Embed Size (px)
Citation preview

ENS-Paris 8
Master 1 de Linguistique Théorique et Descriptive
Directeur de recherche: Paul Egré
Sémantique décompositionnelle et traitement cognitif de most
Marie-Auxille Denis
Juillet 2011

SommaireRésumé..............................................................................................................................................3Introduction.......................................................................................................................................4Préambule : pour une sémantique décompositionnelle des quantificateurs proportionnels most et more than half....................................................................................................................................6
1) Contexte théorique : les quantificateurs comparatifs...............................................................62) most est un quantificateur superlatif........................................................................................73) La TQG ne permet pas de distinguer conceptuellement most et more than half...................10
- la théorie des quantificateurs généralisés............................................................................10- sens d'une expression et traitement d'une expression..........................................................12
I) MOST = MANY + EST...............................................................................................................141) Sémantique des superlatifs.....................................................................................................142) MOST est un superlatif..........................................................................................................15
a) Données de l'allemand.......................................................................................................15b) Données de l'anglais..........................................................................................................21
3) FEW = FEW + EST................................................................................................................22Conclusion..................................................................................................................................26
II) Sémantique décompositionnelle de MOST, un opérateur de comparaison superlative de cardinalités de pluralités..................................................................................................................27
1) Sémantique des superlatifs.....................................................................................................27a) Base sémantique.................................................................................................................27b) L'ambiguïté de lecture des superlatifs................................................................................31
2) Dérivation sémantique de MOST...........................................................................................35a) Base sémantique.................................................................................................................35b) L'ambiguïté de lecture de MOST : lecture proportionnelle mais non lecture absolue......37c) Lecture relative..................................................................................................................40
3) FEWEST proportionnel : des conditions de vérité impossibles.............................................41Conclusion..................................................................................................................................44
III) Des traitements cognitifs différents pour MOST et MORE THAN HALF..............................451) L' argument expérimental de Hackl........................................................................................45
-l'expérience principale..........................................................................................................45-les algorithmes de vérifications naturels de most et more than half.....................................46-résultats et conclusion...........................................................................................................48
2) Hypothèses théoriques sous-jacentes et circularité de l'argument..........................................48Conclusion : ...............................................................................................................................49
Références.......................................................................................................................................50

Résumé
L'article de Martin Hackl On the grammar and processing of Proportionnal Quantifiers (2008) propose une analyse entièrement décompositionnelle du quantificateur proportionnel most.
Dépassant le cadre de la Théorie des Quantificateurs Généralisés qui ne se soucie pas du rôle que jouent les composants internes dans la construction du sens des expressions de la quantification, Hackl fait un détour par la «grammaire» pour établir une sémantique de most plus fine et donc plus prédictive. A l'aide d'une généralisation syntaxique rigoureuse, il prend au sérieux sa terminaison st et montre qu'il se comporte comme un superlatif de type particulier, à lecture proportionnelle.
Cette analyse originale ouvre la voie à une sémantique unifiée des différentes occurrences de most, que l'on pouvait considérer jusque-là comme de simples homonymes (most modifieur d'adjectif, at most, most adverbe intensif).
Par ailleurs, elle permet d'établir une distinction fine entre most et un autre quantificateur proportionnel, more than half, avec lequel il partage exactement les mêmes conditions de vérité.Bien que dénotant l'une et l'autre un même état du monde, ces deux expressions sont grammaticalement distinctes car elles sont composées d'opérateurs linguistiques différents : comme l'indique sa composition morpho-syntaxique, more than half est un comparatif à lecture proportionnelle (Landman, 2004) alors que most est un superlatif à lecture proportionnelle.
Hackl dote également ses hypothèses théoriques d'une base cognitive en appuyant son raisonnement par un argument extérieur à la linguistique. A l'aide d'une méthodologie expérimentale capable de traquer les stratégies de vérification d'expressions impliquant des actions de dénombrement (Self Paced Counting), il montre que dans des tâches d'évaluation de valeur de vérité les deux items déclenchent des algorithmes de vérifications distincts, qui sont censés refléter la particularité de leur composition morpho-syntaxique .
On the grammar and processing of Proportionnal Quantifiers argumente ainsi en faveur d'un niveau de granularité de l'analyse sémantique beaucoup plus fin que celui proposé entre autres par la Théorie des Quantificateurs Généralisés, et ce dans le but de donner des bases théoriques solides à l'étude du traitement cognitif du langage1. Bien qu'il demeure encore de nombreuses obscurités théoriques au niveau des postulats qui décrivent cette relation entre forme logique et compréhension en temps réel, l'article de Hackl a ouvert la voie à de nombreux travaux récents qui s'intéressent en détails aux interactions entre système linguistique et système cognitif en ce qui concerne le maniement des expressions de la quantification2.
Dans cet article, nous nous efforçons de rendre compte en détail de l'analyse originale de most que propose Martin Hackl tout en prenant soin, lorsque cela est nécessaire, d'éclaircir son raisonnement par des références aux autres travaux de recherche qui ont été effectués sur le même sujet.
1 « semantics theories have the responsibility to furnish the pieces that a processing theory requires to draw systematic distinctions that occur during real time comprehension ».
2 Pietroski and al. (2009) et (2010), Solt (2011), Tomaszewicz (2011).
1

Introduction
L'article de Martin Hackl On the grammar and processing of Proportionnal Quantifiers clarifie la sémantique du quantificateur proportionnel most en se fondant sur une analyse syntaxique fine de ses composants internes, many et le morphème superlatif -est.
La définition sémantique de most comme opérateur de superlativisation de cardinalités de pluralités permet ainsi d'apparenter les deux occurrences les plus fréquentes de l'item, the most et
∅ most, en les envisageant, sur le modèle des deux interprétations des superlatifs, comme deux lectures proportionnelle et relative d'un même élément.Afin de les distinguer, on y fera référence dans la suite de ce document à l'aide des notations abrégées mostprop et mostrelatif .
Par cette étude entièrement décompositionnelle, Hackl souhaite affiner le niveau de granularité de l'analyse sémantique avec l'idée qu'elle puisse ainsi fournir des bases théoriques solides à l'étude cognitive du traitement en temps réel des éléments linguistiques.
L'article est divisé en trois grandes parties. Une introduction théorique replace l'analyse de mostprop dans le contexte plus général de la sémantique de la quantification. Tout en reconnaissant l'importance historique qu'a eu la Théorie des Quantificateurs Généralisés (TQG) dans l'approche formalisée du phénomène de quantification dans le langage naturel, Hackl met en avant sa faiblesse et insiste sur l'apport sémantique que peut constituer la morpho-syntaxe des quantificateurs. Il appuie son raisonnement sur la comparaison des formulations des conditions de vérité équivalentes de most et more than half, deux déterminants pourtant radicalement différents au niveau de leur grammaire et des opérateurs sémantiques qui les composent.Dans une deuxième partie, Hackl se base sur des généralisations syntaxiques de l'anglais et de
l'allemand pour fonder rigoureusement l'hypothèse grammaticale selon laquelle most est le superlatif de manyLa dernière partie propose un argument expérimental en faveur de la décomposition de most en
montrant que most prop et more than half engendrent des algorithmes de vérification distincts et que ces effets cognitifs sont justement dus à la morpho-syntaxe des expressions en question.
Nous suivrons l'ordre général de l'article de Martin Hackl en divisant notre compte-rendu en trois parties précédées d'un préambule. Dans ce préambule, nous évoquerons le cadre théorique de l'analyse de la quantification du langage naturel au sein duquel s'inscrit l'analyse de Hackl. Nous montrerons que la décomposition sémantique de most est un argument en faveur de l'ajout de nouvelles primitives à l'ensemble des unités de base servant à décrire formellement le sens des expressions de la quantification.
Dans une première partie, nous reproduirons pas à pas la démonstration de la nature «superlative» de most. A partir de données de l'anglais et de l'allemand, nous montrerons que most partage les mêmes caractéristiques morphologiques et subit les mêmes contraintes syntaxiques que les superlatifs «standard».
Cela nous permettra dans une deuxième partie d'exposer une sémantique entièrement décompositionnelle de most, basée sur la sémantique formelle des superlatifs qui a déjà été largement étudiée dans des travaux précédents (Szabolcsi 1986; Heim 1999; Farkas and Kiss 2000).
Enfin, dans une dernière partie plus critique, nous nous intéresseront à l'argument expérimental de Hackl selon lequel seule l'approche décompositionnnelle du sens de most permettrait de d'expliquer pourquoi deux expressions aux dénotations équivalentes, most et more than half
2

déclenchent des comportements de vérification différents chez les locuteurs.
3

Préambule : pour une sémantique décompositionnelle des quantificateurs proportionnels most et more than half.
1) Contexte théorique : les quantificateurs comparatifs.
Selon Martin Hackl, les déterminants quantificateurs proportionnels most et more than half ne sont pas des expressions fonctionnelles du même type que d'autres déterminants plus classiques comme every et some.
Ils n'appartiennent pas à une classe de mots fermée3: ce sont des expressions complexes dont la sémantique est exprimée par des constructions lexicales résultant d'un agencement d'éléments de sens plus petits.
Dans sa thèse, Hackl a déjà proposé une argumentation en faveur de la reconnaissance d'une sous-catégorie à l'intérieur de la classe des déterminants quantificationnels, celle des déterminants comparatifs (more than n, at least n, etc), dont font partie most et more than half comme le laisse entendre leur sémantique4. Son analyse entre en contradiction avec le cadre théorique traditionnel de l'analyse des quantificateurs, la Théorie des Quantificateurs Généralisés (TQG), qui fournit une sémantique globale du phénomène de quantification dans le langage naturel.
Hackl y fait remarquer que la composition morpho-syntaxique des éléments de cette sous-classe les apparente plus aux expressions comparatives qu'aux autres déterminants de «facture» simple. En outre, il montre que seule la reconnaissance de la particularité de leur composition interne permet de prédire l'irrégularité de leur comportement par rapport à ceux des autres déterminants à la syntaxe standard. Dans une analyse détaillée, il montre que c'est la présence d'un composant essentiel dans leur morphologie, l'opérateur de cardinalité many, qui contraint le DP auquel ils s'adjoignent et la principale de la phrase à laquelle ils appartiennent.
Dans On the grammar and processing of proportional quantifiers, Hackl entame une nouvelle brèche dans l'analyse uniforme du phénomène de quantification.
Avec cette étude il a l'intention de démontrer qu'en plus d'expliquer des phénomènes linguistiques irréguliers, la prise en compte de la morpho-syntaxe des quantificateurs par l'adoption d'une sémantique entièrement décompositionnelle permet d'appréhender avec succès des phénomènes cognitifs fins. C'est pourquoi il s'arrête sur deux items dénotationnellement équivalents mais «cognitivement»5 différents, most et more than half.
Le travail de Hackl sur most est donc assez ambitieux parce qu'il remet en cause le cadre
3 Pour reprendre l'expression de Martin Hackl, ce ne sont pas des «closed-class items» .Une classe de mot fermée est une classe à laquelle on ne peut ajouter de nouveaux membres et qui généralement ne comporte qu'un petit nombre d'éléments en son sein. Habituellement, les classes de mots fermées correspondent à des classes d'éléments fonctionnels ou grammaticaux (classe des déterminants, classe des conjonctions par exemple).4 Selon Martin Hackl, les quantificateurs comparatifs sont des déterminants qui font nécessairement mention d'une
fonction de mesure «cardinalité de» et d'une relation de comparaison (≤ , ≥ ou = ) dans la description de leurs conditions de vérité.
Selon la théorie des quantificateurs généralisés (Keenan 2001), un déterminant D est dit proportionnel si et seulement si:
D (A) (B) = D (A') (B') si |A B| / | A | = |A' B' | / | A' |
Les quantificateurs proportionnels appartiennent donc par définition à la classe des comparatifs dont il forment une sous catégorie.
5 Nous essaierons de déterminer plus en détail sur quoi repose cette distinction cognitive dans notre troisième chapitre.
4

traditionnel d'analyse du phénomène de la quantification et ouvre la voie à une approche théorisée du traitement en temps réel des expressions de la quantification.
2) most est un quantificateur superlatif.En ce qui concerne more than half, il n'est pas difficile de dissocier dans sa forme de surface les
briques de sens qui le composent : une fonction de mesure (many), une relation comparative (-er than) et un standard de comparaison (half)6.
En revanche, le cas de most est plus intriguant car à première vue il semble indécomposable. Pourtant, si on fait un relevé des occurrences de cet item dans des contextes différents7, on parvient à des conclusions intéressantes concernant sa nature grammaticale.
(1) John has climbed most mountains.
(2) John has climbed the most mountains.
(3) a) John has climbed the most beautiful mountains.
b) John has climbed the highest mountains.
(4) John has climbed at most three mountains.
(5) This film was most interesting.
On retrouve des éléments morphologiques apparentés au quantificateur proportionnel (1) dans la constructions d'autres expressions complexes remplissant des fonctions linguistiques clairement distinctes (2 à 5).
Cela semble indiquer que le déterminant most est composé d'éléments plus petits qui sont des opérateurs sémantiques minimaux servant de matériau de base dans la construction d'autres expressions.
Si tel est le cas, on ne devrait pas percevoir les éléments en italique des phrases (1) à (5) comme de simples homonymes dont la ressemblance serait fortuite, mais comme des occurrences d'un même morphème sous – jacent.
La phrase (1) comporte une occurrence de most quantificateur proportionnel, que l'on notera most
prop pour le dissocier des autres usages.
Il est ainsi nommé car la phrase dans laquelle il se trouve est vraie si John a escaladé un nombre de montagnes significativement grand par rapport au nombre total de montagnes en considération. Ces conditions de vérité encore trop approximatives seront précisées par la suite mais on peut d'ores et déjà constater que most est un prédicat vague, qui implique une comparaison de sommes et la référence à un standard numérique issue d'une proportion, ce qui le 6 Pour un traitement plus complet, se référer à la thèse de Hackl, Comparative Quantifiers (1995).7 Les quatre premières phrases de cette liste sont tirées de l'article de Stéphanie Solt, How many most's? (2011). Le dernier provient de la Grammaire explicative de l'anglais (P.Larreya & C.Rivière 2005).
5

