Embed Size (px)
Citation preview

UNIVERSITÉ DE MONASTIRFACULTÉ DES SCIENCES DE MONASTIR
Étude comparative des théories de fusion de sourcesd’information : Application à la classification d’image
de télédétection
Mémoire présenté par Fatma HAOUASSoutenu le: 18/11/2013
c©Fatma Haouas, 2013

ii
“L’ère des grands progrès scientifiques quitransformèrent les civilisations naquıt seulement
lorsque l’homme réussit à distinguer la vérité de lacertitude.”
Gustave Le Bon

iii
Dédicace
Merci à Allah le tout puissant
A celle qui m’a donnée la vie, à celle qui est gravée dans mon cœur à tout jamais, à cellequi m’a englouti avec son amour, sa tendresse et sa bonté angélique, à celle qui m’a appris lapatience et l’amour : à l’âme de ma mère espérant qu’elle sera fière de moi comme je le suismoi d’elle.
A mon très cher papa Mohamed, qui s’est beaucoup démené pour que je réussisse qui n’ajamais cessé de m’encourager et me soutenir pour attendre mes ambitions et c’est grâce à sesencouragements et sa confiance en moi si je suis arrivée aujourd’hui à honorer ses ambitionsen moi, j’espère que je serai toujours à la hauteur de ses espérances. Que dieu lui procurebonne santé et longue vie
A mes deux anges gardiens mes deux chèrs fréres Saif Eddine et Yassine ceux qui n’ontjamais hésité à me soutenir,à m’encourager et qui m’ont épaulés moralement tout au long decette étude afin d’atteindre mes objectifs.
A mes très chères amies Mouna et Imen Attia qui sont comme de vraies sœurs pour moi.Elles étaient toujours à mes côtés pour me conseiller, pour me soutenir et pour m’encoura-ger.

iv
Remerciements
Je tiens d’abord à exprimer ma profonde gratitude à Mlle Zouhour Ben Dhiaf maître assis-tante à la faculté des sciences de Tunis qui s’est montrée toujours présente et à l’écoute
tout au long de la réalisation de ce mémoire ; pour l’inspiration, sa patience, son enthousiasme,sa confiance, son investissement inestimable, le temps qu’elle m’a consacré et pour l’ambiancede travail très agréable qu’elle a créé. Sans elle ce mémoire n’aurait jamais vu le jour. Sesconseils et ses encouragements permanents ont été pour moi un appui substantiel.
J’aimerais exprimer, sincèrement, toute ma reconnaissance au Professeur Bechir Ayeb pourson soutien sans faille, pour ses conseils précieux, ses directives et sa disponibilité.
J’exprime également mes plus vifs remerciements à Mr Atef Hammouda maître assistantà la faculté des sciences de Tunis pour son aide, ses précieux conseils et sa gentillesse. Qu’iltrouve ici un témoignage de ma reconnaissance et mon respect.
Je remercie vivement Mr Khaled Bsaies, Professeur à la Faculté des Sciences de Tunis,pour avoir accepter de m’accueillir dans son laboratoire de recherche LIPAH . Qu’il trouveici l’expression de ma profonde gratitude.
Je suis très reconnaissante à Mr Wady Naanaa, maître de conférence à la Faculté desSciences de Monastir, pour l’honneur qu’il me fait en présidant le jury de ce mémoire .
Je remercie vivement Mr Samir Belaid pour avoir accepté de faire partie du jury de cemémoire et pour sa gentillesse.
Mes remerciements respectueux s’adressent également à tous mes enseignants de la Facultédes Sciences de Monastir, qui ont assuré ma formation initiale en informatique.

v
Je remercie particulièrement Doumitra Nicolescou pour sa gentillesse, ses remarques etson aide.
Je voudrais réserver une place particulière dans ces remerciements à mes deux très chèresamies Wided Ben Abbid et Soumaya Louhichi pour leurs gentillesses, leurs conseils et leurssoutiens tout au long de ce mémoire.
Je ne saurais oublier de remercier mes très chères amies, Amira, Abir, Wala, Nihel, Nawel,Najiba, Narjess, Zohra et Kalthoum pour leurs encouragements, pour leurs sens d’humour,leurs soutiens pendant les moments difficiles durant mon cycle de Master.

vi
Résumé
Notre travail a été orienté vers une étude comparative qui vise à dégager les caractéristiquesinhérentes aux théories de fusion des sources d’information afin de choisir une stratégie dechoix entre ces dernières. Pour le cadre applicatif, nous avons expérimenté les théories despossibilités, des fonctions de croyance (TFC) et du raisonnement plausible et paradoxale(DSmT) pour un problème de fusion des sources d’information d’une scène forestière. Cecia nécessité la modélisation des processus de fusion pour la classification. Nous avons étéamenés pour cela à définir des distributions des possibilités pour la théorie des possibilitéset des distributions de masse pour la TFC et la DSmT. En revanche un apport particuliera été déduit pour calculer le jeu de masse généralisé. Nous avons proposé également unenouvelle méthode pour coder et ordonner les éléments focaux généralisés. A l’aide de cemême procédé de codage, nous avons proposé une méthode pour calculer la cardinalité deDezert et Smarandache pour quelques types de classes composées.
Mots clés: Fusion des données, imperfections d’informations, théorie des possibilités, théo-rie des fonctions de croyance, théorie du raisonnement plausible et paradoxale.

vii
Abstract
Our work has been directed towards a comparative study to determine the characteristicsinherent to the theories of fusion of information sources to choose a strategy for choosing bet-ween them. For the application framework, we tested theories of possibilities, belief functions(BFT) and plausible and paradoxical reasoning (DSmT) to a problem of merging sources ofinformation in a forest scene. This involved modeling the fusion process for classification. Wewere led to define possibilities distributions for possibility theory and mass distributions forthe BFT and DSmT. However a particular contribution was devised to calculate the gene-ralized mass game. We have also proposed a new method to encode and order generalizedfocal elements. Using this same encoding method, we proposed a method to calculate thecardinality of Dezert and Smarandache for some types of compound classes.
Keywords: Data fusion, information imperfections, theory of possibilities, theory of belieffunctions, theory of plausible and paradoxical reasoning.

Table des matières
Introduction générale 1
1 Fusion et imperfections de l’information 41.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41.2 Fusion des données . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
1.2.1 Les étapes de fusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51.2.2 Niveaux de fusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
1.3 Sources d’information . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71.3.1 Relations entre les sources . . . . . . . . . . . . . . . . . . . . . . . . . 71.3.2 Modélisation des sources d’information . . . . . . . . . . . . . . . . . . 81.3.3 Situations de fusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81.3.4 Objectifs et applications de fusion en traitement d’image . . . . . . . . 9
1.4 Classifications des images . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 91.4.1 Classification supervisée . . . . . . . . . . . . . . . . . . . . . . . . . . 101.4.2 Classification non supervisée . . . . . . . . . . . . . . . . . . . . . . . . 10
1.5 Les informations et les imperfections des données . . . . . . . . . . . . . . . . 111.5.1 Les informations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 111.5.2 Les imperfections de l’information . . . . . . . . . . . . . . . . . . . . . 11
1.6 Les approches de fusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 151.6.1 Les approches probabilistes . . . . . . . . . . . . . . . . . . . . . . . . 151.6.2 L’approche floue . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 161.6.3 L’approche possibiliste . . . . . . . . . . . . . . . . . . . . . . . . . . . 161.6.4 L’approche évidentielle . . . . . . . . . . . . . . . . . . . . . . . . . . . 161.6.5 L’approche paradoxale . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
1.7 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
2 Les approches de fusion d’information 182.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 182.2 Théorie des possibilités . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19

ix
2.2.1 Éléments de la théorie des ensembles flous . . . . . . . . . . . . . . . . 192.2.2 Fondements de la théorie des possibilités . . . . . . . . . . . . . . . . . 202.2.3 Fusion par la théorie des possibilités . . . . . . . . . . . . . . . . . . . 22
2.2.3.1 Modélisation . . . . . . . . . . . . . . . . . . . . . . . . . . . 222.2.3.2 Estimation . . . . . . . . . . . . . . . . . . . . . . . . . . . . 222.2.3.3 Combinaison . . . . . . . . . . . . . . . . . . . . . . . . . . . 262.2.3.4 Décision . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
2.2.4 Applications de la théorie des possibilités . . . . . . . . . . . . . . . . . 272.2.5 Intérêts et limites de la théorie des possibilités . . . . . . . . . . . . . . 29
2.2.5.1 Intérêts . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 292.2.5.2 Limites . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
2.3 Théorie des fonctions de croyance . . . . . . . . . . . . . . . . . . . . . . . . . 302.3.1 Fondements de la théorie des fonctions de croyance . . . . . . . . . . . 30
2.3.1.1 Cadre de discernement . . . . . . . . . . . . . . . . . . . . . . 302.3.1.2 La fonction de masse . . . . . . . . . . . . . . . . . . . . . . . 312.3.1.3 La fonction de croyance . . . . . . . . . . . . . . . . . . . . . 312.3.1.4 La fonction de plausibilité . . . . . . . . . . . . . . . . . . . . 32
2.3.2 Fusion par la théorie des fonctions de croyance . . . . . . . . . . . . . . 322.3.2.1 Modélisation . . . . . . . . . . . . . . . . . . . . . . . . . . . 322.3.2.2 Estimation . . . . . . . . . . . . . . . . . . . . . . . . . . . . 322.3.2.3 Combinaison . . . . . . . . . . . . . . . . . . . . . . . . . . . 332.3.2.4 Décision . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
2.3.3 Applications de la théorie des fonctions de croyance . . . . . . . . . . . 352.3.4 Intérêts et limites de la théorie des fonctions de croyance . . . . . . . . 36
2.3.4.1 Intérêts . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 362.3.4.2 Limites . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
2.4 Théorie du raisonnement plausible et paradoxale . . . . . . . . . . . . . . . . . 372.4.1 Fondements de la théorie du raisonnement plausible et paradoxale . . . 37
2.4.1.1 Cadre de discernement généralisé . . . . . . . . . . . . . . . . 382.4.1.2 Fonction de masse généralisée . . . . . . . . . . . . . . . . . . 382.4.1.3 Fonctions de croyance et de plausibilité généralisées . . . . . . 382.4.1.4 Transformation pignistique généralisée . . . . . . . . . . . . . 39
2.4.2 Fusion par la théorie du raisonnement plausible et paradoxale . . . . . 392.4.2.1 Modélisation . . . . . . . . . . . . . . . . . . . . . . . . . . . 392.4.2.2 Estimation . . . . . . . . . . . . . . . . . . . . . . . . . . . . 402.4.2.3 Combinaison . . . . . . . . . . . . . . . . . . . . . . . . . . . 402.4.2.4 Décision . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
2.4.3 Applications de la DSmT . . . . . . . . . . . . . . . . . . . . . . . . . . 412.4.4 Intérêts et limites de la théorie du raisonnement plausible et paradoxale 41
2.5 Comparaison des formalismes de fusion . . . . . . . . . . . . . . . . . . . . . . 42

x
2.5.1 Relation entre les trois théories . . . . . . . . . . . . . . . . . . . . . . 422.5.2 Comparaison de la TFC et la DSmT . . . . . . . . . . . . . . . . . . . 422.5.3 Comparaison de la TFC et la théorie des possibilités . . . . . . . . . . 432.5.4 Stratégie du choix d’un formalisme de fusion . . . . . . . . . . . . . . . 44
2.6 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
3 Processus de fusion par la théorie des possibilités, la TFC et la DSmT 473.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 473.2 Classification par la théorie des possibilités . . . . . . . . . . . . . . . . . . . . 47
3.2.1 Estimation de distribution de possibilités . . . . . . . . . . . . . . . . . 483.2.2 Combinaison des distributions de possibilités . . . . . . . . . . . . . . . 49
3.3 Classification par la théorie des fonctions de croyance . . . . . . . . . . . . . . 503.3.1 Génération du cadre de discernement . . . . . . . . . . . . . . . . . . . 50
3.3.1.1 Raffinement et grossissement . . . . . . . . . . . . . . . . . . 503.3.1.2 Génération de l’ensemble de fusion . . . . . . . . . . . . . . . 523.3.1.3 Réduction de la complexité exponentielle des sources . . . . . 523.3.1.4 Affaiblissement . . . . . . . . . . . . . . . . . . . . . . . . . . 54
3.3.2 Estimation des fonctions de masse . . . . . . . . . . . . . . . . . . . . . 553.3.3 Combinaison des fonctions de masse . . . . . . . . . . . . . . . . . . . . 563.3.4 Intervalle de confiance . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
3.4 Classification par la théorie du raisonnement plausible et paradoxale . . . . . . 583.4.1 Génération de l’ensemble hyper-puissance . . . . . . . . . . . . . . . . 58
3.4.1.1 Modèle libre de DSm . . . . . . . . . . . . . . . . . . . . . . . 583.4.1.2 Modèle hybride de DSm . . . . . . . . . . . . . . . . . . . . . 603.4.1.3 Méthode proposée pour la construction de l’ensemble de fusion 60
3.4.2 Méthode proposée pour la construction des classes composées et esti-mation des fonctions de masse généralisées . . . . . . . . . . . . . . . . 63
3.4.3 Combinaison des fonctions de masses généralisées . . . . . . . . . . . . 653.4.4 Décision . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
3.4.4.1 Méthode proposée pour calculer la cardinalité de DSm avec laméthode de codification proposée . . . . . . . . . . . . . . . . 65
3.5 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68
4 Expérimentations de la théorie des possibilités, la TFC et la DSmT 694.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 694.2 Architectures des processus de fusion . . . . . . . . . . . . . . . . . . . . . . . 69
4.2.1 Architecture du processus de fusion possibiliste . . . . . . . . . . . . . 704.2.2 Architecture du processus de fusion de la TFC . . . . . . . . . . . . . . 704.2.3 Architecture du processus de fusion de la DSmT . . . . . . . . . . . . . 71
4.3 Zone d’étude et sources d’informations . . . . . . . . . . . . . . . . . . . . . . 724.3.1 Sources d’informations . . . . . . . . . . . . . . . . . . . . . . . . . . . 73

xi
4.3.2 Les imperfections présentes . . . . . . . . . . . . . . . . . . . . . . . . 734.4 Classification des images forestières . . . . . . . . . . . . . . . . . . . . . . . . 74
4.4.1 Apprentissage et fenêtres de l’IHR . . . . . . . . . . . . . . . . . . . . . 744.4.1.1 Apprentissage . . . . . . . . . . . . . . . . . . . . . . . . . . . 744.4.1.2 Les fenêtres . . . . . . . . . . . . . . . . . . . . . . . . . . . . 74
4.4.2 Application de la TFC . . . . . . . . . . . . . . . . . . . . . . . . . . . 794.4.2.1 Fusion avec l’inventaire . . . . . . . . . . . . . . . . . . . . . 794.4.2.2 Fusion avec l’image de Hölder . . . . . . . . . . . . . . . . . . 88
4.4.3 Application de la DSmT . . . . . . . . . . . . . . . . . . . . . . . . . . 904.4.3.1 Fusion avec l’inventaire . . . . . . . . . . . . . . . . . . . . . 904.4.3.2 Fusion avec l’image de Hölder . . . . . . . . . . . . . . . . . . 95
4.4.4 Application de la théorie des possibilités . . . . . . . . . . . . . . . . . 974.4.5 Choix d’une stratégie de fusion . . . . . . . . . . . . . . . . . . . . . . 100
4.5 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 102
Conclusion et Perspectives 103
Bibliographie 105
A Image de Hölder 112A.1 Construction de la mesure multifractale . . . . . . . . . . . . . . . . . . . . . . 112A.2 Estimation des exposants de singularité . . . . . . . . . . . . . . . . . . . . . . 113A.3 Estimation des fonctions de masse à partir des histogrammes des exposants de
singularité . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 113
B Sources d’informations 115B.1 Image QuickBird . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 115B.2 Inventaire forestier national . . . . . . . . . . . . . . . . . . . . . . . . . . . . 117
C Matrice de confusion 119C.1 La matrice de confusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 119C.2 Les erreurs d’omission et de commission . . . . . . . . . . . . . . . . . . . . . 119
C.2.1 L’erreur d’omission . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 119C.2.2 L’erreur de commission . . . . . . . . . . . . . . . . . . . . . . . . . . . 120
C.3 Le coefficient Kappa . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 120

Table des figures
1.1 Les différents niveaux et étapes de la fusion. . . . . . . . . . . . . . . . . . . . 61.2 Les principaux types d’imperfection de l’information . . . . . . . . . . . . . . . 14
2.1 Formes de distribution de possibilités. . . . . . . . . . . . . . . . . . . . . . . . 232.2 Choix d’un formalisme de fusion. . . . . . . . . . . . . . . . . . . . . . . . . . 46
3.1 Fonctions de raffinement et de grossissement. . . . . . . . . . . . . . . . . . . . 513.2 Histogrammes des éléments focaux composés. . . . . . . . . . . . . . . . . . . 543.3 Histogrammes des éléments focaux généralisés. . . . . . . . . . . . . . . . . . . 643.4 Diagrammes de Venn. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67
4.1 Étapes de fusion par la théorie des possibilités. . . . . . . . . . . . . . . . . . . 704.2 Étapes de fusion par la TFC. . . . . . . . . . . . . . . . . . . . . . . . . . . . 714.3 Étapes de fusion par la DSmT. . . . . . . . . . . . . . . . . . . . . . . . . . . 724.4 La fenêtre 1 de l’IHR, IFN correspondant, choix des zones d’apprentissage et
image de Hölder correspondante . . . . . . . . . . . . . . . . . . . . . . . . . . 754.5 La deuxième fenêtre de l’IHR, IFN correspondant et choix des zones d’appren-
tissage. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 764.6 La troisième fenêtre de l’IHR et son IFN. . . . . . . . . . . . . . . . . . . . . . 774.7 La quatrième fenêtre de l’IHR et son inventaire. . . . . . . . . . . . . . . . . . 774.8 La cinquième fenêtre et son image de Hölder. . . . . . . . . . . . . . . . . . . . 784.9 La sixième fenêtre de l’IHR, son IFN et son image de Hölder. . . . . . . . . . . 784.10 Image du conflit entre F1 et son IFN. . . . . . . . . . . . . . . . . . . . . . . . 794.11 Superposition du IFN1 sur F1. . . . . . . . . . . . . . . . . . . . . . . . . . . . 804.12 Classification de F1 par la TFC (opérateur orthogonale). . . . . . . . . . . . . 814.13 Classification de F1 par la TFC (PCR5) . . . . . . . . . . . . . . . . . . . . . 824.14 Conflit entre F2 et IFN2 et image de superposition. . . . . . . . . . . . . . . . 844.15 Classification de la F2 par la TFC. . . . . . . . . . . . . . . . . . . . . . . . . 854.16 Classification de la F3 par la TFC. . . . . . . . . . . . . . . . . . . . . . . . . 864.17 Classification de la F4 par la TFC. . . . . . . . . . . . . . . . . . . . . . . . . 874.18 Classification de la F6. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 87

xiii
4.19 Classification texturale de la F1 par la TFC. . . . . . . . . . . . . . . . . . . . 884.20 Classification texturale de la F5 par la TFC. . . . . . . . . . . . . . . . . . . 894.21 Classification texturale de la F6 par la TFC. . . . . . . . . . . . . . . . . . . . 904.22 Classification de la F1 par la DSmT (DSmC). . . . . . . . . . . . . . . . . . . 914.23 Classification de la F1 par la DSmT (PCR5). . . . . . . . . . . . . . . . . . . . 924.24 Classification de la F2 par la DSmT. . . . . . . . . . . . . . . . . . . . . . . . 934.25 Classification de la F3 par la DSmT. . . . . . . . . . . . . . . . . . . . . . . . 934.26 Classification de la F4 par la DSmT. . . . . . . . . . . . . . . . . . . . . . . . 944.27 Classification de la F6 par la DSmT. . . . . . . . . . . . . . . . . . . . . . . . 954.28 Classification texturale de la F1 par la DSmT. . . . . . . . . . . . . . . . . . . 964.29 Classification texturale de la F5 par la DSmT. . . . . . . . . . . . . . . . . . . 964.30 Classification texturale de la F6 par la DSmT. . . . . . . . . . . . . . . . . . . 974.31 Classification possibliste de la F1. . . . . . . . . . . . . . . . . . . . . . . . . . 984.32 Classification possibiliste de la F5. . . . . . . . . . . . . . . . . . . . . . . . . . 994.33 Classification possibiliste de la F6. . . . . . . . . . . . . . . . . . . . . . . . . . 100
B.1 Image QuickBird bande PIR . . . . . . . . . . . . . . . . . . . . . . . . . . . . 115B.2 Fenêtre 2000*2000 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 116B.3 Image de Hölder. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 116B.4 L’inventaire forestier nationale correspondant à l’IHR. . . . . . . . . . . . . . . 117B.5 IFN correspondant à la fenêtre de l’IHR. . . . . . . . . . . . . . . . . . . . . . 118

Table des tableaux
2.1 Les imperfections modélisées par chaque théorie. . . . . . . . . . . . . . . . . . 45
3.1 Combinaison par la règle orthogonale de Dempster. . . . . . . . . . . . . . . . 573.2 Taille de mémoire nécessaire pour quelques hyper-powerset [28]. . . . . . . . . 593.3 Exemple de matrice de codification des éléments de l’hyper-puissance. . . . . . 623.4 Exemples de cardinalités de DSm de deux modéles. . . . . . . . . . . . . . . . 68
4.1 Matrice de confusion de la classification de F1 par la TFC . . . . . . . . . . . 834.2 Matrice de confusion de F2 par la TFC. . . . . . . . . . . . . . . . . . . . . . 854.3 Matrice de confusion de la classification texturale de F1 par la TFC. . . . . . 884.4 Matrice de confusion de la classification texturale de F5 par la TFC. . . . . . . 894.5 Matrice de confusion de la classification texturale de F6 par la TFC. . . . . . 894.6 Matrice de confusion de la classification texturale de la fenêtre F6 par la DSmT. 974.7 Matrice de confusion de la classification texturale par la théorie des possibilités. 984.8 Matrice de confusion de la classification par la théorie des possibilités. . . . . 994.9 Matrice de confusion de la classification par la théorie des possibilités . . . . . 100

Liste des symboles
m : Nombre de sources de donnéesSj : Source numéro jx : Observation (pixel)Ω : univers d discours/cadre de discernementK : nombre de classes qui constituent ΩCi : Classe simple numéro i
Ai : Classe composéeAi : Classe complémentaire de AiΠ(.) : Fonction mesure de possibilitéN(.) : Fonction mesure de nécessitéπ(.) : Fonction degré de possibilitéπSjx (Ci) : Degré de possibilité attribué par la source Sj à x pour qu’il soit Cih : Consensus entre les distributions des possibilités à combiner2Ω : L’ensemble des parties de Ω/ensemble de puissancem(.) : Fonction de masseCr(.) : Fonction de croyancePl() : Fonction de plausibilitéBetP (.) : Fonction de probabilité pignistiqueKnouv : Nombre des éléments focaux dans la TFC/ classes simples et d’uniondans la DSmTDΩ : Ensemble de l’hyper puissanceKgen : Nombre des éléments focaux généraliséeGPT (.) : Fonction de probabilité pignistqiue généraliséeCM : Cardinalité de Dezert et SmarandacheMF : Modèle libre de Dezert et SmarandacheM : Modéle hybride de Dezert et SmarandacheM0 : Modéle de Shaferk : masse de vide/ degré de conflit entre les sourcesfci(x) : La fréquence du niveau de gris x dans la classe cihci : L’histogramme de niveaux de gris de la classe ci

Liste des abréviations
– TFC : Théorie des Fonctions de Croyance– DST :Dempster Shafer Theory– DSmT :Dezert Smarandache Theory– PCR :Proportional Conflict Redistribution– PCR5 :Proportional Conflict Redistribution version five– DSm :Dezert Smarandache– DSmC :Dezert Smarandache Classic– DSmH :Dezert Smarandache Hybrid– IF :Inventaire Forestier– CZ :Chêne Zen– CL :Chêne Liège– SPC :Sol Peu Couvert– SN :Sol Nu

Introduction générale
L’évolution des satellites et des capteurs d’image a permis d’acquérir une multitude d’imagesde la terre présentant des diverses informations et caractéristiques. Ces données présentent
une source importante d’informations qui poussent les chercheurs à s’y intéresser afin depouvoir faire la classification et la cartographie des surfaces observées.
Dans ce contexte, plusieurs approches et techniques de traitement d’image et de classi-fications ont été utilisées et étudiées. Or, les informations mises en jeux sont généralemententachées de plusieurs formes d’imperfections telles que l’incertitude, l’imprécision, et le conflit[13, 8, 14, 6, 41, 40, 4] ce qui rend la tâche de classification plus délicate. Ainsi, une bonnecartographie dépend étroitement des procédures et des méthodes choisies pour faire la classi-fication. En revanche, les approches de classification mono-source qui exploitent les informa-tions extraites d’une seule image donnent des résultats entachés d’erreurs et engendrent desconfusions puisque ces méthodes ne prennent pas en compte les imperfections des données.
Toutefois, la particularité des approches de fusion réside dans leur pouvoir d’exploiterdes informations hétérogènes et imparfaites extraites de plusieurs sources afin d’obtenir unmeilleur résultat [12, 44, 46, 50, 51, 57, 69, 80].
Cependant, il existe une variété d’approche qui permet de réaliser la fusion des images.Ces approches sont répertoriées dans deux catégories. L’une capable de gérer et de modéliserles imperfections de l’information et l’autre en n’est incapable. Les approches qui traitent lesimperfections attachées aux informations se basent sur des fondements mathématiques quisont appelées les approches de l’incertain telle que la théorie des probabilités.Néanmoins, les approches de l’incertain ne modélisent pas les imperfections de la même façonpuisque leurs fondements mathématiques sont différents comme ils ne raisonnent pas de lamême manière. Par ailleurs, les imperfections traitées par l’une peuvent ne pas être prises encompte par l’autre.

Introduction générale 2
Nous citons par exemple : la théorie des probabilités qui est un bon cadre pour représenter etmodéliser les incertitudes attachées aux informations. Par contre, si l’incertitude est accom-pagnée par d’autres formes d’imperfection telle que l’imprécision, l’utilisation de cette théoriepeut mener à confondre ces deux formes d’imperfection. Il est clair que le choix d’un forma-lisme de fusion est une tâche difficile et dépend fortement des caractéristiques des sources etdes informations à traiter.
Dans ce travail de master, nous nous sommes intéressés aux plus récentes théories del’incertain : la théorie des possibilités, la théorie des fonctions de croyance (TFC) et la théoriedu raisonnement plausible et paradoxale (DSmT) afin de les comparer et de les étudier.Cette étude vise à trouver une stratégie qui nous permet de choisir le formalisme le plusadéquat pour fusionner les sources d’informations disponibles.
Dans un premier temps nous avons comparé la théorie des possibilités, la TFC et laDSmT. Ainsi, nous nous sommes concentrés sur les imperfections modélisées et traitées parchaque formalisme. En outre, nous avons étudié la nature des sources d’information et larelation entre elles. Dans cette comparaison nous avons pris en considération la complexitétemporelle de chaque formalisme puisque la théorie des possibilités raisonne sur des singletonsqui représentent les différentes classes qui constituent les sources. Contrairement à la théoriedes fonctions de croyance qui porte son raisonnement sur tous les sous-ensembles possiblesconstruits par la disjonction des hypothèses singletons. A cela s’ajoute, la théorie du raison-nement plausible et paradoxale appelée aussi la théorie de Dezert et Smarandache , et quiest considérée comme une généralisation de la TFC, n’utilise pas uniquement l’opérateur dedisjonction pour construire tous les sous-ensembles possibles par les classes singletons maisaussi l’opérateur de conjonction.Dans un deuxième temps, nous avons mis en œuvre les trois techniques de fusion et de classifi-cation par les théories des possibilités, des fonctions de croyances et la plus récente de Dezertet Smarandache .Finalement, nous avons appliqué les trois processus sur des images forestières afin de choisirle formalisme le plus adéquat pour réaliser un système de classification de la zone d’étude.Ainsi, notre mémoire se présente comme suit :
Le premier chapitre présente des généralités sur la fusion multi-sources et la classificationdes images. Aussi, nous avons détaillé les caractéristiques de l’information et ses types endécrivant les différentes formes d’imperfection qui s’y attachent.
Le chapitre numéro deux dresse en premier lieu l’état de l’art des théories des possibilités,des fonctions de croyance et du raisonnement plausible et paradoxale. De plus, ce chapitreexpose les méthodologies de modélisations des problèmes de fusion relative aux trois théories,et les différentes règles de combinaisons des informations apportées par les sources mises en

Introduction générale 3
jeux. Par la suite il détaille une comparaison théorique de ces trois approches. Il se terminepar la description de la stratégie du choix que nous avons proposé.
Le troisième chapitre détaille les différentes architectures de fusion mises en œuvre. Nousavons mis l’accent sur la complexité temporelle élevée de la théorie des fonctions de croyances.Cette complexité est engendrée par le nombre des combinaisons des hypothèses singletons.Pour cela nous avons utilisé une approche proposée par Ben Dhiaf [7] pour réduire le nombrede classes combinées. Dans un même ordre d’idées, nous avons généralisé cette approche enproposant une méthode pour construire les classes paradoxales suivi d’une deuxième méthodepour ordonner les éléments focaux généralisés au sein de la DSmT. A l’aide de cette dernièrenous sommes parvenus a trouver une troisième méthode pour calculer la cardinalité de DSm.Nous avons exposé pour chaque approche la méthode d’estimation et les règles de combinaisonadoptées.
Le quatrième chapitre expose les résultats de fusion/classifications des images satellites dela zone d’étude par les différents processus mises en place.
Nous terminons par une conclusion et des perspectives.

Chapitre 1Fusion et imperfections de l’information
1.1 Introduction
La fusion est devenue l’une des techniques importantes de traitement de l’information dansplusieurs domaines dans lesquels les informations à fusionner, les objectives et les mé-
thodes peuvent remarquablement varier [51, 80, 2, 17, 36, 53, 63].Dans le traitement d’image l’accent est mis sur la fusion depuis quelques années. Dans cedomaine la fusion d’information doit tenir compte des spécificités des données tout au long dece processus. Elle diffère des autres domaines, d’une part à cause de ces spécificités (donnéeshétérogènes, quantité importante, données surtout issues de capteurs...), d’autre part à causedes principales raisons de la fusion en traitement des images qui défère d’une application àune autre [14, 13]. La fusion est généralement un problème complexe en soi qui se décomposede manière schématique en plusieurs tâches.Plusieurs notions sont attachées à la fusion d’information tels que les différents niveaux defusion, les structures, les types de sources d’informations, les différents types et formes d’im-perfections attachés aux informations à fusionner et les approches utilisées pour faire la fusion[51, 41, 40]. Toutes ces notions vont faire l’objet de ce chapitre.
1.2 Fusion des données
La fusion d’informations est apparue afin de gérer des quantités très importantes de don-nées provenant de plusieurs sources dans le domaine militaire. La fusion est un processus multi-

Chapitre 1. Fusion et imperfections de l’information 5
étapes qui permet de modéliser et de combiner des informations hétérogènes afin d’améliorerla qualité. Cette méthode a été adoptée dans des domaines différents (robotique, militaire,fouille de donnée, traitement d’image, imagerie médicale...).
Plusieurs définitions de la fusion ont été proposées dans la littérature. Dans [80] Waldpropose une définition générale de la fusion des données qui est “La fusion de données constitueun cadre formel dans lequel s’expriment les données provenant de sources diverses. Elle vise àl’obtention d’information de plus grande qualité. La définition “de plus grande qualité ”dépendde l’application”.Par ailleurs, Isabelle Bloch propose une définition plus spécifique[14] “la fusion d’informationconsiste à combiner des informations issues de plusieurs sources afin d’améliorer la prise dedécision ”.
La finalité d’application de la fusion d’informations dépend d’un domaine à un autre etd’une application à une autre. Nous citons par exemple en traitement d’image : l’améliorationde la classification, la segmentation et la détection d’anomalie. D’autre domaine utilise lafusion afin de détecter les obstacles (robotique) ou bien pour détecter les mines (militaire)etc.
1.2.1 Les étapes de fusion
La fusion se déroule généralement sur quatre étapes cruciales qui sont la modélisation,l’estimation, la combinaison et la décision :La modélisation : c’est la première étape de la fusion. Elle consiste à choisir un formalisme
de fusion puis à définir et à présenter les différentes informations à traiter et à fusionner.Cette étape est déterminante pour la suite.
L’estimation : cette phase est très délicate et influence généralement le résultat de la fu-sion. Sa finalité est la représentation de chaque élément d’information par un nombre.Il s’agit par exemple de déterminer les jeux de masses dans la théorie des fonctionsde croyance ou bien la détermination des distributions des possibilités dans la théoriedes possibilités. Souvent des informations supplémentaires sont utilisées afin de mieuxestimer les données.
La combinaison : cette tâche présente la fusion proprement dit. Elle consiste à choisir unopérateur pour combiner et regrouper les informations données. Des informations sup-plémentaires peuvent entrer en jeu pour guider le choix de l’opérateur de combinaison.En effet le choix de l’opérateur est une tâche assez délicate dans certains problèmes.
La décision : c’est la dernière phase du processus de fusion. Elle consiste à choisir unedécision parmi les décisions possibles sur les attributs combinées. En général, il y a

Chapitre 1. Fusion et imperfections de l’information 6
des critères à fixer pour réaliser cette tâche. Le choix du critère se fait en fonction duformalisme (i.e. du choix de la modélisation et de la combinaison). Les connaissancesexternes peuvent ici apporter une aide importante au choix du critère. Habituellement,il s’agit de la maximisation d’une fonction issue de la combinaison. Cette étape doitdonc fournir à l’expert la “ meilleure” décision. Enfin, la prise de décision permet dedéterminer l’action optimale à entreprendre dans une situation donnée.
1.2.2 Niveaux de fusion
Différents niveaux de fusion ont été proposé dans la littérature. Ce qui est communémentretenu, est une division en trois niveaux [18], celui des données (ou bas niveau), celui descaractéristiques (i.e. des paramètres extraits) (ou fusion de niveau intermédiaire) et celui desdécisions (ou fusion de haut niveau). La figure 1.1 résume les différents étapes et niveaux defusion.
Figure 1.1 – Les différents niveaux et étapes de la fusion.
Fusion bas niveau : c’est la fusion des informations issues directement des capteurs. Doncles données sont proches des paramètres physiques mesurés, à titre d’exemple “pixel”dans le cas où la source est une image. Les travaux suivants ont fait la fusion ponctuelle[65, 7, 1, 66].

Chapitre 1. Fusion et imperfections de l’information 7
Fusion moyen niveau : dans ce cas les informations à fusionner sont extraites des donnéesprovenant de la source. Elles peuvent être des attributs, des objets, des paramètres etc.Dans le cas où la source est une image on peut citer la fusion des segments, des para-mètres de texture etc [7].
Fusion haut niveau : on parle de ce niveau de fusion lorsqu’on traite des attributs séman-tiques extraits, genre des décisions. A titre d’exemple fusion des classifieurs [50].
1.3 Sources d’information
Le terme multi-sources se réfère aux différents types de sources utilisées dans le processusde fusion,[46]. Une variété de sources hétérogènes peut être utilisée pour traiter et fusionnerles informations acquises.Il existe plusieurs types de satellites qui nous servent de source. Les satellites optiques telsque SPOT et Landsat. Les multiples satellites radars comme Radarsat, ERS. Comme ilspeuvent être des capteurs tels que les capteurs de vent, de vague et l’échographie. Les avisd’experts constituent une source d’information indispensable dans plusieurs problèmes defusion [25, 47, 53]. Les données numériques / symboliques sont également considérées commeune source d’information importante.Ainsi, la fusion multi-sources exploite cette diversité et la complémentarité entre les différentessources afin d’améliorer le résultat final.
Il faut mentionner que les informations acquises des différentes sources utilisées dans lafusion doivent être prises dans des intervalles de temps relativement étroits pour considé-rer seulement les informations indépendamment du facteur temps. Dans le cas contraire, ils’agirait d’une fusion multi-sources multi-temporelles.
1.3.1 Relations entre les sources
La relation entre les sources impliquées dans le processus de fusion peut être de plusieurstypes. On peut avoir des sources concordantes, discordantes et complémentaires :
– Deux sources sont concordantes, appelées aussi conjonctives si les informations donnéespar les deux sont compatibles et leur fusion améliore la qualité de décision.
– Deux sources sont dites discordantes, ou encore disjonctives voir même conflictuelles siles informations données par ces deux sources sont incompatibles et même contradic-toires. Par conséquent leur fusion peut engendrer un résultat inattendu ou bien dégraderla qualité de décision.

