Embed Size (px)
Citation preview

Int. J. Communication Networks and Distributed Systems , Vol.6, No.1, 2011 1
Copyright © 2011 Inderscience Enterprises Ltd.
Job Division in Service Oriented Computing Based on Time Aspect
Farzad Amirjavid*, Hamid Mcheick*, and Mohamad Dbouk** *Department of Computer Science and Mathematics, University of Quebec at Chicoutimi (UQAC), Quebec, Canada ** Department of Computer Science, Lebanese University, Lebanon E-mail: *[email protected], E-mail: *[email protected], E-mail: **[email protected] *Corresponding author
Abstract: Requests for services and user demands increase continuously and faster than technology development. To keep the service offering time reasonable, we can decrease total elapsed time of servers instead of waiting for newer technologies. In this paper we will focus on division of jobs between computers operating in network and in this way we can improve the computing speed. Furthermore, in this paper, we deal with the problem concerning how to arrange services in a way that the Servers Total Elapsed Time (STET) will be minimized in the best way. Service Oriented Architecture (SOA) principals are used to participate jobs between computers in a network. We have focused on time parameter to design software at the software architecture level and after surveying computing time restrictions; we follow the goal to minimize the Total Computing Elapsed Time or STET. A mathematical model is proposed to express computing time relations and then a simple LP model is applied to find best combination of services regarding computing speed. A case study is presented to demonstrate the time relations in a practical example and to show how to minimize computing time in this case study and finally we discuss the functionality of the proposed model.
Keywords: Software architecture, Computing speed, Service Oriented Architecture (SOA), Separation of Concerns, Job division
Biographical notes: Farzad Amirjavid was born in Tehran and studied in Alborz high school in mathematics and physics. He got 2 Bsc degrees in Computer engineering and business management. His thesis in Msc was about fuzzy systems and he got his Msc degree in industrial engineering and systems productivity in 2009. He is now PhD student in computer science department at the University of Quebec At Chicoutimi (UQAC).
Hamid Mcheick is currently an associate professor in computer science department at the University of Quebec At Chicoutimi (UQAC), Canada. He holds a master degree and PhD. in software engineering and distributed system from Montreal University, Canada. Professor Mcheick is interested in software development and architecture for enterprise applications as well as in separation of concerns (component, services, aspect, etc.). His research is supported by many research grants he has received from the Canadian government, University of Montreal, CRIM (Centre de Recherche informatique de Montreal), University of UQAM, and University of UQAC.

Farzad Amirjavid, Hamid Mcheick and Mohamad Dbouk
Mohamed DBOUK received a Bachelor’s Honor” in Computer Science, Lebanese University, and a PhD from Paris-Sud 11 University (Orsay-France), 1997. He is a full time Associate Professor, at the Lebanese university, Computer Science Department. He is the Founder and Coordinator of the research master “M2R-SI: Information System” at the Lebanese University (2009). His research interests include Software engineering, Information systems, GIS, Cooperative and Multi-Agent Systems, Groupware. He participates in many international projects: Euro-Mediterranean/UNESCO Avicenna e-learning Project, UNDP / RBAS Project; Enhancement of Quality Assurance and Institutional Planning at Arab Universities (2002-2004).
1 Introduction Decreasing total elapsed time in application servers, which means improvement in computing speed and so server performance improvement, has been a traditional goal for researchers for a long time. Traditionally, servers in networks do the processing affairs on their own. However databases transact with each other and data is exchanged between them. To decrease response time in servers there are several approaches. For example, we can use devices which contain multiple CPUs or faster hardware to increase computing speed. These approaches are relatively expensive or at least: we should not be spending time waiting for newer and faster technologies to arrive (Dubray, 2004). Furthermore, as the newer systems arrive, old ones should be dropped out and they should not be used anymore. The question discussed in this paper is to find a way to keep existing devices in network and use new emerging technologies along with the old ones. To answer this question we are thinking about restructuring existing programs and using SOA to run program codes, instead of traditional and single-computer architectures, and of course the program should be restructured at the software architecture level. Our purpose, in this article, is to handle designing programs based on Service Oriented Architecture (SOA). The idea here is that, “if the jobs be divided and assigned to existing computers in network regarding to SOA principals then the newer technologies can be replaced with (or assigned to) the most vital service regarding processing time in service". Applying this concept, it can save and use effectively the best and fast old technologies; also it can handle repetitive jobs in a structured model and scalable format (Division, 2010). Collaborative computing helps to get more effective solution and can be defined to be “the act of working together in a joint intellectual effort” (Agarwal et al., 2002) and (Stephen et al., 2003). Developing information technology, decreasing costs and increasing the demand for information services and also considering high bandwidth demand especially for multimedia services, we have introduced a new architecture which, not only offers a better quality of service to clients regarding response time aspect, but also provides higher security approach and scalability with a simpler and more effective management method. For example, providing needed data for users, configuring mobile phone using personal computer, managing mobile phone contacts, file sharing or other services in the client – server format can be done in our proposed SOA based model (SOA, 2005). In this model we introduce a design to implement distributed computing in the web, based on Service Oriented Architecture (SOA) concepts. According to SOA, each task can be broken based on its technical properties into some group of codes, then assign services to each service provider using messages. According to SOA, Services communicate with each other (by sending and receiving messages) via their interfaces (Division, 2010).

