Embed Size (px)
Citation preview

APLIKASI TANYA JAWAB SEPUTAR HADITS MENGGUNAKAN METODE
SEMANTIC ROLE BERBASIS WEB MOBILE
Proposal Tugas Akhir
Diajukan Untuk Memenuhi Persyaratan Guna Meraih Gelar Sarjana Strata I
Teknik Informatika Universita Muhammadiyah Malang
Nama
niM
JURUSAN TEKNIK INFORMATIKA

JUNI, 2012

1. LATAR BELAKANG
Semakin besarnya volume berita elektronik berbahasa
Indonesia mengakibatkan informasi tersedia dalam jumlah
yang besar, beraneka ragam, dan pada umumnya tidak
terstruktur. Hal ini mendorong terjadinya peningkatan
kebutuhan untuk mencari dan mengelola informasi dengan
baik sehingga dihasilkan pengetahuan yang bermanfaat.
Text mining merupakan upaya pencarian atau
penambangan data yang berupa teks dimana sumber data
biasanya diperoleh dari dokumen, dengan tujuan mencari
kata-kata yang dapat mewakili isi dokumen sehingga
dapat dilakukan analisis keterhubungan antar dokumen.
Text mining memberikan solusi pada masalah-masalah
dalam memproses, mengorganisasi, dan menganalisa
unstructured text dalam jumlah besar. Text mining
mengadopsi dan mengembangkan banyak teknik dan solusi
dari bidang lain, seperti Data Mining, Information
Retrieval, Statistik dan Matematik, Machine Learning,
Linguistic, Visualization, dan Natural Language
Processing.
Aplikasi ini dibangun menggunakan konsep text mining
dimana algoritma yang digunakan adalah algoritma
semantic role. Semantic role adalah salah satu metode
atau algoritma yang sering digunakan untuk sebuah
sistem temu kembali informasi yang biasa dikenal dengan
IRS (Information Retrieval System). Menurut Arifin (dalam

Salton, 1989), “salah satu model IRS yang paling
sederhana namun paling produktif adalah model ruang
vektor” (Arifin, 2002). Algoritma ini merupakan sebuah
model yang digunakan untuk mengukur kemiripan antar
beberapa dokumen (dalam hal ini adalah hadits) dengan
user query atau permintaan user.
Dalam teknik text mining ada sebuah tahapan proses
untuk mengolah kata-kata yang terdapat dalam dokumen
menjadi bentuk kata dasar atau akar dari kata itu
sendiri (tanpa ada awalan, akhiran, atau sisipan),
proses ini disebut proses stemming. Enhanced Confix Stripping
Stemmer merupakan salah satu algoritma yang dapat
mengatasi proses stemming yang spesifik untuk Bahasa
Indonesia.
Aplikasi ini dapat membantu dan mempermudah dalam
proses pencarian informasi mengenai kandungan hadits
secara lebih spesifik dan mendalam bagi siapa saja yang
membutuhkan oleh karena itu penulis membuat tugas akhir
ini dengan judul “APLIKASI TANYA JAWAB SEPUTAR HADITS
MENGGUNAKAN METODE SEMANTIC ROLE BERBASIS WEB MOBILE”.
2. RUMUSAN MASALAH
Berdasarkan latar belakang tersebut maka dapat
diuraikan rumusan masalah yaitu sebagai berikut :
1) Bagaimana merancangan aplikasi Tanya jawab
dengan metode Sematic Role dalam mempermudah
memberikan jawaban atas pertanyaan seputar

hadits?
2) Bagaimana perancangan system metode Sematic Role
dalam menentukan informasi jawaban atas
pertanyaan seputar hadits secara otomatis ?
3. TUJUAN
Dalam penelitian ini terdapat beberapa tujuan
diantaranya adalah sebagai berikut :
1) Merancang sebuah aplikasi tanya jawab untuk
memberikan kemudahan dalam pemberian informasi.
2) Merancang sebuah system menggunakan algoritma
Sematic Role dalam menangani tanya jawab secara
otomatis
3) Mengimplementasiakan penerapan metode Sematic Role
pada aplikasi tanya jawab berbasis web mobile
dan database .
4. BATASAN MASALAH
Terdapat beberapa batasan masalah yang diangkat
sebagai parameter pengerjaan tugas akhir ini
diantaranya adalah sebagai berikut :
1) Aplikasi yang dibangun berbasis web mobile dengan
menggunakan database mysql dan bahasa pemrograman
PHP .
2) Menggunakan metode Sematic Role
3) Pertanyaan yang di inputkan adalah test bahasa
Indonesia baku.