Chapitre 1. Fusion et imperfections de l’information 8
– Deux sources complémentaires appelées aussi sources redondantes, sont appelées ainsilorsque les informations apportées par ces sources sont redondantes est définies sur lemême espace. Cette redondance est généralement utilisée comme avantage pour avoirencore un résultat amélioré.
1.3.2 Modélisation des sources d’information
Supposons que l’on dispose de m sources. Notons la source j par Sj avec j dans 1...m.Chaque source donne des informations sur l’ensemble des observations. Soit x une observation(x peut être un niveau de gris dans le cas où les sources sont des images). Chaque sourcedoit prendre une décision di sur l’observation x de l’ensemble de décisions D=d1,...,dn.A titre d’exemple x appartient à la classe Ci dans le cas où le problème est un problèmede classification. Quelque soit la source Sj de l’ensemble des sources, Sj doit fournir uneinformation sur la décision di pour l’observation x.
1.3.3 Situations de fusion
Selon les applications, les problèmes de fusion peuvent se produire dans des situationsdifférentes, dans lesquelles les types d’informations ne sont pas les mêmes. Les principauxsituations de fusion en traitement d’images sont les suivantes :
– Plusieurs images du même capteur : il s’agit par exemple de plusieurs canaux du mêmesatellite, d’images multi-échos en IRM, ou encore de séquences d’images pour des scènesen mouvement[14].
– Plusieurs images de capteurs différents : c’est le cas le plus fréquent où les principesphysiques différents des capteurs permettent d’avoir des points de vue complémentairessur la scène. Il peut s’agir d’images ERS et SPOT, d’images IRM et ultrasonores, etc[1, 3, 42].
– Images et autres sources d’information : les informations sont très différentes et hétéro-gènes. Dans ce cas les autres sources peuvent être des bases de connaissances, des règles,des informations issues d’expert, des expressions linguistiques, des modèles numériques,etc [7, 65].

Chapitre 1. Fusion et imperfections de l’information 9
1.3.4 Objectifs et applications de fusion en traitement d’image
Le but d’utilisation de la fusion des données varie d’un domaine à un autre comme ildépend du contexte de l’application. Dans ce paragraphe nous citons d’une manière nonexhaustive quelques objectifs de la fusion :Détection : il s’agit de déterminer la présence ou l’absence de l’objet chercher. Par exemple
présence d’un véhicule sur une route, détection d’anomalie du cerveau ou bien recon-naissance de visage et des expressions faciales [45].
Classification et reconnaissance : un objet détecté est alors associé à l’une des famillesd’objets connus ou attendus en fonction de ses critères photométriques, géométriquesou morphologiques. Cette opération peut être conduite sur des objets de niveaux trèsvariés, depuis le pixel jusqu’aux ensembles complexes de composantes de l’image [7, 1,65, 10, 57].
Identification : un objet détecté est reconnu et identifié lorsqu’il est associé à un proto-type unique de sa classe. Ainsi, après avoir détecté un véhicule en imagerie infrarouge, lareconnaissance permettra d’en déduire son type : camion, moto ou voiture et l’identifi-cation conclura au camion du laitier, objet classiquement surveillé dans ce type d’images[20, 50].
Segmentation : il s’agit là d’un objectif plus focalisé que la classification en cherchant àextraire le plus précisément possible des objets déterminés. Il peut s’agir simplementd’utiliser la complémentarité des sources d’information pour mieux identifier les limitesdes composantes homogènes de l’image [64, 45].
Détection de changement : ce type de décision concerne typiquement les images acquisesà des dates différentes, qu’il s’agisse d’une carte et d’une image, ou d’images multi-dates pour le suivi des cultures ou d’une pathologie ou bien la détection du gain deterrain d’une zone urbaine qui s’étend sur les zones forestières. Il peut s’agir égalementde séquences d’images multi-sources [1] .
Mise à jour sur un phénomène ou une scène : ici, contrairement au cas précédent, ladécision consiste à utiliser les informations provenant de différentes sources (éventuelle-ment multi-dates) pour modifier ou compléter une connaissance précédente, par exemplecompléter un réseau routier avec les nouveaux ronds-points pour mettre à jour une carte.
1.4 Classifications des images
Une des finalités de l’utilisation de la fusion est la classification des données.La classification est un processus qui vise à regrouper les données du même type dans une

Chapitre 1. Fusion et imperfections de l’information 10
seule entité ou classe. Comme application en traitement d’images la classification d’une imageconsiste à attribuer chaque pixel à une classe. Ainsi, les pixels de chaque classe ayant des carac-téristiques communes telle que la caractéristique spectrale. L’image générée représente l’imageclassifiée et est formée de plusieurs classes dont les quelles regroupent les pixels semblables ethomogènes.Plusieurs méthodes de classification ont été proposées dans la littérature tels que les réseauxde neurones, les approches probabilistes, K-means et K plus proches voisins.On peut distinguer deux principales catégories de méthode de classification : la classificationsupervisée et la classification non supervisée.
1.4.1 Classification supervisée
Les méthodes de classification supervisée disposent des connaissances à priori sur les diffé-rentes classes (leurs nombres, leurs caractéristiques, etc.). Dans le cas du traitement d’images,ces connaissances peuvent être acquises par un travail de terrain (exemple inventaire fores-tier), les photographies aériennes, etc. Des zones d’apprentissages des régions homogènes sontchoisies pour construire une base d’entraînement. Par la suite on doit associer chaque objetà une classe selon leurs caractéristiques.
Ces méthodes sont développées suivant une multitude d’approches. Nous citons par exemplela méthode du maximum de vraisemblance suivant l’approche probabiliste, la méthode du ré-seau de neurones suivant l’approche connexionniste, la méthode génétique suivant l’approcheévolutionnaire, etc.Parmi les travaux qui ont utilisé la fusion des données afin de faire la classification supervisée,nous citons [7, 1, 66, 22].
1.4.2 Classification non supervisée
Les méthodes de classification non supervisée sont multiples. Contrairement aux méthodessupervisées on ne dispose ni d’informations a priori sur les différentes classes ni de basesd’échantillons d’apprentissages. Dans ce cas le nombre de classes et les règles d’affectation àcelles-ci peuvent être établis à partir d’observations. Parmi ces techniques nous citons K-means(K-moyennes) et la méthode de C-moyen flou.

Chapitre 1. Fusion et imperfections de l’information 11
1.5 Les informations et les imperfections des données
1.5.1 Les informations
Une information est une collection de symboles ou de signes produits soit par l’observationde phénomènes naturels ou artificiels, soit par l’activité cognitive humaine. Elle est destinéeà mieux comprendre les phénomènes et à aider à la prise de décision.
On distingue deux sortes d’information : objective et subjective.Les informations objectives sont issues de l’observation directe des phénomènes comme lesmesures de capteurs. Tandis que celles dites subjectives sont les informations exprimées pardes individus et conçues sans le recours à l’observation directe du réel.
L’information peut prendre deux formes : numérique et symbolique. Les informations nu-mériques (généralement objectives) peuvent prendre différentes formes : nombres, intervallesde nombres, etc. Les informations symboliques (subjectives) sont exprimées en langage na-turel. Néanmoins, une information subjective peut être numérique et l’information objectivepeut être symbolique (un capteur qui fournit des couleurs).
– Les informations sont dites numériques lorsqu’elles sont exprimées sous forme de nombres(niveaux de gris, inventaire, modèle numérique de terrain etc...).
– Les informations sont dites symboliques : lorsqu’elles sont exprimées sous forme desymbole, de règle, de proposition, etc... par exemple les décisions prisent à la fin d’unprocessus de fusion.
En outre, l’information peut être soit quantitative soit qualitative. On parle d’une infor-mation quantitative lorsqu’on peut la quantifier et lui attribuer un nombre, autrement dit, onpeut la mesurer alors que l’information est dite qualitative lorsqu’on ne peut pas l’exprimersous forme de nombre ou bien la mesurer.
1.5.2 Les imperfections de l’information
Les informations acquises des sources sont souvent entachées par des imperfections quisont de différentes formes [41, 40, 14, 4, 8, 60]. Ces imperfections sont généralement dues auxphénomènes observés, aux limites des capteurs, au bruit ou bien au manque de fiabilité etc...c’est pourquoi il est intéressant de combiner plusieurs sources d’information pour amélioreret traiter ces imperfections.Les imperfections de données sont nombreuses. Les principales formes et types d’imperfectionssont l’imprécision, l’incertitude et le conflit [74]. On parle d’une information parfaite lorsqu’elle

Chapitre 1. Fusion et imperfections de l’information 12
est certaine et précise :
L’incertitude : c’est l’imperfection la plus étudiée, elle caractérise le degré de conformité àla réalité d’une information. Une information incertaine décrit une connaissance partiellede la réalité. Elle est décrite comme défaut qualitatif de l’information.L’incertitude correspond à une ignorance partielle ou totale de la connaissance. Ellepeut être décrite à ce titre comme objective ou subjective :– L’incertitude objective : elle est liée à la description du monde et à l’information(exemple : mesure)
– L’incertitude subjective : elle est liée à l’opinion de l’expert sur la vérité.Par ailleurs, on peut distinguer deux types d’incertitudes :– Les incertitudes aléatoires : elles sont dues à la variabilité des phénomènes répétablesou de caractéristiques différentes.
– Les incertitudes épistémiques : elles sont dues au caractère incomplet de la connais-sance. Sachant que les incertitudes épistémiques sont graduelles (progressives) puisquela croyance est souvent une question de degré. Donc elle est liée au caractère imprécisde l’information due à un manque de connaissance et qui résulte par exemple à deserreurs de mesures ou d’avis d’experts.Exemple : Probablement la température va chuter demain.
L’imprécision : l’imprécision d’une information est caractérisée par le contenu de l’informa-tion. Elle est relative à l’information ou à la source. Elle concerne le manque d’exactitudeen quantité, en taille, en durée, au manque de définition d’une proposition qui est ou-verte et à diverses interprétations qui a des frontières vagues et mal définies. Elle mesuredonc un défaut quantitatif de connaissance.Exemple : La température aujourd’hui est entre 35 c et 40 c.
L’incomplétude : l’incomplétude est le manque d’information apporté par la source. L’in-complétude de l’information peut être la cause de l’incertitude et de l’imprécision. Ellepeut se mesurer par la différence de la quantité d’information réellement fournie parla source et de la quantité d’information que la source doit fournir (en cas de bonfonctionnement ou pour répondre à un problème posé).Nous pouvons distinguer deux cas d’incomplétude de l’information : Soit un défautd’information (par exemple une caractéristique ne fournit pas d’information alors qu’elleest sensée les donner (cas d’un défaut de transmission)) soit l’incomplétude est issue d’undéfaut de modélisation de la source ou du problème.Exemple : un radar ne permet pas de fournir une image de sous-marins immergés,l’information ne portant que sur la surface de l’eau.
L’ambiguïté : l’ambiguïté exprime la capacité d’une information de conduire à deux inter-prétations. Elle peut provenir des imperfections précédentes.Exemple : forme d’un avion trop proche d’un autre ne permet pas de l’identifier.

Chapitre 1. Fusion et imperfections de l’information 13
La redondance : la redondance d’information ou de source résulte qu’on a plusieurs reprisela même information. La fusion s’appuie sur la redondance des sources pour confirmerune information.Exemple : l’observation d’un même objet par différentes sources peut permettre desituer l’objet avec précision et de le représenter dans un espace de dimension supérieure.
La complémentarité : la complémentarité est la propriété des sources qui apportent desinformations sur des grandeurs différentes. Elle vient du fait qu’elles ne donnent engénéral pas d’information sur les mêmes caractéristiques du phénomène observé. Elleest exploitée directement dans le processus de fusion pour avoir une information globaleplus complète et pour lever les ambiguïtés.
Vague : ce type d’information est dû spécialement à la limitation du vocabulaire et dansla plupart des cas aux informations subjectives. L’information vague décrit une classed’objets mais les limites de celle-ci ne sont pas bien connues.Exemple : l’information “Tom est mort jeune". Quel sont les limites de “jeune" ? Doncest-ce-que jeune veut dire âge égale 15 ans ou bien âge égale 25 ans ou même âge égale 40ans. L’information vague peut être considérée comme un cas particulier de l’imprécision.
Conflit : deux informations ou plus sont en conflit si elles sont contradictoires. Les originesdu conflit proviennent essentiellement de trois situations– Les sources ne sont pas fiables.– L’information est erronée et peut conduire à une ambiguïté.– Les sources observent des phénomènes différents. Dans ce cas il ne faut pas les com-biner.
Les situations conflictuelles sont fréquentes dans les problèmes de fusion et posent tou-jours des problèmes difficiles à résoudre. Toutefois, la détection des conflits n’est pasforcément facile. Ils peuvent facilement être confondus avec d’autres types d’imperfec-tions.
Relations entre l’incertitude et l’imprécision : L’incertitude et l’imprécision sont étroi-tement liées et sont souvent confondues à tort. L’imprécision est un défaut quantitative de laconnaissance alors que l’incertitude est un défaut qualitative de la connaissance. Autrementdit, l’imprécision est liée au contenu de l’information elle est essentiellement une propriétéde l’information elle-même alors que l’incertitude est une propriété de la relation entre l’in-formation et les connaissances sur le monde puisque elle résulte d’un manque d’informationsur le monde. De plus, la principale cause de l’incertitude d’une information provient de sonimprécision de l’information. En effet, dans le cas d’information quantitative, l’imprécisiond’une donnée entraîne une incertitude sur l’information véhiculée. De même, l’incertitude peutinduire l’imprécision [74, 41].Exemple : dire qu’il pleut 10 mm3/h alors qu’il y en a 15 provoque une incertitude sur letemps qu’il fait.
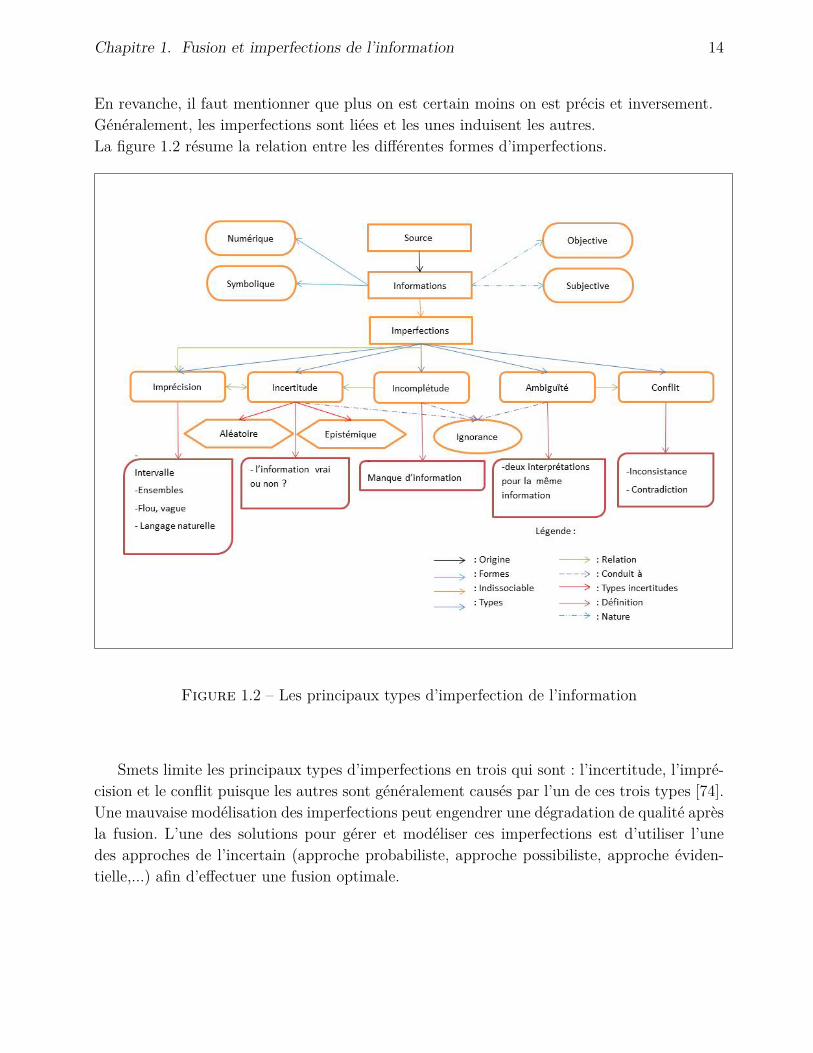
Chapitre 1. Fusion et imperfections de l’information 14
En revanche, il faut mentionner que plus on est certain moins on est précis et inversement.Généralement, les imperfections sont liées et les unes induisent les autres.La figure 1.2 résume la relation entre les différentes formes d’imperfections.
Figure 1.2 – Les principaux types d’imperfection de l’information
Smets limite les principaux types d’imperfections en trois qui sont : l’incertitude, l’impré-cision et le conflit puisque les autres sont généralement causés par l’un de ces trois types [74].Une mauvaise modélisation des imperfections peut engendrer une dégradation de qualité aprèsla fusion. L’une des solutions pour gérer et modéliser ces imperfections est d’utiliser l’unedes approches de l’incertain (approche probabiliste, approche possibiliste, approche éviden-tielle,...) afin d’effectuer une fusion optimale.

Chapitre 1. Fusion et imperfections de l’information 15
1.6 Les approches de fusion
Les approches de fusion sont multiples, on trouve principalement les théories de l’incertainqui sont largement utilisées [60]. Ces approches se divisent principalement en deux catégoriesqui sont les approches qui découlent d’un formalisme probabiliste telles que la théorie desprobabilités imprécises et la théorie de Dempster Shafer [3, 67, 79, 14, 70, 30, 27]. La deuxièmecatégorie se repose sur le fondement flou telles que la théorie des sous-ensembles flous et lathéorie des possibilités [82, 36].On trouve également dans la littérature d’autres méthodes qui permettent de faire la fusiond’information tels que les réseaux de neurones et les filtres de Kalman.
1.6.1 Les approches probabilistes
Les approches probabilistes sont les plus anciennes et les mieux développées mathémati-quement. Elles étaient les seules à interpréter la notion du hasard et de l’incertitude.La notion de probabilité est liée à celle de l’expérience aléatoire. Une expérience est ditealéatoire si on ne peut pas prédire avec certitude le résultat.
Ces approches sont largement utilisées dans plusieurs domaines et plus particulièrementdans le traitement d’image. Parmi ces approches, on trouve l’approche par estimation etl’approche bayésienne. Plusieurs travaux ont mis l’accent sur ces méthodes et ont mis enrelief leurs avantages et leurs limites en fusion multi-sources [14, 3]. La théorie des probabilitéssemble pauvre pour la manipulation et la représentation de la méconnaissance (l’ignorancepartielle ou totale). Elle ne permet pas de représenter d’une manière rigoureuse et propre unétat d’ignorance ou de connaissance partielle.Malgré qu’elles représentent bien l’incertitude qui entache l’information, elles ne permettentpas aisément de représenter son imprécision et elles conduisent souvent à confondre ces deuxnotions.
Les approches probabilistes sont mal adaptées à la modélisation de l’imprécision des opi-nions d’experts et limitent le choix des méthodes de fusion quand il s’agit de synthétiserune information interprétable à partir d’un ensemble d’information provenant de plusieursexperts.Les différents travaux sur les approches probabilistes ont induit de nouvelles théories tellesque la théorie de Dempster Shafer et la théorie de probabilité imprécise.

Chapitre 1. Fusion et imperfections de l’information 16
1.6.2 L’approche floue
La théorie des ensembles flous introduite par Zadeh en 1965 [82] offre un cadre mathéma-tique qui permet de prendre en considération les informations imprécises et vagues.Cette technique non probabiliste permet de modéliser l’appartenance partielle à une classeà limite mal définie. Ainsi, un élément donné peut appartenir à une classe avec un degréd’appartenance qui varie entre 0 et 1.
Cette modélisation a permis aussi de prendre en compte les informations symboliques etles connaissances exprimées en langage naturel. L’inconvénient majeur de cette approche estqu’elle représente uniquement le caractère imprécis de l’information et elle ne présente pasun cadre théorique permettant de prendre en compte l’incertitude qu lui est attachée. Cettethéorie a été utilisé pour réaliser la fusion multi-sources dans plusieurs travaux, nous citons[14, 11].
1.6.3 L’approche possibiliste
La théorie des possibilités appelée aussi théorie des ensembles flous et des possibilitésintroduite par Lotfi Zadeh en 1978 et par la suite développée en France par Dubois et Prade.Elle est dérivée de la théorie des ensembles flous. Elle présente un cadre méthodologiqueimportant en fusion. En effet, cette théorie nous permet de représenter à la fois l’incertitudeet l’imprécision et les informations graduelles à l’aide de deux fonctions qui caractérisent lesévènements.
La théorie des possibilités prend également en compte l’inconsistance entre les sources maiscette modélisation est relativement possible. En effet, si le conflit entre les sources devientélevé la fusion à l’aide de l’approche possibiliste engendre de mauvais résultats. Cette théorieraisonne sur des classes simples qui représentent toutes les hypothèses possibles [65, 15, 5, 54,2].
1.6.4 L’approche évidentielle
La théorie de l’évidence appelée aussi théorie de Dempster Shafer permet de manipuler desensembles finis en se reposant sur un cadre mathématique solide [67]. Cette théorie permet dereprésenter, de gérer les informations imparfaites, surtout les imprécisions et les incertitudesà l’aide des fonctions appelées fonctions de croyance qui opèrent sur le cadre de discernement.

Chapitre 1. Fusion et imperfections de l’information 17
Ce cadre appelé aussi référentiel de travail représente l’ensemble des hypothèses (classes si leproblème est un problème de classification) possible.
Cette approche permet de classifier et d’attribuer les éléments à des classes d’union forméepar la disjonction des hypothèses en ignorant leurs appartenances exactes.On trouve que la théorie de Dempster Shafer est de loin la plus exploitée pour la fusion et laclassification [1, 7, 24, 14, 21, 58].
1.6.5 L’approche paradoxale
La théorie du raisonnement plausible et paradoxale appelée aussi théorie de Dezert Sma-randache est la théorie la plus récente. Elle a été introduite par Jean Dezert et FlorentainSmarandach en 2001 [27, 32, 31, 70, 33]. Cette théorie est considérée comme une généralisa-tion de la théorie de Dempster Shafer. En effet, elle offre un cadre plus riche et plus souplepar rapport à la théorie de l’évidence pour modéliser les informations. Son intérêt majeur ré-side dans son pouvoir de modélisation du paradoxe entre les sources. Outre, l’incertitude estreprésentée par la disjonction des hypothèses de l’information paradoxale qui est introduitepar la conjonction des hypothèses. Dans ce cas on parle de cadre du discernement généralisé.Cette innovation apportée à la théorie de l’évidence a été validée par de nombreux exemplesthéoriques et travaux scientifiques. Elle montre le pouvoir de cette nouvelle théorie de gérerles cas délicats où la théorie de Dempster Shafer est mise à défaut.
1.7 Conclusion
Dans ce chapitre nous avons introduit la fusion des données. Ensuite, nous avons abordé sesdifférentes étapes et niveaux qui permettent la combinaison de données hétérogènes provenantde sources variées. De plus nous avons mis l’accent sur les informations acquises de chaquesource qui sont généralement imparfaites.L’un des défis de la fusion est de gérer et de réduire ces imperfections le maximum possible. Etcela se fait généralement à l’aide des approches mathématiques qui permettent de fusionnerles données en prenant compte des types d’imperfection attachées à ces données.Nous avons cité aussi les différents objectifs de fusion qui sont multiples et nous nous sommesconcentrés sur la classification des images qui est l’une des finalités de ce travail. Nous avonsintroduit brièvement les principales approches mathématique utilisées pour réaliser la fusionqui sont la théorie des ensembles flous, la théorie des probabilités, la théorie des possibilités, lathéorie de Dempster Shafer et finalement la théorie du raisonnement plausible et paradoxale.

Chapitre 2Les approches de fusion d’information
2.1 Introduction
La fusion d’information nécessite des formalismes qui permettent de réaliser la combinaisondes données acquises. Cependant, les résultats de fusion peuvent être erronés et ceci est
dû aux différentes formes d’imperfection qui accompagnent les informations et principalementà l’imprécision, l’incertitude et le conflit.Plusieurs approches permettent de modéliser l’incertitude. Nous citons par exemple la théoriedes probabilités qui est la théorie la plus ancienne et la plus utilisée dans telles situations.Néanmoins, elle ne peut pas tenir compte de l’imprécision et souvent elle conduit à confondreentre ces deux notions (incertitude et imprécision). Pour faire face à ce problème, de nouvellesthéories ont été développées et utilisées.Ces théories se reposent sur des fondements mathématiques qui permettent de modéliser lesphénomènes réels et les imperfections des informations. Parmi lesquelles on trouve la théoriedes possibilités, la théorie des probabilités imprécises, la théorie des fonctions de croyanceavec les différentes extensions qui en découlent comme le modèle de croyance transférableproposé par Smets [73] et la récente théorie du raisonnement plausible et paradoxale proposéepar Dezert et Smarandache [70, 71, 70, 30].
Nous nous intéresserons dans ce chapitre en premier lieu à la théorie des possibilités. Parla suite nous exposerons la théorie des fonctions de croyance. Ensuite, nous introduirons lesfondements de la nouvelle théorie du raisonnement plausible et paradoxale. Par la suite nouscomparerons ces trois approches de fusion. Finalement,avant de conclure nous allons exposernotre stratégie de choix d’un formalisme de fusion selon les informations acquises .

Chapitre 2. Les approches de fusion d’information 19
2.2 Théorie des possibilités
La théorie des possibilités fondée par Zadeh, appelée également théorie des possibilitéset des ensembles flous. Elle est induite par la théorie des ensembles flous introduite aussipar Zadeh [82]. Cette théorie été essentiellement développée par Dubois et Prade en France[39]. Elle se repose sur la fonction de distribution de possibilités qui permet de traiter etmodéliser à la fois l’incertitude et l’imprécision. Cette théorie était l’objet de plusieurs travauxscientifiques[2, 36, 62, 26].Le terme “possibilité”peut supporter plusieurs interprétations. Les plus connues et les plusutilisées sont :
– La première interprétation est “la faisabilité”comme dans l’exemple suivant : il est pos-sible de réparer cet ordinateur.
– Deuxièmement, il y a l’idée de plausibilité comme dans les expressions telle que “il estpossible que quelque chose se produit”.
– Une autre vision de la «possibilité» est celui de la cohérence (c’est-à-dire ne pas secontredire) avec l’information disponible dans l’expression “il est possible qu’il pleuvrademain”.
2.2.1 Éléments de la théorie des ensembles flous
Sous-ensembles flous : Un ensemble classique ou net est composé d’éléments qui satisfontà des propriétés précises. Ainsi, des éléments qui ne satisfont pas ces propriétés n’appar-tiennent pas à cet ensemble. Soient Ω un ensemble net, et X un élément de Ω. Un sousensemble A peut s’écrire à partir de sa fonction caractéristique χA de Ω dans 0,1 :
χA(x) =
1 si x ∈ A0 si x /∈ A
(2.1)
C’est une fonction binaire qui vérifie l’appartenance d’un point x de Ω à A. La théoriedes sous-ensembles flous propose une fonction d’appartenance qui vérifie l’appartenancegraduelle. Ainsi, la fonction caractéristique est une fonction d’appartenance particulière.
Fonction d’appartenance : Un sous-ensemble flou F de Ω est défini par une fonction d’ap-partenance µF (x) qui à tout x de Ω associe une valeur réelle µF (x) dans [0,1] représentantle degré d’appartenance de x au sous-ensemble flou F.Les fonctions d’appartenance décrivent le degré d’appartenance partiel d’un élément àune classe et n’associent pas de bornes strictes. Le degré d’appartenance d’un élémentx à un sous-ensemble flou A est généralement notée µA(x). La fonction d’appartenance

Chapitre 2. Les approches de fusion d’information 20
est alors illustrée par :
µA
Ω 7→ [0, 1]x 7→ µA(x) (2.2)
2.2.2 Fondements de la théorie des possibilités
Univers du discours :Soit Ω le référentiel de définition appelé aussi univers du discours qui présente l’ensemblede toutes les hypothèses possibles modélisant le problème de fusion.
Ω = ω1, ω2, · · · , ωn (2.3)
Distribution des possibilités :La distribution de possibilités notée π est la fonction fondamentale de la théorie despossibilités. Elle associe à chaque hypothèse de Ω un degré de possibilité. La distributionde possibilités est une fonction de Ω dans [0,1] qui vérifie :
supω∈Ωπ(ω) = 1 (2.4)
En d’autre terme, il existe au moins un événement de Ω tel que son degré de possibilitéest égal à 1.Avec π(ω) présente le degré de possibilité pour que l’observation x soit égale à ω sachantque :– Si π(ω) = 0, cela indique qu’il est impossible que x soit égale à ω.– Si π(ω) = 1, cela indique que rien n’empêche que x vaille ω.Soient ω1 et ω2 deux évènements si ω1 ≥ ω2 cela indique que l’égalité entre x et ω1 estplus plausible que l’égalité entre x et ω2.Une information précise est modélisée par la distribution de possibilités comme l’indiquel’expression suivante :
∃! ω0 ∈ Ω tels que
π(ω0) = 1π(ω) = 0 ∀ ω 6= ω0
(2.5)
Cependant, on est dans le cas de l’ignorance totale lorsque :
∀ ω ∈ Ω, π(ω) = 1 (2.6)
Mesure de possibilité :Une mesure de possibilité notée Π est une fonction de 2Ω (l’ensemble des parties de Ω)

Chapitre 2. Les approches de fusion d’information 21
dans [0,1] qui vérifie le système d’équations suivant :
Π(∅) = 0Π(Ω) = 1∀A ∈ 2Ω,Π(A) = supπ(x), x ∈ A
(2.7)
Plus la valeur de possibilité de l’évènement est proche de 1 plus sa réalisation est possible.Si la possibilité d’un événement est nulle cela signifie que cet évènement est impossible.La mesure et la distribution de possibilité permettent de quantifier et de modéliserl’imprécision de l’information.
Mesure de nécessité :Une mesure de nécessité notée N est une fonction de 2Ω dans [0,1] qui vérifie les équationssuivantes :
N(∅) = 0N(Ω) = 1∀A ∈ 2Ω, N(A) = inf1− π(x), x /∈ A
(2.8)
L’équation 2.9 est une équation équivalente de cette définition qui montre la relationentre la mesure de nécessité et la mesure de possibilité.
∀A ∈ 2Ω, N(A) = 1− Π(A) (2.9)
où A désigne le complémentaire de A. La valeur prise d’un évènement donné A par lafonction de nécessité indique le degré de certitude de la réalisation de cet évènement.Plus ce degré est proche de 1 plus il est certain que cet évènement se réalise.
Axiomes de la théorie des possibilités :
∀A,B ⊂ Ω,Π(A ∪B) = max(Π(A),Π(B)) (2.10)∀A,B ⊂ Ω, N(A ∩B) = min(N(A), N(B)) (2.11)
Propriétés de la théorie des possibilités :
∀A ⊂ Ω,max(Π(A),Π(A)) = 1 (2.12)
Ceci veut dire que l’un des deux évènements A et A est complètement possible.
∀A ⊂ Ω,min(N(A), N(A)) = 0 (2.13)
Ceci veut dire que deux événements contraires ne peuvent pas être nécessaires en mêmetemps.
∀A ⊂ Ω, N(A) +N(A) ≤ 1 (2.14)∀A ⊂ Ω,Π(A) + Π(A) ≥ 1 (2.15)

Chapitre 2. Les approches de fusion d’information 22
2.2.3 Fusion par la théorie des possibilités
2.2.3.1 Modélisation
La première tâche de cette étape de fusion consiste à déterminer les différentes hypothèsesqui constituent l’univers du discours Ω. Supposons que nous disposons de m sources, on notepar Sj la source numéro j avec j ∈ 1, ...,m.On note par πjx(ωi) le degré de possibilité pour que la décision numéro i soit valide pourl’observation x selon la source Sj. La relation entre les deux expressions floue et possibilistes’expriment par :
πjx(ωi) = µjωi(x) (2.16)
En termes de classification, c’est le degré de possibilité pour que la vraie classe de l’obser-vation x soit la classe numéro i.
2.2.3.2 Estimation
L’estimation des distributions des possibilités est l’étape la plus difficile. En effet, iln’existe pas de méthode universelle unique pour déterminer la distribution de possibilité etla construire. Généralement l’estimation des distributions des possibilités se fait de la mêmemanière que l’estimation des fonctions d’appartenance au sien de la théorie de sous-ensemblesflous. Donc les méthodes utilisées dans la théorie des sous-ensembles flous sont applicablesdans le cadre de la théorie des possibilités.
La construction d’une distribution de possibilités doit se faire en fonction de la connais-sance disponible qui peut se présenter sous différentes formes (données capteurs, avis d’ex-perts,...) et donc il n’y a pas de forme générale. Les formes linéaires sont fréquentes pour desraisons de simplicité des calculs ultérieurs.La distribution de possibilités peut prendre plusieurs formes. Nous citons les plus connues quisont la forme triangulaire, la forme trapézoïdale et la forme gaussienne. Leurs fonctions sontdes fonctions L-R.
On se donne deux fonctions de forme L(left) et R(right) de <+ dans [0,1], symétriques,non décroissantes sur [0,+∞ [, telles que L(0) = R(0) = 1. Un nombre flou, noté (a−, a+, α,
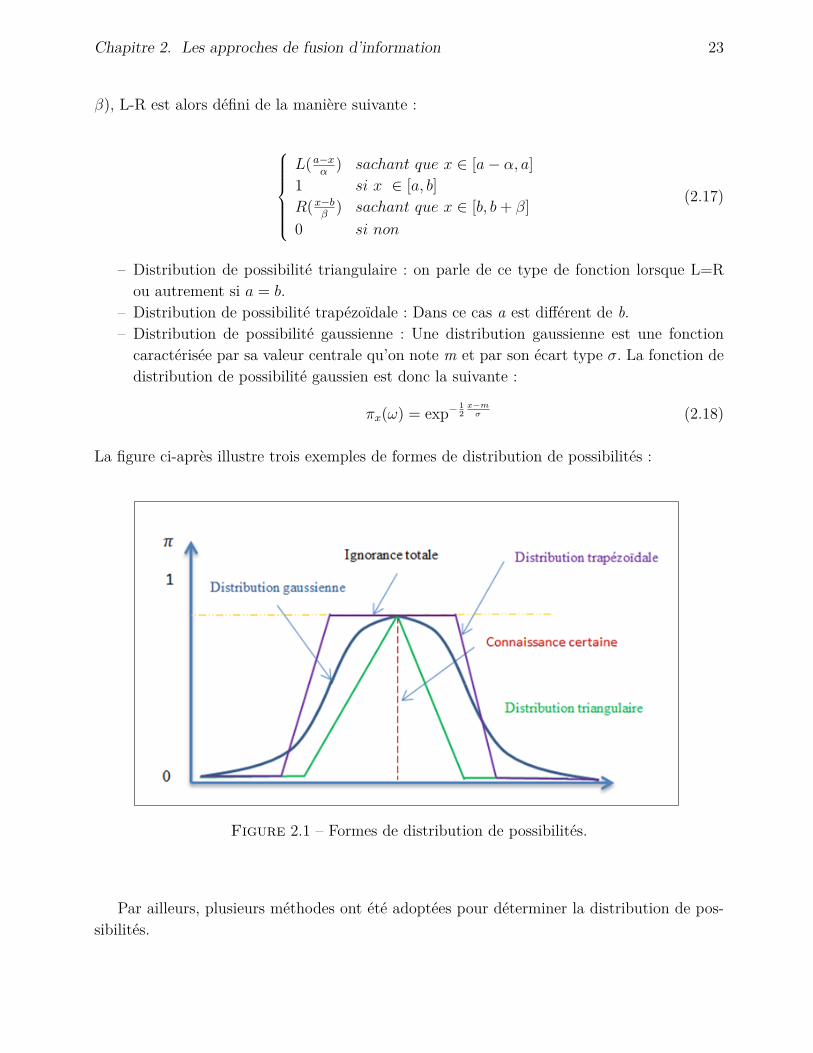
Chapitre 2. Les approches de fusion d’information 23
β), L-R est alors défini de la manière suivante :
L(a−x
α) sachant que x ∈ [a− α, a]
1 si x ∈ [a, b]R(x−b
β) sachant que x ∈ [b, b+ β]
0 si non
(2.17)
– Distribution de possibilité triangulaire : on parle de ce type de fonction lorsque L=Rou autrement si a = b.
– Distribution de possibilité trapézoïdale : Dans ce cas a est différent de b.– Distribution de possibilité gaussienne : Une distribution gaussienne est une fonctioncaractérisée par sa valeur centrale qu’on note m et par son écart type σ. La fonction dedistribution de possibilité gaussien est donc la suivante :
πx(ω) = exp− 12x−mσ (2.18)
La figure ci-après illustre trois exemples de formes de distribution de possibilités :
Figure 2.1 – Formes de distribution de possibilités.
Par ailleurs, plusieurs méthodes ont été adoptées pour déterminer la distribution de pos-sibilités.

