Embed Size (px)
Citation preview

J Europaisches Patentamt
European Patent Office
Office europeen des brevets
0 3 1 6 7 4 3
A 2 © Publication number:
E U R O P E A N PATENT A P P L I C A T I O N
© int. ci*. G06F 15/38 , G06F 1 5 / 2 0 © Application number: 88118645.6
© Date of filing: 09.11.88
@ Applicant: International Business Machines Corporation Old Orchard Road Armonk, N.Y. 10504(US)
@ Inventor: Zamora, Antonio 4601 North Park Avenue Chevy Chase Maryland 20815(US)
© Representative: Blutke, Klaus, Dipl.-lng. IBM Deutschland GmbH Intellectual Property Dept. Schonaicher Strasse 220 O-7030 Boblingen(OE)
® Priority: 18.11.87 US 122305
@ Date of publication of application: 24.05.89 Bulletin 89/21
© Designated Contracting States: OE FR GB
© Method for removing enclitic endings from verbs in romance languages.
© Romance language verbs are frequently modified by the addition of pronouns called enclitic pronouns. The
pronouns can only be added within prescribed grammatical constraints and affect the spelling and, sometimes, the accentuation of the verbs. Many linguistic processes for which automation is desirable, such as synonym look-up or grammatical analysis, require identification of the unmodified verb forms. The methods described herein make is possible to convert a verb modified by enclitic pronouns to its unmodified form.
CO
r s
CO
o . LU
Xerox Copy Centre

EP 0 316 743 A2
METHOD FOR REMOVING ENCLITIC ENDINGS FROM VERBS IN ROMANCE LANGUAGES
The invention disclosed relates to an improved method for removing enclitic endings from verbs- in romance languages.
The disclosure of the patent application A. Zamora, "Paradigm-Based Morphological Text Analysis for si Natural Languages," Serial No. 028,437, filed March 20, 1987, assigned to IBM Corporation is incorporated
herein by reference to serve as a background for the invention disclosed herein. Text processing word processing systems have been developed for both stand-alone applications and
distributed processing applications. The terms text processing and word processing will be used inter- changeably herein to refer to data processing systems primarily used for the creation, editing, communica-
ra tjon, and/or printing of alphanumeric character strings composing written text. A particular distributed processing system for word processing is disclosed in the copending U. S. patent application serial number 781,862 filed September 30, 1985 entitled "Multilingual Processing for Screen Image Build and Command Decode in a Word Processor, with Full Command, Message and Help Support," by K. W. Borgendale, et al. The figures and specification of the Borgendale, et al. patent application are incorporated herein by
rs reference, as an example of a host system within which the subject invention herein can be applied.
A. Spanish Language
It is a well-recognized fact that in Spanish, new words are formed when pronouns are attached to certain verb forms. For example, "dame" (English: "give me") is formed from the imperative verb form "da" plus the pronoun "me." These pronouns are called "enclitic" because they attach to the preceding word to form a new word.
There are eleven Spanish pronouns that can be used in enclitic form. Here they are classified by usage:
20
25
1) se - reflexive or impersonal 2) me, nos - first person (singular, plural) 3) te, os - second person (singular, plural)
40 lo, la, lo, los - third person (accusative) le, les - third person (dative)
3a
Several enclitic pronouns may be added to a word, thus "damelo" (English: "give it to me") not only contains a second enclitic, but also adds an accent to the new word to conform with the basic accentuation rules.
There are three basic accentuation rules in Spanish: 1. All words that are stressed in the last syllable and which end in a vowel or "n" or "s" have an
explicit accent mark. 2. Words stressed in the penultimate syllable have an explicit accent mark if they end in a consonant
which is not "n" or "s." 3. Words stressed before the penultimate syllable always have an explicit accent.
It is understood that the accent mark is written over the vowel of the stressed syllable. In addition, there are rules of euphony that apply to certain verb-pronoun combinations to avoid awkward pronunciations. The plural imperative for the first person "vamos" (English: "we go") loses the final "s" when the enclitic "nos" is added. Thus, "vamos" plus "nos" yields "vamonos" (English: "let's go!"). The double "s" that would result from adding the enclitic "se" to the plural for the first person is omitted so that "hagamos" plus "se" plus "lo" yields "hagamoselo" (English: Let's do it for them!). The final "d" of the plural second person imperative is dropped when the enclitic "os" follows so that "corned" plus "os" yields "comeos" (English: "you eat!").
One peculiarity of Spanish enclitic formation is that not all forms of a verb may form enclitics. Only the infinitive, the gerund (present participle) and the five forms of the imperative may take enclitic pronouns. The forms of the verb "amar" (English: "love") given below show some valid enclitic forms:
35
40,
45
50

EP 0 316 743 A2
Grammatical verb example form
infinitive amar amarla (English: "to love her") gerund amando amandola (English: "loving her") imperative 2s ama amala (English: "(thou) love her!") imperative 3s ame amela (English: "(he) love her!") imperative 1p amemos amemosla (English: "let's love her!") imperative 2p amad amadla (English: "(you) love her!") imperative 3p amen amenla (English: "(they) love her!") 10
In this table 1, 2, and 3 indicate the first, second, and third person; the "s" and the "p" indicate singular and plural form, respectively.
Spanish grammar requires a strict order of priority for enclitic pronouns: "se" always goes first, followed 75 by second person, then first person, and finally third person pronouns. Of course, each of these is optional,
but it is rare when more than two pronouns are attached to a verb.
B. Italian Language 20 —
An attribute of the Italian language is that new words are formed when pronouns are attached to certain verb forms. For example, "dammi" (English: "give me") is formed from the imperative verb form "da" plus the pronoun "mi" (the first letter of the pronoun is doubled in this case). These pronouns are called "enclitic" because they attach to the preceding word to form a new word. Not all forms of a verb may form enclitics. Only the infinitive, the gerund and the five forms of the imperative may take enclitic pronouns.
There are 17 Italian pronouns and particles that can be used in enclitic form. Here they are classified by
usage:
25
WEAK STRONG
mi me - first person singular Ci ce - first person plural ti te - second person singular
WEAK STRONG (continued)
vi ve - second person plural sj se - third person reflexive gli giie - third person masculine singular mici - - first person sing. + particle "ci" tici - -" second person sing. + particle "ci" vici - - second person plural- + particle "ci"
COMPLEMENTARY
lo, li - third person masculine (singular, plural) la, le - third person feminine (singular, plural) ne - third person plural adverbial particle
30
35
40
45
Several enclitic pronouns may be added to a word, but they have to follow specific agglutination rules. The verb form must end in either a weak or a complementary form. If more than one pronoun occurs, the strong form of a pronoun followed by a complementary form is used, except for the combinations "mici," "tici," and "vici" which have been included under the weak forms for uniformity of processing since "ci" is a demonstrative and not a personal pronoun in these cases.
In addition, two spelling modification rules are used: 1) the infinitive form of a verb drops the final "e" when an enclitic pronoun is added except when the infinitive form of the verb ends in "rre" in which case the final "re" is dropped, and 2) if an imperative form of the verb form is stressed in the last syllable, the consonant of the enclitic closest to the verb is doubled (except for "gli," "glie"). The following table shows examples of these cases:
50
55

