Embed Size (px)
Citation preview

1. Explicación teórica
Lo que se busca es comprobar la relación entre los Ocupados y diferentes variables macro económicas, peropara ello es preciso primero hacer un acercamiento a las definiciones de cada una y establecer relacionesa priori.
Para el modelo se tuvo en cuenta la distribución de la población total, tal como se muestra acontinuación:
(Ministerio de Protección Social, 2007)
Descripción de las variables
A continuación hacemos un acercamiento teórico a las diferentes variables utilizadas, para concluir sobrela posible relación a priori de las mismas

A. Ocupados (OC) (Ibídem)Según el Ministerio de Protección Social, se definen a los ocupados como:
Aquellas personas que durante el período de referencia se encontraban en una de las siguientes situaciones:
o Ejercieron una actividad en la producción de bienes y servicios de por lo menos una hora remunerada a la semana.
o Los trabajadores familiares sin remuneración y trabajadores familiares sin remuneración en empresas o negocios de otros hogares,que laboraron por lo menos 1 hora a la semana.
o Las que no trabajaron en la semana de referencia pero tenían un empleo o trabajo (estaban vinculadas a un proceso de produccióncualquiera). Además los policías bachilleres y guardas penitenciarios bachilleres que regresan en las noches a sus hogares.
B. Población Económicamente Activa (ICESI, 2008)
Remitiéndonos a la definición más común, encontramos que la PEA como comúnmente se le conoce:
Corresponde a la fuerza laboral efectiva de un país, al estar constituida por las Personas en Edad de Trabajar (P ET) que están laborando obuscan trabajo. En otras palabras, corresponde a los individuos que participan del mercado de trabajo, ya sea que hayan encontrado unempleo o no.
C. Formación Bruta de Capital Fijo (FBKF) (ICESI, 2009)

La FBKF es parte importante del PIB, donde aparece en el cálculo del mismo desde la óptica de la demanda.Puede calcularse para cada uno de los sectores económicos y por producto.
Se define como: el valor de mercado de los bienes fijos (durables) que adquieren las unidades productivas residentes en el país, cuyo usose destina al proceso productivo, entre ellos se consideran la maquinaria y equipos de producción, edificios, construcciones, equipos detransporte entre otros.
Para Colombia es El DANE quien calcula la FBKF. Ésta es una parte de la formación bruta de capital, queademás recoge la inversión en existencias (inventarios y otros bienes no durables) y la inversión enobjetos valiosos (piedras preciosas, cuadros, etc. Adquiridos como depósito de valor).
D. Exportaciones FOB(Eco-Finanzas, 2009)
El tema de las exportaciones tiene varios componentes en nuestro caso tomamos las tipo FOB, es deciraquellas medidas mediante el valor de Mercado en las aduanas fronterizas de un país incluidos todos los Costos de transporte de losBienes, los derechos de exportación y el Costo de colocar los Bienes en el medio de transporte utilizado, a menos que este último costo corra acargo del transportista. Es un concepto ampliamente utilizado en informes y estudios económicos
E. Variación Porcentual del IPC(Banrep, 2014)
Es preciso entender que las variaciones pueden ser absolutas o relativas, en este caso es relativa.

Ahora bien, el índice de precios al consumidor (IPC) mide la evolución del costo promedio de una canasta de bienes y serviciosrepresentativa del consumo final de los hogares, expresado en relación con un período base. La variación porcentual del IPC entre dosperiodos de tiempo representa la inflación observada en dicho lapso. El cálculo del IPC para Colombia se hace mensualmente en elDepartamento Administrativo Nacional de Estadística (DANE).
F. Consumo Final de los Hogares(Mankiw, 2002)El consumo de los hogares hace parte de la famosa ecuación de la IS-LM, la cual se conoce como demanda yoferta agregada, este ítem hace parte específicamente de la IS. Es definido como el consumo que realizan loshogares residentes del país en la compra de bienes y servicios de consumo; por lo que quedan excluidas las compras de viviendas u objetosvaliosos.
La relación a priori que se espera es positiva con todas las variables.
2. GRÁFICOS DE DISPERSIÓN
Dado que le modelo utilizado es LOG-LOG, las gráficas asociaran el Logaritmo de la Y (ocupados) contra elLogaritmo de cada variable independiente (Xs)
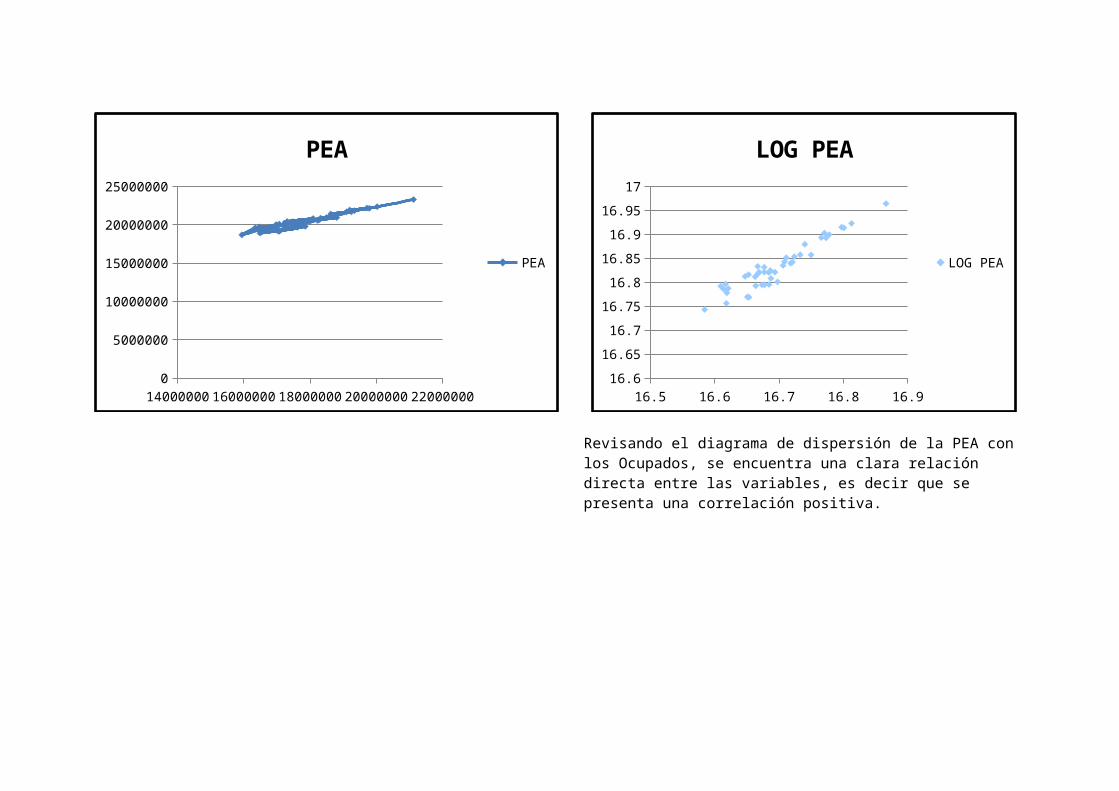
14000000 16000000 18000000 20000000 220000000
5000000
10000000
15000000
20000000
25000000
PEA
PEA
16.5 16.6 16.7 16.8 16.916.616.6516.716.7516.816.8516.916.95
17
LOG PEA
LOG PEA
Revisando el diagrama de dispersión de la PEA con los Ocupados, se encuentra una clara relación directa entre las variables, es decir que se presenta una correlación positiva.
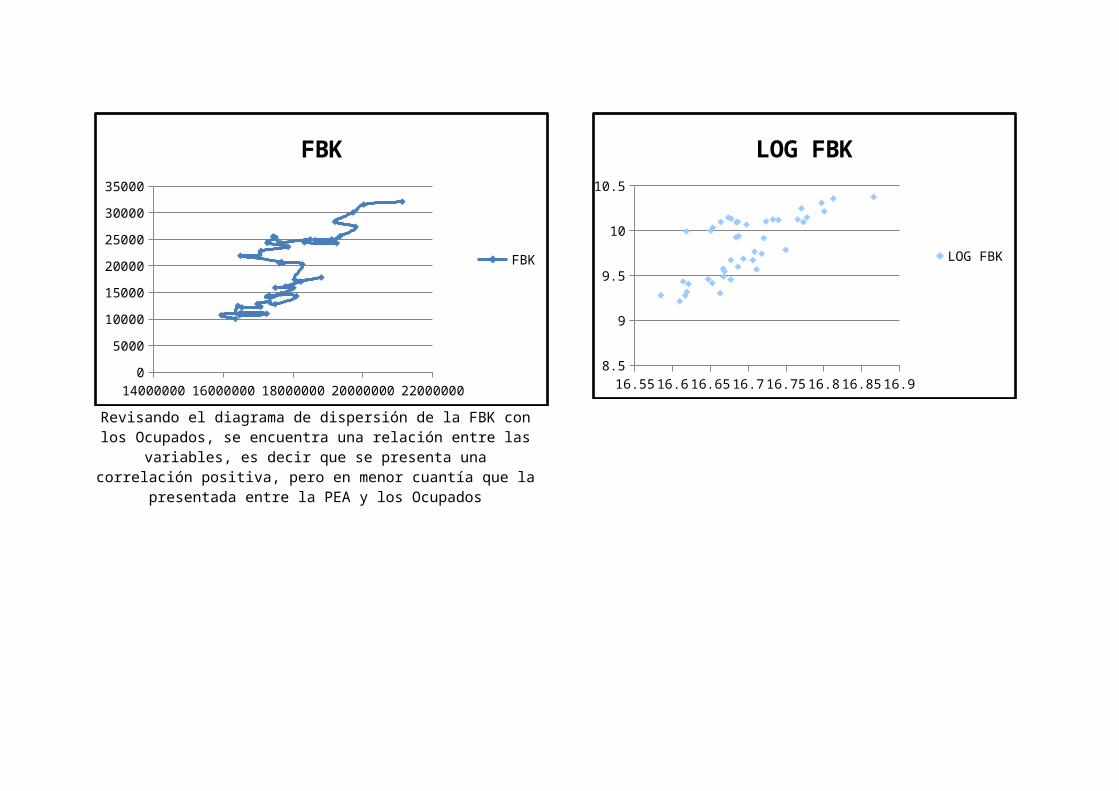
14000000 16000000 18000000 20000000 220000000
5000100001500020000250003000035000
FBK
FBK
Revisando el diagrama de dispersión de la FBK conlos Ocupados, se encuentra una relación entre las
variables, es decir que se presenta unacorrelación positiva, pero en menor cuantía que la
presentada entre la PEA y los Ocupados
16.5516.616.6516.716.7516.816.8516.98.5
9
9.5
10
10.5
LOG FBK
LOG FBK

