Embed Size (px)
Citation preview

1
Optimizing the Throughput of Data-DrivenPeer-to-Peer Streaming
Meng Zhang, Student Member, IEEE, Yongqiang Xiong, Member, IEEE, Qian Zhang, Senior Member, IEEE,Lifeng Sun, Member, IEEE, and Shiqiang Yang, Member, IEEE
Abstract— During recent years, the Internet has witnessed arapid growth in deployment of data-driven (or swarming based)peer-to-peer (P2P) media streaming. In these applications, eachnode independently selects some other nodes as its neighbors(i.e. gossip-style overlay construction), and exchanges streamingdata with the neighbors (i.e. data scheduling). To improve theperformance of such protocol, many existing works focus on thegossip-style overlay construction issue. However, few of themconcentrate on optimizing the streaming data scheduling to max-imize the throughput of a constructed overlay. In this paper, weanalytically study the scheduling problem in data-driven stream-ing system and model it as a classical min-cost network flowproblem. We then propose both the global optimal schedulingscheme and distributed heuristic algorithm to optimize the systemthroughput. Furthermore, we introduce layered video coding intodata-driven protocol and extend our algorithm to deal with theend-host heterogeneity. The results of simulation with the real-world traces indicate that our distributed algorithm significantlyoutperforms conventional ad hoc scheduling strategies especiallyin stringent buffer and bandwidth constraints.
Index Terms— peer-to-peer, data-driven, block scheduling,min-cost flow, throughput, delivery ratio
I. INTRODUCTION
The Internet has witnessed a rapid growth in deployment ofdata-driven or swarming based peer-to-peer streaming systems(P2P streaming systems) from the year of 2005, such as [1], [2],[3], since the data-driven protocol is first proposed in academia[4], [5], [6], [7], [8]. Such protocol achieves great success mainlydue to the good scalability as well as the robustness to the highchurn of the participating nodes. Recent exciting reports showthat systems based on this type of protocol have the power toenable over 230,000 users simultaneously watching a hot liveevent with 300∼500 Kbps by only one streaming server on theglobal Internet [2], [1].
The basic idea of data-driven streaming protocol is very simpleand similar to that of Bit-Torrent [9]. The protocol containstwo steps. In the first step, each node independently selects itsneighbors so as to form an unstructured overlay network, calledthe gossip-style overlay construction or membership management.
Supported by National Basic Research Program of China under grantNo.2006CB303103, NSFC under grant No.60503063 & No.60773158, RGCthe contracts CERG 622407 & N HKUST609/07, the NSFC oversea YoungInvestigator grant under grant No. 60629203, and 863 Program under grantNo.2006AA01Z321
Meng ZHANG, Prof. Shiqiang YANG and Prof. Lifeng SUN are withthe Department of Computer Science and Technology, Tsinghua University,Beijing 100084, P. R. China. (email: [email protected] {yangshq,sunlf}@tsinghua.edu.cn)
Dr. Yongqiang XIONG is with Microsoft Research Asia, Beijing 100080,P. R. China . (email: [email protected])
Prof. Qian ZHANG is with Department of Computer Science, HongKong University of Science and Technology, Hong Kong, China. (email:[email protected])
The second step is named block scheduling: the live mediacontent is divided into blocks (or segments, packets) and everynode announces what blocks it has to its neighbors. Then eachnode explicitly requests the blocks of interest from its neighborsaccording to their announcement. Obviously, the performance ofdata-driven protocol directly relies on the algorithms in these twosteps.
To improve the performance of data-driven protocol, mostof the recent papers focused on the construction problem ofthe first step. Researchers proposed different schemes to buildunstructured overlays to improve its efficiency or robustness [10],[11], [12]. However, the second step, i.e., the block schedulinghas not been well discussed in the literature yet. The schedulingmethods used in most of the pioneering works with respect tothe data-driven/swarming based streaming are somewhat ad hoc.These conventional scheduling strategies mainly include purerandom strategy [4], local rarest-first strategy [6] and round-robin strategy [5]. Actually, how to do optimal block schedulingto maximize the throughput of data-driven streaming under aconstructed overlay network is a challenge issue.
In this paper, we present our analytical model and correspond-ing solutions to tackle the block scheduling problem in data-driven protocol. We first model this scheduling problem as aclassical min-cost network flow problem and propose a globaloptimal solution in order to find out the ideal throughput improve-ment in theory. Since this solution is centralized and requiresglobal knowledge, based on its basic idea, we then propose aheuristic algorithm which is fully distributed and asynchronouswith only local information exchange. Furthermore, we employlayered video coding to encode the video into multiple rates andextend our algorithm to improve the satisfaction of the users withheterogeneous access bandwidth. Simulation results indicate thatour distributed algorithm significantly outperforms other differentconventional ad hoc scheduling strategies gains in both of thesingle rate and multi-rate scenarios.
The remainder of this paper is organized as follows: Section IIpresents our model for the block scheduling problem and givesthe global optimal scheduling solution. Section III describes ourheuristic distributed algorithm. Then in Section IV, we employlayered video coding and extend our algorithm for multiplestreaming rates. In Section V, we conduct simulations to evaluatethe performance of our algorithm. The related work of this paperis briefly reviewed in Section VI. Finally, we conclude this paperand give our future work in Section VII.
II. BLOCK SCHEDULING: PROBLEM STATEMENT AND
FORMULATION
First of all, we briefly review the data-driven protocol here.The idea of data-driven peer-to-peer streaming system is very

2
similar to that of Bit-Torrent protocol [9]. In such protocol,each node independently finds its neighbors in the overlay sothat an unstructured random overlay mesh is formed. The mediastreaming is divided into blocks with the equal size, each ofwhich has a unique sequence number. Every node has a slidingwindow which contains all the up-to-date blocks on the node andgoes forward continuously at the speed of streaming rate. Wecall the front part of the sliding window exchanging window.The blocks in the exchanging window are the ones before theplayback deadline, and only these blocks is requested if they arenot received. The unavailable blocks beyond playback deadlinewill be no more requested. The blocks that have been playedare buffered in the sliding window and they can be requestedby other nodes. Every node periodically pushes all its neighborsa bit vector called buffer map in which each bit represents theavailability of a block in its sliding window to announce whatblocks it holds. Due to the announcement of the neighbors, eachnode periodically sends requests to its neighbors for the desiredblocks in its exchanging window. We call the time between tworequests a request period, or period for short, typically 1∼6 sec.Then each node decides from which neighbor to ask for whichblocks at the beginning of each request period. When a blockdoes not arrive after its request is issued for a while and is still inthe exchanging window, it should be requested in the followingperiod again.
In following subsections, we first intuitively explain whatwe optimize in data-driven streaming and then formulate thisproblem. Our basic approach is comprehensive. We define apriority for every desired block of each node due to the blockimportance, such as the block rarity, the block emergency andblock layer if layered video coding is used. Our goal is tomaximize the average priority sum of all streaming blocks that aredelivered to each node in one request period under heterogeneousbandwidth constraints.
A. Block Scheduling Problem
(a) LRF scheduling (b) Optimal scheduling
Fig. 1: Illustration of block scheduling problem (I)
In this section, we introduce the block scheduling problemin data-driven P2P streaming. Fig. 1 and Fig. 2 give intuitiveexamples of block scheduling problem, BSP for short. The twonumbers beside the pipe of each node represent the maximumblocks that can be downloaded and uploaded in each request pe-riod respectively, denoting the inbound and outbound bandwidthconstraints of each node. The blocks close to each node illustratewhat blocks the node currently holds. We compare the local rarestfirst (LRF) scheduling strategy used in [6] and optimal schedulingin these examples. In Fig. 1a, node 4 asks for blocks from node 1,
(a) LRF scheduling (b) Optimal scheduling
Fig. 2: Illustration of block scheduling problem (II)
2 and 3. In LRF scheduling strategy used in [6] a block that hasthe minimum number of holders among the neighbors is requestedfirst. If multiple neighbors hold this block, it is assigned to theone with the maximum surplus bandwidth in turn. As illustratedin Fig. 1a, using LRF, block 3 has only one holder, so it isassigned to node 3. Then the surplus upload bandwidth of node 3
is reduced to 1. After that block 2 is assigned to node 2 since thesurplus bandwidth of node 2 is larger than node 1 and the surplusbandwidth of node 2 becomes 1. Next, LRF strategy assigns block4 to node 1 whose surplus bandwidth then descends to 0. Finally,after node 2 gets block 5, there is no more blocks can be furtherassigned. Fig. 1a shows the scheduling result using LRF. Fourblocks are delivered. On the other hand, one optimal schedulingsolution is illustrated in Fig. 1b and five blocks can be deliveredwith a gain of 25% compared to LRF. In fact, using LRF methodusually cannot derive the maximum throughput. As shown in Fig.1a, the upload bandwidth at node 3 and download bandwidth atnode 4 are not fully utilized. Fig. 2a shows another scenario thatnode 3 and 4 may competitively request blocks from node 1, thatis, their requests are congested at node 1. However, node 4 hasmore options. The optimal way is that node 4 requests blocks fromnode 2 while node 3 requests from node 1 as shown in Fig. 2b.In fact, compared to LRF, random strategies used in [4] would beeven worse. Moreover, the real situation is more complex becausethe bandwidth bottlenecks are not only at the last mile whiledifferent blocks have different importance. As a consequence,more intelligent scheduling algorithms should be developed toimprove the throughput of data-driven protocol under bandwidthconstraints.
B. Model
To maximize the throughput of the system, our approach is tomaximize the number of blocks that are requested successfullyunder bandwidth constraints as much as possible within everyperiod.
