Embed Size (px)
Citation preview

Computers in Biology and Medicine 36 (2006) 748–767www.intl.elsevierhealth.com/journals/cobm
Building an ontology of adverse drug reactions for automatedsignal generation in pharmacovigilance
Corneliu Henegara, Cédric Bousqueta,b, Agnès Lillo-Le Louëtb, Patrice Degouleta,Marie-Christine Jaulenta,∗
aINSERM, U729, F-75006 Paris, FrancebCentre Régional de Pharmacovigilance, Hôpital Européen Georges Pompidou, Paris, France
Received 5 April 2005; accepted 5 April 2005
Abstract
Automated signal generation in pharmacovigilance implements unsupervised statistical machine learning tech-niques in order to discover unknown adverse drug reactions (ADR) in spontaneous reporting systems. The impact ofthe terminology used for coding ADRs has not been addressed previously. The Medical Dictionary for RegulatoryActivities (MedDRA) used worldwide in pharmacovigilance cases does not provide formal definitions of terms. Wehave built an ontology ofADRs to describe semantics of MedDRA terms. Ontological subsumption and approximatematching inferences allow a better grouping of medically related conditions. Signal generation performances aresignificantly improved but time consumption related to modelization remains very important.� 2005 Elsevier Ltd. All rights reserved.
Keywords: Adverse drug reaction reporting systems; Terminology; Automatic data processing; Knowledge representation(computer); Description logic; Ontological modeling
∗ Corresponding author. INSERM U729, Université Paris Descartes, Faculté de médecine, 15 rue de 1’école de médecine75006 Paris, France. Tel.: +33 1 42 34 69 86; fax: +33 1 53 10 92 01.
E-mail address: [email protected] (M. Jaulent).
0010-4825/$ - see front matter � 2005 Elsevier Ltd. All rights reserved.doi:10.1016/j.compbiomed.2005.04.009

C. Henegar et al. / Computers in Biology and Medicine 36 (2006) 748–767 749
1. Introduction
1.1. Medical context: signal generation in pharmacovigilance
The World Health Organization (WHO) defines a signal in pharmacovigilance as “any reported in-formation on a possible causal relationship between a drug and an adverse drug reaction (ADR), therelationship being unknown or incompletely documented previously” [1]. A continuous review of allreported drug–ADR combinations is needed in order to detect serious or unexpected events, which con-stitute the main objective of any pharmacovigilance reporting system. Traditionally, analysis is carriedout by a systematic manual expert review of spontaneous reports sent by physicians and registered inpharmacovigilance database systems.
Qualitative review by experts of all reported drug–ADR combinations is becoming increasingly difficultbecause of the constant raise in the number of cases stored in national and international databases.Moreover, the continuous development of new drugs requires an early detection of their unknown adverseeffects.
Drawing expert’s attention on relevant combinations [2] is becoming necessary. During the last 5 years,automated signal detection methods have been developed to supplement qualitative clinicalmethods [1,3–5]. While these automated methods cannot replace expert clinical reviewers, they can pro-vide assistance with the difficult task of screening huge numbers of drug–ADR combinations in databasesfor potential signals. Commonly used methods search databases for significant occurrence disproportion-alities. Dependencies between drug–ADR pairs are based on an underlying model of statistical association[6].
1.2. Statistical approaches for signal generation
Techniques based on Bayesian methods were proposed for the exploitation of huge pharmacovigilancedatabases in the WHO Uppsala Center for drug safety reports [7] and the Food and Drug Administrationpharmacovigilance database [8]. Proportionate Reporting Ratios and �2 test are implemented in theMedicines Control Agency [9] and the Drug Safety Research Unit [10] in Great Britain. Reporting oddsratios (RORs) are associated with logistic regression to test for confounding factors and the identificationof drug–drug interactions and drug syndromes in the Netherlands [11].
However, to date, these methods have not been prospectively evaluated, as there is no true gold standardfor signal detection [6]. Moreover, the number of cases needed to trigger a signal is not well defined.It is not usual to accept a signal when the number of cases is lower than three because the reportingof cases may be the result of a random process. Recently, Van Puijenbroeck assessed the performancesof most commonly used signal detection methods on Dutch data by choosing the Bayesian method asreference. He showed that the main limitation for these methods was the small number of occurrences ofeach drug–ADR combination in the database [1].
Our working hypothesis was that performances of these quantitative methods could be ameliorated bygrouping similar cases based on semantic information existing in the controlled vocabularies used to codeADR in case reports. Such an approach is susceptible to increase the number of occurrences of similardrug–ADR combinations in databases and thus ameliorate statistical relevance. Although the issue ofterminology was quoted by several authors, no study was realized to test the choice of a system of codingADRs on the performances of signal detection systems [12,6].

750 C. Henegar et al. / Computers in Biology and Medicine 36 (2006) 748–767
1.3. Terminological systems for adverse event coding
Until recently, pharmacovigilance cases were recorded in most Spontaneous Reporting Systems (SRS)by means of the World Health Organization—Adverse Reactions Terminology (WHO-ART) vocabularyor one of its derivatives, for example Coding Symbols for a Thesaurus of Adverse Reactions Terms(COSTART) previously used in the Food and Drug Administration system. The International Conferenceof Harmonization (ICH4) imposed the coding of adverse effects by means of the Medical Dictionary forDrug Regulatory Activities (MedDRA) terminology developed by the Maintenance Services and SupportOrganization (MSSO) [13]. MedDRA resumes most of the terms stemming from ADR dictionaries,for example WHO-ART terms but also terms stemming from other terminologies such as InternationalClassification of Diseases (ICD-9). MedDRA introduces numerous new terms with regard to the previousdictionaries that allow to code ADR descriptions in a more precise way than before. It organizes terms inseveral system organ classes (SOCs) without being truly multi-axial. Terms are not described in a formalway like, for example, by means of a description logic language and thus no inference is possible basedon their semantic content.
1.4. Objectives of the work
The main objective of our work was to build a formal representation of MedDRA terms using knowledgeengineering techniques in order to automatically retrieve and group terms describing similar medicalconditions.
In this paper, we describe the main terminological systems used in medicine, the limits of MedDRAand the principles of building ontologies from a medical terminology. The third section describes theconstruction of an ADR ontology from MedDRA and the application of terminological reasoning tech-niques. The fourth section presents the overall architecture of the built system as well as the working dataextracted from the French national base. Obtained results are given in the fifth section. Finally, we discussthe interest of a formal representation of MedDRA terms for signal generation in pharmacovigilance.
2. Background
2.1. Terminological systems in medicine
Rossi Mori classified terminological systems in medicine within three categories: first-generationsystems that represent terms as strings; second-generation systems that dissect terminological phrasesinto sets of simpler terms; and third-generation systems that provide advanced features to automaticallyretrieve the position of new terms in the classification and group sets of meaning-related terms [14]. Thistypology is based on the “Model for representation of semantics in medicine” project of the EuropeanCommittee for Standardization [15].
• First-generation terminological systems such as the ICD are based on textual descriptions of concepts[16]. No categorical structure is provided, and concepts are designated by codes and strings. Thesetraditional systems are paper-based but can be electronically available to allow the storage, transmission