15000000 20000000 25000000-0.50%
0.00%
0.50%
1.00%
1.50%
2.00%
Variación % IPC
Variación % IPC
No es muy clara la relación entre la variación delIPC medida porcentualmente y los ocupados, no se
puede determinar si es positiva o negativa.
16.5 16.6 16.7 16.8 16.9
-9-8-7-6-5-4-3-2-10
LOG Variación % IPC
LOG Variación % IPC
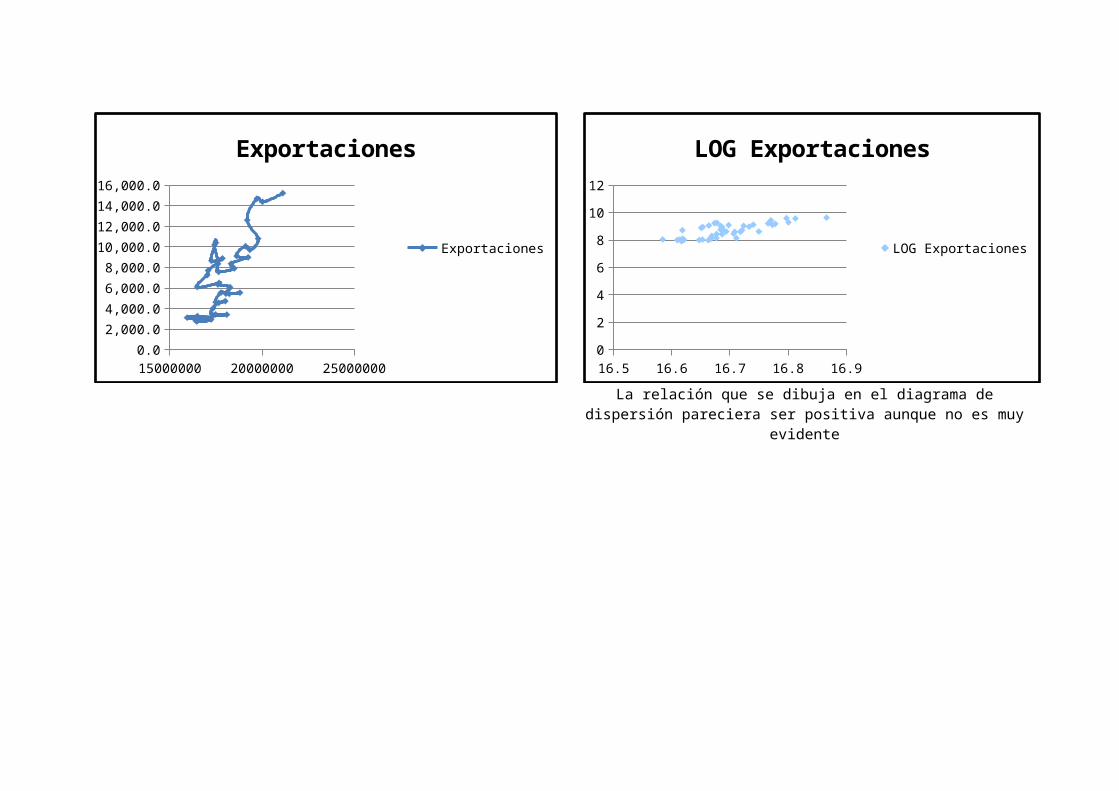
15000000 20000000 250000000.0
2,000.04,000.06,000.08,000.010,000.012,000.014,000.016,000.0
Exportaciones
Exportaciones
16.5 16.6 16.7 16.8 16.90
2
4
6
8
10
12
LOG Exportaciones
LOG Exportaciones
La relación que se dibuja en el diagrama dedispersión pareciera ser positiva aunque no es muy
evidente
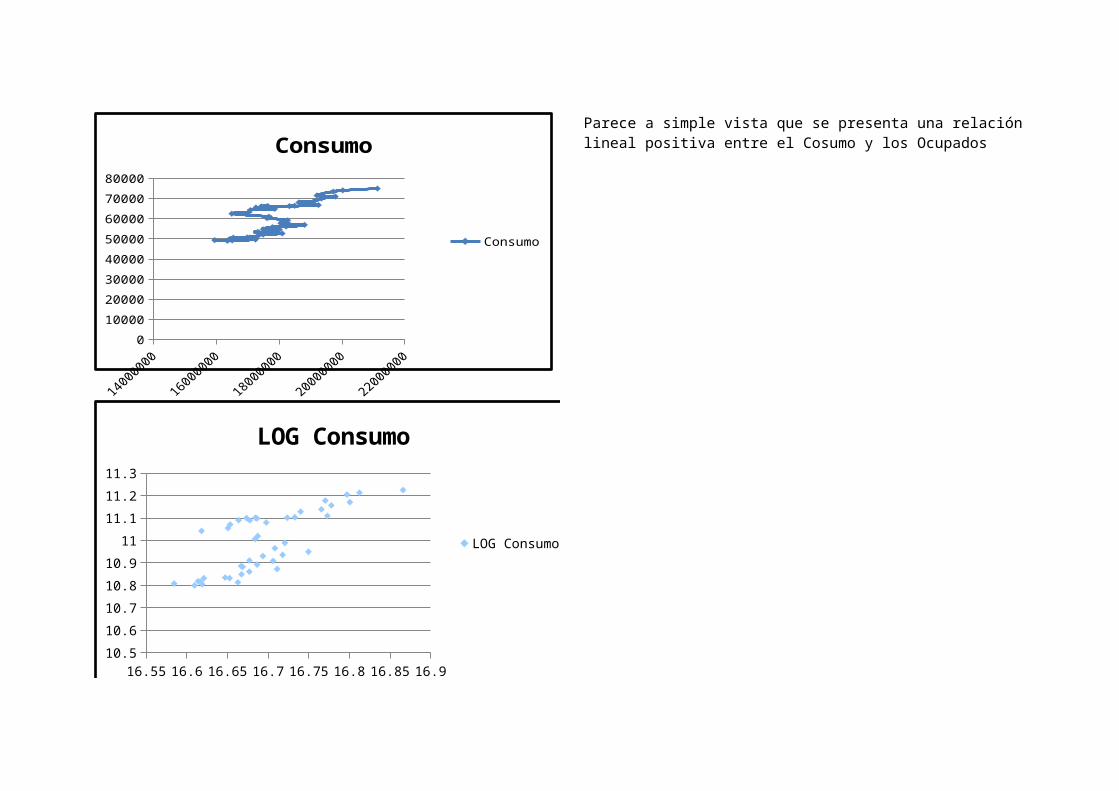
01000020000300004000050000600007000080000
Consumo
Consumo
16.55 16.6 16.65 16.7 16.75 16.8 16.85 16.910.510.610.710.810.911
11.111.211.3
LOG Consumo
LOG Consumo
Parece a simple vista que se presenta una relaciónlineal positiva entre el Cosumo y los Ocupados

3. ESTIMACIÓN ECONOMETRICA
El modelo en forma implícita queda expresado de la siguiente manera: Ocupados = f (PEA, FBKF, EXPO, Consumo, Variación Promedio IPC)
En donde:
Ocupados: Número de personas trabajando PEA: Población Económicamente Activa1
FBKF: Formación Bruta de Capital Fijo2
EXPO: Exportaciones en dólares FOB3
Consumo final de los hogares 4
Variación promedio IPC Trimestral5
1 Para Ocupados y PEA los datos fueron tomados de http://www.mintrabajo.gov.co/empleo/indicadores-del-mercado-laboral.html desde el 2003, para series anteriores a este año los datos fueron tomados de la Encuesta Nacional deHogares y Encuesta Continua de Hogares del DANE. http://www.dane.gov.co/index.php/mercado-laboral/empleo-y-desempleo2 Del DANE se tomó la información de la FIBK trimestral en millones de pesos expresado en precios corrientes (Base2000) entre Marzo de 2000 y Diciembre de 2009 http://www.dane.gov.co/index.php/pib-cuentas-nacionales/cuentas-trimestrales3Datos tomados de http://www.banrep.gov.co/es/series-estadisticas/see_s_externo.htm 4 Estos datos se obtuvieron de la pagina del DANE, en su sección Cuentas nacionales trimestrales,http://www.dane.gov.co/index.php/pib-cuentas-nacionales/cuentas-trimestrales5 Datos extraidos del DANE, en su sección Índice de Precios al Consumidor - Base 2008.http://www.dane.gov.co/index.php/indices-de-precios-y-costos/indice-de-precios-al-consumidor-ipc