First, we define some notations that are used in the formulation.We let N denote the set of all receiver nodes in the overlay.Let Ii, Oi(i = 0, · · · , |N |) represent the inbound and outboundbandwidth of node i and let Eik(i, k = 0, · · · , |N |) representthe maximal end-to-end available bandwidth from node i to k.Since it is assumed that all the blocks have equal length, we letIi, Oi and Eik measured in blocks per second for convenience.Meanwhile, we use Di to denote the set of all the desired blocksof node i in its current exchanging window. Let hij ∈ {0, 1}denote whether node i holds block j. We assume the size of theexchanging window is WT measured in seconds. We let Ci anddi
j denote the current clock on node i and the playback time,i.e., the deadline of block j on node i respectively. Any desired

3
TABLE I: NotationsNotation DescriptionN Set of all nodes in the overlay except the source
node 0, that is, N = {1, · · · , |N |} noder The streaming rateIi, i = 0, · · · , |N | The inbound bandwidth capacity of node iOi, i = 0, · · · , |N | The outbound bandwidth capacity of node iEik, i = 0, · · · , |N | The maximal end-to-end available bandwidth be-
tween node i and khij ∈ {0, 1} “hij = 1” denotes node i holds block j; “hij =
0”, otherwiseNBRi Set of neighbors of node iτ The request periodWT The exchanging window size measured in sec-
ondsCi The current clock time at node idi
j Play out deadline of block j at node i
L Number of encoded layersrl, l = 1, · · · , L The cumulative rate from layer 1 to layer l,
blocks per secondΛ(r) Λ(r) = max
{l : rl ≤ r, i ∈ {1, 2, · · · , L}
},
the highest layer that can be achieved with rater
lj The layer of block jDs
i , Dmi Set of all desired blocks in the current exchanging
window of node i for single rate and multi-ratescenario respectively. Ds
i = {j : hij = 0, Ci <di
j < Ci + WT }, Dmi = {j : hij = 0, Ci <
dij < Ci + WT , lj ≤ Λ(Ii)}
P sij , P m
i,j The block priority for single rate and multi-ratescenario respectively
block j of node i should satisfy Ci < dij < Ci + WT , that is,
in exchanging window. Table I summarizes the notations in therest of this paper. In data-driven protocol, different blocks havedifferent significance. For instance, the blocks that have fewersuppliers should be requested preemptively so that they can bespread more quickly. Accordingly, defining different priority forblocks is important. Two properties have been considered in ourpriority definition: since the previous empirical study has shownthat “rarest-first” is a very efficient strategy in data dissemination[9], [13], [14], the rarity property is considered first. While asstreaming application has real-time constraint, the second one weconsidered is the emergency property. A block in danger of beingdelayed beyond the deadline should be more preemptive than theone just entering the exchanging window. Consequently, we definethe priority P s
ij of block j ∈ Di for node i ∈ N for the singlerate scenario. The priority for the multi-rate scenario is definedin IV):
P sij = αPR
( ∑
k∈NBR(i)
hjk
)+ (1− α)PE(di
j − Ci) (1)
Here α satisfies 0 ≤ α ≤ 1. The function PR(∗) in the first itemrepresents the rarity property, and
∑k∈NBRi
hjk is the number of
node i’s neighbors that hold block j. The function PE(∗) in thesecond item denotes the emergency property, and di
j − Ci is theremaining time of block j till the playback deadline. Both PR(∗)and PE(∗) should be monotonously non-increasing. For priorityparameter, we set PR(R) = 108−R, when R = 1, .., 8, otherwise,PR(R) = 1. And we hope that each request period in exchangingwindow has different priority in terms of their remaining time tillplayback deadline, so we define PE(T ) = 108−bT∗τ/WT c, whenbT ∗ τ/WT c ≤ 8, otherwise, PE(T ) = 1. We give the proper
value of α by a simple simulation approach in Section V.Then we define the decision variable xi
kj to denote whethernode i ∈ N requests block j ∈ Di from its neighbor k ∈ NBRi:
xikj =
{1, node i requests block j from neighbor k
0, otherwise(2)
Our target is to maximize the average priority sum of eachnode, so we have the following optimization:
max 1|N |
∑i∈N
∑j∈Di
∑k∈NBRi
Pijhkjxikj
s.t.(a)
∑k∈NBRi
xikj ≤ 1, ∀i ∈ N, j ∈ Di
(b)∑
j∈Di
∑k∈NBRi
xikj ≤ τIi, ∀i ∈ N
(c)∑
i∈NBRk
∑j∈Di
xikj ≤ τOk, ∀k ∈ N ∪ {0}
(d)∑
j∈Di
xikj ≤ τEki, ∀i ∈ N, k ∈ NBRi
(e) xikj ∈ {0, 1}, ∀i ∈ N, k ∈ NBRi, j ∈ Di
(3)
In (3), Di = Dsi , for all i ∈ N and Pij = P s
ij , for alli ∈ N, j ∈ Di. Constraint a) guarantees that each block shouldbe fetched from at most one neighbor so that no duplicate blocksare requested. Constraints b) and c) ensure the block schedulingsatisfy the inbound and outbound bandwidth capacity limitationsrespectively; Constraint d) ensures the maximal end-to-end avail-able bandwidth limitation. The last constraint e) indicates thisoptimization would be a 0-1 programming problem. We callformulation (3) a global block scheduling problem (global BSPfor short).
C. Solution
In this section, we show that the global BSP can be transformedinto an equivalent min-cost flow problem that can be solved withinpolynomial time. The min-cost flow problem is briefly depicted asfollows [15]. Let G = (V, A) be a directed network defined by aset V of n vertices and a set A of m directed arcs. Each arc (i, j) ∈A has an associated cost cij denoting the cost per unit flow overthat arc. A lower and an upper bound of capacity l(i, j) and u(i, j)
is associated to the arc (i, j) to denote the minimum and maxi-mum amount that can flow through the arc. Let f(i, j) denote theflow amount on arc (i, j), which is the decision variables. Themin-cost flow problem is an optimization model formulated asfollows:
min∑
(i,j)∈A c(i, j)f(i, j)
s.t.(a)
∑j:(i,j)∈A f(i, j)−∑
j:(j,i)∈A f(i, j) = b(i), ∀i ∈ V
(b) l(i, j) ≤ f(i, j) ≤ u(i, j), ∀(i, j) ∈ A
where∑n
i=1 b(i) = 0 and f(i, j) ∈ Z+
(4)Such min-cost flow problem can be solved in polynomial time,
and by double scaling algorithm [15], the time complexity formin-cost flow problem is bounded by O(nm(log log U) log(nC)),where U and C are the largest magnitude of arc capacity and costrespectively. In our model, we let b(i) = 0, for all i ∈ V andl(i, j) = 0, for all arcs. We can start the transformation with therules in TABLE II, where rules a) ∼ e) and f) ∼ k) respectivelygive the vertex and arc meanings.

4
TABLE II: Transformation rulesa) Put two virtual vertices in set V : s (the source vertex) and t (the sink
vertex);b) ∀ i ∈ N , insert a vertex ri to V , called receiver vertex;c) ∀ i ∈ N ∪ {0}, insert a vertex si to V , called sender vertex;d) If node k ∈ NBRi, insert a vertex nki to V , called neighbor vertex;e) If block j ∈ Di (the desired block j is in the current exchanging
windows of node i), then insert a vertex bij to V , called block vertex;f) Arcs between source vertex and sender vertices (outbound bandwidth
capacity constraints): insert an arc (s, sk) to A, where k ∈ N ∪{0}.The capacity of this arc is τOk (that is the maximal blocks which canbe sent out from node k in one period), and the unit cost is 0;
g) Arcs between receiver vertices and sink vertex (inbound bandwidthcapacity constraints): insert an arc (ri, t) to A, where i ∈ N . Thecapacity of the arc is τIi, and the unit cost is 0;
h) Arcs between sender vertices and neighbor vertices (end-to-end avail-able bandwidth constraints): if sk ∈ V and nki ∈ V , insert an arc(sk, nki) to A, where the capacity is τEki (the maximal blocks thatcan be transmitted through path from node k to i in one period);
i) Arcs between neighbor vertices and block vertices (representing blocksavailability): if k ∈ NBRi, hkj = 1, nki ∈ V and bij ∈ V , that is,node k holds block j and node i has not received block j, then insertan arc (nki, bij) to A, where the unit cost is 0 and the capacity is 1;
j) Arcs between block vertices and receiver vertices (for blocks priorityand duplicate avoidance): if bij ∈ V , then insert an arc (bij , ri) toA, where the unit cost is −Pij/|N | and the capacity is 1.
k) Insert an assistant arc (t, s) to A, where the unit cost is 0 and thecapacity is +∞.
Applying these rules, we can transform global BSP (3) into acorresponding min-cost flow problem, and we have the followingtheorem:
Theorem 1: The optimal flow amount f(nki, bij)∗ of the cor-
responding min-cost flow problem on arcs (nki, bij) (∀i ∈ N ,j ∈ Di and k ∈ NBRi) is also an optimal solution to the globalBSP.
Fig. 3: A global block scheduling problem
The proof of the theorem is in Appendix A. Fig. 3 and Fig. 4show a sample of global BSP with four nodes and its min-costflow modeling respectively. In Fig. 4, the two numbers close to anarc represent the capacity and per unit flow cost of the arc. Ratherthan describe the general model formally, we merely describe themodel ingredients for these figures. In data-driven streaming, wedecompose a node into its three roles: a send, a receiver and aneighbor. We model each sender k as a vertex sk, each receiveri as a vertex ri, and each neighbor k of node i as a vertex nik.Further, we model a desired block j for node i as a vertex bij .Besides we add two virtual vertices: a source vertex s and a sinkvertex t. The decision variables for this problem are whether torequest block j from neighbor k of node i which we represent byan arc from vertex nik to vertex bij if block j is a desired by node
Fig. 4: Model as a min cost flow problem
i. These arcs are capacitated by 1 and their per unit flow cost is 0.And we insert arc from vertex nik to bij to indicate that neighbork of node i holds block j. To avoid duplicate blocks, we add arccapacitated by 1 from bij to ri and set the per unit flow cost asthe priority of block j for node i multiplied a constant −1/|N |.To satisfy the outbound bandwidth constraint of node k, we addarc between vertex s and vertex sk whose capacity is τOk. Andfor the maximum end-to-end available bandwidth from neighbork to node i, we insert arc from vertex sk to nik with capacityτEik. Finally, to incorporate the inbound bandwidth constraint ofnode i, we introduce arc between ri and t with capacity τIi. Toguarantee maximum number of blocks are delivered, we insertuncapacitated arc from vertex t to s.
