в системе не будет значений связанных с ошибками написания или непонимания семантики значения;

• домены позволяют ограничивать сравнения (важнейшее свойство, позволяет избегать семантически некорректных операций), т.е. если значения атрибутов взяты из одного и того же домена, тогда операции над этими атрибутами (например, сравнение) будут иметь смысл, т.к. операция будет проводиться над между подобными по семантике атрибутами; если значения атрибутов взяты из различных доменов, то операции над ними, скорее всего, не будут иметь смысла (в основном предназначается для предотвращения грубых ошибок (механических описок или недостаточного знания модели)).
Домены имеют концептуальную природу. Для наличия возможности ограничения сравнений в системе нужно, чтобы домены, по крайней мере, были описаны в рамках определений БД, имели уникальные имена, и все атрибуты отношений имели бы ссылку на домен (при этом для упрощения системы наборы значений доменов могут в ней не храниться). На практике – большинство программных продуктов поддержки сравнений не обеспечивают, а смысл атрибутов и источник их значений определяется (иногда и только в случае небольшого количества значений) в других таблицах – не домены, а их замена (например, названия всех дней недели определяются в одной таблице (содержит только один атрибут), а в другой таблице пользователю разрешен выбор значений атрибута только из значений первой таблицы).
5.1.3. Отношения. Свойства отношений Отношение R, определенное на множестве доменов D1, D2, …, Dn (не обязательно
различных), содержит две части: заголовок (строка заголовков столбцов в таблице) и тело (строки таблицы).
Заголовок содержит фиксированное множество атрибутов или пар вида <имя_атрибута : имя_домена>:
{<A1:D1>, <A2:D2>, …, <An:Dn>}, причем каждый атрибут Aj соответствует одному и только одному из лежащих в
основе доменов Dj (j=1,2,…,n). Все имена атрибутов A1, A2, …, An - разные. Тело содержит множество кортежей. Каждый кортеж, в свою очередь, содержит
множество пар <имя_атрибута : значение _атрибута>: {<A1:vi1>, <A2:vi2>, …, <An:vin>}, (i=1,2,…,m, где m – количество кортежей в этом множестве). В каждом таком
кортеже есть одна пара такая пара <имя_атрибута : значение_атрибута>, т.е. <Aj:vij>, для каждого атрибута Aj в заголовке. Для любой такой пары <Aj:vij> vij является значением из уникального домена Dj, который связан с атрибутом Aj.
Значения m и n называются соответственно кардинальным числом и степенью отношения R.
Для выше приведенного рисунка 5.1: • домены – S#, NAME, GROUP, RATING; • заголовок – {<S#:S#>, <S_NAME:NAME>, <GROUP:GROUP>,
<RATING:RATING>}; • кортеж отношения (элемент тела) – {<S#:S1>, <S_NAME:’Иванов’>, <GROUP:1>,
<RATING:20>}; • тело отношения (без указания имен доменов, порядок перечисления значений в
кортежах должен совпадать с порядком перечисления атрибутов в заголовке) – {(S1,’Иванов’,1,20), (S2,’Петров’,2,10), …,
(S5,’Джонс’,3,30)}. Свойства отношений: • отношение имеет уникальное имя (т.е. отличное от имен других отношений в
БД); • в любом отношении нет одинаковых кортежей (это свойство следует из того
факта, что тело отношения – математическое множество (кортежей), а множества в

математике по определению не содержат одинаковых элементов); важное следствие из этого свойства – т.к. отношение не содержит одинаковых кортежей, то всегда существует первичный ключ отношения;
• в любом отношении кортежи не упорядочены (т.е. нет упорядоченности «сверху-вниз») (это свойство следует из того, что тело отношения – математическое множество, а простые множества в математике неупорядочены); следствие – нет понятий позиции кортежа и последовательности кортежей в отношении, кортеж в отношении всегда определяется по первичному ключу;
• в любом отношении атрибуты не упорядочены (т.е. нет упорядоченности «слева-направо») (это свойство следует из того, что заголовок отношения также определен как множество атрибутов); следствие – атрибут всегда определяется по имени, нет понятий позиции атрибута и последовательности атрибутов в отношении;
• в отношении все значения атрибутов атомарные (неделимые) (это следует из того, что все лежащие в основе домены содержат только атомарные значения); следствие – в каждой ячейке на пересечении столбца и строки в таблице расположено только одно значение, отношения при этом представлены в первой нормальной форме (не содержат групп повторения) – простота структуры отношения приводит к упрощению все системы (и облегчает операции с отношениями).
Как видно из свойств отношения, отношение и таблица на самом деле не одно и то же: таблица – конкретное представление (упорядоченное, обычно графическое) абстрактного объекта отношение.
Для каждого отношения существует связанная с ним интерпретация (например, отношение S (см. рисунок 5.1) можно интерпретировать (не совсем формально) так: «студент с определенным номером (S#) имеет определенное имя (S_NAME), принадлежит определенной группе (GROUP) и имеет определенную оценку (RATING); не может быть нескольких студентов с одинаковыми номерами»). Эта интерпретация (или предикат) – функция значения истинности (после подстановки значений в эту функцию, она может принимать только два значения: истина или ложь). Отношение может содержать только те кортежи, для которых предикат является истиной.
Тогда для того чтобы добавить (вставить) новый кортеж в отношение, необходимо подставить значения из этого кортежа в функцию истинности для данного отношения и если значение этой функции - истина, то вставка кортежа (или возможность обновления данного отношения) будет допустима (при этом предикат составляет критерий возможности обновления (по крайней мере «правдоподобного»)). Для приведенного примера, СУБД будет считать кортеж приемлемым, если выполнены условия: значение S# принадлежит домену S#, значение S_NAME принадлежит домену NAME, значение GROUP принадлежит домену GROUP, значение RATING принадлежит домену RATING и значение S# является уникальным среди всех значений отношения - т.е. можно определить как логическое умножение (логическое «AND») всех правил целостности для отношения S.
Переменная отношения – именованное отношение, которое может иметь разные значения в разное время (однако все возможные значения этой переменной будут иметь одинаковые заголовки; этот термин предназначен для подчеркивания возможности изменения тела отношения, т.е. его динамичности (при этом термин «отношение» считается неудачным), при статичности описания отношения).
Различают множество видов отношений (теория): • именованное отношение – переменная отношения, определенная с помощью DDL
в СУБД; • базовое отношение – именованное отношение, которое является автономным (на
практике – логически важные отношения, хранимые в БД (обычно соответствует некоторому объекту в концептуальной схеме));

• производное отношение – отношение, определенное посредством реляционного выражения через другие именованные отношения;
• выражаемое отношение – отношение, которое можно получить из набора именованных отношений посредством некоторого реляционного выражения (множество выражаемых отношений охватывает множество всех базовых и всех производных отношений);
• представление – именованное производное отношение (виртуально – представлено в системе только через определение в терминах других именованных отношений);
• снимок – именованное производное отношение, в отличие от представлений, снимок реален (не виртуален), т.е. имеет свои данные (отдельные от других именованных отношений);
• результат запроса – неименованное производное отношение, содержащее результат запроса (временное существование);
• промежуточный результат – неименованное производное отношение, являющееся результатом некоторого реляционного выражения, вложенного в другое, большее выражение;
• хранимое отношение – отношение, которое поддерживается в физической памяти. Между понятиями домена и унарного отношения (степень отношения равна
единице (один атрибут)) есть значительная разница (теория): домены статичны (содержат все возможные значения и не меняют их описание), а отношения динамичны (изменяют содержимое со временем).
Реляционная БД – БД, воспринимаемая пользователем как набор нормализованных отношений (идея реляционной модели применима к внешнему и концептуальному уровню системы баз данных – т.е. на уровне абстракции (логическом уровне)).
5.1.4. Представление Представление – динамический результат одной или нескольких реляционных
операций над базовыми отношениями, является виртуальным отношением (т.е. реально в базе не существует, а содержит части реально существующих (базовых) отношений). Содержимое представления изменяется, если изменяется содержимое частей базовых таблиц, связанных с данным представлением. Если пользователи вносят допустимые изменения в содержимое представления, то эти изменения «одновременно» вносятся и в базовые отношения. Представление описывает не всю внешнюю модель пользователя (представление пользователя), а только его некоторую часть.
Представления предназначены для: • скрытия некоторых частей базы данных от определенных пользователей
(групп) (например, инспектор получит доступ только к объектам, которые он контролирует) – часть механизма защиты;
• организации доступа пользователей к данным наиболее удобным для них образом (например, переименование групп атрибутов для придания им определенной специфики – реализация поддержки логической независимости пользователя от данных);
• упрощения сложных операций с базовыми отношениями (для пользователя обращение к представлению будет выглядеть достаточно просто (т.е. он будет работать с ним как с одним отношением, реальные же операции над базовыми отношениями будут поддерживаться автоматически));
• изоляции пользователей от реорганизации концептуальной схемы (например, если базовое отношение при необходимости будет разбито на несколько других, то это будет скрыто от пользователя с помощью представления).
По возможности обновления, представления делят на теоретически необновляемые, теоретически обновляемые и частично обновляемые (т.к. изменения в

представлении могут быть отражены на базовые отношения только при определенных условиях (например, если представление построено только простого запроса к единственному базовому отношению и содержит ключ базового отношения – то оно допускает обновление)).
5.1.5. Индексирование Термин «индекс» тесно связан с понятием «ключ», хотя между ними есть и
некоторое отличие. Под индексом понимают средство ускорения операции поиска записей в таблице,
следовательно, и других операций, использующих поиск: извлечение, модификация, сортировка и т. д. Таблицу, для которой используется индекс, называют индексированной.
Индекс выполняет роль оглавления таблицы, просмотр которого предшествует обращению к записям таблицы. В некоторых системах, индексы хранятся в индексных файлах, хранимых отдельно от табличных файлов.
Примечание. Создание и использование индексов в MS SQL Server будет рассмотрено в пункте 3
(Базы данных в MS SQL Server 2008) этой лекции. Физическая реализация индексов подробно описана в лекции 15 (Физические модели базы данных).
5.2. Связывание таблиц. Целостность реляционных данных При проектировании реальных БД информацию обычно размещают в нескольких
таблицах. Таблицы при этом связаны семантикой информации. В реляционных СУБД для указания связей таблиц производят операцию их связывания.
Укажем выигрыш, обеспечиваемый в результате связывания таблиц. Многие СУБД при связывании таблиц автоматически выполняют контроль целостности вводимых в базу данных в соответствии с установленными связями. В конечном итоге это повышает достоверность хранимой в БД информации.
Кроме того, установление связи между таблицами облегчает доступ к данным. Связывание таблиц при выполнении таких операций как поиск, просмотр, редактирование, выборка и подготовка отчетов обычно обеспечивает возможность обращения к произвольным полям связанных записей. Это уменьшает количество явных обращений к таблицам данных и число манипуляций в каждой из них.
Основные виды связи таблиц Между таблицами могут устанавливаться бинарные (между двумя таблицами),
тернарные (между тремя таблицами) и, в общем случае, парные связи. Рассмотрим наиболее часто встречающиеся бинарные связи.
При связывании двух таблиц выделяют основную и дополнительную (подчиненную) таблицы. Логическое связывание таблиц производится с помощью ключа связи.
Ключ связи, по аналогии с обычным ключом таблицы, состоит из одного или нескольких полей, которые в данном случае называют полями связи (ПС).
Суть связывания состоит в установлении соответствия полей связи основной и дополнительной таблиц. Поля связи основной таблицы могут быть обычными и ключевыми. В качестве полей связи подчиненной таблицы чаще всего используют ключевые поля.
В зависимости от того, как определены поля связи основной и дополнительной таблиц (как соотносятся ключевые поля с полями связи), между двумя таблицами в общем случае могут устанавливаться следующие 4 основные вида связи:
• один — один (1:1);

• один — много (1:М); • много — один (М:1); • много — много (М:М или M:N).
Примечание. Создание связей между таблицами базы данных и обеспечение контроля
целостности будут рассмотрены в пункте 3 (Базы данных в MS SQL Server 2008) этой лекции. Тема основных видов связи будет рассмотрена в лекции 7 (Проектирование реляционных БД. Концептуальные модели данных).
Целостность реляционных данных Целостность данных предназначена для сохранения в БД «отражения
действительности реального мира», т.е. устранения недопустимых конфигураций (состояний) значений и связей (например, вес детали может быть только положительным), которые не имеют смысла в реальном мире (не следует путать с «безопасностью» - хоть и есть некоторое сходство, но безопасность относится к защите от несанкционированного доступа, а целостность – защита БД от санкционированных пользователей). Целостность данных – наиболее изменчивая часть, т.к. эта часть реляционной модели имеет наименее твердую научную основу (по сравнению с другими частями модели).
Правила целостности данных можно разделить на: • специфические или корпоративные ограничения целостности – правила,
определяемые пользователями или администратором БД, которые указывают дополнительные ограничения, специфические для конкретных БД (например, максимальные и минимальные значения некоторых атрибутов (диапазон оценок));
• общие правила целостности – правила, которые применимы к любой реляционной БД (относятся к потенциальным (первичным) и к внешним ключам).
5.2.1. Потенциальные ключи Пусть R – некоторое отношение. Тогда потенциальный ключ K для R – это
подмножество множества атрибутов R, обладающее следующими свойствами: • свойством уникальности – нет двух различных кортежей в отношении R (в
текущем значении) с одинаковым значением K (каждое отношение имеет как минимум один потенциальный ключ, т.к. не содержит одинаковых кортежей, важно чтобы уникальность соблюдалась не только для конкретного содержания отношения (на данный момент времени), а всегда (т.е. для множества всех возможных значений отношения в любой момент времени) – для этого при определении потенциального ключа важно знать смысл атрибутов отношения);
• свойством неизбыточности (неприводимости) – никакое из подмножеств K не обладает свойством уникальности (если определенный «потенциальный ключ» на самом деле не является неизбыточным, то система не сможет обеспечить должным образом соответствующее ограничение целостности (например, если вместо номера студента {S#}, потенциальный ключ будет определен как номер студента и номер группы {S#,GROUP}, то уникальность номера студента будет поддерживаться системой в более узком (локальном) смысле – только в пределах одной группы)).
Простой потенциальный ключ – потенциальный ключ, состоящий из одного атрибута.
Составной потенциальный ключ – потенциальный ключ, состоящий более чем из одного атрибута.
Логическое понятие потенциального ключа не следует путать с физическим понятием уникального индекса (это разные вещи с точки зрения реляционной модели данных, хотя на практике они обычно совмещаются).

Потенциальные ключи обеспечивают основной механизм адресации на уровне кортежей в реляционной системе (единственный гарантируемый системой способ точно указать некоторый кортеж – это указать значение некоторого потенциального ключа).
Отношение может иметь несколько (хотя это довольно редко применяется) потенциальных ключей. По традиции (исторически) один из потенциальных ключей должен быть выбран в качестве первичного ключа отношения (отношение всегда имеет первичный ключ PK (уникально идентифицирует запись, кортеж)), а остальные потенциальные ключи будут называться альтернативными ключами. Выбор одного из потенциальных ключей в качестве первичного – вопрос философский и фактически выходит за рамки реляционной модели данных.
5.2.2 . Внешние ключи Пусть R2 – базовое отношение. Тогда внешний ключ FK в отношении R2 – это
подмножество множества атрибутов R2, такое что: • существует базовое отношение R1 (R1 и R2 не обязательно различны) с
потенциальным ключом K; • каждое значение FK в текущем значении R2 всегда совпадает со значением
K некоторого кортежа в текущем значении R1 (обратное не требуется, т.е. потенциальный ключ, соответствующий данному внешнему ключу, может содержать значение, которое в данный момент не является значением внешнего ключа).
Внешний ключ будет составным (т.е. будет состоять из более чем одного атрибута), тогда и только тогда, когда соответствующий потенциальный ключ также будет составным. Соответственно, внешний ключ будет простым тогда и только тогда, когда соответствующий потенциальный ключ также будет простым.
Каждый атрибут, входящий в внешний ключ, должен быть определен на том же домене, что и соответствующий атрибут соответствующего потенциального ключа.
Внешним ключом может быть любой атрибут (или сочетание атрибутов) отношения, а не только компонент потенциального ключа.
Значение внешнего ключа называется ссылкой к кортежу, содержащему соответствующее значение потенциального ключа (ссылочный кортеж или целевой кортеж). Отношение, которое содержит внешний ключ, называется ссылающимся отношением, а отношением, которое содержит соответствующий потенциальный ключ – ссылочным или целевым отношением.
Для упрощения понимания, ссылки можно представлять с помощью ссылочных диаграмм – каждая стрелка обозначает внешний ключ в отношении, из которого эта стрелка выходит, этот ключ ссылается на первичный (потенциальный) ключ отношения, на который стрелка указывает (допустимо дополнительно указывать над стрелками атрибуты, которые составляют внешний ключ):
Отношение может быть одновременно ссылочным и ссылающимся (цепочка
стрелок из Rn в R1 называется ссылочный путь):
Также выделяют самоссылающиеся отношения (в них возникают ссылочные
циклы):
5.2.3. Целостность сущности и ссылок

Правило ссылочной целостности – база данных не должна содержать несогласованных значений внешних ключей (здесь «несогласованное значение внешнего ключа» - это значение внешнего ключа, для которого не существует отвечающего ему значения соответствующего потенциального ключа в соответствующем целевом отношении) – т.е. если B ссылается на A, тогда A должно существовать.
Понятия «внешний ключ» и «ссылочная целостность» определены в терминах друг друга, т.е. «поддержка внешних ключей» и «поддержка ссылочной целостности» означают одно и то же.
Для поддержки ссылочной целостности необходимо внести компенсацию в БД в случаях (не в рамках реляционной модели):
• при удалении объекта ссылки внешнего ключа (возможные действия: ограничить – запрет операции удаления объекта, до тех пор, пока на этот объект есть ссылки; каскадировать – при удалении объекта удалить все объекты, ссылающиеся на него);
• при попытке обновить потенциальный ключ, на который ссылается внешний ключ (возможные действия: ограничить – запрет операции обновления объекта, до тех пор, пока на этот объект есть ссылки; каскадировать – при обновлении объекта обновить внешний ключ во всех объектах, ссылающиеся на него).
На практике, кроме перечисленных действий («ограничить» и «каскадировать»), должна быть возможность вызова процедуры баз данных (хранимой процедуры или процедуры триггеров), для частного решения возникшей проблемы.
С логической точки зрения, все операции с объектами БД (обновление и удаление) всегда атомарны (все или ничего), даже если они выполняются каскадно.
При рассмотрении реакции системы на операции с объектом (обновление или удаление) следует рассматривать все возможные ссылочные пути. Для самоссылающихся отношений некоторые проверки ограничений не могут быть выполнены во время одного обновления (они обычно откладываются на более позднее время – время фиксации).
5.2.4 . NULL-значения NULL-значения (определитель NULL) введены для обозначения значений
атрибутов, которые на настоящий момент неизвестны или неприемлемы для некоторого кортежа – т.е. логическая величина «неизвестно». Это не значение по умолчанию, а отсутствие какого-либо значения (например, данные об адресе нового сотрудника неизвестны (на данный момент)).
Для каждого атрибута должно быть установлено, может ли он принимать NULL-значения или нет.
Применение определителя NULL может вызвать проблемы на этапе реализации системы, т.к. реляционная модель основана на исчислении предикатов первого порядка (они обладают двузначной (булевой) логикой (т.е. могут иметь только два значения: «истина» или «ложь»)), а применение NULL-значений приводит к работе с логикой более высокого порядка (трехзначной или даже четырехзначной (Э. Кодд)).
Использование NULL-значений – вопрос теоретически спорный (Э. Кодд рассматривает NULL-значения как неотъемлемую часть реляционной модели, Date – «являются фундаментальным заблуждением и не должны иметь места в чистой формальной системе», вместо них можно использовать значение по умолчанию (упрощает правила целостности)). Не во всех реляционных системах поддерживается работа с определителем NULL.
NULL-значения влияют на концепции потенциальных и внешних ключей реляционной модели данных:
1) целостность объектов – в реляционной модели данных ни один атрибут потенциального ключа (в некоторых источниках – только первичные ключи) базового

отношения не может содержать NULL-значений (т.к. реляционная БД не должна хранить информацию о чем-то, чего мы не можем определить и однозначно сослаться).
2) ссылочная целостность – если в реляционной модели в отношении существует внешний ключ, то значение внешнего ключа должно либо соответствовать значению потенциального ключа некоторого кортежа в целевом отношении, либо задаваться определителем NULL (здесь NULL-значение обозначает не «значение неизвестно», а – «значение не существует»).
Определение внешнего ключа с учетом NULL-значений: Пусть R2 – базовое отношение. Тогда внешний ключ FK в отношении R2 – это
подмножество множества атрибутов R2, такое что: • существует базовое отношение R1 (R1 и R2 не обязательно различны) с
потенциальным ключом K; • каждое значение FK в текущем значении R2 или является NULL-значением,
или совпадает со значением K некоторого кортежа в текущем значении R1. • При этом вносится дополнительное действие для поддержки ссылочной
целостности в случаях (не в рамках реляционной модели): • при удалении объекта ссылки внешнего ключа (дополнительное действие:
аннулировать – для всех ссылок на объект устанавливаются NULL-значения, а затем сам объект удаляется);
• при попытке обновить потенциальный ключ, на который ссылается внешний ключ (дополнительное действие: аннулировать – для всех ссылок на объект устанавливаются NULL-значения, а затем сам объект обновляется).
5.2.5 Третье средство обеспечения общей целостности в реляционной модели Домены (ограничения домена) – обеспечивают целостность атрибутов (т.к.
значения каждого атрибута берутся из соответствующего домена). 5.3. Реляционные базы данных в Microsoft SQL Server 2008 5.3.1 СУБД Microsoft SQL Server 2008 Microsoft SQL Server (MS SQL Server) — система управления реляционными
базами данных (СУБД), разработанная корпорацией Microsoft. Основной используемый язык запросов — Transact-SQL, создан совместно Microsoft и Sybase. Используется для работы с базами данных размером от персональных до крупных баз данных масштаба предприятия; конкурирует с другими СУБД в этом сегменте рынка.
Microsoft SQL Server Express является бесплатно распространяемой версией SQL Server. Данная версия имеет некоторые технические ограничения. Такие ограничения делают её непригодной для развертывания больших баз данных, но она вполне годится для ведения программных комплексов в масштабах небольшой компании. Фактически, это полноценный MS SQL Server, включая все его компоненты программирования, поддержку национальных алфавитов и Unicode. Поэтому используется в приложениях, при проектировании или для самостоятельного изучения.
При изучение дисциплины «Базы данных», работать придется именно с этой СУБД (Microsoft SQL Server Express).
Примечание. Более подробно СУБД Microsoft SQL Server будет изучена в лекции 15
(Современные СУБД). Так же в этой лекции будут описаны и другие современные СУБД. Подробно по загрузке и установке можно узнать на сайте msdn.microsoft.com и других сайтов схожей тематикой.
5.3.2. Microsoft SQL Server Manager

Среда SQL Server Management Studio Express (SSMSE) реализует графическое
средство управления экземплярами SQL Server 2008 Express (SQL Server Express. Пользовательский интерфейс среды SSMSE является частью среды SQL Server Management Studio, которая доступна в других выпусках SQL Server 2008. В среде SSMSE объединяет графические инструменты управления базами данных с богатой средой разработки. Среда SSMSE позволяет получить доступ к компоненту Database Engine (и управлять им), а также создавать инструкции Transact-SQL.
Примечание. Подробно о среде SQL Server Management Studio Express и работе с ней можно, а
также инструкцию по загрузке и установке можно узнать на сайте msdn.microsoft.com и других сайтов схожей тематикой.
Соединение с SQL Server Express Чтобы подключиться к экземпляру компонента SQL Server ExpressDatabase Engine
с помощью среды SSMSE, в диалоговом окне Соединение с сервером укажите один из следующих параметров:
.\sqlexpress, (local)\sqlexpress или имя_сервера\sqlexpress.
Рис. 5.2. Окно подключения к SQL Server Express
Подключиться к MS SQL Server можно используя Windows Authentication
(внутренняя аутентификация Windows) или SQL Server Authentication (Внутренняя аутентификация SQL Server). Пока будем использовать первый вариант подключения к серверу.
Примечание. Подробно о способах аутентификации, правилах входа и политике безопасности
будет рассказано в лекции 14 (Использование баз данных). Основное окно SSMSE На рисунке 5.3. представлено основное окно Microsoft SQL Server Manager. В
основном при изучении баз данных мы не будем использовать все окна и возможности SSMSE, а только то, что непосредственно необходимо для получения основных знаний по базам данных и работе с MS SQL Server.