rapproche dénotationellement de more than half. Il forme un DP quantificationnel qui peut se trouver en position sujet ou en position objet.
En (2), on retrouve l'item complexe most, cette fois-ci précédé d'un article défini. Il engendre une comparaison entre le nombre de montagnes escaladées par John et le nombre de montagnes escaladées par les autres membres de l'ensemble des individus déterminés par le contexte et dont John fait partie. La phrase est vraie si ce nombre est supérieur aux autres.
On le notera par la suite most relatif car ses conditions de vérité consistent à évaluer le degré d'une qualité possédée par un individu relativement aux degrés de cette même qualité possédée par tous les autres individus en considération.
En (3) a) most modifie l'adjectif pour lui donner un sens superlatif.En (4) most entre dans la composition d'un quantificateur superlatif de la forme at most n, où n
est un entier supérieur à 0 et at est une préposition adverbiale indiquant une limite numérique.Enfin en (5) most est un adverbe d'intensité à sens superlatif.
On peut établir plusieurs remarques à partir de ce relevé. Tout d'abord, le fait que most apparaisse dans des contextes fonctionnels différents de celui du déterminant proportionnel semble indiquer que ce n'est pas une unité primitive de quantification au même titre que some ou every.
De plus, on constate qu'il y a un trait de sens commun à toutes ces occurrences, le trait superlatif. C'est tout à fait visible en ce qui concerne les trois premières occurrences de notre liste (1 à 3), toutes désignent une opération de superlativisation. Cette opération consiste à mettre en avant un individu par rapport à tous les autres individus au motif qu'il possède une propriété au plus au degré que tous les autres individus auquel il est comparé. En (1) le locuteur met en avant les montagnes escaladées par John en insistant sur le fait qu'elles sont plus nombreuses que les montagnes qu'il n'a pas escaladées. Le locuteur de la phrase (2) met John au premier plan parce qu'il possède la propriété d'avoir escaladé beaucoup de montagnes plus que tout le monde autour de lui. En (3), le locuteur insiste sur le degré supérieur de beauté qui met à part un sous ensemble de montagnes parmi l'ensemble de toutes les montagnes en considération.
Par ailleurs, la nature superlative de most apparaît clairement dans les phrases (3) a) et (3) b). Le parallélisme entre ces deux phrases suggère que la fonction remplie par most dans le DP en a) est la même que celle remplie par le morphème superlatif seul (-est) dans le DP en b). C'est seulement un critère morphologique8 qui commande l'usage de l'une ou l'autre forme : most modifie les adjectif longs, -est les adjectifs courts, et tous les deux donnent un sens superlatif au DP qu'ils forment
Le trait de sens commun aux occurrences du quantificateur proportionnel est encore plus visible en français9.
8 Vraisemblablement le fruit d'une évolution diachronique.9 Il y a de légères différences entre l'anglais et le français qui ne disqualifient pas pour autant la pertinence d'une étude translinguistique de MOST.Le quantificateur français ne peut qu'avoir une forme partitive mais cette caractéristique ne semble pas avoir d'influence majeure sur la sémantique de l'ensemble du DP. De plus, les deux formes (partitive et non partitive) sont disponibles en anglais et ont les mêmes conditions de vérité :
α) In this university, [DP most students] are American.
β) In this university, [DP most of the students] are American.
Mais on a :
6

Le relevé des occurrences de MOST10 ci-dessous correspond point par point à celui de l'anglais.
(1) Jean a escaladé la plupart/la majorité des montagnes.
(2) Jean a escaladé le plus de montagnes.
(3) Jean a escaladé (tout) au plus trois montagnes.
(4) Jean a escaladé la montagne la plus haute.
(5) Ce film était des plus intéressants11.
Il apparaît plus manifestement qu'en anglais que le quantificateur proportionnel est apparenté au superlatif12 puisque nous retrouvons la marque de l'opération de superlativisation (article défini+ morphème comparatif) dans les situations où l'anglais emploie most.
On pourrait cependant douter de la pertinence de l'argument translinguistique en objectant que le rapprochement entre l'anglais et le français est abusif puisque les deux langues ne semblent pas du tout comparables au niveau de la forme de l'item qu'elles emploient comme déterminant proportionnel.
Le quantificateur proportionnel existe en français sous la forme de deux expressions complexes, la majorité et la plupart, dont les compositions morphologiques semblent très éloignées des autres occurrences (2 à 5) clairement apparentées au superlatif par la présence en leur sein d'un même composé sémantique ( article défini+plus de). Ce n'est pas la même situation que l'anglais qui garde le même item (most) dans tous les usages.
Mais si l'on se penche sur la composition interne de la majorité et la plupart, on voit que la différence de forme n'est qu'apparente puisque les deux items contiennent l'opérateur superlatif sous des formes ou bien condensée (a) ou bien archaïque (b).
(a) La plupart = la plus part = la plus grande des parties.
(b) La majorité13 = major [le superlatif latin de multus (beaucoup) ] + té [suffixe qui sélectionne
γ) *In this university, [DP most of students] are American.
Le contraste entre α, β et γ indique que le partitif impose la présence de l'article défini parce qu'il correspond à une partie bien délimitée dans l'ensemble qui est dénoté par le prédicat.10 La notation en lettre capitale MOST renvoie au quantificateur proportionnel du langage naturel, quelle que soit sa forme qui peut varier selon les idiomes.11 On peut également traduire la phrase This film was most interesting par Ce film était très intéressant mais nous avons choisi la traduction qui rendait plus manifeste le sens comparatif/superlatif.12 Le morphème -plus de est certes le morphème du comparatif mais c'est l'ensemble article défini (le/la/des)+ -plus de qu'on retrouve dans toutes les occurrences de la liste. Ce fait n'est pas si déroutant si on considère que la superlativisation est une comparaison universelle :
la montagne la plus haute (superlativisation ) = la montagne plus haute que toutes les montagnes du monde (comparaison)13 Il est pertinent de se demander si la plupart de et la majorité de ont exactement les mêmes conditions de vérité. Une première intuition nous pousserait à considérer que le DP quantificateur la majorité de s'interprète différemment de la plupart, si l'on reste fidèle à une prise en compte sémantique de la composition morpho-syntaxique des quantificateurs. Cependant, même si l'on suit l'approche décompositionnelle prônée par Hackl, on parvient à une sémantique identique pour la majorité et la plupart, les deux items étant composés des mêmes unités de sens : un opérateur de degré s'apparentant au superlatif (composé lui-même de l'article défini et du morphème comparatif plus
7

un adjectif et forme un nom].
Ainsi, comme more than half, most est un élément complexe composé d'opérateurs de sens minimaux : l'opérateur superlatif -est et l'opérateur de cardinalité many.
more than half et most sont donc tous les deux des quantificateurs proportionnels qui ont le même sens mais qui diffèrent par leur composition interne.
Jusqu'ici nous nous sommes basés sur de simples observations empiriques pour mettre en évidence la forme complexe de most et élucider sa nature grammaticale.
Il va falloir à présent prouver qu'il est un superlatif à partir de généralisations syntaxiques (chapitre 1) et construire une sémantique décompositionnelle efficace (chapitre 2) qui puisse engendrer l'algorithme de vérification qui lui est attaché et qui est nécessairement différent de celui de more than half (chapitre 3).
3) La TQG ne permet pas de distinguer conceptuellement most et more than half
- la théorie des quantificateurs généralisés L'idée que la sémantique de most n'est véritablement appréhendée qu'au moyen d'une analyse fine de sa composition interne va à l'encontre du cadre traditionnel d'analyse du phénomène de quantification proposé par la Théorie des Quantificateurs Généralisés (Mostowski, 1957). Selon la TQG, les déterminants quantificationnels constituent une classe uniforme à laquelle il est possible de donner une sémantique unifiée. Ce sont des déterminants qui dénotent des relations d'ensemble (inclusion, intersection non vide, etc...). Associés à un NP, ils forment un Quantificateur Généralisé.
La sémantique des quantificateurs est toujours analysée sur le même modèle, quel que soit le déterminant : il suffit d'identifier le sens lexical du NP, le sens lexical du prédicat de la principale et le sens du déterminant qui donne le mode de combinaison des deux éléments pour parvenir à une sémantique. L'analyse syntaxique ne rentre donc pas dans les détails de la composition interne du déterminant puisqu'elle consiste seulement à isoler le restricteur (B) et la portée nucléaire (A) du QP.
(6) [QP most of the mountains] are ancient = DET (A) (B) avec A: {mountains}, B :{ancient}, DET : |A B| > |A - B |
(7) [QP some mountains] are beautiful = DET (A) (B) avec A :{mountains}, B :{beautiful}, DET : |A B | > 0
(8) John has climbed [QP more than 5 mountains] = DET (A) (B), avec A :{mountains},
de/major) et un opérateur de cardinalité.En revanche, une différence semble exister entre la majorité et une majorité, l'un étant un quantificateur vague et l'autre faisant référence à une notion de dénombrement précise.
α) La majorité des électeurs ont voté pour le président sortant.
β) Une majorité d'électeurs ont voté pour le président sortant.
Les deux phrases ont des conditions de vérité divergentes car on peut trouver des cas où α) est fausse mais β) est vraie.
8

B :{climbed by John}, DET : | A B| > 5
Les quantificateurs sont vus comme des expressions idiomatiques, un tout opaque dont les composants internes n'interagissent pas avec le reste de la phrase.
C'est paradoxalement le quantificateur most prop qui a justifié l'adoption de la TQG et la notation des conditions de vérité des quantificateurs en termes de prédicats de second ordre (Barwise et Cooper, 1981).En effet, contrairement à every, il est impossible de le définir à partir de la logique du premier ordre :
[[every (A) (B)]] = 1 si et seulement si ∀ x [ A(x) → B(x) ]
* [[most prop (A) (B)]] = 1 si et seulement si Mx [ A(x) { ¬, &,v, → } B(x)]
most ne peut être défini comme every en (1), sous la forme :
D (A) (B) = D (E) h (A,B) où A, B ⊆ E et h est une fonction booléenne à deux arguments.
Autrement dit, il n'y a aucun quantificateur du premier ordre Mx tel qu'associé à une fonction booléenne opérant sur deux ensembles A et B, il donne une définition de most (A) (B) comme les A qui sont B sont plus nombreux que les A qui ne sont pas B.
En revanche la formulation de most en terme de relations d'ensemble est satisfaisante :
[[ most prop (A) (B)]] = |A B| > |A - A B |14
Le cadre ensembliste permet tout aussi bien de définir les entrées lexicales de déterminants inexprimables ou difficilement exprimables par la logique du premier ordre (most, more than half) que celles qui pouvait l'être (every, some), sans pour autant engendrer de perte d'expressivité dans la formulation de leurs conditions de vérité:
[[every (A) (B)]] = A ⊆ B ⇔ x ∀ [ A (x) → B(x) ]
[[some (A) (B)]] = A B > 0 x [ A (x) ⇔ ∃ → B(x) ]
14 On peut simplifier la notation |A B| - | B | en |A – B|.
9
A A-B
B A∩B

* [[more than half (A) (B) ]] = Mx [ A(x) { ¬, &,v, → } B(x)]
[[more than half (A) (B)]] = | A B| > 1/2 | A |
* [[most prop (A) (B)]] = Mx [ A(x) { ¬, &,v, → } B(x)]
[[ most prop (A) (B)]] = |A B| > |A B| - | B |
Cette approche résout donc le problème théorique de la sémantique de la quantification dans le langage naturel mais au prix d'une insensibilité à la composition interne des items quantificateurs. Bien que clairement distincts morphologiquement, most prop et more than half ont les mêmes conditions de vérité dans ce cadre théorique puisque les formulations qui les décrivent sont équivalentes logiquement :
| A B| > |A - A B | = | A B| > ½ | A |
Démonstration :
| A B| > |A - A B | = | A B| + | A B| > |A|=2| A B| > |A|= | A B| > ½ | A |.
- sens d'une expression et traitement d'une expressionCette équivalence, quoique juste sur le plan logique, contredit nos intuitions conceptuelles. La
préférence que nous avons pour une manière précise de décrire les conditions de vérité d'une expression n'est pas anodine, elle est guidée par une intuition linguistique forte selon laquelle la structure syntaxique d'une expression participe à son sens et donc que des propositions distinctes syntaxiquement mais équivalentes logiquement ne véhiculent pas la même structure informationnelle15.
On le voit, les deux formulations n'encodent pas les mêmes opérations de calcul :
a) | A B| > ½ | A |
-opérateur de mesure (λx . |x|).-opérateur de division de moitié (λx. ½ |x|).-opérateur de comparaison à un standard numérique exacte (λx. |x| > n).
b)| A B| > |A - A B |
-opérateur de mesure λx . |x|.-opérateur de soustraction d'ensembles (λX λY. X-Y).-opérateur de comparaison entre deux quantités (λx λy. x > y).
15 Ce principe explique par exemple le fait que dire « 2+4 » ne revient pas exactement à dire « 6 ». Sur la distinction entre représentations vériconditionnelles et propositions structurées voir Structured meanings (M.Cresswell 1985).
10

Elles n'impliquent pas les mêmes opérateurs mentaux : a) décrit une comparaison de sommes exactes tandis que b) décrit une comparaison d'ensembles.
On voit que b) correspond mieux à most, elle encode plus adéquatement le type de computation que requiert son usage.
En choisissant le critère de plausibilité cognitive pour différencier les deux formulations de condition de vérité de most, Hackl postule la thèse selon laquelle les formulations de conditions de vérité sont des hypothèses psychologiques qui codifient l'algorithme de vérification impliquée par une expression.
11

