Embed Size (px)
Citation preview

596 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS—PART A: SYSTEMS AND HUMANS, VOL. 40, NO. 3, MAY 2010
Segmentation of Human Body Parts UsingDeformable Triangulation
Jun-Wei Hsieh, Member, IEEE, Chi-Hung Chuang, Sin-Yu Chen, Chih-Chiang Chen, andKuo-Chin Fan, Member, IEEE
Abstract—This paper presents a novel segmentation algorithmto segment a body posture into different body parts using the tech-nique of deformable triangulation. To analyze each posture moreaccurately, they are segmented into triangular meshes, where aspanning tree can be found from the meshes using a depth-firstsearch scheme. Then, we can decompose the tree into differentsubsegments, where each subsegment can be considered as a limb.Then, two hybrid methods (i.e., the skeleton-based and model-driven methods) are proposed for segmenting the posture into dif-ferent body parts according to its occlusion conditions. To analyzeocclusion conditions, a novel clustering scheme is proposed to clus-ter the training samples into a set of key postures. Then, a modelspace can be used to classify and segment each posture. If theinput posture belongs to the nonocclusion category, the skeleton-based method is used to divide it into different body parts thatcan be refined using a set of Gaussian mixture models (GMMs).For the occlusion case, we propose a model-driven technique toselect a good reference model for guiding the process of body partsegmentation. However, if two postures’ contours are similar, therewill be some ambiguity that can lead to failure during the modelselection process. Thus, this paper proposes a tree structure thatuses a tracking technique so that the best model can be selectednot only from the current frame but also from its previous frame.Then, a suitable GMM-based segmentation scheme can be used tofinely segment a body posture into the different body parts. Theexperimental results show that the proposed method for body partsegmentation is robust, accurate, and powerful.
Index Terms—Abnormal event detection, behavior analysis,body part segmentation, video surveillance.
Manuscript received April 26, 2008; revised March 16, 2009. First publishedMarch 4, 2010; current version published April 14, 2010. This work wassupported in part by the National Science Council of Taiwan under GrantNSC97-2221-E-155-060 and in part by the Ministry of Economic Affairs underContract 97-EC-17-A-02-S1-032. This paper was recommended by AssociateEditor Q. Ji.
J.-W. Hsieh is with the Department of Computer Science and Engineering,National Taiwan Ocean University, Keelung 202, Taiwan, and also with theDepartment of Electrical Engineering, Yuan Ze University, Chung-Li 320,Taiwan (e-mail: [email protected]).
C.-H. Chuang is with the Department of Learning and Digital Technology, FoGuang University, Yilan 26247, Taiwan (e-mail: [email protected]).
S.-Y. Chen and C.-C. Chen are with the Department of Electrical En-gineering, Yuan Ze University, Chung-Li 320, Taiwan (e-mail: [email protected]; [email protected]).
K.-C. Fan is with the Department of Learning and Digital Technology, FoGuang University, Yilan 26247, Taiwan, and also with the Department ofComputer Science and Information Engineering, National Central University,Chung-Li 320, Taiwan (e-mail: [email protected]).
Color versions of one or more of the figures in this paper are available onlineat http://ieeexplore.ieee.org.
Digital Object Identifier 10.1109/TSMCA.2010.2040272
I. INTRODUCTION
HUMAN behavior analysis is an important task in var-ious applications like video surveillance [1]–[9], video
retrieval, human interaction systems [10], [11], and medicaldiagnostics. A challenging problem for this type of analysisis the segmentation of the human body into different majorbody parts, such as the head, hands, torso, and feet [12].This problem is challenging due to the ambiguities caused byself-occluded or mutually occluded body parts or body partsand clothes with similar colors. During the past few decades,extensive studies [14]–[23] have been conducted on segmentinga human body to its different parts directly from videos. Forexample, Haritaoglu et al. [14], [15] proposed a recursiveconvex-hull algorithm to construct a silhouette-based model ofthe body for finding possible body parts. In [16], Micilotta et al.detected different body parts using several boosted body partdetectors that were trained in advance by the Adaboost algo-rithm [38]. In [17], Wu and Nevatia trained four body partdetectors and then combined their responses together to createa more accurate detector. In addition, Wren et al. [18] proposeda Pfinder system that uses 2-D contour analysis to coarselyidentify the locations of the head, hands, and feet and thenperforms fine body part segmentation using a 2-D blob model.Park and Aggarwal [20], [21] used a similar blob model toidentify the human body and then segmented it into differentbody parts using dynamic Bayesian networks. This blob-basedapproach is very promising for analyzing human behavior,but it is very sensitive to changes in lighting. In addition toblobs, the silhouette is another important feature of body partsegmentation. For example, Weik and Liedtke [22] tracked thenegative minimum curvatures along body contours and thenanalyzed each body part using a modified iterative closest pointalgorithm. In [13], Rosin traced the convexity of object contourto segment an object into different parts. In addition to usingsilhouettes, Song et al. [23] proposed a corner-based methodto study human posture and determine body parts from videosequences.
Another way to analyze human actions is to recover thearticulated poses of a human from videos or static images. Forexample, Mori et al. [24] integrated the features of contours,shapes, shading, and focus to detect various limbs so that theycould be assembled together to form a body. In [26], Courand Shi built different shape templates and then searched andscored each template’s ability to recognize articulated objects(like horses) from still images. In [29], Hua et al. formulatedthe human pose estimation problem as a Markov network and
1083-4427/$26.00 © 2010 IEEE

HSIEH et al.: SEGMENTATION OF HUMAN BODY PARTS USING DEFORMABLE TRIANGULATION 597
Fig. 1. Flowchart of the proposed system to extracting different body parts showing the (a) training stage and the (b) segmentation stage.
then estimated its parameters using a brief propagation MonteCarlo algorithm. Ramanan [27], [28] proposed a tree structureto iteratively parse an edge-based deformable model so that dif-ferent poses of articulated objects could be estimated from stillimages. In [32], Flzenszwalb and Huttenlocher used genericpart-based models to represent human poses and then recoveredtheir parameters by restricting these models to trees. Then, adynamic programming technique can be used for making theminimization problem polynomial rather than exponential time.Beyond trees, Lan and Huttenlocher used undirected graphicalmodels for 2-D human pose recovery and estimated the param-eters of the models using a residual covariance analysis [33].In general, human pose estimation methods [2] usually adopta probabilistic graphical model (tree or nontree structures) tomodel interactions between body parts. Then, a constrainedoptimization method is applied to find the best set of param-eters from a high-dimensional model space. Although this typeof scheme is useful for analyzing human actions, it is toocomplex for real-time surveillance applications. In addition,local optimal solutions can be found if the initial values are notaccurate.
In this paper, a novel triangulation-based scheme is proposedfor segmenting a human posture into different body parts. Thetask of body part segmentation is still unsolved (or ill-posed) bycomputer-vision methods due to occlusion between body parts.To make this problem solvable, this paper assumes that all of theanalyzed behavior types have been collected in advance. Thisassumption is commonly used in training-based approacheswhere several samples are collected for training a detector torecognize various objects like vehicles or faces. Then, differentmodels can be developed and used for segmenting a postureinto different body parts. To tackle this problem, we use thetechnique of Delaunay triangulation [37] to decompose a bodyposture into triangular meshes. Then, we take advantage of adepth-first search (dfs) to obtain a spanning tree from the resultof the triangulation. Then, the tree can be decomposed into dif-ferent subsegments if we remove all of its branch nodes, whereeach subsegment can be considered as a limb. With this roughsegmentation, a novel feature called the “centroid context” canbe then extracted for representing each posture. Based on thefeature, a novel clustering scheme is then proposed to clusterthe training samples into different classes, i.e., key postures.
The set of key postures forms a model space and can be used forposture classification. If a posture belongs to the nonocclusioncategory, we propose a skeleton-based method for decomposingit into different body segments. This decomposition is a roughsegmentation that can be further refined using a Gaussian mix-ture model (GMM)-based technique. For the case of occlusion,a novel model-driven approach is proposed to make the ill-posed problem solvable. However, the ambiguity caused bysimilar contours between models can cause the model selectionprocess to fail. In response, this paper proposes a tree structurevia a tracking technique so that a suitable segmentation schemecan be found and an occluded posture can be well segmentedinto different body parts. Because no complicated processes areinvolved at the segmentation stage, all of the occluded posturescan be analyzed and segmented to different body parts in realtime (about 15 fps for a typical PC). The experimental resultsreveal the feasibility and superiority of the proposed approachin body part segmentation.
The rest of this paper is organized as follows. In the nextsection, a flowchart of our proposed system for body partsegmentation is introduced. Then, the technique of Delaunaytriangulation is described in Section III. Section IV describesthe details of the skeleton-based scheme for body part segmen-tation, and Section V describes the details of the model-drivenapproach. Section VI reports the experimental results. Finally,conclusions are drawn in Section VII.
