Embed Size (px)
Citation preview

BibTEX entry of my PhD thesis:
@PhDThesis{ hartrumpf02,
author = {Sven Hartrumpf},
title = {Hybrid Disambiguation in Natural Language Analysis},
school = {FernUniversit{\"a}t Hagen, Fachbereich Informatik},
year = 2002,
address = {Hagen, Germany},
month = jun
}
and the corresponding book published by Der Andere Verlag(http://www.der-andere-verlag.de):
@Book{ hartrumpf03,
author = {Sven Hartrumpf},
title = {Hybrid Disambiguation in Natural Language Analysis},
publisher = {Der Andere Verlag},
year = 2003,
address = {Osnabr{\"u}ck, Germany},
note = {ISBN 3-89959-080-5}
}
Front matter and back matter of this book follow.


Hybrid Disambiguation in
Natural Language Analysis
Vom Fachbereich Informatikder FernUniversitat Hagen
angenommene
Dissertation
zur Erlangung des akademischen Grades einesDoktors der Naturwissenschaften
(Dr. rer. nat.)
vonDipl.-Inform.
Sven Hartrumpf
Gutachter: Prof. Dr. Hermann Helbig und Prof. Dr. Istvan Batori
Datum der mundlichen Prufung: 28. Juni 2002
Hagen, Juni 2002

c© 2002, Sven HartrumpfE-mail: [email protected], [email protected] rights reserved
11 10 09 08 07 06 05 04 03 02 6 5 4 3 2 1
Colophon
This PhD thesis was written in the SGML DocBook format 4.2. It was trans-formed to LATEX by a tool written by the author and typeset using the LATEXtypesetting system (by Leslie Lamport) and the memoir document class (by PeterR. Wilson). The text is set 10/12pt on a 29pc measure with Computer ModernRoman designed by Donald E. Knuth.

Contents
Contents vii
List of Figures xi
List of Tables xiii
Abstract xv
Preface xvii
1 Introduction 11.1 Motivation and Theses . . . . . . . . . . . . . . . . . . . . . . . . 11.2 State of the Art . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21.3 Chapter Overview . . . . . . . . . . . . . . . . . . . . . . . . . . 31.4 Context and Embedding of the Thesis . . . . . . . . . . . . . . . 31.5 Typographical and Notational Conventions . . . . . . . . . . . . 6
2 Foundations 72.1 Ambiguity in Natural Language . . . . . . . . . . . . . . . . . . . 72.2 Knowledge Representation Language . . . . . . . . . . . . . . . . 7
2.2.1 MultiNet Relations . . . . . . . . . . . . . . . . . . . . . . 82.2.2 MultiNet Sorts and Semantic Features in the Lexicon . . 92.2.3 MultiNet Layers . . . . . . . . . . . . . . . . . . . . . . . 18
2.3 Parsing Technology . . . . . . . . . . . . . . . . . . . . . . . . . . 232.4 Knowledge Sources . . . . . . . . . . . . . . . . . . . . . . . . . . 24
2.4.1 Corpora . . . . . . . . . . . . . . . . . . . . . . . . . . . . 242.4.2 Lexica . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
2.5 Methods and Computational Tools . . . . . . . . . . . . . . . . . 302.5.1 Hybridization . . . . . . . . . . . . . . . . . . . . . . . . . 302.5.2 Tools for Lexical Knowledge . . . . . . . . . . . . . . . . . 302.5.3 Evaluation . . . . . . . . . . . . . . . . . . . . . . . . . . 31
3 The WOCADI Parser 353.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 353.2 Basic Concepts of WCFA . . . . . . . . . . . . . . . . . . . . . . 363.3 Analyzing Simple Noun Phrases . . . . . . . . . . . . . . . . . . . 373.4 Analyzing Complex Noun Phrases . . . . . . . . . . . . . . . . . 45

viii Contents
3.5 Analyzing Simple Propositions . . . . . . . . . . . . . . . . . . . 483.6 Analyzing Complex Propositions . . . . . . . . . . . . . . . . . . 483.7 Relationship between the Parser and the Disambiguation Modules 493.8 WOCADI’s Extensions over Earlier WCFA Work . . . . . . . . . 503.9 Robust Parsing . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
3.9.1 Lexical Robustness . . . . . . . . . . . . . . . . . . . . . . 513.9.2 Grammatical Robustness . . . . . . . . . . . . . . . . . . 52
3.10 Implementation Details . . . . . . . . . . . . . . . . . . . . . . . 533.11 Applications of the Parser . . . . . . . . . . . . . . . . . . . . . . 533.12 Related Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54
4 General Disambiguation Approach 574.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 574.2 Traditional Linguistic Component: Rules . . . . . . . . . . . . . 574.3 Statistical Component: Multidimensional Back-off Models . . . . 58
4.3.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . 584.3.2 Formalization of Multidimensional Back-off Models . . . . 614.3.3 Lexicographically Ordered Dimension Abstraction Func-
tions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 664.4 Comparison to Other Statistical Models . . . . . . . . . . . . . . 66
4.4.1 Back-off Models . . . . . . . . . . . . . . . . . . . . . . . 664.4.2 Maximum Entropy Models . . . . . . . . . . . . . . . . . 674.4.3 Memory-Based Learning . . . . . . . . . . . . . . . . . . . 68
5 Prepositional Phrase Disambiguation 695.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 695.2 Data . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71
5.2.1 PP Interpretation Rules . . . . . . . . . . . . . . . . . . . 715.2.2 Corpus Annotations for PP Disambiguation . . . . . . . . 755.2.3 Systematic Ambiguity of PP Attachment . . . . . . . . . 86
5.3 Hybrid Disambiguation Method . . . . . . . . . . . . . . . . . . . 885.3.1 Basic Ideas . . . . . . . . . . . . . . . . . . . . . . . . . . 885.3.2 Determination of Alternatives by Rules . . . . . . . . . . 905.3.3 Interpretation Disambiguation . . . . . . . . . . . . . . . 925.3.4 Attachment Disambiguation . . . . . . . . . . . . . . . . . 96
5.4 PP Disambiguation and Constituent Ambiguity . . . . . . . . . . 1035.5 Evaluation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1055.6 Multiple PP Attachment Problem . . . . . . . . . . . . . . . . . 1085.7 Achievements and Potentials for Prepositional Phrase Disam-
biguation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1095.8 Related Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1095.9 Conclusions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 110
6 Coreference Resolution 1116.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1116.2 Coreference Types . . . . . . . . . . . . . . . . . . . . . . . . . . 1136.3 Coreference Data . . . . . . . . . . . . . . . . . . . . . . . . . . . 116

Contents ix
6.3.1 Coreference Rules . . . . . . . . . . . . . . . . . . . . . . 1176.3.2 Corpus Annotations for Coreference Resolution . . . . . . 1186.3.3 Coreference Annotation Guidelines . . . . . . . . . . . . . 1276.3.4 Minimal Markables for Fairer Evaluation . . . . . . . . . 134
6.4 Coreference Resolution Method . . . . . . . . . . . . . . . . . . . 1356.4.1 Algorithm Overview . . . . . . . . . . . . . . . . . . . . . 1356.4.2 Coreference and Semantic Molecules . . . . . . . . . . . . 1406.4.3 Identifying Markables . . . . . . . . . . . . . . . . . . . . 1436.4.4 Limiting the Search Space with Coreference Rules . . . . 1456.4.5 Searching for the Correct Partition of Markables . . . . . 1466.4.6 Filtering Constraints for Coreference Partitions . . . . . . 1466.4.7 Probabilities as Scores for Coreference Partitions . . . . . 1536.4.8 Bonus Factors for Coreference Partitions . . . . . . . . . . 155
6.5 Evaluation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1576.6 Parallel Corpora for Efficient Annotation and System Comparison 1606.7 Stepping Beyond Identity . . . . . . . . . . . . . . . . . . . . . . 1606.8 Achievements and Potentials for Coreference Resolution . . . . . 1616.9 Related Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1626.10 Conclusions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 163
7 Word Sense Disambiguation 1657.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1657.2 Word Sense Disambiguation for PPs . . . . . . . . . . . . . . . . 166
7.2.1 Basic Ideas . . . . . . . . . . . . . . . . . . . . . . . . . . 1667.2.2 Corpus Annotations for Word Sense Disambiguation in
PP Contexts . . . . . . . . . . . . . . . . . . . . . . . . . 1687.2.3 Combination with the PP Disambiguation Module . . . . 168
7.3 Evaluation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1697.4 Achievements and Potentials for Word Sense Disambiguation . . 1717.5 Situation Sense Disambiguation . . . . . . . . . . . . . . . . . . . 172
7.5.1 Basic Ideas . . . . . . . . . . . . . . . . . . . . . . . . . . 1727.5.2 Disambiguation Method . . . . . . . . . . . . . . . . . . . 172
7.6 Related Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1737.7 Conclusions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 174
8 Extensions 1758.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1758.2 Subordinate Clause Attachment and Interpretation . . . . . . . . 1758.3 Relative Clause Attachment . . . . . . . . . . . . . . . . . . . . . 1768.4 Resolution of Ellipsis in Coordinative Constructions . . . . . . . 1768.5 Genitive NP Attachment and Interpretation . . . . . . . . . . . . 1778.6 Scope of Quantifiers . . . . . . . . . . . . . . . . . . . . . . . . . 1788.7 Adverbial Attachment . . . . . . . . . . . . . . . . . . . . . . . . 178

x Contents
9 Conclusions 1819.1 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1819.2 Contributions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1829.3 Perspectives . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 182
Bibliography 185
Index 197