I) MOST = MANY + EST
Pour rendre compte de la sémantique de MOST d'une manière plus subtile que la théorie des quantificateurs généralisés, Martin Hackl fait l'hypothèse que celui-ci est le superlatif de MANY.
Il fonde son intuition à partir d'observations empiriques qu'il va tenter de justifier au niveau de la structure syntaxique.
A travers les langues, on l'a vu, on constate une ressemblance morphologique entre MOST et l'opérateur du superlatif. En français et en italien par exemple, les éléments déterminants comparables au most anglais sont morpho-syntactiquement apparentés au superlatif de l'adjectif gradable MANY/NUMEROUS.
Cependant ces observations de surface ne suffisent pas à justifier rigoureusement une quelconque hypothèse portant sur la nature grammaticale du quantificateur. Il faut passer par une analyse en profondeur de la distribution syntaxique de MOST en anglais et en allemand. Nous allons tenter de restituer cette généralisation.
1) Sémantique des superlatifs
Pour affirmer que MOST est le superlatif de MANY, il faut pouvoir montrer que MOST est sensible aux mêmes facteurs environnementaux que les superlatifs ordinaires.
(9) John climbed the highest mountain.
John a escaladé la plus haute montagne.
Les superlatifs ont habituellement deux lectures : une absolue (a) et une lecture relative (b).
(a) John climbed the highest of all mountains.
De toutes les montagnes, John a escaladé la plus haute.
(b) The mountain that John climbed was higher than the mountains climbed by anyone else (in the context).
La montagne que John a escaladée était plus haute que toutes les montagnes escaladées par n'importe qui d'autre (dans le contexte de l'énonciation).
Ces deux lectures ont des conditions de vérité divergentes. Imaginons que John a escaladé le mont Everest et que personne d'autres parmi l'ensemble déterminé par le contexte de l'énonciation n'a monté de montagne plus haute. Dans ce cas-là, la phrase (b) est vraie tandis que la phrase (a) ne l'est pas.
Il est cependant à noter que dans des cas de restriction de contexte, fréquents dans l'usage quotidien du langage, il devient assez difficile de distinguer la lecture absolue en contexte
12

restreint de la lecture relative16.On reviendra dans notre deuxième partie sur l'analyse détaillée du phénomène syntaxique qui
fonde l'ambiguïté entre ces deux interprétations (la différence de portée du morphème superlatif après un mouvement au niveau de la forme logique).
Puisque nous avons posé l'hypothèse selon laquelle MOST est un superlatif, on devrait obtenir pour celui-ci les mêmes lectures que celles des superlatifs en général.
Dans le relevé distributionnel que l'on a fait en préambule, on a mis en valeur deux usages principaux de MOST, le déterminant proportionnel et le déterminant relatif (mostprop et mostrelatif).
On fait alors la prédiction que ces occurrences sont des formes de surface indiquant deux lectures d'un même élément sous-jacent et qu'elles correspondent aux deux lectures du superlatif que l'on vient d'évoquer.
2) MOST est un superlatif
Hypothèse:
MOST = MANY + ESTmost = many + ESTdie meisten = viel + EST
a) Données de l'allemand.Pour rendre plus visible la correspondance, Hackl teste cette prédiction à partir de données
issues de l'allemand.
(10) Hans hat die meisten Buecher gelesen.
John has the most books read.
John a lu le plus de livres17.
(a) Lecture relative : John read more books than anybody else in the context.
16 Les cas de restrictions contextuelles des domaines de la quantification sont inhérents à notre usage du langage naturel.
(α) Tous les enfants sont au gymnase.
La phrase α par exemple a peu de chance de signifier « absolument tous les enfants de l'univers sont présents au gymnase ». Pour des raisons extérieures au système linguistique, le quantificateur universel quantifie sur un ensemble restreint : ici, les enfants de l'école dont parle le locuteur.De même, la classe de comparaison introduite par le superlatif de la phrase (5) ne contient probablement pas toutes les montagnes de l'univers. On peut imaginer que le locuteur a en tête toutes les montagnes de France lorsqu'il prononce cette phrase, et il n'est dès lors pas impossible que si Jean a escaladé le mont Blanc, la phrase soit vraie pour les deux lectures, relative et absolue.
17 Traductions mot à mot de la phrase de l'allemand à l'anglais et au français pour rendre compte de la forme du DP, qui est précédé de l'article défini. La traduction correcte suit en français et en anglais en (a) et (b).
13

John a lu plus de livres que quiconque dans le contexte de l'énonciation.
(b) Lecture proportionnelle : John read more than half of the books.
John a lu la plupart/plus de la moitié des livres.
Contrairement à l'anglais, les lectures proportionnelle (10) (b) et relative (10) (a) de l'item MOST allemand ont la même forme de surface, die meisten. L'article défini die est présent dans les deux usages. Cette ressemblance morphologique avec les superlatifs indique pour MOST une ambiguïté de même nature que celle qui gouverne les superlatifs. En effet, on a vu en (9) que le superlatif relatif et le superlatif absolu de « high » sont désignés par une même forme de surface composée d'un article défini et d'un NP (« the highest mountain »).
On verra par la suite quel rôle il conviendra d'associer à l'article défini dans la composition du sens.
En anglais en revanche, les deux lectures disponibles, (11) (a) et (11) (b), sont exprimées par des formes différentes : [∅ most] et [the most].
(11)(a) Lecture relative : John had read the most books.
(b) Lecture proportionnelle : John had read ∅ most books.
Pour vérifier si MOST obéit aux mêmes propriétés que les superlatifs en général, on va faire jouer les conditions d'apparition des différentes lectures.
Selon Sabolczi, la lecture relative18 des superlatifs réagit à des contraintes spécifiques.
(9) John climbed the highest mountain.
John a escaladé la plus haute montagne.
(12) JOHNF climbed the highest mountain.
John, lui, a escaladé la plus haute montagne.
C'est John qui a escaladé la plus haute montagne19.
(13) Who climbed the highest mountain?
Qui a escaladé la plus haute montagne?
18 Sabolczi, Farkas et Kiss parlent de lecture comparative du superlatif là où nous parlons de lecture relative. Il s'agit du même phénomène.19 Dans notre traduction, nous essayons de rendre plus clairement compte de la mise en valeur prosodique du DP par
le phénomène du focus au moyen du pronom d'insistance ou du pseudo-clivage. Ces deux structures syntaxiques ont pour effet de mettre en avant l'élément DP dans la phrase.
14

Alors que (9) était structurellement ambiguë (les deux lectures coexistent), en (12) et (13) la lecture relative est nettement plus aisée que la lecture absolue.
Elle est favorisée par la présence d'éléments WH20 et de sujets focusés. Ils jouent le rôle de légitimeurs car il permettent la création implicite d'une structure de comparaison en introduisant une proposition contenant une variable :
JOHNF = John, par opposition aux autres.
Qui = Quel x parmi tous les individus du contexte d'énonciation.
On peut expliciter cette structure de comparaison sans changer le sens de la phrase qui la contient :
(13)' Who is the one who climbed the highest mountain?
Qui est celui qui a escaladé la plus haute montagne?
Par ailleurs, on s'aperçoit en (14) et (15) que ces légitimeurs doivent être locaux, c'est-à-dire qu'ils doivent appartenir à la même proposition que le superlatif21.
(14)Who said that he climbed the highest mountain?
Qui a dit qu'il a escaladé la plus haute montagne?
(15) Who do you think has climbed the highest mountain?
Qui crois-tu qui a escaladé la plus haute montagne?
20 En réalité, comme l'ont montré Farkas et Kiss, seul un sous-ensemble restreint parmi les éléments WH autorise la lecture relative.On a :
α) I saw the man who climbed the highest mountain.
β) I saw a man who climbed the highest mountain.
La phrase β) n'autorise pas la lecture relative, bien que comportant un élément WH.Comme la définition de l'extension de ces éléments WH légitimeurs est sujette à discussion et qu'elle ne concerne pas directement notre sujet, nous nous contenterons d'utiliser des légitimeurs WH en position interrogative, dont on sait qu'ils permettent toujours la lecture relative des superlatifs.21 La contrainte de localité qui régit les éléments permettant la lecture relative des superlatifs est malaisée à définir. Une formulation moins vague de la condition serait la suivante :
condition de localité: la lecture relative n'est rendue possible que si le superlatif et la variable liée par l'opérateur légitimeur ne sont pas séparés par une barrière.
Encore une fois, comme ce problème de définition ne concerne pas directement notre sujet, et pour éviter de nous exposer à de trop amples difficultés théoriques, nous nous abstenons de rentrer dans les détails.
15

En (14) seule la lecture absolue est obtenue tandis qu'en (15) les deux lectures sont possibles.Pourtant il y a mouvement de l'élément WH dans les deux phrases :
(14) Who1 t1 [said that he climbed the highest mountain]?
(15) Who1 do you think [ t1 has climbed the highest mountain]?
Bien qu'en surface la position de l'élément WH soit la même, c'est la structure d'avant mouvement qui explique les différences d'interprétation des deux phrases.
En (15) l'expression WH est extraite de la proposition enchâssée qui accueille également le superlatif. Le légitimeur est local puisque la trace de l'élément WH est dans la même proposition que le superlatif. En (14) en revanche, la trace et le superlatif sont séparés par une barrière de proposition.
(16) Every family has climbed the highest mountain.
Toutes les familles ont escaladé la plus haute montagne.
Enfin, la phrase (16) nous indique que l'existence d'un unique individu possédant la propriété gradable au plus au degré est nécessaire à l'interprétation relative des superlatifs. Le quantificateur universel force la lecture absolue : il empêche l'opération de superlativisation, qui consiste à sélectionner un individu unique ayant la propriété prédiquée au plus au degré, en distribuant uniformément à tous cette propriété. On ne peut dès lors plus comparer les individus en fonction de la hauteur des montagnes qu'ils ont escaladées.
On a à présent à notre disposition une liste de paramètres bloquant ou favorisant l'une et l'autre lecture des superlatifs : sujets focusés et éléments WH locaux, présence d'un unique individu ayant la propriété prédiquée au plus au degré.
Si on veut tester notre hypothèse selon laquelle MOST est le superlatif de MANY, on doit faire jouer ces éléments pour voir s'il réagit à leur présence de la même manière que les superlatifs standard. Plaçons-nous dans un environnement qui, tout en rendant possible les deux lectures des superlatifs, favorise nettement l'interprétation relative.
(17) Die FLACHAUERF haben den hoechsten Berg beschneit.
The FlachauersF have on the highest mountain snow made.
Les habitants de FlachauF ont mis de la neige artificielle sur la plus haute montagne.
Deux lectures disponibles : la lecture absolue et la lecture relative.
Un tel environnement est fournit par (17) où le sujet focusé incite le locuteur à retenir présente à
16

l'esprit la lecture relative.
(18) Die FLACHAUERF haben die meisten Bergen beschneit.
The FlachauersF have made snow on more mountains than anybody else.
The FlachauersF have made snow on more than half of the mountains.
Les habitants de FlachauF ont mis de la neige artificielle sur le plus de montagnes.
Les habitants de FlachauF ont mis de la neige artificielle sur la plupart des montagnes.
Deux lectures disponibles : la lecture proportionnelle et la lecture relative.
On obtient également deux lectures pour die meisten en 18 : une lecture relative et une lecture proportionnelle.
Afin de clarifier notre première impression, plaçons-nous dans des cas où seule la lecture absolue est disponible:
(19) Es schneite auf den hoechten Berg.
It snowed on the highest mountain.
Il a neigé sur la plus haute montagne.
Une seule interprétation : la lecture absolue.
En (19), comme aucun élément légitimeur n'est présent, la lecture relative du superlatif n'est pas possible.
(20) Es schneite auf den meisten Bergen.
It snowed on more than half of the mountains.
Il a neigé sur la plupart des montagnes.
Une seule interprétation: la lecture proportionnelle.
Dans cet environnement de lecture absolue forcée (20), c'est la lecture proportionnelle que l'on obtient pour die meisten.
On en conclut provisoirement qu'il y a interaction entre les environnements rendant possibles les deux lectures des superlatifs et l'apparition des deux lectures disponibles de die meisten.Dans tous les cas où les deux lectures sont disponibles pour les superlatifs, on obtient les lectures relatives et proportionnelles pour die meisten et à chaque fois que la lecture relative des superlatifs est impossible, c'est la lecture proportionnelle de die meisten qui émerge.
17