C. Henegar et al. / Computers in Biology and Medicine 36 (2006) 748–767 751
and retrieval of strings and codes attached to the concepts. This type of vocabulary has a fixed andusually unique hierarchy devoted to a single application.
• Second-generation systems are compositional systems such as SNOMED which are built using acategorical structure and a cross thesaurus [17]. The categorical structure is composed of a set ofmeta-term descriptors to describe a concept in a domain of expertise. For instance, Gastric ulcerhemorrhage is linked to the topography axis (stomach) and the morphology axis (hemorrhage, ulcer).Terms that cannot be further dissected are “atomic” terms, for example ulcer, stomach, hemorrhage.The cross thesaurus is a multi-axial thesaurus that provides the atomic terms to enter descriptors fromthe categorical structure.
• Using a formal approach for the definition of terms is an active field of research in terminology. Theformal models constitute third-generation systems such as Generalized Architecture for Languages,Encyclopedias and Nomenclatures (GALEN) [18] or such as Systematized Nomenclature of MedicineReference Terminology (SNOMED RT) [19]. In formal taxonomic systems, concepts are describedusing a logical language and the position of concepts in the hierarchy is found by computing sub-sumption relations. For example, “gastric ulcer hemorrhage” is a “hemorrhage” caused by an “ulcer”localized in the “stomach”.
Unified Medical Language System (UMLS) [20] presents a particular status with regard to this classi-fication. UMLS contains a meta-thesaurus with medical concepts and a semantic network, which pro-vides information on the semantic relationships between medical concepts. These concepts are takenfrom established vocabularies such as SNOMED, ICD-9-CM, MeSH and MedDRA, amongothers.
2.2. Limits of MedDRA
The aim of the new MedDRA terminology is to provide an internationally approved classificationfor efficient communication of ADR data between countries. Several studies have evaluated the domaincompleteness of MedDRA and whether encoded terms are coherent with physicians’ original verbatimdescriptions of the adverse events.
MedDRA terms are organized in five levels: SOC, high-level group terms (HLGT), high-level terms(HLT), preferred terms (PT) and low-level terms (LLT). Although terms may belong to different SOCs,no PT is related to more than one HLT within the same SOC. Although this hierarchical property ensuresthat terms cannot be counted twice in statistical studies, it does not allow appropriate semantic groupingof PTs. For this purpose, Special Search Categories (collections of PTs assembled from various SOCs)have been introduced in MedDRA to group terms with similar meaning. However, only a small numberof categories are currently available, and the criteria used to construct these categories manually have notbeen clarified.
Studies of the impact of MedDRA on automated signal detection have pointed out that taxonomiclimitations decrease the sensitivity and specificity of the signal [21,22]: the meaning of a medical conceptis usually split into several PTs and terms expressing similar conditions may be far apart in the hierarchy.
MedDRA is a first-generation system: there is no formal representation of MedDRA terms. The multi-axiality of MedDRA is limited to the fact that a PT can belong to several SOCs and cannot be comparedto the multi-axial properties of other terminological systems such as SNOMED, which allows multipleviews on data according to the axis (morphological, topographic, etc.) [23].

752 C. Henegar et al. / Computers in Biology and Medicine 36 (2006) 748–767
The need for concept-oriented terminologies has been recognized and addressed by many medicalinformatics researchers [24,25].
In a recent paper, we applied Cimino’s desiderata to show that MedDRA is not compatible with theproperties of third-generation systems [26]. Consequently, no tool can help for the automated positioningof new terms inside the hierarchy, and SSCs have to be entered manually rather than automaticallyusing the MedDRA files. One solution could be to link MedDRA to a third-generation system. Withthis objective in mind, we developed an ontology of ADR using a description logics formalism andimplemented terminological reasoning techniques based on the subsumption mechanism in the concepthierarchy in order to group similar cases.
2.3. Ontology learning and building from medical terminology
An ontology is frequently defined to be “an explicit representation of a conceptualization” [27–29]. Inthe medical field, ontologies are currently perceived as the solution to encompass all problems related tobiomedical terminology.
The critical issue is the construction of the ontology which means identifying, defining and enteringconcept definitions. Two main approaches are currently helping this task. The first one relies on machinelearning and automated language-processing techniques to extract concepts and ontological relationsfrom structured and unstructured data such as databases and text (ontology learning) [30].
Most tools are based on the differential linguistic approach, allowing the definition of classes of conceptsand relations using a distributional analysis of the contexts of the terms in a given text corpus. These toolsalready contributed extensively to the construction of ontologies but different experimentations showedthat great attention should guide the choice of the corpus and tools [31–33].
The second approach facilitates manual ontology engineering by providing tools, including editors,consistency checkers, to support shared decisions about information on concept designations, conceptcharacteristics or the relation between concepts. Protégé [34] and Oiled [35] are examples of such toolsets[36]. The role of consistency checker is to integrate all information in the part of the ontology constructedthus far. The result is shown to the user as a representation of the ontology comprising relations betweenconcepts and features of individual concepts. Inconsistencies and other errors are pointed out by the toolwhich proposes corrections and changes to the ontology as new information makes this necessary.
Sowa notes that “subsets of the terminology can be used as starting points for formalization”, andthat this is a valid endeavour since “most fields of science, engineering, business and law have evolvedsystems of terminology or nomenclature for naming, classifying and standardizing their concepts” [37].
Building an ontology from a terminology meets some requirements proposed by Cimino [38]. TheDesiderata is a set of standards necessary for the development of a reusable multi-purpose terminol-ogy. Some of the requirements of the Desiderata include domain content coverage, concept orientation,nonsemantic concept identifiers, polyhierarchy, multiple granularities and multiple consistent views. Aterminology must be able to provide appropriate coverage of the domain’s concepts (domain coverage).The concept is the unit of representation and must have a single, coherent meaning within the termi-nology (concept orientation). The concepts must be represented by meaningless, unique identifiers thatare free of hierarchical meaning (nonsemantic identifiers). Such identifiers allow for multiple classi-fications and rearrangement of concepts within a hierarchy. A terminology should have a hierarchicalarrangement that allows assignment of concepts in one or more areas of the hierarchy (polyhierarchy).In addition, to provide for multiple user functionality, a terminology must provide different levels of

C. Henegar et al. / Computers in Biology and Medicine 36 (2006) 748–767 753
granularity and must maintain a consistent view throughout its hierarchy (multiple granularities andconsistent views).
2.4. Ontology coding
Frame-based model with a hierarchy structure is currently used as formal representation of concepts.The hierarchical relationships from child to parent are of ‘is a’ type and each concept node can also beviewed as a frame with named slots. Slots may have values associated with them. Each concept node canalso be viewed as having nonhierarchical relationships to other nodes through named slots or semanticlinks.
Description Logics (DL)-based languages, rooted in frame systems, are characterized by their expres-siveness and clearly defined semantics. Formal representations based on Description Logics or closelyrelated formalisms are increasingly used for representing medical terminologies of third generation [39].
DLs capture the meaning of the data by concentrating on entities related by relationships. The meaningis represented as “descriptions” which can be concepts (classes of individuals), roles (binary relationsamong individuals) and individuals (instances). The resultant knowledge bases (terminological bases)are structured on two levels: representation and manipulation of concepts and roles are realized at theterminological level (TBox), while description and manipulation of the individuals belongs to the factuallevel (assertions or ABOX).
At the terminological level, the entities (concepts and roles) can be primitive or defined. Primitiveentities, comparable to atoms, allow the construction of defined entities (for example, the primitiveconcepts “Inflammation” and “Liver” are used in the definition of the defined concept “Hepatitis”).
Terminological reasoning in DL (reasoning with descriptions) is based on operations of classificationand instantiation on the hierarchies of concepts and roles. The classification allows determining automat-ically the position of a concept or a role in their respective hierarchies, by automatically comparing theirdescriptions (for instance, the defined concept “hepatitis cytolitic” is subsumed by the more general con-cept “hepatitis”), while instantiation allows finding all the concepts of which an individual is susceptibleto be an instance.
The main effort of modeling in DL is steered today towards the indexation and the search for informationon the Web and automatic treatment of natural language [40]. Relatively few research projects wereinterested in the “intelligent” integration of the information and in datamining, in spite of the fact thatthis kind of application was proposed for a long time [40,41].
3. Methods
The development of an ontology of ADRs from the MedDRA terminology useful to group similarmedical conditions included the three following steps:
1. To evaluate and choose among available formal representation languages, ontology editors and infer-ence engines
The ontology was developed within OilEd ontology editor [35]. The knowledge representation languagewas the SHIQ description logic (DAML+OIL language) [42]. We used the RACER inference engine tobuild the ontology and perform terminological reasoning [43].