II. SYSTEM OVERVIEW
The problem of body part segmentation [2] is still ill-posedfor computer vision method. To make this problem solvable,like other training approaches [8], [11], [12], this paper assumesthat all the analyzed behavior types are known in advance.Thus, we propose a triangulation-based system for segmentinga posture into the different body parts. The detailed componentsof this system are shown in Fig. 1. First of all, in Fig. 1(a),the method of background subtraction is used to extract eachbody posture from video sequences. Then, we obtain its bodycontours through a contour-tracing technique. After that, atriangulation technique [37] is used to divide the body intotriangular meshes. Then, we apply a graph search method tofind a spanning tree from which different features like skeleton

598 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS—PART A: SYSTEMS AND HUMANS, VOL. 40, NO. 3, MAY 2010
Fig. 2. All the vertices are indexed counterclockwise such that the interior ofV is located on the left.
and centroid context can be extracted to represent the posture.Subsequently, a clustering scheme is used to cluster the trainingpostures into different classes that form the model space.During the segmentation stage, which is shown in Fig. 1(b),if a posture belongs to the nonocclusion class, the skeleton-based method will be adopted for segmenting it into differentbody parts. Otherwise, the model-driven method will be used toextract the occluded limbs. Next, the technique of deformabletriangulation will be described. Then, the task of model con-struction will be discussed.
III. DEFORMABLE TRIANGULATIONS
This paper assumes that all of the analyzed video sequencesare captured by a still camera. When the camera is static,the background of the captured video sequence can be recon-structed using a mixture of Gaussian models [36]. This allowssamples to be detected and foreground objects to be detectedby subtracting the background. Then, we apply some simplemorphological operations to remove noise. After these pre-processing steps, we partition a foreground human posture intotriangular meshes using the constrained Delaunay triangulationtechnique.
Assume that P is the analyzed posture, which is a binary mapand extracted via background subtraction. In addition, assumethat V is the set of control points sampled along the contour ofP . Each point in V is indexed counterclockwise and modulatedby the size of V . If any two adjacent points in V are connectedby an edge, then V can be considered as a polygon. We adoptthe technique of constrained Delaunay triangulation proposedby Chew [37] to divide V to triangular meshes.
As shown in Fig. 2, Φ is the set of interior points of V inR2. For a triangulation T ⊂ Φ, T is said to be a constrainedDelaunay triangulation of V if each edge of T is an edge of V ,and for each remaining edge e of T , there exists a circle C suchthat the endpoints of e are on the boundary of C. Moreover, ifa vertex of V is inside C, then it cannot be seen from at leastone of the endpoints of e. More precisely, given three verticesvi, vj , and vk on V , the triangle Δ(vi, vj , vk) belongs to theconstrained Delaunay triangulation if and only if the followingproperties are true.
1) vk∈Uij , where Uij ={v∈V |e(vi, v)⊂Φ, e(vj , v)⊂Φ}.2) C(vi, vj , vk) ∩ Uij = ∅, where C is a circumcircle of vi,
vj , and vk. That is, the interior of C(vi, vj , vk) does nothave a vertex such that v ∈ Uij .
By using this definition, Chew [37] proposed a recur-sive divide-and-conquer algorithm to execute a constrained
Fig. 3. Triangulation of a human posture. (a) Input posture. (b) Triangulationof (a).
Delaunay triangulation of V in O(n log n) time. When Vcontains only three vertices, V itself is the result of the triangu-lation. However, when V contains more than three vertices, wechoose an edge from V and search for the corresponding thirdvertex that satisfies properties 1) and 2). Then, we subdivideV into two subpolygons Va and Vb. The same procedure isapplied recursively to Va and Vb until the processed polygoncontains only one triangle. In summary, the four steps of theaforementioned algorithm are as follows:
1. Choose a starting edge e(vi, vj).2. Find the third vertex vk of V that satisfies properties 1)
and 2).3. Subdivide V into two subpolygons: Va = {vi, vk,
vk+1, . . . , vi−1, vi} and Vb = {vj , vj+1, . . . , vk, vj}.4. Repeat Steps 1)–3) on Va and Vb until the processed
polygon consists of only one triangle.
The details of this algorithm are given by Bern and Eppstein[40]. Fig. 3 shows one example of the triangulation result.
IV. SKELETON EXTRACTION AND
BODY PART SEGMENTATION
In this section, the skeleton feature will be extracted fromthe result of triangulation for body part segmentation. Tradi-tional methods to extract skeleton features are mainly based onbody contours. In these methods, different feature points withnegative minimum curvatures are extracted along the posturecontour for constructing its body skeleton. However, the rulesto construct skeletons are very heuristic and easily disturbed bynoise. Thus, in what follows, we will use a graph search schemeto find a dfs tree from the result of triangulation. The tree willcorrespond to a specified body skeleton.
A. Triangulation-Based Skeleton Extraction
After triangulation, a binary posture P will be decomposed toa set ΩP of triangular meshes, i.e., ΩP = {Λi}i=0,1,...,NTP
−1.Each mesh Λi in ΩP has the centroid CΛi
. Given two meshesΛi and Λj , they are connected if they share one common edge.Then, according to this connectivity, P can be converted to anundirected graph GP , where all centroids CΛi
in ΩP are thenodes in GP and an edge exists between CΛi
and CΛjif Λi
and Λj are connected. Then, we can perform a graph searchingscheme on GP for extracting its skeleton feature.

HSIEH et al.: SEGMENTATION OF HUMAN BODY PARTS USING DEFORMABLE TRIANGULATION 599
Fig. 4. Body component extraction. (a) Triangulation result of a posture.(b) A dfs tree of (a).
First, we seek a node H whose degree is one and positionis the highest for all the nodes in GP . Then, starting from H ,we perform a depth-first search [35] to find a dfs tree TP
dfs. Thetree TP
dfs will capture the skeleton feature of P . In Fig. 4, (b) isthe dfs tree of (a). In what follows, details of the algorithm aresummarized.
Triangulation-Based Skeleton Extraction Algorithm:Input: A set ΩP of triangular meshes extracted from a posture
P .Output: The skeleton SP of P .Step 1: Construct the graph GP from ΩP according to the
connectivity of nodes in ΩP .Step 2: Get the node H whose degree is one and position is
the highest from all nodes in GP .Step 3: Apply the depth-first search to GP , and find its dfs
tree TPdfs.
Step 4: Return TPdfs as the skeleton SP of P .
B. Body Part Segmentation Using Skeletons
In the previous section, we presented a tree-searching methodto find a dfs tree TP
dfs from P . In this tree, if a node containsmore than one child, we call it as a branch node. The branchnode is important for decomposing P to different body parts.As shown in Fig. 4, there are three branch nodes in (b),i.e., b0, b1, and b2. If we take off all the branch nodes fromTP
dfs, TPdfs can be decomposed to different branch paths LP
i .Then, each path LP
i corresponds to one of the body parts inP . For example, as shown in Fig. 4(b), if we remove b0 fromTP
dfs, two branch paths will be formed, i.e., one path from noden0 to b0 and another path from b0 to node n1. The first pathcorresponds to the head and neck of P , and the second pathcorresponds to the hand of P . In some cases, like the path fromb0 to b1, there is no corresponding high-level semantic bodycomponent. However, if the path length is further consideredand constrained, oversegmentation can be easily avoided. Bycarefully collecting the set of triangular meshes along eachpath LP
i , different body parts can be extracted from P . The
algorithm used to obtain the different body parts from P usingits skeletons is as follows.
Skeleton-Based Body Part Segmentation Algorithm:Input: A posture P and its dfs tree TP
dfs.Output: A set ΓP of body parts.Step 1: Find and remove all of the branch nodes bk from TP
dfs.Step 2: Find all of the paths LP
i from TPdfs by checking the
broken segments remaining in TPdfs.
Step 3: Extract each body part Γi by collecting all of thepixels of the triangular meshes obtained along each path LP
i .Step 4: Collect all of the body parts Γi in the set ΓP to form
the result of the body part segmentation.
C. Body Part Segmentation Using Blobs
In the previous section, we presented a skeleton-basedmethod for finding the different body parts from a posture P .Assume that Γi is the body part found along the path LP
i fromP . Since a set of triangular meshes is used to represent Γi,the result provided by removing branch points is only a roughapproximation of the body part segmentation. Therefore, thissection uses the concept of blobs to resegment P so that thebody parts can be more accurately extracted.
This paper uses a GMM to model each body part. For eachpixel s(x, y) in Γi, we model its feature distribution by
pΓi(s) =
K∑k=1
pΓi(s|k)αΓi,k
(1)
where αΓi,kis the prior probability, K is the number of
Gaussian models used in the modeling process, and pΓi(s|k)
is the kth conditional probability. In this paper, each body part(like a leg) is assumed to have two major components (like theshank and thigh). Thus, K is set to two. In addition, pΓi
(s|k)is a Gaussian distribution that is parameterized by two features,including the colors and positions of Γi
pΓi(s|k)=(2πΣi,k)−
d2 exp
[−(fs−μi,k)tΣ−1
i,k(fs − μi,k)]
(2)
where Σi,k and μi,k are the covariance matrix and mean of thekth Gaussian cluster of the ith body part, respectively, and dis the feature dimension. In addition, fs = (x, y, r, g, b) is afeature vector that describes s, where (x, y) and (r, g, b) denotethe coordinates and color features of s, respectively.