List of Figures
1.1 Context of the thesis . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2.1 Relations and functions in MultiNet without lexrel, semrel, and *funsubhierarchies . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.2 Relations in MultiNet: lexrel subhierarchy . . . . . . . . . . . . . . . 92.3 Relations in MultiNet: semrel subhierarchy . . . . . . . . . . . . . . 102.4 Functions in MultiNet . . . . . . . . . . . . . . . . . . . . . . . . . . 112.6 Sort hierarchy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 132.8 Subtypes of entity without the con-object, abs-object, and situation
subhierarchies . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 152.9 Subtypes of con-object . . . . . . . . . . . . . . . . . . . . . . . . . . 162.10 Subtypes of abs-object . . . . . . . . . . . . . . . . . . . . . . . . . . 172.11 Subtypes of situation . . . . . . . . . . . . . . . . . . . . . . . . . . . 182.14 The feature type lay . . . . . . . . . . . . . . . . . . . . . . . . . . . 222.15 Values for layer features . . . . . . . . . . . . . . . . . . . . . . . . . 222.16 Hierarchy of knowledge types (ktype) . . . . . . . . . . . . . . . . . . 232.17 Graphical semantic network for sentence (1) . . . . . . . . . . . . . . 252.18 Textual semantic network for sentence (1) . . . . . . . . . . . . . . . 262.19 Lexical entry for drangen.1.1 in IBL format . . . . . . . . . . . . . . 272.20 Expanded lexical entry for drangen.1.1 . . . . . . . . . . . . . . . . . 282.21 Formal syntax of typed feature structures . . . . . . . . . . . . . . . 29
3.1 Transition diagram for WCFM’s states during NP analysis . . . . . 373.3 Simplified opening act of the WCF adv . . . . . . . . . . . . . . . . 393.4 Architecture of the WOCADI parser (data flow diagram) . . . . . . 403.5 Simplified algorithm for level 1 of the WCFM . . . . . . . . . . . . . 423.7 Contents of the AM after step 3 (top box), 6 (middle box), and 23
(bottom box) with parts of feature structures . . . . . . . . . . . . . 443.8 Semantic network for sentence (5) . . . . . . . . . . . . . . . . . . . 463.9 Semantic network for sentence (6) . . . . . . . . . . . . . . . . . . . 473.10 Modules of the WOCADI parser . . . . . . . . . . . . . . . . . . . . 54
4.1 Formal top-level syntax of interpretation rules . . . . . . . . . . . . . 584.2 Dimensions in a multidimensional back-off model for PP attachment 61
5.1 Examples of PP interpretation rules for uber . . . . . . . . . . . . . 72

xii List of Figures
5.2 Formal syntax of interpretation rules . . . . . . . . . . . . . . . . . . 735.3 Example of a coreference rule . . . . . . . . . . . . . . . . . . . . . . 745.4 Interpretation rules and corpus examples of auf -PPs (part 1/2) . . . 755.5 Interpretation rules and corpus examples of auf -PPs (part 2/2) . . . 765.6 Interpretation rules and corpus examples of aus-PPs (part 1/2) . . . 775.7 Interpretation rules and corpus examples of aus-PPs (part 2/2) . . . 785.8 Interpretation rules and corpus examples of bei -PPs . . . . . . . . . 795.9 Interpretation rules and corpus examples of uber -PPs (part 1/2) . . 805.10 Interpretation rules and corpus examples of uber -PPs (part 2/2) . . 815.11 Interpretation rules and corpus examples of vor -PPs (part 1/2) . . . 825.12 Interpretation rules and corpus examples of vor -PPs (part 2/2) . . . 835.13 Interpretation rule and corpus example of wegen-PPs . . . . . . . . . 835.19 Architecture of the PAIRUDIS module (data flow diagram) . . . . . 915.20 Disambiguation algorithm for PP attachment and interpretation . . 93
6.4 Coreference rules for personal pronouns . . . . . . . . . . . . . . . . 1216.5 Coreference rules between nouns . . . . . . . . . . . . . . . . . . . . 1226.6 Coreference rules for pronouns other than personal pronouns . . . . 1236.7 Coreference rules for determiners . . . . . . . . . . . . . . . . . . . . 1246.8 Coreference rules for special cases . . . . . . . . . . . . . . . . . . . . 1256.9 Coreference annotations in SGML format for sentence (33) . . . . . 1266.10 Keys for corpus text 19990201polit f as stored in the coreference keys
file . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1276.11 Keys for corpus text 19990201polit f in graphical form . . . . . . . . 1286.13 Bell numbers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1366.14 Coreference resolution algorithm . . . . . . . . . . . . . . . . . . . . 1376.15 Architecture of the CORUDIS module (data flow diagram) . . . . . 1396.16 Molecule and nonmolecule relevant to example (78) . . . . . . . . . . 1426.17 Molecule and nonmolecule relevant to example (79) . . . . . . . . . . 1446.20 Coreference distances in the corpus measured in markables . . . . . 1506.21 Coreference distances in the corpus measured in sentences . . . . . . 1516.22 Coreference distances in the corpus measured in paragraphs . . . . . 152

List of Tables
2.5 Description of semantic relations important in this work . . . . . . . 122.7 Semantic Boolean features in the lexicon . . . . . . . . . . . . . . . . 142.12 Entity types in the lexicon (part 1/2) . . . . . . . . . . . . . . . . . 192.13 Entity types in the lexicon (part 2/2) . . . . . . . . . . . . . . . . . 202.22 Important features in the lexicon . . . . . . . . . . . . . . . . . . . . 29
3.2 Word class functions in the WOCADI parser . . . . . . . . . . . . . 383.6 Analysis process of sentence (2) on level 1 . . . . . . . . . . . . . . . 43
5.14 Problem cases for the PP disambiguation module . . . . . . . . . . . 855.15 Attachment data from the evaluation corpus . . . . . . . . . . . . . 865.16 Attachment-interpretation matrix for sentence (24) (after step 1) . . 905.17 Attachment-interpretation matrix for sentence (24) (after step 2) . . 905.18 Attachment-interpretation matrix for sentence (24) (after step 3) . . 905.21 Results of PP interpretation rules for (correct) mothers . . . . . . . 945.22 Statistical data for PP interpretation (aus) . . . . . . . . . . . . . . 975.23 Statistical data for PP attachment (aus) . . . . . . . . . . . . . . . . 1015.24 Results of hybrid PP disambiguation for individual prepositions . . . 1065.25 Results of hybrid PP disambiguation for all evaluated prepositions . 106
6.1 Features in coreference rules . . . . . . . . . . . . . . . . . . . . . . . 1176.2 Predicates in coreference rules (part 1/2) . . . . . . . . . . . . . . . 1196.3 Predicates in coreference rules (part 2/2) . . . . . . . . . . . . . . . 1206.12 Characteristics of the annotated texts . . . . . . . . . . . . . . . . . 1296.18 Results for markable identification . . . . . . . . . . . . . . . . . . . 1456.19 Number of antecedent candidates per identified markable . . . . . . 1456.23 Statistical data for coreference . . . . . . . . . . . . . . . . . . . . . 1566.24 Coreference resolution results . . . . . . . . . . . . . . . . . . . . . . 158
7.1 Word sense ambiguities for mothers and alternative mothers of PPs 1677.2 Word sense ambiguities for sister NPs of prepositions . . . . . . . . . 1687.3 Word sense disambiguation results of PAIRUDIS/WSD for mother
constituents of prepositional phrases . . . . . . . . . . . . . . . . . . 1697.4 Word sense disambiguation results of PAIRUDIS/WSD for sister
consituents of prepositions . . . . . . . . . . . . . . . . . . . . . . . . 170

xiv List of Tables
7.5 Improvements of hybrid PP disambiguation by word sense disam-biguation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 170
7.6 Error classes for PP disambiguation and word sense disambiguation 1717.7 Solution classes for word sense disambiguation . . . . . . . . . . . . 172

Abstract
This PhD thesis proposes, formalizes, and evaluates a new hybrid disambigua-tion method for ambiguity problems in natural language processing (NLP): rule-centered multidimensional back-off. The first eight chapters are summarized inthe following eight paragraphs in turn.
As an introduction, the context and the embedding of the work are described.Three main theses are formulated and the work is motivated.
A general classification of ambiguities is given and the concept of hybridiza-tion is introduced. The most important parts of the embedding of the thesisare described: the employed semantic representation formalism (MultiNet), theWOCADI parser applied for the disambiguation modules, the knowledge sourcesrequired by the parser (corpora and lexica), and the tools for lexical knowledge.Basic concepts of evaluation techniques are explained because the disambigua-tion method is thoroughly evaluated for three paradigmatic ambiguity problemsin NLP using annotated corpora of German newspaper articles.
The WOCADI parser is described in more detail because it is required — todifferent extents (phrase or sentence parsing) — for the disambiguation modules.Its architecture, some principles, and example results are presented.
Before approaches for specific disambiguation problems are developed, the gen-eral approach is introduced. The solution is hybrid and combines interpretationrules expressing valuable linguistic knowledge and statistics on top of the ap-plicability of these rules for annotated corpora. For the statistical part, a newstatistical model is defined: multidimensional back-off models that extend theconcept of traditional back-off models considerably.
The three ambiguity problems, whose treatment together with the general dis-ambiguation approach is the scientific center of the thesis, are prominent examplesthat span a whole range of disambiguation problems. First, the problem of prepo-sitional phrase attachment and interpretation (a structural ambiguity) is tackledwith an instantiation of the general disambiguation approach and the additionof bonus factors from syntax and semantics. The resulting PAIRUDIS system isevaluated on a corpus.
Second, the problem of coreference resolution (a referential ambiguity) is de-scribed and a hybrid solution with rules and disambiguation statistics, the CO-RUDIS system, is proposed and evaluated. The evaluation includes additionalbonus factors like syntactic or semantic parallelism of constituents.
Third, the problem of word sense disambiguation (WSD; a lexical ambiguity)is treated for a subproblem, namely WSD for words in prepositional phrase con-

xvi Abstract
texts. The resulting system is evaluated and the improvements achieved for thePAIRUDIS system are determined.
Finally, further ambiguity problems in NLP are briefly introduced. For themajority of them, a hybrid solution with a rule-centered multidimensional back-off model is sketched.
Keywords: computational linguistics, natural language understanding, rule-centered multidimensional back-off, prepositional phrase disambiguation, corefer-ence resolution, word sense disambiguation.

Preface
I would like to thank many people who helped me finish my PhD thesis and finishit the way it went. My doctoral advisor Prof. Dr. Hermann Helbig was alwaysopen to discuss the ambiguity problems described in this work. He fostered mywriting of this thesis with open-minded and intense discussions about a great va-riety of neighboring areas like knowledge representation (especially his paradigmof Multilayered Extended Semantic Networks — MultiNet), parsing, natural lan-guage processing applications, etc. I am also grateful to my second referee, Prof.Dr. Istvan Batori, for his insightful comments. He always tried to open my eyesfor longer perspectives and wider interconnections in the fields of natural languageprocessing and linguistics.
My colleagues from the chair of Applied Computer Science VII at the Uni-versity of Hagen (Praktische Informatik VII, FernUniversitat Hagen) helped mewith fruitful discussions and cooperations: Andreas Mertens, Rainer Osswald,and Marion Schulz, in the areas of computational linguistics; Carsten Gnorlichand Johannes Leveling in the areas of natural language interfaces and knowledgerepresentation. Rainer Osswald also gave me thorough feedback on several earlierversions of this thesis.
Furthermore, I want to thank all the student workers who contributed help-ful linguistic resources, programs, and comments: Dieter Staudt, Markus Greif,Sara Hakemi, Johannes Maeso, Steffen Marthen, Robert Standera, and ThorstenTollner. Monika Kleinen and Christoph Doppelbauer helped in technical andnontechnical organization issues.
Ingo Glockner provided very useful comments starting with the cooperativeresearch project Virtual Knowledge Factory (Virtuelle Wissensfabrik), a projectof the German federal state of Nordrhein-Westfalen.
I would also like to mention the organizers and participants of RANLP-97 inTzigov Chark, Bulgaria, because this conference encouraged me to put even moreemphasis on practical systems that are built from corpus data and rigidly evaluatedon corpora containing real-world texts. This seems central to me if one wants tofollow the language engineering approach to computational linguistics.
Manuel Serrano, the author of the Bigloo Scheme compiler, and Felix Winkel-mann, the author of the Chicken Scheme compiler, helped me to make the WO-CADI parser used in this thesis practical, robust, and efficient. They alwaysreacted very kindly to my sometimes presumptuous requests with improvementsuggestions, compiler extensions, or compiler bug fixes.

