Embed Size (px)
Citation preview

THE
ROBERT GORDON
UNIVERSITY
Technical Report No. 95/2Knowledge-based Re�nement ofKnowledge Based SystemsSusan Craw and D. SleemanJanuary 1995School of Computer and Mathematical SciencesFACULTY OF SCIENCE AND TECHNOLOGYTHE ROBERT GORDON UNIVERSITY

Knowledge-based Re�nement of Knowledge Based SystemsSusan CrawSchool of Computer and Mathematical Sciences,The Robert Gordon University, St Andrew Street,Aberdeen AB1 1HG, ScotlandD. SleemanDepartment of Computing ScienceUniversity of Aberdeen, Elphinstone Road,Aberdeen AB9 2UB, [email protected], [email protected] paper describes KRUST, an automated re�nement system for knowledge basedsystems. Its aim is to ful�ll a maintenance, rather than acquisition, role and so it concen-trates on (re-)using available knowledge, which in practice often does not include a largeset of faults to be �xed. Our approach to knowledge re�nement combines a best �rstsearch of possible re�nements, with the implementation of repairs in the form of smallchanges available from additional knowledge hierarchies. The expert provides the correctanswer for a wrongly solved task and this task-solution pair is used as a training case forthe re�nement process. KRUST is unusual in generating many re�nements initially andthen selectively removing those re�nements or re�ned KBs that are shown to be ine�ec-tive, before �nally recommending the change(s) which it deems to be best. As KRUSTsearches for suitable repairs, in addition to a static analysis of the declarative knowledge,it also takes account of the con ict resolution strategy used by the control mechanism.Later, during the implementation of re�nements, KRUST is able to gradually alter condi-tions with the e�ect that it produces re�ned knowledge bases that are semantically closeto the original knowledge base; a desirable feature for knowledge base maintenance. Inaddition, it also has the normal re�nement operators to remove rules and conditions, andto add new rules.1 IntroductionThe widespread use of Knowledge Based Systems (KBS) has led to increasing interest in thedesign of automated tools to ease the Knowledge Acquisition Bottleneck, by relieving theknowledge engineer and the domain expert of some of the repetitive tasks. Tools such asMOLE and SALT (Marcus, 1988) have concentrated on the acquisition of domain knowledge,being guided by the requirements of the KBS's speci�ed problem solving strategy. However,Carbonell (Carbonell, 1991) has shown that knowledge re�nement is a signi�cant componentwithin the knowledge acquisition task, and claims that it forms a bottleneck in its own right.Automated knowledge re�nement seeks to ease this problem by reducing the time requiredby humans to re�ne Knowledge Bases (KBs). This paper describes KRUST, an automated1

re�nement system for KBSs which combines a best �rst search of possible re�nements, withthe implementation of repairs which gradually alter the faulty knowledge, using hierarchiesof background knowledge.KRUST is directed towards the later stages of knowledge acquisition and focuses on therole of maintenance, where a re�nement aims to create a revised KB, modelled on the existingdomain knowledge already in the KB. The assumption is that a fairly mature KB alreadyexists. In our experience real applications are often not accompanied by a large set of ex-amples, and in particular faults are rarely left to accumulate. Therefore KRUST does notrely on inductive learning and instead tries to build useful re�nements from a single piece ofevidence and the additional domain knowledge readily available from the acquisition process;e.g. hierarchies of related objects.The process of re�nement is made up of the following basic steps and sub-tasks:� interpret a fault:{ acquiring the evidence that the KB contains a fault, and{ analysing possible causes of the fault;� re�ne the KB to remove the fault by:{ suggesting ways to �x the fault, and{ implementing the repair on the KB.In common with many re�nement and revision systems, KRUST re�nes a KB when the expertidenti�es a fault by providing the correct answer for a wrongly solved task. This task-solutionpair is used as a training case for the re�nement process. Although KRUST applies the generalprocess described above, it is unusual in several respects.� It implements many KB re�nements that may overcome a fault (Craw & Sleeman,1990) and is able to postpone its decision about which ones are most appropriate untilit has con�rming evidence of their suitability.� In addition to a static analysis of the declarative knowledge, it also takes account ofthe con ict resolution strategy when generating possible re�nements; this is importantgiven that the control mechanism is an integral part of a KBS.� As well as adding/removing whole rules and conditions, it is able to gradually alterthe KB by replacing faulty knowledge with knowledge that is semantically close; adesirable feature for KB maintenance.Our target application is a backward-chaining, propositional, rule-based KBS where arule's antecedent is a conjunction of conditions, represented as Object-Attribute-Value triples(OAVs), and its conclusion is a single OAV. However, we allow OAVs to have a richer semanticsthan standard propositions and this representation �ts well with many industrial applications,which often lack the sophistication of a full �rst order representation. Each attribute mayhave an associated semantics that allows the value to be interpreted as a range of possiblevalues. For example, an OAV concerning price may represent an upper bound for the price,and so price(wine, 5) is a shorthand for price(wine, X) ^ X � 5. Other attributes may uselower bounds, 2-sided intervals, or standard discrete propositional values; e.g. colour(wine,2

red). The OAVs do not contain the bound information directly, but instead the type of rangeis attached to the attribute name in meta-knowledge. Therefore, the KBS matcher must takeaccount of an attribute's meta-knowledge; e.g. using the semantics described above, the factprice(wine, 4) satis�es the condition price(wine, 5).KRUST
IMPLEMENT CHANGES
GENERATEREFINEMENTS
SELECTRULES
TrainingCase
CHOOSEBEST
Meta-Knowledge
Heuristics
Task-solution Pairs FILTER
FILTERFigure 1: The Steps within KRUSTKRUST's architecture is illustrated in Figure 1. Sections 2{6 describe in detail the pro-cesses that appear as the main stages in the diagram: selecting rules to be changed, generatingre�nements, implementing the changes within re�ned KBs and choosing the best re�ned KB.Section 7 evaluates the behaviour of KRUST. Related research is discussed in Section 8 withfurther work being indicated in Section 9. Finally, we summarise the paper in Section 10.3

2 Interpretation of FaultsThe interpretation phase must acquire the evidence that indicates that the KB is faulty, andwill identify why particular fault(s) occurred. This is a crucial part of the re�nement process,since a detailed study of how a fault happened often reveals possible steps to prevent thisproblem recurring. For the current version of KRUST, the evidence of a fault is a task-solutionpair provided by the expert, where the expert's solution is di�erent from that predicted bythe KBS, or the KBS fails to solve the task. Such a task-solution pair becomes KRUST'straining case.H- H+
Condition/Conclusion which is true
Condition/Conclusion which is falsePlaces to Refine
Figure 2: Exploring Solution GraphsKRUST uses the training task to explore the proof tree that produced the faulty solution,and hence to identify possibly faulty knowledge. Similarly, it explores backwards from theexpert's solution to identify suitable, but currently unsatis�ed, proof trees for the expert'ssolution. Figure 2 illustrates a possible situation where the nodes indicate the conditions andconclusions of rules. An AND link represents a rule consisting of a conjunction of conditionsrepresented by the children nodes and a conclusion represented by the parent node. An ORlink represents a rule consisting of a disjunction of conditions represented by the childrennodes and a conclusion represented by the parent node; i.e. a set of Prolog clauses with thesame head. In this diagram we represent the expert's solution as H+ and the KBS's (incorrect)solution is H�. The shape of each node indicates whether the node is satis�ed (true) for thetraining task; a circle indicates true, a diamond false. Thus the root of an AND link is a4

circle if and only if all the children are circles, and the root of an OR link is a diamond if andonly if all the children are diamonds. The shape of the leaf nodes is determined by the initialfacts. We note that the aim of the re�nement generator is to identify nodes, that if theirshape is changed, will alter the shape of the H+ and H� nodes, to a circle and a diamondrespectively. Suitable nodes are found by exploring the proof trees, marking all nodes thatboth have the wrong shape and a�ect the shape of their parent node. These nodes have beenshaded in the �gure. We note that pruning of a subtree occurs when its root node alreadyappears as the \correct" shape (circle or diamond) for the proof tree in which it appears (H+or H� respectively). A re�nement is a combination of the appropriate changes to a su�cientnumber of these nodes, to a�ect the root nodes in the proof trees. This proof tree containsall possible proofs; KBSs that contain con ict resolution will prefer a particular subtree.KRUST con�nes itself at its rule classi�cation stage to considering the rules at the root ofthe proof tree and the potentially preferable proof trees, only. The exploration of paths lowerin the proof tree is undertaken later by the re�nement generator. This top-level investigationselects and classi�es a subset of the KB rules.2.1 Rule Classi�cation without Con ict ResolutionIn a purely declarative theory where logical closure forms deductions, rule classi�cation issimple. Let us adopt the notation C ! H to represent the rule with antecedent C andconclusion H. The antecedent may be satis�ed, in which case it is written as T; or unsatis�ed,when it appears as F. The conclusion may correspond to the expert's solution, written asH+; or not, H�. Thus we have the following four possibilities for rules with hypotheses asconclusions.� T ! H+ is behaving correctly. The example with the conclusion from this rule �ringwould be classed as a True Positive for H+, since both the expert and the system agree.� T! H� must be prevented from �ring. The example with the conclusion from this rule�ring would be classed as a False Positive for H�, since the expert conclusion is H+.� F ! H+ should be allowed to �re. This rule does not �re so this example is a FalseNegative for H+, if there is no rule of the form T ! H+.� F ! H� is behaving correctly.We note that re�nements are directed towards only two of the above classes, namely:� error-causing rules have the form T ! H�; and� target rules have the form F ! H+.2.2 Rule Classi�cation with Con ict ResolutionWhen the KBS includes a con ict resolution strategy rather than returning all possible solu-tions (e.g. all diagnoses), the situation is more complicated. In particular, for a rule to �re,and thus to provide a conclusion, not only must its antecedent be satis�ed, but also, it mustbe selected by the con ict resolution strategy, in preference to other satis�ed rules. We makea �ner classi�cation of both the error-causing and target rules. During the rule classi�cationphase, it is easy to probe further the reasons for each classi�cation, and these de�ne high-levelaims for suitable re�nements, later. The �ner classi�cation is:5