Chapitre 2. Les approches de fusion d’information 24
1. Les transformations histogrammes-possibilités :Plusieurs méthodes ont été proposées dans la littérature pour passer d’une distributionde probabilités à une distribution de possibilités.Dubois et Prade proposent de définir une distribution de possibilité à partir d’un histo-gramme [38, 37]. Une condition de cohérence entre la probabilité et la possibilité est :
∀A un sous− ensemble : P (A) ≤ Π(A) (2.19)
D’où l’histogramme donne une distribution de probabilités P pour chaque élément ω deΩ :
π(ωi) =n∑k=1
min(P (ωi), P (ωk)) (2.20)
La fonction de distribution de possibilités est complètement définie si on connaît toutesles mesures associées à chaque élément de l’univers du discours.Une autre formule définie par Dubois et Prade :
π(ωi) =∑
P (ωj)≤P (ωi)P (ωj) (2.21)
2. Méthode basée sur l’histogramme de niveaux de gris :(a) Méthode proposée par Bloch :
Bloch [11] a proposé une méthode non supervisée pour estimer les degrés d’ap-partenance à partir des données statistiques. Cette étude résout deux problèmes :comment définir le critère que la fonction d’appartenance doit vérifier et commentles optimisées. Bloch a énoncé deux types de critères :– Le premier est basé sur une ressemblance entre les niveaux de gris de l’histo-gramme et la fonction d’appartenance sous la forme d’une distance entre lesdeux distributions.
– Le deuxième prend en compte l’information a priori concernant la forme espéréede la fonction d’appartenance. Une des informations à priori est le fait que lespixels appartenant à la classe i sans aucune ambiguïté doivent avoir leur fonctiond’appartenance à cette classe égale à 1, quelle que soit la fréquence d’apparitionde ses caractéristiques associées.
Cette approche se fait en deux étapes :– Estimation de la fonction µi′ qui minimise le critère de distance pour l’histo-gramme.
– Normalisation de µ en fonction de µi′ afin d’inclure l’information a priori.Les fonctions µi sont définies ici comme des fonctions trapézoïdales.
(b) Méthode proposée par Dou :Cette méthode définie dans [35] consiste également à estimer la distribution depossibilité à partir de l’histogramme de niveaux de gris. Son principe se résumepar les étapes suivantes :

Chapitre 2. Les approches de fusion d’information 25
– Analyse des caractéristiques de l’histogramme : Après la construction et la nor-malisation de l’histogramme Dou met en évidence les caractéristiques de l’histo-gramme :Les pics : Par exemple les pics relient la population locale de pixels avec leurs
niveaux de gris. Cette méthode a été appliquée sur les images IRM de cerveauoù Il y a trois pics : il résulte que le pic le plus élevé correspond à la matièregrise MG, le second à la matière blanche MB et le troisième au liquidecéphalo-rachidien LCR.
les vallées : La vallée signifie une transition du niveau de gris d’un tissu à unautre.
– Définir des relations entre les niveaux de gris et les fonctions d’appartenance.– Génération des fonctions d’appartenance.
3. Les approches psychométriques :Ce sont les différentes méthodes permettant d’interroger un expert afin de lui fairenumériser un concept linguistique. Il s’agit d’un exercice de psychométrie. Il existeplusieurs méthodes psychométriques pour l’obtention de la fonction d’appartenance.(a) Méthodes noyaux supports :
Il s’agit d’interroger l’expert de manière à lui faire définir le noyau et le supportde la fonction d’appartenance. Ainsi, l’expert est appelé à faire produire quatreparamètres (p1, p2, p3 et p4). Ces paramètres permettent de construire une fonctionde maximum 1 atteinte sur [p2, p3] et de minimum 0 à l’extérieur de [p1, p4] noncroissante sur [p3,p4] et non décroissante sur [p1,p2].
(b) Méthode grille répertoire :Cette méthode de "grille répertoire" [61] consiste à interroger l’expert afin de luifaire préciser la signification de termes vagues à l’aide de d’autres termes linguis-tiques eux-mêmes vagues. Les résultats répertoriés dans une grille seront ensuiteconvertis en numériques. Pour chaque terme flou, l’expert fournit le terme anta-goniste (i.e., pour "grand" l’expert répond "petit"). Une échelle bipolaire est ainsicréée graduée de 1 à 5 par exemple (i.e., elle peut être graduée de 1 à 3 ou de 1à 9) de telle sorte que les chiffres représentent pour l’expert : 1 : très grand ; 2 :grand ; 3 : taille moyenne ; 4 : petit ; 5 : très petit.
Plusieurs autres méthodes ont été utilisées, nous citons par exemple : le C-moyens flous, leC-moyens possibiliste et les réseaux de neurones.

Chapitre 2. Les approches de fusion d’information 26
2.2.3.3 Combinaison
L’un des intérêts majeurs de la fusion par la théorie des possibilités est la grande variétéd’opérateurs de fusion permettant la combinaison des distributions de possibilités.Le grand nombre des opérateurs pousse à un classement de ceux-ci afin de permettre le choixde l’opérateur le plus adéquat à l’application. Ce choix peut se faire selon plusieurs critèresliés aux propriétés des opérateurs [9]. Il est courant de considérer les opérateurs conjonctifs,disjonctifs ou de compromis, c’est-à-dire qui ont respectivement des comportements sévères,indulgents ou prudents.
Opérateurs conjonctifs : Ils combinent l’information à la façon d’un “ET logique”(conjonction). De cette façon le résultat sera proche de 1 si et seulement si toutes les valeursà combiner sont proches de 1. Parmi ces opérateurs les normes triangulaires ou t-norme sontles plus employées et permettent de réduire légèrement cette sévérité.Voici quelques t-normes pour deux sources S1 et S2.
– T-norme de Zadeh :π(ω) = min(πS1(ω), πS2(ω)) (2.22)
– T-norme probabiliste :π(ω) = πS1(ω) ∗ πS2(ω) (2.23)
– T-norme Lukasiewicz :
π(ω) = max(0, πS1(ω) + πS2(ω)− 1) (2.24)
Les opérateurs conjonctifs sont généralement utilisés lorsque les sources sont concordantes etfiables.
Opérateurs disjonctifs : Ils combinent l’information à la façon du “OU logique ” (dis-jonction). La valeur du résultat de la combinaison sera grande dès lors qu’une des valeurscombinées le sera. Le comportement sera donc indulgent.Les principaux opérateurs disjonctifs sont les conormes triangulaires ou t-conormes.Voici quelques t-conormes appliquées pour deux sources S1 et S2 :
– T-conorme de Zadeh :π(ω) = max(πS1(ω), πS2(ω)) (2.25)
– T-conorme probabiliste :
π(ω) = πS1(ω) + πS2(ω)− πS1(ω) ∗ πS2(ω) (2.26)

Chapitre 2. Les approches de fusion d’information 27
– T-conorme Lukasiewicz :
π(ω) = min(πS1(ω) + πS2(ω)− 1, 1) (2.27)
On fait recourt à ce type d’opérateur lorsque les sources sont discordantes et non fiables.
Opérateur de compromis : Ils ont un comportement moins sévère que les opérateursconjonctifs et moins indulgent que les opérateurs disjonctifs.Nous citons ici un opérateur introduit par Dubois et Prade. Cet opérateur est adaptatif enfonction du conflit entre les sources. Il se comporte comme un minimum s’il y a peu de conflitentre les sources et comme un maximum si le conflit est élevé.Une mesure du conflit est introduite notée h et calculée de la manière suivante :
h = maxω(min(πS1(ω), πS2(ω))) (2.28)
L’opérateur est donc :
π(ω) = max(min(πS1(ω), πS2(ω))h
,min(max(πS1(ω), πS2(ω)), 1− h)) (2.29)
Il existe d’autres catégories d’opérateurs de combinaisons telles que : les opérateurs demoyenne, les intégrales floues...[14, 50]
2.2.3.4 Décision
La décision se fait généralement par la maximisation d’un critère. Une fois les informationsissues des sources combinées, la décision se fait par la maximisation de la possibilité ou bienpar de la nécessité. Ainsi, on choisit la décision dk si :
πk(x) = max(πi(x), i = 1..n) (2.30)
2.2.4 Applications de la théorie des possibilités
Comme nous avons déjà mentionné, la théorie des possibilités a été l’objet de plusieurstravaux de recherche. Nous présentons ici de manière non exhaustive quelques applicationsde cette théorie intéressante.
– En robotique : la théorie des possibilités est utilisée pour la localisation des robots àl’aide de capteurs à infra-rouge et oedométrique [49].

Chapitre 2. Les approches de fusion d’information 28
– En traitement d’image : on trouve dans la littérature abondante plusieurs applica-tions de cette théorie, nous citons par exemple : la reconnaissance de partitions musicalesà partir d’images optiques afin d’automatiser l’archivage et d’autres travaux qui étudientla reconnaissance d’images médicales 3D du cerveau pour la détection d’anomalies[11].Dans [65] deux approches de combinaison (par priorité et adaptative) sont étudiées àdes fins de classification d’images satellites. En outre, elle est exploitée pour faire lasegmentation à partir d’une représentation symbolique de la luminance et des nuances.Fusion des mesures de déplacement issues de l’imagerie SAR : on cherche à reconstruirele déplacement 3D de la surface terrestre à partir d’un nombre croissant de projectionsissues de l’imagerie SAR [81].
– En classification : citons la classification d’objets sous-marins [20], de comportementsou de données radar où l’intégrale de Sugeno et différentes combinaisons (conjonctiveset disjonctives) sont comparées. Dans le cadre de la classification d’images sonar Mar-tin [50] compare la théorie des possibilités, la théorie des croyances et la méthode devote pour faire la fusion des classifieurs et dans ce contexte la théorie des possibilités adonnée des résultats intéressants.
– Gestion des risques : risque sismique : dans [62] une méthodologie pour représenterles incertitudes épistémiques à savoir celles liées à une information vague, incomplèteou imprécise, l’expert est cependant souvent capable de donner beaucoup plus d’infor-mation à savoir des plages de valeurs préférentielles pour chaque alternative. Dans cecontexte, la théorie des possibilités a été appliquée sur l’exemple de la chaîne de traite-ment du risque sismique ARMAGEDOM, développée au BRGM avec une applicationsur le scénario sismique de la ville de Lourdes.
– Géophysiques : depuis ces dernières années, la théorie des possibilités commence àattirer l’attention pour gérer les incertitudes en géosciences, notamment les incertitudesépistémiques. Dans ce contexte [81] propose trois stratégies de fusion et différentes repré-sentations d’incertitude afin de réduire l’incertitude associée d’une part à l’estimationdu déplacement en 3 dimensions (3D) à la surface de la terre, d’autre part à la modéli-sation physique qui décrit la source en profondeur du déplacement observé en surface.
– Diagnostique des défauts : dans ce contexte [15] propose une approche qui traitel’incertitude et l’incomplétude et applique cette extension dans une application de diag-nostic de défaut par satellite.
– Autre domaine : Assaghir [5] a utilisé la fusion dans le cadre possibiliste dans ledomaine agricole. En effet, la question de l’expert est d’estimer des valeurs des caracté-ristiques de pesticide provenant de plusieurs sources pour calculer des indices environ-

Chapitre 2. Les approches de fusion d’information 29
nementaux et détaillés pour évaluer la méthode de fusion proposée. Et dans ce cadrede ce travail [5] a considéré les informations numériques représentées dans le cadre dela théorie des possibilités.
2.2.5 Intérêts et limites de la théorie des possibilités
2.2.5.1 Intérêts
La théorie des possibilités présente un cadre théorique intéressant qui permet de fusionnerles informations hétérogènes et ceci grâce à sa capacité de :
– Modéliser et interpréter les informations d’une manière qui facilite le calcul des distri-butions de possibilités (les différentes formes linaires : triangule, trapèze ...).
– Tenir compte de l’information spatiale en traitement d’images.– Combiner des informations très variées grâce à la richesse et la souplesse des opérateursproposés.
– Gérer le conflit faible grâce aux opérateurs adaptatifs.– Distinguer les états plausibles, les états peu plausibles et utilisation d’ensembles flousde valeurs mutuellement exclusives.
– Représenter des informations très hétérogènes extraites directement des images ou issuesde connaissances externes comme des connaissances des experts ou génériques sur undomaine ou un problème.
En revanche, la complexité combinatoire n’est généralement pas élevée et cela revient à lasimplicité des opérateurs qui ne demandent généralement pas un grand nombre d’itération etaussi à la cardinalité de l’univers du discours qui ne contient que des singletons.
2.2.5.2 Limites
Malgré la simplicité de la théorie des possibilités et la richesse des opérateurs proposés, lathéorie des possibilités ne permet pas de prendre en compte :
– Le conflit élevé entre les sources.– L’incertitude aléatoire.– L’ambiguïté et l’ignorance totale (méconnaissance).
Par ailleurs, bien que la variété des opérateurs est un avantage certain, le choix d’un opérateuradéquat au problème étudié devient difficile face à ce grand nombre d’opérateurs proposés.Un autre limite de ce formalisme qui se résume par son impuissance de fusionner des sourcesayant des univers du discours complémentaires (différents).

Chapitre 2. Les approches de fusion d’information 30
2.3 Théorie des fonctions de croyance
La théorie de Dempster Shafer (DST) était à la base de la théorie des fonctions de croyance(TFC). Cette théorie a été introduite par Dempster puis développée par Shafer [67], elle estappelée aussi théorie de l’évidence. Elle se repose sur un fondement mathématique solide quipermet de donner des solutions satisfaisantes en terme de modélisation [79, 10].
2.3.1 Fondements de la théorie des fonctions de croyance
2.3.1.1 Cadre de discernement
Le cadre de discernement noté Ω contient toutes les hypothèses nécessaires pour décrirele problème de fusion.
Ω = ω1, ω2, ..., ωn (2.31)
Ce cadre doit être exhaustif c’est-à-dire il doit contenir toutes les hypothèses possibles quidécrivent le problème abordé. En revanche, une situation peut toujours être décrite par unehypothèse d’oméga. En outre, les hypothèses doivent être mutuellement exclusives c’est-à-direaucune hypothèse ne peut être exprimée à l’aide de d’autres hypothèses. Plus précisément leséléments sont deux-à-deux disjoints ce qui conduit à l’unicité de la solution. Contrairement àla théorie des possibilités, le raisonnement ici porte sur 2Ω qui représente l’ensemble de toutesles parties de Ω. En effet, 2Ω appelé “power-set ”ou bien ensemble des puissances qui contientà côté des singletons (hypothèses simples) les sous-ensembles formés par la disjonction dessingletons.Exemple : Soit oméga un cadre formé de trois hypothèses : Ω = ω1, ω2, ω3
2Ω = ∅, ω1, ω2, ω3, ω1 ∪ ω2, ω1 ∪ ω3, ω2 ∪ ω3
La cardinalité de l’ensemble des parties est égale à 2(|(Ω)|) avec |.| représente la cardinalité deΩ.

Chapitre 2. Les approches de fusion d’information 31
2.3.1.2 La fonction de masse
La fonction fondamentale de cette théorie est appelée fonction de masse notée m(.). Ellepermet d’associer à chaque élément de 2Ω un degré de confiance dans [0,1] :
m : 2Ω 7→ [0, 1]A 7→ m(A) (2.32)
Cette fonction doit vérifier les axiomes suivants :
m(∅) = 0m(Ω) = 1∑A∈2Ω m(A) = 1
(2.33)
L’entité m(A) est appelée masse de A et elle représente la confiance portée strictementdans A sans que celle-ci puisse être répartie sur les hypothèses singletons qui la composent.On appelle éléments focaux les éléments de 2Ω de masse non nulles.Une proposition B ∈ 2Ω, par exemple B = ω1 ∪ ω2, représente explicitement le doute entreles hypothèses composant B mais la masse de croyance m(B) allouée à B ne donne aucuneinformation sur les hypothèses et sous-ensembles formant B.Ainsi, les masses correspondantes aux hypothèses simples expriment la certitude d’une classepar rapport aux autres alors que les masses correspondantes aux hypothèses composées ex-priment la confusion associée au manque d’information pour décider entre une classe ou uneautre.
2.3.1.3 La fonction de croyance
La fonction de croyance déterminée à partir des fonctions de masse est notée Cr(A) mesureà quel point les informations données par la source soutient l’hypothèse A. Autrement c’estla croyance que la vérité est dans A. Elle est définit de 2Ω dans [0,1] et vérifie :
∀A ∈ 2Ω, Cr(A) =∑B⊆A
m(B) (2.34)

Chapitre 2. Les approches de fusion d’information 32
2.3.1.4 La fonction de plausibilité
La fonction de plausibilité notée Pl(A) dénote la plausibilité que la vérité est dans A. C’estaussi la somme des masses des propositions dont l’intersection avec A est non nulle. Elle estdéfinie de 2Ω dans [0,1] et vérifie :
∀A ∈ 2Ω, P l(A) =∑
B∩A 6=∅m(B) (2.35)
2.3.2 Fusion par la théorie des fonctions de croyance
2.3.2.1 Modélisation
La première tâche de modélisation consiste à définir le cadre de discernement qui dépendde l’application. Si le problème est un problème de classification, les différentes hypothèsesqui forment le référentiel du travail représentent les différentes classes possibles. La secondetâche est donc la construction de l’ensemble des parties 2Ω.
2.3.2.2 Estimation
Comme la théorie des possibilités cette phase est difficile. L’estimation des fonctions demasse est un problème délicat est crucial. En effet, il n’existe pas de méthodes mathématiquesuniverselles permettant de réaliser cette étape. En revanche, le choix d’une méthode dépenddu problème abordé et des informations acquises. Voici quelques méthodes d’estimation desfonctions de masse :
– Modèles probabilistes :Il y a des travaux qui ont estimé la masse de croyance en se basant sur des probabilitésconditionnelles et une normalisation à la phase de combinaison.– Estimation de masse bayésienne :Elle est la méthode la plus simple pour l’estimation des masses. D’ailleurs, on utilisesouvent cette méthode pour un premier test d’estimation des fonctions de masse.
– Modèle de transfert d’Appriou :Dans le modèle initial, Appriou [3] suppose que la densité de probabilité p(xj/ωi)soit connue, elle est estimée à partir des données issues de la source Sj pour cha-cune des classes singletons constituant le cadre de discernement Ω. Au départ, lamasse entière est associée aux hypothèses disjointes ωi. En respectant les axiomes

Chapitre 2. Les approches de fusion d’information 33
de cohérence avec la théorie des probabilités, Appriou [3] a développé un modèle quine considère que deux classes seulement : une classe d’intérêt et sa classe complé-mentaire. Généralement les problèmes de fusion traitent des cas où la cardinalité ducadre de discernement est supérieure à deux. Il est donc nécessaire de généraliser cetteapproche pour le cas de plus de deux classes.
– Modèles de distance :Les travaux d’estimation des fonctions de masse en utilisant l’algorithme des plusproches voisins ont commencé avec Denoeux [22] au milieu des années 90. Des travauxrécents utilisent les Kpp (K-plus-proches voisins) font un mixage avec le flou.
– Estimation des fonctions de masse sur des sous-ensembles flous :Le raisonnement évidentiel flou nécessite l’estimation de fonctions de masse sur deséléments focaux flous afin de modéliser l’incertitude floue contenue dans l’informationtraitée [44, 67]. Les méthodes d’estimation de ces fonctions de masse diffèrent d’uneapplication à une autre.
– Estimation de fonctions de masse en utilisant les C-moyennes floues :Un algorithme évidentiel des C-moyennes (ECM : Evidential C-Means) qui opère surdes partitions crédales. Les partitions crédales sont plus générales que les partitionsnettes, floues et possibilistes. Le nombre de degrés de liberté est plus important que dansd’autres types de partitions et ce qui permet donc d’envisager une meilleure modélisationet une description plus riche de données complexes.
– Estimation à partir des histogrammes :D’autres approches ont été proposées pour l’estimation des fonctions de masse. Rombautet Zhu [64] proposent une approche pour les cas où x est dans un espace à une dimensionfacilement représentable par un histogramme. Les masses sur les hypothèses composéessont définies dans les zones de recouvrement et chaque pic correspond à un singleton.Toute la difficulté réside dans la détermination des seuils de l’histogramme mais cetteapproche conduit à des résultats intéressants en segmentation d’images médicales [77, 64]ou d’images sonar [56].
2.3.2.3 Combinaison
La combinaison des informations provenant de différentes sources vise à exploiter cettedifférence afin d’obtenir une fonction de masse combinée plus focalisée que les fonctions demasse initiales.
Une diversité d’opérateurs a été proposée pour accomplir la combinaison au sein de laTFC. Cependant, l’opérateur conjonctif de Dempster est le plus utilisé. L’opérateur de sommeorthogonal proposé par Dempster fait la combinaison en affectant la masse a des propositionsdont le nombre d’élément est plus faible que celui des propositions initiales. Pour deux sources

Chapitre 2. Les approches de fusion d’information 34
S1 et S2 cette règle s’écrit comme suit :
∀A ∈ 2Ω,m(A) = [ms1 ⊕ms2 ](A) =∑
B∩C=AmS1(B) ∗mS2(C) (2.36)
Cette forme est appelée la forme non normalisée ou bien règle de Dempster non normalisée.L’inconvénient de cette forme c’est que la masse de vide peut être différente de zéro ce qui estinacceptable car la masse de vide doit être égale à zéro. Cet inconvénient pousse à normaliserla règle conjonctive comme suit :
k = ∑
C1∩C2=∅ms1(C1) ∗ms2(C2)
∀A ∈ 2Ω,m(A) = [ms1 ⊕ms2 ](A) = ∑B∩C=A
ms1 (B)∗ms2 (C)1−k
(2.37)
k est appelée masse de vide ou encore inconsistance de fusion. Elle permet de modéliserle conflit entre les sources.La constante k appartient à l’intervalle [0,1]. Lorsque k est très grande (i.e. très proche de1) les sources sont très conflictuelles et leur fusion dégrade la qualité si on applique cetterègle. Cependant, si k égal à 1 la somme orthogonale n’existe pas dans ce cas les sources sonttotalement contradictoires et leur fusion devient impossible.
Des travaux ont prouvé que la combinaison avec la règle de Dempster normalisée peut êtreentachée d’erreur lorsque le conflit est élevé. Par ailleurs, une variété de règles a été proposéepour gérer ce problème nous citons quelques uns : la règle disjonctive, la règle de Smets et larègle de Yager [14, 50, 59].
2.3.2.4 Décision
La théorie des fonctions de croyance offre plusieurs critères pour réaliser la décision qui sebase sur la maximisation. Le choix de la règle de décision dépend généralement de l’applicationou du problème abordé. Voici les règles de décision les plus utilisées :
1. Maximum de crédibilité :Ce critère de décision consiste à choisir la classe (l’hypothèse) qui a la plus grande valeurde crédibilité. Ainsi, pour l’observation x on décide Ai si :
Cr(Ai)(x) = maxCr(Aj)(x), 1 ≤ j ≤ |2Ω| (2.38)
Ce critère constitue un critère pessimiste. En effet, l’utilisation de cette règle a pour butde favoriser les singletons en donnant le minimum de chance aux disjonctions. Ainsi,elle ne retient que les éléments qui ont un degré d’incertitude minimale.

Chapitre 2. Les approches de fusion d’information 35
2. Maximum de plausibilité :Un deuxième critère qui permet de choisir la décision qui a le maximum de plausibilité.Donc pour chaque observation donnée la décision se fait comme suit :
Pl(Ai)(x) = maxPl(Aj)(x), 1 ≤ j ≤ |2Ω| (2.39)
Ce critère est moins sélectif que le premier. Il correspond à la recherche la plus optimistede solution qui favorise généralement les classes qui ont un maximum d’incertitude.
3. Maximum de probabilité pignistique :La probabilité pignistique introduite par Smets [72]. Elle répartit équitablement lesmasses placées sur des éléments différents d’un singleton sur les singletons qui les com-posent ainsi, pour chaque élément de 2Ω la probabilité se calcule comme suit :
BetP (A) =∑
B∈2Ω,B 6=∅
|A ∩B||B|
m(B) (2.40)
Le critère de maximum de probabilité pignistque constitue un critère prudent. Ainsi,cette règle revient à décider ωi pour l’observation x si :
BetP (ωj)(x) = maxBetP (ωj)(x), 1 ≤ j ≤ |Ω| (2.41)
2.3.3 Applications de la théorie des fonctions de croyance
La modélisation sur un espace d’hypothèses composées sur 2Ω est un avantage qui a pousséplusieurs chercheurs à étudier la théorie des fonctions de croyance et l’appliquer dans plusieursdomaines tels que l’analyse de données, le diagnostic, l’aide à la décision, la perception multi-capteurs et le traitement d’image.
– La classification : la classification est sans doute l’application la plus étudiée avec touttype de donnée. Plus particulièrement en traitement d’images : le traitement d’imagestelles que satellitaires [1, 7], optiques (segmentation, fusion de pixels), ainsi que lesimages sonar haute fréquence (caractérisation de sédiments) et basse fréquence (détec-tion de mines enfouies) et davantage les images radar [51] a fait l’objet de plusieurstravaux de recherche.
– Localisation des robots : la localisation est un problème souvent abordé en fusiond’information en général. La théorie des croyances a été employée et adaptée pour lalocalisation de robots à partir d’images à ultrason. Mais aussi pour l’exploitation d’unréseau autoroutier.

Chapitre 2. Les approches de fusion d’information 36
– Applications d’imagerie médicale : diagnostic : Bloch et Maitre montrent dans [14]l’intérêt de la théorie des fonctions de croyance dans les applications de fusion d’imagespour la classification, la segmentation ou la reconnaissance et les avantages par rap-port aux approches classiques probabilistes et bayésiennes. Leur document illustre unegrande flexibilité des modélisations possibles prenant en compte à la fois l’incertitudeet l’imprécision, l’ignorance partielle ou globale, la fiabilité des sources, la capacité dechaque source à fournir des informations fiables ou non sur chaque classe, des infor-mations a priori qui ne sont pas forcément représentables par des probabilités, etc...L’illustration est faite sur un cas d’application de diagnostic médical pour la mise enévidence des zones de volume partiel. La décision a été prise en faveur d’une hypothèsecomposée s’adaptant au mode de raisonnement du médecin [10].
– Reconnaissance du visage : dans le travail [45], Hammal s’est intéressée à la segmen-tation des yeux, des sourcils et la reconnaissance des expressions faciaux pour pouvoirmodéliser le doute entre plusieurs expressions et le cas des expressions inconnues. LeModèle de Croyance Transférable (MCT une extension de la TFC proposée par Smets[73]) est utilisé comme processus de fusion pour la classification des expressions faciales.
2.3.4 Intérêts et limites de la théorie des fonctions de croyance
2.3.4.1 Intérêts
la TFC présente un formalisme de fusion intéressant et cela revient à :– Sa modélisation riche et souple qui vient du fait de pouvoir raisonner sur des hypothèsescomposées ce qui permet d’offrir un cadre plus sophistiqué pour traiter l’incertitude.
– Son pouvoir de traiter et de gérer plusieurs formes d’imperfections tels que l’imprécision,l’incertitude, l’ambiguïté, l’ignorance partielle et totale et le conflit partiel, en analysantles capacités de chaque source à donner une information sur chaque décision possible.
– Son pouvoir de fusionner des sources distinctes et complémentaires qui fournissent desinformations formant des cadres de discernement différents mais complémentaires.
– Son pouvoir de diminuer l’incertitude sur une prédiction en utilisant la redondance etla complémentarité des sources d’information et cela au cours de l’étape d’agrégation.
– Sa richesse du côté décision ainsi la décision peut être prise à l’aide d’une variété derègles.

Chapitre 2. Les approches de fusion d’information 37
2.3.4.2 Limites
Si cette théorie (la TFC) semble très séduisante, elle présente néanmoins certaines limites.– La complexité à croissance exponentielle en fonction de la taille du cadre de discernement
Ω.– La sensibilité de phase de combinaison aux choix de l’opérateur. En effet, la sensibi-lité de l’opérateur de Dempster a été démontrée dans plusieurs travaux. Dans certainessituations, cet opérateur ne peut être utilisé, c’est le cas lorsque la contrainte d’indépen-dance des sources d’information (hypothèse d’indépendance : S1 ne dépend pas de m2 etS2 ne dépend pas de m1) n’est pas vérifiée ou quand les sources ne sont pas parfaitementfiables.
– La TFC est généralement impuissante devant le conflit fort entre les sources.
2.4 Théorie du raisonnement plausible et paradoxale
La théorie de Dezert et Smarandche (DSmT) appelée aussi théorie du raisonnement plau-sible offre une nouvelle modélisation pour les problèmes de fusion permettant de résoudre descas délicats pour lesquels la TFC figure incapable de bien les gérer et donne des résultatserronés [27, 70, 71].
2.4.1 Fondements de la théorie du raisonnement plausible et para-doxale
La mise en œuvre de la DSmT est dûe à la nécessité de résoudre et surmonter les limitesinhérentes à la TFC qui sont étroitement liées aux contraintes imposées par cette dernière.
La première contrainte se résume par le fait que la TFC considère uniquement un cadrede discernement basé sur un ensemble discret, fini, exhaustif et exclusif d’hypothèses élémen-taires. Alors que la seconde vient du fait que la TFC suppose que les sources sont deux àdeux distinctes (aucune source ne partage la connaissance des autres sources) et fournissentles mesures de crédibilités sur l’ensemble de puissance.
Dezert et Smarandache ont fondé leur théorie sur la réfutation de ces deux contraintes. Eneffet, les classes du cadre de discernement généralisé de la DSmT ne sont pas nécessairementexclusives. Ainsi, on peut traiter le paradoxe entre les sources plus aisément que dans le cadrede la TFC. Par ailleurs, la DSmT s’affranchit à la seconde contrainte et ceci en utilisant

Chapitre 2. Les approches de fusion d’information 38
des sources d’évidence distincts qui fournissent une interprétation subjective et plus réalistesur le même cadre de discernement. Contrairement à la TFC où elles ont une interprétationobjective et idéale, la DSmT intègre la possibilité de s’occuper des évidences qui parviennentde différentes sources d’information qui n’ont pas accès à l’interprétation absolue des élémentsd’oméga.
2.4.1.1 Cadre de discernement généralisé
Soit oméga Ω le cadre de discernement généralisé qui contient n éléments distincts etnon nécessairement exclusifs. L’ensemble “hyper power set” noté DΩ est l’ensemble de toutesles parties formées à partir d’oméga en utilisant l’opérateur disjonctive “∪” et l’opérateurconjonctive “∩” tel que :
– ∅, ω1, ω2, ..., ωn ∈ DΩ
– ∀Ai et ∀Aj ∈ DΩ, Ai ∪ Aj ∈ DΩ et Ai ∩ Aj ∈ DΩ
Exemple :Si Ω = ω1, ω2, alors l’ensemble de l’hyper-puissance est : DΩ = ∅, ω1, ω2, ω1 ∪ ω2, ω1 ∩ ω2
2.4.1.2 Fonction de masse généralisée
Considérant un cadre de discernement généralisé, chaque source Sj est affectée par un jeude masse généralisé de croyance m définit de DΩ dans [0,1] par :
m(∅) = 0∑A∈DΩ m(A) = 1 (2.42)
La quantité m(A) appelée masse élémentaire de croyance généralisée en A. Comme la TFCtout élément de l’ensemble de l’hyper-puissance ayant une masse différente de zéro est appeléélément focal. L’ensemble des éléments focaux est appelé noyau est noté K(m) c.à.d :
K(m) = Ai ∈ DΩ| m(Ai) > 0 (2.43)
2.4.1.3 Fonctions de croyance et de plausibilité généralisées
En s’appuyant sur la fonction de masse généralisée on peut définir la fonction de crédibilitégénéralisée et la fonction de plausibilité généralisée comme suit :

Chapitre 2. Les approches de fusion d’information 39
∀A ∈ DΩ, Cr(A) =∑B⊆A
m(B), P l(A) =∑
B∩A 6=∅m(B) (2.44)
2.4.1.4 Transformation pignistique généralisée
Une nouvelle notion présentée dans [34] attachée à la définition de la transformation pi-gnistique généralisée qui est la cardinalité de Dezert Smarandache. La cardinalité de DSmnotée CM définit pour chaque élément de DΩ correspond au nombre de parties de Ai dans lediagramme de Venn. Ainsi, on peut définir la transformation pignistique généralisée permet-tant de construire la mesure de probabilité subjective à partir de tout jeu de masse généralisém(.) défini sur l’ensemble de l’hyper-puissance DΩ cette relation est définit par :
∀ Ai ∈ DΩ, GPT (Ai) =∑
Aj∈DΩ
CM(Ai ∩ Aj)CM(Aj)
∗m(Aj) (2.45)
2.4.2 Fusion par la théorie du raisonnement plausible et paradoxale
2.4.2.1 Modélisation
Une fois le cadre de discernement généralisé oméga est déterminé, la seconde tâche consisteà choisir le modèle de fusion pour construire l’ensemble de l’hyper puissance DΩ. La DSmTpropose trois modèles appelés : modèle libre, modèle hybride et modèle de Shafer.
– Le Modèle libre : noté MF représente la situation où l’ensemble de l’hyper-puissanceDΩ est considérée en totalité. Autrement dit à côté des singletons, la DSmT considèretoutes les combinaisons possibles entre les classes du cadre de discernement en utilisantl’opérateur conjonctif et l’opérateur disjonctif.
– Le modèle hybride : noté M obtenu par l’introduction soit des contraintes de non exis-tence soit par des contraintes d’exclusivité ou même des contraintes mixtes. Ainsi, lescontraintes peuvent être de type :• Contraintes d’exclusivité ωi ∩ ωj = ∅, pour quelques ωi et ωj de Ω.• Contrainte de non-existence ωi ∪ ωj ∪ ωk = ∅, pour quelques ωi, ωj et ωk de Ω• Des contraintes composées de deux dernières contraintes.
– Le modèle de Shafer : ce modèle noté M0 est obtenu lorsque toutes les contraintesd’exclusivité sont imposées dans ce cas on se trouve dans le cadre de la théorie desfonctions de croyance.