Рис. 5.3. Основное окно среды SSMSE
1) Под цифрой 1 показано основное меню среды SSMSE; 2) Под цифрой 2 показано вспомогательное меню среды SSMSE; 3) Под цифрой 3 показано окно Object Explorer (Обозреватель объектов) и
сами объекты SQL Server. Основной объект, с которым придется работать – это Databases (Базы данных).
Работа с остальными объектами будет описана в лекции 18 (Использование баз данных). Примечание.
Для удобства работы со средой SSMSE необходимо изменить параметры следующим образом: tools (настройки)-options (параметры)-designers (конструктор)-prevent saving changes that require table re-creation (запретить изменение таблиц требующих пересоздание) убрать отметку.
5.3.3. Типы данных в MS SQL Server 2008 СУБД MS SQL Server 2008 поддерживает следующие типы данных, приведенные в
таблице 5.1.
Таб. 5.1. Типы данных в MS SQL Server 2008 Тип
данных в MS SQL Server
Описание
binary Бинарные данные. Максимальная размер 8000 байт. char Строка символов. Максимальный размер 8000 байт. varbinary Бинарные данные с переменным размером. 0 - 8000 байт. varchar Строка символов с переменным размером 0 - 8000 байт. binary Бинарный тип данных Bit Бит bit null Бит разрешающие хранение значения NULL. char Строка символов. Максимальный размер 8000 байт. datetime Тип данных для хранения: значения даты/времени в 8 байтовом
формате. smalldateti
me Тип данных для хранения: значения даты/времени в 4 байтовом
формате.
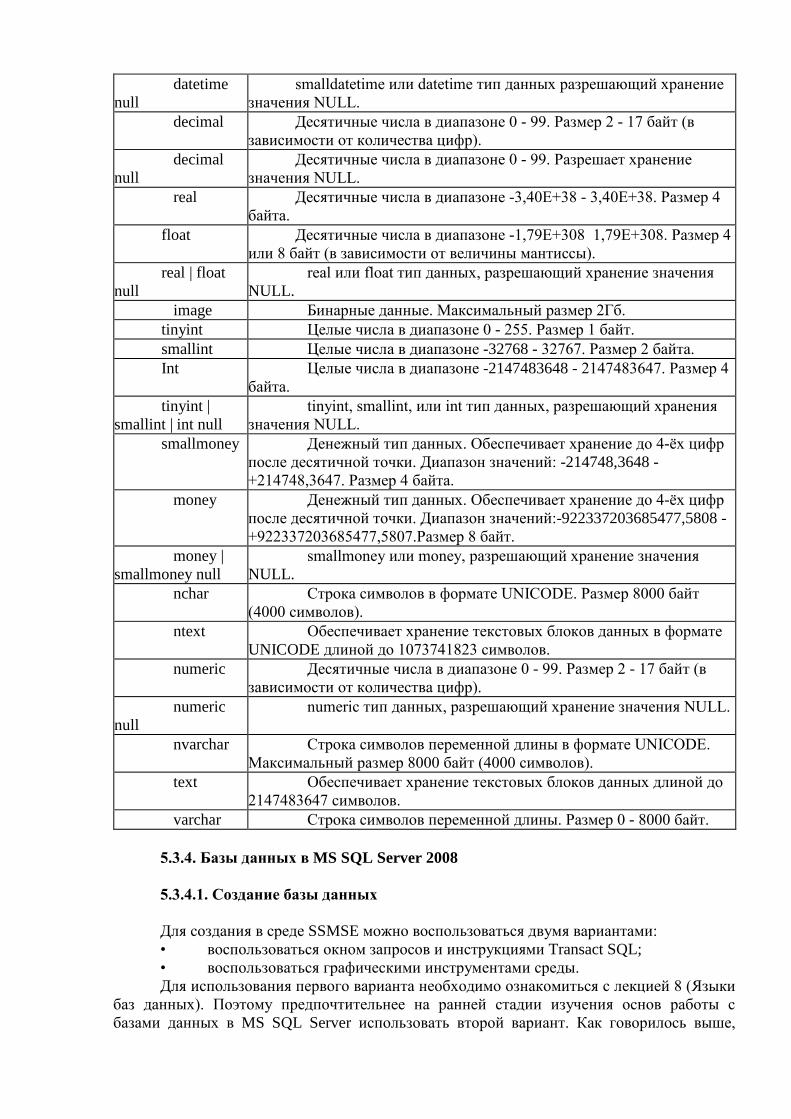
datetime null
smalldatetime или datetime тип данных разрешающий хранение значения NULL.
decimal Десятичные числа в диапазоне 0 - 99. Размер 2 - 17 байт (в зависимости от количества цифр).
decimal null
Десятичные числа в диапазоне 0 - 99. Разрешает хранение значения NULL.
real Десятичные числа в диапазоне -3,40Е+38 - 3,40Е+38. Размер 4 байта.
float Десятичные числа в диапазоне -1,79Е+308 1,79Е+308. Размер 4 или 8 байт (в зависимости от величины мантиссы).
real | float null
real или float тип данных, разрешающий хранение значения NULL.
image Бинарные данные. Максимальный размер 2Гб. tinyint Целые числа в диапазоне 0 - 255. Размер 1 байт. smallint Целые числа в диапазоне -32768 - 32767. Размер 2 байта. Int Целые числа в диапазоне -2147483648 - 2147483647. Размер 4
байта. tinyint |
smallint | int null tinyint, smallint, или int тип данных, разрешающий хранения
значения NULL. smallmoney Денежный тип данных. Обеспечивает хранение до 4-ёх цифр
после десятичной точки. Диапазон значений: -214748,3648 - +214748,3647. Размер 4 байта.
money Денежный тип данных. Обеспечивает хранение до 4-ёх цифр после десятичной точки. Диапазон значений:-922337203685477,5808 - +922337203685477,5807.Размер 8 байт.
money | smallmoney null
smallmoney или money, разрешающий хранение значения NULL.
nchar Строка символов в формате UNICODE. Размер 8000 байт (4000 символов).
ntext Обеспечивает хранение текстовых блоков данных в формате UNICODE длиной до 1073741823 символов.
numeric Десятичные числа в диапазоне 0 - 99. Размер 2 - 17 байт (в зависимости от количества цифр).
numeric null
numeric тип данных, разрешающий хранение значения NULL.
nvarchar Строка символов переменной длины в формате UNICODE. Максимальный размер 8000 байт (4000 символов).
text Обеспечивает хранение текстовых блоков данных длиной до 2147483647 символов.
varchar Строка символов переменной длины. Размер 0 - 8000 байт.
5.3.4. Базы данных в MS SQL Server 2008 5.3.4.1. Создание базы данных Для создания в среде SSMSE можно воспользоваться двумя вариантами: • воспользоваться окном запросов и инструкциями Transact SQL; • воспользоваться графическими инструментами среды. Для использования первого варианта необходимо ознакомиться с лекцией 8 (Языки
баз данных). Поэтому предпочтительнее на ранней стадии изучения основ работы с базами данных в MS SQL Server использовать второй вариант. Как говорилось выше,
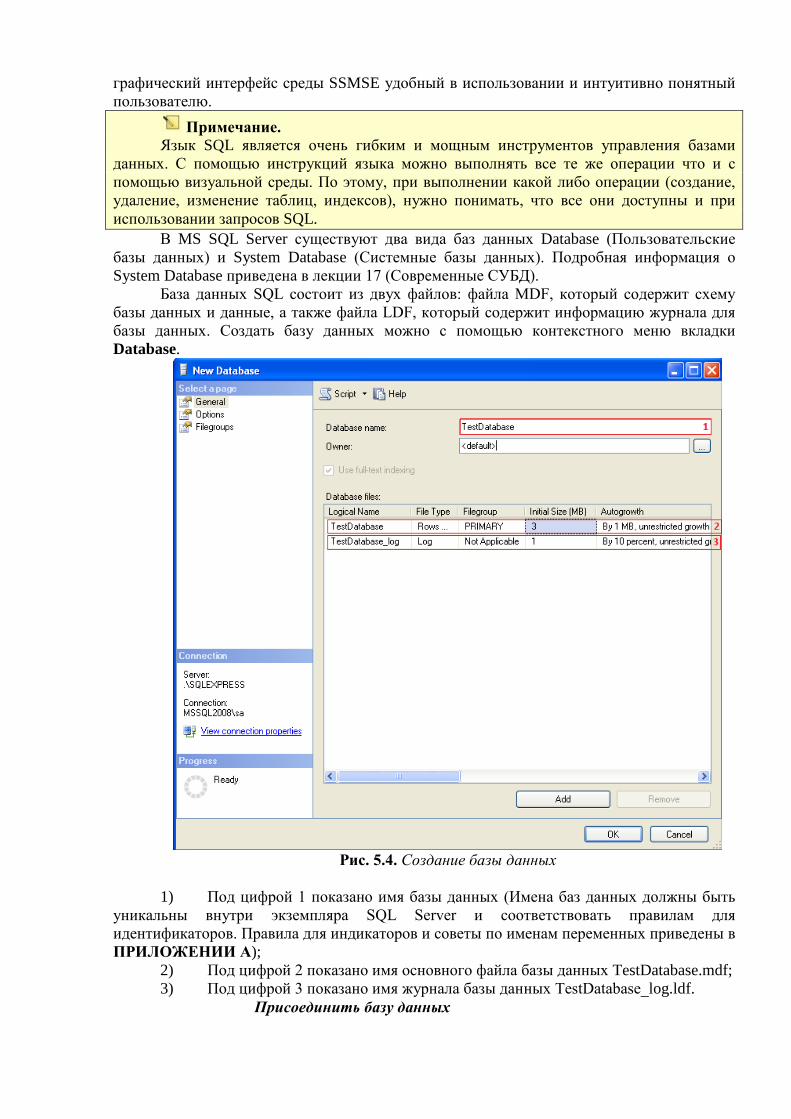
графический интерфейс среды SSMSE удобный в использовании и интуитивно понятный пользователю.
Примечание. Язык SQL является очень гибким и мощным инструментов управления базами
данных. С помощью инструкций языка можно выполнять все те же операции что и с помощью визуальной среды. По этому, при выполнении какой либо операции (создание, удаление, изменение таблиц, индексов), нужно понимать, что все они доступны и при использовании запросов SQL.
В MS SQL Server существуют два вида баз данных Database (Пользовательские базы данных) и System Database (Системные базы данных). Подробная информация о System Database приведена в лекции 17 (Современные СУБД).
База данных SQL состоит из двух файлов: файла MDF, который содержит схему базы данных и данные, а также файла LDF, который содержит информацию журнала для базы данных. Создать базу данных можно с помощью контекстного меню вкладки Database.
Рис. 5.4. Создание базы данных
1) Под цифрой 1 показано имя базы данных (Имена баз данных должны быть
уникальны внутри экземпляра SQL Server и соответствовать правилам для идентификаторов. Правила для индикаторов и советы по именам переменных приведены в ПРИЛОЖЕНИИ А);
2) Под цифрой 2 показано имя основного файла базы данных TestDatabase.mdf; 3) Под цифрой 3 показано имя журнала базы данных TestDatabase_log.ldf. Присоединить базу данных

Если уже существует база данных, то её необходимо подсоединить к серверу. Присоединить базу данных к серверу можно с помощью сервиса Attach (Присоединить), указав место нахождения файлов базы данных. Отсоединяется база данных командой Task-Detach.
Объекты базы данных База данных - это специальным образом организованно пространство памяти для
хранения определенных групп данных, снабженное специальным программным обеспечением для поддержания их (этих данных) в активном состоянии, а также для создания возможности пользователю отсылать свою информацию в это пространство и получать из него любую другую информацию. Под группами данных мы понимаем следующие элементы (рис. 5.5):
Рис. 5.5. Основные объекты базы данных
1) Database Diagrams (Схема/диаграмма базы данных) - формально
определяется как набор объектов в базе данных, объединенных общим пространством имен. Проще всего представить себе схему как некий логический контейнер в базе данных, которому могут принадлежать таблицы, представления, хранимые процедуры, пользовательские функции, ограничения целостности, пользовательские типы данных и другие объекты базы данных. Этот контейнер удобно использовать как для именования

объектов и их логической группировки, так и для предоставления разрешений. Например, если в базе данных есть набор таблиц с финансовой информацией, удобно поместить их в одну схему и предоставлять пользователям разрешения на эту схему (т. е. на этот набор таблиц);
2) Tables (Таблица) - так называемые прямоугольные реляционные (т. е. связанные между собой некоторыми отношениями) таблицы данных;
3) Trigger (Триггер) — это особая разновидность хранимой процедуры, выполняемая автоматически при возникновении события на сервере базы данных. Триггеры языка обработки данных выполняются по событиям, вызванным попыткой пользователя изменить данные с помощью языка обработки данных (см. лекцию 13);
4) Index (Индекс) - средство ускорения операции поиска записей в таблице, следовательно, и других операций, использующих поиск: извлечение, модификация, сортировка;
5) View (Представления) - это виртуальные таблицы. Они выглядят и работают как таблицы базы данных, но на самом деле являются операторами выборки, которые хранятся в базе данных. Когда вы смотрите на содержимое представления, то на самом деле вы смотрите на результирующий набор оператора выборки (см. лекцию 13);
6) Stored Procedures (Хранимые процедуры) - фрагменты программного кода на Transact-SQL, которые выполняются на сервере. Они могут запускаться вызывающим их приложением, триггерами или при проверке выполняемости правил целостности данных. Хранимые процедуры могут иметь параметры, обеспечивающие возможность передавать в нее значения и получать обратно значения, выбираемые из таблиц или вычисляемые при выполнении процедуры. В сравнении с использованием динамических операторов языка SQL хранимые процедуры имеют следующие преимущества: высокая производительность, поскольку компилируются при первом выполнении с использованием оптимизации доступа к информации из таблиц; возможность выполнения на локальном и на удаленном сервере (см. лекцию 13);
7) Function (Пользовательские функции) – подпрограммы (фрагменты программного кода на Transact-SQL), которые принимают параметры, выполняют некоторое действие, например сложный расчет, и возвращают результат этого действия в виде значения. Возвращаемое значение может быть либо единичным скалярным значением, либо результирующим набором (см. лекцию 13).
Примечание.
Остальные объекты базы данных будут подробнее рассмотрены в лекции 17. (Современные СУБД).
5.3.4.2. Создание таблиц Создать таблицу можно так же с помощью контекстного меню вкладки Tables. При
создании столбцов таблицы, необходимо указать имя столбца (Правила для индикаторов ПРИЛОЖЕНИЕ А), тип данных и возможность хранения значения NULL (рис. 5.6). После создания всех полей таблицы, её сохраняют, вводя имя таблицы (Правила для индикаторов).
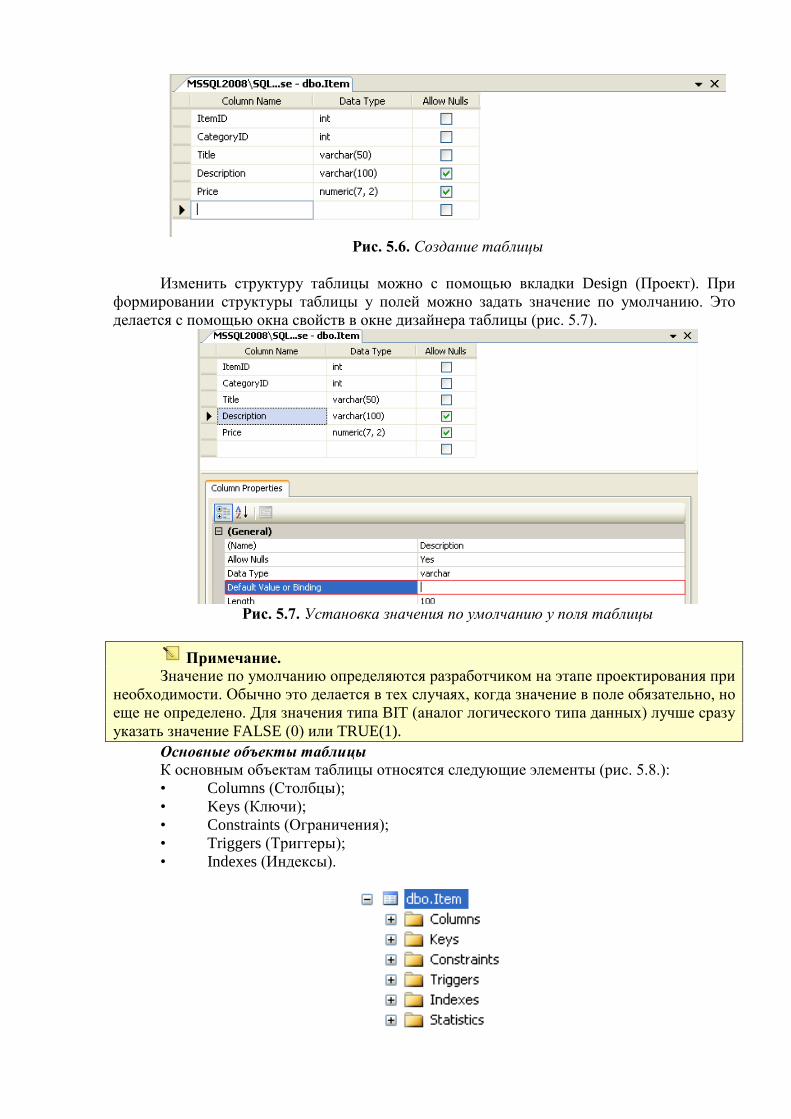
Рис. 5.6. Создание таблицы
Изменить структуру таблицы можно с помощью вкладки Design (Проект). При
формировании структуры таблицы у полей можно задать значение по умолчанию. Это делается с помощью окна свойств в окне дизайнера таблицы (рис. 5.7).
Рис. 5.7. Установка значения по умолчанию у поля таблицы
Примечание.
Значение по умолчанию определяются разработчиком на этапе проектирования при необходимости. Обычно это делается в тех случаях, когда значение в поле обязательно, но еще не определено. Для значения типа BIT (аналог логического типа данных) лучше сразу указать значение FALSE (0) или TRUE(1).
Основные объекты таблицы К основным объектам таблицы относятся следующие элементы (рис. 5.8.): • Columns (Столбцы); • Keys (Ключи); • Constraints (Ограничения); • Triggers (Триггеры); • Indexes (Индексы).

Рис. 5.8. Основные объекты таблицы
Об объектах Constraints (Ограничения) и Triggers (Триггеры) речь пойдет в следующих лекциях.
5.3.4.3. Ключи и индексы Выделяют следующие типы ключей: 1) Первичный ключ - это столбец или группа столбцов, однозначно
определяющие запись. Первичный ключ по определению уникален: в таблице не может быть двух разных строк с одинаковыми значениями первичного ключа. Столбцы, составляющие первичный ключ, не могут иметь значение NULL. Для каждой таблицы первичный ключ может быть только один;
2) Уникальный ключ - это столбец или группа столбцов, значения (комбинация значений для группы столбцов) которых не могут повторяться. Отличия уникального ключа от первичного - в том, что:
• уникальных ключей для одной таблицы может быть несколько; • уникальные ключи могут иметь значения NULL, при этом если имеется
несколько строк со значениями уникального ключа NULL, такие строки согласно стандарту SQL 92 считаются различными (уникальными);
3) Внешний ключ - это столбец или группа столбцов, ссылающиеся на столбец или группу столбцов другой (или этой же) таблицы.
• Таблица, на которую ссылается внешний ключ, называется родительской таблицей, а столбцы, на которые ссылается внешний ключ - родительским ключом. Родительский ключ должен быть первичным или уникальным ключом, значения же внешнего ключа могут повторяться хоть сколько раз. То есть с помощью внешних ключей поддерживаются связи "один ко многим". Типы данных (а в некоторых СУБД и размерности) соответствующих столбцов внешнего и родительского ключа должны совпадать;
• Все значения внешнего ключа должны совпадать с каким-либо из значений родительского ключа. Появление значений внешнего ключа, для которых нет соответствующих значений родительского ключа, недопустимо. (Ссылочная целостность будет описана в следующем разделе);
• Внешние ключи создаются только в момент создания связей. 5.3.4.3.1. Первичный ключ Для указания первичного ключа таблицы необходимо выделить нужный столбец и
отменить с помощью кнопки Set Primary Key (Установить первичный ключ).
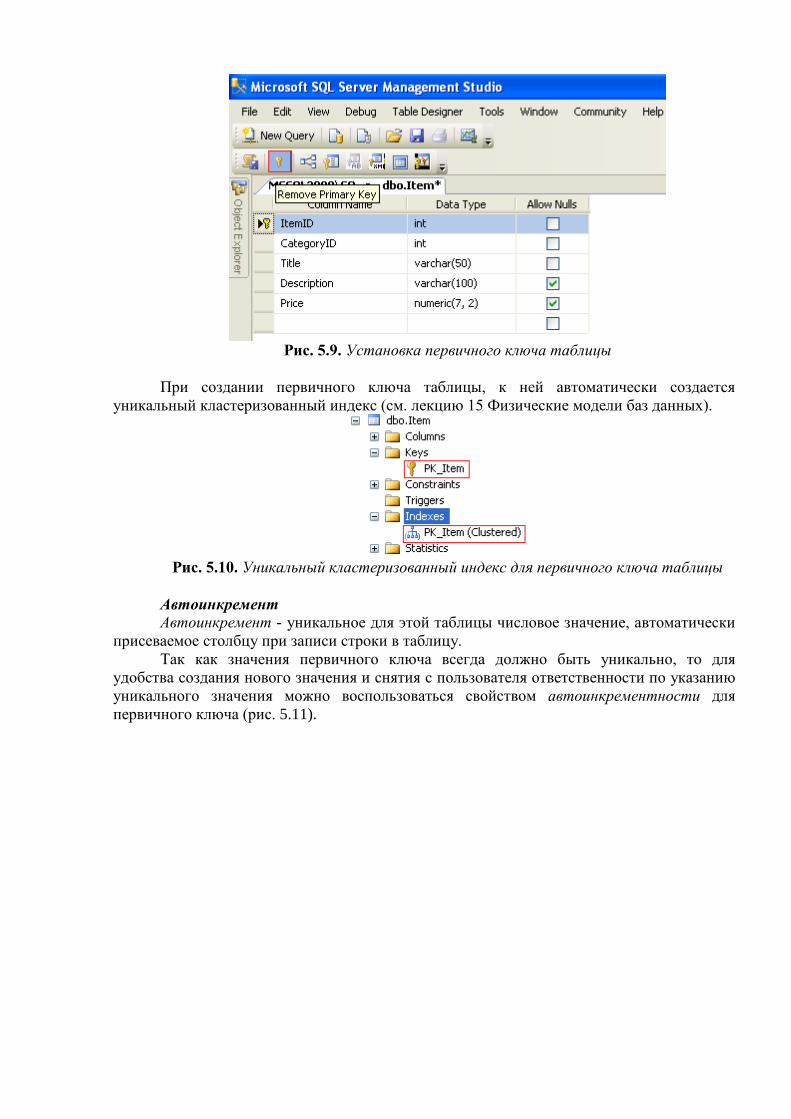
Рис. 5.9. Установка первичного ключа таблицы
При создании первичного ключа таблицы, к ней автоматически создается
уникальный кластеризованный индекс (см. лекцию 15 Физические модели баз данных).
Рис. 5.10. Уникальный кластеризованный индекс для первичного ключа таблицы
Автоинкремент Автоинкремент - уникальное для этой таблицы числовое значение, автоматически
присеваемое столбцу при записи строки в таблицу. Так как значения первичного ключа всегда должно быть уникально, то для
удобства создания нового значения и снятия с пользователя ответственности по указанию уникального значения можно воспользоваться свойством автоинкрементности для первичного ключа (рис. 5.11).
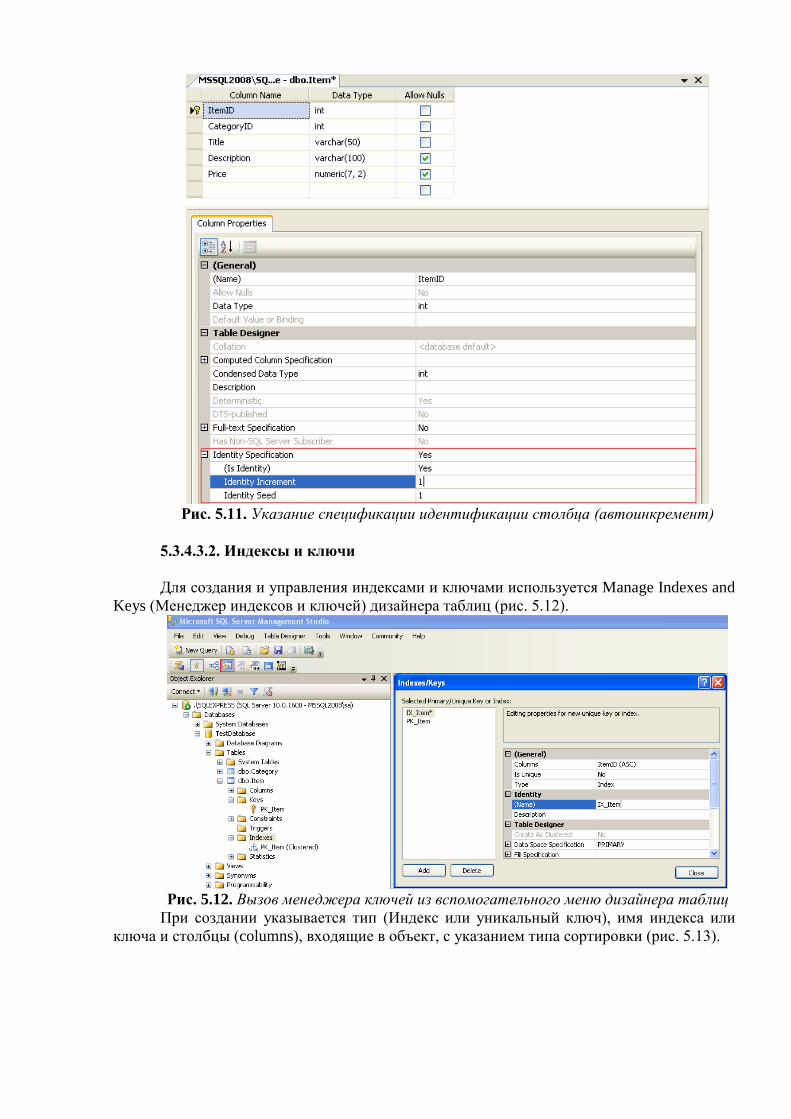
Рис. 5.11. Указание спецификации идентификации столбца (автоинкремент)
5.3.4.3.2. Индексы и ключи Для создания и управления индексами и ключами используется Manage Indexes and
Keys (Менеджер индексов и ключей) дизайнера таблиц (рис. 5.12).
Рис. 5.12. Вызов менеджера ключей из вспомогательного меню дизайнера таблиц
При создании указывается тип (Индекс или уникальный ключ), имя индекса или ключа и столбцы (columns), входящие в объект, с указанием типа сортировки (рис. 5.13).
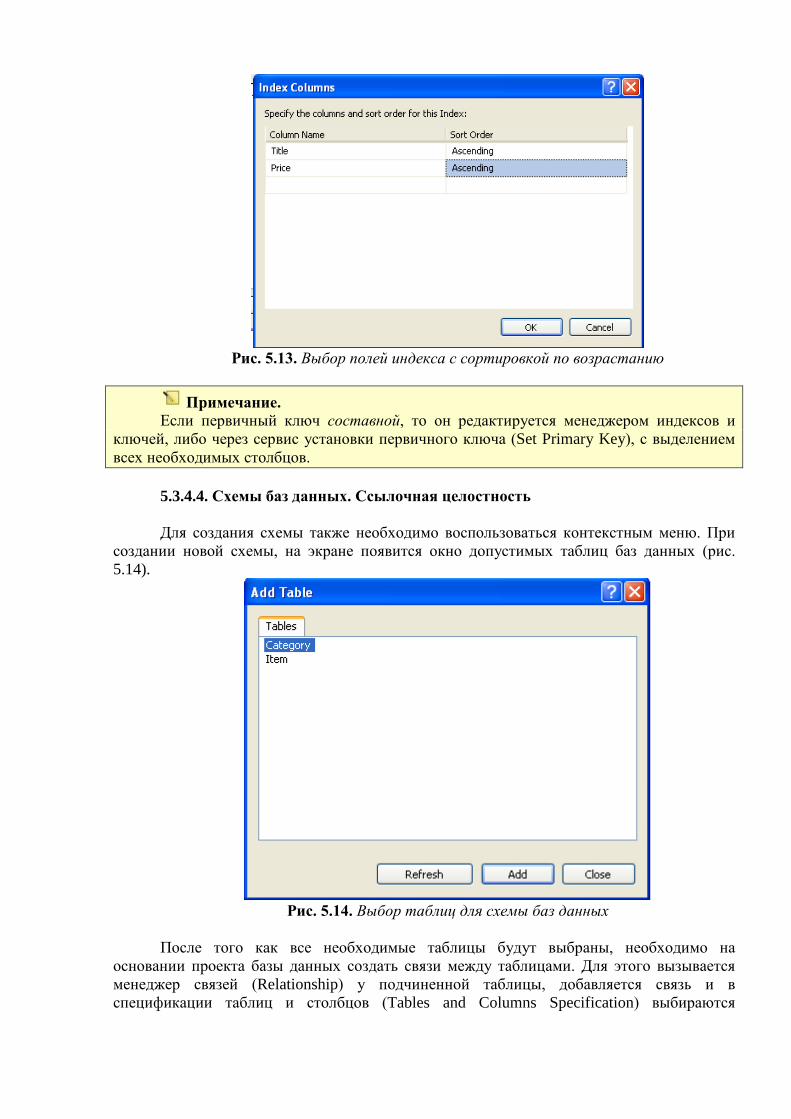
Рис. 5.13. Выбор полей индекса с сортировкой по возрастанию
Примечание.
Если первичный ключ составной, то он редактируется менеджером индексов и ключей, либо через сервис установки первичного ключа (Set Primary Key), с выделением всех необходимых столбцов.
5.3.4.4. Схемы баз данных. Ссылочная целостность Для создания схемы также необходимо воспользоваться контекстным меню. При
создании новой схемы, на экране появится окно допустимых таблиц баз данных (рис. 5.14).
Рис. 5.14. Выбор таблиц для схемы баз данных
После того как все необходимые таблицы будут выбраны, необходимо на
основании проекта базы данных создать связи между таблицами. Для этого вызывается менеджер связей (Relationship) у подчиненной таблицы, добавляется связь и в спецификации таблиц и столбцов (Tables and Columns Specification) выбираются
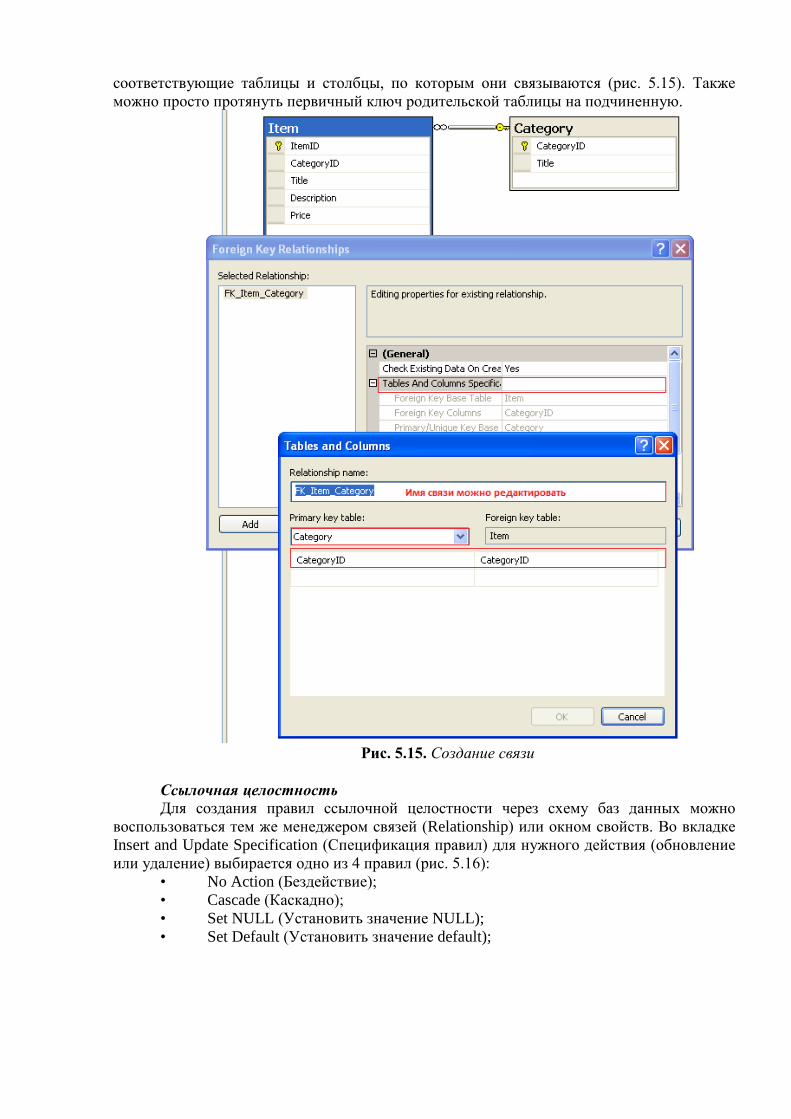
соответствующие таблицы и столбцы, по которым они связываются (рис. 5.15). Также можно просто протянуть первичный ключ родительской таблицы на подчиненную.
Рис. 5.15. Создание связи
Ссылочная целостность Для создания правил ссылочной целостности через схему баз данных можно
воспользоваться тем же менеджером связей (Relationship) или окном свойств. Во вкладке Insert and Update Specification (Спецификация правил) для нужного действия (обновление или удаление) выбирается одно из 4 правил (рис. 5.16):
• No Action (Бездействие); • Cascade (Каскадно); • Set NULL (Установить значение NULL); • Set Default (Установить значение default);

Рис. 5.16. Установка правил на удаление для сохранения ссылочной целостности
В качестве примера, если установить для правила Delete Rule (удаление) значение
Cascade (Каскадно), то при удалении категории товара из таблицы Category, все товары этой категории будут автоматически удалены из таблицы Item.
Примечание. Теоритическое обоснование сохранения ссылочной целостности можно посмотреть
в начале этой лекции. Нужно запомнить, что действие удаления или обновления производится над родительской таблицей, а правило срабатывает для записей подчиненной таблицы. Для установки более сложных правил сохранения целостности и наложения правил на родительскую таблицу нужно использовать триггеры (см. лекцию 13).
5.3.4.5. Занесение и редактирование данных таблицы Вставлять, изменять и удалять данные в таблице можно либо через
соответствующие инструкции SQL в окне запросов, или использовать вкладку Edit (Редактировать) контекстного меню таблицы (рис. 5.17).
Рис. 5.17. Редактирование записей таблицы Category
Окно Edit (Редактировать) намного мощнее, чем просто сервис редактирования данных. С помощью него можно создавать сложные запросы, используя панель диаграмм (в этом панели можно добавлять не только таблицы, но и представления и пользовательские функции), критерии отбора (удобный конструктор сортировок, группировок и выражений), окно запросов и окно результатов с возможность изменения записей. Подробнее о использовании этого инструмента описано в разделе 3 (Структурированный язык запросов SQL).


