Embed Size (px)
Citation preview

<http://www.cepis.org>
CEPIS, Council of European Professional Informatics
Societies, is a non-profit organisation seeking to improve and promote high standards among informatics
professionals in recognition of the impact that informatics has on employment, business and society.
CEPIS unites 36 professional informatics societies over 32 European countries, representing more than
200,000 ICT professionals.
CEPIS promotes
<http://www.eucip.com> <http://www.ecdl.com>
<http://www.upgrade-cepis.org>

* This monograph will be also published in Spanish (full version printed; summary, abstracts, and somearticles online) by Novática, journal of the Spanish CEPIS society ATI (Asociación de Técnicos deInformática) at <http://www.ati.es/novatica/>, and in Italian (online edition only, containing summary,abstracts, and some articles) by the Italian CEPIS society ALSI (Associazione nazionale Laureati in Scienzedell’informazione e Informatica) and the Italian IT portal Tecnoteca at <http://www.tecnoteca.it>.
Vol. VI, issue No. 3, June 2005
UPGRADE is the European Journal for theInformatics Professional, published bimonthly
at <http://www.upgrade-cepis.org/>
UPGRADE is the anchor point for UPENET (UPGRADE EuropeanNETwork), the network of CEPIS member societies’ publications, thatcurrently includes the following ones:• Mondo Digitale, digital journal from the Italian CEPIS society AICA• Novática, journal from the Spanish CEPIS society ATI• OCG Journal, journal from the Austrian CEPIS society OCG• Pliroforiki, journal from the Cyprus CEPIS society CCS• Pro Dialog, journal from the Polish CEPIS society PTI-PIPS
PublisherUPGRADE is published on behalf of CEPIS (Council of European ProfessionalInformatics Societies, <http://www.cepis.org/>) by Novática<http://www.ati.es/novatica/>, journal of the Spanish CEPIS society ATI(Asociación de Técnicos de Informática, <http://www.ati.es/>)
UPGRADE monographs are also published in Spanish (full version printed; summary,abstracts and some articles online) by Novática, and in Italian (summary, abstracts andsome articles online) by the Italian CEPIS society ALSI (Associazione nazionaleLaureati in Scienze dell’informazione e Informatica, <http://www.alsi.it>) and theItalian IT portal Tecnoteca <http://www.tecnoteca.it/>
UPGRADE was created in October 2000 by CEPIS and was first published byNovática and INFORMATIK/INFORMATIQUE, bimonthly journal of SVI/FSI (SwissFederation of Professional Informatics Societies, <http://www.svifsi.ch/>)
Editorial TeamChief Editor: Rafael Fernández Calvo, Spain, <[email protected]>Associate Editors:François Louis Nicolet, Switzerland, <[email protected]>Roberto Carniel, Italy, <[email protected]>Zakaria Maamar, Arab Emirates, <Zakaria. Maamar@ zu.ac.ae>Soraya Kouadri Mostéfaoui, Switzerland,<[email protected]>
Editorial BoardProf. Wolffried Stucky, CEPIS Past PresidentProf. Nello Scarabottolo, CEPIS Vice PresidentFernando Piera Gómez andRafael Fernández Calvo, ATI (Spain)François Louis Nicolet, SI (Switzerland)Roberto Carniel, ALSI – Tecnoteca (Italy)
UPENET Advisory BoardFranco Filippazzi (Mondo Digitale, Italy)Rafael Fernández Calvo (Novática, Spain)Veith Risak (OCG Journal, Austria)Panicos Masouras (Pliroforiki, Cyprus)Andrzej Marciniak (Pro Dialog, Poland)
English Editors: Mike Andersson, Richard Butchart, David Cash, Arthur Cook,Tracey Darch, Laura Davies, Nick Dunn, Rodney Fennemore, Hilary Green,Roger Harris, Michael Hird, Jim Holder, Alasdair MacLeod, Pat Moody, AdamDavid Moss, Phil Parkin, Brian Robson
Cover page designed by Antonio Crespo Foix, © ATI 2005Layout Design: François Louis NicoletComposition: Jorge Llácer-Gil de Ramales
Editorial correspondence: Rafael Fernández Calvo <[email protected]>Advertising correspondence: <[email protected]>
UPGRADE Newslist available at<http://www.upgrade-cepis.org/pages/editinfo.html#newslist>
Copyright© Novática 2005 (for the monograph and the cover page)© CEPIS 2005 (for the sections MOSAIC and UPENET)All rights reserved. Abstracting is permitted with credit to the source. For copying,reprint, or republication permission, contact the Editorial Team
The opinions expressed by the authors are their exclusive responsibility
ISSN 1684-5285
Monograph of next issue (August 2005):"Normalisation & Standardisation
in IT Security"(The full schedule of UPGRADE
is available at our website)