The initial values of Σi,k and μi,k can be obtained bydividing Γi into two components: Γi,1 and Γi,2. Assume thatΛΓi
is the triangular mesh that includes the center of Γi. Ifthe centroid of ΛΓi
is removed from the path LPi , LP
i will bebroken into two subpaths LP
i,1 and LPi,2. Then, Γi,1 and Γi,2 can
be obtained by collecting the meshes from the subpaths LPi,1
and LPi,2, respectively. Thus, the values of Σi,k and μi,k can
be obtained by analyzing the statistics of the pixels in Γi,k fork = 1 and 2.
In practice, each body part has different orientations. Ifthe orientation of Γi,k is further considered, the probabilitypΓi
(s|k) can be more accurately estimated. Assume that φΓi,k
is the major orientation of Γi,k and obtained by analyzing

600 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS—PART A: SYSTEMS AND HUMANS, VOL. 40, NO. 3, MAY 2010
Fig. 5. Occlusion between two legs.
the moments of Γi,k [42]. For each pixel in Γi,k, we map itscoordinates (x, y) into elliptic coordinates (u, v) as follows:(
uv
)=
(cos φΓi,k
− sin φΓi,k
sinφΓi,kcos φΓi,k
)(x − xΓi,k
y − yΓi,k
)(3)
where (xΓi,k, yΓi,k
) is the center of Γi,k. Thus, for each pixel sin Γi,k, its feature vector will become fs = (u, v, r, g, b).
Assume that θi = {(μi,k,Σi,k, αΓi,k)}k=1,...,K is the set of
parameters of the K finite GMMs. The initialization of theprior probability αΓi,k
is assumed to be equal, i.e., αΓi,k=
1/K. Then, the expectation maximization algorithm [39] isused to refine Σi,k and μi,k. Suppose that our training dataare S = {s1, . . . , sn, . . . , sN} and st
n,i,k = (sn − μti,k)(sn −
μti,k)T . With S, the (t + 1)th estimate of μt
i,k and Σti,k can be
obtained
μt+1i,k =
N∑n=1
q (k|zn, θti) sn
N∑n=1
q (k|zn, θti)
Σt+1i,k =
N∑n=1
stn,i,kq (k|zn, θt
i)
N∑n=1
q (k|zn, θti)
where q(k|sn, θti) = (αt
Γi,kpΓi
(sn|k, θti)/pΓi
(sn|θti)) and
αtΓi,k
= (∑N
n=1 q (k|sn, θt−1i ) /
∑Nn=1
∑Kk=1 q (k|sn, θt−1
i )).Once the model pΓi
(s) has been established, we can use areprojection technique to more accurately segment P intodifferent body parts.
V. MODEL-DRIVEN BODY PART SEGMENTATION
Body parts, sometimes, will occlude together due to similarcolors, posture types, or the existence of shadows. As shown inFig. 5, the legs are occluded due to the “standing” posture andshadows. To solve such an ill-posed problem, a model-drivenmethod will be proposed for segmenting an occluded postureinto different body parts.
A. Posture Classification Using Centroid Contexts
The model-driven method attempts to choose a suitablemodel for segmenting an occluded posture into different bodyparts. However, what is the model space? In addition, howcan we decide whether a posture is occluded and thus choosebetween the skeleton-based or model-driven schemes for thebody part segmentation? This paper calls a posture “occluded”if there are two or more body parts occluded together in it.When a posture is occluded, how can the best model be chosen
Fig. 6. Polar transform of a human posture.
from the model space for the task of segmentation? To answerthese questions, a novel posture descriptor called the “centroidcontext” is presented hereinafter. Then, a clustering scheme isproposed for constructing the model space.
In Section III, we have presented a triangulation-based ap-proach to divide a posture into different triangular meshes. Inthis section, we project these meshes onto polar coordinates andlabel each mesh. Then, we can define a novel shape descriptor,i.e., a centroid context to finely represent this posture. The log-polar mapping benefits from the technique of shape context[25]. Assume that all of the postures are normalized to a unitsize. We use m to represent the number of shells used toquantize the radial axis and n to represent the number of sectorsthat we want to quantize in each shell. Therefore, the totalnumber of bins used to construct the centroid context is m × n.Fig. 6 shows an example of a polar transform of a humanposture with three shells and eight sectors. For the centroidr of the triangular mesh of a posture, we construct a vectorhistogram hr = (hr(1), . . . , hr(k), . . . , hr(mn)), where hr(k)is the number of triangular mesh centroids in the kth bin whenr is considered as the origin
hr(k) = #{q|q �= r, (q − r) ∈ bink
}(4)
where bink is the kth bin of the polar coordinate. Then, thedistance between the two given histograms hri
(k) and hrj(k)
can be measured by a normalized intersection
C(ri, rj) = 1 − 1Nmesh
Kbin∑k=1
min{hri
(k), hrj(k)
}(5)
where Kbin is the number of bins and Nmesh denotes thenumber of meshes calculated from a posture. Using (4) and (5),we will define a centroid context to describe the characteristicsof an arbitrary posture P .
In Section IV-B, given a posture P , a novel skeleton extrac-tion scheme was proposed for extracting the body parts. LetΓP
i be one of the body parts, and let cPi be the centroid of the
triangular mesh closest to the center of ΓPi . As shown in Fig. 7,
cP0 is the centroid extracted from the path ΓP
0 that begins at n0
and ends at bP0 (see Fig. 4). Given the centroid cP
i , we can obtainits corresponding histogram hcP
i(k) using (4). Assume that V P
is the set of centroids cPi of all of the body parts ΓP
i in P . Basedon V P , the centroid context of P is defined as follows:
P ={
hcPi
}i=0,...,|V P |−1
where |V P | is the number of elements in V P . Given twopostures P and Q, the distance between their centroid contexts

HSIEH et al.: SEGMENTATION OF HUMAN BODY PARTS USING DEFORMABLE TRIANGULATION 601
Fig. 7. Centroids of different parts derived from Fig. 4.
is measured by
dcc(P,Q) =1
2|V P |
|V P |−1∑i=0
wPi min
0≤j<|V P |C
(cPi , cQ
j
)
+1
2|V Q|
|V Q|−1∑j=0
wQj min
0≤i<|V Q|C
(cPi , cQ
j
)(6)
where wPi and wQ
j are the area ratios of the ith and jth bodyparts residing in P and Q, respectively. Based on (6), anarbitrary pair of postures can be compared.
The shape context descriptor [25] has been commonly usedfor shape recognition in previous studies. This descriptor ex-tracts different feature points along the object contour, anddense feature points are matched to calculate the distance be-tween two objects. If the number of feature points is n, the timecomplexity for obtaining the set of dense correspondences isO(n2). As for our region-based centroid context, the most time-consuming process is “triangulation” whose time complexity isO(n log n). Thus, our scheme has a lower time complexity andcan be performed in real time to match two postures than the“shape context” scheme [25]. More importantly, our approachcan directly obtain a rough segmentation of the body parts ofa posture. Thus, a posture can be more accurately representedand classified up to a “syntactic” level.
B. Key Model Selection Through Clustering
Once each posture is represented using its centroid context, aclustering technique can be used to select a set of key posturesfrom a set of training samples to construct the model space.The set of training samples will be first manually labeledas “occluded” or “nonoccluded.” Then, as shown in Fig. 8,different key postures (or models) can be selected using theclustering technique. Each circle corresponds to a cluster center,and only the postures located within the blue circles (labeled asoccluded) are segmented using the model-driven approach. Forthe postures shown with other colors (labeled as nonoccluded),the skeleton-based approach is used for segmentation. In realimplementation, the ratio of the samples between the MD(model-driven method) and SB (skeleton-based method) is 5 : 1.
Fig. 8. Space of key postures after clustering. For the blue postures located inthe circles, the model-driven approach is adopted for body part segmentation.Other postures will be segmented with the skeleton-based scheme.