A taxonomy and classification of web service QoS elements
As the jobs are divided and assigned to services, jobs can be done simultaneously and we can mostly expect a faster response rather than traditional ones. Of course if the job division is not done in a rational manner, then in a chromatic manner, the total response time can be even increased or may not be optimum. In this paper, we have introduced time relations which can help us to find a way to reach an optimum computing speed at the software architecture level. Introduced time relations are then applied as restriction functions in a mathematical model which aims at minimizing the total spent processing time. Mathematical model can be optimized using Linear Programming (LP) techniques (or Non Linear Programming techniques (NLP) if one or more of used functions is non-linear). Here processing time aspect will be the only effective considered parameter in this research, however more parameters such as designing time or resource restrictions can be also considered in our model. It is recommended to the future researchers dealing with (study) other parameters in these kinds of problems. In this study, the power of computer (CPU speed, number of computers, energy, and other parameters) are not considered. Our goal is to select best combination of services and computers to satisfy a linear programming model. Section 2 describes the background of this paper. Separation of Services in Distributed Collaborative Computing Model and its implementation are given in sections 3 and 4 respectively. Section 5 describes the services. Communication is given in section 6. Section 7 shows temporal relation model. Advantages of Distributed Computing Model are discussed in section 8. At the end of this paper (section 9), a case study is introduced to show the implementation of the mathematical model and using LP methods the model is optimized to find the fastest way that the justified processes can be handle the introduced general model format. Finally, a discussion of this research and conclusion are given in section 10 and 11 respectively.
2 Background There are routine solutions to decrease the retrieving time for providing repetitive demanded data for users. Public news websites such as http://www.bbc.com or http://www.cnn.com are so popular and so many people refer to these websites daily. They look for data which was already provided for other users. There are many ways to provide this service, but the simplest approach to provide such a service is to use a single computer to show today’s news (of course we do not consider communication services such as DNS). In these examples, news is the data which is to be daily repetitively retrieved. Another example in the web environment is the weblog websites; in these websites data is repetitively retrieved for many users (Microsoft, 2010).
To increase data retrieve speed (service quality) for these kinds of websites, cash technique (which can also be provided in the Internet Service Provider’s side) is an ordinary solution that can effectively help us (Microsoft, 2010). Let’s make clear here we are not about to check such these cases out. But providing user’s customized data may contain calling repetitive procedures. For example, in a search engine, the instruction “select * from datatable1” can be called repetitively. Another example can be presenting user’s picture when the user logs on. Traditionally these instructions are all run on a single computer per user. This paper presents a SOA model (technique) to deal with such these cases.

Farzad Amirjavid, Hamid Mcheick and Mohamad Dbouk
Considering this repetitive, but non similar and variable processes (for instance calling repetitively SELECT command) which on the lower layers (hardware) does many comparisons, CPU will be frequently busy.
Another example is that many users would like to perform search some words and request other additional services. Accordingly, we can see two different process types. Considering all different jobs are done traditionally on a single computer, this computer will search its database, find related images and sometimes needs to check access permissions and etc. This way we will be able to guaranty our quality of service (QOS) for just specific number of users. That is just because available resources are restricted on our single computer and we have not predicted or assumed a scalable design.
To solve this problem, some approaches are already proposed. One approach for not
having to deal the busy server is to use the expensive super computers containing lots of CPUs and memories. However, this approach is expensive and not sufficient. Another approach is to use clusters and load balancing techniques like dividing jobs between computers based on various algorithms. Although, this can be a cheaper solution and it includes component based restrictions such as difficulty in security, restricted capacity and still cost. Here, we are proposing a new model to do the old job in a better and more efficient way.
Service orientated computing. First, let us create contexts in which services are used
and combined and secondly express intent rather than specific requests. In constructing software phase, it is better to make service oriented software rather than component oriented one (Brown, 2008) (Sommerville, 2010). Our society should be a great source of inspiration to design modern enterprise systems and architectures or understand what kind of services these systems will consume or provide (Dubray, 2004).
There are several reasons for choosing SOA as manner of designation of introduced
model. The first reason is that it shows clearly we are talking about software architecture level and respecting abstraction principle we don’t take into account system hardware or lower layer entities. The more important reason is about SOA nature. SOA is the last recommended architecture by the professionals. It responds to today’s needs in networking, Web, OS based applications and many environments. Although SOA is not a new idea, the infrastructure to implement SOA based applications was not prepared yet. Connected world is the most important platform to develop applications based on this architecture (Dubray, 2004). OOP and component based programming gave us important advantages to develop programs in architecture level and made reliable programming methods to programmers. Each one helped to implement more abstracted layers. The extreme abstraction concept until now is included in Service Oriented Architecture (adtmag, 2003). Two decades ago, many recommendations have been done to develop programs which can support changes easily and codes are independent to each other. Therefore, Object Oriented Programming (OOP) was introduced to make abstractions between objects; similarly the need for abstraction within components (collection of objects) was satisfied. Currently, we are living in a connected world and infrastructure for a Service Oriented Architecture exists. For example when one wants to go to eat lunch there are many restaurants or precooked foods to choose from. Instead of cooking foods he can use existing services and hence concentrate on the main job which he can do better than others. In this way, he doesn’t care how the food is cooked or who works for this