La expresión matemática escogida para el modelo es de tipo sumativo siguiendo los planteamientos generales en cuanto al estudio de los fenómenos económicos, considerando que estos tienen teóricamente un comportamiento lineal entre sus variables.
Se aplicara el método de mínimos cuadrados a las 32 observaciones correspondientes a lasvariables involucradas en el modelo, para los años 2001 al 2008. El modelo estimado se presenta entonces de la siguiente manera:
Ocupados=c+β1PEA+β2EXPO+β3FBC+β4CONSUMO+β5VariacionIpc+ut
Dónde: c: constante. β1: se define como el impacto marginal de la PEA trimestral para Colombia en el trimestre t
en el número de ocupados trimestral para Colombia en el trimestret. β2: se define como el impacto marginal de las exportaciones para Colombia en el trimestre t
en el número de ocupados trimestral para Colombia en el trimestret. β3: se define como el impacto marginal de la formación Bruta de Capital Fijo para Colombia
en el trimestre t en el número de ocupados trimestral para Colombia en el trimestret. β4: se define como el impacto marginal del consumo final de los hogares para Colombia en el
trimestre t en el número de ocupados trimestral para Colombia en el trimestret. β5: se define como el impacto marginal de la variación promedio del IPC trimestral para
Colombia en el trimestre t en el número de ocupados trimestral para Colombia en el trimestret.
εt: termino de error estocástico.
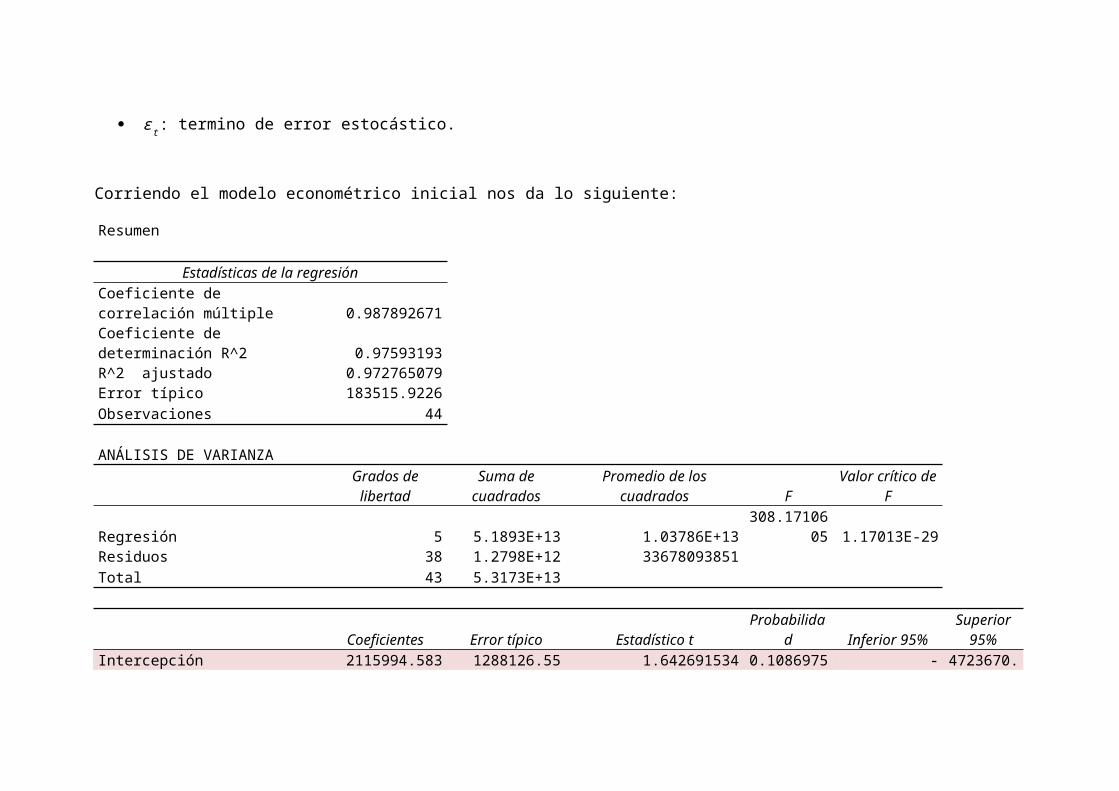
Corriendo el modelo econométrico inicial nos da lo siguiente:
Resumen
Estadísticas de la regresiónCoeficiente de correlación múltiple 0.987892671Coeficiente de determinación R^2 0.97593193R^2 ajustado 0.972765079Error típico 183515.9226Observaciones 44
ANÁLISIS DE VARIANZAGrados de
libertadSuma de
cuadradosPromedio de los
cuadrados FValor crítico de
F
Regresión 5 5.1893E+13 1.03786E+13308.17106
05 1.17013E-29Residuos 38 1.2798E+12 33678093851Total 43 5.3173E+13
Coeficientes Error típico Estadístico tProbabilida
d Inferior 95%Superior
95%Intercepción 2115994.583 1288126.55 1.642691534 0.1086975 - 4723670.
95 491681.2922 46
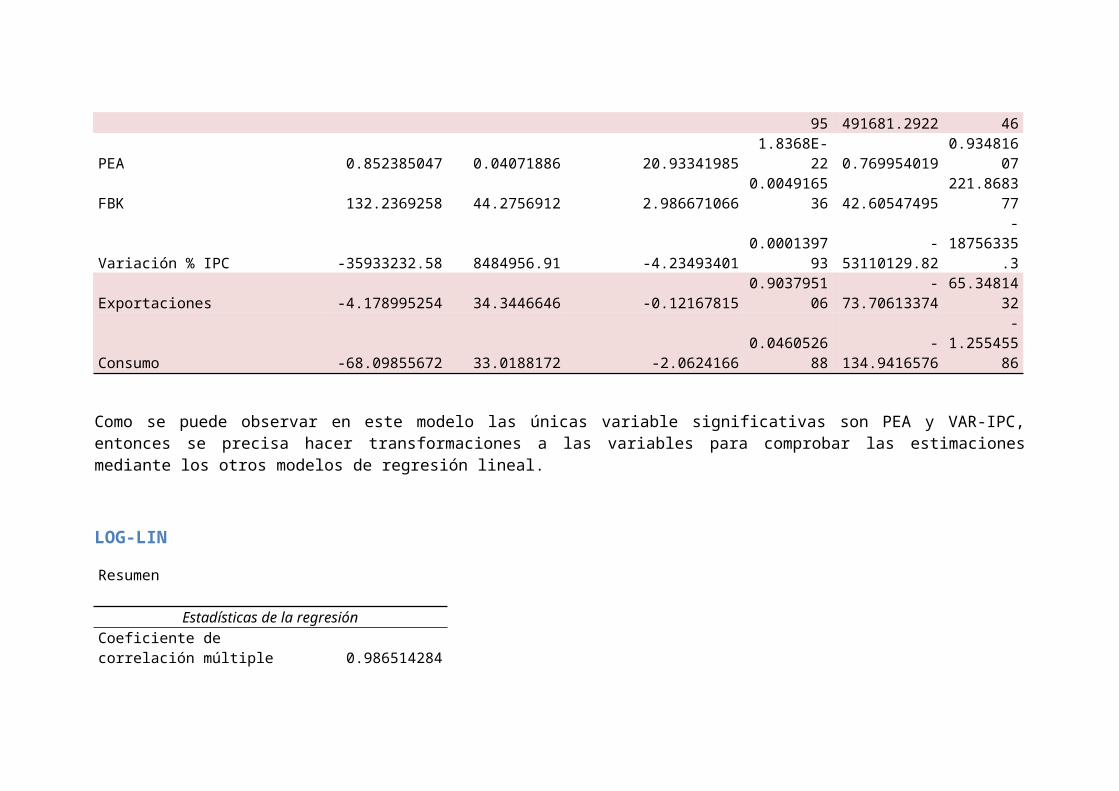
PEA 0.852385047 0.04071886 20.933419851.8368E-
22 0.7699540190.934816
07
FBK 132.2369258 44.2756912 2.9866710660.0049165
36 42.60547495221.8683
77
Variación % IPC -35933232.58 8484956.91 -4.234934010.0001397
93-
53110129.82
-18756335
.3
Exportaciones -4.178995254 34.3446646 -0.121678150.9037951
06-
73.7061337465.34814
32
Consumo -68.09855672 33.0188172 -2.06241660.0460526
88-
134.9416576
-1.255455
86
Como se puede observar en este modelo las únicas variable significativas son PEA y VAR-IPC,entonces se precisa hacer transformaciones a las variables para comprobar las estimacionesmediante los otros modelos de regresión lineal.
LOG-LIN
Resumen
Estadísticas de la regresiónCoeficiente de correlación múltiple 0.986514284
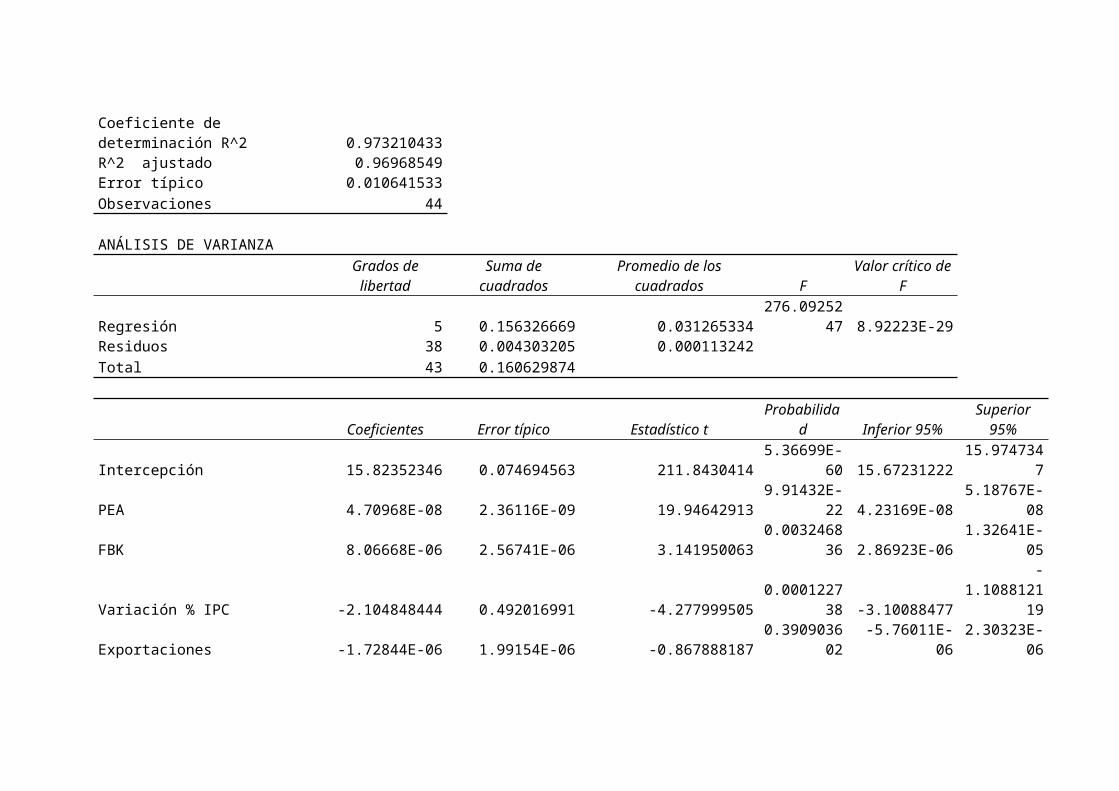
Coeficiente de determinación R^2 0.973210433R^2 ajustado 0.96968549Error típico 0.010641533Observaciones 44
ANÁLISIS DE VARIANZAGrados de
libertadSuma de
cuadradosPromedio de los
cuadrados FValor crítico de
F
Regresión 5 0.156326669 0.031265334276.09252
47 8.92223E-29Residuos 38 0.004303205 0.000113242Total 43 0.160629874
Coeficientes Error típico Estadístico tProbabilida
d Inferior 95%Superior
95%
Intercepción 15.82352346 0.074694563 211.84304145.36699E-
60 15.6723122215.974734
7
PEA 4.70968E-08 2.36116E-09 19.946429139.91432E-
22 4.23169E-085.18767E-
08
FBK 8.06668E-06 2.56741E-06 3.1419500630.0032468
36 2.86923E-061.32641E-
05
Variación % IPC -2.104848444 0.492016991 -4.2779995050.0001227
38 -3.10088477
-1.1088121
19
Exportaciones -1.72844E-06 1.99154E-06 -0.8678881870.3909036
02-5.76011E-
062.30323E-
06
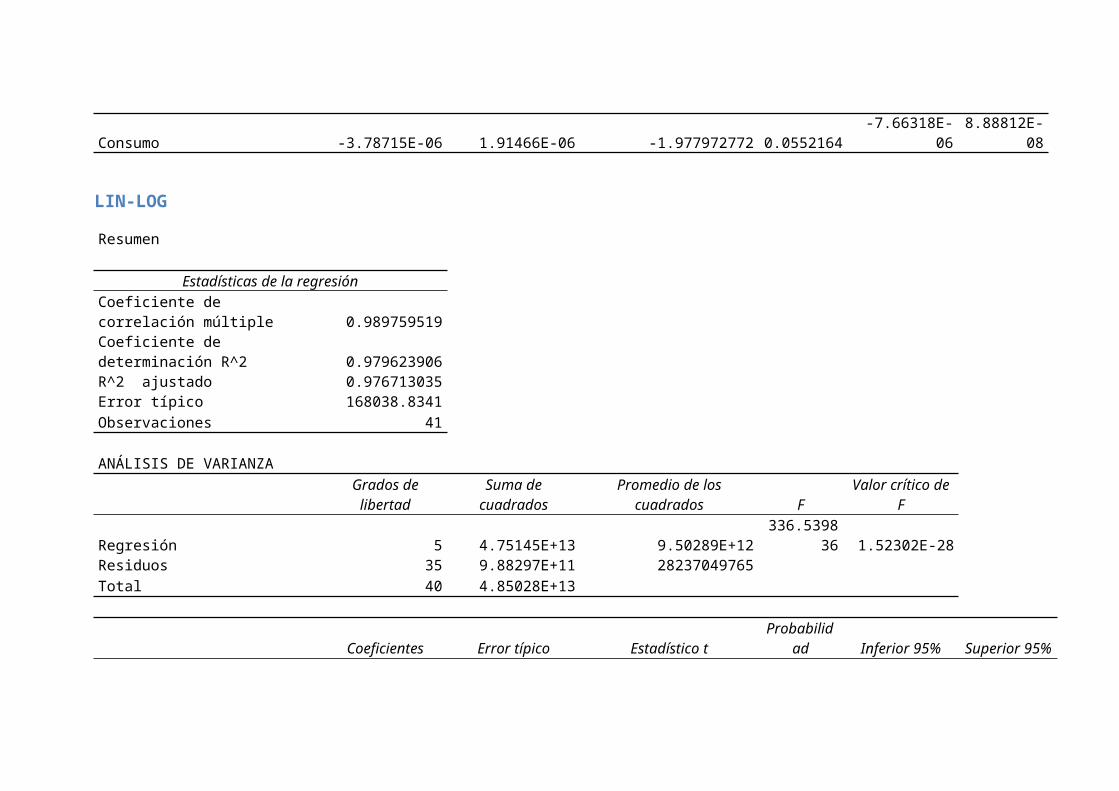
Consumo -3.78715E-06 1.91466E-06 -1.977972772 0.0552164-7.66318E-
068.88812E-
08
LIN-LOG
Resumen
Estadísticas de la regresiónCoeficiente de correlación múltiple 0.989759519Coeficiente de determinación R^2 0.979623906R^2 ajustado 0.976713035Error típico 168038.8341Observaciones 41
ANÁLISIS DE VARIANZAGrados de
libertadSuma de
cuadradosPromedio de los
cuadrados FValor crítico de
F
Regresión 5 4.75145E+13 9.50289E+12336.5398
36 1.52302E-28Residuos 35 9.88297E+11 28237049765Total 40 4.85028E+13
Coeficientes Error típico Estadístico tProbabilid
ad Inferior 95% Superior 95%