5. METODOLOGI
Langkah-langkah yang akan ditempuh dalam
pengerjaan Tugas Akhir ini ada beberapa metode yang
harus dipelajari meliputi:
1) Textmining
Text mining memiliki definisi menambang data
yang berupa text dimana sumber data biasanya
didapatkan dari dokumen, dan tujuannya adalah
mencari kata-kata yang dapat mewakili isi dari
dokumen sehingga dapat dilakukan analisa
keterhubungan antar dokumen (Raymond, 2006).
Dengan text mining tugas-tugas yang berhubungan
dengan penganalisaan teks dengan jumlah yang
besar, penemuan pola serta penggalian informasi
yang mungkin berguna dari suatu teks dapat
dilakukan.
Proses text mining dibagi menjadi 3 tahap
utama, yaitu proses awal terhadap teks (text
preprocessing), transformasi teks ke dalam bentuk
antara (text transformation/feature generation),
dan penemuan pola (pattern discovery) (Even dan
Zohar: 2002).
2) Pembobotan
Untuk meningkatkan precision, digunakanlah
representasi Inverse Document Frequency (IDF) untuk
term-term, yang didefinisikan sebagai logaritma
dari rasio jumlah keseluruhan dokumen yang

diproses dengan jumlah dokumen yang memiliki term
bersangkutan. Ini berarti bahwa term-term yang
tingkat kemunculannya jarang akan memiliki nilai
IDF yang tinggi. Experimen yang dilakukan oleh
Spärck Jones membuktikan bahwa penggunaan IDF
akan menghasilkan performa retrieval yang lebih
efektif jika dibandingkan dengan penggunaan
frekuensi term saja. Ini yang kemudian
menginspirasi Salton untuk mengkombinasikan kedua
metode pembobotan tersebut, dengan
mempertimbangkan frekuensi inter-dokumen dan
frekuensi intra-dokumen dari suatu term. Dengan
menggunakan frekuensi term pada suatu dokumen dan
distribusinya pada keseluruhan dokumen, yakni
kemunculan pada dokumen-dokumen lain (IDF).
Salton menarik suatu kesimpulan melalui
eksperimennya bahwa term-term dengan total
frekuensi menengah, lebih berguna dalam retrieval
jika dibandingkan dengan term-term yang total
frekuensinya terlalu tinggi atau terlalu rendah.
Konsep frekuensi intra-dokumen dan inter-dokumen
ini kemudian dikenal sebagai metode TF-IDF.
(Mahendra, 2008)
Rumus yang digunakan untuk menyatakan bobot
(w) masing-masing dokumen terhadap kata kunci
adalah:

Wd,t = tf d,t IDFt
Dimana:
d = dokumen ke-d
t = kata ke-t dari kata kunci
Wd,t = bobot dokumen ke-d terhadap kata
ke-t
3) Sematic Role
Perbandingan kemiripan (similarity) yang digunakan
disini adalah standard Sematic Role dengan rumus
:
SDiDj : Similarity Dokumen ke I dan ke j
Menurut Fred R. McFadden dan Jeffrey A.
Hoffer (1994,p8), database adalah sekumpulan data
logikal yang dirancang untuk memenuhi
kebutuhan informasi dari berbagai pengguna dan
sebuah organisasi. Data dalam database disimpan
dalam satu dari 3 tipe struktur data yaitu file,
tabel, dan objek.
Keunggulan dari database adalah:
Database dapat menyediakan manipulasi data
yang baik. Database dapat mengurangi
redundansi data.
Database menjaga independensi data. Database