A taxonomy and classification of web service QoS elements
food or how much time was spent. He just pays the price and uses the service to concentrate on the more important job. The same story applies in software. In this research, SOA is used to keep abstraction in extremity and is found as the best coordinator between groups of systems, which not only contain noticeable differences between their assigned jobs, but also they perform the same job in different manners (Dubray, 2004).
3 Separation of Services in Distributed Collaborative Computing Model In this section, an architecture model is introduced in which each service is broken into sub services. Then, each one of them (sub services) is assigned to a domain which consists of a group of computers. Each sub service can connect to other services through interfaces. The main server (can be a domain) verifies users authentication and uses messages to assign the tasks to sub service providers, controls the sequence of affairs and finally commands to the communication server (by message passing via interfaces) the concerning page to be demonstrated.
The goal of this model is to provide user specific pages containing concerned user’s images, data and text then the user’s identity was checked.
Although, job division on this model could be done in various ways. Jobs are divided based on codes context. Services are also chosen based on jobs to be done. Finally, selecting service borders can be done directly based on job division or its context. For example, many services have been considered such as file service, data service, image service, user identification service.
In this model, a program user refers to a website and requests its own page, which contains its picture, data and texts. To process this request, at first main server, sends a message to security access server and checks user’s permissions. Then the related image is searched and found.
When all concerning data, texts images are found, they can be gathered somewhere before they are monitored to the user. Another way is to just pass the concerning links to the user in provided page and the in this way the content can be fetched directly from servers.
In our case study we have considered a communication server which cashes finalized data for each user and transfers it to the concerning user. More services can be used in a more general model.
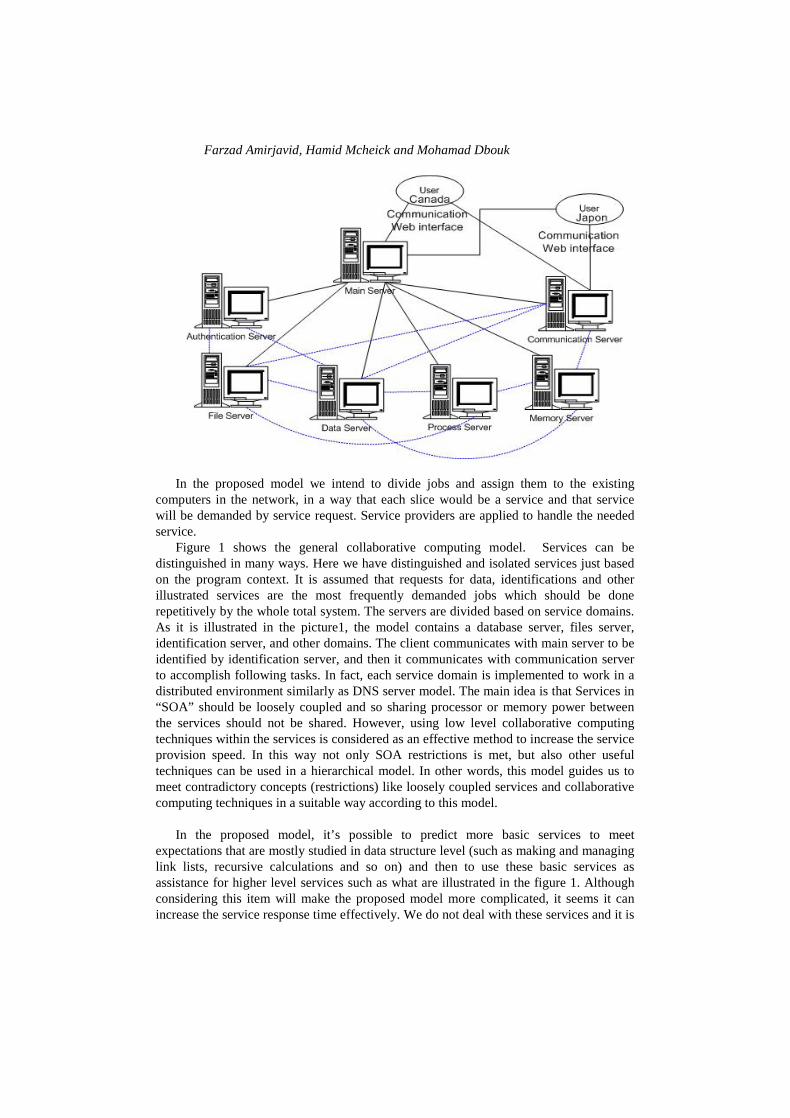
Figure 1 Distributed Collaborative Computing Model
Farzad Amirjavid, Hamid Mcheick and Mohamad Dbouk
In the proposed model we intend to divide jobs and assign them to the existing
computers in the network, in a way that each slice would be a service and that service will be demanded by service request. Service providers are applied to handle the needed service.
Figure 1 shows the general collaborative computing model. Services can be distinguished in many ways. Here we have distinguished and isolated services just based on the program context. It is assumed that requests for data, identifications and other illustrated services are the most frequently demanded jobs which should be done repetitively by the whole total system. The servers are divided based on service domains. As it is illustrated in the picture1, the model contains a database server, files server, identification server, and other domains. The client communicates with main server to be identified by identification server, and then it communicates with communication server to accomplish following tasks. In fact, each service domain is implemented to work in a distributed environment similarly as DNS server model. The main idea is that Services in “SOA” should be loosely coupled and so sharing processor or memory power between the services should not be shared. However, using low level collaborative computing techniques within the services is considered as an effective method to increase the service provision speed. In this way not only SOA restrictions is met, but also other useful techniques can be used in a hierarchical model. In other words, this model guides us to meet contradictory concepts (restrictions) like loosely coupled services and collaborative computing techniques in a suitable way according to this model.
In the proposed model, it’s possible to predict more basic services to meet
expectations that are mostly studied in data structure level (such as making and managing link lists, recursive calculations and so on) and then to use these basic services as assistance for higher level services such as what are illustrated in the figure 1. Although considering this item will make the proposed model more complicated, it seems it can increase the service response time effectively. We do not deal with these services and it is

