Embed Size (px)
Citation preview

Improving Basic Thread Operations with Batches of Threads
Ioannis E. VenetisBritish Hellenic College, 10682 Athens, Greece
POSTER PAPER
ABSTRACT
Multi-core architectures provide the means to efficientlyhandle more fine-grained and larger numbers of paralleltasks. However, software still does not take advantage ofthese new possibilities, retaining the high cost associatedwith managing large numbers of threads. Batches ofThreads have been introduced to reduce this cost andallow applications to express their inherent parallelismin a more fine-grained manner. In this paper, their useis extended, in order to improve two significant aspectsof threading run-time systems. Firstly, to schedule largenumbers of threads to processors. Secondly, to recycledata structures of threads that have finished execution.Both improvements can be implemented internally inthreading run-time systems and thus are transparent to theprogrammer. The experimental evaluation demonstratesthat basic thread operations improve significantly.
KEYWORDS: Fine-grained and massive parallelism,threading run-time systems, load-balancing.
1. INTRODUCTION
Multi-core processors are already extensively used in thefield of high-performance computing and the numberof execution units bundled into these architectures risesquickly. This makes it necessary to include improvementsthat allow faster handling of parallelism in the hardware.Barriers, context-switching and faster implementationsof mutual exclusion [1] in hardware are some examples.The purpose of these mechanisms is to allow softwareto reduce the cost of handling parallelism, in order forit to exploit all available execution units of a processor.To achieve this, however, the task to be performed hasto be divided into an increasing number of smaller tasks.Typically, a run-time system is employed to handle tasksthat can be executed in parallel by means of threads.
Such run-time systems rely on queues to perform mostof their operations. For example, a newly created threadis enqueued into a ready-queue. During execution of theapplication, the scheduler of the run-time system willtake that thread from the ready-queue and execute it on aprocessor. After execution, the data structure describing athread (descriptor) is usually enqueued into a recycling-queue, in order for new threads to be created faster.Such run-time systems have already started exploitingthe aforementioned hardware techniques [2]. However,the purpose in these cases is to reduce the time requiredto perform “traditional” operations of threading run-timesystems. Threads are still handled through queues, withthe only difference being that these new synchronizationmethods are exploited to gain faster access to queues.
A well known category of applications that couldeasily take advantage of fine-grained parallelism is theone that includes embarrassingly parallel and irregularapplications, i.e., tasks have no dependencies among themand each data point does not require the same amountof time to be calculated. Although simple, this categoryincludes some important applications like ray-tracing,fractals calculations and critical point extraction in flowsimulations. Theoretically, the best method to parallelizesuch an application is to create a thread for each datapoint. If a processor requires more time to calculate adata point, there are numerous other threads that can beexecuted on all other processors. This automatically leadsto a load-balanced execution. However, assigning eachdata point to a separate thread requires the creation ofa large number of threads. The cost to handle such anamount of parallelism becomes extremely high on mostthreading run-time systems and execution time actuallyworsens, despite good load-balancing.
Several ideas have been proposed to reduce theamount of time required to complete basic operations in

Descriptor
Pointer
Pointer
Descriptor
Pointer
Descriptor
Pointer
Descriptor
Pointer. . .
Batch of Threads
Pointer
Figure 1. Representation of a Batch of Threads.
threading run-time systems. An important methodologyis recycling of used objects, in order to avoid expensiveallocations of memory. Others include lazy techniques [3],memory aware creation of parallel tasks and self-adaptingtechniques for applications [4], [5]. Due to the importanceof this problem, even hardware solutions have beenproposed, like queues in hardware [6]. However, thislimits the number of threads that can be present in a queue.
In this paper we extend the use of Batches of Threads(BoTs) [7]. Whereas previously BoTs were exploited toonly create threads faster, now they are used to improvetwo more significant aspects of threading run-timesystems: (1) Schedule threads to processors, and (2)Recycle data structures of threads that have finishedtheir execution. This, in conjunction with the fact thatmodern parallel architectures are able to handle a largenumber of threads, allows us to significantly reducecost of handling parallelism and allows applications toexpress their parallelism at a more fine-grained level. Theproposed scheduling and recycling strategies have beenimplemented in the context of NthLib [8]. We furtherimprove on this by exploiting the hardware provided aidsto reduce overhead of mutual exclusion inside NthLib.