Intercepción -255394227.3 15364314.68 -16.622559013.4798E-
18 -286585444.4
-224203010.
3
LOG PEA 18104405.11 697460.6816 25.957599591.8804E-
24 16688484.6519520325.5
6
LOG FBK 1491757.002 544934.7564 2.7374965250.009664
63 385480.63282598033.37
1
LOG Variación % IPC -114354.1282 33470.96886 -3.4165168230.001622
63 -182303.8074
-46404.4489
5
LOG Exportaciones 887421.6726 300357.9527 2.9545469490.005568
07 277662.61161497180.73
4
LOG Consumo -4957606.861 1663835.376 -2.9796258280.005217
91 -8335372.249
-1579841.47
2
LOG-LOG
Resumen
Estadísticas de la regresiónCoeficiente de correlación múltiple 0.99018188Coeficiente de determinación R^2 0.98046016
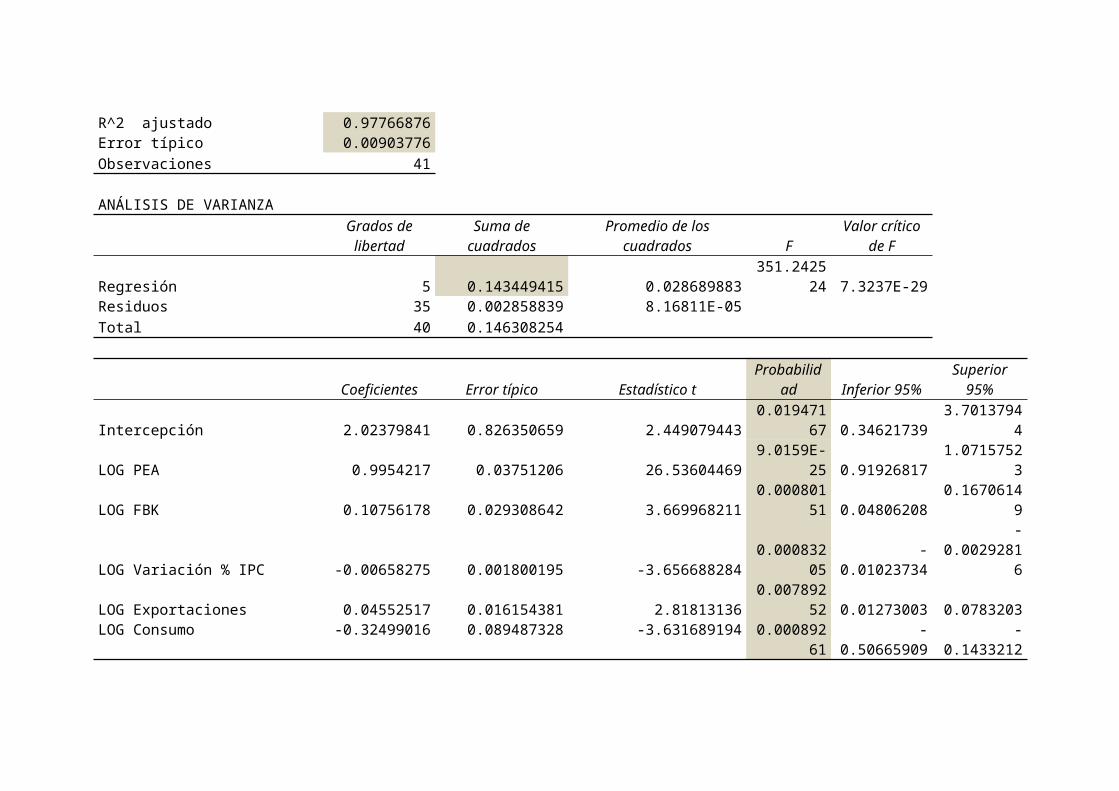
R^2 ajustado 0.97766876Error típico 0.00903776Observaciones 41
ANÁLISIS DE VARIANZAGrados de
libertadSuma de
cuadradosPromedio de los
cuadrados FValor crítico
de F
Regresión 5 0.143449415 0.028689883351.2425
24 7.3237E-29Residuos 35 0.002858839 8.16811E-05Total 40 0.146308254
Coeficientes Error típico Estadístico tProbabilid
ad Inferior 95%Superior
95%
Intercepción 2.02379841 0.826350659 2.4490794430.019471
67 0.346217393.7013794
4
LOG PEA 0.9954217 0.03751206 26.536044699.0159E-
25 0.919268171.0715752
3
LOG FBK 0.10756178 0.029308642 3.6699682110.000801
51 0.048062080.1670614
9
LOG Variación % IPC -0.00658275 0.001800195 -3.6566882840.000832
05-
0.01023734
-0.0029281
6
LOG Exportaciones 0.04552517 0.016154381 2.818131360.007892
52 0.01273003 0.0783203LOG Consumo -0.32499016 0.089487328 -3.631689194 0.000892
61-
0.50665909-
0.1433212
3
En todos los modelos excepto en el LIN-LOG y LOG-LOG vemos que no son significativos niExportaciones ni Consumo, entonces eliminamos estas variables de los modelos, encontrando lossiguientes resultados:
LIN-LIN CORREGIDO
Resumen
Estadísticas de la regresiónCoeficiente de correlación múltiple 0.999949377Coeficiente de determinación R^2 0.999898757R^2 ajustado 0.975503575Error típico 186422.1169Observaciones 44
ANÁLISIS DE VARIANZAGrados de
libertadSuma de
cuadradosPromedio de los
cuadrados FValor crítico de
F
Regresión 3 1.40725E+16 4.69084E+15134975.69
13 4.01573E-80Residuos 41 1.42488E+12 34753205668Total 44 1.40739E+16
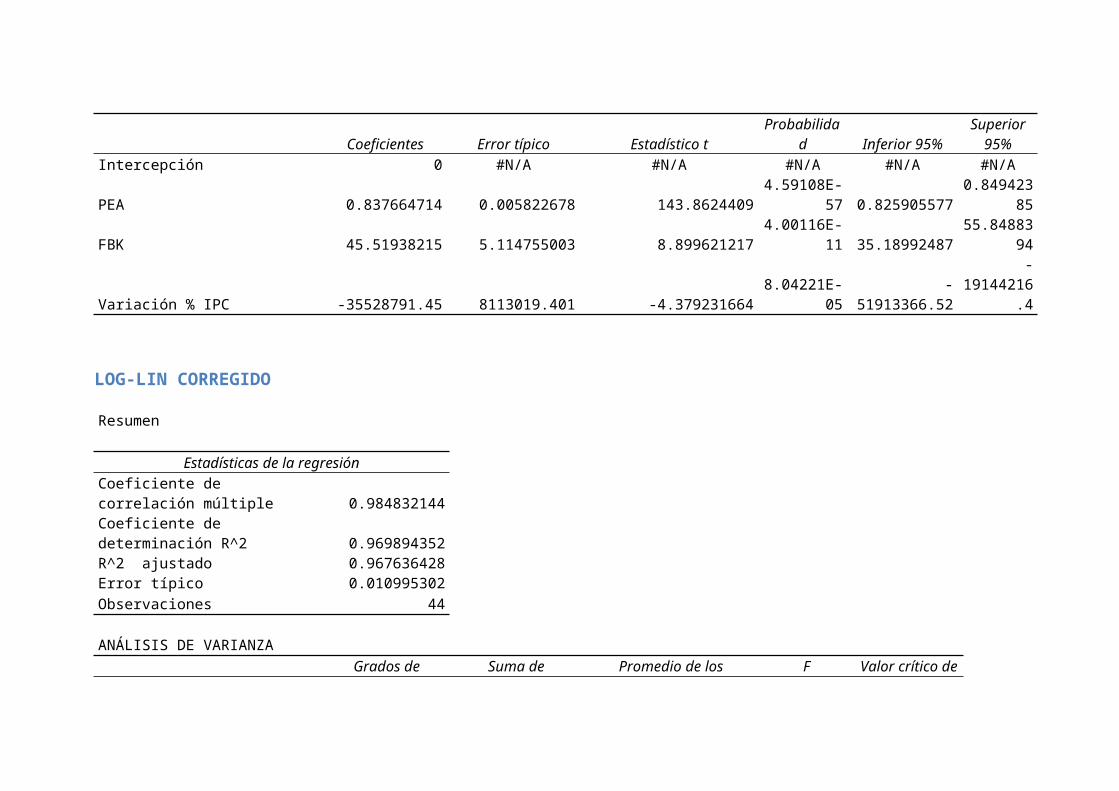
Coeficientes Error típico Estadístico tProbabilida
d Inferior 95%Superior
95%Intercepción 0 #N/A #N/A #N/A #N/A #N/A
PEA 0.837664714 0.005822678 143.86244094.59108E-
57 0.8259055770.849423
85
FBK 45.51938215 5.114755003 8.8996212174.00116E-
11 35.1899248755.84883
94
Variación % IPC -35528791.45 8113019.401 -4.3792316648.04221E-
05-
51913366.52
-19144216
.4
LOG-LIN CORREGIDO
Resumen
Estadísticas de la regresiónCoeficiente de correlación múltiple 0.984832144Coeficiente de determinación R^2 0.969894352R^2 ajustado 0.967636428Error típico 0.010995302Observaciones 44
ANÁLISIS DE VARIANZAGrados de Suma de Promedio de los F Valor crítico de
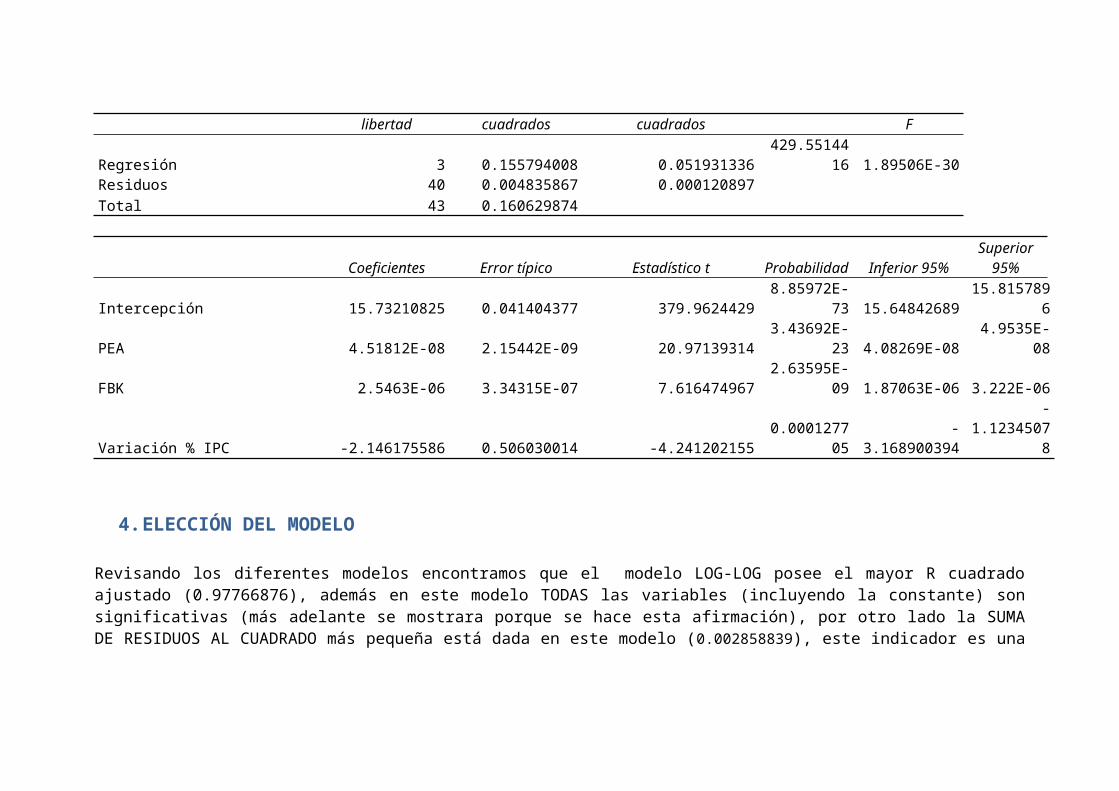
libertad cuadrados cuadrados F
Regresión 3 0.155794008 0.051931336429.55144
16 1.89506E-30Residuos 40 0.004835867 0.000120897Total 43 0.160629874
Coeficientes Error típico Estadístico t Probabilidad Inferior 95%Superior
95%
Intercepción 15.73210825 0.041404377 379.96244298.85972E-
73 15.6484268915.815789
6
PEA 4.51812E-08 2.15442E-09 20.971393143.43692E-
23 4.08269E-084.9535E-
08
FBK 2.5463E-06 3.34315E-07 7.6164749672.63595E-
09 1.87063E-06 3.222E-06
Variación % IPC -2.146175586 0.506030014 -4.2412021550.0001277
05-
3.168900394
-1.1234507
8
4.ELECCIÓN DEL MODELO
Revisando los diferentes modelos encontramos que el modelo LOG-LOG posee el mayor R cuadradoajustado (0.97766876), además en este modelo TODAS las variables (incluyendo la constante) sonsignificativas (más adelante se mostrara porque se hace esta afirmación), por otro lado la SUMADE RESIDUOS AL CUADRADO más pequeña está dada en este modelo (0.002858839), este indicador es una