� error-causing rules are partitioned as follows:{ the Error-causing rule is the rule whose antecedent is satis�ed and it wins thecon ict resolution (this rule �res);{ the Potentially Error-causing rules are all the other satis�ed rules whose con-clusion is an hypothesis other than the expert's.� target rules are split as follows:{ No Fire rules fail, only, because their antecedent is not satis�ed (they are alreadycapable of winning the con ict resolution);{ Can Fire rules have a satis�ed antecedent but they fail because they do not winthe con ict resolution; and{ NoCan Fire rules fail because, both, their antecedent is not satis�ed and theydo not win the con ict resolution.2.3 A Simple ExampleTable 1 shows a very simple wine-advising KB containing only 5 rules. We assume a con ictstrategy that chooses the �rst rule that is satis�ed.R1: IF body is medium AND colour is red AND origin is Other Europe yTHEN recommend Bulgarian Cabernet SauvignonR2: IF body is medium AND colour is red AND price is under $5THEN recommend Cotes du RhoneR3: IF colour is red AND origin is Other Europe AND price is under $4THEN recommend Bulgarian Cabernet SauvignonR4: IF colour is red AND the origin is France AND price is under $5THEN recommend BeaujolaisR5: IF colour is red AND body is medium to fullTHEN recommend Bulgarian Cabernet Sauvignony The class Other Europe contains the European countries other than France, Germany and Italy.Table 1: A Simple KBSuppose we want a recommendation for someone who likes a wine with the followingcharacteristics: a French-style, red wine with medium body, priced at $3.50. Therefore thefollowing conditions will be satis�ed: an origin containing France, the colour red, a bodycontaining medium, a price limit of more than $3.50. However, suppose the expert decidesthat the price is too low to buy a French wine of this type and recommends BulgarianCabernet Sauvignon! We note that the KBS suggests Cotes du Rhone; rule R2 being the �rstsatis�ed rule. Because the expert and KBS disagree, this training case triggers re�nement ofthe KB. 6

As a �rst step, KRUST classi�es the rules for the training task according to the de�nitionsin Section 2.2. This is done by considering the truth of each condition and the recommendationin the conclusion. If we extend the notation above so that t and f represent the truth ofconditions, rather than the whole antecedent, we get the simpli�ed rule representation shownin Table 2. R1: t ^ t ^ f ! H+ R4: t ^ t ^ t ! H�R2: t ^ t ^ t ! H� R5: t ^ t ! H+R3: t ^ f ^ t ! H+Table 2: Truths for the Simple KBWe can easily classify the rules as:No Fire R1Error-causing R2NoCan Fire R3Potentially Error-causing R4Can Fire R5We note that there may be any number of rules in each class, except for Error-causing; itwill have at most one member for this con ict resolution strategy. Also, if there is no Error-causing rule (i.e. the KBS gives no solution), then there can be no Potentially Error-causing,Can Fire nor NoCan Fire rules; all the classi�ed rules must be No Fire rules1.3 Re�nement GenerationThe re�nement phase will produce possible re�nements that should remove the faults identi-�ed by the training case. The general aim is to prevent error-causing rules from �ring, andto enable target rules to �re instead. An error-causing rule can be prevented from �ring by:� specialising any one of its conditions so that it is no longer satis�ed; or� giving the rule a lower precedence with respect to the con ict resolution strategy.In contrast a target rule can be enabled to �re by:� generalising all unsatis�ed conditions so that they are now satis�ed; and/or� giving the rule a higher precedence with respect to the con ict resolution strategy.Alternatively new rules may be added and given a higher precedence than the Error-causingrule. Of course the various classi�cations of rules interact to provide a variety of suitablere�nements. We now focus on the di�erent types of target rule one at a time, and specifychanges that can make them �re correctly.1None of the rules that conclude an hypothesis is satis�ed, because the �rst would be the Error-causing.Therefore all the classi�ed rules are not satis�ed. They are No Fire, not NoCan Fire rules, because each wouldwin the con ict resolution strategy if they were satis�ed; having no competitors!7

3.1 Rule Classi�cation Assists Re�nementNo Fire rules have failed to �re because they contain at least one unsatis�ed condition.Each No Fire rule generates one re�nement: generalise all its unsatis�ed condition(s).The Error-causing rule can be corrected by simply changing its conclusion from H� to thecorrect solution, H+. Other corrections involve target rules and are described below.Can Fire rules have failed to �re, only, because they have not won the con ict resolution;i.e. they are satis�ed but the Error-causing rule (and possibly some potentially error-causing rules) has a higher priority under the con ict resolution strategy. Our simplecon ict resolution strategy uses rule order to select a \winning" rule. Thus favouring isachieved by moving a rule up in the KB, and similarly penalising is achieved by movinga rule down. Each Can Fire rule may generate several re�nements as follows:� move the Can Fire rule above the Error-causing rule; or� prevent the Error-causing, and each of the Potentially Error-causing rules with ahigher precedence, from �ring by either:{ specialising one of its conditions; or{ moving it below the Can Fire rule.NoCan Fire rules have failed to �re not only because they have too low a precedence, butalso because they are not satis�ed. They are enabled to �re by combining a No Fireand a Can Fire re�nement:� generalise the unsatis�ed conditions in the NoCan Fire rule; and allow it to �reby:{ moving the NoCan Fire rule above the Error-causing rule; or{ for the Error-causing, and each of the Potentially Error-causing rules with ahigher precedence, specialising one of its conditions or moving it down belowthe NoCan Fire rule.New rules may also be acquired and inserted. KRUST simply builds a new rule whoseantecedent is the conjunction of facts in the task and whose conclusion is the expert'sconclusion H+. In the future this will be improved by applying a suitable knowledge-based induction method, a technique commonly used by theory revision systems.23.2 AlgorithmFigures 3 - 5 contain the pseudocode for re�nement generation. Figure 3 contains the overallre�nement generation steps and Figure 4 describes the various changes to allow a Can Firerule to �re. A description of the enable and disable procedures are postponed until Figure 5since Section 3.4 is devoted to dealing with rule chains when weakening and strengtheningrules. In all these �gures we adopt the terminology that RefsList is a list of re�nements, eachof which is a list representing a conjunction of individual rule changes. Thus each member ofRefsList can be considered to be a complete re�nement. PartialRefsList is a list, each of whose2KRUST does not have the same reliance on learning new rules and conditions as many theory revisionsystems because it is not restricted to simply removing rules or conditions, see Section 5.8

members is a list of re�nements to achieve a partial e�ect, and these partial e�ects must beconjoined to achieve the desired re�nement. Thus one complete re�nement is formed by takingthe conjunction of one partial re�nement selected from each of the lists in PartialRefsList. Wecan consider RefsList to be a set of re�nements expressed in Disjunctive Normal Form (DNF),whereas PartialRefsList is a set of re�nements expressed in Conjunctive Normal Form (CNF).Thus the procedure demorgan, to convert CNF to (and from) DNF, in particular convertsre�nements expressed as PartialRefsList to a standard RefsList representation.getrefs(Classified-Rules, Expert)\rule{0em}{3ex}RefsList = [], PECs = [], ECfound = false, CanFire1 = falsefor each Rule in Classified-Rulesif CFfoundthen add new(Facts, Expert, PECs) to RefsListreturn RefsListelse case RuleNoFire: append enable(Rule) to RefsListErrorCausing: ECfound = trueadd Rule to PECsNewECRule = Rule.conditions -> ConcNewECRef = replace Rule with NewECRuleadd NewECRef to RefsListPErrorCausing: Add Rule to PECsCanFire: CanFire1 = Ruleappend canfirerefs(Rule, PECs, CanFire1) to RefsListNoCanFire: ERef = enable(Rule)CanRef = canfirerefs(Rule, PECs, CanFire1)append demorgan([ERef, CanRef]) to RefsListif PECs is emptythen NewPrec = minimum precedence of all rules in KBelse NewPrec = maximum precedence of all rules in PECsNewRef = insert rule: conjunction of Facts -> Expert with NewPrecadd NewRef to RefsListreturn RefsList Figure 3: Re�nement Generation Algorithm3.3 The Simple Example ContinuedWe now generate re�nements for the simple example introduced in Section 2.3. The re�ne-ments will be displayed here as follows:Rule Classi�cation (E�ect)# Description of re�nement(s)where # is the number of re�nements generated.9

canfirerefs(Rule, PECs, CanFire1)PartialRefsList = []for each RuleToStop in PECsDown = assign RuleToStop a lower precedence than RuleDisablers = disable(RuleToStop)add Down to Disablersadd Disablers to PartialRefsListif not CanFire1then UpCF = assign Rule a higher precedence than CanFire1add UpCF to PartialRefsListPrecedence = maximum precedence of all rules in PECsUp = assign Rule a precedence of PrecedenceRefsList = add Up to demorgan(PartialRefsList)return(RefsList) Figure 4: Re�nements to Fire CanFire RulesNo Fire (R1 will �re)1 Generalise the false condition in R1.Error-causing (R2 will �re correctly now)1 Replace H� in R2 by H+.Can Fire (R5 will �re)1 Move R5 above R2.9 Prevent R2 from �ring by specialising any one of its 3 conditions and similarly preventR4 from �ring by specialising any one of its 3 conditions.1 Move R2 and R4 below R5.3 Prevent R2 from �ring by specialising any of its 3 conditions and move R4 below R5.3 Prevent R4 from �ring by specialising any of its 3 conditions and move R2 below R5.NoCan Fire (R3 will �re)1 Allow R3 to �re by generalising its false condition and move R3 above R2.3 Allow R3 to �re by generalising its false condition and prevent R2 from �ring by spe-cialising any one of its 3 conditions.1 Allow R3 to �re by generalising its false condition and move R2 below R3.10