2. THE CONCEPT OF BOTS
Operations on queues take up a significant percentageof the time required to handle parallelism in a threadingmodel. An obvious thought is to use lock-free mechanismsto insert into and extract objects from queues. However,this is not always possible. For example, if it is requiredto access a queue from both the head and the tail, thedata structure that represents a queue must maintain twopointers. Insertion or extraction of an object impliesthat both pointers must be updated together atomically.Hence, the underlying hardware must provide thenecessary instructions to allow this kind of operations,which is not always the case. There are other solutionsfor this problem, which however have other inefficienciesassociated with them, like the ABA problem.
The observation that leads us to a more generalsolution is the fact that the associated cost for operations
on queues is measured per thread, which reveals anobvious way that allows reduction of this cost. If anoperation on a queue is performed on a team of threads,the cost can be amortized among the threads of theteam. This allows us to introduce the notion of a Batchof Threads (BoT), which can be defined as a team ofthreads, that are handled as an indivisible entity withrespect to operations on queues. The above definition isvery general and does not include any details about howto implement BoTs. The solution adopted is to use thepointer already present in each descriptor, that is used tomanage threads in queues [7]. As can be seen in Figure 1,each member of a BoT uses this pointer to keep track ofthe next member, except of the last one that terminatesthe BoT. In order to be able to efficiently insert a BoTinto a queue, it is necessary to use two pointers, thatpoint to the first and the last member of it. Under thisscheme, a BoT is a queue of its own, which has not yetbeen inserted into a predefined queue, like the ready-and the recycling-queues. The applicability of BoTs hasalready been demonstrated in the context of NthLib [7].
An optimization implemented internally in NthLibis the exploitation of all hardware provided methodsto improve mutual exclusion to access queues. Thesemethods differ among all supported platforms in NthLiband special care has been taken to use the most efficientin each case. It has to be pointed out that this optimizationis independent of using BoTs and it is used wheneveraccess to a queue is required, regardless whether theoperation is performed on a single thread or a BoT.
The basic idea behind BoTs and their initial usehas been to improve thread creation time, which wasfacilitated with the introduction of a new API. The mainconcerns while designing this API were simplicity andease of use. In order to achieve these goals, the API hasbeen designed to be as similar as possible to existingand widely used APIs. The chosen design allows both,the original and the new API for creating threads to beused simultaneously in an application, if the programmerdecides that this would benefit the application.
It is important to notice that the underlying assumptionwhen using BoTs is the fact that the application will create

Head
Tail
...
...
...
Heads ofLocal Queues
Tails ofLocal Queues
BoT is inserted into a ready-queue
Create BoT
...
BoT is moved into a Batch Box
Batch Box
CPU
Threads are dispatched to CPU from Batch Box
Accumulation Box
Finished threads are accumulated
...
Heads ofRecycle Queues
Tails ofRecycle Queues
BoT is moved into a Recycle Queue
Use descriptors to create BoTs
Figure 2. The Use of BoTs in All Threading Management Procedures.
a large number of threads, compared to the number of pro-cessors that will be used to execute the application. Onlyin this case is the use of BoTs justified and improvementsin basic threading operations are expected. Based on theobservation about the number of threads when using BoTs,two new possibilities of exploiting them have surfaced.
3. SCHEDULING AND RECYCLING
In the following paragraphs the main contributions of thispaper are described, i.e., use of BoTs to schedule threadsand to recycle thread descriptors for later use. As it willbecome evident, these operations reduce the contentionon queues and hence result in improved execution timeof parallel applications.
The scheduling and recycle mechanisms introduced inthis paper are completely transparent to the programmer.They are implemented internally in the threading run-timesystem. Therefore, no further modifications are requiredin the source code of an application, with the exceptionof using the API to create threads using BoTs.
We make the following assumptions, which are validfor most threading run-time systems. We assume thatevery processor has its own ready-queue, where threadsare inserted in order to be executed by that processor.After execution of a thread, its descriptor is insertedinto a recycling-queue, which is again unique for eachprocessor. New threads are created by looking first intothe recycling-queues for available descriptors. If there arenot enough descriptors to create a thread or a BoT, newones are allocated from memory. Finally, we assume thatWork Stealing can be enabled, i.e., if a processor doesnot find a thread in its local ready-queue, it searches theready-queues of other processors. If a thread is found,it is taken and executed. Although this technique is
commonly used to improve load-balancing, it can alsobe used during thread creation. If a new thread has tobe created and there is no available descriptor in thelocal recycling-queue, then the recycling-queues of otherprocessors can be checked. Only if there is no descriptoravailable in any queue will one be allocated.