III. HEURISTIC DISTRIBUTED ALGORITHM
We give the algorithm to do global optimal scheduling inSection II. However, requiring global knowledg, such as blockavailability, bandwidth information and request synchronizationmake the algorithm not scalable. In this section, based on thebasic idea of the global optimal solution, we present the heuristicpractical algorithm, which is fully distributed and asynchronous.In our distributed algorithm, each node decides from whichneighbor to fetch which blocks at the beginning of its requestperiod. As the request period is relatively short, such as 3 seconds,our scheduling algorithm should make decision as rapidly aspossible. So in the distributed algorithm, we do a local optimalblock scheduling on each node based on the current knowledgeof the block availability among the neighbors. The local optimalblock scheduling can also be modeled as a min-cost flow problem.As shown in Fig. 4, the sub min-cost flow problem in the eachrectangle is just the local optimal block scheduling.
However, one problem to do local scheduling is that each nodedoes not know the optimal flow amount on arcs (sk, nki) (≤ Ok).In other words, we should estimate the proper upper-bound ofthe bandwidth from each neighbor. For simplicity, here we usea purely heuristic way for each node to estimate the maximumrate at which each neighbor can send blocks. Our approach isto use the historical traffic from each neighbor to do this. Moreformally, let Qki denote the estimated maximum rate at whichneighbor k ∈ NBRi can deliver to node i. Of course, Qki should

5
Fig. 5: An example for min-cost flow problem of the correspond-ing local BSP
not exceed Ok. We let g(p)ki denote the total number of blocks
received by node i from neighbor k in the pth period. In eachrequest period, we use the average traffic received by node i inthe previous P periods to estimate Qki in the (p + 1)th period:
Qki = γ ·( p∑
ω=p−P+1
g(ω)ki
)/Pτ (5)
Parameter γ(> 1) is a constant called aggressive coefficient. Asmall number of γ may lead to a waste of bandwidth. On the otherhand, augmenting this parameter tends to a sufficient utilizationof the outbound bandwidth of the neighbor nodes. However, morerequest congestion may happen at some nodes, that is, the blockrequests from neighbors may be beyond outbound bandwidth. Theimpact of this parameter will be investigated in Section V. Wesimply set the initial value of estimated rate from neighbor i asr/|NBRi|.
max∑
j∈Di
∑k∈NBRi
Pijhkjxikj
s.t.(a)
∑
k∈NBRi
xikj ≤ 1, ∀j ∈ Di,
(b)∑
j∈Di
∑
k∈NBRi
xikj ≤ τIi, ∀i ∈ N
(c)∑
j∈Di
xikj ≤ τQki, ∀i ∈ N, k ∈ NBRi,
(d) xikj ∈ {0, 1}, ∀k ∈ NBRi, j ∈ Di
(6)
Similar to global BSP, the local BSP (6) can also be trans-formed to an equivalent min-cost flow problem by inserting avirtual source node and a virtual sink node with an assistant arcbetween them to the sub min-cost flow problem in global BSP.Since it is much easier than the global BSP, we only give anexample here. Figure 5 shows the corresponding min-cost flowproblem of the local BSP on node 1 for the topology illustratedin Figure 3. The flow amount on arcs (nki, bij) ∈ {0, 1} is thevalue of xi
kj , for all i ∈ N , and k ∈ NBRi.We summarize our distributed algorithm. In the beginning of
each request period, do the steps in TABLE III. Our distributedalgorithm is heuristic and we will examine its performance andthe gap between the distributed algorithm and the global optimalsolution by simulation in Section V.
IV. EXTENDING FOR MULTIPLE STREAMING RATES
A lot of measurement studies in peer-to-peer overlay networks[16] reveal that the bottleneck bandwidth between the end hosts
TABLE III: Heuristic distributed algorithma) Node i estimates the bandwidth Q
(m+1)ki
that its neighbor k canallocate it in the (m + 1)th period with the traffic received fromthat neighbor in the previous P periods, as shown in (5);
b) Based on Q(m+1)ki
, node i performs the block scheduling (6) usingmin-cost network flow model. The results xi
kj ∈ {0, 1} representwhether node i should request block j from neighbor k;
c) Send requests to every neighbor.
exhibits extremely heterogeneity. To deal with the users hetero-geneity in streaming multicast applications, numerous solutionshas been proposed for both IP multicast [17] and overlay multicast[18], [19]. Their basic way is to encode the source video intomultiple layers using layered video coding, and each receiversubscribes an appropriate number of layers due to its bandwidthcapacity. In this section, we will show that by simply modifyingthe block priority definition, data-driven protocol can be extendedto combine with layered coding to tackle the heterogeneity issue.Similar to single rate scenario, we divide each layer encoded intoblocks. It should be noted that, in layered video coding, videois encoded into a base layer and several enhanced layers and ahigher layer can only be decoded if all lower layers are availableand we call this the layer dependency. Therefore, each block hasan additional important property, i.e., the layer property.
We define some additional notations, all of which are sum-marized in Table I. We let L represent the number of layersthat the video is encoded into and let rl(where l = 1, · · · , L)
denote the cumulative rate from layer 1 to layer l. And we defineΛ(r) = max{l : rl ≤ r, i ∈ {1, 2, · · · , L}}, so Λ(Ii) representsthe maximum layer that node i with inbound bandwidth Ii canachieve. We assume that each node only try to request blockswhose layers are equal to or lower than Λ(Ii). Let lj representthe layer of block j. So we definition the set of node i’s desiredblocks in current exchanging window for multi-rate scenario asDm
i = {j : hij = 0, Ci < dij < Ci + WT , lj ≤ Λ(Ii)}. Then we
define block j’s priority value Pmij of node i for the multi-rate
scenario as follows:
Pmij = βP s
ij + (1− β)θPL(lj)
where β = (dij − Ci)/WT
(7)
P sij is defined as in (1). Function PL represents the layer
property of block j and satisfies ΠL(lj1) À ΠL(lj2) whenlj1 < lj2 , for any block j1 and j2 so as to guarantee the layerdependency requirement. Parameter 0 ≤ β ≤ 1 represents thecurrent position block j in the exchanging window. We let θ haverelatively large value, that is, θ À 1. In this priority definition,when a block just entered the exchanging window (β is large), thefirst item has more weight in order to provide more block diversityto the system; meanwhile, when a block is to be played back soon(β is small), the second item contributes more in the priorityto ensure the blocks at lower layer are requested preemptively.Although this block priority definition is just a simple linearcombination of the two properties, it can guarantee the followingkey requirements: a) a lower-layer block, especially when it isto be played back soon, has much higher priority than any otherupper-layer blocks since θ is large; b) a block with fewer holdershas higher priority than the one with more holders in the samelayer and the same position in exchanging window.
6
V. PERFORMANCE EVALUATION
A. Simulation Configuration
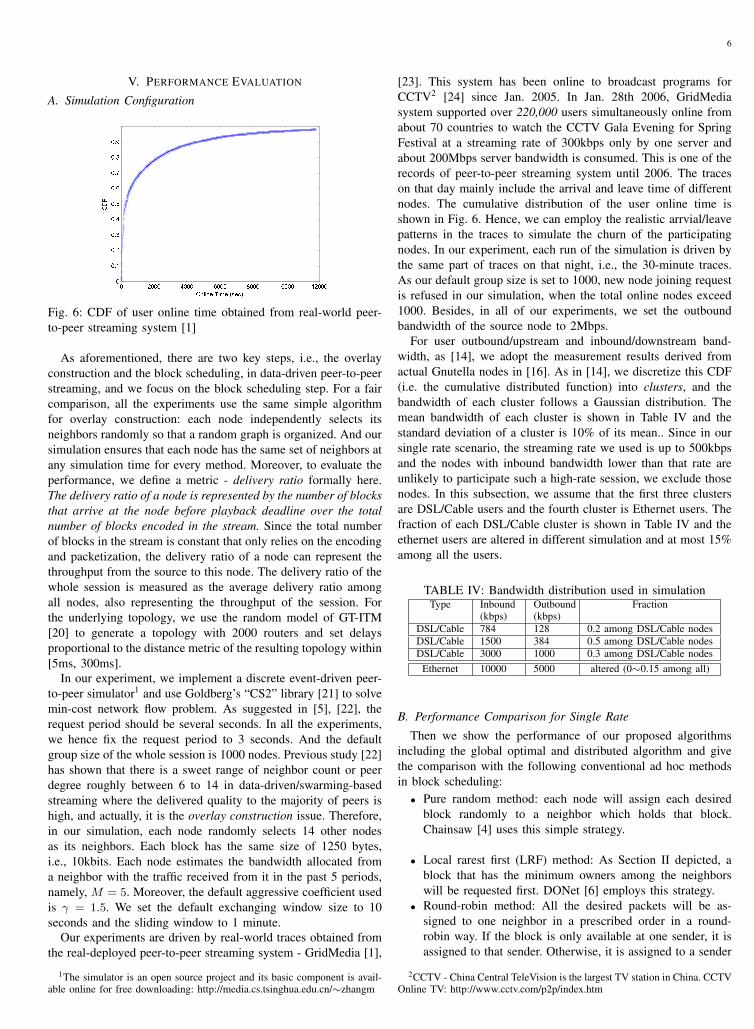
Fig. 6: CDF of user online time obtained from real-world peer-to-peer streaming system [1]
As aforementioned, there are two key steps, i.e., the overlayconstruction and the block scheduling, in data-driven peer-to-peerstreaming, and we focus on the block scheduling step. For a faircomparison, all the experiments use the same simple algorithmfor overlay construction: each node independently selects itsneighbors randomly so that a random graph is organized. And oursimulation ensures that each node has the same set of neighbors atany simulation time for every method. Moreover, to evaluate theperformance, we define a metric - delivery ratio formally here.The delivery ratio of a node is represented by the number of blocksthat arrive at the node before playback deadline over the totalnumber of blocks encoded in the stream. Since the total numberof blocks in the stream is constant that only relies on the encodingand packetization, the delivery ratio of a node can represent thethroughput from the source to this node. The delivery ratio of thewhole session is measured as the average delivery ratio amongall nodes, also representing the throughput of the session. Forthe underlying topology, we use the random model of GT-ITM[20] to generate a topology with 2000 routers and set delaysproportional to the distance metric of the resulting topology within[5ms, 300ms].