754 C. Henegar et al. / Computers in Biology and Medicine 36 (2006) 748–767
2. To select a group of MedDRA terms corresponding to the WHO-ART terms actually used in Frenchnational pharmacovigilance database
In the French database, ADR case reports are historically coded with WHO-ART but a new version of thedatabase including MedDRA is under study by the French national Agency. Within the material extractedfrom the French database for the purpose of our study (see Section 3.3), we selected 846 WHO-ARTPTs used to code adverse events. From these, we selected 694 equivalent MedDRA PTs using a table ofterminological correspondences between WHO-ART and MedDRA. This table was established for thepurpose of this work and makes use of the UMLS network.
3. To build up a formal ontology modeling (formalizing the meaning of), the previous corpus of MedDRAterms and propose techniques of terminological reasoning in order to automatically cluster MedDRAterms describing similar medical conditions.
3.1. Ontology building
The ontology was constructed in two steps: (1) structuring the hierarchies of primitive concepts andrelations, (2) definition of complex concepts.
3.1.1. Primitive concepts hierarchy and relationsThe structure of the primitive concepts hierarchy was partly inspired by the GALEN CORE model
[39]. Additional primitive concepts were continuously added to the hierarchy when required during themodeling of complex MedDRA concepts. The hierarchy is divided into two main branches. The firstbranch includes “Self-Standing” primitive concepts such as “inflammation”, “infection”, “hemorrhage”or “liver”, which allows description of the semantic content of MedDRA terms, grouped in four maincategories (Fig. 4):
• types of disorders (e.g. functional or structural disorders, signs and symptoms),• physiological functions (e.g. physical or mental),• pathogenic agents (e.g. biological, chemical or physical),• physical structural levels (e.g. organs and systems, structural levels or topographic divisions of the
body).
Whenever possible, the “physical structural levels” branch was organized using direct taxonomic relationsbetween concepts (is-a) to avoid partonomic relations “part-of”, in order to simplify the descriptionof complex concepts and the reasoning with these descriptions. This was done by representing insidethe ontology only the generality level of the considered physical structure component. For instance,a “cytoplasmic structural level” “is-a” type of “cellular structural level” which “is-a” type of “tissuestructural level”.
The second main branch contained primitive concepts to refine complex abstract descriptions (refiningconcepts), and express nuances and degrees of intensity with regard to the properties of concepts such asacute, chronic, hypo, hyper, normal, abnormal, increased, decreased, etc.
We also developed a hierarchy of “roles” (conceptual relations) to compose the descriptions of com-plex concepts. Two types of roles were defined. “Relating properties” were defined and used to connect

C. Henegar et al. / Computers in Biology and Medicine 36 (2006) 748–767 755
primitive self-standing concepts in order to compose complex descriptions. There are organized in a hi-erarchy. For example, IsResultOf (towards the condition producing the result) has a subrole IsResultOf-Function (towards the physiologic function producing the result). “Refining Properties” were used torefine complex descriptions. For instance, hasEvolutionValueType (towards the type of evolution, acute,chronic, etc). The roles were organized by hand and are not formally defined nowadays.
3.1.2. Definition of complex conceptsThe primitive concepts hierarchy and the definition of complex concepts were constructed simultane-
ously. The position of complex defined concepts within the concept hierarchy was automatically inferredby the RACER engine based on the provided conceptual descriptions, and led to a coherent ontology. Tofacilitate the development of a terminological reasoning approach, we individualized the two hierarchiesof concepts (primitive and complex) by proscribing “is-a” links between the two types of concepts. Forexample, the complex concept “Hepatitis” (liver inflammation) was defined by the following expression:
Hepatitis • (isStructuralDisorderOf some HepaticStructuralLevels) and (hasTypeOfDisorder some
InflamationTypes) (1)
In the above expression, “isStructuralDisorderOf” and “hasTypeOfDisorder” are relations (relating prop-erties) and “HepaticStructuralLevels” and “InflamationTypes” are primitive concepts.
To facilitate the definition of complex concepts, we constrained the use of primitive concepts andrelations establishing rules for concept description (or ontological modeling).
• The most general model to describe a pathological entity has to first specify the general type of disorder(structural or functional).
• In the case of a structural disorder, the involved structural level has to be set together with the type ofstructural disorder (e.g. infection, inflammation) like in example (1).
• If it is a functional disorder, the type of function and the physical structure which is responsible hasto be indicated.
Mixed disorders were described using a conjunction and/or disjunction of functional and/or structuraldisorders like in examples (2) and (3)
Hepatitis_cholestatic • (isStructuralDisorderOf some HepaticStructuralLevels) and
(hasTypeOfDisorder some InflamationTypes) and (isFunctionalDisorderOf some
(Excretion and (isFunctionOf some HepaticStructuralLevels))) (2)
Hepatic_enzymes_and_function_abnormalities • (isStructuralDisorderOf some
HepatocytesStructuralLevels) or(isFunctionalDisorderOf some
(Functions and (isFunctionOf some HepaticStructuralLevels))) (3)
Then conceptual descriptions were refined by specifying the sense of a disorder (hypo- or hyperfunction)or by placing it in a temporal context (acute, chronic, fulminant) and so on like in example (4)
Hepatitis_fulminant • (isStructuralDisorderOf some HepaticStructuralLevels) and
(hasTypeOfDisorder some InflamationTypes) and (hasEvolution some FulminantEvolutionType) (4)
756 C. Henegar et al. / Computers in Biology and Medicine 36 (2006) 748–767
Case n˚1 Case n˚2
Drug X
(HLT) Hepatitis
(PT) Hepatitis Cholestatic
(PT) Cytolytic Hepatitis
(HLT) Cholestasis and jaundice
(HLGT) Hepatobiliar
Disorder
Case n˚1 Case n˚2
Drug X
(PT) Hepatitis Cholestatic
(PT) Cytolytic Hepatitis
(HLT) Cholestasis and jaundice
(HLGT) HepatobiliarDisorders
(HLT) Hepatitis
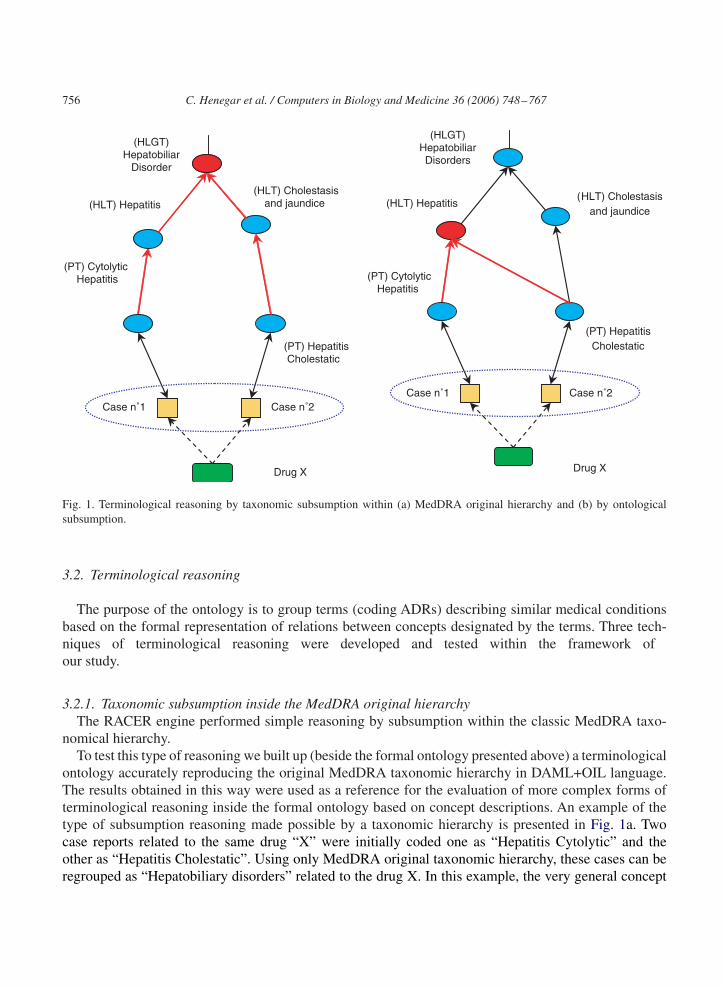
Fig. 1. Terminological reasoning by taxonomic subsumption within (a) MedDRA original hierarchy and (b) by ontologicalsubsumption.
3.2. Terminological reasoning
The purpose of the ontology is to group terms (coding ADRs) describing similar medical conditionsbased on the formal representation of relations between concepts designated by the terms. Three tech-niques of terminological reasoning were developed and tested within the framework ofour study.
3.2.1. Taxonomic subsumption inside the MedDRA original hierarchyThe RACER engine performed simple reasoning by subsumption within the classic MedDRA taxo-
nomical hierarchy.To test this type of reasoning we built up (beside the formal ontology presented above) a terminological
ontology accurately reproducing the original MedDRA taxonomic hierarchy in DAML+OIL language.The results obtained in this way were used as a reference for the evaluation of more complex forms ofterminological reasoning inside the formal ontology based on concept descriptions. An example of thetype of subsumption reasoning made possible by a taxonomic hierarchy is presented in Fig. 1a. Twocase reports related to the same drug “X” were initially coded one as “Hepatitis Cytolytic” and theother as “Hepatitis Cholestatic”. Using only MedDRA original taxonomic hierarchy, these cases can beregrouped as “Hepatobiliary disorders” related to the drug X. In this example, the very general concept