Monograph: Libre Software as A Field of Study (published jointly with Novática*, in cooperation with the
European project CALIBRE)Guest Editors: Jesús M. González-Barahona and Stefan Koch
2 PresentationLibre Software under The Microscope — Jesús M. González-Barahonaand Stefan Koch
5 CALIBRE at The Crest of European Open Source Software Wave —Andrea Deverell and Par Agerfalk
6 Libre Software Movement: The Next Evolution of The IT ProductionOrganization? — Nicolas Jullien
13 Measuring Libre Software Using Debian 3.1 (Sarge) as A Case Study:Preliminary Results — Juan-José Amor-Iglesias, Jesús M. González-Barahona, Gregorio Robles-Martínez, and Israel Herráiz-Tabernero
17 An Institutional Analysis Approach to Studying Libre Software‘Commons’ — Charles M. Schweik
28 About Closed-door Free/Libre/Open Source (FLOSS) Projects: Lessonsfrom the Mozilla Firefox Developer Recruitment Approach — SandeepKrishnamurthy
33 Agility and Libre Software Development — Alberto Sillitti and GiancarloSucci
38 The Challenges of Using Open Source Software as A Reuse Strategy —Christian Neumann and Christoph Breidert
43 Computational LinguisticsMultilingual Approaches to Text Categorisation — Juan-José García-Adeva, Rafael A. Calvo, and Diego López de Ipiña
52 Software EngineeringA Two Parameter Software Reliability Growth Model with An Im-plicit Adjustment Factor for Better Software Failure Prediction — S.Venkateswaran, K. Ekambavanan, and P. Vivekanandan
59 News & Events: Proposal of Directive on Software Patents Rejectedby The European Parliament
61 From Pliroforiki (CCS, Cyprus)Informatics LawSecurity, Surveillance and Monitoring of Electronic Communicationsat The Workplace — Olga Georgiades-Van der Pol
66 From Mondo Digitale (AICA, Italy)Evolutionary ComputationEvolutionary Algorithms: Concepts and Applications — Andrea G. B.Tettamanzi
UPENET (UPGRADE European NETwork)
MOSAIC

2 UPGRADE Vol. VI, No. 3, June 2005 © Novática
Libre Software as A Field of Study
PresentationLibre Software under The Microscope
Jesús M. González-Barahona and Stefan Koch
1 ForewordLibre (free, open source) software has evolved during
the last decade from an obscure, marginal phenomenon intoa relatively well-known, widely available, extensively usedset of applications. Libre software solutions are even mar-ket leaders in some segments and are experiencing hugegrowth in others. Products such as OpenOffice.org, Linux,Apache, Firefox and many others are part of the daily expe-rience of many users. Companies and public administra-tions alike are paying more and more attention to the ben-efits that libre software can provide when used extensively.
However, despite this increasing popularity, libre soft-ware is still poorly understood. Perhaps because of this, inrecent years the research community has started to focussome attention on libre software itself: its developmentmodels, the business models that surround it, the motivationsof the developers, etc. In this context, we (invited by UP-GRADE and Novática, two journals that have shown foryears a serious interest in this field1) felt that the time wasripe to put together this monograph on "Libre Software as AField of Study". Consequently, we issued a call for contri-butions, which led to a process in which each proposal wasreviewed by at least two experts in the field.
2 DefinitionThe term "Libre Software" is used in this introduction,
and in the title of this special issue, to refer to both "freesoftware" (according to the Free Software Foundation, FSF,definition) and "open source software" (as defined by theOpen Source Initiative, OSI). "Libre" is a term well under-stood in romance languages (i.e. from Latin origin), such as
Spanish, French, Catalan, Portuguese and Italian, and un-derstandable in many others. It avoids the ambiguity of"free" in English, since "libre" means only "free as in freespeech", and the term is used in Europe in particular, al-though its first use can be traced to the United States2 .
Libre software is distributed under a license that com-plies with the "four freedoms", as stated by Richard Stallmanin "The Free Software Definition": The freedom to run the program for any purpose (free-
dom 0). The freedom to study how the program works and adapt
it to your needs (freedom 1). Access to the source codeis a precondition for this.
The freedom to redistribute copies so you can help yourneighbour (freedom 2).
