Embed Size (px)
Citation preview

Networked Environment for Music Analysis (NEMA): PHASE I
Official Project Proposal
Submitted to The Andrew W. Mellon Foundation
c/o Don Waters, PhD Program Officer, Scholarly Communications
Submitted by J. Stephen Downie, PhD
[email protected] Graduate School of Library and Information Science
University of Illinois at Urbana-Champaign
Project Start Date: 1 January 2008 Project End Date: 31 December 2010
10 October 2007

1
NETWORKED ENVIRONMENT FOR MUSIC ANALYSIS: PHASE I 10 October 2007
EXECUTIVE SUMMARY
Phase I of the Networked Environment for Music Analysis (NEMA) framework project is a multinational, multidisciplinary cyberinfrastructure project for music information processing that builds upon and extends the music information retrieval research being conducted by the International Music Information Retrieval Systems Evaluation Laboratory (IMIRSEL) at the University of Illinois at Urbana-Champaign (UIUC). NEMA brings together the collective projects and the associated tools of six world leaders in the domains of music information retrieval (MIR), computational musicology (CM) and e-humanities research. The NEMA team aims to create an open and extensible webservice-based resource framework that facilitates the integration of music data and analytic/evaluative tools that can be used by the global MIR and CM research and education communities on a basis independent of time or location. To help achieve this goal, the NEMA team will be working co-operatively with the UIUC-based, Mellon-funded, Software Environment for the Advancement of Scholarly Research (SEASR) project to exploit SEASR’s expertise and technologies in the domains of data mining and webservice-based resource framework development.
Project Leadership Principal Investigator: J. Stephen Downie (UIUC) Co-Principal Investigator: Ichiro Fujinaga (McGill University)
Key Research Partners David De Roure (University of Southampton, UK) Mark Sandler (Queen Mary, University of London, UK) Tim Crawford (Goldsmiths, University of London, UK) David Bainbridge (University of Waikato, NZ)
Projected Budget: $1.2 Million USD Time Frame: 1 Jan 2008 to 31 December 2010
1.0 GENERAL INTRODUCTION AND ORIGINAL MOTIVATION
The Networked Environment for Music Analysis (NEMA) project was inspired by the lessons learned over the course of the Mellon-funded Music Information Retrieval/Music Digital Library Evaluation Project (2003-2007) being led by Downie and his IMIRSEL team at UIUC [JSD1-2]1. Downie’s experience in running the annual Music Information Retrieval Evaluation eXchange (MIREX) [JSD3-4] on behalf of the MIR community has brought to the fore three important issues that have a direct impact on the present NEMA proposal. The automation, distribution and integration of MIR and CM research tool development, evaluation and use are but some of the important issues being addressed under the NEMA rubric.
1.1 Need to Automate and Distribute the Research and Evaluation Cycle. The amount of human effort required to run and then evaluate the MIR algorithms2 submitted to MIREX each year is becoming a limiting factor on the growth and sustainability of MIREX. Thus, new techniques are needed to automate and to distribute (both physically and temporally) the cyclic processes of system set up, evaluation, revision and follow-up evaluation, etc. As explained in [JSD4] the current set-up has shown the following weaknesses:
1 The IMIRSEL lab is located within UIUC’s Graduate School of Library and Information Science (GSLIS). 2 There have been a total of 316 algorithm runs for MIREX 2005, MIREX 2006, and MIREX 2007.

2
1. The time constraints imposed by constant debugging of code have made the rerunning of previous evaluation tasks difficult (which hinders meaningful comparisons across years).
2. The participating labs only see the “final” results sets which are made available shortly before the MIREX plenary which makes the de facto research cycle at least a year long.
3. Non-participants who have novel MIR techniques cannot determine whether or not their techniques are reaching state-of-the-art effectiveness.
4. The “feature sets” generated by many of the algorithms can be larger than the underlying music they represent and can take hundreds of CPU hours to compute but are currently discarded and not made available for others to use and explore.
1.2 Need to Integrate Tools, Techniques and Collections. Many of the algorithms evaluated under the MIREX framework have interrelated goals and represent the possibility of mutually supportive advancements of great potential impact for MIR/CM research. However, as it stands now, these promising technologies are not capable of integrating with one another nor are they easily placed within a larger, more general collaborative research and evaluation framework. There are many interesting and promising MIR and music analysis tools that are reaching a significant level of maturity. A short list includes Music-to-Knowledge (M2K)3, Music Analysis, Retrieval and Synthesis for Audio Signals (MARSYAS)4, CLAM (C++ Library for Audio and Music)5, and jMIR6, and the OMRAS2 MIR tools (shortly to be released as open source)7, etc. Each of these makes important contributions, in various ways, to specific sub-tasks in the MIR and music analysis domains. However, since each of these systems is the product of disparate research endeavors, it is not practicable for researchers to integrate them into more productive hybridized types of systems that exploit their individual accomplishments. One underlying technical reason for this lack of integration is the non-standardized way in which the systems access, ingest and represent music resources. For example, the idiosyncratic nature of the feature sets that systems create and then manipulate as part of their analytic processes make the sharing of feature sets among the various systems extraordinarily difficult. Since the generation of these feature sets is both time and space intensive, any progress that can be made in the reuse and sharing of these valuable resources can only benefit the MIR/CM communities. Also, and more importantly, the creation of more standardized mechanisms for feature set creation, representation, extension, discovery and provenance verification will allow the research community to establish access to new standardized research and evaluation collections beyond those currently housed at IMIRSEL. This would allow the creation of on-demand hybrid collections consisting of, say, works independently located in Montreal, London, and Champaign.
For reasons delineated in Section 3.5, the NEMA team has chosen to work co-operatively with the SEASR team which is being led by Michael Welge of UIUC’s National Center for Supercomputing Applications (NCSA) and GSLIS, John Unsworth of GSLIS, and Loretta Auvil of NCSA. The SEASR team’s ongoing development work in the data mining, webservice and workflow management domains, offers NEMA a set of tools and techniques that have the very real potential for making NEMA’s combined automation, distribution, and integration “vision” a reality. Figure 1 (next page) presents a preliminary illustration of the SEASR framework in the NEMA context.
2.0 BEYOND MIREX: THE FURTHER CASE FOR NEMA.
In this section we will use a simplified “train-test” research scenario (explained below) as an illustrative exemplar of the current state-of-the-art in MIR/CM research methods. By walking through the specific steps involved in a classic train-test experiment, this section will highlight the various impediments to
3 See http://www.music-ir.org/evaluation/m2k/. 4 See http://marsyas.sness.net/. 5 See http://clam.iua.upf.edu/. 6 See http://jmir.sourceforge.net/. 7 See http://www.omras2.org/.

3
research advancement brought to the fore by key aspects of the MIR/CM research process as it currently exists. In the summary section which follows (Section 2.2), we will extrapolate from the issues surrounding the specific steps to develop the broader, more general, problem set that NEMA will address. Finally, we will conclude with a potential use scenario (Section 2.3) that illustrates how the NEMA approach to research infrastructure building will help to overcome these impediments and thus greatly advance the state-of-the-art of MIR/CM research methods and findings.
Figure 1. A preliminary SEASR framework model within the NEMA context.
2.1 Train-Test Research Example. There are as many different kinds of music analyses that can be performed on music data as there are researchers to ask questions. However, it is possible to present a highly simplified abstract model of a very popular style of classification analysis called the “train-test” scenario. The train-test scenario forms the basis for such MIR tasks as Audio Genre Classification, Symbolic Genre Classification, Audio Mood Classification, Audio Classical Composer Identification, Audio Artist Identification8, etc. The basic steps in the train-test scenario are:
1.a decide what kind of tests/experiments to run; and, 1.b then create or locate “ground-truth” data to run evaluation tests9
2.a decide what music to analyse; and, 2.b then create a music collection
3.a decide what features to extract; and, 3.b then extract features
8 These task names come from the official evaluation task names used over the life of MIREX. 9 The actual ordering of Steps 1 and 2 is rather fluid. It is akin to the “chicken and the egg” problem. For example, if one has a ground-truth set in mind, then one needs to find/build the associated collection; or, if one has a collection in mind, then one needs to find/create the appropriate ground-truth.
4
4.a decide what classifier to use; and, 4.b then build a model
5.a decide what kinds of model validation experiments to run; and, 5.b then re-use current ground-truth or locate/create more ground-truth
2.1.1 Step 1. Ground-truth issues. Using the aforementioned MIR tasks as a starting point, a researcher might decide to test out some new ideas about, say, Audio Mood Classification or Audio Genre Classification. Under the “train-test” scenario, a researcher will need to establish or locate “ground-truth” data that will allow the researcher to know whether the system being examined is actually performing very well. Ground-truth data varies across research questions but does have the fundamental form of associating some music item (e.g., a song) with some trustworthy/validated answer or label (e.g., a genre, or composer name, or mood term, etc.). For example, in the Audio Mood Classification case, an abridged listing of the mood ground-truth might look like:
Track ID Track Name Mood Truth
00001.wav “Farmer in the Dell” Happy 00002.wav “Funeral March” Sad 00003.wav “Rock Around The Clock” Boisterous Etc. Etc. Etc. 09999.wav “White Christmas” – Twisted Sister Angry 10000.wav “White Christmas” – Charlie Parker Cool
In the Audio Genre Classification case, an abridged listing of the genre ground-truth might look like:
Track ID Track Name Genre Truth 00001.wav “Farmer in the Dell” Folk 00002.wav “Funeral March” Classical 00003.wav “Rock Around The Clock” Rock Etc. Etc. Etc. 09999.wav “White Christmas” – Twisted Sister Heavy Metal 10000.wav “White Christmas” – Charlie Parker Jazz
Researchers take whatever ground-truth they have chosen and use it in two important ways. First, during the “training” phase of their work, the labels are used to group together the items so that the classifier they have chosen (Step 4) can analyze the extracted features (Step 3) to determine what each group has in common in order to help it build its classification model. In the Genre Classification case, all the “Folk” songs would be grouped together, all the “Classical”, etc. and then the classifier would work to determine which features identify “Folk” and which “Classical”, etc. Second, the ground-truth data come into play again in the Step 5 “validation” experiments but this will be discussed later in Section 2.1.5.
The current state-of-the-art with regard to ground-truth data is far from ideal. Since experimental decisions are based upon the ground-truth data, it is very important that the ground-truth data are accurate and consistent. To accomplish this almost always requires the human creation of data. This can be extraordinarily time consuming. For example, imagine listening to 20,000 tracks of music so that one can apply appropriate genre or mood labels. Some experimenters have used automated approaches to acquiring ground-truth (e.g., taking genre labels from the genre tags embedded in MP3s, etc.). However, experience has shown (especially in the running of the MIREX experiments) that such ground-truth is very flawed and contains such errors as inconsistent label names and inappropriately applied labels (e.g., an obvious “rock” song labeled “classical”, etc.). These inconsistent and inappropriate labels wreak havoc on the classifiers leading to erroneous classification models. Also, at present, there are no standardized

5
repository mechanisms nor locating tools for sharing/re-using high-quality, trustworthy ground-truth data that might be used to mitigate against the need to constantly devote the time resources required to manually create/re-create trustworthy ground-truth sets. An added complexity with regard to ground-truth data is that ground-truth can be the product of specific cultural or subjective processes (e.g., both genre and mood labels can vary across different user groups, etc.) leading to the situation that a single music collection might have multiple sets of task-specific ground-truth labels associated with it.
2.1.2 Step 2. Collection building issues. At present deciding what music to analyze is greatly constrained by questions of music availability. Most research is at present being conducted on locally available collections of music usually comprising the idiosyncratic CD or MP3 collections of the individual researchers. These collections tend to be limited in both breadth (i.e., number of different styles, etc.) and depth (i.e., number of examples of each style, etc.). Cost is one important limiting factor: even assuming the purchase of tracks at iTunes’ $0.99 rate, it still takes close to $10,000 to build a modest collection of 10,000 tracks. Given the current state of music intellectual property law, is unlikely that a researcher can simply “borrow” a collection from another lab in an effort to avoid the collection acquisition costs. Local storage resources also limit collection size opportunities for all but the best funded labs. Moreover, once the collection has been put together, researchers still need to make sure that they can find or create the appropriate ground-truth data for their collection(s) and experiments. Similarly, locating and/or generating reliable and universally acceptable metadata for audio tracks has proven consistently difficult. Without reliable metadata, the overall usefulness of a music collection is severely limited.
2.1.3 Step 3. Feature extraction issues. An almost limitless number and combination of features can be extracted from music or about music items. In the audio domain, researchers select from a wide variety of low-level signal processing techniques which include such things a Fast Fourier Transforms (FFT), Mel Frequency Cepstral Co-efficients (MFCC), wavelets, Discrete Cosine Transforms (DTC), etc. At a higher level, these features might be used in combination to create Beats per Minute (BPM), harmonic centrality (i.e., Key), or noise ratio features, etc. The feature sets might also include such external non-content-based metadata as human created text (e.g., from reviewers or social-tagging systems, etc.). The creation and selection of the optimal set of features for a particular analysis or retrieval task is an entire research question unto itself and remains a vibrant research domain. The creation of feature sets can be computationally expensive and storage intensive. Some feature sets take weeks to create and some FFT processes can generate data that is twice the size of the original collection. Sometimes, researchers are not concerned with the optimal feature set and are more concerned with examining the behaviors of different classifiers instead. This situation argues for the re-use/sharing of pre-existing feature sets. However, at present, this is not generally feasible. First, there are no agreed standards for the description of the feature sets (i.e., no way for external researchers to know how the data were created nor what parameters were used in the calculation of the features, etc.). Second, there is no central repository nor search tool in existence to help locate feature sets. Third, there is also no agreed mechanism for linking the specific source item to its feature set(s) (i.e., identifying accurately which specific recording of a specific song was used to generate the feature set). This linking aspect is important as researchers need to know which specific song version is being represented in order to, in turn, link it with the appropriate ground-truth data. Fourth, and finally, there are currently no mechanisms in place to easily merge or amalgamate aspects of different feature sets that represent the same underlying data. Such an ability would greatly enhance the research opportunities of the MIR/CM community by allowing novel feature sets to be created from previously constructed data.
2.1.4 Step 4. Classifier and model building issues. Like feature extraction, there are a vast number of classifier decision options open to researchers. Researchers choose from such classifier algorithms as Support Vector Machines (SVM), Decision Trees (DT), Naïve Bayesian (NB), Neural Networks (NN), etc. Each of these has many different “flavors” and, in turn, each flavor has many different parameter options. Again, like feature extraction, the