C. Henegar et al. / Computers in Biology and Medicine 36 (2006) 748–767 757
of “Hepatobiliary Disorders” is the only concept which is subsuming, inside the taxonomical hierarchy,both conditions observed in the two cases.
3.2.2. Subsumption inside the structure of the ADR ontologyThe RACER engine performed simple reasoning by subsumption within the formal ontology.The subsumption inside the structure of a formal ontology is the most widespread method of termi-
nological reasoning [44]. As in the case of taxonomic subsumption, this type of reasoning is based onthe transitivity of the conceptual relations established between a subsumant and a subsumed, within anontological structure. The difference is that in the case of a formal ontology these relations are inferredsystematically by comparison of concept descriptions, while in a terminological ontology (or taxonomichierarchy), they are indicated explicitly, without any possibility of further evolution with the additionof new concepts. The example previously used to explain taxonomic subsumption can be further usedto exemplify formal ontological subsumption (Fig. 1b). Because of conceptual descriptions availablewithin the ontology, new relations can be established between concepts. For example the concepts “Hep-atitis Cytolytic” and “Hepatitis Cholestatic” will be both subsumed by the concept “Hepatitis”. Thisresult in a more precise case regroupment because “Hepatitis” designs a more precise information than“Hepatobiliary Disorders” thus increasing the specificity value of a signal generated as a result of caseregroupment.
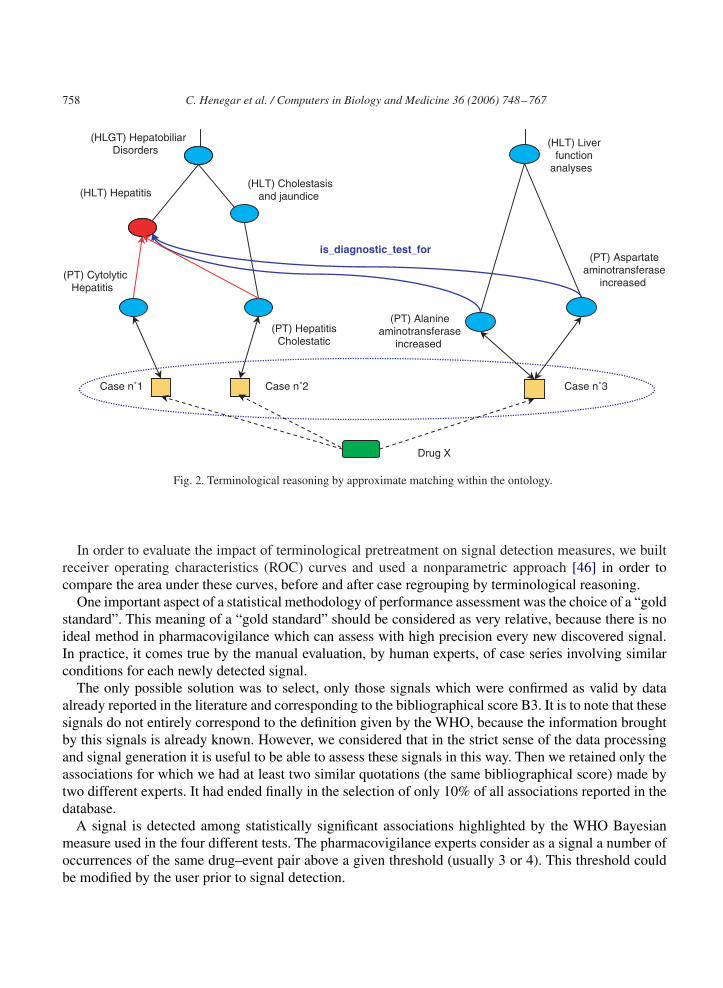
3.2.3. Reasoning by approximate matchingReasoning by approximate matching was proposed essentially to optimize the use of cases encoded by
means of abnormal laboratory findings or symptoms, in the place of well-determined pathological entities.We implemented a method of extended subsumption, to complement strict subsumption inapplicable inthese situations. In this purpose we defined a special type of role “isDiagnosticTestFor” allowing linksbetween diagnostic tests and pathological entities. These links were then used to group systematically,by approximate matching, all the cases which satisfied a customizable number of conditions, modeled asdisjunctive subsets of conceptual properties. For example under the concept of “Hepatitis”, besides directinstances, we were able to group all the cases which contained at least one of the following disjunctivesubsets of adverse events: (“high ASAT” and “high ALAT”) or (“high ASAT” and “cholestasis”) or(“jaundice” and “cytolysis”) or . . . In Fig. 2, we exemplify terminological reasoning by approximatematching. A third case comprising two abnormal laboratory tests “Aspartate aminotransferase increased”and “Alanine aminotransferase increased” could be regrouped with the previous two cases and consideredas a “Hepatitis” condition related to drug X.
3.3. Material and evaluation methodology
Data were extracted from the French national pharmacovigilance database. According to the Frenchmethod for unexpected or toxic drug reaction assessment, a bibliographical score (B) is registered foreach case to indicate the extent to which the association between the drug and the adverse event is alreadyknown. This score ranges from B0 for an unknown association to B3 for a notorious association [45].
The test database, including 42,284 cases, was supplied by the French Medicines Agency (AFSSAPS).It contains all of the cases reported in the national database between January 2001 and 2003 and generates230,676 drug–ADR combinations. Of this, 159,166 (69%) associations occurred only once.
758 C. Henegar et al. / Computers in Biology and Medicine 36 (2006) 748–767
Drug X
(HLT) Hepatitis
(PT) Hepatitis Cholestatic
(PT) CytolyticHepatitis
Case n˚1
(HLT) Cholestasis and jaundice
Case n˚2
(HLGT) HepatobiliarDisorders
Case n˚3
(PT) Alanine aminotransferase
increased
(HLT) Liver function
analyses
(PT) Aspartate aminotransferase
increased
is_diagnostic_test_for
Fig. 2. Terminological reasoning by approximate matching within the ontology.
In order to evaluate the impact of terminological pretreatment on signal detection measures, we builtreceiver operating characteristics (ROC) curves and used a nonparametric approach [46] in order tocompare the area under these curves, before and after case regrouping by terminological reasoning.
One important aspect of a statistical methodology of performance assessment was the choice of a “goldstandard”. This meaning of a “gold standard” should be considered as very relative, because there is noideal method in pharmacovigilance which can assess with high precision every new discovered signal.In practice, it comes true by the manual evaluation, by human experts, of case series involving similarconditions for each newly detected signal.
The only possible solution was to select, only those signals which were confirmed as valid by dataalready reported in the literature and corresponding to the bibliographical score B3. It is to note that thesesignals do not entirely correspond to the definition given by the WHO, because the information broughtby this signals is already known. However, we considered that in the strict sense of the data processingand signal generation it is useful to be able to assess these signals in this way. Then we retained only theassociations for which we had at least two similar quotations (the same bibliographical score) made bytwo different experts. It had ended finally in the selection of only 10% of all associations reported in thedatabase.
A signal is detected among statistically significant associations highlighted by the WHO Bayesianmeasure used in the four different tests. The pharmacovigilance experts consider as a signal a number ofoccurrences of the same drug–event pair above a given threshold (usually 3 or 4). This threshold couldbe modified by the user prior to signal detection.