Assume that SP is the collection of training postures. Weassume that each element ei in SP individually forms a clusterzi. Then, given the two cluster elements zi and zj in SP ,two measures are defined to measure the distance between theelements. The first measure is the maximum distance
dmax(zi, zj) = Maxem∈zi,en∈zj
dcc(em, en) (7)
where dcc(., .) is defined in (6). The second measure is theaverage distance
davg(zi, zj) =1
|zi||zj |∑
em∈zi
∑en∈zj
dcc(em, en) (8)
where |zk| is the number of elements in zk. According to (7),we can use an iterative merging scheme to find a compact setof key postures from SP . Let zt
i and Zt be the ith cluster andthe collection of all clusters zt
i obtained at the tth iteration,respectively. At each iteration, we choose a pair of clusters, zt
i
and ztj , whose distance dmax(zi, zj) is the minimum among all
pairs in Zt
(zi, zj) = arg min(zm,zn)
dmax(zm, zn),
for all zm ∈ Zt, zn ∈ Zt, and zm �= zn. (9)
If dmax(zi, zj) is less than Td, then zti and zt
j are merged toform a new cluster and construct a new collection of clustersZt+1. The merging process is executed iteratively until no fur-ther merging is possible. In (9), the merging criterion considersonly the “within-class” distance between zt
i and ztj . Similar to
Ward’s algorithm [39], if two clusters zti and zt
j are merged,we also require their sum-of-root square error after merging tobe small enough. More precisely, the sum-of-root square errorafter merging two clusters zt
i and ztj is defined as
∑k �=i,j
√∣∣d2avg
(ztij , z
tk
)− davg (zt
i , ztk) davg
(ztj , z
tk
)∣∣ (10)
where davg(., .) is defined in (8) and ztij is the merged cluster of
zti and zt
j . Equation (10) shows that if zti and zt
j are similarenough, the average distances davg(zt
i , ztk) and davg(zt
j , ztk)

602 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS—PART A: SYSTEMS AND HUMANS, VOL. 40, NO. 3, MAY 2010
Fig. 9. Two key postures after clustering, where (b) and (d) are referencedmaps of (a) and (c) for body part segmentation.
Fig. 10. Two postures with similar contours. [(a) and (b)] Postures with twosimilar contours. [(c) and (d)] Distance maps of (a) and (d), respectively.
should be similar to davg(ztij , z
tk). After normalization, (10) can
be rewritten as
dbetween(zi, zj)
=1
|Zt| − 2
∑k �=i,j
√∣∣d2avg(zij , zk) − davg(zi, zk)davg(zj , zk)
∣∣davg(zi, zk)davg(zj , zk)
(11)
where |Zt| is the number of elements in Zt. Thus, in addition to(9), we also require zt
i and ztj to satisfy the following criterion:
dbetween(zi, zj) < Tb (12)
if they are merged into a new cluster ztij . The distance
dbetween(., .) is a ratio that measures the variations between twoclusters. Thus, it is quite easy to set the threshold Tb to controlthe posture clustering. For this study, we set Tb to 0.1 for allof the experiments. Fig. 9 shows some results of this methodof posture selection, where the binary patterns are the referencemaps used for body part segmentation. After clustering, if a keyposture is labeled as “occluded,” the model-driven approach isused for segmentation.
C. Tree Structure for Reference Model Selection
In some cases, two different postures will have similarcontours. For instance, in Fig. 10, the two people have sim-ilar contours but different hand gestures. Thus, it is not easyto determine which model pattern is better for guiding thesegmentation process if only the contour feature is used. Totackle this problem, a hierarchical tree structure is proposedfor choosing the best reference model from the constructed
Fig. 11. Tree structures used for the task of reference model selection wherethe models’ contours are similar.
model space. In this tree structure, first, the root model ismatched using the centroid context. If the root has no branch, itscorresponding model pattern will be used for the model-drivenmethod. Otherwise, its branch nodes will be searched further.For the nodes of the branch models, a distance transformationis used to resolve the inner features and then match them.
Assume that DTP is the distance map of a posture P . For apixel r in DTP , its value is the shortest distance between thepixel and all of the edge pixels in P
DTP (r) = minq∈EP
d(r, q) (13)
where EP is the set of edge pixels in P and d(r, q) is theEuclidian distance between r and q. Given two postures P andD, the distance between their distance maps is defined as
dedge(P,D) =1
|DTP |∑
r
|DTP (r) − DTQ(r)| (14)
where |DTP | denotes the image size of DTP . When calculating(14), P and D must be normalized to unity, and their centersare set to the origins of DTP and DTD, respectively. Fig. 10shows two examples of this distance transformation. Althoughthe contours of (a) and (b) are similar, their distance maps,which are respectively shown in (c) and (d), are different.Thus, using the tree structure, different input postures can bewell categorized and then segmented into different body partseven though their contours are similar. Fig. 11 shows threedifferent tree structures used for selecting a reference model. Toautomatically construct the tree structure, we can first use thecentroid contexts to cluster the collection of training posturesinto the clusters zi (see Section V-B). For each cluster zi,the distance map is then used to cluster all of the collectedpostures. Then, a two-layer tree structure can be formed andused to select the reference model. As shown in Fig. 11, threeclusters were found using the centroid context. Then, the feature“distance map” was used to split each cluster into differentmodels for body part segmentation.
In addition to the tree structure, the similarity or consistencybetween two adjacent postures is another useful feature formodel selection. Fig. 12 shows that, when (a) is observed,the probability that (b) is the next posture type of (a) shouldbe higher than that of (c). To find the consistency between
HSIEH et al.: SEGMENTATION OF HUMAN BODY PARTS USING DEFORMABLE TRIANGULATION 603
Fig. 12. Consistency between postures. The probability that (b) is the posturenext to (a) is higher than that of (c).
Fig. 13. Model for body part segmentation. (a) A posture. (b) A model forsegmenting (a) into different body parts.
postures, we can consider each key posture as a state. Then,similar to the hidden Markov models used for speech recog-nition, a state transition matrix, which is obtained using theBaum–Welch algorithm [41], can be trained and constructed torecord the state transition probability between any states. Letp(ci|cj) denote the transition probability of the previous statecj transiting to the current state ci. Then, given a posture P , wecan use its centroid context to search for its best cluster zP fromthe set Z of all the key clusters (obtained in Section V-B). Then,the best reference model c of P is obtained from zP as follows:
c = arg maxci∈zP
p(ci|cj) Pr(ci|P ) (15)
where Pr(ci|P ) is the likelihood between ci and P defined asfollows:
Pr(ci|P ) = exp (−dedge(ci, P )) .
By using (15), the best reference model of P can be automat-ically selected for body part segmentation.
D. Model-Driven Segmentation Scheme
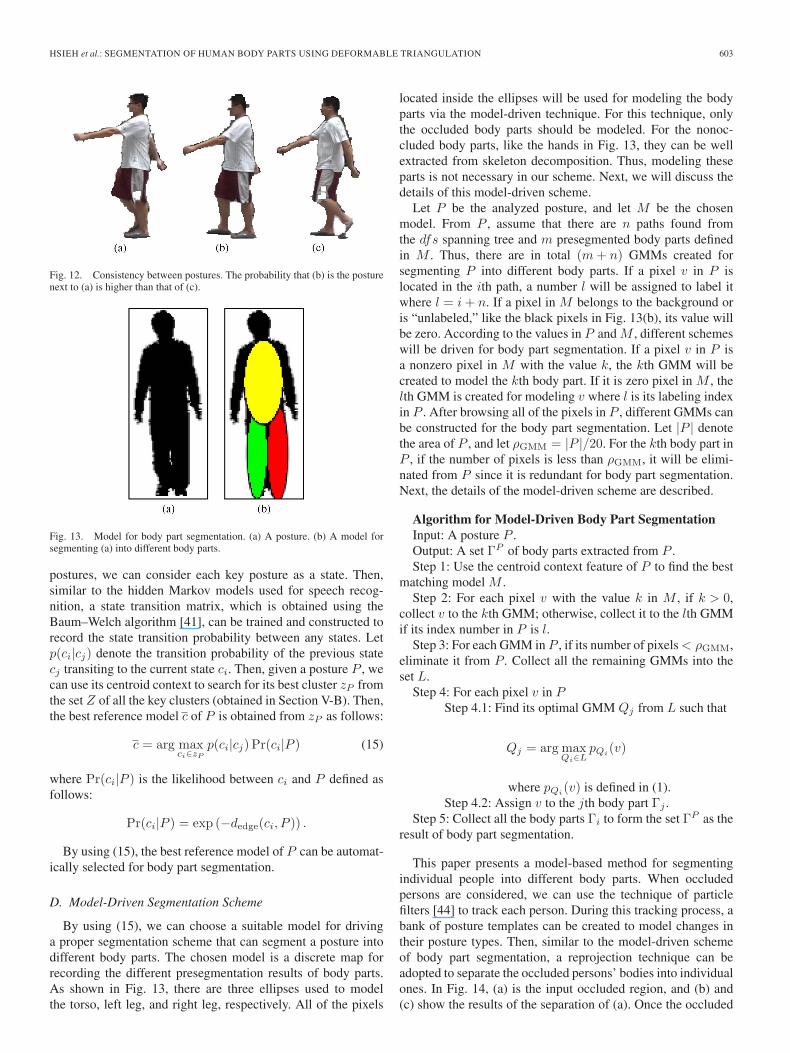
By using (15), we can choose a suitable model for drivinga proper segmentation scheme that can segment a posture intodifferent body parts. The chosen model is a discrete map forrecording the different presegmentation results of body parts.As shown in Fig. 13, there are three ellipses used to modelthe torso, left leg, and right leg, respectively. All of the pixels
located inside the ellipses will be used for modeling the bodyparts via the model-driven technique. For this technique, onlythe occluded body parts should be modeled. For the nonoc-cluded body parts, like the hands in Fig. 13, they can be wellextracted from skeleton decomposition. Thus, modeling theseparts is not necessary in our scheme. Next, we will discuss thedetails of this model-driven scheme.