In our experiment, we implement a discrete event-driven peer-to-peer simulator1 and use Goldberg’s “CS2” library [21] to solvemin-cost network flow problem. As suggested in [5], [22], therequest period should be several seconds. In all the experiments,we hence fix the request period to 3 seconds. And the defaultgroup size of the whole session is 1000 nodes. Previous study [22]has shown that there is a sweet range of neighbor count or peerdegree roughly between 6 to 14 in data-driven/swarming-basedstreaming where the delivered quality to the majority of peers ishigh, and actually, it is the overlay construction issue. Therefore,in our simulation, each node randomly selects 14 other nodesas its neighbors. Each block has the same size of 1250 bytes,i.e., 10kbits. Each node estimates the bandwidth allocated froma neighbor with the traffic received from it in the past 5 periods,namely, M = 5. Moreover, the default aggressive coefficient usedis γ = 1.5. We set the default exchanging window size to 10seconds and the sliding window to 1 minute.
Our experiments are driven by real-world traces obtained fromthe real-deployed peer-to-peer streaming system - GridMedia [1],
1The simulator is an open source project and its basic component is avail-able online for free downloading: http://media.cs.tsinghua.edu.cn/∼zhangm
[23]. This system has been online to broadcast programs forCCTV2 [24] since Jan. 2005. In Jan. 28th 2006, GridMediasystem supported over 220,000 users simultaneously online fromabout 70 countries to watch the CCTV Gala Evening for SpringFestival at a streaming rate of 300kbps only by one server andabout 200Mbps server bandwidth is consumed. This is one of therecords of peer-to-peer streaming system until 2006. The traceson that day mainly include the arrival and leave time of differentnodes. The cumulative distribution of the user online time isshown in Fig. 6. Hence, we can employ the realistic arrvial/leavepatterns in the traces to simulate the churn of the participatingnodes. In our experiment, each run of the simulation is driven bythe same part of traces on that night, i.e., the 30-minute traces.As our default group size is set to 1000, new node joining requestis refused in our simulation, when the total online nodes exceed1000. Besides, in all of our experiments, we set the outboundbandwidth of the source node to 2Mbps.
For user outbound/upstream and inbound/downstream band-width, as [14], we adopt the measurement results derived fromactual Gnutella nodes in [16]. As in [14], we discretize this CDF(i.e. the cumulative distributed function) into clusters, and thebandwidth of each cluster follows a Gaussian distribution. Themean bandwidth of each cluster is shown in Table IV and thestandard deviation of a cluster is 10% of its mean.. Since in oursingle rate scenario, the streaming rate we used is up to 500kbpsand the nodes with inbound bandwidth lower than that rate areunlikely to participate such a high-rate session, we exclude thosenodes. In this subsection, we assume that the first three clustersare DSL/Cable users and the fourth cluster is Ethernet users. Thefraction of each DSL/Cable cluster is shown in Table IV and theethernet users are altered in different simulation and at most 15%among all the users.
TABLE IV: Bandwidth distribution used in simulationType Inbound
(kbps)Outbound(kbps)
Fraction
DSL/Cable 784 128 0.2 among DSL/Cable nodesDSL/Cable 1500 384 0.5 among DSL/Cable nodesDSL/Cable 3000 1000 0.3 among DSL/Cable nodes
Ethernet 10000 5000 altered (0∼0.15 among all)
B. Performance Comparison for Single Rate
Then we show the performance of our proposed algorithmsincluding the global optimal and distributed algorithm and givethe comparison with the following conventional ad hoc methodsin block scheduling:• Pure random method: each node will assign each desired
block randomly to a neighbor which holds that block.Chainsaw [4] uses this simple strategy.
• Local rarest first (LRF) method: As Section II depicted, ablock that has the minimum owners among the neighborswill be requested first. DONet [6] employs this strategy.
• Round-robin method: All the desired packets will be as-signed to one neighbor in a prescribed order in a round-robin way. If the block is only available at one sender, it isassigned to that sender. Otherwise, it is assigned to a sender
2CCTV - China Central TeleVision is the largest TV station in China. CCTVOnline TV: http://www.cctv.com/p2p/index.htm
7
that has the maximum surplus available bandwidth. Whena block is assigned to a neighbor, the surplus bandwidth ofthat neighbor will be recalculated by subtracting the amountthe block consumes. These steps are repeated till there is nosurplus bandwidth or no blocks can be assigned.
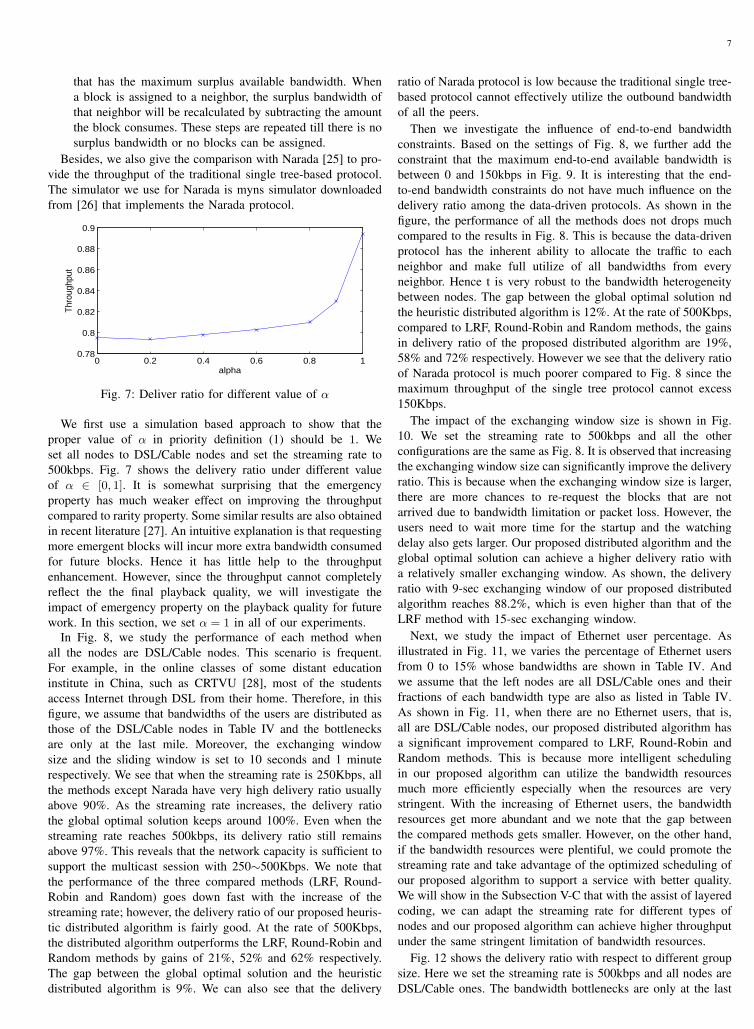
Besides, we also give the comparison with Narada [25] to pro-vide the throughput of the traditional single tree-based protocol.The simulator we use for Narada is myns simulator downloadedfrom [26] that implements the Narada protocol.
0 0.2 0.4 0.6 0.8 10.78
0.8
0.82
0.84
0.86
0.88
0.9
alpha
Thro
ughp
ut
Fig. 7: Deliver ratio for different value of α
We first use a simulation based approach to show that theproper value of α in priority definition (1) should be 1. Weset all nodes to DSL/Cable nodes and set the streaming rate to500kbps. Fig. 7 shows the delivery ratio under different valueof α ∈ [0, 1]. It is somewhat surprising that the emergencyproperty has much weaker effect on improving the throughputcompared to rarity property. Some similar results are also obtainedin recent literature [27]. An intuitive explanation is that requestingmore emergent blocks will incur more extra bandwidth consumedfor future blocks. Hence it has little help to the throughputenhancement. However, since the throughput cannot completelyreflect the the final playback quality, we will investigate theimpact of emergency property on the playback quality for futurework. In this section, we set α = 1 in all of our experiments.
In Fig. 8, we study the performance of each method whenall the nodes are DSL/Cable nodes. This scenario is frequent.For example, in the online classes of some distant educationinstitute in China, such as CRTVU [28], most of the studentsaccess Internet through DSL from their home. Therefore, in thisfigure, we assume that bandwidths of the users are distributed asthose of the DSL/Cable nodes in Table IV and the bottlenecksare only at the last mile. Moreover, the exchanging windowsize and the sliding window is set to 10 seconds and 1 minuterespectively. We see that when the streaming rate is 250Kbps, allthe methods except Narada have very high delivery ratio usuallyabove 90%. As the streaming rate increases, the delivery ratiothe global optimal solution keeps around 100%. Even when thestreaming rate reaches 500kbps, its delivery ratio still remainsabove 97%. This reveals that the network capacity is sufficient tosupport the multicast session with 250∼500Kbps. We note thatthe performance of the three compared methods (LRF, Round-Robin and Random) goes down fast with the increase of thestreaming rate; however, the delivery ratio of our proposed heuris-tic distributed algorithm is fairly good. At the rate of 500Kbps,the distributed algorithm outperforms the LRF, Round-Robin andRandom methods by gains of 21%, 52% and 62% respectively.The gap between the global optimal solution and the heuristicdistributed algorithm is 9%. We can also see that the delivery
ratio of Narada protocol is low because the traditional single tree-based protocol cannot effectively utilize the outbound bandwidthof all the peers.