C. Henegar et al. / Computers in Biology and Medicine 36 (2006) 748–767 759
4. Results
4.1. Ontology modeling
The ontological modeling necessitated 300 h of development and produced an ontology with 390primitive concepts, 42 types of relations, and 530 complex concepts belonging to 10 MedDRA SOC. Acomparison between a portion of the original MedDRA hierarchy and the equivalent ontological structureobtained by automatic classification of concepts based on their descriptions is presented in Fig. 3. In thisexample, it is possible to identify some of the aforesaid taxonomical limitations and to examine theresult of the ontological modeling. For example, the concept “Hepatitis_cholestatic ” acquires a multipleinheritance, comporting the notion of hepatitis but also that of hepatic functional disorder expressedas a cholestasis. The concept “Hepatic_disorder_NOS” acquires a very high position in the ontologicalhierarchy, in accord with the degree of generality of its semantic content.
Figs. 4 and 5 present partial views of primitive and defined concepts hierarchy within the Oiled editor.
4.2. Functional architecture of the system
A specific tool was developed to test the impact of the three terminological reasoning techniques onthe automated signal generation. The main functionalities of this software are:
• To load the ontological file and construct dynamically the terminological level (TBox) of the knowledgebase using the RACER engine.An interface allowed the user to visualize the structure of the knowledgebase with the hierarchy of concepts corresponding to MedDRA terms.
• To build the factual level (ABox) of the knowledge base by instantiating concepts with pharmacovig-ilance cases. Adverse events from the cases coded with MedDRA were automatically linked with aconcept in the TBox.
Fig. 3. A portion of the original taxonomical MedDRA hierarchy (to the left) and the equivalent ontological structure establishedautomatically in accord with concept descriptions (to the right).