EP 0 316 743 A2
Grammatical verb example form
infinitive parlare parlarti (English: "to speak to you") infinitive produrre produrlo (English: "to produce it") infinitive dire dirtelo (English: "to say it to you") gerund pensando pensandolo (English: "thinking about it") imperative 2s di dillo (English: "(thou) say it!")
(2s = second person singular) 10
The complexity of the rules and multitude of verb forms that may take enclitics require powerful dictionaries and analytical procedures to decompose enclitic verb forms. There are many words which on the basis of morphology, appear to have enclitics, e.g. "Oslo," "cola," but which in reality are not enclitic endings at all. Some verb forms in Italian such as the imperfect subjunctive have endings in "si" which could also be confused with the reflexive pronoun with inadequate analysis. Although there have been some computer based dictionaries that contain verbs with enclitic endings, none of the prior art has addressed the problem of removing the enclitics automatically to obtain the base form of the verb which is necessary for many applications.
It is therefore an object of the invention to provide an improved method for removing enclitic endings from verbs in romance languages, especially in Spanish, Italian, Portuguese, French, and other Romance languages.
The object of the invention is accomplished by the features of claim 1 and 2. Further advantages of the invention are characterized in the subclaims. The invention includes a process for the removal of enclitic endings to identify the verb which was used to generate the enclitic form. The process combines the morphological transformations that reverse the enclitic formation rules, accentuation reversal rules and dictionary look-up which can identify valid verb forms and ambiguities.
75
20
25
30 Applications of the Invention
1) Word verification in word processing systems. The very productive combinatorial mechanisms of enclitic pronouns make it hard to have good coverage of verb forms by exhaustive listing. Therefore, a procedure to identify and generate the forms of the verbs without enclitics can be used as an effective way
35 of word verification. 2) In any language analysis application such as natural language data base access, it is necessary to
interpret queries by isolating the verb forms used in the query. The normalization of enclitic forms makes it possible to process Romance language verb forms.
3) Machine translation requires identification of enclitic forms and generation of verb forms without 40 their enclitic pronouns. This invention makes it possible to process Romance language verbs for machine
translation applications.
The foregoing and other advantages of the invention will be more fully appreciated with reference to the accompanying figures.
45 Fig. 1 is a flow diagram of the method for removal of enclitic endings from Spanish verbs. Fig. 2 is a flow diagram of the method for the removal of enclitic endings from Italian verbs. Fig. 3 is a flow diagram of the method for the removal of enclitic endings from Portuguese verbs.
50 A. Spanish Language
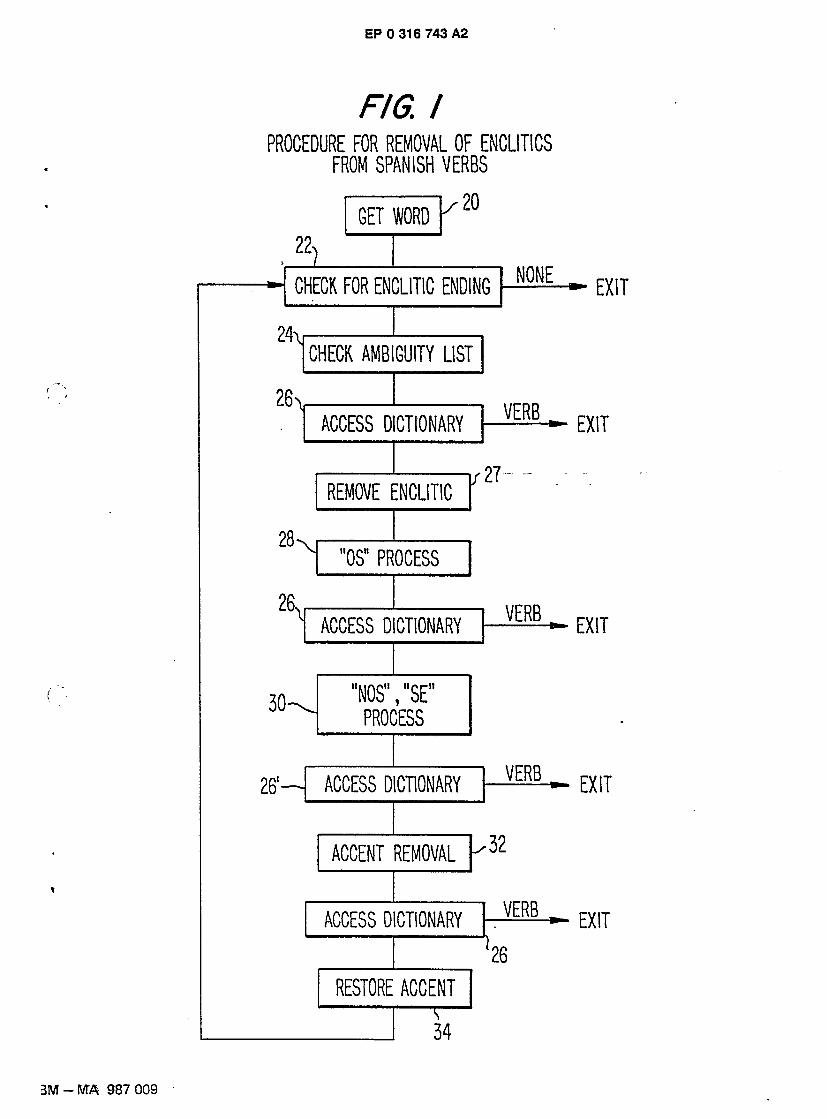
This embodiment of the invention consists of an iterative process applied to the Spanish language for removal of enclitic endings to identify the verb which was used to generate the enclitic form. The iterative process combines: 1) morphological transformations that reverse the enclitic formation and accentuation rules and 2) look-up in a dictionary that can identify valid verb forms. The process is best described by reference to Fig. t .
Step 20 specifies the process of getting an input word for the enclitic removal process. The word is
55

EP 0 316 743 A2
converted to lower case if necessary to assure a common font for the dictionary look-up. The ending of the word is checked against the list of 1 1 enclitic pronouns in Step 22. If the word does not have an enclitic ending or if the enclitics occur in the wrong sequence, or if more than three enclitics are found, then the
process terminates since the word does not have valid enclitic endings. 5 In Step 24 the list of ambiguous words is checked. For example, the word "salte" can be "sal" plus
"te" (English: "(thou) get out") or if we interpret the word without an enclitic it means "(you) jump." When a word is found in the list, the output word form is located associated with the input word in the list.
Step 26 is the dictionary look-up process. This involves locating the word form in the dictionary to determine if it is a verb. If it is a verb, its corresponding paradigm (Table 1) is accessed to determine which
10 form of the verb it is. The paradigm matching procedure involves matching the ending of the word form
against endings specified in the paradigm table. The endings that match are associated in the table with their corresponding grammatical forms. This matching procedure makes it possible to determine if the verb form is one which can take enclitic endings or not. If it is, the lemma form of the verb (generally the infinitive) can be obtained by replacing the ending that matched with the ending for the infinitive. A
75 successful match terminates the procedure. The enclitic ending is removed in Step 27. The enclitic is saved because it is referenced in Steps 28
and 30. Step 28 is the process applied when the enclitic pronoun "os" is removed. Generally, the enclitic "os is
simply removed, but if the letter preceding "os" is one of the vowels "a," "e," "i," or "i" (with an accent 20 mark), the enclitic "os" is removed and replaced with a "d." For example, "reios" becomes "reid" and
"burlaos" becomes "burlad," but "obedeceros" simply becomes "obedecer." Step 30 is the process applied when the enclitics "nos" or "se" are removed. When these enclitics are
found, they are removed and if they are preceded by the characters "mo" (which indicates a plural verb
form), an "s" replaces the removed enclitic. For example, "preparemonos" becomes "preparemos," but
25 "rianse" becomes "rian." This step is independent of accent removal; some of the word forms created at this step will not match against the dictionary because they have incorrect accents.
Step 32 removes the accents, if any, to try to match again against the dictionary with the corrected spelling.
Step 34 restores accents that may have been removed in trying to match an accented word that has
30 multiple enclitics such as "freidmelo" (English: "(you) fry it for me!"). In the first try, only the first enclitic is removed yielding "freidme," but since this does not match, the accent is removed in Step 32. Step 34 restores the accent before sending the word back to Step 22 where the additional enclitic ending will be detected and later removed.
Pseudocode for the preferred embodiment of the process is given in Table 2. While this embodiment of
35 the invention has been described with reference to a specific sequence of steps, the order of some of these
steps is somewhat discretionary. It is possible to streamline the process by combining several operations, such as the enclitic removal and the accent removal into one single operation which takes into consideration the syllables of the input word.
40
45
50
55