Лекция 6 БАЗИСНЫЕ СРЕДСТВА МАНИПУЛИРОВАНИЯ РЕЛЯЦИОННЫМИ
ДАННЫМИ Содержание 6.1. Теоретические языки запросов 6.2. Реляционная алгебра 6.2.1 Операции реляционной алгебры Кодда 6.2.2. Дополнительные операции 6.2.3. Основные правила записи выражений 6.3. Реляционное исчисление 6.4. Связь реляционного исчисления и реляционной алгебры Связанные темы Модели данных. Логическая модель данных (см. лекцию 4). Концептуальные модели данных. Проектирование реляционных БД (см.
лекцию 7). Структурированный язык запросов SQL (см. раздел 3). Компиляторы SQL. Проблемы оптимизации (см. лекцию 14). 6.1. Теоретические языки запросов Операции, выполняемые над отношениями, можно разделить на две группы.
Первую группу составляют операции над множествами, к которым относятся операции: объединения, пересечения, разности, деления и декартова произведения. Вторую группу составляют специальные операции над отношениями, к которым, в частности, относятся операции: проекции, соединения, выбора.
В различных СУБД реализована некоторая часть операций над отношениями, определяющая в какой-то мере возможности данной СУБД и сложность реализации запросов к БД.
В реляционных СУБД для выполнения операций над отношениями используются две группы языков, имеющие в качестве своей математической основы теоретические языки запросов, предложенные Э.Коддом:
• реляционная алгебра; • реляционное исчисление. Эти языки представляют минимальные возможности реальных языков
манипулирования данными в соответствии с реляционной моделью и эквивалентны друг другу по своим выразительным возможностям. Существуют не очень сложные правила преобразования запросов между ними.
В реляционной алгебре операнды и результаты всех действий являются отношениями. Языки реляционной алгебры являются процедурными, так как отношение, являющееся результатом запроса к реляционной БД, вычисляется при выполнении последовательности реляционных операторов, применяемым к отношениям. Операторы состоят из операндов, в роли которых выступают отношения, и реляционных операций. Результатом реляционной операции является отношение.
Языки исчислений, в отличие от реляционной алгебры, являются непроцедурными (описательными, или декларативными) и позволяют выражать запросы с помощью, предиката первого порядка (высказывания в виде функции), которому должны удовлетворять кортежи или домены отношений. Запрос к БД, выполненный с использованием подобного языка, содержит лишь информацию о желаемом результате.
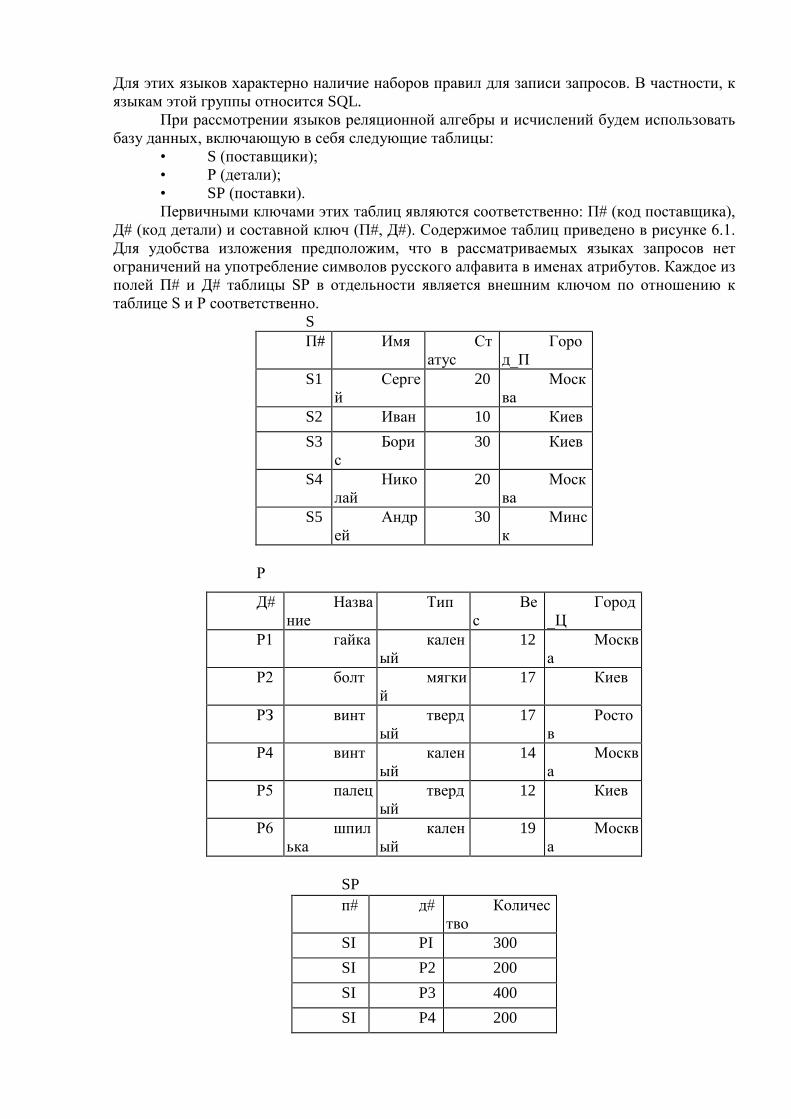
Для этих языков характерно наличие наборов правил для записи запросов. В частности, к языкам этой группы относится SQL.
При рассмотрении языков реляционной алгебры и исчислений будем использовать базу данных, включающую в себя следующие таблицы:
• S (поставщики); • Р (детали); • SP (поставки). Первичными ключами этих таблиц являются соответственно: П# (код поставщика),
Д# (код детали) и составной ключ (П#, Д#). Содержимое таблиц приведено в рисунке 6.1. Для удобства изложения предположим, что в рассматриваемых языках запросов нет ограничений на употребление символов русского алфавита в именах атрибутов. Каждое из полей П# и Д# таблицы SP в отдельности является внешним ключом по отношению к таблице S и Р соответственно.
S П# Имя Ст
атус Горо
д_П S1 Серге
й 20 Моск
ва S2 Иван 10 Киев S3 Бори
с 30 Киев
S4 Николай
20 Москва
S5 Андрей
30 Минск
Р
Д# Название
Тип Вес
Город_Ц
Р1 гайка каленый
12 Москва
Р2 болт мягкий
17 Киев
РЗ винт твердый
17 Ростов
Р4 винт каленый
14 Москва
Р5 палец твердый
12 Киев
Р6 шпилька
каленый
19 Москва
SP п# д# Количес
тво SI PI 300 SI P2 200 SI P3 400 SI P4 200

SI P5 100 SI P6 100 S2 PI 300 S2 P2 400 S3 P2 200 S4 P2 200 S4 P4 300 S4 P5 400
Рис. 6.1. Таблицы поставщиков, деталей и поставок
Предположим, что имена доменов (множеств допустимых значений) совпадают с именами атрибутов. Исключение составляют атрибуты Город_П (город, в котором находится поставщик) и 1ород_Д (город, в котором выпускается деталь), которые имеют общий домен: множество названий городов. Имя этого домена может быть , например, просто Город. Характеристики доменов как типов данных следующие: Д# — строка символов длиной 5, Имя — строка символов длиной 20, Статус — цифровое длиной 5, Город — строка символов длиной 15, Д# — строка символов длиной 6, Тип — строка символов длиной 6, Вес — цифровое длиной 5, Количество — цифровое длиной 5.
6.2. Реляционная алгебра Реляционная алгебра как теоретический язык запросов по сравнению с
реляционным исчислением более наглядно описывает выполняемые над отношениями действия.
Примером языка запросов, основанного на реляционной алгебре, является ISBL (Information System Base Language — базовый язык информационных систем). Языки запросов, построенные на основе реляционной алгебры, в современных СУБД широкого распространения не получили. Однако знакомство с ней полезно для понимания сути реляционных операций, выражаемых другими используемыми языками.
Вариант реляционной алгебры, предложенный Коддом, включает в себя следующие основные операции: объединение, разность (вычитание), пересечение, декартово (прямое) произведение (или произведение), выборка (селекция, ограничение), проекция, деление и соединение. Упрощенное графическое представление этих операций приведено на рисунке 6.2.

Рис. 6.2. Основные операции реляционной алгебры
По справедливому замечанию Дейта, реляционная алгебра Кодда обладает
несколькими недостатками. Во-первых, восемь перечисленных операций по охвату своих функций, с одной стороны, избыточны, так как минимально необходимый набор составляют пять операций: объединение, вычитание, произведение, проекция и выборка.
Три другие операции (пересечение, соединение и деление) можно определить через пять минимально необходимых. Так, например, соединение — это проекция выборки произведения.
Во-вторых, этих восьми операций недостаточно для построения реальной СУБД на принципах реляционной алгебры. Требуются расширения, включающие операции: переименования атрибутов, образования новых вычисляемых атрибутов, вычисления итоговых функций, построения сложных алгебраических выражений, присвоения, сравнения и т.д.
Рассмотрим перечисленные операции более подробно, сначала — операции реляционной алгебры Кодда, а затем — дополнительные операции, введенные Дейтон.
6.2.1 Операции реляционной алгебры Кодда
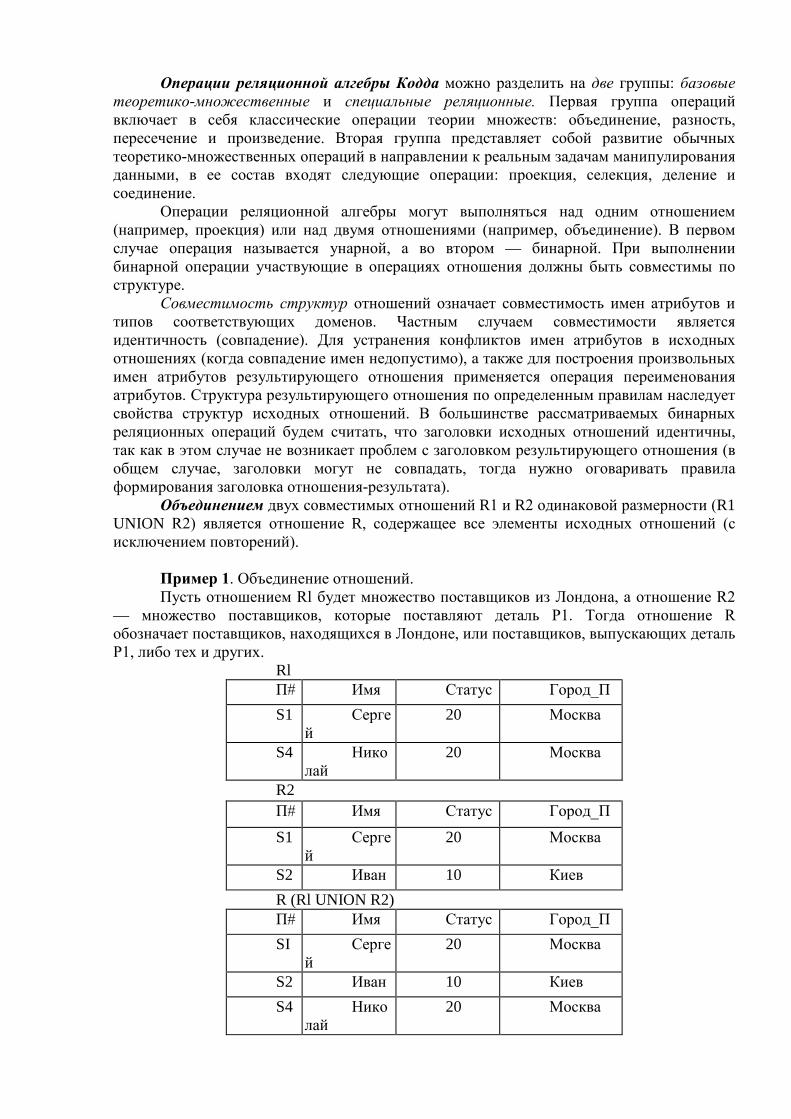
Операции реляционной алгебры Кодда можно разделить на две группы: базовые теоретико-множественные и специальные реляционные. Первая группа операций включает в себя классические операции теории множеств: объединение, разность, пересечение и произведение. Вторая группа представляет собой развитие обычных теоретико-множественных операций в направлении к реальным задачам манипулирования данными, в ее состав входят следующие операции: проекция, селекция, деление и соединение.
Операции реляционной алгебры могут выполняться над одним отношением (например, проекция) или над двумя отношениями (например, объединение). В первом случае операция называется унарной, а во втором — бинарной. При выполнении бинарной операции участвующие в операциях отношения должны быть совместимы по структуре.
Совместимость структур отношений означает совместимость имен атрибутов и типов соответствующих доменов. Частным случаем совместимости является идентичность (совпадение). Для устранения конфликтов имен атрибутов в исходных отношениях (когда совпадение имен недопустимо), а также для построения произвольных имен атрибутов результирующего отношения применяется операция переименования атрибутов. Структура результирующего отношения по определенным правилам наследует свойства структур исходных отношений. В большинстве рассматриваемых бинарных реляционных операций будем считать, что заголовки исходных отношений идентичны, так как в этом случае не возникает проблем с заголовком результирующего отношения (в общем случае, заголовки могут не совпадать, тогда нужно оговаривать правила формирования заголовка отношения-результата).
Объединением двух совместимых отношений R1 и R2 одинаковой размерности (R1 UNION R2) является отношение R, содержащее все элементы исходных отношений (с исключением повторений).
Пример 1. Объединение отношений. Пусть отношением Rl будет множество поставщиков из Лондона, а отношение R2
— множество поставщиков, которые поставляют деталь Р1. Тогда отношение R обозначает поставщиков, находящихся в Лондоне, или поставщиков, выпускающих деталь Р1, либо тех и других.
Rl П# Имя Статус Город_П S1 Серге
й 20 Москва
S4 Николай
20 Москва
R2 П# Имя Статус Город_П
S1 Сергей
20 Москва
S2 Иван 10 Киев R (Rl UNION R2) П# Имя Статус Город_П SI Серге
й 20 Москва
S2 Иван 10 Киев S4 Нико
лай 20 Москва

Вычитание совместимых отношений Rl и R2 одинаковой размерности (R1 MINUS R2) есть отношение, тело которого состоит из множества кортежей, принадлежащих Rl, но не принадлежащих отношению R2. Для тех же отношений Rl и R2 из предыдущего примера отношение R будет представлять собой множество поставщиков, находящихся в Лондоне, но не выпускающих деталь Р1, т.е. R={(S4, Николай, 20, Москва)}.
Заметим, что результат операции вычитания зависит от порядка следования операндов, т. с. R1 MINUS R2 и R2 MINUS Rl - не одно и то же.
Пересечение двух совместимых отношений Rl и R2 одинаковой размерности (Rl .INTERSECT R2) порождает отношение R с телом, включающим в себя кортежи, одновременно принадлежащие обоим исходным отношениям. Для отношений Rl и R2 результирующее отношение R будет означать всех производителей из Лондона, выпускающих деталь Р1. Тело отношения R состоит из единственного элемента (SI, Сергей, 20, Москва).
Произведение отношения Rl степени к1 и отношения R2 степени к2 (R1 TIMES R2), которые не имеют одинаковых имен атрибутов, есть такое отношение R степени (к1+к2), заголовок которого представляет сцепление заголовков отношений Rl и R2, а тело — имеет кортежи, такие, что первые к1 элементов кортежей принадлежат множеству Rl, а последние к2 элементов ~ множеству R2. При необходимости получить произведение двух отношений, имеющих одинаковые имена одного или нескольких атрибутов, применяется операция переименования RENAME, рассматриваемая далее.
Пример 2. Произведение отношений. Пусть отношение Rl представляет собой множество номеров всех текущих
поставщиков {SI, S2, S3, S4, S5}, а отношение R2 — множество номеров всех текущих деталей {Р1, Р2, РЗ, Р4, Р5, Р6}. Результатом операции R1 TIMES R2 является множество всех пар типа «поставщик-деталь», т. е. {(S1,P1), (S1,P2), (S1,РЗ), (S1,Р4), (S1,P5), (S1,P6), (S2,P1), ... , (S5,P6)}.
Заметим, что в теории множеств результатом операции прямого произведения является множество, каждый элемент которого является парой элементов, первый из которых принадлежит Rl, а второй — принадлежит R2. Поэтому кортежами декартова произведения бинарных отношений будут кортежи вида: ((а, б), (в, г)), где кортеж (а, б) принадлежит отношению Rl, а кортеж (в, г) — принадлежит отношению R2. В реляционной алгебре применяется расширенный вариант прямого произведения, при котором элементы кортежей двух исходных отношений сливаются, что при записи кортежей результирующего отношения означает удаление лишних скобок, т.е. (а, б, в, г).
Выборка (R WHERE 1) отношения R по формуле f представляет собой новое отношение с таким же заголовком и телом, состоящим из таких кортежей отношения R, которые удовлетворяют истинности логического выражения, заданного формулой f.
Для записи формулы используются операнды — имена атрибутов (или номера столбцов), константы, логические операции (AND — И, OR — ИЛИ, NOT — НЕ), операции сравнения и скобки.
Примеры 3. Выборки. Р WHERE Вес < 14
Д# Название
Тип
Вес
Город_П
Р1 гайка каленый
12
Москва
Р5 палец твердый
12
Киев
SP WHERE П# = "S1" AND Д# = "Р1" П# д# Количес
тво S1 Р1 300

Проекция отношения А на атрибуты X, Y, ..., Z (А [X, Y, ... , Z]), где множество {X, Y, ..., Z} является подмножеством полного списка атрибутов заголовка отношения А, представляет собой отношение с заголовком X, Y, ..., Z и телом, содержащим кортежи отношения А, за исключением повторяющихся кортежей. Повторение одинаковых атрибутов в списке X, Y, ..., Z запрещается. Операция проекции допускает следующие дополнительные варианты записи:
• отсутствие списка атрибутов подразумевает указание всех атрибутов (операция тождественной проекции);
• выражение вида R[ ] означает пустую проекцию, результатом которой является пустое множество;
• операция проекции может применяться к произвольному отношению, в том числе и к результату выборки.
Примеры 4. Проекции. Р[Тип, Город_Д]
Тип Город_Д
Калёный
Москва
Мягкий
Киев
Твёрдый
Ростов
Твёрдый
Киев
(S WHERE Город_П=”Киев”)[П#] П# Город_
П S2 Киев S3 Киев
Результатом деления отношения RI с атрибутами iA и В на отношение R2 с атрибутом В (RI DIVIDEBY R2), где А и В простые или составные атрибуты, причем атрибут В — общий атрибут, определенный на одном и том же домене (множестве доменов составного атрибута), является отношение R с заголовком А и телом, состоящим из кортежей r таких, что в отношении RI имеются кортежи (г, s), причем множество значений s включает множество значений атрибута В отношения R2.
Пример 5. Деление отношения. Пусть R1 — проекция SP [П#, Д#], a R2 — отношение с заголовком Д# и телом {Р2,
Р4}, тогда результатом деления R1 на R2 будет отношение R с заголовком П# и телом {S1, S4}.
R1 П# д# S1 Р1 S1 Р2 S1 РЗ
S1 Р4 S1 Р5
S1 Р6 S2 Р1 S2 Р2

S3 Р2 S4 Р2 S4 Р4 S4 Р5
R2 Д# Р2 Р4
R1 DIVIDEBY R2
Д# P2 P4
Соединение Cf (R1, R2) отношений R1 и R2 по условию, заданному формулой f, представляет собой отношение R, которое можно получить путем Декартова произведения отношений R1 и R2 с последующим применением к результату операции выборки по формуле f. Правила записи формулы f такие же, как и для операции селекции.
Другими словами, соединением отношения R1 по атрибуту А с отношением R2 по атрибуту В (отношения не имеют общих имен атрибутов) является результат выполнения операции вида: (R1 TIMES R2) WHERE A Θ В,
где Q — логическое выражение над атрибутами, определенными на одном (нескольких — для составного атрибута) домене. Соединение C.(R1, R2), где формула f имеет произвольный вид (в отличие от частных случаев, рассматриваемых далее), называют также Q-соединением.
Важными с практической точки зрения частными случаями соединения являются эквисоединение и естественное соединение.
Операция эквисоединения характеризуется тем, что формула задает равенство операндов. Приведенный выше пример демонстрирует частный случай операции эквисоединения по одному столбцу. Иногда эквисоединение двух отношений выполняется по таким столбцам, атрибуты которых в обоих отношениях имеют соответственно одинаковые имена и домены. В этом случае говорят об эквисоединении по общему атрибуту.
Операция естественного соединения (операция JOIN) применяется к двум отношениям, имеющим общий атрибут (простой или составной). Этот атрибут в отношениях имеет одно и то же имя (совокупность имен) и определен на одном и том же домене (доменах).
Результатом операции естественного соединения является отношение R, которое представляет собой проекцию эквисоединения отношений R1 и R2 по общему атрибуту на объединенную совокупность атрибутов обоих отношений.
Пример 6. Q-соединение. Необходимо найти соединение отношений S и Р по атрибутам Город_П и Город _Д
соответственно, причем кортежи результирующего отношения должны удовлетворять отношению «больше» (в смысле лексикографического порядка — по алфавиту).
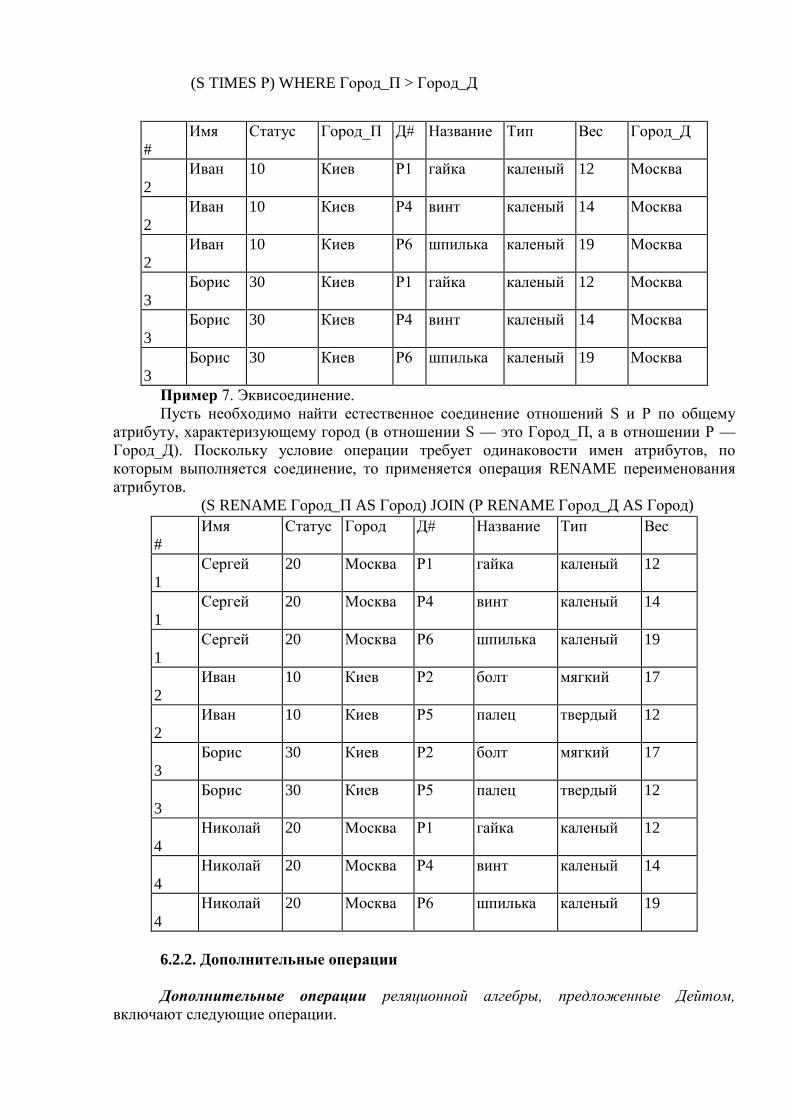
(S TIMES Р) WHERE Город_П > Город_Д
# Имя Статус Город_П Д# Название Тип Вес Город_Д
2 Иван 10 Киев Р1 гайка каленый 12 Москва
2 Иван 10 Киев Р4 винт каленый 14 Москва
2 Иван 10 Киев Р6 шпилька каленый 19 Москва
3 Борис 30 Киев Р1 гайка каленый 12 Москва
3 Борис 30 Киев Р4 винт каленый 14 Москва
3 Борис 30 Киев Р6 шпилька каленый 19 Москва
Пример 7. Эквисоединение. Пусть необходимо найти естественное соединение отношений S и Р по общему
атрибуту, характеризующему город (в отношении S — это Город_П, а в отношении Р — Город_Д). Поскольку условие операции требует одинаковости имен атрибутов, по которым выполняется соединение, то применяется операция RENAME переименования атрибутов.
(S RENAME Город_П AS Город) JOIN (Р RENAME Город_Д AS Город)
# Имя Статус Город Д# Название Тип Вес
1 Сергей 20 Москва Р1 гайка каленый 12
1 Сергей 20 Москва Р4 винт каленый 14
1 Сергей 20 Москва Р6 шпилька каленый 19
2 Иван 10 Киев Р2 болт мягкий 17
2 Иван 10 Киев Р5 палец твердый 12
3 Борис 30 Киев Р2 болт мягкий 17
3 Борис 30 Киев Р5 палец твердый 12
4 Николай 20 Москва Р1 гайка каленый 12
4 Николай 20 Москва Р4 винт каленый 14
4 Николай 20 Москва Р6 шпилька каленый 19
6.2.2. Дополнительные операции Дополнительные операции реляционной алгебры, предложенные Дейтом,
включают следующие операции.

Операция переименования позволяет изменить имя атрибута отношения и имеет вид:
RENAME <исходное отношение> <старое имя атрибута> AS <новое имя атрибута>,
где <исходное отношение> задается именем отношения либо выражением реляционной алгебры. В последнем случае выражение заключают в круглые скобки. Например, RENAME 1ород_П AS Город_размещения_Поставщика.
Замечание. Для удобства записи выражений одновременного переименования нескольких
атрибутов Дейтом введена операция множественного переименования, которая представима следующим образом:
RENAME <отн.> <ст. имя атр.1> AS <нов. имя атр.1>,<ст. имя атр.2> AS <нов. имя атр.2>, ... ,<ст. имя aтp.N> AS <нов. имя aтp,N>. Операция расширения порождает новое отношение, похожее на исходное, но
отличающееся наличием добавленного атрибута, значения которого получаются путем некоторых скалярных вычислений. Операция расширения имеет вид:
EXTEND <исходное отношение> ADD <выражение> AS <новый атрибут>, где к исходному отношению добавляется (ключевое слово ADD) <новый атрибут>,
подсчитываемый по правилам, заданным <выражением>. Исходное отношение может быть задано именем отношения и с помощью выражения реляционной алгебры, заключенного в круглые скобки. При этом имя нового атрибута не должно входить в заголовок исходного отношения и не может использоваться в <выражении>. Помимо обычных арифметических операций и операций сравнения, в выражении можно использовать различные функции, называемые итоговыми, такие как: COUNT (количество), SUM (сумма), AVG (среднее), МАХ (максимальное), MIN (минимальное). Например,
EXTEND (PJOIN SP) ADD (Вес * Количество) AS Общий_Вес. Замечания. • Пользуясь операцией расширения, можно выполнить переименование
атрибута. Для этого нужно в выражении указать имя атрибута, в конструкции AS определить новое имя этого атрибута, затем выполнить проекцию полученного отношения на множество атрибутов, исключая старый атрибут. Таким образом, запись (EXTEND S ADD Город_П AS Город) [П#, Имя, Статус, Город] эквивалента конструкции S RENAME Город_П AS Город.
• Подобно тому, как это сделано для операции переименования, Дейт определил операцию множественного расширения, которая позволяет в одной синтаксической конструкции вычислять несколько новых атрибутов. Формально операция представима следующим образом:
EXTEND<отн.>ADD<выр.1>AS<атр.1>,<выр.2>AS<атр.2>,...,<выр.N> AS<aтp.N>. Операция подведения итогов SUMMARIZE выполняет «вертикальные» или
групповые вычисления и имеет следующий формат: SUMMARIZE<исх.отн.>BY«список атрибутов»ADD<выр> AS<новый атрибут>, где исходное отношение задается именем отношения либо заключенным в круглые
скобки выражением реляционной алгебры, <список атрибутов> представляет собой разделенные запятыми имена атрибутов исходного отношения А1, А2, ... , AN, <выр.> — скалярное выражение, аналогичное выражению операции EXTERN D, а <новыи атрибут> — имя формируемого атрибута. В списке атрибутов и в выражении не должен использоваться <новыи атрибут>.

Результатом операции SUMMARIZE является отношение R с заголовком, состоящим из атрибутов списка, расширенного новым атрибутом. Для получения тела отношения R сначала выполняется проецирование (назовем проекцию R1) исходного отношения на атрибуты А1, А2, ... , AN, после чего каждый кортеж проекции расширяется новым (N+1)-м атрибутом. Поскольку проецирование, как правило, приводит к сокращенные количества кортежей по отношению к исходному отношению (удаляются одинаковые кортежи), то можно считать, что происходит своеобразное группирование кортежей исходного отношения: одному кортежу отношения R1 соответствует один или более (если было дублирование при проецировании) кортежей исходного отношения. Значение (N+1)-го атрибута каждого кортежа отношения R формируется путем вычисления выражения над соответствующей этому кортежу группой кортежей исходного отношения.
Пример 8. Подведение итогов. Пусть требуется вычислить количество поставок по каждому из поставщиков. SUMMARIZE SP BY (П#) ADD COUNT AS Количество_поставок П# Количество поставок S1 6 S2 2
S3 1
S4 3 Отметим, что функция COUNT определяет количество кортежей в каждой из групп
исходного отношения. Операция множественного подведения итогов, подобно соответствующим
операциям переименования и расширения, выполняет одновременно несколько «вертикальных» вычислений и записывает результаты в отдельные новые атрибуты. Простейшим примером такой операции может служить следующая запись:
SUMMARIZE SP BY (Д#) ADD SUM Количество AS 0бщее_число_поставок AVG Количество AS Среднее_число_поставок.
К основным операторам, позволяющим изменять тело существующего отношения, отнесем операции реляционного присвоения, вставки, обновления и удаления.
Операцию присвоения можно представить следующим образом: <выражение-цель> := <выражение-источник>, где оба выражения задают совместимые (точнее, эквивалентные) по структуре
отношения. Типичный случай выражений: в левой части — имя отношения, а в правой — некоторое выражение реляционной алгебры. Выполнение операции присвоения сводится к замене предыдущего значения отношения на новое (начальное значение, если тело отношения было пустым), определенное выражением-источником.
С помощью операции присвоения можно не только полностью заменить все значения отношения-цели, но и добавить или удалить кортежи. Приведем пример, в котором в отношение S дописывается один кортеж:
S := S UNION {{< П# : 'S6' >, < Имя : 'Борис' >, < Статус : '50' >, < Город_П : 'Мадрид' >}}. Более удобными операциями изменения тела отношения являются операции
вставки, обновления и удаления. Операция вставки INSERT имеет следующий вид: INSERT <выражение-источник> INTO <выражение-цель>, где оба выражения должны быть совместимы по структуре. Выполнение операции
сводится к вычислению <выражение-источник> и вставке полученных кортежей в отношение, заданное <выражение-цель>.