Then we investigate the influence of end-to-end bandwidthconstraints. Based on the settings of Fig. 8, we further add theconstraint that the maximum end-to-end available bandwidth isbetween 0 and 150kbps in Fig. 9. It is interesting that the end-to-end bandwidth constraints do not have much influence on thedelivery ratio among the data-driven protocols. As shown in thefigure, the performance of all the methods does not drops muchcompared to the results in Fig. 8. This is because the data-drivenprotocol has the inherent ability to allocate the traffic to eachneighbor and make full utilize of all bandwidths from everyneighbor. Hence t is very robust to the bandwidth heterogeneitybetween nodes. The gap between the global optimal solution ndthe heuristic distributed algorithm is 12%. At the rate of 500Kbps,compared to LRF, Round-Robin and Random methods, the gainsin delivery ratio of the proposed distributed algorithm are 19%,58% and 72% respectively. However we see that the delivery ratioof Narada protocol is much poorer compared to Fig. 8 since themaximum throughput of the single tree protocol cannot excess150Kbps.
The impact of the exchanging window size is shown in Fig.10. We set the streaming rate to 500kbps and all the otherconfigurations are the same as Fig. 8. It is observed that increasingthe exchanging window size can significantly improve the deliveryratio. This is because when the exchanging window size is larger,there are more chances to re-request the blocks that are notarrived due to bandwidth limitation or packet loss. However, theusers need to wait more time for the startup and the watchingdelay also gets larger. Our proposed distributed algorithm and theglobal optimal solution can achieve a higher delivery ratio witha relatively smaller exchanging window. As shown, the deliveryratio with 9-sec exchanging window of our proposed distributedalgorithm reaches 88.2%, which is even higher than that of theLRF method with 15-sec exchanging window.
Next, we study the impact of Ethernet user percentage. Asillustrated in Fig. 11, we varies the percentage of Ethernet usersfrom 0 to 15% whose bandwidths are shown in Table IV. Andwe assume that the left nodes are all DSL/Cable ones and theirfractions of each bandwidth type are also as listed in Table IV.As shown in Fig. 11, when there are no Ethernet users, that is,all are DSL/Cable nodes, our proposed distributed algorithm hasa significant improvement compared to LRF, Round-Robin andRandom methods. This is because more intelligent schedulingin our proposed algorithm can utilize the bandwidth resourcesmuch more efficiently especially when the resources are verystringent. With the increasing of Ethernet users, the bandwidthresources get more abundant and we note that the gap betweenthe compared methods gets smaller. However, on the other hand,if the bandwidth resources were plentiful, we could promote thestreaming rate and take advantage of the optimized scheduling ofour proposed algorithm to support a service with better quality.We will show in the Subsection V-C that with the assist of layeredcoding, we can adapt the streaming rate for different types ofnodes and our proposed algorithm can achieve higher throughputunder the same stringent limitation of bandwidth resources.
Fig. 12 shows the delivery ratio with respect to different groupsize. Here we set the streaming rate is 500kbps and all nodes areDSL/Cable ones. The bandwidth bottlenecks are only at the last
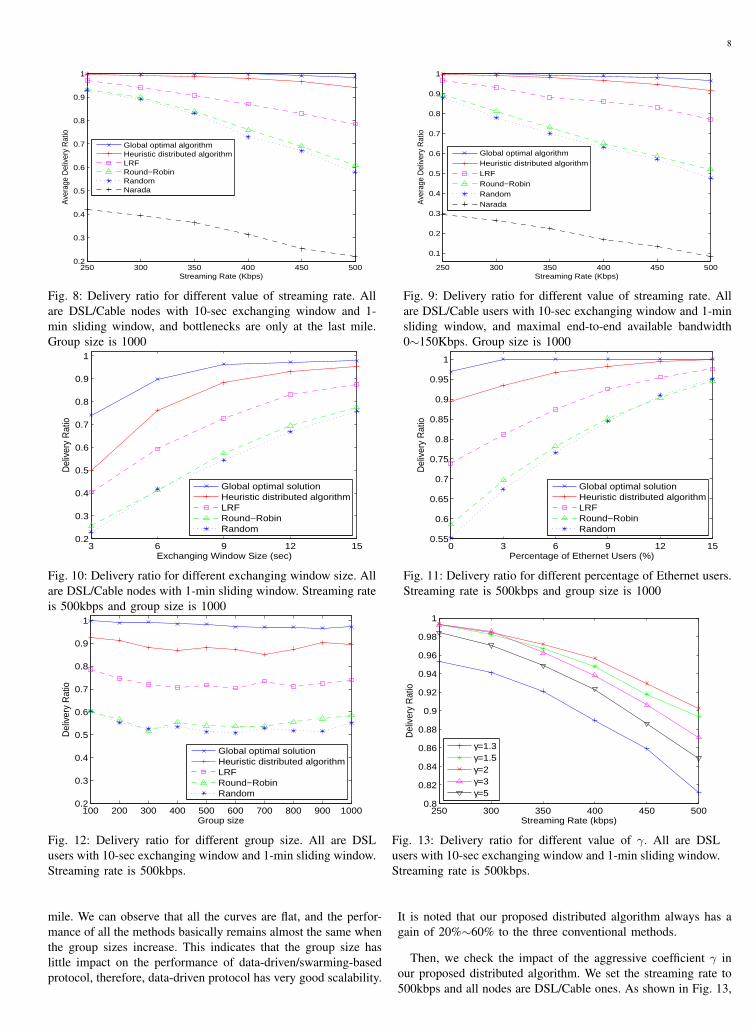
8
250 300 350 400 450 5000.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Streaming Rate (Kbps)
Ave
rage
Del
iver
y R
atio
Global optimal algorithmHeuristic distributed algorithmLRFRound−RobinRandomNarada
Fig. 8: Delivery ratio for different value of streaming rate. Allare DSL/Cable nodes with 10-sec exchanging window and 1-min sliding window, and bottlenecks are only at the last mile.Group size is 1000
250 300 350 400 450 500
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Streaming Rate (Kbps)
Ave
rage
Del
iver
y R
atio
Global optimal algorithmHeuristic distributed algorithmLRFRound−RobinRandomNarada
Fig. 9: Delivery ratio for different value of streaming rate. Allare DSL/Cable users with 10-sec exchanging window and 1-minsliding window, and maximal end-to-end available bandwidth0∼150Kbps. Group size is 1000
3 6 9 12 150.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Exchanging Window Size (sec)
Del
iver
y R
atio
Global optimal solutionHeuristic distributed algorithmLRFRound−RobinRandom
Fig. 10: Delivery ratio for different exchanging window size. Allare DSL/Cable nodes with 1-min sliding window. Streaming rateis 500kbps and group size is 1000
0 3 6 9 12 150.55
0.6
0.65
0.7
0.75
0.8
0.85
0.9
0.95
1
Percentage of Ethernet Users (%)
Del
iver
y R
atio
Global optimal solutionHeuristic distributed algorithmLRFRound−RobinRandom
Fig. 11: Delivery ratio for different percentage of Ethernet users.Streaming rate is 500kbps and group size is 1000
100 200 300 400 500 600 700 800 900 10000.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Group size
Del
iver
y R
atio
Global optimal solutionHeuristic distributed algorithmLRFRound−RobinRandom
Fig. 12: Delivery ratio for different group size. All are DSLusers with 10-sec exchanging window and 1-min sliding window.Streaming rate is 500kbps.
250 300 350 400 450 5000.8
0.82
0.84
0.86
0.88
0.9
0.92
0.94
0.96
0.98
1
Streaming Rate (kbps)
Del
iver
y R
atio
γ=1.3γ=1.5γ=2γ=3γ=5
Fig. 13: Delivery ratio for different value of γ. All are DSLusers with 10-sec exchanging window and 1-min sliding window.Streaming rate is 500kbps.
mile. We can observe that all the curves are flat, and the perfor-mance of all the methods basically remains almost the same whenthe group sizes increase. This indicates that the group size haslittle impact on the performance of data-driven/swarming-basedprotocol, therefore, data-driven protocol has very good scalability.
It is noted that our proposed distributed algorithm always has again of 20%∼60% to the three conventional methods.
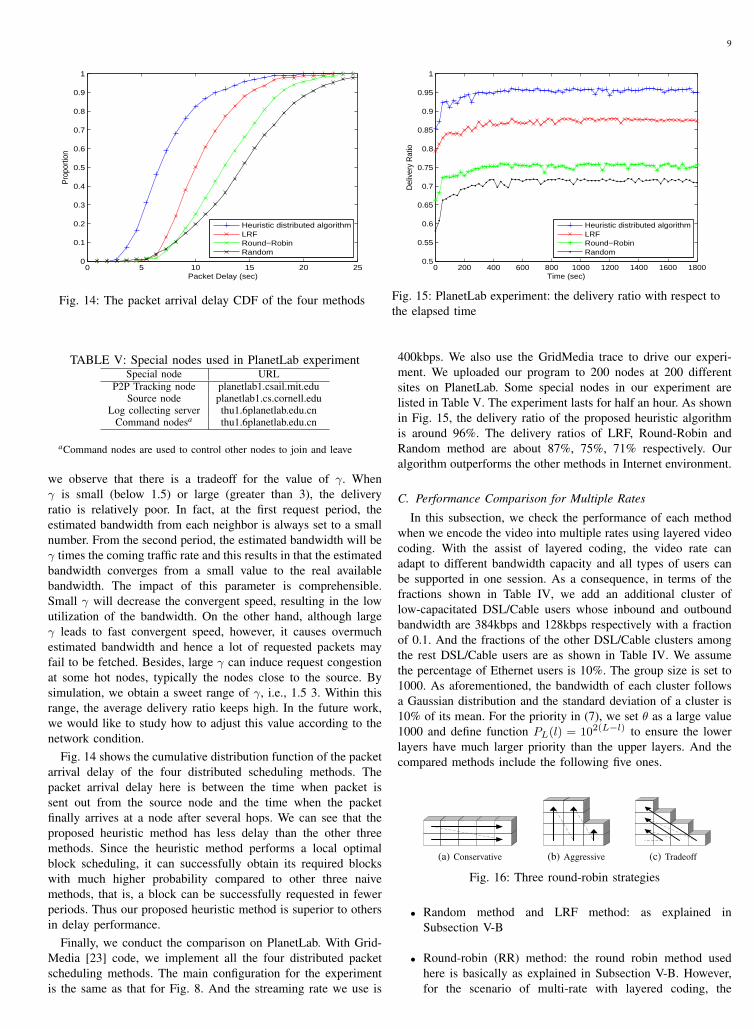
Then, we check the impact of the aggressive coefficient γ inour proposed distributed algorithm. We set the streaming rate to500kbps and all nodes are DSL/Cable ones. As shown in Fig. 13,
9
0 5 10 15 20 250
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Packet Delay (sec)
Pro
porti
on
Heuristic distributed algorithmLRFRound−RobinRandom
Fig. 14: The packet arrival delay CDF of the four methods
0 200 400 600 800 1000 1200 1400 1600 18000.5
0.55
0.6
0.65
0.7
0.75
0.8
0.85
0.9
0.95
1
Time (sec)
Del
iver
y R
atio
Heuristic distributed algorithmLRFRound−RobinRandom
Fig. 15: PlanetLab experiment: the delivery ratio with respect tothe elapsed time
TABLE V: Special nodes used in PlanetLab experimentSpecial node URL
P2P Tracking node planetlab1.csail.mit.eduSource node planetlab1.cs.cornell.edu
Log collecting server thu1.6planetlab.edu.cnCommand nodesa thu1.6planetlab.edu.cn
aCommand nodes are used to control other nodes to join and leave
we observe that there is a tradeoff for the value of γ. Whenγ is small (below 1.5) or large (greater than 3), the deliveryratio is relatively poor. In fact, at the first request period, theestimated bandwidth from each neighbor is always set to a smallnumber. From the second period, the estimated bandwidth will beγ times the coming traffic rate and this results in that the estimatedbandwidth converges from a small value to the real availablebandwidth. The impact of this parameter is comprehensible.Small γ will decrease the convergent speed, resulting in the lowutilization of the bandwidth. On the other hand, although largeγ leads to fast convergent speed, however, it causes overmuchestimated bandwidth and hence a lot of requested packets mayfail to be fetched. Besides, large γ can induce request congestionat some hot nodes, typically the nodes close to the source. Bysimulation, we obtain a sweet range of γ, i.e., 1.5 3. Within thisrange, the average delivery ratio keeps high. In the future work,we would like to study how to adjust this value according to thenetwork condition.