EP 0 316 743 A2
P a r a d i g m f o r r e g u l a r " . . a r " v e r b
* FORMAS NO PERSONALES
i n f i n i t i v o ar ( l e m m a )
g e r u n d i o a n d o
p a r t i c i p i o a d o 10
* MODO I N D I C A T I V O * p r e s e n t e
75 p r e s l o
p r e s 2 a s
p r e s 3 a
p r e s 4 a m o s 20 p r e s 5 a i s
p r e s 6 a n * p r e t e r i t o i m p e r f e c t o
25 p a s i l a b a
p a s i 2 a b a s
p a s i 3 a b a
30
35
40
45
50
55

EP 0 316 743 A2
p a s i 4 a b a m o s
p a s i 5 a b a i s
p a s i 6 a b a n * p r e t e r i t e p e r f e c t o s i m p l e
p a s p l e
p a s p 2 a s t e
p a s p 3 o
p a s p 4 a m o s p a s p 5 a s t e i s
p a s p 6 a r o n * f u t u r o
f u t u l a r e f u t u 2 a r a s f u t u 3 a r a f u t u 4 a r e m o s f u t u 5 a r e i s
f u t u 6 a r a n * c o n d i c i o n a l
c o n d l a r i a
cond2 a r i a s
cond3 a r i a
cond4 ' a r i a m o s
cond5 a r i a i s
cond6 a r i a n * MODO SUBJUNTIVO * p r e s e n t e
s p r e l " e
s p r e 2 e s
s p r e 3 e
s p r e 4 e m o s
s p r e 5 e i s
s p r e 6 . e n fC r-\̂*> *-\ 4* /"̂ -V" A 4— /— . A A"l**t Jf̂ V* £i r̂ *m ■!• --»
m
15
20
25
30
35
40
45
60 s p a i l a r a , a s e
s p a i 2 a r a s , a s e s
55

EP 0 316 743 A2
s p a i 3 a r a , a s e
s p a i 4 a r e m o s , a s e m o s
s p a i 5 a r a i s , a s e i s
s p a i 6 a r a n , a s e n * f u t u r o
s f u t l a r e
s f u t 2 a r e s
s f u t 3 a r e s f u t 4 a r e m o s s f u t 5 a r e i s
s f u t 6 a r e n
* MODO IMPERATIVO
i m p e l
impe2 a
impe3 e
impe4 e m o s
impe5 a d
impe6 e n
ia
rs
20
25
30
TABLE 1 - EXAMPLE OF SPAUISH REGULAR VERB PARADIGIi
35
TABLE 2 - PSEUDOCODE FOR SPANISH ENCLITIC PROCESS
I n p u t : word l e n g t h ,
i n p u t w o r d .
O u t p u t : r e t u r n c o d e
= 8 i n p u t word i s n o t a v e r b OR
i n p u t word i s n o t a v e r b w i t h
e n c l i t i c e n d i n g
so = 4 i n p u t word i s a m b i g u o u s , mos t l i k e l y e n c l i t i c e n c l i t i c i n t e r p r e t a t i o n
p r o v i d e d .
55

EP 0 316 743 A2
= 0 i n p u t word i s a v e r b w i t h e n c l i t i c
e n d i n g
5 I f r e t u r n code i s 0 or 4 , t h e i n p u t word w i t h o u t
t h e e n c l i t i c e n d i n g and t he lemma w i l l b e
r e t u r n e d . (The word may have d i f f e r e n t
a c c e n t u a t i o n and e x t r a l e t t e r s , e . g . , " v a m o n o s "
w i l l r e t u r n " v a m o s " as t h e o u t p u t word and " i r " a s t h e lemma f o r t h e i n p u t w o r d . )
T5 o u t p u t word l e n g t h ,
o u t p u t w o r d .
lemma l e n g t h
20 lemma f o r i n p u t w o r d .
T h i s p r o c e d u r e i m p l e m e n t s an i t e r a t i v e p r o c e s s f o r 25 t h e r e m o v a l of e n c l i t i c e n d i n g s t h a t r e s u l t s
in t h e i d e n t i f i c a t i o n of t h e lemma of t h e w o r d
and t h e word fo rm f rom w h i c h t h e e n c l i t i c w a s
30 g e n e r a t e d .
Get i n p u t _ w o r d .
t r a n s l a t e i n p u t _ w o r d to l o w e r c a s e ;
w o r d _ f o r m = i n p u t _ w o r d ;
l o o p c t = 0 ;
p r e v _ c o d e = 0 ;
35
40
a l p h a :
45
l o o p c t = l o o p c t + 1 ;
i f l o o p c t > 3 t h e n EXIT w i t h re = 8 ; Check e n d i n g and i t s c o d e :
55

EP 0 316 743 A2
e n d i n g : ( l o s , n o s , l a s , l e s , l a , l e , l o , me, s e , t e , o s )
c o d e : ( 1, 2, 1, 1, 1, 1, 1, 2, 4, 3 , 3)
I f e n d i n g d o e s n ' t m a t c h , e n c l i t i c i s no t p o s s i b l e E X I T
ra w i t h re = 8 /* The c o d e s i n d i c a t e t h e p r i o r i t y o r d e r i n w h i c h
e n c l i t i c p r o n o u n s a r e e x p e c t e d to o c c u r , t h i s
p r e v e n t s p r o c e s s i n g w o r d s l i k e " t e c o l o t e " m o r e 7 or t h a n n e c e s s a r y to r e j e c t them * /
I f c o d e <= p r e v _ c o d e t h e n EXIT w i t h re = 8 ;
p r e v _ c o d e = c o d e ; za
TABLE 2 (CONTINUED)
25 I f w o r d _ f o r m _ l e n g t h - e n c l i t i c _ l e n g t h >= 2
t h e n e n c l i t i c i s p o s s i b l e . I f e n c l i t i c i s n ' t p o s s i b l e EXIT w i t h re = 8
3C C h e c k l i s t of a m b i g u i t i e s
(e . g . , " s a l t e " w i l l be in t h i s l i s t ( -> " s a l + t e " - > " s a l i r " ) w i t h o u t t h i s l i s t , p a r a d i g m
as p r o c e s s i n g w o u l d g i v e " s a l t e " -> " s a l t a r , " t h e p r o c e s s makes i t p o s s i b l e to r e s o l v e " s a l t e l a " to -> " s a l t e + l a " -> " s a l t a r . "
In c a s e s w h e r e t h e a m b i g u i t y c a n n o t b e
r e s o l v e d , e . g . , " d a t e " -> " d a + t e " <dar) o r " d a t e " ( d a t a r ) , p r e f e r e n c e is g i v e n to t h e
e n c l i t i c i n t e r p r e t a t i o n s i n c e t h e o t h e r 45 i n t e r p r e t a t i o n i s r e a d i l y a v a i l a b l e t h r o u g h
p a r a d i g m p r o c e s s i n g .
( n o t e : w o r d s w h i c h become a m b i g u o u s when t h e
so; e n c l i t i c s a r e r e m o v e d , a r e a l s o s t o r e d i n t h i s l i s t , e . g . , " v e t e " -> " v e + t e " r e t u r n s " i r " in t h e lemma in a d d i t i o n to "ve" as t h e
55
10