(21)Wer1 t1 hat gesagt [dass sie den hoechsten Berg beschneit haben]?
Who1 t1 said [that they made snow on the highest mountains]?
Qui1 t1 a dit [qu'ils avaient mis de la neige artificielle sur les plus hautes montagnes]?
Une seule lecture obtenue : la lecture absolue.
Wer1 hat t1 gesagt [dass sie die meisten Berge beschneit haben]?
Who1 t1 said [that they made snow on top of more than half of the mountains]?
Qui1 t1 a dit [qu'ils avaient mis de la neige artificielle sur le sommet de la plupart des montagnes]?
Une seule lecture : la lecture proportionelle.
(23) Wer1 glaubst du hat [t1 den hoechsten Berg beschneit] ?
Who1 do you think [t1 has made snow on top of the highest mountains] ?
Qui1 penses-tu [t1 qui a mis de la neige artificielle sur le sommet de la plus haute montagne]?
Deux lectures disponibles : la lecture absolue et la lecture relative, avec préférence pour la lecture relative.
(24) Wer1 glaubst du hat [t1die meisten Berge beschneit] ?
Who1 do you think [t1 has made snow on top of the most mountains] ?
Who1 do you think [t1 has made snow on top of more than half mountains] ?
Qui1 penses-tu [t1 qui a mis de la neige artificielle sur le sommet de la plupart des montagnes]?
Qui1 penses-tu [t1 qui a mis de la neige artificielle sur le sommet de plus de montagnes/du plus grand nombre de montagnes]?
Deux lectures disponibles : la lecture relative et la lecture proportionnelle.
Notre conclusion est confirmée en (21-24). Les légitimeurs superlatifs, ici la localité de l'élément WH, sont opérants pour die meisten, ils
18

permettent les deux interprétations. Comme pour les superlatifs, ils sont contraignants : leur absence bloque une des deux interprétation, qui est la même pour die meisten et den hoechsten. En (21) et (22) c'est la lecture relative qui est empêchée. Il n'y a pas de lecture absolue pour die meisten mais une lecture proportionnelle dont les environnements sont similaires à ceux qui forcent la lecture absolue des superlatifs.
A partir de ces généralisations, on prédit que die meisten va être interprété comme un proportionnel dans des environnements comme (25) où la lecture relative du superlatif est impossible à cause du NP universel every, qui force la lecture absolue en empêchant l'existence d'un unique individu ayant la propriété gradable au plus haut degré que tout autre individu.
(25) Jede Geimeinde hat den hoechsten Berg beschneit.
Every town has on the highest mountain snow made.
Toutes les villes ont mis de la neige artificielle sur la plus haute montagne.
Seule lecture obtenue : la lecture absolue.
(26) Jede Geimeinde hat die meisten Berge beschneit.
Every town has made snow on top of more than half of the mountains.
Seule lecture obtenue : la lecture proportionnelle.
C'est bien ce que l'on obtient en (26). On parvient alors à la généralisation suivante:
-die meisten n'a pas de lecture absolue disponible mais permet une lecture proportionnelle à chaque fois que les superlatifs ont une lecture absolue.
-il a une lecture relative déclenchée et empêchée par les mêmes paramètres que ceux qui régissent la lecture relative des superlatifs.
Cette généralisation ne concerne pas seulement le déterminant allemand. Elle correspond au comportement de MOST en général. C'est ce que l'on va tenter de montrer en testant l'anglais.
b) Données de l'anglais.On constate qu'en anglais, les interprétations disponibles pour MOST sont contrôlées par la
présence ou l'absence de l'article défini the. Comme on l'a vu en (11), [∅ most] donne une lecture proportionnelle à la phrase contenant le
DP quantifié et [the most] une lecture relative. On a à notre disposition un paramètre qui, couplé à notre hypothèse, peut nous permettre de produire des implications théoriques que l'on va confronter aux données. On prédit que the most ne donne pas d'interprétation dans les environnements qui ne sont pas marqués par la présence d'éléments favorisant la lecture relative des superlatifs. Au contraire, dans ces situations-là, ∅ most sera acceptable et donnera une lecture proportionnelle à la phrase.
19

(27) *It snowed on top of the most mountains22.
(28) *Who said that Mary made snow on top of the most mountains?
(29) *Who all made snow on top of the most mountains?
Mais on a:
(30) It snowed on top of most mountains.
(31) Who said that Mary made snow on top of most mountains?
(32) Who all made snow on top of the most mountains?
Maintenant que la contribution de l'article défini a été mise au jour, on peut voir que l'anglais suit la même généralisation distributionnelle que l'allemand :
- l'item most, précédé ou non de l'article défini ne donne jamais lieu à une lecture absolue.- à chaque fois que les superlatifs ont une lecture absolue, on a ∅ most qui ne peut donner
qu'une lecture proportionnelle à la phrase qui le contient.- the most donne une lecture relative déclenchée et empêchée par les mêmes paramètres que
ceux qui régissent la lecture relative des superlatifs.
3) FEW = FEW + EST
La théorie des quantificateurs généralisés mettait de côté l'analyse décompositionnelle des quantificateurs car elle était été envisagée comme n'apportant aucune prédiction supplémentaire au phénomène de la quantification dans le langage naturel.
Au contraire, l'idée que défend Martin Hackl est que la décomposition de MOST en MANY + le morphème superlatif permet d'expliquer des faits sémantiques réels.
Si l'on fait un relevé empirique de formes à travers les langues, on parvient à une observation de surface qui n'est pas expliquée par la TQG. Dans les idiomes (comme l'anglais ou l'allemand) où il existe un item spécifique pour MOST, il n'existe pas d'opposé polaire23 signifiant less than half.
Alors qu'en anglais MOSTrelatif (the most) a un opposé polaire ( the fewest), MOSTprop n'en a pas : most existe mais *fewest n'est pas attesté.
Le cas de l'anglais à ce titre est plus clair que l'allemand : il différencie en surface la forme
22 La phrase redevient grammaticale si on ajoute un légitimeur caché qui implicitement crée une structure de comparaison:
(α) It snowed on top of the most mountains this year.= It snowed on top of the most mountains this year than it snowed any other years before.
[[(α )]]=1 si et seulement si il a neigé sur un plus grand nombre de montagnes cette année qu'il n'a neigé toutes les autres années.23 C'est-à-dire d'antonyme qui a une polarité inverse sur une échelle sémantique. Martin Hackl emploie le terme
« polar opposite ».
20

relative et la forme proportionnelle. Il est donc plus facile de s'apercevoir de l'absence de lecture proportionnelle de FEW par un simple inventaire des formes.
Pour l'allemand c'est surtout la généralisation syntaxique qui permet d'établir ce manque : die wenigsten ne veux jamais dire moins de la moitié, qui serait la valeur sémantique contraire de die meisten dans son sens proportionnel.
Dans les cas où il n'existe pas d'item spécifique, l'opposé polaire de MOSTprop, que l'on imagine vraisemblablement composé sur le même modèle, n'existe pas. En français, l'équivalent complexe de MOSTrelatif est le plus de, son opposé polaire est le moins de. L'opposé polaire de MOSTprop, la majorité de, signifierait moins de la moitié de. On peut imaginer que ce sens serait véhiculé par l'item composé morpho-syntaxiquement sur son modèle : la minorité de. Or si cette expression existe bien, elle n'a jamais le sens et l'emploi d'un déterminant quantificateur proportionnel24.
De plus, le relevé des usages de FEWEST en anglais et en français reflète qu'il n'y a pas de correspondance terme à terme avec celui de MOST établi dans le préambule, bien que MOST soit son opposé polaire :
1) *John has climbed fewest mountains.
2) Jonh has climbed the fewest mountains.
3) John has climbed at least three mountains.
4) John has climbed the least high mountains.
1) *Jean a escaladé la minorité de montagnes.
2) Jean a escaladé le moins de montagnes.
3) Jean a escaladé au moins trois montagnes.
4) Jean a escaladé les montagnes les moins hautes.
Seule une analyse décompositionnelle de MOST qui fait de cet item un superlatif permet de donner une explication scientifique au fait que MOSTprop existe alors que FEWESTprop n'est pas attesté.
On se donne pour tâche d'expliquer ce trou dans l'inventaire des quantificateurs antonymes
24 (α) *Jean a escaladé [la minorité de montagnes].
(β) *[La minorité d'étudiants] a redoublé.
Les phrases ci-dessous ne sont pas des contre-exemples:
(γ) [Une minorité d'étudiant] a redoublé cette année.
(δ)[La minorité] a toujours raison dans ce genre de situations.
En (γ), l'item contenu dans le DP sujet n'est pas l'opposé polaire de MOSTprop : ce n'est pas un déterminant proportionnel mais un déterminant quantificationnel vague signifiant un petit nombre de.
En (δ), le DP n'est pas non plus l'opposé polaire MOSTprop puisque ce n'est pas un déterminant mais un NP.
21

MOST/FEW d'une manière systématique, à l'aide des prédictions de l'hypothèse de la nature superlative de MOST.
Poursuivons notre raisonnement :
MOST = MANY + EST
FEWEST = FEW + EST
On établit un parallèle de construction sémantique entre MOST et son opposé polaire.Cette décomposition apparaît d'ailleurs de manière plus évidente dans la forme anglaise qui est très visiblement la concaténation de l'adjectif gradable few et du morphème superlatif -est.
En allemand, l'opposé de die meisten est die wenigsten. La généralisation que l'on a effectuée plus haut sur le comportement de die meisten nous permet d'établir des prédictions au sujet de die wenigsten.
Dans des cas d'interprétation relative impossible, on devrait obtenir une lecture propositionnelle; dans les cas où les deux interprétations sont possibles, on devrait avoir la lecture relative et la lecture proportionnelle.
Lorsque les phrases ci-dessous sont dépourvues d'interprétation, on a choisi de les accompagner de leur contreparties françaises et anglaises précédées d'un astérisque indiquant leur caractère également ininterprétable.
(33) *Es schneite auf den wenigsten Bergen.
Aucune interprétation disponible.
*It snowed on top of less than half of the mountains.
*Il a neigé sur moins de la moitié des montagnes/sur la minorité de montagnes.
(34) Die FLAUCHAUERF haben die wenigsten Berge beschneit.
Une seule interprétation disponible: lecture relative.
The FlachauersF made snow on fewer mountains than anybody else.
Les habitants de FlachauF, eux, ont mis de la neige artificielle sur le moins de montagnes.
Or ce que nous obtenons dans les phrases (33) et (34) est assez étonnant : il y a bien lecture relative quand c'est autorisé par un environnement marqué par un légitimeur (le sujet focusé comme en (28)), mais toutes les fois où l'environnement ne permet que la lecture absolue et où on s'attend à une lecture proportionnelle, aucune interprétation n'est acceptable et la phrase est agrammaticale.
(35) * Wer hat gesagt dass wenigsten Berge beschneit haben?
Aucune lecture disponible.
22

* Who said that they made snow on top of less than half of the mountains?
* Qui a dit qu'ils ont mis de la neige artificielle sur la minorité de montagnes/moins de la moitié des montagnes?
(36) Wer glaubst du hat die wenigsten Berge beschneit?
Seule lecture disponible: la lecture relative.
Who do you think made snow on top of fewer mountains than anybody else?
Qui a mis de la neige artificielle sur le moins de montagnes?
Il semble que die wenigsten n'ait pas de lecture proportionnelle. Pour en être sûr, on vérifie une autre situation couverte par notre hypothèse. On s'intéresse aux phrases qui comportent un quantificateur universel qui force la lecture absolue des superlatifs et la lecture proportionnelle de MOST, et on fait la prédiction qu'elles vont être inacceptables.
(37) *Jede Geminde hat die wenigsgten Berge beschneit.
Aucune lecture disponible.
*Every town has made snow on top of less than half of the mountains.
*Toute les villes on mis de la neige artificielle sur le sommet de la minorité de montagnes/sur moins de la moitié de montagnes.
C'est bien ce que l'on obtient. On en conclut donc que FEWEST, en allemand du moins, n'a pas de lecture proportionnelle.
Essayons de voir si ce phénomène se reproduit en anglais. On suppose que fewest est construit sur le même modèle que son opposé polaire, la présence ou l'absence de l'article the contrôlant l'interprétation des deux lectures potentielles (relatives et proportionnelles).
(38) John read *fewest books.
Phrase agrammaticale.
(39) John read the fewest books.
Seule la lecture relative est disponible.
(40) *It snowed on top of the fewest mountains.
23

Phrase agrammaticale car la lecture relative est impossible dans ce contexte.
(41) *It snowed on top of fewest mountains.
Phrase agrammaticale.
(42) *Who said that Mary made snow on top of the fewest mountains?
Phrase agrammaticale car la lecture relative est impossible dans ce contexte.
(43) *Who said that Mary made snow on top of fewest mountains?
Phrase agrammaticale.
(44) *Who all made snow on top of the fewest mountains?
Phrase agrammaticale car la lecture relative est impossible dans ce contexte.
(45) *Who all made snow on top of fewest mountains?
Phrase agrammaticale.
Les phrases (38) à (45) montrent que the fewest ne peut en aucun cas être interprété comme un superlatif absolu et que ∅ fewest n'est jamais acceptable.
On déduit de ces généralisations que le déterminant quantificationnel FEWEST n'a pas de lecture proportionnelle.
ConclusionMOST et FEWEST sont sensibles aux mêmes facteurs environnementaux que les superlatifs en
général, bien que leurs usages présentent certaines particularités qui les distinguent des superlatifs ordinaires :
- MOST et FEWEST n'ont pas de lecture absolue. - MOST a une lecture proportionnelle dans des environnements de lecture absolue forcée, alors que dans ces cas-là FEWEST n'est jamais attesté, bien que le sens proportionnel de FEWEST soit concevable logiquement et qu'il existe sous la forme de l'opposé polaire de more than half.
Afin d'expliquer systématiquement ces bizarreries et d'éviter le recours à de simples descriptions taxinomiques, on met en place les bases d'une sémantique décompositionnelle de la quantification plus prédictive.
24