3.1. Scheduling Threads to Processors
To explain the scheduling mechanism that uses BoTs, theexample of Figure 2 will be used. We assume that a newBoT has been created (upper left part of Figure 2) whichis then inserted as a whole into a local ready-queue ofa specific processor. Previously, each processor woulddispatch one thread from the ready-queue, execute it andthen dispatch the next one. Thus, for every thread to beexecuted an access to a queue has to be performed.
The alternative proposed in this paper is to extracta whole BoT from the ready-queue and assign it forexecution to a processor. However, some importantissues arise in this case. Firstly, should the size of theBoT during thread creation and during dispatching toprocessors be the same? There does not seem to beany reason why this should be the case. Therefore, ourimplementation allows different sizes. This leads to thesecond implication. The run-time system must be able tohandle the case when a processor tries to dispatch a BoTand there are not enough threads in the ready-queue.The solution adopted in the current implementation isto extract as many threads as there are available at thatpoint. The last issue is related to work stealing. If it isenabled in a threading run-time system, when should it beused? Obviously, when a local ready-queue is completelyempty, a processor can steal a BoT from the ready-queueof another processor. What happens, however, when onlya smaller BoT can be found in the local ready-queue

0,0
0,5
1,0
1,5
2,0
2,5
3,0
3,5
4,0
4,5
(1,1,1) (1,1,2) (1,2,1) (2,1,1) (1,2,2) (2,2,1) (4,1,1) (2,2,2) (4,2,1) (4,2,2)
Natural Batch (C) Batch (S)
0
100
200
300
400
500
600
700
1 2 4 6 8
Natural Batch (C) Batch (S)
Figure 3. Execution Time for the Synthetic Benchmark on the Intel and SMTSIM Platforms.
of a processor? As already mentioned, in the currentimplementation this smaller BoT is extracted. Onealternative would be to supplement this smaller BoTwith more threads from another ready-queue. However,this strategy does not seem to offer anything. The costto access another ready-queue, in order to supplementthe smaller BoT, would be the same as accessing lateranother queue to steal a BoT from it. Therefore, thisstrategy does not offer any advantage.
Threads have to be executed on a processor one ata time. Hence, the question what to do with a BoT thathas been dispatched is the next one to be answered.The notion of a Batch Box is introduced to solve thisissue. As can be seen in Figure 2, a Batch Box is aspecial memory location reserved for each processor.Every BoT dispatched is transferred into the Batch Boxof a processor. Since the idea behind using BoTs toschedule threads is to reduce the overhead associatedwith managing queues, the Batch Box is accessedwithout using any mutual exclusion. This means thatthe Batch Box must be local to each processor and thatwork stealing cannot be applied at this level. Processorsdispatch threads from the Batch Box for execution. Whenthere are no more threads in the Batch Box, a new BoTis transferred from a ready-queue.
At first sight, using BoTs to schedule threads might seemto revoke one of their objectives, which is to improveload-balancing. Transferring a BoT to a Batch Boxmakes it local to a processor, disallowing use of workstealing. However, the small size of a BoT, comparedto the total large number of threads in the applicationmakes this issue of minor importance. On the otherhand, some could argue that using BoTs to schedulethreads is effectively the same as packing several datapoints together and assigning them to a processor. Thedifference is that packing data points together is currently
a task that has to be performed by the programmer,whose responsibility is also to find the most appropriateway to package these data points to achieve the desiredperformance. Using BoTs, however, the programmeris relieved from these tasks, which are now performedtransparently in the context of the run-time system itself,using a mechanism that reduces considerably the cost ofhandling parallelism.
3.2. Recycling Thread Descriptors
After a thread finishes execution, the descriptor of thatthread is not required anymore and can be discarded.However, in order to avoid expensive memory allocationswhile creating threads, descriptors are reused throughrecycling-queues. As in the case of executing a thread, aqueue has to be accessed every time when a descriptorhas to be added to it after a thread terminates.