New Rule (New Rule will �re)1 Insert, above R2, the new rule:R01: IF body is medium AND colour is red AND origin is FranceAND price is under $3.50THEN recommend Bulgarian Cabernet SauvignonThis example generates a total of 25 re�nements. We note however that all the rules inthis KB contain conclusions that are hypotheses; i.e. wine recommendations. The followingsection describes the generation of re�nements for KBs containing rule chains.3.4 Chaining RulesAdditional re�nements can be generated when the KB contains rules that chain; i.e. theconclusion of one rule may appear as a condition in another. In addition to generalising orspecialising conditions in the target or error-causing rules directly, the rules' �ring abilitycan be a�ected by altering rules whose conclusion matches the condition. We note howeverthat the initial classi�cation of rules is una�ected. Figure 5 contains the enable/disablealgorithms for rules which generalise/specialise conditions in the current rule or undertakesuitable changes in other rules in the chain. We can generalise a condition C by:� weakening the condition C itself; or� allowing any rule, concluding C, to be satis�ed, so that this rule satis�es condition Cin the original rule. This secondary rule is currently not satis�ed so it must have atleast one unsatis�ed condition. This condition, itself, may be generalised directly, or itin turn may be satis�ed by altering the next rule in the rule chain.Similarly, we can specialise a condition C by:� strengthening the condition C itself; or� preventing all satis�ed rules, concluding C, from being satis�ed, so that they preventcondition C in the original rule from being satis�ed. A condition in each of thesesecondary rules must be specialised directly, or they in turn may be prevented frombeing satis�ed by altering all the rules one more step along the rule chain.3.5 A Chaining ExampleWe now extend the simple example introduced in Section 2.3 with additional chaining rulesas shown in Table 3. The training case is also adapted to utilise these additional rules:� we want a recommendation for someone who likes a French-style, red wine to drinkwith chicken in a red wine sauce for $3.50. Therefore the following conditions will besatis�ed: an origin containing France, the colour red, a meal containing some form ofchicken, a sauce containing red wine, a price limit more than $3.50; and� the expert still recommends Bulgarian Cabernet Sauvignon.11

enable(Rule)PartialRefsList = []for each unsatisfied condition C in RuleRefineHere = generalise C in RuleRefineInChain = enable-any(C)add [RefineHere, RefineInChain] to PartialRefsListreturn demorgan(PartialRefsList)enable-any (C)RefsList = []for each Rule whose conclusion matches Cappend enable(Rule) to RefsListreturn RefsListdisable(Rule)RefsList = []for each condition C in RuleRefineHere = specialise C in RuleRefineInChain = disable-all(C)append [RefineHere | RefineInChain] to RefsListreturn RefsListdisable-all (C)PartialRefsList = []for each satisfied Rule whose conclusion matches Cadd disable(Rule) to PartialRefsListreturn demorgan(PartialRefsList)Figure 5: Enabling and Disabling AlgorithmsTable 4 contains the truth patterns as before, except now we have labelled truths which aredependent on other rules with the subscript corresponding to the rule, for identi�cation. Wenote that the truth pattern for rules R1 to R5, and hence the rule classi�cation, is unchangedfrom Section 2.3.However, the re�nement generation is more proli�c, since changes to rules R6, R7 and R8are included. In the following, only the additional re�nements generated are described.No Fire (R1 will �re)1 Generalise the false condition in R6 to satisfy R6 and hence the false condition in R1.Can Fire (R5 will �re)12 Prevent R2 from �ring by preventing both R7 and R8 from being satis�ed by specialisingeither of their conditions, and specialise R4 as before (R4 specialisations are una�ectedbecause there are no suitable chains). 12

R1: IF body is medium AND colour is red AND origin is Other EuropeTHEN recommend Bulgarian Cabernet SauvignonR2: IF body is light to medium AND colour is red AND price is under $5THEN recommend Cotes du RhoneR3: IF colour is red AND origin is Other Europe AND price is under $4THEN recommend Bulgarian Cabernet SauvignonR4: IF colour is red AND the origin is France AND price is under $5THEN recommend BeaujolaisR5: IF colour is red AND body is medium to fullTHEN recommend Bulgarian Cabernet SauvignonR6: IF body is full AND colour is red AND price is under $3.50THEN origin is Other EuropeR7: IF meal is chicken AND sauce is red wineTHEN body is medium to fullR8: IF meal is chicken AND colour is redTHEN body is light to mediumTable 3: A Chaining KBR1: t ^ t ^ f6 ! H+ R5: t ^ t7 ! H+R2: t8 ^ t ^ t ! H� R6: f ^ t ^ t ! f6R3: t ^ f6 ^ t ! H+ R7: t ^ t ! t7R4: t ^ t ^ t ! H� R8: t ^ t ! t8Table 4: Truths for the Chaining KB4 Prevent R2 from �ring by preventing both R7 and R8 from being satis�ed by specialisingeither of their conditions, and move R4 below R5.NoCan Fire (R3 will �re)4 Allow R3 to �re by generalising its false condition directly and prevent R2 �ring bypreventing both R7 and R8 from being satis�ed by specialising either of their conditions.1 Allow R3 to �re by generalising the false condition in R6 to satisfy R6 and hence thefalse condition in R3, and move R3 above R2.3 Allow R3 to �re by generalising the false condition in R6 to satisfy R6 and hence thefalse condition in R3, and prevent R2 �ring by specialising any one of its 3 conditions.1 Allow R3 to �re by generalising the false condition in R6 to satisfy R6 and hence thefalse condition in R3, and move R2 below R3.13

4 Allow R3 to �re by generalising the false condition in R6 to satisfy R6 and hence thefalse condition in R3, and prevent R2 �ring by preventing both R7 and R8 from beingsatis�ed by specialising either of their conditions.New Rule (New Rule will �re)1 Insert, above R2, the new rule:R02: IF colour is red AND origin is France AND meal is chickenAND sauce is red wine AND price is under $3.50THEN recommend Bulgarian Cabernet SauvignonThe new rule re�nement replaces the earlier new rule re�nement. This new re�nementsimply has di�erent conditions, because the task has changed to utilise the additionalrules in the KB.This example generates 30 additional re�nements and 1 replacement re�nement, giving 55re�nements altogether.3.6 The Role of Con ict ResolutionThe approach used to favour or penalise Can Fire and NoCan Fire rules has been implementedfor rule order con ict resolution. However, we feel that this approach of reverse engineeringthe e�ect that is desired can be adapted to other con ict resolution strategies. In certaintyfactor systems where the rule with the highest certainty wins, a rule's certainty is increased tofavour a rule, or conversely decreased to penalise. Where a MYCIN-like integration functionselects the \winning" hypothesis by calculating the overall certainty from the contributionof possibly several rules, the increase (or decrease) must be shared out among the set ofrules whose certainties form the input for the integration function. These ideas are similarto the network back-propagation approach of RAPTURE (Mahoney & Mooney, 1994) onMYCIN-like KBs. Finally, we consider the standard OPS-5 strategies: speci�city and recency.Speci�city provides a rule ordering in the KB and so can be dealt with analogously to our ruleorder resolution but now alterations to the priority is dependent on altering the number ofconditions; increasing the priority would necessitate an induction component, unless prioritydecreases were su�cient. Recency is dynamically in uenced by the contents of the workingmemory and so increasing a rule's priority is equivalent to placing its requirements in workingmemory more recently, and hence is related to the �ring of other rules; in fact rearrangingthe subtrees in the solution graph. Recency will require a more extensive adaptation of ourapproach.4 Removing Unlikely Re�nementsThe re�nement phase has generated many possible re�nements, see Figure 1. These re�ne-ments are in the form of recipes to change the KB; e.g. generalise condition C in rule Ri,favour rule Ri over Rj under the con ict resolution, specialise condition C in rule Ri, etc.KRUST is able to reject some of these re�nements if it has reason to believe that they areunlikely to succeed. We note that this �ltering occurs before the changes to the KB are ac-tually implemented. Although some of this �ltering may be incorporated in a more selective14

generation procedure, this e�ciency has not been required to date. We have implemented 3�lters but these can be replaced, removed or added to, as appropriate.Removing Redundancy A re�nement contains redundant changes if a subset of the changesin the re�nement appears as another re�nement. The re�nement with the larger numberof changes therefore contains unnecessary changes to correct this training example and,since we wish to implement minimal changes, the re�nement with the larger number ofchanges is removed, even though it may give better overall performance.Not Changing \Good" Rules Meta-knowledge about rule quality can guide KRUST toreject a re�nement that alters a rule that is believed to be correct. This meta-knowledgemay be acquired from the expert if he is able to identify rules which he believes shouldnot be changed, or he may be able to assign a measure of belief to rules. For ourtesting, we assembled meta-knowledge by analysing the behaviour of the KB on a set oftask-solution pairs, see Section 6.2. The user de�nes a suitable threshold for the qualitymetric and KRUST removes any re�nements that contain generalising or specialisingchanges to rules whose quality meta-knowledge is below the threshold. Alternatively,if there is no way to judge the quality of rules in the KB then this �lter will have noe�ect.Preferring \Good" Re�nements There may be some quality metric for re�nementsthat orders the re�nements generated. In testing we decided that KRUST should favourre�nements containing few changes and the re�nements were ordered according to thenumber of changes they contained. An ordering metric like this allows KRUST to rejectsu�ciently many unfavoured re�nements to meet the knowledge engineer's limit on thenumber of re�ned KBs which should be implemented. Other metrics are possible: forsome con ict resolution strategies it may not be desirable to alter the precedence ofa rule (e.g. a rule's certainty is accurately determined) and in this case re�nementsfavouring or penalising rules should be removed.In the future we plan to make it possible to specify, during execution, which �lters to use.5 Implementing Re�nementsKRUST's re�nement generator and �lter mechanism provide the implementation phase withinstructions for possible changes to rules: generalise condition C in rule Ri, move rule Riabove rule Rj , change the conclusion of rule Ri, or insert rule R0i above rule Ri. The changesthat specify moving or inserting a rule, or changing a conclusion, are explicit, and need nofurther explanation. In contrast, the generalising and specialising instructions give the aim,but not the extent of changes and we now describe their implementation.KRUST uses a �ner generalising and specialising mechanism than the rule/condition dele-tion/addition approach of most re�nement systems. Instead, it changes the value in OAV con-ditions just enough to have the desired e�ect for the particular training task. If no suitablechange can be found, then KRUST reverts to the standard actions of removing the condi-tion as the ultimate generalisation, or removing the rule as the ultimate specialisation. Thisgradual changing of rule conditions means that KRUST does not need to rely on inductivemethods to put back into rules, information which has been removed during rule or conditiondeletion. 15

