Embed Size (px)
Citation preview

Curso de Mejoramiento Genético
Universidad Autónoma de
Tlaxcala
Dr. Vicente E. Vega Murillo – INIFAP
Julio 1998

Estimacion de Valores Geneticos
Modelo:
Donde:
P =Valor fenotipico del individuo
Gd= Valor genetico directo de l individuo
M = Efecto materno de la madre
E = Efecto aleatorio ambiental

Valor Genotipico
Gd + Gm = Ad + Dd + Id + Am + Dm + Im
Gd = Valor genotipico del animal para efectos directos
Gm = Valor genotipico del animal para efectos maternos
A = Valor genetico
D = Valor de dominancia
E = Valor de epistasis
I y D usualmente son ignorados. Por lo tanto el valor genetico
total de un animal es Ad + Am.

El efecto materno (M) es debido al valor genetico de la madre
y efectos aleatorios ambientales sobre su habilidad materna.
Podemos escribir el modelo para el comportamiento de la
progenie con efectos directos y maternos de la siguiente
manera:
Debido a que los efectos aleatorios ambientales que afectan
directamente el comportamiento de la progenie y los efectos
aleatorios ambientales sobre la habilidad materna de la madre no
pueden ser separados

El problema es estimar el valor genetico para efectos geneticos
directos y maternos para cada animal. Para hacer esto con mayor
precision debe usarse toda la informacion disponible.
Cada registro fenotipico provee informacion acerca del valor
genetico del individuo.
• PI, PS y PD proveen informacion sobre AId
• PD y Pmhs contienen informacion sobre AId y Ad
m
•Ps y PP proveen de informacion sobre Asd

En cualquier caso, el problema es de tipo estadistico.
Necesitamos obtener la ponderacion optima para cada registro
para tener el estimador mas preciso del valor genetico de los
individuos de interes.
El estimador mas preciso es aquel que maximiza la correlacion
ente el valor genetico verdadero y el valor genetico estimado.
Este es tambien el estimador con el error de prediccion mas
pequeño.
La solucion involucra de regresion multiple. Este procedimiento
produce un coeficiente para cada registro fenotipico que resulta
en mayor precision del valor genetico estimado a partir de la
informacion disponible.

Regression Multiple.
Y = porcentaje de carne magra en una canal de cerdos,
X1 = grasa dorsal estimada en el animal vivo, y
X2 = el area de ojo de la chuleta, estimada en el animal vivo
Objetivo:
Aplicar un programa de seleccion en el cual el porcentaje de
carne magra se seleccionaria en animales vivos basandose en la
prediccion a partir de una ecuacion.

El problema es encontrar una ecuacion que pueda predecir Y a
partir de X1 y X2. El primer paso en la solucion es hacer un
experimento con una muestra grande de cerdos donde X1 y X2 y
Y puedan ser medidos. A partir de la informacion pueden
calcularse medias y varianzas para cada caracteristica y las
covarianzas entre caracteristicas
•Media de X1 = X1 V(X1) = S12 Cov(X1,X2) = s12
•Media de X2 = X2 V(X2) = S22 Cov(X2,Y) = s2y
•Media de Y = Y V(Y) = SY Cov(X1,Y) = s1y

El modelo que relaciona Y con X1 y X2. Es:
Y = a + b1X1 + b2X2 + e
Donde:
a = Iintercepto de Y,
b1 = Regresion parcial de Y en X1,
b2 = Regresion parcial de Y en X2,
e = Error residual aleatorio
La ecuacion de regresion para predecir la media de Y para
valores especificos de X1 y X2 es:

El problema ahora es encontrar valores de b1 y b2 que minimizen
la correlacion entre Y y YAj Estos son los mismos valores de b
que minimizan V(e), la varianza del error de prediccion.
Para resolver el problema necesitamos proponer un sistema de
ecuaciones . El numero de ecuaciones es igual al numero de
valores de b desconocidos. La forma de la ecuaciones es la
siguiente:
Y

La primera matrix 2x2 se le conoce como V = matrix de
varianzas y covarianzas, la segunda matrix 2x1 de b1 y b2 se le
conoce como b y la ultima matriz 2x1 de s1y y s2y, se le
conoce como RHS, entonces podemos representar estas
matrices como: Vb=RHS
En notacion matricial, estas ecuaciones pueden ser escritas de la
siguiente manera:

Las soluciones pueden encontrarse a partir de las ecuaciones
a continuacion, donde –1 denota la inversa de una matriz.
or b =V-1RHS

una vez que se obtienen los valores de b, podemos predecir Y
para valores especificos de X a partir de
Para obtener la precision de la prediccion necesitamos
calcular la correlacion entre Y y YAj .

EJEMPLO: Porcentaje de carne magra (Y), grasa dorsal (X1) y
area del ojo de la chuleta (X2) medidas en una muestra de 100
cerdos utilizando un aparato de ultrasonido de tiempo real para X1
y X2, posteriormente los animales fueron sacrificados para
determinar el porcentaje de carne magra. La grasa dorsal fue
medida en tres diferentes sitio de tal manera que X1 es la media de
estas tres mediciones. El area del ojo de la chuleta fue medida a
nivel de la decima costilla. El analisis de la informacion produjo
los siguientes estadisticos

A partir de estos datos, sabemos que s1 = .1, s2 = .4, sy = 2.6,
r12 = -.40, r1y = -.70 y r2y = .50
Para encontrar los valores de b para predecir el porcentaje de
carne magra, necesitamos formar las ecuaciones:
En notacion matricial las ecuaciones son:

las soluciones pueden obtenerse invirtiendo la matrix V y
multiplicando el resultado por RHS.