The freedom to improve the program and release yourimprovements to the public, so that the whole commu-nity benefits (freedom 3). Access to the source code is aprecondition for this.Therefore, libre software is defined by what users can
do when they receive a copy of the software, and not byhow that software was developed, nor by whom, nor withwhat intentions.
However, although there is nothing in the definitionabout how the software has to be produced or marketed tobecome "libre", the four freedoms enable some develop-ment and business models while making others difficult orimpossible. This is why we often talk about "libre softwaredevelopment models" or "libre software business models".Both terms are not to be understood as "models to be fol-
The Guest Editors
Jesús M. González-Barahona teaches and researches at theUniversidad Rey Juan Carlos, Madrid, Spain. He started workingin the promotion of libre software in the early 1990s. Since thenhe has been involved in several activities in this area, such asthe organization of seminars and courses, and the participationin working groups on libre software. He currently collaboratesin several libre software projects (including Debian), andparticipates in or collaborates with associations related to libresoftware. He writes in several media about topics related to li-bre software, and consults for companies on matters related totheir strategy regarding these issues. His research interestsinclude libre software engineering and, in particular, quantitativemeasures of libre software development and distributed toolsfor collaboration in libre software projects. He is editor of theFree Software section of Novática since 1997 and has been guesteditor of several monographs of Novática and UPGRADE onthe subject. <[email protected]>
Stefan Koch is an Assistant professor of Information Businessat the Vienna University of Economics and BusinessAdministration, Austria. He received a MBA in ManagementInformation Systems from Vienna University and ViennaTechnical University, and a Ph.D. from Vienna University ofEconomics and Business Administration. His research interestsinclude libre software development, effort estimation for soft-ware projects, software process improvement, the evaluation ofbenefits from information systems and ERP systems. He is alsothe editor of the book “Free/Open Source SoftwareDevelopment”, published by IGP in 2004. <[email protected]>.

UPGRADE Vol. VI, No. 3, June 2005 3© Novática
Libre Software as A Field of Study
lowed to qualify as libre software", but simply as modelswhich are possible, perhaps common, in the world of libresoftware.
3 Aspects of StudyTaking this definition as our framework, there has been
a great deal of research in recent years about developmentand business models for libre software, about themotivations of developers producing that software, andabout the implications (economic, legal, engineering) of thisnew approach. In other words, libre software has becomein itself a subject for study; a new field in which differentresearch approaches are being tried in order to increase ourunderstanding of it How is libre software actually beingproduced, what room for improvement is still left, whichbest practices can be identified, what implications does libresoftware have for users and producers of software, how canlibre software development be improved, which ideas andprocesses can be transferred to the production of propri-etary software, what insights can be gained into open crea-tion processes and user integration, etc. are just some of thequestions being addressed by this research. Some of themare standard questions only now being put to the libre soft-ware world; others are quite specific and new.
4 Papers in This MonographThis monograph issues contains seven papers that cover
several of the topics mentioned above and make use of agreat variety of empirical and theoretical approaches. Thefirst paper, by Andrea Deverell and Par Agerfalk, is aboutthe CALIBRE (Co-ordination Action for LIBRE Software)project, funded by the European Commission to improveEuropean research in the field of libre software.
After this comes a paper entitled "Libre Software Move-ment: The Next Evolution of The IT Production Organiza-tion?", written by Nicolas Jullien, which discusses the dis-semination of libre software. It argues from a historical per-spective that libre software constitutes the next evolutionin industrial IT organization.
The next few papers deal with workings within libresoftware projects. Juan-José Amor-Iglesias, Jesús M.González-Barahona, Gregorio Robles-Martínez and IsraelHerráiz-Tabernero, in their paper "Measuring Libre Soft-ware Using Debian 3.1 (Sarge) as A Case Study: Prelimi-nary Results", show empirical results from one of the mostpopular and largest projects in existence, based on an analy-sis of source code. Charles M. Schweik tries to identifydesign principles leading to a project’s success or failure;in his paper "An Institutional Analysis Approach to Study-
ing Libre Software ‘Commons’" he presents a frameworkfor analysing the institutional design of commons settingsto be applied to libre software projects. Finally, SandeepKrishnamurthy, using Mozilla Firefox as an example, chal-lenges the view that in libre software projects, anyone canparticipate without hindrance. He coins the term "closed-door project" for projects with a tight control and explainswhy such a strategy might be adopted in his paper "AboutClosed-door Free/Libre/Open Source (FLOSS) Projects:Lessons from the Mozilla Firefox Developer RecruitmentApproach".