meningkatkan keamanan data. Database menjaga
konsistensi data. Database meningkatkan
integritas data.
Dengan database data menjadi lebih mudah
untuk diakses dan digunakan.
Database dapat meningkatkan produktivitas.
Database meningkatkan pelayanan backup dan
recovery. Database memiliki suatu standar.
Database memudahkan dalam data sharing.
Pengguna dari sistem database akan mendapatkan
fasilitas untuk melakukan berbagai aksi pada file
termasuk :
Menambah file baru yang kosong ke database.
Menyisipkan data baru ke file yang sudah ada.
Memperoleh kembali data dari file yang sudah ada.
Mengupdate data di file yang sudah ada. Menghapus
data dari file yang sudah ada. emindah file yang ada
dari database.
Untuk menganalisa sistem informasi yang
dibutuhkan oleh suatu perusahaan atau organisasi,
maka diperlukan normalisasi yang bertujuan untuk
mengidentifikasi relasi antar entity ataupun atribut
pada database.
Entity merupakan objek nyata yang berhubungan
dengan sistem basis data yang akan dibuat. Atribut
merupakan keterangan dari entity. Relasi adalah

hubungan atau asosiasi antara entity.
4) MySQL
Menurut Abdul Kadir (2003,p353) MySQL adalah
salah satu jenis database server yang sangat populer.
Kepopuleran ini disebabkan karena MySQL
menggunakan SQL sebagai bahasa dasar dalam
mengakses databasenya. Selain itu MySQL bersifat
free pada berbagai platform. MySQL termasuk jenis
RDBMS (Relational Database Management System), oleh
karena itu istilah seperti tabel, baris dan kolom
digunakan dalam MySQL. Pada MySQL database
mengandung satu atau sejumlah tabel. Tabel terdiri
dari sejumlah baris dan setiap baris mengandung
satu atau beberapa kolom.
5) PHP
Menurut Abdul Kadir (2003,p1) yang diambil
dari dokumen resmi PHP, PHP merupakan singkatan
dari PHP Hypertext Preprocesor. PHP merupakan bahasa
yang berbentuk script yang ditempatkan dalam server
dan diproses di server. Hasilnyalah yang dikirimkan
kepada klien, tempat pemakai menggunakan browser.
Secara khusus PHP dirancang untuk membentuk
web dinamis. Artinya, ia dapat membentuk suatu
tampilan berdasarkan permintaan terkini. Misalnya,
kemampuan untuk bisa menampilkan isi database ke
halaman web. Pada prinsipnya PHP mempunyai fungsi
yang sama dengan script-script seperti ASP (Active Server

Page), Cold Fusion, ataupun Perl.
6) HTML 5
Beberapa kelebihan yang dijanjikan pada HTML
5: Dapat ditulis dalam sintaks HTML (dengan tipe
media text/html) dan XML, Integrasi yang lebih
baik dengan aplikasi web dan pemrosesannya,
Integrasi (’inline’) MathML dan SVG dengan doctype
yang lebih sederhana, Penulisan kode yang lebih
efisien, Dapat dimengerti oleh peramban lawas
(backwards compatible). Sehingga istilah
‘deprecated’ tidak akan diperlukan lagi.
Yang masih diperdebatkan dalam pengembangan
HTML 5: Makna semantik beberapa elemen
presentasioal, dan fitur aksesibilitasnya. Seperti
atribut alt dan summary
7) Teknologi apa yang akan di perkenalkan HTML 5
API (Aplication Programming Interface)
merupakan teknologi yang akan di usung oleh HTML5,
berikut ini adalah batasan-batasannya :
1. Offline Data Storage
Memungkinkan kita bisa mengakses data
lama di broser dalam keadaan offline. Contoh
offline data seperti kita membaca arsip e-
mail pada program Outlook atau Thunderbird.
2. Drag and Drop