Пример. INSERT (S WHERE Город_П=’Москва’) INTO Temp. Операция обновления UPDATE имеет следующий вид: UPDATE <выражение-цель> <список элементов>, где <список элементов> представляет собой последовательность разделенных
запятыми операций присвоения <атрибут> := <скалярное выражение>. Результатом выполнения операции обновления является отношение, полученное после присвоения соответствующих значений атрибутам отношения, заданного целевым выражением.
Например, UPDATE Р WHERE Тип='каленый' Город:= 'Киев'. Эта операция предписывает изменить значение атрибута Город (независимо от того, каким оно было) на новое значение — 'Киев' таких кортежей отношения Р, атрибут Тип которых имеет значение 'каленый'.
Операция удаления DELETE имеет следующий вид: DELETE <выражение-цель>, где <выражение-цель> представляет собой реляционное выражение, описывающее
удаляемые кортежи. Например, DELETE S WHERE Статус < 20. Операция реляционного сравнения может использоваться для прямого сравнения
двух отношений. Она имеет синтаксис: <выражение1> Q <выражение2>, где оба выражения задают совместимые по структуре отношения, а знак Θ — один
из следующих операторов сравнения: = (равно), ≠ (не равно), ≤ (собственное подмножество), < (подмножество), ≥ (надмножество), > (собственное надмножество).
Например, сравнение: "Совпадают ли города поставщиков и города хранения деталей?" можно записать так: S [Город_П] == Р [Город_Д].
6.2.3. Основные правила записи выражений Как отмечалось, результатом произвольной реляционной операции является
отношение, которое, в свою очередь, может участвовать в другой реляционной операции. Это свойство реляционной алгебры называется свойством замкнутости.
Свойство замкнутости позволяет записывать вложенные выражения реляционной алгебры, основой которых выступают рассмотренные ранее элементарные операции: объединение, проекция, пересечение, выборка и т. д.
При записи произвольного выражения реляционной алгебры надо принимать во внимание следующее.
1. В реляционной алгебре должен быть определен приоритет выполнения операций (например, операция пересечение более приоритетна, чем операция объединение), который нужно учитывать при записи выражений. Для изменения порядка выполнения операций в выражениях можно использовать круглые скобки.
2. Существуют тождественные преобразования, позволяющие по-разному записывать одно и то же выражение. Например, следующие выражения эквивалентны (здесь А — отношение, С, С1,С2— выражения):
A WHERE Cl AND С2 и (A WHERE Cl) INTERSECT (A WHERE С2), A WHERE Cl OR С2 и (A WHERE Cl) UNION (A WHERE С2), A WHERE NOT С и A MINUS (A WHERE С). 3. Составляя выражение, нужно обеспечивать совместимость участвующих в
операциях отношений. При необходимости изменения заголовков следует выполнять переименование атрибутов.
6.3. Реляционное исчисление

Как отмечалось ранее, принципиальное различие между реляционной алгеброй и реляционным исчислением состоит в том, что в первом случае процесс получения искомого результата описывается явным образом путем указания набора операций, которые надо выполнить для получения результата, а во втором — указываются свойства искомого отношения без конкретизации процедуры его получения.
Внешне подходы сильно различаются: один из них предписывающий (реляционная алгебра), а другой описательный (реляционное исчисление). На более низком уровне рассмотрения подходы эквивалентны, так как любые выражения реляционной алгебры могут быть преобразованы в семантически эквивалентные выражения реляционного исчисления и наоборот. Возможность такого преобразования доказывалась многими авторами, в частности, для этого можно использовать алгоритм редукции Кодда.
Для названного алгоритма преобразования покажем на содержательном уровне возможности формулировки одного и того же запроса с помощью реляционной алгебры и реляционного исчисления на простом примере.
Пусть запрос выглядит следующим образом: "Получить номера и города поставщиков, выпускающих деталь Р2".
Словесно алгебраическая версия этого запроса описывается так: • образовать естественное соединение отношений S и SP по атрибуту П#; • выбрать из результата этого соединения кортежи с деталью Р2 (в поле Д#
должна быть строка Р2); • спроецировать результат предыдущей операции на атрибуты П# и Город_П. Этот же запрос в терминах реляционного исчисления можно сформулировать
примерно так: "Получить атрибуты П# и Город_П для таких поставщиков, для которых существует поставка в отношении SP с тем же значением атрибута П# и со значением Р" атрибута Д#".
Результатом выполнения запроса будет отношение R вида: П# Город_П
S1 Москва S2 Киев
S3 Киев S4 Москва
Читатель может самостоятельно убедиться в этом, проделав описанные выше операции реляционной алгебры.
Преимуществом реляционного исчисления перед реляционной алгеброй можно считать то, что пользователю не требуется самому строить алгоритм выполнения запроса. Программа СУБД (при достаточной ее интеллектуальности) сама строит эффективный алгоритм.
Отметим, что поставленную задачу выборки можно решить более оптимально с точки зрения потребности в оперативной памяти. Более экономичный вариант решения в терминах операциях реляционной алгебры выглядит так:
• выбрать из отношения SP кортежи, относящиеся к детали Р2; • выполнить естественное соединение отношения S и отношения,
полученного на предыдущем шаге; • спроецировать текущее отношение на атрибуты П# и Город_П. Экономия памяти при реализации этого алгоритма в сравнении с первоначальным
вариантом достигается за счет снижения размерности участвующих в операциях временных таблиц, необходимых для хранения промежуточных результатов. Если в предыдущем случае размерность временной таблицы была 12*6 (12 строк на 6 колонок), то в последнем случае — 4*6.

Математической основой реляционного исчисления является исчисление предикатов — один из разделов математической логики. Понятие реляционного исчисления как языка работы с базами данных впервые предложено Коддом. Им же был разработан язык ALPHA — прототип программно реализованного языка QUEL, который некоторое время конкурировал с языком SQL.
Существует два варианта исчислений: исчисление кортежей и исчисление доменов. Ц первом случае для описания отношений используются переменные, допустимыми значениями которых являются кортежи отношения, а во втором случае — элементы домена.
Реляционное исчисление, основанное на кортежах (исчисление кортежей), предложено и реализовано при разработке упоминавшегося языка ALPHA. В нем, как и в процедурных языках программирования, сначала нужно описать используемые переменные, а затем записывать некоторые выражения. Описательную часть исчисления можно представить в виде:
RANGE OF <переменная> IS <список>, где прописными буквами записаны ключевые слова языка, <переменная> —
идентификатор переменной кортежа (области значений), а <список> — последовательность одного или более элементов, разделенных запятыми, т.е. конструкция вида:
x1 [,x2 [...,xn ]...]. Вся конструкция RANGE указывает идентификатор переменной и область ее
допустимых значений. Список элементов x1 [,x2 [...,xn ]...] содержит элементы, каждый из которых является либо отношением, либо выражением над отношением (порядок записи выражений описывается далее). Все элементы списка должны быть совместимы по типу, т.е. соответствующие элементам отношения должны иметь идентичные заголовки. Область допустимых значений <переменной> образуется путем объединения значений всех элементов списка. Так, запись вида RANGE OF Т IS X1,Х2 означает, что область определения переменной Т включает в себя все значения из отношения, которое является объединением отношений X1 и Х2.
Пример 1. Варианты описаний. RANGE ОF SX IS S; RANGE OF SPX IS SP; RANGE OF SY IS (SX) WHERE SX.Город_П - 'Москва', (SX) WHERE EXISTS SPX (SPX.П# = SX.П# AND SРХ.Д# = ’Р1’); Переменные SX и SPX в первых двух примерах определены соответственно на
отношениях S и SP соответственно (рис. 3.7). Третий пример иллюстрирует запись выражений при определении переменной кортежа. Переменная SY здесь может принимать значения из множества кортежей отношения S для поставщиков из Лондона или поставщиков, которые поставляют деталь Р1 (или для тех и других).
Синтаксис выражений исчисления рассматривается ниже. Запись выражения, формулирующего запрос на языке исчисления кортежей с помощью формы Бэкуса-Наура, упрощенно можно представить следующим образом:
<выражение> ::= (у1 [, у2 [...,уm ]...]) [WHERE wff] у ::= {<переменная> | <переменная>.<атрибут> } [ AS <атрибут> ] wff ::= <условие> | NOT wff | <условие> AND wff | <условие> OR wff | IF <условие> THEN wff | EXISTS <переменная> (wff) | FORALL <переменная> (wff) |

(wff) Общий смысл записи выражения состоит в перечислении атрибутов
результирующего (целевого) отношения, атрибуты которого должны удовлетворять условию истинности формулы wff (well formulated formula — правильно построенная формула). Список атрибутов целевого отношения, или целевой список, в терминах реляционной алгебры по существу определяет операцию проекции, а формула wff — селекцию кортежей.
В паре <переменная>.<атри6ут> первая составляющая служит для указания переменной кортежа (определенной конструкцией RANGE), а вторая — для определения атрибута отношения, на котором изменяется переменная кортежа. Необязательная часть "AS <атрибут>" используется для переименования целевого отношения. Если она отсутствует, то имя атрибута целевого отношения наследуется от соответствующего имени атрибута исходного отношения.
Употребление в качестве элемента целевого отношения просто имени переменной Т равносильно перечислению в списке всех соответствующих атрибутов, т.е. Т.А1, Т.А2, ... , Т.Аn, где А1, A2 ... , Аn — атрибуты отношения, сопоставляемого с переменной Т.
Пример 2. Варианты записи пары <переменная>.<атри6ут>. SХ.П# SХ.П# AS Город_Поставщика SX SX.П#, SX.Гopoд_П AS Город_Поставщика, РХ.Д#, РХ.Город_Д# AS
Город_Детали В приведенном определении wff<условие> представляет собой либо формулу wff,
заключенную в скобки, либо простое сравнение вида: <операнд1> Θ <операнд2>, где в качестве любого операнда выступает переменная или скалярная константа, а
символ Θ обозначает операцию сравнения =, ≠, >, ≥, <, ≤ и т.д. Ключевые слова NOT, AND и OR обозначают логические операции
соответственно: И, НЕ и ИЛИ. Ключевые слова IF и THEN переводятся соответственно «если» и «то». И, наконец, ключевые слова EXISTS и FORALE называются кванторами. Первый из них — квантор существования, а второй — квантор всеобщности. Рассмотрим эти кванторы несколько подробнее.
Формула wff вида: EXISTS х (f) означает: "Существует по крайней мере одно такое значение переменной х, что вычисление формулы f дает значение истина". Выражение вида: FORALL х (f) интерпретируется как высказывание: "Для всех значений переменной х вычисление формулы f дает значение истина". В общем случае переменные кортежей в формулах могут быть свободными или связанными. В формулах EXISTS х (f) и FORALL х (f) переменные кортежей х всегда являются связанными.
Пример 3. Запись выражения. Приведем запись выражения, соответствующее запросу: "Получить имена
поставщиков, которые поставляют все детали". SX.Город_П WHERE FORALL PX (EXISTS SPX (SPX.П# = SX.П#
AND SPX.Д# = SX.Д# )) Равносильное этому выражение выглядит так: SХ.Город_П WHERE NOT EXISTS PX (NOT EXISTS SPX (SPX.П# = SX.П# AND SPX.Д# = SX.Д#)) Описанное исчисление не обладает вычислительной полнотой, так как не позволяет
выполнять вычисления, связанные с обработкой данных в базах. Добавление вычислительных функций в это исчисление можно реализовать путем расширения определения операндов сравнения и элементов целевого списка таким образом, чтобы они

допускали использование скалярных выражений с литералами, ссылками на атрибуты и итоговыми функциями. В качестве итоговых могут выступать следующие функции: COUNT (количество), SUM (сумма), AVG (среднее), МАХ (максимальное), MIN (минимальное). Для целевых элементов целесообразно использовать спецификацию вида "AS <имя атрибута>", позволяющую явно задать имя результирующему атрибуту, если нет очевидного наследуемого имени.
Пример 4. Запись запроса. Пусть требуется получить информацию о каждой поставке с полными данными о
деталях и общем весе поставки. Запрос па дополненном функциями языке реляционного исчисления кортежей может выглядеть следующим образом:
(SPX.П#, SPX.Количество, PX, РХ.Вес * SРХ.Количество AS Общий_Вес) WHERE РХ.Д# = SPXД#
Вариант реляционного исчисления, основанного на доменах (исчисление доменов), предложен Лакроиксом и Пиротте (Lacroix and Pirotte), которые также разработали на его основе соответствующий язык ILL. Другими языками, основанными на исчислении доменов, являются: FQL, DEDUCE, а также QBE с некоторыми оговорками.
По утверждению Дейта, язык QBE включает элементы исчисления кортежей и исчисления доменов, но более близок ко второму. Он не является реляционно полным, так как не поддерживает операцию отрицания квантора существования (NOT EXISTS). Несмотря на этот недостаток, язык QBE получил широкое распространение в современных СУБД. Тем более, что реализации этого языка, как правило, шире исходного языка.
Исчисление доменов имеет много сходства с исчислением кортежей. В отличие от исчисления кортежей, в исчислении доменов основой любого выражения запроса выступают переменные доменов. Переменная домена — это скалярная переменная, значения которой охватывают элементы некоторого домена.
Большая часть различий рассматриваемых исчислений заключается в том, что исчисление доменов поддерживает дополнительную форму условия, называемую условием принадлежности. В общем, виде условие принадлежности записывается в виде:
R (A1:ϑ1,A2:ϑ2,...), где Аi — атрибут отношения R, а ϑi — переменная домена или литерал.
Проверяемое условие истинно, если и только если существует кортеж в отношении R, имеющий атрибуты А, равные заданным в выражении соответствующим значениям ϑ.
Например, выражение SP (П# : 'S1', Д# : ‘Р1’) истинно, если в отношении SP существует хотя бы один кортеж со значением 'S1' атрибута» П# и значением ‘Р1’ атрибута Д#. Аналогично, выражение SP (П# : SX, Д# : РХ) истинно, если в отношении SP существует кортеж, в котором значение атрибута П# эквивалентно текущему значению переменной домена SX, а значение атрибута Д# эквивалентно текущему значению переменной домена РХ.
В следующих примерах будем подразумевать существование (объявленное каким-либо образом, подобно оператору RANGE исчисления кортежей) следующих переменных доменов: SX (домен П#), РХ (домен Д#), NAMEX (домен Имя).
Пример 5. Выражения исчисления доменов. (SX) WHERE S (П# : SX) (SX) WHERE S (П# : SX, Город_П : 'Москва') NAMEX WHERE EXISTS SX ( S (П#: SX, Имя : NAMEX) AND FORALL РХ (IF P (Д# : РХ ) THEN SP (П#: SX, Д#: РХ))) Первое выражение означает множество всех номеров поставщиков отношения S,
второе — множество номеров поставщиков из Лондона. Третье выражение соответствует запросу на получение имен поставщиков, производящих все детали.

6.4 Связь реляционного исчисления и реляционной алгебры Существует алгоритм («алгоритм редукции Кодда»), с помощью которого
выражение реляционного исчисления (кортежей) можно преобразовать в семантически эквивалентное выражение реляционной алгебры (т.е. реляционная алгебра и реляционное исчисление эквивалентны – каждому выражению в реляционной алгебре соответствует эквивалентное выражение в исчислении, и наоборот).
Так как реляционное исчисление носит описательный характер (описывает, что надо получить) – ближе к естественным языкам, а реляционная алгебра носит предписывающий характер (указывает, каким образом (как) должен быть получен результат) – ближе к машинным языкам, и между ними есть однозначное соответствие, то возможна компьютерная обработка запросов написанных с помощью реляционного исчисления (запрос берется у пользователя как выражение исчисления (легче описывается), к этому запросу применяется алгоритм редукции и вычисляется полученное реляционное выражение (+ оптимизация)).
Реляционно полный язык – язык по своим возможностям не уступающий реляционному исчислению или реляционной алгебре (т.е. реализующий операции эквивалентные основным операциям реляционной алгебры). Желательно чтобы в таком языке была и вычислительная полнота (наличие большинства вычислимых функций (+, -, * и т.п.)).

Лекция 7
ПРОЕКТИРОВАНИЕ РЕЛЯЦИОННЫХ БД. КОНЦЕПТУПЛЬНЫЕ МОДЕЛИ ДАННЫХ
Содержание
7.1. Проблемы проектирования 7.1.1. Избыточное дублирование данных и аномалии 7.1.2. Формирование исходного отношения 7.2. Метод нормальных форм 7.2.1. Зависимости между атрибутами 7.2.2. Нормальные формы 7.2.2.1. Первая нормальная форма (1НФ) 7.2.2.2. Вторая нормальная форма (2НФ) 7.2.2.3. Третья нормальная форма (3НФ) 7.2.2.4. Усиленная 3НФ или нормальная форма Бойса-Кодда (НФБК) 7.2.2.5. Четвертая нормальная форма (4НФ) 7.2.2.6. Пятая нормальная форма (5НФ) 7.3. Рекомендации по разработке структур 7.3.1. Какими должны быть таблицы сущностей 7.3.2. Организация связи сущностей 7.3.3. Обеспечение целостности 7.4. Концептуальные модели данных 7.4.1. Семантическое моделирование данных 7.4.2. Метод Entity-Relationship (Сущность-Связи) 7.4.2.1. Основные понятия метода 7.4.2.2. Этапы проектирования 7.4.2.3. Правила формирования отношений 7.4.2.3.1. Формирование отношений для связи 1:1 7.4.2.3.2. Формирование отношений для связи 1:М 7.4.2.3.3. Формирование отношений для связи М:М 7.4.2.4. Пример проектирования учебной части 7.4.3. EER-модель (Расширенная ER-модель) Связанные темы
Модели данных. Логическая модель данных (см. лекцию 4). Реляционная модель данных (см. лекцию 5). Средства автоматизации проектирования (см. лекцию 8). Физические модели баз данных (см. лекцию 15). 7.1 Проблемы проектирования

Проектирование информационных систем, включающих в себя базы данных, осуществляется на физическом и логическом уровнях. Решение проблем проектирования на физическом уровне зависит от используемой СУБД, зачастую автоматизировано и скрыто от пользователя. В ряде случаев пользователю предоставляется возможность настройки отдельных параметров системы, которая не составляет большой проблемы.
Логическое проектирование заключается в определении числа и структуры таблиц, формировании запросов к БД, определении типов отчетных документов, разработке алгоритмов обработки информации, создании форм для ввода и редактирования данных в базе и решении ряда других задач.
Решение задач логического проектирования БД в основном определяется спецификой задач предметной области. Наиболее важной здесь является проблема структуризации данных, на ней мы сосредоточим основное внимание.
При проектировании структур данных для автоматизированных систем можно выделить три основных подхода:
1. Сбор информации об объектах решаемой задачи в рамках одной таблицы (одного отношения) и последующая декомпозиция ее на несколько взаимосвязанных таблиц на основе процедуры нормализации отношений.
2. Формулирование знаний о системе (определение типов исходных данных и их взаимосвязей) и требований к обработке данных, получение с помощью CASE-системы (системы автоматизации проектирования и разработки баз данных) готовой схемы БД или даже готовой прикладной информационной системы.
3. Структурирование информации для использования в информационной системе в процессе проведения системного анализа на основе совокупности правил и рекомендаций.
Ниже мы рассмотрим первый из названных подходов, являющийся классическим и исторически первым. Прежде всего охарактеризуем основные проблемы, имеющие место при определении структур данных в отношениях реляционной модели.
7.1.1. Избыточное дублирование данных и аномалии Следует различать простое (неизбыточное) и избыточное дублирование данных.
Наличие первого из них допускается в базах данных, а избыточное дублирование данных может приводить к проблемам при обработке данных. Приведем примеры обоих вариантов дублирования.
Пример неизбыточного дублирования данных представляет приведенное в таблице рис. 7.1 отношение С_Т с атрибутами Сотрудник и Телефон. Для сотрудников, находящихся в одном помещении, номера телефонов совпадают. Номер телефона 4328 встречается несколько раз, хотя для каждого служащего номер телефона уникален. Поэтому ни один из номеров не является избыточным. Действительно, при удалении одного из номеров телефонов будет утеряна информация о том, по какому номеру можно дозвониться до одного из служащих.
С_Т Сотрудник Телефон Иванов 3721 Петров 4328 Сидоров 4328 Егоров 4328 Рис. 7.1. Неизбыточное дублирование
Пример избыточного дублирования (избыточности) представляет приведенное на рис.
7.2 а отношение С_Т_Н, которое, в отличие от отношения С_Т, дополнено атрибутом Н_комн (номер комнаты сотрудника). Естественно предположить, что все служащие в одной комнате имеют один и тот же телефон. Следовательно, в рассматриваемом отношении имеется

избыточное дублирование данных. Так, в связи с тем, что Сидоров и Егоров находятся в одной и той же комнате, что и Петров, их номера можно узнать из кортежа со сведениями о Петрове.
С_Т_Н С_Т_Н Сотруд Теле
н Н_ком Сотруд Теле
н Н_к
н Иванов 3721 109 Иванов 3721 109 Петров 4328 111 Петров 4328 111 Сидоро 4328 111 Сидоро ----- 111 Егоров 4328 111 Егоров ----- 111
а) б) Рис. 7.2. Избыточное дублирование
На рис. 7.2 б приведен пример неудачного отношения С_Т_Н, в котором вместо
телефонов Сидорова и Егорова поставлены прочерки (неопределенные значения). Неудачность подобного способа исключения избыточности заключается в следующем. Во-первых, при программировании придется потратить дополнительные усилия на создание механизма поиска информации для прочерков таблицы. Во-вторых, память все равно выделяется под атрибуты с прочерками, хотя дублирование данных и исключено. В-третьих, что особенно важно, при исключении из коллектива Петрова кортеж со сведениями о нем будет исключен из отношения, а значит уничтожена информация о телефоне 111-й комнаты, что недопустимо.
Возможный способ выхода из данной ситуации приведен на рисунке 7.3. Здесь показаны два отношения С_Р и Н_Т, полученные путем декомпозиции исходного отношения С_Т_Н. Первое из них содержит информацию о номерах комнат, в которых располагаются сотрудники, а второе – информацию о номерах телефонов в каждой из комнат. Теперь, если Петрова и уволят из учреждения и, как следствие этого, удалят всякую информацию о нем из баз данных учреждения, это не приведет к утрате информации о номере телефона в 111-й комнате.
Т_Н С_Н Телеф Н_ком Сотруд Н_ком 3721 109 Иванов 109 4328 111 Петров 111 Сидоро 111 Егоров 111
Рис. 7.3. Исключение избыточного дублирования
Процедура декомпозиции отношения С_Т_Н на два отношения С_Н и Н_Т является основной процедурой нормализации отношений.
Избыточное дублирование данных создает проблемы при обработке кортежей отношения, названные Э.Коддом “аномалиями обновления отношения”. Он показал, что для некоторых отношений проблемы возникают при попытке удаления, добавления или редактирования их кортежей.
Аномалиями будет называть такую ситуацию в таблицах БД, которая приводит к противоречиям в БД, либо существенно усложняют обработку данных.
Выделяют три основные вида аномалий: аномалий модификации (или редактирования), аномалий удалении и аномалий добавления.
Аномалий модификации проявляются в том, что изменение значения одного данного может повлечет за собой просмотр всей таблицы и соответствующее изменение некоторых других записей таблицы.
Так, например, изменение номера телефона в комнате 111 (рис. 7.2а), что представляет собой один единственный факт, потребует просмотра всей таблицы С_Т_Н и изменения поля Н_комн согласно текущему содержимому таблицы в записях, относящихся к Петрову, Сидорову и Егорову.

Аномалий удаления состоит в том, что при удалении какого-либо данного из таблицы может пропасть и другая информация, которая не связана напрямую с удаляемым данным.
В той же таблице С_Т_Н удаление записи о сотруднике Иванове (например, по причине увольнения или ухода на заслуженный отдых) приводит к исчезновению информации о номере телефона, установленного в 109-й комнате.
Аномалий добавления возникают в случаях, когда информацию в таблицу нельзя поместить до тех пор, пока она неполная, либо вставка новой записи требует дополнительного просмотра таблицы.
Примером может служить операция добавления нового сотрудника все в ту же таблицу С_Т_Н. Очевидно, будет противоестественным хранение сведений в этой таблице только о комнате и номере телефона в ней, пока никто из сотрудников не помещен в нее. Более того, если в таблице С_Т_Н поле Служащий является ключевым, то хранение в ней неполных записей с отсутствующей фамилией служащего просто недопустимо из-за неопределенности значения ключевого поля.
Вторым примером возникновения аномалии добавления может быть ситуация включения в таблицу нового сотрудника. При добавлении таких записей для исключения противоречий желательно проверить номер телефона и соответствующий номер комнаты хотя бы с одним из сотрудников, сидящих с новым сотрудников в той же комнате. Если же окажется, что у нескольких сотрудников, сидящих в одной комнате, имеются разные телефоны, то вообще не ясно, что делать (то ли в комнате несколько телефонов, то ли какой-то из номеров ошибочный).
7.1.2. Формирование исходного отношения Проектирование БД начинается с определения всех объектов, сведения о которых будут
включены в базу, и определения их атрибутов. Затем атрибуты сводятся в одну таблицу – исходное отношение.
Пример. Формирование исходного отношения. Предположим, что для учебной части факультета создается БД о преподавателях. На
первом этапе проектирования БД в результате общения с заказчиком (заведующим учебной частью) должны быть определены содержащиеся в базе сведения о том, как она должна использоваться и какую информацию заказчик хочет получать в процессе ее эксплуатации. В результате устанавливаются атрибуты, которые должны содержаться в отношениях БД, и связи между ними. Перечислим имена выделенных атрибутов и их краткие характеристики:
ФИО – фамилия и инициалы преподавателя. Исключаем возможность совпадения фамилии и инициалов у преподавателей.
Должн – должность, занимаемая преподавателей. Оклад – оклад преподавателем. Стаж – преподавательский стаж. Д_Стаж – надбавка за стаж. Каф - номер кафедры, на которой числится преподаватель. Предм – название предмета (дисциплины), читаемого преподавателем. Группа – номер группы, в которой преподаватель проводит занятия. ВидЗан – вид занятий, проводимых преподавателем в учебной группе. Одно из требований к отношениям заключается в том, чтобы все атрибуты отношения
имели атомарные (простые) значения. В исходном отношении каждый атрибут кортежа также должен быть простым. Пример исходного отношения ПРЕПОДАВАТЕЛЬ приведен на рис. 7.4.
Указанное отношение имеет следующую схему ПРЕПОДАВАТЕЛЬ (ФИО, Должн, Оклад, Стаж, Д_Стаж, Каф, Предм, Группа, ВидЗан).
Исходное отношение ПРЕПОДАВАТЕЛЬ содержит избыточное дублирование данных, которое и является причиной аномалий редактирования. Различают избыточность явную и неявную.
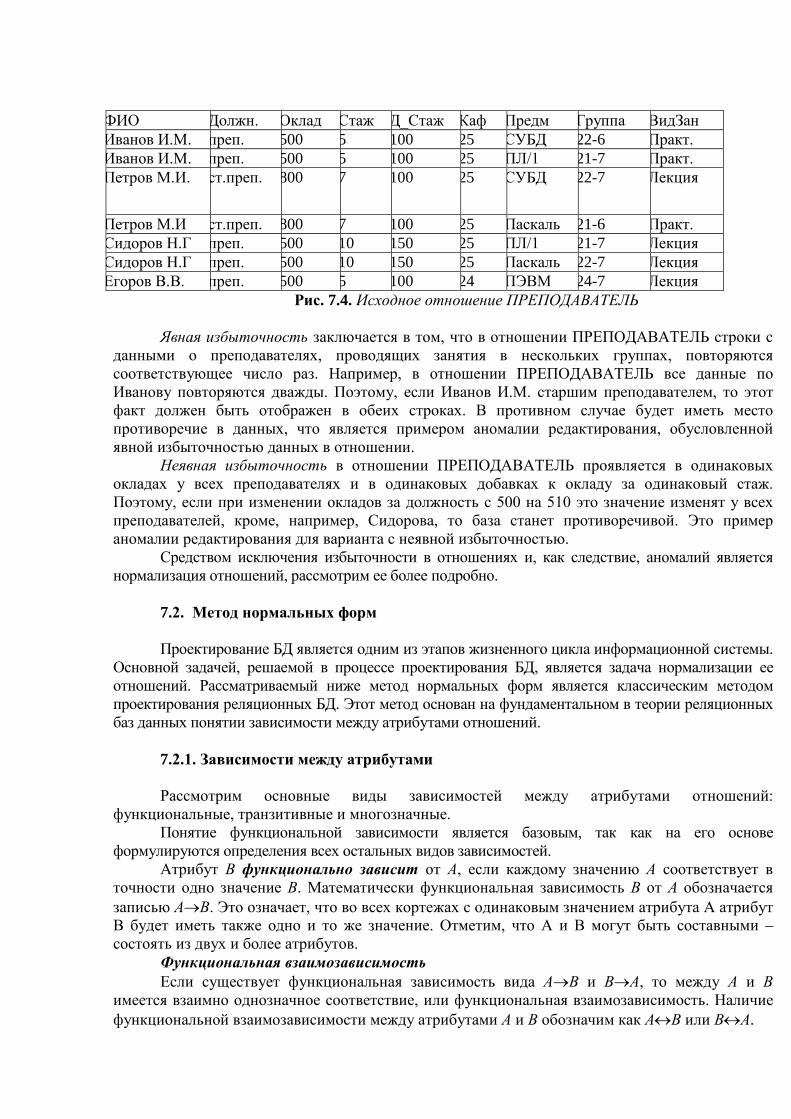
ФИО Должн. Оклад Стаж Д_Стаж Каф Предм Группа ВидЗан Иванов И.М. преп. 500 5 100 25 СУБД 22-6 Практ. Иванов И.М. преп. 500 5 100 25 ПЛ/1 21-7 Практ. Петров М.И. ст.преп. 800 7 100 25 СУБД 22-7 Лекция
Петров М.И ст.преп. 800 7 100 25 Паскаль 21-6 Практ. Сидоров Н.Г преп. 500 10 150 25 ПЛ/1 21-7 Лекция Сидоров Н.Г преп. 500 10 150 25 Паскаль 22-7 Лекция Егоров В.В. преп. 500 5 100 24 ПЭВМ 24-7 Лекция
Рис. 7.4. Исходное отношение ПРЕПОДАВАТЕЛЬ
Явная избыточность заключается в том, что в отношении ПРЕПОДАВАТЕЛЬ строки с данными о преподавателях, проводящих занятия в нескольких группах, повторяются соответствующее число раз. Например, в отношении ПРЕПОДАВАТЕЛЬ все данные по Иванову повторяются дважды. Поэтому, если Иванов И.М. старшим преподавателем, то этот факт должен быть отображен в обеих строках. В противном случае будет иметь место противоречие в данных, что является примером аномалии редактирования, обусловленной явной избыточностью данных в отношении.
Неявная избыточность в отношении ПРЕПОДАВАТЕЛЬ проявляется в одинаковых окладах у всех преподавателях и в одинаковых добавках к окладу за одинаковый стаж. Поэтому, если при изменении окладов за должность с 500 на 510 это значение изменят у всех преподавателей, кроме, например, Сидорова, то база станет противоречивой. Это пример аномалии редактирования для варианта с неявной избыточностью.
Средством исключения избыточности в отношениях и, как следствие, аномалий является нормализация отношений, рассмотрим ее более подробно.
7.2. Метод нормальных форм Проектирование БД является одним из этапов жизненного цикла информационной системы.
Основной задачей, решаемой в процессе проектирования БД, является задача нормализации ее отношений. Рассматриваемый ниже метод нормальных форм является классическим методом проектирования реляционных БД. Этот метод основан на фундаментальном в теории реляционных баз данных понятии зависимости между атрибутами отношений.
7.2.1. Зависимости между атрибутами Рассмотрим основные виды зависимостей между атрибутами отношений:
функциональные, транзитивные и многозначные. Понятие функциональной зависимости является базовым, так как на его основе
формулируются определения всех остальных видов зависимостей. Атрибут В функционально зависит от А, если каждому значению А соответствует в
точности одно значение В. Математически функциональная зависимость В от А обозначается записью А→В. Это означает, что во всех кортежах с одинаковым значением атрибута А атрибут В будет иметь также одно и то же значение. Отметим, что А и В могут быть составными – состоять из двух и более атрибутов.
Функциональная взаимозависимость Если существует функциональная зависимость вида А→В и В→А, то между А и В
имеется взаимно однозначное соответствие, или функциональная взаимозависимость. Наличие функциональной взаимозависимости между атрибутами А и В обозначим как А↔В или В↔А.