Let P be the analyzed posture, and let M be the chosenmodel. From P , assume that there are n paths found fromthe dfs spanning tree and m presegmented body parts definedin M . Thus, there are in total (m + n) GMMs created forsegmenting P into different body parts. If a pixel v in P islocated in the ith path, a number l will be assigned to label itwhere l = i + n. If a pixel in M belongs to the background oris “unlabeled,” like the black pixels in Fig. 13(b), its value willbe zero. According to the values in P and M , different schemeswill be driven for body part segmentation. If a pixel v in P isa nonzero pixel in M with the value k, the kth GMM will becreated to model the kth body part. If it is zero pixel in M , thelth GMM is created for modeling v where l is its labeling indexin P . After browsing all of the pixels in P , different GMMs canbe constructed for the body part segmentation. Let |P | denotethe area of P , and let ρGMM = |P |/20. For the kth body part inP , if the number of pixels is less than ρGMM, it will be elimi-nated from P since it is redundant for body part segmentation.Next, the details of the model-driven scheme are described.
Algorithm for Model-Driven Body Part SegmentationInput: A posture P .Output: A set ΓP of body parts extracted from P .Step 1: Use the centroid context feature of P to find the best
matching model M .Step 2: For each pixel v with the value k in M , if k > 0,
collect v to the kth GMM; otherwise, collect it to the lth GMMif its index number in P is l.
Step 3: For each GMM in P , if its number of pixels < ρGMM,eliminate it from P . Collect all the remaining GMMs into theset L.
Step 4: For each pixel v in PStep 4.1: Find its optimal GMM Qj from L such that
Qj = arg maxQi∈L
pQi(v)
where pQi(v) is defined in (1).
Step 4.2: Assign v to the jth body part Γj .Step 5: Collect all the body parts Γi to form the set ΓP as the
result of body part segmentation.
This paper presents a model-based method for segmentingindividual people into different body parts. When occludedpersons are considered, we can use the technique of particlefilters [44] to track each person. During this tracking process, abank of posture templates can be created to model changes intheir posture types. Then, similar to the model-driven schemeof body part segmentation, a reprojection technique can beadopted to separate the occluded persons’ bodies into individualones. In Fig. 14, (a) is the input occluded region, and (b) and(c) show the results of the separation of (a). Once the occluded

604 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS—PART A: SYSTEMS AND HUMANS, VOL. 40, NO. 3, MAY 2010
Fig.14. Separation of two occluded bodies. (a) The original image. [(b) and(c)] The separation results of the bodies in (a).
Fig. 15. Snapshot of our body part segmentation system.
Fig. 16. Seventeen posture models used for the model-driven approach whenthe front view was handled.
region is separated into individual bodies, the scheme of bodypart segmentation can be applied for segmenting each personinto different body parts.
VI. EXPERIMENTAL RESULTS
In order to analyze the performance of our proposed bodypart segmentation method, a test database, including differ-ent videos captured under different view angles, weathers,and lighting conditions, was collected. For this performanceanalysis, 12 people were collected in this database. Fig. 15shows a snapshot of our proposed system, which can clusterhuman postures to form the model space and then segment eachinput posture into different body parts. The number of posturescollected for the body part segmentation was 3531, where 2803and 728 postures were collected for the model-driven approachand the skeleton-based approach, respectively.
The first set of experiments tested the ability of our clusteringscheme to extract important key postures from videos collectedfor body part segmentation. When the front view was consid-ered, there were 17 types of body models used for handlingoccluded postures; Fig. 16 shows the 17 body models. For theperformance evaluation, there were 34 movement sequences(two sequences per type) collected. For each sequence, a set
Fig. 17. Clustering results using the distance dbetween(zi, zj).
of key postures was manually selected as the ground truth.Let ZM
key and ZSkey denote the sets of key postures selected by
a manual method and our approach, respectively. In addition,|ZM
key| and |ZSkey| are the numbers of elements in ZM
key and ZSkey,
respectively. Then, the accuracy of the key posture selectionprocess can be defined as follows:
12
NCSM∣∣∣ZSkey
∣∣∣ +12
NCMS∣∣∣ZMkey
∣∣∣where NC
SM is the number of key postures in ZSkey that correctly
match one of the elements in ZMkey and NC
MS is the number ofelements in ZM
key that correctly match one of the elements inZS
key. We considered two postures to be “correctly matched”if their distance dcc was smaller than 0.1 Td, where Td is theaverage value of the distances for all pairs of postures. Threedistance measures were used in this paper for merging two clus-ters when they were close enough, i.e., davg, dmax, and dbetween
as defined in (7), (8), and (11), respectively. Fig. 17 shows theclustering result using dbetween(zi, zj). All of the desired keypostures were correctly extracted using our clustering scheme.Due to space limits of this paper, other clustering results usingdmax(zi, zj) and dbetween(zi, zj) are not shown. Table I showsthe accuracy comparisons for these three measurements. Theaverage accuracies using dbetween, davg, and dmax are 95.34,93.65, and 93.48, respectively. Clearly, the accuracy of cluster-ing using dbetween is highest. Thus, it is adopted in this paperfor key posture extraction.
In the second set of experiments, we evaluated the perfor-mance of our segmentation scheme to segment a posture intodifferent body parts. To examine the robustness of our method,five views were analyzed in this paper. Fig. 18 shows the fiveviews adopted for the performance evaluation: viewing angleswith −90◦,−45◦, 0◦, 45◦, and 90◦, respectively. In order to au-tomatically evaluate the accuracy of the body part segmentationfor each posture type, we created its corresponding segmenta-tion result to represent the ground truth. Then, given a posture,we searched for its segmentation model using its centroidcontexts. Then, after normalizing its size unity, the overlappingrate between its segmentation result and the reference modelcould be measured. Thus, if the rate is higher than 0.85, thesegmentation result is considered as correct. Actually, if thehead is not considered, there are five body parts modeled in ourscheme. When a body part is extracted incorrectly, the error ratewill be larger than 20%. Thus, if a human body is wrongly seg-mented, its corresponding accuracy will decrease significantly(to less than 75%). This can explain why the threshold “0.85”is chosen. Thus, many manual judgments can be much reducedso that a fairer accuracy analysis can be achieved. It is notablethat these models were created for the accuracy measurements

HSIEH et al.: SEGMENTATION OF HUMAN BODY PARTS USING DEFORMABLE TRIANGULATION 605
TABLE ICLUSTERING ACCURACY (%) FOR DIFFERENT DISTANCES
Fig. 18. Five views used for the performance evaluation are shown here.(a) Side view with −90◦. (b) Side view with −45◦. (c) Front view. (d) Sideview with 45◦. (e) Side view with 90◦.
Fig. 19. Segmentation results when the front view was handled. [(a) and (c)]Original images. (b) Segmentation result using the skeleton-based approachfrom (a). (d) Segmentation result using the model-based approach from (c).
Fig. 20. Segmentation results when the people lifted their left or right hands.[(a) and (b)] Results when left hands were lifted. [(c) and (d)] Results whenright hands were lifted.
and not used in the segmentation process. Fig. 19 shows twosegmentation results judged as “correct” using the overlappingcriterion, where (a) and (c) are the original images, (b) is thesegmentation result of (a) using the skeleton-based method, and(d) shows the result of (c) when the model-driven approach wasused. Although the posture in (c) included some occlusions, ourmethod was still able to segment it into different body parts.
Fig. 20 shows the cases when the persons lifted their lefthands or their right hands. Fig. 21 shows the case where bothhands were lifted. Even though the body postures had differentocclusions, our method still worked very well at segmentingthem into different body parts. Table II lists the accuracyresults of the body part segmentation when the front view wasobserved. The average accuracy of body part segmentation ofthe front view was about 95.4%.
Lighting is another important factor that can degrade theaccuracy of the body part segmentation method. To examinethe lighting effects, 300 posture samples were captured undervarious lighting environments. Fig. 22 shows the segmentation
Fig. 21. Segmentation results when the people lifted both of their hands.
TABLE IIACCURACY ANALYSES OF BODY PART SEGMENTATION
FOR THE DIFFERENT HAND LIFTING TYPES
Fig. 22. Results of body part segmentation under various lighting conditions.
TABLE IIIACCURACY ANALYSES OF BODY PART SEGMENTATION
UNDER DIFFERENT LIGHTING CONDITIONS
Fig. 23. Segmentation results when complicated backgrounds were tested areshown here.
results when different lighting conditions were handled. Eventhough the postures were poorly lighted, our method was stillable to segment them into different body parts. Table III lists theaccuracy analyses of the body part segmentation for differentlighting conditions. Naturally, the dark environments producedworse results than the lighted environments. In addition to thelighting conditions, we also examined our scheme for variousbackgrounds. In this set of experiments, 1429 and 2077 pos-tures were collected for simple and complicated backgrounds,respectively. Fig. 23 shows two results of the body part seg-mentation tests when complicated backgrounds were handled.