760 C. Henegar et al. / Computers in Biology and Medicine 36 (2006) 748–767
Fig. 4. Partial view of the primitive concepts hierarchy.
• To pre-process the data from theABox to provide the list of all drug–ADR combinations in the databaseand to build the contingency table containing the number of cases reported for each combination. Thisis further used to compute the statistic measure for signal detection and the result of this process isavailable to the user.
• To perform terminological reasoning (TR) on the pre-processed data (terminological pre-processeddata). Regroupment of cases was realized only at the ADR level (and not at the drug level) by replacingthe term initially used to code a medical condition observed in that case with a more general oneusing a subsumption technique. For example the concept of “Hepatitis Cytolytic” can be replaced bythe more general concept “Hepatitis” which includes the semantic meaning of the first one. In thisway, all the initial drug–ADR combinations containing “Cytolitic Hepatitis”, as well as “CholestaticHepatitis”, etc. were replaced with new drug–ADR combinations containing “Hepatitis”. By that meanthese combinations were regrouped in order to increase the number of cases reported per drug–ADRcombinations.
C. Henegar et al. / Computers in Biology and Medicine 36 (2006) 748–767 761
Fig. 5. Partial view of the defined concepts hierarchy.
The three terminological reasoning techniques are respecting the same basic principle described abovefor case regroupment, but they differ by the way in which they are using taxonomical or ontologicalstructures of terms in order to establish terminological correspondences.
• To apply the WHO Bayesian signal detection measure on the pre-processed data
The software was used in four different conditions:
1. The WHO Bayesian signal generation measure is applied directly on the pre-processed data (MedDRAwithout TR).
2. The WHO Bayesian signal generation measure is applied on the terminological pre-processed datausing taxonomic subsumption inside the MedDRA original hierarchy (MedDRA TR).
3. The WHO Bayesian signal generation measure is applied on the terminological pre-process data usingtaxonomic subsumption inside the structure of the ADR ontology (Ontology TR).
4. The WHO Bayesian signal generation measure is applied on the terminological pre-process data usingboth taxonomic subsumption inside the structure of the ADR ontology and reasoning by approximatematching (Ontology TR and AM).
762 C. Henegar et al. / Computers in Biology and Medicine 36 (2006) 748–767
1 - Specificity
0.0 0.2 0.4 0.6 0.8 1.0
Sens
ibili
ty
0.0
0.2
0.4
0.6
0.8
1.0
Ontology TR & AMOntology TRMedDRA TRMedDRA without TR
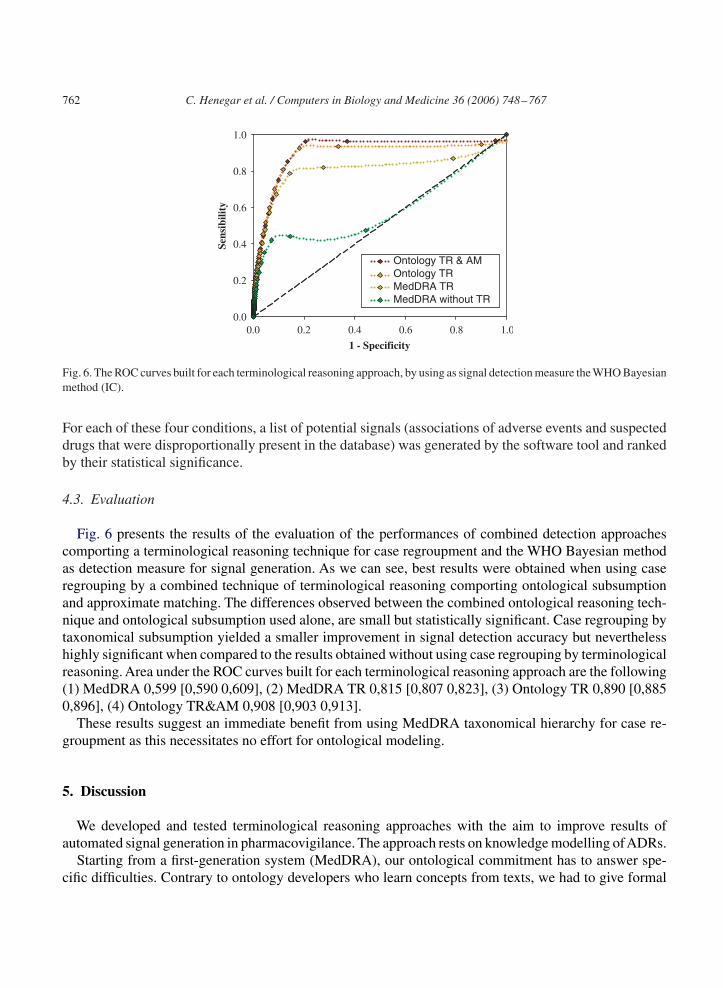
Fig. 6. The ROC curves built for each terminological reasoning approach, by using as signal detection measure the WHO Bayesianmethod (IC).
For each of these four conditions, a list of potential signals (associations of adverse events and suspecteddrugs that were disproportionally present in the database) was generated by the software tool and rankedby their statistical significance.
4.3. Evaluation
Fig. 6 presents the results of the evaluation of the performances of combined detection approachescomporting a terminological reasoning technique for case regroupment and the WHO Bayesian methodas detection measure for signal generation. As we can see, best results were obtained when using caseregrouping by a combined technique of terminological reasoning comporting ontological subsumptionand approximate matching. The differences observed between the combined ontological reasoning tech-nique and ontological subsumption used alone, are small but statistically significant. Case regrouping bytaxonomical subsumption yielded a smaller improvement in signal detection accuracy but neverthelesshighly significant when compared to the results obtained without using case regrouping by terminologicalreasoning. Area under the ROC curves built for each terminological reasoning approach are the following(1) MedDRA 0,599 [0,590 0,609], (2) MedDRA TR 0,815 [0,807 0,823], (3) Ontology TR 0,890 [0,8850,896], (4) Ontology TR&AM 0,908 [0,903 0,913].
These results suggest an immediate benefit from using MedDRA taxonomical hierarchy for case re-groupment as this necessitates no effort for ontological modeling.
5. Discussion
We developed and tested terminological reasoning approaches with the aim to improve results ofautomated signal generation in pharmacovigilance. The approach rests on knowledge modelling ofADRs.
Starting from a first-generation system (MedDRA), our ontological commitment has to answer spe-cific difficulties. Contrary to ontology developers who learn concepts from texts, we had to give formal

C. Henegar et al. / Computers in Biology and Medicine 36 (2006) 748–767 763
definitions to terms that are not really part of the domain. No Elsewhere Classified (NEC) qualifiers areprovided to classify on the basis of an inclusion/exclusion mechanism. No Elsewhere Specified (NOS)qualifiers express our ignorance about the description of a disease; this disease could be described ina more precise way but we lack information and prefer to say that it is not otherwise specified. NOSand NEC qualifiers do not work properly in ontological definitions. Numerous terms with same meaningappear in MedDRA at different hierarchical levels creating problems for the ontological modelling, asfor example in the case of the term “gastro-intestinal diseases” which is found under various forms inall the hierarchical levels MedDRA: “Gastrointestinal disorders” (SOC), “Gastrointestinal conditionsNEC” (HLGT), “Gastrointestinal disorders NEC” (HLT), “Gastrointestinal disorder” (PT). Another dif-ficulty we met during ontological modeling concerns the granularity level of the knowledge model-ing required for efficient case regroupment and signal generation. Some MedDRA terms convey veryprecise meaning and we had to develop very accurate and lengthy definitions of these fine granularconcepts.
Our approach inspired from the Galen experience was extended to include original features, whichgreatly simplified knowledge modeling, like the representation of physical structural levels and the stan-dardized rules for complex concept description. Some of the MedDRA limitations, pointed out in thebackground section were overcome by the ontology. Thus, in the ontological modeling, the concept “Hep-atitis cholestatic” acquired multiple inheritances, and expressed both the notion of hepatitis and hepaticfunctional disorder in the form of cholestasis. Furthermore, the concept of “Hepatic_disorder_NOS”,defined as PT in MedDRA, acquired a very high position in the ontological hierarchy, in agreement withits very general semantic content.
The addition of terminological reasoning significantly improved the performance of algorithms forautomated signal detection in a pharmacovigilance setting. For signal detection, it is important to notethat the significant gain in signal quality relies on a time-consuming effort of modeling. Besides this, itappeared that the simple mechanism of subsumption, applied to the classic MedDRA hierarchy, provideda gain in signal detection less important when compared with the ontological reasoning but neverthelesshighly significant. This result suggests an immediate practical benefit of terminological reasoning basedon the MedDRA structure while we continue to develop the formal ontology.
It is likely that MedDRA will continue to evolve in terms of a first-generation system in next versions.Although ontological modeling brings numerous advantages (coherence, maintenance, formal definitionof terms), the strict structure of MedDRA has advantages in terms of reproducibility of the coding anddata presentation [26]. Single inheritance inside a SOC is necessary during statistical exploitation of datato avoid counting the same concept several times in different categories.
The definition of 530 complex concepts (corresponding to MedDRA terms) necessitates 300 h ofdevelopment of an expert of the domain. The required time to modelize the remaining 15,000 PTs isestimated at 4 years for a single physician. This knowledge modeling difficulty (in time and humanresources) must be put in balance with the advantages brought by the ontology. Indeed, although theformal description of MedDRA terms requires a huge effort, this could be balanced in the future bydeveloping additional tools relying on the ontological representation of MedDRA terms which mayimprove not only the signal generation but also the coding phase of the data from abstract description ofthe cases in spontaneous reports.
Evaluation remains a problem because all studies, including ours, are retrospective [3]. The evaluationof signal generation was envisaged only for associations previously described in the literature (B3 scorein the French database). In particular, the current gold standard is not applicable for new signals that have