The issue concludes with two papers which aim to putlibre software and its development in the context of ‘main-stream’ software engineering practices. Alberto Sillitti andGiancarlo Succi in their paper "Agility and Libre SoftwareDevelopment" evaluate the relationship and commonalitiesbetween agile software development methodologies, in par-ticular eXtreme Programming, and libre software develop-ment. Christian Neumann and Christoph Breidert presenta framework for comparing different reuse strategies in soft-ware development. In their paper titled "The Challenges ofUsing Open Source Software as a Reuse Strategy" they givespecial consideration to the required technical and economi-cal evaluation.
AcknowledgmentsAs with any work, this monograph would not have been
possible without the help of several people. Naturally, themost important work was carried out by the authors them-selves, and the reviewers also devoted their time to help inselecting and improving the submissions. In total, 16 au-thors contributed submissions, and 16 people provided valu-able feedback and assistance by helping with the review-ing. Following the ideals of libre software development,these reviewers are named here in order to give special rec-ognition of their contribution: Olivier Berger, CorneliaBoldyreff, Andrea Capiluppi, Jean Michel Dalle, RishabGhosh, Stefan Haefliger, Michael Hahsler, George Kuk,Björn Lundell, Martin Michlmayr, Hans Mitloehner,Martin Schreier, Ioannis Stamelos, Ed Steinmueller,Susanne Strahringer, and Thomas Wieland.
The cooperation of the team in the CALIBRE projecthas also been very useful, both in providing ideas and incollaborating with their effort. Finally, we would also liketo acknowledge the help, assistance and guidance of RafaelFernández Calvo, Chief Editor of UPGRADE andNovática, during the entire process of preparing and as-sembling this special issue.
1 Novática, in addition to have a section dedicated to this field since1997, has published three monographs on it – 1997, 2001, and 2003 –jointly with UPGRADE in the last two cases (see <http://www.ati.es/novatica/indice.html> and <http://www.upgrade-cepis.org/pages/pastissues.html>).
2 For a brief study of the origins of the term "libre software", visit <http://sinetgy.org/jgb/articulos/libre-software-origin/libre-software-origin.html>.

4 UPGRADE Vol. VI, No. 3, June 2005 © Novática
Libre Software as A Field of Study
Useful References on Libre Software as A Field of Study
In addition to the references included in the papers thatmake part of this monograph, readers who wish to understand thelibre (free, open source) software phenomenon in greater detailmay be interested in consulting the following sources.
Books· C. DiBona, S. Ockman, and M. Stone (eds.). Open Sources:
Voices from the Open Source Revolution. O’Reilly and Associ-ates, Cambridge, Massachusetts, 1999. Available at <http://www.oreilly.com/catalog/opensources/book/toc.html>.
· J. Feller and B. Fitzgerald. Understanding Open Source Soft-ware Development. Addison-Wesley, London, 2002.
· J. Feller, B. Fitzgerald, S.A. Hissam, and K.R. Lakhani (eds.).Perspectives on Free and Open Source Software. The MIT Press,Boston, Massachusetts, 2005.
· J. García, A. Romeo, C. Prieto. La Pastilla Roja, 2003. ISBN:84-932888-5-3. <http://www.lapastillaroja.net/>. (In Spanish.)
· S. Koch (ed.). Free/Open Source Software Development. IdeaGroup Publishing, Hershey, PA, 2004.
· V. Matellán Olivera, J.M. González Barahona, P. de las HerasQuirós, G. Robles Martínez (eds.). Sobre software libre.
Compilación de ensayos sobre software libre. GSYC,Universidad Rey Juan Carlos, 2003. Available at <http://gsyc.escet.urjc.es/~grex/sobre-libre/>. (In Spanish.)
· E.S. Raymond. The Cathedral and the Bazaar: Musings on Linuxand Open Source by an Accidental Revolutionary. O’Reilly andAssociates, Sebastopol, California, 1999.
· R.M. Stallman. Free Software, Free Society: Selected Essays ofRichard M. Stallman. GNU Press, Boston, Massachusetts, 2002.Also avalaible at <http://www.gnu.org/philosophy/fsfs/rms-essays.pdf >.
Web Sites· Opensource, a collection of publicly accessible papers about libre
software. <http://opensource.mit.edu>.· Slashdot, the community site for the worldwide libre software
community. <http://slashdot.org>.· Sourceforge, the largest hosting site for libre software projects.