II) Sémantique décompositionnelle de MOST, un opérateur de comparaison superlative de cardinalités de pluralités.
A présent que la nature grammaticale de MOST a été élucidée, nous pouvons bâtir une sémantique entièrement décompositionnelle des phrases contenant ce déterminant quantificateur.
1) Sémantique des superlatifs
a) Base sémantique
Partons de la sémantique formalisée et détaillée des superlatifs, telle qu'elle a été élaborée par Heim (1999) et Szabolcsi (1986)25.
(46) John saw [DP the nicest]26.
(47) John saw [DP the nicest paintings].
(48) *John saw [DP most].
(49) *John saw [DP the most].
(50) John saw [DP most paintings].
(51) John saw [DP the most paintings].
Il est possible des trouver des occurrences de superlatifs ordinaires en position prédicative comme en (46) mais on ne parvient pas à en trouver pour MOST, comme le montre l'agrammaticalité des phrases (48) et (49).
Etant donné que le processus de dérivation sémantique des phrases contenant un DP superlatif va nous servir de modèle pour décrire la composition du sens des phrases contenant un MOST DP, on laisse de côté ce type de construction, dont le sens est d'ailleurs plus facilement formalisable.
On s'intéresse exclusivement au superlatif modifieur de NP.
Un DP superlatif (type « the nicest paintings ») est constitué d'un article, d'un nom (un prédicat à une place), et d'un adjectif gradable auquel se combine un morphème superlatif.
Sa sémantique va dépendre de la sémantique de chacun des éléments qui le composent :
1. L'article du DP est un opérateur sémantique réalisé superficiellement par une forme définie
25 Nous leur empruntons sans vraiment les interroger les présupposés de la sémantique des superlatifs : les adjectifs vus comme des relations entre degrés et individus, la cause structurelle de l'ambiguïté de lecture au niveau de la forme logique. Cependant de tout autres conceptions théoriques qui parviendraient à prédire correctement le comportement des superlatifs (une explication contextuelle de l'ambiguïté de lecture par exemple) sont tout à fait compatibles avec l'analyse de MOST que Martin Hackl propose.
26 Cette phrase est grammaticale à supposer qu'il y ait élision d'un NP :
(46)bis John saw [DP the nicest (girl)]
25

dans le cas de la lecture absolue et dans le cas de la lecture relative.
2. Aucune restriction ne semble porter sur le choix du NP, si ce n'est qu'il soit compatible avec le fait de posséder à un certain degré la propriété dénotée par l'adjectif gradable qui le modifie.
3. Un adjectif gradable exprime une propriété qui peut être ordonnée en fonction du plus ou moins de degrés qu'elle a. Cette caractéristique distingue les adjectifs gradables des autres adjectifs, la comparaison étant un test pour établir leur nature :
α) ??Jeanne est plus enceinte que Sara27.
β) Jeanne est plus grande que Sara.
«enceinte» n'est pas un adjectif gradable, alors que « grande » en est un puisqu'il autorise la structure comparative dans la phrase qui le contient.
Comme le superlatif est une forme particulière de comparaison, seuls les modifieurs gradables sont présents dans les DP superlatifs.Un adjectif gradable est une relation R entre un individu et un degré.C'est une fonction de mesure : il associe les individus à des degrés d'une qualité de façon à rendre compte dans quelle mesure ces individus possèdent cette qualité.
entrée lexicale : Une relation R28 prend trois arguments : un degré, un individu et une propriété P.Elle est de type <d, <et, et >>.
R (d, P, x) =λdλxλP. P (x) ∧ R(d)(x)≥d.
On peut abréger la formule :
R (d, P, x)= λdλxλP. P (x) ∧ x is d-R.
Les prédicats gradables sont des fonctions monotones.Une fonction R entre un individu et un degré d est monotone si et seulement si :
∀ x, d, d' [R (x ,d) ∧ d > d' → R (x, d')].
exemple: [[John est un grand garçon]] = garçon(John) grand (John ) ≥ d.∧L'ensemble des degrés auxquels John est un grand garçon est l'ensemble de tous les degrés à partir du bas de l'échelle de grandeur jusqu'au degré le plus haut de grandeur pour lequel il est vrai que John est un grand garçon.
Ce sont des prédicats vagues : le standard de comparaison en vue duquel est évalué le degré possédé par l'individu n'est généralement pas explicite et il varie en fonction du contexte29.27 Il est toujours possible d'interpréter des adjectifs non gradables au sein d'une structure comparative lorsqu'on se place dans un cadre métaphorique. Il demeure cependant un fort contraste de naturalité entre des phrases contenant une comparaison en fonction d'une propriété gradable (α) et celles contenant une comparaison en fonction d'une propriété non gradable (β).28 Dans la position de modifieur de NP, celle qui nous intéresse pour comprendre MOST.29 α) John is a tall man for a jockey
26

4. Un superlatif est une sorte de comparatif qui compare un DP avec un élément quantifié universellement contenu dans une proposition introduite par than/que:
the highest mountain = a mountain higher than any other mountain.la plus grande montagne = la montagne plus grande que toutes les montagnes.
On va donc parvenir à comprendre la sémantique des superlatifs en passant par celle des comparatifs.
1 ) s émantique du morphème comparatif :
-er than dénote une relation entre deux ensembles de telle sorte que l'élément maximal du premier est ordonné en fonction de l'élément maximal de l'autre :
(α) John is higher than Bill.[[(α)]] = max {d: high (John) ≥ d}> max {d: high (Bill) ≥ d}
On remarque que la monotonie de l'adjectif gradable rend nécessaire la présence d'un opérateur de maximalisation pour établir la comparaison des deux ensembles de degrés.
opérateur de maximalité :
P étant un prédicat gradable, max (P)= ι d. P(d) ∧ ∀ d' [P(d')→ d' ≤ d].
2 ) s émantique du morphème superlatif :
On l'a vu dans la note 5, les quantificateurs sont souvent soumis à des restrictions implicites de leur domaine en langage naturel. Pour rendre compte de ce phénomène, on suppose qu'ils ont un troisième argument, l'argument de domaine C.C'est un prédicat en général non réalisé phonétiquement, qui apparaît au côté du déterminant au niveau de la forme logique et qui reçoit une valeur du contexte de l'énonciation.
Il est défini si et seulement si :x ∈ C C⊆ P, P étant le restricteur du quantificateur.
On suppose que le morphème superlatif possède un argument de contexte comme les quantificateurs habituels.
John est un homme grand pour un jockey.
Dans la phrase α), la classe de comparaison du modifieur gradable « tall » est explicite : C = {all the men who are jockeys in the world}.
β) Les politiques publiques mises en place par le gouvernement n'ont pas coûté cher.
En β) on voit que la détermination de la classe de comparaison en fonction du contexte est nécessaire à la bonne interprétation de la phrase. La proposition n'est pas délirante si on évalue le coût des politiques publiques au regard des autres dépenses étatiques. Si on suppose que la phrase est vraie, on a : C = {dépenses de l'état} et non C = {toutes les choses qui ont un coût}.
27

Le morphème superlatif est donc un opérateur de degré composé de trois arguments (x, R, C), qui choisit la valeur la plus extrême à l'intérieur d'un ensemble de valeurs constituée par la classe de comparaison. Comme le comparatif il ordonne des éléments maximaux.
Il est de type <<d,et>, et>.
Soit : - R une relation ( un adjectif à deux arguments),- x un individu de type e 30,- C une classe de comparaison,
-est(x, R,C)= λRλx. 1 si et seulement si y C [y ≠ x∀ ∈ → max {d' : R (d')(x) }> max {d' : R(d') (y) }]. -est(x, R,C)=1 si est seulement si x a la propriété de degré R au plus au degré que tout autre alternative de x dans C.Par ailleurs, le morphème [-est] est défini si et seulement si x C et si C n'est pas un singleton∈ 31.
On a désormais tous les éléments pour définir décompositionnellement les conditions de vérité d'un DP superlatif entier :
Exemple : the tallest man.
Forme logique : [DP the [ DP [est-Ci] [NP [AP di-tall] [NP man ]]]]
Représentation arborescente :
30 On verra que dans le cas de la relation MANY, les individus sont forcément des pluralités.31 L'ensemble de comparaison doit contenir au moins deux éléments distincts, comme le montre le contraste
d'acceptabilité des deux phrases suivantes (Fox 2000) :
α)??You're the best mother I have.??Tu es la meilleure mère que j'ai.
Mais on a :
β)You're the best brother I have.Tu es le meilleur frère que j'ai.
28

Composition du sens total de l'expression, nœud par nœud :NP2 : man. type <e,t>
λx.man' (x)
AP: di-tall type <d, et, et>λdλP. λx. P(x) tall'(d)(x)∧
La composition du nœud NP1 contrevient à la règle de modification prédicative. NP1: di-tall man. type <d, e,t>
λd.λx. man'(x) tall'(d)(x)∧
-est Ci : type <<d, et> et>λRλx. y C [y ≠ x∀ ∈ → max {d' : R (d')(x) }> max {d' : R(d') (y) }].
DP2 : tallest man. type <e, t>λx. y C [y ≠ x∀ ∈ → {d' : man'(x) x is d'-tall }> max {d' : man'(y) y is d'-tall}]∧ ∧
D : the type < et, et>λQ.λP. x [Q(x) P(x)]∃ ∧
DP1 : the tallest man. type <e,t>λQ. x . y C [y ≠ x∃ ∀ ∈ → {d' : man'(x) x is d'-tall }> max {d' : man'(y) y is d'-tall}]∧ ∧
L'expression est vraie si et seulement si il existe un homme x tel qu'il a un degré de grandeur plus haut que le degré de grandeur de tout autre homme dans C.
b) L'ambiguïté de lecture des superlatifs.Comme l'ont montré Heim et Szabolczi, l'ambiguïté des superlatifs entre lecture relative (9b) et
lecture absolue (9a) s'explique par une différence structurelle, une différence de portée du morphème superlatif [-est] au niveau de la forme logique.
(9) John climbed the highest mountain.
(a) John climbed the highest of all mountains.
(b) John climbed a higher mountain than the mountain climbed by anyone else.
Il est engendré à l'intérieur du DP, puis se déplace en laissant une variable de degré dans la structure d'argument de l'adjectif. Cette relation de dépendance est représentée sur la forme logique et les représentations arborescentes par un indice i .
Le mouvement donne lieu à deux formes logiques qui encodent syntaxiquement une différence de portée. Les deux portées correspondent à deux structures d'argument distinctes pour le morphème superlatif [-est] .
Une même opération de «superlativisation» est donc à l'œuvre dans les deux interprétations, mais elle ne concerne pas le même ensemble C, la classe de comparaison en (a) étant différente de la classe de comparaison en (b).
29

-lecture absolue
Forme logique : (a)[TP [John] [VP climbed [DP the [DP -estCi [NP [AP di -high] [NP mountain]] ]]]]
Représentation arborescente :
En (a) [-est] est interne au DP; la classe de comparaison donnée par le contexte est alors constituée par l'ensemble dénoté par le NP (l'ensemble des montagnes hautes au degré d) .La composition du sens de la phrase, nœud par nœud, est la suivante :
Par le contexte on a: C = {toutes les montagnes du monde}= {Everest, Kilimandjaro, Anapurna, etc ...}
NP2: mountain type <e,t>λx. mountain' (x)
AP: di-high type <d, et,et >λdλP.λx. P(x)∧ high'(d) (x)
NP1: di-high mountain. type <d,e,t>λd.λx. mountain' (x)∧ high'(d) (x)
D: -est Ci. type <<d, et >, et >λR.λx. y C[y ≠ x∀ ∈ → max {d' : R (d') (x)}> max {d' : R (x)(y)}]
DP2: highest mountain. type <e,t>λx. y C [y ≠ x∀ ∈ → max {d': mountain' (x) x is d'-high}> max {d' : mountain'(y) y is d'-∧ ∧
high }]
D : the. type < et, et>λQ.λP. x [Q(x) P(x)]∃ ∧
DP1: the highest mountain. type < e, t >λQ. x y C [y ≠ x∃ ∀ ∈ → max {d' : mountain' (x) x is d'-high}> max {d' : mountain'(y) y is∧ ∧
30

d'-high }]V: climbed. type <e, et >
λx.λz. z climbed x.
VP : climbed the highest mountain. type < e, t > λz. z climbed x x. y C [y ≠ x∧ ∃ ∀ ∈ → max {d': x is a d'-high mountain}> max {d': y is a d'-high mountain}]
TP : John climbed the highest mountain. type t x. John climbed x y C [y ≠ x∃ ∧∀ ∈ → max {d': x is a d'-high mountain}> max {d': y is a d'-
high mountain}]
La phrase est vraie si et seulement si John a escaladé x tel que x est une haute montagne et que le degré maximal d' auquel x est haut est supérieur au degré maximal auquel sont hauts les autres membres de C, qui tous sont des montagnes.
Dans notre exemple on a défini l'ensemble C comme contenant toutes les montagnes du monde. La phrase (a) est donc vraie si John a escaladé l'Everest.
31

-lecture relative
Forme logique : (b) [TP [DP John ] [ VP [-est C i] [VP climbed [DP a [DP [AP di-high] [NP mountain]]]]]]
En (b) [-est] a une portée plus large, au niveau du VP. La classe de comparaison, donnée par le contexte, correspond à l'ensemble des individus dont l'argument individu de [-est] est membre.
La composition du sens de la phrase, nœud par nœud, est la suivante :
Par le contexte, on a : C = {tous les individus qui ont escaladé une haute montagne} = {John, Bill, Hermann, etc...}
On est obligé de sauter les étapes de dérivation situées en dessous de VP1 car Hackl ne donne pas de solutions aux nombreux problèmes théoriques qui se posent à l'intérieur de ce nœud.
VP1:climbed the highest mountain. type <e,t >λx. y C [y ≠ x∀ ∈ → max {d' : x climbed a d'-tall mountain}> max {d' : y climbed a d'-tall mountain }]
TP: John climbed the highest mountain. type t y C [y ≠ x∀ ∈ → max {d' : John climbed a d'-tall mountain}> max {d' : y climbed a d'-tall mountain }]
La phrase est vraie si le degré maximal d' auquel est haut la montagne que John a escaladée est supérieur au degré maximal d' auquel sont hautes les montagnes escaladées par les autres membres du contexte, qui ont tous obligatoirement escaladé une montagne (dans notre exemple: Bill, Hermann, etc...).
Appliquons cette sémantique à most32.
32 Cette deuxième partie aborde la sémantique décompositionnelle du quantificateur MOST à travers les données de
32