In this paper, we propose a mechanism that furtherimproves this procedure. As depicted in Figure 2, thismechanism is the opposite of the one used to schedulethreads to processors. After a thread finishes execution,its descriptor is put into an Accumulation Box, that islocal to each processor. Only after a whole BoT has beenaccumulated is it inserted into the local recycling-queueof the processor. Thus, the cost of accessing a queue isagain amortized among the threads that constitute theBoT. The size of the accumulated BoT can again bedifferent, compared to the size of a BoT when creating orscheduling threads. Since recycling-queues are accessedwhen creating threads, this mechanism is expected tolower the time required for that operation.
4. EXPERIMENTAL EVALUATION
In order to evaluate our approach, we implemented theproposed mechanisms in the context of NthLib. Ourexperiments were run on two hardware platforms. The
0
1000
2000
3000
4000
5000
6000
7000
8000
(1,1
,1)
(1,1
,2)
(1,2
,1)
(2,1
,1)
(1,2
,2)
(2,2
,1)
(4,1
,1)
(2,2
,2)
(4,2
,1)
(4,2
,2)
Natural Batch (C) Batch (S)
0
1000
2000
3000
4000
5000
6000
(1,1
,1)
(1,1
,2)
(1,2
,1)
(2,1
,1)
(1,2
,2)
(2,2
,1)
(4,1
,1)
(2,2
,2)
(4,2
,1)
(4,2
,2)
Natural Batch (C) Batch (S)
0
20000
40000
60000
80000
100000
120000
140000
160000
180000
200000
220000
(1,1
,1)
(1,1
,2)
(1,2
,1)
(2,1
,1)
(1,2
,2)
(2,2
,1)
(4,1
,1)
(2,2
,2)
(4,2
,1)
(4,2
,2)
Natural Batch (C) Batch (S)
0
1000
2000
3000
4000
5000
6000
(1,1
,1)
(1,1
,2)
(1,2
,1)
(2,1
,1)
(1,2
,2)
(2,2
,1)
(4,1
,1)
(2,2
,2)
(4,2
,1)
(4,2
,2)
Natural Batch (C) Batch (S)
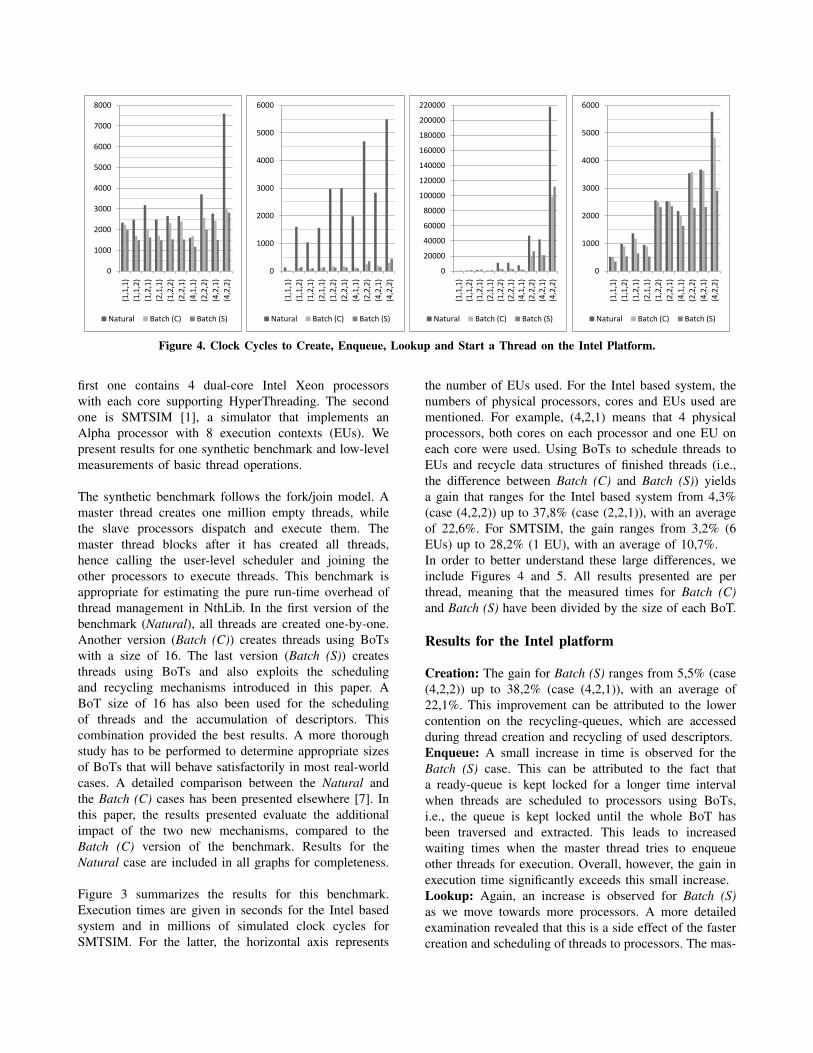
Figure 4. Clock Cycles to Create, Enqueue, Lookup and Start a Thread on the Intel Platform.