xviii Preface
My parents facilitated my way to university with a happy and protected child-hood. I am very grateful for that.
The person who suffered most during thesis preparation was certainly my wifeTanja. I would like to thank her for loving and patient support. She made my lifeso much different throughout the years we share. Finally, I want to mention ourson Nicolas who joined the dissertation effort during the first months of his lifeand is now looking forward to see his father more often.
Sven HartrumpfHagen, Germany
June 2002

Chapter 1
Introduction
1.1 Motivation and Theses
The main motivation for this PhD thesis is the fact that ambiguity is omnipresentin natural language processing (NLP). Most cases of ambiguity are not recognizedby native speakers but are only due to the current insufficient state of methodsin computational linguistics that are far from reaching the wonderful abilities ofpeople to speak and understand with ease and virtuosity.
This work maintains three main theses.
Thesis A The seamless integration, not a mere juxtaposition, of a linguistic rule-based component and a statistical component that relies on knowledge ex-tracted from text corpora can improve disambiguation results significantlycompared to purely rule-based or purely statistical approaches.
Thesis B The new statistical model in this thesis, the multidimensional back-offmodel, suits a hybrid approach as described in Thesis A very well.
Thesis C The hybrid approach with rules and multidimensional back-off mod-els (rule-centered multidimensional back-off) is general enough to besuccessfully applied for ambiguity problems from many diverse areas in NLP.
These claims are supported by theoretical arguments and empirical evaluationsfor three prototypical disambiguation problems spanning a whole range of disam-biguation problems: prepositional phrase attachment and interpretation, corefer-ence resolution, and finally word sense disambiguation. The empirical evaluationsare enabled by the complete implementation of all three disambiguation mod-ules and the implementation of a semantically oriented parser for the Germanlanguage.
Why hybrid disambiguation? Because hybridity protects against the hybristhat a pure traditional rule system or a pure statistic approach can achieve thebest results for natural language understanding (NLU). Hybridization is a pop-ular methodology in many sciences. The influential book The Balancing Act –Combining Symbolic and Statistical Approaches to Language edited by Klavansand Resnik (1996) summarizes a first state of the art for hybridization in compu-tational linguistics.

2 Introduction
Statistical approaches often do not rely on linguistic data like syntax and se-mantics. So one can build large-scale (wide coverage) systems efficiently and portsystems from one domain to another without starting from scratch. But duringrecent years deep linguistic knowledge bases like lexica with semantic informationhave grown to interesting sizes so that it is promising not to throw these awaybut to throw these in the arena of statistics. Adding statistics in effective ways tomore traditional rule systems involving linguistic ambiguities is the overall themeof this work.
The hybridization aimed at is a thorough integration and fusion of rules andstatistics where each profits from the advantages of the other and each compen-sates for the disadvantages of the other as far as possible. Just putting two differentsystems side by side and letting an arbiter combine the decisions of the two is notconsidered enough for a considerable improvement in the area of automatic dis-ambiguation. The hybrid disambiguation modules developed in this thesis shouldoutperform purely rule-based methods and purely statistical methods.
Sometimes it is a helpful introduction to say what one should not expect fromreading a piece of scientific literature. Here is such a hint. It is neither a complexnew statistical paradigm, nor stepping beyond established grammar paradigms likeHead-Driven Phrase Structure Grammar (HPSG) or Lexical Functional Grammar(LFG).
Nevertheless, there are several important points one can expect from this work:a powerful new combination of valuable linguistic knowledge and statistics thatimproves on its components. Its application for diverse important problems ofNLU is promising. Its strengths and weaknesses are extensively empirically eval-uated proving successes and identifying directions for further research.
1.2 State of the Art
Most theses should first review the state of the art in the relevant area of re-search. As I cover three quite diverse areas, I decided to let the state of the artreviews mainly stay in their corresponding chapters. So, this section is just a cross-reference to three sections: for prepositional phrase disambiguation see section 5.8,for coreference resolution see section 6.9, and for word sense disambiguation seesection 7.6.
Here is only a short overview. The first approaches to disambiguation are mainlyrule-based. Later approaches rely on learning: supervised learning achieves thebest results but requires annotated corpora; in recent years, unsupervised learningbecame more popular because it does away with labor-intensive manual annota-tion. The performance of unsupervised methods comes close to the performanceof supervised methods, but there remains a significant advantage of supervisedmethods for most disambiguation problems in NLP. A thorough and rich intro-duction into learning approaches and statistical NLP is given by Manning andSchutze (1999).
Besides this trend from rule-based system to statistical systems, a separatetrend appears to be hybridization: the combination of different approaches inorder to increase the system performance (correctness, recall, precision, etc.) on

1.3. Chapter Overview 3
NLP tasks. An overview of some hybrid systems in NLP is provided by Klavansand Resnik (1996)
For two of the three disambiguation problems discussed in detail in this thesis,there exist special issues of the journal Computational Linguistics. Number 4of volume 27 is devoted to computational anaphora resolution, and number 1 ofvolume 24 covers word sense disambiguation.
1.3 Chapter Overview
In this first chapter, the topic of this PhD thesis is motivated and the mainindividual theses are described. The context and embedding of the thesis at theChair of Applied Computer Science VII at the University of Hagen is characterized.Typographical and notational conventions are explained.
The following chapter provides foundations for many areas vital in subsequentchapters: types of ambiguity in natural language, the knowledge representationlanguage used throughout this work, parsing technology, main knowledge sourceslike annotated corpora and lexica, and methods and computational tools.
Chapter 3 presents the WOCADI parser which is applied — to different extent— for integrating and evaluating the disambiguation modules PAIRUDIS (Prepo-sitional phrase Attachment and Interpretation with RUles and DIsambiguationStatistics, CORUDIS (COreference RUles with DIsambiguation Statistics), andPAIRUDIS with WSD (Word Sense Disambiguation) described in chapters 5 to 7.The four chapters 4 to 7 form the scientific center and the main contribution ofthis work.
The statistical model adapted in all disambiguation modules, the multidimen-sional back-off model, is introduced in its general form in chapter 4.
Then, three paradigmatic ambiguity problems are treated with a hybrid disam-biguation module: prepositional phrase attachment and interpretation (chapter 5),coreference resolution (chapter 6), and word sense disambiguation (chapter 7).Each of these three chapters contains an introduction, description of the detailsand specializations of each disambiguation method, an evaluation, related work,and conclusions.
Chapter 8 describes many other prominent ambiguity problems and indicateshow they can be tackled by the hybrid method exemplified before.
The last chapter contains a summary, a description of the scientific contributionsin the thesis, and perspectives for future work.
The back matter of this thesis consists of the bibliography and the index con-taining subjects, citations, and acronyms.
1.4 Context and Embedding of the Thesis
The disambiguation modules I developed for this thesis and the parser I imple-mented and improved during thesis preparation should not be seen in isolation.They all build on many other components like formalisms, linguistic resources,or programs that were authored by colleagues at the chair of Applied Computer
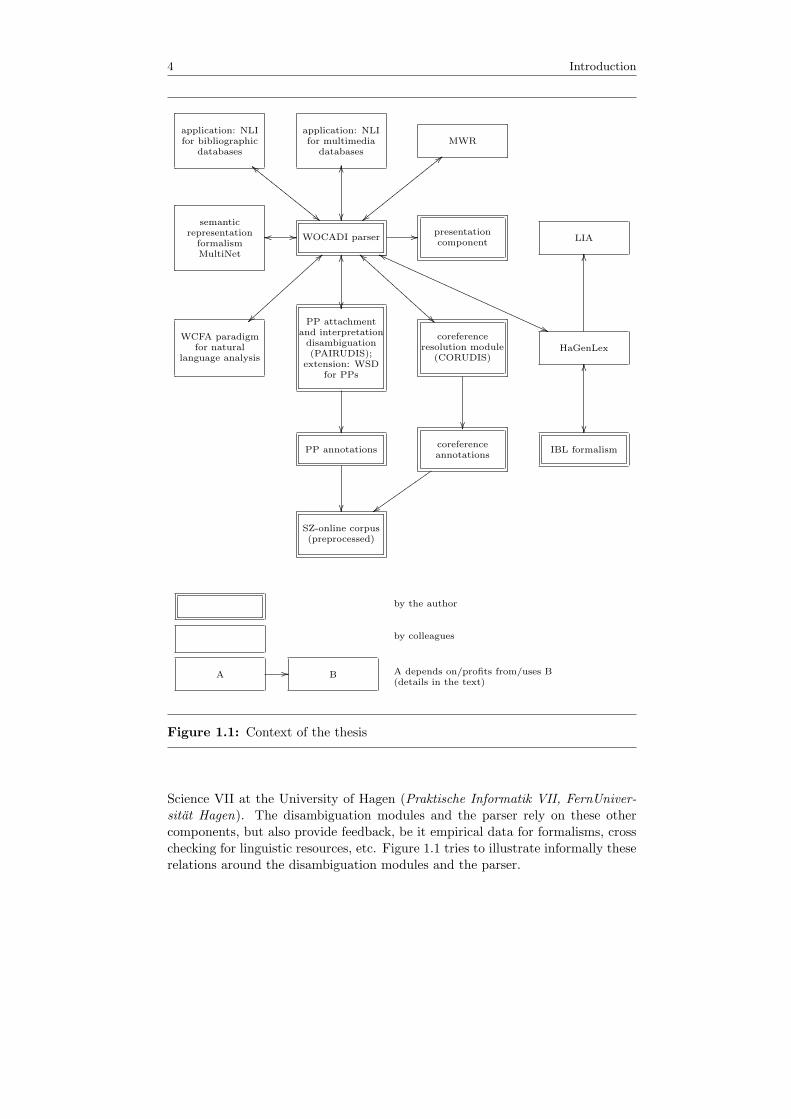
4 Introduction
application: NLIfor bibliographic
databases
application: NLIfor multimedia
databasesMWR
semanticrepresentation
formalismMultiNet
WOCADI parser//oo //""
bbEEEEEEEEEEEEEE ��
OO
||
<<yyyyyyyyyyyyyyyy
>>
~~||||||||||||||| OO
��
aa
!!BBBBBBBBBBBBBBBB hh
((QQQQQQQQQQQQQQQQQQQQQQQQQQQQ
presentationcomponent LIA
WCFA paradigmfor natural
language analysis
PP attachmentand interpretationdisambiguation(PAIRUDIS);
extension: WSDfor PPs
��
coreferenceresolution module
(CORUDIS)
��
HaGenLex
OO
��
OO
PP annotations
��
coreferenceannotations
zzuuuuuuuuuuu
IBL formalism
SZ-online corpus(preprocessed)
by the author
by colleagues
A // B A depends on/profits from/uses B(details in the text)
Figure 1.1: Context of the thesis
Science VII at the University of Hagen (Praktische Informatik VII, FernUniver-sitat Hagen). The disambiguation modules and the parser rely on these othercomponents, but also provide feedback, be it empirical data for formalisms, crosschecking for linguistic resources, etc. Figure 1.1 tries to illustrate informally theserelations around the disambiguation modules and the parser.