Если отношение находится в 1НФ, то все неключевые атрибуты функционально зависят от ключа с различной степенью зависимости.
Частичной зависимостью (частичной функциональной зависимостью) называется зависимость неключевого атрибута от части составного ключа.
Альтернативным вариантом является полная функциональная зависимость неключевого атрибута от всего составного ключа.
Атрибут С зависит от атрибута А транзитивно (существует транзитивная зависимость), если для атрибутов А, В, С выполняются условия А→В и В→С, но обратная зависимость отсутствует.
Между атрибутами может иметь место многозначная зависимость. В отношении R атрибут В многозначно зависит от атрибута А, если каждому значению
А соответствует множество значений В, не связанных с другими атрибутами из R. Многозначные зависимости могут быть один ко многим (1:М), многие к одному (М:1)
или многие ко многим (М:N), обозначаемые соответственно: А⇒В, А⇐В и А⇔В. Замечание В общем случае между двумя атрибутами одного отношения могут существовать
зависимости: 1:1, 1:М, М:1 и М:М. Поскольку зависимость между атрибутами является причиной аномалий, стараются расчленить отношения с зависимостями атрибутов на несколько отношений. В результате образуется совокупность связанных отношений (таблиц) со связями вида 1:1, 1:М, М:1 и М:М. Связи между таблицами отражают зависимости между атрибутами различных отношений.
Взаимно независимые атрибуты Два или более атрибута называются взаимно независимыми, если ни один из этих
атрибутов не является функционально зависимым от других атрибутов. В случае двух атрибутов отсутствие зависимости атрибута А от атрибута В можно
обозначить так: А ¬ → В. Случай, когда А¬ → В и В ¬ → А, можно обозначить А ¬ = В. Выявление зависимостей между атрибутами Выявление зависимостей между атрибутами необходимо для выполнения проектирования БД
методом нормальных форм, рассматриваемого далее. Основной способ определения наличия функциональных зависимостей – внимательный
анализ семантики атрибутов. Для каждого отношения существует, но не всегда, определенное множество функциональных зависимостей между атрибутами. Причем если в некотором отношении существует одна или несколько функциональных зависимостей, можно вывести другие функциональные зависимости, существующие в этом отношении.
Пример. Пусть задано отношение R со схемой R(A1, A2, A3) и числовыми значениями, приведенными в следующей таблице:
1 2 3 Априори известно, что в R существуют функциональные
1 4
зависимости А1→А2 и А2→А3.
1 4
Анализируя это отношение, можно увидеть, что в нем
4 3
существуют еще зависимости
5 1
А1→А3, А1А2→А3, А1А2А3→А1А2, А1А2→А2А3 и т.п.
3 5
В то же время в отношении нет других функциональных
2 2
зависимостей, что во введенных нами обозначениях можно
отразит следующим образом А2¬→А1, А3¬→А1 и т.д.

Отсутствие зависимости А1 от А2 (А2¬→А1) объясняется тем, что одному и тому же значению атрибута А2 (21) соответствуют разные значения атрибута А1 (12 и 17). Другими словами, имеет место многозначность, а не функциональность.
Перечислив все существующие функциональные зависимости в отношении R, получим полное множество функциональных зависимостей, которое обозначим +F
Таким образом, для последнего примера исходное множество F=(A1→A2, A2→A3), а полное множество +F =(А1→А2, А2→А3, А1→А3, А1А2→А3, А1А2А3→А1А2, А1А2→А2А3, …).
Для построения +F из F необходимо иметь ряд правил (или аксиом) вывода одних функциональных зависимостей из других.
Существует 8 основных аксиом вывода: рефлексивности, пополнения, транзитивности, расширения, продолжения, псевдотранзитивности, объединения и декомпозиции. Перечисленные аксиомы обеспечивают получение всех ФЗ, т.е. их совокупность применительно к процедуре вывода можно считать “функционально полной”.
Выявим зависимости между атрибутами отношения ПРЕПОДАВАТЕЛЬ, приведенного на рис. 7.4. При этом учтем следующее условие, которое выполняется в данном отношении: один преподаватель в одной группе может проводить один вид занятий (лекции или практические занятия).
В результате анализа отношения получаем зависимости между атрибутами, показанные на рис. 7.5.
б) а) ФИО→Оклад ФИО→Должн ФИО→Стаж ФИО→Д_Стаж ФИО→Каф Стаж→Д_Стаж Должн→Оклад Оклад→Должн ФИО.Предм.Группа→ВидЗан
ФИО Предм Группа
Должн
Стаж Каф ВидЗан
Оклад
Д_Стаж
Рис. 7.5. Зависимости между атрибутами К выделению этих ФЗ для рассматриваемого примера приводят следующие
соображения. Фамилия, имя, и отчество у преподавателей факультета уникальны. Каждому
преподавателю однозначно соответствует его стаж, т.е. имеет место функциональная зависимость ФИО→Стаж. Обратное утверждение неверно, так как одинаковый стаж может быть у разных преподавателей.
Каждый преподаватель имеет определенную добавку за стаж, т.е. имеет место функциональная зависимость ФИО→Д_Стаж, но обратная функциональная зависимость отсутствует, так как одну и ту же надбавку могут иметь несколько преподавателей.
Каждый преподаватель имеет определенную должность, но одну и ту же должность могут иметь несколько преподавателей, т.е. имеет место функциональная зависимость ФИО→Должн, а обратная функциональная зависимость отсутствует.
Каждый преподаватель является сотрудником одной и только одной кафедры. Поэтому функциональная зависимость ФИО→Каф имеет место. С другой стороны, на каждой кафедре много преподавателей, поэтому обратной функциональной зависимости нет.
Каждому преподавателю соответствует конкретный оклад, который одинаков для всех педагогов с одинаковыми должностями, что учитывается зависимостями ФИО→Оклад и Должн→Оклад.

Нами не были выделены зависимости между функциональными зависимостями между атрибутами ФИО, Предм и Группа, поскольку они образуют составной ключ и не учитываются в процессе нормализации исходного отношения.
После того, как выделены все функциональные зависимости, следует проверить их согласованность с данными исходного отношения ПРЕПОДАВАТЕЛЬ (рисунок 7.5.).
7.2.2. Нормальные формы Процесс проектирования БД с использованием метода нормальных форм является
итерационным и заключается в последовательном переводе отношений из первой нормальной формы в нормальные формы более высокого порядка по определенным правилам. Каждая следующая нормальная форма ограничивает определенный тип функциональных зависимостей, устраняет соответствующие аномалии при выполнении операций над отношениями БД и сохраняет свойства предшествующих нормальных форм.
Выделяют следующую последовательность нормальных форм: - первая нормальная форма (1НФ); - вторая нормальная форма (2НФ); - третья нормальная форма (3НФ); - усиленная третья нормальная форма, или нормальная форма Бойса-Кодда (НФБК); - четвертая нормальная форма (4НФ); - пятая нормальная форма (5НФ). 7.2.2.1. Первая нормальная форма (1НФ) Отношение находится в 1НФ, если все его атрибуты являются простыми (имеют
единственное значение). Исходное отношение строится таким образом, чтобы оно было в 1НФ. Перевод отношения в следующую нормальную форму осуществляется методом
“декомпозиции без потерь”. Такая декомпозиция должна обеспечить то, что запросы (выборка данных по условию) к исходному отношению и к отношениям, получаемым в результате декомпозиции, дадут одинаковый результат.
Основной операцией метода является операция проекции. Поясним ее на примере. Предположим, что в отношении R(A,B,C,D,E,...) устранение функциональной зависимости C→D позволит перевести его в следующую нормальную форму. Для решения этой задачи выполним декомпозицию отношения R на два новых отношения R1(A,B,C,E, ...) и R2(C,D). Отношение R2 является проекцией отношения R на атрибуты C и D.
Исходное отношение ПРЕПОДАВАТЕЛЬ, используемое для иллюстрации метода, имеет составной ключ ФИО,Предм.Группа и находится в 1НФ, поскольку все его атрибуты простые.
В этом отношении в соответствии с рис.6.5 б можно выделить частичную зависимость атрибутов Стаж, Д_Стаж, Каф, Должн, Оклад от ключа – указанные атрибуты находятся в функциональной зависимости от атрибута ФИО, являющегося частью составного ключа.
Эта частичная зависимость от ключа приводит к следующему: 1. В отношении присутствует явное и неявное избыточное дублирование данных,
например: • повторение сведений о стаже, должности и окладе преподавателей, проводящих
занятия в нескольких группах и/или по разным предметам; • повторение сведений об окладах для одной и той же должности или о надбавках
за одинаковый стаж. 2. Следствием избыточного дублирования данных является проблема их редактирования.
Например, изменение должности у преподавателя Иванова И.М. потребует просмотра всех

кортежей отношения и внесения изменений в те из них, которые содержат сведения о данном преподавателе.
Часть избыточности устраняется при переводе отношения во 2НФ. 7.2.2.2. Вторая нормальная форма (2НФ) Отношение находится во 2НФ, если оно находится в 1НФ и каждый неключевой атрибут
функционально полно зависит от первичного ключа (составного). Для устранения частичной зависимости и перевода отношения во 2НФ необходимо,
используя операцию проекции, разложить его на несколько отношений следующим образом: • построить проекцию без атрибутов, находящихся в частичной функциональной
зависимости от первичного ключа; • построить проекции на части составного первичного ключа и атрибуты,
зависящие от этих частей. В результате получим два отношения R1 и R2 во 2НФ (рис. 7.6).
R2
ФИО Должн Оклад Стаж Д_Стаж Каф Иванов И.М Преп 500 5 100 25 Петров М.И. Ст.преп 800 7 100 25 Сидоров Н.Г. Преп 500 10 150 25 Егоров В.В. Преп 500 5 100 24
ФИО Должн
Стаж
Д_Стаж Каф
ФИО Предм Группа ВидЗан Иванов И.М СУБД 256 Практ Иванов И.М ПЛ/1 123 Практ Петров М.И. СУБД 256 Лекция Петров М.И. Паскаль 256 Практ Сидоров Н.Г. ПЛ/1 123 Лекция Сидоров Н.Г. Паскаль 256 Лекция Егоров В.В. ПЭВМ 244 Лекция
ФИО Предм Группа
ВидЗан
R1 а) б)
Оклад
Рис. 7.6. Отношение БД во 2НФ
В отношении R1 первичный ключ является составным и состоит из атрибутов ФИО, Предм, Группа. Напомним, что данный ключ в отношении R1 получен в предположении, что каждый преподаватель в одной группе по одному предмету может либо читать лекции, либо проводить практические занятия. В отношении R2 ключ ФИО.
Исследование R1 и R2 показывает, что переход ко 2НФ позволил исключить явную избыточность данных в таблице R2 – повторение строк со сведениями о преподавателях. В R2 по-прежнему имеет место неявное дублирование данных.
Для дальнейшего совершенствования отношения необходимо преобразовать его в 3НФ. 7.2.2.3. Третья нормальная форма (3НФ) Определение 1. Отношение находится в 3НФ, если оно находится во 2НФ и каждый
неключевой атрибут нетранзитивно зависит от первичного ключа. Существует и альтернативное определение. Определение 2. Отношение находится в 3НФ в том и только в том случае, если все
неключевые атрибуты отношения взаимно независимы и полностью зависят от первичного ключа.

Доказать справедливость этого утверждения несложно. Действительно, то, что неключевые атрибуты полностью зависят от первичного ключа, означает, что данное отношение находится в форме 2НФ. Взаимная независимость атрибутов (определение приведено выше) означает отсутствие всякой зависимости между атрибутами отношения, в том числе и транзитивной зависимости между ними. Таким образом, второе определение 3НФ сводится к первому определению.
Если в отношении R1 транзитивные зависимости отсутствуют, то в отношении R2 они есть:
ФИО→Долж→Оклад, ФИО→ Оклад →Долж, ФИО→ Стаж →Д_Стаж. Транзитивные зависимости также порождает избыточное дублирование информации в
отношении. Устраним их. Для этого, используя операцию проекции на атрибуты, являющиеся причиной транзитивных зависимостей, преобразуем отношение R2, получив при этом отношения R3, R4 и R5, каждое из которых находится в 3НФ (рис. 7.7а). Графически эти отношения представлены на рис. 7.7б. Заметим, что отношение R2 можно преобразовать по-другому, а именно: в отношении R3 вместо атрибута Должн взять атрибут Оклад.
На практике построение 3НФ схем отношений в большинстве случаев является достаточным и приведением к ним процесс проектирования реляционной БД заканчивается. Действительно, приведение отношений к 3НФ в нашем примере, привело к устранению избыточного дублирования.
Если в отношении имеется зависимость атрибутов составного ключа от неключевых атрибутов, то необходимо перейти к усиленной 3НФ.
ФИО Должн Стаж Каф Иванов И.М. Преп 5 25 Петров М.И. Ст.преп 7 25 Сидоров Н.Г. Преп 10 25 Егоров В.В. Преп 5 24
R3
R4
Должн Оклад Преп 500 Ст.преп 800
Стаж Д_Стаж 5 100 7 100 10 150
а) б)
ФИО Стаж
Должн
Каф
Должн Оклад
Стаж Д_Стаж
Рис. 7.7. Отношение БД в 3НФ
7.2.2.4. Усиленная 3НФ или нормальная форма Бойса-Кодда (НФБК) Отношение находится в нормальной форме Бойса-Кодда (НФБК), если оно находится в
3НФ и в нем отсутствуют зависимости (атрибутов составного ключа) ключей от неключевых атрибутов.
У нас подобной зависимости нет, поэтому процесс проектирования на этом заканчивается. Результатом проектирования является БД, состоящая из следующих таблиц: R1,
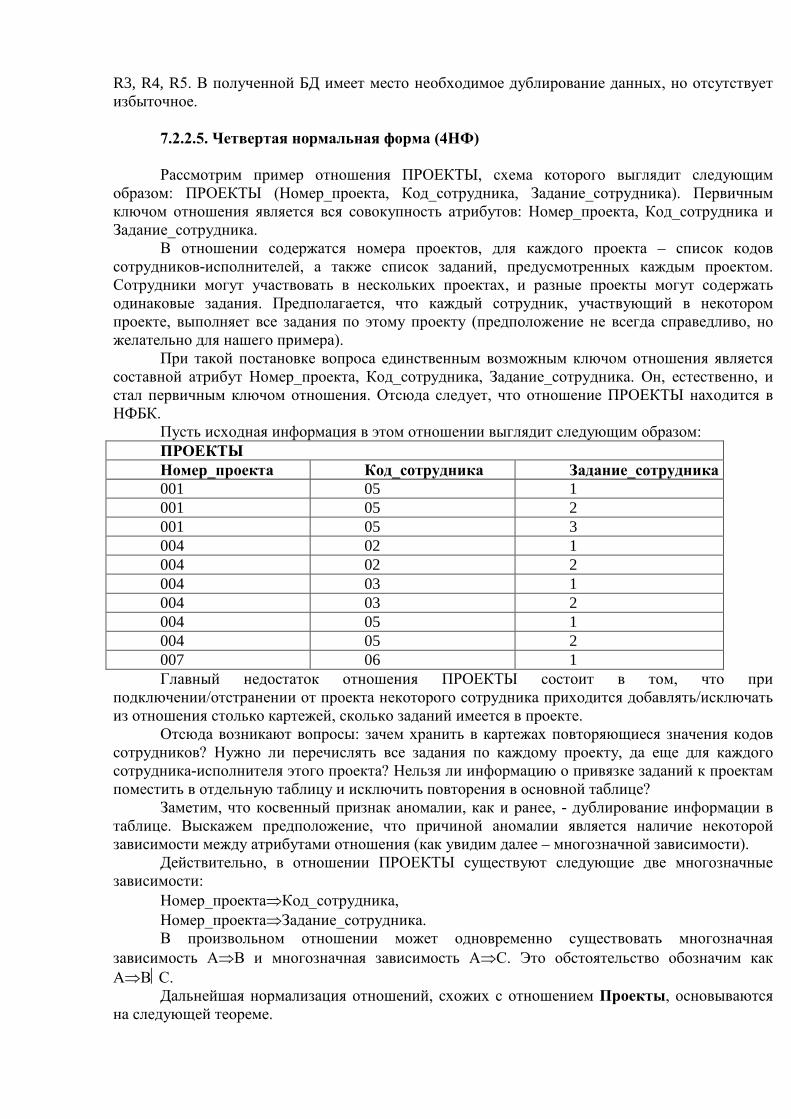
R3, R4, R5. В полученной БД имеет место необходимое дублирование данных, но отсутствует избыточное.
7.2.2.5. Четвертая нормальная форма (4НФ) Рассмотрим пример отношения ПРОЕКТЫ, схема которого выглядит следующим
образом: ПРОЕКТЫ (Номер_проекта, Код_сотрудника, Задание_сотрудника). Первичным ключом отношения является вся совокупность атрибутов: Номер_проекта, Код_сотрудника и Задание_сотрудника.
В отношении содержатся номера проектов, для каждого проекта – список кодов сотрудников-исполнителей, а также список заданий, предусмотренных каждым проектом. Сотрудники могут участвовать в нескольких проектах, и разные проекты могут содержать одинаковые задания. Предполагается, что каждый сотрудник, участвующий в некотором проекте, выполняет все задания по этому проекту (предположение не всегда справедливо, но желательно для нашего примера).
При такой постановке вопроса единственным возможным ключом отношения является составной атрибут Номер_проекта, Код_сотрудника, Задание_сотрудника. Он, естественно, и стал первичным ключом отношения. Отсюда следует, что отношение ПРОЕКТЫ находится в НФБК.
Пусть исходная информация в этом отношении выглядит следующим образом: ПРОЕКТЫ Номер_проекта Код_сотрудника Задание_сотрудника 001 05 1 001 05 2 001 05 3 004 02 1 004 02 2 004 03 1 004 03 2 004 05 1 004 05 2 007 06 1 Главный недостаток отношения ПРОЕКТЫ состоит в том, что при
подключении/отстранении от проекта некоторого сотрудника приходится добавлять/исключать из отношения столько картежей, сколько заданий имеется в проекте.
Отсюда возникают вопросы: зачем хранить в картежах повторяющиеся значения кодов сотрудников? Нужно ли перечислять все задания по каждому проекту, да еще для каждого сотрудника-исполнителя этого проекта? Нельзя ли информацию о привязке заданий к проектам поместить в отдельную таблицу и исключить повторения в основной таблице?
Заметим, что косвенный признак аномалии, как и ранее, - дублирование информации в таблице. Выскажем предположение, что причиной аномалии является наличие некоторой зависимости между атрибутами отношения (как увидим далее – многозначной зависимости).
Действительно, в отношении ПРОЕКТЫ существуют следующие две многозначные зависимости:
Номер_проекта⇒Код_сотрудника, Номер_проекта⇒Задание_сотрудника. В произвольном отношении может одновременно существовать многозначная
зависимость А⇒В и многозначная зависимость А⇒С. Это обстоятельство обозначим как А⇒ВС.
Дальнейшая нормализация отношений, схожих с отношением Проекты, основываются на следующей теореме.

Теорема Фейджина (Fagin R.). Отношение R(A,B,C) можно спроецировать без потерь в отношения R1(A,B) и R2(A,C) в том и только в том случае, когда существует зависимость А⇒ВС.
Под проецированием без потерь здесь понимается такой способ декомпозиции отношения, при котором исходное отношение полностью и без избыточности восстанавливается путем естественного соединения полученных отношений.
Поясним проецирование без потерь на примере. Имеем простейшее отношение R(A,B,C), построим проекции R1 и R2 на атрибуты A,B и
A,C соответственно (отношение R и проекции R1 и R2 представлены ниже). R2 А С К 1 К 2 Л 1 М 1
М М Результатом операции соединения бинарных отношений R1(А,В) и R2(А,С) по атрибуту
А является тернарное отношение с атрибутами А, В, и С, кортежи которого получаются путем связывания отношений R1 и R2 по типу 1:М на основе совпадения значений атрибута А.
Так, связывание кортежей (К,15) и {(К,1),(К,2)} дает кортежи {(К,15,1), (К,15,2)}. Нетрудно видеть, что связывание R1(А,В) и R2(А,С) в точности порождает исходное
отношение R(А,В,С). В отношении R нет лишних кортежей, нет и потерь. Определение четвертой нормальной формы. Отношение R находится в четвертой
нормальной форме (4НФ) в том и только в том случае, когда существует многозначная зависимость А⇒В, а все остальные атрибуты R функционально зависят от А.
Приведенное выше отношение ПРОЕКТЫ можно представить в виде двух отношений: ПРОЕКТЫ_СОТРУДНИКИ и ПРОЕКТЫ_ЗАДАНИЯ. Эти отношения имеют следующую структуру:
ПРОЕКТЫ_СОТРУДНИКИ (Номер_проекта, Код_сотрудника), Первичный ключ отношения: Номер_проекта, Код_сотрудника. ПРОЕКТЫ_ЗАДАНИЯ (Номер_проекта, Задание_сотрудника), Первичный ключ отношения: Номер_проекта, Задание_сотрудника. Содержимое соответствующих таблиц будет теперь таким: ПРОЕКТЫ_ЗАДАНИЯ ПРОЕКТЫ_СОТРУДНИКИ Номер_про
а Задание_сотрудни Номер_про
а Код_сотрудн
а 001 1 001 05 001 2 004 02 001 3 004 03 004 1 004 05 004 2 007 06 007 1 Как легко увидеть, оба этих отношения находятся в 4НФ и свободны от замеченных
недостатков. Дублирование значений атрибутов кодов сотрудников пропало. Попробуйте самостоятельно соединить эти отношения и убедиться в том, что в точности получится отношение ПРОЕКТЫ.
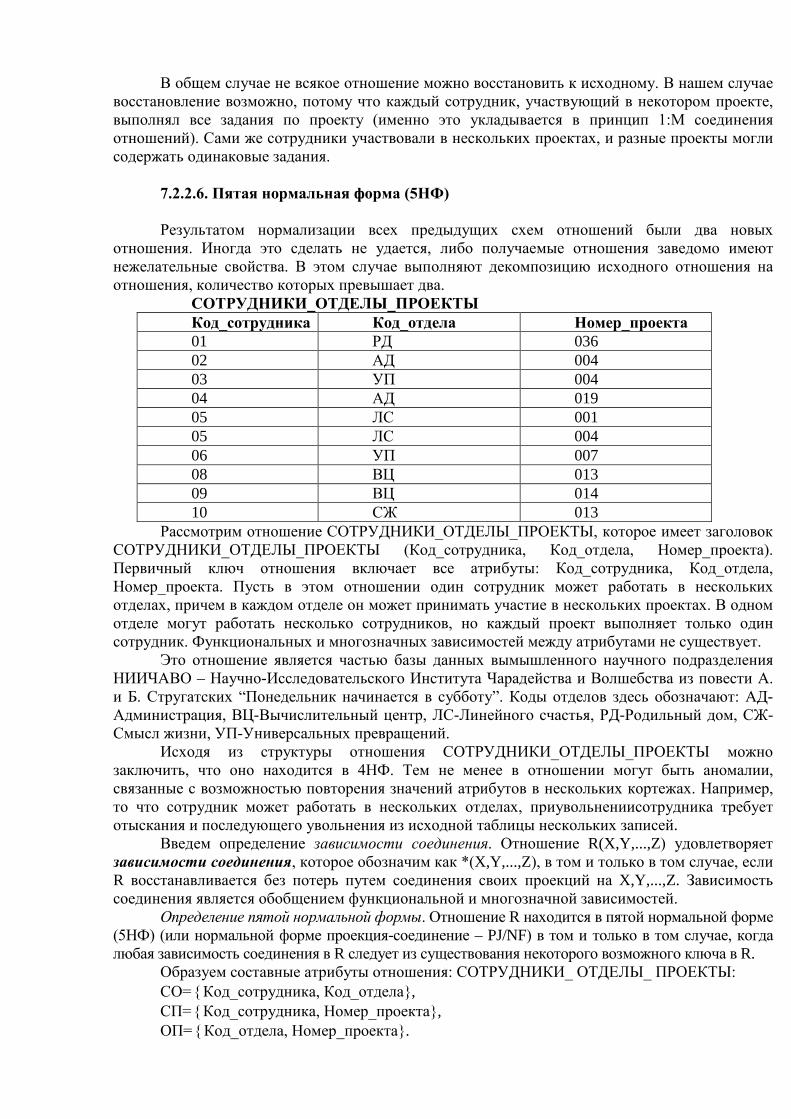
В общем случае не всякое отношение можно восстановить к исходному. В нашем случае восстановление возможно, потому что каждый сотрудник, участвующий в некотором проекте, выполнял все задания по проекту (именно это укладывается в принцип 1:М соединения отношений). Сами же сотрудники участвовали в нескольких проектах, и разные проекты могли содержать одинаковые задания.
7.2.2.6. Пятая нормальная форма (5НФ) Результатом нормализации всех предыдущих схем отношений были два новых
отношения. Иногда это сделать не удается, либо получаемые отношения заведомо имеют нежелательные свойства. В этом случае выполняют декомпозицию исходного отношения на отношения, количество которых превышает два.
СОТРУДНИКИ_ОТДЕЛЫ_ПРОЕКТЫ Код_сотрудника Код_отдела Номер_проекта 01 РД 036 02 АД 004 03 УП 004 04 АД 019 05 ЛС 001 05 ЛС 004 06 УП 007 08 ВЦ 013 09 ВЦ 014 10 СЖ 013
Рассмотрим отношение СОТРУДНИКИ_ОТДЕЛЫ_ПРОЕКТЫ, которое имеет заголовок СОТРУДНИКИ_ОТДЕЛЫ_ПРОЕКТЫ (Код_сотрудника, Код_отдела, Номер_проекта). Первичный ключ отношения включает все атрибуты: Код_сотрудника, Код_отдела, Номер_проекта. Пусть в этом отношении один сотрудник может работать в нескольких отделах, причем в каждом отделе он может принимать участие в нескольких проектах. В одном отделе могут работать несколько сотрудников, но каждый проект выполняет только один сотрудник. Функциональных и многозначных зависимостей между атрибутами не существует.
Это отношение является частью базы данных вымышленного научного подразделения НИИЧАВО – Научно-Исследовательского Института Чарадейства и Волшебства из повести А. и Б. Стругатских “Понедельник начинается в субботу”. Коды отделов здесь обозначают: АД-Администрация, ВЦ-Вычислительный центр, ЛС-Линейного счастья, РД-Родильный дом, СЖ-Смысл жизни, УП-Универсальных превращений.
Исходя из структуры отношения СОТРУДНИКИ_ОТДЕЛЫ_ПРОЕКТЫ можно заключить, что оно находится в 4НФ. Тем не менее в отношении могут быть аномалии, связанные с возможностью повторения значений атрибутов в нескольких кортежах. Например, то что сотрудник может работать в нескольких отделах, приувольнениисотрудника требует отыскания и последующего увольнения из исходной таблицы нескольких записей.
Введем определение зависимости соединения. Отношение R(X,Y,...,Z) удовлетворяет зависимости соединения, которое обозначим как *(X,Y,...,Z), в том и только в том случае, если R восстанавливается без потерь путем соединения своих проекций на X,Y,...,Z. Зависимость соединения является обобщением функциональной и многозначной зависимостей.
Определение пятой нормальной формы. Отношение R находится в пятой нормальной форме (5НФ) (или нормальной форме проекция-соединение – PJ/NF) в том и только в том случае, когда любая зависимость соединения в R следует из существования некоторого возможного ключа в R.
Образуем составные атрибуты отношения: СОТРУДНИКИ_ ОТДЕЛЫ_ ПРОЕКТЫ: СО= {Код_сотрудника, Код_отдела}, СП= {Код_сотрудника, Номер_проекта}, ОП= {Код_отдела, Номер_проекта}.
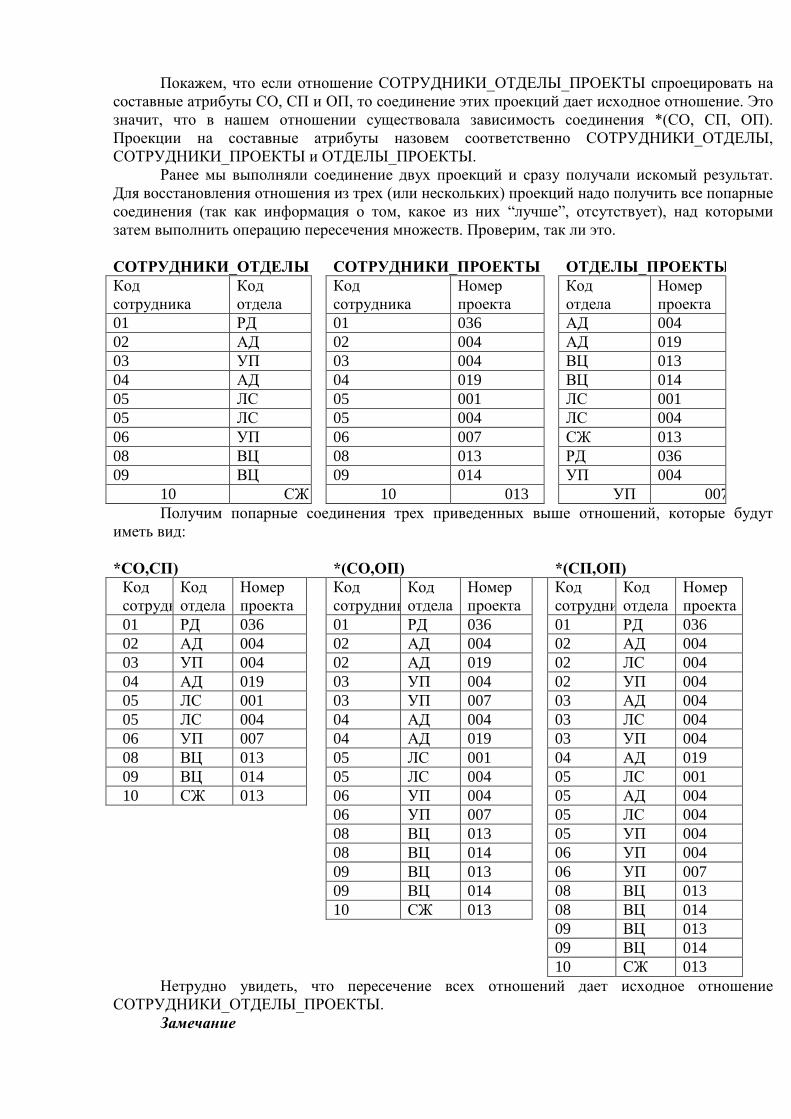
Покажем, что если отношение СОТРУДНИКИ_ОТДЕЛЫ_ПРОЕКТЫ спроецировать на составные атрибуты СО, СП и ОП, то соединение этих проекций дает исходное отношение. Это значит, что в нашем отношении существовала зависимость соединения *(СО, СП, ОП). Проекции на составные атрибуты назовем соответственно СОТРУДНИКИ_ОТДЕЛЫ, СОТРУДНИКИ_ПРОЕКТЫ и ОТДЕЛЫ_ПРОЕКТЫ.
Ранее мы выполняли соединение двух проекций и сразу получали искомый результат. Для восстановления отношения из трех (или нескольких) проекций надо получить все попарные соединения (так как информация о том, какое из них “лучше”, отсутствует), над которыми затем выполнить операцию пересечения множеств. Проверим, так ли это.
СОТРУДНИКИ_ОТДЕЛЫ СОТРУДНИКИ_ПРОЕКТЫ ОТДЕЛЫ_ПРОЕКТЫ Код сотрудника
Код отдела
Код сотрудника
Номер проекта
Код отдела
Номер проекта
01 РД 01 036 АД 004 02 АД 02 004 АД 019 03 УП 03 004 ВЦ 013 04 АД 04 019 ВЦ 014 05 ЛС 05 001 ЛС 001 05 ЛС 05 004 ЛС 004 06 УП 06 007 СЖ 013 08 ВЦ 08 013 РД 036 09 ВЦ 09 014 УП 004
10 СЖ 10 013 УП 007 Получим попарные соединения трех приведенных выше отношений, которые будут
иметь вид:
*СО,СП) *(СО,ОП) *(СП,ОП) Код сотрудн
Код отдела
Номер проекта
Код сотрудник
Код отдела
Номер проекта
Код сотрудни
Код отдела
Номер проекта
01 РД 036 01 РД 036 01 РД 036 02 АД 004 02 АД 004 02 АД 004 03 УП 004 02 АД 019 02 ЛС 004 04 АД 019 03 УП 004 02 УП 004 05 ЛС 001 03 УП 007 03 АД 004 05 ЛС 004 04 АД 004 03 ЛС 004 06 УП 007 04 АД 019 03 УП 004 08 ВЦ 013 05 ЛС 001 04 АД 019 09 ВЦ 014 05 ЛС 004 05 ЛС 001 10 СЖ 013 06 УП 004 05 АД 004
06 УП 007 05 ЛС 004 08 ВЦ 013 05 УП 004 08 ВЦ 014 06 УП 004 09 ВЦ 013 06 УП 007 09 ВЦ 014 08 ВЦ 013 10 СЖ 013 08 ВЦ 014 09 ВЦ 013 09 ВЦ 014 10 СЖ 013 Нетрудно увидеть, что пересечение всех отношений дает исходное отношение
СОТРУДНИКИ_ОТДЕЛЫ_ПРОЕКТЫ. Замечание