<http://sourceforge.net>.· Free Software Foundation. <http://fsf.org>.· Open Source Initiative (OSI). <http://opensource.org>.· BarraPunto, the community site for the Spanish libre software
community. <http://barrapunto.com>.

UPGRADE Vol. VI, No. 3, June 2005 5© Novática
Libre Software as A Field of Study
CALIBRE (Co-ordination Action for Libre Software)1,a EUR 1.5 million EU-funded project which aims to revo-lutionise how European industry leverages software andservices, was officially launched on Friday 10 September2004 in Ireland. CALIBRE comprises an interdisciplinaryconsortium of 12 academic and industrial research teamsfrom Ireland, France, Italy, the Netherlands, Poland, Spain,Sweden, the UK and China.
Libre software, more widely known as "open sourcesoftware" (OSS), is seen as a significant challenge to thedominance of proprietary software vendors. The open sourcephenomenon, which has produced such headline productsas the Linux operating system, involves the sharing of soft-ware source code with active encouragement to modify andredistribute the code. Open source has lead to the emer-gence of innovative new business models for software andservices, in which organisations have to compete on prod-uct and service attributes other than licensing prices. Froma broader business perspective, several innovative businessmodels and new business opportunities have emerged as aresult of the OSS phenomenon, and many organisations havebegun to capitalise on this. In terms of competitiveness, theOSS phenomenon has created a new service market for com-mercial enterprises to exploit and there are several exam-ples whereby these companies have innovatively forgedcompetitive advantage. Since purchase price and license feesare not a factor, OSS companies have to compete predomi-nantly in terms of customer service. Since OSS countersthe trend towards proprietary monopolies, the OSS modelinherently promotes competitiveness and an open market.Also, by having access to source code, traditional barriersto entry which militate against new entrants are lowered.This provides a great opportunity for small and mediumsized enterprises to collaborate and compete in segmentstraditionally dominated by multinationals.
Although much of the recent OSS debate has focused pri-marily on desktop applications (Open Office, Mozilla Firefox,etc.), the origins and strengths of OSS have been in the plat-form-enabling tools and infrastructure components that under-pin the Internet and Web services; software like GNU/Linux,Apache, Bind, etc. This suggests that OSS may have a particu-larly important role to play in the secondary software sector;i.e. in domains where software is used as a component in otherproducts, such as embedded software in the automotive sector,consumer electronics, mobile systems, telecommunications,and utilities (electricity, gas, oil, etc.). With a focus on the sec-
CALIBRE at The Crest of European Open Source Software WaveAndrea Deverell and Par Agerfalk
This paper is copyrighted under the CreativeCommons Attribution-NonCommercial-NoDerivs 2.5 license available at <http://
creativecommons.org/licenses/by-nc-nd/2.5/>
ondary software sector, different vertical issues, such as em-bedded software and safety critical applications, are broughtto the fore. The differences in how horizontal issues play outacross different vertical sectors can be dramatic. For example,the nuances of the software development context in the bank-ing sector are very different from those which apply in theconsumer electronics or telecommunications sectors. A vibrantEuropean secondary software sector provides fertile researchground for studying the potential benefits of OSS from a com-mercial perspective.
Professor Brian Fitzgerald at the University of Limer-ick believes that "there is enormous potential to provideincreased productivity and competitiveness for Europeanindustry by challenging the proprietary models that domi-nate software development, acquisition and use".
As part of the two-year CALIBRE project a Europeanindustry open source software research policy forum hasbeen established. Known as CALIBRATION it comprisesa number of influential organisations such as Philips Medi-cal, Zope Europe, Connecta, Vodafone and others. The aimof this forum is to facilitate the adoption of next generationsoftware engineering methods and tools by European in-dustry, particularly in the ‘secondary’ software sector (e.g.automotive, telecommunications, consumer electronics, etc.)where Europe is acknowledged to have particular competi-tive strengths. The forum also plays a central role in theEuropean Union policy process.