6
creation/optimization of classifiers for a particular music analysis task is an entire research question unto itself and remains a vibrant research domain. Building classification models can also be computationally and storage intensive. Against large datasets, classification times measured in months are not unknown. Sometimes, researchers are more concerned with examining the interaction of feature set choices than they are concerned with specific classifier optimization. In situations like these, having access to pre-built classification models would greatly speed up the research process. However, this is currently not a generally available option for the research community. First, there is no standard mechanism for locating pre-built models (i.e., like the feature set location problem). Second, the models themselves tend to be idiosyncratic with regard to data input and output formats which makes re-use tricky. Third, the models tend to be program language/platform dependent which makes re-use in different environments problematic.
2.1.5 Step 5. Model validation issues. Once a researcher has extracted some features and then built a classification model, the researcher needs to determine if the model does what it was intended to do and how much room for improvement exists. One traditional method is called n-fold cross-validation. Imagine that a researcher has a set of 1,000 songs and the ground-truth associated with those 1,000 songs. Further imagine that the researcher divides up the data into 5 equal groups (aka “folds”) where each fold of 200 songs contains roughly equal numbers of the classes being used to classify. That is, in the genre case, each fold contains roughly equal numbers of songs in each of the genres. For the sake of illustration, assume each fold has an identifying label such as fold-A, fold-B, fold-C, fold-D and fold-E. In this 5-fold cross-validation example, the researcher would set aside or “hold back” fold-A and then build a model using folds B through E. The researcher would then take fold-A, strip out its associated ground-truth and submit it to the model. It is now the model’s “task” to apply what it “thinks” is the appropriate label for each song in the fold-A set. The researcher then compares the model’s applied labels against the ground-truth labels for fold-A. By counting up the number of correct and incorrect answers, the researcher begins to see if the model is functioning properly. Because of issues of sampling, the researcher then repeats this basic process by next holding back the fold-B data and rebuilding the model using the fold-A, fold-C, fold-D, and fold-E data. The researcher again strips off the fold-B ground-truth labels and gets the model to apply its “guesses” which are then checked against the ground-truth answers. This process is repeated similarly for a total of 5 times (once for each fold) and the results are averaged across the entire set of folds.
This n-fold cross-validation process has a long tradition of use and can be informative. However, it has one particular weakness that hinders the creation of useful and robust models that can be applied in the real world. This problem is known as “overfitting.” Overfitting describes the situation where a model works very well on a particular test collection because it has been using a particular collection over and over to help refine it. The problem is, however, that the model ends up becoming too specialized with regard to the particular data set that was used to refine it and can no longer can be relied upon to work in a broader, real-world, context. The best way to overcome overfitting is to have completely distinct large data sets that are divided into non-overlapping train and test sets. The bigger each of these sets is, the better. Ideally, there would be many different large-scale test sets available for each possible research question. However, as discussed before, issues of ground-truth location/creation, collection building, etc., all currently hinder the realization of this ideal scenario.
2.2 Summary of Key Impediment Issues. In Section 1, we highlighted three key needs brought to the fore by our experience in running MIREX: automation, distribution, and integration. We believe these three are consistent with the several larger issues that run within and across the specific steps involved in the train-test research scenario outlined above. It is the goal of NEMA to explore and provide prototype solutions to these problems. The key problems made evident in both Section 1 and above that need to be addressed by NEMA are best summarized as:

7
1. Resource accessibility. For example, new means to provide access to good ground-truth sets, to broad-based music collections, to feature sets, and to pre-built models, etc. must be found. Also, in the case of music collections where items from the music collections will not be able to move about, new ways of bringing researchers and their tools to the data need to be constructed. It is important to envision a future where many different collections of music materials are independently made available in such a way as to create a much larger and diverse “super-collection.” Such “super-collections” are needed to address the overfitting issue. They are also needed to allow for better scalability/stress testing of approaches. Finally, new methods of creating and providing on-demand computational and storage resources to the MIR/CM community need to be explored.
2. Resource discovery. For example, even if the aforementioned resources were readily available it is still necessary to create appropriate music-specific location and discovery tools so that individual items or resource subsets might be put to use.
3. Resource sharing/re-use. For example, new standards for ground-truth and feature sets must be developed to facilitate their re-use. Mechanisms need to put into place to make it easy for researchers to store or make their own sets available to others. In the same manner, mechanisms must be put in place to overcome the interoperability problems that limit the re-use of research code, including feature extractors, classifiers, and pre-built classification models, etc.
4. Resource customization. For example, new ways need to be developed to help researchers amalgamate aspects of independently produced feature sets to create novel feature sets. New techniques must be found to easily create on-demand “virtual” collections that span across several real-world collections regardless of their physical location. Again, interoperability problems among research code sets must be overcome so that researchers can create customized hybrid systems that integrate tools from many different research labs.
2.3 Conclusion: The NEMA Vision for the Future. By making progress toward overcoming these problems, NEMA Phase I offers the promise of a new and expanded MIR/CM research paradigm. Under this new paradigm, it should become possible for MIR/CM researchers to overcome limitations of time-specific and location-specific resources. In the new NEMA reality, for example, it should become common place for researchers at Lab A to easily build a virtual collection from Library B and Lab C, acquire the necessary ground-truth from Lab D, incorporate a feature extractor from Lab E, amalgamate the extracted features with those provided by Lab F, build a set of models based on pair of classifiers from Labs G and H and then validate the results against another virtual collection taken from Lab I and Library J. Once completed, the results and newly created features sets would be, in turn, made available for others to build upon.
3.0 THE NEMA SOLUTION: BRINGING TOGETHER KEY RESEARCHERS, THEIR TECHNOLOGIES, AND THEIR EXPERTISE
The NEMA team has been constructed because each member brings to the project a set of interlocking tools, techniques, research experiences and institutional affiliations that, when brought together, can simultaneously lay the foundation for real progress on the resource availability, discovery, sharing/re-use and customization problems discussed above. Since a core strength of the NEMA project is its membership we suggest you examine Appendix A where introductory biographies and institutional affiliation information are provided for each NEMA member.
In Sections 3.1-3.4, we present the specific collections, technologies and research goals that the NEMA team will bring to bear in realizing prototype solutions to the four problem areas outlined in Section 2.2. As will become readily apparent in reading through Sections 3.1-3.4, the NEMA team will be integrating

8
and further developing a wide range of MIR/CM tools. In Section 3.5 we explicate the special relationship between the NEMA and SEASR projects that will help facilitate NEMA’s automation, distribution and integration goals. In subsection 3.6 we bring together the various constituent pieces of NEMA Phase I under the NEMA Portal framework. Figure 2 (p. 17) is a visualization of how the NEMA Portal is designed to make NEMA Phase I a reality.
3.1 Resource Accessibility. 3.1.1. Test collections Distributed access to independently located music collections is a cornerstone of the NEMA project. To model how to develop the appropriate tools and security mechanisms for accessing such music collections NEMA Phase I is bringing together the following test-bed music collections:
1. UIUC: a. MIREX. The MIREX collection housed at IMIRSEL comprises roughly 2 TB and
30,000 tracks of audio data divided among subcollections representing popular, classical and Americana musical styles.
b. Database of Recorded American Music (DRAM; www.dramonline.org/). There are “…over 1,500 CDs (9,800 compositions) in DRAM. The basis for the current collection is the diverse catalogue of American music recordings by New World Records…[has]…substantial ongoing support from The Andrew W. Mellon Foundation and its participating institutions.”10
2. McGill: a. Codaich The Codaich [IF3] music database can be used either as training and evaluation
ground truth or directly as a basis for study. Codaich includes over 25,000 audio and MIDI files from many different styles and musical traditions. Codaich is designed to be integrated with Daniel McEnnis’11 On-demand Metadata Extraction Network (OMEN) framework [IF4] (discussed in Section 3.1.2)
3. Queen Mary: a. Jamendo (www.jamendo.com) is a web service that provides access to Creative
Commons licenced musical material. The site hosts over 4000 albums of popular music genres. Preliminary navigation tools based on text metadata and the Music Ontology have been developed within OMRAS2 (discussed in Section 3.3).
b. Magnatune (www.magnatune.com) is an on-line record label providing about 700 albums of high quality music (many genres) for free streaming, downloading and purchase. Its CEO, John Buckman is an advisor to the Centre for Digital Music. Preliminary navigation tools based on text metadata and the Music Ontology (discussed later) have been developed within OMRAS2
4. Waikato: a. MidiMax is a dataset of over 100,000 MIDI files (3.3 GB) useful for symbolic music
information retrieval tasks, e.g., [DB1]. The files are harvested from the Web which, arguably, means they are a faithful reflection of popular music tasks. As MIR/CM research broadens to look at more sociological aspects, the usefulness of this dataset will grow beyond its original symbolic MIR focus. MidiMax2 is an initiative currently underway to increase the set to half a million songs, and the results of this will be made available to NEMA in due course.
10 Formal access to this collection has yet to be negotiated. However, we have a high confidence that a copy of this active, real-world, New York-based collection will be acquired. This copy will be mounted at UIUC in order to minimize server-overload and security risks to DRAM’s ongoing services. See Master Budget Appendix, Item #11, for acquisition costs (~$3000) estimated from an email exchange with DRAM’s Lisa Kahlden dated 9/26/2007. 11 McEnnis is currently a PhD student in Bainbridge’s department at the University of Waikato.

9
3.1.2 Key access technologies The central technological goal of NEMA is the development of a flexible webservice framework. In co-operation with the SEASR team, NEMA Phase I plans to build upon, extend and integrate four key web-service access technologies currently under development: OMEN, OMRAS@HOME, M2K/MIREX DIY, and Greenstone.
OMEN (McGill/Waikato): The On-demand Metadata Extraction Network (OMEN) framework [IF4] is designed to extract and to distribute researcher-defined features sets extracted from copyrighted music databases on-site so that researchers can gain access to needed information in a variety of music databases without violating copyright laws. OMEN was originally designed to exploit the large collections of digitized music available at many libraries. According to [IF4]:
Using OMEN, libraries will be able to perform on-demand feature extraction on site, returning feature values to researchers instead of providing direct access to the recordings themselves. This avoids copyright difficulties, since the underlying music never leaves the library that owns it. The analysis is performed using grid-style computation on library machines that are otherwise underused (e.g., devoted to patron web and catalogue use).
The OMEN system currently exists in a stand-alone prototype form. It has been tested using only small, in-house music collections. During the course of NEMA Phase I, the McGill, Waikato and SEASR research groups will work closely together to make OMEN a integral and pivotal resource within the NEMA system.
OMRAS@HOME/OMRAS2 (Queen Mary): Similar to OMEN with a slightly different focus, Queen Mary has developed a novel automatic playlist generator, called SoundBite12 This works with iTunes, and generates a playlist by calculating similarity to a target or seed track across a personal collection. The spectral envelope features calculated for this similarity are sent to a server, where they are cleaned, collected and organized. They can then be used to build a music recommendation system. Currently, while no single user has a collection larger than about 10,000 songs, the server hosts features for nearly 250,000 songs. This infrastructure has deliberately been designed so that the local SoundBite client can be upgraded to calculate new features. In this way, the OMRAS2 project is able to calculate a host of different musical features, such as chord sequences, structure, rhythm profiles, etc. on each client and hence build a large repository without having to own the original content, and in such a way that copyright is not infringed. So far, this upgradability has not been exploited, but will form a core aspect of the NEMA project. Additionally, this architecture could be extended so that there are multiple servers, each compiling either different music features, or compiling them across different collection types (e.g., a server for classical music, a server for jazz, and so on) which enables different research groups to provide these services without needing to provide large, fast servers.
M2K/MIREX DIY (UIUC): M2K represents the open-source, music-specific set of D2K (Data to Knowledge)13 modules designed to create a Virtual Research Lab (VRL) for MIR development, prototyping, and evaluation. M2K currently comprises approximately 300 music-specific feature extraction, music mining, and evaluation modules. Up to the Fall 2006 term, work on M2K focused on the foundational development of M2K primarily as a “stand-alone” toolkit. However, in late Fall 2006, IMIRSEL unveiled a grid/webservices M2K-based prototype, called the MIREX “Do-It-Yourself” (DIY) Evaluation Framework14. The MIREX DIY webservice is currently built upon an implementation of the D2K framework called D2KWS (D2K Web Services). The Tomcat/Java-based D2KWS prototype will be extended in the next-generation SEASR environment (detailed in section 3.4) such that related M2K/D2K projects can begin to experiment with independent, domain-specific (e.g., music retrieval evaluation) prototype deployments. A principal benefit to be realized by NEMA’s extension of this prototype DIY 12Available from http:// www.isophonics.org . 13 See http://alg.ncsa.uiuc.edu/do/tools/d2k. 14 Feel free to experiment with http://cluster3.lis.uiuc.edu:8080/mirexdiydemo/.