medida de la precisión. El modelo más preciso tendría menos error, lo que lleva a una suma decuadrados del error más pequeño y por ende a una mayor ajuste.
Luego de esta revisión puntual se decide elegir el MODELO LOG-LIN.
Log Ocupados = 2.023798412 + 0.9954217 LOG PEA + 0.107561784 LOG FBK -0.006582751 LOG VAR_IPC +0.045525168 LOG Exportaciones -0.32499016 LOG consumo +μ
5. INTERPRETACIÓN DE LOS PARÁMETROS:
Para el caso del modelo analizado los Betas representan variaciones porcentuales, denominadaselasticidades, por eso cada Beta se interpreta de forma porcentual, a fin de obtener lainterpretación adecuada.
PEA: β1=0.9954217Es decir si la población económicamente activa se incrementa en uno porciento, se espera que los ocupados aumenten, en promedio, en un 0.9954217 %, dejando lasdemás variables constantes.
FBK: β2=0.107561784Es decir que si la formación bruta de capital fijo se incrementan enuno por ciento, se espera que los ocupados aumenten, en promedio, en un 0.107561784%,dejando las demás variables constantes.

Variación IPC: β3=−0.006582751Es decir que si la variación del IPC se incrementa en unopor ciento, se espera que los ocupados disminuyan, en promedio, en un −0.006582751%,dejando las demás variables constantes.
Exportaciones: β3=0.045525168Es decir que si las exportaciones tipo FOB se incrementan enuno por ciento, se espera que los ocupados aumenten, en promedio, en un 0.045525168%,dejando las demás variables constantes.
Consumo: β3=−0.32499016Es decir que si el consumo final de los hogares se incrementa enuna unidad porcentual, se espera que los ocupados disminuyan, en promedio, en un−0.32499016%, dejando las demás variables constantes.
La constante NO tiene interpretación económica ya que no hay posibilidad de que las variables Xstomen el valor de cero.
6. SIGNIFICANCIA INDIVIDUAL DE LAS VARIABLES:
Coeficientes Estadístico tProbabilid
ad Inferior 95%Superior
95%
Intercepción2.0237984
12.44907944
30.019471
670.3462173
93.7013794
4LOG PEA 0.9954217 26.5360446 9.0159E- 0.9192681 1.0715752