Chapitre 2. Les approches de fusion d’information 40
2.4.2.2 Estimation
Dans le cadre de la théorie du raisonnement plausible et paradoxale, l’estimation de jeude masse se fait généralement en exploitant les mêmes méthodes utilisées par la TFC.Dans [68] l’estimation est faite en utilisant le modèle gaussien pour faire la fusion multispectrale des images faciales afin d’aboutir à la reconnaissance.Par ailleurs, dans le but d’appliquer la TFC et la DSmT pour réaliser la cartographie del’occupation du sol et la mise en évidence des changements survenus dans une région del’espace terrestre dans [1] Abass a utilisé le modèle d’Appriou et le modèle gaussien pour ladétermination des masses des différentes classes.
2.4.2.3 Combinaison
Dezert et Smarandche ont proposé plusieurs règles pour combiner les masses généralisées.– Règle de combinaison de Dezert-Smarandache : appelée aussi règle de DSm classique(DSmC) qui est en fait la règle de Dempster généralisée. Considérons deux sources dis-tinctes d’évidence S1 et S2 de nature quelconque (incertaine, paradoxale,...) définies parrapport à un cadre de discernement généralisé oméga avec les jeux de masses généralisésmS1(.) , mS2(.) associés.La fonction de masse globale s’obtient par la combinaison de mS1(.) et mS2(.) en utili-sant la règle suivante :
∀A ∈ DΩ,m(A) = (mS1 ⊕mS1)(A) =∑
B,C∈DΩ,B∩C=AmS1(B) ∗mS2(C) (2.46)
Cette règle est associative, commutative et applicable pour des sources de nature quel-conque (en particulier pour des sources hautement conflictuelle) contrairement à la règlede Dempster.
– Règle de combinaison de redistribution proportionnelle du conflit : on trouve dans lalittérature plusieurs versions de cette règle qui est symbolisée PCR. Nous allons mettrel’accent sur la règle la plus sophistiquée qui est la PCR5. Elle est développée dans lecadre de la DSmT et qui présente l’une des alternatives efficace de la règle de Dempster.Sa particularité réside essentiellement dans sa façon de traiter le conflit. En effet, lePCR5 redistribue chaque conflit partiel uniquement sur les éléments qui y’sont réel-lement impliqués et proportionnellement aux jeux de masses correspondants à chaquesource le générant. L’expression suivante donne cette règle pour deux sources données : mpcr5(∅) = 0∀A ∈ DΩ,mpcr5(A) = (mS1 ⊕mS2)(A) + ∑
A∪B=∅mS1 (A)2mS2 (B)mS1 (A)+mS2 (B) + mS2 (A)2mS2 (B)
mS2 (A)+mS1 (B)(2.47)

Chapitre 2. Les approches de fusion d’information 41
2.4.2.4 Décision
Comme la TFC, la DSmT offre une variété de règles qui permettent de prendre la décisionsur les nouvelles classes résultantes de la phase de combinaison.
– Maximum de croyance et maximum de plausibilité : la maximisation de crédibilité etde plausibilité se fait de manière analogue que la TFC.
– Maximum de probabilité pignistique :
GPT (Aj)(x) = maxGPT (Aj)(x), 1 ≤ j ≤ |DΩ| (2.48)
2.4.3 Applications de la DSmT
– Classification : Martin et Osswaled [53] ont exploité la DSmT pour faire la fusion desinformations experts afin de faire la classification des images sonar et dans ce contexteplusieurs modèles de fusion ont été proposés.Par ailleurs, dans [1] la TFC et la DSmT ont été étudiées dans le but de réaliser la fu-sion multi-sources multi-temporelles des images satellites pour aboutir à la classificationde la zone étudiée. Singh et al [68] ont utilisé cette théorie pour fusionner des imagesfaciales.
– Construction de cartes quadrillées : la théorie de Dezert-Smarandach a été exploi-tée pour fusionner des informations provenant de capteurs homogènes ou hétérogènes dedifférentes fiabilités. Puis, ils ont construit le modèle de croyance de la carte quadrilléesonar. Le robot mobile a servi comme une plateforme expérimentale et une carte 3D aété construite en ligne à l’aide de la théorie du raisonnement plausible et paradoxale.Dans ce contexte la DSmT a été exploité pour l’étude simultanée d’un environnementdynamique inconnu et la construction d’une carte multi-robots [48].La théorie du raisonnement plausible et paradoxale a été appliquée dans d’autres do-maines telle que la gestion des risques [76]
2.4.4 Intérêts et limites de la théorie du raisonnement plausible etparadoxale
Cette théorie est en fait une extension généralisée de la TFC, ainsi elle présente les mêmesavantages de modélisation et de fusion. En revanche, l’avantage majeur de la théorie duraisonnement plausible et paradoxale vient du fait de sa modélisation riche par rapport àla TFC qui permet de modéliser et de traiter le paradoxe ainsi que le conflit élevé entre les

Chapitre 2. Les approches de fusion d’information 42
sources d’évidence .Bien que cette théorie semble séduisante elle est extrêmement coûteuse dont la complexitéest encore plus élevée que celle de la TFC et dans certains cas on peut pas l’appliquer (lacardinalité du cadre de discernement généralisé est élevé ) d’une part, d’autre part elle nepermet pas de fusionner des fonctions de masses associées a des cadres de discernementcontinus.
2.5 Comparaison des formalismes de fusion
2.5.1 Relation entre les trois théories
La relation entre la TFC et la DSmT :Comme cela a été mentionné auparavant, la théorie du raisonnement plausible et paradoxaleest considérée comme une généralisation de la théorie de Dempster-Shafer (TFC). Le passagedu cadre de discernement généralisé au cadre de discernement non généralisé se fait par leprocessus de raffinement. En outre, le troisième modèle de la DSmT (modèle de Shafer) n’estque la théorie des fonctions de croyance.
La relation entre La TFC et la théorie des possibilités :La théorie des possibilités est un cas particulier de la théorie des fonctions de croyance eneffet : si dans le cadre de la TFC les éléments focaux sont emboités, on se trouve dans leformalisme de la théorie des possibilités :Soit F = A1, A2, ..., An tel que A1 ⊆ A2...An−1 ⊆ An avec F est l’ensemble d’élémentsfocaux de notre cadre. On a :
Cr(A ∩B) = min(Cr(A), Cr(B)) et P l(A ∪B) = max(Pl(A), P l(B)) (2.49)
Dans ce cas la fonction de croyance est l’équivalente de la fonction mesure de nécessité tandisque la fonction de plausibilité est l’équivalence de la fonction mesure de possibilité.
2.5.2 Comparaison de la TFC et la DSmT
Il est vrai que la DSmT est considérée comme une généralisation de la TFC, néanmoinson peut citer quelques différences fondamentales telles que :

Chapitre 2. Les approches de fusion d’information 43
– Le cadre de discernement de la TFC est exhaustif et exclusif. Cependant, le cadre dediscernement généralisé de la DSmT n’est pas nécessairement exclusif et par conséquentla DSmT gère le paradoxe.
– On peut passer de la DSmT vers la TFC à l’aide du raffinement. Par contre, le raffi-nement n’est pas toujours possible surtout lorsque il existe des éléments dans le cadrede discernement qui n’ont pas des frontières claires (couleurs, ensembles vagues, deshypothèses qui ne sont pas claires,... ) ; Et dans tel cadre la TFC n’est pas puissantetandis que la DSmT semble la théorie la plus appropriée pour résoudre tel problème.
– La DSmT offre des règles de combinaison puissantes et meilleures que celles donnéespar la TFC. Citons la règle PCR5 “Proportional Conflict Redistribution” qui tient encompte le conflit et qui est plus sophistiquée et plus puissante que la règle de Dempsternormalisée [70]. Par ailleurs, la règle DSmH (règle de combinaison hybride) est adaptéedans la fusion dynamique tandis que la règle de Dubois et Prade (la règle de combi-naison mixte au sein de la TFC) ne peut être adaptée dans ce même cas sachant quela DSmH est une extension de la règle de Dubois et Prade [70]. Dans le même ordred’idées la DSmC permet de combiner des fonctions de masse hautement conflictuellescontrairement à la règle de Dempster normalisée.
– La complexité au sein de la TFC est exponentielle et cela est due à la cardinalité ducadre de discernement et l’explosion combinatoire de ses éléments, néanmoins la com-plexité au sein de la DSmT est beaucoup plus élevée (exemple : si |Ω| = 4 alors |2Ω| = 32et |DΩ| = 167).Généralement quelques éléments de l’ensemble de l’hyper-puissance n’ont pas une signi-fication. On peut remarquer cela surtout lorsque le modèle choisi est le modèle libre.
2.5.3 Comparaison de la TFC et la théorie des possibilités
Plusieurs études ont été élaborées pour comparer la théorie des possibilités et la TFC [75]et [6] par ailleurs il y a d’autres travaux qui ont fait des comparaisons dans des situationset des cadres particuliers tels que la fusion des classifieurs pour aboutir à la classificationdes images sonar[50], la fusion d’opinions d’experts [25], la détection des anomalies [14] etla classification des images satellites [42]. Voici quelques points de différences entre ces deuxformalismes :
– L’univers du discours et le cadre de discernement sont exhaustifs et exclusifs sauf quela théorie des possibilités raisonne que sur des hypothèses simples tandis que le raison-nement dans le cadre de la TFC porte sur 2Ω.
– La complexité au sein de la théorie des possibilités est beaucoup moins élevée que celleau sein de la TFC.
– La TFC permet de traiter et gérer le conflit entre les sources en utilisant plusieursméthodes (affaiblissement, normalisation de la règle de Dempster et l’introduction d’une

Chapitre 2. Les approches de fusion d’information 44
approche en monde ouvert par Smets). En revanche, le traitement du conflit dans lecadre de la théorie des possibilités est relatif vu que cette théorie n’offre pas des moyenspour aborder ce problème. Pour résoudre ce problème, Dubois et Prade ont proposél’opérateur adaptatif qui permet de prendre en compte le conflit faible entre les sourcesd’information.
– La TFC permet de fusionner des sources ayant des cadres de discernement différentsmais complémentaires et ceci se fait à l’aide d’un processus de raffinement ou bien degrossissement ce qui n’est pas possible au sein de la théorie des possibilités.
– La TFC permet de traiter l’ignorance totale à l’aide de disjonction des hypothèses cequi n’est pas possible au sein de la théorie des possibilités.
– La théorie des possibilités offre une grande variété d’opérateurs pour réaliser la combi-naison.
– La TFC offre plusieurs règles et critères de décision.
2.5.4 Stratégie du choix d’un formalisme de fusion
Face à un problème de fusion, la première tâche à faire c’est de choisir un formalismequi s’adapte le mieux possible avec le problème abordé afin d’aboutir à une fusion optimale.Or, le choix n’est pas souvent évident. Par conséquent un mauvais choix peut entrainer desrésultats non attendus et voir même mauvais.Dans cette section nous allons essayer de discuter les critères de choix d’un formalisme selonle problème présent et les informations acquises.Un des premiers articles dans ce sens est celui de Phillipe Smets [75] dans lequel l’auteura comparé la théorie des probabilités, des possibilités et des fonctions de croyance afin derésoudre la question qui résulte du manque d’un modèle unique pour représenter l’incertitudemesurée à savoir : quel modèle devrait être appliqué dans quelles situations ? Et ceci enconsidérant que l’imprécision est souvent à la base de l’incertitude.
Un travail assez récent propose un « guide pratique» pour le choix d’un langage de modé-lisation des imperfections de l’information dans une modélisation multi-critère [6]. Par contre,cette étude n’inclue pas le modèle de Dezert-Smarandache.
Au-delà des différences, il apparaît pourtant bien difficile de conclure sur la supériorité del’une ou l’autre des théories présentées. Il est clair en tout cas que les objets mathématiquesmanipulés sont proches mais ces théories ne modélisent pas exactement les mêmes choses,n’ont ni la même sémantique ni le même pouvoir de représentation et du raisonnement.
La théorie de Dezert Smarandache (DSmT) peut être considérée comme la théorie la plusgénérale puisque d’une part elle est considérée comme une extension de la TFC d’autre part

Chapitre 2. Les approches de fusion d’information 45
le troisième modèle de fusion proposé par Dezert et Smarandache qui est nommé le modèlede Shafer n’est que la théorie de Dempster Shafer (TFC). En deuxième lieu la TFC peut êtreconsidérée comme plus générale que la théorie des possibilités puisque on retrouve celle-cicomme un cas particulier.
La théorie des possibilités offre un cadre formel pour la représentation des données impré-cises et d’informations pauvres. Cette dernière permet de représenter des classes d’objets dontles critères d’appartenance sont graduels comme elle permet de manipuler les informationssymboliques et les informations exprimées en langage naturel. Ainsi, cette théorie représentele formalisme approprié pour fusionner les informations expertes [25]. En revanche, la théoriedes possibilités permet la manipulation de l’incertitude sur des connaissances imprécises ouvagues et fiables sachant que les incertitudes visées par cette théorie ne sont pas de typealéatoire mais plutôt épistémique [41].
La théorie de Dempster-Shafer (TFC) est basée sur la notion de preuves utilisant lesfonctions de croyance et le raisonnement plausible. Elle permet de manipuler l’imprécision etles incertitudes aléatoires, épistémiques et subjectives et l’ambiguïté. Toutefois, le bon cadrede l’application de cette théorie est l’univers discret. Pour des mesures continues, elle n’estplus la théorie appropriée. Par ailleurs, si les sources ne sont pas fiables il vaut mieux choisir leformalisme évidentiel (TFC) pour fusionner les informations fournies par ces sources [52, 23].
Toutefois, la théorie du raisonnement plausible et paradoxale permet de manipuler l’im-précision, les incertitudes épistémique et aléatoire, l’ambiguïté et surtout le paradoxe entreles sources d’évidence sur des univers discrets. Ainsi, cette théorie manipule la majorité desformes d’imperfection qui accompagnent les informations et fusionne des sources ayant desfiabilités très différentes. Cependant, il vaut mieux utiliser cette théorie lorsque surtout leconflit est élevé.Le tableau suivant résume notre étude du choix du modèle de fusion selon les imperfectionsattachées aux informations acquises.
Imprécision Incertitude Ambiguïté incomplétude ConflitEpistémique Aléatoire Faible Elevé
Théorie des possibilités X X X XDST X X X X X XDSmT X X X X X X X
Table 2.1 – Les imperfections modélisées par chaque théorie.
Finalement, nous avons mis en place une stratégie du choix qui nous permet de choisirl’approche de fusion la plus adéquate selon les sources et les informations disponibles en te-

Chapitre 2. Les approches de fusion d’information 46
nant compte des imperfections présentes. Cette stratégie est illustrée par la figure suivante.
Figure 2.2 – Choix d’un formalisme de fusion.
2.6 Conclusion
Dans ce chapitre nous avons présenté trois approches de fusion qui sont les théories despossibilités, des fonctions de croyance (TFC) et du raisonnement plausible et paradoxale(DSmt). Nous avons vu que chaque approche modélise et traite l’information à fusionnerd’une façon différente des autres approches ce qui rend la comparaison de ces formalismes defusion difficile et n’est pas évidente. Ces approches sont largement utilisées pour réaliser lafusion des sources incertaines et imprécises dans plusieurs applications. Ce qui nous a poussésétablir une stratégie du choix qui nous permet de choisir le formalisme le plus approprié pourfusionner les sources d’information disponibles.

Chapitre 3Processus de fusion par la théorie despossibilités, la TFC et la DSmT
3.1 Introduction
Les méthodologies de fusion/classification par la théorie des possibilités, la TFC et la DSmTnécessitent le passage par les quatre étapes du modèle de fusion.
Les modèles possibiliste, crédibiliste (TFC) et paradoxale (DSmT) ont été développés dansun cadre ponctuel en tenant compte de l’information spectrale des classes.Dans ce chapitre, nous allons détailler les trois processus de classifications mis en œuvre,ainsi nous allons exposer pour chaque formalisme la méthode d’organisation des classes puisla méthode adoptée pour faire l’estimation et par la suite les opérateurs de combinaison choisis.
3.2 Classification par la théorie des possibilités
La théorie des possibilités est la théorie la plus simple et la moins complexe parmi les troisthéories que nous avons exposé dans le deuxième chapitre.La classification possibiliste nécessite la détermination des différentes classes qui composentl’univers du discours dans un premier temps, puis la génération des distributions de possibi-lités correspondantes.

Chapitre 3. Processus de fusion par la théorie des possibilités, la TFC et la DSmT 48
3.2.1 Estimation de distribution de possibilités
La méthode adoptée pour estimer les différentes distributions de possibilités associéesaux classes qui constituent l’univers du discours Ω, a été proposée par Dubois et Prade etgénéralisée par Masson [54]. L’idée est de passer à partir d’une distribution de probabilités àune distribution de possibilités spécifique.Supposons que l’univers du discours est constitué de K classes Ω = C1, C2, ..., CK. Et qu’ondispose de N observations réparties sur les différentes classes suivant une distribution deprobabilité IPx.Soit ni le nombre d’observations réparties dans la iéme classe Ci. Le vecteur n = (n1, ..., nK)est la réalisation d’une variable aléatoire multinomiale de paramètres p = (p1, ..., pK), oùchaque pi = IPx(Ci) > 0 est la probabilité d’apparition de la iéme classe Ci (ou proportionde la classe i). Sachant que ∑K
i=1 Pi = 1.Cette approche se base sur l’estimation des pi à l’aide des intervalles de confiance simultanésavec un niveau de confiance donné 1 − α sur les proportions d’une loi multinomiale puis àen déduire une distribution de possibilités qui dominera la vraie distribution de probabilitésdans au moins 100(1− α)% des cas.La construction des intervalles de confiance simultanés [p−i , p+
i ] avec un degré de confiancejoint 1− α revient à calculer les quantités suivantes :
A = χ2(1− α/K, 1) +N (3.1)
Avec χ2(1 − α/K, 1) désigne le quantile de niveau (1 − α/K) d’une distribution chi 2 a undegré de liberté :
Bi = χ2(1− α/K, 1) + 2ni (3.2)
Ci = niN
(3.3)
∆i = B2i − 4ACi (3.4)
Les bornes de l’intervalle de confiance s’obtiennent par l’équation suivante :
[p−i , p+i ] = [Bi −∆
12i
2A ,Bi + ∆
12i
2A ] (3.5)
La deuxième étape consiste à déterminer la distribution de possibilités la plus spécifiquedominant toute distribution de probabilités définies par pi ∈ [p−i , p+
i ] ∀i.

Chapitre 3. Processus de fusion par la théorie des possibilités, la TFC et la DSmT 49
Pour déterminer la distribution de possibilités la plus spécifique, on suit les étapes suivantes :Étant donné P l’ordre partiel induit par les intervalles [Pi] = [p−i , p+
i ] ∀i tel que :
(Ci, Cj) ∈ P⇔ p+i < p−j (3.6)
Cet ordre partiel peut être assimilé à l’ensemble de ses extensions linéaires Λ(P ) = Ll, l =1..L ou bien de façon équivalente à l’ensemble des permutations correspondantes σl, l =1..L.Pour toute permutation possible σl associée à une extension linéaire dans Λ(P ), et chaqueclasse Ci il faut résoudre le programme linaire suivant :
πσli = maxp1,...,pK
∑|σ−1
l(j)<=σ−1
l(i)
pj (3.7)
Sous les contraintes : ∑Ki=1 pi = 1
p−i ≤ pi ≤ p+i ∀i ∈ 1..K
pσ
(1)l
≤ pσ
(2)l
≤ ... ≤ pσ
(K)l
(3.8)
Finalement la distribution de possibilité la plus spécifique dominant toutes les distributionsπσl est :
πi = maxl=1..L(πσli ) (3.9)
3.2.2 Combinaison des distributions de possibilités
Les opérateurs choisis pour réaliser la combinaison des différentes distributions de possi-bilités sont au nombre de deux : le premier de type conjonctif et le second est un opérateuradaptatif.
– L’opérateur conjonctif de Zadeh : c’est l’opérateur ”min”. La combinaison des dis-tributions de possibilités avec cet opérateur consiste à considérer le plus petit degré depossibilité attribué à l’observation x.Exemple :Soient πS1
x (C1) = 0.5, πS2x (C1) = 0.35 et πS3
x (C1) = 0.67, trois degrés de possibilitéattribués a un niveau de gris x par trois sources S1, S2 et S3.πx(C1) = min(πS1
x (C1), πS2x (C1), πS3
x (C1)) = min(0.5, 0.35, 0.67) = 0.35
– L’opérateur adaptatif de Dubois et Prade : cet opérateur a été proposé parDubois et Prade dans [40]. Il est lié à un consensus h entre les différentes distributionsde possibilités mises en jeux à savoir la borne supérieure de leurs intersections comme

Chapitre 3. Processus de fusion par la théorie des possibilités, la TFC et la DSmT 50
il est indiqué dans le système des équations suivant :h = maxC(min(πS1(C), πS2(C), πS3(C)))
π(C) = max(min(πS1 (C),πS2 (C),πS3 (C))h
,min(max(πS1(C), πS2(C), πS3(C)), 1− h))(3.10)
La particularité de cet opérateur de combinaison réside dans son pouvoir de traitementde conflit selon son degré. Ainsi, si le conflit est élevé (h tend vers 0) il se comportecomme un max (opérateur disjonctive de zadeh), par contre si le conflit est faible (htend vers 1) il se comporte comme l’opérateur min.Le terme min(πS1 (C),πS2 (C),πS3 (C))
hreprésente la normalisation de la combinaison conjonc-
tive des sources. Tandis que le deuxième termemin(max(πS1(C), πS2(C), πS3(C)), 1−h)représente l’ensemble des solutions plausibles en dehors de la zone de consensus.Exemple :Si nous appliquons cet opérateur sur l’exemple précédent et si nous supposons queh = 0.5 nous obtenons :πx(C1) = max(min(0.5,0.35,0.67)
0.5 ,min(max(0.5, 0.35, 0.67), 1− 0.5)) = max(0.7, 0.5) = 0.7
3.3 Classification par la théorie des fonctions de croyance
L’un des avantages de la classification par la théorie des fonctions de croyance est lagénération de nouvelles classes composées par l’union des classes singletons qui nous permetde mieux prendre en compte l’incertitude et la méconnaissance.
3.3.1 Génération du cadre de discernement
3.3.1.1 Raffinement et grossissement
La théorie des fonctions de croyance offre la possibilité de fusionner des sources d’évi-dence ayant des cadres de discernement complémentaires. Ceci en appliquant le processus deraffinement et grossissement qui permet d’unifier les référentiels complémentaires.
Soient deux cadres de discernement Ω1 = C11 , ..., C
1k1 et Ω2 = C2
1 , ..., C2k2.
Un raffinement R est une fonction qui associe à chaque classe C1i de Ω1 un sous ensemble
R(C1i ) du cadre de discernement Ω2 tel que R(C1
i ), ..., R(C1k1) constitue une partition de Ω2.

Chapitre 3. Processus de fusion par la théorie des possibilités, la TFC et la DSmT 51
Donc l’opération de raffinement consiste à considérer que chaque classe de Ω1 est lui-mêmereprésentative d’un sous-ensemble encore plus détaillé.La fonction de masse m1(.) définit sur Ω1 fournit une fonction de masse m2(.) définit sur Ω2.L’équation suivante illustre la relation entre les deux fonctions de masses :
∀A ⊆ Ω1,m2(R(A)) = m1(A) (3.11)
Le grossissement R−1 est l’opération inverse de R qui consiste à regrouper les singletonsde Ω2 en des sous-ensembles exclusifs R(C1
i ) qui sont alors associés au singleton C1i .
Une fonction de masse m2(.) définit sur Ω2 conduit dans ces conditions à une fonction m1(.)sur Ω1 par la transformation suivante :
m1(A) =∑
B⊆Ω2A=C1i |R(C1
i )∩B 6=∅m2(B) (3.12)
Exemple :Soient deux cadres de discernement Ω1 et Ω2 et une fonction de raffinement R schématiséspar la figure suivante :
Figure 3.1 – Fonctions de raffinement et de grossissement.
Soit mΩ1 une fonction de masse définit sur Ω1 = C1, C2, C3 telle que mΩ1(C1) = 0.7 ,mΩ1(C2, C3) = 0.3. Soit Ω2 = C ′1, ..., C ′7 est un raffinement de Ω1.Par la suite le jeu des masses mΩ1 exprimé sur le cadre raffiné Ω2 par mΩ2(C ′3, C ′4, C ′5) = 0.7et mΩ2(C ′1, C ′2, C ′6, C ′7) = 0.3

Chapitre 3. Processus de fusion par la théorie des possibilités, la TFC et la DSmT 52
Le grossissement : supposons que la fonction de masse d’évidence mΩ2 définit sur mΩ2 parmΩ2(C ′3) = 0.6 et mΩ2(C ′1, C ′6) = 0.4 le jeu des masses mΩ2 peut être exprimé sur le cadregrossier mΩ1 par mΩ1(C1) = 0.6 et mΩ1(C2, C3) = 0.4
3.3.1.2 Génération de l’ensemble de fusion
La génération de l’ensemble de fusion 2Ω est effectuée suivant un ordre d’énumérationdes éléments de cet ensemble exprimé en caractères binaires. Le nombre de bits est égal à lacardinalité de Ω. Chaque bit représente une classe de gauche à droite (le bit d’extrême gauchereprésente la classe numéro 1 et le dernier bit représente la dernière classe). Ainsi, si le bitqui représente la classe égal à 1, l’élément inclut cette classe [7].Exemple :Supposons que Ω = C1, C2, C3. Alors, le power-set obtenu selon un ordre d’énumération deses éléments, s’écrit comme suit :A0 = ∅ = 000 A1 = C1 = 100A2 = C2 = 010 A3 = C3 = 001A4 = C1 ∪ C2 = 110 A5 = C1 ∪ C3 = 101A6 = C2 ∪ C3 = 011 A7 = C1 ∪ C2 ∪ C3 = 111Donc chaque élément Ai de l’ensemble power-set est représenté sur trois bits.
3.3.1.3 Réduction de la complexité exponentielle des sources
L’un des inconvénients majeurs de la théorie des fonctions de croyances est sa complexitétemporelle exponentielle. En effet, elle est due en premier lieu à l’explosion combinatoiredes éléments du cadre de discernement et en deuxième lieu à l’utilisation de l’opérateur deDempster dont le coût augmente exponentiellement lorsque le nombre des sources et desclasses devient important.
Pour spécifier une fonction de croyance, on pourra avoir besoin de calculer 2|Ω|−1 nombres(les masses de croyance pour chaque sous-ensemble non vide du référentiel de définition) cequi implique une complexité temporelle exponentielle en fonction de la cardinalité du cadrede discernement |Ω|.
Plusieurs approches de la littérature ont essayé de résoudre ce problème et de réduire lacomplexité. On peut distinguer deux grandes catégories d’approches, la première raisonne surle calcul des fonctions de masses afin de le simplifier. Nous pouvons citer la transformationrapide de Möbius, algorithme de Barnett, propagation dans les arbres. Tandis que l’autre vise

Chapitre 3. Processus de fusion par la théorie des possibilités, la TFC et la DSmT 53
à réduire le nombre d’éléments focaux.Nous allons nous intéresser à la deuxième catégorie.
1. l’approche de réduction du nombre des éléments focaux :
La réduction du nombre d’éléments focaux est généralement faite par l’agrégation, lasommation ou l’élimination d’éléments focaux avant ou après l’étape de combinaison desmasses de croyance. Certaines approches éliminent les éléments focaux peu significatifs,c’est-à-dire de poids faible. Les paramètres pouvant intervenir dans la sélection sontle pourcentage total de poids des éléments focaux conservés et le nombre minimal et/ou maximal d’éléments focaux. La réduction du nombre d’éléments focaux suite àl’estimation préalable des fonctions de masse nécessite une redistribution des massesd’évidence pour assurer de nouveau la condition de normalisation (somme des masseségale à 1).
2. Réduction du référentiel de définition :
Cette approche a été proposée par Ben Dhiaf dans [7]. Elle se base sur la réduction duréférentiel de définition exclusivement à l’ensemble des éléments focaux avant l’étaped’estimation des masses.Le principe de cette méthode se résume par les étapes suivantes :(a) Pour chaque classe Ci ∈ Ω avec i ∈ 1...|Ω| représenter par une zone d’apprentis-
sage ou plus, on détermine sa fonction histogramme hCi : [0, 255]→ N , qui associeà chaque valeur x le nombre hCi(x) d’apparitions de cette valeur dans l’ensembled’échantillons de la classe Ci.Donc Ci est considéré un élément focal pour un élément x si elle vérifie l’équationsuivante :
hCi(x) > 0, Ci ∈ Ω (3.13)
(b) Pour chaque élément focal composé A, on détermine son histogramme associé hA.Cet histogramme est construit par les bornes inférieures de tous les histogrammeshCi des classes Ci incluses dans A.
hA(x) = minhCi(x) | Ci ⊂ A, i ∈ 1..K (3.14)
En adaptant cette approche, on élimine plusieurs classes composées et on garde les élémentsfocaux pertinents. Toutefois, cette méthode permet de réduire remarquablement le nombredes éléments focaux et par la suite la complexité temporelle est réduite.Exemple :Soient trois classes C1, C2 et C3. Leurs histogrammes de niveaux de gris correspondants sontreprésentés par la figure ci-après :
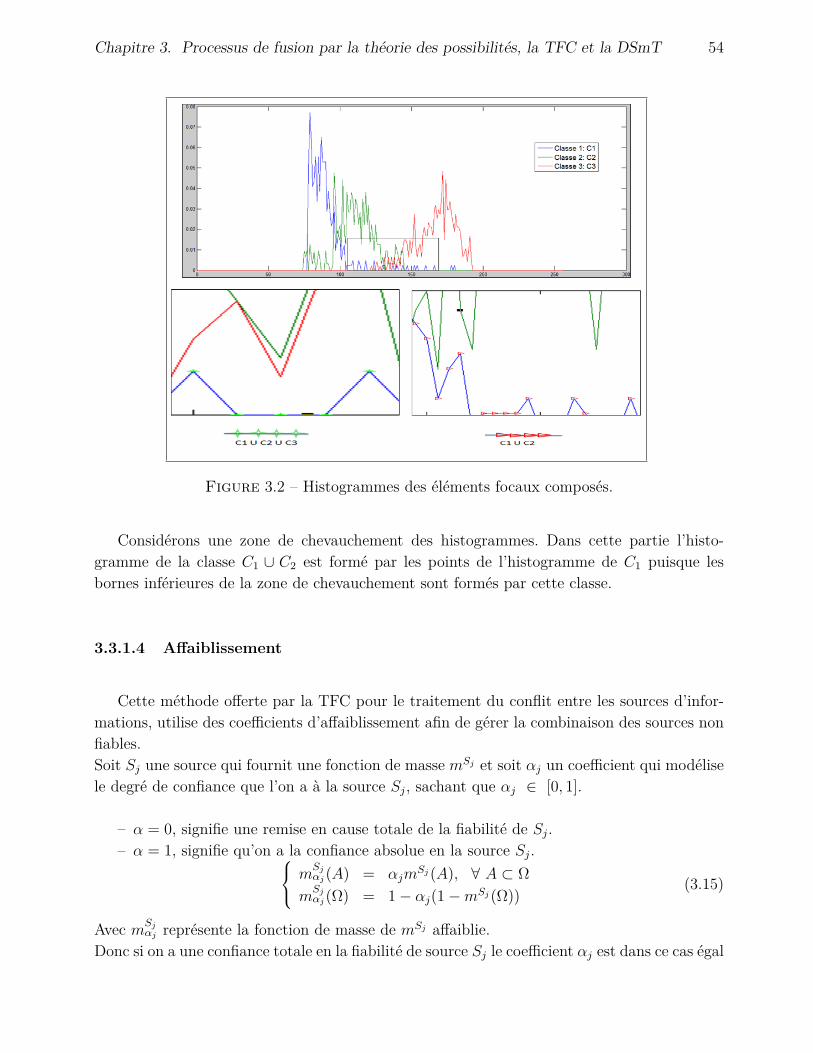
Chapitre 3. Processus de fusion par la théorie des possibilités, la TFC et la DSmT 54
Figure 3.2 – Histogrammes des éléments focaux composés.
Considérons une zone de chevauchement des histogrammes. Dans cette partie l’histo-gramme de la classe C1 ∪ C2 est formé par les points de l’histogramme de C1 puisque lesbornes inférieures de la zone de chevauchement sont formés par cette classe.
3.3.1.4 Affaiblissement
Cette méthode offerte par la TFC pour le traitement du conflit entre les sources d’infor-mations, utilise des coefficients d’affaiblissement afin de gérer la combinaison des sources nonfiables.Soit Sj une source qui fournit une fonction de masse mSj et soit αj un coefficient qui modélisele degré de confiance que l’on a à la source Sj, sachant que αj ∈ [0, 1].
– α = 0, signifie une remise en cause totale de la fiabilité de Sj.– α = 1, signifie qu’on a la confiance absolue en la source Sj. m
Sjαj(A) = αjm
Sj(A), ∀ A ⊂ ΩmSjαj(Ω) = 1− αj(1−mSj(Ω))
(3.15)
Avec mSjαj représente la fonction de masse de mSj affaiblie.
Donc si on a une confiance totale en la fiabilité de source Sj le coefficient αj est dans ce cas égal

Chapitre 3. Processus de fusion par la théorie des possibilités, la TFC et la DSmT 55
à 1 et la fonction de croyance n’est alors pas modifiée ce qui équivaut à dire que l’informationapportée par cette source ne devrait pas engendrer un conflit lors de la combinaison.Dans le cas contraire, si on suppose que la source Sj n’est pas fiable, lors de la combinaisonavec d’autres sources celle-ci peut alors produire une information conflictuelle.En introduisant un coefficient αj = 0 , la fonction de croyance mSj associée à la source Sjdevient alors une fonction de croyance d’ignorance totale et donc un élément neutre pour lacombinaison de Dempster (croyance de l’ignorance totale peut s’écrire sous la forme :mSj
αj(Ω)).
3.3.2 Estimation des fonctions de masse
L’estimation des fonctions de masses des éléments focaux se base sur l’information spec-trale en utilisant leurs histogrammes de niveaux de gris. Cette méthode a été proposée dans[7].Cette approche exploite les fréquences des histogrammes de niveaux de gris des zones d’ap-prentissage associées aux classes du cadre de discernement. L’auteur propose de diviser cha-cune des fréquences par le pic de l’histogramme de fréquence correspondant. Ainsi, pourchaque classe Ci et étant donné son histogramme hCi calculé sur la zone d’apprentissage, unefonction fCi est déduite qui associe à chaque niveau de gris x, la valeur de sa fréquence hCi(x)divisée par le pic de son histogramme hCi .Cette division a pour but de normaliser l’histogramme de niveaux de gris et par la suite lesvaleurs de fCi sont comprises entre 0 et 1.Donc si on applique ce même principe sur chaque histogramme hAi on obtient un nouvel his-togramme fAi . Ainsi, à chaque histogramme hefi on associe un autre histogramme fefi suivantl’équation suivante :
fefi(x) = hefi(x)max(hefi(x)) (3.16)
Finalement, les masses de croyance de chaque élément focal efi sont calculées à partir de sonhistogramme de niveaux de gris associé comme l’indique l’équation suivante :
m(efi) = fefi(x)norm
(3.17)
Avec norm = ∑Knouvi=1 fefi(x)
Norm : désigne le facteur de normalisation, et la division sur ce facteur garantie que la sommedes masses des éléments focaux est égale à 1.Knouv : c’est le nombre des éléments focaux.