10
webservice framework for MIREX is the labor shift from the IMIRSEL team back to submitters themselves. If implemented correctly, this labor shift actually provides tangible benefits to the research community in exchange for their added effort. For example, a properly realized set of NEMA-developed DIY prototypes would be available to the community 24/7/365. This would also benefit the research community by affording the ability to see how algorithms are performing in near real-time with respect to their peers, which will greatly decrease development and evaluation times. Finally, the SEASR environment has a robust automatic, on-demand mechanism for locating and distributing available computational resources. This feature will be further developed to help overcome issues of large computation times for many MIR/CM tasks.
Appendix B provides a series of screenshots that show two MIREX DIY prototypes in use. The first is our original general prototype. The second is a task-specific (Audio Key Finding) prototype designed to illustrate how researchers could use the system to run evaluations and then quickly compare results against those of other researchers.
Greenstone (Waikato): Greenstone is one of the world’s leading open-source digital library (DL) toolkits [DB2]15 driven by, and encapsulating, over a decade of research [DB3]. It is multi-platform and multilingual (translated into over 50 languages). It is interoperable with many other DL solutions, including Fedora, DSpace and Cheshire [DB4]. Greenstone’s role in NEMA is to provide a repository—leveraging, where appropriate, interoperability with other externally developed DL components—through which resource discovery and sharing can be supported. These are discussed in more detail below.
3.2 Resource Discovery. Presented below are the key starting point technologies that NEMA Phase I will further develop to realize solutions to the resource discovery issues outlined in Section 2.2.
Greenstone (Waikato): Given the vast array of resources being assembled under the NEMA rubric, the ability for researchers to be able to discover what they need is an important enabling technology. Bringing order and providing access methods to data is the cornerstone of DL research, and the Waikato team’s role in NEMA will be central to this part of the project. Waikato brings expertise in the areas of interoperability [DB4], webservices [DB5], distributed resource access [DB6], heterogeneous data sources [DB7], and human computer interaction [DB8] that are particularly germane to this proposal. This skill set intersects with others in the NEMA team, and synergies will be exploited in these areas with a representative example of this given below. Details that clarify the relationship between Greenstone and SEASR, which also involves a DL technology development component, are also provided below.
Rapid prototyping is a key strength of the Greenstone digital library (GSDL) toolkit. This will greatly assist in the collaborative development of NEMA capabilities, as everyone gets to see the current state of development through a functioning system. Prototyping naturally transitions to production-level in Greenstone, as attested by work, for example, for the BBC where Greenstone was scaled up to index their entire catalogue (over 13 million items) in a matter of days after a proof-of-concept demonstration. Using GSDL, a functioning e-mail archive and code repository can be realized in a matter of weeks which will be critical in meeting NEMAs ambitious timelines (see Section 4.5). The envisioned distributed collection of music sets can also be met by current capabilities of the Greenstone software, but is a more substantial undertaking. Resource discovery, however, is not limited to plain-text or music sets. The heterogeneous outputs of researchers are also to be harnessed (e.g., feature sets and experimental results) and ingested into the GSDL repository. These more ambitious capabilities will be met through the interoperability of Fedora with Greenstone.
To consider how DL capabilities will be reshaped and evolved in combination with others on the NEMA team, we give exporting as an example. Greenstone includes a “berry-basket” feature (akin to checking
15 Dr. Michael Lesk, a leading digital library researcher, states in his latest book that with regard to digital library software systems, “…the Greenstone open source system is particularly important.”

11
out items into a shopping cart at an on-line store). It also has an extremely versatile export ability (FedoraXML is only one of the many existing choices). Putting these two together, a user can locate songs (or sets of songs) using GSDL’s searching and browsing capabilities, marking the ones of interest with the berry-basket feature. When satisfied with the selected songs, the user can then export this customized collection information using, say, the Music Ontology format. Tighter integration can be accomplished through webservices allowing the development of applications that seamlessly access information sources in the NEMA repository, its internal collections, and such external collections as Jamendo and Magnatune, for example.
Given NEMA’s collaborative ties with SEASR—a project that also leverages off DL technologies—it is important to clarify the role of Greenstone in the project. As a technology Greenstone, in fact, complements rather than conflicts with the DL aspirations of SEASR. Given that the main technical focus of SEASR is the transformation of unstructured data into structured information through analysis techniques, the role digital libraries play is principally as a means to an end: passively providing a corpus of unstructured items for analysis.
In NEMA, Greenstone’s rapid prototyping and practical approach to interoperability serves as the counterpoint to SEASR’ necessarily nascent implementation of DL services16—indeed, Greenstone is an eminently suitable candidate for SEASR to integrate with for many of their corpus discovery capabilities. However, it is important to state that time will not be wasted duplicating work. As SEASR capabilities come on-stream, Greenstone's proven flexible architecture will be able to take advantage of these new capabilities. It is the opinion of the NEMA team that Greenstone will most likely be the first non-SEASR DL product to actually use the SEASR toolset in a general, non-music environment. Notwithstanding this dimension, paramount for NEMA is its need for a ready-to-deploy DL capability to meet its very tight timelines, and on this score, Greenstone delivers, without question.
jMIR (McGill): jMIR is an open-source software suite designed for use in a wide variety of music information retrieval (MIR) research areas, including both pure research and applied commercial projects, and ranging from research in the humanities to technical areas. A special emphasis has been placed on providing an easy-to-use interface that makes the software accessible to researchers with a diversity of technical backgrounds and on designing an architecture that facilitates future expansion and customization. jMIR includes the jAudio [IF1], jSymbolic [IF2] and jWebMiner feature extractors. These respectively extract useful information from audio recordings, symbolic recordings (e.g. in MIDI or Humdrum) and from cultural information available on the internet.
3.3 Resource Sharing/Re-Use. For meaningful resource sharing/re-use to occur, much work needs to be done to overcome the overwhelming incompatibilities existing among present-day music information data formats. Data integrity issues also abound in the music analysis realm which simultaneously need be addressed. NEMA will build upon the following tools and techniques to help mitigate this state of affairs.
MusicMetadataManager/jMIR (McGill)17: MusicMetaManager is part of the jMIR software suite and is used to manage the Codaich music research database. The jMusicMetaManager software package is designed to help profile and manage large research (and other) collections of music and to detect metadata errors and inconsistencies in such collections.
The metadata that one finds associated with music from sources such as the ID3 tags of MP3 recordings or the Gracenote CD Database is often noisy in terms of reliability and consistency. This is problematic, as the quality of such metadata can be essential in many music information retrieval (MIR) research projects. Manual correction can be extremely time consuming, and even the most conscientious
16 The SEASR project has be operational for less than six months. 17 Text for this section taken from http://www.music.mcgill.ca/~cmckay/software.html.

12
proofreaders can miss errors when dealing with huge collections of music. Automatic metadata correction tools such as jMusicMetaManager are clearly necessary.
Some of the important problems that jMusicMetaManager detects are the inconsistencies and redundancies caused by multiple spellings of what should be one value. For example, uncorrected occurrences of both “Lynyrd Skynyrd” and “Leonard Skinard,” or of the multiple valid spellings of composers such as Stravinsky, would be problematic for an artist identification system that would be incorrectly trained to see works actually by the same artists as being by different artists. Another important advantage of jMusicMetaManager is that it detects redundant and potentially mislabeled copies of recordings that could contaminate evaluation results by being placed in both training and testing subsets.
ACE XML (McGill): ACE XML is part of the jMIR software suite. ACE XML is a set of file formats developed to enable communication between the various jMIR software components. These file formats have been designed to be very flexible and expressive, and it is hoped that they will eventually be adopted beyond the limited scope of jMIR as a multi-purpose standardized format by the MIR/CM research community. ACE is discussed in Section 3.4.
Maestro (Southampton): The recently begun Maestro project at Southampton is designed to bring together Southampton’s software tools and extensive experience in Semantic Grid18, semantic annotation and the use of workflows and software agents to support automation in the music domain – these are the techniques needed to take NEMA above the level of a simple service-oriented infrastructure. Maestro’s contribution is premised on the notion that metadata infrastructure is crucial to the project, bringing together the resources and services in a flexible and extensible framework. For this we will be using RDF (Resource Description Framework) together with RDF ‘triplestores’ which enable us to manage, store and query the metadata. These techniques have become well established in a number of projects across multiple disciplines and are known to be particularly effective when working with heterogeneous resources and metadata on this scale. In particular they facilitate reuse of resources.
Where appropriate we will use simple ontologies for describing resources, service and annotations, and we will adopt existing schema and ontologies where available with a special emphasis on the Queen Mary/Goldsmiths Music Ontology system (discussed next). The emphasis is on openness and ease of re-use rather than building a closed system. This infrastructure will also enable additional research, such as innovative work on the use of ontologies in feature extraction, drawing on experience in other domains (in particular those established in the “Semantic Grid” activities in the UK e-Science program).
One of the applications of RDF will be to share and reuse the annotations which are achieved manually (such as the “ground-truth” and tagging), are the results of feature extraction, or are simply the results of user interaction with the resources. This provides the benefits of explicit sharing of annotations and also the network effects achieved as users add value simply through usage. The emphasis is on lightweight and user-centric solutions. We will also use RDF to maintain provenance information so that the precise origins of derived data can be established, which in turn supports reuse and trust.
Adopting some of the higher-level techniques from the Grid-community, which are designed for achieving tasks over multiple data resources and services, we will provide a degree of automatic processing in support of the activities of the project – this includes data processing and curation, for housekeeping purposes and in support of queries etc.
Music Ontology (Queen Mary/Goldsmiths): Queen Mary and Goldsmiths are jointly developing an open-source music-specific Semantic Grid ontology called the Music Ontology. This ontology is built upon four constituent ontologies that provide a foundation for music-related concepts. These are:
18 See http://semanticgrid.org/.

13
1. Time 2. Event 3. Functional Requirements for Bibliographic Records (FRBR) 4. Friend of a Friend (FOAF)
This combination of taxonomies has shown itself to be very useful in a variety of demonstration installations that show off its ability to inter-link data repositories and services. So far, in the music realm, the following datasets have been published as Music Ontology instance data and interlinked with other relevant datasets: Musicbrainz, Jamendo, Magnatune, the RSAMD HotBed database and the BBC John Peel sessions. For example, the links between Jamendo and Musicbrainz provide a way to access detailed editorial information from Musicbrainz, as well as the content itself from the Jamendo database. The links from Jamendo to Geonames provide detailed geographic information about the location of artists. Accessing the resource http://dbtune.org/jamendo/artist/5 indeed gives, among others, the following statement:
@prefix foaf: <http://xmlns.com/foaf/0.1/>. <http://dbtune.org/jamendo/artist/5> foaf:based_near <http://sws.geonames.org/2991627/>.
Getting the geonames resource can provide the user agent with detailed information about this particular location19. Work has already begun within the Mellon-funded MeTAMuSE project (joint PIs Crawford and Prof. Geraint Wiggins), and the new Purcell Plus project (funded by AHRC; Crawford is PI) at Goldsmiths on extending the Music Ontology into the domain of musical score-notation in order to allow inferential reasoning about music represented in this form analogous to the OMRAS2 work with audio. Further work at Goldsmiths is being carried out on the use of ontology-like methods to represent, for example, a high-level musical question such as might be posed by a musicologist as an appropriate set of low-level MIR queries.
A close colleague of Crawford, and the Goldsmiths PI on OMRAS2, Michael Casey (Goldsmiths), was an editor of the MPEG-7 International Standard for Multimedia Content Description (ISO15938-4 Audio 2002), a highly-influential standard for automatic organization of multimedia databases; the feature-extraction tools developed by him at Goldsmiths within OMRAS2 are a direct implementation of this standard.
Greenstone (Waikato): The digital library infrastructure for the repository is the enabling technology we will use to underpin the sharing of resources. As part of their NEMA work, the Waikato team will develop the necessary functionality to support this. The overarching aim of this aspect of the project is to inject a “dynamic” dimension to digital library functionality that helps foster and support the community’s activities. Taking their lead from the Creative Commons Science Commons20, technical capabilities include access rights, licensing, and annotations, amongst other things.
3.4 Resource Customization. The successful integration of tools from disparate sources is a primary focus for NEMA under the resource customization rubric. The following components are the basis for the “High-Level Services” found in Figure 2 and explained in Section 3.6.
ACE/jMIR (McGill): The ACE [IF1] meta-learning framework automatically applies a variety of machine learning strategies to features that have been extracted in order to automatically classify music in a variety of ways or reveal meaningful patterns. As part of jMIR, ACE is designed to be extensible and 19 This description is taken from a soon to be published paper: Raimond, Yves, and Mark Sandler (2007). Using the semantic web for enhanced audio experiences. In Proceeding of the 123rd Convention of the Audio Engineering Society, 2007, 5-8 October, New York. (in press).. 20 http://sciencecommons.org/