EP 0 316 743 A2
o u t p u t word s i n c e "ve" by i t s e l f i s t h e
i m p e r a t i v e of " i r " or " v e r " b u t " v e t e " i s
n e v e r u s e d f o r t h e l a t t e r . 5
I f word i s in l i s t , s e t o u t p u t word f o r m , EXIT w i t h r e
= 4
;o C a l l p a r a d i g m p r o g r a m I f a v e r b lemma i s a v a i l a b l e t h e n d o ;
/* e . g . : a c a r a m e l o => a c a r a m e l a r * /
i f t h e w o r d _ f o r m = i n p u t _ w o r d t h e n EXIT w i t h re = 8 ; 75
e l s e s e t o u t p u t word f o r m , EXIT w i t h re = 0 ;
end ;
20 i f o n l y n o n - v e r b lemmas a r e a v a i l a b l e OR word c a n n o t b e
a v e r b t h e n do; /* e . g . : " e s t e , " " e s t e , " " s o l o , "
O s l o , " , " c o l a " * /
25 E x i t w i t h re = 8 ;
e n d ;
/* word i s n o t in d i c t i o n a r y OR
word can be a v e r b , b u t a lemma i s n o t a v a i l a b l e * / 30
s t e p = 0 ; /* w o r d - m o d i f i c a t i o n s t e p 0 * /
r emove e n c l i t i c f rom w o r d _ f o r m . i f we r e m o v e d "os " and t h e p r e c e d i n g c h a r a c t e r i s " a , "
35 " e , " " i " o r
" i " ( w i t h an a c c e n t mark) t h e n d o ;
/* " r e i - o s , " " b u r l a - o s " a r e p r o c e s s e d * /
4o /* " o b e d e c e r - o s " f a l l s t h r o u g h * /
add "d" to w o r d _ f o r m ;
N o t e : I t i s i m p o r t a n t to p r o c e s s r e m o v a l of "o s " a t 45
t h i s p o i n t b e c a u s e i f t h e "d" i s n o t a d d e d a n o n -
i m p e r a t i v e v e r b form r e s u l t s ( e . g . , " r e i " i n s t e a d
of " r e i d , " " b u r l a " i n s t e a d of " b u r l a d " ) . 50
55
11

EP 0 316 743 A2
TABLE 2 (CONTINUED)
e n d ; 5
b e t a :
C a l l p a r a d i g m p r o g r a m I f a v e r b lemma is a v a i l a b l e t h e n d o ;
10 I* e . g . : dame => da * /
s e t o u t p u t word f o r m , EXIT w i t h re = 0 ;
e n d ;
75 i f o n l y n o n - v e r b lemmas a r e a v a i l a b l e OR word c a n n o t b e
a v e r b t h e n
EXIT w i t h re = 8 ;
/* word i s n o t in d i c t i o n a r y OR 20
w o r d can be a v e r b , b u t a lemma is n o t a v a i l a b l e * /
i f s t e p = 0 t h e n do; /* may h a v e to add l e t t e r * /
s t e p = 1 ; 25 i f we r e m o v e d " n o s " or " s e " and t h e p r e c e d i n g t w o
c h a r a c t e r s
a r e "mo" t h e n d o ;
30 I* " p r e p a r e m o n o s , " " u n a m o - n o s " a r e p r o c e s s e d * /
/* " r i a n s e " f a l l s t h r o u g h * /
add "s" to w o r d _ f o r m ;
g o t o b e t a ; 35
e n d ;
/* f a l l t h r o u g h to a c c e n t r e m o v a l * /
e n d ; 40
i f s t e p = 1 t h e n do; /* may have to r e m o v e a c c e n t * / i f w o r d _ f o r m has no a c c e n t t h e n g o t o a l p h a ;
45 /* " f r e i d m e - l o , " " c o s e - l o " a r e p r o c e s s e d * /
s a v e _ a c c = w o r d _ f o r m ;
r e m o v e a c c e n t f rom w o r d _ f o r m ;
s t e p = 2 ; 50
g o t o b e t a ;
e n d ;
55
12

EP 0 316 743 A2
i f - s t e p = 2 t h e n do; /* we h a v e to r e s t o r e a c c e n t * /
/* " f r e i d m e " i s r e s t o r e d to " f r e i d m e " * /
w o r d _ f o r m = s a v e _ a c c ; e n d ;
g o t o a l p h a ;
10
B. Italian Language
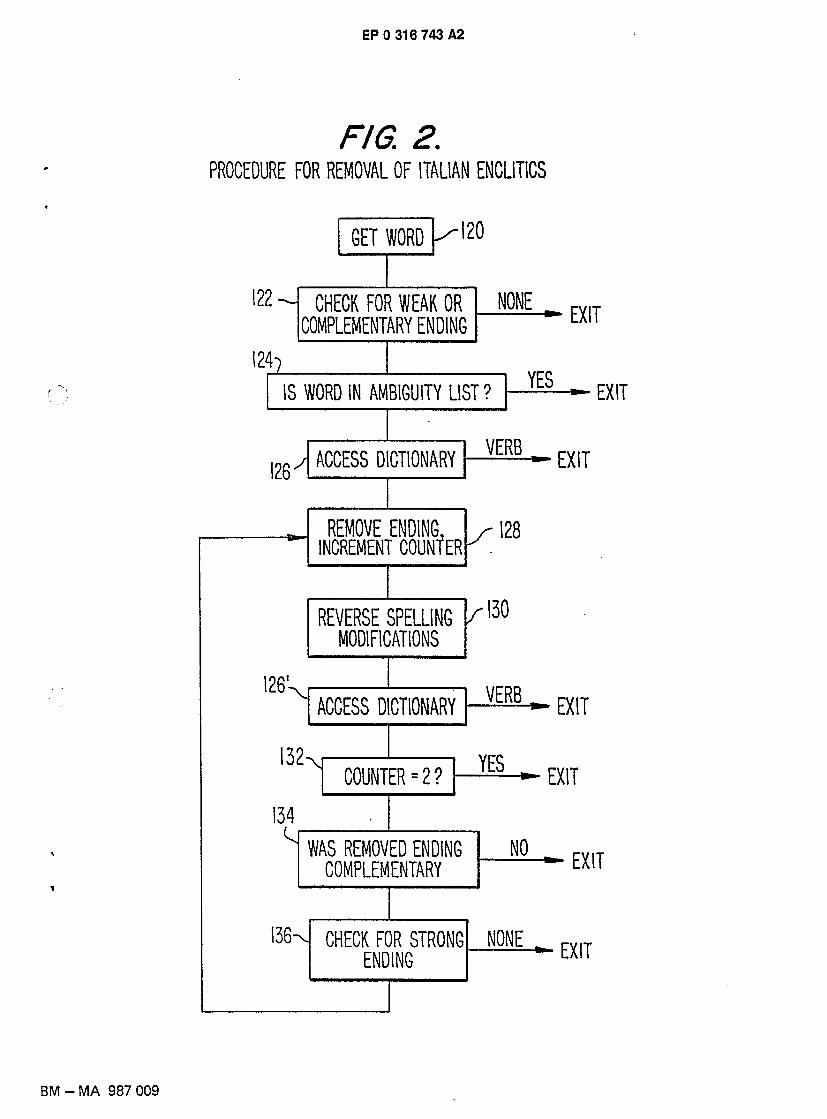
This embodiment of the invention consists of a process applied to the Italian language for removal of 15 enclitic endings to identify the verb which was used to generate the enclitic form. The process combines: 1)
morphological transformations that reverse the enclitic formation and accentuation rules and 2) look-up in a dictionary that can identify valid verb forms. The process is best described by reference to Fig. 2.-
Step 120 specifies the process of getting an input word for the enclitic removal process. The word is converted to lower case if necessary to assure a common font for the dictionary look-up.
20 In Step 122, the ending of the input word is checked against the list of weak and complementary pronouns. If the word does not have an enclitic ending, then the process terminates since the word does not have valid enclitic endings.
In Step 124 the word is checked against the list of ambiguous words. This insures that if a word with an enclitic pronoun can also be a valid verb form, the enclitic form can be recognized as such. The list of
25 ambiguous words consists of the ambiguous word, the corresponding verb form without the enclitic, and optionally, the lemma form of the verb. A match against this list terminates the procedure. For example, the word "segnalo" can be the first person singular present of the verb "segnalare" (English: "to signal") or it can be the third person singular imperative of "segnare" (English: "to mark") plus the enclitic "lo."
Step 126 is the dictionary look-up process. This involves locating the word form in the dictionary to 30 determine if it is a verb. If it is a verb, its corresponding paradigm (Table 3) is accessed to determine which
form of the verb it is. The paradigm matching procedure involves matching the ending of the word form against the endings specified in the paradigm table. The endings that match are associated in the table with their corresponding grammatical forms. This matching procedure makes it possible to determine if the verb form is one which can take enclitic endings or not. If it is, the lemma form of the verb (the infinitive) can be
35 obtained by replacing the ending that matched with the ending for the infinitive. A successful match terminates the procedure.
The enclitic ending is removed in Step 128 and saved for examination in Step 134. A counter, initially set to zero, is incremented at this point to keep track of how many enclitic endings have been removed; the counter is referenced in Step 1 32.
40 Step 130 reverses the spelling modifications that are applied during enclitic formation. That is, if the letter preceding the enclitic pronoun which was removed is "r," then an "e" or "re" is added since the verb form must be the infinitive. Otherwise, if the letter preceding the removed enclitic is the same as the first letter of the enclitic, then this doubled letter is also removed since this is likely an imperative verb form with stressed final syllable. The exceptions for "gli" and "glie" are taken into consideration.
45 Step 132 checks to see how many enclitic endings have been removed from the word by referencing the counter incremented in Step 128. If two endings have been removed and the dictionary access has thus far failed to confirm the remainder of the word as a verb, the process ends without identifying an enclitic.
Step 134 checks to see if the ending that was removed was a complementary ending because if it is, the possibility of multiple enclitic pronouns must be examined. However, if the enclitic ending was not
50 complementary then we exit without having found an enclitic ending since the preceding dictionary access failed to find a verb form, and therefore the perceived enclitic ending was a false enclitic.
In Step 136, the ending of the word without the complementary enclitic is checked against the list of strong pronouns. If none is found, the process terminates and the previously found complementary enclitic is considered a false enclitic since the previous dictionary access did not find a verb. However, if a strong
55 pronoun is found, processing continues in Step 128 where the ending is removed and subsequently the spelling is normalized and the dictionary accessed again.
Pseudocode for the preferred embodiment of the process is given in Table 4. While this embodiment of the invention has been described with reference to a specific sequence of steps, the order of some of these
13