Существуют и другие способы восстановления исходного отношения из его проекций. Так, для восстановления отношения СОТРУДНИКИ_ОТДЕЛЫ_ПРОЕКТЫ можно соединить отношения СОТРУДНИКИ_ОТДЕЛЫ и СОТРУДНИКИ_ПРОЕКТЫ по атрибуту Код_сотрудника, после чего полученное отношение соединить с отношением ОТДЕЛЫ_ПРОЕКТЫ по составному атрибуту (Код_отдела, Номер_проекта).
Отношения СОТРУДНИКИ_ОТДЕЛЫ, СОТРУДНИКИ_ПРОЕКТЫ и ОТДЕЛЫ_ПРОЕКТЫ находятся в 5НФ. Эта форма является последней из известных. Условия ее получения довольно нетривиальны и поэтому она почти не используется на практике. Более того, она имеет определенные недостатки!
Предположим, необходимо узнать, где и какие проекты исполняет сотрудник с кодом 02. Для этого в отношении СОТРУДНИКИ_ОТДЕЛЫ найдем, что сотрудник с кодом 02 работает в отделе АД, а из отношения ОТДЕЛЫ_ПРОЕКТЫ найдем, что в отделе АД выполняются проекты 004 и 019. А это значит, что сотрудник 02 должен выполнять проекты 004 и 019. Увы, информация о том, что сотрудник с кодом 02 выполняет проект 019 ошибочна (см. исходное отношение СОТРУДНИКИ_ОТДЕЛЫ_ПРОЕКТЫ).
Такие противоречия можно устранить только путем совместного рассмотрения всех проекций основного отношения. Именно поэтому после соединения проекций и выполнялась операция их пересечения. Безусловно, это – недостаток. Отметим, что наличие недостатков не требует обязательного отказа от определенных видов нормальных форм. Надо учитывать недостатки и условия их проявления. В некоторых постановках задач недостатки не проявляются.
На практике обычно ограничиваются структурой БД, соответствующей 3НФ или НФБК. Поэтому процесс нормализации отношений методом нормальных форм предполагает последовательное удаление из исходного отношения следующих межатрибутных зависмостей:
• частичных зависимостей неключевых атрибутов от ключа (удовлетворение требований 2НФ);
• транзитивных зависимостей неключевых атрибутов от ключа (удовлетворение требований 3НФ);
• зависимости ключей (атрибутов составных ключей) от неключевых атрибутов (удовлетворение требований НФБК).
Кроме метода нормальных форм Кодда, используемого для проектирования небольших БД, применяют и другие методы, например, метод ER-диаграмм (метод “Сущность-связь”). Этот метод используется при проектировании больших БД, на нем основан ряд средств проектирования БД. Метод ER-диаграмм рассматривается в следующем разделе.
На последнем этапе метода ER-диаграмм отношения, полученные в результате проектирования, проверяются на принадлежность их к НФБК. Этот этап может выполняться уже с использованием метода нормальных форм. После завершения проектирования создается БД с помощью СУБД.
7.3. Рекомендации по разработке структур В качестве обобщения материала предыдущего подраздела приведем наиболее важные
рекомендации, не учет которых может привести к аномалиям при обработке данных в базах. Остановимся на двух вопросах:
• исходя из каких соображений нужно создавать отношения (таблицы), • каким образом следует их (таблицы) связывать. 7.3.1. Какими должны быть таблицы сущностей Основное правило при создании таблиц сущностей – это “каждой сущности – отдельную
таблицу” (как в популярном лозунге: “каждой семье – отдельную квартиру”).

Поля таблиц сущностей могут быть двух видов: ключевые и неключевые. Введение ключей в таблице практически во всех реляционных СУБД позволяет обеспечить уникальность значений в записях таблицы по ключу, ускорить обработку записей таблицы, а также выполнить автоматическую сортировку записей по значениям в ключевых полях.
Обычно достаточно определения простого ключа, реже – вводят составной ключ. Таблицей с составным ключом может быть, например, таблица хранения списка сотрудников (фамилия, имя и отчество), в котором встречаются однофамильцы. В некоторых СУБД пользователем предполагается определить автоматически создаваемое ключевое поле нумерации (в Access – это поле типа “счетчик”), которое упрощает решение проблемы уникальности записей таблицы.
Иногда в таблицах сущностей имеются поля описания свойств или характеристик объектов. Если в таблице есть значительное число повторений по этим полям и эта информация имеет существенный объем, то лучше их выделить в отдельную таблицу (придерживаясь правила: “каждой сущности – отдельную таблицу”). Тем более, следует образовать доплнительную таблицу, если свойства взаимосвязаны.
В более общем виде последние рекомендации можно сформулировать так: информацию о сущностях следует представить таким образом, чтобы неключевые поля в таблицах были взаимно независимыми и полностью зависели от ключа (см. определение 3НФ).
В процессе обработки таблиц сущностей надо иметь в виду следующее. Новую сущность легко добавить и изменить, но при удалении – следует уничтожить все ссылки на нее из таблиц связей, иначе таблицы связей будут некорректными. Многие современные СУБД блокируют некорректные действия в подобных операциях.
7.3.2. Организация связи сущностей Записи таблицы связей предназначены для отображения связей между сущностями,
информация о которых находится в соответствующих таблицах сущностей. Обычно одна таблица связей описывает взаимосвязь двух сущностей. Поскольку
таблицы сущностей в простейшем случае имеют по одному ключевому полю, то таблица связей двух таблиц для обеспечения уникальности записей о связях должна иметь два ключа. Можно создать таблицу связей, как и таблицу объектов, и без ключей, но тогда функции контроля за уникальностью записей ложатся на пользователя.
Более сложные связи (не бинарные) следует сводить к бинарным. Для описания взаимосвязей N объектов требуется N+1 таблиц связей. Транзитивных связей не должно быть. Избыток связей приводит к противоречиям (см. пример отношений СОТРУДНИКИ-ОТДЕЛЫ, СОТРУДНИКИ-ПРОЕКТЫ и ОТДЕЛЫ-ПРОЕКТЫ предыдущего подраздела).
Не следует включать в таблицы связей характеристики сущностей, иначе неизбежны аномалии. Их лучше хранить в отдельных таблицах сущностей.
С помощью таблиц связей можно описывать и несколько специфичный вид связи – линейную связь, или слабую связь. Примером линейной можно считать отношение принадлежности сущностей некоторой другой сущности более высокого порядка (системы, состоящие из узлов; лекарства, состоящие из компонентов; сплавы металлов и т.д.). В этом случае для описания связей достаточно одной таблицы связей.
При работе с таблицами связей следует иметь в виду, что любая запись из таблицы связей легко может быть удалена, поскольку сущности некоторое время могут обойтись и без связей. При добавлении или изменении содержимого записей таблицы надо контролировать правильность ссылок на существующие объекты, так как связь без объектов существовать не может. Большинство современных СУБД контролируют правильность ссылок на объекты.
7.3.3. Обеспечение целостности

Под целостностью понимают свойство базы данных, означающее, что она содержит полную, непротиворечивую и адекватно отражающую предметную область информацию.
Различают физическую и логическую целостность. Физическая целостность означает наличие физического доступа к данным и то, что данные не утрачены. Логическая целостность означает отсутствие логических ошибок в базе данных, к которым относятся нарушение структуры БД или ее объектов, удаление или изменение установленных связей между объектами и т.д. В дальнейшем речь будет вести о логической целостности.
Поддержание целостности БД включает проверку (контроль) целостности и ее восстановление в случае обнаружения противоречий в базе. Целостное состояние БД задается с помощью ограничений целостности в виде условий, которым должны удовлетворять хранимые в базе данные.
Среди ограничений целостности можно выделить два основных типа ограничений: ограничений значений атрибутов отношений и структурные ограничения на кортежи отношений.
Примером ограничений значений атрибутов отношений является требование недопустимости пустых или повторяющихся значений в атрибутах, а также контроль принадлежности значений атрибутов заданному диапазону. Так, в записях отношений о кадрах значения атрибута Дата_рождения не могут превышать значений атрибута Дата_приема.
Наиболее гибким средством реализации контроля значений атрибутов являются хранимые процедуры и триггеры, имеющиеся в некоторых СУБД.
Структурные ограничения определяют требования целостности сущностей и целостности ссылок. Каждому экземпляру сущности, представленному в отношении, соответствует только один его кортеж. Требование целостности сущностей состоит в том, что любой кортеж отношения должен быть отличным от любого другого кортежа этого отношения, т.е. иными словами, любое отношение должно обладать первичным ключом.
Формулировка требования и целостности ссылок тесно связана с понятием внешнего ключа. Напомним, что внешние ключи служат для связи отношений (таблиц БД) между собой. При этом атрибут одного отношения (родительского) называется внешним ключом данного отношения, если он является первичным ключом другого отношения (дочернего). Говорят, что отношение, в котором определен внешний ключ, ссылается на отношение, в котором этот же атрибут является первичным ключом.
Требование целостности ссылок состоит в том, что для каждого значения внешнего ключа родительской таблицы должна найтись строка в дочерней таблице с таким же значением первичного ключа. Например, если в отношении R1 (рис. 7.8) содержатся сведения о сотрудниках кафедры, а атрибут этого отношения Должн является первичным ключом отношения R2, то в этом отношении для каждой должности из R1 должна быть строка с соответствующим ей окладом.
Во многих современных СУБД имеются средства обеспечения контроля целостности БД. Родительская таблица Дочерняя таблица R1 R2 ФИО Долж Ка Ст Долж Оклад Иванов И.М преп 25 5 преп 500 Петров М.И. ст.пр 25 7 ст.пре 800 Сидоров Н.Г преп 25 10 Егоров В.В. преп 24 5
Рис. 7.8. Связь отношений с помощью внешнего ключа

7.4. Концептуальные модели данных 7.4.1. Семантическое моделирование данных Семантическое моделирование данных – область исследований о способах
представления смыслового значения данных. Это направление получило интенсивное развитие в конце 1970-х, мотив - для расширения понимания смыслового значения данных (хотелось бы, чтобы СУБД была более «разумной» и могла понимать что «вес товара» и «количество поставок» являются хотя и числовыми, но все же семантически разными величинами).
Общий подход к проблеме семантического моделирования состоит из четырех этапов: 1) Задание множества семантических концепций (понятий), которые полезны при
обсуждении реального мира: мир состоит из объектов (определяются интуитивно); для объектов есть разделение на типы объектов (обобщенное определение группы однотипных объектов) и экземпляры объектов (конкретный объект из группы); все объекты определенного типа обладают общими свойствами, и существует такое свойство (свойства), которое позволяет различать объекты в группе (т.е. каждый объект обладает идентичностью); группы объектов могут связываться с другими группами объектов с помощью отношений.
2) Определение множества соответствующих символических (т.е. формальных) объектов, которые могут быть использованы для представления определенных выше семантических концепций (однако разные пользователи могут рассматривать один и тот же предмет реального мира по-разному (как объект, как свойство или как отношение) – гибкость интерпретации данных в семантическом моделировании).
3) Вывод множества формальных правил целостности для работы с формальными объектами.
4) Задание множества формальных операторов для манипулирования формальными объектами (однако, с точки зрения проектировщика БД, операторы являются менее важной частью модели по сравнению с объектами и правилами целостности).
Идеи семантического моделирования могут быть полезны при проектировании БД даже при отсутствии непосредственной поддержки этих идей в СУБД – при проектировании макета БД. Методологии проектирования, основанные на идеях семантического моделирования, называются нисходящими методологиями, т.к. они начинаются на высшем уровне абстракции с конструкций «реального мира» (объектов), а заканчиваются на сравнительно низком уровне абстракции, представленном конкретной структурой БД.
7.4.2. Метод Entity-Relationship («Сущность-Связь» или «объект/отношение»)
ER-модель была предложена Ченом (Chen P.P.) в 1976 г и представляет собой высокоуровневую концептуальную модель данных (основана на идеях семантического моделирования, содержит набор концепций, которые описывают структуру данных и связанные с ней транзакции обновления и извлечения данных, не зависящие от конкретной СУБД или аппаратной платформы).
Основа популярности модели – наличие диаграммной техники (ER-диаграмм) – графического представления логической структуры БД (используются в качестве основы для методики проектирования БД, причем диаграмма может не включать в себя все идеи ER-модели).
Метод «сущность-связь» называют также методом «ER-диаграмм»: во-первых, ER - аббревиатура от слов Entity (сущность) и Relation (связь), во-вторых, метод основан на

использовании диаграмм, называемых соответственно диаграммами ER-экземпляров и диаграммами ER-типа.
7.4.2.1. Основные понятия метода
Основными понятиями метода сущность-связь являются следующие:
• сущность (объекты/типы объектов), • экземпляр сущности (объект) • атрибут сущности (свойство), • ключ сущности, • связь между сущностями, • степень связи, • класс принадлежности экземпляров сущности, • диаграммы ER-экземпляров, • диаграммы ER-типа. Сущность (объекты) – множество объектов реального мира с одинаковыми
свойствами, характеризуются независимым существованием и могут быть объектом как с реальным (физическим) существованием (например, «работник», «деталь», «поставщик»), так и объектом с абстрактным (концептуальным) существованием (например, «рабочий стаж», «осмотр объекта»). Разные разработчики могут выделять разные типы объектов. Каждая сущность (тип объекта) идентифицируется именем и списком свойств. Названиями сущностей являются, как правило, существительные, например: ПРЕПОДАВАТЕЛЬ, ДИСЦИПЛИНА, КАФЕДРА, ГРУППА.
Экземпляр сущности (объект) – «предмет, который может быть четко идентифицирован» на основе свойств (т.к. обладает уникальным набором свойств среди объектов одного типа).
Типы объектов классифицируются как сильные и слабые: • слабый тип объекта (дочерний, зависимый или подчиненный) – тип объекта,
существование которого зависит от какого-то другого типа объекта; • сильный тип объекта (родительский, владелец или доминантный) – тип
объекта, существование которого не зависит от какого-то другого типа объекта. Представление объектов на диаграмме: сильный тип объекта – прямоугольник, с
именем внутри него; слабый тип объекта – прямоугольник с двойным контуром (деление объектов на сильные и слабые – по желанию проектировщика).
Свойства (атрибуты) – служат для описания типов объектов или отношений. Значения свойств каждого типа извлекаются из соответствующего множества значений (в этом множестве определяются все потенциальные значения свойства, различные свойства могут использовать одно множество значений). Так, атрибутами сущности ПРЕПОДАВАТЕЛЬ может быть его Фамилия, Должность, Стаж (преподавательский) и т. д.
Свойства делят по характеристикам: • простые и составные: простое свойство состоит из одного компонента с
независимым существованием (такое свойство – атомарное (не может быть разделено на более мелкие компоненты); например «зарплата», «пол»); составное свойство – состоит из нескольких компонентов, каждый из которых характеризуется независимым существованием (могут быть разделены на более мелкие части (например, «адрес»), но решение о представлении такого атрибута (как простой или составной) зависит от проектировщика);

• однозначные и многозначные: однозначное свойство – свойство, которое может содержать только одно значение для одного объекта; многозначное свойство – может содержать несколько значений для одного объекта (например, «телефон компании»);
• производные и базовые: производное свойство - представляет значение, производное от значения связанного с ним свойства или некоторого множества свойств, принадлежащих некоторому типу объектов (не обязательно одному), например, «сумма деталей», «возраст сотрудника»; базовое – не зависит от других свойств.
• Ключевое и не ключевое: ключ – свойство (набор свойств), которое однозначно определяет (идентифицирует) объект из всех объектов данного типа (например, «номер паспорта»); ключи делят на: потенциальные – содержит значения, которые позволяют уникально идентифицировать каждый отдельный экземпляр типа объекта (тип объекта может иметь несколько потенциальных ключей); первичные – один из потенциальных ключей для типа объекта, который выбран для идентификации объектов (должен гарантировать уникальность значений не только в текущий период, но и в обозримом будущем, лучше чтобы он содержал меньшее число свойств (например, «номер сотрудника», «номер паспорта»)); альтернативные – все потенциальные ключи, кроме первичного; составной ключ – потенциальный ключ, который состоит из 2-х и более свойств (позволяет определить уникальность объекта, не вводя лишних уникальных свойств).
Представление свойств на диаграмме: в виде эллипсов с именем внутри него, присоединенных линией к типу объекта; для производных свойств – эллипс окружен пунктирным контуром, для многозначных – двойным; имя свойства, которое является первичным ключом – подчеркивается.
Связь (типы отношений) – осмысленная ассоциация между сущностями, каждая связь (отношение) имеет имя, описывающее его функцию.
Экземпляр отношения (отношение) – ассоциация (связь) между экземплярами объектов, включающая по одному экземпляру объекта с каждой стороны связи.
Объекты, включенные в отношение, называются участниками этого отношения (при этом в связях для определения функций каждого участника могут присваиваться ролевые имена). Количество участников данного отношения называется степенью этого отношения (два участника – бинарная (наиболее часто применима), три – тернарная, четыре – кватернарная, n-участников – n-арная). Существуют унарные (рекурсивные) отношения - в них одни и те же типы объектов участвуют несколько раз и в разных ролях.
Рис. 7.9. Свойство отношения (составного объекта). Унарное отношение
Примечание.
Унарное отношение (связь) часто используется в иерархических справочниках. Например для хранения в таблице и групп объектов и самих объектов.
Отношения можно рассматривать как своего рода объекты (объектные множества или составные объекты), т.е. разделение объектов и отношений достаточно зыбко и зависит от представлений проектировщика (при этом для отношений возможно наличие свойств – это обычно означает, что отношение скрывает некоторую неопределенную сущность).

Представление отношений на диаграмме: в виде ромба с указанным в нем именем связи и соединенного линиями с участниками отношения.
Название связи обычно представляется глаголом. Примерами связей между сущностями являются следующие: ПРЕПОДАВАТЕЛЬ ВЕДЕТ ДИСЦИПЛИНУ (Иванов ВЕДЕТ “Базы данных”), ПРЕПОДАВАТЕЛЬ ПРЕПОДАЕТ-В ГРУППЕ (Иванов ПРЕПОДАЕТ-В 256 группе), ПРЕПОДАВАТЕЛЬ РАБОТАЕТ-НА КАФЕДРЕ (Иванов РАБОТАЕТ-НА 25 кафедре).
Приведенные определения сущности и связи не полностью формализованы, но приемлемы для практики. Следует иметь в виду, что в результате проектирования могут быть получены несколько вариантов одной БД. Так, два разных проектировщика, рассматривая одну и ту же проблему с разных точек зрения, могут получить различные наборы сущностей и связей. При этом оба варианта могут быть рабочими, а выбор лучшего из них будет результатом личных предпочтений.
С целью повышения наглядности и удобства проектирования для представления сущностей, экземпляров сущностей и связей между ними используются следующие графические средства:
• диаграммы ER-экземпляров, • диаграммы ER-muna, или ER-диаграммы. На рис. 7.10 приведена диаграмма ER-экземпляров для сущностей
ПРЕПОДАВАТЕЛЬ и ДИСЦИПЛИНА со связью ВЕДЕТ.
Рис. 7.10. Диаграмма ER-экземпляров
Диаграмма ER-экземпляров показывает, какую конкретно дисциплину (СУБД,
ПЛ/1 и т.д.) ведет каждый из преподавателей. На рис. 6.11 представлена диаграмма ER-типа, соответствующая рассмотренной диаграмме ER-экземпляров.
Рис. 7.11. Диаграмма ER-типа
На начальном этапе проектирования БД выделяются атрибуты, составляющие
ключи сущностей. На основе анализа диаграмм ER-типа формируются отношения проектируемой БД.
При этом учитывается степень связи сущностей и класс их принадлежности, которые, в свою очередь, определяются на основе анализа диаграмм ER-экземпляров соответствующих сущностей.
Степень связи является характеристикой связи между сущностями, которая может быть типа: 1:1, 1:М, М:1, М:М.
Класс принадлежности (КП) сущности может быть: обязательным и необязательным. Класс принадлежности сущности является обязательным, если все экземпляры этой сущности обязательно участвуют в рассматриваемой связи, в противном случае класс принадлежности сущности является необязательным.
Варьируя классом принадлежности сущностей для каждого из названных типов связи, можно получить несколько вариантов диаграмм ER-типа. Рассмотрим примеры

некоторых из них. Пример 1. Связи типа 1:1 и необязательный класс принадлежности. В приведенной
на рис. 7.11 диаграмме степень связи между сущностями 1:1, а класс принадлежности обеих сущностей необязательный. Действительно, из рисунка видно следующее:
• каждый преподаватель ведет не более одной дисциплины, а каждая дисциплина ведется не более чем одним преподавателем (степень связи 1:1);
• некоторые преподаватели не ведут ни одной дисциплины и имеются дисциплины, которые не ведет ни один из преподавателей (класс принадлежности обеих сущностей необязательный).
Пример 2. Связи типа 1:1 и обязательный класс принадлежности. На рис. 7.12 приведены диаграммы, у которых степень связи между сущностями 1:1, а класс принадлежности обеих сущностей обязательный.
В этом случае каждый преподаватель ведет одну дисциплину, и каждая дисциплина ведется одним преподавателем.
Возможны два промежуточных варианта с необязательным классом принадлежности одной из сущностей.
Замечания • На диаграммах ER-типа обязательное участие в связи экземпляров
сущности отмечается блоком с точкой внутри, смежным с блоком этой сущности (рис. 7.12б).
• При необязательном участии экземпляров сущности в связи дополнительный блок к блоку сущности не пристраивается, а точка размещается на линии связи (рис. 7.11).
• Символы на линии связи указывают на степень связи. а) ER-экземпляров
Рис. 7.12. Диаграммы для связи 1:1 и обязательным КП обеих сущностей
Под каждым блоком, соответствующим некоторой сущности, указывается ее ключ,
выделяемый подчеркиванием. Многоточие за ключевыми атрибутами означает, что возможны другие атрибуты сущности, но ни один из них не может быть частью ее ключа. Эти атрибуты выявляются после формирования отношений.
На практике степень связи и класс принадлежности сущностей при проектировании БД определяется спецификой предметной области. Рассмотрим примеры вариантов со степенью связи 1:М или М:1.
Пример 3. Связи типа 1:М. Каждый преподаватель может вести несколько дисциплин, но каждая дисциплина
ведется одним преподавателем. Пример 4. Связи типа М:1. Каждый преподаватель может вести одну дисциплину, но каждую дисциплину
могут вести несколько преподавателей.