1.4. Context and Embedding of the Thesis 5
Some of the main dependency or usage relations from or to the complex ofparser plus disambiguation modules can be elaborated as follows:
1. Semantic representation formalism MultiNet (Hermann Helbig, see also sec-tion 2.2). The WOCADI parser and the disambiguation modules adoptedthis formalism as the common language for semantic representations. In re-turn, the application of MultiNet in these programs provides feedback aboutthe practical implications of the massive and pervasive use of MultiNet.
2. Word Class Function Analysis (WCFA) paradigm (Hermann Helbig, seealso chapter 3). The paradigm of WCFA (Helbig, 1986, 1994) and a firstimplementation for the German language provided a solid ground and manybuilding blocks for my further development of WCFA and a new implemen-tation with substantial extensions, the WOCADI parser. The extensionsin WOCADI and the empirical results from millions of different parses hasproduced ideas for refinements of WCFA.
3. HaGenLex (concept: Marion Schulz, Sven Hartrumpf; entries: many col-leagues and student workers; see also section 2.4.2). This lexicon with itsrich syntactic and semantic content is vital for the parser (and indirectly forthe disambiguation modules too). As feedback, the parser is applied to spoterrors in the lexicon, e.g. by trying to parse the example sentences of lexi-cal entries, by parse success rate comparisons, etc. There are also projectsthat put this idea one step further to a bootstrap approach. Staudt (2002)develops a tool that learns noun semantics for unknown words by using WO-CADI’s parse results. The learned semantic refinements for entries can thenbe used to improve parse results and the whole process can start again.
4. IBL formalism (section 2.4.2). This lexicon formalism is applied for Ha-GenLex. This lexicon is the first large-scale application of IBL and helpedidentify strengths and deficiencies of IBL and its implementation.
5. LIA (Rainer Osswald, Marion Schulz; see section 2.5.2). The workbench forlexicographers LIA increases the speed and quality of entering and main-taining lexemes in HaGenLex.
6. MWR (Carsten Gnorlich, see section 2.5.2). This editor with a graphicaluser interface allows to enter, modify, view, combine, etc. semantic networks.Some of MWR’s operations are helpful for investigating WOCADI results,whose semantic part is a semantic network of the MultiNet formalism (amulti-net). In the opposite dependency relation, MWR provides a directlink to the parser so that instead of manually entering networks one cantype a corresponding sentence and MWR receives the semantic networkrepresentation for the sentence from WOCADI.
7. Presentation component for parse results. The parser uses this componentto visualize its results for humans. So, these results can be checked, furtherevaluated, etc.

6 Introduction
8. Application: NLI (natural language interface) for databases (Johannes Lev-eling: an NLI for bibliographic databases on the Internet; Carsten Gnor-lich: an NLI for SQL databases containing bibliographic information; ErnstHoffmann: an NLI for SQL databases containing product information; seesection 3.11). The parser development profited from the ongoing use of itsresults in these natural language interfaces. Modifications of multi-nets de-livered as parse results were triggered by this feedback. The applications ofcourse critically rely on WOCADI’s parse results.
9. Application: NLI for multimedia databases (see section 3.11). The twodependencies mentioned in item 8 also apply here.
To sum up, the close and deep semantic interaction of systems, tools, andformalisms characterized above is a big advantage for the disambiguation methodsdescribed in this thesis.
1.5 Typographical and Notational Conventions
Throughout this work, different kinds of content has been marked up differently.So, these different kinds of content are rendered in a consistent way to ease reading.First, the language related conventions are explained, then the more technicallyoriented conventions.
Natural language expressions that are cited or discussed appear in italics, e.g.the preposition in is highly ambiguous. Names of concepts underlying naturallanguage expressions (or IDs of word readings or senses) appear sans serif, e.g.the concepts for two readings of the English noun field : field.1.1 and field.1.2.Foreign language expression like a priori and sans serif in the preceding sentenceare also set in italics. Important terms are in bold face on their first occurrencelike lexical ambiguity in section 2.1. Mathematical expressions, variables, etc. arerendered in italics: f , C, etc.
The conventions for technical material in this work are all related to featurestructures. Features like orth (orthography) or the feature path syn cat (syn-tactic category) are in small capitals, (feature) values (or types) like acc (thesyntactic case accusative) appear in italics, which are used for several things butthe context should clarify what the marked up material refers to.
As the object language of most linguistic examples in this thesis is German andnot English there is a need for glosses. Each gloss starts with the original sentencein German, followed by a word-to-word translation into English (or a so-calledinterlinear translation), and ends with an English translation (omitted if identicalto the word-to-word translation). This is illustrated by example (1) in section 2.3.Linguistic examples are numbered with a natural number in parentheses as in thesentence before, while equations are numbered with the chapter number and arunning number in parentheses like equation (2.1) in section 2.5.3.

Bibliography
Abney, Steven (1996). Statistical methods and linguistics. In Klavans and Resnik(1996), pp. 1–26.
Aone, Chinatsu and Scott William Bennett (1996). Applying machine learning toanaphora resolution. In Wermter et al. (1996), pp. 302–314.
Apresjan, Jurij (1974). Regular polysemy. Linguistics, 142:5–32.
Baayen, R. Harald, Richard Piepenbrock, and Leon Gulikers (1995). The CELEXLexical Database. Release 2 (CD-ROM). Linguistic Data Consortium, Univer-sity of Pennsylvania, Philadelphia, Pennsylvania.
Baldwin, Breck (1997). CogNIAC: High precision coreference with limited knowl-edge and linguistic resources. In Proceedings of the ACL-EACL’97 Workshop onOperational Factors in Practical, Robust Anaphora Resolution for UnrestrictedTexts, pp. 38–45. Madrid, Spain.
Barker, Ken, Terry Copeck, Sylvain Delisle, and Stan Szpakowicz (1997). Sys-tematic construction of a versatile case system. Natural Language Engineering,3(4):279–315.
Basili, Roberto, Marie-Helene Candito, Maria Teresa Pazienza, and Paola Velardi(1997). Evaluating the information gain of probability-based PP-disambiguationmethods. In Jones and Somers (1997), pp. 241–255.
Batori, Istvan (1969). Disambiguating verbs with multiple meaning in the MT-system of IBM Germany. In Proceedings of the 3rd International Conferenceon Computational Linguistics (COLING 69). Sanga-Saby, Sweden. URL http://www.nodali.sics.se/bibliotek/kval/coling69/.
Bell, Eric T. (1934). Exponential numbers. American Mathematical Monthly,41:411–419.
Berger, Adam L., Stephen A. Della Pietra, and Vincent J. Della Pietra (1996).A maximum entropy approach to natural language processing. ComputationalLinguistics, 22(1):39–71.
Bierwisch, Manfred (1983). Semantische und konzeptuelle Reprasentationlexikalischer Einheiten. In Untersuchungen zur Semantik (edited by RudolfRuzicka and Wolfgang Motsch), Studia grammatica XXII, pp. 61–99. Akademie-Verlag, Berlin.

186 Bibliography
Brachman, Ronald J. (1978). Structured inheritance networks. Technical ReportNo. 3742, Bolt Beranek & Newman, Cambridge, Massachusetts.
Brachman, Ronald J. and J. G. Schmolze (1985). An overview of the KL-ONEknowledge representation system. Cognitive Science, 9(2):171–216.
Brill, Eric and Philip Resnik (1994). A rule-based approach to prepositional phraseattachment disambiguation. In Proceedings of the 15th International Conferenceon Computational Linguistics (COLING 94), pp. 1198–1204.
Broker, Norbert, Udo Hahn, and Susanne Schacht (1994). Concurrent lexicalizeddependency parsing: The ParseTalk model. In Proceedings of the 15th Interna-tional Conference on Computational Linguistics (COLING 94), pp. 379–385.
Broker, Norbert, Michael Strube, Susanne Schacht, and Udo Hahn (1997). Coarse-grained parallelism in natural language understanding: Parsing as message pass-ing. In Jones and Somers (1997), pp. 301–317.
Buitelaar, Paul (1998). CoreLex: Systematic Polysemy and Underspecification.Ph.D. thesis, Brandeis University, Waltham, Massachusetts.
Byron, Donna K. (2001). The uncommon denominator: A proposal for consistentreporting of pronoun resolution results. Computational Linguistics, 27(4):569–577.
Cardie, Claire and Kiri Wagstaff (1999). Noun phrase coreference as cluster-ing. In Proceedings of the Joint Conference on Empirical Methods in NaturalLanguage Processing and Very Large Corpora (EMNLP/VLC-99), pp. 82–89.College Park, Maryland.
Carpenter, Bob (1992). The Logic of Typed Feature Structures. Cambridge Tractsin Theoretical Computer Science. Cambridge University Press, New York.
Clark, Herbert H. (1977). Bridging. In Thinking: Readings in Cognitive Sci-ence (edited by Philip N. Johnson-Laird and Peter C. Wason), pp. 411–420.Cambridge University Press, Cambridge, England.
Collins, Michael and James Brooks (1995). Prepositional phrase attachmentthrough a backed-off model. In Proceedings of the 3rd Workshop on VeryLarge Corpora (WVLC-3), pp. 27–38. Cambridge, Massachusetts. URL http://xxx.lanl.gov/abs/cmp-lg/9506021.
Connolly, Dennis, John D. Burger, and David S. Day (1994). A machine learningapproach to anaphoric reference. In Proceedings of the International Conferenceon New Methods in Language Processing (NeMLaP), pp. 255–261. Manchester,England.
Crain, Stephen and Mark Steedman (1985). On not being led up the garden path:the use of context by the psychological syntax processor. In Dowty et al. (1985),pp. 320–358.