764 C. Henegar et al. / Computers in Biology and Medicine 36 (2006) 748–767
not been described in the literature, and those detected in the national base need to be confirmed by expertevaluation.
6. Conclusion
Some authors have proposed that concepts relevant to a knowledge domain should be extracted fromtext corpora. Although we approve this method, we were constrained to make use of a more pragmaticapproach because terms in pharmacovigilance databases are already coded with MedDRA. One couldsuggest that coding of medical concepts with ontology would be a more appropriate solution to ourproblem. MedDRA is a first-generation system and we had to provide a formal semantic definition toMedDRA terms in order to implement an efficient ontological reasoning procedure. Some authors haveproposed that thesaurus-based terminologies could be presented to physicians but with formal semanticsin the background to implement efficient mechanisms for treatment of data. This is the case of the FrenchClassification des Actes Médicaux which was developed by using Galen tools [25] but provides a morefriendly hierarchical structure to the end user.
We hope that our experience could encourage MedDRA developers (the MSSO) to add some third-generation features to MedDRA but keeping the organization that physicians have got accustomed to.From a research point of view, our current perspective is to work on knowledge extraction from UMLS inorder to end up with a methodology that will ease the step of formal definition of concepts from MedDRAterms. From a practical point of view, our short-term perspective is to have some prototype (subsumptionon the classic MedDRA hierarchy) in order to evaluate to what extent such tool can help experts to focuson relevant associations.
Acknowledgments
We acknowledge the French network of 31 pharmacovigilance regional centers that have collected,analyzed and registered ADR case reports in the French national database. UMLS meta-thesaurus wasprovided by the National Library of Medicine, after the accomplishment of the required formalities inorder to obtain a user license (Lic. Agreement no. 02236).
References
[1] E.P. van Puijenbroek, A. Bate, H.G. Leufkens, M. Lindquist M, R. Orre, A.C. Egberts, A comparison of measures ofdisproportionality for signal detection in spontaneous reporting systems for adverse drug reactions, Pharmacoepidemiol.Drug Saf. 11 (1) (2002) 3–10.
[2] R.H.B. Meyboom, M. Lindquist, A.C.G. Egberts, I.R. Edwards, Signal selection and follow-up in pharmacovigilance,Drug Saf. 25 (6) (2002) 459–465.
[3] A. Bate, M. Lindquist, I.R. Edwards, R. Orre, A data mining approach for signal detection and analysis, Drug Saf. 25 (6)(2002) 393–397.
[4] A. Bate, M. Lindquist, R. Orre, I.R. Edwards, R.H. Meyboom, Data-mining analyses of pharmacovigilance signals inrelation to relevant comparison drugs, Eur. J. Clin. Pharmacol. 58 (7) (2002) 483–490.
[5] A. Szarfman, S.G. Machado, R.T. O’Neill, Use of screening algorithms and computer systems to efficiently signal higher-than-expected combinations of drugs and events in the US FDA’s spontaneous reports database, Drug Saf. 25 (6) (2002)381–392.

C. Henegar et al. / Computers in Biology and Medicine 36 (2006) 748–767 765
[6] M. Hauben, X. Zhou, Quantitative methods in pharmacovigilance: focus on signal detection, Drug Saf. 26 (3) (2003)159–186.
[7] A. Bate, M. Lindquist, I.R. Edwards, S. Olsson, R. Orre, A. Lansner, R.M. De Freitas, A bayesian neural network methodfor adverse drug reaction signal generation, Eur. J. Clin. Pharmacol. 54 (1998) 315–321.
[8] W. DuMouchel, Bayesian data mining in large frequency tables, with an application to the FDA spontaneous reportingsystem, Am. Statist. 53 (1999) 177–202.
[9] S.J. Evans, P.C. Waller, S. Davis, Use of proportional reporting ratios (PRRs) for signal generation from spontaneousadverse drug reaction reports, Pharmacoepidemiol. Drug Saf. 10 (6) (2001) 483–486.
[10] E. Heeley, L.V. Wilton, S.A.W. Shakir, Automated signal generation in prescription-event-monitoring, Drug Saf. 25 (6)(2002) 423–432.
[11] A.C. Egberts, R.H. Meyboom, E.P. van Puijenbroek, Use of measures of disproportionality in pharmacovigilance: threeDutch examples, Drug Saf. 25 (6) (2002) 453–458.
[12] M. Lindquist, M. Stahl, A. Bate, I.R. Edwards, R.H. Meyboom, A retrospective evaluation of a data mining approach toaid finding new adverse drug reaction signals in the WHO international database, Drug Saf. 23 (6) (2000) 533–542.
[13] E.G. Brown, L. Wood, S. Wood, The medical dictionary for regulatory activities (MedDRA), Drug Saf. 20 (2) (1999)109–117.
[14] A. Rossi Mori, F. Consorti, E. Galeazzi, Standards to support development of terminological systems for healthcaretelematics, Methods Inform. Med. 37 (1998) 551–563.
[15] CEN TC 251, Medical informatics—categorical structures of systems of concepts—model for representation of semantics,CEN TC 251 WG2, Final Draft prENV 12264, 1995.
[16] WHO World Health Organisation, Manual of the international statistical classification of diseases, injuries and causes ofdeath. Tenth revision of the international classification of diseases, Geneva, 1993.
[17] R.A. Coté, D.J. Rothwell, J.L. Palotay, R.S. Becket, L. Brochu, SNOMED International, College of American Pathologists,1993.
[18] A.L. Rector, W.D. Solomon, W.A. Nowlan, T.W. Rush, P.E. Zanstra, W.M.A. Claassen, Terminology server for medicallanguages and medical information systems, Methods Inform. Med. 34 (1995) 147–157.
[19] K.A. Spackman, K.E. Campbell, R.A. Coté RA, SNOMED RT: a reference terminology for health care, Proc. AMIA Annu.Fall Symp. (1997) 640–644.
[20] D.B.A. Lindberg, B.L. Humphreys, A.T. McCray, The unified medical language system, Methods Inform. Med. 32 (1993)281–291.
[21] E.G. Brown, Effects of coding dictionary on signal generation, A consideration of use of MedDRA compared with WHO-ART, Drug Saf. 25 (6) (2002) 445–452.
[22] M. Yokotsuka, M. Aoyama, K. Kubota, The use of a medical dictionary for regulatory activities terminology (MedDRA)in prescription-event monitoring in Japan (J-PEM), Int. J. Med. Inform. 57 (2–3) (2000) 139–153.
[23] Y.A. Lussier, D.J. Rothwell, R.A. Coté, The SNOMED model: a knowledge source for the controlled terminology of thecomputerized patient record, Methods Inform. Med. 37 (2) (1998) 161–164.
[24] C.G. Chute, et al.,A framework for comprehensive health terminology systems in the United States: development guidelines,criteria for selection, and public policy implications, ANSI Healthcare Informatics Standards Board Vocabulary WorkingGroup and the Computer-Based Patient Records Institute Working Group on Codes and Structures, J. Am. Med. Inform.Assoc. 5 (1998) 503.
[25] B. Trombert-Paviot, J.M. Rodrigues, J.E. Rogers, et al., Galen: a third generation terminology tool to support a multipurposenational coding system for surgical procedures, Int. J. Med. Inform. 58–59 (2000) 71–85.
[26] C. Bousquet, G. Lagier, A. Lillo-Le Louët, C. Le Beller, A. Venot, M.-C. Jaulent, Appraisal of MedDRA conceptualstructure for describing and grouping adverse drug reactions, Drug Saf., 28 (1) (2005)19–34.
[27] A. Farquhar, R. Fikes, J. Rice, The Ontolingua Server: a tool for collaborative ontology construction, Int. J.Human–Computer Stud. 46 (1997) 707–727.
[28] T. Gruber, A translation approach to portable ontology specifications, Knowledge Acquisition 5 (2) (1993) 199–220.[29] M. Uschold, M. Gruninger, Ontologies: Principles, methods and applications. Knowledge Engineering Review 11 (2)
(1996) 93–113.[30] A. Maedche, S. Staab, Ontology learning for the semantic web, IEEE Intelligent Systems 16 (2) (2001) 72–79.[31] L. Gillam, M. Tariq, Ontology via terminology? Workshop on Terminology, Ontology and Knowledge Representation,
Lyon, France, January 2004.