Примеры с типом связи 1:М или М:1 могут иметь ряд вариантов, отличающихся классом принадлежности одной или обеих сущностей. Обозначим обязательный класс принадлежности символом “О”, а необязательный - символом “Н“, тогда варианты для связи типа 1:М условно можно представить как: О-О, О-Н, Н-О, Н-Н. Для связи типа М:1 также имеются 4 аналогичных варианта.
Пример 5. Связи типа 1:М вариант Н-О. Каждый преподаватель может вести несколько дисциплин или ни одной, но каждая
дисциплина ведется одним преподавателем (рис. 7.13). По аналогии легко составить диаграммы и для остальных вариантов.
Рис. 7.13. Диаграммы для связи типа 1:М варианта Н-О
Пример 6. Связи типа М:М. Каждый преподаватель может вести несколько дисциплин, а каждая дисциплина
может вестись несколькими преподавателями. Как и в случае других типов связей, для связи типа М:М возможны 4 варианта,
отличающиеся классом принадлежности сущностей. Пример 7. Связи типа М:М и вариант класса принадлежности 0-Н. Допустим, что каждый преподаватель ведет не менее одной дисциплины, а
дисциплина может вестись более чем одним преподавателем, есть и такие дисциплины, которые никто не ведет. Соответствующие этому случаю диаграммы приведены на рис. 7.14.
Выявление сущностей и связей между ними, а также формирование на их основе диаграмм ER-типа выполняется на начальных этапах метода сущность-связь. Рассмотрим этапы реализации метода.

Рис. 7.14. Диаграммы для связи типа М : М и варианта О-Н
7.4.2.2. Этапы проектирования Процесс проектирования базы данных является итерационным - допускающим
возврат к предыдущим этапам для пересмотра ранее принятых решений и включает следующие этапы:
1. Выделение сущностей и связей между ними. 2. Построение диаграмм ER-типа с учетом всех сущностей и их связей. 3. Формирование набора предварительных отношений с указанием
предполагаемого первичного ключа для каждого отношения и использованием диаграмм ER-типа.
4. Добавление неключевых атрибутов в отношения. 5. Приведение предварительных отношений к нормальной форме Бойса-Кодда,
например, с помощью метода нормальных форм. 6. Пересмотр ER-диаграмм в следующих случаях: • некоторые отношения не приводятся к нормальной форме Бойса-Кодда; • некоторым атрибутам не находится логически обоснованных мест в
предварительных отношениях. После преобразования ER-диаграмм осуществляется повторное выполнение
предыдущих этапов проектирования (возврат к этапу 1). Одним из узловых этапов проектирования является этап формирования отношений.
Рассмотрим процесс формирования предварительных отношений, составляющих первичный вариант схемы БД.
В рассмотренных выше примерах связь ВЕДЕТ всегда соединяет две сущности и поэтому является бинарной. Сформулированные ниже правила формирования отношений из диаграмм ER-типа распространяются именно на бинарные связи. Поэтому, когда речь идет о связях, слово “бинарные” далее опускается.
7.4.2.3. Правила формирования отношений Правила формирования отношений основываются на учете следующего: • степени связи между сущностями (1:1, 1:М, М:1, М:М); • класса принадлежности экземпляров сущностей (обязательный и
необязательный). Рассмотрим формулировки шести правил формирования отношений на основе диаграмм ER-тина.

7.4.2.3.1. Формирование отношений для связи 1:1 Правило 1. Если степень бинарной связи 1:1 и класс принадлежности обеих
сущностей обязательный, то формируется одно отношение. Первичным ключом этого отношения может быть ключ любой из двух сущностей.
На рис. 7.15 приведены диаграмма ER-типа и отношение, сформированное по правилу 1 на се основе.
Рис. 7.15. Диаграмма и отношения для правила 1
На рисунке используются следующие обозначения: Cl, C2 - сущности 1 и 2; Kl, K2 - ключи первой и второй сущности соответственно; R1 - отношение 1, сформированное на основе первой и второй сущностей; Kl ∨ К2,... означает, что ключом формированного отношения может быть либо К1,
либо К2. Это и другие правила будем проверять, рассматривая различные варианты связи,
ПРЕПОДАВАТЕЛЬ ВЕДЕТ ДИСЦИПЛИНУ. Пусть сущность ПРЕПОДАВАТЕЛЬ характеризуется атрибутами НП (идентификационный номер преподавателя), ФИО (фамилия, имя и отчество), Стаж (стаж преподавателя). Сущность ДИСЦИПЛИНА характеризуется соответственно атрибутами КД (код дисциплины), Часы (часы, отводимые на дисциплину). Тогда схема отношения, содержащего информацию об обеих сущностях, и само отношение для случая, когда степень связи равна 1:1, а КП обязательный для всех сущностей, могут иметь вид, показанный на рис. 7.16.
ПРЕПОДАВАТЕЛЬ_ДИСЦИПЛИНА (НД,ФИО, Стаж, КД, Часы) ПРЕПОДАВАТЕЛЬ_ДИСЦИПЛИНА
НП ФИО Стаж КД Часы П1 Иванов 5 К1 62 П2 Петров 7 К2 74 П3 Сидоров 10 К3 102 П4 Егоров 5 К4 80
Рис. 7.16. Полученные по правилу 1 схема и отношение
Сформированное отношение содержит полную информацию о преподавателях, дисциплинах и о том, как они связаны между собой. Так, преподаватель Иванов ведет только дисциплину с кодом К1, а дисциплина К1 ведется только Ивановым (связь 1:1). В этом отношении отсутствуют пустые поля (КП обязательный для всех сущностей), т. к. нет преподавателей, которые бы что-то не вели, и нет дисциплин, которые никто не ведет. Таким образом, одного отношения в данном случае достаточно. В качестве первичного ключа может быть выбран ключ первого отношения НП или ключ второго отношения КД.
Правило 2. Если степень связи 1:1 и класс принадлежности одной сущности обязательный, а второй - необязательный, то под каждую из сущностей формируется по отношению с первичными ключами, являющимися ключами соответствующих сущностей. Далее к отношению, сущность которого имеет обязательный КП, добавляется в качестве атрибута ключ сущности с необязательным КП.
На рис. 7.17 приведены диаграмма ER-типа и отношения, сформированные по правилу 2 на ее основе.
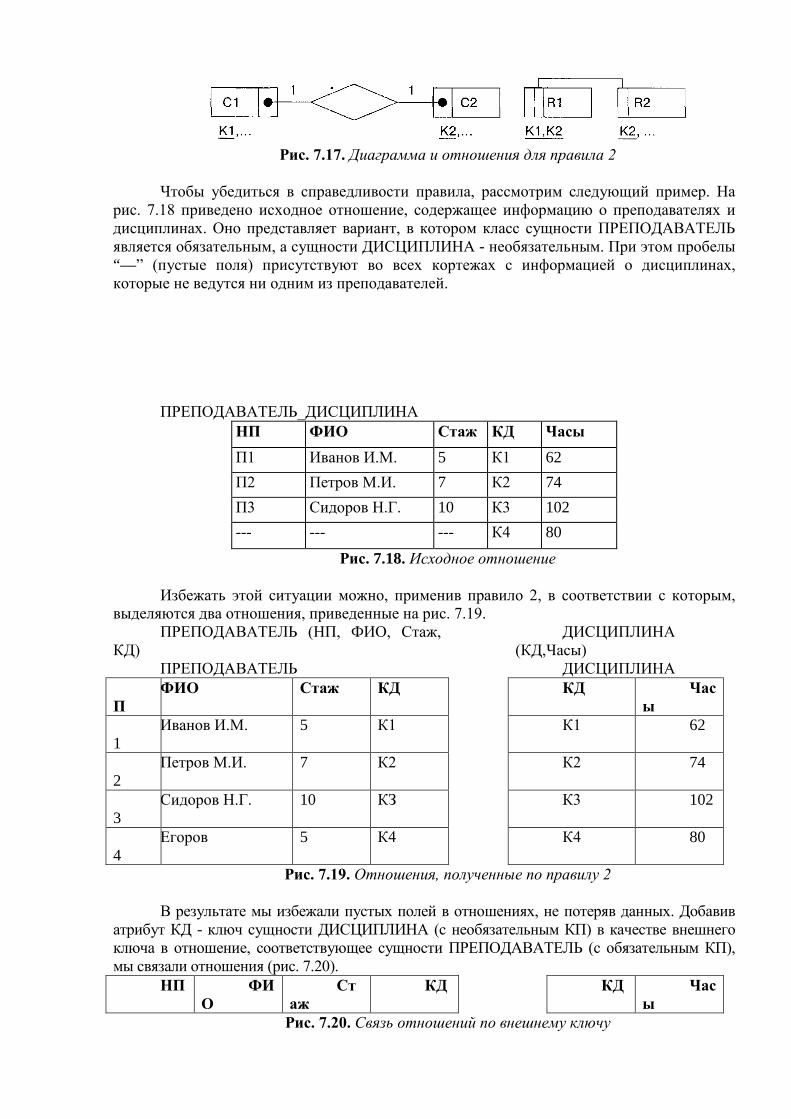
Рис. 7.17. Диаграмма и отношения для правила 2
Чтобы убедиться в справедливости правила, рассмотрим следующий пример. На
рис. 7.18 приведено исходное отношение, содержащее информацию о преподавателях и дисциплинах. Оно представляет вариант, в котором класс сущности ПРЕПОДАВАТЕЛЬ является обязательным, а сущности ДИСЦИПЛИНА - необязательным. При этом пробелы “—” (пустые поля) присутствуют во всех кортежах с информацией о дисциплинах, которые не ведутся ни одним из преподавателей.
ПРЕПОДАВАТЕЛЬ_ДИСЦИПЛИНА
НП ФИО Стаж КД Часы П1 Иванов И.М. 5 К1 62 П2 Петров М.И. 7 К2 74 П3 Сидоров Н.Г. 10 К3 102 --- --- --- К4 80
Рис. 7.18. Исходное отношение
Избежать этой ситуации можно, применив правило 2, в соответствии с которым, выделяются два отношения, приведенные на рис. 7.19.
ПРЕПОДАВАТЕЛЬ (НП, ФИО, Стаж, КД)
ДИСЦИПЛИНА (КД,Часы)
ПРЕПОДАВАТЕЛЬ ДИСЦИПЛИНА Н
П ФИО Стаж КД КД Час
ы П
1 Иванов И.М. 5 К1 К1 62
П2
Петров М.И. 7 К2 К2 74
П3
Сидоров Н.Г. 10 КЗ К3 102
П4
Егоров 5 К4 К4 80
Рис. 7.19. Отношения, полученные по правилу 2
В результате мы избежали пустых полей в отношениях, не потеряв данных. Добавив атрибут КД - ключ сущности ДИСЦИПЛИНА (с необязательным КП) в качестве внешнего ключа в отношение, соответствующее сущности ПРЕПОДАВАТЕЛЬ (с обязательным КП), мы связали отношения (рис. 7.20).
НП ФИО
Стаж
КД КД Часы
Рис. 7.20. Связь отношений по внешнему ключу
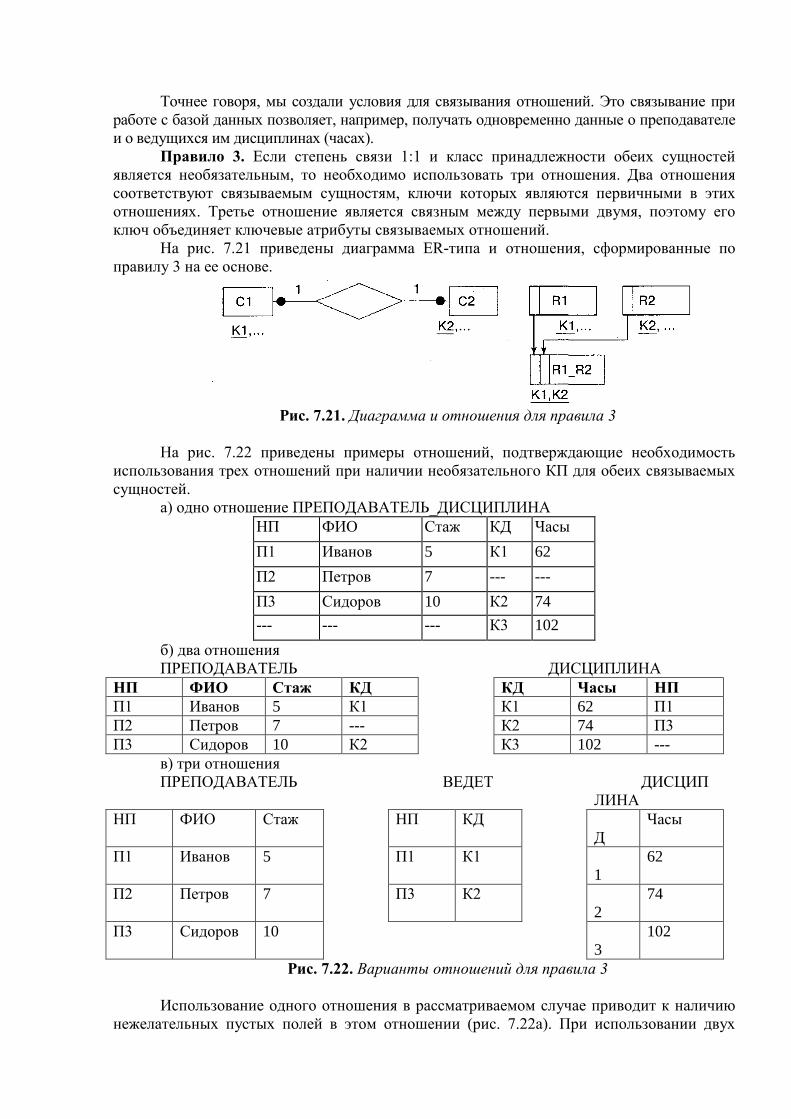
Точнее говоря, мы создали условия для связывания отношений. Это связывание при
работе с базой данных позволяет, например, получать одновременно данные о преподавателе и о ведущихся им дисциплинах (часах).
Правило 3. Если степень связи 1:1 и класс принадлежности обеих сущностей является необязательным, то необходимо использовать три отношения. Два отношения соответствуют связываемым сущностям, ключи которых являются первичными в этих отношениях. Третье отношение является связным между первыми двумя, поэтому его ключ объединяет ключевые атрибуты связываемых отношений.
На рис. 7.21 приведены диаграмма ER-типа и отношения, сформированные по правилу 3 на ее основе.
Рис. 7.21. Диаграмма и отношения для правила 3
На рис. 7.22 приведены примеры отношений, подтверждающие необходимость
использования трех отношений при наличии необязательного КП для обеих связываемых сущностей.
а) одно отношение ПРЕПОДАВАТЕЛЬ_ДИСЦИПЛИНА НП ФИО Стаж КД Часы П1 Иванов 5 К1 62 П2 Петров 7 --- --- П3 Сидоров 10 К2 74 --- --- --- К3 102
б) два отношения ПРЕПОДАВАТЕЛЬ ДИСЦИПЛИНА
НП ФИО Стаж КД КД Часы НП П1 Иванов 5 К1 К1 62 П1 П2 Петров 7 --- К2 74 П3 П3 Сидоров 10 К2 К3 102 ---
в) три отношения ПРЕПОДАВАТЕЛЬ ВЕДЕТ ДИСЦИП
ЛИНА НП ФИО Стаж НП КД
Д Часы
П1 Иванов 5 П1 К1 1
62
П2 Петров 7 П3 К2 2
74
П3 Сидоров 10 3
102
Рис. 7.22. Варианты отношений для правила 3
Использование одного отношения в рассматриваемом случае приводит к наличию нежелательных пустых полей в этом отношении (рис. 7.22а). При использовании двух

отношений (рис. 7.22б) нам пришлось добавить ключи каждой из сущностей в отношение, соответствующее другой сущности, чтобы не потерять сведения о том, какую дисциплину ведет каждый преподаватель и наоборот. При этом также появились пустые поля.
Выход заключается в использовании трех отношений, сформированных по правилу 3 (рис. 7.22в). Объектные отношения (с атрибутами сущностей) содержат полную информацию обо всех преподавателях и дисциплинах соответственно. Связное отношение ВЕДЕТ содержит данные о преподавателях, которые ведут дисциплины и о дисциплинах, которые ведутся преподавателями. При этом в нем имеется только одно упоминание о каждом преподавателе и дисциплине в силу связи 1:1. Это отношение содержит в данном случае только ключевые атрибуты обеих сущностей, но может иметь и другие атрибуты, характеризующие эту связь. Например, номер семестра, в котором преподаватель ведет дисциплину.
Итак, сформулированы три правила, позволяющие формировать отношения на основе ER-диаграмм, для вариантов со степенью связи типа 1:1. Сформулируем аналогичные два правила для вариантов, степень связи, между сущностями которых 1:М.
7.4.2.3.2. Формирование отношений для связи 1:М Если две сущности С1 и С2 связаны как 1 :М, сущность С1 будем называть
односвязной (1-связной), а сущность С2 - многосвязной (М-связной). Определяющим фактором при формировании отношений, связанных этим видом связи, является класс принадлежности М-связной сущности. Так, если класс принадлежности М-связной сущности обязательный, то в результате применения правила получим два отношения, если необязательный - три отношения. Класс принадлежности односвязной сущности не влияет на результат.
Чтобы убедиться в этом, рассмотрим отношение ПРЕПОДАВАТЕЛЬ_ДИСЦИПЛИНА (рис. 7.23), соответствующее диаграммам, приведенным на рис. 7.23, т.е. случаю, когда: связь типа 1:М, класс принадлежности М-связной сущности обязательный, 1-связной - необязательный.
ПРЕПОДАВАТЕЛЬ.ДИСЦИПЛИНА Н
П ФИО Ст
аж К
Д Ч
асы П
1 Иванов 5 К
1 6
2 П
1 Иванов 5 К
2 7
4 П
2 Петров 7 К
4 8
0 П
3 Сидоров 10 К
5 9
6 П
3 Сидоров 10 К
6 1
20 П
4 Егоров 5 К
3 1
02 П
4 Егоров 5 К
7 8
9 П
5 Козлов 8 -
-- -
-- Рис. 7.23. Исходное отношение
С отношением ПРЕПОДАВАТЕЛЬ_ДИСЦИПЛИНА (рис. 7.23) связаны
следующие проблемы:

• имеются кортежи с пустыми полями, (преподаватель не ведет дисциплины), • избыточное дублирование данных (повторяется стаж преподавателя) в
кортежах со сведениями о преподавателях, ведущих несколько дисциплин. Если бы класс принадлежности 1-связной сущности был обязательным (нет
преподавателя без дисциплины), то исчезли бы пустые поля, но повторяющиеся данные в атрибутах преподавателя сохранились бы. Для устранения названных проблем отношения могут быть сформированы по следующему правилу.
Правило 4. Если степень связи между сущностями 1:М (или М:1) и класс принадлежности М-связной сущности обязательный, то достаточно формирование двух отношений (по одному на каждую из сущностей). При этом первичными ключами этих отношений являются ключи их сущностей. Кроме того, ключ 1-связной сущности добавляется как атрибут (внешний ключ) в отношение, соответствующее М-связпой сущности.
На рис. 7.24 приведены диаграмма ER-типа и отношения, сформированные по правилу 4.
Рис. 7.24. Диаграмма и отношения для правила 4
В соответствии с правилом 4 преобразуем отношение на рис. 7.25 в два отношения. ПРЕПОДАВАТЕЛЬ ДИСЦИПЛИНА Н
П Ф
ИО С
таж К
Д Ч
асы Н
П П
1 И
ванов 5 К
1 6
2 П
1 П
2 П
етров 7 К
2 7
4 П
1 П
3 С
идоров 1
0 К
3 1
02 П
4 П
4 Е
горов 5 К
4 8
0 П
2 П
5 К
озлов 8 К
5 9
6 П
3 К
6 1
20 П
3 К
7 8
9 П
4 Рис. 7.25. Отношения, полученные по правилу 4
Из рис. 7.25 видно, что пустые поля и дублирование информации удалось
устранить. Потери сведений о том, кто из преподавателей ведет какую дисциплину, не произошло благодаря введению ключа НП сущности ПРЕПОДАВАТЕЛЬ в качестве внешнего ключа в отношение ДИСЦИПЛИНА.
Для формулирования и обоснования необходимости использования следующего правила рассмотрим следующий пример.
Пример. Связь между сущностями 1:М, а класс принадлежности М-связной сущности необязательный.
Пусть класс принадлежности 1-связной сущности также необязательный, хотя это и не принципиально, так как определяющим является класс принадлежности М-связной
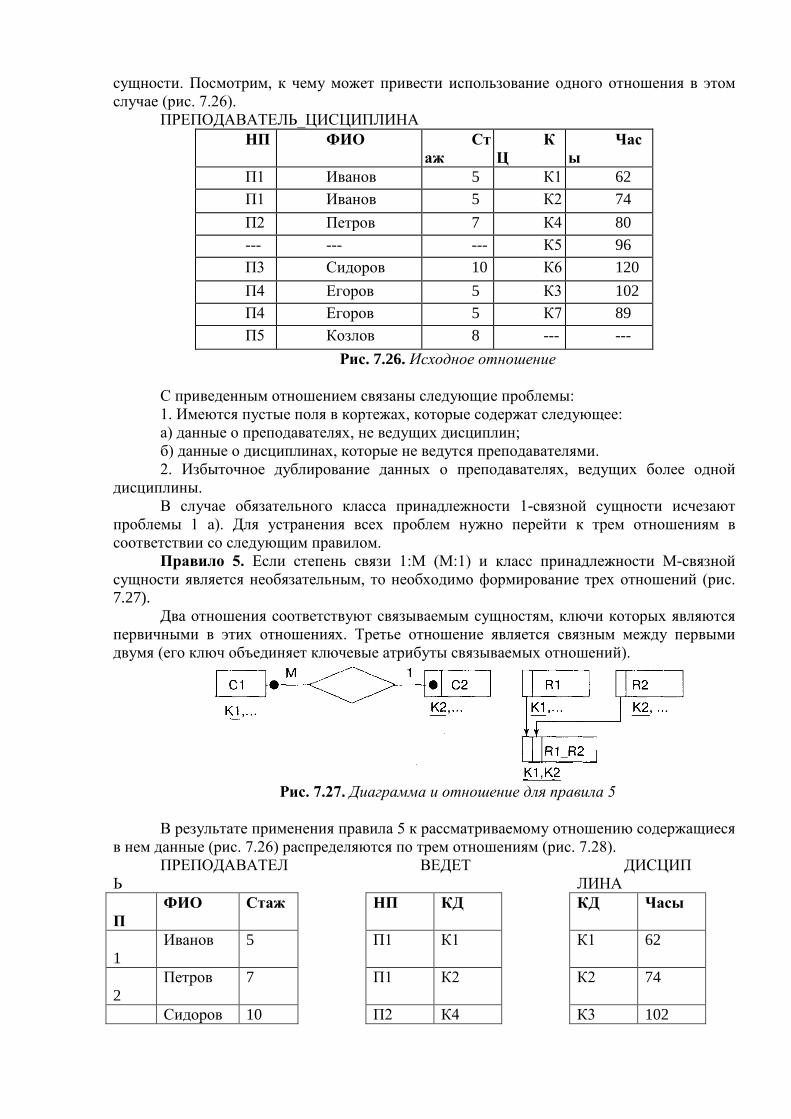
сущности. Посмотрим, к чему может привести использование одного отношения в этом случае (рис. 7.26).
ПРЕПОДАВАТЕЛЬ_ЦИСЦИПЛИНА НП ФИО Ст
аж К
Ц Час
ы П1 Иванов 5 К1 62 П1 Иванов 5 К2 74 П2 Петров 7 К4 80 --- --- --- К5 96 П3 Сидоров 10 К6 120 П4 Егоров 5 К3 102 П4 Егоров 5 К7 89 П5 Козлов 8 --- ---
Рис. 7.26. Исходное отношение С приведенным отношением связаны следующие проблемы: 1. Имеются пустые поля в кортежах, которые содержат следующее: а) данные о преподавателях, не ведущих дисциплин; б) данные о дисциплинах, которые не ведутся преподавателями. 2. Избыточное дублирование данных о преподавателях, ведущих более одной
дисциплины. В случае обязательного класса принадлежности 1-связной сущности исчезают
проблемы 1 а). Для устранения всех проблем нужно перейти к трем отношениям в соответствии со следующим правилом.
Правило 5. Если степень связи 1:М (М:1) и класс принадлежности М-связной сущности является необязательным, то необходимо формирование трех отношений (рис. 7.27).
Два отношения соответствуют связываемым сущностям, ключи которых являются первичными в этих отношениях. Третье отношение является связным между первыми двумя (его ключ объединяет ключевые атрибуты связываемых отношений).
Рис. 7.27. Диаграмма и отношение для правила 5
В результате применения правила 5 к рассматриваемому отношению содержащиеся
в нем данные (рис. 7.26) распределяются по трем отношениям (рис. 7.28). ПРЕПОДАВАТЕЛ
Ь ВЕДЕТ ДИСЦИП
ЛИНА
П ФИО Стаж НП КД КД Часы
1 Иванов 5 П1 К1 К1 62
2 Петров 7 П1 К2 К2 74
Сидоров 10 П2 К4 К3 102

3
4 Егоров 5 П3 К6 К4 80
5 Козлов 8 П4 К3 К5 96
П4 К7 К6 120 К7 89
Рис. 7.28. Отношения, полученные по правилу 5 Таким образом, указанные проблемы удалось разрешить. Ключ в связном
отношении ВЕДЕТ является составным и включает в себя ключевые атрибуты обоих связываемых отношений (сущностей). В практических ситуациях связное отношение может содержать и другие характеризующие связь атрибуты.
Подчеркнем, что определяющим фактором при выборе между 4-м или 5-м правилом является класс принадлежности М-связной сущности.
7.4.2.3.3. Формирование отношений для связи М:М При наличии связи М:М между двумя сущностями необходимо три отношения
независимо от класса принадлежности любой из сущностей. Использование одного или двух отношений в этом случае не избавляет от пустых полей или избыточно дублируемых данных.
Правило 6. Если степень связи М:М, то независимо от класса принадлежности сущностей формируются три отношения. Два отношения соответствуют связываемым сущностям и их ключи являются первичными ключами этих отношений. Третье отношение является связным между первыми двумя, а его ключ объединяет ключевые атрибуты связываемых отношений.
На рис. 7.29 приведены диаграмма ER-типа и отношения, сформированные по правилу 6. Нами показан вариант с классом принадлежности сущностей Н-Н, хотя, согласно правилу 6, он может быть произвольным.
Рис. 7.29. Диаграмма и отношения для правила 6
Применим правило 6 к примеру, приведенному на рис. 7.13. В нем степень связи равна
М:М, класс принадлежности для сущности ПРЕПОДАВАТЕЛЬ обязательный, а для сущности ДИСЦИПЛИНА - необязательный. Соответствующее этому примеру исходное отношение показано на рис. 7.30.
ПРЕПОДАВАТЕЛЬ_ДИСЦИПЛИНА
НП ФИО Стаж КД Часы П1 Иванов 5 К1 62 П1 Иванов 5 К2 74 П2 Петров 7 К4 80 --- --- --- КЗ 102

П3 Сидоров 10 К6 120 П4 Егоров 5 К2 74 П4 Егоров 5 К7 89 П5 Козлов 8 К5 96
Рис. 7.30. Исходное отношение В результате применения правила 6 получаются три отношения (рис. 7.31).
ПРЕПОДАВАТЕЛЬ ВЕДЕТ ДИСЦИПЛИНА
П ФИО Стаж НП КД КД Часы
1 Иванов 5 П1 К1 К1 62
2 Петров 7 П1 К2 К2 74
3 Сидоров 10 П2 К4 К3 102
4 Егоров 5 П3 К6 К4 80
5 Козлов 8 П4 К3 К5 96
П4 К7 К6 120 К7 89
Рис. 7.31. Отношения, полученные по правилу 6 Аналогичные результаты получаются и для трех других вариантов, различающихся
классами принадлежности их сущностей. Рассмотрим применение сформулированных правил на примерах проектирования БД методом сущность-связь.
7.4.2.4. Пример проектирования учебной части Применим описанные правила, к примеру, рассмотренному при изучении метода
нормальных форм (подраздел 7.2). Напомним, что речь шла о БД для учебной части, содержащей следующие сведения:
ФИО - фамилия и инициалы преподавателя (возможность совпадения фамилии и инициалов у преподавателей исключена).
Должн - должность, занимаемая преподавателем. Оклад - оклад преподавателя. Стаж - преподавательский стаж. Д_Стаж - надбавка
за стаж. Каф - номер кафедры, на которой работает преподаватель. Предм - название дисциплины (предмета), ведомой преподавателем. Группа - номер группы, в которой преподаватель проводит занятия. ВидЗан - вид занятий, проводимых преподавателем в учебной группе
(преподаватель в одной группе ведет только один вид занятий). Исходное отношение ПРЕПОДАВАТЕЛЬ. При проектировании будем придерживаться этапов, описанных в подразделе 7.4.2. Первый этап проектирования - выделение сущностей и связей между ними. Выделим следующие сущности: • ПРЕПОДАВАТЕЛЬ (Ключ - ФИО), • ЗАНЯТИЕ (Ключ - Группа. Предм),

• СТАЖ (Ключ - Стаж), • ДОЛЖНОСТЬ (Ключ - Должн). Выделим связи между сущностями: • ПРЕПОДАВАТЕЛЬ ИМЕЕТ СТАЖ, • ПРЕПОДАВАТЕЛЬ ВЕДЕТ ЗАНЯТИЕ, • ПРЕПОДАВАТЕЛЬ ЗАНИМАЕТ ДОЛЖНОСТЬ. Второй этап проектирования - построение диаграммы ER-типа с учетом всех
сущностей и связей между ними. Диаграмма ER-типа для рассматриваемого примера приведена на рис. 7.32.
Связь ИМЕЕТ является связью типа М:1, т. к. одинаковый стаж могут иметь несколько преподавателей. Сущность ПРЕПОДАВАТЕЛЬ имеет обязательный класс принадлежности, поскольку каждый преподаватель имеет свой стаж. Сущность СТАЖ имеет необязательный класс принадлежности, так как возможны такие значения стажа, которые не имеет ни один из преподавателей.
Связь ВЕДЕТ имеет тип М:М, так как преподаватель может вести несколько занятий, а каждое занятие может проводиться несколькими преподавателями. Занятие может быть лекционным или практическим, проводимым преподавателем в учебной группе по одной из дисциплин. Обе сущности в данной связи имеют КП обязательный, в предположении, что нет преподавателей, которые не проводят занятий, и нет занятий, которые не обеспечены преподавателями.
Рис. 7.32. Диаграмма ER-типа
Связь ЗАНИМАЕТ имеет тип М:1, так как каждый преподаватель занимает
определенную должность и одинаковые должности могут занимать несколько преподавателей. Сущность ПРЕПОДАВАТЕЛЬ имеет обязательный класс принадлежности, так как предполагаем, что каждый преподаватель занимает должность. Сущность ДОЛЖНОСТЬ имеет необязательный КП, так как не исключаем, например, отсутствие должности профессора на кафедре, а значит и преподавателя, который ее занимает.
Третий этап проектирования - формирование набора предварительных отношений с указанием предполагаемого первичного ключа для каждого отношения, используя диаграммы ER-типа.
На основе анализа диаграммы ER-типа (рис. 7.32) с помощью шести сформулированных выше правил получаем набор предварительных отношений, представленных следующими схемами отношений.
Связь ИМЕЕТ удовлетворяет условиям правила 4, в соответствии с которым получаем два отношения:
1. ПРЕПОДАВАТЕЛЬ (ФИО. Стаж....) - добавился ключевой атрибут Стаж. 2. СТАЖ (Стаж....). Связь ВЕДЕТ удовлетворяет условиям правила 6, в соответствии с которым
получаем три отношения: 1. ПРЕПОДАВАТЕЛЬ (ФИО. Стаж....). 2. ЗАНЯТИЕ (Группа: Предм....).