A taxonomy and classification of web service QoS elements
suggested to the future researchers to offer a more general model considering data structure concepts as services. 4 Model Implementation In this architecture, SOA Concepts and properties are used to make an SOA design. Every domain is responsible for providing a specific service (for example data service). Every service can communicate with others through pre-defined functions in interfaces using a message passing technique. This way, the components will be loosely coupled. A daily repetitive task is now broken into some services (Sub services) and each service provider is responsible for a specific task. Using this manner, hardware and software arrangement would be better done. For example, file server needs a great Hard disk capacity, however the memory server needs just a huge memory (not so much Hard disk is needed) and of course it is better to provide a group of some expensive powerful computers to provide services, although all the resources of a computer may not be used in simultaneously.
5 Services Services are logical grouping of components to achieve business functionality and they work together. They have to communicate with each other and SOA says message passing is the best way for services to communicate with each other. Every service (sub service) consists of a domain of computers and computers in a domain can just communicate with each other through predefined functions. A domain manager or service manager is responsible for the domain computers and actually services communicate through service managers existing in their domains. No other external computers can access computers in a domain, except through domain manager. This way security implementation would be easier done (See Figure 2).
Figure 2 Service domains and handlers
Managing service domains can be done using Service domain handlers. This way,
services are loosely coupled, and in the heart of each service provider, computers can take part in computing jobs.

Farzad Amirjavid, Hamid Mcheick and Mohamad Dbouk
In the proposed model, jobs are divided into services based on job general types. For example if we need to access data in database server, we use data service. Furthermore for security and file and other service needs, especial service provider domains are considered. Process service provider domain can also use network connected computers (which are not member of other service providers domain) to help to perform process tasks for other service domains.
6 Communication
Two communication aspects are surveyed in the proposed model. The first one is communications between services. The second one is the communication between client and communication service provider domain.
6.1 Communication between services Services communicate with each other through their interfaces (which are often implemented in XML) by messages, however sometimes files, dataflow, data and other type of contents need to be exchanged. In each domain computers communicate with each other. As the type of exchanged data is various and also we need to maintain servers near local service consumers, different communication types are preferred. For example, in each domain computers can use distributed computing technique. However, they shouldn’t use other computers in other domains, because services in SOA are supposed to be loosely coupled. In this situation, different protocols would be needed to achieve the best communication type between computers in a domain and communication between services. In the case of web services SOAP over HTTP is used to communicate between the services. Web services can also use other technologies such as RESTful (Representational State Transfer) implementations on top of HTTP. RESTful web services use XML and native HTTP methods to define their interfaces. REST sufficiently satisfies the condition of platform independence.
6.2 Messages Messages are used for communication between services. The receiver checks the source of the received message and its content using predefined functions. The reply can be a text code in a message. Using a general ID (which can be an external key) for each user, concerning files, texts and other data would be easily accessible.
For example, a user requests his web page. The main server sends a message to the access security server to check his permissions. This message has the following format:
Securityservice.sendMessage(“user”)
Security access server checks his account and if this account exists in its user table, it
will send a reply like:
Mainservice.sendMessage(“71820”)