14
customizable. Like MIREX DIY, ACE (and jMIR) are Java applications and because of this, one of the first NEMA development tasks will be to work on integrating the capabilities of the two systems.
OMRAS2 Task Workflow Modules (TWM) (Goldsmiths): Within the OMRAS2 project, in addition to the low-level MIR tools under development, the Goldsmiths team also works on user-related aspects of MIR research, in particular workflow issues such as the framing of high-level musical research questions as low-level MIR tasks, and the development of novel graphical resource-building, query and retrieval interfaces to enhance the usability and efficiency of the system. A major research challenge being addressed by the Goldsmiths team is to match each high-level ‘musical’ MIR task to an appropriate choice of low-level OMRAS2 tools together with a set of parameters specialized for the specific task and the data under investigation and to provide for each task a suitable graphical interface and documentation as necessary. The OMRAS2 team calls such a combination of task-related items a ‘task workflow module’ (TWM). As an example of the necessity for such a mechanism, a recent OMRAS2 paper [TC3] describes experiments on three related, yet subtly different, high-level audio MIR tasks:
1. the correct identification of mis-attributed recordings; 2. the recognition of different performances of the same piano work; and, 3. the retrieval of edited and sampled versions of a query track by remix artists.
Each of these, although using the same retrieval algorithm, requires extraction of a different feature-set from the database and the query files, and different sets of parameters for indexing and retrieval (some of which are dependent on the makeup of the database as a whole). This complex of numerical values is related to a matrix of invariant properties which is different for each of the three tasks, and can be seen as a step towards a high-level description of that task.
Since webservices access to the low-level MIR tools is being developed within OMRAS2, such low-level access can be provided in principle to a broader scheme such as NEMA. An outline descriptive protocol for the higher-level TWMs is being developed within OMRAS2; a more formal description will be essential for the wider context of NEMA.
myExperiment (Southampton): myExperiment21 is a collaborative environment which supports researchers sharing workflows and other digital items, built using a Web 2.0 approach for familiarity, ease of use and to facilitate community development. Unlike other social web sites, myExperiment provides support for provenance, annotation, complex sharing policies and federated identity, as required for use within varied research communities. Developed under the UK’s JISC Virtual Research Environment program, the software can be downloaded and customized for use in individual projects and is designed to integrate with multiple backend stores and a variety of user interfaces – it has a RESTful architecture22 and it is straightforward to utilize myExperiment functionality within other applications.
myExperiment is designed for use in multiple disciplines using multiple workflow systems. It is currently being used to share workflows in life sciences, chemistry and music, using the Taverna23 and Triana24 workflow systems, and this has demonstrated that MIR/CM tasks map naturally to the myExperiment model [DDR4].
myExperiment provides some complementary functions to the other systems in use within NEMA. In particular it provides support for recording provenance information collected when workflows, content and data products are used, and then providing new functionality based on this information. This facilitates sharing, reuse, recommendations and trust. It will also enable access to NEMA services and
21 See http://myexperiment.org/. 22 Representational State Transfer (REST) is a style of software architecture in which data are typically transferred over HTTP without any additional messaging layers, hence it is very simple to use and sits naturally within the basic Web infrastructure. 23 See http://taverna.sourceforge.net/. 24 See http://www.trianacode.org/.

15
content through the myExperiment RESTful developer’s API, for ease of building alternative interfaces, reusing components developed in the myExperiment community, and performing “mashups”. As well as complementary functionality to that provided by the SEASR framework, there is considerable potential for symbiotic research exchanges between SEASR and myExperiment. For example, myExperiment is geared around multimedia and scientific data while SEASR has a much stronger set of text analytic features; SEASR provides access to execution mechanisms which are not yet supported in myExperiment; and, each currently supports different workflow systems.
MIREX DIY/SEASR (UIUC): As illustrated in Appendix B, IMIRSEL’s Java-based, prototype MIREX DIY system currently has been using an informal, wrapper-style mechanism for running researcher code written for such common environments as Marsyas, Weka and Matlab. As the NEMA project moves forward, the MIREX DIY team will work closely with the SEASR team to move away from the current ad hoc state-of-affairs to develop more integrative (i.e., more formal) APIs for such external systems within the SEASR framework. Furthermore, because D2KWS—the underlying webservice system for M2K and MIREX DIY—is evolving into a next-generation, more generalized framework under SEASR, NEMA will leverage the improved capabilities of the SEASR environment for the NEMA-specific problem set by converting MIREX DIY components to SEASR components and then exposing MIREX DIY itineraries as SEASR workflows within the MIREX DIY framework (see Figure 2).
3.5 SEASR and NEMA: Opportunities and Issues. There are complex interactions and dependencies among the NEMA team’s contributing technologies and the SEASR framework that go beyond those already explained with regard to the M2K and the MIREX DIY systems. In the following subsections we explicate and highlight the opportunities and issues surrounding these interactions and dependencies.
3.5.1 M2K, MIREX DIY and SEASR. The M2K toolkit is named “community” project within the SEASR research plan and budget. Since the new SEASR framework will make M2K’s and MIREX DIY’s underlying execution systems (D2K and D2KWS) obsolete, the SEASR team was quite forward thinking and generous in securing funding from Mellon to pay for the basic re-coding necessary to move M2K from the D2K/D2KWS environments to the much-improved SEASR environment. IMIRSEL is grateful for this funding as opens up new technological opportunities for M2K’s future enhancement. IMIRSEL further applauds this opportunity as it helps to overcome on of the biggest drawbacks of the original D2K/D2KWS systems, namely, their non-open-source license regimes. This lack of openness has been a hindrance to the broader adoption of M2K as research tool. With SEASR being released as an open-source system, the M2K team believes that this will greatly increase the user base for M2K. It is important to note at this point, however, that the funding secured from Mellon for M2K’s necessary transition from D2K to SEASR does not include the costs of developing SEASR tools to handle the myriad challenges presented by the much broader NEMA framework.
3.5.2 NEMA and SEASR: Beyond M2K. The NEMA team is requesting support beyond that already provided for in the original SEASR proposal to help NEMA exploit the promise of SEASR within the more far-reaching NEMA context. NEMA is requesting support at the ½ FTE level to fund the SEASR team’s extended NEMA-related work on:
1. adapting the SEASR framework to meet NEMA’s domain-specific needs including NEMA’s special on-demand distributed and cluster computing requirements (e.g., OMEN, etc.), and the data management of music-specific media files, etc.;
2. converting sample NEMA feature-extraction analytics to SEASR components;
3. training and supporting NEMA developers to create SEASR components and flows;

16
4. situating SEASR as NEMA’s framework “glue” that can help bind together into a coherent whole the sundry sub-components that constitute the aforementioned OMRAS2, jMIR, myExperiment, and Greenstone, etc. systems.
There are six reasons why NEMA has decided to adopt SEASR as its framework “glue.”
First, it is early days in the SEASR development cycle. This affords the NEMA team the rare opportunity to work closely with SEASR developers to ensure that music-related issues are dealt with a priori and not as an afterthought.
Second, the open-source licensing of SEASR enables the participation of the NEMA team members in contributing their technologies and expertise. It also should encourage the future developmental participation of the MIR/CM research community as a whole.
Third, SEASR improves upon D2KWS, as well as D2K’s existing analytics approaches. Drawing upon the most current informatics research, the SEASR team is leveraging IBM’s UIMA (Unstructured Information Management Architecture) and the best practices of NCSA’s D2K machine learning to produce an even more powerful, yet still component-based, analytic framework. This service-oriented approach has a significant advantage over massive, single-application frameworks as it enables developers to develop, integrate, deploy, and sustain a set of reusable and extensible software components as well as workflows. Moreover, SEASR’s framework will help NEMA:
1. provide portability through developing tools that can be installed on hardware footprints small and large, so that the tools can be brought to data sets where they are housed and where users choose to work with them;
2. integrate repositories for open-source components and workflows that supports sharing and publishing among users (workflow sharing is not currently possible, for example, within MIREX DIY, which is based on D2KWS); and,
3. enable scalability so that components may run on a large variety of hardware footprints, including shared memory processors and clusters.
Fourth, M2K and MIREX DIY are already dependent on SEASR for their future development and deployment. Given these dependencies, it would not be productive to find yet another (non-SEASR) framework within which to integrate NEMA’s component parts.
Fifth, the NEMA and SEASR teams share a common vision concerning the importance of on-demand computational resource allocation mechanisms that are designed to be useable by both scientists and non-scientists. This vision is, unfortunately, very rare in the grid-computing/framework development community and NEMA considers itself fortunate to be working with the enlightened members of the SEASR group.
Sixth, it would be counter-productive to eschew the opportunity for two Mellon-funded projects to maximize the very real cross-pollinating synergies that the SEASR-NEMA interaction will provide. These synergies will simultaneously help fulfill SEASR's promise as a customizable environment designed to support specialized, disciplinary research—such as in the case of literary (textual) analysis with the MONK (Metadata Offer New Knowledge) project—and help NEMA establish itself as the state-of-the-art framework for music information analysis research, development and evaluation.
17
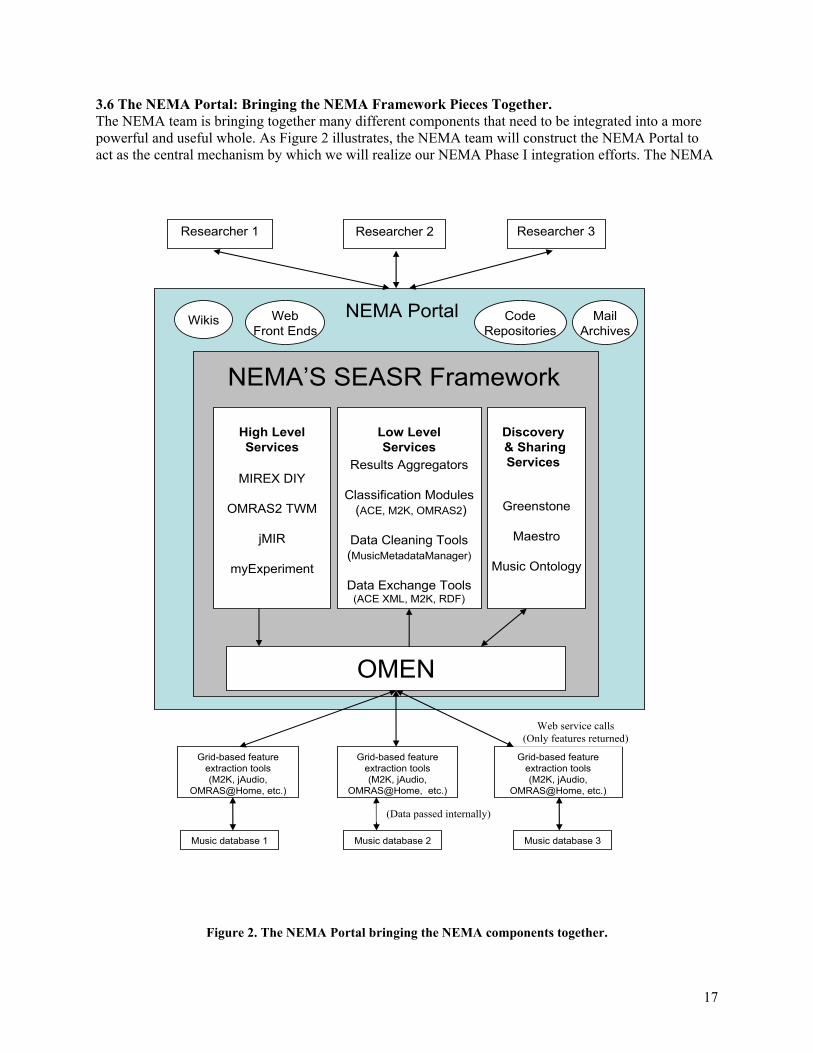
3.6 The NEMA Portal: Bringing the NEMA Framework Pieces Together. The NEMA team is bringing together many different components that need to be integrated into a more powerful and useful whole. As Figure 2 illustrates, the NEMA team will construct the NEMA Portal to act as the central mechanism by which we will realize our NEMA Phase I integration efforts. The NEMA
Researcher 1 Researcher 2 Researcher 3
MIREX DIY
OMRAS2 TWM
jMIR
myExperiment
Grid-based feature extraction tools(M2K, jAudio,
OMRAS@Home, etc.)
Music database 1 Music database 2 Music database 3
Grid-based feature extraction tools(M2K, jAudio,
OMRAS@Home, etc.)
Grid-based feature extraction tools(M2K, jAudio,
OMRAS@Home, etc.)
Web service calls(Only features returned)
(Data passed internally)
Greenstone
Maestro
Music Ontology
NEMA’S SEASR Framework
NEMA Portal
OMEN
Results Aggregators
Classification Modules(ACE, M2K, OMRAS2)
Data Cleaning Tools(MusicMetadataManager)
Data Exchange Tools(ACE XML, M2K, RDF)
High Level Services
Low Level Services
Discovery& Sharing Services
WebFront Ends
Wikis CodeRepositories
MailArchives
Figure 2. The NEMA Portal bringing the NEMA components together.