5.1 Background KnowledgeMany OAV triples belong to knowledge hierarchies which can be used to obtain the truthof conditions; e.g. a rule whose condition is origin(wine, Europe) is satis�ed by the fact ori-gin(wine, France) if it is known that France is a subclass of Europe. In such cases the \value"in the OAV is implicitly specifying a set of satisfying OAVs. For some KBS representationsthe knowledge is explicit; <(price, 5), but our KB representation uses price(wine, 5) withmeta-knowledge stating that price de�nes an upper bound. KRUST alters the condition sothat it is satis�ed by fewer or more OAVs. If no such hierarchy knowledge is available fora particular attribute then KRUST performs rule and condition deletion, like most otherre�nement systems.Each attribute is associated with meta-knowledge that speci�es the type of range repre-sented by the OAV value and an underlying structure of possible values. KRUST allows thefollowing types of range:two-sided: sweetness(wine, [dry, medium]) { the sweetness lies between dry and medium;upper-bounded: price(wine, 5) { the price is at most 5;lower-bounded: body(wine, medium!) { at least a medium-bodied wine;singletons: colour(wine, red) { a red wine.In our KB, each value in a condition appears as a pair for a two-sided range or a sin-gleton for single-sided ranges as well as singleton values; the semantics is contained in meta-knowledge. In this paper we have made the semantics explicit by inserting arrows to indicateranges. Conditions in other KBs may require di�erent ways to weaken and strengthen condi-tions. Hierarchies of related conditions must be provided in some as background knowledge.5.2 Changing ConditionsWe now describe how KRUST constructs a re�ned condition by altering the value within theOAV condition. The bounded ranges allow KRUST to choose suitable new values for OAVsfrom the hierarchies attached to an attribute. Singletons require an exact match and aretreated separately in Section 5.3.5.2.1 Numerical StructuresThe integers form a fully ordered set and so a condition is specialised by \shrinking" the range,until the training task is excluded. Conversely, a condition is generalised by \stretching" therange to include the training task. For two-sided ranges, KRUST moves whichever boundrequires the least change.Generalise [2, 5] to [M, 5] or [2, N], where M<2, N>52! to M!, where M<2 5 to N, where N>5Specialise [2, 5] to [M, 5] or [2, N], where M>2, N<52! to M!, where M>2 5 to N, where N<5We note that this approach applies to sets that are �nite, in�nite, discrete or continuous.However, with continuous sets a suitable increment will also be required within the attributemeta-knowledge. 16

5.2.2 Ordered ListsStructures that are ordered lists also de�ne a full ordering, and so analogous changes are made.Suppose the sweetness of wine is associated with the ordered list [very-dry, dry, medium,medium-sweet, sweet].Generalise [dry, medium] to [dry, medium-sweet], [dry, sweet]or [very-dry, medium]dry! to very-dry! medium to medium-sweet or sweetSpecialise [dry, medium] to [dry, dry] or [medium, medium]dry! to medium!, medium-sweet! or sweet! medium to dry or very-dry5.2.3 Partially Ordered Hierarchies
Loire
France
BurgundyBordeaux
Alsace Rhone
Europe
Other Germany
Rhine
USA Other
World
ItalyFigure 6: A Generalisation Hierarchy for Wine OriginGeneralisation hierarchies do not de�ne a full ordering, only a partial ordering. However,the method described above does not rely on the full ordering property of these structures.Thus, analogous changes can be made for attributes attached to generalisation hierarchies:by generalising to the least general covering concept and specialising to the most generalnon-covering concepts. Suppose the origin of wine has the hierarchy shown in Figure 6. Thehierarchy allows all values in a subtree to satisfy a condition whose value appears at the root17

of the subtree; i.e. origin(wine, Loire), and all its siblings, satis�es a condition of the formorigin(wine, France). Thus a condition in a rule is generalised by selecting its ancestor node;specialisation chooses a descendant node.Generalise France to EuropeSpecialise France to Loire, Rhone, Burgundy, : : :Specialisation introduces a particular problem since each child node is a possible specialisation.KRUST selects those children that are not satis�ed and creates one replacement rule for eachsuitable specialisation; equivalent to adding a disjunctive condition.These notions of gradual change extend the ideas of Wogulis & Pazzani (Wogulis & Paz-zani, 1993) from syntactic closeness to semantic proximity. Wogulis & Pazzani suggest thata syntactic distance metric between KBs is complementary to accuracy as a measure forcomparing the quality of revised theories with respect to the original. They de�ne the dis-tance between two theories to be the number of literal edits, but here a gradual alterationof an OAV value is only a partial edit and is not as drastic as an OAV addition or removal.KRUST's ability to alter KBs gradually, as well as preferring re�nements with few changes,is consistent with Wogulis' & Pazzani's idea that revisions a small distance from the originalmay be preferred, but extends the notion to semantic closeness.5.3 SingletonsThe term singleton refers to the type of range in the OAV and the associated meta-knowledgestructure of possible values may still be a numerical set, an ordered list, a generalisationhierarchy, or additionally, a totally unordered set. The underlying structure of possible valuesis irrelevant since an exact match is required for conditions of this type. Singleton conditionsare changed by adding or deleting a rule. Suppose the attribute colour has structure fred,white, ros�eg.Generalise red to any colour C 2 fred, white, ros�eg which is true and add acopy of the rule with this as the colour conditionSpecialise red by removing the ruleThese changes are equivalent to adding another disjunct to the condition in generalisationand removing the o�ending disjunct in specialisation, because in our representation disjunctsare expressed as multiple rules.6 Choosing the Best Re�ned KBSection 5 described how KRUST implements the re�nements as re�ned KBs. It now does afurther pruning, before executing a fairly sophisticated evaluation to identify the \best" KB.6.1 Pruning FailuresThe re�ned KBs can now be evaluated on a set of sample cases. We have identi�ed two typesof cases that can be used to reject KBs. KRUST must ensure that the Training Case,itself, is correctly solved, because, although the re�nements have been assembled to correctlysolve the training task, rule interaction may prevent this. KRUST also uses a set of specialtask-solution pairs, chestnuts; the expert has indicated that it is essential that these are18

answered correctly by the KBS. In particular, chestnuts may be the set of task-solution pairsalready used as training cases, or a set of prototypical cases on di�cult \borderline" tasks.KRUST rejects those re�ned KBs that answer the training case or a chestnut wrongly.6.2 Evaluating Re�ned Knowledge BasesKRUST's �nal step identi�es the most suitable from the remaining re�ned KBs. The initialset of generated re�nements may be huge, but after the two �ltering processes, a small numberof re�ned KBs remain; typically fewer than 10 in our testing. Therefore, it is worthwhile usinga fairly intensive empirical evaluation for the selection process. KRUST uses a compromisemethod between a simple accuracy metric and a complex bucket-brigade blame assignmentmethod (Holland, 1986). Two numerical slots, SPEC and GEN, are attached to each ruleand they indicate the level of evidence that the rule is too general or too speci�c. KRUSTgenerates the evidence for these slots by running the KB on a set of sample cases. Cases thatare incorrectly solved trigger KRUST's re�nement generator and every time a rule appearsin a generalising re�nement its GEN slot is incremented; similarly a specialising re�nementincrements the SPEC slot. The quality of the KB is inversely proportional to the averageblame for the rules in the KB, normalised to take account of correctly solved cases. KRUSTrecommends the KB with the lowest blame.AverageBlame = PR2KBmaxfSPECR; GENRgN � � � ��where SPECR, GENR = value of R's specialise, generalise counter;N = number of rules in KB; = number of correct sample cases;� = number sample cases;� = number of re�nements generated.Other KB metrics may be used to evaluate the remaining KBs instead of the blame metricdescribed here, or alternatively, it may be convenient for the user to make the decision aboutwhich KB is the most suitable. We have experimented with accuracy as a metric but it is notsu�ciently discriminating and our metric is rarely in disagreement with the accuracy ranking.For the runs described in Section 7.2.1:� our metric recommends on average 1.1 best re�ned KBs whereas the accuracy metriccannot distinguish between 6.1 re�ned KBs;� the accuracy metrics could not separate the remaining re�ned KBs in 12 of the 15 runs;and� the rankings by our metric and the accuracy metric di�ered (slightly) in only 3 of the15 runs, and any disparity did not a�ect the re�ned KB which was recommended.7 EvaluationThis section describes our testing of KRUST. Readers who are expecting to �nd standardlearning curves showing the accuracy of the original and learned results will be disappointed.The aim of KRUST is not to alter the KB so that it now works correctly on a large set of19