A taxonomy and classification of web service QoS elements
“71820” is user’s global id in every domain. Then the main server that is responsible for controlling the sequence of codes will send the user id to the file server to find his image and other service providers. Finally main server will send user’s id to the communication service provider to show his final page.
6.3 Client service communication
A communication server is considered in the proposed model. This service can make a distinction between different clients. Clients can be classified based on many parameters. Geographical location, computer type, user priority are some of criteria for classifying the clients. Communication server can offer a customized and better way to provide the service. For example, a user can demand to send SMS message to his/her mobile phone using his/her personal computer. Many times clients do not wish to receive their service on the same way they requested it. For example consider a post office. Client can ask to send a package in a post office. He/she does not expect to receive the reply in the post office, but at home, his/her office. Considering communication service we can better provide SMS, VOIP and other services in different protocol types.
Except for support of different communication protocols, other aspect that can be considered in communication server is management of handheld devices. For example, contacts existing on a mobile phone can be sent to database server using SMS bandwidth and the user can access his/her contacts anywhere else in world. File management and configuration of mobile handheld devices can be other examples of using communication server. Although we are not introducing new technology, each communication type is considered as a service. If communication service is considered locally, more economical aspects would be expected. In this case, just report of offered service would be necessary to send to the log servers or main server (not whole the data which may occupy a lot of available bandwidth will be contained).
7 Temporal relation The only parameter to be surveyed is time. Reducing computing total time leads directly to increase computation time and service quality. It is important to increase the total computation speed; also it is important to optimize it to find the best combination of services. To optimize the total computation time, Linear Problem (LP) techniques are used.
7.1 Model goal In this LP model, the goal is to minimize the total time spent for calculation. If the service number 1 is assigned to computer number 2; then the time spent by this service 1 is dealt with on the computer 2: TSC12. “ak” is a Boolean parameter that indicates if the concerning combination (assignment of services to computers arrangement) should be considered. The mathematical expression of object function is shown as below:
Min Z= a1 (TSC11 + TSC21 + … + TSC33 + ….) +
a2 (TSC12 + TSC23 + … + TSC31 + ….) + … Therefore : Min Z = ∑ ak TSC ij

Farzad Amirjavid, Hamid Mcheick and Mohamad Dbouk
i = 1..n (services) j = 1..m (computer) ak : Boolean parameter to choose the combination of services and computers.
7.2 Service request transfer and service response time relation It was already mentioned that it is possible to make a service for each repetitive job. However, it can be so partial. In the proposed time mathematical model, we intend to restrict the service definition cycle by considering time limitations. The idea is that, communication time for transmission and receipt of service request should not be greater than service response time. If a computer spends ct time for communication and service time is St, then it would not be rational to use its power to deal with communication affaires and it is better to do the job by itself rather than assigning it to a third party. Consequently, the first relation indicates rationality of service definition.
Ct < St Time Relation 1
It is not necessary to apply this limitation to the mathematical model. An automatic filter of combinations which do not respect this constraint is used (just to reduce computation complexities).
7.3 Number of computers As the number of available computers in network is not unrestricted, the second constraint is resource limitation. It means that two or more services can be dealt with in one computer. In other words number of available computers can be less than needed services. It is presumed that “n” indicates the number of available computers. This item is not necessary to be considered in mathematical model and that is already automatically considered in other restrictions.
7.4 Service oriented approach should be faster than single computer approach
The purpose of this article is to introduce a better approach rather than single computer approach. Each service arrangement considered should already respect the condition that the spent time for that arrangement should be lower than single computer approach; else just the resources are wasted. If TSCOM is the spent time in single computer approach, then the mathematical expression for this restriction is given as follows:
TSC11 + TSC21 + … + TSC33 + …. < TSCOM . . . TSC12 + TSC23 + … + TSC31 + …. < TSCOM Such as TSCOM is a single computer time.
7.5 Mathematical LP model The expression of mathematical model which contains goal function and its restrictions is finally shown as formula 1. The objective is to minimize total spent time for collaborative

A taxonomy and classification of web service QoS elements
computing and the resource and time restrictions should be considered. Although each response satisfied the restrictions is acceptable, but using LP techniques the optimized response can be realized.
Min Z = a1 (TSC11 + TSC21 + … + TSC33 + ….) +
a2 (TSC12 + TSC23 + … + TSC31 + ….) + … s.t: TSC11 + TSC21 + … + TSC33 + …. < TSCOM . . . TSC12 + TSC23 + … + TSC31 + …. < TSCOM Ct < St TSCij < TSCkl i<k I,j,k,l <=0 ai= 1 or 0,
Formula 1 – mathematical model
8 Advantages of distributed computing model
Instead of just one computer doing the work, the task was divided among a number of computers. Therefore, the increase in capacity of service is expected. Also the higher speed in provision of service is expected. Another aspect is to use the power of unused computers and devices. Furthermore as domains are assigned specific repetitive tasks, computers need to be equipped with some suitable hardware, not a complete set of hardware.
Transparency: the user requests its service without knowing how the desired data is provided.
Scalability: introduced model in this article, presents a structure to provide service for a great number of users and each task is divided between domains of computers. Each domain can be extended using distributed systems techniques by adding new computers.
Ease of security implementation: the communication between computers is done through interfaces and predefined functions. Also, computers in a domain cannot communicate with external addresses. Therefore, it is necessary to install firewalls on the domain managers rather than in all the computers.
Local plan: If we assign each geographical region a set of service providers, then not only we will be able to provide quicker service, but we also will not occupy bandwidth for every request. Some messages to log the activities are sent to the main server.
SOA compliance: Nowadays, SOA is one of the most respected software architectures, especially for repetitive jobs. The structure of introduced model highly obeys SOA principals. Therefore, we expect to impart SOA advantages such as isolation between services, service measurements and others.