Drag and Drop ini kita dapat dengan
memudahkan mendrag atau mendrop misalnya
text, hyperlink, bahkan file di aplikasi
dekstop sekalipun.
3. Geolocation
Aplikasi ini memungkinkan kita untuk
untuk mengetahui lokasi geografis, sumber
informasi di ambil dari GPS (Global Position
System).
Masih terdapat banyak API lainya dan
terus di kembangkan. Dalam implementasinya,
Anda akan memerlukan pemrogramanan Java
Script untuk menjembatani penggunaan API ini.
8) Elemen Baru Di HTML 5
Demi mewujudkan struktur halaman web yang
lebih baik semantik dan aksesibilitasnya,
dikenalkanlah beberapa elemen baru, diantaranya:
section serupa seperti h1-h6, article bisa berupa
entri blog atau tulisan konten, aside menyajikan
konten pelengkap. header bisa menyajikan judul,
deskripsi, bahkan nav untuk navigasi, footer
berisi catatan kaki seperti informasi hak cipta,
penulis, kontak, dan sebagainya, dialog yang
dikombinasikan dengan dt dan dd (seperti pada
halaman FAQ) dapat digunakan untuk menyajikan
percakapan, yang fenomenal adalah penggunaan

elemen figure, video, audio, source, embed,
canvas, dan elemen terkait berkas multimedia
lainnya.
9) Atribut Baru Di HTML 5
Dikenalkan pula beberapa atribut baru,
seperti: atribut media, ping pada elemen pranala,
autofocus, placeholder, required, autocomplete,
dan sebagainya, terkait elemen input dan form,
reversed pada elemen ol untuk urutan besar ke
kecil.
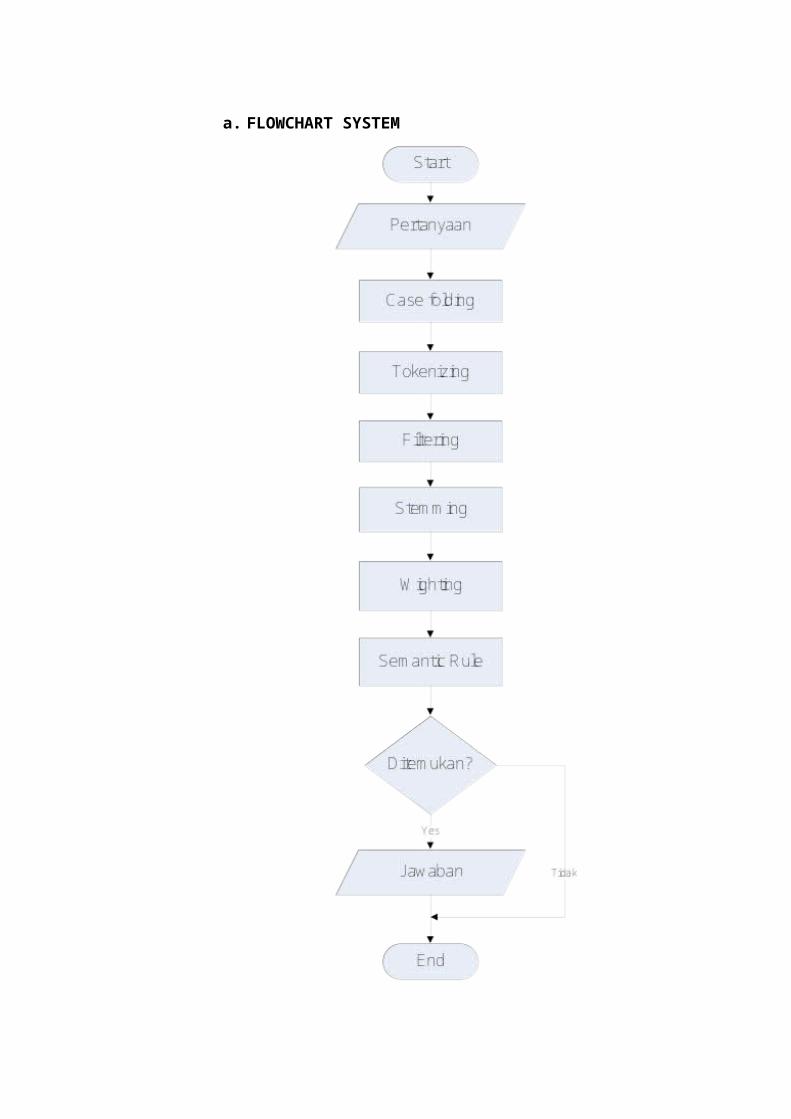
a. FLOWCHART SYSTEM
Gambar 2. Rancangan Flowchart System
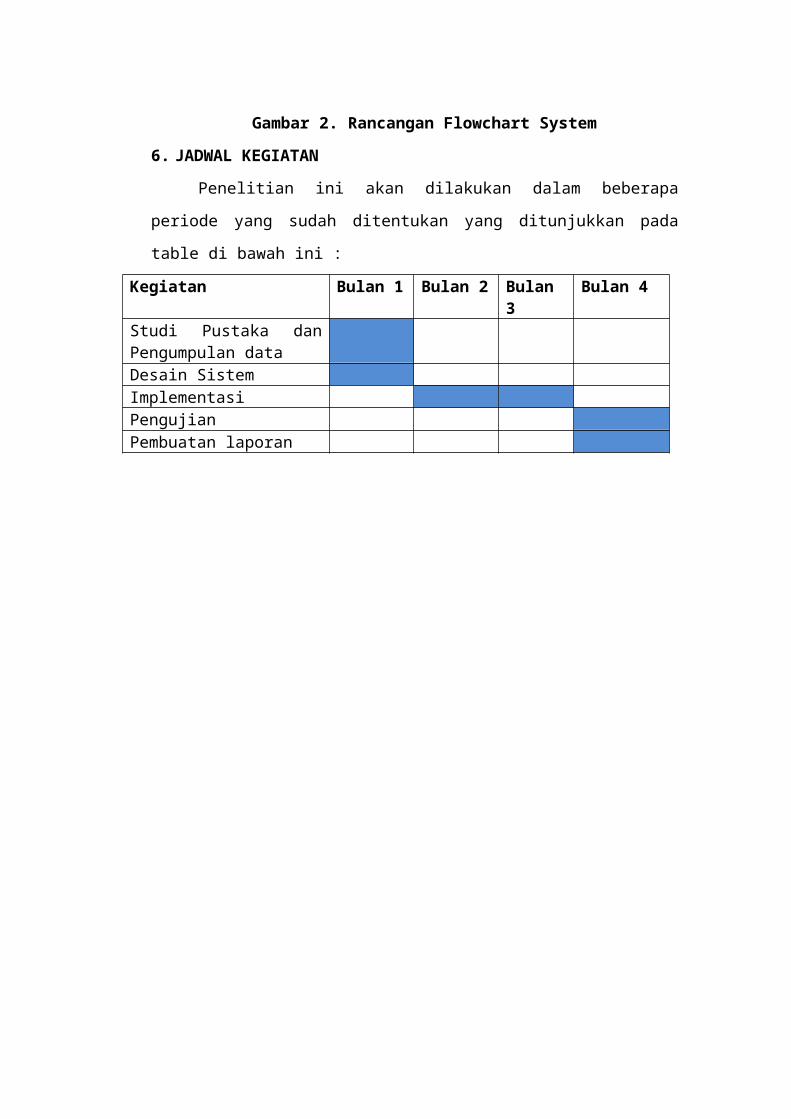
6. JADWAL KEGIATAN
Penelitian ini akan dilakukan dalam beberapa
periode yang sudah ditentukan yang ditunjukkan pada
table di bawah ini :
Kegiatan Bulan 1 Bulan 2 Bulan3
Bulan 4
Studi Pustaka danPengumpulan data Desain SistemImplementasiPengujian Pembuatan laporan

DAFTAR PUSTAKA
Mahendra, I Putu Adhi Kerta., 2008, Penggunaan AlgoritmaSemut Dan Confix Stripping Stemmer Untuk Klasifikasi DokumenBerbahasa Indonesia, Surabaya: Jurusan Teknik InformatikaITS Surabaya.





