EP 0 316 743 A2
steps is somewhat discretionary. It is possible to streamline the process by combining several operations, such as the enclitic removal and the reverse spelling modifications.
P a r a d i g m f o r r e g u l a r " - e r e " v e r b
E x a m p l e : t e m e r e
* FORME IMPERSONALI
w i n f i n i t o e m e r e ( l e m m a )
g e r u n d i o e m e n d o
p a r t i c i p i o p a s s a t o e m u t o
75 * MODO INDICATIVO * p r e s e n t e
p r e s l emo 20 p r e s 2 e m i
p r e s 3 erne
p r e s 4 e m i a m o
25 p r e s 5 e m e t e
p r e s 6 e m o n o * i m p e r f e t t o
p a s i l e m e v o 30
p a s i 2 e m e v i
p a s i 3 e m e v a
p a s i 4 e m e v a m o 35 p a s i 5 e m e v a t e
p a s i 6 e m e v a n o * p a s s a t o r e m o t o
40 p a s p l e m e i , e m e t t i
p a s p 2 e m e s t i
p a s p 3 erne , e m e t t e
p a s p 4 ememmo 45
p a s p 5 e m e s t e
50
55
14

EP 0 316 743 A2
p a s p 6 e m e r o n o , e m e t t e r o * f u t u r o s e m p l i c e
f u t u l e m e r o
f u t u 2 e m e r a i
f u t u 3 e m e r a
f u t u 4 e m e r e m o
™ f u t u 5 e m e r e t e
f u t u 6 e m e r a n n o * MODO CONDIZIONALE * p r e s e n t e 75 c o n d l e m e r e i
cond2 e m e r e s t i
cond3 e m e r e b b e 20 , . cond4 e m e r e m m o
cond5 e m e r e s t e
cond6 e m e r e b b e r o
25 * HODO CONGIU1ITIVO * p r e s e n t e
s p r e l e raa
s p r e 2 e tna
s p r e 3 e m a
s p r e 4 e m i a m o
s p r e 5 e m i a t e
s p r e 6 e m a n o * i m p e r f e t t o
s p a i l e m e s s i
s p a i 2 e m e s s i
s p a i 3 e m e s s e
s p a i 4 ernes s i m o
s p a i 5 e m e s t e
s p a i 6 e m e s s e r o
* IIODO IMPERATIVO
i m p e l -
impe2 e m i
30
35
40
45
50
55
15

EP 0 316 743 A2
impe3 e ina
impe4 e m i a m o
impe5 e m e t e
impe6 e m a n o S'
TABLE 3 - EXAMPLE OF ITALIAN REGULAR VERB PARADIGM
TABLE 4 - PSEUDOCODE FOR ITALIAN ENCLITIC PROCESS
I n p u t : word l e n g t h ,
i n p u t w o r d .
ra
t s
m O u t p u t : r e t u r n code = 8 i n p u t word i s n o t a v e r b OR
i n p u t word i s n o t a v e r b w i t h
e n c l i t i c e n d i n g 25
= 4 i n p u t word i s a m b i g u o u s , m o s t
l i k e l y e n c l i t i c e n c l i t i c
i n t e r p r e t a t i o n p r o v i d e d .
3a = 0 i n p u t word i s a v e r b w i t h
e n c l i t i c e n d i n g
I f r e t u r n code i s 0 or 4 , t h e i n p u t w o r d
35 w i t h o u t t h e e n c l i t i c e n d i n g and t h e l e m m a
w i l l
be r e t u r n e d .
( E . g . , " p a r l a r t i " w i l l r e t u r n " p a r l a r e " a s
t h e
word fo rm w i t h o u t t h e e n c l i t i c . )
o u t p u t word l e n g t h , 45 o u t p u t w o r d ,
lemma l e n g t h
lemma f o r i n p u t w o r d .
50? This procedure implements an iterative process for the removal of enclitic endings that results in the
identification of the lemma of the word and the word form from which the enclitic was generated.
ss-
16

EP 0 316 743 A2
Get i n p u t _ w o r d .
t r a n s l a t e i n p u t _ w o r d to l o w e r c a s e ; Check f o r one of t h e f o l l o w i n g e n d i n g s :
(mi, c i , t i , v i , s i , g l i , m i c i , t i c i , v i c i , l o , l i ,
l a , l e , n e )
I f e n d i n g d o e s n ' t m a t c h , e n c l i t i c is no t p o s s i b l e ; E X I T
to w i t h re = 8
Check l i s t of a m b i g u i t i e s .
N o t e : P r e f e r e n c e i s g i v e n to t h e e n c l i t i c
7S ■ i n t e r p r e t a t i o n
s i n c e t h e o t h e r i n t e r p r e t a t i o n is r e a d i l y a v a i l a b l e
t h r o u g h
p a r a d i g m p r o c e s s i n g . 20 I f word i s in l i s t , s e t o u t p u t word f o rm , EXIT w i t h r e
= 4
I f w o r d _ f o r m _ l e n g t h - e n c l i t i c _ l e n g t h >=2
25 t h e n e n c l i t i c i s p o s s i b l e .
I f e n c l i t i c i s n ' t p o s s i b l e EXIT w i t h re = 8
C a l l p a r a d i g m p r o g r a m ( a c c e s s d i c t i o n a r y ) .
30 I f a v e r b lemma i s a v a i l a b l e t h e n EXIT w i t h re = 8? i f o n l y n o n - v e r b lemmas a r e a v a i l a b l e OR word c a n n o t b e
a v e r b
t h e n do; /* e . g . : " O s l o , " " c o l a " * / 35 EXIT w i t h re = 8 ;
40 , TABLE 4 (CONTINUED)
e n d ;
/* word i s n o t in d i c t i o n a r y OR
50
55
17