Farzad Amirjavid, Hamid Mcheick and Mohamad Dbouk
9 Case study In the introduced case study, a simple program, implemented in a single computer is run. In this program a user logs in and after that his account was checked, the necessary data and text and image are searched and fetched for the user. This simple job will then be implemented by service oriented architecture.
In this case study, Visual studio 2005 is the programming environment, application type is Web Application and VB.net is the coding language. MS Access is used as database. Using Date.now.millisiseconds command, the elapsed time was calculated. Our computers use Intel Pentium t2330 @1.60 GHZ.
In this case-study five methods of implementation have been tried and compared with one another. These case-studies are “single computer approach”, “completely service independent approach” see figure 3, “independent data and file service approach”, “combination of identification, image and text services in one side and data, name and demonstration services at the other side” and finally “combination of identification and text services in one side and image, data, name and demonstration at the other side”.
Figure 3 Second approach
If we apply single computer approach for any number of users, we argue that the Servers Total Elapsed Time (STET) will increase linearly as the number of users increases. Figure 4 illustrates this idea.
Figure 4 Single computer architecture approach
A taxonomy and classification of web service QoS elements
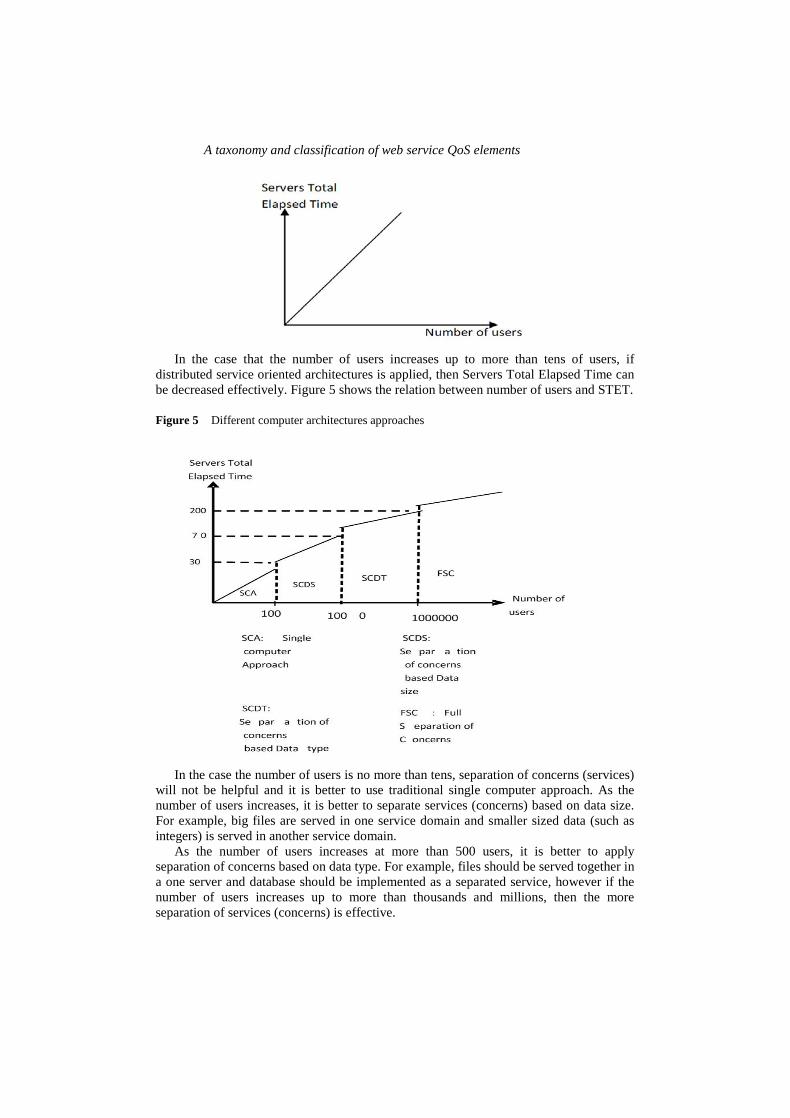
In the case that the number of users increases up to more than tens of users, if
distributed service oriented architectures is applied, then Servers Total Elapsed Time can be decreased effectively. Figure 5 shows the relation between number of users and STET.
Figure 5 Different computer architectures approaches
In the case the number of users is no more than tens, separation of concerns (services)
will not be helpful and it is better to use traditional single computer approach. As the number of users increases, it is better to separate services (concerns) based on data size. For example, big files are served in one service domain and smaller sized data (such as integers) is served in another service domain.
As the number of users increases at more than 500 users, it is better to apply separation of concerns based on data type. For example, files should be served together in a one server and database should be implemented as a separated service, however if the number of users increases up to more than thousands and millions, then the more separation of services (concerns) is effective.