Chapitre 3. Processus de fusion par la théorie des possibilités, la TFC et la DSmT 56
3.3.3 Combinaison des fonctions de masse
La phase de combinaison des masses de croyance issues des sources mises en jeu est unetâche déterminante et complexe.La règle la plus utilisée pour achever cette tâche est la règle de Dempster décrite par l’équation2.37 du second chapitre car elle présente des propriétés intéressantes telles que la commuta-tivité et l’associativité, néanmoins elle présente de grosses déficiences.En effet, elle permet de combiner des fonctions de masses issues de plusieurs sources sauf quele nombre de ces éléments est souvent exponentiel (due à l’explosion combinatoire des classesdu cadre de discernement). Ainsi, la complexité croît avec le nombre des sources d’évidenceet la cardinalité des cadres de discernement.
Les croyances à combiner sont généralement définies initialement sur des cadres de dis-cernement différents. Ainsi, il faut chercher une manière de les unifier. En appliquant cetteunification en présence de différentes sources avec des cadres différents et un grand nombred’hypothèses, le cadre de discernement devient énorme et ainsi se heurte à un sérieux problèmede complexité.
En deuxième lieu la règle orthogonale de Dempster devient inapplicable lorsque les sourcessont hautement conflictuelles et par la suite la combinaison avec cet opérateur génère desrésultats non satisfaisants même si on utilise la version normalisée décrite par l’équation 2.37.Par ailleurs, un récent travail sur la TFC et plus précisément sur cette fameuse règle a montréque non seulement cet opérateur engendre des résultats non attendus lorsque le conflit estélevé entre les sources d’évidence mais également quand elles sont faiblement en conflit [78].
Une alternative à cette règle est proposée dans [27, 30, 43] qui est la règle PCR5 (Propor-tional Conflict Redistribution) et qui découle de la famille des règles qui redistribue le conflitproportionnellement et qui est illustrée par l’équation 2.47.La particularité de cette règle réside dans sa capacité de redistribuer le conflit créé par larègle conjonctive, entre deux fonctions de masses, aux éléments focaux qui sont à la base dece conflit partiel. Cependant, cette règle de combinaison est encore plus complexe que cellede Dempster mais permet de combiner des sources conflictuelles. En outre, il faut soulignerque cette règle n’est pas associative ni commutative.Exemple :Supposons que nous avons deux sources S1 et S2. Le cadre de discernement est consti-tué de deux classes élémentaires C1 et C2, Ω = C1, C2 donc l’ensemble de puissance2Ω = ∅, C1, C2, C1 ∪ C2. Le tableau suivant donne les fonctions de masses données parles deux sources et le résultat de fusion par la règle de Dempster normalisée :

Chapitre 3. Processus de fusion par la théorie des possibilités, la TFC et la DSmT 57
C1 C2 C1 ∪ C2
mS1 0.6 0 0.4mS2 0 0.3 0.7
m (non normalisée) 0.42 0.12 0.28m (normalisé) 0.5122 0.1463 0.3415
Table 3.1 – Combinaison par la règle orthogonale de Dempster.
La masse conflictuelle k = mS1(C1) ∗mS2(C2) +mS1(C2) ∗mS2(C1) = 0.6 ∗ 0.3 + 0 = 0.18.En utilisant la PCR5, la masse conflictuelle est redistribuée proportionnellement à C1 et C2.Soit X la masse conflictuelle redistribuée a C1 et Y celle redistribuée sur C2 :X0.6 = Y
0.3 = X+Y0.6+0.3 = 0.18
0.9 = 0.2Donc X = 0.2 ∗ 0.6 = 0.12 et Y = 0.2 ∗ 0.3 = 0.06Par la suite le résultat de la PCR5 est :mpcr5(C1) = 0.42 + 0.12 = 0.54mpcr5(C2) = 0.12 + 0.06 = 0.18mpcr5(C1 ∪ C2) = 0.28 + 0 = 0.28
3.3.4 Intervalle de confiance
Dans le cas de la théorie des possibilités la valeur de nécessité quantifie la certitude del’évènement. Autrement dit, plus N est proche de 1 plus on est certain de la réalisation decet événement.
Dans le cas de la TFC, la valeur de crédibilité d’une hypothèse Ai peut-être interprétéecomme la valeur minimale de l’incertitude attribuée à cette hypothèse. Tandis que sa valeurde plausibilité peut être interprétée comme la valeur maximale d’incertitude autour de Ai.Donc l’incertitude autour de l’hypothèseAi peut-être représenté par l’intervalle [Cr(Ai), P l(Ai)]qui est appelé intervalle de confiance.La langueur de cet intervalle quantifie l’ignorance de la source sur cette hypothèse.
Ing(Ai) = Pl(Ai)− Cr(Ai) (3.18)

Chapitre 3. Processus de fusion par la théorie des possibilités, la TFC et la DSmT 58
3.4 Classification par la théorie du raisonnement plau-sible et paradoxale
La première différence entre la DSmT et la TFC est la non exclusivité du cadre de dis-cernement qui est modélisée par l’intersection des classes et qui traduit le paradoxe, sachantque les classes formées par l’union représentent l’incertitude.Ainsi, on parle de l’ensemble de l’hyper-puissances et non pas de l’ensemble de puissances.Exemple :Soit Ω = C1, C2, donc DΩ = ∅, C1, C2, C1 ∪ C2, C1 ∩ C2.La somme des masses des éléments de DΩ est égale à 1 donc :m(C1) +m(C2) +m(C1 ∪ C2) +m(C1 ∩ C2) = 1Sachant que m(C1 ∪ C2) modélise l’incertitude et m(C1 ∩ C2) modélise le paradoxe.Par contre la génération de l’hyper-puissance devient un problème de plus en plus difficileet délicat lorsque la cardinalité Ω est supérieur à deux. Puisque le nombre de combinaisonsdevient énorme.
3.4.1 Génération de l’ensemble hyper-puissance
Avant de générer les éléments de l’ensemble l’hyper-puissances, il faut choisir un modèlede fusion parmi les trois modèles de la DSmT qui sont : le modèle libre, le modèle hybride etle modèle de Shafer.Le choix du modèle de fusion dépend généralement des informations disponibles sur le pro-blème abordé et des contraintes présentes.
3.4.1.1 Modèle libre de DSm
Rappelons que le modèle libre MF de la DSmT prend en compte, en plus des classessimples, toutes les combinaisons possibles entre les classes du cadre de discernement généra-lisé en utilisant les opérateurs logiques d’intersection ∩ et d’union ∪.Selon Dezert et Smarandache [28] la cardinalité de l’ensemble de DΩ suit les nombres deDedekind [19], 1, 2, 5, 19, 167, ... (i.e si|Ω|=2 | alors DΩ|=5,| Ω|=3 alors |DΩ|=19).Cependant, un récent travail [16] a montré qu’on peut supprimer quelques combinaisons enraison de la redondance.En effet, pour Ω = C1, C2, C3 d’après Dezert et Smarandache l’ensemble de l’hyper-puissanceest :

Chapitre 3. Processus de fusion par la théorie des possibilités, la TFC et la DSmT 59
DΩ = ∅, C1, C2, C3, C1∪C2, C1∪C3, C2∪C3, C1∪C2∪C3, C1∩C2, C1∩C3, C2∩C3, C1∩C2 ∩ C3, C1 ∩ (C2 ∪ C3), C2 ∩ (C1 ∪ C3), C3 ∩ (C1 ∪ C2), C1 ∪ (C2 ∩ C3), C2 ∪ (C1 ∩ C3), C3 ∪(C1 ∩ C2), (C1 ∩ C2) ∪ (C1 ∩ C3) ∪ (C2 ∩ C3).Or Cholvy a montré que, C1 ∩ (C2 ∪ C3) ∈ DΩ par contre (C1 ∩ C2) ∪ (C1 ∩ C3) /∈ DΩ parcequ’elle caractérise le même élément.D’autre côté, (C1∩C2)∪C3 est un élément de l’hyper-puissance par contre (C1∪C3)∩(C2∪C3)n’est pas un élément de DΩ puisque elle représente le même élément. Donc on peut éliminerl’élément (C1 ∩ C2) ∪ (C1 ∩ C3) ∪ (C2 ∩ C3) de DΩ
Cependant, le modèle libre est extrêmement coûteux surtout pour |Ω| ≥ 5. Dans le cas oùon utilise la codification de Dezert et Smarandache [28, 29], il est facile de calculer la taille dela mémoire nécessaire pour stocker les éléments de DΩ en fonction de la cardinalité du cadrede discernement Ω.
|Ω| |DΩ| Taille d’un élément Taille de la mémoire2 4 1 octet 4 octets3 18 1 octet 18 octets4 167 2 octets 0.32 Ko5 7569 4 octets ≈ 30 Ko6 7828352 8 octets ≈ 59 Mo7 2414682040996 16 octets ≈ 3.6 ∗ 104 Go8 ≈ 5.6 ∗ 1021 32 octets ≈ 1.7 ∗ 1015 Go
Table 3.2 – Taille de mémoire nécessaire pour quelques hyper-powerset [28].
Il est claire que la modélisation d’un problème de fusion où la cardinalité du cadre dediscernement généralisé supérieur ou égale à sept devient une tâche d’extrême difficulté pournos machine. D’une part le nombre de combinaison tend vers l’infinie et d’autre part on aurabesoin d’une très grande mémoire (problème de complexité temporelle et spatiale ).A côté de sa complexité exponentielle le modèle libre présente un autre inconvénient quiest la signification des classes de l’ensemble de l’hyper puissance. En effet, l’utilisation desopérateurs d’union “∪” et d’intersection “∩” pour construire des classes peut engendrer denouvelles classes non significatives. Ces classes rendent le calcul plus complexe. Finalement,on peut avoir des résultats erronés lorsque des observations seront attribuées à ces classes.

Chapitre 3. Processus de fusion par la théorie des possibilités, la TFC et la DSmT 60
3.4.1.2 Modèle hybride de DSm
Le second modèle de la DsmT est le modèle hybride qu’nous avons choisi pour appliquerla DSmT dans notre travail de master.Pour des problèmes de fusion, on peut constater que certains éléments du cadre de discer-nement sont exclusifs. Ainsi, si on dispose des informations et des connaissances sur la zoned’étude, on peut introduire des contraintes d’exclusivité sur quelques éléments de l’ensembleDΩ afin de forcer l’intersection à être le vide.Ce modèle semble intéressent puisque il nous permet de réduire la cardinalité de DΩ et parla suite de réduire la complexité du calcul et de combinaison. Sachant que ce modèle peuts’obtenir non seulement par l’introduction des contraintes d’exclusivité mais aussi par descontraintes de non existence. Et donc ce modèle nous donne l’occasion d’éliminer des classesnon utiles et non significatives qui peuvent d’une part rendre les temps du calcul plus impor-tant et d’autre part augmenter le taux d’erreur surtout dans la phase de décision.
3.4.1.3 Méthode proposée pour la construction de l’ensemble de fusion
Dans le cadre de la théorie du raisonnement plausible et paradoxale, Dezert et Sma-randache ont proposé quelques méthodes pour construire l’ensemble de fusion et l’ordonner[28, 29]. Parmi ces méthodes nous citons la suivante :Étant donné un cadre de discernement Ω = C1, C2, ..., Cn qui satisfait le modèle libre duDSm (les classes sont deux à deux non exclusives et aucune contrainte de non existence n’estimposée) représenté par le diagramme de Venn. Tous les éléments de DΩ peuvent être obtenuspar la résolution d’un système d’équations linéaires simples :
dn = Dn.un (3.19)
Où dn est le vecteur des éléments de DΩ, un est le vecteur de codification de Smarandache etDn est une matrice binaire particulière. Le résultat final dn est obtenu du produit matricielprécédent après avoir identifier les opérateurs “+” et “.” avec “∪” et “∩”, 0.X avec ∅ et1.X avec X. La matrice obtenue est binaire correspondante aux fonctions booléennes isotones(c’est-à-dire : non décroissantes).
Méthode proposée : dans notre travail de master, nous avons proposé une nouvelleméthode pour construire et ordonner les différentes classes de l’ensemble de l’hyper-puissance.La méthode que nous avons proposée consiste à générer une matrice qui contient la codificationde tous les éléments focaux en précisant pour chaque élément son type (i.e classe singleton,classe d’intersection,...). Sachant que les lignes de cette matrice sont classées suivant un ordrebien définit.

Chapitre 3. Processus de fusion par la théorie des possibilités, la TFC et la DSmT 61
Tout d’abord nous avons divisé l’ensemble des éléments focaux en quatre catégories quisont : les classes singletons, les classes d’union simple, les classes d’intersection simple et lesclasses d’union et d’intersection (classes mixtes).Le nombre de lignes de la matrice de codification est égal au nombre des éléments focaux. Lenombre de ses colonnes est la somme des nombre de classes singletons, le nombre de classesd’union simple, nombre de classes d’intersections simple et de deux autres colonnes qui nousaident à distinguer les types des classes.Supposons que le cadre de discernement contient trois classes qui sont deux à deux nonexclusives, Ω = C1, C2, C3. Donc l’ensemble d’hyper puissance DΩ contient 18 classes quenous les notons de A0 à A17 et qui sont respectivement :DΩ = ∅, C1, C2, C3, C1∪C2, C1∪C3, C2∪C3, C1∪C2∪C3, C1∩C2, C1∩C3, C2∩C3, C1∩C2∩C3,
C1 ∩ (C2 ∪C3), C2 ∩ (C1 ∪C3), C3 ∩ (C1 ∪C2), C1 ∪ (C2 ∩C3), C2 ∪ (C1 ∩C3), C3 ∪ (C1 ∩C2).Cet ensemble est ordonné de sorte qu on trouve les classes singletons suivies par les classesformées par l’opérateur d’union et dans un troisième lieu on trouve les classes composéespar l’opérateur d’intersection et finalement on trouve les classes mixtes c’est-à-dire les classesformé par les deux opérateurs. Les lignes de la matrice représentent la codification des élémentsqui composent l’ensemble hyper-puissance. Les colonnes de A1 à A11 représentent les classesqui composent les éléments de DΩ tandis que les deux dernières colonnes donnent les typesd’opérateurs utilisés pour former les classes composées.Classes singletons : si la classe est de type singleton telle que A2, sa codification consiste
à mettre un 1 dans la ligne et la colonne qui correspond à la classe elle-même et le restede colonnes nous mettons des zéros.
Classes d’union : si la classe est de type union tel que A5, alors nous choisissons la ligne quicontient la codification de cette classe, ensuite nous mettons des uns dans les colonnesqui correspondent aux classes singletons qui la composent et un autre un dans la colonned’union.
Classes d’intersection : si la classe est une classe formée par l’opérateur d’intersectionseulement genre A9. Dans la ligne correspondante à cette classe, nous mettons des unsdans les colonnes des classes qui la forment et un autre un dans la dernière colonne quicorrespond à l’opérateur d’intersection.
Classes mixtes : si la classe est une classe formée par les opérateurs d’union et d’intersec-tion, nous avons alors deux cas :– Dans le premier cas, la classe est formée par l’intersection d’une classe singleton (oubien une classe paradoxale) et d’une classe d’union, comme A12, dans ce cas dans laligne correspondante nous mettons un dans la colonne de la classe simple (ou biendes uns dans les classes qui forment la classe paradoxale) et nous mettons des unsdans les colonnes des classes d’unions. Le reste des colonnes contient des zéros saufles deux dernières colonnes.
– Dans le second cas, la classe est formée par l’union des classes simples (ou bien uneclasse d’union), tel que A16, avec une ou plusieurs classes paradoxales. Ainsi, nous

Chapitre 3. Processus de fusion par la théorie des possibilités, la TFC et la DSmT 62
allons mettre des uns dans les colonnes des classes qui forment l’union et des 1 dansles colonnes des classes paradoxales simples. De même les deux dernières colonnescontiennent des uns et le reste contient des zéros.
La matrice de codification et d’ordonnancement qui correspond à cet exemple est donnée parle tableau suivant :
A1 A2 A3 A4 A5 A6 A7 A8 A9 A10 A11 ∪ ∩A0 0 0 0 0 0 0 0 0 0 0 0 0 0A1 1 0 0 0 0 0 0 0 0 0 0 0 0A2 0 1 0 0 0 0 0 0 0 0 0 0 0A3 0 0 1 0 0 0 0 0 0 0 0 0 0A4 1 1 0 0 0 0 0 0 0 0 0 1 0A5 1 0 1 0 0 0 0 0 0 0 0 1 0A6 0 1 1 0 0 0 0 0 0 0 0 1 0A7 1 1 1 0 0 0 0 0 0 0 0 1 0A8 1 1 0 0 0 0 0 0 0 0 0 0 1A9 1 0 1 0 0 0 0 0 0 0 0 0 1A10 0 1 1 0 0 0 0 0 0 0 0 0 1A11 1 1 1 0 0 0 0 0 0 0 0 0 1A12 1 0 0 0 0 1 0 0 0 0 0 1 1A13 0 1 0 0 1 0 0 0 0 0 0 1 1A14 0 0 1 1 0 0 0 0 0 0 0 1 1A15 1 0 0 0 0 0 0 0 0 1 0 1 1A16 0 1 0 0 0 0 0 0 1 0 0 1 1A17 0 0 1 0 0 0 0 1 0 0 0 1 1
Table 3.3 – Exemple de matrice de codification des éléments de l’hyper-puissance.
Avantages de la méthode proposée :Le principal avantage de cette méthode de codification et d’ordonnancement se résume par lasimplicité de sa mise en œuvre d’une part, d’autre part la phase de combinaison devient plussimple puisque nous pouvons déterminer facilement le type de classe (singleton, incertaine,paradoxale) et cela à l’aide des deux dernières colonnes de la matrice. Nous pouvons facilementconnaître les classes qui constituent les différents éléments de DΩ.Nous avons exploité cette méthode pour calculer la cardinalité de Dezert et Smarandacheafin de pourvoir calculer la transformation pignistique généralisée. Nous avons détaillé cetteméthode dans la section “Méthode proposée pour calculer la cardinalité de DSm avec laméthode de codification proposée” de ce chapitre.

Chapitre 3. Processus de fusion par la théorie des possibilités, la TFC et la DSmT 63
3.4.2 Méthode proposée pour la construction des classes compo-sées et estimation des fonctions de masse généralisées
Pour estimer les fonctions de masse généralisées nous devant respecter l’interprétation desclasses composées, c’est-à-dire l’incertitude et l’ambiguïté qui sont représenter par les classescomposées respectivement par l’opérateur d’union et celui d’intersection. Mais avant d’estimerles jeux de masse nous devons d’abord construire et déterminer les différents éléments focaux.Dans ce travail, la méthode appliquée pour construire les classes de l’ensemble de l’hyper-puissance s’étend de la solution proposée par Ben Dhiaf dans [7] avec laquelle elle a déterminéles classes composées au sein de la TFC en utilisant les histogrammes de niveaux de gris etque nous l’avons déjà décris dans la section “Génération de l’ensemble de fusion”.
Rappelons que dans [7] l’histogramme d’un élément focal composé par l’union des classesest construit en considérant les bornes inférieures de la zone des chevauchements des diffé-rentes classes qui le composent.Dans ce même contexte nous proposons de mieux exploité la zone de confusion qui résulte duchevauchement des histogrammes des classes puisque cette zone représente d’une part l’incer-titude, d’autre part l’ambiguïté et le paradoxe.En effet, nous avons utilisé la même méthode pour déterminer les histogrammes des classescomposées par l’opérateur d’union. Mais afin de construire l’histogramme d’une classe para-doxale (composée par l’opérateur d’intersection), nous considérons les bornes supérieures dela zone résultante des chevauchements des classes qui la construisent.Donc le principe de cette approche se résume par les trois étapes suivantes :
1. Pour chaque classe Ci ∈ Ω avec Ci représentée par une zone d’apprentissage ou plus,nous déterminons sa fonction histogramme hCi : [0, 255] → N qui associe à chaquevaleur x le nombre hCi(x) d’apparitions de cette valeur dans l’ensemble d’échantillonsde la classe Ci. Donc Ci est considérée un élément focal pour un élément x si elle vérifiel’équation suivante :
hCi(x) > 0, Ci ∈ Ω (3.20)
2. Pour chaque élément focal A composé par l’union de d’autres classes, nous déterminonsson histogramme associé hA. Cet histogramme est construit par les bornes inférieuresde tous les histogrammes hCi des classes Ci incluses dans A.
hA(x) = minhCi(x) | Ci ⊂ A, i ∈ 1..K (3.21)
3. Pour chaque élément focal B composé par l’intersection de d’autres classes, nous dé-terminons son histogramme associé hB. Cet histogramme est construit par les bornessupérieures de la zone de chevauchement des histogrammes hCi des classes Ci qui formentpar leur intersection la classe B.
hB(x) = maxhCh(x) | Ci ∩B = B, i ∈ 1..K (3.22)
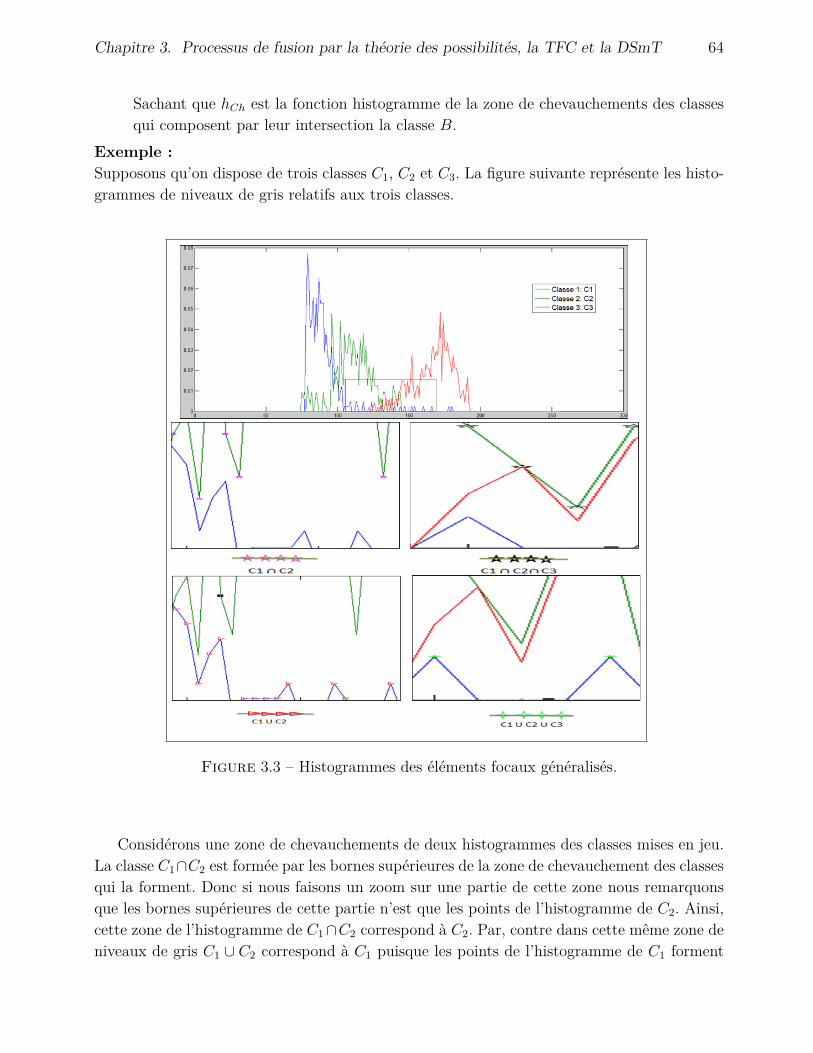
Chapitre 3. Processus de fusion par la théorie des possibilités, la TFC et la DSmT 64
Sachant que hCh est la fonction histogramme de la zone de chevauchements des classesqui composent par leur intersection la classe B.
Exemple :Supposons qu’on dispose de trois classes C1, C2 et C3. La figure suivante représente les histo-grammes de niveaux de gris relatifs aux trois classes.
Figure 3.3 – Histogrammes des éléments focaux généralisés.
Considérons une zone de chevauchements de deux histogrammes des classes mises en jeu.La classe C1∩C2 est formée par les bornes supérieures de la zone de chevauchement des classesqui la forment. Donc si nous faisons un zoom sur une partie de cette zone nous remarquonsque les bornes supérieures de cette partie n’est que les points de l’histogramme de C2. Ainsi,cette zone de l’histogramme de C1∩C2 correspond à C2. Par, contre dans cette même zone deniveaux de gris C1 ∪ C2 correspond à C1 puisque les points de l’histogramme de C1 forment

Chapitre 3. Processus de fusion par la théorie des possibilités, la TFC et la DSmT 65
les bornes inférieurs de la zone de chevauchement.
Une fois les différents histogrammes sont déterminés, l’estimation des jeux de masse gé-néralisées se fait de la même manière que l’estimation des fonctions de masse de l’évidence(TFC) que nous avons déjà décrite dans la sous-section “Estimation des fonctions de masse”de la section “Classification par la théorie des fonctions de croyance” .
3.4.3 Combinaison des fonctions de masses généralisées
Une diversité de règles de combinaison a été proposée dans [70] pour combiner les massesdes éléments focaux généralisés et pour prendre en compte le mieux possible le paradoxe entreles sources. Nous citons par exemple la règle de combinaison de DSm classique (DSmC ), larègle de combinaison de DSm hybride (DSmH ) et les cinq règles de combinaison de redistri-bution proportionnelle du conflit (PCR).
Nous allons nous intéresser uniquement aux deux règles. La première règle de combinaisonest la règle de DSm classique notéeDSmC qui n’est que la règle de Dempster généralisée. LaDSmC est donnée par l’équation 2.46.La seconde règle utilisée est la cinquième version des règles de combinaison de redistributionproportionnelle du conflit qui est la PCR5 2.47.
3.4.4 Décision
Les règles de décision au sein de la TFC sont généralement utilisées dans le cadre dela DSmT. En revanche, la définition de la fonction de probabilité pignistique a changé enintroduisant la cardinalité du DSm qui diffère de la notion de cardinalité des ensembles [34].La cardinalité de DSm est le nombre de parties qui constituent les classes dans le diagrammede Venn du problème.
3.4.4.1 Méthode proposée pour calculer la cardinalité de DSm avec la méthodede codification proposée
Pour calculer la cardinalité de DSm d’une classe de l’ensemble de l’hyper-puissance ondoit avoir recours au diagramme de Venn qui représente le modèle choisi (libre, hybride oubien de Shafer) et le problème abordé.

Chapitre 3. Processus de fusion par la théorie des possibilités, la TFC et la DSmT 66
Sauf qu’on ne dispose pas des règles mathématiques qui nous permettent de calculer cettecardinalité quel que soit le modèle et le type de classe.
Avec la méthode de codification que nous avons proposée, nous sommes parvenus à calculerla cardinalite de DSm des éléments focaux de type singletons, union simple, intersection simplequel que soit la cardinalité du cadre de discernement généralisé.En exploitant les résultats du calcul de la cardinalité des éléments que nous avons cités noussommes parvenus aussi à calculer la cardinalité des éléments de type classe paradoxale interclasse d’union. Par contre, il faut souligner que le nombre de classes initiales ne doit pasdépasser quatre (cardinalité du cadre de discernement généralisé ≤ 4).
Pour calculer la cardinalité de chaque classe à partir de la matrice des codifications pro-posée, nous suivons les étapes suivantes :Soient K le nombre des classes singletons (cardinalité du cadre de discernement), Knouv lenombre des classes singletons plus le nombre des classes d’union et Kgen le nombre de toutesles classes (nombre des éléments focaux généralisés).
1. Si la classe Ai avec i ≤ K est de type singleton dans ce cas nous considérons la colonne Aià partir de la première ligne jusqu’à la ligne numéro Knouv de la matrice de codification.La cardinalité de Ai est égale au nombre des uns dans la partie considérée de la colonnede la classe.Exemple :Reprenons la matrice de la codification de l’exemple de la section 3.4.1.3 le diagramme“a” de la figure 3.4 correspond à cet exemple : K=3, Knouv = 8 et Kgen = 18. Lacardinalité de A2 = 4, qui est le nombre des uns dans la colonne A2 à partir de A0
jusqu’à A7.2. Si la classe Ai est une classe composée par l’union des singletons donc on a i>K eti <= Knouv. Dans ce cas nous considérons la sous matrice formée par Knouv lignes (àpartir de ligne numéro 1 de la matrice de codification jusqu’à la ligne numéro Knouv etpar les colonnes qui correspondent aux classes qui composent Ai. La cardinalité de DSmde la classe Ai est le nombre des lignes qui contiennent au moins une colonne différentede zéro.Exemple :Pour calculer la cardinalité de la classe A4 = C1 ∪ C2, de la matrice de codification dela section 3.4.1.3 nous procédons comme suit :Nous considérons la sous matrice formée par les deux colonnes A1 = C1 et A2 = C2 etles huit premières lignes. Les lignes qui contiennent des 1 sont A1, A2, A4, A5, A6 et A7.Ainsi, la cardinalité de A4 = 6.
3. Si la classe Ai est formée par l’intersection des p classes singletons, dans ce cas nousconsidérons la sous matrice formée par ( Kgen − Knouv ) lignes (à partir de la ligne

Chapitre 3. Processus de fusion par la théorie des possibilités, la TFC et la DSmT 67
Knouv + 1 jusqu’à la ligne Kgen) et par les colonnes qui correspondent aux classes quiconstituent Ai. Par la suite nous éliminons les lignes des codifications des classes com-posées par l’intersection et l’union des singletons. Dans ce cas la cardinalité de Ai estégale au nombre de lignes qui contient p uns.Ou bien, nous pouvons considérer la sous matrice formée par Knouv lignes, en commen-çant par la ligne numéro un jusqu’à la ligne numéro Knouv et bien sûr les colonnes quicorrespondent aux classes qui constituent Ai. De même, la cardinalité de Ai est égaleau nombre de lignes qui contient que des uns.Exemple :Pour calculer la cardinalité de la classe A9 = C1 ∩ C3 nous procédons comme suit :Nous considérons la sous matrice formée par les colonnes A1 et A3 et les lignes à partirde A1 jusqu’à la ligne A7. Les lignes qui contiennent que des uns sont A5 et A7 d’où lacardinalité de A9 = 2.
4. Si la classe Ai est de genre C1 ∩ (C2 ∪ C3) et |Ω| ≤ 4.CM(Ai) = CM(C1 ∩ C2) + CM(C1 ∩ C3)− CM(C1 ∩ C2 ∩ C3)Ainsi, la cardinalité de A12 = C1 ∩ (C2 ∪ C3) = 2 + 2− 1 = 3.
5. Si la classe Ai est de genre C1 ∪ (C2 ∩ C3) et |Ω| ≤ 4. CM(Ai) = CM(C1) + CM(C2 ∩C3)− CM(C1 ∩ C2 ∩ C3)Donc la cardinalité de A15 = C1 ∪ (C2 ∩ C3) = 4 + 2− 1 = 5.
Exemple :La figure ci-après contient deux exemples de diagrammes de Venn. Le figure « a » représentele diagramme de Venn de trois classes qui sont deux à deux non exclusives (modèle libre deDSm). Sa matrice de codification est celle présentée dans la section 3.4.1.3.Le diagramme « b » représente un exemple de trois classes qui ne sont pas deux a deux nonexclusives (modèle hybride) :
Figure 3.4 – Diagrammes de Venn.

Chapitre 3. Processus de fusion par la théorie des possibilités, la TFC et la DSmT 68
Classes Cardinalités du modèle libre Cardinalités du modèle hybrideC1 4 2C2 4 3C3 4 2
C1 ∪ C2 6 4C1 ∪ C3 6 4C2 ∪ C3 6 4
C1 ∪ C2 ∪ C3 7 5C1 ∩ C2 2 1C1 ∩ C3 2 0C2 ∩ C3 2 1
C1 ∩ C2 ∩ C3 1 0C1 ∩ (C2 ∪ C3) 3 1C2 ∩ (C1 ∪ C3) 3 2C3 ∩ (C1 ∪ C2) 3 1C1 ∪ (C2 ∩ C3) 5 3C2 ∪ (C1 ∩ C3) 5 3C3 ∪ (C1 ∩ C2) 5 3
Table 3.4 – Exemples de cardinalités de DSm de deux modéles.
3.5 Conclusion
Pour l’estimation des classes possibilistes, nous avons utilisé une méthode probabilisteproposée par Dubois et Prade et généralisée par Denoeux et Masson [55], qui permet dedéterminer la distribution des possibilités la plus spécifique. Pour le modèle de fusion relatifà la TFC l’estimation est faite aussi à l’aide d’une méthode probabiliste proposée par BenDhiaf [7] et qui exploite les fréquences des observations pour déterminer les jeux de masse.Nous avons proposé une nouvelle méthode pour construire les classes paradoxales au sein dela DSmT qui représentent l’ambiguïté et le conflit à partir des histogrammes de niveaux degris. Nous avons également proposé une méthode pour ordonner et coder les éléments focauxgénéralisés. Par la suite nous avons proposé une méthode qui nous permet de calculer lacardinalité de DSm à l’aide de la matrice de codification que nous avons introduite. Pourestimer les fonctions de masses généralisées nous avons exploité la même méthode utilisé ausein de la TFC. Afin de combiner les distributions des possibilités et les distributions demasses nous avons appliqué quelques règles conjonctives de combinaisons. Finalement, nousavons mis en œuvre les règles de décisions appropriées pour chaque modèle.

Chapitre 4Expérimentations de la théorie des possibilités,la TFC et la DSmT
4.1 Introduction
Les processus de fusion que nous avons étudiés et mis en œuvre associés à la théorie despossibilités, la TFC et la DSmT ont été appliqués dans un contexte multi sources afin
de choisir la théorie la plus adéquate pour mettre en place un système de classification desimages forestières.Dans un premier temps nous avons présenté les architectures des processus de fusion relativesaux trois approches.Ensuite, nous avons exposé le site d’étude, les sources d’information et les imperfections quiaccompagnent les différentes sources. La troisième partie de ce chapitre est consacrée auxrésultats de fusion/classification par les trois processus et les évaluations.
4.2 Architectures des processus de fusion
Tout au long de ce travail, nous avons mis en place un processus de fusion pour chaqueapproche étudiée. Chaque processus se déroule suivant un enchaînement d’étapes bien définies.

Chapitre 4. Expérimentations de la théorie des possibilités, la TFC et la DSmT 70
4.2.1 Architecture du processus de fusion possibiliste
Le processus de fusion relatif à la théorie des possibilités que nous avons mis en œuvre sedéroule selon plusieurs étapes qui sont :
1. Modélisation :– Détermination de l’univers du discours.– Choix des zones d’apprentissage.
2. Estimation :– Choix du facteur d’affaiblissement.– Calcul des distributions des probabilités.– Transformation des distributions de probabilités à des distributions de possibilités.– Choix de la distribution de possibilités la plus spécifique pour chaque classe.
3. Combinaison.4. Décision.
Ces étapes se résument par la figure suivante :
Figure 4.1 – Étapes de fusion par la théorie des possibilités.
4.2.2 Architecture du processus de fusion de la TFC
L’architecture du processus de fusion qui correspond à la TFC diffère de celui de la théoriedes possibilités et nous pouvons remarquer cela dès la première phase de la fusion (modélisa-

Chapitre 4. Expérimentations de la théorie des possibilités, la TFC et la DSmT 71
tion). La fusion/classification par ce processus se déroule suivant ces étapes :1. Modélisation :
– Détermination du cadre de discernement relatif à chaque source.– Raffinement/Grossissement des cadres de discernement (s’il est nécessaire).– Choix des zones d’apprentissage.– Détermination de l’ensemble des éléments focaux.– Réduction de l’ensemble des éléments focaux.
2. Estimation :– Calcul des masses de croyance.– Affaiblissement des masses (s’il est nécessaire).
3. Combinaison.4. Décision.
Ces étapes sont illustrées par la figure suivante :
Figure 4.2 – Étapes de fusion par la TFC.
4.2.3 Architecture du processus de fusion de la DSmT
Le processus de fusion par la DSmT que nous avons mis en place ressemble à celui de laTFC que nous avons présenté dans la sous section précédente.Ce processus se déroule selon les étapes suivantes :

Chapitre 4. Expérimentations de la théorie des possibilités, la TFC et la DSmT 72
1. Modélisation :– Détermination des cadres de discernement.– Raffinement/Grossissement (s’il est nécessaire).– Choix des zones d’apprentissage.– Choix du modèle de fusion.– Construction de l’ensemble des éléments focaux généralisés.– Réduction de l’ensemble des éléments focaux.– Codification et ordonnancement des éléments focaux.
2. Estimation.3. Combinaison.4. Décision.
La figure suivante illustre l’enchaînement des étapes de fusion par le processus relatif à laDSmT :
Figure 4.3 – Étapes de fusion par la DSmT.
4.3 Zone d’étude et sources d’informations
Le site d’étude considéré est une région forestière située dans la ville d’Ain-Drahim dugouvernorat de Jendouba (Tunisie). Cette zone est caractérisée par : la diversité de strates,l’abondance des espèces forestières ainsi que les variations de l’altitude.

Chapitre 4. Expérimentations de la théorie des possibilités, la TFC et la DSmT 73
4.3.1 Sources d’informations
Nous disposons de deux sources d’informations :1. Une image satellite haute résolution acquise par le capteur QuickBird (0.61 mètres/pixel)
qui date de juin 2006 (IHR).2. Un inventaire forestier numérisé (IFN).
L’inventaire est basé sur la notion de stratification. Une strate étant définie comme unefraction représentative d’une population.Les renseignements attendus de l’élaboration d’un inventaire forestier sont des rensei-gnements quantitatifs et qualitatifs sur toutes les forêts du pays. Ces renseignementssont principalement les suivants :– Densité des peuplements.– Volume et accroissement des bois.
4.3.2 Les imperfections présentes
L’imprécision : l’information fournie par les sources est entachée par des imprécisions. Eneffet, les informations acquises par une source ne nous permettent pas de décider danscertains cas sur l’appartenance exacte d’un pixel à une classe donnée. Nous pouvonsremarquer ceci dans le cas du chevauchement des histogrammes des niveaux de gris.Par ailleurs, l’inventaire est imprécis puisque les strates ne représentent pas une seuleclasse mais dans la plupart des cas ils symbolisent un ensemble de classes.
L’incertitude : la nature imprécise et même vague de l’inventaire induit l’incertitude. Commenous avons précisé précédemment, ces deux types d’imperfections sont étroitement liéesc’est à dire la présence de l’une indique la présence de l’autre.Rappelons que l’incertitude se limite principalement à deux types qui sont l’incertitudeépistémique et l’incertitude aléatoire. Dans notre cas, l’incertitude à laquelle nous fai-sons face est de type épistémique et ceci est dû au fait que les informations fournies parl’inventaire sont manquantes et vagues. En effet, l’inventaire nous donne une idée surles différentes espèces qui constituent les différentes strates et polygones. Néanmoins,les strates ne correspondent pas toujours à une seule classe d’occupation. En effet, plu-sieurs polygones dans l’inventaire numérisé correspondent à un mélange d’espèces (casdu mélange Chêne Liège et Chêne Zén).Aussi, pour un pixel donné de l’image haute résolution, nous disposons au niveau del’inventaire d’un polygone de la région qui l’entoure et non une information spécifique.
Le conflit : la nature imprécise et incertaine des sources et l’absence d’informations spectraledu coté de l’inventaire favorise l’apparition du conflit. En outre, les sources n’ont pasle même référentiel de temps (image QuickBird 2006 , inventaire 2000) et donc des

Chapitre 4. Expérimentations de la théorie des possibilités, la TFC et la DSmT 74
changements ont eu lieu surtout au niveau de la couverture forestière ce qui engendrel’ambiguïté et le conflit.
4.4 Classification des images forestières
4.4.1 Apprentissage et fenêtres de l’IHR
4.4.1.1 Apprentissage
Nous avons appliqué les trois approches de fusion sur plusieurs fenêtres de l’image QuickB-bird. Pour chaque fenêtre nous avons déterminé une base d’apprentissage qui contient lesclasses thématiques. Les classes d’occupation sont à priori définies à travers des zones d’ap-prentissage qui correspondent à l’inventaire numérisé en strates. Pour chaque classe, nousavons défini des zones d’apprentissage sous forme de polygones et nous avons formé ainsi unebase d’apprentissage qui sera utilisée pour la caractérisation de chaque type d’occupation dusol.
4.4.1.2 Les fenêtres
Les processus de fusion sont appliqués et testés sur plusieurs fenêtres de l’image QuickBirdde taille 250*250. Nous allons présenté dans cette section six fenêtres de l’IHR avec leursinventaires forestier nationale (IFN).Image de Hölder : Une troisième source déduite à partir de l’IHR est introduite pour réaliserla classification des images forestières qui est l’image de Hölder. Cette dernière nous donne uneidée sur l’information de texture relative à l’IHR. L’utilisation de cette image étant commeune source dans la classification des images satélitaires a été proposée dans [7]. L’image deHölder à été obtenue par l’outil multi-fractal. L’annexe A illustre les étapes nécessaires pourla mise en œuvre de cette image.
Les fenêtres que nous avons choisies présentent un ensemble de classes qui sont : la classeChêne Zen (CZ), la classe Chêne liège (CL), la classe Pins(Pin), la classe Sol Peu Couvert(SPC) et la classe Sol Nu (SN). A coté de ces prises de l’IHR, nous allons illustrer pourcertaines fenêtres leurs images de Hölder et la prise des échantillons sur les images de l’IHR.La figure 4.4 illustre la fenêtre numéro 1 de l’IHR que nous notons (F1), l’inventaire forestierqui lui correspond, l’image de Hölder correspondante et le choix des zones d’apprentissage sur

Chapitre 4. Expérimentations de la théorie des possibilités, la TFC et la DSmT 75
cette fenêtre.
Figure 4.4 – La fenêtre 1 de l’IHR, IFN correspondant, choix des zones d’apprentissage etimage de Hölder correspondante .
Cette fenêtre ainsi que son image de Hölder présentent quatre classes qui sont CZ ,CL, SPCet SN. Cependant, l’IFN correspondant est uniquement formé par deux classes. La premièreclasse est constituée par CZ et CL et la seconde classe par SPC.Les couronnes correspondantes à la classe chêne zen (CZ) ont un niveau de gris proche dublanc dans l’IHR. Par contre, les couronnes de la chêne liège (CL) sont gris claire.
La seconde fenêtre (F2) de l’IHR que nous avons choisie est illustrée par la figure 4.5. Lesmêmes classes qui constituent F1 sont présentes dans F2.