EP 0 316 743 A2
word can be a v e r b , b u t a lemma i s n o t a v a i l a b l e
* /
C o u n t e r = 0 ; 5 a l p h a :
r e m o v e e n c l i t i c f rom w o r d _ f o r m .
C o u n t e r = C o u n t e r + 1 ; /* i n c r e m e n t c o u n t e r * /
io I f t h e w o r d _ f o r m e n d s in " r " add "e" to w o r d _ f o r m a n d
l o o k i t u p
in t h e d i c t i o n a r y , i f n o t f o u n d add " r e " i n s t e a d o f
H _ II 75
e l s e i f t h e l a s t c h a r a c t e r of t h e w o r d _ f o r m i s t h e s a m e
as t h e f i r s t c h a r a c t e r of t h e r e m o v e d e n c l i t i c t h e n
r e m o v e t h e l a s t c h a r a c t e r of t h e w o r d _ f o r m . 20 C a l l p a r a d i g m p r o g r a m ( a c c e s s d i c t i o n a r y )
I f a v e r b lemma is a v a i l a b l e t h e n d o ;
s e t o u t p u t word f o r m , EXIT w i t h re = 0 ;
25 e n d ;
I f o n l y n o n - v e r b l emmas a r e a v a i l a b l e OR word c a n n o t
be a v e r b t h e n EXIT w i t h re = 8 ;
/* word is n o t in d i c t i o n a r y OR
word can be a v e r b , b u t a lemma is n o t a v a i l a b l e * /
I f C o u n t e r = 2 t h e n EXIT w i t h re = 8 ;
I f e n c l i t i c r e m o v e d was n o t one of t h e f o l l o w i n g :
35~ ( l o , l i , l a , l e , ne) t h e n EXIT w i t h r c = 8 ;
Check f o r one of t h e f o l l o w i n g e n d i n g s :
(me, ce , t e , ve , s e , g l i e )
40 I f e n d i n g d o e s n ' t m a t c h EXIT w i t h re = 8
I f w o r d _ _ f o r m _ l e n g t h - e n c l i t i c _ l e n g t h < 2 t h e n E X I T
w i t h re = 8 g o t o a l p h a ;
45
C. Portuguese Language
50 Structure of Portuguese Enclitic Pronouns
Portuguese enclitic pronouns, unlike Spanish or Italian enclitics, may be embedded within verb forms. The following paragraphs describe the rules for forming these enclitics. This information is then used in the
55 design of an algorithm to remove the enclitics from a verb form to generate the original form of the verb to which the enclitic pronouns were added.
30
18

EP 0 316 743 A2
Categories of pronouns and contractions:
R e f l e x i v e P r o n o u n (RP) :
P e r s o n
- s e 3
P e r s o n a l P r o n o u n s (PP) :
Number , P e r s o n
-me S , 1
- t e S , 2
- n o s -no P , l
- v o s -vo P , 2
TO
C a s e : A c c u s a t i v e and D a t i v e
T5
20 I m p e r s o n a l P r o n o u n s (IP) :
G e n d e r , N u m b e r , Per son C a s e :
-o - l o -no M , S , 3
- o s - l o s - n o s M , P , 3
-a - l a - n a F , S , 3
- a s - l a s - n a s F , P , 3
A c c u s a t i v e
25
30
I n d i r e c t O b j e c t P r o n o u n s (10) :
Number , P e r s o n
- l h e S , 3
- l h e s P , 3
C a s e : D a t i v e
35
PP / IP c o n t r a c t i o n s (PPIPC) :
C a s e : D a t i v e + A c c u s a t i v e
me + IP t e + I P
40
45
50
55
19

EP 0 316 743 A2
- m ' o -mo - t ' o - t o
-in1 os -mos - t ' o s - t o s
- i n ' a -ma - t ' a - t a 5
- m ' a s -mas - t ' a s - t a s
10 / IP c o n t r a c t i o n s {IOIPC) :
10 C a s e : D a t i v e + A c c u s a t i v e
l h e + I P
75 - l h ' o - l h o
- l h ' o s - l h o s
- l h ' a - l h a
- I h ' a s - l h a s 20
Brazilian Portuguese can use the contractions with apostrophes and also the special contraction -Ih' instead of -lhe- when the enclitic is embedded by itself in the future or conditional form of the verb, e.g., dar-lh'emos.
25
General Enclitic Formation Rules:
Any verb form may have from one to three enclitics. Each enclitic is appended to or embedded in the 30 verb form separated by a hyphen. If one enclitic is used, it can be either RP, PP, 10, IP, PPIPC or IOIPC. If
two enclitics are used, they can be PP + IP, RP + PP, RP + IO, RP + PPIPC or RP + IOIPC. The combination RP + IP is never used. If three enclitics are used only RP + PP + IP is valid, where PP is "nos" or "vos" subject to the transformation rules.
Each enclitic pronoun is separated from the verb form or from the previous pronoun by a hyphen. 35 Contractions, except -Ih1 by itself, are considered to be two pronouns and are used in the combinations
stated above. The IP forms starting with "I" or "n" are used only when the transformation rules given below apply.
40 Embedding Rules:
Future and conditional verb forms are decomposed into stem and ending before the enclitics are embedded, then the ending is added following the enclitics and separated from them by a hyphen. The verb stem or the enclitics themselves may undergo transformations according to the rules given below.
45 The future endings are: -ei, -as, -a, -emos, -eis, -ao. The conditional endings are: -ia, -ias, -ia, -iamos, -ieis, -iam. Examples: dar-lhe-emos dar-lho-emos
50 The future and conditional of the verbs "fazer," "dizer," and "trazer" are irregular in that they are derived from the short infinitive of Latin "far(e)," "dir(e)," "trar(e)," but the rules for embedding are the same as above and also follow the transformation rules, e.g., farei + o => fa-lo-ei.
55 Transformation Rules:
The IP forms -lo, -los, -la, and -las exist only as transformations of the forms -o, -os, -a, and -as under the following two conditions:
20

EP 0 316 743 A2
1) When an infinitive verb form (or a future or a conditional which consists of the infinitive plus an ending) needs to take the enclitics -o, -os, -a, or -as, the "r" of the infinitive stem is dropped and the enclitic is transformed to -lo, -los, -la, or-las, respectively. If the vowel preceding the "r" is "a," it changes to "a," if it is "e" but not "oe," it changes to "e," and if it is "o" it changes to "o."
2) When forms ending in "z" of the verbs "trazer," "fazer," dizer" and their derivatives such as "afazer," "satisfazer," "bendizer," etc., need to take the enclitics -o, -os, -a, or -as, the "z" is dropped and the enclitic is transformed to -lo, -los, -la, or -las, respectively. If the vowel preceding the "z" is "a," it changes to 7a" and if it is "e" it changes to "-e."
3) When a verb form ending in "s" needs to take the enclitics -o, -os, -a, or -as, the "s" is dropped and the enclitic is transformed to -lo, -los, -la, or -las, respectively.
4) The final "s" of a first person plural verb form ending in "mos" is dropped when followed by the enclitic "-nos" to generate "mo-nos." This rule does not apply to the future and conditional forms which embed the enclitics.
5) When the pronouns "nos" and "vos" are to be followed by -o, -os, -a or -as, the "s" of the "nos" or "vos" is dropped and the following enclitic is transformed to -lo, -los, -la, or -las, respectively.
These rules apply even when the enclitic endings are embedded.
w
75
Example:
dar + o => da-lo traz + o => tra-lo p oes + o = > p oe-lo darei + o => da-lo-ei daria + as => da-las-ia viveriam + o => vive-lo-iam trazes + nos + o => trazes-no-lo trazem + vos + o => trazem-vo-lo dispor + o => dispo-o-lo
20
25
30
The IP forms -no, -nos, -na, and -nas are transformations of the forms -o, -os, -a and -as when they occur after a verbal form ending with the letter "m" or after the nasal vowel combinations "ao" and "6e." The fact that the ending -nos is also a personal pronoun is a potential ambiguity.
35
40
45
SO
55
21