Farzad Amirjavid, Hamid Mcheick and Mohamad Dbouk
It can be inferred that, as the implemented architecture contains more abstracted services (concerns), then the communication time between services increases and it makes the Servers Total Elapsed Time to increase.
10 Discussion
To illustrate the efficiency of the presented mathematical model, we have considered a search engine operating on the web. We calculated the response time when searching for a special string like “Service Oriented Architecture” as tg. We presume that this amount of time will increase linearly, as the number of users increase. Our goal is to develop this service that i) can operate as fast as mentioned search engine, ii) Although, can operate in a simpler and less expensive architecture and able to serve a huge number of clients (20000 users).
Because it is wished to serve 20000 users, separation of concerns based on data type is desired (see mentioned results in figure 3). In our case study, we search the same string through text contexts existing in database. Also, temporal restrictions allow us to use a process server to improve search in data base (this is mentioned as a subservice and each subservice can satisfy its concerning temporal model by its own conditions).
The following architecture is finally proposed in figure 6.
Figure 6 Distributed Computing Model
The goal is to minimize Servers Total Elapsed Time (STET) which means the fastest service provision approach in the condition that the range of users is around 20000.
The following formula shows mathematically our desired model: Min z= t1+t2+t3+t4 t1+t
2+t3+t
4 < comm12+ comm 23+ comm 32+ comm 24

A taxonomy and classification of web service QoS elements
(In the presented model the mentioned constraints are satisfied)
Therefore, if operational time in each service domain lasts less than tg/4, then we can
introduce a faster approach. Maybe we ask why we consider each service domain as fast as other service domains. In other words, why do we want each service domain does its job in less than t
g/4? The answer is that we do not intend to look for faster and more expensive systems, which can decrease the time more than tg/4.
Considering it is desirable that each service domain should serve in maximum tg/4
time, and considering our experiments in section 9, we could even decrease Servers Total Elapsed Time (STET) down to 37% than the traditional single computer approach. Therefore, by applying four fast computers as the domain handlers we can expect an effective improvement in STET. In each sub domain, dividing jobs between some other computers it is possible to even improve each STET for each sub domain and therefore in that way we can expect the STET for each service domain be improved better than 37%. The division of jobs can be continued up to circumstances that the communication time between services be slower than processing time on a single computer.
Figure 7 Servers Total Elapsed Time (STET) improvement in job division
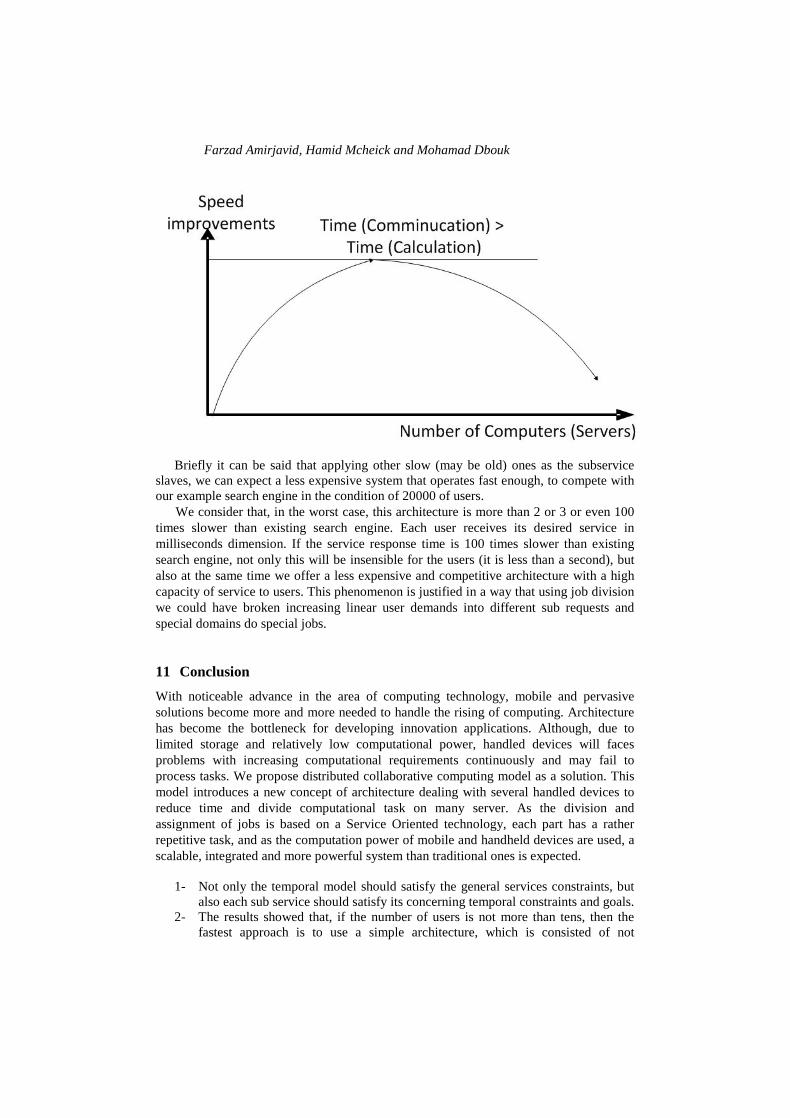
Figure 7 shows that speed improvements continue to be increased until n servers. We
note these improvements as follows: T, 37%T, 37%T + (37%*T *37%), etc. Then, these improvements are decreased when we continue to divide the job into different servers. Figure 8 shows the optimal point where the time of communication is greater then time of calculation.
Figure 8 Relation of number of servers and speed improvements
Farzad Amirjavid, Hamid Mcheick and Mohamad Dbouk
Briefly it can be said that applying other slow (may be old) ones as the subservice
slaves, we can expect a less expensive system that operates fast enough, to compete with our example search engine in the condition of 20000 of users.
We consider that, in the worst case, this architecture is more than 2 or 3 or even 100 times slower than existing search engine. Each user receives its desired service in milliseconds dimension. If the service response time is 100 times slower than existing search engine, not only this will be insensible for the users (it is less than a second), but also at the same time we offer a less expensive and competitive architecture with a high capacity of service to users. This phenomenon is justified in a way that using job division we could have broken increasing linear user demands into different sub requests and special domains do special jobs.
11 Conclusion With noticeable advance in the area of computing technology, mobile and pervasive solutions become more and more needed to handle the rising of computing. Architecture has become the bottleneck for developing innovation applications. Although, due to limited storage and relatively low computational power, handled devices will faces problems with increasing computational requirements continuously and may fail to process tasks. We propose distributed collaborative computing model as a solution. This model introduces a new concept of architecture dealing with several handled devices to reduce time and divide computational task on many server. As the division and assignment of jobs is based on a Service Oriented technology, each part has a rather repetitive task, and as the computation power of mobile and handheld devices are used, a scalable, integrated and more powerful system than traditional ones is expected.
1- Not only the temporal model should satisfy the general services constraints, but
also each sub service should satisfy its concerning temporal constraints and goals. 2- The results showed that, if the number of users is not more than tens, then the
fastest approach is to use a simple architecture, which is consisted of not