Fig. 14 shows the cumulative distribution function of the packetarrival delay of the four distributed scheduling methods. Thepacket arrival delay here is between the time when packet issent out from the source node and the time when the packetfinally arrives at a node after several hops. We can see that theproposed heuristic method has less delay than the other threemethods. Since the heuristic method performs a local optimalblock scheduling, it can successfully obtain its required blockswith much higher probability compared to other three naivemethods, that is, a block can be successfully requested in fewerperiods. Thus our proposed heuristic method is superior to othersin delay performance.
Finally, we conduct the comparison on PlanetLab. With Grid-Media [23] code, we implement all the four distributed packetscheduling methods. The main configuration for the experimentis the same as that for Fig. 8. And the streaming rate we use is
400kbps. We also use the GridMedia trace to drive our experi-ment. We uploaded our program to 200 nodes at 200 differentsites on PlanetLab. Some special nodes in our experiment arelisted in Table V. The experiment lasts for half an hour. As shownin Fig. 15, the delivery ratio of the proposed heuristic algorithmis around 96%. The delivery ratios of LRF, Round-Robin andRandom method are about 87%, 75%, 71% respectively. Ouralgorithm outperforms the other methods in Internet environment.
C. Performance Comparison for Multiple Rates
In this subsection, we check the performance of each methodwhen we encode the video into multiple rates using layered videocoding. With the assist of layered coding, the video rate canadapt to different bandwidth capacity and all types of users canbe supported in one session. As a consequence, in terms of thefractions shown in Table IV, we add an additional cluster oflow-capacitated DSL/Cable users whose inbound and outboundbandwidth are 384kbps and 128kbps respectively with a fractionof 0.1. And the fractions of the other DSL/Cable clusters amongthe rest DSL/Cable users are as shown in Table IV. We assumethe percentage of Ethernet users is 10%. The group size is set to1000. As aforementioned, the bandwidth of each cluster followsa Gaussian distribution and the standard deviation of a cluster is10% of its mean. For the priority in (7), we set θ as a large value1000 and define function PL(l) = 102(L−l) to ensure the lowerlayers have much larger priority than the upper layers. And thecompared methods include the following five ones.
(a) Conservative (b) Aggressive (c) Tradeoff
Fig. 16: Three round-robin strategies
• Random method and LRF method: as explained inSubsection V-B
• Round-robin (RR) method: the round robin method usedhere is basically as explained in Subsection V-B. However,for the scenario of multi-rate with layered coding, the

10
round-robin method is usually classified into three differentways with respect to the block ordering sequence sillustrated in Fig 16. Fig. 16a shows the conservative blockordering: it always requests blocks of lower layers first.On the contrary, aggressive block ordering scheme requestsblocks of all layers with lowest sequence number (or timestamp) preemptively as illustrated in Fig. 16b. Fig. 16cuses a zigzag ordering which is a tradeoff between the twoextreme schemes. Since the first two schemes evidently hasits own limitations [5]. We only compare with the thirdscheme (we call it RR-tradeoff for short).
As mentioned previously, each node i only requests the blockswhose layers are not beyond its capacity, i.e., any block j ∈ Dm
i
should satisfy lj ≤ Λ(Ii). To evaluate the performance undermulti-rate scenario, we define the delivery ratio at layer l of thewhole session as the average delivery ratio at layer l among allthe nodes that can achieve layer l. We first encode the videointo 10 layers and set the rate of each layer as 100kbps. Hencethe steaming rate can be up to 1Mbps. We assume that thebandwidth bottlenecks are only at the last mile here. Actually, inour configuration, the bandwidth resources are very stringent. Dueto the fractions of the nodes with different bandwidth capacity,the total outbound bandwidth can be computed as 1000× (0.1×128 + (0.2× 128 + 0.5× 384 + 0.3× 1000) ∗ 0.8 + 0.1× 5000) =
926880. And the total bandwidth needed can be computed as thesum of the streaming rate needed for different types of nodes:1000× (0.1× 300+(0.2× 700+0.5× 1000+0.3× 1000)× 0.8+
0.1×1000) = 882000. Note that they are very close to each other.
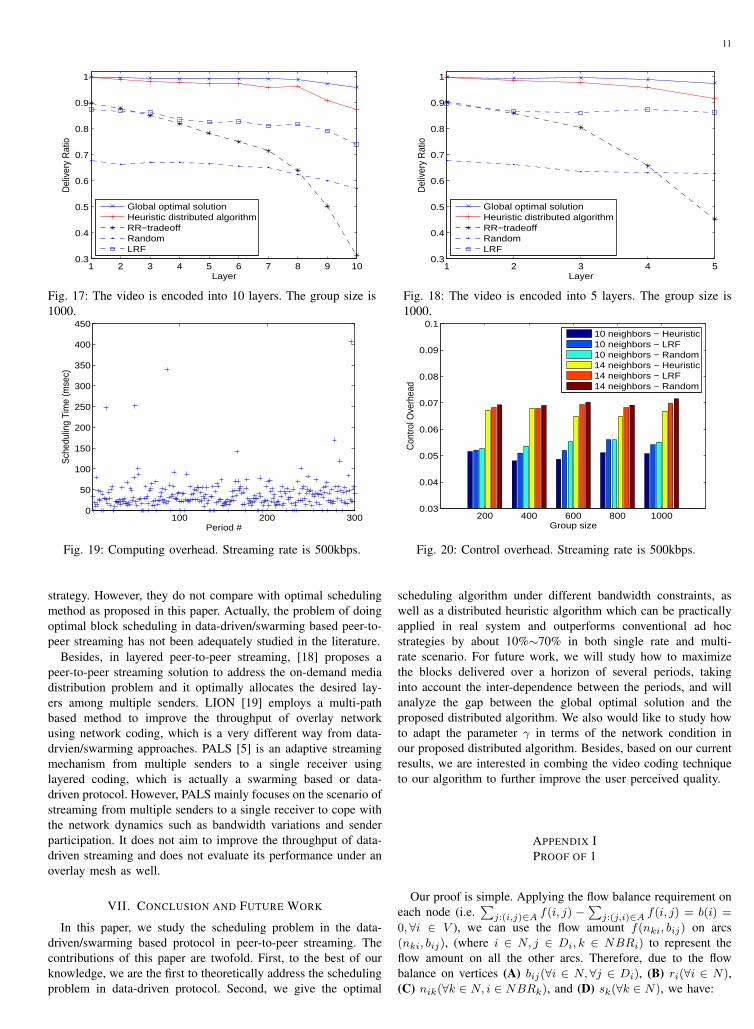
Fig. 17 gives the delivery ratio at each layer. We note thatthe global optimal solution has the best performance, and thedelivery ratio in all layers is nearly 1. This demonstrates that thegenerated topologies have sufficient capacity to support all thenodes to receive all layers that they can achieve. The performanceof distributed algorithm is fairly good. Most of the delivery ratioin lower layers has nearly 1 and most in higher layers is alsoabove 0.9. For RR-tradeoff method, we use zigzag ordering withslope of 0.1. And it can be seen that RR-tradeoff has muchmore better delivery ratio at lower layers than higher layers. Butthe delivery ratio at all layers is not so good as the proposeddistributed algorithm. We note that the LRF strategy has evenhigher delivery ratio than round-robin scheme. However, the curveis flat. This means it cannot tackle the layer dependency problem,that is, many nodes cannot watch even the base layer, althoughmore blocks of higher layers are propagated. Finally, the randomstrategy has the poorest performance. As shown in Fig. 17, ourdistributed method outperforms other strategies much with a gainof 10%∼50% in most layers. In Fig. 18, the video is encodedinto 5 layers, each of which is 200kbps. We observe that theperformance of each layer is similar to that in Fig. 17. Ourproposed distributed algorithm is still the best among all thedistributed methods. We note that the delivery ratio of all themethod is a little higher than that of Fig. 17. This is because,compared to 10 layers, ncoding the video into 5 layers is morecoarse and thus many nodes will request a lower rate of streamingsince the larger mismatch between the streaming rate and theinbound bandwidth. So more residual available bandwidth can beused to support transmission at lower layers.