examples. Instead we wish to make small changes to the KB which will �x individual bugsthat are identi�ed by the expert. Since standard train/test routines are neither feasible nordesired we have instead attempted to evaluate several di�erent aspects of KRUST's re�nementperformance. We have also included some standard accuracy results but these demonstratethe inconclusive nature of this type of testing in these circumstances. We have performedexperiments that try to answer the following questions:� Can KRUST cope with the generation and management of multiple re�nements whenit improves a faulty KB? (Section 7.1)� Do the re�ned KBs provide increased accuracy? (Section 7.2)� Can intentional corruptions of KBs be identi�ed and recti�ed? (Section 7.3)� Is the overhead of managing multiple re�nements justi�ed by the variety of the set ofKBs recommended? (Section 7.4)The testing reported in this paper is based on a wine advising KB, containing approxi-mately 200 rules with 1-3 conditions and normally producing proof trees of depth 2 or 3. TheKB contains OAVs built from 10 attributes.7.1 Improving a Faulty KBThis section describes testing where KRUST's aim was to repair the KB so that wronglysolved cases would now be answered correctly. Here we investigate whether KRUST is ableto manage all the possible re�nements it generates by pruning unsuitable re�nements earlyenough in the cycle.7.1.1 Constructing Data for this ExperimentKRUST's learning mechanism uses a set of task solution pairs as follows:� a training case provides evidence that a fault exists and is used to generate re�nements;� a set of chestnut cases rejects unsuitable re�ned KBs; and� a set of sample cases ranks the re�ned KBs with respect to accuracy.We constructed synthetic task-solution pairs for use as training, chestnut and sample cases.Testing was undertaken in 4 batches; we �rst outline the data required for a batch of testruns, before specifying exactly how the task-solution pairs were prepared.The data for a batch of testing consisted of 15 correctly-solved task-solution pairs and 15wrongly-solved task-solution pairs. Each of the 15 wrongly-solved cases was chosen in turn asthe training case for a run, with the remaining 14 wrongly-solved cases being used as samplecases for this run. Ten of the correctly-solved cases were selected as the chestnut cases for alltest runs. The remaining 5 correctly-solved cases were added to the set of sample cases for atest run. Figure 7 contains an illustration of this construction. For each batch of testing, therule quality meta-knowledge was formed by statistically allocating the blame to the rules inthe KB according to the the set of 20 sample cases in this batch; i.e. the 15 wrongly-solvedand 5 correctly-solved. 20

Training Case
Correctly-SolvedTask-Solution
Pairs
Chestnuts
Wrongly-SolvedTask-Solution
Pairs
Sample Cases
Figure 7: Creating Testing DataWe now describe how the data for 4 batches of 15 test runs were created. The correctly-solved task-solution pairs were generated once and used for all 4 batches. The wrongly-solvedcases were formed by constructing a set of 15 tasks and pairing each with a solution accordingto the batch being constructed.Batch 1: Each task was paired with the KBS's second solution. (Our KBS used Prolog'scontrol and so we could get all possible solutions in the order they were found).Batch 2: Each task was paired with the KBS's second or third solution (73% of tasks werepaired with the third solution).Batch 3: Each task was paired with any of the KBS's solutions, except the �rst, or a solutionwhich did not appear in the KBS's solutions (33% had no KBS solution and the averageposition in the solutions of the rest was 3.6).Batch 4: The solution for each of the training tasks was chosen randomly from the pairedsolution in batches 1, 2 or 3 (13% had no KBS solution and the average position in thesolutions of the rest was 2.7).In summary, 4 sets of test data have been produced. Each set consists of 10 chestnutcases, 5 correctly-solved sample cases, and 15 wrongly-solved sample cases, each of which isused as a training case for a test run. Batch 1 contains the least demanding task-solutionpairs, batch 2 is of intermediate di�culty, batch 3 is the most demanding, and batch 4 israndomly selected from the other 3 batches. Batch 4 provides an assorted level of di�cultyand therefore consists of a fairly realistic mixture of wrongly-solved cases. An alternativeview is that batch 1 is re�ning a KB with only 1 error, for batch 2 the KB can have 2 errors,in batch 3 several errors may occur in the KB and again batch 4 is mixed.7.1.2 Feasibility to Manage Multiple Re�nementsThis analysis aims to show that although KRUST proposes all possible re�nements initially,it is able to increasingly constrain the number of re�nements actually implemented and �nallyevaluated. For this experiment, we analyse the number of re�nements initially generated andthe e�ectiveness of the �ltering procedures for the 60 test runs constructed above.21

Table 5 shows the number of re�nements generated and implemented, the number ofre�ned KBs evaluated, and the number of KBs �nally recommended. These �gures aredisplayed as the average, maximum and minimum number for each batch, and also for allthe test runs. The results demonstrate that in practice the number of re�nements generatedremains manageable, the �ltering processes are e�ective at ensuring that the implementationand evaluation phases are applied to an appropriately small number of re�nements.Number ofBatch Measure Re�nements Re�ned KBs Re�ned KBs Re�ned KBsGenerated Implemented Evaluated Recommended1 Average 39.9 17.8 6.3 1.7Minimum 10 10 1 1Maximum 191 33z 12 42 Average 76.1 24.4 10.2 1.3Minimum 14 6 1 1Maximum 166 38z 20 23 Average 250.7 13.7 5.2 1.3Minimum 4y 4 1 1Maximum 1409y 34 11 44 Average 98.2 20.3 8.7 1.1Minimum 10 7 1 1Maximum 516 33z 20 2All Average 116.2 19.1 7.6 1.4Minimum 4y 4 1 1Maximum 1409y 38z 20 4Table 5: Number of Re�nements and Re�ned KBsIn fact, KRUST has a mechanism to control the number of re�nements being generated,but this rarely needs to be used. It comes into e�ect when a particular re�nement aim(altering the satisfaction of a particular condition in a particular rule) can be realised in avery large number of ways, because many other rules may be changed that a�ect the truthof this condition. KRUST anticipates this and therefore does not generate them all. We notethat the re�nements that have been prevented from being generated normally contain a largenumber of changes, and that �ltering removes long re�nements later, anyway. In our testing,this threshold was set to 1000 and runs in which such re�nements have been removed aremarked y in Table 5. We also restricted to 40 the number of re�nements to be implementedby pruning those re�nements containing the largest number of changes; runs in which thisheuristic a�ected the number of re�nements are marked z in Table 5.The results in the rightmost column of Table 5 may seem counter-intuitive; Batch 1contains the easiest re�nement tasks but recommends the largest number of re�ned KBs.However, the di�culty of the re�nement task a�ects the number of possible re�nementsproposed, whereas the number of re�ned KBs recommended depends on the similarity of thechanges as judged by their a�ect on the set of sample cases. It seems quite reasonable thatsince Batch 1 repairs are smaller they do not have a great a�ect on the sample cases and sothey are more di�cult to di�erentiate. The fact that small tweakings of the KB to �x singlefaults do not greatly a�ect the overall accuracy (although they completely �x the input fault)22

will be addressed in the next section.A theoretical analysis (Craw, 1991) shows that the number of re�nements is exponentialwith respect to the lengths of deductions, because the re�nements are generated by searchingthe proof trees of the KB. However, the number of proof trees that are accessible from H+ andH� depends on the size of the sets of No Fire, Can Fire, NoCan Fire and Potentially Error-causing rules for a particular training case, and in practice these sets are small as illustratedin Table 6. In addition, large portions of the search space need not be explored at all, as wasshown in Figure 2.Batch No Fire Potentially Error-causing Can Fire NoCan Fire1 0.8 1.7 1.1 0.82 0.8 2.1 1.0 0.73 0.8 1.9 0.8 0.94 0.8 1.8 0.9 0.8All 0.8 1.9 1.0 0.8Table 6: Average Number of Rules in Each Classi�cation7.2 Accuracy of Re�ned KBsThis section compares the accuracy achieved by the original KB and the re�ned KBs. Wenote that KRUST contains an evaluation phase within its execution. Thus the best re�nedKB is best according to this evaluation. Also it is possible to incorporate other evaluationmetrics at this stage, depending on the overall goal of the improvement.The �rst set of results considers the accuracy of re�ned KBs produced by the runs de-scribed in the previous section when applied to the training data. The second evaluationapplies a more rigorous approach by randomly partitioning the data into training and testingsets.7.2.1 Accuracy from Original RunsEach batch of testing in the previous section used a dataset of 30 task solution pairs. However,the datasets for batchi and batchj (for di�erent i and j) are mutually inconsistent since, forthe training cases, they assign di�erent expert solutions to the same tasks. We have chosento use the data from batch 4 and therefore have only 30 task solution pairs. However, allthese cases have already been used during KRUST's re�nement: one task solution pair as thetraining case, 10 as chestnuts to reject any re�ned KBs which fail for them, and the remaining19 as samples cases to rank the re�ned KBs. Thus, we do not have access to an independenttesting set.We have compared the accuracy of each re�ned KB with the original KB. The original KBachieves a 50.0% accuracy with respect to the expert's solutions averaged over the 30 Batch 4tasks. When KRUST is applied to �x the KB for the training case the best re�ned KB achievesan accuracy of 54.7% averaged over the 30 tasks and the 15 test runs. We note that in eachrun we have re�ned the KB using one task-solution pair and used the remaining task-solutionpairs to heuristically select the most promising re�nements. Therefore, we expect the re�nedKB to correctly solve at least one more case (the training case), to not answer correctly many23