Chapitre 4. Expérimentations de la théorie des possibilités, la TFC et la DSmT 76
Figure 4.5 – La deuxième fenêtre de l’IHR, IFN correspondant et choix des zones d’appren-tissage.
Les classes formant l’inventaire correspondant à la seconde fenêtre choisi sont de l’ordrede deux. La première présente les deux chênes (CL) et (CZ), la seconde le sol peu couvert(SPC) et le sol nu (SN).La figure 4.6 représente la troisième fenêtre de l’IHR (F3) et l’inventaire qui lui correspond.Cette fenêtre est formée par quatre classes qui sont CZ, CL, PIN, et SN. Par contre l’IFN quilui correspond est constitué de deux classes. La première représente CZ et CL et la secondePIN.

Chapitre 4. Expérimentations de la théorie des possibilités, la TFC et la DSmT 77
Figure 4.6 – La troisième fenêtre de l’IHR et son IFN.
La quatrième fenêtre (F4) que nous avons choisie est illustrée avec son IFN par la figure4.7. Les classes présentent dans cette fenêtres sont CZ, CL, SPC et SN.
Figure 4.7 – La quatrième fenêtre de l’IHR et son inventaire.
La figure 4.8 représente la cinquième fenêtre de l’IHR et son image de Hölder correspon-dante.La dernière fenêtre choisie est illustrée avec son IFN et son image de Hölder par la figure 4.9.

Chapitre 4. Expérimentations de la théorie des possibilités, la TFC et la DSmT 78
Figure 4.8 – La cinquième fenêtre et son image de Hölder.
Figure 4.9 – La sixième fenêtre de l’IHR, son IFN et son image de Hölder.

Chapitre 4. Expérimentations de la théorie des possibilités, la TFC et la DSmT 79
4.4.2 Application de la TFC
Le processus de la TFC que nous avons mis en œuvre a été utilisé pour réaliser la classi-fication des fenêtres de l’IHR que nous avons présenté dans la section précédente.
4.4.2.1 Fusion avec l’inventaire
1. Classification de la fenêtre une :Dans un premier temps nous avons fusionné la fenêtre F1 avec l’inventaire qui lui corres-pond 4.4. Cependant, les deux sources sont conflictuelles et ceci revient principalementau décalage temporel entre elles.La figure suivante représente l’image du conflit entre les deux sources.
Figure 4.10 – Image du conflit entre F1 et son IFN.
Les pixels qui ont un niveau de gris blanc indiquent que le conflit entre les deux sourcesest élevé. Comme nous avons mentionné précédemment, les dates de prises des deuxsources sont différentes. Ainsi, nous pouvons voir clairement les changements survenussur les classes d’occupation lorsque nous avons superposé l’inventaire forestier sur lafenêtre de l’image haute résolution (F1) 4.11. Nous remarquons qu’il y a des couronnesd’arbres qui ont dépassé la frontière qui sépare les deux classes de l’IFN.Ces dernières correspondent à la classe SPC dans l’IFN. Les pixels correspondants à cescouronnes dans l’image du confit ont un niveau de gris qui tend vers le blanc.

Chapitre 4. Expérimentations de la théorie des possibilités, la TFC et la DSmT 80
Figure 4.11 – Superposition du IFN1 sur F1.
Raffinement de l’inventaire :Avant de fusionner les deux sources, nous devons unifier les cadres de discernement re-latifs aux sources. Cette unification se fait à l’aide du processus du raffinement.Soient ΩF1 = C1, C2, C3, C4 le cadre de discernement de la fenêtre une correspondantau choix des zones d’apprentissage décrit par la figure 4.4 et ΩIFN = C ′1, C ′2 le cadrede discernement de l’inventaire correspondant. Avec C1 = CZ, C2 = CL ,C3 = SPC,C4 = SN , C ′1 = CZ ∪ CL et C ′2 = SPC ∪ SN .Selon la localisation des échantillons des zones d’apprentissage choisies, nous déduisonsles correspondances suivantes : C ′1 = C1 ∪ C2 et C ′2 = C3 ∪ C4.Si nous faisons le raisonnement inverse en associant aux zones d’apprentissage les typesde l’IFN dont nous disposons pour la fenêtre une (F1), nous obtenons les correspon-dances suivantes : C1 = C ′1, C2 = C ′1, C3 = C ′2 et C4 = C ′2.
Combinaison avec l’opérateur orthogonale :Dans un premier temps nous avons appliqué l’opérateur orthogonale normalisé pourcombiner les jeux de masses des deux sources nous avons alors obtenu les résultats illus-trés par la figure suivante 4.12 :
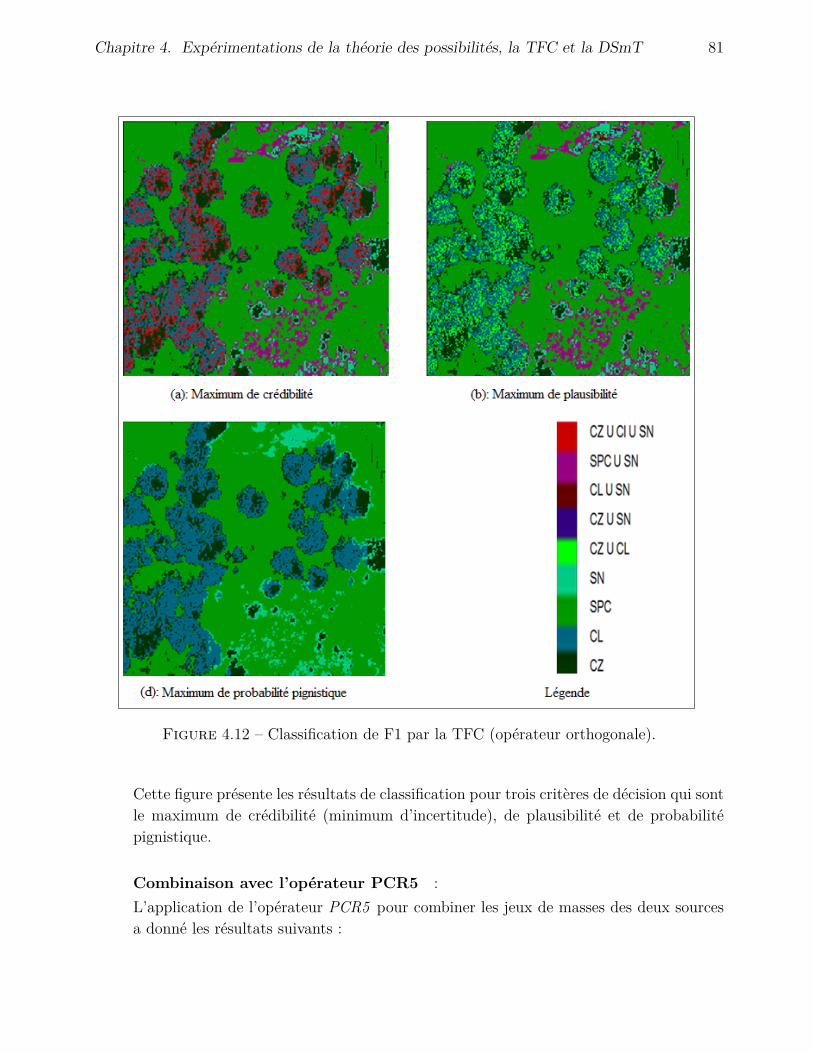
Chapitre 4. Expérimentations de la théorie des possibilités, la TFC et la DSmT 81
Figure 4.12 – Classification de F1 par la TFC (opérateur orthogonale).
Cette figure présente les résultats de classification pour trois critères de décision qui sontle maximum de crédibilité (minimum d’incertitude), de plausibilité et de probabilitépignistique.
Combinaison avec l’opérateur PCR5 :L’application de l’opérateur PCR5 pour combiner les jeux de masses des deux sourcesa donné les résultats suivants :
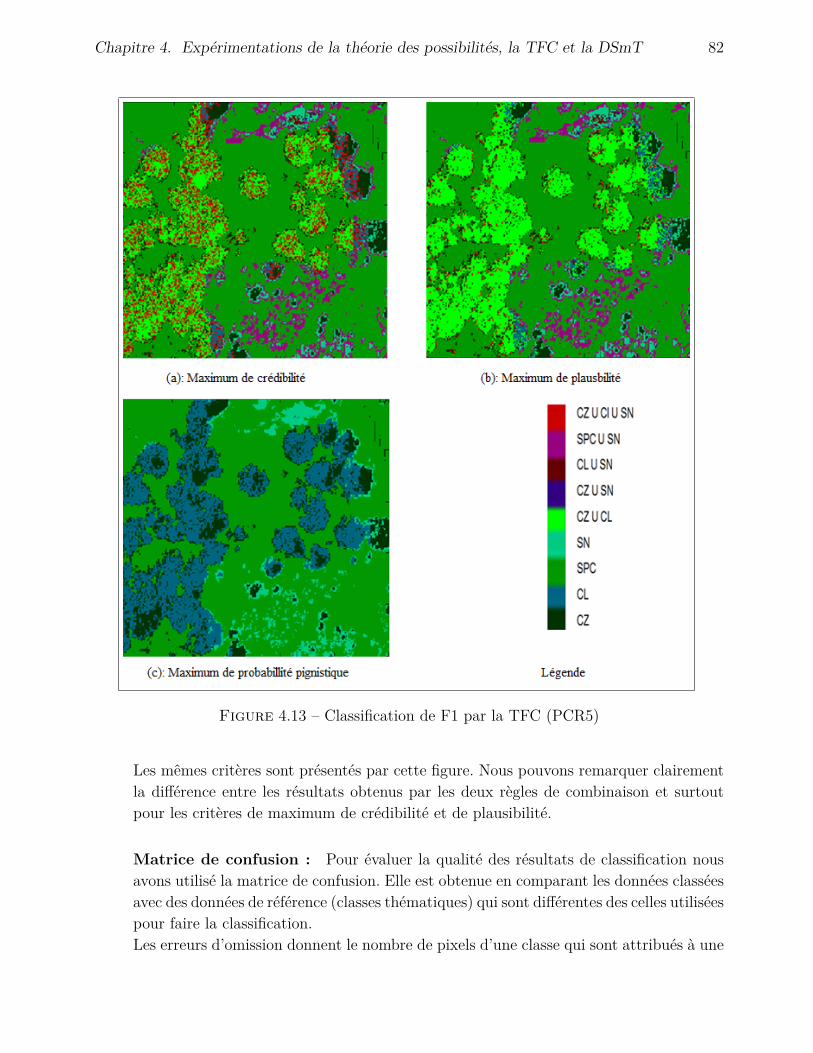
Chapitre 4. Expérimentations de la théorie des possibilités, la TFC et la DSmT 82
Figure 4.13 – Classification de F1 par la TFC (PCR5)
Les mêmes critères sont présentés par cette figure. Nous pouvons remarquer clairementla différence entre les résultats obtenus par les deux règles de combinaison et surtoutpour les critères de maximum de crédibilité et de plausibilité.
Matrice de confusion : Pour évaluer la qualité des résultats de classification nousavons utilisé la matrice de confusion. Elle est obtenue en comparant les données classéesavec des données de référence (classes thématiques) qui sont différentes des celles utiliséespour faire la classification.Les erreurs d’omission donnent le nombre de pixels d’une classe qui sont attribués à une
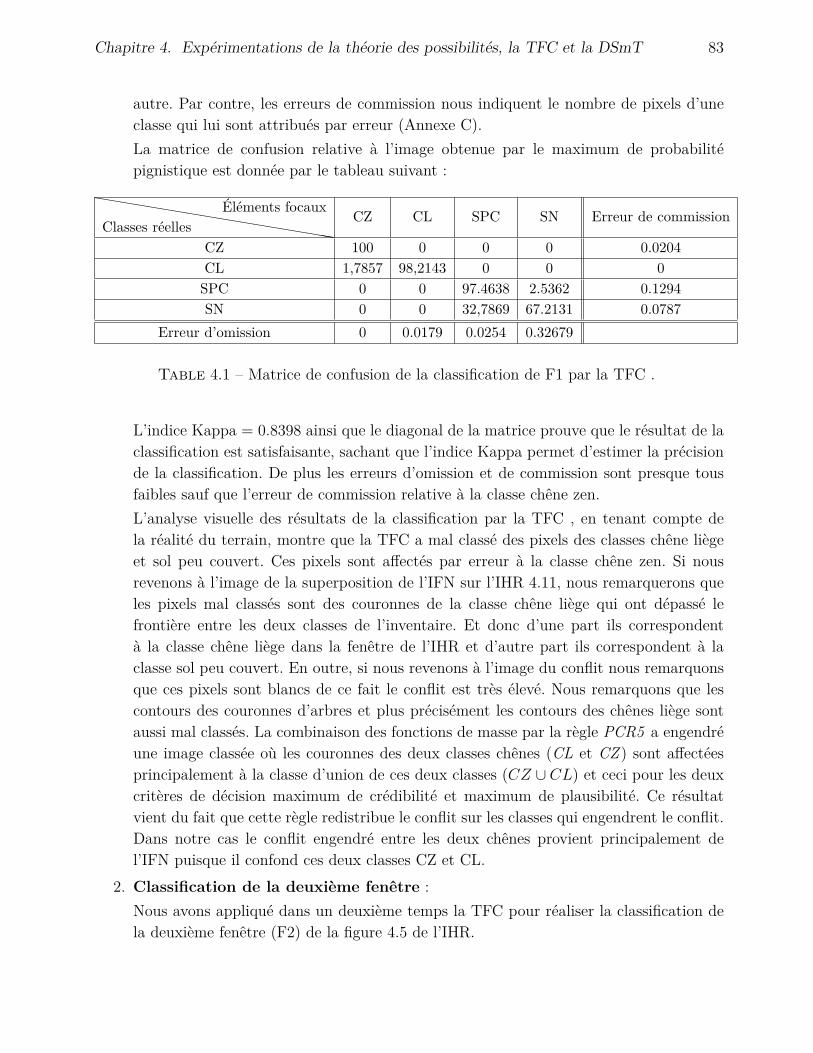
Chapitre 4. Expérimentations de la théorie des possibilités, la TFC et la DSmT 83
autre. Par contre, les erreurs de commission nous indiquent le nombre de pixels d’uneclasse qui lui sont attribués par erreur (Annexe C).La matrice de confusion relative à l’image obtenue par le maximum de probabilitépignistique est donnée par le tableau suivant :
hhhhhhhhhhhhhhhhhhhClasses réellesÉléments focaux CZ CL SPC SN Erreur de commission
CZ 100 0 0 0 0.0204CL 1,7857 98,2143 0 0 0
SPC 0 0 97.4638 2.5362 0.1294SN 0 0 32,7869 67.2131 0.0787
Erreur d’omission 0 0.0179 0.0254 0.32679
Table 4.1 – Matrice de confusion de la classification de F1 par la TFC .
L’indice Kappa = 0.8398 ainsi que le diagonal de la matrice prouve que le résultat de laclassification est satisfaisante, sachant que l’indice Kappa permet d’estimer la précisionde la classification. De plus les erreurs d’omission et de commission sont presque tousfaibles sauf que l’erreur de commission relative à la classe chêne zen.L’analyse visuelle des résultats de la classification par la TFC , en tenant compte dela réalité du terrain, montre que la TFC a mal classé des pixels des classes chêne liègeet sol peu couvert. Ces pixels sont affectés par erreur à la classe chêne zen. Si nousrevenons à l’image de la superposition de l’IFN sur l’IHR 4.11, nous remarquerons queles pixels mal classés sont des couronnes de la classe chêne liège qui ont dépassé lefrontière entre les deux classes de l’inventaire. Et donc d’une part ils correspondentà la classe chêne liège dans la fenêtre de l’IHR et d’autre part ils correspondent à laclasse sol peu couvert. En outre, si nous revenons à l’image du conflit nous remarquonsque ces pixels sont blancs de ce fait le conflit est très élevé. Nous remarquons que lescontours des couronnes d’arbres et plus précisément les contours des chênes liège sontaussi mal classés. La combinaison des fonctions de masse par la règle PCR5 a engendréune image classée où les couronnes des deux classes chênes (CL et CZ ) sont affectéesprincipalement à la classe d’union de ces deux classes (CZ ∪ CL) et ceci pour les deuxcritères de décision maximum de crédibilité et maximum de plausibilité. Ce résultatvient du fait que cette règle redistribue le conflit sur les classes qui engendrent le conflit.Dans notre cas le conflit engendré entre les deux chênes provient principalement del’IFN puisque il confond ces deux classes CZ et CL.
2. Classification de la deuxième fenêtre :Nous avons appliqué dans un deuxième temps la TFC pour réaliser la classification dela deuxième fenêtre (F2) de la figure 4.5 de l’IHR.
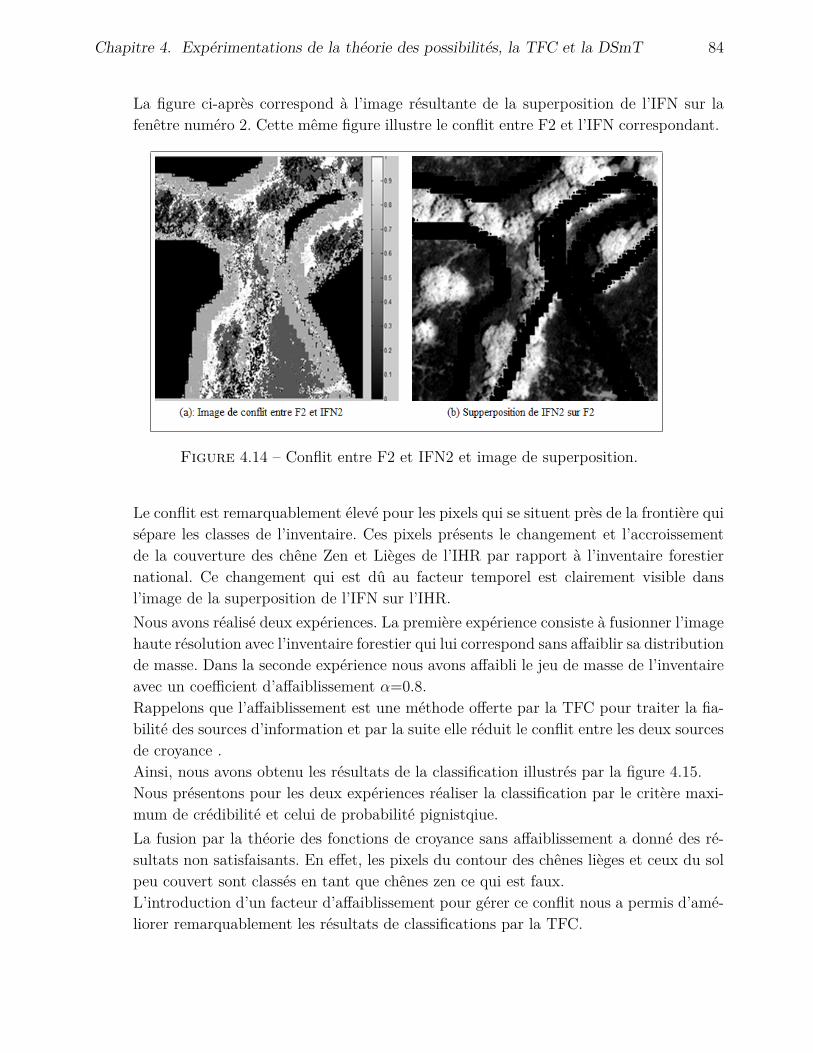
Chapitre 4. Expérimentations de la théorie des possibilités, la TFC et la DSmT 84
La figure ci-après correspond à l’image résultante de la superposition de l’IFN sur lafenêtre numéro 2. Cette même figure illustre le conflit entre F2 et l’IFN correspondant.
Figure 4.14 – Conflit entre F2 et IFN2 et image de superposition.
Le conflit est remarquablement élevé pour les pixels qui se situent près de la frontière quisépare les classes de l’inventaire. Ces pixels présents le changement et l’accroissementde la couverture des chêne Zen et Lièges de l’IHR par rapport à l’inventaire forestiernational. Ce changement qui est dû au facteur temporel est clairement visible dansl’image de la superposition de l’IFN sur l’IHR.Nous avons réalisé deux expériences. La première expérience consiste à fusionner l’imagehaute résolution avec l’inventaire forestier qui lui correspond sans affaiblir sa distributionde masse. Dans la seconde expérience nous avons affaibli le jeu de masse de l’inventaireavec un coefficient d’affaiblissement α=0.8.Rappelons que l’affaiblissement est une méthode offerte par la TFC pour traiter la fia-bilité des sources d’information et par la suite elle réduit le conflit entre les deux sourcesde croyance .Ainsi, nous avons obtenu les résultats de la classification illustrés par la figure 4.15.Nous présentons pour les deux expériences réaliser la classification par le critère maxi-mum de crédibilité et celui de probabilité pignistqiue.La fusion par la théorie des fonctions de croyance sans affaiblissement a donné des ré-sultats non satisfaisants. En effet, les pixels du contour des chênes lièges et ceux du solpeu couvert sont classés en tant que chênes zen ce qui est faux.L’introduction d’un facteur d’affaiblissement pour gérer ce conflit nous a permis d’amé-liorer remarquablement les résultats de classifications par la TFC.
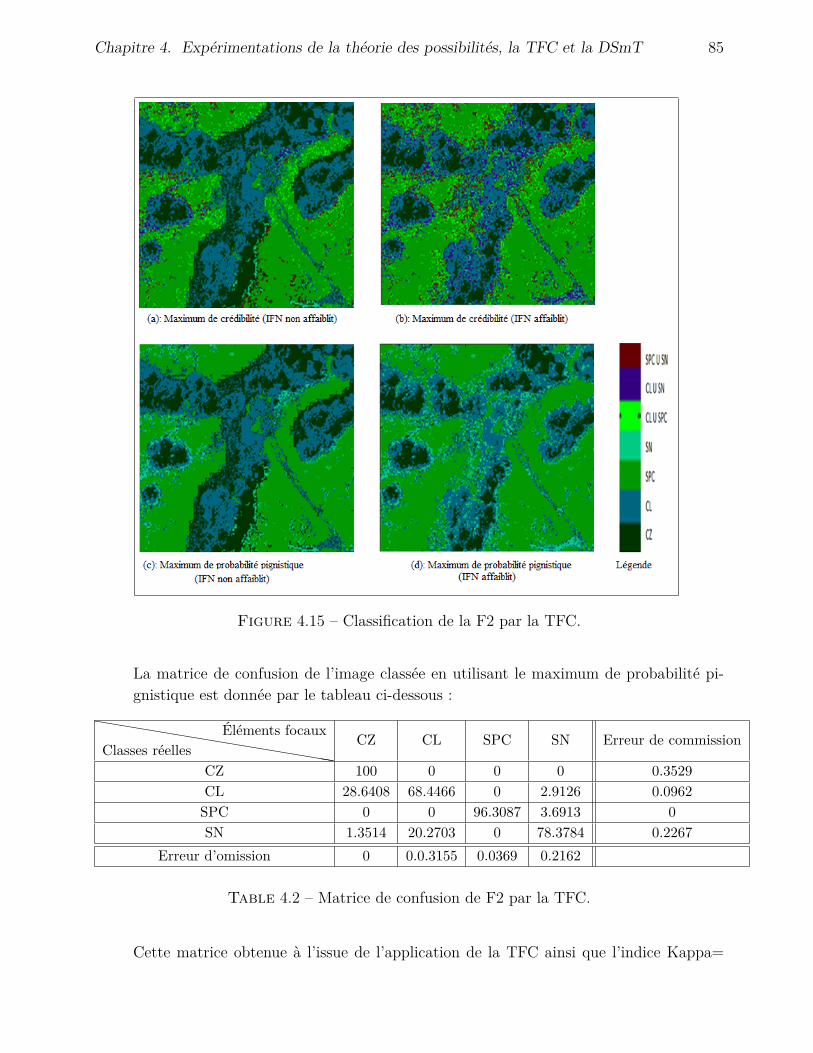
Chapitre 4. Expérimentations de la théorie des possibilités, la TFC et la DSmT 85
Figure 4.15 – Classification de la F2 par la TFC.
La matrice de confusion de l’image classée en utilisant le maximum de probabilité pi-gnistique est donnée par le tableau ci-dessous :
hhhhhhhhhhhhhhhhhhhClasses réellesÉléments focaux CZ CL SPC SN Erreur de commission
CZ 100 0 0 0 0.3529CL 28.6408 68.4466 0 2.9126 0.0962
SPC 0 0 96.3087 3.6913 0SN 1.3514 20.2703 0 78.3784 0.2267
Erreur d’omission 0 0.0.3155 0.0369 0.2162
Table 4.2 – Matrice de confusion de F2 par la TFC.
Cette matrice obtenue à l’issue de l’application de la TFC ainsi que l’indice Kappa=
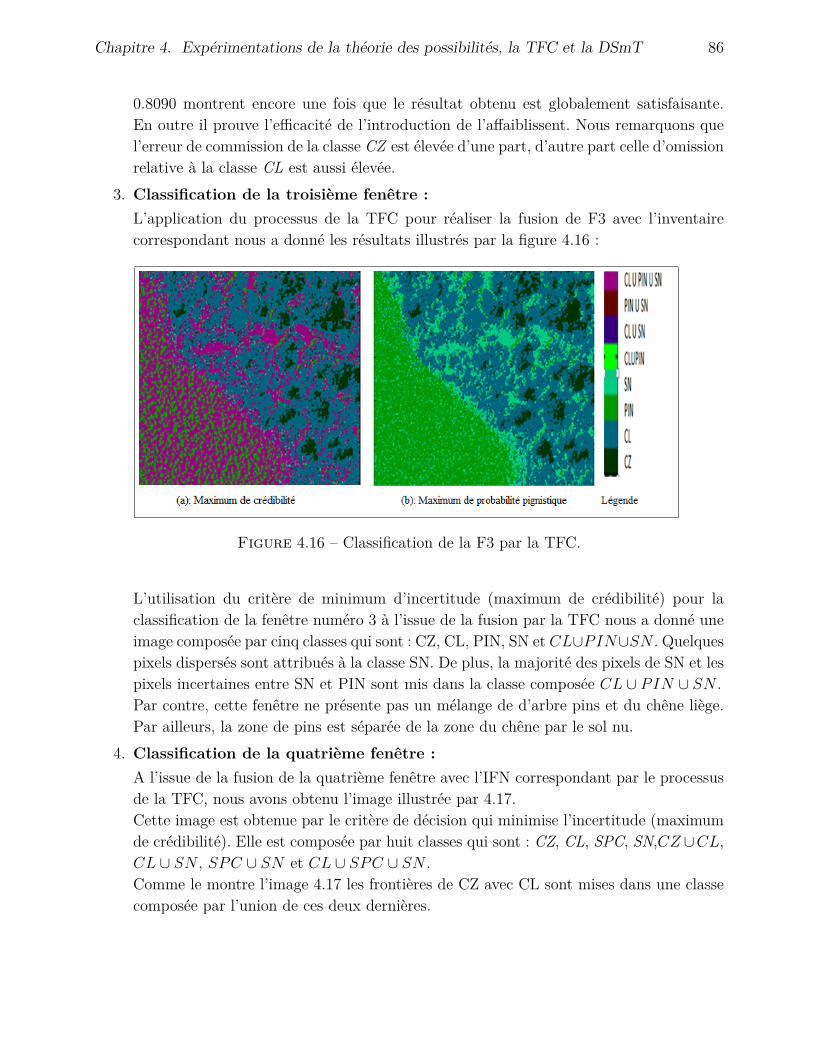
Chapitre 4. Expérimentations de la théorie des possibilités, la TFC et la DSmT 86
0.8090 montrent encore une fois que le résultat obtenu est globalement satisfaisante.En outre il prouve l’efficacité de l’introduction de l’affaiblissent. Nous remarquons quel’erreur de commission de la classe CZ est élevée d’une part, d’autre part celle d’omissionrelative à la classe CL est aussi élevée.
3. Classification de la troisième fenêtre :L’application du processus de la TFC pour réaliser la fusion de F3 avec l’inventairecorrespondant nous a donné les résultats illustrés par la figure 4.16 :
Figure 4.16 – Classification de la F3 par la TFC.
L’utilisation du critère de minimum d’incertitude (maximum de crédibilité) pour laclassification de la fenêtre numéro 3 à l’issue de la fusion par la TFC nous a donné uneimage composée par cinq classes qui sont : CZ, CL, PIN, SN et CL∪PIN∪SN . Quelquespixels dispersés sont attribués à la classe SN. De plus, la majorité des pixels de SN et lespixels incertaines entre SN et PIN sont mis dans la classe composée CL ∪ PIN ∪ SN .Par contre, cette fenêtre ne présente pas un mélange de d’arbre pins et du chêne liège.Par ailleurs, la zone de pins est séparée de la zone du chêne par le sol nu.
4. Classification de la quatrième fenêtre :A l’issue de la fusion de la quatrième fenêtre avec l’IFN correspondant par le processusde la TFC, nous avons obtenu l’image illustrée par 4.17.Cette image est obtenue par le critère de décision qui minimise l’incertitude (maximumde crédibilité). Elle est composée par huit classes qui sont : CZ, CL, SPC, SN,CZ ∪CL,CL ∪ SN , SPC ∪ SN et CL ∪ SPC ∪ SN .Comme le montre l’image 4.17 les frontières de CZ avec CL sont mises dans une classecomposée par l’union de ces deux dernières.
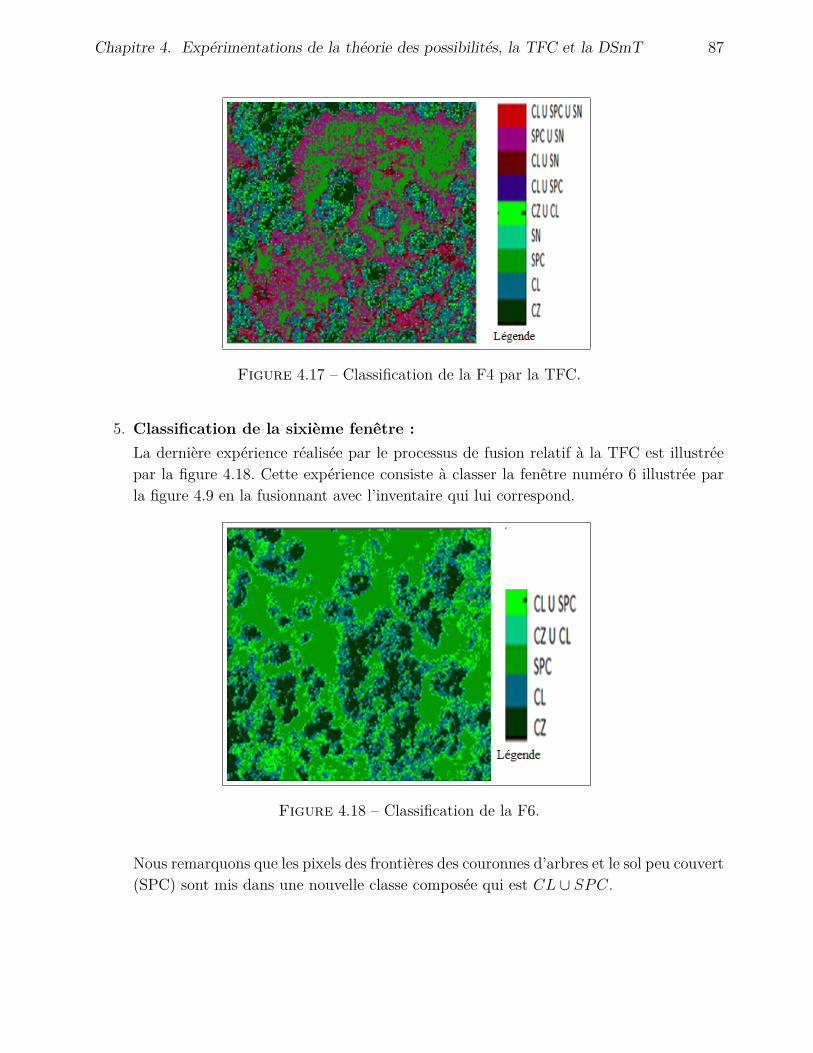
Chapitre 4. Expérimentations de la théorie des possibilités, la TFC et la DSmT 87
Figure 4.17 – Classification de la F4 par la TFC.
5. Classification de la sixième fenêtre :La dernière expérience réalisée par le processus de fusion relatif à la TFC est illustréepar la figure 4.18. Cette expérience consiste à classer la fenêtre numéro 6 illustrée parla figure 4.9 en la fusionnant avec l’inventaire qui lui correspond.
Figure 4.18 – Classification de la F6.
Nous remarquons que les pixels des frontières des couronnes d’arbres et le sol peu couvert(SPC) sont mis dans une nouvelle classe composée qui est CL ∪ SPC.
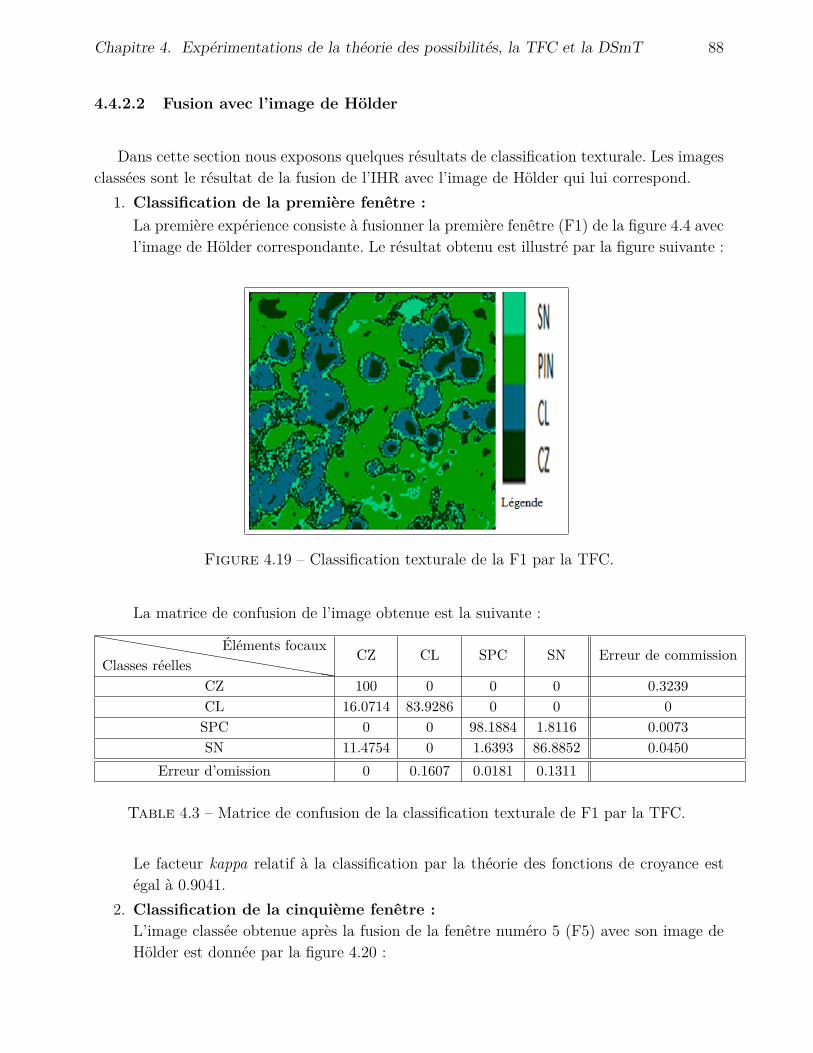
Chapitre 4. Expérimentations de la théorie des possibilités, la TFC et la DSmT 88
4.4.2.2 Fusion avec l’image de Hölder
Dans cette section nous exposons quelques résultats de classification texturale. Les imagesclassées sont le résultat de la fusion de l’IHR avec l’image de Hölder qui lui correspond.
1. Classification de la première fenêtre :La première expérience consiste à fusionner la première fenêtre (F1) de la figure 4.4 avecl’image de Hölder correspondante. Le résultat obtenu est illustré par la figure suivante :
Figure 4.19 – Classification texturale de la F1 par la TFC.
La matrice de confusion de l’image obtenue est la suivante :hhhhhhhhhhhhhhhhhhhClasses réelles
Éléments focaux CZ CL SPC SN Erreur de commission
CZ 100 0 0 0 0.3239CL 16.0714 83.9286 0 0 0
SPC 0 0 98.1884 1.8116 0.0073SN 11.4754 0 1.6393 86.8852 0.0450
Erreur d’omission 0 0.1607 0.0181 0.1311
Table 4.3 – Matrice de confusion de la classification texturale de F1 par la TFC.
Le facteur kappa relatif à la classification par la théorie des fonctions de croyance estégal à 0.9041.
2. Classification de la cinquième fenêtre :L’image classée obtenue après la fusion de la fenêtre numéro 5 (F5) avec son image deHölder est donnée par la figure 4.20 :
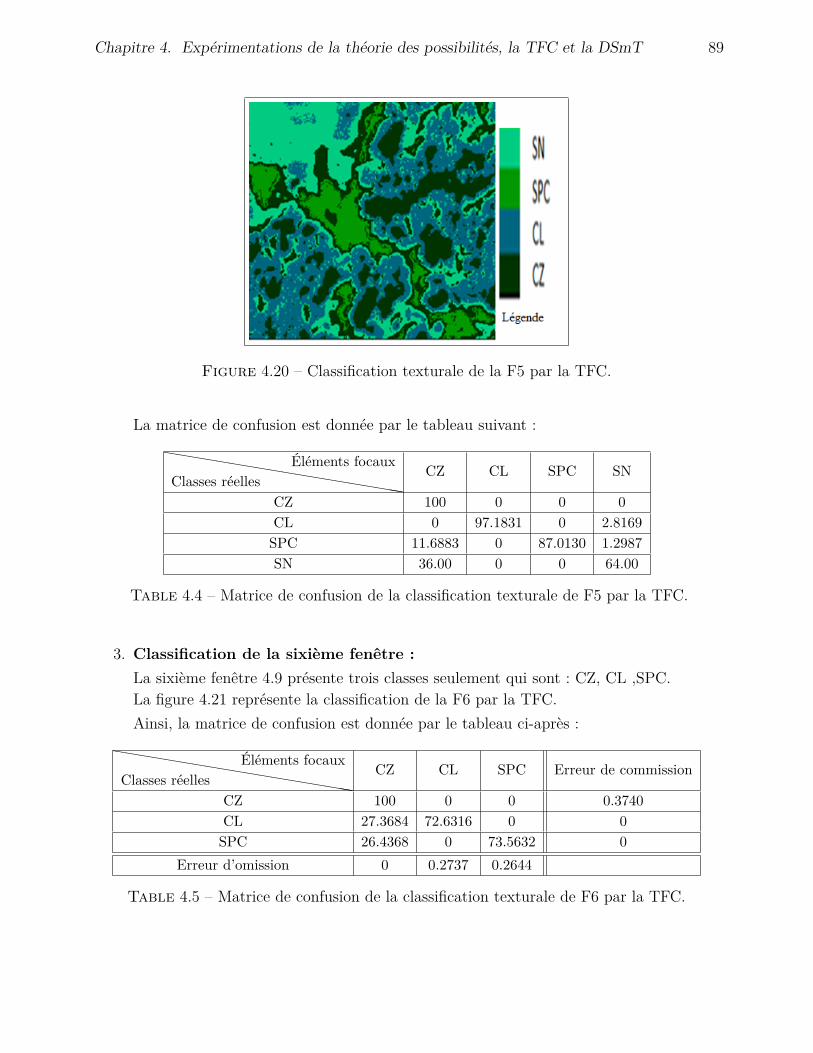
Chapitre 4. Expérimentations de la théorie des possibilités, la TFC et la DSmT 89
Figure 4.20 – Classification texturale de la F5 par la TFC.
La matrice de confusion est donnée par le tableau suivant :hhhhhhhhhhhhhhhhhhhClasses réelles
Éléments focaux CZ CL SPC SN
CZ 100 0 0 0CL 0 97.1831 0 2.8169
SPC 11.6883 0 87.0130 1.2987SN 36.00 0 0 64.00
Table 4.4 – Matrice de confusion de la classification texturale de F5 par la TFC.
3. Classification de la sixième fenêtre :La sixième fenêtre 4.9 présente trois classes seulement qui sont : CZ, CL ,SPC.La figure 4.21 représente la classification de la F6 par la TFC.Ainsi, la matrice de confusion est donnée par le tableau ci-après :
hhhhhhhhhhhhhhhhhhhClasses réellesÉléments focaux CZ CL SPC Erreur de commission
CZ 100 0 0 0.3740CL 27.3684 72.6316 0 0
SPC 26.4368 0 73.5632 0Erreur d’omission 0 0.2737 0.2644
Table 4.5 – Matrice de confusion de la classification texturale de F6 par la TFC.