CALIBRE is focused on three scientific research pillars:open source software, agile methods and globally-distributedsoftware development. The CALIBRE consortium comprisesthe leading researchers in each of these areas. The intention isto closely link these researchers with the key industrial part-ners through the CALIBRATION Industry Policy Forum anda series of dissemination events. Enabling the industrial part-ners to refine and reshape the CALIBRE research agenda. Thiswill allow for rapid dissemination, and the proactive formula-tion of policy initiatives. Upcoming events organised or co-organised by CALIBRE include: 11th -15th July, OSS 2005, Genova, Italy. 9th September 2005, University of Limerick, Ireland,
title of conference: "The Next Generation of Software En-gineering: Integrating Open Source, Agile Methods and Glo-bal Software Development". CALIBRE Workshop on Quality and Security in OSS,
18 Oct 2005 at the 7th National Conference on SoftwareEngineering, Krakow, 18-21 Oct 2005.
For further information please visit <http://www.calibre.ie> or contact: Andrea Deverell, CALIBRE Eventsand Industry Forum Co-ordinator, University of Limerick,Phone: +353 61 202737. Email: <[email protected]>
1 CALIBRE has cooperated with UPGRADE and Nováticafor the production of this monograph.

6 UPGRADE Vol. VI, No. 3, June 2005 © Novática
Libre Software as A Field of Study
Keywords: Evolution of The IT Industry, FLOSS, Free/Libre/OpenSource/Software, Industrial Economics.
1 IntroductionThe diffusion of Libre Software products eventually
changes the way programs are elaborated, distributed andsold, and thus may cause profound changes to an IT (Infor-mation Technology) industrial organization. It would be farfrom an exceptional phenomenon, as, in the field of Infor-mation Technology, the industrial structure has undergonetwo major changes since fifty years1.
Considering these points, we may wonder whether weare on the eve of a new industrial structure and whether itwill be based on a libre organization.
To do so, we show that the IT industry today presentsthe same characteristics as those viewed in former evolutions(part 1). In part 2 we present the arguments which cause usto believe that libre organization is becoming a dominantorganization for the computer industry.
2 Some Characteristics of The Computer Industry2.1 Economics SpecificitiesFirst of all, a software program can be considered as a
"public good", given that21:- "it is non-rivalrous, meaning that it does not exhibit
scarcity, and that once it has been produced, everyone canbenefit from it.
- it is non-excludable, meaning that once it has been
Libre Software Movement: The Next Evolution ofThe IT Production Organization?
Nicolas Jullien
© Verbatim copy of this article is permitted only in whole, without modifications and provided that authorship is recognized
Free (Libre) software diffusion represents one of the main evolutions of the Information Technology (IT) industry in recentyears. It is not the least surprising either. In this article we first try to replace this diffusion in its historical context. We firstshow that the IT industry today presents the same characteristics as those viewed in former evolutions. And we present thearguments which explain why we think that libre may become a dominant organization for the computer industry.
Nicolas Jullien defended his PhD work on the economy of li-bre software in 2001. He is today in charge of coordinating aresearch group on the uses of IT applications in Brittany (France),called M@rsouin (Môle Armoricain de Recherche sur la SOciétéde l’information et les Usages d’INternet, <http://www.marsouin.org>). He also manages the European CALIBRE(Coordination Action for LIBRE Software Engineering) projectfor GET (Groupe des Écoles des Télécommunications, <http://www.get-telecom.fr/fr_accueil.html>), one of the participantsof the project. <[email protected]>
created, it is impossible to prevent people from gaining ac-cess to the good."
In addition, this good is not destroyed by use, so it canbe bought one for all.
The second characteristic of a computer product is thatit is not made of one piece but rather of a superposition ofseveral components: hardware (with one specific piece, themicroprocessor), the operating system and the programs.This implies coordination between different producers, orthat a single producer produces all the components.
The third characteristic, which actually is a consequenceof the first two, is that computer products, and especially,software are subject to "increasing returns to adoption", touse the term from Arthur [1]. He has defined 5 types ofIncreasing Returns to Adoption, impacting directly from thesingle user to the whole market, and these five are presentin the computer software industry:
Learning effect, meaning that you learn to use a pro-gram, but also a programming language, making it harderto switch to another offer.
Network externalities (the choices of the people you ex-change with have an impact on the evaluation you make forthe quality of a good). For instance, even if a particular texteditor is not the one which is most appropriate to your docu-ment creation needs, you may choose it because everybodyyou exchange with sends you text in that format, and soyou need this editor to read the texts.
Economy of scale: because the production of computerparts involves substantial fixed costs, the average cost perunit decreases when production increases. This is especiallythe case for software where there are almost only fixed costs1 To avoid the ambiguity of the nouns "Free" (as freedom) or "Open Source"
software, we prefer the French acceptation, increasingly used, of 'Libre'.In any case, we are here speaking of software for which the licensee canget the source code, is allowed to modify this code and redistribute thesoftware and the modifications.