606 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS—PART A: SYSTEMS AND HUMANS, VOL. 40, NO. 3, MAY 2010
TABLE IVACCURACY RESULTS FOR THE BODY PART SEGMENTATION
WHEN VARIOUS BACKGROUNDS WERE TESTED
Fig. 24. Segmentation results when textured clothes were considered.
TABLE VACCURACY RESULTS OF THE BODY PART SEGMENTATION FOR
DIFFERENT COLORED OR TEXTURED CLOTHES
Fig. 25. Segmentation results for different clothes and trouser types. (a) Shortshirt and shorts. (b) Short shirt and slacks. (c) Jacket and slacks. (d) Short shirtand skirt.
Table IV lists the accuracy results for the different backgrounds.Clearly, our method was able to handle various postures eventhough they were captured with complicated backgrounds.
In addition to posture types and lighting conditions, vari-ous colors and types of clothes will also affect the accuracyof the body part segmentation technique. Thus, an experi-ment was performed to examine the effect of the colors andtypes of clothes on the body part segmentation. There were1574 postures recorded for different colors of clothes and1932 postures captured for textured clothes. Fig. 24 shows thesegmentation results when postures with textured clothes werehandled. Table V lists the accuracy analyses of the body partsegmentation for people wearing colorful or textured clothes.The results show that our method was able to analyze the bodieseven for these variables. Furthermore, we also examined theeffects of different types of clothes and trousers on the bodypart segmentation. Four combinations of clothes and trousertypes were collected: 1) short shirt and shorts; 2) short shirt andslacks; 3) jacket and slacks; and 4) a short shirt and skirt. Fig. 25shows the segmentation results for these four types of clothescombinations. The numbers of body postures collected forthese four types were 453, 1273, 1511, and 349, respectively.Table VI lists the accuracy analyses for these four types, wherethe average accuracy was 96.37%. Even though postures withdifferent clothes and trouser types were handled, our proposedmethod was still able to segment the postures into differentbody parts.
TABLE VIACCURACY RESULTS OF THE BODY PART SEGMENTATION
FOR DIFFERENT CLOTHES TYPES
Five angled views were also tested with our proposed tech-nique. Table VII gives the accuracy results for the front view us-ing the model-driven approach for the 17 posture types (shownin Fig. 16). The average accuracy of body part segmentationwas 95.87%. In addition to the front view, we also examinedour proposed method for four other viewing angles, i.e., −90◦,−45◦, 45◦, and 90◦ (see Fig. 18). The model patterns usedfor the view angles −45◦ and 45◦ were the same as the frontview since the differences in the postures for these views weresmall. The numbers of model patterns used for the body partsegmentation for the viewing angles of −90◦ and 90◦ were28 and 27, respectively. Fig. 26 shows some of the modelpatterns for the viewing angle of −90◦. Fig. 27 shows the seg-mentation results when different viewing angles were handled.Fig. 28 shows another set of segmentation results when theviewing angles −90◦ and 90◦ were handled. Fig. 29 shows thesegmentation results when the viewing angles −45◦ and 45◦
were handled. The numbers of postures used for testing theviewing angles −90◦,−45◦, 45◦, and 90◦ were 442, 400, 759,and 433, respectively. Table VIII lists the average accuraciesof the body part segmentation for these four viewing angles.The results show that our method was able to segment posturesinto different body parts even though they were captured fromdifferent angles.
In some cases, the contours of two postures will be similar.The following set of experiments was used to test the abilityof our method to solve this problem. In Section V-C, a treestructure was proposed to classify similar postures to differentclasses using a distance map. Fig. 30 shows comparisons of theposture-matching technique when the distance map was used ornot. In (c), when the distance map was not used, an incorrectresult was produced. However, in (e), a correct posture typewas found when the distance map was used. Table IX liststhe accuracy results of the posture-matching technique whenthe distance map was used or not. The accuracies reported inTable IX can be further improved if a posture transition matrixis used. Fig. 31 shows two segmentation results for tests whenthe postures’ contours were similar. Fig. 32 shows the resultsfor a walking sequence. When an action sequence was handled,there were many postures with similar contours. According toeach posture’s centroid context, the skeleton-based method andthe model-driven approach were alternately chosen for the bodypart segmentation. For example, the skeleton-based methodwas chosen for handling Fig. 32(a)–(c), and the model-drivenapproach was chosen for the other figures. For the model-driven approach, the best reference model was well selectedusing the “consistence” rule (see Section V-C). Fig. 33 shows aseries of segmentation results of another action type observedfrom another viewing angle. Even though various postureswith similar contours were handled, they were still accuratelysegmented into different body parts.

HSIEH et al.: SEGMENTATION OF HUMAN BODY PARTS USING DEFORMABLE TRIANGULATION 607
TABLE VIIACCURACY RESULTS FOR THE BODY PART SEGMENTATION USING THE MODEL-DRIVEN APPROACH WHEN THE FRONT VIEW WAS HANDLED
Fig. 26. Some model-driven patterns used for the body part segmentationwhen the viewing angle was −90◦.
Fig. 27. Segmentation results when different views were handled. (a) Viewingangle of −90◦. (b) Viewing angle of −45◦. (c) Viewing angle of 45◦.(d) Viewing angle of 90◦.
Fig. 28. Results of body part segmentation for the viewing angles −90◦ and90◦. (a) Viewing angle of −90◦. (b) Viewing angle of 90◦.
Fig. 29. Results of body part segmentation for the viewing angles −45◦ and45◦. (a) Viewing angle −45◦. (b) Viewing angle of 45◦.
TABLE VIIIACCURACY RESULTS FOR THE VIEWING ANGLES
−90◦,−45◦, 45◦, AND 90◦
Fig. 30. Results of posture matching when the distance map was used or not.(a) Input posture. (c) Matching result without the distance map. (e) Matchingresult with the distance map. [(b), (d), and (f)] Binary maps of (a), (c), and (e),respectively.
TABLE IXACCURACY RESULTS OF POSTURE MATCHING WHEN
THE DISTANCE MAP WAS USED OR NOT
Fig. 31. Segmentation results when postures are with similar contours.
Fig. 32. Segmentation results obtained from a walking action sequence.
Fig. 33. Segment results when a pick-up action sequence was tested.

608 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS—PART A: SYSTEMS AND HUMANS, VOL. 40, NO. 3, MAY 2010
Fig. 34. Segmentation results where some holes appeared.
Fig. 35. Segmentation result when a false foreground region was found.(a) Original image. (b) Result of the body part segmentation.
Fig. 36. Segmentation results when a person performed different actions.(a) Dancing. (b) Gesture. (c) Jog. (d) Dancing.
Fig. 37. Segmentation results when dancing persons were handled.
Furthermore, we also tested our proposed method underdifferent noisy conditions. Fig. 34 shows the segmentationresults for a test when some holes appeared in the analyzedpostures. Fig. 35 shows the case when a false foreground regionwas detected. In both figures, due to different noisy backgroundobjects like leaves, some holes or false foreground regionswere detected. However, our proposed method was still ableto segment the postures into the different body parts. Overall,there were 728 and 2803 posture samples collected for theskeleton-based and the model-driven methods, and the averageaccuracies were 99.31% and 96.47%, respectively.
In addition, we also tested our method on a public dataset, i.e., the HumanEva database [34]. This database includes
Fig. 38. Segmentation results when people walked or jogged.
Fig. 39. Segmentation results when hand gestures were handled.
Fig. 40. Result when a person put his left hand on the waist. (a) Originalimage. (b) Result of triangulation. (c) Result of body part segmentation.