On va démontrer qu'une analyse décompositionnelle permet d'expliquer les faits déroutants observés au chapitre précédent au cours de nos généralisations syntaxiques (la lecture proportionnelle et non absolue de MOST et l'absence d'interprétation de FEWEST dans des environnements propices à une lecture absolue des superlatifs) .
2) Dérivation sémantique de MOST.
a) Base sémantique.
Puisqu'on suppose que most est le superlatif de many, on établit facilement la structure du DP qui le contient.
MOST DP est composé des mêmes éléments que ceux que comportent les DP superlatifs : un article, la relation R many, un prédicat et le morphème superlatif. On observe cependant des variations, mais qui ne sont jamais obtenues de manière ad hoc. Toutes dérivent de manière régulière de la composition du sens initial des éléments sémantiques de base.
1. En surface, l'article est défini dans la lecture relative, indéfini dans la lecture proportionnelle33.
2. Le modifieur gradable many est un adjectif gradable qui ne peut modifier que des noms qui désignent des pluralités pouvant être divisées en parties atomiques.C'est un opérateur de cardinalité de pluralité dont l'entrée lexicale est la suivante :
many = λx λ*P.*P(x) ∧ |x| ≥ d λx λ*P.*P(x) ∧ x has d-many atomic parts.
L'opérateur de pluralité est défini ainsi :
plur = λPλx. x ∈ *{P(y)=1}
3. Le prédicat P doit donc obligatoirement dénoter des pluralités pouvant être divisées en parties atomiques (ce que l'on pourrait appeler d'une manière imprécise des pluralités dénombrables) :
(52) * I've seen many water on the table.
(53) I've seen many glasses of water on the table.
4. Le morphème superlatif à trois arguments est défini de la même manière que pour les superlatifs ordinaires.
Exemple: most men.
Le DP est clos par un quantificateur existentiel34.
l'anglais par ce que c'est la langue à partir de laquelle Martin Hackl fonde ses hypothèses linguistiques.33 On l'a vu plus haut : en allemand, l'article de surface est défini dans les deux types de lectures.34 Pour des raisons techniques, nous le symbolisons à l'aide d'un 0 sur notre représentation arborescente.
33
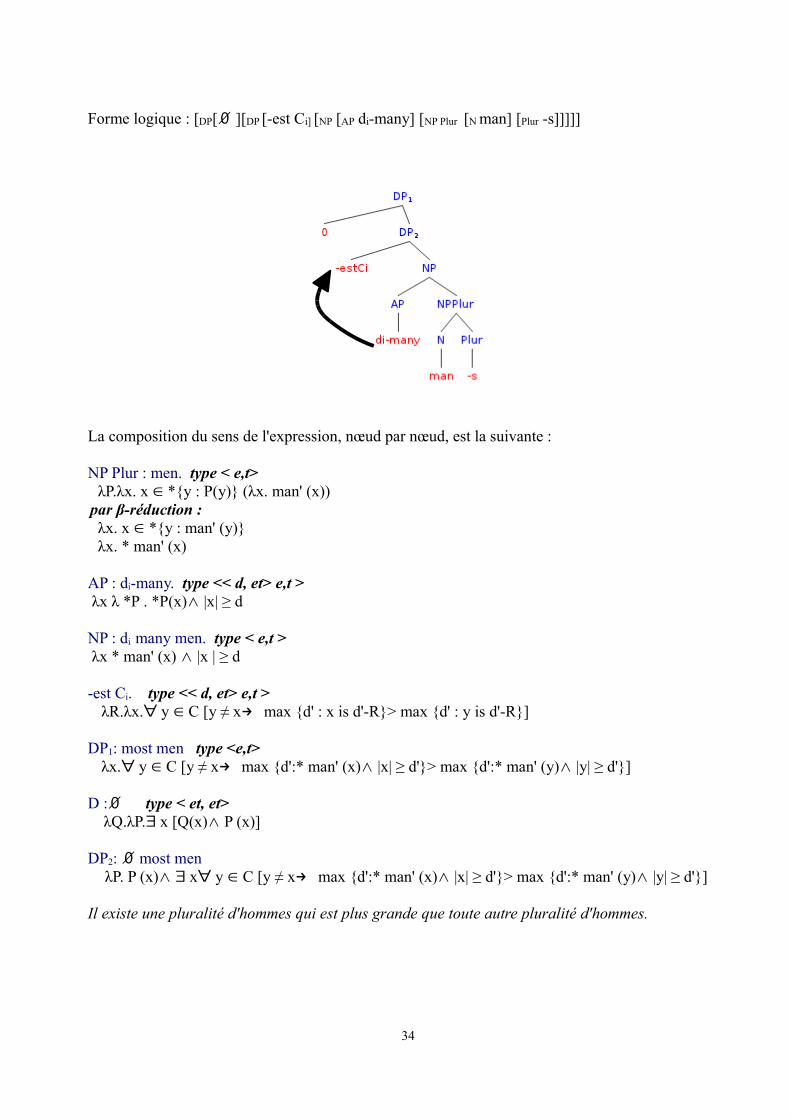
Forme logique : [DP[∅ ][DP [-est Ci] [NP [AP di-many] [NP Plur [N man] [Plur -s]]]]]
La composition du sens de l'expression, nœud par nœud, est la suivante :
NP Plur : men. type < e,t>λP.λx. x *{y : P(y)} (λx. man' (x))∈
par β-réduction :λx. x *{y : man' (y)}∈λx. * man' (x)
AP : di-many. type << d, et> e,t > λx λ *P . *P(x)∧ |x| ≥ d
NP : di many men. type < e,t > λx * man' (x) |x | ≥ d ∧
-est Ci. type << d, et> e,t >λR.λx. y C [y ≠ x∀ ∈ → max {d' : x is d'-R}> max {d' : y is d'-R}]
DP1: most men type <e,t>λx. y C [y ≠ x∀ ∈ → max {d':* man' (x) |x| ≥ d'}> max {d':∧ * man' (y) |y| ≥ d'}]∧
D :∅ type < et, et>λQ.λP. x [Q(x) P (x)]∃ ∧
DP2: ∅ most men
λP. P (x) ∧ x y C [y ≠ x∃ ∀ ∈ → max {d':* man' (x) |x| ≥ d'}> max {d':∧ * man' (y) |y| ≥ d'}]∧
Il existe une pluralité d'hommes qui est plus grande que toute autre pluralité d'hommes.
34

b) L'ambiguïté de lecture de MOST : lecture proportionnelle mais non lecture absolue.
Comme tous les superlatifs, most a deux lectures qui correspondent à deux formes logiques différentes et qui sont caractérisées par un mouvement du morphème superlatif hors du DP dont nous venons d'expliciter la structure.
On a vu que la sémantique des superlatifs permettaient de décrire compositionellement le sens de MOST DP en général.
On s'intéresse maintenant exclusivement au MOST DP en lecture proportionnelle car, bien que l'on sache grâce à l'analyse syntaxique que MOST est un superlatif alors qu'il est interprété comme un proportionnel, on veut essayer de comprendre ce qui dans la composition du sens infléchit la lecture absolue régulière en lecture proportionnelle.
(54) John saw ∅ most students.
L'environnement syntaxique de la principale dans laquelle se trouve le déterminant (absence des légitimeurs cités au chapitre 1) nous indique qu'on est dans le cas d'une lecture absolue de superlatif, bien que celle-ci soit toujours interprétée avec un sens proportionnel. On en déduit alors la forme logique suivante, qui correspond au mouvement de la lecture absolue décrit plus haut :
[TP [DP John] [VP saw [DP [∅ DP -estCi ] [NP [AP di-many] [NP Plur [N man] [Plur -s]]]]]]]
DP2: ∅ most men type e x y C [y ≠ x∃ ∀ ∈ → max {d':* man' (x) |x| ≥ d'}> max {d':∧ * man' (y) |y| ≥ d'}]∧
V : saw type < e, et>
35

λx λz. z saw' x
VP : saw most men. type < e,t >λz. x.z saw' x ∃ ∧ y C [y ≠ x∀ ∈ → max {d':* man' (x) |x| ≥ d'}> max {d':∧ * man' (y) |y| ≥∧ d'}]
TP: John saw most men. type t John' saw' x ∧ y C [y ≠ x∀ ∈ → max {d':* man' (x) |x| ≥ d'}> max {d':∧ * man' (y) |y| ≥ d'}]∧
La phrase est vraie si la pluralité d'hommes que John a vue a une cardinalité plus grande que toute autre pluralité d'hommes, différente d'elle et comprise dans C.
Vérifions empiriquement la justesse de notre sémantique en confrontant la phrase que l'on vient de dériver à une situation concrète (tâche d'évaluation de conditions de vérité).
Exemple :
On imagine que John a surpris des hommes en flagrant délit de cambriolage. Trois hommes était présents dans l'appartement au moment du délit : Albert, Christian et Bertrand mais John n'a eu le temps que d'en voir deux, Albert et Bertrand.
On veut savoir si l'énoncé (54) John saw most men est vrai.On a donc C = {a, b, c} dans notre contexte d'énonciation : le domaine du quantificateur est
restreint car il n'inclut pas tous les hommes de l'univers mais seulement les trois cambrioleurs. Les lettres a, b et c symbolisent les trois individus en question.
On sait que la phrase est vraie si :
John' saw' x ∧ y C [y ≠ x∀ ∈ → max {d':* man' (x) |x| ≥ d'}> max {d':∧ * man' (y) |y| ≥ d'}],∧
c'est-à-dire si la pluralité d'hommes que John a vu a une cardinalité plus grande que toute autre pluralité d'homme, différente d'elle, comprise dans C.
Comme on compare entre elles des pluralités en fonction de combien de parties elles ont, il faut établir leur liste exhaustive à partir des éléments de C.
Soit C un ensemble, *C est le plus petit ensemble qui satisfait les deux conditions suivantes : (i) C *C⊆(ii) x y[ x *C ∀ ∀ ∈ ∧ y *C ∈ → x y *C] ⊕ ∈
Comme C = {a, b, c} alors *C = {a, b, c, a b, a c, b c, a b c}.⊕ ⊕ ⊕ ⊕ ⊕ *C contient toutes les pluralités possibles d'hommes à partir d'un ensemble fini C d' hommes.
On représente les éléments de *C selon une structure en semi-treillis :
a b c⊕ ⊕
a b a c b c ⊕ ⊕ ⊕
a b c Comme l'opérateur MANY est une fonction de mesure des pluralités, on ordonne notre ensemble fini en fonction de la dimension de cette fonction de mesure :
36

a b c⊕ ⊕ → 3
a b a c b c ⊕ ⊕ ⊕ → 2
a b c → 1
Sur la représentation ci-dessus, on schématise d'une manière informelle l'opération sémantique effectuée par MANY en associant, à l'aide du symbole →, à chaque pluralité son degré de cardinalité. A une pluralité composée de trois éléments, on associe 3, à une pluralité composée de deux éléments, 2 etc...
Le morphème superlatif invite à comparer ces pluralités entre elles en fonction de leur degré de many-ness (= la cardinalité). Il faut donc savoir comment distinguer les pluralités les unes par rapport aux autres.
On a à notre disposition deux types de critères de distinction de pluralité : un critère strict qui postule que deux pluralités sont distinctes si elles n'ont aucun élément en commun, et un critère lâche selon lequel deux pluralités sont distinctes à partir du moment où elles possèdent au moins un élément différent.
Evaluons la validité de ces critères à la lumière de notre exemple.
1. Si l'on adopte le critère d'identité lâche, c'est-à-dire le critère de non-chevauchement d'au moins une des parties de pluralités, on sélectionne la pluralité a b c⊕ ⊕ comme la pluralité d'hommes plus grande que tout autre pluralité alternative dans *C. En effet, comme on a :
a b c⊕ ⊕ ≠ a b⊕ a b c⊕ ⊕ ≠ b c⊕ a b c⊕ ⊕ ≠ a c⊕ a b c⊕ ⊕ ≠ a a b c⊕ ⊕ ≠ b
a b c⊕ ⊕ ≠ c(puisque dans chaque cas il y a une élément de non-chevauchement) a b⊕ , b c⊕ , a c⊕ , a ,b, c sont les alternatives de a b c⊕ ⊕ dans *C. a b c ⊕ ⊕ est bien l'unique pluralité dont la cardinalité est plus grande que ses alternatives dans C, puisqu'on a :
| a b c⊕ ⊕ |>|a b⊕ || a b c⊕ ⊕ |>|b c⊕ || a b c⊕ ⊕ |> |a c⊕ || a b c⊕ ⊕ |>|a|| a b c⊕ ⊕ |>|b|| a b c⊕ ⊕ |>|c|
Cela reviendrait à dire que dans le contexte, la phrase John saw most men est vraie si et seulement si John saw three men. Or en raisonnant de cette manière, on trivialise most puisqu'on ramène ses conditions de vérité à celles de all (tout).
Bien que l'on puisse à juste titre se demander si le sens de all est présent dans le sens
37

pragmatique de most35, on voit que most est utilisé dans des contextes rigoureusement différents de ceux de all, dont l'emploi sous-entend une certitude de la part du locuteur, alors que most, lui, s'apparente à un prédicat vague.
De plus, le critère d'identité lâche, bien qu'étant une possibilité théorique, est peu vraisemblable psychologiquement. A cause de la présence de many qui introduit la notion de cardinalité, l'usage de most implique qu'il y ait activité de dénombrement dans la computation du sens. Dès lors qu'il est question de dénombrement, il faut nécessairement qu'il y ait un critère d'identité strict qui différencie deux pluralités en ce qu'elles ont aucun éléments en commun.
2. En tenant compte du critère strict de pluralité, on élimine la pluralité a b c ⊕ ⊕ car elle n'a plus aucune alternative dans *C étant donné qu'on a : ¬ ( a b c⊕ ⊕ ≠ a ⊕ b), ¬ (a ⊕ b ⊕ c ≠ b ⊕ c), ¬ (a ⊕ b ⊕ c ≠ a ⊕ c), ¬ (a ⊕ b ⊕ c ≠ a), ¬ (a ⊕ b ⊕ c ≠ b), ¬ (a ⊕ b ⊕ c ≠ c ) ,et que C est un ensemble qui requiert au moins deux éléments.
On sélectionne la pluralité a ⊕ b dont les alternatives sont b et c puisque : a ⊕ b ≠ b, a ⊕ b ≠ c et ¬ (a ⊕ b ≠ b ⊕ c), ¬ (a ⊕ b ≠ a ⊕ c) et ¬ (a ⊕ b ≠ a ).On voit que c'est un bon candidat pour notre pluralité «superlativisée» x car c'est la pluralité la plus nombreuse de toutes ses alternatives dans C : |a ⊕ b| > |b| et |a ⊕ b| > |c|.Les pluralités b ⊕ c et a ⊕ c sont aussi désignées par la variable x.
La phrase est donc vraie si John a vu une des trois pluralités d'hommes possibles de cardinalité deux (b ⊕ c, a ⊕ c et a ⊕ b).
La phrase John saw most men vraie si John a surpris au moins Bertrand et Christian, ou Albert et Christian ou Albert et Bertrand, c'est-à-dire s'il a surpris au moins deux hommes sur les trois présents.
Dans le contexte défini par l'exemple, la phrase est vraie. Cela coïncide bien avec nos intuitions sur l'emploi de most.
La lecture proportionnelle est donc un genre particulier de lecture absolue à cause de la nature de l'objet de la comparaison superlative (une pluralité) imposée par le prédicat many.
c) Lecture relative.
(55) JOHNF read the most books.
La lecture relative ne pose pas autant de problèmes théoriques que la lecture relative puisqu'on ne compare plus des cardinalités de pluralités, mais des individus.
En (55), les individus sont comparés en fonction de combien de livres ils ont lus. Le critère de distinction entre deux individus n'est pas discutable comme l'était celui des pluralités où on pouvait à juste titre hésiter entre identité stricte et identité lâche.
Forme logique : [TP[DP John][VP[-estCi][VP[V read][DP[D a][NP[AP di-many][NPLUR[N book] [PLUR -s]]]]]]]
35 La question de savoir si une phrase de la forme most A B est nécessairement incompatible avec une situation où tous les A seraient B est l'objet d'un débat théorique dans lequel s'opposent les partisans d'une sémantique unilatérale qui envisagent most comme un élément lower bounded, (c'est-à-dire n'encodant dans sa sémantique qu'une limite basse de 50%) aux partisans d'une sémantique bilatérale qui considèrent most comme un élément à la fois lower bounded et upper bounded (c'est-à-dire contraint par deux limites sémantiques, 50% et 99%). Pour plus de détail voir Ariel, Horn (2005), Papafragou and Schwarz (2006).
38