D. Overhead
Finally, we examine the overhead of our proposed distributedalgorithm including the computing and control overhead. Fig. 19shows the computing overhead - the time consumed for blockscheduling in every period on a typical node that schedules blocksamong its 14 neighbors. Our experiment is done on a PentiumIII 600MHz machine. The streaming rate here is 500kbps and therequest period is 3 seconds. Since the block size is 1250 bytes,there are 150 blocks needing scheduling in a period. From Fig. 19,we note that most of the scheduling can be finished in 80 ms andvery few cases cost more than 100ms. Since the request period is 3second, this computing overhead is low and practically acceptable.Furthermore, for the control overhead, it mainly includes theneighbor maintenance packets, buffer map packets and requestpackets. As shown in Fig. 20, we plot the control overhead withrespect to the different neighbor numbers and different group sizefor our proposed method as well as LRF and Random method.We see that our proposed heuristic algorithm has a little lowercontrol overhead than the other methods. This is because theproposed algorithm can successfully obtain a packet in fewerperiods compared to naive scheduling methods. So fewer requestpackets are needed to send. Besides, it can be observed thatthe control overhead has little relationship with the group sizebecause each node only communicates with its own neighbors,which demonstrates the good scalability of our algorithm.
VI. RELATED WORK
Due to the difficulty of Internet-wide deployment of IP multi-cast, overlay multicast especially peer-to-peer based multicast isregarded as a very promising alternative to support live streamingapplications. Traditional overlay multicast can be classified intothree categories in terms of the tree building approaches [29]:tree-first, such as YOID [30]; mesh-first, such as Narada [25];implicit protocol, such as SCRIBE [31]. To utilize the uploadbandwidth of end hosts more efficiently, some protocols based onmultiple trees are also proposed, such as SplitStream [32]. Ratherthan building trees, recently proposed data-driven/swarming basedprotocols organize the nodes into an unstructured overlay network,i.e., the overlay construction. Meanwhile each node independentlyfetches the absent data from its own neighbors according tothe notification of data availability, i.e., the scheduling, verysimilar to the mechanism used in some file sharing systems,such as BitTorrent [9], Bullet’ [13]. These data-driven protocolsinclude Chainsaw [4], DONet [6], PALS [5], PRIME [8]. Mostrecent result [33] shows that this type of protocol outperformsthe traditional multi-tree approaches much in many aspects. Toimprove the performance of data-driven protocol, much efforts aremade on the overlay construction [11], [12], [10]. [11] discusseshow to construct an efficient random graph under heterogeneousenvironment and Randpeer [12] adds QoS-awareness feature tounstructured overlay. Whereas, the scheduling issue has not beenwell addressed yet. Most of the proposed methods are simplystrategy-based and ad hoc. Chainsaw [4] uses a pure randomway to deal with the scheduling. DONet [6] employs a localrarest first strategy as the block scheduling method, i.e., greedymethod, and selects suppliers with the highest bandwidth andenough available time first. PRIME [8] encodes the video intoMultiple Description Coding (MDC) and employs joint diffusionand swarming techniques. Similar result shows that the schedulingusing rarity factor is better than the random sender selection
11
1 2 3 4 5 6 7 8 9 100.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Layer
Del
iver
y R
atio
Global optimal solutionHeuristic distributed algorithmRR−tradeoffRandomLRF
Fig. 17: The video is encoded into 10 layers. The group size is1000.
1 2 3 4 50.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Layer
Del
iver
y R
atio
Global optimal solutionHeuristic distributed algorithmRR−tradeoffRandomLRF
Fig. 18: The video is encoded into 5 layers. The group size is1000.
100 200 3000
50
100
150
200
250
300
350
400
450
Period #
Sch
edul
ing
Tim
e (m
sec)
Fig. 19: Computing overhead. Streaming rate is 500kbps.
200 400 600 800 10000.03
0.04
0.05
0.06
0.07
0.08
0.09
0.1
Group size
Con
trol O
verh
ead
10 neighbors − Heuristic10 neighbors − LRF10 neighbors − Random14 neighbors − Heuristic14 neighbors − LRF14 neighbors − Random
Fig. 20: Control overhead. Streaming rate is 500kbps.
strategy. However, they do not compare with optimal schedulingmethod as proposed in this paper. Actually, the problem of doingoptimal block scheduling in data-driven/swarming based peer-to-peer streaming has not been adequately studied in the literature.
Besides, in layered peer-to-peer streaming, [18] proposes apeer-to-peer streaming solution to address the on-demand mediadistribution problem and it optimally allocates the desired lay-ers among multiple senders. LION [19] employs a multi-pathbased method to improve the throughput of overlay networkusing network coding, which is a very different way from data-drvien/swarming approaches. PALS [5] is an adaptive streamingmechanism from multiple senders to a single receiver usinglayered coding, which is actually a swarming based or data-driven protocol. However, PALS mainly focuses on the scenario ofstreaming from multiple senders to a single receiver to cope withthe network dynamics such as bandwidth variations and senderparticipation. It does not aim to improve the throughput of data-driven streaming and does not evaluate its performance under anoverlay mesh as well.
VII. CONCLUSION AND FUTURE WORK
In this paper, we study the scheduling problem in the data-driven/swarming based protocol in peer-to-peer streaming. Thecontributions of this paper are twofold. First, to the best of ourknowledge, we are the first to theoretically address the schedulingproblem in data-driven protocol. Second, we give the optimal
scheduling algorithm under different bandwidth constraints, aswell as a distributed heuristic algorithm which can be practicallyapplied in real system and outperforms conventional ad hocstrategies by about 10%∼70% in both single rate and multi-rate scenario. For future work, we will study how to maximizethe blocks delivered over a horizon of several periods, takinginto account the inter-dependence between the periods, and willanalyze the gap between the global optimal solution and theproposed distributed algorithm. We also would like to study howto adapt the parameter γ in terms of the network condition inour proposed distributed algorithm. Besides, based on our currentresults, we are interested in combing the video coding techniqueto our algorithm to further improve the user perceived quality.
APPENDIX IPROOF OF 1
Our proof is simple. Applying the flow balance requirement oneach node (i.e.
∑j:(i,j)∈A f(i, j) −∑
j:(j,i)∈A f(i, j) = b(i) =
0, ∀i ∈ V ), we can use the flow amount f(nki, bij) on arcs(nki, bij), (where i ∈ N, j ∈ Di, k ∈ NBRi) to represent theflow amount on all the other arcs. Therefore, due to the flowbalance on vertices (A) bij(∀i ∈ N, ∀j ∈ Di), (B) ri(∀i ∈ N),(C) nik(∀k ∈ N, i ∈ NBRk), and (D) sk(∀k ∈ N), we have:

12
(A) f(bij , ri) =∑
k∈NBRi
f(nik, bij)
(B) f(ri, t) =∑
j∈Di
f(bij , ri) =∑
j∈Di
∑k∈NBRi
f(nik, bij)
(C) f(sk, nki) =∑
j∈Di
f(nik, bij)
(D) f(s, sk) =∑
i∈N
f(sk, nki) =∑
i∈N
∑j∈Di
f(nik, bij)
(8)Due to the capacity constraints on each arcs (A) (bij , ri), ∀i ∈
N, ∀j ∈ Di, and (B) (ri, t), ∀i ∈ N , (C) (s, sk), ∀k ∈ N∪{0}, (D)(sk, nki), ∀i ∈ N, ∀k ∈ NBRi, we have the following constraints:
(A) f(bij , ri) =∑
k∈NBRi
f(nik, bij) ≤ 1
(B) f(ri, t) =∑
j∈Di
∑k∈NBRi
f(nik, bij) ≤ τIi
(C) f(s, sk) =∑
i∈N
∑j∈Di
f(nik, bij) ≤ τO3
(D) f(sk, nki) =∑
j∈Di
f(nik, bij) ≤ τEki
(9)
Due to the capacity constraint on arcs (nki, bi,j), ∀i ∈ N, ∀j ∈Di, ∀k ∈ NBRi, and all the flow amount is integer, we have
f(nki, bi,j) ∈ {0, 1} (10)
The objective of the min-cost network to minimize the sum ofthe cost among all arcs. Since only arcs (bij , ri), ∀i ∈ N, ∀j ∈ Di
have non-zero unit cost, we have the objective function of themin-cost flow problem:
min∑
(i,j)∈A c(i, j)f(i, j)
= min∑∀i∈N
∑∀j∈Di
(−Pij)f(bij , ri)
= min∑∀i∈N
∑∀j∈Di
∑k∈NBRi
(−Pij)f(nik, bij)
(11)
⇔1
|N | max∑
∀i∈N
∑
∀j∈Di
∑
k∈NBRi
Pijf(nik, bij) (12)
From (12) and (9), we observe that the the flow amounts onarcs (nki, bi,j), ∀i ∈ N, ∀j ∈ Di, ∀k ∈ NBRi have the sameconstraints as xi
kj in global BSP (3). And (10) demonstrates thatthe min-cost flow problem has an equivalent objective functionas global BSP (3). Therefore, we prove Theorem 1.
REFERENCES
[1] “Gridmedia,” 2006. [Online]. Available: http://www.gridmedia.com.cn/[2] “Pplive,” 2008. [Online]. Available: http://www.pplive.com/[3] “Zatto,” 2008. [Online]. Available: http://www.zattoo.com/[4] V. Pai, K. Kumar, and et al, “Chainsaw: Eliminating trees from overlay
multicast,” in IEEE INFOCOM 2005, Conell, US, Feb. 2005.[5] V. Agarwal and R. Rejaie, “Adaptive multi-source streaming in heteroge-
neous peer-to-peer networks,” in Multimedia Computing and Networking2005 (MMCN), San Jose, CA, USA, Jan. 2005.
[6] X. Zhang, J. Liu, B. Li, and T.-S. P. Yum, “Coolstreaming/donet: Adata-driven overlay network for efficent media streaming,” in IEEEINFOCOM 2005, Miami, US, Mar. 2005.