La correlacion entre Y y Yaj es:
Es de interes ver que tan bien puede ser predicho el porcentaje
de carne magra a partir de la grasa dorsal y el area del ojo de la
chuleta, comparado con la prediccion a partir de cada una de las
caracteristicas por si mismas.
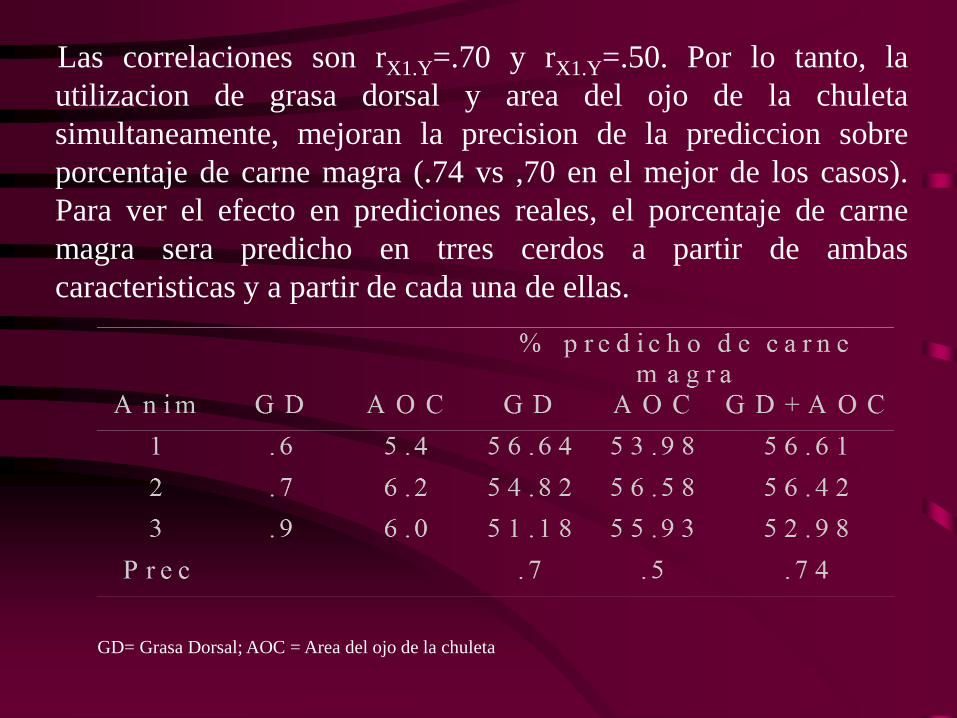
Las correlaciones son rX1.Y=.70 y rX1.Y=.50. Por lo tanto, la
utilizacion de grasa dorsal y area del ojo de la chuleta
simultaneamente, mejoran la precision de la prediccion sobre
porcentaje de carne magra (.74 vs ,70 en el mejor de los casos).
Para ver el efecto en prediciones reales, el porcentaje de carne
magra sera predicho en trres cerdos a partir de ambas
caracteristicas y a partir de cada una de ellas.
GD= Grasa Dorsal; AOC = Area del ojo de la chuleta

Los principios de regresion multiple pueden ser extendidos a
cualquier numero de variables en el modelo. Por ejemplo, si el
modelo es:
Los valores de bi pueden encontrarse resolviendo cuatro
ecuaciones con cuatro incognitas, de la siguiente manera:

Prediccion del Valor Genetico El problema es predecir el valor genetico de individuos a partir de
registros fenotipicos. Por ejemplo, si los registros incluyen el
fenotipo del individuo (P1), su padre (Ps) y su madre (Pd),
necesitamos los valores de bi que ponderan cada fenotipo para
maximizar la correlacion entre
y las ecuaciones son:
El modelo es:

La solucion a estas ecuaciones se obtienen a partir de:
El valor genetico de I, AId, es estimado como:
Ademas de predecir , el valor genetico directo de I,
podriamos estar interesados en predecir el valor genetico
materno de I, AIm

Debido a que la informacion fenotipica es la misma (PI, PS y
PD), el lado izquierdo de la ecuacion permanece igual. El unico
cambio es en el lado derecho de la ecuacion el cual ahora
contiene
Podriamos tener registros del individuo (PI) y uno de sus
medios hermanos (Phs) y un hermano completo (Pfs).
Usariamos nuevamente el mismo procedimiento, tres
ecuaciones con tres valores de b a ser estimados.

El problema es encontrar las varianzas y covarianzas apropiadas
y resolver las ecuaciones. De manera similar, los valores en la
diagonal principal son las varianzas fenotipicas de los registros.
Por lo tanto, antes de continuar debemos desarrollar un
procedimiento para calcular las varianzas y covaraianzas
necesarias.






