18
Portal will be the gateway for users to learn about, communicate about, and also interact with the NEMA framework’s constituent collections, resources, systems and sub-systems, etc. Portal resources—the “Wikis”, “Code Repositories” “Mail Archives” and “Web Front Ends” in Figure 2— will serve as part of the NEMA Portal’s outreach (i.e., communications and documentation), feedback (i.e., acquiring design suggestions and bug notifications), and user problem-solving services for NEMA Phase I.
Another critical purpose of the NEMA Portal is to hide NEMA’s complex infrastructure so that users can concentrate on their individual music analysis tasks. The “Discovery & Sharing Services” (e.g., Greenstone, Maestro, and the Music Ontology) will serve as a first step in simplifying users’ interactions with NEMA. For example, at the NEMA Portal users will be presented with a large pool of analytical tools that can be applied to a variety of large, customized and/or virtual music collections. These collections can be, in fact, an aggregate of several distributed databases physically located all over the world, but users need not be concerned about their locations nor how to access them because of the discovery and access capabilities that Discovery & Sharing Services like Greenstone, Maestro, and the Music Ontology will collectively bring to NEMA.
Users’ requests collected at the NEMA Portal will be managed by services that correspond to the analytical tools (or combinations of tools) that users have chosen. Initially, as shown in Figure 2, there will be four “High Level Services”: MIREX DIY, OMRAS2 TWM, jMIR, and myExperiment. Assisted by the SEASR framework technology, each of these services will be constructed to cross-exploit/interlink the wide variety of “Low Level Services” the others have to offer, such as musical feature extractors, classifiers, and metadata transformers. Thus, the High Level and Low Level Services come together under the SEASR framework, which acts as a “glue,” or unified liaison, between the NEMA Portal and the available grid-based computing clusters that will be located in locations around the world.
The complex task of distributing and scheduling requests to several clusters will be handled by OMEN’s specialized technologies. The OMEN service is designed to facilitate communications with external grid clusters that may have different hardware, operating systems, and extraction algorithms (See the “Grid-based feature extraction tools” in Figure 2.). At each available database site (e.g., Codaich, Magnatune, MidiMax, DRAM)—represented as “Music database 1, Music database 2, etc.” in Figure 2—multiple, grid-based computers will be configured to perform the necessary user-defined feature extraction calculations. There are three major advantages to this grid-based computing design:
1. the proximity to data allows efficient transfer of the large amount of data that is required for processing;
2. grid computing is needed to process often computing-intensive calculations required to extract music features in a timely manner; and,
3. the design also circumvents the legal issues of moving copyrighted material outside its restricted domain (e.g., a university campus).
The resulting set of extracted features (metadata) is sent back to the OMEN service in a standardized format (e.g., ACE XML), which in turn hands it back to the particular High Level Service or combination of High Level Services (e.g., MIREX DIY, OMRAS2 TWM, jMIR, and/or myExperiment) where the request initiated. At this point further processing will typically be performed by some combination of the Low Level Services, such as conducting a classification task or training a supervised machine learning model, etc.
Once completed, the combined final results are then sent back to the users via the NEMA Portal. Users might also wish to contribute their experimental designs, collection configurations, and result sets via the NEMA Portal’s Wikis, Code Repositories, Mail Archives, etc., which, in turn, will be made more readily available via the NEMA Portal’s Discovery & Sharing Services.

19
4.0 WORKPLAN
In this section we outline the objectives, special work plan strategies, communication mechanisms and timelines for the successful realization of NEMA Phase I.
4.1 Main Phase I Objectives. The principal goal of NEMA Phase I is the creation of a coherent and cohesive cyberinfrastructure based upon the NEMA teams’ various current technologies. In the spirit of walking before running, Phase I will have a strong (almost exclusive) intramural focus. That is, we will consider Phase I a resounding success when, at the end of Year 3, we can demonstrate to the world the promise and capabilities of the NEMA “vision” (Section 2.3) using the NEMA team’s internal collections (Section 3.1.1) and its in-house technologies (Sections 3.1-3.4). If Phase I is the “intramural” period of NEMA, then Phase II is best conceived of as NEMA’s “extramural” period. It will be during the Phase II extramural period when the NEMA framework gets connected to the broader world, beyond the confines of the NEMA laboratories, and into individual homes, classrooms, laboratories, libraries, archives, and commercial purveyors of music. Phase I needs to completed in order to convince the broader world that NEMA’s models of resource sharing and off-site computing/feature extraction are simultaneously robust, stable and secure. This is particularly important with regard to the OMEN model of distributed feature-extraction where we will be asking holders of music collections (both public and private) to install our OMEN extractors within their own premises. NEMA must be able to show them that their computational resources will not be overwhelmed and that their underlying musical properties will not be compromised. Notwithstanding the intramural focus of Phase I, by the end of Year 3, the broader MIR/CM community will have access to a set of very useful and quite broad ranging resources that they otherwise would not have had. The two most visible Phase I resources that will be available to the MIR/CM community will be the NEMA Portal and a set MIREX DIY systems that will have ever increasing functionality across the span of Years 1 through 3.
4.2 Special Workplan Strategies: NEMA Portal and MIREX DIY. The NEMA Portal and MIREX DIY play special roles in the Phase I workplan. These two aspects of the NEMA project will function as primary “rallying points” in our campaign to make NEMA a reality. The NEMA Portal, while ultimately intended to be a community-wide resource, will function in its early days as the mechanism through which the NEMA team itself communicates. A first priority of Phase I will be to get the NEMA Portal server up and running. The team will then use the NEMA Portal’s Wikis, Code Repositories, Mail Archives, etc. in an in-house mode to co-ordinate its development efforts. As time goes by, and parts of the NEMA Portal are ready for exposure to the world, these systems will also be opened up to the community. One particular advantage to using the NEMA Portal as an internal NEMA team resource is that it will have had many thousands of hours of use (and debugging) before external users come to use it.
Because MIREX is held each year and has specific deadlines, work on realizing and incrementally improving, the MIREX DIY system is particularly important to the timely development of the NEMA infrastructure. In fact, it is a goal of NEMA to have at least one fully functional, SEASR-based, MIREX DIY prototype system in place by mid-Year 1 so that it can be used in one (or more) of the MIREX 2008 tasks. Also, it will be the MIREX DIY system through which the MIR/CM community will initially become aware of the NEMA vision. This means that the NEMA team will have its first round of real-world user feedback before the end of Year 1 upon which to base developmental improvements. In successive years, the MIREX DIY system will broaden its range of tasks and capabilities and thus will also broaden its user pool from which more useful input can be obtained.
4.3 Internal Communications. As mentioned above, the main communication channel for the NEMA team will be the NEMA Portal itself. This will be augmented through the use of such online technologies as Skype, basic email, and video conferencing. Both Queen Mary and GSLIS are installing new, state-of-the-art, video conferencing

20
equipment. Every member of the NEMA team has had considerable experience managing complex research tasks over great distances. For example, Downie (US) and Bainbridge (NZ) have co-authored half a dozen peer-reviewed papers exclusively over the Internet25. De Roure leads the OMII-UK partnership which involves regular virtual meetings with UK and international partners, and routinely participates in the virtual activities of standards bodies such as the Open Grid Forum (where he has published with Downie) and the World Wide Web Consortium. Sandler (UK), Crawford (UK), Fujinaga (CA), Bainbridge (NZ), and Downie (US) also came together virtually to organize the very successful ISMIR 2005, in London.
For face-to-face meetings, NEMA members will interact mostly on a lab-by-lab basis. This will be easiest, of course, for the UK labs as they are only a subway or train ride apart. We do envision Downie and Fujinaga as PI and Co-PI to do a fair amount of traveling on lab visits to ensure that work is proceeding properly. Dual-purposing conference travel will, however, also help facilitate face-to-face interactions and lower travel expenditures. For example, Bainbridge, Downie and Fujinaga are regular attendees of the Joint Conference on Digital Libraries (JCDL) and can extend their conference visits to include NEMA development meetings. ISMIR, the principal conference for the MIR community will also be used to hold plenary (“All-Hands”) meetings of the NEMA team as a whole. The one exception to this will be the All-Hands Meeting I which will be convened within the first six months of the project in order to solidify the team and to unify the intellectual aspects of the project by exposing each participant to an in-depth explication of each of the contributing technologies (i.e., M2K, OMRAS2, Greenstone, OMEN, myExperiment, SEASR, etc.). The All-Hands Meeting I will be crucial to realizing milestones P1.6 and P2.5 (Inter-technology function scoping and prioritizing) mentioned below in Section 4.5.
4.4 External Communications. The NEMA team is multidisciplinary and as such has a collective history of publishing in a variety of venues. These venues include ISMIR, JCDL, Computing in Musicology, ACM Special Interest Group on Information Retrieval, Journal of the American Society of Information Science and Technology, Information Processing and Management, Journal of New Music Research, IEEE Transactions on Multimedia, IEEE Transactions on Audio Speech and Language Processing, IEEE Multimedia Magazine, IEEE Signal Processing Magazine, Digital Humanities, DLib Magazine, Global Grid Forum, and so on. NEMA team members will use these venues as their scholarly communication channels to make sure that NEMA is known to as broad an audience as possible. We also intend to hold at least one NEMA workshop each year with ISMIR being our first-choice venue. NEMA has already been given tentative approval for the first NEMA workshop at ISMIR 2008 in Philadelphia.
4.5 Timelines.
In this section we present the workplan timelines and milestones for NEMA Phase I broken down into six, six-month periods (P).
P1: Y0 to end Y0.5 (January 2008 through June 2008) 1. Final NEMA agreements signed (All labs) 2. Lab workers hired (All labs) 3. NEMA All-Hands Meeting I held (All labs + SEASR; Venue to be determined) 4. NEMA Portal server up, including base GSDL install (UIUC/Waikato) 5. Communication channels established (via NEMA Portal, UIUC) 6. Inter-technology function scoping and prioritizing begun (All labs + SEASR)
25 This document itself is a product of Internet-based communications technologies. At no time have all the NEMA members been together in the same room.

21
P2: Y0.5 to end Y1.0 (July 2008 through December 2008) 1. MIREX DIY v1 up (UIUC + SEASR) 2. NEMA All-Hands Meeting II held (All labs + SEASR, Philadelphia [ISMIR 2008]) 3. NEMA Workshop I held (All labs + SEASR, Philadelphia) 4. NEMA servers interconnected (All labs via NEMA Portal @ UIUC) 5. Inter-technology function scoping and prioritizing completed (All labs with UIUC/McGill leading
and input from SEASR) 6. Installation of High Level Services on NEMA Portal begun (All labs + SEASR) 7. First tests of the OMEN model in the NEMA/SEASR environment begun
(McGill/UIUC/Waikato first target databases) 8. First tests of Greenstone (Waikato), Maestro (Southampton) and Music Ontology (Queen
Mary/Goldsmiths) in the NEMA/SEASR environment begun 9. First modeling of standards for data interchange, interoperability, APIs, etc. begun (All labs +
SEASR) 10. Identification of potential early-adopters/trusted users for NEMA Portal begun (All labs)
P3: Y1.0 to end Y1.5 (January 2009 through June 2009) 1. Analysis of MIREX DIY v1 strengths and weaknesses completed (UIUC) 2. Revision/enhancement of MIREX DIY v1 technology begun (UIUC + SEASR with input from
all labs) 3. Analysis of Workshop I feedback completed (All labs) 4. Revisions of OMEN (McGill/Waikato), Greenstone (Waikato), Maestro (Southampton), Music
Ontology (Queen Mary/Goldsmiths) in the NEMA/SEASR environment, begun 5. First drafts of standards for data interchange, component interoperability, APIs, etc. completed
and disseminated for feedback (All labs + SEASR with UIUC/McGill leading)
P4: Y1.5 to end Y2.0 (July 2009 through December 2009) 1. MIREX DIY v2 up (UIUC + SEASR with the goal of incorporating several aspects of the
contributing technologies, especially OMEN and Greenstone for virtual collection building) 2. NEMA All-Hands Meeting III held (All labs + SEASR; Kobe, Japan [ISMIR 2009]) 3. NEMA Workshop II held (All labs + SEASR,; Kobe, Japan) 4. Stress testing of OMEN (McGill/Waikato), Greenstone (Waikato), Maestro (Southampton),
Music Ontology (Queen Mary/Goldsmiths), etc. under larger loads (i.e., other NEMA collections included) begun (with input from SEASR)
5. Revision of standards for data interchange, component interoperability, APIs, etc (All labs + SEASR with UIUC/McGill leading).
6. Opening of NEMA Portal to select early-adopters/trusted users (UIUC to decide) 7. Identification of Phase II stakeholders and participants begun (All labs)
P5: Y2.0 to end Y2.5 (January 2010 through June 2010) 1. Analysis of MIREX DIY v2 strengths and weaknesses completed (UIUC) 2. Revision/enhancement of MIREX DIY v2 technology begun (UIUC + SEASR with input from
all labs) 3. Analysis of Workshop II feedback completed (All labs) 4. Revisions of OMEN (McGill/Waikato), Greenstone (Waikato), Maestro (Southampton), Music
Ontology (Queen Mary/Goldsmiths) in the NEMA environment, continued 5. Second drafts of standards for data interchange, component interoperability, APIs, etc. completed
and disseminated for feedback (All labs + SEASR with UIUC/McGill leading) 6. Analysis of feedback from early-adopters/trusted users begun (UIUC with input from all labs) 7. Broadening of NEMA Portal user-base begun (All labs with UIUC deciding) 8. Problem set identification for Phase II proposals begun including identification of technologies
that might warrant further work (All labs + SEASR)