first one contains 4 dual-core Intel Xeon processorswith each core supporting HyperThreading. The secondone is SMTSIM [1], a simulator that implements anAlpha processor with 8 execution contexts (EUs). Wepresent results for one synthetic benchmark and low-levelmeasurements of basic thread operations.
The synthetic benchmark follows the fork/join model. Amaster thread creates one million empty threads, whilethe slave processors dispatch and execute them. Themaster thread blocks after it has created all threads,hence calling the user-level scheduler and joining theother processors to execute threads. This benchmark isappropriate for estimating the pure run-time overhead ofthread management in NthLib. In the first version of thebenchmark (Natural), all threads are created one-by-one.Another version (Batch (C)) creates threads using BoTswith a size of 16. The last version (Batch (S)) createsthreads using BoTs and also exploits the schedulingand recycling mechanisms introduced in this paper. ABoT size of 16 has also been used for the schedulingof threads and the accumulation of descriptors. Thiscombination provided the best results. A more thoroughstudy has to be performed to determine appropriate sizesof BoTs that will behave satisfactorily in most real-worldcases. A detailed comparison between the Natural andthe Batch (C) cases has been presented elsewhere [7]. Inthis paper, the results presented evaluate the additionalimpact of the two new mechanisms, compared to theBatch (C) version of the benchmark. Results for theNatural case are included in all graphs for completeness.
Figure 3 summarizes the results for this benchmark.Execution times are given in seconds for the Intel basedsystem and in millions of simulated clock cycles forSMTSIM. For the latter, the horizontal axis represents
the number of EUs used. For the Intel based system, thenumbers of physical processors, cores and EUs used arementioned. For example, (4,2,1) means that 4 physicalprocessors, both cores on each processor and one EU oneach core were used. Using BoTs to schedule threads toEUs and recycle data structures of finished threads (i.e.,the difference between Batch (C) and Batch (S)) yieldsa gain that ranges for the Intel based system from 4,3%(case (4,2,2)) up to 37,8% (case (2,2,1)), with an averageof 22,6%. For SMTSIM, the gain ranges from 3,2% (6EUs) up to 28,2% (1 EU), with an average of 10,7%.In order to better understand these large differences, weinclude Figures 4 and 5. All results presented are perthread, meaning that the measured times for Batch (C)and Batch (S) have been divided by the size of each BoT.
Results for the Intel platform
Creation: The gain for Batch (S) ranges from 5,5% (case(4,2,2)) up to 38,2% (case (4,2,1)), with an average of22,1%. This improvement can be attributed to the lowercontention on the recycling-queues, which are accessedduring thread creation and recycling of used descriptors.Enqueue: A small increase in time is observed for theBatch (S) case. This can be attributed to the fact thata ready-queue is kept locked for a longer time intervalwhen threads are scheduled to processors using BoTs,i.e., the queue is kept locked until the whole BoT hasbeen traversed and extracted. This leads to increasedwaiting times when the master thread tries to enqueueother threads for execution. Overall, however, the gain inexecution time significantly exceeds this small increase.Lookup: Again, an increase is observed for Batch (S)as we move towards more processors. A more detailedexamination revealed that this is a side effect of the fastercreation and scheduling of threads to processors. The mas-

0
50
100
150
200
250
300
1 2 4 6 8
Natural Batch (C) Batch (S)
0
50
100
150
200
250
300
350
400
1 2 4 6 8
Natural Batch (C) Batch (S)
0
200
400
600
800
1000
1200
1400
1600
1800
1 2 4 6 8
Natural Batch (C) Batch (S)
0
50
100
150
200
250
300
350
400
450
500
1 2 4 6 8
Natural Batch (C) Batch (S)
Figure 5. Clock Cycles to Create, Enqueue, Lookup and Start a Thread on SMTSIM.