EP 0 316 743 A2
E x a m p l e : l a v a v a m + os => l a v a v a t n - n o s
t r a z e m + o => t r a s e m - n o
/* P s e u d o c o d e f o r P o r t u g u e s e E n c l i t i c P r o c e s s * /
/* A n t o n i o Z a m o r a - S e p t e m b e r 1, 1987 * /
10
I n p u t : word l e n g t h ,
word in c o d e p a g e 500 c h a r a c t e r s e t .
75 O u t p u t : r e t u r n c o d e
= 8 i n p u t word i s n o t a v e r b OR
i n p u t word i s n o t a v e r b w i t h e n c l i t i c 20 e n d i n g
= 4 i n p u t word i s a m b i g u o u s , m o s t l i k e l y
e n c l i t i c i n t e r p r e t a t i o n p r o v i d e d
25 = 0 i n p u t word is a v e r b w i t h e n c l i t i c
e n d i n g
30
35
40
45
50
55
22

EP 0 316 743 A2
I f r e t u r n code i s 0 or 4, t h e i n p u t word w i t h o u t t h e
t h e e n c l i t i c e n d i n g and t h e lemma w i l l be r e t u r n e d .
word l e n g t h ,
T h i s p r o c e d u r e i m p l e m e n t s a p r o c e s s f o r t h e r e m o v a l o f
e n c l i t i c e n d i n g s t h a t r e s u l t s in t h e i d e n t i f i c a t i o n o f
t h e word fo rm f rom w h i c h t h e e n c l i t i c was g e n e r a t e d .
70
75
Get i n p u t _ w o r d .
t r a n s l a t e i n p u t _ w o r d to l o w e r c a s e ;
word = i n p u t _ w o r d ;
s c a n t h e word f o r a h y p h e n ;
i f word has no h y p h e n EXIT w i t h r e
20
= 8 ;
s c a n f rom t h e end of t h e word f o r a h y p h e n o r
a p o s t r o p h e ;
e n d i n g = s u b s t r i n g f rom h y p h e n or a p o s t r o p h e to end o f
w o r d . ^ i f e n d i n g = f e i ' | ' a s ' | 'a1 | ' e m o s ' | ' e l s ' | «ao ' |
• ia1 | ' i a s ' | ' l a m o s ' | ' i e i s 1 | ' i am1
t h e n s a v e e n d i n g ;
e l s e e n d i n g = ' ' ;
s c a n f rom t h e b e g i n n i n g of t h e word f o r a h y p h e n ;
h e a d = s u b s t r i n g of word up to h y p h e n ;
i f t h e l e t t e r p r e c e d i n g t h e h y p h e n i s ' a 1 , ' e ' , or ' o '
t h e n d o ;
i f e n d i n g = ' ' a n d
25
30
35
40
45
50
55
23

EP 0 316 743 A2
h e a d i s a f o r m of " f a z e r , " " d i z e r " or " t r a z e r " t h a t s h o u l d end in "z" t h e n r e m o v e a c c e n t , add "z" and EXIT w i t h r c = 0 ;
5 i f t h e n e x t e n c l i t i c i s ' - l a 1 , ' - l a s ' , ' - l o 1 ,
' - l o s 1 f o l l o w e d by a h y p h e n or t h e end of t h e word t h e n
d o ; 10 c h a n g e ' a ' in h e a d to ' a r 1
or c h a n g e ' e ' in h e a d to ' e r 1 ;
e n d ;
7S o u t p u t _ w o r d = h e a d | j e n d i n g ;
EXIT w i t h re = 0 ;
e n d ;
/* p r o c e s s u n a c c e n t e d h e a d * / 20
i f e n d i n g = • ' t h e n d o ;
i f h e a d i s a f o r m of " f a z e r , " " d i z e r " or " t r a z e r " t h a t s h o u l d end in "z" t h e n add "z" and EXIT w i t h re =
25 0 ;
i f t h e l a s t two l e t t e r s p r e c e d i n g t h e h y p h e n a r e 'mo1 t h e n d o ;
30 i f ( t h e n e x t e n c l i t i c i s ' - l a ' , ' - l a s ' , ' - l o ' , ' - l o s 1 f o l l o w e d by a h y p h e n or t h e end of t h e word) J
( t h e n e x t e n c l i t i c i s ' - n o s ' f o l l o w e d by end of word) J
35 ( t h e n e x t e n c l i t i c i s ' - n o 1 f o l l o w e d by h y p h e n )
t h e n d o ;
c h a n g e 'mo' in h e a d to ' m o s ' 40 o u t p u t _ w o r d = h e a d ;
EXIT w i t h re = 0 ;
e n d ;
45 end ; , i f t h e n e x t e n c l i t i c i s ' - l a 1 , ' - l a s ' , ' - l o 1 , ' - l o s 1 t h e n d o ;
h e a d = h e a d + ' s1 ; 50
o u t p u t _ w o r d = h e a d ;
EXIT w i t h re = 0 ;
55
24

EP 0 316 743 A2
e n d ;
e n d ;
/* t h e r e i s an e n d i n g * /
i f t h e n e x t e n c l i t i c is ' - l a 1 , ' - l a s ' , ' - l o 1 , ' - l o s 1
t h e n
h e a d = head + ' r ' ; 70 o u t p u t _ w o r d = h e a d j \ e n d i n g ;
EXIT w i t h re = 0 ;
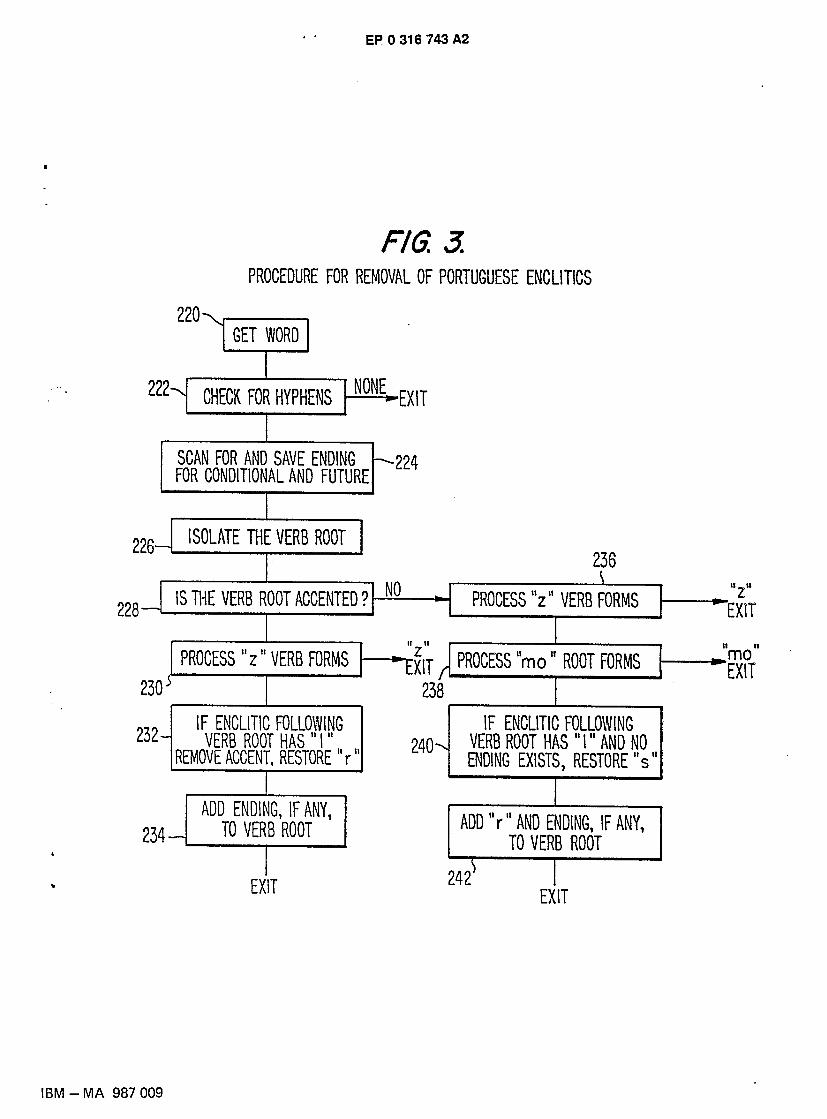
15 The process is best described by reference to Fig. 3. Step 220 specifies the process of getting an input word for the enclitic removal process. In Step 222, the word is checked to make sure it has hyphens. If the word does not have hyphens it
cannot have a Portuguese enclitic ending and the process terminates. In Step 224, the last hyphenated string of the word is checked to see if it is a conditional or future verb
20 ending. If it is, the ending is saved for future use. In Step 226, the first string of the word (up to the first hyphen) is isolated. This corresponds to the verb
root or the head of the word. This verb root will be examined to determine subsequent processing. Step 228 examines the last character of the verb root to see if it is accented. If it is, processing
continues in Step 230. Unaccented verb roots are processed starting in Step 236. 25 Step 230 applies the "z" process. This consists of identifying by look-up in a list the accented verb
roots that should be restored to "z" rather than to "r." The list consists of entries such as "contrafa" which comes from "contrafaz" and other verb forms which are derived from the verbs "fazer," "dizer" and "trazer." The "z" process applies only when there are no conditional or future endings.
Step 232 checks to see if the enclitic following the verb root is "-la," "-las," "-lo" or "-los." If it does, 30 then the accented letter is replaced by the unaccented letter and the "r" is restored for the verb root.
Step 234 adds the future or conditional ending, if any, to the verb root to create the reconstituted verb and the process terminates.
Step 236 applies the "z" process to verb roots without accents. The process is identical to Step 230, except that the list of words examined consists of unaccented entries such as as "contrafi" which comes
35 from "contrafiz." Step 238 applies the "mo" process. This process examines verb roots that end in "mo" to determine
whether an "s" has been elided. If the enclitic following the verb root is "-la," "-las," "-lo," "-los" or "-nos," or "-no" followed by another enclitic, then an "s" is added to the verb root and the process terminates.
Step 240 checks to see if the enclitic following the verb root is "-la," "-las," "-lo" or "-los." If it does 40 and there is no future or conditional ending, an "s" is restored for the verb root and the process terminates.
Step 242 adds an "r" plus the future or conditional ending, if any, to the verb root to reconstitute the verb and the process terminates.
10
45 D. French Language
French Enclitics:
so French enclitics are appended to the end of a verb separated by hyphens. The presence of the enclitic does not affect the spelling or the accentuation of the preceding verb. Thus, French enclitics are the easiest to recognize and remove in order to restore the verb to its original state. In addition to enclitics, some French words append adverbial particles which must be differentiated from the enclitics.
The following enclitic pronouns are used in French: ce, ces, cet, cette, elle, elles, en, eux, il, ils, je, la, 55 le, les, leur, lui, me, moi, nous, on, te, toi, tu, vous, and y. Sometimes the pronouns are separated from the
verb by the "euphonic" particle "t" as in "a-t-il." The "t" is used only for euphonic purposes and does not represent a pronoun. The pronouns "me" and "te" are contracted when followed by certain other pronouns. Thus, "me" followed by "en" is contracted to "m'en" as in "montrez-m'en" (show it to me). Except for
25