3. ВЕДЕТ (ФИО. Группа. Предм. ...У Связь ЗАНИМАЕТ аналогично связи ИМЕЕТ удовлетворяет условиям правила 4,
поэтому имеем следующие два отношения 1. ПРЕПОДАВАТЕЛЬ (ФИО. Стаж. Должн....) добавился ключевой атрибут Должн. 2. ДОЛЖНОСТЬ (Должн,.,.). Третий этап проектирования - добавление неключевых атрибутов, которые не
были выбраны в качестве ключевых раньше, и назначение их одному из предварительных отношений с тем условием, чтобы отношения отвечали требованиям нормальной формы Бойса-Кодда.
После добавления неключевых атрибутов схемы отношений примут следующий вид:
ПРЕПОДАВАТЕЛЬ (ФИО. Стаж. Должн. Каф.), СТАЖ (Стаж. Д_Стаж), ЗАНЯТИЕ (Группа. Предм.), ВЕДЕТ (ФИО. Группа. Предм. ВидЗан), ДОЛЖНОСТЬ (Должн. Оклад). После определения отношений следует проверить их на соответствие требованиям
нормальной формы Бойса-Кодда. В нашем случае мы получили те же отношения, что и при проектировании примера методом нормальных форм. Полученная схема базы данных приведена на рис. 7.33.
Рис. 7.33. Схема базы данных
Замечания • В нашем примере отношение ЗАНЯТИЕ, кроме ключевых атрибутов
(Группа. Предм). других атрибутов не имеет. Поэтому оно не несет дополнительной информации, кроме содержащейся в отношении ВЕДЕТ. Действительно, это отношение включает в себя атрибуты Группа. Предм. Поэтому отношение ЗАНЯТИЕ нужно исключить из формируемой схемы БД (на рис. 7.33 оно перечеркнуто). Если бы имелись другие атрибуты, например атрибут Семестр, в котором некоторая группа изучает конкретную дисциплину, то получили бы отношение ЗАНЯТИЕ (Группа. Предм. Семестр), которое вошло бы в БД.
• На последнем этапе проектирования предварительные отношения анализируются на предмет избыточного дублирования информации. При этом возможно рассмотрение нескольких кортежей каждого отношения. При наличии избыточности возможно либо перепроектирование соответствующей части проекта (ER-диаграмм), либо декомпозиция соответствующих отношений с использованием метода нормальных форм. Конечный результат преобразований представляет собой совокупность отношений в нормальной форме Бойса-Кодда.
• Рассмотренные правила проектирования БД позволяют моделировать многие практические ситуации. Построение ряда других реальных моделей может потребовать использования дополнительных конструкций. В частности, может возникнуть необходимость использования связей более высокого порядка, чем бинарные, например, тернарные, связывающие три сущности.

7.2.3. EER-модель (Расширенная ER-модель) С помощью ER-модели можно представлять большинство схем БД в
административно-управленческих приложениях. Однако для создания БД в приложениях автоматизированного проектирования (CAD), автоматизированного создания программ (CASE) и мультимедийных приложениях необходимо введение новых понятий (понятий ER-модели недостаточно). В результате дополнения ER-модели новыми семантическими концепциями была создана EER-модель (Enhanced ER – расширенная ER-модель).
ERR-модель включает все концепции ER-модели плюс дополнительные концепции специализации, генерализации и категоризации.
Дополнительные концепции связаны с новыми понятиями типов объектов (суперклассами и подклассами), а также с процессом наследования атрибутов.
Суперкласс – тип объекта, включающий различные подклассы. Подкласс – член суперкласса, который представляет собой некоторый тип объекта
имеющий общие черты с суперклассом, но играющий отдельную роль (например, суперкласс – сотрудник, подклассы – менеджер, секретарь, бухгалтер и т.п.). Связь между суперклассом и любым его подклассом называется отношением «суперкласс/подкласс» (тип «один к одному»). Некоторые суперклассы могут содержать перекрывающиеся подклассы (например, сотрудник может быть менеджером и инспектором одновременно), а также не все члены суперкласса обязаны входить в какой либо его подкласс.
Причины введения понятий суперклассов и подклассов: • исключение описания внутри одного типа объекта его различных видов с
возможно разными атрибутами – уменьшение числа неопределенных атрибутов для типа объекта (а также возможных отношений характерных только для определенного вида объекта);
• позволяет избежать повторного определения сходных понятий (за счет наследования атрибутов - экономия времени и лучшая читаемость диаграмм);
• больше семантической информации включено в модель (причем в более привычной для человека форме (например, «менеджер является сотрудником»)).
Объект подкласса обладает как специфическими атрибутами (характерными только для него), так и атрибутами, связанными с суперклассом (наследование атрибутов). Так как подкласс также является типом объекта, то он в свою очередь может иметь собственные подклассы (иерархии типа).
Специализация – процесс увеличения различий между отдельными типами объектов за счет выделения их отличительных характеристик (нисходящий подход к определению множеств суперклассов и связанных с ними подклассов).
Генерализация – процесс сведения различий между объектами к минимуму путем выделения их общих характеристик (восходящий подход, позволяет создать обобщенный суперкласс на основе различных исходных подклассов (противоположность подходу специализации) – поиск сходств (общих атрибутов и связей)).
На специализацию могут накладываться следующие ограничения (ограничения пересечения и участия для специализации и генерализации отличаются):
• ограничение непересечения - если подклассы некоторой специализации не пересекаются, то каждый отдельный объект может быть членом только одного из подклассов данной специализации (для представления непересекающейся специализации используется символ «d», расположенный в центре кружка, соединяющего подклассы с суперклассом; для пересекающейся – «o»);
• ограничение участия – полное (означает, что каждый объект суперкласса должен быть членом подкласса этой специализации (между суперклассом и кружком специализации проводят двойную линию)) или частичное (означает, что объект не обязательно должен быть членом любого подкласса этой специализации (ординарная линия)).

Категоризация – процесс моделирования единственного подкласса (категории) со связью, которая охватывает несколько суперклассов.
Операцию категоризации можно детализировать с учетом полного (каждый экземпляр всех суперклассов должен быть представлен в данной категории (обозначается двойной линией, соединяющей категорию с кружком категоризации)) или частичного (не все экземпляры суперклассов могут присутствовать в данной категории) участия сторон.

Раздел 3 СТРУКТУРИРОВАННЫЙ ЯЗЫК ЗАПРОСОВ SQL Лекция 9. Общие сведения Лекция 10. Язык DDL SQL. Создание объектов базы данных Лекция 11. Язык DML SQL. Манипулирование данными Лекция 12. Язык DQL SQL. Выборка данных Лекция 13. Использование SQL при прикладном программировании

Лекция 9 ОБЩИЕ СВЕДЕНИЯ Содержание 9.1. Введение 9.2. Основные особенности 9.3. Преимущества и недостатки 9.3.1. Преимущества 9.3.2. Недостатки 9.4. Типы команд 9.5. Transact SQL Связанные темы Введение в базы данных (см. лекцию 1). Реляционная модель данных (см. лекцию 5). Концептуальные модели данных. Проектирование реляционных БД (см. лекция 7) Использование баз данных (см. раздел 5). 9.1. Введение SQL (Structured Query Language) – структурированный язык запросов,
предназначенный для управления реляционными базами данных. В настоящее время имеет очень широкое распространение.
В 1974 г. Д.Чамберлин (работал вместе с Е.Ф.Коддом в лаборатории IBM в Сан-Хосе, США) опубликовал определение языка SEQUEL (Structured English Query Language). В 1976 г. вышла переработанная версия языка – SEQUEL/2, в последствии из юридических соображений это название было изменено на SQL, поэтому в ходу остались два варианта произношения «си-кью-эл» и «эс-кью-эл».
Тестовая версия SQL входила в состав экспериментальной реляционной СУБД «System R». В 1981 г. IBM объявила о своем первом, основанном на SQL программном продукте – SQL/DS. Чуть позже к ней присоединились ORACLE и другие производители РСУБД.
В 1982 г. ANSI (американский национальный институт стандартов) начал работу над языком RDL (Relation Database Language). В работе над этим языком были использованы разработки языка SQL корпорации IBM. В 1983 г. К разработке языка подключился ISO (международный комитет по стандартизации). В процессе разработки название языка было заменено на SQL, первый стандарт которого вышел в 1987 г. Этот вариант языка был подвергнут критике со стороны разработчиков реляционной модели данных (отсутствие ссылочной целостности, недостаточное число операторов, чрезмерная избыточность языка), но стандарт был принят для развития основы языков реляционных БД. В 1992 г. вышла обновленная версия языка - SQL-92 или SQL2. Расширение версии языка SQL2 для поддержки объектно-ориентированного управления данными называется SQL3, но этот вариант еще фактически находится в доработке, и в рамках курса рассматриваться не будет.
На сегодня для реляционных БД SQL является основным стандартом языка обработки данных. Разные СУБД реализуют стандарт SQL с добавлением дополнительных функций и синтаксических конструкций - расширений, поэтому можно говорить о различных диалектах языка SQL.
Поскольку SQL не является языком программирования (то есть не предоставляет средств для автоматизации операций с данными), вводимые разными производителями
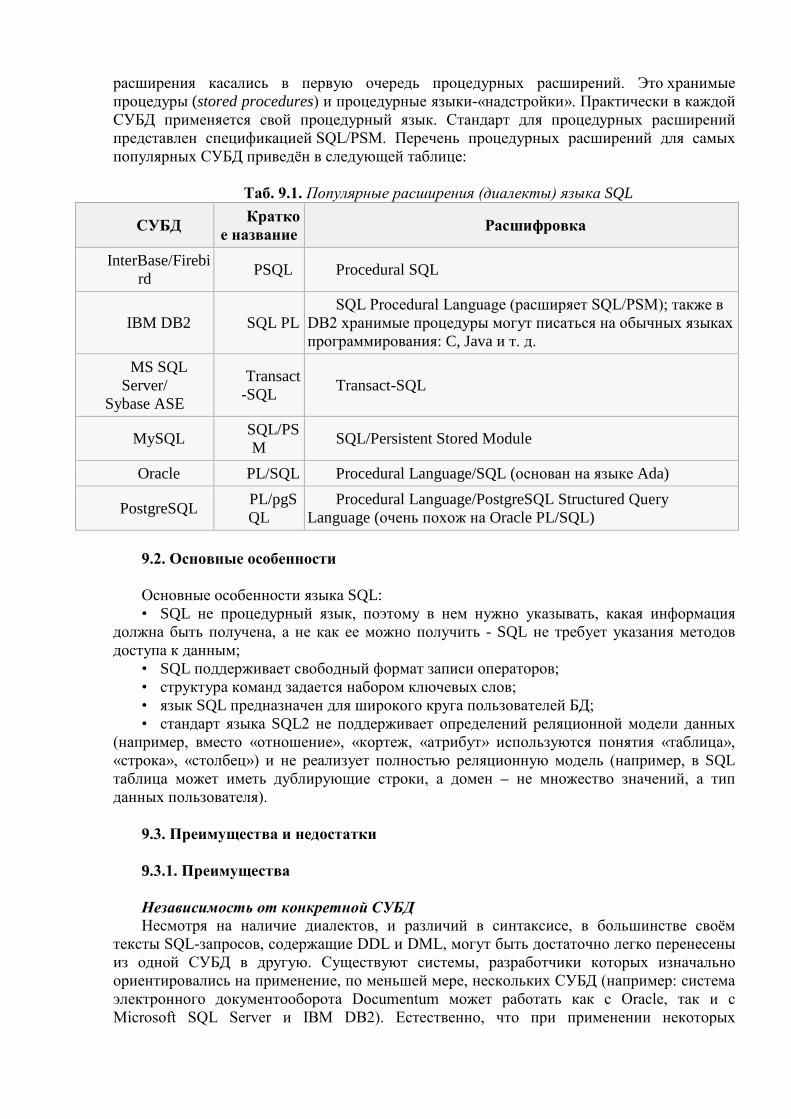
расширения касались в первую очередь процедурных расширений. Это хранимые процедуры (stored procedures) и процедурные языки-«надстройки». Практически в каждой СУБД применяется свой процедурный язык. Стандарт для процедурных расширений представлен спецификацией SQL/PSM. Перечень процедурных расширений для самых популярных СУБД приведён в следующей таблице:
Таб. 9.1. Популярные расширения (диалекты) языка SQL
СУБД Краткое название Расшифровка
InterBase/Firebird PSQL Procedural SQL
IBM DB2 SQL PL SQL Procedural Language (расширяет SQL/PSM); также в
DB2 хранимые процедуры могут писаться на обычных языках программирования: C, Java и т. д.
MS SQL Server/
Sybase ASE
Transact-SQL Transact-SQL
MySQL SQL/PSM SQL/Persistent Stored Module
Oracle PL/SQL Procedural Language/SQL (основан на языке Ada)
PostgreSQL PL/pgSQL
Procedural Language/PostgreSQL Structured Query Language (очень похож на Oracle PL/SQL)
9.2. Основные особенности Основные особенности языка SQL: • SQL не процедурный язык, поэтому в нем нужно указывать, какая информация
должна быть получена, а не как ее можно получить - SQL не требует указания методов доступа к данным;
• SQL поддерживает свободный формат записи операторов; • структура команд задается набором ключевых слов; • язык SQL предназначен для широкого круга пользователей БД; • стандарт языка SQL2 не поддерживает определений реляционной модели данных
(например, вместо «отношение», «кортеж, «атрибут» используются понятия «таблица», «строка», «столбец») и не реализует полностью реляционную модель (например, в SQL таблица может иметь дублирующие строки, а домен – не множество значений, а тип данных пользователя).
9.3. Преимущества и недостатки 9.3.1. Преимущества Независимость от конкретной СУБД Несмотря на наличие диалектов, и различий в синтаксисе, в большинстве своём
тексты SQL-запросов, содержащие DDL и DML, могут быть достаточно легко перенесены из одной СУБД в другую. Существуют системы, разработчики которых изначально ориентировались на применение, по меньшей мере, нескольких СУБД (например: система электронного документооборота Documentum может работать как с Oracle, так и с Microsoft SQL Server и IBM DB2). Естественно, что при применении некоторых

специфичных для реализации возможностей такой переносимости добиться уже очень трудно.
Наличие стандартов Наличие стандартов и набора тестов для выявления совместимости и соответствия
конкретной реализации SQL общепринятому стандарту только способствует «стабилизации» языка.
Декларативность С помощью SQL программист описывает только то, какие данные нужно извлечь или
модифицировать. То, каким образом это сделать, решает СУБД непосредственно при обработке SQL-запроса. Однако не стоит думать, что это полностью универсальный принцип — программист описывает набор данных для выборки или модификации, однако ему при этом полезно представлять, как СУБД будет разбирать текст его запроса. Чем сложнее сконструирован запрос, тем больше он допускает вариантов написания, различных по скорости выполнения, но одинаковых по итоговому набору данных.
9.3.2. Недостатки Несоответствие реляционной модели данных Создатели реляционной модели данных Эдгар Кодд, Кристофер Дейт и их сторонники
указывают на то, что SQL не является истинно реляционным языком. В частности, они указывают на следующие проблемы SQL:
• Повторяющиеся строки; • Неопределённые значения (NULL); • Явное указание порядка колонок слева направо; • Колонки без имени и дублирующийся имена колонок; • Отсутствие поддержки свойства «=»; • Использование указателей; • Высокая избыточность. Сложность Хотя SQL и задумывался как средство работы конечного пользователя, в конце
концов, он стал настолько сложным, что превратился в инструмент программиста. Отступления от стандартов Несмотря на наличие международного стандарта ANSI SQL-92, многие компании,
занимающиеся разработкой СУБД (например, Oracle, Sybase, Microsoft, MySQL), вносят изменения в язык SQL, применяемый в разрабатываемой СУБД, тем самым отступая от стандарта. Таким образом, появляются специфичные для каждой конкретной СУБД диалекты языка SQL.
Сложность работы с иерархическими структурами Ранее диалекты SQL большинства СУБД не предлагали способа манипуляции
древовидными структурами. Некоторые поставщики СУБД предлагали свои решения (например, Oracle использует выражение CONNECT BY). В настоящее время в ANSI стандартизована рекурсивная конструкция WITH из диалекта SQL DB2. В MS SQL Server рекурсивные запросы появились лишь в версии MS SQL Server 2005.
9.4. Типы команд
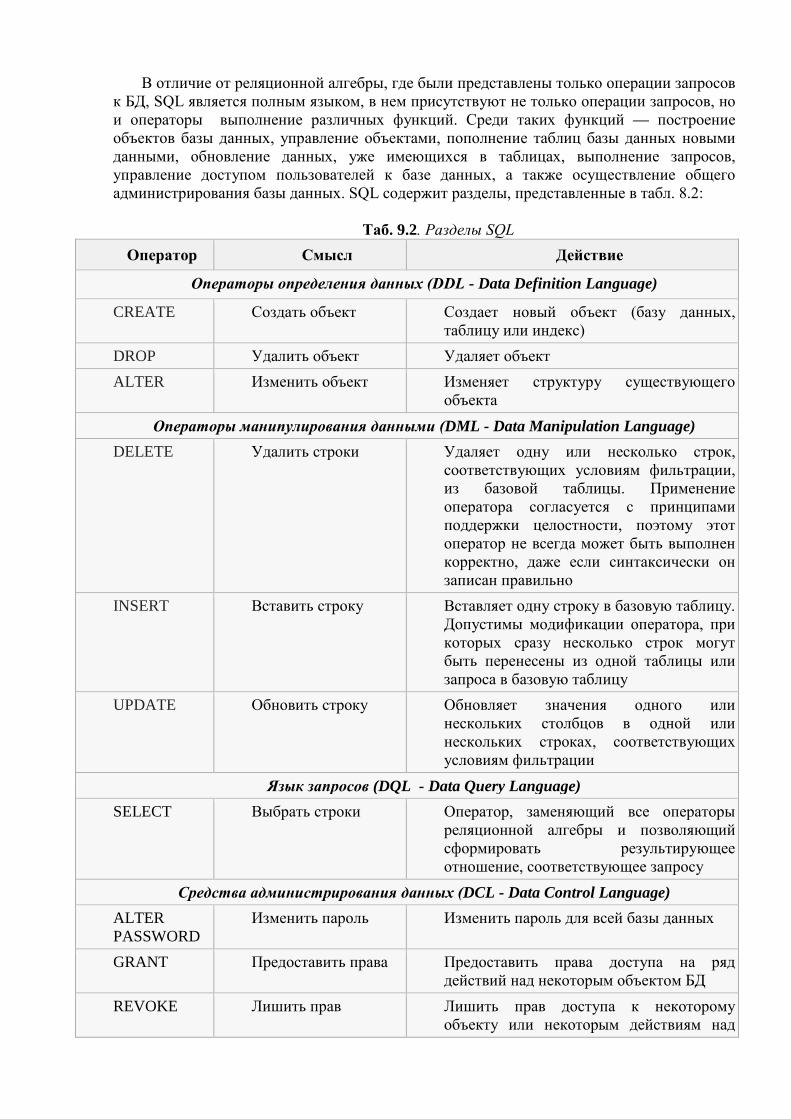
В отличие от реляционной алгебры, где были представлены только операции запросов к БД, SQL является полным языком, в нем присутствуют не только операции запросов, но и операторы выполнение различных функций. Среди таких функций — построение объектов базы данных, управление объектами, пополнение таблиц базы данных новыми данными, обновление данных, уже имеющихся в таблицах, выполнение запросов, управление доступом пользователей к базе данных, а также осуществление общего администрирования базы данных. SQL содержит разделы, представленные в табл. 8.2:
Таб. 9.2. Разделы SQL
Оператор Смысл Действие
Операторы определения данных (DDL - Data Definition Language)
CREATE Создать объект Создает новый объект (базу данных, таблицу или индекс)
DROP Удалить объект Удаляет объект ALTER Изменить объект Изменяет структуру существующего
объекта Операторы манипулирования данными (DML - Data Manipulation Language)
DELETE Удалить строки Удаляет одну или несколько строк, соответствующих условиям фильтрации, из базовой таблицы. Применение оператора согласуется с принципами поддержки целостности, поэтому этот оператор не всегда может быть выполнен корректно, даже если синтаксически он записан правильно
INSERT Вставить строку Вставляет одну строку в базовую таблицу. Допустимы модификации оператора, при которых сразу несколько строк могут быть перенесены из одной таблицы или запроса в базовую таблицу
UPDATE Обновить строку Обновляет значения одного или нескольких столбцов в одной или нескольких строках, соответствующих условиям фильтрации
Язык запросов (DQL - Data Query Language) SELECT Выбрать строки Оператор, заменяющий все операторы
реляционной алгебры и позволяющий сформировать результирующее отношение, соответствующее запросу
Средства администрирования данных (DCL - Data Control Language) ALTER PASSWORD
Изменить пароль Изменить пароль для всей базы данных
GRANT Предоставить права Предоставить права доступа на ряд действий над некоторым объектом БД
REVOKE Лишить прав Лишить прав доступа к некоторому объекту или некоторым действиям над
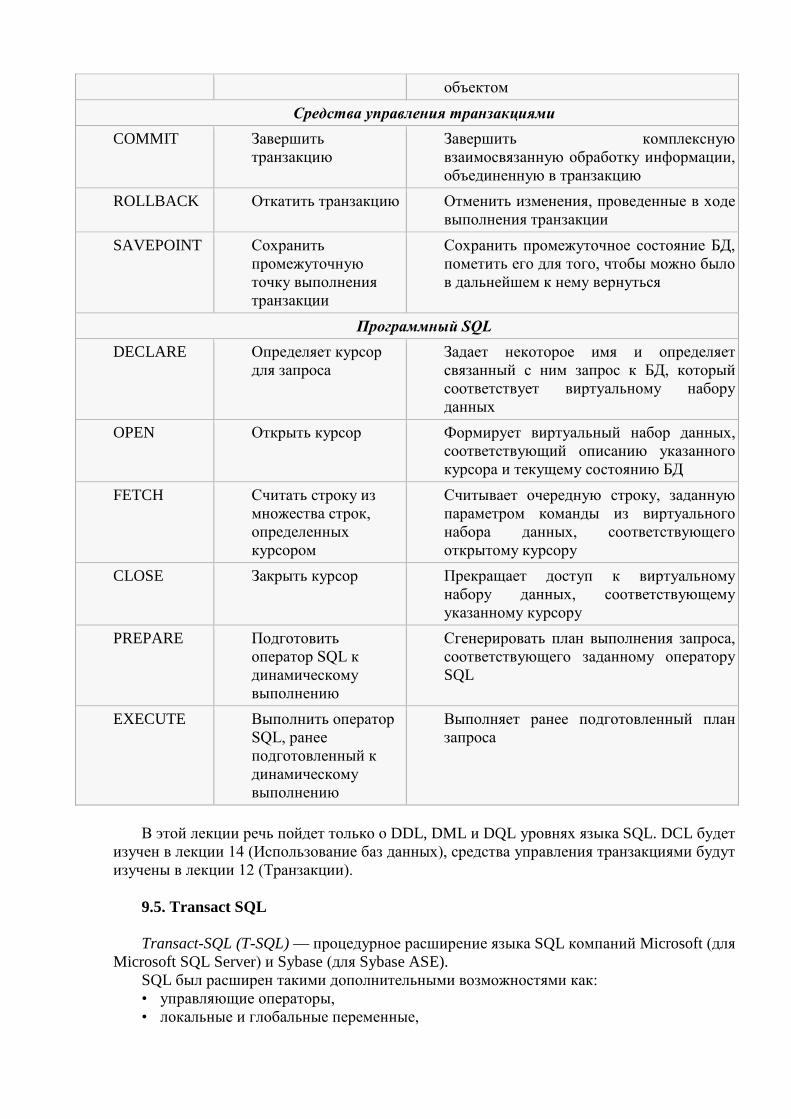
объектом Средства управления транзакциями
COMMIT Завершить транзакцию
Завершить комплексную взаимосвязанную обработку информации, объединенную в транзакцию
ROLLBACK Откатить транзакцию Отменить изменения, проведенные в ходе выполнения транзакции
SAVEPOINT Сохранить промежуточную точку выполнения транзакции
Сохранить промежуточное состояние БД, пометить его для того, чтобы можно было в дальнейшем к нему вернуться
Программный SQL DECLARE Определяет курсор
для запроса Задает некоторое имя и определяет связанный с ним запрос к БД, который соответствует виртуальному набору данных
OPEN Открыть курсор Формирует виртуальный набор данных, соответствующий описанию указанного курсора и текущему состоянию БД
FETCH Считать строку из множества строк, определенных курсором
Считывает очередную строку, заданную параметром команды из виртуального набора данных, соответствующего открытому курсору
CLOSE Закрыть курсор Прекращает доступ к виртуальному набору данных, соответствующему указанному курсору
PREPARE Подготовить оператор SQL к динамическому выполнению
Сгенерировать план выполнения запроса, соответствующего заданному оператору SQL
EXECUTE Выполнить оператор SQL, ранее подготовленный к динамическому выполнению
Выполняет ранее подготовленный план запроса
В этой лекции речь пойдет только о DDL, DML и DQL уровнях языка SQL. DCL будет
изучен в лекции 14 (Использование баз данных), средства управления транзакциями будут изучены в лекции 12 (Транзакции).
9.5. Transact SQL Transact-SQL (T-SQL) — процедурное расширение языка SQL компаний Microsoft (для
Microsoft SQL Server) и Sybase (для Sybase ASE). SQL был расширен такими дополнительными возможностями как: • управляющие операторы, • локальные и глобальные переменные,

• различные дополнительные функции для обработки строк, дат, математически и т. п.,
• поддержка аутентификации Microsoft Windows. Язык Transact-SQL является ключом к использованию MS SQL Server. Все
приложения, взаимодействующие с экземпляром MS SQL Server, независимо от их реализации и пользовательского интерфейса, отправляют серверу инструкции Transact-SQL. Именно на примере синтаксиса Transact SQL будут приведены примеры использования языка SQL.
Элементы синтаксиса Директивы сценария Директивы сценария — это специфические команды, которые используются только в
MS SQL. Эти команды помогают серверу определять правила работы со скриптом и транзакциями. Типичные представители: GO — сигнализирует SQL-серверу об окончании транзакции, EXEC (или EXECUTE) — выполняет процедуру или скалярную функцию.
Примечание. Транзакция - это совокупность операций, обеспечивающих завершенность некоторого
действия. Подробнее о транзакциях будет рассказано в лекции 16 (Транзакции). Комментарии Комментарии используются для создания пояснений для блоков сценариев, а также
для временного отключения команд при отладке скрипта. Комментарии бывают как строковыми, так и блоковыми:
-- — строковый комментарий исключает из выполнения только одну строку, перед которой стоят два минуса.
/* */ — блоковый комментарий исключает из выполнения целый блок команд, заключенный в указанную конструкцию.
Идентификаторы Идентификаторы — это специальные символы, которые используются с переменными
для идентифицирования их типа или для группировки слов в переменную. Типы идентификаторов:
• @ — идентификатор локальной переменной (пользовательской); • @@ — идентификатор глобальной переменной (встроенной); • # — идентификатор локальной таблицы или процедуры; • ## — идентификатор глобальной таблицы или процедуры; • [ ] — идентификатор группировки слов в переменную. Переменные Переменные используются в сценариях и для хранения временных данных. Чтобы
работать с переменной, ее нужно объявить, притом объявление должно быть осуществлено в той транзакции, в которой выполняется команда, использующая эту переменную. Иначе говоря, после завершения транзакции, то есть после команды GO, переменная уничтожается.
Объявление переменной выполняется командой DECLARE, задание значения переменной осуществляется либо командой SET, либо SELECT:
USE TestDatabase -- Объявление переменных DECLARE @EmpID INT, @EmpName VARCHAR(40)

-- Задание значения переменной @EmpID SET @EmpID = 1 -- Задание значения переменной @EmpName SELECT @EmpName = UserName FROM Users WHERE UserID = @EmpID -- Вывод переменной @EmpName в результат запроса SELECT @EmpName AS [Employee Name] GO
Примечание. В этом примере используется группировка слов в переменную — конструкция
[Employee Name] воспринимается как одна переменная, так как слова заключены в квадратные скобки.
Управление выполнением сценария В Transact-SQL существуют специальные команды, которые позволяют управлять
потоком выполнения сценария, прерывая его или направляя в нужную логику. • Блок группировки — структура, объединяющая список выражений в один
логический блок (BEGIN … END); • Блок условия — структура, проверяющая выполнения определенного условия (IF
… ELSE); • Блок цикла — структура, организующая повторение выполнения логического
блока (WHILE … BREAK … CONTINUE); • Переход — команда, выполняющая переход потока выполнения сценария на
указанную метку (GOTO); • Задержка — команда, задерживающая выполнение сценария (WAITFOR) • Вызов ошибки — команда, генерирующая ошибку выполнения сценария
(RAISERROR).






