Chapitre 4. Expérimentations de la théorie des possibilités, la TFC et la DSmT 90
Figure 4.21 – Classification texturale de la F6 par la TFC.
4.4.3 Application de la DSmT
Dans cette section nous allons présenter certaines expériences réalisées avec le processusrelatif à la DSmT.Les résultats obtenus par la DSmT ne sont pas formés par les classes singletons seulement.En effet, le critère du maximum de probabilité pignistique au sein de la TFC nous permetd’obtenir une image formée que par les singletons. Par contre, le critère de décision par lemaximum de probabilité pignistique généralisée au sien de la DSmT ne nous permet pasd’obtenir une image formée par les classes du départ. Dans ce cas l’utilisation de la matricede confusion pour évaluer la classification par la DSmT n’est pas possible.Dans cette section nous allons présenter dans un premier temps les résultats obtenus par lafusion des images haute résolution avec leurs inventaires correspondants. Puis nous allonsexposer quelques résultats de la classification texturale par le processus de la DSmT.
4.4.3.1 Fusion avec l’inventaire
1. Classification de la première fenêtre par la DSmT :L’image 4.10 nous a donné une idée sur le conflit entre les deux sources (F1 et IFN14.4). Nous avons remarqué que le conflit pour quelques pixels est élevé.
Combinaison avec la DSmC :La première expérience réalisée consiste à appliquer la DSmC pour combiner les fonc-tions de masses. Ainsi nous avons obtenu les résultats ci-après :
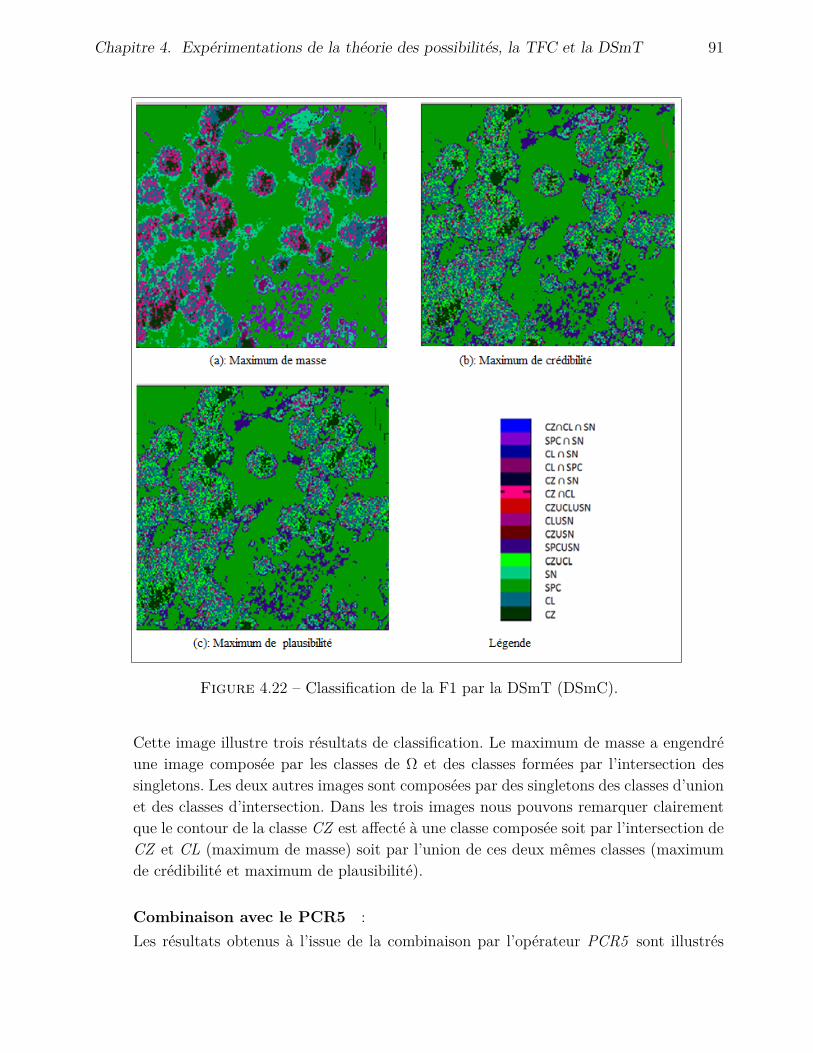
Chapitre 4. Expérimentations de la théorie des possibilités, la TFC et la DSmT 91
Figure 4.22 – Classification de la F1 par la DSmT (DSmC).
Cette image illustre trois résultats de classification. Le maximum de masse a engendréune image composée par les classes de Ω et des classes formées par l’intersection dessingletons. Les deux autres images sont composées par des singletons des classes d’unionet des classes d’intersection. Dans les trois images nous pouvons remarquer clairementque le contour de la classe CZ est affecté à une classe composée soit par l’intersection deCZ et CL (maximum de masse) soit par l’union de ces deux mêmes classes (maximumde crédibilité et maximum de plausibilité).
Combinaison avec le PCR5 :Les résultats obtenus à l’issue de la combinaison par l’opérateur PCR5 sont illustrés
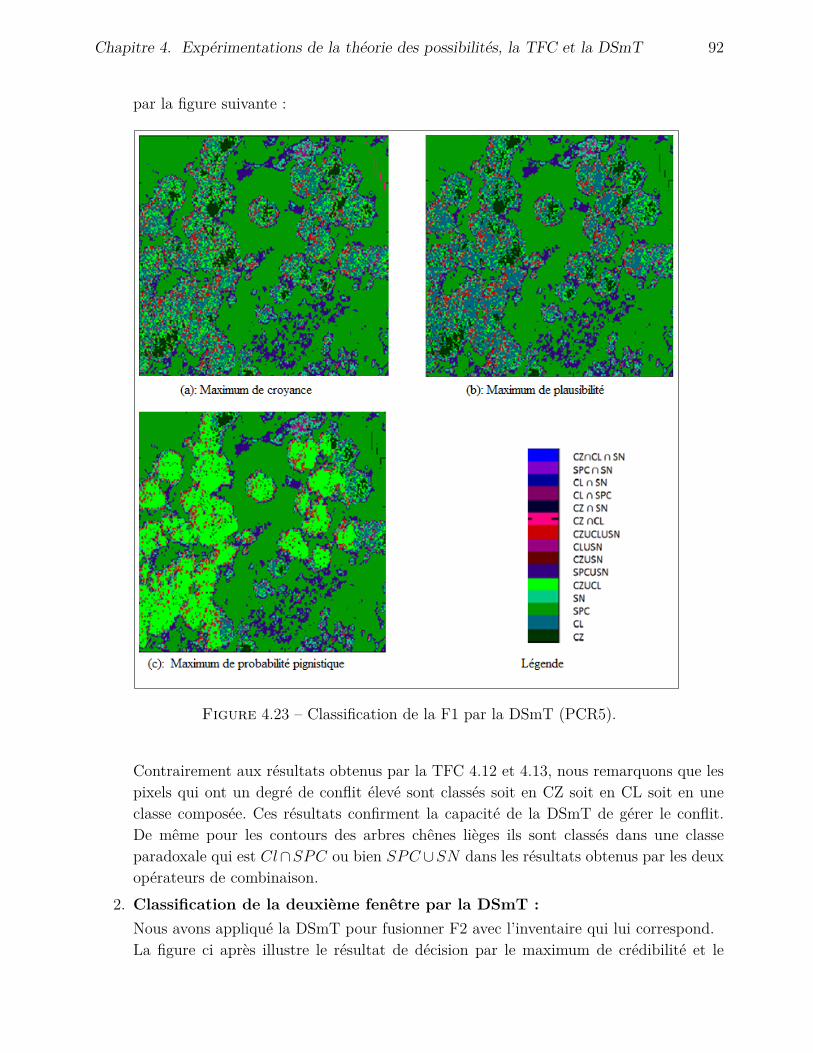
Chapitre 4. Expérimentations de la théorie des possibilités, la TFC et la DSmT 92
par la figure suivante :
Figure 4.23 – Classification de la F1 par la DSmT (PCR5).
Contrairement aux résultats obtenus par la TFC 4.12 et 4.13, nous remarquons que lespixels qui ont un degré de conflit élevé sont classés soit en CZ soit en CL soit en uneclasse composée. Ces résultats confirment la capacité de la DSmT de gérer le conflit.De même pour les contours des arbres chênes lièges ils sont classés dans une classeparadoxale qui est Cl∩SPC ou bien SPC ∪SN dans les résultats obtenus par les deuxopérateurs de combinaison.
2. Classification de la deuxième fenêtre par la DSmT :Nous avons appliqué la DSmT pour fusionner F2 avec l’inventaire qui lui correspond.La figure ci après illustre le résultat de décision par le maximum de crédibilité et le
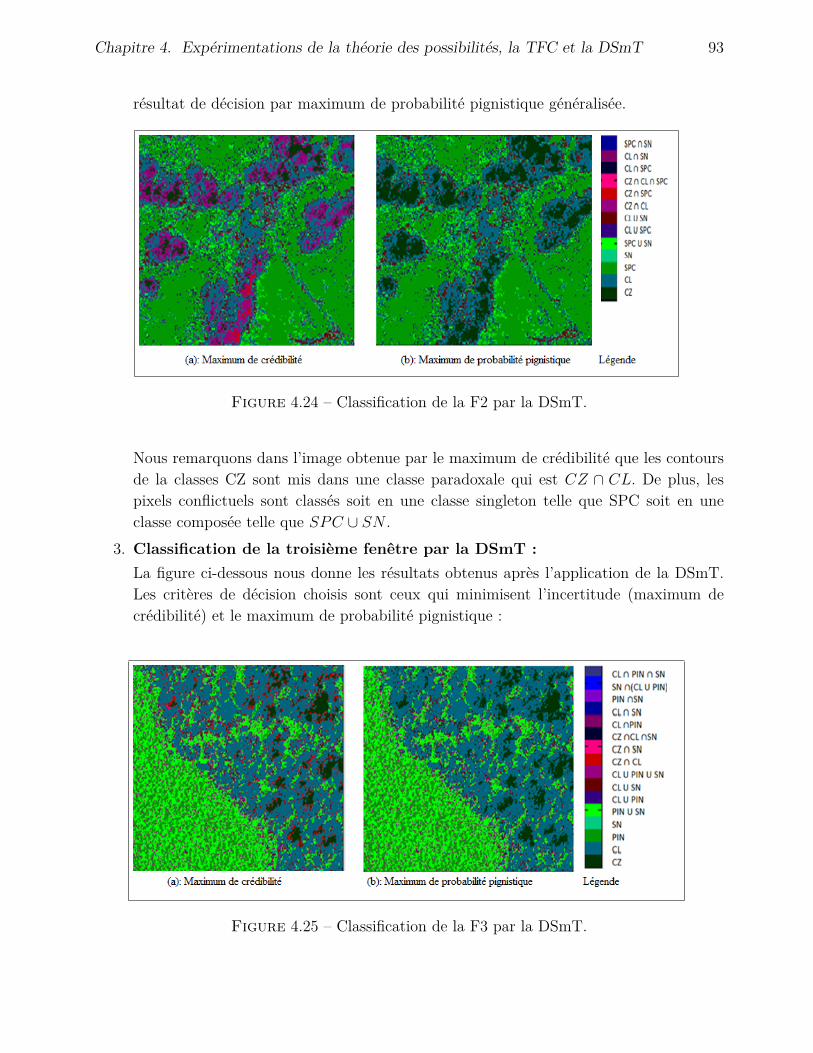
Chapitre 4. Expérimentations de la théorie des possibilités, la TFC et la DSmT 93
résultat de décision par maximum de probabilité pignistique généralisée.
Figure 4.24 – Classification de la F2 par la DSmT.
Nous remarquons dans l’image obtenue par le maximum de crédibilité que les contoursde la classes CZ sont mis dans une classe paradoxale qui est CZ ∩ CL. De plus, lespixels conflictuels sont classés soit en une classe singleton telle que SPC soit en uneclasse composée telle que SPC ∪ SN .
3. Classification de la troisième fenêtre par la DSmT :La figure ci-dessous nous donne les résultats obtenus après l’application de la DSmT.Les critères de décision choisis sont ceux qui minimisent l’incertitude (maximum decrédibilité) et le maximum de probabilité pignistique :
Figure 4.25 – Classification de la F3 par la DSmT.
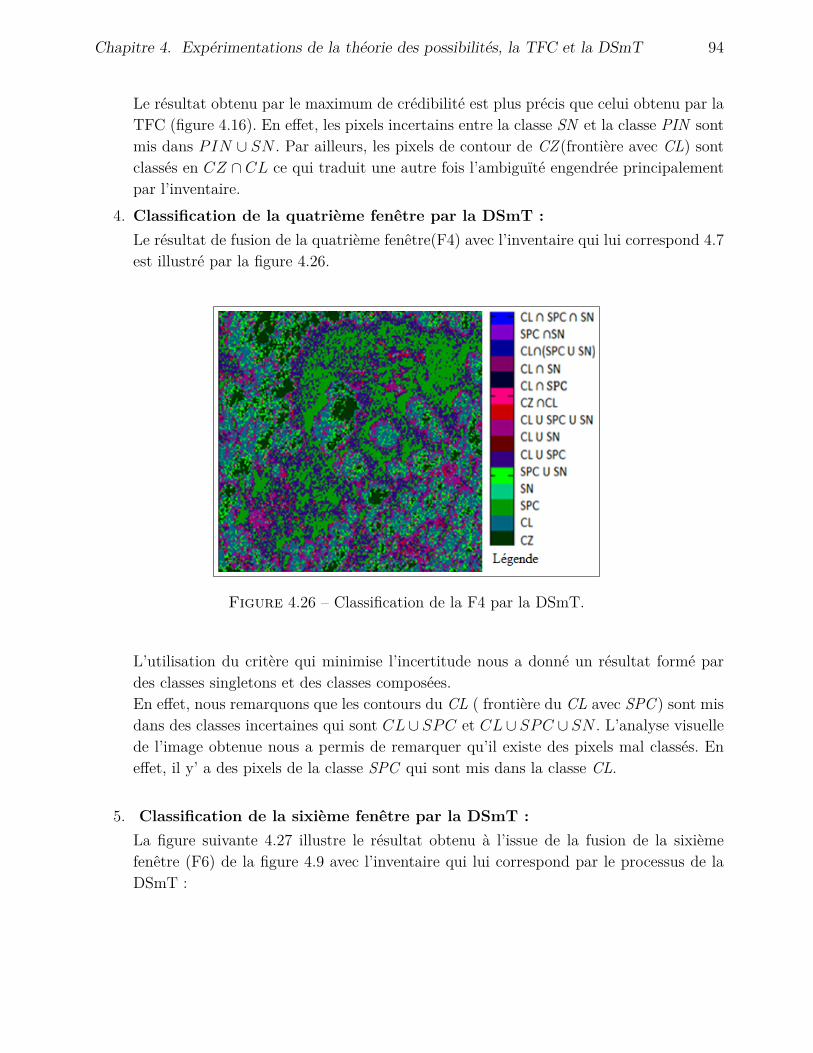
Chapitre 4. Expérimentations de la théorie des possibilités, la TFC et la DSmT 94
Le résultat obtenu par le maximum de crédibilité est plus précis que celui obtenu par laTFC (figure 4.16). En effet, les pixels incertains entre la classe SN et la classe PIN sontmis dans PIN ∪ SN . Par ailleurs, les pixels de contour de CZ (frontière avec CL) sontclassés en CZ ∩ CL ce qui traduit une autre fois l’ambiguïté engendrée principalementpar l’inventaire.
4. Classification de la quatrième fenêtre par la DSmT :Le résultat de fusion de la quatrième fenêtre(F4) avec l’inventaire qui lui correspond 4.7est illustré par la figure 4.26.
Figure 4.26 – Classification de la F4 par la DSmT.
L’utilisation du critère qui minimise l’incertitude nous a donné un résultat formé pardes classes singletons et des classes composées.En effet, nous remarquons que les contours du CL ( frontière du CL avec SPC ) sont misdans des classes incertaines qui sont CL∪ SPC et CL∪ SPC ∪ SN . L’analyse visuellede l’image obtenue nous a permis de remarquer qu’il existe des pixels mal classés. Eneffet, il y’ a des pixels de la classe SPC qui sont mis dans la classe CL.
5. Classification de la sixième fenêtre par la DSmT :La figure suivante 4.27 illustre le résultat obtenu à l’issue de la fusion de la sixièmefenêtre (F6) de la figure 4.9 avec l’inventaire qui lui correspond par le processus de laDSmT :
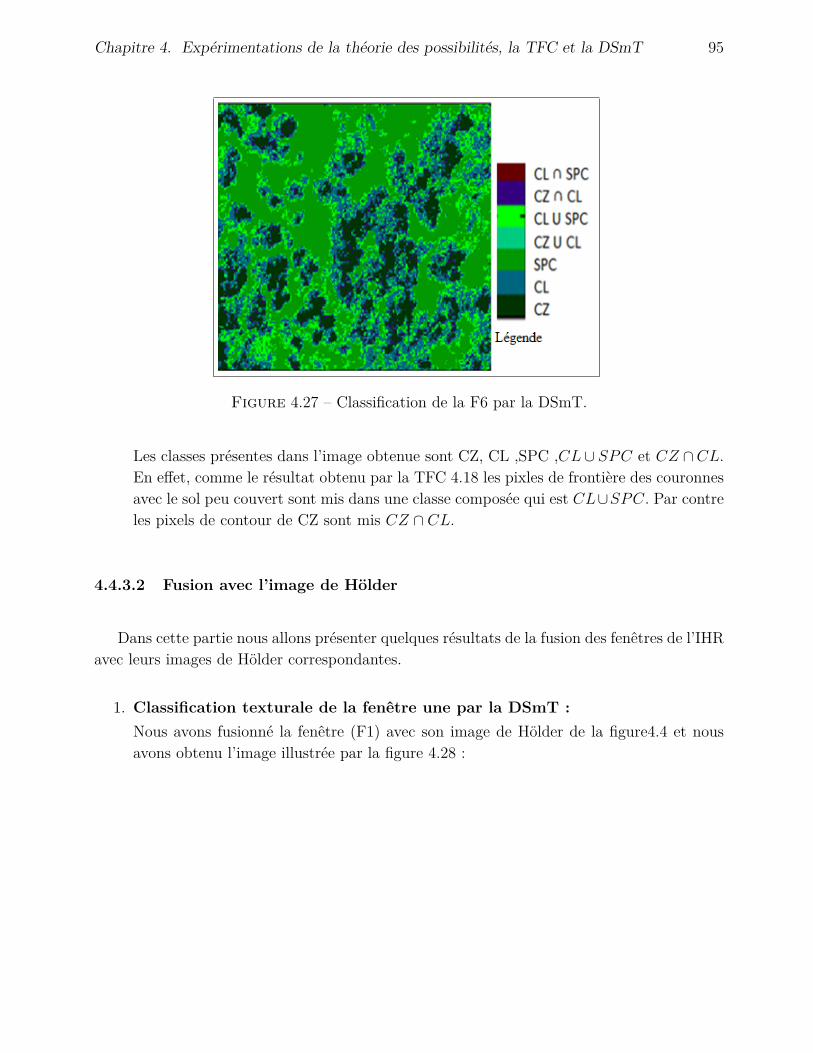
Chapitre 4. Expérimentations de la théorie des possibilités, la TFC et la DSmT 95
Figure 4.27 – Classification de la F6 par la DSmT.
Les classes présentes dans l’image obtenue sont CZ, CL ,SPC ,CL∪ SPC et CZ ∩CL.En effet, comme le résultat obtenu par la TFC 4.18 les pixles de frontière des couronnesavec le sol peu couvert sont mis dans une classe composée qui est CL∪SPC. Par contreles pixels de contour de CZ sont mis CZ ∩ CL.
4.4.3.2 Fusion avec l’image de Hölder
Dans cette partie nous allons présenter quelques résultats de la fusion des fenêtres de l’IHRavec leurs images de Hölder correspondantes.
1. Classification texturale de la fenêtre une par la DSmT :Nous avons fusionné la fenêtre (F1) avec son image de Hölder de la figure4.4 et nousavons obtenu l’image illustrée par la figure 4.28 :
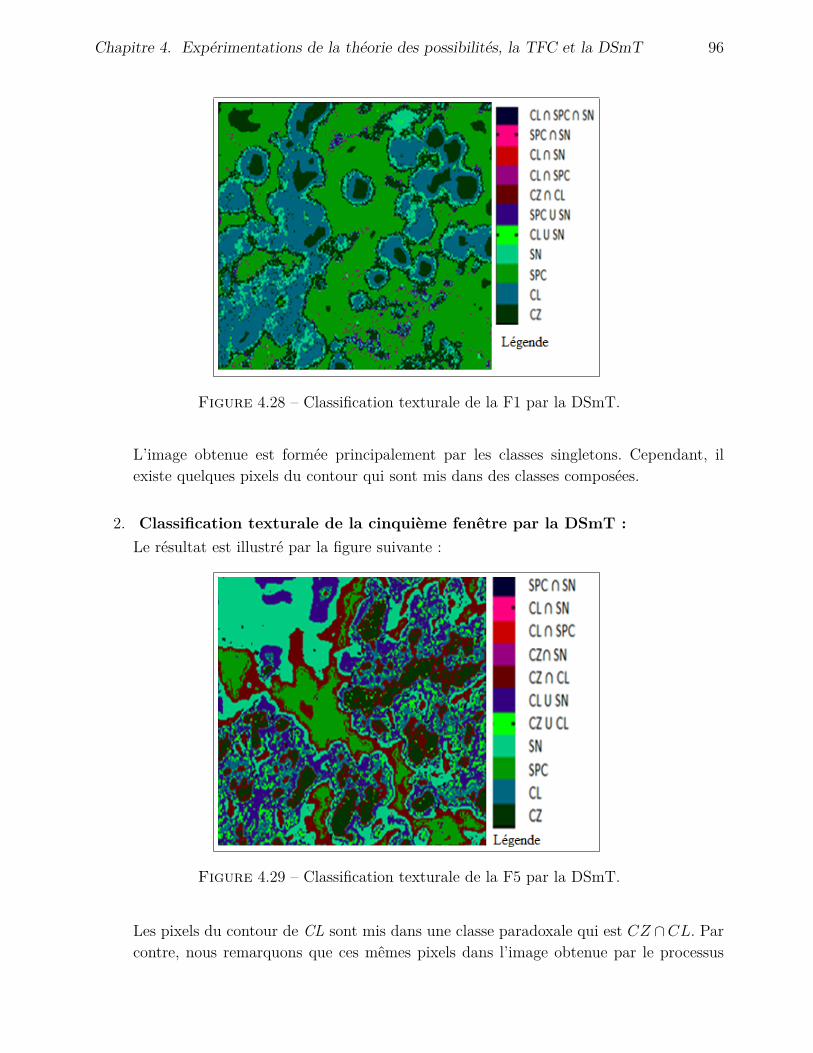
Chapitre 4. Expérimentations de la théorie des possibilités, la TFC et la DSmT 96
Figure 4.28 – Classification texturale de la F1 par la DSmT.
L’image obtenue est formée principalement par les classes singletons. Cependant, ilexiste quelques pixels du contour qui sont mis dans des classes composées.
2. Classification texturale de la cinquième fenêtre par la DSmT :Le résultat est illustré par la figure suivante :
Figure 4.29 – Classification texturale de la F5 par la DSmT.
Les pixels du contour de CL sont mis dans une classe paradoxale qui est CZ ∩CL. Parcontre, nous remarquons que ces mêmes pixels dans l’image obtenue par le processus

Chapitre 4. Expérimentations de la théorie des possibilités, la TFC et la DSmT 97
relatif à la TFC sont classés en tant que chêne zen ce qui est faux.3. Classification texturale de la sixième fenêtre par la DSmT :
L’image classée que nous avons obtenue à l’issue de la décision par le critère de maximumde probabilité pignistique est formée par des classes singletons comme le montre la figuresuivante :
Figure 4.30 – Classification texturale de la F6 par la DSmT.
Ainsi la matrice de confusion de l’image obtenue est donnée par le tableau suivant :hhhhhhhhhhhhhhhhhhhClasses réelles
Éléments focaux CZ CL SPC Erreur de commission
CZ 100 0 0 0.3740CL 27.3684 72.6316 0 0
SPC 26.4368 0 73.5632 0Erreur d’omission 0 0.2737 0.2644
Table 4.6 – Matrice de confusion de la classification texturale de la fenêtre F6 par la DSmT.
4.4.4 Application de la théorie des possibilités
L’application de la théorie des possibilités pour fusionner les fenêtres de l’IHR avec l’IFNcorrespondant n’est pas possible. En effet, les univers du discours des deux sources sontcomplémentaires et différents. Par contre la fusion des fenêtres de l’IHR avec les images de

Chapitre 4. Expérimentations de la théorie des possibilités, la TFC et la DSmT 98
Hölder correspondantes est possible vue que les univers du discours des deux sources sontidentiques.
Les images classées que nous exposerons dans cette section sont obtenues à l’issue del’opérateur adaptatif du Dubois et Prade.
1. Classification possibiliste de la première fenêtre :L’image obtenue à l’issue de la fusion possibiliste est illustrée par la figure 4.31 :
Figure 4.31 – Classification possibliste de la F1.
La matrice de confusion de l’image obtenue est donnée par le tableau suivant :hhhhhhhhhhhhhhhhhhhClasses réelles
Éléments focaux CZ CL SPC SN Erreur de commission
CZ 100 0 0 0 0.3425CL 17.8571 82.1429 0 0 0
SPC 0 0 98.9130 1.0870 0.0250SN 12.2951 0 5.7377 81.9672 0.0291
Erreur d’omission 0 0.1786 0.0109 0.1803
Table 4.7 – Matrice de confusion de la classification texturale par la théorie des possibilités.
L’indice Kappaposs = 0.8874. Rappelons que KappaTFC = 0.9041. Ainsi KappaTFC >
Kappaposs ce qui traduit que le résultat de la classification texturale de la fenêtre unepar la TFC est meilleur que celle de la théorie des possibilités.

Chapitre 4. Expérimentations de la théorie des possibilités, la TFC et la DSmT 99
2. Classification possibiliste de la cinquième fenêtre :La classification texturale de la cinquième fenêtre nous a donné l’image illustrée par lafigure 4.32 :
Figure 4.32 – Classification possibiliste de la F5.
hhhhhhhhhhhhhhhhhhhClasses réellesÉléments focaux CZ CL SPC SN
CZ 100 0 0 0CL 1.4085 85.9155 0 12.6761
SPC 12.9870 0 85.7143 1.2987SN 36.00 0 0 64.00
Table 4.8 – Matrice de confusion de la classification par la théorie des possibilités.
Kappaposs = 0.6736 < KappaTFC = 0.7047.3. Classification possibiliste de la sixième fenêtre :
La dernière expérience réalisée consiste à fusionner la sixième fenêtre 4.9 avec son imagede Hölder.L’application de l’opérateur du Dubois et Prade pour combiner les distributions despossibilités des deux sources nous a permis d’obtenir l’image classée représentée par lafigure 4.33.La matrice de confusion relative à l’image obtenue est donnée par le tableau 4.9.Kappaposs = 0.7182 < KappaTFC = KappaDSmT = 0.7238.
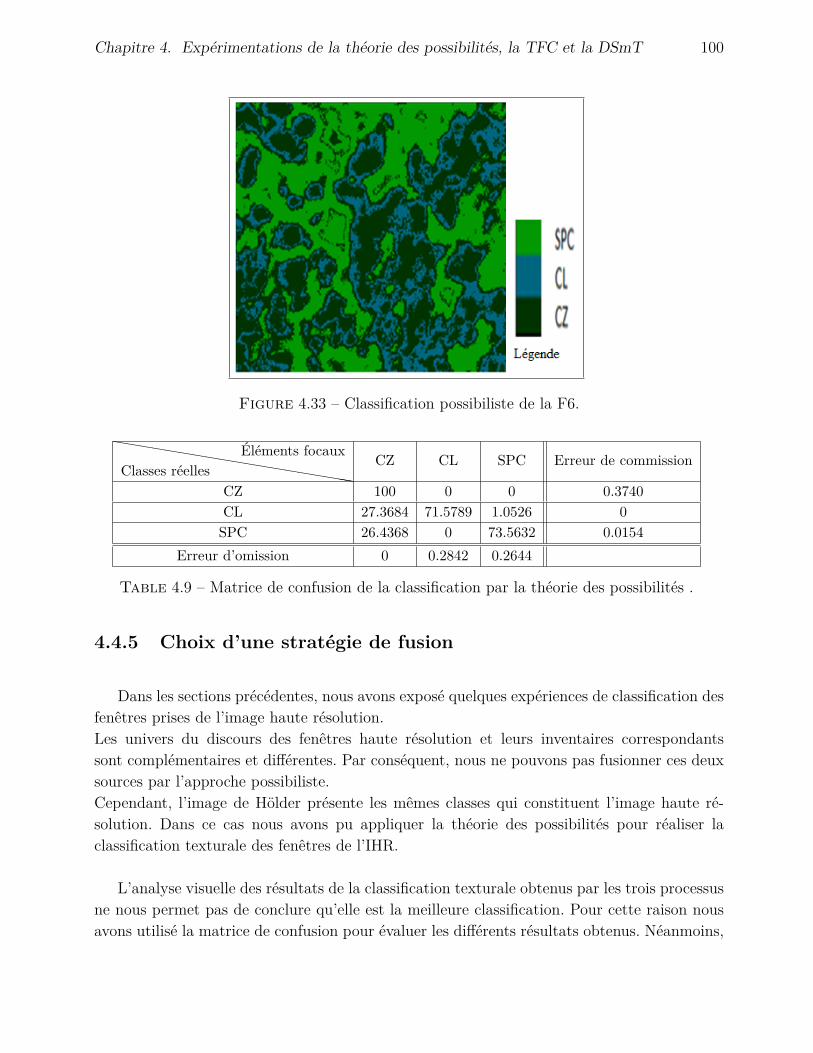
Chapitre 4. Expérimentations de la théorie des possibilités, la TFC et la DSmT 100
Figure 4.33 – Classification possibiliste de la F6.
hhhhhhhhhhhhhhhhhhhClasses réellesÉléments focaux CZ CL SPC Erreur de commission
CZ 100 0 0 0.3740CL 27.3684 71.5789 1.0526 0
SPC 26.4368 0 73.5632 0.0154Erreur d’omission 0 0.2842 0.2644
Table 4.9 – Matrice de confusion de la classification par la théorie des possibilités .
4.4.5 Choix d’une stratégie de fusion
Dans les sections précédentes, nous avons exposé quelques expériences de classification desfenêtres prises de l’image haute résolution.Les univers du discours des fenêtres haute résolution et leurs inventaires correspondantssont complémentaires et différentes. Par conséquent, nous ne pouvons pas fusionner ces deuxsources par l’approche possibiliste.Cependant, l’image de Hölder présente les mêmes classes qui constituent l’image haute ré-solution. Dans ce cas nous avons pu appliquer la théorie des possibilités pour réaliser laclassification texturale des fenêtres de l’IHR.
L’analyse visuelle des résultats de la classification texturale obtenus par les trois processusne nous permet pas de conclure qu’elle est la meilleure classification. Pour cette raison nousavons utilisé la matrice de confusion pour évaluer les différents résultats obtenus. Néanmoins,

Chapitre 4. Expérimentations de la théorie des possibilités, la TFC et la DSmT 101
nous ne pouvons pas appliquer cette méthode pour évaluer les résultats de classification parla DSmT vu que les critères offerts par cette approche ne nous permets pas d’obtenir uneimage formée uniquement par les classes du cadre de discernement généralisé .En conséquence, l’analyse des matrices de confusion relatives aux résultats de classification parla théorie des possibilités confirme la capacité de cette approche à modéliser l’information spa-tiale (texture), l’incertitude et l’imprécision ce qui confirme notre étude théorique(deuxièmechapitre). De ce fait nous pouvons conclure que les résultats obtenus à l’issue de l’applicationdu formalisme possibiliste sont satisfaisantes.D’autre côté, si nous comparons les résultats des évaluations des classifications texturaleobtenus par les processus possibiliste et crédibiliste (TFC) en analysant les diagonales desmatrices de confusion et les indices Kappa, nous constatons que les images résultats de laclassification par la TFC sont meilleurs. Et donc les deux formalismes donnent des résultatsgénéralement satisfaisantes et légèrement différents pour des sources qui ne sont pas haute-ment conflictuelles. Ce qui valide encore une fois notre étude théorique sur les capacités deces deux formalisme de fusionner des sources incertaines, imprécises et faiblement en conflit.
Par ailleurs, les théories des fonctions de croyance et du raisonnement plausible et para-doxale permettent de modéliser et de fusionner les fenêtres de l’IHR et l’IFN correspondants.Rappelons que les référentiels temporelles de ces deux sources sont différents. Par conséquent,des changements ont survenu sur la croissance de la couverture forestière et ceci apparaitclairement lorsque nous avons superposé l’inventaire et l’IHR. Ce qui a favorisé l’apparitiond’un conflit important entre ces deux sources pendant la fusion.Les images que nous avons obtenues après l’application de la TFC sans l’introduction d’unfacteur d’affaiblissement sont clairement non satisfaisantes. Par contre, l’affaiblissement desjeux de masses de l’inventaire nous a permis d’améliorer remarquablement les résultats de laclassification. Toutefois, nous avons obtenu des résultats non satisfaisants pour quelques ex-périences, sachant que nous n’avons pas introduit l’affaiblissement pour fusionner les sourcespar la DSmT.Nous avons appliqué les processus relatifs à la TFC et la DSmT pour réaliser la fusion basniveau en tenant compte uniquement de l’information spectrale pour combiner les fenêtres del’IHR avec l’IFN correspondants. Cependant, ce niveau de fusion est très délicat et l’erreur declassification peut être grande surtout que nous nous reposons que sur l’information spectralequi est des fois insuffisante, puisque un niveau de gris peut appartenir à plus qu’une classe. Ceproblème apparaît clairement avec les deux classes chêne zen et chêne liège et les frontièresentre ces deux espèces.
Dans les exemples précédents en appliquant la DSmT la frontière entre les deux classeschênes, en général, est affectée à une classe paradoxale ou bien incertaine. Par contre, lorsquenous avons appliqué la TFC les mêmes pixels sont affectés soit à la classe chêne liège soit àla classe chêne zen.