VP1: read the most books. type <e,t>λz. x z read' x y C [y ≠ z∃ ∧ ∀ ∈ → max {d' : * book' (x) x is d'-many}> max {d' : * book'∧
(y) y is d'-many}] z read' x.∧ ∧
TP: John read the most books. type t x John read' x y C [y ≠ z∃ ∧∀ ∈ → max {d' : * book' (x) x is d'-many}> max {d' : * book'∧
(y) y is d'-many}]∧
La phrase est vraie si la pluralité de livres que John a lue est plus grande que la pluralité de livres lues par tout autre membre de C.
Exemple : Imaginons que John fasse partie d'un club de lecture qui comporte quatre autres membres : Bill, Hermann, Peter et Hans. Ils ont eu à lire dix livres au total sur l'année, John en a lu huit, Hermann sept, Bill cinq et Peter et Hans trois.On veut savoir si la phrase John read the most books est vraie.On a C = {John, Bill, Peter, Hans, Hermann}On sait que l'énoncé est vrai si:
x John read' x y C [y ≠ z∃ ∧∀ ∈ → max {d' : * book' (x) x is d'-many}> max {d' : * book'∧ (y) y is d'-many}]∧
Le maximum des degré d auquel est nombreuse la pluralité de livres lues par John est 8.Le maximum des degré d auquel est nombreuse la pluralité de livres lues par tout autres alternatives de John dans C est 7.On a bien 8 > 7 , la phrase est donc vraie.
3) FEWEST proportionnel : des conditions de vérité impossibles.
La sémantique décompositionnelle des superlatifs va nous permettre d'expliquer l'absence de lecture proportionnelle pour FEWEST. FEWEST est un opérateur de comparaison de cardinalité de pluralités en fonction du petit nombre qu'elles ont, c'est l'opposé polaire de MOST. On en déduit l'entrée lexicale suivante :
39

fewest = λPλx. y C[y ≠ x∀ ∈ → max {d: * P (x) |x| ≥ d} ∧ < max {d: * P (y) |y| ≥ d}]∧
On n'a pas de difficulté à dériver le sens de FEWEST en lecture relative.
(56) JOHNF read the fewest books.
Forme logique: [TP[DP John][VP[-estCi][VP[V read][DP[D a][NP[AP di-few][NPLUR[N book] [PLUR -s]]]]]]]
Conditions de vérité :
[[TP John read the fewest books]]= x. John read' x y C [y ≠ z∃ ∧∀ ∈ → max {d' : * book' (x) x is d'-many}< max {d' : * book' (y)∧ y is d'-many}]∧
La phrase est vraie si la pluralité de livres que John a lue est plus petite que la pluralité de livres lues par tout autre membre de C.
Représentation arborescente:
Reprenons l'exemple précédent :
On veut savoir si la phrase John read the fewest books est vraie.On a C = {John, Bill, Peter, Hans, Hermann}On sait que l'énoncé est vrai si :
x. John read' x y C [y ≠ z∃ ∧∀ ∈ → max {d' : * book' (x) x is d'-many}< max {d' : * book' (y)∧ y is d'-many}]∧
Le maximum des degré d' auquel est petite la pluralité de livres lue par John est 8.Le maximum des degré d' auquel est petite la pluralité de livres lue par tout autres alternatives de John dans C est 5.Or ¬ (8 < 5), la phrase donc est fausse .
En revanche la lecture proportionnelle est impossible pour FEWEST, on va essayer de montrer
40

pourquoi.
(57) * John saw fewest men.
Forme logique :[TP[DP John] [VP saw [DP [0] [DP est-Ci[NP[AP di-few] [NPPlur [N man] [Plur -s]]]]]]]
Représentation arborescente :
Dérivation sémantique :TP: John saw fewest men. type t
John saw' x ∧ y C [y ≠ x∀ ∈ → max {d':* man' (x) x is d'-few}< max {d':∧ * man' (y) y is∧ d'-few}]
La phrase est vraie si John a vu une pluralité d'hommes x telle qu'elle est plus petite que tout autre pluralité différente d'elle dans C.
Or ces conditions de vérités ne sont pas possibles.Pour le prouver, reprenons l'exemple du cambriolage que l'on avait utilisé pour évaluer les
conditions de vérité de most prop.
Exemple :On imagine que John a surpris des hommes en flagrant délit de cambriolage. Trois hommes
était présents dans l'appartement au moment du délit : Albert, Christian et Bertrand mais John n'a eu le temps que d'en voir deux, Albert et Bertrand.
On veut savoir si l'énoncé John saw fewest men est vrai.On a C = {a, b, c} et on sait que la phrase est vraie si :
John saw' x x y C[y ≠ x∧ ∃ ∀ ∈ → max {d': * man' (x) x is d'-few}< max {d': * man (y) y is∧ ∧ d'-few}].c'est-à-dire s'il existe une pluralité d'hommes x vue par John qui est plus petite que tout autre pluralité différente d'elle dans C.On a la même structure de pluralité en semi-treillis, ordonnée en fonction de son degré de cardinalité :
41

a b c⊕ ⊕ → 3
a b a c b c ⊕ ⊕ ⊕ → 2
a b c → 1
On ne peut pas trouver de pluralité si petite qu'il n'existe aucune pluralité strictement plus petite (< )qu'elle.
En effet, si on conserve le critère de non identité strict, la pluralité maximale a b c⊕ ⊕ , qui autrement satisferait les conditions de vérités parce qu'aucune alternative n'est plus petite qu'elle, est éliminée pour respecter la présupposition de C comme ensemble contenant plus d'un élément.
Dès lors que l'on s'intéresse à une pluralité, si petite soit-elle, on trouve toujours plus petite ou égale qu'elle dans l'ensemble *C.
Conclusion
On est parvenu à une sémantique de MOST qui est beaucoup plus satisfaisante que celle offerte par la TQG.
Elle permet de mettre en place les bases d'une sémantique unifiée qui pourrait inclure les autres usages qu'on a évoqué dans le préambule :- most composé le quantificateur superlatif complexe at most n.- most modificateur d'adjectif.- most adverbe.
Dans plusieurs articles36, Stéphanie Solt a proposé de résoudre le problème que posait la décomposition de ces autres usages en s'appuyant sur une approche de many différente de celle qu'a choisie Hackl pour rendre compte de mostprop. Elle propose de considérer l'opérateur de cardinalité comme un adjectif de quantité et non comme un élément adjectival du même type que les prédicats scalaires.
De nombreux points restent encore à éclaircir dans le détail de cette sémantique mais cela ne remet pas en cause le fait qu'une idée d'unification des usages de MOST soit à la fois judicieuse et possible.
Ainsi, la sémantique de MOST que Hackl propose dans son article est suffisamment subtile pour rendre compte de la différence morpho-syntaxique entre les quantificateurs most et more than half en produisant deux formes logiques distinctes, tout en aboutissant à un calcul de conditions de vérité équivalent.
36 Many and diverse cases : Q-adjectives and conjunction (2008), How many mosts? (2011).
42

III) Des traitements cognitifs différents pour MOST et MORE THAN HALF
Dans la dernière partie de son article, Hackl justifie l'hypothèse de la nature superlative de most par un second argument expérimental.
Il ne s'agit pas pour lui de montrer que most et more than half ont des conditions de vérité ou des usages distincts,37 mais de mettre en évidence qu'ils ne sont pas traités en temps réel d'une manière identique. Cette divergence de processus cognitifs constituerait une preuve de différence de forme logique, reflet de la morpho-syntaxe propre à chaque item.
Cependant l'argument de Hackl repose sur des postulats théoriques qui ne sont pas explicités dans son article. En tentant de les formuler, on relève une certaine circularité dans le raisonnement qui ne rend pas très convaincante l'utilisation des données expérimentales comme une preuve supplémentaire de la nature superlative de most. En effet, les résultats expérimentaux apparaissent plus comme un fait prédit par l'hypothèse principale que comme un argument en faveur de l'adoption de cette même hypothèse.
Malgré cette faiblesse, l'argument expérimental de Hackl reste intéressant en ce qu'il montre comment une sémantique aux primitives plus fines permet d'envisager une étude quantitative du traitement cognitif des expressions du langage naturel. Selon Hackl, une bonne sémantique ne doit pas s'arrêter à la seule détermination des conditions de vérité : «semantics theories have the responsibility to furnish the pieces that a processing theory requires to draw systematic distinctions that occur during real time comprehension». En formulant un objectif aussi ambitieux, l'article soulève sans y répondre de nombreuses interrogations théoriques concernant l'interaction entre système linguistique et système cognitif lors de la compréhension en temps réel des expressions du langage naturel. Il a cependant le mérite de jeter clairement les bases d'une coopération étroite entre psychologie et linguistique.
1) L'argument expérimental de Hackl
Hackl veut prouver que most et more than half sont deux expressions distinctes au niveau de leur forme logique en montrant qu'elles ne déclenchent pas les mêmes stratégies de vérification. Pour cela, il met en place trois expériences : une expérience principale, une expérience contrôle et une expérience de renforcement.
-l'expérience principaleL'expérience principale décrit le comportement des locuteurs lors d'une tâche d'évaluation véri-
conditionnelle de deux propositions α) et β) à partir de scènes visuelles représentant des points bleus, définis comme cibles, parmi des points d'une autre couleur, définis comme distracteurs. La composition des scènes visuelles (la disposition et la proportion des éléments) constitue la variable de l'expérience puisqu'en en la modifiant on espère tirer des observations pertinentes sur la nature morpho-syntaxique des deux items que l'on teste.
α) Most of the dots are blue.La plupart des points sont bleus.
37 C'est en revanche ce que font Ariel (2003, 2004) et Solt (2011) en insistant sur le renforcement pragmatique nécessaire au maniement correct de mostprop.
43

β) More than half of the dots are blue.Plus de la moitié des points sont bleu.
Ce type de tâche fréquemment utilisé en psychologie offre aux locuteurs une liberté de stratégie telle, qu'il est difficile d'observer une corrélation significative entre comportement de vérification et forme linguistique à l'aide de la seule mesure dont on dispose habituellement dans ces paradigmes expérimentaux simples, celle du temps de réaction total. Afin de contraindre la marge de manœuvre des locuteurs, Hackl adopte le paradigme de Self Paced Counting:38 cet outil expérimental révèle progressivement aux locuteurs le contenu des scènes visuelles en faisant se succéder plusieurs écrans sur un ordinateur à chaque fois qu'ils appuient sur une touche. Les participants entendent ainsi la phrase α) ou la phrase β), puis voient s'afficher sur un ordinateur deux lignes de points vides : au fur et à mesure qu'ils appuient, les points sont colorés par lot de deux ou trois tandis que les points colorés auparavant sont masqués. Les sujets peuvent répondre vrai ou faux à n'importe quel moment et sont encouragés à répondre le plus vite et le plus correctement possible. On enregistre ainsi le temps de réaction total et le temps de réaction entre chaque incrémentation de scène. Les premiers écrans ont été dessinés de telle sorte à favoriser ce que l'on suppose être l'algorithme de vérification «naturel»39 encodé dans la morpho-syntaxe de most.
-les algorithmes de vérifications naturels de most et more than half Hackl a déterminé au préalable et par hypothèse les algorithmes naturellement déclenchés par les deux quantificateurs, set qui sont upposés refléter leur forme logique :
α) [[most (A)(B)]] = |A B| > |A-B| = stratégie de comparaison de quantités par majorité
β)[[more than half (A)(B)]] = |A B| > ½ |A| = stratégie de comparaison de quantités à un critère numérique précis (dénombrement decardinalités puis comparaison à un critère numérique exacte)
Cette équivalence entre forme logique et algorithme est le résultat d'un raisonnement dont nous explicitons les étapes. Tout d'abord, Hackl postule une correspondance entre les opérateurs sémantiques qui composent les expressions linguistiques d'une phrase et les opérations mentales qui sont requises pour traiter cognitivement cette même phrase. Selon ce postulat, le sens encodé dans les expressions d'une phrase contraint les locuteurs dans les procédures de vérification qu'ils vont employer pour s'assurer de la vérité de cette phrase40.
Les formulations des conditions de vérité ne sont donc pas de pures variations notationnelles et la composition morpho-syntaxique d'une expression devient le critère pour déterminer quelle est la meilleure description parmi des alternatives concurrentes. On l'a vu dans le préambule, alors que le cadre de la théorie des quantificateurs généralisés permet une trop grande liberté dans la manière de décrire les conditions de vérité d'une expression
38 Conçu sur le même modèle que le paradigme de Self Paced Reading.39 C'est le terme exacte qu'emploie Hackl.
40 Pietroski (2011) appelle cette position la thèse de la transparence de l'interface entre sens linguistique et système cognitif.
44