(or even any) previously wrongly solved sample cases, but probably not to answer wronglyany previously correctly answered sample or chestnut cases, since the training case, chestnutsand sample cases have all been used to select the best re�ned KB. An analysis of the increasedaccuracy showed that in 3 runs 3 previously wrongly solved cases were correctly solved bythe re�ned KB and in the remaining 12 runs only 1 wrongly solved case was improved. Wealso note that the best re�ned KB will normally necessarily achieve an accuracy of at least37% since only re�ned KBs which answer the 1 training and 10 chestnut cases correctly arenormally retained.7.2.2 Accuracy with Distinct Training/Testing SetsThe data from batch 4 was again used, this time for a standard train/test evaluation wherethe 30 cases were randomly split into 2 equal training and testing sets. For each train/testrun, KRUST's training case was selected as before and the remaining 29 task-solution pairswere randomly partitioned into a set of 14 sample cases to be used by KRUST to choose thebest re�ned KB3 and a testing set of 15 cases to evaluate the re�ned KB with respect to theoriginal KB.We have compared the accuracy of each re�ned KB with the accuracy of the original KBfor the independent set of testing cases. The original KB achieves a 52.9% accuracy withrespect to the expert's solutions averaged over the 15 testing tasks. The average accuracy ofthe re�ned KBs is also 52.9% averaged over the 15 runs of KRUST. An analysis of the changesin accuracy showed that in 9 runs there was no overall change in the number of correctly solvedcases, 2 runs showed one fewer correctly solved case, 1 run showed three fewer, 1 run gainedone correctly solved case and 2 runs showed a gain of two. These results are much more variedthan the results in the previous section, consistent with the independence of the training andtesting sets. They con�rm our belief that this type of evaluation is unsuitable for systemswhich have access to only a small number of examples.For completeness we have compared the accuracy of each re�ned KB with the original KBon the training and sample cases for each run, as in Section 7.2.1. The original KB achieves a47.1% accuracy with respect to the expert's solutions averaged over the training case and 14sample cases. When KRUST is applied to �x the KB for the training case the best re�ned KBachieves an accuracy of 54.2% averaged over the 15 tasks and the 15 test runs. An analysisof the increased accuracy showed that in only 1 run two previously wrongly solved cases werecorrectly solved by the re�ned KB and in the remaining 14 runs only one wrongly solved casewas improved.Although our main concern is accuracy, we include a view of the complexity of re�nementgeneration for KRUST with this reduced training set of 1 training case and 14 sample cases;Table 7 compares these runs with the original batch 4 runs. The generation of possiblere�nements and the �ltering and implementation of these re�nements were totally una�ectedsince they do not rely on chestnut or sample cases. In contrast, having no chestnut cases toreject some re�ned KBs increases the number of re�ned KBs to be evaluated, and the smallerset of sample cases means that the evaluation is less discriminating and so more than 1 re�nedKB is recommended as best in more runs than with the original data.3There are only 15 cases for re�nement so we decided to have an empty set of chestnut cases.24
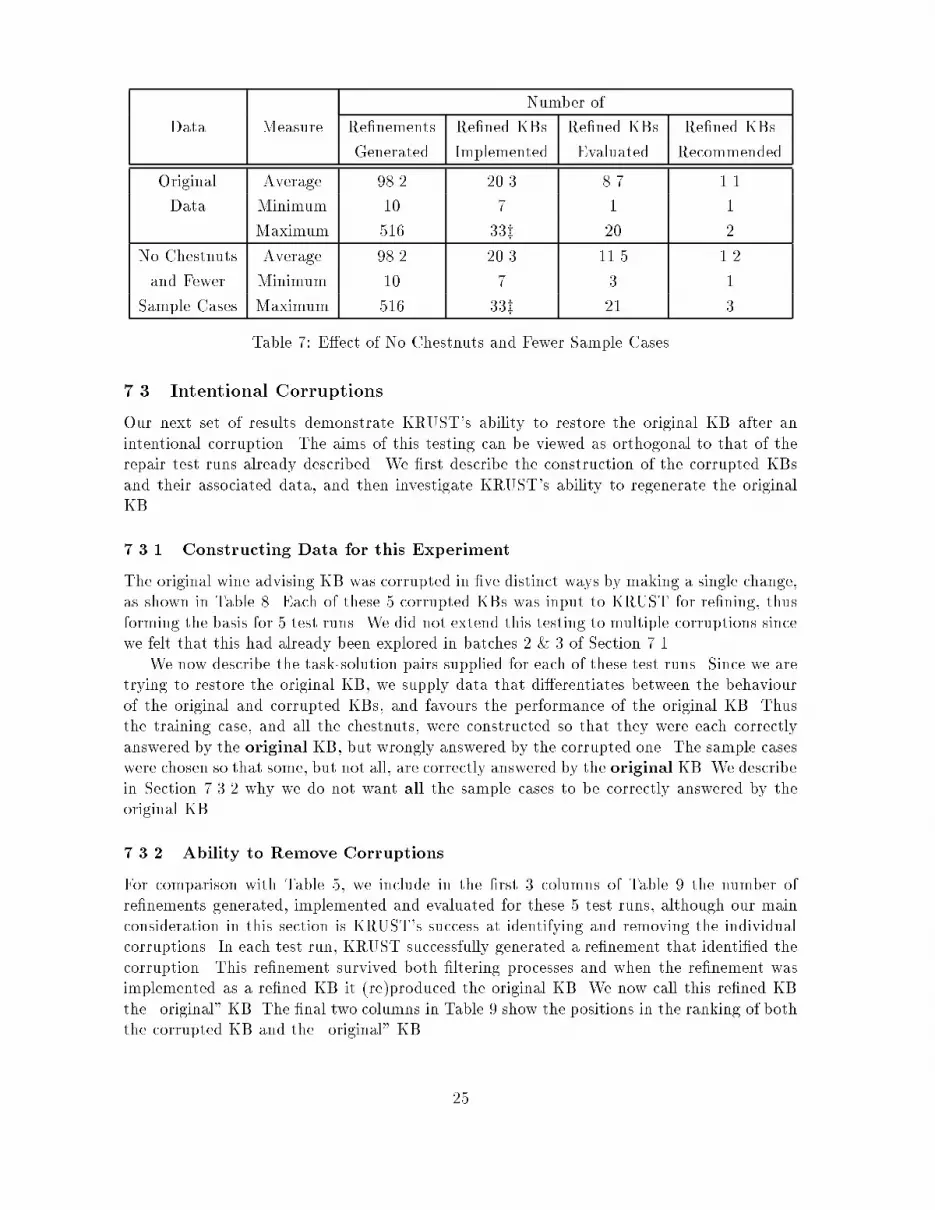
Number ofData Measure Re�nements Re�ned KBs Re�ned KBs Re�ned KBsGenerated Implemented Evaluated RecommendedOriginal Average 98.2 20.3 8.7 1.1Data Minimum 10 7 1 1Maximum 516 33z 20 2No Chestnuts Average 98.2 20.3 11.5 1.2and Fewer Minimum 10 7 3 1Sample Cases Maximum 516 33z 21 3Table 7: E�ect of No Chestnuts and Fewer Sample Cases7.3 Intentional CorruptionsOur next set of results demonstrate KRUST's ability to restore the original KB after anintentional corruption. The aims of this testing can be viewed as orthogonal to that of therepair test runs already described. We �rst describe the construction of the corrupted KBsand their associated data, and then investigate KRUST's ability to regenerate the originalKB.7.3.1 Constructing Data for this ExperimentThe original wine advising KB was corrupted in �ve distinct ways by making a single change,as shown in Table 8. Each of these 5 corrupted KBs was input to KRUST for re�ning, thusforming the basis for 5 test runs. We did not extend this testing to multiple corruptions sincewe felt that this had already been explored in batches 2 & 3 of Section 7.1.We now describe the task-solution pairs supplied for each of these test runs. Since we aretrying to restore the original KB, we supply data that di�erentiates between the behaviourof the original and corrupted KBs, and favours the performance of the original KB. Thusthe training case, and all the chestnuts, were constructed so that they were each correctlyanswered by the original KB, but wrongly answered by the corrupted one. The sample caseswere chosen so that some, but not all, are correctly answered by the original KB. We describein Section 7.3.2 why we do not want all the sample cases to be correctly answered by theoriginal KB.7.3.2 Ability to Remove CorruptionsFor comparison with Table 5, we include in the �rst 3 columns of Table 9 the number ofre�nements generated, implemented and evaluated for these 5 test runs, although our mainconsideration in this section is KRUST's success at identifying and removing the individualcorruptions. In each test run, KRUST successfully generated a re�nement that identi�ed thecorruption. This re�nement survived both �ltering processes and when the re�nement wasimplemented as a re�ned KB it (re)produced the original KB. We now call this re�ned KBthe \original" KB. The �nal two columns in Table 9 show the positions in the ranking of boththe corrupted KB and the \original" KB. 25

KB Original Rule(s) CorruptionA IF colour is redAND origin is Europe origin is Other EuropeAND body is medium to fullTHEN recommend RiojaB IF colour is redAND origin is EuropeAND body is medium to fullTHEN recommend Rioja recommend Bulgarian Cabernet SauvignonC IF colour is redAND origin is EuropeAND body is medium to fullTHEN recommend Rioja Interchange these rulesIF colour is redAND origin is EuropeAND body is mediumTHEN recommendBulgarian Cabernet SauvignonD IF colour is redAND origin is France origin is EuropeAND body is mediumTHEN recommend Red BurgundyE IF ingredient of meal is non-meat ingredient of meal is vegetableTHEN colour is red Table 8: Simple CorruptionsNumber of Position in Ranking ofRun Re�nements Re�ned KBs Re�ned KBs Original CorruptedGenerated Implemented Evaluated KB KBA 41 23 3 4th 2ndB 219 9z 2 2nd 3rdC 16 11 6 3rd 4thD 16 11 6 5th 7thE 35 19 8 2nd= 9thAverage 65.4 14.6 5 3rd 5thTable 9: Restoration Test Runs26