TABLE XACCURACY ANALYSES OF BODY PART SEGMENTATION FOR
THE FOUR ACTORS IN THE HUMANEVA DATABASE
four actors performing six actions, including jog, walking,gestures, throwing and catching, boxing, and a combination ofactions. Fig. 36 shows the results of the body part segmentationfor a person performing different actions. Fig. 37 shows theresults when dancing postures were handled. Fig. 38 showsthe segmentation results when walking or jogging actions werehandled. Fig. 39 shows the results for people performing dif-ferent gestures. In some cases, there were loops in the skeletongraph, e.g., a human put his hands on his waist. According tothe definition of dfs, our method was able to find a desireddfs spanning tree. Fig. 40 shows the result of the body partsegmentation when a person put his left hand on his waist. Tomeasure the performance of our method using the HumanEva
HSIEH et al.: SEGMENTATION OF HUMAN BODY PARTS USING DEFORMABLE TRIANGULATION 609
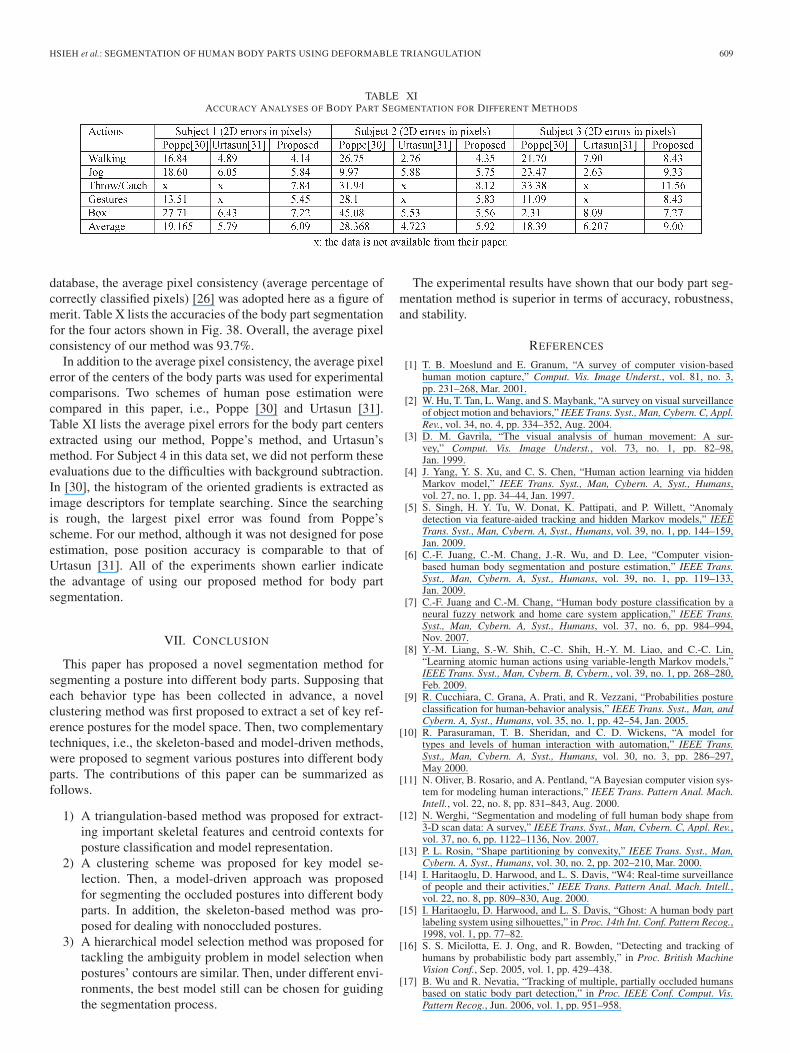
TABLE XIACCURACY ANALYSES OF BODY PART SEGMENTATION FOR DIFFERENT METHODS
database, the average pixel consistency (average percentage ofcorrectly classified pixels) [26] was adopted here as a figure ofmerit. Table X lists the accuracies of the body part segmentationfor the four actors shown in Fig. 38. Overall, the average pixelconsistency of our method was 93.7%.
In addition to the average pixel consistency, the average pixelerror of the centers of the body parts was used for experimentalcomparisons. Two schemes of human pose estimation werecompared in this paper, i.e., Poppe [30] and Urtasun [31].Table XI lists the average pixel errors for the body part centersextracted using our method, Poppe’s method, and Urtasun’smethod. For Subject 4 in this data set, we did not perform theseevaluations due to the difficulties with background subtraction.In [30], the histogram of the oriented gradients is extracted asimage descriptors for template searching. Since the searchingis rough, the largest pixel error was found from Poppe’sscheme. For our method, although it was not designed for poseestimation, pose position accuracy is comparable to that ofUrtasun [31]. All of the experiments shown earlier indicatethe advantage of using our proposed method for body partsegmentation.
VII. CONCLUSION
This paper has proposed a novel segmentation method forsegmenting a posture into different body parts. Supposing thateach behavior type has been collected in advance, a novelclustering method was first proposed to extract a set of key ref-erence postures for the model space. Then, two complementarytechniques, i.e., the skeleton-based and model-driven methods,were proposed to segment various postures into different bodyparts. The contributions of this paper can be summarized asfollows.
1) A triangulation-based method was proposed for extract-ing important skeletal features and centroid contexts forposture classification and model representation.
2) A clustering scheme was proposed for key model se-lection. Then, a model-driven approach was proposedfor segmenting the occluded postures into different bodyparts. In addition, the skeleton-based method was pro-posed for dealing with nonoccluded postures.
3) A hierarchical model selection method was proposed fortackling the ambiguity problem in model selection whenpostures’ contours are similar. Then, under different envi-ronments, the best model still can be chosen for guidingthe segmentation process.
The experimental results have shown that our body part seg-mentation method is superior in terms of accuracy, robustness,and stability.
REFERENCES
[1] T. B. Moeslund and E. Granum, “A survey of computer vision-basedhuman motion capture,” Comput. Vis. Image Underst., vol. 81, no. 3,pp. 231–268, Mar. 2001.
[2] W. Hu, T. Tan, L. Wang, and S. Maybank, “A survey on visual surveillanceof object motion and behaviors,” IEEE Trans. Syst., Man, Cybern. C, Appl.Rev., vol. 34, no. 4, pp. 334–352, Aug. 2004.
[3] D. M. Gavrila, “The visual analysis of human movement: A sur-vey,” Comput. Vis. Image Underst., vol. 73, no. 1, pp. 82–98,Jan. 1999.
[4] J. Yang, Y. S. Xu, and C. S. Chen, “Human action learning via hiddenMarkov model,” IEEE Trans. Syst., Man, Cybern. A, Syst., Humans,vol. 27, no. 1, pp. 34–44, Jan. 1997.
[5] S. Singh, H. Y. Tu, W. Donat, K. Pattipati, and P. Willett, “Anomalydetection via feature-aided tracking and hidden Markov models,” IEEETrans. Syst., Man, Cybern. A, Syst., Humans, vol. 39, no. 1, pp. 144–159,Jan. 2009.
[6] C.-F. Juang, C.-M. Chang, J.-R. Wu, and D. Lee, “Computer vision-based human body segmentation and posture estimation,” IEEE Trans.Syst., Man, Cybern. A, Syst., Humans, vol. 39, no. 1, pp. 119–133,Jan. 2009.
[7] C.-F. Juang and C.-M. Chang, “Human body posture classification by aneural fuzzy network and home care system application,” IEEE Trans.Syst., Man, Cybern. A, Syst., Humans, vol. 37, no. 6, pp. 984–994,Nov. 2007.
[8] Y.-M. Liang, S.-W. Shih, C.-C. Shih, H.-Y. M. Liao, and C.-C. Lin,“Learning atomic human actions using variable-length Markov models,”IEEE Trans. Syst., Man, Cybern. B, Cybern., vol. 39, no. 1, pp. 268–280,Feb. 2009.
[9] R. Cucchiara, C. Grana, A. Prati, and R. Vezzani, “Probabilities postureclassification for human-behavior analysis,” IEEE Trans. Syst., Man, andCybern. A, Syst., Humans, vol. 35, no. 1, pp. 42–54, Jan. 2005.
[10] R. Parasuraman, T. B. Sheridan, and C. D. Wickens, “A model fortypes and levels of human interaction with automation,” IEEE Trans.Syst., Man, Cybern. A, Syst., Humans, vol. 30, no. 3, pp. 286–297,May 2000.
[11] N. Oliver, B. Rosario, and A. Pentland, “A Bayesian computer vision sys-tem for modeling human interactions,” IEEE Trans. Pattern Anal. Mach.Intell., vol. 22, no. 8, pp. 831–843, Aug. 2000.
[12] N. Werghi, “Segmentation and modeling of full human body shape from3-D scan data: A survey,” IEEE Trans. Syst., Man, Cybern. C, Appl. Rev.,vol. 37, no. 6, pp. 1122–1136, Nov. 2007.
[13] P. L. Rosin, “Shape partitioning by convexity,” IEEE Trans. Syst., Man,Cybern. A, Syst., Humans, vol. 30, no. 2, pp. 202–210, Mar. 2000.
[14] I. Haritaoglu, D. Harwood, and L. S. Davis, “W4: Real-time surveillanceof people and their activities,” IEEE Trans. Pattern Anal. Mach. Intell.,vol. 22, no. 8, pp. 809–830, Aug. 2000.
[15] I. Haritaoglu, D. Harwood, and L. S. Davis, “Ghost: A human body partlabeling system using silhouettes,” in Proc. 14th Int. Conf. Pattern Recog.,1998, vol. 1, pp. 77–82.
[16] S. S. Micilotta, E. J. Ong, and R. Bowden, “Detecting and tracking ofhumans by probabilistic body part assembly,” in Proc. British MachineVision Conf., Sep. 2005, vol. 1, pp. 429–438.
[17] B. Wu and R. Nevatia, “Tracking of multiple, partially occluded humansbased on static body part detection,” in Proc. IEEE Conf. Comput. Vis.Pattern Recog., Jun. 2006, vol. 1, pp. 951–958.

610 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS—PART A: SYSTEMS AND HUMANS, VOL. 40, NO. 3, MAY 2010
[18] C. R. Wren, A. J. Azarbayejani, T. J. Darrell, and A. P. Pentland, “Pfinder:Real-time tracking of the human body,” IEEE Trans. Pattern Anal. Mach.Intell., vol. 19, no. 7, pp. 780–785, Jul. 1997.