2 Our understanding of the history of the information technology owesmuch the work of Breton [5], Genthon [13] and Dréan [11]. The analy-sis of the organization of the IT industry is also based on the work ofGérard-Varet and Zimmermann [16], introduced in Delapierre et al. [10].Lastly, our analysis of the economy and industry of software programsowes much to Mowery [25] and Horn [19], whose works, it seems to us,are a reference in this field. We encourage all those who are eager toknow more about these subjects to read these studies.

UPGRADE Vol. VI, No. 3, June 2005 7© Novática
Libre Software as A Field of Study
(this is a consequence of the fact that it presents the charac-teristics of a public good).
Increasing return to information: one speaks more ofLinux since it is widely distributed.
Technological interrelations: as already explained, apiece of software does not work alone, but with some mate-rial and other pieces of software. What makes the 'value' ofan operating system is the number of programs availablefor this system. And the greater the number of people whochoose an operating system, the wider the range of soft-ware programs for this very system, and vice versa.
This means that this industry has four original charac-teristics, in terms of competition structure, according toRichardson [31].
software being "public goods", the development and pro-duction costs do not depend on the size of user population,and extending this population can be done at a cost, which,if not null, is negligible compared to development costs.
The pace of innovation is huge, because since the prod-uct is not destroyed by use, only innovative, or at least dif-ferent, products can be resold. This results in the reductionof the product’s life length.
These two characteristics lead to fierce competition,aggressive pricing, and firms trying to impose their solu-tion as the standard in order to take advantage of monopolyrent.
The other two characteristics are consequences of the"network effect" and of "technological interrelations":
Firms owning a program have an incentive to developsome pieces of software which complement the one theyalready have. But they are unable to respond to the wholespectrum of demand connected to their original device (es-pecially when speaking of key programs such as operatingsystems). So, at the same time, new firms appear to respondto new needs.
The consequence is that standards play a very importantrole because they make it possible for complementary goodsto work together. Here again, controlling a program, if itmeans controlling a standard, is an asset. But to meet all thedemands, one has to make public the characteristics of thestandard (or at least a part of it).
Knowing these characteristics and their consequenceshelp us to understand the evolutions of the industry sinceits emergence in the middle of the last century.
2.2 Technological Progress, New Markets, VerticalDisintegrations and New "Competition Regimes"
We will see that each period is characterized by a tech-nology which has allowed firms to propose new productsto new consumers.
1. A dominant technological concept: in the first pe-riod (mid 1940s to mid 1960s), there was no real differen-tiation between hardware and software, and computers were'unique' research products, built for a unique project. Thanksto technological progress (miniaturization of transistors,compilers and operating systems), in the second period(early 1960s to early 1980s), the scope of use extended in
two directions: the reduction of size and the price of com-puters, raising the number of organizations able to affordthem, and the increase in computing capacities, allowingthe same computer to serve different uses. But the mainevolution characterizing the period was that the same pro-gram could be implemented in different computers (fromthe same family), allowing the program to evolve, to growin size, and to serve a growing number of users. The com-puter had become a 'classical' good, to be changed once nolonger efficient or too old, but without losing the invest-ments made in software. With the arrival of the micro-proc-essor, the third period began in the late 1970s. Once againthe scope of use extended in two directions (increase inpower and reduction in size and price of low-end comput-ers), the dominant technological concept being that the sameprogram can be packaged and distributed to different per-sons or organizations, in the same way as for other tangiblegoods.
2. … for a dominant use: in the first period, comput-ers were computing tools, or research tools, for researchcenters (often military ones). In the second period (early1960s to the beginning of the 1980s), they had become toolsfor centralized processing of information for organizations(statistics, payment of salaries, etc.), the size of organiza-tions having access to this tool decreasing during the pe-riod. The third period is that of personal, but professional,information processing.
3. … and a dominant type of increasing return toadoption. Being a tool for specialists, where each projectallowed producers and users to better understand the possi-bilities of such machines, the first period was dominated bylearning and using, thus with significant R&D (Research &Development) costs. In the second period, this learning byusing effect did not disappear, as users were able to keeptheir home-made programs while changing their computer.This possibility also created the dominant increasing returnto adoption effect: technological interrelations. As, factu-ally, a program was developed for and worked with onesingle operating system, it became difficult for a client tobreak the commercial relation, once initiated, with a pro-ducer. In "exchange" this client no longer even needed tounderstand the hardware part of the machine. As in the sec-ond period, this effect did not disappear in the third. But thethird period is dominated by the economy of scope thanksto the distribution of computers, especially PC productionorganization3 but principally because of the developmentof standardized programs [25].