A taxonomy and classification of web service QoS elements
separated servers. In fact, separation of concerns does not decrease the Servers Total Elapsed time for this state.
3- Considering full separated servers (concerns) would be helpful just in case the number of users is millions (more than 106). Such a number is rarely reached in reality. However, we can offer services to users in a more effective time for global services on the net using this architecture such as DNS.
4- If the number of users is great, but less than a million the best architecture would be a compromise between a full separated architecture and stand-alone server. In fact, it is not necessary to purchase a super computer to increase service offering speed.
5- If more computers are used, it is expected that the main computer elapsed time will just decrease, so in this way it can deal with other processes in his free time.
6- In the proposed architecture, it is true that, each user should wait a few milliseconds more than in traditional architectures should. In fact, this time is less than 1 second and user will not even mention it. Furthermore, servers, especially main server will save a little bit time per each user, and our case study shows this can improve the service speed up to 37%, and this is effective in Server Total Elapsed Time.
7- Mentioning more abstracted concerns (Services) in architectures depends on the number of users, in way that as the number of users increases, abstracting more concerns (services) can lead to Servers Total Elapsed Time decrease.
8- If service demand congestion makes bottleneck, we are able to reinforce just the slow service domain not the whole system.
For the future works, we suggest to consider other parameters rather than time, such as communication costs to separate the concerns. Although, we will investigate more dynamic service assignments for different range of users to keep the service response time smoothly for different range of member of users.
References Brown, P.C (2008). SOA Implementation: total architecture in practice. Addison Wesley. Coulouris, G. Dollimore, J., Kindberg, T. (2005). Distributed Systems: concepts and design.
Addison Wesley, forth edition. Young, G.O. (1964). Introduction to Personal Digital Assistants. J.Peters, Ed. New York:
McGraw-Hill, 1964, pp. 15-64.
Diya, H.Y. (2005). A Framework for Mobile Collaborative Environnements. World Academy of Science, Engineering and Technology journal, 2005, pp164-166.
Weniger, S. and Zitterbart, S. (2004). Ether: a remote execution service for mobile devices, School of Computing, University of Utah. Technical report.
Agarwal, D. McParland, C. and Perry M. (2002). Supporting Collaborative Computing and Interaction, Proceedings of the Grace Hopper Celebration of Women in Computing 2002 Conference, October 9-12, Vancouver, Canada.
Stephen, S. Yau, Sandeep K. S. Fariaz Karim, Sheikh I. Ahmed, Yu Wang, and Bin Wang. (2003). Smart Classroom: Enhancing Collaboartive Learning Using Pervasive Computing Technology. Proc. Of American Society of Engineering Education 2003 Annual Conference, June, 2003.
http://whatis.techtarget.com/definition/0,,sid9_gci760724,00.html

Farzad Amirjavid, Hamid Mcheick and Mohamad Dbouk
Dubray, J. Constructing Software For Service Oriented Architecture (2004), lecture in Pennsylvania State Universityim.
(Adtmag, 2003): http://adtmag.com/articles/2003/02/28/principles-of-soa.aspx (Division, 2010): http://en.wikipedia.org/wiki/Division_of_labour (SOA, 2005) http://www.javaworld.com/javaworld/jw-06-2005/jw-0613-soa.html (SOA, 2010) http://en.wikipedia.org/wiki/Service-oriented_architecture (Microsoft 2010) http://msdn.microsoft.com/en-us/kb/kb00323290.aspx Sommerville, I., (2007). Software Engineering, eighth edition, Addison-Wesley.





