EP 0 316 743 A2
these euphonic and contraction conventions, one or more French enclitic pronouns can be appended at the end of the verb separated by hyphens, e.g., "donnez-le-moi" (give it to me). The order of these pronouns is governed by the rules of French grammar.
In addition to enclitic pronouns, French words can take the adverbial particles "ci" and "la" separated 5 by hyphens (e.g., "fille-ci"). These should not be confused with enclitic pronouns.
Although specific embodiments of the invention have been disclosed, it will be understood by those having skill in the art that minor changes can be made to the form and the details of those disclosed embodiments without departing from the spirit and the scope of the invention.
m Claims
1 . A method for removing enclitic endings to identify the verb which was used to generate the enclitic form in a romance language, comprising the steps of:
TS inputting a word from input word stream; comparing the word against a list of enclitic pronouns to determine the presence of a valid enclitic ending; comparing the word with a list of ambiguous words and producing an output word form when a match is made; accessing a dictionary to determine if the input word is a verb and accessing the corresponding paradigm
za to determine the verb form for the word, by matching the ending of the word against the ending specified in a paradigm table wherein endings that match are associated in the table with their corresponding grammatical forms, to determine if the verb form is one which can take enclitic endings, the lemma form of the verb being obtained by replacing the matched ending with ending for the infinitive; outputting said lemma representing the verb form of the word with the enclitic ending removed.
25 2. A method for manipulating verb forms containing enclitic pronouns in order to identify the enclitic pronouns and to generate corresponding verb forms without enclitics in a word processing system or natural language analysis system, the steps comprising: inputting a word from an input word stream; examining the word for the presence of enclitic pronouns;
3a removing the enclitic pronouns; outputting a word form without enclitics.
3. The method of claim 2 modified to access a dictionary to identify verb forms. 4. The method of claim 2 modified to reference a list of ambiguous words to be able to output multiple
verb forms when appropriate. 35 5. The method of claim 2 modified to output a list of enclitic pronouns in addition to the verb form
without the enclitics. 6. The method of claim 2 modified to output the lemma of the verb in addition to the verb form without
the enclitics. 7. The method of claim 2 modified to apply morphological transformations including addition or removal
40 of letters or accents to reconstruct the verb form without the enclitics.
45
50
55
26
EP 0 316 743 A2
F I G . I
PROCEDURE FOR REMOVAL OF ENCLITICS FROM SPANISH VERBS
20 / GET WORD
a .
NONE CHECK FOR ENCLITIC ENDING — • EXIT
2 4 ^ CHECK AMBIGUITY LIST
2 6 v VERB
ACCESS DICTIONARY EXIT
i r 2 7 - REMOVE ENCLITIC
28- "OS" PROCESS
26, VERB
^ E X I T ACCESS DICTIONARY
" N O S ' V S E "
PROCESS 30-
VERB EXIT 26'- ACCESS DICTIONARY
■32 ACCENT REMOVAL
VERB ACCESS DICTIONARY — EXIT
(26
RESTORE ACCENT
3 4
BM — MA 987 009
EP 0 316 743 A2
F I G . 2 .
PROCEDURE FOR REMOVAL OF ITALIAN ENCLITICS
I20
IS WORD IN AMBIGUITY LIST? — EXIT
VERB ACCESS DICTIONARY EXIT y I26
REMOVE ENDING, INCREMENT COUNf ER
^ 1 2 8
/ - I 3 0 REVERSE SPELLING MODIFICATIONS
I26- VERB
EXIT ACCESS DICTIONARY
132- YES COUNTER = 2 ? — EXIT
I34
NO WAS REMOVED ENDING COMPLEMENTARY EXIT
I36- NONE .. CHECK FOR STRONG
ENDING EXIT
BM - MA 987 009
EP 0 316 743 A2
F / G . 3 .
PROCEDURE FOR REMOVAL OF PORTUGUESE ENCLITICS
220- GET WORD
NONE 222- CHECK FOR HYPHENS •EXIT
SCAN FOR AND SAVE ENDING FOR CONDITIONAL AND FUTURE
-224
ISOLATE THE VERB ROOT 226 — I
228 — -
236 \
NO "z" IS THE VERB ROOT ACCENTED? PROCESS V VERB FORMS """EXIT
V ■I ig
EXIT PROCESS V VERB FORMS PROCESS "mo " ROOT FORMS i x n >
238 230-
IF ENCLITIC FOLLOWING VERB ROOT HAS " I "
REMOVE ACCENT, RESTORE V
IF ENCLITIC FOLLOWING VERB ROOT HAS "I "AND NO ENDING EXISTS, RESTORE V
2 3 2 - 240-
ADD ENDING, IF ANY, TO VERB ROOT ADD "
r " AND ENDING, IF ANY, TO VERB ROOT 234 —
242 EXIT EXIT
IBM -MA 987 009





