22
P6: Y2.5 to end Y3.0 (July 2010 through December 2010) 1. MIREX DIY v3 up (UIUC + SEASR leading with the idea that v3 will showcase aspects of all
contributing technologies) 2. NEMA All-Hands Meeting IV held (All labs + SEASR; Utrecht, Netherlands [ISMIR 2010]) 3. NEMA Workshop III held with an emphasis on potential Phase II stakeholders and participants
All labs + SEASR; Utrecht, Netherlands) 4. Broader proof-of-concept demonstrations of NEMA technologies to establish Phase II
stakeholders and research participants held (All labs (in sub-groups, +/- SEASR) at various times in various venues)
5. Final analyses of MIREX DIY v3, Workshop III and standards feedback completed (UIUC) 6. Final standards documentation completed and disseminated (All labs + SEASR with
UIUC/McGill leading). 7. Phase II problem set identification completed including decisions on which technologies do not
warrant inclusion/further work in Phase II (All labs) 8. Phase II funding proposals created and submitted (All labs)
5.0 ADMINISTRATIVE STRUCTURES
NEMA Phase I is an ambitious multinational research project involving 6 institutions and 4 different countries. It is important to clarify the proposed administrative first principals and structures so that each member can co-ordinate a set of institutional permissions necessary to facilitate their contribution to the success of the project.
5.1 Role of Partners. Downie is the PI, and GSLIS at UIUC the lead institution of the NEMA project. As such, Downie will be NEMA’s primary intellectual, fiduciary and administrative leader. Downie will also be responsible for leading and overseeing the outcomes of the NEMA-SEASR collaborations. Fujinaga is Co-PI and will assist Downie in the co-ordination and intellectual direction of the project. Given that each NEMA partner is a senior researcher with an international reputation for high-quality work, it is NEMA’s intention to grant each member as much autonomy as possible. Consistent with this idea, is the very strong desire not to micro-manage each member’s research contributions nor to inflict any more administrative overhead than absolutely necessary. It is expected that members will need to call upon (or reallocate) resources from within their institutions (including both physical and personnel resources) as the research needs dictate. It is the position of the NEMA PI that each member should be free to do so as they see fit as long as they stay within their overall budget allocations.
5.2 Budget Issues. GSLIS and UIUC will be the officially funded business location for administrative purposes and will be responsible for budgetary oversight, reporting, etc. For administrative purposes, each NEMA member will be a sub-contractor to NEMA.
As sub-contractors, each member has been allocated a line of funds (see Master Budget Appendix). Each lab leader has indicated that he can deliver on his research contributions to NEMA within the allocated amounts. Generally, this means that each partner can fund graduate student research assistant time, acquire necessary equipment, support some project-related travel, etc. The individual NEMA member budgets are presented in the Sub-Award Budgets Appendix. Each six months, the members will submit invoices to GSLIS to cover the allocations associated with that period’s work (i.e., ~50% of their allocated amount for that year).
5.3 Intellectual Property. Since the NEMA project is specifically designed to build upon the prior work of each of its members, it is important to respect the intellectual property status/terms of each technology brought to the project. Crudely put, each member “keeps” what he came to the project with. This stance should also encourage, as NEMA matures in a more robust system in future phases, the participation of commercially oriented

23
developers to create/adopt NEMA APIs that would allow their tools to be “plugged into” the NEMA framework. A review of the member-developed technologies under consideration for integration into the NEMA Phase I framework finds them all to be distributed under open-source licenses. The resultant NEMA-funded tools and techniques will be developed and distributed under an open-source regime. In the unlikely case that NEMA encounters incompatibilities among the licenses associated with a NEMA team member’s prior art, the adoption of a “plug-and-play” API approach should mitigate any potential problems. That is, for the problem component(s) (and those coming from commercial sources with non-open-source IP regimes), work would proceed on creating APIs through which the incompatible/commercial tools could communicate without having to actually integrate the underlying code base of the problematic component(s) into NEMA’s code base. This is the model that IMIRSEL has successfully adopted for M2K. For example, instead of incorporating Weka, Marsyas or Matlab code directly into M2K (each has different license terms), M2K created informal, ad hoc wrappers that can crudely communicate back and forth with these programs as independent entities26.
The NEMA project will adopt (and modify as necessary) the intellectual property agreement struck between the Mellon Foundation and the University of Illinois on behalf of the MONK project, dated 29 September 2004. A copy of the original text is found in Appendix C.
6.0 REFERENCES
[DB1]. Bainbridge, D., Nevill-Manning, C.G., Witten, I.H., Smith, L.A. and McNab, R.J. Towards a digital library of popular music. Proceeding of the Fourth ACM Conference on Digital Libraries Proceedings, Berkley, CA, August 11-14, 1999, pp. 161–169.
[DB2] Lesk, Michael (2005). Understanding Digital Libraries (2nd ed.). Boston: Elsevier.
[DB3]. Witten, I.H. and Bainbridge, D. (2007). A retrospective look at Greenstone: lessons from the first decade. Seventh Joint ACM/IEEE Conference on Digital Libraries (JCDL),Vancouver, June, 2007, pp. 147–156.
[DB4] Bainbridge, D., Ke, K.-Y. J. and Witten, I. H. (2006). Document level interoperability for collection creators. Proceedings of the Sixth ACM/IEEE-CS Joint Conference on Digital Libraries (JCDL'06): Opening Information Horizons, Chapel Hill, NC, June, ACM, New York, pp. 105-106.
[DB5] Buchanan, G., Bainbridge, D., Don, K.J., and Witten, I.H. (2005) “A new framework for building digital library collections” Proceedings of the 5th ACM/IEEE-CS joint conference on Digital libraries, Denver, CO, USA, pp. 23–31.
[DB6] Bainbridge, D., Don, K. J., Buchanan, G. R., Witten, I. H., Jones, S., Jones, M. and Barr, M. I. (2004). Dynamic digital library construction and configuration. Heery, R. and Lyon, L. (eds). Proceedings of the Eighth European Conference on Research and Advanced Technology for Digital Libraries (ECDL'04), LNCS 3232, Bath, UK, September, 1-13. Springer-Verlag, Berlin.
[DB7] Witten I H, Bainbridge D, Boddie S J, Paynter G W. (2002). The Greenstone plugin architecture. Proceedings of the Second ACM/IEEE-CS Joint Conference on Digital Libraries Portland, Oregon July 14-18 200, pp. 285-286.
[DB8] David M. Nichols, D.M., Bainbridge, D. and Twidale, M.B. (2007). Constructing digital library interfaces. Proceedings of the Joint ACM/IEEE Conference on Digital libraries, Vancouver, BC, Canada, pp. 331–332.
[DB9] Pomerantz, Jeffrey, Sanghee Oh, Seungwon Yang, Edward A. Fox and Barbara M. Wildemuth (2006). The core: digital library education in library and information science programs. D-Lib Magazine 12 (1). 26 As stated in Section 3.4, the NEMA team will work closely with the SEASR team to move away from the current ad hoc state-of-affairs to develop more integrative (i.e., more formal) APIs for such external systems.

24
[DB10] The University of Waikato. Details of PBRF included in article. Available at http://en.wikipedia.org/wiki/University_of_Waikato.
[DB11] Bainbridge, David, Michael Dewsnip, and Ian H. Witten (2005). Searching digital music libraries. Information Processing Management 41(1): 41-56.
[DB12] Bainbridge, David, Sally Jo Cunningham, John McPherson, J. Stephen Downie, and Nina Reeves (2005). Designing a music digital library: discovering what people really want. In Theng, Yin-Leng and Schubert Foo, eds., Design and Usability of Digital Libraries: Case Studies in the Asia Pacific. London: Information Science Publishing, pp. 313-333.
[DB13] Bainbridge, David, Sally Jo Cunningham and J. Stephen Downie (2004). Visual collaging of music in a digital library. In Fifth International Conference on Music Information Retrieval (ISMIR 2004), 10-14 October 2004, Barcelona, Spain. Barcelona, Spain: Universitat Pompeu Fabra, pp. 397-402.
[DB14] Lobb, Richard, Tim C. Bell, and David Bainbridge (2005). Fast capture of sheet music for an agile digital music library. In Proceedings of the Sixth International Conference on Music Information Retrieval (ISMIR 2005), London, UK, 11-15 September 2005. Queen Mary, UK: University of London, pp. 145-152.
[DB15] Bainbridge, David, and Tim C. Bell (2001). The challenge of optical music recognition. Computers and the Humanities 35 (2): 95-121.
[DB16] Bainbridge, David, Craig G. Nevill-Manning, Ian H. Witten, Lloyd A. Smith, and Rodger J. McNab (1999). Towards a digital library of popular music. In Proceedings of the Fourth ACM Conference on Digital Libraries, Berkley, CA, 11-14 August 1999. pp. 161-169.
[DB17] Mostafa, Javed (2005). Seeking Better Web Searches. Scientific American 292 (2): 67-73.
[DB18] Bainbridge, David and Tim Bell (2003). A music notation construction engine for optical music recognition. Software Practice and Experience 33(2): 173-200.
[DB19] Bainbridge, David, Sally Jo Cunningham and J. Stephen Downie (2003). Analysis of queries to a Wizard-of-Oz music information retrieval system: Challenging assumptions about what people really want. In Proceedings of the Fourth International Conference on Music Information Retrieval (ISMIR 2003), 26-30 October 2002, Baltimore, Maryland. Baltimore, MD: Johns Hopkins University , pp. 221-222.
[DB20] Downie, J. Stephen and Sally Jo Cunningham (2002). Toward a theory of music information retrieval queries: System design implications. In Proceedings of the Third International Conference on Music Information Retrieval (ISMIR 2002), 13-17 October 2002, Paris. Paris: IRCAM, pp. 299-300.
[DDR1] De Roure, David, Nicholas R. Jennings, and Nigel R. Shadbolt (2005). The semantic grid: past, present and future. In Proceedings of the IEEE 93 (3): 669-681.
[DDR2] De Roure, David and Steven G. Blackburn (2000). Content-based navigation of music using melodic pitch contours. Multimedia Systems 8 (3): 190-200.
[DDR3] Atkinson, Malcolm P., David De Roure, Alistair N. Dunlop, Geoffery Fox, Peter Henderson, Tony Hey, Norman W. Paton, Steven Newhouse, Savas Parastatidis, Anne E. Trefethen, Paul Watson, and J. Webber (2005). Web Service Grids: an evolutionary approach. Concurrency and Computation: Practice and Experience 17 (2-4): 377-389.
[DDR4] De Roure, David and Carole Goble (2007). myExperiment - A Web 2.0 virtual research environment. In Proceedings of the International Workshop on Virtual Research Environments and Collaborative Work Environments, Edinburgh, UK. [In press].

25
[DDR5] Page, Keven. R., Danius T. Michaelides, Shum. J. Buckingham, Yun-Heh Chen-Burger, Jeff Dalton, David C. De Roure, Marc Eisenstadt, Stephen Potter, Nigel R. Shadbolt, Austin Tate, Michelle Bachler, and Jiri Komzak (2005). Collaboration in the semantic grid: a basis for e-learning. Applied Artificial Intelligence 19 (9-10): 881-904.
[IF1] McKay, Cory and Ichiro Fujinaga (2007). Style-independent computer-assisted exploratory analysis of large music collections. Journal of Interdisciplinary Music Studies 1 (1): 63–85.
[IF2] McEnnis, Daniel, Cory McKay and Ichiro Fujinaga (2006). jAudio: additions and improvements. In Proceedings of the Seventh International Conference on Music Information Retrieval (ISMIR 2006), Victoria, 8-12 October, 2006. Victoria, Canada: University of Victoria, pp. 385–386.
[IF3] McKay, Cory, Daniel McEnnis and Ichiro Fujinaga (2006). A large publicly accessible prototype audio database for music research. In Proceedings of the Seventh International Conference on Music Information Retrieval (ISMIR 2006), Victoria, 8-12 October, 2006. Victoria, Canada: University of Victoria, pp. 160–163.
[IF4] McEnnis, Daniel, Cory McKay and Ichiro Fujinaga (2006). Overview of OMEN. In Proceedings of the Seventh International Conference on Music Information Retrieval (ISMIR 2006), Victoria, 8-12 October, 2006. Victoria, Canada: University of Victoria, pp. 7-12.
[JSD1] Downie, J. Stephen (2004). The scientific evaluation of music information retrieval systems: Foundations and future. Computer Music Journal 28 (3): 12-23.
[JSD2] Downie, J. Stephen (2004). IMIRSEL: A secure music retrieval testing environment. In SPIE International Symposium, IT COM 2004, Information Technology and Communication, 25-28 October 2004, Philadelphia, Pennsylvania (Proceedings of SPIE, vol 5601). Bellingham, WA: SPIE, 91-99.
[JSD3] Downie, J Stephen, Kris West, Andreas Ehmann and Emmanuel Vincent (2005). The 2005 Music Information Retrieval Evaluation eXchange (MIREX 2005): Preliminary Overview. In Proceedings of the Sixth International Conference on Music Information Retrieval (ISMIR 2005), London, UK, 11-15 September 2005. Queen Mary, UK: University of London, pp. 320-323.
[JSD4] Downie, J. Stephen (2006). The Music Information Retrieval Evaluation eXchange (MIREX). D-Lib Magazine 12 (12). Available: http://dlib.org/dlib/december06/downie/12downie.html.
[JSD5] Downie, J. Stephen, Joe Futrelle and David Tcheng (2004). The International Music Information Retrieval Systems Evaluation Laboratory: Governance, access, and security. In Fifth International Conference on Music Information Retrieval (ISMIR 2004), 10-14 October 2004, Barcelona, Spain. Barcelona, Spain: Universitat Pompeu Fabra, 9-14.
[JSD6] Lee, Jin Ha and J. Stephen Downie (2004). Survey of music information needs, uses, and seeking behaviours: Preliminary findings. In Fifth International Conference on Music Information Retrieval (ISMIR 2004), 10-14 October 2004, Barcelona, Spain. Barcelona, Spain: Universitat Pompeu Fabra, 441-446.
[JSD7] Downie, J. Stephen, Andreas F. Ehmann and Xiao Hu (2005). Music-to-Knowledge (M2K): a prototyping and evaluation environment for music digital library research. In Proceedings of the 5th ACM/IEEE-CS Joint Conference on Digital Libraries (JCDL 2005), Denver, CO, 7-11 June, 2005. New York, NY: ACM Press, p.376.
[MS1] Bello, J.P, L. Daudet, S. Abdallah, C. Duxbury, M. Davies and M. B. Sandler (2005). A tutorial on onset detection in music signals. IEEE Trans. Speech & Audio Processing 13 (5), Part 2, Sept. 2005, pp. 1035 – 1047.
[MS2] Aucouturier, J-J., F. Pachet and M. Sandler (2005). The way it sounds: timbre models for analysis and retrieval of polyphonic music signals. IEEE Trans. Multimedia 7 (6): 1028-1035.