[7] M. Zhang, J.-G. Luo, L. Zhao, and S.-Q. Yang, “A peer-to-peer net-work for live media streaming using a push-pull approach,” in ACMMultimedia 2005, Singapore, Nov. 2005.
[8] N. Magharei and R. Rejaie, “Prime: Peer-to-peer receiver-driven mesh-based streaming,” in In IEEE INFOCOM 2007, Anchorage, Alaska,USA, May 2007.
[9] B. Cohen, “Bittorrent: http://bitconjuer.com.”[10] V. Venkataraman and P. Francis., “Chunkyspread: Multi-tree unstruc-
tured end system multicast,” in IPTPS 2006, San Babara, CA, USA,Feb. 2006.
[11] V. Venkataraman and P. Francis, “On heterogeneous overlay constructionand random node selection in unstructured p2p networks,” in IEEEINFOCOM 2006, Barcelona, Spain, Apr. 2006.
[12] J. Liang and K. Nahrstedt, “Randpeer: Membership management forqos sensitive peer-to-peer applications,” in IEEE INFOCOM 2006,Barcelona, Spain, Apr. 2006.
[13] D. Kostic and et al, “Maintaining high bandwidth under dynamicnetwork conditions,” in USENIX Annual Technical Conference, 2005.
[14] A. R. Bharambe, C. Herley, and V. N. Padmanabhan, “Analyzing andimproving a bittorrent networks performance mechanisms,” in IEEEINFOCOM 2006, Barcelona, Spain, Apr. 2006.
[15] R. K. Ahuja, T. L. Magnanti, and J. B. Orlin, Network Flows: Theory,Algorithms, and Applications. Prentice Hall.
[16] S. Saroiu, P. Gummadi, and S. Gribble, “A measurement study of peer-to-peer file sharing systems,” in ACM/SPIE MMCN 2002, San Jose,California, 2002.
[17] S. McCanne, V. Jacobson, and M. Vetterli, “Receiver-driven layeredmulticast,” in ACM SIGCOMM 1996, Sept. 1996.
[18] Y. Cui and K. Nahrstedt, “Layered peer-to-peer streaming,” in NOSS-DAV, 2003.
[19] J. Zhao, F. Yang, Q. Zhang, Z. Zhang, and F. Zhang, “Lion: Layeredoverlay multicast with network coding,” IEEE Transactions on Multi-media, vol. 8, no. 5, Oct. 2006.
[20] K. C. Ellen W. Zegura and S. Bhattacharjee, “How to model aninternetwork,” in IEEE Infocom 1996, San Francisco, CA, USA.
[21] A. Goldberg, “Andrew goldberg’s network optimization library.”[Online]. Available: http://www.avglab.com/andrew/soft.html
[22] N. Magharei and R. Rejaie, “Understanding mesh based peer-to-peerstreaming,” in ACM NOSSDAV 2006, Newport, Rhode Island, USA,2006.
[23] M. Zhang, L. Zhao, Y. Tang, J. Luo, and S. Yang, “Large-scale livemedia streaming over peer-to-peer networks through global internet,”in ACM workshop on Advances in peer-to-peer multimedia streaming(P2PMMS), Singapore, Nov. 2005, pp. 21–28.
[24] “Cctv online tv,” 2007. [Online]. Available:http://www.cctv.com/p2p/index.htm
[25] Y. Chu, S. Rao, and H. Zhang, “A case for end system multicast,” inACM Sigmetrics 2000, Santa Clara, California, USA, June 2000.
[26] 2002. [Online]. Available: http://www.cs.umd.edu/∼suman/research/myns/index.html[27] D. Li, Y. Cui, K. Xu, and J. Wu, “Segment-sending schedule in data-
driven overlay network,” in IEEE ICC 2006, Istanbul, Turkey, 2006.[28] “China central radio and tv university,” 2006. [Online]. Available:
http://www.crtvu.edu.cn/[29] S. Banerjee and B. Bhattacharjee, “A comparative study of
application layer multicast protocols,” 2002. [Online]. Available:http://www.cs.wisc.edu/∼suman/pubs.html
[30] P. Francis, “White paper, yoid: Extending the internet multicastarchitecture,” 2006. [Online]. Available: http://www.icir.org/yoid/
[31] M. Castro, P. Druschel, A.-M. Kermarrec, and A. Rowstron, “Scribe: Alarge-scale and decentralized application-level multicast infrastructure,”IEEE Journal on Selected Areas in communications (JSAC), vol. 20,no. 8, 2002.
[32] M. Castro, P. Druschel, A.-M. Kermarrec, A. Nandi, A. I. T. Rowstron,and A. Singhr, “Splitstream: high-bandwidth multicast in cooperativeenvironments,” in Symposium on Operating Systems Principles (SOSP)2003, New York, USA, Oct. 2003.
[33] N. Magharei, R. Rejaie, and Y. Guo, “Mesh or multiple-tree: A com-parative study of p2p live streaming services,” in To Appear in IEEEINFOCOM 2007, Anchorage, Alaska, USA, May 2007.

13
Meng ZHANG (M’05) received the BEng degree inComputer Science and Technology from TsinghuaUniversity, Beijing, China, in 2004. He is currentlya PhD candidate in the Department of ComputerScience and Technology in Tsinghua University. Hisresearch interests are in all areas in multimedianetworking, particularly in QoS issue of peer-to-peerstreaming, peer-to-peer Video-on-Demand, multime-dia streaming on overlay networks, etc. And he haspublished over 10 papers in multimedia networking.Besides, he is the key designer and developer of
GridMedia - one of the earliest very large scale peer-to-peer live streamingsystem in the world.
Yongqiang XIONG (M05) received the B.S., M.S.,and Ph.D. degrees from Tsinghua University, Bei-jing, China, in 1996, 1998, and 2001, respectively,all in computer science. He is with the Wirelessand Networking Group, Microsoft Research Asia,as a Researcher. He has published about 20 referredpapers, and served as TPC member or reviewers forthe international key conferences and leading jour-nals in wireless and networking area. His researchinterests include peer-to-peer networking, routingprotocols for both MANETs and overlay networks,
and network security.
Qian ZHANG (M00-SM04) received the B.S.,M.S., and Ph.D. degrees from Wuhan University,China, in 1994, 1996, and 1999, respectively, all incomputer science.
Dr. Zhang joined Hong Kong University of Sci-ence and Technology in Sept. 2005 as an AssociateProfessor. Before that, she was in Microsoft Re-search, Asia, Beijing, China, from July 1999, whereshe was the research manager of the Wireless andNetworking Group. Dr. Zhang has published about150 refereed papers in international leading journals
and key conferences in the areas of wireless/Internet multimedia networking,wireless communications and networking, and overlay networking. She is theinventor of about 30 pending patents. Her current research interests are in theareas of wireless communications, IP networking, multimedia, P2P overlay,and wireless security. She also participated many activities in the IETF ROHC(Robust Header Compression) WG group for TCP/IP header compression.
Dr. Zhang is the Associate Editor for IEEE Transactions on WirelessCommunications, IEEE Transactions on Multimedia, IEEE Transactions onVehicular Technologies, Computer Networks and Computer Communications.She also served as Guest Editor for IEEE JSAC, IEEE Wireless Communica-tions, Computer Networks, and ACM/Springer MONET. Dr. Zhang has beeninvolved in organization committee for many important IEEE conferences,including ICC, Globecom, WCNC, Infocom, etc. Dr. Zhang has received TR100 (MIT Technology Review) world’s top young innovator award. She alsoreceived the Best Asia Pacific (AP) Young Researcher Award elected by IEEECommunication Society in year 2004. She received the Best Paper Award inMultimedia Technical Committee (MMTC) of IEEE Communication Societyand Best Paper Award in QShine 2006. She received the Oversea YoungInvestigator Award from the National Natural Science Foundation of China(NSFC) in 2006. Dr. Zhang is the vice-chair of Multimedia CommunicationTechnical Committee of the IEEE Communications Society.
Lifeng SUN (M’05). Dr. Lifeng Sun was born inXi’an, China, 1972. He received his B.S. Degreeand Ph.D. Degrees in System Engineering in 1995and 2000 separately from National University ofDefense Technology, Changsha, Hunan, China. Dr.Sun’s professional interests lie in the broad areaof ad hoc network streaming, peer-to-peer videostreaming, interactive multi-view video, distributedvideo coding, he has published over 50 papers inthe above domain. He was on the Post Doctorresearch of the Department of Computer Science and
Technology at Tsinghua University from 2001 to2003; He is now on theFaculty of the Department of Computer Science and Technology at TsinghuaUniversity. Dr. Sun is the secretary-general of Multimedia Committee ofChina Computer Federation, Vice Director of Tsinghua-Microsoft Media andNetwork Key Lab of Ministry of Education (MOE). Dr. Sun serviced as TPCmember of Pacific-Rim Conference on Multimedia (PCM) 2005, Pacific-RimConference on Multimedia (PCM) 2006, IEEE International MultiMedia Mod-elling Conference (MMM) 2007, IEEE International MultiMedia ModellingConference (MMM) 2006, and reviewed papers for IEEE ICME 2006, IEEECSVT special issue on multiview video coding.
Shiqiang YANG is a chief professor at TsinghuaUniversity with department of Computer Scienceand Technology. He r eceived the B.S, M.S in Com-puter Science from Tsinghua University , Beijing ,China in 1977 and 1983, respectively.
From 1980 to 1992, he worked as an assistant pro-fessor at Tsinghua University, Beijing, China. From1992 to 1994, he visited City University of HongKong and was a research assistant at the Departmentof Manufacture Engineering. As the associate headerof Department of Computer Science and Technology
at Tsinghua University since 1994, he served as the associate professor from1994 to 1999 and then as the professor since 1999.
He is currently the President of Multimedia Committee of China ComputerFederation, Beijing, China and the co-director of Microsoft-Tsinghua Multi-media Joint Lab, Tsinghua University, Beijing, China. His research interestsmainly include multimedia application, video procession, streaming mediaand embedded multimedia. In recent three years, he has published more than60 papers in international conferences and journals, as well as more than 10proposals within MPEG and AVS standardization.





