[19] I. Mikic, M. Trivedi, E. Hunter, and P. Cosman, “Human body modelacquisition and tracking using voxel data,” Int. J. Comput. Vis., vol. 53,no. 3, pp. 199–223, Jul./Aug. 2003.
[20] S. Park and J. K. Aggarwal, “Segmentation and tracking of interacting hu-man body parts under occlusion and shadowing,” in Proc. IEEE WorkshopMotion Video Comput., Orlando, FL, 2002, pp. 105–111.
[21] S. Park and J. K. Aggarwal, “Semantic-level understanding of humanactions and interactions using event hierarchy,” in Proc. Conf. Comput.Vis. Pattern Recog. Workshop, Washington, DC, Jun. 27–Jul. 2, 2004,p. 12.
[22] S. Weik and C. E. Liedtke, “Hierarchical 3D pose estimation for articu-lated human body models from a sequence of volume data,” in Proc. Int.Workshop Robot Vis., Auckland, New Zealand, Feb. 2001, pp. 27–34.
[23] Y. Song, L. Goncalves, and P. Perona, “Unsupervised learning of humanmotion,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 25, no. 7, pp. 814–827, Jul. 2003.
[24] G. Mori, X. Ren, A. A. Efros, and J. Malik, “Recovering human bodyconfiguration: Combining segmentation and recognition,” in Proc. IEEEConf. Comput. Vis. Pattern Recog., 2004, vol. 2, pp. 326–333.
[25] S. Belongie, J. Malik, and J. Puzicha, “Shape matching and object recog-nition using shape contexts,” IEEE Trans. Pattern Anal. Mach. Intell.,vol. 24, no. 4, pp. 509–522, Apr. 2002.
[26] T. Cour and J. Shi, “Recognizing objects by piecing together the seg-mentation puzzle,” in Proc. IEEE Conf. Comput. Vis. Pattern Recog., Jun.2007, pp. 1–8.
[27] D. Ramanan, “Learning to parse images of articulated bodies,” presentedat the Adv. Neural Inf. Process. Syst. Conf., 2006. [Online]. Available:http://books.nips.cc/papers/files/nips19/NIPS2006_0899.pdf
[28] D. Ramanan and C. Sminchisescu, “Training deformable models for lo-calization,” in Proc. IEEE Conf. Comput. Vis. Pattern Recog., Jun. 2006,vol. 1, pp. 206–213.
[29] G. Hua, M.-H. Yang, and Y. Wu, “Learning to estimate human pose withdata driven brief propagation,” in Proc. IEEE Conf. Comput. Vis. PatternRecog., Jun. 2005, vol. 2, pp. 747–754.
[30] R. Poppe, “Evaluating example-based pose estimation: Experiments onthe HumanEva sets,” presented at the CVPR 2nd Workshop Eval. Articu-lated Human Motion Pose Estimation (EHuM2), 2007.
[31] R. Urtasun and T. Darrell, “Sparse probabilistic regression for activity-independent human pose inference,” in Proc. IEEE Comput. Soc. Conf.Comput. Vis. Pattern Recog., 2008, pp. 1–8.
[32] P. F. Flzenszwalb and D. Huttenlocher, “Pictorial structures for objectrecognition,” Int. J. Comput. Vis., vol. 61, no. 6, pp. 55–79, Jan. 2005.
[33] X. Lan and D. Huttenlocher, “Beyond trees: Common-factor modelsfor 2D human pose recovery,” in Proc. IEEE Int. Conf. Comput. Vis.,Oct. 2005, vol. 1, pp. 470–477.
[34] L. Sigal and M. J. Black, “HumanEva: Synchronized video and motioncapture dataset for evaluation of articulated human motion,” Brown Univ.,Providence, RI, Tech. Rep. CS-06-08, 2006.
[35] E. Horowitz, S. Sahni, and S. A. Freed, Fundamentals of Data Structurein C. New York: Freeman.
[36] C. Stauffer and E. Grimson, “Learning patterns of activity using real-timetracking,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 22, no. 8, pp. 747–757, Aug. 2000.
[37] L. P. Chew, “Constrained Delaunay triangulations,” Algorithmica, vol. 4,no. 1, pp. 97–108, 1989.
[38] Y. Freund and R. E. Schapire, “A decision-theoretic generalization of on-line learning and an application to boosting,” in Proc. 2nd Eur. Conf.Comput. Learn. Theory, 1995, pp. 23–37.
[39] R. O. Duda, P. E. Hart, and D. G. Stork, Pattern Classification, 2nd ed.New York: Wiley-Interscience, 2000.
[40] M. Bern and D. Eppstein, “Mesh generation and optimal triangulation,” inComputing in Euclidean Geometry, 2nd ed. Singapore: World Scientific,1995, pp. 47–123.
[41] L. R. Rabiner and B. H. Juang, “A tutorial on hidden Markov models andselected applications in speech recognition,” Proc. IEEE, vol. 77, no. 2,pp. 257–286, Feb. 1989.
[42] M. Sonka, V. Hlavac, and R. Boyle, Image Processing, Analysis andMachine Vision. London, U.K.: Chapman & Hall, 1993.
[43] A. Sundaresan and R. Chellappa, “Model driven segmentation and reg-istration of articulating humans in Laplacian eigenspace,” IEEE Trans.Pattern Anal. Mach. Intell., vol. 10, no. 3, pp. 1771–1785, Oct. 2008.
[44] M. Isard and A. Blake, “CONDENSATION: Conditional density propa-gation for visual tracking,” Int. J. Comput. Vis., vol. 29, no. 1, pp. 5–28,1998.
Jun-Wei Hsieh (M’06) received the B.S. de-gree in computer science from Tonghai University,Taichung, Taiwan, in 1990 and the Ph.D. degreein computer engineering from the National CentralUniversity, Chung-Li, Taiwan, in 1995.
From 1996 to 2000, he was a Researcher Fellowwith the Industrial Technology Researcher Institute,Hsinchu, Taiwan, and managed a team to developvideo-related technologies. In 2000, he joined theDepartment of Electrical Engineering, Yuan Ze Uni-versity, Chung-Li, where he became an Associate
Professor in 2004. He is currently a Professor with the Department of ComputerScience and Engineering, National Taiwan Ocean University, Keelung, Taiwan.His research interests include content-based multimedia databases, video sur-veillance, computer vision, and pattern recognition.
Dr. Hsieh received Best Paper Awards from the Image Processing and PatternRecognition Society of Taiwan, in 2005, 2006, and 2007. He also received aPhai-Tao-Phai award when he graduated.
Chi-Hung Chuang was born in Tainan, Taiwan,in 1975. He received the B.S. degree in com-puter science and information engineering fromChung-Hua University, Hsinchu, Taiwan, in 1999,the M.S. degree in electrical engineering fromYuan Ze University, Chung-Li, Taiwan, in 2003, andthe Ph.D. degree in computer engineering from theNational Central University, Chung-Li, in 2009.
He is currently an Assistant Professor with theDepartment of Learning and Digital Technology,Fo Guang University, Yilan, Taiwan. His research
interests include pattern recognition, computer vision, and machine learning.
Sin-Yu Chen was born in Taipei, Taiwan, in 1982.He received the B.S. degree in electrical engineer-ing from Yuan Ze University, Chung-Li, Taiwan, in2005, where he is currently working toward the Ph.D.degree in electrical engineering.
His research interests include image processing,computer vision, and video surveillance.
Chih-Chiang Chen was born in Taipei, Taiwan,in 1982. He received the B.S. and M.S. degreesin electrical engineering from Yuan Ze University,Chung-Li, Taiwan, in 2004 and 2008, respectively.
His research interests include image processing,behavior analysis, and video surveillance.
Kuo-Chin Fan (S’88–M’88) was born in Hsinchu,Taiwan, on June 21, 1959. He received the B.S.degree in electrical engineering from the NationalTsing-Hua University, Hsinchu, Taiwan, in 1981 andthe M.S. and Ph.D. degrees from the University ofFlorida, Gainesville, in 1985 and 1989, respectively.
In 1983, he joined the Electronic Research andService Organization, Taiwan, as a Computer Engi-neer. From 1984 to 1989, he was a Research As-sistant with the Center for Information Research,University of Florida. In 1989, he joined the De-
partment of Computer Science and Information Engineering, National CentralUniversity, Chung-Li, Taiwan, where he became a Professor in 1994 and wasthe Chairman of the department from 1994 to 1997. Currently, he is the Directorof the Computer Center. He is also with the Department of Learning and DigitalTechnology, Fo Guang University, Yilan, Taiwan. His current research interestsinclude image analysis, optical character recognition, and document analysis.
Prof. Fan is a member of the Society of Photo-optical InstrumentationEngineers (SPIE).


![Pre-clinical evaluation of implicit deformable models for three-dimensional segmentation of brain aneurysms from CTA images [5032-139]](https://img.pdfslide.net/doc/110x75/6334f1efa1ced1126c0a8f4a/pre-clinical-evaluation-of-implicit-deformable-models-for-three-dimensional-segmentation.jpg)
