Bibliography 187
Daelemans, Walter, Jakub Zavrel, Ko van der Sloot, and Antal van den Bosch(2002). TiMBL: Tilburg memory based learner, version 4.2, reference guide.Technical Report 02-01, ILK. URL http://ilk.kub.nl/downloads/pub/papers/.
Dagan, Ido and Alon Itai (1990). Automatic processing of large corpora for theresolution of anaphora references. In Proceedings of the 13th International Con-ference on Computational Linguistics (COLING 90), volume 3, pp. 330–332.Helsinki, Finland.
Davidson, Donald and Gilbert H. Harman (editors) (1972). Semantics of NaturalLanguage. D. Reidel, Dordrecht, The Netherlands.
Davies, Sarah and Massimo Poesio (1998). MATE deliverable D1.1 supportedcoding schemes - coding schemes for co-reference. Technical report, MATE.URL http://www.dfki.de/mate/d11/.
Day, David, John Aberdeen, Lynette Hirschman, Robyn Kozierok, Patricia Robin-son, and Marc Vilain (1997). Mixed-initiative development of language process-ing systems. In Proceedings of the 5th Conference on Applied Natural LanguageProcessing (ANLP-97). Washington D.C., USA.
Diab, Mona and Philip Resnik (2002). An unsupervised method for word sensetagging using parallel corpora. In Proceedings of the 40th Annual Meeting of theAssociation for Computational Linguistics (ACL-2002), pp. 255–262. Philadel-phia.
Dowty, David R., Lauri Karttunen, and Arnold M. Zwicky (editors) (1985). Natu-ral Language Parsing: Psychological, Computational, and Theoretical Perspec-tives. Cambridge University Press, Cambridge, England.
Eimermacher, Michael (1988). Wortorientiertes Parsen. Ph.D. thesis, TU Berlin,Berlin.
Erku, Feride and Jeanette Gundel (1987). The pragmatics of indirect anaphors.In The Pragmatic Perspective: Selected Papers from the 1985 InternationalPragmatics Conference (edited by Jef Verschueren and Marcella Bertuccelli-Papi), pp. 533–545. John Benjamins, Amsterdam, The Netherlands.
Franz, Alexander (1996a). Automatic Ambiguity Resolution in Natural LanguageProcessing, volume 1171 of LNAI. Springer, Berlin.
Franz, Alexander (1996b). Learning PP attachment from corpus statistics. InWermter et al. (1996), pp. 188–202.
Fujii, Atsushi, Kentaro Inui, Takenobu Tokunaga, and Hozumi Tanaka (1998). Se-lective sampling for example-based word sense disambiguation. ComputationalLinguistics, 24(4):573–597.
Gnorlich, Carsten (2002). Technologische Grundlagen der Wissensverwaltungfur die automatische Sprachverarbeitung. Ph.D. thesis, FernUniversitat Hagen,Fachbereich Informatik, Hagen, Germany.

188 Bibliography
Gomez, Fernando, Carlos Segami, and Richard Hull (1997). Determining prepo-sitional attachment, prepositional meaning, verb meaning, and thematic roles.Computational Intelligence, 13(1):1–31.
Grosz, Barbara J., Aaravind K. Joshi, and Scott Weinstein (1995). Centering:A framework for modeling the local coherence of discourse. ComputationalLinguistics, 21(2):203–225.
Haegeman, Liliane (1994). Introduction to Government and Binding Theory.Blackwell, Oxford, England, 2nd edition.
Hahn, Udo and Michael Strube (1996). ParseTalk about functional anaphora.In Proceedings of the 11th Biennial Conference of the Canadian Society forComputational Studies of Intelligence (edited by Gordon McCalla), volume 1081of LNAI, pp. 133–145. Springer, Berlin.
Harabagiu, Sanda M. and Steven J. Maiorano (2000). Multilingual coreference res-olution. In Proceedings of the Language Technology Joint Conference on AppliedNatural Language Processing and the North American Chapter of the Associ-ation for Computational Linguistics (ANLP-NAACL’2000). Seattle, Washing-ton.
Hart, Peter E., Nils J. Nilsson, and Bertram Raphael (1968). A formal basisfor the heuristic determination of minimum cost paths. IEEE Transactions onSystems Science and Cybernetics, 4(2):100–107.
Hartrumpf, Sven (1994). IBL: An inheritance-based lexicon formalism. AI-report1994-05, University of Georgia, Artificial Intelligence Center, Athens, Georgia.URL ftp://ai.uga.edu/pub/ai.reports/ai199405.ps.Z.
Hartrumpf, Sven (1996). Redundanzarme Lexika durch Vererbung. Master’s thesis,Universitat Koblenz-Landau, Koblenz, Germany.
Hartrumpf, Sven (1999). Hybrid disambiguation of prepositional phrase at-tachment and interpretation. In Proceedings of the Joint Conference onEmpirical Methods in Natural Language Processing and Very Large Corpora(EMNLP/VLC-99), pp. 111–120. College Park, Maryland. URL http://www.aclweb.org/anthology/W99-0614.
Hartrumpf, Sven (2000). Partial evaluation for efficient access to inheritance lex-icons. In Recent Advances in Natural Language Processing II: Selected Papersfrom RANLP’97 (edited by Nicolas Nicolov and Ruslan Mitkov), volume 189 ofCurrent Issues in Linguistic Theory, pp. 57–68. John Benjamins, Amsterdam,The Netherlands.
Hartrumpf, Sven (2001). Coreference resolution with syntactico-semantic rules andcorpus statistics. In Proceedings of the Fifth Computational Natural LanguageLearning Workshop (CoNLL-2001), pp. 137–144. Toulouse, France.
Hartrumpf, Sven and Hermann Helbig (2002). The generation and use of layerinformation in multilayered extended semantic networks. In Proceedings of the

Bibliography 189
5th International Conference on Text, Speech and Dialogue (TSD 2002) (editedby Petr Sojka, Ivan Kopecek, and Karel Pala), Lecture Notes in Artificial In-telligence LNCS/LNAI 2448, pp. 89–98. Brno, Czech Republic.
Hartrumpf, Sven, Hermann Helbig, and Rainer Osswald (2003). The semanticallybased computer lexicon HaGenLex – Structure and technological environment.Traitement automatique des langues, 44(2). In preparation.
Hartrumpf, Sven and Marion Schulz (1997). Reducing lexical redundancy byaugmenting conceptual knowledge. In Proceedings of the 21st Annual Ger-man Conference on Artificial Intelligence (KI-97) (edited by Gerhard Brewka,Christopher Habel, and Bernhard Nebel), number 1303 in Lecture Notes inComputer Science, pp. 393–396. Springer, Berlin.
Helbig, Hermann (1986). Syntactic-semantic analysis of natural language by a newword-class controlled functional analysis. Computers and Artificial Intelligence,5(1):53–59.
Helbig, Hermann (1994). Der Einsatz von Wortklassenagenten fur die automatis-che Sprachverarbeitung – Teil II – Die vier Verarbeitungsstufen. Informatik-Bericht 159, FernUniversitat Hagen, Hagen, Germany.
Helbig, Hermann (2001). Die semantische Struktur naturlicher Sprache: Wis-sensreprasentation mit MultiNet. Springer, Berlin.
Helbig, Hermann, Carsten Gnorlich, and Johannes Leveling (2000). Naturlich-sprachlicher Zugang zu Informationsanbietern im Internet und zu lokalen Daten-banken. In Sprachtechnologie fur eine dynamische Wirtschaft im Medienzeitalter(edited by Klaus-Dirk Schmitz), pp. 79–94. TermNet, Wien, Austria.
Helbig, Hermann and Sven Hartrumpf (1997). Word class functions for syntactic-semantic analysis. In Proceedings of the 2nd International Conference on RecentAdvances in Natural Language Processing (RANLP’97), pp. 312–317. TzigovChark, Bulgaria.
Helbig, Hermann, Andreas Mertens, and Marion Schulz (1994). Die Rolle desLexikons bei der Disambiguierung. In KONVENS-94 – Verarbeitung naturlicherSprache (edited by Harald Trost), pp. 151–160. Berlin.
Hemforth, Barbara (1993). Kognitives Parsing: Reprasentation und Verarbeitungsprachlichen Wissens, volume 40 of Dissertationen zur Kunstlichen Intelligenz(DISKI). Infix, Sankt Augustin, Germany.
Hindle, Donald and Mats Rooth (1993). Structural ambiguity and lexical relations.Computational Linguistics, 19(1):103–120.
Hirschman, Lynette and Nancy Chinchor (1997). MUC-7 coreference task defini-tion (version 3.0). In Proceedings of the 7th Message Understanding Conference(MUC-7). URL http://www.itl.nist.gov/iaui/894.02/related projects/muc/.

190 Bibliography
Hirschman, Lynette, Patricia Robinson, John Burger, and Marc Vilain (1998).Automating coreference: The role of annotated training data. In Proceedings ofthe AAAI Spring Symposium on Applying Machine Learning to Discourse Pro-cessing. Stanford, California. URL http://xxx.lanl.gov/abs/cmp-lg/9803001.
Hirst, Graeme (editor) (1987). Semantic Interpretation and the Resolution of Am-biguity. Studies in Natural Language Processing. Cambridge University Press,Cambridge, England.
Ide, Nancy, Greg Priest-Dorman, and Jean Veronis (1996). Corpus EncodingStandard. URL http://www.cs.vassar.edu/CES/.
Jones, Daniel and Harold Somers (editors) (1997). New Methods in LanguageProcessing. University College Press, London.
Kamp, Hans and Uwe Reyle (1993). From Discourse to Logic: Introduction toModeltheoretic Semantics of Natural Language, Formal Logic and DiscourseRepresentation Theory. Number 42 in Studies in Linguistics and Philosophy.Kluwer Academic Publishers, Dordrecht, The Netherlands.
Katz, Slava M. (1987). Estimation of probabilities from sparse data for the lan-guage model component of a speech recognizer. IEEE Transactions on Acous-tics, Speech and Signal Processing, 35(3):400–401.
Kehler, Andrew (1997). Probabilistic coreference in information extraction. InProceedings of the 2nd Conference on Empirical Methods in Natural LanguageProcessing (EMNLP-2), pp. 163–173. Brown University, Providence, Rhode Is-land.
Kelsey, Richard, William Clinger, and Jonathan Rees (1998). Revised5 reporton the algorithmic language Scheme. Higher-Order and Symbolic Computation,11(1):7–105.
Kennedy, Christopher and Branimir Boguarev (1996). Anaphora for everyone:Pronominal anaphora resolution without a parser. In Proceedings of the 16thInternational Conference on Computational Linguistics (COLING 96), pp. 113–118. Copenhagen, Denmark.
Kimball, John (1973). Seven principles of surface structure parsing in naturallanguage. Cognition, 2:15–47.
Klavans, Judith L. and Philip Resnik (editors) (1996). The Balancing Act: Com-bining Symbolic and Statistical Approaches to Language. Language, Speech, andCommunication. MIT Press, Cambridge, Massachusetts.
Knoll, Alois, Christian Altenschmidt, Joachim Biskup, Hans-Martin Bluthgen,Ingo Glockner, Sven Hartrumpf, Hermann Helbig, Christiane Henning, Yu-cel Karabulut, Reinhard Luling, Burkhard Monien, Tobias Noll, and NorbertSensen (1998a). An integrated approach to semantic evaluation and content-based retrieval of multimedia documents. In Proceedings of the 2nd EuropeanConference on Digital Libraries (ECDL’98) (edited by Christos Nikolaou and