ter thread cannot keep up in this case with the pace thatthreads are taken from ready-queues and executed. Theresult is that ready-queues become empty and processorshave to wait until new threads arrive. This waiting time,however, is taken into account in these measurements.Startup: The gain for the Batch (S) case is quite signif-icant and ranges from 6,9% (case (2,2,1)) up to 48,5%(case (1,2,1)), with the average gain being 30,5%. Thisadditional improvement is due to better cache utilization.It is highly probable that the thread descriptors of aBoT that executed on a processor will be later used tocreate new threads for the same processor. Hence, a largeramount of threads will be executed on the same processor,in comparison when not using BoTs. Therefore, the prob-ability for the cache to still contain useful information ishigher, which in turn results to decreased startup time.
Results for the SMTSIM platform
Creation: An increase in time is observed for 4 EUs(2,6%) for Batch (S). For all other cases, an improvementof 13,8% (8 EUs) up to 61,2% (1 EU) is observed. Theaverage gain, including the 4 EUs case, is 23,3%. Thisimprovement can be explained as for the Intel case.Enqueue: Some improvement for the Batch (S) caseis observed for 1 EU and 2 EUs (11,1% and 23,9%respectively). For 4 or more EUs, however, we observe anincrease in the time required to enqueue a thread, whichcan be explained as for the Intel platform.Lookup: For the Batch (S) case the same phenomenon ason the Intel platform appears, where time to find the nextthread to be executed slightly worsens.Startup: A large gain appears for the Batch (S) case,ranging from 16,7% (6 EUs) up to 42,2% (1 EU). Thisimprovement actually compensates for the loss in Batch(C), compared to the Natural case.
REFERENCES
[1] D. Tullsen, S. Eggers, and H. Levy, “Simultaneous Mul-tithreading: Maximizing On-Chip Parallelism,” in Proceed-ings of the 22nd Annual International Symposium on Com-puter Architecture, S. Margherita Ligure, Italy, 1995.
[2] B. Saha, A.-R. Adl-Tabatabai, R. L. Hudson, V. Menon,T. Shpeisman, M. Rajagopalan, A. Ghuloum, E. Sprangle,A. Rohillah, and D. Carmean, “Runtime Environment forTera-scale Platforms,” Intel Technology Journal, vol. Volume11, Issue 3, Aug. 2007.
[3] S. C. Goldstein, K. E. Schauser, and D. E. Culler, “LazyThreads: Implementing a Fast Parallel Call,” Journal ofParallel and Distributed Computing, vol. Volume 37, Issue1, pp. 5–20, August 1996.
[4] C. D. Antonopoulos, D. S. Nikolopoulos, and T. S. Pap-atheodorou, “Scheduling Algorithms with Bus BandwidthConsiderations for SMPs,” in Proceedings of the 32nd In-ternational Conference on Parallel Processing, Kaohsiung,Taiwan, Oct. 2003.
[5] D. S. Nikolopoulos, T. S. Papatheodorou, C. D. Poly-chronopoulos, J. Labarta, and E. Ayguade, “Is Data Distribu-tion Necessary in OpenMP?” in Proceedings of Supercom-puting’2000: High Performance Computing and NetworkingConference, Dallas, TX, Nov. 2000.
[6] S. Kumar, C. J. Hughes, and A. Nguyen, “ArchitecturalSupport for Fine-Grained Parallelism on Multi-core Archi-tectures,” Intel Technology Journal, vol. Volume 11, Issue3, Aug. 2007.
[7] I. E. Venetis and T. S. Papatheodorou, “Handling MassiveParallelism Efficiently: Introducing Batches of Threads,”in Proceedings of the 2009 International Conference onParallel Computing (ParCo 2009), Lyon, Sep. 2009.
[8] X. Martorell, J. Labarta, N. Navarro, and E. Ayguade, “ALibrary Implementation of the Nano-Threads ProgrammingModel,” in Proceedings of the 2nd International EuroParConference, Lyon, France, August 1996, pp. 644–649.





