Chapitre 4. Expérimentations de la théorie des possibilités, la TFC et la DSmT 102
La théorie du raisonnement plausible et paradoxale ne nous offre pas un critère de décisionqui favorise uniquement les classes singletons. Ainsi, nous ne pouvons pas évaluer les imagesobtenues par la matrice de confusion. Par conséquent, nous ne pouvons pas comparer lesrésultats obtenus par la TFC et la DSmT. En revanche, l’analyse visuelle des images classéespar ces deux approches montre que la DSmT modélise mieux le conflit entre les sources etpermet de détecter les changements survenus sur la zone d’étude ce qui confirme encore unefois notre étude théorique.
À la lumière de ce qui précède, nous ne pouvons choisir la théorie des possibilités pourréaliser un système de classification des images forestiers puisque d’une part l’image hauterésolution et l’inventaire ne sont pas définis sur les mêmes univers du discours, d’autre partces deux sources sont hautement conflictuelles.Donc le choix se limite entre les théories des fonctions de croyance et du raisonnement plausibleet paradoxale. Malgré l’introduction de l’affaiblissement et l’amélioration des résultats obtenuspar la TFC, il est certain que les résultats issues de l’application de la DSmT sont meilleurs.Tout bien considéré, il est évident que la DSmT est la théorie la plus adéquate pour fusionnerles sources disponibles pour réaliser la cartographie de la zone d’étude.
4.5 Conclusion
Dans ce chapitre nous avons exposé quelques expériences que nous avons établies surdes fenêtres de l’image haute résolution de la zone d’étude. L’application de la théorie despossibilités pour fusionner les fenêtres de l’IHR avec l’inventaire correspondant n’est paspossible vu que les sources n’ont pas les mêmes univers du discours. Par contre, nous avonsutilisé les trois formalismes pour effectuer la classification texturale. Nous avons interprétéet discuté les différents résultats de classifications pour chaque expériences. Finalement, nousavons conclu que la théorie du raisonnement plausible et paradoxale est la théorie la plusadéquate pour faire un système de classification de notre zone d’étude.

Conclusion et Perspectives
Tout au long de notre travail, nous nous sommes intéressés à la fusion des informationsmulti-sources. Dans ce contexte, nous nous sommes concentrés sur trois approches de
l’incertain qui permettent de réaliser la fusion et qui sont : la théorie des possibilités, lathéorie des fonctions de croyance (TFC) et la théorie du raisonnement plausible et paradoxale(DSmT). L’étude de ces techniques de fusion vise à trouver une stratégie qui nous permetde choisir une approche selon les sources et les informations disponibles puisque d’une partces formalismes ne disposent pas du mêmes pouvoirs de raisonnement ni de modélisation etd’autre part un choix arbitraire peut conduire a des résultats non satisfaisantes.
Dans un premier temps nous avons étudié et comparé les trois formalismes. Dans un mêmeordre d’idées, nous avons déterminé pour chaque formalisme les imperfections modélisées et larelation entre les sources mises en jeux. De surcroît, nous avons tiré les intérêts et les limitesde chaque approche. Ainsi, nous avons établi une stratégie permettant de guider le choix d’uneapproche de fusion selon les informations acquises des sources mises en jeu.
Dans un deuxième temps, nous avons mis en place pour chaque formalisme un processus defusion/classification. Ainsi, nous avons choisi une méthode d’estimation pour chaque proces-sus. Pour la théorie des possibilités, nous avons choisi la méthode proposée par Masson dans[54] pour estimer les distributions des possibilités. Pour l’estimation des jeux de masses dansles cadres des théories des fonctions de croyance et du raisonnement plausible et paradoxalela méthode d’estimation utilisée a été proposée dans [7].
Parmi les difficultés que nous avons rencontrées au cours de la réalisation de ce travail :la modélisation de l’ensemble des éléments focaux généralisés au sein de la théorie du raison-nement plausible et paradoxale. Pour résoudre ce problème, nous avons utilisé la méthodeproposée par Ben Dhiaf [7] pour construire les classes composées par l’union des singletons.Ensuite, nous avons proposé une nouvelle méthode pour construire les classes composées par

Conclusion et Perspectives 104
l’intersection de d’autres. Cette méthode nous a permis de modéliser l’information ambiguë.Nous avons également proposé une méthode pour ordonner et coder les éléments focaux gé-néralisés. A l’aide de cette dernière nous avons proposé aussi une méthode pour calculer lacardinalité de DSm afin de calculer la transformation pignistique généralisée.
L’application de la théorie des possibilités pour la fusion de l’image haute résolution etl’inventaire forestier n’est pas possible puisque les univers du discours de ces deux sources sontde nature complémentaire d’une part, d’autre part le conflit entre ces deux mêmes sourcesest remarquablement élevé.Toutefois, les résultats obtenus par la théorie des fonctions de croyance sont encourageants.En outre, l’application de la théorie du raisonnement plausible et paradoxale nous a permisd’obtenir des résultats satisfaisants. Cette dernière nous a poussé à la choisir en tant quel’approche la plus adéquate pour mettre en place une système de classification de la zoned’étude.
Bien que nos résultats soient très encourageants, nous citons quelques perspectives de cetravail de recherche :
– Application de la DSmT pour la fusion et la classification contextuelle.– Expérimentation d’autres méthodes d’estimation.– Étude de la théorie des probabilités imprécises pour la classification des images fores-tières.
– Application de la théorie des possibilités, la TFC et la DSmT pour la fusion distribuée.– Extension de la TFC et la DSmT à des référentiels continus.– Amélioration de la gestion du conflit au sein des théories des possibilités et des fonctionsde croyances.
– Exploration d’autres méthodes pour réduire et gérer la complexité au sein de la théoriedu raisonnement plausible et paradoxale.
– Intégration d’autres sources d’information.– Développement d’un système intelligent qui choisit la théorie la plus adéquate pourfusionner les sources disponibles selon les imperfections présentes.

Bibliographie
[1] Nassim Abbass. Développement de modèles de fusion et de classification contextuelled’images satellitaires par la théorie de l’évidence et la théorie du raisonnement plausible etparadoxal. Master’s thesis, université des sciences et de la technologie houari Boumedienefaculté d’électronique et informatique Algérie, 2009.
[2] Mohammad Homam Alsun, Laurent Lecornu, Basel Solaiman, Clara Le Guillou, andJean Michel Cauvin. Medical diagnosis by possibilistic classification reasoning. In Infor-mation Fusion (FUSION), 2010 13th Conference on, pages 1–7. IEEE, 2010.
[3] Alain Appriou. Probabilités et incertitude en fusion de données multisenseurs. RevueScientifique et Technique de la Défense., 11 :27–40, 1991.
[4] Alain Appriou. Approche générique de la gestion de l’incertain dans les processus defusion multisenseur. 2005.
[5] Zainab Assaghir. Analyse formelle de concepts et fusion d’informations : applicationà l’estimation et au contrôle d’incertitude des indicateurs agri-environnementaux. PhDthesis, Institut National Polytechnique de Lorraine-INPL, 2010.
[6] Sarah Ben Ben Amor and Jean-Marc Martel. Le choix d’un langage de modélisationdes imperfections de l’information en aide à la décision. In Annual Conference of theAdministrative Sciences Association of Canada, volume 25, 2004.
[7] Zouhour Ben Dhiaf. Fusion de sources d’information pour l’interprétation dimages detélédétection moyenne et haute résolution : Application à l’inventaire forestier. PhDthesis, Université de Tunis El Manar : Faculté des Sciences Tunis, 2011.
[8] Isabelle Bloch. Incertitude, imprécision et additivité en fusion de données : point de vuehistorique. TS. Traitement du signal, 13(4) :267–288, 1996.
[9] Isabelle Bloch. Information combination operators for data fusion : A comparative reviewwith classification. Systems, Man and Cybernetics, Part A : Systems and Humans, IEEETransactions on, 26(1) :52–67, 1996.

BIBLIOGRAPHIE 106
[10] Isabelle Bloch. Some aspects of dempster-shafer evidence theory for classification ofmulti-modality medical images taking partial volume effect into account. Pattern Recog-nition Letters, 17(8) :905–919, 1996.
[11] Isabelle Bloch. Estimation of class membership functions for gray-level based imagefusion. Image Processing, 1997. Proceedings., 3 :268–271, 1997.
[12] Isabelle Bloch. Fusion d’informations numériques : panorama méthodologique. JournéesNationales de la Recherche en Robotique, page 79, 2005.
[13] Isabelle Bloch and H Maître. Fusion de données en traitement d’images : modèles d’in-formation et décisions. TS. Traitement du signal, 11(6) :435–446, 1994.
[14] Isabelle Bloch and Henri Maıtre. Les méthodes de raisonnement dans les images. EcoleNationale Supérieure des Télécommunications-CNRS UMR, 5141, 2004.
[15] Didier Cayrac, Didier Dubois, and Henri Prade. Handling uncertainty with possibilitytheory and fuzzy sets in a satellite fault diagnosis application. Fuzzy Systems, IEEETransactions on, 4(3) :251–269, 1996.
[16] Laurence Cholvy. Non-exclusive hypotheses in dempster–shafer theory. InternationalJournal of Approximate Reasoning, 53(4) :493–501, 2012.
[17] Samuel Corgne, Laurence Hubert-Moy, Jean Dezert, and Grégoire Mercier. Land coverchange prediction with a new theory of plausible and paradoxical reasoning. In Proc. ofFusion, pages 8–11, 2003.
[18] Belur V Dasarathy. Sensor fusion potential exploitation-innovative architectures andillustrative applications. Proceedings of the IEEE, 85(1) :24–38, 1997.
[19] Richard Dedekind. Über zerlegungen von zahlen durch ihre grössten gemeinsammenteiler. In Collected Works, 1 :103–148, 1897.
[20] M Delplanque, AM Desodt-Jolly, D Jolly, and J Jamin. Fusion dissymétrique d’informa-tions incomplètes pour la classification d’objets sous-marins. TS. Traitement du signal,14(5) :511–522, 1997.
[21] Thierry DENCEUX. Application du modèle des croyances transférables en reconnais-sance de formes. rn (A), 1 :2, 1998.
[22] Thierry Denoeux. A k-nearest neighbor classification rule based on dempster-shafertheory. Systems, Man and Cybernetics, IEEE Transactions on, 25(5) :804–813, 1995.
[23] Thierry Denœux. Théorie des fonctions de croyance et classification. Séminaire, themeASTRID, UTC, 2004.

BIBLIOGRAPHIE 107
[24] Thierry Denoeux. Application du formalisme des fonctions de croyance en fusion d’in-formations et en classification. Séminaire de l’Institut National de Recherche sur lesTransports et leurs Sécurité (INRETS), 2005.
[25] Sebastien Destercke, Didier Dubois, and Eric Chojnacki. Fusion d’opinions d’expertset théories de l’incertain. Proc. Rencontres Francophones sur la logique floue et sesapplications, 2006.
[26] S Deveughele and B Dubuisson. Adaptabilité et combinaison possibiliste : application àla vision multi-caméras. TS. Traitement du signal, 11(6) :559–568, 1994.
[27] Jean Dezert. Foundations for a new theory of plausible and paradoxical reasoning. In-formation and Security, 9 :13–57, 2002.
[28] Jean Dezert and Florentin Smarandache. On the generation of hyper-powersets for thedsmt. arXiv preprint math/0309431, 2003.
[29] Jean Dezert and Florentin Smarandache. Partial ordering of hyper-powersets and matrixrepresentation of belief functions within dsmt. arXiv preprint math/0309401, 2003.
[30] Jean Dezert and Florentin Smarandache. The dsmt approach for information fusion andsome open problems. 2005.
[31] Jean Dezert and Florentin Smarandache. Dsmt : A new paradigm shift for informationfusion. arXiv preprint cs/0610175, 2006.
[32] Jean Dezert and Florentin Smarandache. Introduction to the fusion of quantitative andqualitative beliefs. Information & Security Journal, 20, 2006.
[33] Jean Dezert and Florentin Smarandache. An introduction to dsmt. arXiv preprintarXiv :0903.0279, 2009.
[34] Jean Dezert, Florentin Smarandache, and Milan Daniel. The generalized pignistic trans-formation. arXiv preprint cs/0409007, 2004.
[35] Weibei Dou. Segmentation d’images multispectrales basée sur la fusion d’informations :application aux images IRM. PhD thesis, Université de Caen, 2006.
[36] D Dubois and H Prade. Possibility theory and its applications : a retrospective and pros-pective view. In Fuzzy Systems, 2003. FUZZ’03. The 12th IEEE International Conferenceon, volume 1, pages 5–11. IEEE, 2003.
[37] Didier Dubois, Laurent Foulloy, Gilles Mauris, and Henri Prade. Probability-possibilitytransformations, triangular fuzzy sets, and probabilistic inequalities. Reliable computing,10(4) :273–297, 2004.

BIBLIOGRAPHIE 108
[38] Didier Dubois and Henri Prade. Additions of interactive fuzzy numbers. AutomaticControl, IEEE Transactions on, 26(4) :926–936, 1981.
[39] Didier Dubois and Henri Prade. Théorie des possibilités. Applications i Représentationdes Connaissances en Informatique. Collection Méthode+ Programmes, Masson, Paris.l MAGE EVALUATION TEST TARGET, 1985.
[40] Didier Dubois and Henri Prade. La fusion d’informations imprécises. TS. Traitement dusignal, 11(6) :447–458, 1994.
[41] Didier Dubois and Henri Prade. Formal representations of uncertainty. Decision-MakingProcess : Concepts and Methods, pages 85–156, 2009.
[42] Imed Riadh Farah, Wadii Boulila, K Saheb Ettabaa, Basel Solaiman, and M Ben Ahmed.Interpretation of multisensor remote sensing images : Multiapproach fusion of uncertaininformation. Geoscience and Remote Sensing, IEEE Transactions on, 46(12) :4142–4152,2008.
[43] MC Florea, Jean Dezert, Pierre Valin, Florentin Smarandache, and Anne-Laure Jous-selme. Adaptative combination rule and proportional conflict redistribution rule forinformation fusion. arXiv preprint cs/0604042, 2006.
[44] Mickaël Germain, Jean-Marc Boucher, Goze B Bénié, and E Beaudry. Fusion évidentiellemulti source basée sur une nouvelle approche statistique floue. ISIVC04, Brest, France,2004.
[45] Zakia Hammal. Segmentation des Traits du Visage, Analyse et Reconnaissance des Ex-pressions Faciales par les Modèles de Croyance Transférable. PhD thesis, UniversitéJoseph-Fourier-Grenoble I, 2006.
[46] Bahador Khaleghi, Alaa Khamis, Fakhreddine O Karray, and Saiedeh N Razavi. Multi-sensor data fusion : A review of the state-of-the-art. Information Fusion, 2011.
[47] I Leiss, Stefan Sandmeier, Klaus I Itten, and Tobias W Kellenberger. Use of expertknowledge and possibility theory in land use classification. In Progress in EnvironmentalRemote Sensing Research and Applicartions ; Proceedings of the 15th EARSeL Sympo-sium, pages 133–137, 1995.
[48] Xinde Li, Xinhan Huang, and Min Wang. Robot map building from sonar sensors anddsmt. Information & Security Journal, Bulg. Acad. of Sci., Sofia, 20, 2006.
[49] Hichem MAAREF, Mourad OUSSALAH, and Claude BARRETI. Fusion de donnéescapteurs en vue de la localisation absolue d’un robot mobile par une méthode basée surla théorie des possibilités. comparaison avec le filtre de kalman. Traitement du Signal,16(5), 1999.

BIBLIOGRAPHIE 109
[50] Arnaud Martin. La fusion dinformations. Polycopié de cours ENSIETA-Réf, 1484 :117,2005.
[51] Arnaud Martin. Fusion de classifieurs pour la classification d’images sonar. arXiv preprintarXiv :0806.2006, 2008.
[52] Arnaud Martin. Le conflit dans la théorie des fonctions de croyance. In EGC, pages655–666, 2010.
[53] Arnaud Martin and Christophe Osswald. Human expert fusion for image classification.arXiv preprint arXiv :0806.1798, 2008.
[54] Marie-Hélène Masson. Apports de la théorie des possibilités et des fonctions de croyanceà lanalyse de données imprécises. PhD thesis, Université de Technologie de Compiègne,2005.
[55] Marie-Hélène Masson and Thierry Denœux. Inferring a possibility distribution fromempirical data. Fuzzy sets and systems, 157(3) :319–340, 2006.
[56] Frédéric Maussang, Michèle Rombaut, Jocelyn Chanussot, et al. Détection en imageriesas par fusion de données de statistiques locales. 7e Journées d’Acoustique Sous-Marine(JASM’04), pages 185–194, 2004.
[57] Nada Milisavljević, Isabelle Bloch, Vito Alberga, and Giuseppe Satalino. Three strate-gies for fusion of land cover classification results of polarimetric sar data. "Sensor andData Fusion", book edited by Nada Milisavljevic, ISBN 978-3-902613-52-3, Published :February 1, 2009 under CC BY-NC-SA 3.0 license, 2009.
[58] Vincent Nimier and Alain Appriou. Utilisation de la théorie de dempster-shafer pour lafusion d’informations. In 15 Colloque sur le traitement du signal et des images, FRA,1995. GRETSI, Groupe dEtudes du Traitement du Signal et des Images, 1995.
[59] Christophe Osswald and A Martin. Understanding the large family of dempster-shafertheory’s fusion operators-a decision-based measure. In Information Fusion, 2006 9thInternational Conference on, pages 1–7. IEEE, 2006.
[60] Simon Parsons and Anthony Hunter. A review of uncertainty handling formalisms. InApplications of uncertainty formalisms, pages 8–37. Springer, 1998.
[61] Enric Plaza, Claudi Alsina, R López de Mántaras, J Aguilar, and Jaume Agusti. Consen-sus and knowledge acquisition. In Uncertainty in Knowledge-Based Systems, pages 294–306. Springer, 1987.
[62] Jérémy Rohmer. La théorie des possibilités comme outil de représentation des incerti-tudes épistémiques d’une chaîne de traitement du risque sismique. Proceedings AFPS2007, 2007.

BIBLIOGRAPHIE 110
[63] Michèle Rombaut. Fusion : état de lart et perspectives. In Convention DSP, volume 99,page 078, 2001.
[64] Michèle Rombaut and Yue Min Zhu. Study of dempster–shafer theory for image segmen-tation applications. Image and vision computing, 20(1) :15–23, 2002.
[65] Ludovic Roux and Jacky Desachy. Satellite image classification based on multi-sourceinformation-fusion with possibility theory. In Geoscience and Remote Sensing Sympo-sium, 1994. IGARSS’94. Surface and Atmospheric Remote Sensing : Technologies, DataAnalysis and Interpretation., International, volume 2, pages 885–887. IEEE, 1994.
[66] Ludovic Roux and Jacky Desachy. Information fusion for supervised classification in a sa-tellite image. In Fuzzy Systems, 1995. International Joint Conference of the Fourth IEEEInternational Conference on Fuzzy Systems and The Second International Fuzzy Engi-neering Symposium., Proceedings of 1995 IEEE International Conference on, volume 3,pages 1119–1124. IEEE, 1995.
[67] Glenn Shafer. Perspectives on the theory and practice of belief functions. InternationalJournal of Approximate Reasoning, 4(5) :323–362, 1990.
[68] Richa Singh, Mayank Vatsa, and Afzel Noore. Integrated multilevel image fusion andmatch score fusion of visible and infrared face images for robust face recognition. PatternRecognition, 41(3) :880–893, 2008.
[69] Florentin Smarandache. Unification of fusion theories (uft). Advances and Challenges inMultisensor Data and Information Processing, 8 :114, 2007.
[70] Florentin Smarandache and Jean Dezert. Advances and applications of DSmT for infor-mation fusion : collected works, volume 2. American Research Press, 2006.
[71] Florentin Smarandache and Jean Dezert. An introduction to the dsm theory for the com-bination of paradoxical, uncertain, and imprecise sources of information. arXiv preprintcs/0608002, 2006.
[72] Philippe Smets. Constructing the pignistic probability function in a context of uncer-tainty. In Uncertainty in artificial intelligence, volume 5, pages 29–39, 1990.
[73] Philippe Smets. The transferable belief model and other interpretations of dempster-shafers model. In Uncertainty in Artificial Intelligence, volume 6, pages 375–383, 1990.
[74] Philippe Smets. Imperfect information : Imprecision and uncertainty. In UncertaintyManagement in Information Systems, pages 225–254. Springer, 1997.
[75] Philippe Smets. Probability, possibility, belief : which and where. Handbook of defeasiblereasoning and uncertainty management systems, 1 :1–24, 1998.

BIBLIOGRAPHIE 111
[76] Jean-Marc Tacnet. Prise en compte de l’incertitude dans l’expertise des risques natu-rels en montagne par analyse multicritères et fusion d’information. PhD thesis, EcoleNationale Supérieure des Mines de Saint-Etienne, 2009.
[77] Abdelmalik Taleb-Ahmed, Laurent Gautier, and Michèle Rombaut. Architecture defusion de données basée sur la théorie de lévidence pour la reconstruction dun vertèbre.Traitement du Signal, 19(4) :267–283, 2002.
[78] Albena Tchamova and Jean Dezert. On the behavior of dempster’s rule of combinationand the foundations of dempster-shafer theory. In Intelligent Systems (IS), 2012 6thIEEE International Conference, pages 108–113. IEEE, 2012.
[79] Patrick Vannoorenberghe. Un état de l’art sur les fonctions de croyance appliquées autraitement de l’information. Revue I3, 3(2) :9–45, 2003.
[80] Lucien Wald. Some terms of reference in data fusion. Geoscience and Remote Sensing,IEEE Transactions on, 37(3) :1190–1193, 1999.
[81] Yajing Yan. Fusion de mesures de déplacement issues d’imagerie SAR : Application auxmodélisations séismo-volcaniques. PhD thesis, Université de Savoie, 2011.
[82] Lotfi Askar Zadeh. Fuzzy algorithms. Information and control, 12 :94–102, 1968.

Annexe AImage de Hölder
Dans cette annexe, nous présentons brièvement l’outil multifractale et les exposants desingularités ainsi la méthode qui ont permis d’avoir l’image Hölder et par la suite l’obtentiondes nouvelles mesures de masse de croyance (respectivement des distributions de possibilités).Cette méthode a été présentée dans [7].
A.1 Construction de la mesure multifractale
Pour une image I représentée par sa fonction de luminance I(−→x ) en chaque−→x , on introduitune mesure de densité µ s’écrivant sous la forme suivante :
dµ ≡ d−→x |∇I|(−→x ) (A.1)
Où |∇I|(−→x ) désigne la norme de gradient ∇I de l’image I en chaque pixel −→x .La mesure multifractale d’un sous ensemble quelconque A de l’image est donc donnée parl’équation :
µ(A) =∫Ad−→x |∇I|(−→x ) (A.2)
Le comportement local de l’intensité I en chaque pixel −→x de l’image peut être caractérisé parl’évaluation de la mesure µ dans une boule Br(−→x ) pour différents rayons r centré en un pixel−→x tels qu’illustré comme suit par l’équation suivante :
µ(Br(−→x )) =∫Br(−→x )
d−→y |∇I|(−→y ) (A.3)

Annexe A. Image de Hölder 113
Cette mesure donne une idée de la variabilité locale des niveaux de gris autour du point−→x .Par définition, µ est dite multifractale si la mesure µ(Br(−→x )) de la boule Br(−→x ) évolue commeune puissance de r à un exposant caractéristique h(−→x ), ne dépendant que de −→x lorsque rtend vers 0. Cette mesure s’écrit selon l’équation suivante :
µ((Br(−→x ))) = α(−→x )rd+h(−→x ) + o(rd+h(−→x )) (A.4)
Où d désigne la dimension de l’espace (d=2 pour des images) et où le coefficient α(−→x ) nedépend pas de l’échelle r.
A.2 Estimation des exposants de singularité
Les exposants de singularité h(−→x ) apparaissant dans l’équation A.4 permettent de carac-tériser la structure multifractale de l’image Ils représentent le degré de singularité s’ils sontinférieurs à 0 ou de régularité de l’image s’ils sont supérieurs à 0. Pour mieux estimer cesexposants, on utilise une projection en ondelettes dont l’intérêt principal est de réaliser uneinterpolation continue de l’image. Ce qui permet d’étudier l’évolution de la mesure µ sousl’effet de changement d’échelle dans le but de caractériser le comportement local de l’intensitéde l’image I en chaque pixel −→x . En effet, pour un choix d’ondelettes analysante appropriée,la projection de la mesure multifractale exhibera également un comportement multifractal,dont la relation est décrite par l’équation :
TΨ(µ(−→x , r)) = αΨ(−→x )rh(−→x ) + o(|r|h(−→x )) (A.5)
Les exposants de singularité h(−→x ) peuvent être estimés à partir des projections en ondelettes Tà l’aide d’une Log-Log régression sur l’équation précédente. Ce qui donne l’équation suivante :
h(−→x ) = limr→0
log(TΨ(µ(−→x , r)))log(r) (A.6)
Sachant que Log-Log régression représente la régression linéaire sur le nuage de coordonnées(logTΨµ(−→x , r), log r) dont la pente fournit l’exposant h(−→x ).
A.3 Estimation des fonctions de masse à partir des his-togrammes des exposants de singularité
Étant donné qu’on se situe dans le cadre d’un système de classification supervisée, lesdistributions des coefficients de Hölder associées à chacune des zones d’apprentissages et

Annexe A. Image de Hölder 114
correspondant aux classes de l’ensemble de définition peuvent être représentées par leurshistogrammes de singularités. Pour simplifier l’exploitation de l’image des exposants de sin-gularités et permettre son adaptation à la méthode d’estimation des fonctions de masse, onmultiplie l’image des exposants de singularités par un facteur permettant d’avoir les mêmesbornes que l’image des niveaux de gris (intervalle [0, 255]). La détermination du référentielde définition dépendra par conséquent de la distribution des coefficients de Hölder et doncdes histogrammes tracés à partir des singularités de l’image. Nous obtenons des fonctions demasse pour chaque élément de ce référentiel de définition.

Annexe BSources d’informations
Nous exposons dans cet annexe les sources d’information utilisées dans notre travail.
B.1 Image QuickBird
Les fenêtres que nous avons utilisé dans les expériences de classifications avec les troisthéories ont été prises d’une image satellite QuickBird haute résolution.
Figure B.1 – Image QuickBird bande PIR

Annexe B. Sources d’informations 116
Dans un premier temps nous avons pris une fenêtre 2000*2000 de l’image haute résolutionqui est illustrée par la figure suivante :
Figure B.2 – Fenêtre 2000*2000
Par la suite, nous avons extrait des fenêtres de taille 250*250 que nous les avons présentédans le quatrième chapitre. L’image de Hölder de la fenêtre 2000*2000 est illustrée par lafigure suivante :
Figure B.3 – Image de Hölder.
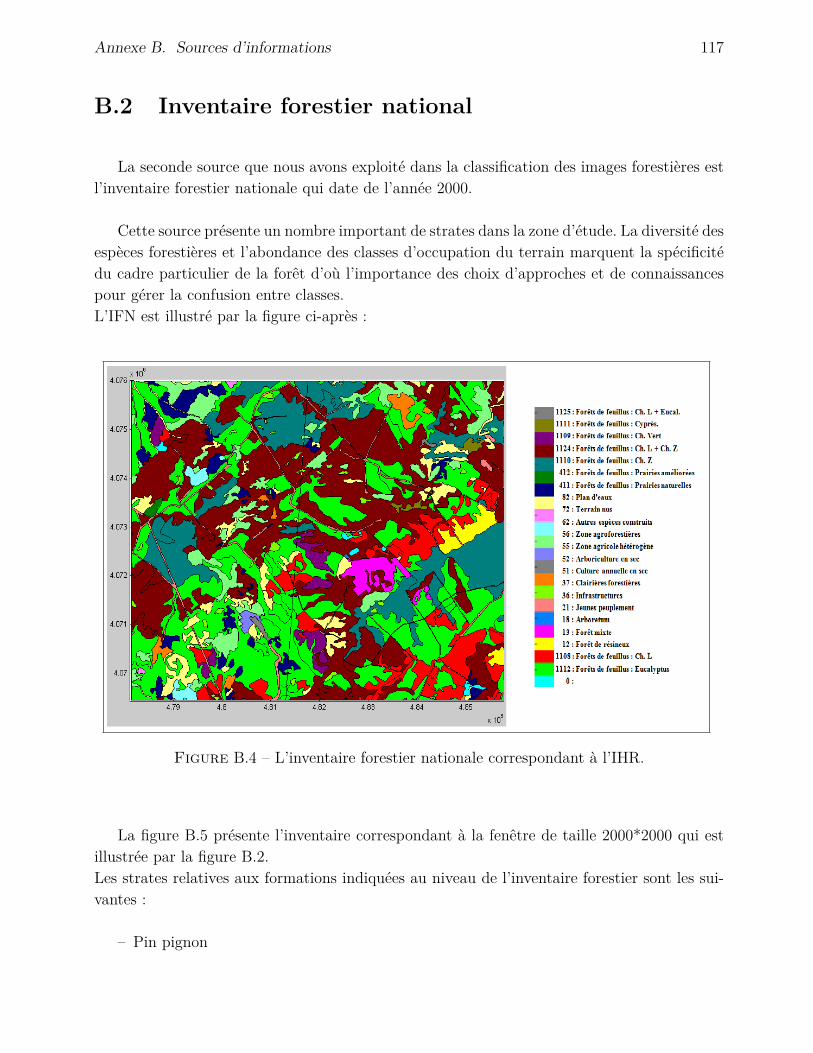
Annexe B. Sources d’informations 117
B.2 Inventaire forestier national
La seconde source que nous avons exploité dans la classification des images forestières estl’inventaire forestier nationale qui date de l’année 2000.
Cette source présente un nombre important de strates dans la zone d’étude. La diversité desespèces forestières et l’abondance des classes d’occupation du terrain marquent la spécificitédu cadre particulier de la forêt d’où l’importance des choix d’approches et de connaissancespour gérer la confusion entre classes.L’IFN est illustré par la figure ci-après :
Figure B.4 – L’inventaire forestier nationale correspondant à l’IHR.
La figure B.5 présente l’inventaire correspondant à la fenêtre de taille 2000*2000 qui estillustrée par la figure B.2.Les strates relatives aux formations indiquées au niveau de l’inventaire forestier sont les sui-vantes :
– Pin pignon

Annexe B. Sources d’informations 118
– Pin maritime– Chêne liège– Chêne zen– Cyprès– Mélange chêne liège et chêne zen– Forêt mixte
Figure B.5 – IFN correspondant à la fenêtre de l’IHR.

Annexe CMatrice de confusion
C.1 La matrice de confusion
La matrice de confusion permet de confronter des vérités terrains au résultat de la classi-fication et d’évaluer la précision de la classification par rapport à la référence sur le terrain.Sous forme d’un tableau (ou matrice), on extrait, les informations thématiques correspondantaux classes de terrain (données horizontales) et les informations thématiques résultant dela classification non dirigée de l’image (données verticales). Les cellules de la matrice repré-sentent le nombre de pixels affiliés à chacune des classes dans la carte classifiée et dans la cartede référence. Dans la diagonale, on a le nombre de pixels correctement classifiés et la sommecorrespond au nombre total de pixels correctement classifiés. Le rapport du nombre total depixels correctement classifiés sur le nombre total de pixels de la matrice obtenue donne la «précision globale » de la classification.
C.2 Les erreurs d’omission et de commission
C.2.1 L’erreur d’omission
Cette mesure est le rapport entre le total des valeurs dans les cellules non diagonales d’uneligne dans la matrice de confusion et la somme des valeurs des cellules de cette ligne. Elle

Annexe C. Matrice de confusion 120
représente le taux de pixels incorrectement exclus d’une classe.
nombre de pixels mal classifiés pour une classe ( verité de terrain)nombre total de pixels de cette classe ( verité de terrain) ∗ 100 (C.1)
C.2.2 L’erreur de commission
Le rapport sur une colonne des pixels mal classifiés sur le nombre total d’une colonne. Ellereprésente le taux de pixels assignés incorrectement à une classe qui appartiennent en fait àune autre classe.
nombre de pixels mal classifiés pour une classe ( carte classifiée)nombre de pixels mal classifiés pour une classe( carte classifiée) ∗ 100 (C.2)
C.3 Le coefficient Kappa
Le coefficient Kappa est un estimateur de qualité qui tient compte des erreurs en lignes eten colonnes. Il exprime la réduction proportionnelle de l’erreur obtenue par une classification,comparée à l’erreur obtenue par une classification complètement au hasard. Cette mesure estentre -1 et 1 et donc si :
– Si −1 ≤ Kappa < 0 ceci signifie un désaccord.– Si 0 ≤ Kappa ≤ 0.2 ceci implique un très faible accord.– Si 0.21 ≤ Kappa ≤ 0.4 ceci indique que l’accord est faible.– Si 0.41 ≤ Kappa ≤ 0.6 dans ce cas l’accord est modéré.– Si 0.61 ≤ Kappa ≤ 0.8 ceci prouve que l’accord est fort– Si 0.81 ≤ Kappa ≤ 1 l’accord est presque parfait
Cette mesure de précision est calculée avec l’équation suivante :
Kappa = P0 − Pc1− Pc
(C.3)
Avec : P0 = 1N∗∑c
i=1 n(i, i) : la proportion de bonne classification.Pc = 1
N2 ∗∑ci=1 n(., i)n(i, .) : la proportion de bonne classification due au hasard.
n(i, .) : la somme sur la i-ème ligne.n(., i) : la somme sur la i-ème colonne.c : le nombre de classe.N = ∑c
i=1∑cj=1 n(i, j) : le nombre de pixels.





