766 C. Henegar et al. / Computers in Biology and Medicine 36 (2006) 748–767
[32] R. Navigli, P.Velardi, Ontology learning and its application to automated terminology translation, IEEE Intelligent Systems,January/February 2003, pp. 22–31.
[33] S. Le Moigno, J. Charlet, D. Bourigault, P. Degoulet, M-C. Jaulent, Terminology extraction from text to build an ontologyin surgical intensive care, Proceedings of the AMIA Symposium, 2002, pp. 430–434.
[34] N. Noy, R. Fergerson, M. Musen, The knowledge model of Protege-2000: combining interoperability and flexibility, SecondInternational Conference on Knowledge Engineering and Knowledge Management (EKAW’2000), 2000.
[35] S. Bechhofer, I. Horrocks, C. Goble, R. Stevens, OilEd: a reasonable ontology editor for the semantic web, Proceedingsof KI2001, Joint German/Austrian Conference on Artificial Intelligence, LNAI, Springer, Berlin, 2001.
[36] A. Gomez-Perez, et al., A survey on ontology tools, OntoWeb Consortium, 2002, pp. 13–34.[37] J.F. Sowa, Knowledge Representation: Logical, Philosophical, and Computational Foundations, Brooks Cole Publishing
Co., Pacific Grove, CA, 2000, pp. 492, 497 et seq.[38] J.J. Cimino, Desiderata for controlled medical vocabularies in the twenty-first century, Methods Inform. Med. 37 (1998)
394–403.[39] A.L. Rector, P.E. Zanstra, W.D. Solomon, et al., Reconciling users’ needs and formal requirements: issues in developing a
reusable ontology for medicine, IEEE Trans. Inform. Technol. Biomed. 2 (4) (1998) 229–242.[40] D.L. McGuinness, Description logics emerge from ivory towers, in: D.L. McGuinness, P.F. Patel-Schneider, C. Goble, R.
Möller, Proceedings of the 2001 International Workshop on Description Logics (DL2001), Stanford, CA, USA, Availableonline as CEUR Publication Volume 49, 2001.
[41] E. Fanconi, Description logics for conceptual design, information access, and ontology integration: research trendsbibliography [Web Page], Available at http://www.cs.man.ac.uk/∼franconi/dl/course/phd-course/biblio.html (Accessed28 January 2003).
[42] I. Horrocks, U. Sattler, S. Tobies, Reasoning with individuals for the description logic SHIQ, Proceedings of the 17thInternational Conference on Automated Deduction (CADE-17), 2000, pp. 482–496.
[43] V. Haarslev, R. Möller, Description of the RACER system and its applications, Proceedings of the International Workshopon Description Logics (DL-2001), Stanford, USA, 1–3, 2001, pp. 132–214.
[44] N. Guarino, Identity and subsumption, LADSEB-CNR Internal Report 01/2001, 2001.[45] B. Begaud, J.C. Evreux, J. Jouglard, G. Lagier, Imputation of the unexpected or toxic effects of drugs, Actualization of the
method used in France, Therapie 40 (2) (1985) 111–118.[46] J.A. Hanley, Receiver operating characteristic (ROC) methodology: the state of the art, Crit. Rev. Diagn. Imag. 29 (3)
(1989) 307–335.
Cornéliu Hénégar graduated in Medicine in 1996 and in Informatics in 1998 from Romania. Between 1999 and 2005 he didhis residency training in Internal Medicine at Saint-Antoine Faculty of Medicine of Paris VI University (France). In 2003, afterone year of research fellowship, he got his Master Degree in Medical Informatics from Paris VII University and joined, as afellow researcher, the Inserm U729 unit. Since the fall of 2003 he started a Ph.D. fellowship in Bioinformatics within the GaliléeDoctoral School of Paris XIII University. His current scientific work focuses on developing knowledge engineering techniquesdesigned for data processing in biology and medicine, with a special application to functional genomics.
Cédric Bousquet graduated in Pharmacy in 2001 and got his Ph.D. degree in Medical informatics in 2004. From May 2005,Cédric Bousquet is a clinical fellow in the medical informatics department of Prof. Degoulet in the Georges Pompidou EuropeanHospital (HEGP) in Paris, France. Since 2001, he has been working half time in the pharmacovigilance regional centre of theHEGP and has acted as an expert to the drug safety French agency; and half time at INSERM in research positions. He is nowco-ordinating a project on adverse drug reaction terminologies and signal generation in pharmacovigilance that is funded by theFrench ministry of research.
Agnès Lillo-Le Louët is the head of the pharmacovigilance regional centre of the Georges Pompidou European Hospital inParis, France. She is a medical doctor and after working in geriatrics, she graduated in pharmacology in 2000. She acts as anexpert to the drug safety French agency, especially for drug interactions and haemostatics drugs.
Patrice Degoulet, M.D. Ph.D. is Professor in Broussais-Hotel-Dieu school of Medicine and the chief information officer of thePompidou university hospital (HEGP). He is vice-president of the International Medical Informatics Association (IMIA) and

C. Henegar et al. / Computers in Biology and Medicine 36 (2006) 748–767 767
member of several scientific journals on medical informatics including JAMIA, Methods of Information in Medicine and theInternational Journal of Medical Informatics. His main domains of interest concern hospital information systems and softwareengineering issues for complex information systems. Directly involved since 1989 in several European telematics projects(HELIOS1, HELIOS2, SYNAPSES, and SYNEX), Patrice Degoulet has endorsed since 1996 the responsibility of the analysis,design and deployment of the COHERENCE, the component-based clinical information system of HEGP hospital.
Marie-Christine Jaulent, Ph.D. is originally a computer scientist (a graduate from ENSEEIHT, France) with an emphasis onartificial intelligence methods. Her Ph.D. degree is on fuzzy logics. Since 1990, she is a full-time researcher at the INSERMinstitute and since 2002 she is the head of the INSERM U729 research laboratory on “knowledge engineering in e-Health”in Paris. Her main domains of interest include the development of methods to extract knowledge from large databases andtextual corpus, tools for collaborative work modeling, qualitative approaches for data mining (terminological reasoning), andnew languages for knowledge representation (description logic and other languages for ontologies).
















![[Pharmacovigilance in Portugal: Activity of the Central Pharmacovigilance Unit]](https://img.pdfslide.net/doc/110x75/634de38cd38be601b805f100/pharmacovigilance-in-portugal-activity-of-the-central-pharmacovigilance-unit.jpg)