quantificationnelle, la sémantique mise en place par Hackl est satisfaisante puisqu'elle permet de distinguer a) et b) en fonction de leur plus ou moins correspondance avec la composition morpho-syntaxique des expressions auxquelles elles correspondent.
a) |A B| > ½ | A |
b) |A B| > |A - A B |
La forme logique obtenue à l'aide de la prise en compte du principe de compositionalité et de la nature superlative de MOST est fidèlement traduite en b).
Démonstration :
(58) It snowed on most montains.
[[(58)]]= 1 si et seulement si : x. it snowed on x & y C [x ≠ y→ max {d' : *mountain (x)∃ ∀ ∈ ∧|x| ≥ d ' }> max {d' : *mountain (y) ∧ |y| ≥ d'}].[[(58)]]= 1 si et seulement si il existe une pluralité de montagnes sur laquelle il neige qui est plus nombreuse que toute autre pluralité de montagnes différente d'elle.
On remplace les pluralités par des sous ensembles X. Sachant que A = {montagnes} et B = {choses sur lesquels il a neigé}, on traduit les conditions de vérités ci-dessus ainsi :
[[(58)]] = 1 si et seulement si : X [X∃ ⊆ A X B |X| > |A-X| ∧ ⊆ ∧
[[(58)]] = 1 si et seulement si il existe un ensemble X tel qu'il est inclus dans A, inclus dans B et que sa cardinalité est plus grande que celle de l'ensemble complémentaire des A.
Ce que l'on peut reformuler en :
[[(58)]] = 1 si et seulement si :|A B| > |A-B|
Enfin, Hackl infère41à partir des formes logiques des items, les algorithmes de vérification que leur traitement est censé déclencher chez les locuteurs : α) décrit une opération de comparaison de sommes entre elles qui ne requiert pas nécessairement d'avoir effectué un dénombrement précis de celles-ci. La formule encode un algorithme de vérification que Hackl nomme lead counting qui consiste à vérifier entre deux ensembles quel est celui qui «mène» en terme de cardinalité. Pour chaque élément de A B on s'assure qu'il y a un élément de A-B correspondant. S'il existe au moins un élément de |A B| qui n'a pas de contrepartie en |A-B|, alors la phrase est vraie. β) décrit une opération de comparaison d'une somme à un critère numérique exact résultant d'une opération de division par moitié. La stratégie qu'elle encode consiste à déterminer la cardinalité de l'ensemble A, diviser le résultat numérique obtenu par 2 et comparer cette proportion à la cardinalité de l'ensemble A B après l'avoir calculée. 41 C'est une pure spéculation de sa part, ce qui met fortement en cause la valeur de l'argument expérimental comme
preuve de la nature superlative de most.
45

-résultats et conclusion Dans l'expérience principale, la manière dont est révélée l'information permettant de juger la proposition vraie ou fausse favorise nettement la stratégie (supposée ) de most. En effet, les quatre premiers écrans sont dessinés de façon à rendre nettement plus facile la stratégie de lead counting : sur chaque écran il y a entre deux et trois points en tout, et au moins un point de chaque couleur. Ces contraintes respectent les présuppositions attribuées à most (cf chapitre 2) et garantissent le fait que la différence entre le nombre de points cibles et le nombre de distracteurs est toujours petite (jamais plus de deux). Cela «court-circuite» le recours à un dénombrement explicite et encourage la stratégie qui consiste seulement à traquer écran par écran quelle couleur « mène ». Les résultats obtenus lors de l'expérience sont conformes aux attentes théoriques :
• Les pourcentages de réponses correctes et le temps général de réaction sont équivalents pour les tâches impliquant most et celles impliquant more than half.
Les sujets traitent donc most et more than half de façon équivalente.• Les temps de réactions de most mesurant les premiers écrans sont constamment plus
rapides que les temps de réaction de more than half.Hackl en conclut que le type de traitement cognitif engendré par la forme de most est bien distinct de celui qu'engendre la forme de more than half.
L'expérience contrôle vise à mettre en évidence que ce n'est pas une différence morphologique de surface qui a été capturée dans la première expérience mais bien une différence de forme logique. Hackl montre que deux déterminants (more than n et at most n) qui sont distincts par leur morphologie (et construits sur le même modèle que more than half et most, l'un étant morphologiquement un comparatif et l'autre un superlatif ) déclenchent pourtant des stratégies de vérification identiques qui sont le reflet de leur forme logique commune. Ce sont tous les deux des opérateurs de dénombrement et de comparaison à un critère numérique précis.
La dernière expérience est une expérience de renforcement en ce qu'elle vise à prouver les résultats obtenus lors de la première expérience en inversant le paramètre variable. Hackl manipule la distribution des points au début ou à la fin de la séquence d'écran de telle sorte que la vérification de most devienne plus dure. Le temps entre les défilements des écrans dans les tâches impliquant most est affecté, tandis que celui de more than half ne varie pas.
Hackl conclut de ces trois expériences complémentaires que most et more than half ne déclenchent pas les mêmes stratégies de vérification et que cela est dû à une différence syntaxique profonde entre ces items de natures grammaticales radicalement distinctes.
2) Hypothèses théoriques sous-jacentes et circularité de l'argument
Hackl laisse dans l'ombre une série de postulats nécessaires à l'intégration de l'interprétation des résultats expérimentaux au sein de son raisonnement général sur la nature grammaticale de most.
Il ne précise pas clairement quel est le lien entre forme logique et stratégie de vérification : l'article laisse entendre qu'il faut contraindre les tâches de vérification pour éviter que les locuteurs soient trop libres et adoptent un algorithme qui ne nous renseigne pas sur la forme logique de l'expression. On en déduit que la stratégie de vérification naturelle n'est pas forcément déclenchée par la compréhension d'un item. Pietroski (2009) a pointé cette difficultés du doigt en distinguant lexicalement deux types d'algorithmes de vérification : l'algorithme canonique et l'algorithme effectif. Dans l'expérience principale, Hackl a contraint la scène visuelle pour faire de
46

l'algorithme canonique l'algorithme effectif. Seulement à partir du moment où l'on prend en compte ce principe qui paraît théoriquement vraisemblable, tester le comportement des locuteurs lors d'une tâche d'évaluation véri-conditionnelle d'un item ne permet pas d'établir en quoi consiste l'algorithme naturel déclenchée par l'item en question. Dès lors comment savoir quelle est la stratégie de vérification canonique d'un item? Hackl ignore ce problème et ne fait que supposer la nature de ces algorithmes, sans jamais les prouver ni les justifier théoriquement.
L'argument expérimental est donc circulaire puisqu'il veut justifier la différence de formes logiques à l'aide d'une différence de comportements qui ont été testés en vertus de propriétés définies à partir des formes logiques...
L'argument ne perd cependant pas totalement sa valeur théorique : il ne constitue certes pas une preuve convaincante de l'hypothèse générale sur la nature de most au même titre que la généralisation syntaxique sur les données de l'anglais et de l'allemand mais on peut l'envisager comme une prédiction utilisée pour tester la robustesse de l'hypothèse elle-même .
Conclusion : Hackl voulait que la série d'expériences de la dernière partie de son article corrobore l'hypothèse théorique sur la nature grammaticale de MOST. Beaucoup de postulats sous-jacents au raisonnement manquent encore pour faire des résultats expérimentaux des preuves convaincantes.
47

Références
Ariel, Mira. 2003. Does most mean ‘more than half’? Berkeley Linguistics Society29.17–30.
Ariel, Mira. 2004. Most. Language 80: 4. (pp. 658-706).
Acland, Ben, Jorie Koster-Moeller, Jason Varvoutis, and Martin Hackl. 2008. Self-Paced Counting : An Experimental Technique to Study Verification Procedures for Quantified Statements.
Barwise, Jon and Robin Cooper. 1981. Generealized Quantifiers and Natural Language. Linguistics and Philosophy. 4: 159-219.
Beyssade Claire et Brenda Laca. Quantification. In D. Godard, L. Roussarie et F. Corblin (éd.),Sémanticlopédie: dictionnaire de sémantique, GDR Sémantique & Modélisation, CNRS, http://www.semantique-gdr.net/dico/.
Bresnan, Joan van. 1973. Syntax of the comparative clause construction in English.Linguistic Inquiry, 4:275–343.
Dehaene, Stanislas. 1997. The number sense : How the mind creates mathematics. Oxford University Press, Oxford.
Farkas, Donka and E.Katalin Kiss. 2000. On the comparative and absolute readings of superlatives. Natural Language and Linguistic Theory 18: 417–455.
Feigenson Lisa, Stanislas Dehaene, and Elizabeth Spelke. 2004. Core systems of number.Trends in Cognitive Science, 8:307–314.
Fintel, Kai von. 1994. Restrictions on quantifier domains. Ph.D. dissertation, Universityof Massachusetts, Amherst.
Fults, Scott. 2011.Vagueness and Scales. In Paul Egré and Nathan Klinedinst, editors, Vagueness and Language Use. Palgrave Macmillan, New York.
Fox, Danny and Martin Hackl. 2006. The Universal Density of Measurement. Linguisitics and Philosophy 29:537-586.
Gallistel,C.R and Rochel Gelman. 2000. Non-verbal numerical cognition: From realsto integers. Trends in Cognitive Science, 4:59–65.
Hackl, Martin. 2008. On the grammar and processing of proportional quantifiers : Most versus More than Half, (to appear in NLS).
Hackl, Martin. Some remarks on Proportional quantifiers. Unpublished notes.
48

Hackl, Martin. 2006. On the composition of proportional quantifiers. Rutgers Semantics Workshop.
Hackl, Martin. 2002. Comparative Quantifiers and Plural Predication.in Megerdoomian, K., Bar-el, L.A.(eds.): Proceedings of the 20th West Coast Conference on Formal Linguistics, Somerville, MA : Cascadilla Press. (2002): 234-247.
Hackl, Martin.1995. Comparative Quantifiers, PhD dissertation MIT, MITWPL, Cambridge, M.A.
Hackl, Martin. Distinct Verification Strategies for Most and More Than Half : Experimental Evidence for a Decompositional Analysis of Quantificational Determiners.
Halberda Justin, Len Taing, and Jeffrey Lidz. 2008. The development of “most” comprehensionand its potential dependence on counting-ability in preschoolers.Language Learning and Development, 4(2):99–121.
Heim, Irene. 1999. Notes on superlatives. Unpublished manuscript.
Heim, Irene. 2000. Degree operator and scope.
Horn, Laurence R. 2005. The border wars : A neo-gricean perspective. In Klaus von Heusinger and Ken Turner, editors, Where semantics meets pragmatics. Elsevier, Amsterdam.
Kennedy, Christopher. 2004. Comparatives, Semantics of.
Landmann, Fred. 2004. Indefinites and the type of sets. Oxford. Blackwell.
Link, Godehard. 1983. The Logical Analysis of Plurals and Mass Terms: A Lattice-theoretical Approach. Meaning, Use and Interpretation of Language, eds.Rainer Bauerle, Christoph Schwarze and Arnim von Stechow, 302-323. Berlin: de Gruyter.
Mostowksi, Andrzej. 1957. On a Generalization of Quantifiers. Fundamenta Mathematicae 44:12-36.
Papafragou, Anna and Naomi Schwartz. 2006. Most wanted. Language Acquisition 13 (Special Issue: On the Acquisition of Quantification): 207-251.
Pietroski Paul, Jeffrey Lidz, Tim Hunter, and Justin Halberda. 2009. The meaning of «most» : semantics, numerosity and psychology. Mind and Language, 24(5):554–585.
Pietroski Paul, Jeffrey Lidz, Tim Hunter, and Justin Halberda. 2010. Interface Transparency and the Psychosemantics of most.Manuscript.
Rooij, Robert van. 2011. Implicit versus explicit comparatives. In Paul Egré and NathanKlinedinst, editors, Vagueness and Language Use. Palgrave Macmillan, New York.
Sassoon, Galit. 2010. Measurement theory in linguistics. Synthese, 174:151–180.
49

Solt, Stephanie. 2011. How many most's? In Reich, Ingo et al. (eds.), Proceedings of Sinn & Bedeutung 15,pp. 1–15. Universaar – Saarland Unversity Press: Saarbrücken, Germany .
Solt, Stephanie. 2011. On measurement and quantification:the case of most and more than half.Zentrum f¨ur Allgemeine Sprachwissenschaft, Berlin.
Szabolcsi, Anna. 1986. Comparative Superlatives in Papers in Theoretical Linguistics. Naoki Fukui, Tova Rapoport, Elisabeth Sagey, 245-265.MITWPL 8.
Tomaszewicz, Barbara. 2011. Verification Strategies for Two Majority Quantifiers in Polish. In Reich, Ingo et al. (eds.), Proceedings of Sinn & Bedeutung 15,pp. 1–15. Universaar – Saarland Unversity Press: Saarbrücken, Germany.
50










![Hydrierwärmen, II. Hydrierwärme des Bicyclo[2.1.0]pent-2-ens, ein antiaromatisches System](https://img.pdfslide.net/doc/110x75/63549c6314cd96dfe105a2a7/hydrierwaermen-ii-hydrierwaerme-des-bicyclo210pent-2-ens-ein-antiaromatisches.jpg)


