We note that in all but one run, the \original" KB was ranked higher than the corruptedKB, but it was never rated best. We believe that this is partially explained by the choice ofthe sample cases. In the extreme case, where the sample cases are chosen so that they areall answered correctly by the original KB, then it is guaranteed that the \original" KB isgiven the best ranking, since it has zero blame for these sample cases. However our samplecases were intentionally not so biased towards the original KB.7.4 Varied Set of Changes RecommendedOur criticism of many re�nement systems is that they choose the re�nement to be executedby considering similarities in the training examples and often without further justi�cation toeliminate problems caused by interacting rules. Many systems use a \hill-climbing" heuristicwhere changes a�ecting the most training examples are selected with no regard to training ex-amples that need additional, perhaps unpopular, changes before they are correctly answered.In contrast, KRUST is able to perform a \best �rst" search by continuing to investigate severalre�nements before �nally deciding, when additional, more dependable, evidence is available.However, KRUST's approach would be overly cumbersome if the recommended re�ned KBscontained changes of predominantly one type. This section investigates the variety of changesapplied for the recommended re�ned KBs.7.4.1 Constructing Data for this ExperimentNo new data was constructed for this experiment. Instead, we analysed the changes imple-mented in the re�ned KBs recommended by the test runs from Sections 7.1 & 7.3.7.4.2 Changes RecommendedFor this evaluation, we identi�ed the type of changes implemented in the recommended re�nedKB from each test run. We categorised these changes as:� No Fire rule �res { it is generalised;� Error-causing rule �res { its conclusion is changed;� Can Fire rule �res { its precedence is raised or Error-Causing and Potentially Error-causing rules are prevented from �ring (by lowering their precedence or specialisation);� NoCan Fire rule �res { it is generalised and Can Fire changes are implemented;� New rule �res { it is inserted.In this categorisation, rules may be generalised (or specialised) both directly within the rule orelsewhere in the rule chains, as described in Section 3.4. Table 10 shows this analysis for the60 test runs from Section 7.1 (Batches 1{4) and the 5 \corrupted" test runs from Section 7.3.An alternative analysis, categorising the actual operations applied to form the recommendedKBs, appears in (Craw, 1991). We note that although we analysed 65 test runs, 72 re�nedKBs were inspected, since some test runs �nally recommended more than one re�ned KB.Although the majority of changes a�ected the �ring of Can Fire rules, these were achievedwith a variety of changes consisting of combinations of specialising (Potentially) Error-causingrules, lowering the priority of (Potentially) Error-causing rules, or raising the priority of Can27

Batch Number of Type of Rule Firing in Best Re�ned KBRe�ned KBs No Fire Error-Causing Can Fire NoCan Fire New1 18 0 3 13 0 22 16 0 2 11 1 23 16 0 1 5 2 84 17 1 0 10 1 5Corrupted 5 0 1 1 0 3All 72 1 7 40 4 20Table 10: Rule Firing Correctly in Best Re�ned KBsFire rules. Also re�nements a�ecting NoCan Fire rules are often removed by the re�nement�lter since a subset of the changes constitute a re�nement for a Can Fire rule.We note that not only did our testing produce a range of re�nement types, but also,the two types of testing, Batches 1-4 and Corrupted, favoured di�ering re�nements. Thissupports KRUST's \generate, discard and rank" behaviour as a suitable mechanism to provide exibility in re�nement (Craw & Sleeman, 1991).8 Related WorkIn this section we compare the approach of KRUST with other re�nement systems. Thereare two terms for systems which alter knowledge to improve its performance: knowledgere�nement and theory revision systems. We feel that these two terms distinguish betweentwo slightly di�erent approaches. Our general view is that knowledge re�nement systemsare built within the knowledge acquisition community where a range of problem solvingapproaches and representations abound and automation is of lesser importance; it beingimportant that they provide some assistance for the human domain expert and/or knowledgeengineer. In contrast, Machine Learning researchers tend to build automated theory revisionsystems whose target theory is often Horn Clauses or Prolog-based, and where many trainingexamples exist. These two approaches are brought closer together by multi-strategy revisionsystems where inductive techniques are integrated with learning using other sources such ascausal models, meta-knowledge, user interaction, etc. We suggest the following categorisationand typical examples:� Knowledge re�nement occurs late in the process of knowledge acquisition. Thereforetechniques developed within this community have focused on updating the knowledge ina fairly mature system. In particular the knowledge representation and problem-solvingmethod is �xed and much of the knowledge is acceptable. Therefore many systemshave been designed round particular KBSs and shells. Examples include: TEIRESIAS(Davis, 1984), SEEK (Ginsberg, 1988; Politakis, 1985), ODYSSEUS (Wilkins, 1990;Wilkins & Tan, 1989).� Theory revision uses automated learning to revise Horn clause theories where any satis-�ed rule may �re, and so there is no additional control. Examples include EITHER(Ourston & Mooney, 1990), FORTE (Richards & Mooney, 1991) and AUDREY-II(Wogulis & Pazzani, 1993). 28

� Multi-strategy revision systems apply several learning techniques to a range of knowl-edge sources. Examples include: WHY (Saitta, Botta, & Neri, 1993), MOBAL (Morik,Wrobel, Kietz, & Emde, 1993) and CLINT (De Raedt, 1992).In general there are many possible changes to a KB that achieve the desired e�ect. Avariety of techniques have been used by knowledge re�nement systems to make this choice:TEIRESIAS asks the user to agree a suitable change, Waterman's POKER playing learningprogram (Waterman, 1970) applies the �rst successful re�nement, SEEK chooses the re�ne-ment that repairs the most faults in a set of training examples. Theory revision systems,such as EITHER, FORTE and AUDREY-II, often consider many repairs but choose to im-plement the revision that repairs the most faults in a set of training examples by making ahill-climbing choice during the generation of revisions. On the other hand, KRUST appliesa range of re�nement generation techniques from the POKER, TEIRESIAS and SEEK sys-tems to generate many possible re�nements which it implements. It postpones the choiceof best re�ned KB until after it has reduced the number of re�nements being considered. Itis therefore able to implement and run the re�ned KBs to identify interactions between therevised knowledge and the original KB and �nally evaluate the KB against a series of tasks.Many theory revision systems such as EITHER, FORTE, AUDREY-II get good results byrestricting their changes to deleting a rule, inserting a rule, deleting a condition or insertinga condition. EITHER (Ourston & Mooney, 1994) has now adopted our approach of increas-ing and decreasing numerical ranges but has not yet incorporated the generality o�ered byour hierarchies. However, in general, these systems rely on a plentiful supply of examplesfrom which to induce new rules and conditions, required to replace the knowledge that hasbeen removed during re�nement. We have tried to avoid using many examples during there�nement process because, in our experience, industrial KBs often are not accompanied bya large number of examples suitable for training. KRUST applies a more knowledge-based,rather than data based, approach to implement more gradual changes to individual condi-tions, in contrast to the more coarse specialisation and generalisation operators that addor delete complete rules or conditions. The justi�cation knowledge described by Smith etal. (Smith, Winston, Mitchell, & Buchanan, 1985) is considerably more di�cult to acquirethan the meta-knowledge used by KRUST which are domain hierarchies; our hierarchies arefrequently collected during the general knowledge acquisition phase.Early KBS re�nement systems such as TEIRESIAS were very expert intensive but latersystems reduced the interaction with the expert by incorporating learning techniques; e.g.SEEK applies a statistical analysis and ODYSSEUS suspects faulty domain knowledge whenproblem-solving meta-knowledge fails to match the current situation. ODYSSEUS' approachextends the task-driven method found in the MOLE and SALT knowledge acquisition tools(Marcus, 1988). Smith et al.'s re�nement of the Dipmeter Adviser requires access to a largesource of meta-knowledge justifying the causal links between items of domain knowledge(Smith et al., 1985). Multi-strategy systems exploit a range of knowledge sources, includingthe expert, in the process of repairing knowledge. WHY revises a theory by learning fromboth a causal model and examples; MOBAL contains many knowledge acquisition tools withaccess to a wide range of knowledge sources; and CLINT combines inductive learning withuser interaction. The evolution of theory revision systems has been more directly related toinductive techniques and these systems often rely on the quality of their inductive learnersto learn appropriate new knowledge. Thus induction plays a central role in EITHER,FORTE and CLINT. In contrast, KRUST, with its knowledge acquisition perspective, favours29