Bibliography 191
Constantine Stephanidis), number 1513 in Lecture Notes in Computer Science,pp. 409–428. Springer, Berlin.
Knoll, Alois, Ingo Glockner, Hermann Helbig, and Sven Hartrumpf (1998b). Asystem for the content-based retrieval of textual and non-textual documentsusing a natural language interface. Informatik-Bericht 232, FernUniversitatHagen, Hagen, Germany. URL http://pi7.fernuni-hagen.de/papers/ib232.pdf.
Lappin, Shalom and Herbert Leass (1994). An algorithm for pronominal anaphoraresolution. Computational Linguistics, 20(4):535–561.
Leveling, Johannes and Hermann Helbig (2002). A robust natural language in-terface for access to bibliographic databases. In Proceedings of the 6th WorldMulticonference on Systemics, Cybernetics and Informatics (SCI 2002) (editedby Nagib Callaos, Maurice Margenstern, and Belkis Sanchez), volume XI, pp.133–138. International Institute of Informatics and Systemics (IIIS), Orlando,Florida.
Mann, William C. and Sandra A. Thompson (1988). Rhetorical structure theory:Toward a functional theory of text organization. Text, 8(3):243–281.
Manning, Christopher D. and Hinrich Schutze (1999). Foundations of StatisticalNatural Language Processing. MIT Press, Cambridge, Massachusetts.
Markert, Katja and Udo Hahn (1997). On the interaction of metonymies andanaphora. In Proceedings of the 15th International Joint Conference on Artifi-cial Intelligence (IJCAI-97) (edited by Martha Pollack), pp. 1010–1015. Nagoya,Japan.
Marthen, Steffen (2002). Untersuchungen zur Assimilation großerer Wissens-bestande aus textueller Information. Master’s thesis, FernUniversitat Hagen,Hagen, Germany.
McRoy, Susan W. (1992). Using multiple knowledge sources for word sense dis-crimination. Computational Linguistics, 18(1):1–30.
Mehl, Stephan, Hagen Langer, and Martin Volk (1998). Statistische Verfahren zurZuordnung von Prapositionalphrasen. In Proceedings of the 4th Conference onNatural Language Processing – KONVENS-98 (edited by Bernhard Schroder,Winfried Lenders, Wolfgang Hess, and Thomas Portele), number 1 in Com-puters, Linguistics, and Phonetics between Language and Speech, pp. 97–110.Peter Lang, Frankfurt, Germany.
Merlo, Paola, Matthew W. Crocker, and Cathy Berthouzoz (1997). Attaching mul-tiple prepositional phrases: Generalized backed-off estimation. In Proceedingsof the 2nd Conference on Empirical Methods in Natural Language Processing(EMNLP-2), pp. 149–155. Brown University, Providence, Rhode Island.
Minsky, Marvin (1975). A framework for representing knowledge. In The Psychol-ogy of Computer Vision (edited by Patrick H. Winston), pp. 211–277. McGraw-Hill, New York.

192 Bibliography
Mitkov, Ruslan (1995). An uncertainty reasoning approach for anaphora resolu-tion. In Proceedings of the Natural Language Processing Pacific Rim Symposium(NLPRS’95), pp. 149–154. Seoul, Korea.
Mitkov, Ruslan (1997). Two engines are better than one: Generating more powerand confidence in the search for the antecedent. In Recent Advances in Natu-ral Language Processing: Selected Papers from RANLP’95 (edited by RuslanMitkov and Nicolas Nicolov), pp. 225–234. John Benjamins, Amsterdam, TheNetherlands.
Mitkov, Ruslan (1998a). Evaluating anaphora resolution approaches. In Proceed-ings of the Second Colloquium on Discourse Anaphora and Anaphor Resolution(DAARC 2), pp. 164–177. Lancaster, England.
Mitkov, Ruslan (1998b). Robust pronoun resolution with limited knowledge. InProceedings of the 17th International Conference on Computational Linguis-tics and 36th Annual Meeting of the Association for Computational Linguistics(COLING-ACL’98), pp. 869–875. Montreal, Canada.
Mitkov, Ruslan (1999a). Anaphora resolution: The state of the art. Workingpaper, University of Wolverhampton, Wolverhampton, England.
Mitkov, Ruslan (1999b). Multilingual anaphora resolution. Machine Translation,14:281–299.
Mitkov, Ruslan (2001). Outstanding issues in anaphora resolution. In Proceedingsof the 2nd International Conference on Computational Linguistics and Intelli-gent Text Processing (CICLing 2001) (edited by Alexander Gelbukh), number2004 in Lecture Notes in Computer Science, pp. 110–125. Springer, Berlin.
MUC-7 (1998). Proceedings of the 7th Message Understanding Conference (MUC-7). Morgan Kaufmann, San Francisco, California. URL http://www.itl.nist.gov/iaui/894.02/related projects/muc/.
Osswald, Rainer (2002). A Logic of Classification – with Applications to LinguisticTheory. Ph.D. thesis, FernUniversitat Hagen, Fachbereich Informatik, Hagen,Germany.
Palomar, Manuel, Antonio Ferrandez, Lidia Moreno, Patricio Martınez-Barco,Jesus Peral, Maximiliano Saiz-Noeda, and Rafael Munoz (2001). An algorithmfor anaphora resolution in Spanish texts. Computational Linguistics, 27(4):545–567.
Pantel, Patrick and Dekang Lin (2000). An unsupervised approach to prepositionalphrase attachment using contextually similar words. In Proceedings of the 38thAnnual Meeting of the Association for Computational Linguistics (ACL-2000),pp. 101–108. Hong Kong.
Partee, Barbara H. (1972). Opacity, coreference, and pronouns. In Davidson andHarman (1972), pp. 415–441.

Bibliography 193
Poesio, Massimo (1996). Semantic ambiguity and perceived ambiguity. In Seman-tic Ambiguity and Underspecification (edited by Kees van Deemter and StanleyPeters), number 55 in CSLI Lecture Notes, pp. 159–201. Center for the Studyof Language and Information, Stanford, California.
Poesio, Massimo (2000). The GNOME annotation scheme manual. Technicalreport. URL http://www.hcrc.ed.ac.uk/∼gnome/document.html.
Poesio, Massimo, Florence Bruneseaux, and Laurent Romary (1999). The MATEmeta-scheme for coreference in dialogues in multiple languages. In Proceedings ofthe ACL’99 Workshop on Standards for Discourse Tagging, pp. 65–74. CollegePark, Maryland.
Poesio, Massimo and Renata Vieira (1998). A corpus-based investigation of defi-nite description use. Computational Linguistics, 24(2):183–216.
Pollard, Carl and Ivan A. Sag (1994). Head-Driven Phrase Structure Grammar.Studies in Contemporary Linguistics. University of Chicago Press, Chicago,Illinois.
Pustejovsky, James (1995). The Generative Lexicon. MIT Press, Cambridge,Massachusetts.
Quillian, M. Ross (1968). Semantic memory. In Semantic Information Process-ing (edited by Marvin Minsky), pp. 227–270. MIT Press, Cambridge, Mas-sachusetts.
Ratnaparkhi, Adwait (1998). Statistical models for unsupervised prepositionalphrase attachment. In Proceedings of the 17th International Conferenceon Computational Linguistics and 36th Annual Meeting of the Associationfor Computational Linguistics (COLING-ACL’98), pp. 1079–1085. Montreal,Canada. URL http://xxx.lanl.gov/abs/cmp-lg/9807011.
Ratnaparkhi, Adwait, Jeff Reynar, and Salim Roukos (1994). A maximum entropymodel for prepositional phrase attachment. In Proceedings of the ARPA HumanLanguage Technology Workshop, pp. 250–255.
Reiners, Ludwig (1963). Stilfibel. Deutscher Taschenbuch Verlag, Munchen, Ger-many.
Rosenfeld, Ronald and Xuedong Huang (1992). Improvements in stochastic lan-guage modeling. In Proceedings of the DARPA Speech and Natural LanguageWorkshop, pp. 107–111. Morgan Kaufmann.
Samuelsson, Christer (1996). Handling sparse data by successive abstraction. InProceedings of the 16th International Conference on Computational Linguistics(COLING 96), pp. 895–900. Copenhagen, Denmark.
Schulz, Marion (1998). Eine Werkbank zur interaktiven Erstellung semantik-basierter Computerlexika. Ph.D. thesis, FernUniversitat Hagen, FachbereichInformatik, Hagen, Germany.

194 Bibliography
Schulz, Marion and Hermann Helbig (1996). COLEX: Ein Computerlexikon furdie automatische Sprachverarbeitung. Informatik-Bericht 210, FernUniversitatHagen, Hagen, Germany.
Small, Steven (1981). Viewing word expert parsing as linguistic theory. In Proceed-ings of the 7th International Joint Conference on Artificial Intelligence (IJCAI-81), pp. 70–76.
Small, Steven (1987). A distributed word-based approach to parsing. In NaturalLanguage Parsing Systems (edited by Leonard Bolc), pp. 161–201. Springer,Berlin.
Small, Steven and Chuck Rieger (1982). Parsing and comprehending with wordexperts (a theory and its realization). In Strategies for Natural Language Pro-cessing (edited by Wendy Lehnert and Martin Ringle), pp. 89–147. Erlbaum,Hillsdale, New Jersey.
Soon, Wee Meng, Hwee Tou Ng, and Chung Yong Lim (1999). Corpus-basedlearning for noun-phrase coreference resolution. In Proceedings of the JointConference on Empirical Methods in Natural Language Processing and VeryLarge Corpora (EMNLP/VLC-99), pp. 285–291. College Park, Maryland.
Soon, Wee Meng, Hwee Tou Ng, and Daniel Chung Yong Lim (2001). A machinelearning approach to coreference resolution of noun phrases. ComputationalLinguistics, 27(4):521–544.
Staudt, Dieter (2002). Automatische Akquisition lexikalisch-semantischer Infor-mationen aus Textkorpora: Eine Untersuchung zur Kategorie der Nomina. Mag-isterarbeit, Ruhr-Universitat Bochum, Bochum, Germany.
Stetina, Jiri and Makoto Nagao (1997). Corpus based PP attachment ambiguityresolution with a semantic dictionary. In Proceedings of the 5th Workshop onVery Large Corpora (WVLC-5), pp. 66–80.
Stevenson, Mark and Yorick Wilks (2001). The interaction of knowledge sourcesin word sense disambiguation. Computational Linguistics, 27(3):321–349.
Strube, Michael and Udo Hahn (1999). Functional centering – grounding referen-tial coherence in information structure. Computational Linguistics, 25(3):309–344.
Tetreault, Joel R. (2001). A corpus-based evaluation of centering and pronounresolution. Computational Linguistics, 27(4):507–520.
Tjaden, Ingo (1996). Semantische Prapositionsinterpretation im Rahmen derWortklassen-gesteuerten Analyse. Master’s thesis, FernUniversitat Hagen, Ha-gen, Germany.
van Deemter, Kees and Rodger Kibble (2000). On coreferring: Coreference inMUC and related annotation schemes. Computational Linguistics, 26(4):629–637.