26
[MS3] Bello, J. P., L. Daudet and M. B. Sandler (2006). Automatic piano transcription using frequency and time-domain information. IEEE Trans. Audio, Speech and Language Processing, 14 (6): 2242-2251.
[MS4] Levy, M and M. Sandler (2007). Structural segmentation of musical audio by constrained clustering,. IEEE Trans. Audio, Speech and Language Processing, Special Issue on Music Information Retrieval, in press.
[MS5] Raimond, Y., S. Abdallah, M. Sandler, and F. Giasson (2007). The Music Ontology. In Proceedings of the Eighth International Conference on Music Information Retrieval (ISMIR 2007), Vienna, Austria, 23-27 September, 2007. Vienna, Austria: Technical University of Vienna, in press.
[MS6] Raimond, Y., C. Sutton and M. Sandler (2007). A distributed data-space for music related information, In Proceedings of WMS ’07, ACM Multimedia, International Workshop on Multimedia Semantics, Augsburg, Germany, Sept 2007, in press.
[TC1] Byrd, D. and T.C. Crawford (2002). Problems of music information retrieval in the real world. Information Processing and Management 38: 249-272,
[TC2] Crawford, Tim and Gibson, Lorna, eds. (2007/2008). Modern Methods for Musicology. Ashgate. [forthcoming].
[TC3] Casey, M., Rhodes, C. and Slaney, M. (under review, 2008). Analysis of minimum distances in high-dimensional musical spaces. IEEE Transactions in Audio, Speech and Language Processing.

34
APPENDIX A
A.1 J. Stephen Downie (PI) A.1.1 Biography: J. Stephen Downie is an Associate Professor at the Graduate School of Library and Information Science, University of Illinois at Urbana-Champaign (UIUC). He is Director of the International Music Information Retrieval Systems Evaluation Laboratory (IMIRSEL) [JSD5]. Downie is Principal Investigator on the Human Use of Music Information Retrieval Systems (HUMIRS) [JSD6] and the Music-to-Knowledge (M2K) [JSD7] music data-mining projects. He has been very active in the establishment of the Music Information Retrieval and Music Digital Library communities through his ongoing work with the ISMIR series of MIR conferences as a member of the ISMIR steering committee. He holds a BA (Music Theory and Composition; 1988), a MLIS (1992), and a PhD in Library and Information Science (1999), all earned at the University of Western Ontario.
A.1.2 Affiliations: IMIRSEL is located at GSLIS at UIUC. GSLIS is ranked 1st among Library and Information Science programs in the United States. IMIRSEL has a close and ongoing collaborative research relationship with the Automated Learning Group (ALG) of the National Center for Supercomputing Applications (NCSA). The ALG team was responsible for the development of the Data-to-Knowledge (D2K)27 and D2KWS (D2K Web Services) frameworks upon which the Music-to-Knowledge (M2K) and the MIREX DIY systems are currently based. Connections between IMIRSEL and ALG are further strengthened by the co-operative research being undertaken between them under the rubric of the Networked Environmental Sonic-Toolkits for Exploratory Research (NESTER) Project which was recently funded over three years from UIUC's Critical Initiatives in Research and Scholarship (CIRS) Program. The goal of NESTER is to build audio research tools for avian and other environmental researchers using M2K and SEASR as technological foundations. Furthermore, M2K is a named development project in its own right within ALG’s recently awarded SEASR grant from the Mellon Foundation.
A.2 Ichiro Fujinaga (Co-PI) A.2.1 Biography: Ichiro Fujinaga is an Associate Professor in Music Technology Area at the Schulich School of Music at McGill University. He has Bachelor's degrees in Music/Percussion and Mathematics from University of Alberta, and a Master's degree in Music Theory, and a Ph.D. in Music Technology from McGill University. In 2003-4, he was the Acting Director of the Center for Interdisciplinary Research in Music Media and Technology (CIRMMT) at McGill. In 2002-3, he was the Chair of the Music Technology Area at the School of Music. Before that he was a faculty member of the Computer Music Department at the Peabody Conservatory of Music of the Johns Hopkins University. Research interests include music theory, machine learning, music perception, digital signal processing, genetic algorithms, and music information acquisition, preservation, and retrieval.
A.2.2 Affiliations: Music Technology program within the Schulich School of Music, McGill University is one of the largest program of this kind in the world with five full-time professors. Currently, there are five post-doctoral fellows, thirteen PhD students, and fifteen Masters students. CIRMMT is a research center with eighteen full members and fourteen associate members. Its goal is the development of innovative approaches to the scientific study of music, media and technology, including the creation, transmission, and perception of music and sound and the scientific study of the cognitive operations involved in the performance and perception of music.
A.3 Mark Sandler A.3.1 Biography: Mark Sandler is Professor of Signal Processing in the Department of Electronic Engineering at Queen Mary University of London. He is also Director of the Centre for Digital Music, one of Europe's largest research groups in Sound and Music Computing, with a special emphasis on Music Informatics. He has a Bachelors degree (1978) and a PhD (1983) from the University of Essex.
27 See http://alg.ncsa.uiuc.edu/do/tools/d2k.

35
A.3.2 Affiliations: The Centre for Digital Music has nearly 40 active researchers (including faculty from both Electronic Engineering and Computer Science) and current grants worth well over £3M. The largest of these is OMRAS2 (Online Music Recognition and Search 2) funded by the UK's EPSRC and worth about £2.5M in total (approximately 1/3 to Goldsmiths College). Another large grant is the EU funded EASAIER, which is developing advanced intelligent retrieval systems for music and audio archives. This involves 5 partners across Europe. Other grants are on Sound Source Separation, Object-based Audio Coding, Music Segmentation, Music Information Dynamics and so on [MS1-4]. Other leading researchers in the Centre are Dr. Simon Dixon, who is a leading expert on rhythmic description, Dr. Mark Plumbley who is a leading expert on Source Separation and Dr. Josh Reiss, a leading expert on Music Information Retrieval systems.
A.4 David De Roure A.4.1 Biography: David De Roure is Professor of Computer Science in the School of Electronics and Computer Science at the University of Southampton, where he was a founding member of the Intelligence, Agents, Multimedia Group and leads the e-Research activities. Dr. De Roure eaned a BSc (hons) Mathematics with Physics in 1984 and his PhD in Computer Science (1990) at Southampton. He pioneered the Semantic Grid initiative [DDR1] and leads the Semantic Grid Research Group in the Open Grid Forum, where he sits on the Grid Forum Steering Group as Area Director for e-Science. He is Chair of the Open Middleware Infrastructure Institute UK and leads the Southampton middleware team. His research interest is in the application of knowledge technologies and collaborative tools in e-Research. He is a member of the W3C Advisory Committee and national committees including the JISC Committee for Support of Research and the Arts and Humanities Research Council e-Science committee. He is a Fellow of the British Computer Society.
A.4.2 Affiliations: The Intelligence, Agents, Multimedia group is a broad-based, multi- and inter- disciplinary group with around 120 researchers, focusing on the design and application of computing systems for complex information and knowledge processing tasks [DDR2-3]. The group led a 6 year multi-site collaboration on Advanced Knowledge Technologies and has had very significant involvement with the UK e-Science programme. Current funding includes an Arts and Humanities eScience grant (i.e., musicSpace: Using and Evaluating e-Science Design Methods and Technologies to Improve Access to Heterogeneous Music Resources for Musicology) and a JISC Virtual Research Environment project to build the myExperiment collaborative environment [DDR4] for researchers sharing digital content, which uses both Web 2.0 and Semantic Web techniques.
A.5 Tim Crawford A.5.1 Biography: Tim Crawford is Senior Lecturer in the Department of Computing at Goldsmiths, University of London, where he is Principal Investigator for a number of projects. Although no longer active as a professional performer, he was for 15 years a freelance lutenist and theorbo player, working with most of the leading conductors and performers in Baroque music. Prior to coming to Goldsmiths, he was a member of the Department of Music, King's College London. A focus of his work has been using computers to aid with musicological investigation. Among his projects is a program for the editing, playback (via MIDI) and printing of music written in lute tablature for the Macintosh computer, as well as TabCode, a special code intended for the representation of tablature notation on computers in ASCII text.
A.5.2 Affiliations: Crawford currently divides his time between two large research groups. As part of the Media Futures Laboratory, Crawford, who coordinated the original OMRAS project [TC1], is closely involved with OMRAS2, the EPSRC's first `Large Grant' (worth almost £2.5m), devoted to Information Retrieval tasks on large corpora of audio recordings and in close collaboration with Professor Michael Casey within the group and researchers at the project's partner institution Queen Mary, University of London. Within the Intelligent Sound and Music Systems group at Goldsmiths, Crawford focuses on computer musicology [TC2-3].