exploiting existing knowledge sources. Therefore it does not yet include an induction module,although we plan to integrate this as another means of generating possible re�nements.Theory revision systems have evolved in a Machine Learning background where HornClauses are a common representation. Therefore a main aim of researchers in theory revisionhas been extend the techniques from propositional theories (e.g. EITHER), through M-of-Ntheories (e.g. NEITHER (Ba�es & Mooney, 1993))4, to restricted �rst order theories systems(e.g. AUDREY-II, FORTE, WHY, MOBAL, CLINT). In contrast many expert systems arepropositional, or at least use representational schema which do not need the full power ofFirst Order Predicate Calculus.The inference engine is an integral part of a KBS and may specify whether inference takesplace in a forward or backward direction, what con ict resolution strategy to use, what taskbased decomposition to use, etc. Theory revision systems can ignore many of these e�ectssince their underlying theories are applied using logical closure, where deductions are basedsimply on truth. Despite the importance of the inference engine to KBSs, re�nement systemsoften do not alter the particular control mechanism, although ODYSSEUS does use controlknowledge to focus on possible faults. It is felt that a uni�ed approach to re�nement isdesirable, where both control and domain knowledge should be considered and subject tore�nement. KRUST takes a step in this direction by suggesting re�nements that alter boththe knowledge in the KB and the behaviour of the knowledge under the control mechanism.KRUST was the basis of the Improvement Tool of the ViVa Esprit-III project (ViVa Part-ners, 1992), whose aim was to develop a toolbox and method to assist with the Veri�cation,Improvement and Validation of KBSs. A deliverable from the applications workpackage (Al-lard & Lackinger, 1993) contains an evaluation of KRUST on two real-world KBSs: a Crystal5expert system and an EMICAT6 application. Validation and re�nement tools integrate welltogether because a similar exploration of the KB is undertaken by both processes and a vali-dation tool can often provide evidence for the need to re�ne the KB (Craw & Sleeman, 1994).In addition Validation and Veri�cation research is often concerned with developing metricsand testing tools which could be used by KRUST for evaluating the re�ned KBs.9 Future WorkIn this paper we have described KRUST's re�nement of a propositional KBSs. However, weare currently adapting KRUST to re�ne KBs with a restricted �rst order representation, asused by the student loan domain (Pazzani & Brunk, 1991). The representation that KRUSTre�ned in this paper closely matches that required but the re�nement process must be adaptedto cope with variables and their bindings. The inclusion of variables a�ects all stages ofKRUST's re�nement process; e.g. bindings alter the truths of later conditions, retrievingrules whose conclusions match a condition is di�erent, changing the knowledge must preservethe structure of conditions, etc. We have also implemented an iterative version of KRUSTwhich processes a set of training examples. The initial set of chestnuts is augmented bytraining cases once they have been used for re�nement. We are now investigating variousmethods to cope with backtracking when a re�nement cycle fails. We are also experimentingwith inductive techniques to provide suitable new rules and conditions for the re�nement4Incidentally, SEEK, also, re�nes M-of-N style KBSs5Crystal is a PC expert system shell6EMICAT is a Prolog-based KBS development tool.30

process and to organise the processing of multiple training examples.10 SummaryWe have described the KRUST system that generates and manages a set of possible re�ne-ments to correct a wrongly solved training example. During re�nement generation it suggestschanges to the KB, but in addition to considering the static knowledge, it exploits the waythis knowledge is handled by the problem-solving method. Thus, although it does not di-rectly alter the problem-solver, it does change its e�ect. The re�ned KBs are implementedto achieve the aims of the re�nements, previously generated. In KRUST's case, a much �ner,more gradual approach is taken to specialising and generalising than is common in re�nementsystems. Instead of relying on the availability of e�ective newly acquired, or induced, knowl-edge to replace deleted knowledge, it gradually alters the knowledge by retrieving possiblereplacement conditions from knowledge hierarchies until the e�ect desired by the re�nementis achieved. If gradual changing is unable to attain the required re�nement then KRUSTreverts to the deletion of rules or conditions. The nuances of the knowledge in KBSs ensurethat gradual re�nement can a�ect the conclusions for seemingly close cases and is thus notas extreme as knowledge deletion and addition.Testing has shown that KRUST has been able to control the number of re�nements andre�ned KBs generated. By continually �ltering unwanted re�nements and KBs, KRUST isable to apply increasingly informative heuristics to select smaller and smaller sets of possiblere�nements and re�ned KBs. KRUST is also su�ciently open-minded during re�nementgeneration to propose even rare re�nements and is able to consider them seriously for specialcases when they are needed. Re�nement systems that choose their recommended re�nementat an early stage are prone to reject rare re�nements as unlikely to succeed.KBS re�nement is dogged by the lack of access to real KBs. In addition, the wide rangeof representations and problem solving methods found in modern expert system shells andtools demand the tailoring of general re�nement methods to suit their particular formalisms.We look forward to applying KRUST's techniques to more real-world KBSs so that we canextend the methods to other representations and larger, more sophisticated KBs.AcknowledgementsThe authors thank Luc de Raedt for constructive comments on an earlier version of thispaper. We also wish to thank the anonymous reviewers whose useful comments encouragedus to focus our attention on the distinction between theory revision and knowledge re�nementsystems; a theme which we have previously explored (Craw, Sleeman, Boswell, & Carbonara,1994).ReferencesAllard, F., & Lackinger, F. (1993). Evaluation of toolset 1. Deliverable:D2-109-WP1.4-ESA,ESPRIT III Project 6125.Ba�es, P. T., & Mooney, R. J. (1993). Symbolic revision of theories with M-of-N rules.In Bajcsy, R. (Ed.), Proceedings of the Thirteenth IJCAI Conference, pp. 1135{1140Chambery, FRANCE. 31

Carbonell, J. G. (1991). Scaling up knowledge-based systems via machine learning. InvitedTalk, Fifth European Working Session on Learning (EWSL-91).Craw, S. (1991). Automating the Re�nement of Knowledge Based Systems. Ph.D. thesis,University of Aberdeen.Craw, S., & Sleeman, D. (1990). Automating the re�nement of knowledge-based systems.In Aiello, L. C. (Ed.), Proceedings of the ECAI90 Conference, pp. 167{172 Stockholm,SWEDEN. Pitman.Craw, S., & Sleeman, D. (1991). The exibility of speculative re�nement. In Birnbaum,L., & Collins, G. (Eds.), Machine Learning: Proceedings of the Eighth InternationalWorkshop on Machine Learning, pp. 28{32 Evanston, IL. Morgan Kaufmann.Craw, S., & Sleeman, D. (1994). Re�nement in response to validation. Expert Systems withApplications, 8 (2). Also appears in J. Carde~nosa and P. Meseguer, editors, Proceedingsof the EUROVAV93 Workshop, pages 85{99, Palma, SPAIN, 1993.Craw, S., Sleeman, D., Boswell, R., & Carbonara, L. (1994). Is knowledge re�nement dif-ferent from theory revision?. In Wrobel, S. (Ed.), Proceedings MLNet FamiliarizationWorkshop on Theory Revision and Restructuring in Machine Learning (at ECML-94,Catania, ITALY), No. 842 in Arbeitspapiere der GMD, pp. 32{34 GMD, Pf. 1316, 53754Sankt Augustin, Germany.Davis, R. (1984). Interactive transfer of expertise. In Buchanan, B., & Shortli�e, E. H. (Eds.),Rule-Based Expert Systems, pp. 171{205. Addison-Wesley, Reading, MA.De Raedt, L. (1992). Interactive Theory Revision. Academic Press, London.Ginsberg, A. (1988). Automatic Re�nement of Expert System Knowledge Bases. ResearchNotes in Arti�cial Intelligence. Pitman, London.Holland, J. H. (1986). Escaping brittleness: The possibilities of general-purpose learningalgorithms applied to parallel rule-based systems. In Michalski, R. S., Carbonell, J. G.,& Mitchell, T. M. (Eds.),Machine Learning Volume II, pp. 593{623. Morgan Kau�man,Los Altos, CA.Mahoney, J. J., & Mooney, R. J. (1994). Combining connectionist and symbolic learning tore�ne certainty-factor rule-bases. Connection Science (Special issue on Architecturesfor Integrating Neural and Symbolic Processing), 5.Marcus, S. (Ed.). (1988). Automating Knowledge Acquisition for Expert Systems. Kluwer,Boston.Morik, K., Wrobel, S., Kietz, J.-U., & Emde, W. (1993). Knowledge Acquisition and MachineLearning. Academic Press, London.Ourston, D., & Mooney, R. (1990). Changing the rules: A comprehensive approach to theoryre�nement. In Proceedings of the Eighth National Conference on Arti�cial Intelligence,pp. 815{820 Cambridge, MA. 32

Ourston, D., & Mooney, R. (1994). Theory re�nement combining analytical and empiricalmethods. Arti�cial Intelligence, 66, 273{309.Pazzani, M. J., & Brunk, C. A. (1991). Detecting and correcting errors in rule-based ex-pert systems: An integration of empirical and explanation-based learning. KnowledgeAcquisition, 3, 157{173.Politakis, P. G. (1985). Empirical Analysis for Expert Systems. Research Notes in Arti�cialIntelligence. Pitman, London.Richards, B. L., & Mooney, R. J. (1991). First-order theory revision. In Birnbaum, L., &Collins, G. (Eds.),Machine Learning: Proceedings of the Eighth International Workshopon Machine Learning, pp. 447{451 Evanston, IL. Morgan Kaufmann.Saitta, L., Botta, M., & Neri, F. (1993). Multistrategy learning and theory revision. MachineLearning, 11 (2/3), 153{172.Smith, R. G., Winston, H. A., Mitchell, T. M., & Buchanan, B. G. (1985). Representationand use of explicit justi�cations for knowledge base re�nement. In Proceedings of theNinth IJCAI Conference, pp. 367{374 Los Angeles, CA.ViVa Partners (1992). Veri�cation, improvement & validation of knowledge based systems.Technical annexe, ESPRIT III Project 6125.Waterman, D. A. (1970). Generalization learning techniques for automating the learning ofheuristics. Arti�cial Intelligence, 1, 29{120.Wilkins, D. C. (1990). Knowledge base re�nement as improving an incorrect and incompletedomain theory. In Kodrato�, Y., & Michalski, R. S. (Eds.), Machine Learning VolumeIII, pp. 493{513. Morgan Kaufmann, San Mateo, CA.Wilkins, D. C., & Tan, K.-W. (1989). Knowledge base re�nement as improving an incorrect,inconsistent and incomplete domain theory. In Spatz, B. (Ed.), Proceedings of theSixth International Workshop on Machine Learning, pp. 332{337 Ithaca, NY. MorganKau�man.Wogulis, J., & Pazzani, M. (1993). A methodology for evaluating theory revision systems:Results with AUDREY II. In Bajcsy, R. (Ed.), Proceedings of the Thirteenth IJCAIConference, pp. 1128{1134 Chambery, FRANCE.33





