Bibliography 195
van Rijsbergen, Cornelis J. (1975). Information Retrieval. Butterworths, London,England.
Vieira, Renata and Massimo Poesio (2000). An empirically based system forprocessing definite descriptions. Computational Linguistics, 26(4):539–593.
Vilain, Marc, John Burger, John Aberdeen, Dennis Connolly, and LynetteHirschman (1995). A model-theoretic coreference scoring scheme. In Proceed-ings of the 6th Message Understanding Conference (MUC-6), pp. 45–52. MorganKaufmann, San Mateo, California.
Volk, Martin (2000). Scaling up. Using the WWW to resolve PP attachment am-biguities. In Proceedings of the 5th Conference on Natural Language Process-ing – KONVENS-2000 (edited by Werner Zuhlke and Ernst Gunter Schukat-Talamazzini), pp. 151–155. Ilmenau, Germany.
Volk, Martin (2001). Exploiting the WWW as a corpus to resolve PP attachmentambiguities. In Proceedings of the Corpus Linguistics Conference 2001, pp.601–606. Lancaster, England.
Weiss, Sholom M. and Casimir A. Kulikowski (1991). Computer Systems ThatLearn: Classification and Prediction Methods from Statistics, Neural Nets, Ma-chine Learning, and Expert Systems. Morgan Kaufmann, San Mateo, California.
Wermter, Stefan, Ellen Riloff, and Gabriele Scheler (editors) (1996). Connec-tionist, Statistical, and Symbolic Approaches to Learning for Natural LanguageProcessing, volume 1040 of LNAI. Springer, Berlin.
Wilks, Yorick and Mark Stevenson (1998). The grammar of sense: Using part-of-speech tags as a first step in semantic disambiguation. Natural LanguageEngineering, 4(2):135–143.
Winograd, Terry (1972). Understanding Natural Language. Academic Press, NewYork.
Wu, Haodong and Teiji Furugori (1996). A hybrid disambiguation model forprepositional phrase attachment. Literary and Linguistic Computing, 11(4):187–192.
Yeh, Alexander S. (2000). More accurate tests for the statistical significance ofresult differences. In Proceedings of the 18th International Conference on Com-putational Linguistics (COLING-2000), pp. 947–953. Saarbrucken, Germany.
Yeh, Alexander S. and Marc B. Vilain (1998). Some properties of prepositionand subordinate conjunction attachments. In Proceedings of the 17th Interna-tional Conference on Computational Linguistics and 36th Annual Meeting of theAssociation for Computational Linguistics (COLING-ACL’98), pp. 1436–1442.Montreal, Canada.

196 Bibliography
Zavrel, Jakub, Walter Daelemans, and Jorn Veenstra (1997). Resolving PP at-tachment ambiguities with memory-based learning. In Proceedings of the Work-shop on Computational Natural Language Learning (CoNLL-97), pp. 136–144.Madrid, Spain.

Index
Abney (1996), 36abstracted representation, 62abstraction function, 62abstraction level, 62accumulation level function, 64, 95, 99,
107, 154, 160adverbial attachment, 178AM, see analysis memoryambiguity, 7
lexical, 7, 165–167, 182referential, 7, 182scopal, 7structural, 7, 182
analysis memory, 36anaphor, 112
lexical, 114anaphora, 114
direct, 115functional, 115indirect, 115
anaphora resolutionpronominal, 114
anaphoric, 113antecedent, 111, 112Aone and Bennett (1996), 162apposition, 126, 131Apresjan (1974), 14
Baayen et al. (1995), 31back-off
alternative, 60continuous, 95detail, 60discontinuous, 95early, 63late, 63
back-off direction function, 63–66, 95,99, 154, 183
back-off modelmultidimensional, 60
Baldwin (1997), 162Barker et al. (1997), 103Basili et al. (1997), 107Batori (1969), 173Bell (1934), 135Bell number, 135Berger et al. (1996), 67Bierwisch (1983), 14bonus factor, 57, 89, 100, 102, 137, 141,
146, 155, 157Brachman (1978), 8Brachman and Schmolze (1985), 8bridging, 114, 115
attachment-object, 116attribute-object, 116element-set, 116part-whole, 116, 118possessor-object, 116subset-set, 116thematic role, 116
bridging reference, see bridgingBrill and Resnik (1994), 109, 183Broker et al. (1994), 55Broker et al. (1997), 55Buitelaar (1998), 14Byron (2001), 159
c-command, 74, 118, 119, 121, 123, 125,137
Cardie and Wagstaff (1999), 163Carpenter (1992), 18, 27cataphor, 112, 113cataphoric, see cataphor

198 Index
CELEX, 31, 51chunk, see parse modeClark (1977), 114co-indexation, 111COLEX, 48Collins and Brooks (1995), 59, 67, 107,
110completing act, 35compound analysis, 31, 50, 51, 84, 104,
155concept, 8concept family, 14, 166conclusion, 58conjunction reduction, 176Connolly et al. (1994), 162constraint
constituent, 117distance, 146interconstituent, 117semantic compatibility, 146, 147
coordinationof NPs, 134
coreference, 111attribute-value, 115identity, 112intersentential, 112intrasentential, 112name-object, 115part-whole, 112
coreference alternative, 153coreference chain, 111, 126, 127, 129,
140, 147, 148, 155, 157, 161coreference key, 111, 124, 126, 127coreference link, 111Coreference Rules with Disambiguation
Statistics, see CORUDIScoreferential, 111correlate
sentence, 130subject, 130
CORUDIS, 3, 50, 115, 134, 135, 138,139, 141, 155, 160–162
Crain and Steedman (1985), 109cross-validation, 32
Daelemans et al. (2002), 31, 68, 108,173
Dagan and Itai (1990), 162data flow diagram, 40, 91, 139data representation model, 62Davies and Poesio (1998), 129Day et al. (1997), 31definite
inferred, 116development corpus, 140Diab and Resnik (2002), 173dimension abstraction function, 62, 66,
96, 183dimension combination function, 62, 66,
95, 99, 154dimension levels, 63, 94, 98, 106, 107,
153, 159disambiguation, 7discourse-new, 118, 135, 137, 138discourse-old, 135distance
candidate, 146markable, 146paragraph, 146sentence, 146
dotted type, 14
Eimermacher (1988), 55endophoric, 113equivalence closure, 125Erku and Gundel (1987), 115error rate
apparent, 31true, 32
exophoric, 113exponential number, 135
F-measure, see F-scoreF-score, 33, 158, 160, 163facet, 14, 74, 119, 140, 143, 155, 161,
168feature
amother, 76animal, 14animate, 14artif, 14axial, 14c, 76c-id, 71, 76

Index 199
card, 21, 24case, 71, 155cat, 117compat-r, 48, 90entity, 14, 18, 62, 110, 117, 141,
143, 147, 173etype, 9, 21, 24, 71, 72, 117, 141,
143example, 29f, 74fact, 9, 21, 24gend, 72, 117, 148gener, 9, 21, 24geogr, 14human, 14id, 120, 129info, 14instit, 14instru, 14ktype, 18lay, 141, 143, 147lay quant, 147lay refer, 41, 147lay varia, 147legper, 14mental, 14, 18method, 14min, 134, 135molec, 14morph, 29morph base, 29mother, 76mother-c-id, 105, 168movable, 14num, 29, 71, 72, 117orth, 6p-status, 36perf-aux, 28pers, 29, 72, 117potag, 14proper, 117quant, 21, 24ref, 120, 129refer, 21, 24, 117, 147select, 29sem, 29semsel, 29
semsel c-id, 29semsel compat-r, 29, 93semsel select, 29semsel select . . . oblig, 29semsel select . . . rel, 29semsel select . . . sel, 29semsel sem, 29, 143semsel sem entity, 14, 29, 72,
140, 143semsel sem entity sort, 14, 29semsel sem lay, 29, 72, 143semsel sem lay fact, 175semsel sem net, 29, 41sentence-id, 117sister, 75sister-c-id, 105, 168sort, 9, 14, 18, 24, 71, 72, 94, 97,
98, 100, 101, 117, 173spatial, 14syn, 28, 29syn agr, 29, 72syn cat, 6, 29syn mod, 175syn perf-aux, 28, 29syn sep-prefix, 29syn tem, 175thconc, 14type, 129varia, 21, 24
feature path, 28feature structure
typed, 27first-mention, 135fold, 32Franz (1996a), 110Franz (1996b), 110Fujii et al. (1998), 173
GermaNet, 110, 155, 163, 173Gnorlich (2002), 31Gomez et al. (1997), 110Grosz et al. (1995), 157, 163
Haegeman (1994), 118HaGenLex, 27, 30, 72Hahn and Strube (1996), 115Harabagiu and Maiorano (2000), 163

200 Index
Hart et al. (1968), 149Hartrumpf (1994), 27Hartrumpf (1996), 27Hartrumpf (1999), 71, 85Hartrumpf (2000), 27Hartrumpf (2001), 113Hartrumpf and Helbig (2002), 51Hartrumpf and Schulz (1997), 27Hartrumpf et al. (2003), 27Helbig (1986), 5, 23, 35Helbig (1994), 5, 23, 35Helbig (2001), 8, 14Helbig and Hartrumpf (1997), 36Helbig et al. (1994), 108, 109Helbig et al. (2000), 8, 53Hemforth (1993), 36Hindle and Rooth (1993), 86, 88, 92,
109Hirschman and Chinchor (1997), 112,
118, 129, 131, 176Hirschman et al. (1998), 120Hirst (1987), 109, 168homography, 165homonymy, 165homophony, 165
IBL, see Inheritance Based Lexicon For-malism
Ide et al. (1996), 24, 120Inheritance Based Lexicon Formalism,
5, 27
Kamp and Reyle (1993), 8Katz (1987), 67Kehler (1997), 162Kelsey et al. (1998), 53Kennedy and Boguarev (1996), 162key, 31Kimball (1973), 108Klavans and Resnik (1996), 1, 3, 30Knoll et al. (1998a), 8, 53Knoll et al. (1998b), 53knowledge type, 21
Lappin and Leass (1994), 162layer feature, 9, 18, 24, 29, 51, 55learning
memory-based, 58, 68, 106, 108, 110Leveling and Helbig (2002), 8, 53lexicon
deep, 31flat, 31
Mann and Thompson (1988), 23Manning and Schutze (1999), 2, 62markable, 112
missing, 140nonreferable, 135relevant, 127, 129, 134, 140, 143,
145, 157, 159spurious, 140
Markert and Hahn (1997), 162Marthen (2002), 54, 115maximum likelihood estimate, 59McRoy (1992), 173Mehl et al. (1998), 107, 109Merlo et al. (1997), 110MESNET, 51Message Understanding Conference, 112,
115, 118, 126, 127, 129–132,134, 160, 162, 163, 176
metonymy, 132, 162Minsky (1975), 8Mitkov (1995), 162Mitkov (1997), 162Mitkov (1998a), 159Mitkov (1998b), 162Mitkov (1999a), 113, 163Mitkov (1999b), 162Mitkov (2001), 163MLE, see maximum likelihood estimatemolecule, 14, 74, 94, 119, 140, 142, 144,
155, 161, 166, 168mother, 71
alternative, 76, 135, 166candidate, 76, 84, 86, 88, 90, 92,
98, 103, 108mother constituent, see motherMUC, see Message Understanding Con-
ferenceMUC-7 (1998), 160multi-net, 5, 8, 9, 23, 24, 31, 50, 53, 55,
118multidimensional back-off