36
A.6 David Bainbridge A.6.1 Biography: David Bainbridge is a senior lecturer in the Department of Computer Science at the University of Waikato, New Zealand. He is also co-director of the New Zealand Digital Library Project where Greenstone28, arguably the world's leading open source digital library software [DB2], is produced. Through his digital library work he has worked with the BBC, several national libraries (New Zealand, Australia, and Portugal) and various UN agencies. Music based research interests include music digital libraries, optical music recognition, symbolic music information retrieval, and human computer interaction [DB11–20]. He is twice the recipient of best paper awards at the ACM/IEEE Digital Library Conference Series—Towards a digital library of popular music (1999), and Realistic Documents (2003)—and the book, How to Build a Digital Library (by Witten and Bainbridge) was recently shown to be the most used text book in the field [DB9]. He holds a PhD (1996) from the University of Canterbury, New Zealand where he studied as a Commonwealth scholar, and a Bachelor's degree from the University of Edinburgh, Scotland (1991) where he was the class medalist in Computer Science.
2.6.2 Affiliations: The digital library project has over 20 active researchers, and currently grants worth more than US $2.5M. The largest of these (US $1.7M) is Multimedia Management and Delivery where Bainbridge is the PI. Wider research connections within the Waikato Computer Science department are also central to Bainbridge’s NEMA collaboration. The department is ranked 1st for computer science research in New Zealand [DB10]. It is also home to two further world class research groups pertinent to this proposal: machine learning and human computer interaction. Weka29, for example, an open source machine learning workbench produced by Waikato, is already utilized by the IMIRSEL M2K/MIREX DIY projects at Illinois. Further collaborative links within the department will be exploited as needs dictate.
28 See http://www.greenstone.org/. 29 See http://www.cs.waikato.ac.nz/ml/weka/.
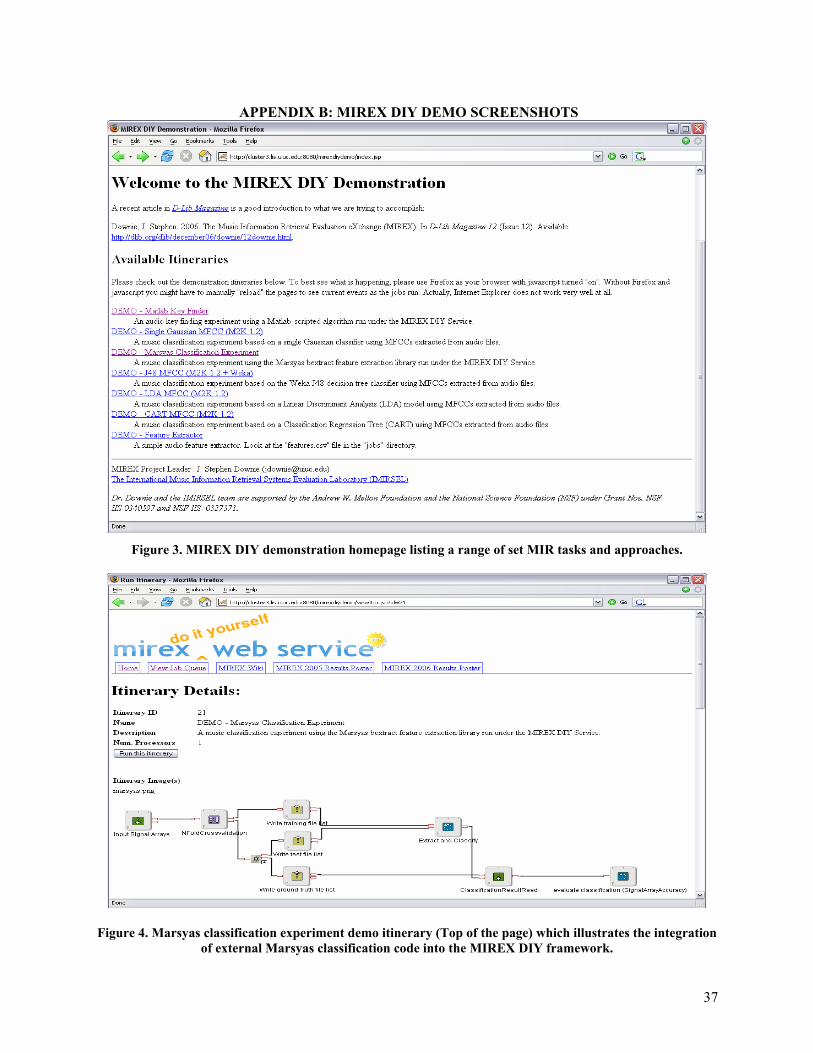
37
APPENDIX B: MIREX DIY DEMO SCREENSHOTS
Figure 3. MIREX DIY demonstration homepage listing a range of set MIR tasks and approaches.
Figure 4. Marsyas classification experiment demo itinerary (Top of the page) which illustrates the integration of external Marsyas classification code into the MIREX DIY framework.
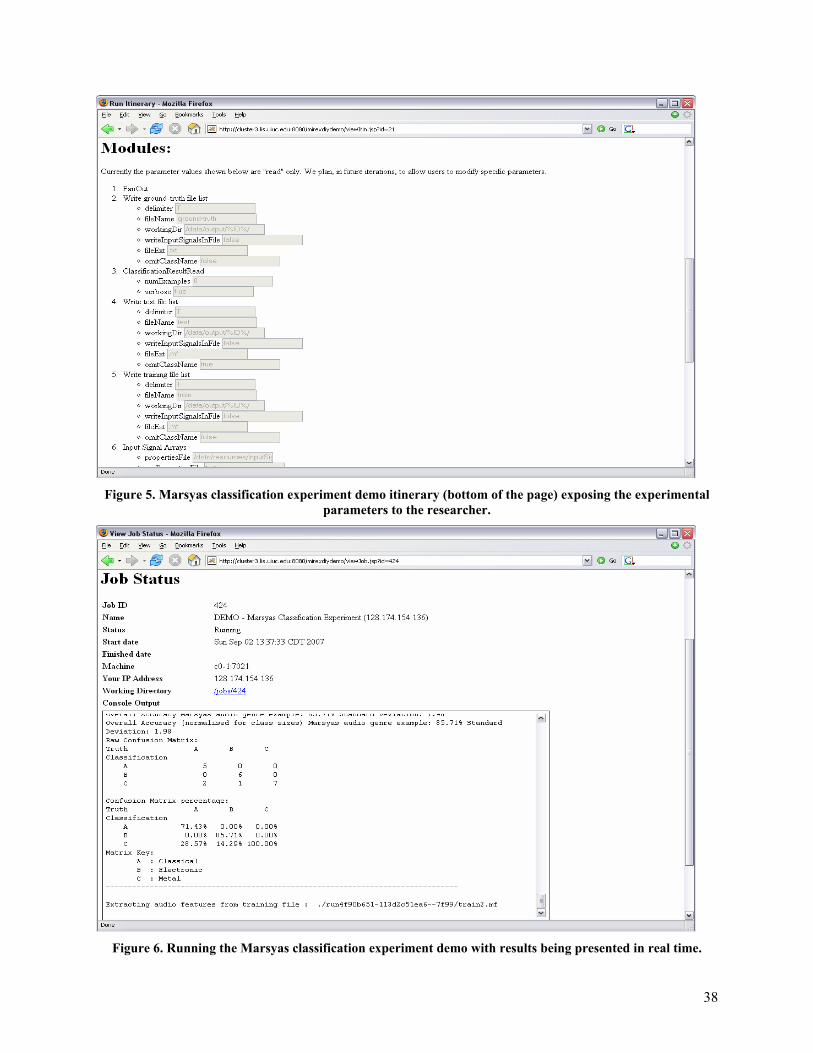
38
Figure 5. Marsyas classification experiment demo itinerary (bottom of the page) exposing the experimental
parameters to the researcher.
Figure 6. Running the Marsyas classification experiment demo with results being presented in real time.
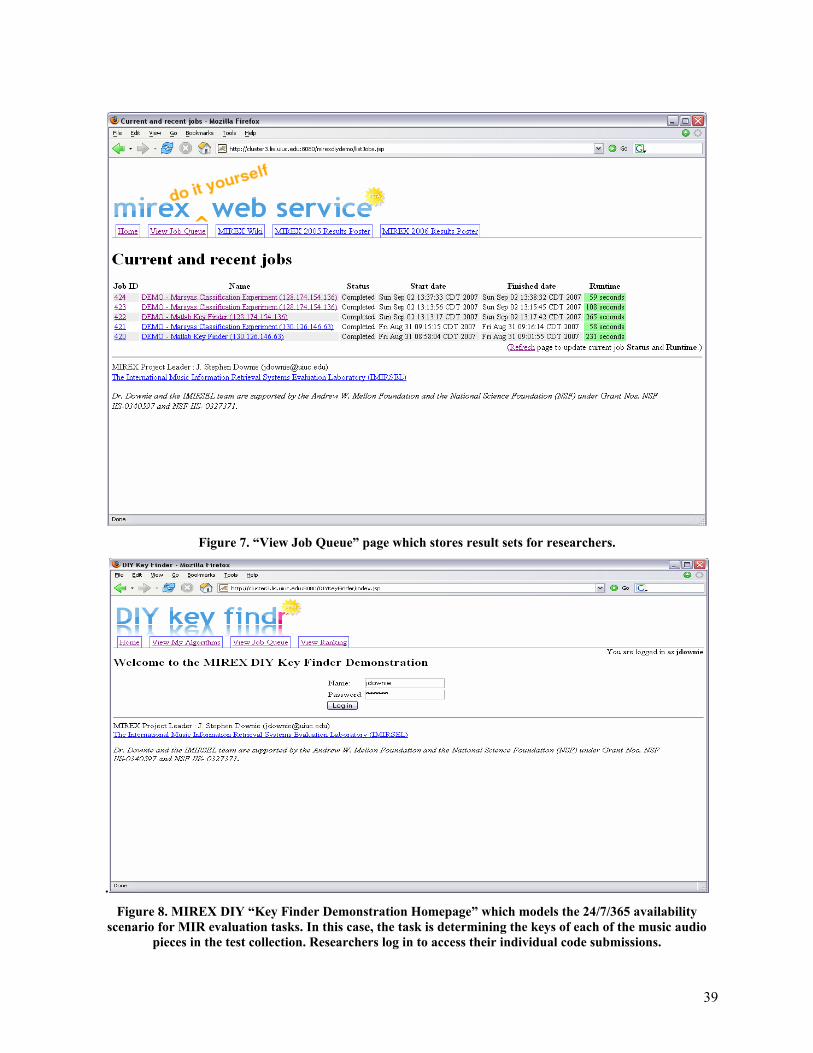
39
Figure 7. “View Job Queue” page which stores result sets for researchers.
.
Figure 8. MIREX DIY “Key Finder Demonstration Homepage” which models the 24/7/365 availability scenario for MIR evaluation tasks. In this case, the task is determining the keys of each of the music audio
pieces in the test collection. Researchers log in to access their individual code submissions.
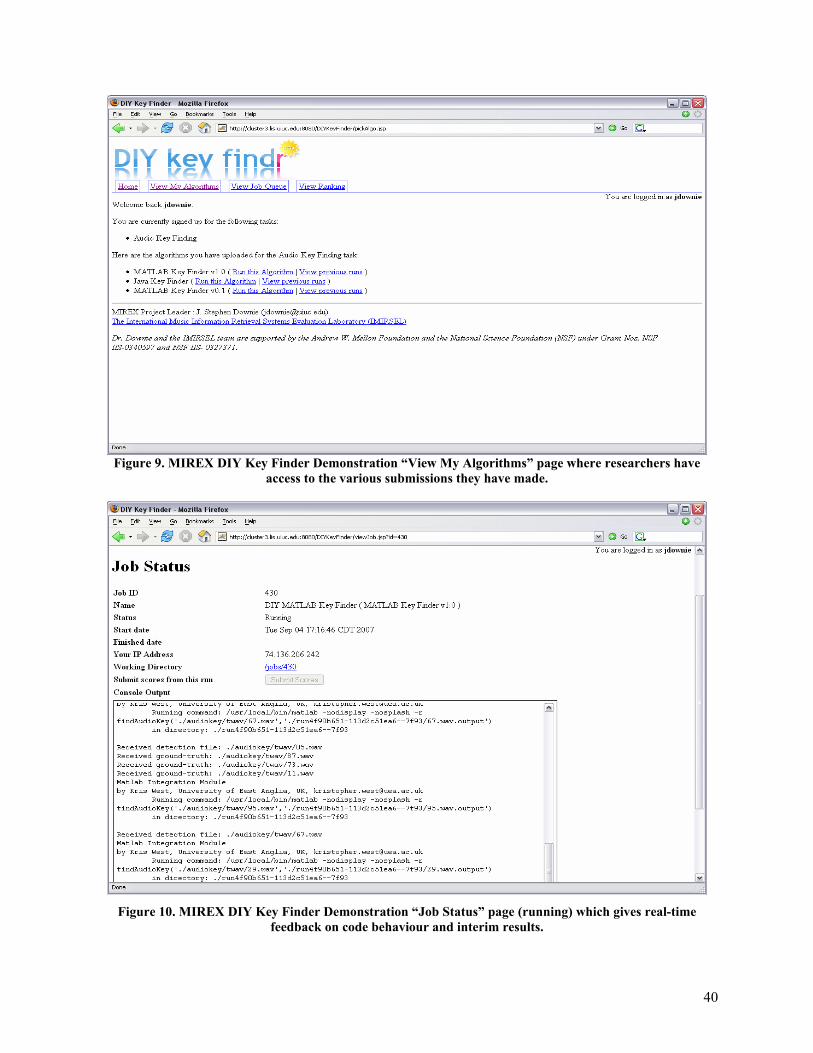
40
Figure 9. MIREX DIY Key Finder Demonstration “View My Algorithms” page where researchers have
access to the various submissions they have made.
Figure 10. MIREX DIY Key Finder Demonstration “Job Status” page (running) which gives real-time
feedback on code behaviour and interim results.
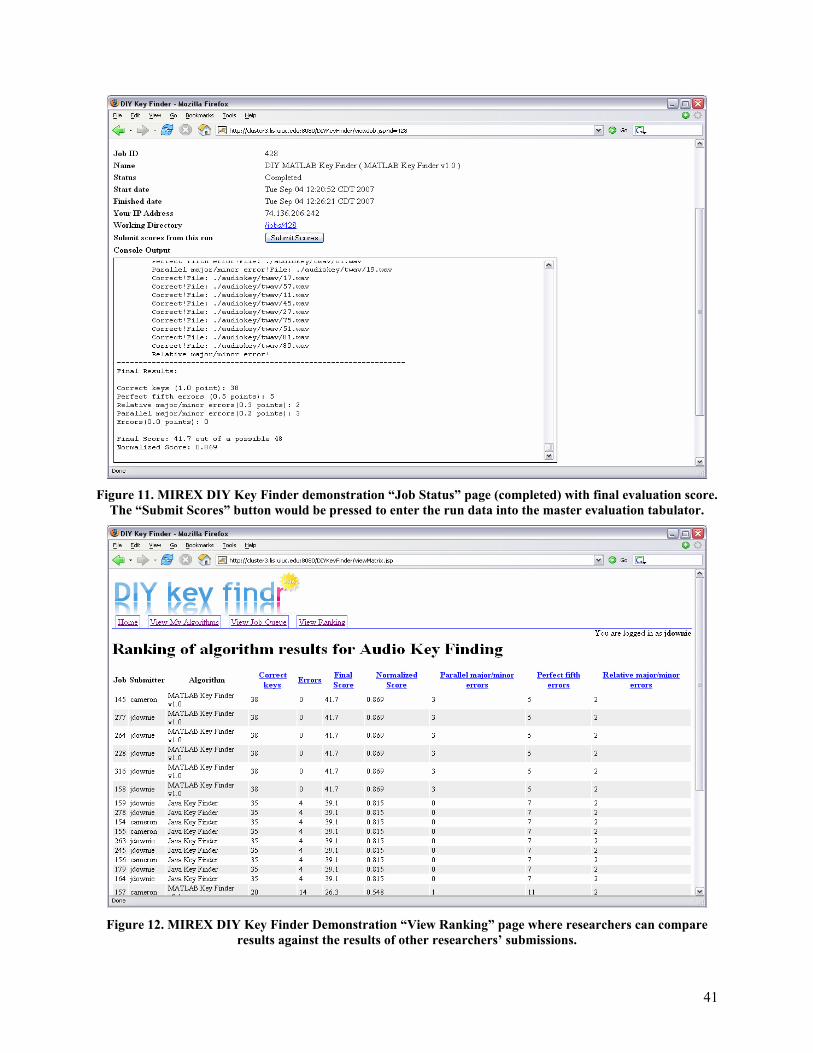
41
Figure 11. MIREX DIY Key Finder demonstration “Job Status” page (completed) with final evaluation score.
The “Submit Scores” button would be pressed to enter the run data into the master evaluation tabulator.
Figure 12. MIREX DIY Key Finder Demonstration “View Ranking” page where researchers can compare
results against the results of other researchers’ submissions.





