9 25 7 3
LOG FBK0.1075617
83.66996821
10.000801
510.0480620
80.1670614
9
LOG Variación % IPC
-0.0065827
5
-3.65668828
40.000832
05
-0.0102373
4
-0.0029281
6LOG Exportaciones
0.04552517 2.81813136
0.00789252
0.01273003 0.0783203
LOG Consumo
-0.3249901
6
-3.63168919
40.000892
61
-0.5066590
9
-0.1433212
3
Constante:H°:c=0vs.H':c≠0. Como el valor de probabilidad del estadístico t es 0.01947167,entonces se evidencia estadísticamente que se rechaza la hipotesis nula de que H°:β1=0a unnivel de significancia del 5%, es decir, que la constante es significativa en el modelo.
PEA: H°:β1=0vs.H':β1≠0. Como el valor de probabilidad del estadístico t es 9.0159E-25,
entonces se evidencia estadísticamente que se rechaza la hipotesis nula de que H°:β1=0a unnivel de significancia del 5%, es decir, que la PEA es significativo en el modelo.
FORMACIÓN INTERNA BRUTA DE CAPITAL: H°:β3=0vs.H':β3≠0. Como el valor de probabilidad del
estadístico t es 0.00080151, entonces se evidencia estadísticamente que se rechaza lahipotesis nula de que H°:β2=0a un nivel de significancia del 5%, es decir, que la FormaciónBruta de Capital o Inversión es significativa en el modelo.
VARIACIÓN PORCENTUAL IPC: H°:β2=0vs.H':β2≠0. Como el valor de probabilidad del estadístico
t es 0.00083205, entonces se evidencia estadísticamente que se rechaza la hipotesis nula de
que H°:β2=0a un nivel de significancia del 5%, es decir, que la Variación % del IPC essignificativa en el modelo.
EXPORTACIONES FOB: H°:β2=0vs.H':β2≠0. Como el valor de probabilidad del estadístico t es
0.00789252, entonces se evidencia estadísticamente que se rechaza la hipotesis nula de queH°:β2=0a un nivel de significancia del 5%, es decir, que las Exportaciones sonsignificativas en el modelo.
CONSUMO FINAL DE LOS HOGARES: H°:β2=0vs.H':β2≠0. Como el valor de probabilidad del
estadístico t es 0.00089261, entonces se evidencia estadísticamente que se rechaza lahipotesis nula de que H°:β2=0a un nivel de significancia del 5%, es decir, que el Consumoes significativi en el modelo.
Además revisando los intervalos de confianza, ninguno de los estimadores contiene al cero, loque refuerza la significancia de estos parámetros.
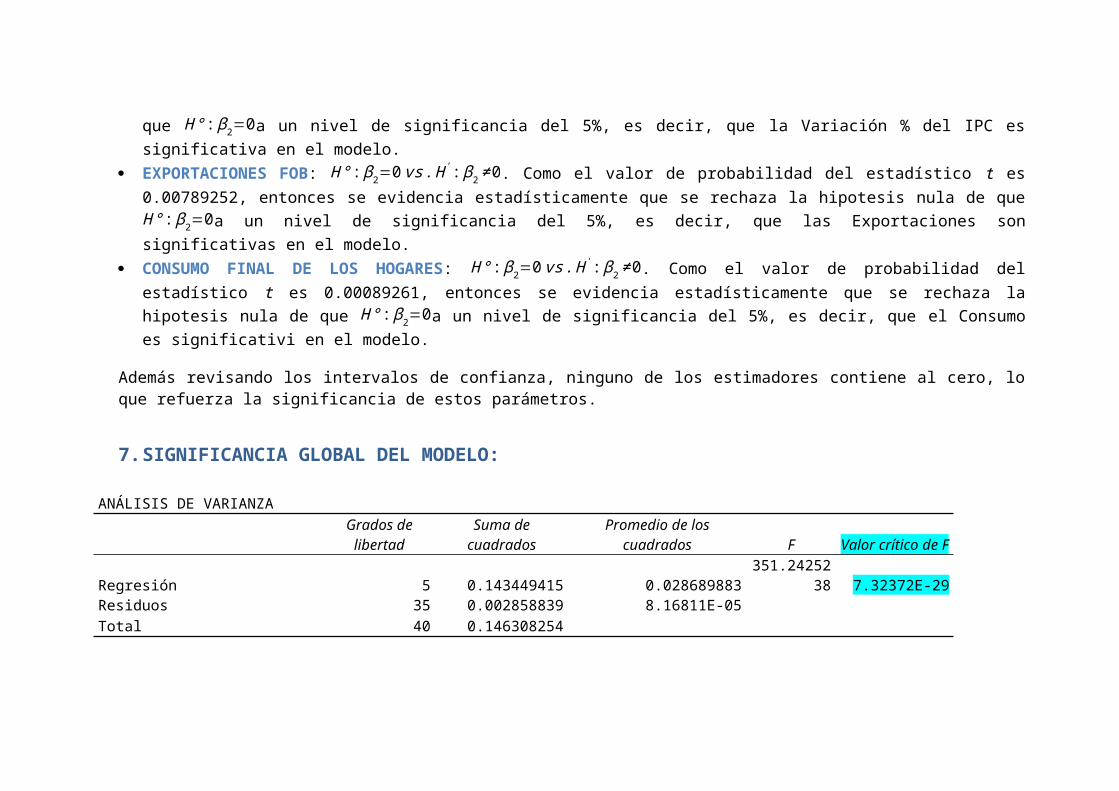
7.SIGNIFICANCIA GLOBAL DEL MODELO:
ANÁLISIS DE VARIANZAGrados de
libertadSuma de
cuadradosPromedio de los
cuadrados F Valor crítico de F
Regresión 5 0.143449415 0.028689883351.24252
38 7.32372E-29Residuos 35 0.002858839 8.16811E-05Total 40 0.146308254

Se plantea la siguiente prueba de hipótesis
H°:β1=β2=β3=0vs.H':Almenosunβi≠0,i=1,2.
Como el valor de probabilidad del estadístico F es 7.32372E-29, entonces se evidenciaestadísticamente que se rechaza la hipotesis nula de que H°:β1=β2=β3=0a un nivel designificancia del 5%, es decir, que al menos una variable es significativa en el modelo, odicho de otra manera, el modelo propuesto es estadisticamente significativo.
Coeficiente de Determinación Ajustado: R2=0.977668759, eso significa que la variación de latasa de ocupados está explicado en un 97.77% por la variación de las variables PEA, FIBK,VAR_IPC_TRIMES, EXPORTACIONES Y CONSUMO.
8.EVALUACIÓN DE SUPUESTOS
A. MULTICOLINEALIDAD
Conceptos tomados de (Gujarati, 2004)
La multicolinealidad tiene que ver con la relación lineal entre algún conjunto de variablesindependientes en un modelo de regresión. Supóngase el siguiente modelo con cuatro variablesindependientes:

Cualquier relación lineal entre las variables independientes de este modelo, por ejemplo X2 con X3, o X2 con X5 y X4 puede generar problemas de multicolinealidad. Por lo general, existen dos tipos de multicolinealidad:
Multicolinealidad Perfecta: Para entender el concepto de multicolinealidad perfecta esnecesario expresar las variables independientes del modelo en términos de una combinaciónlineal cuya suma algebraica sea igual a cero. Para el modelo presentado la combinaciónlineal sería:
Los valores de λ pueden ser positivos o negativos y formar muchas combinaciones. Cuandola suma algebraica para todas las observaciones de la muestra de esta combinación lineales cero se dice que existe multicolinealidad perfecta. De este caso se exceptúa quesimultáneamente los valores de λ sean cero, pues esta es una solución trivial de laecuación. En otras palabras, la multicolinealidad perfecta se presenta cuando unacombinación lineal de uno o más vectores de variables explicativas generan de maneraperfecta uno o más vectores idénticos a cualquiera de las variables explicativas en labase de datos.
Multicolinealidad Alta: Esta se presenta cuando la colinealidad que existe entre variables independientes es muy fuerte aunque no perfecta.

La multicolinealidad se presenta debido a la tendencia definida de ciertas variables a lolargo de la muestra o a través del tiempo. Tendencias o patrones de comportamiento similaresde las variables independientes en un modelo de regresión sustentan la multicolinealidad. Lamulticolinealidad se puede presentar en datos provenientes de series de tiempo.
El problema de multicolinealidad también es un problema ocasionado por las observaciones enlos datos recopilados de la muestra. La presencia de multicolinealidad afecta directamentela estimación de los parámetros del modelo.
De acuerdo con el estimador por mínimos cuadrados ordinarios:
Si existe multicolinealidad perfecta entre las variables independientes de un modelo deregresión, (X'X)−1 no existe. Cuando esto ocurre no es posible estimar β̂. En presencia dealta multicolinealidad se genera una ampliación del error estándar de β̂, por lo que el valorde los estadísticos "t" para cada uno de los parámetros del modelo serán mucho menores queen ausencia de multicolinealidad, aumentándose la probabilidad de cometer error de tipo II,es decir, que acepte Ho no siendo verdadera. Por consiguiente, el modelo no tiene validezpara realizar pruebas de relevancia.
Detección de Multicolinealidad
Para evaluar si hay efectos de multicolinealidad en el modelo, primero se observa la matrizde correlaciones de las variables exógenas:
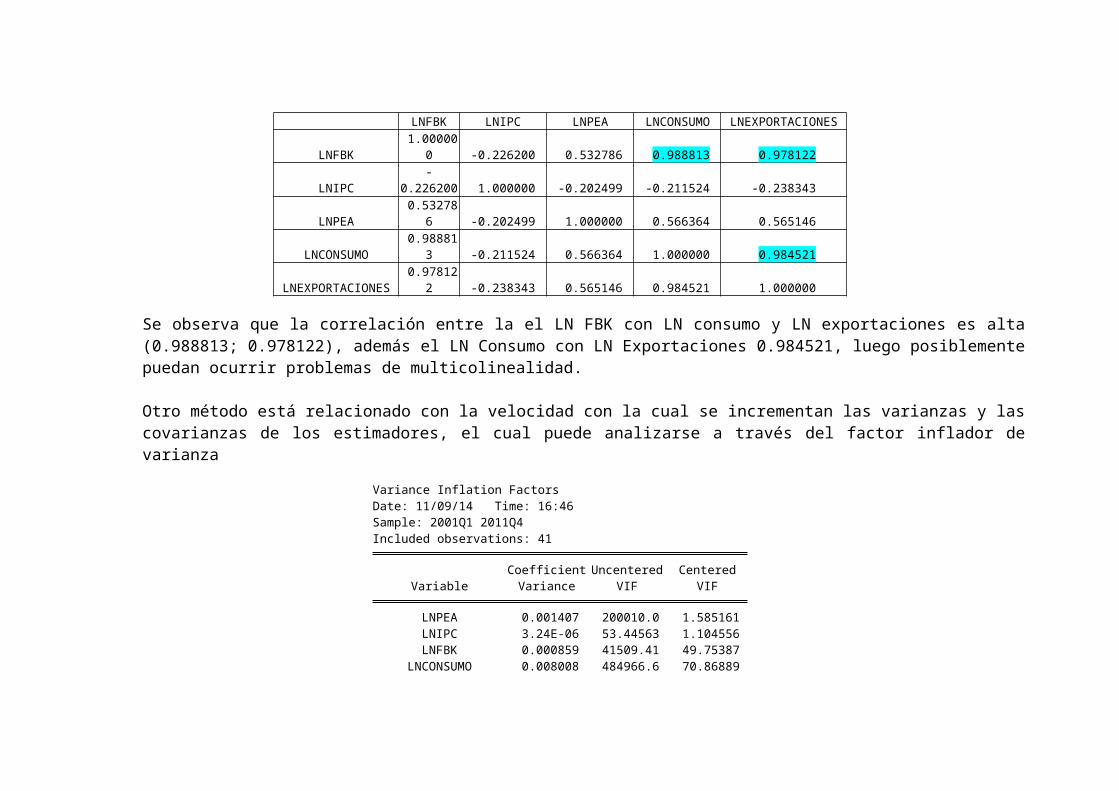
LNFBK LNIPC LNPEA LNCONSUMO LNEXPORTACIONES
LNFBK 1.00000
0 -0.226200 0.532786 0.988813 0.978122
LNIPC-
0.226200 1.000000 -0.202499 -0.211524 -0.238343
LNPEA 0.53278
6 -0.202499 1.000000 0.566364 0.565146
LNCONSUMO 0.98881
3 -0.211524 0.566364 1.000000 0.984521
LNEXPORTACIONES 0.97812
2 -0.238343 0.565146 0.984521 1.000000
Se observa que la correlación entre la el LN FBK con LN consumo y LN exportaciones es alta(0.988813; 0.978122), además el LN Consumo con LN Exportaciones 0.984521, luego posiblementepuedan ocurrir problemas de multicolinealidad.
Otro método está relacionado con la velocidad con la cual se incrementan las varianzas y lascovarianzas de los estimadores, el cual puede analizarse a través del factor inflador devarianza
Variance Inflation FactorsDate: 11/09/14 Time: 16:46Sample: 2001Q1 2011Q4Included observations: 41
Coefficient Uncentered CenteredVariable Variance VIF VIF
LNPEA 0.001407 200010.0 1.585161LNIPC 3.24E-06 53.44563 1.104556LNFBK 0.000859 41509.41 49.75387
LNCONSUMO 0.008008 484966.6 70.86889