Index 201
rule-centered, 1, 57, 71, 110, 160,167, 182
MultiNet, 4, 5, 8, 18, 27, 40, 41, 51, 72,84, 115, 155
natural language interface, 6, 8, 36, 70natural language processing, 1, 35, 58,
61, 62, 67, 70, 85, 88, 113, 138,162, 166, 175, 182, 183
natural language understanding, 1, 2, 7negative, 33negative link, 147, 148, 161NEGRA corpus, 84, 167, 177NLI, see natural language interfaceNLP, see natural language processingNLU, see natural language understand-
ing
opening act, 35Osswald (2002), 18
PAIRUDIS, 3, 88, 91, 103, 104, 106–108, 110, 166, 170
Palomar et al. (2001), 137Pantel and Lin (2000), 107parse mode
chunk, 50, 52, 55, 124, 137sentence, 52, 124, 137text, 23, 49, 50
ParseTalk, 55part of speech, 35, 62, 67, 134, 173Partee (1972), 114partition element, 32, 112, 126, 129, 137,
146, 147, 157, 158Poesio (1996), 7Poesio (2000), 113, 129Poesio and Vieira (1998), 118Poesio et al. (1999), 132Pollard and Sag (1994), 48polysemy, 165
regular, 14PoS, see part of speechpositive, 33postcedent, 112, 118, 130PP attachment, see prepositional phrase
attachment
PP Attachment and Interpretation withRUles and DIsambiguation Statis-tics, see PAIRUDIS
PP disambiguation, see prepositional phrasedisambiguation
PP interpretation, see prepositional phraseinterpretation
PPD, see prepositional phrase disam-biguation
precision, 32premise, 58preposition
contracted, 132prepositional phrase attachment, 7, 30,
40, 59–61, 67–70, 75, 88, 93,96, 100, 105, 109, 110, 135, 166,175, 177
multiple, 108prepositional phrase disambiguation, 23,
48, 70, 84, 88–91, 96, 103, 105,109, 166, 168, 169, 171, 172
prepositional phrase interpretation, 40,69–72, 76, 88, 92, 96, 97, 105,110, 166, 175, 177
principle of parsimony, 109probability
empirical, 65pronoun
bound, 114expletive, 130paycheck, 114pleonastic, 130
Pustejovsky (1995), 14
Quillian (1968), 8
Ratnaparkhi (1998), 110Ratnaparkhi et al. (1994), 107, 110recall, 32recurrence
logical, 115reflexive verb
real, 132Reiners (1963), 45relation, 8
*an, 12, 46*auf, 12, 75, 76

202 Index
*bei, 12, 79*flp, 12, 81*opdiv, 76*opminus, 12, 83*ueber, 12, 72, 80*vor, 12, 82, 83aff, 47agt, 12, 25, 46, 47, 75ante, 12, 82anto, 12, 119, 120arg1, 46arg2, 46assoc, 12, 25, 52, 79attch, 12, 25, 47, 79attr, 12, 25, 80benf, 87caus, 12, 49chea, 84chsa, 84chsp2, 25, 47circ, 12, 47, 75, 79cstr, 47, 77, 82dircl, 12, 46, 72, 75, 80, 82dur, 12, 76equ, 12, 118exp, 46init, 77instr, 12, 80just, 12, 83loc, 12, 46, 72, 76, 79, 80, 83mannr, 178mcont, 12, 69, 81meth, 12, 81obj, 25, 46, 47origl, 12, 77origm, 12, 77ornt, 25, 47pars, 12, 77, 118pred, 12, 46, 47prop, 12, 25, 46, 47, 178purp, 87scar, 46sourc, 12, 78sub, 12, 24, 25, 46, 47subs, 12, 25, 46, 47syno, 12temp, 12, 25, 46, 47, 78, 81, 83
val, 12, 25, 80via, 70, 81
relative clause attachment, 76, 176response, 31right association principle, 100, 106, 108robustness, 51Rosenfeld and Huang (1992), 67rule activation
missing, 140spurious, 140
rule component, 75rule selection
incorrect, 140
Samuelsson (1996), 67Schulz (1998), 30Schulz and Helbig (1996), 48scope of quantifiers, 178semantic kernel, 36semantic molecule, see moleculesentence connective, 113signature, 9, 12, 90, 93SISD, see situation sense disambigua-
tionsister constituent, 71situation sense disambiguation, 172skip function, 64, 65, 96, 100, 154Small (1981), 54Small (1987), 54Small and Rieger (1982), 54Soon et al. (1999), 162Soon et al. (2001), 162sort, 8, 9, 13, 24, 84, 94, 98, 102span
of words, 24sparse data, 58, 59, 66, 95, 96, 103, 112,
157statistical component, 75Staudt (2002), 5, 31Stetina and Nagao (1997), 107Stevenson and Wilks (2001), 173stopping criterion, 65, 96, 99, 154Strube and Hahn (1999), 163subsequent-mention, 135synecdoche
generalizing, 162particularizing, 162

Index 203
systematic ambiguity, 86causal, 87contents, 86locative, 86, 133temporal, 87
systematic indeterminacy, see system-atic ambiguity
test set, 32Tetreault (2001), 163TiMBL, 31, 68, 106, 108, 173Tjaden (1996), 74train and test set approach, 32train set, 32type
ab, 13abs, 13, 84abs-geogr, 20abs-info, 20abs-object, 15, 17, 20abs-potag, 20abs-situation, 20acc, 6, 71action, 19ad, 13animal-object, 20animate-object, 14, 20aq, 13art-con-geogr, 20art-substance, 20as, 13, 84ass-quality, 19at, 13attribute, 20ax-mov-art-discrete, 20categ, 21, 24closed, 36co, 13, 18com-quality, 19completing, 36con, 21con-geogr, 20con-info, 20con-object, 15, 16, 18, 20, 120con-potag, 20d, 13, 24, 100da, 13, 98
dat, 71dempro, 148det, 21, 41, 147dn, 13, 98dy, 13dyn-abs-situation, 20dyn-situation, 19ent, 9, 13entity, 15, 19event, 19fe, 13fem, 148for-entity, 19fq, 13fquant, 21fun-quality, 19ge, 9, 21gen, 71gq, 13gr, 13graduator, 19haben, 28human-object, 14, 20, 120, 141, 143hypo, 9, 21ident, 129indefpro, 148indet, 21, 147institution, 14, 20, 141io, 13, 100ktype, 23l, 13l-sign, 27lay, 22lg, 13loc-sit-descriptor, 19m, 13masc, 148md, 13me, 13meas-quality, 19meas-unit, 19measurement, 19ment-action, 19ment-dyn-abs-situation, 20ment-event, 19ment-stat-abs-situation, 20ment-stat-situation, 19

204 Index
mo, 13mod-sit-descriptor, 19modality, 20mov-art-discrete, 20mov-nat-discrete, 20mov-nonanimate-con-potag, 20mq, 13mult, 21n, 117na, 13nat-con-geogr, 20nat-discrete, 20nat-substance, 20neut, 148nfquant, 21ng, 13nn, 13nolay, 21nonanimate-con-potag, 20nonax-mov-art-discrete, 20noninstit-abs-potag, 20nonmeas-quality, 19nonment-action, 19nonment-dyn-abs-situation, 20, 161nonment-event, 19nonment-stat-abs-situation, 20, 161nonment-stat-situation, 19nonmov-art-discrete, 20, 143nonmov-nat-discrete, 20nonmov-nonanimate-con-potag, 20nonnum-quantifier, 19nonoper-attribute, 20nonreal, 21nonthc-relation, 20nq, 13nu, 13num-quantifier, 19o, 13, 18, 94oa, 13object, 19, 31, 119one, 21open, 36oper-attribute, 20oq, 13ord-quality, 19osi-entity, 18, 19p, 13
perspro, 117, 148pl, 117, 119plant-object, 20possdet, 117, 148posspro, 148property, 19prot-abs-object, 20prot-con-object, 20prot-discrete, 20prot-method, 20prot-substance, 20prot-theor-concept, 20, 161proto, 21, 24qf, 13ql, 13qn, 13qual-graduator, 19quality, 19quan-graduator, 19quant, 147quantifier, 19quantity, 19re, 13real, 9, 21reflpro, 117, 148rel-quality, 19relation, 20rq, 13s, 13sd, 13sg, 117, 119si, 13, 18, 21, 84si-lay, 21sit-descriptor, 19situa, 21, 24situation, 15, 18, 19sp, 9, 21st, 13, 84, 98, 100stat-abs-situation, 20stat-situation, 19substance, 119t, 13, 74t’, 74ta, 13tem-abstractum, 20tem-sit-descriptor, 19thc-relation, 20

Index 205
tot-quality, 19tq, 13var, 21
van Deemter and Kibble (2000), 112van Rijsbergen (1975), 33variant, 14Vieira and Poesio (2000), 138Vilain et al. (1995), 158Volk (2000), 85Volk (2001), 107, 109
WCF, see word class functionWCF machine, 36WCFA, 4, 23, 35, 37, 50WCFM, see WCF machineWeiss and Kulikowski (1991), 32Wilks and Stevenson (1998), 173Winograd (1972), 70, 112WOCADI, 5, 23, 27, 30, 35, 40, 50, 72,
84, 117, 124, 134, 139, 143, 176WOrd ClAss based DIsambiguating parser,
see WOCADIword class function, 35word expert parsing, 54word sense disambiguation, 23, 49, 104,
109, 165, 166, 171, 172world knowledge, 70, 112, 114, 115, 161,
162, 172, 176, 178, 179WSD, see word sense disambiguationWu and Furugori (1996), 30WWW, 107, 166
Yeh (2000), 32Yeh and Vilain (1998), 109
Zavrel et al. (1997), 110





