LNEXPORTACIONES 0.000261 9854.683 34.66623C 0.682855 342760.6 NA
Ahora bien,
Los VIF de cada uno de los estimadores cuyo valor sea superior a 10 indican que la variable a laque acompañan puede considerarse como una combinación lineal de otras variables independientes.
Alternativamente suele observarse el índice de Tolerancia (1/VIF). Un índice de tolerancia iguala 0.1 es equivalente a un VIF de 10. Valores de tolerancia inferiores a 0.1 (0.333 para los menosconservadores) indican presencia moderada o severa de multicolinealidad.
Variable 1/ VIF
LNPEA0.630850
75
LNIPC0.905341
15
LNFBK0.020098
94
LNCONSUMO0.014110
56LNEXPORTACIONES 0.028846

52
Tenemos entonces que los Centered VIF de LNFBK; LNCONSUMO; LNEXPORTACIONES son mayores a diez(10), además el índice de tolerancia (1/VIF) es menor a 0.1, por ende nuestro modelo presentaproblemas de Multicolinealidad
Corrección
En nuestro modelo NO es necesario corregir este problema, dado que trayendo a colación lomencionado en (Gujarati, 2004), sabemos que si se satisfacen los supuestos del modelo clásico,los estimadores de MCO de los coeficientes de regresión son MELI (o MEI, si se añade el supuestode normalidad). Ahora puede demostrarse que, aunque la multicolinealidad sea muy alta, como en elcaso de casi multicolinealidad, los estimadores de MCO conservarán la propiedad MELI (MejoresEstimadores Linealmente Insesgados).
Entonces, ¿cuáles son los inconvenientes de la multicolinealidad? Christopher Achen comenta alrespecto:
Los novatos en el estudio de la metodología en ocasiones se preocupan porque sus variables independientes estén correlacionadas:el llamado problema de multicolinealidad. Sin embargo, la multicolinealidad no viola los supuestos básicos de la regresión. Sepresentarán estimaciones consistentes e insesgadas y sus errores estándar se estimarán en la forma correcta. El único efecto de lamulticolinealidad tiene que ver con la dificultad de obtener los coeficientes estimados con errores estándar pequeños. Sinembargo, se presenta el mismo problema al contar con un número reducido de observaciones o al tener variables independientescon varianzas pequeñas. (De hecho, en el nivel teórico, los conceptos de multicolinealidad, número reducido de observaciones y

varianzas pequeñas en las variables independientes forman parte esencial del mismo problema.) Por tanto, la pregunta “¿qué debehacerse entonces con la multicolinealidad?” es similar a “¿qué debe hacerse si no se tienen muchas observaciones?” Al respecto nohay una respuesta estadística. (Achen, 1982)
B. HETEROSCEDASTICIDAD:
La heteroscedasticidad significa que la varianza de las perturbaciones no es constante a lo largode las observaciones, violando un supuesto básico del modelo. En términos generales, en presenciade heteroscedasticidad la varianza de los estimadores está sesgada (sobrestimada o subestimada).En estos casos no se puede confiar en las pruebas t y F. Visto de otro modo, si el modelo estábien especificado no debería existir un patrón definido entre los residuales del modelo y lavariable dependiente pronosticada. Cuando la varianza de los residuales no es constante se diceque la varianza de los residuales es heteroscedástica. Existen métodos gráficos y métodosformales para detectar heteroscedasticidad
La prueba de Hipótesis es la siguiente:
H°:ElmodeloeshomoscedasticoH°:ElmodeloNOeshomoscedastico
Con un α = 5% (0.05), se rechazara Ho si el p value de los estadísticos asociados a las pruebas es menor aeste α
Detección de Heteroscedasticidad
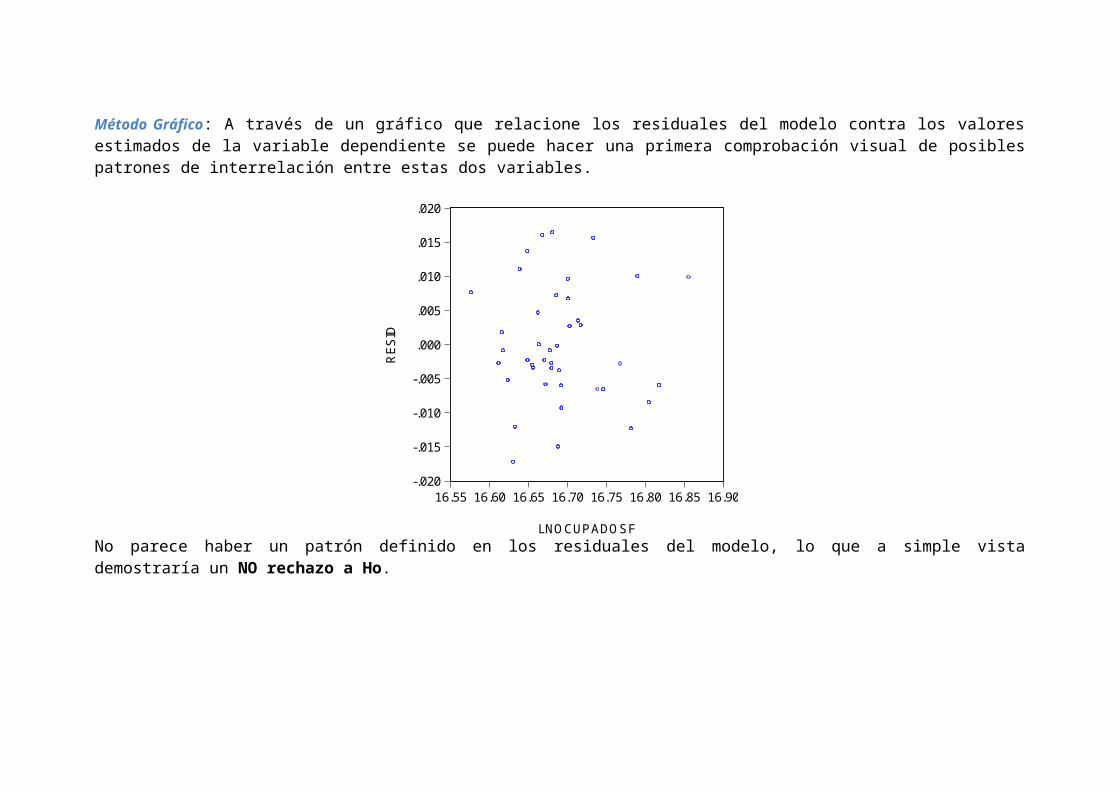
Método Gráfico: A través de un gráfico que relacione los residuales del modelo contra los valoresestimados de la variable dependiente se puede hacer una primera comprobación visual de posiblespatrones de interrelación entre estas dos variables.
-.020
-.015
-.010
-.005
.000
.005
.010
.015
.020
16.55 16.60 16.65 16.70 16.75 16.80 16.85 16.90
LNO CUPADO SF
RESID
No parece haber un patrón definido en los residuales del modelo, lo que a simple vistademostraría un NO rechazo a Ho.
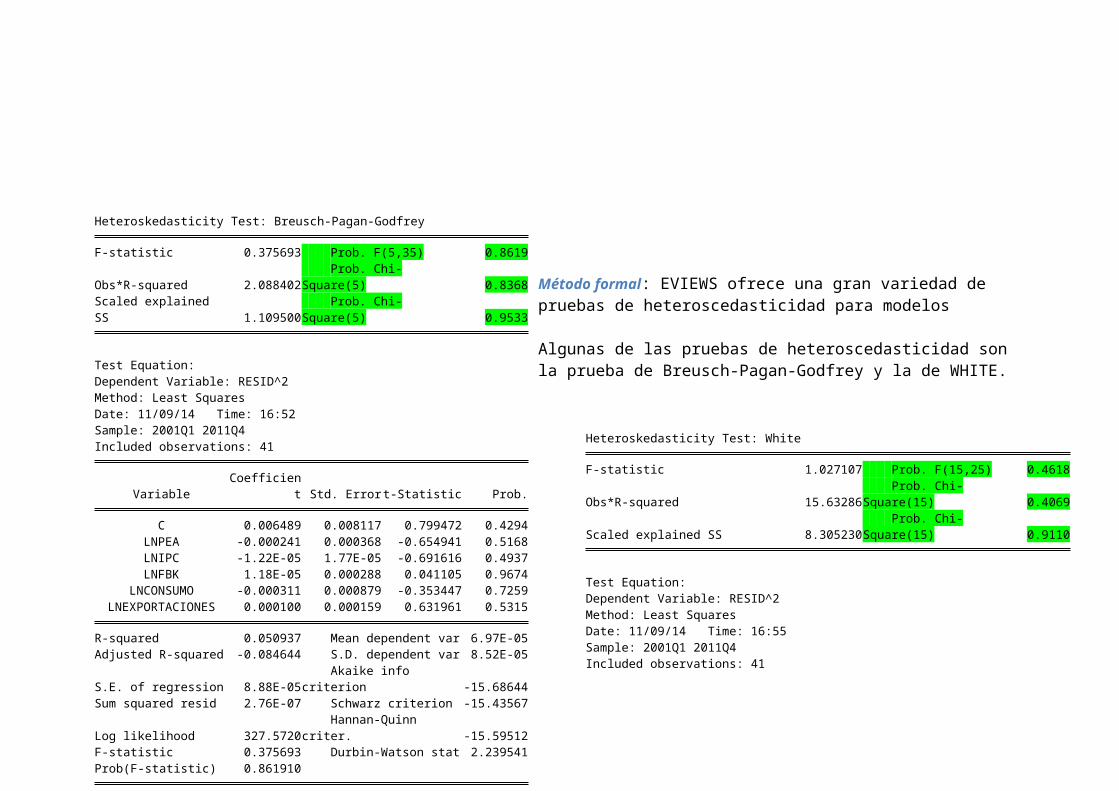
Método formal: EVIEWS ofrece una gran variedad de pruebas de heteroscedasticidad para modelos
Algunas de las pruebas de heteroscedasticidad son la prueba de Breusch-Pagan-Godfrey y la de WHITE.
Heteroskedasticity Test: White
F-statistic 1.027107 Prob. F(15,25) 0.4618
Obs*R-squared 15.63286 Prob. Chi-Square(15) 0.4069
Scaled explained SS 8.305230 Prob. Chi-Square(15) 0.9110
Test Equation:Dependent Variable: RESID^2Method: Least SquaresDate: 11/09/14 Time: 16:55Sample: 2001Q1 2011Q4Included observations: 41
Heteroskedasticity Test: Breusch-Pagan-Godfrey
F-statistic 0.375693 Prob. F(5,35) 0.8619
Obs*R-squared 2.088402 Prob. Chi-Square(5) 0.8368
Scaled explained SS 1.109500
Prob. Chi-Square(5) 0.9533
Test Equation:Dependent Variable: RESID^2Method: Least SquaresDate: 11/09/14 Time: 16:52Sample: 2001Q1 2011Q4Included observations: 41
VariableCoefficien
t Std. Errort-Statistic Prob.
C 0.006489 0.008117 0.799472 0.4294LNPEA -0.000241 0.000368 -0.654941 0.5168LNIPC -1.22E-05 1.77E-05 -0.691616 0.4937LNFBK 1.18E-05 0.000288 0.041105 0.9674
LNCONSUMO -0.000311 0.000879 -0.353447 0.7259LNEXPORTACIONES 0.000100 0.000159 0.631961 0.5315
R-squared 0.050937 Mean dependent var 6.97E-05Adjusted R-squared -0.084644 S.D. dependent var 8.52E-05
S.E. of regression 8.88E-05 Akaike info criterion -15.68644
Sum squared resid 2.76E-07 Schwarz criterion -15.43567
Log likelihood 327.5720 Hannan-Quinn criter. -15.59512
F-statistic 0.375693 Durbin-Watson stat 2.239541Prob(F-statistic) 0.861910

Collinear test regressors dropped from specification
VariableCoefficien
t Std. Error
t-Statisti
c Prob.
C -0.034239 0.285261-
0.120027 0.9054LNPEA 0.013217 0.023399 0.564881 0.5772
LNPEA*LNIPC 0.000120 0.000556 0.216549 0.8303LNPEA*LNFBK 0.002374 0.002739 0.866744 0.3943
LNPEA*LNCONSUMO -0.001459 0.001480-
0.986121 0.3335
LNPEA*LNEXPORTACIONES -0.002403 0.001555-
1.545215 0.1349
LNIPC -0.014006 0.012520-
1.118732 0.2739
LNIPC^2 -5.12E-05 2.19E-05-
2.337359 0.0277
LNIPC*LNFBK -0.000664 0.000485-
1.368225 0.1834LNIPC*LNCONSUMO 0.001614 0.001296 1.246129 0.2243
LNIPC*LNEXPORTACIONES 1.73E-05 0.000207 0.083539 0.9341
LNFBK -0.021716 0.032311-
0.672118 0.5077
LNFBK^2 -0.001641 0.002662-
0.616453 0.5432
LNFBK*LNEXPORTACIONES 0.001222 0.003621 0.337604 0.7385LNCONSUMO*LNEXPORTACIONES 0.003820 0.002972 1.285578 0.2104
LNEXPORTACIONES^2 -0.000778 0.001224-
0.635502 0.5309
R-squared 0.381289 Mean dependent var 6.97E-05
Adjusted R-squared 0.010063 S.D. dependent var 8.52E-05
S.E. of regression 8.48E-05 Akaike info criterion -15.62647
Sum squared resid 1.80E-07 Schwarz criterion -14.95776
Log likelihood 336.3426 Hannan-Quinn criter. -15.38296
F-statistic 1.027107 Durbin-Watson stat 2.480400
Prob(F-statistic) 0.461760
Como se puede observar en las dos pruebas o Test, el valor p del estadístico F y Chi cuadrado, esmayor al α (5%), lo que significa que NO RECHAZO Ho, es decir los errores del modelo son homoscedasticos o NO presentan problemas de Heteroscedasticidad.

C. NORMALIDAD
Uno de los supuestos claves en el modelo de regresión que permite desarrollar pruebashipótesis basadas en los estadísticos F y t, es la normalidad de los errores. Si losresiduos del modelo no siguen distribución normal se restringe la validez estadística de laspruebas.
Detección de Normalidad
Ho: los errores siguen distribución normal.H1: los errores no siguen distribución normal.
Con un α = 5% (0.05), se rechazara Ho si el p value de los estadísticos asociados a las pruebases menor a este α
Estadístico de Jarque-Bera
Es una prueba para muestras grandes, basada en los residuos de mínimos cuadrados ordinarios.Requiere calcular la asimetría y curtosis de los residuos.
El estadístico de prueba es:

La hipotesis nula es rechazada si JB > χ2gl2 a un nivel α de significancia. A se denomina asimetría
y K curtósis. Estas son medidas descriptivas de una variable aleatoria que hacen referencia alsesgo de la distribución y el apuntamiento de la distribución, respectivamente. Si una variabletiene A= 0 y K = 3, entonces ésta sigue distribución normal. La fórmula de cálculo de estasmedidas es la siguiente:
En este caso X corresponde a los errores del modelo de mínimos cuadrados ordinarios.
Ahora bien, utilizando la prueba.
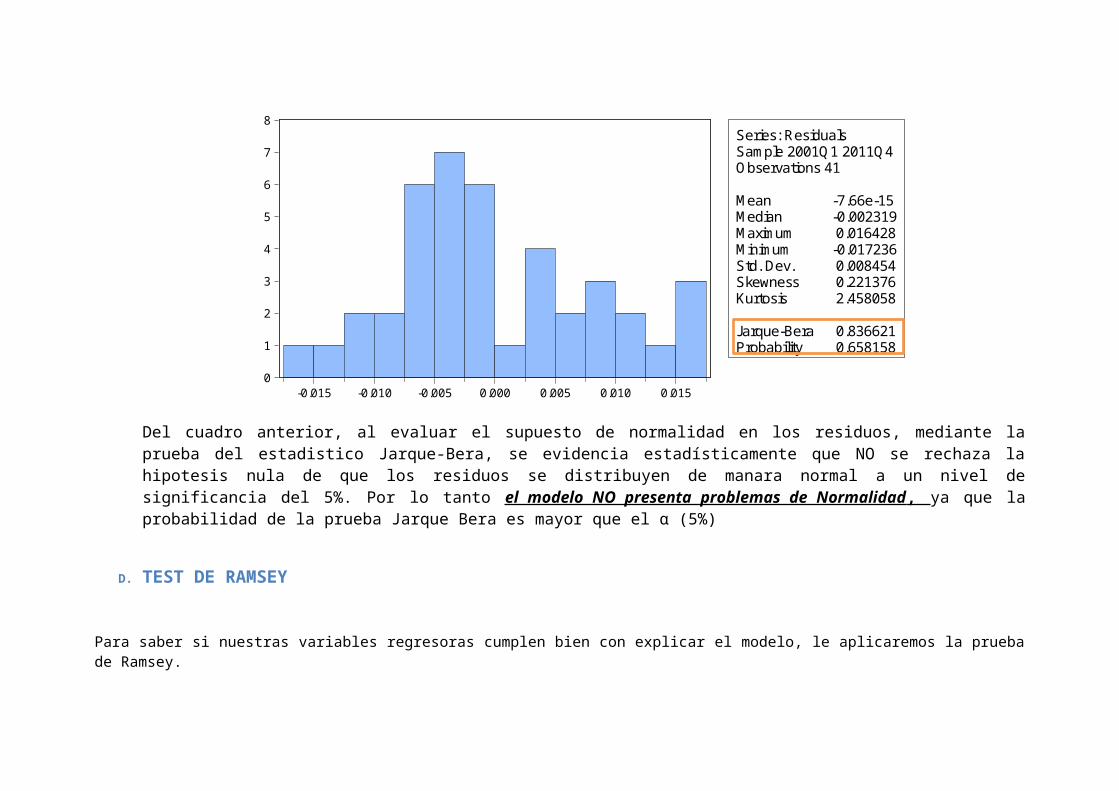
0
1
2
3
4
5
6
7
8
-0.015 -0.010 -0.005 0.000 0.005 0.010 0.015
Series: ResidualsSample 2001Q1 2011Q4Observations 41
Mean -7.66e-15Median -0.002319Maximum 0.016428Minimum -0.017236Std. Dev. 0.008454Skewness 0.221376Kurtosis 2.458058
Jarque-Bera 0.836621Probability 0.658158
Del cuadro anterior, al evaluar el supuesto de normalidad en los residuos, mediante laprueba del estadistico Jarque-Bera, se evidencia estadísticamente que NO se rechaza lahipotesis nula de que los residuos se distribuyen de manara normal a un nivel designificancia del 5%. Por lo tanto el modelo NO presenta problemas de Normalidad , ya que laprobabilidad de la prueba Jarque Bera es mayor que el α (5%)
D. TEST DE RAMSEY
Para saber si nuestras variables regresoras cumplen bien con explicar el modelo, le aplicaremos la pruebade Ramsey.

H 0: El modelo está bien especificado.H 1: El modelo no esté bien especificado.
La alternativa para tratar la no linealidad consiste en transformar el modelo.
Lo principal es la forma en la que se encuentra los parámetros en la ecuación, pues mediante logaritmos oexponentes se puede convertir en lineales.
Ramsey RESET TestEquation: LOG_LOGSpecification: LNOCUPADOS LNPEA LNIPC LNFBK LNCONSUMO LNEXPORTACIONES COmitted Variables: Squares of fitted values
Value dfProbabilit
yt-statistic 0.233277 34 0.8169F-statistic 0.054418 (1, 34) 0.8169Likelihood ratio 0.065569 1 0.7979
F-test summary:Sum ofSq. df
MeanSquares
Test SSR 4.57E-06 1 4.57E-06Restricted SSR 0.002859 35 8.17E-05Unrestricted SSR 0.002854 34 8.39E-05Unrestricted SSR 0.002854 34 8.39E-05
LR test summary:Value df
Restricted LogL 138.0272 35

Unrestricted LogL 138.0600 34
Notemos que, la probabilidad asociada al F estadístico del test de Ramsey RESET es igual a 81.69%(p>5%,por lo no se rechaza la hipótesis nula). Por lo tanto NO SE RECHAZA la hipótesis nula deque el modelo está bien especificado. Es decir que las variables regresoras cumplen con elobjetivo de explicar bien el modelo.
E. CONCLUSIONES
El modelo estimado presenta buenos resultados en general, especialmente en el tema de Bondad de Ajuste ysignificancia de las variables explicativas, así como del cumplimiento de la mayoría de los supuestosevaluados, excepto el de colinealidad
Se puede afirmar que el número de ocupados se relaciona de forma directa con la población económicamenteactiva, la formación de capital fijo, las exportaciones e inversamente con la variación del IPC y elconsumo de los hogares
La variación de la tasa de ocupados está explicado en un 97.77% por la variación de las variablesPEA, FIBK, VAR_IPC_TRIMES, EXPORTACIONES Y CONSUMO
El modelo mas adecuado para el pronostico es el de elasticidades, donde la variable dependiente ylas independientes estan medidas en logaritmos.

Realizando la prueba de especificacion del modelo, se detalla que según el test de Ramsey, lasvariables regresoras cumplen con el objetivo de explicar bien el modelo, por ende se puede decirque el modelo es adecuado para explicar el numero de ocupados en la economia.
La variable que genera mayor impacto sobre los ocupados es la Población Económicamente Activadebido a su beta (0,9954217%), mientras que la menos genera impacto son las exportaciones(0,045525168%).
Si hablasemos de elasticidades, los ocupados es inelastico frente a las variables independientes,debido a que sus betas son menores a UNO.





