These technological characteristics provide elements tobetter understand the structure of the computer industry:
3 'Opening' the hardware part of PC, IBM allowed competitors to producesimilar machines and component producers to distribute their productsto different producers. This has increased competition, in terms of pricebut also in terms of component efficiency. In return, the distribution ofPC has allowed producers to increase the volume of components sold,and thus to decrease their price, as this production is mainly a fixed costproduction (the R&D and the construction of the capacities of produc-tion).

8 UPGRADE Vol. VI, No. 3, June 2005 © Novática
Libre Software as A Field of Study
the increasing returns to adoption provide those companieswhich control them with dominant positions.
In the first period the more you participated in projects,the more able you were to propose innovations for the nextproject, thanks to the knowledge accumulated. This explainsthe quick emergence of seven dominant firms (in the USA).
The second period was initiated by IBM, with the re-lease of the 360 Series, the first family of computers shar-ing the same operating system. At the end of the period,IBM was the dominant firm (even sued for abusing a mo-nopoly position), even if incomers like HP and Digital hadgained significant positions with mini-computers. Oncethese companies had installed a computer for a client, tech-nological interrelations meant that this client would facesubstantial costs if switching to another family run by an-other operating system. And the more clients they served,the more they could invest in R&D to develop the efficiencyof their computer family, but also the more they could spendon marketing to capture new clients. Once again this favoredthe concentration in manufacturing business.
In the third period, once again, the winners were thosewho controlled the key elements of the computer, central interms of technological interrelation: operating systems still,but also micro-processors. They were the companies whichcaptured the greatest part of the economy of scale benefits,as competition made prices fall in the other sectors, in par-ticular for the machines which were a source of high profitbefore, but also for other components.
If this standardization is one of the key elements whichmade the distribution of computers possible, it also gener-ates some inefficiencies because the control of such stand-ards by a single company can lead to this company abusingits dominant/monopoly position. This suspicion occurredat the end of the seventies concerning IBM, and todayMicrosoft has been sued for abusing its dominant position.It is not our aim to debate the reality of these practices. Butthe existence of such processes proves that some actors donot feel that the redistribution of increasing return to adop-tion benefits is efficient.
3 On The Eve of A New Step in The History ofThe Information Technology Industry?
3.1 A Need for Normalized "Mass-custom made"Products
3.1.1 New Technologies.During the 1990s, with the arrival of the Internet, the
principal technical evolution in information technology was,of course, the generalization of computer networking, bothinside and outside organizations. Miniaturization also al-lowed the appearance of a new range of 'nomad' products('organizers' like Psion and Palm , music players, mobilephones).
This falls within the constant evolution of informationtechnology products. One has gone from a single machine,dedicated to one task known in advance and reserved for
the entire organization, to multiple, linked machines whichare used to carry out different tasks, varying in time, andwhich are integrated within various organizations. Network-ing, exchanging between heterogeneous systems, commu-nication between these machines have all become crucial.
In parallel with this evolution, software program tech-nologies have evolved too [17:126-128]: the arrival of ob-ject-oriented programming languages (C++, Java) allowedalready developed software components to be re-used. Thishas led to the concept of "modular software programs": theidea is to develop an ensemble of small software programs(modules or software components), which would each havea specific function. They could be associated with and us-able on any machine since their communication interfaceswould be standard.
3.1.2 New Dominant Increasing Return to AdoptionThus, the diffusion of the Internet, and the growth of the
exchanges outside the organization has made the network ex-ternalities the dominant increasing return to adoption.
3.1.3 New Dominant UsesAnd these programs and these materials are often pro-
duced by different firms, for different users. It is necessaryfor these firms to guarantee their availability in the future,in spite of changing versions.
Indeed, within client firms, the demand has become moreand more heterogeneous with the networking of varioussystems and the need for users working in the firm to sharethe same tools. Software programs (and more particularly,software packages) have to be adapted to the needs andknowledge of every individual without losing the economyof scale benefits, thus the standardization of the programsupon which the solution is based.
It then becomes logical that client firms should seek moreopen solutions which would guarantee them greater con-trol. For example, what the Internet did was not to offer a"protocol" in order to allow the simple transmission of data,since this already existed, but to offer a sufficiently simpleand flexible one that allowed it to impose itself as a stand-ard for exchange.
This is so much the case that Horn [19] defends the ideathat we may have entered a new phase in production: "masscustom-made production".
3.1.4 Towards A New Industrial Organization?However, these service relationships have not proved to
be efficient enough. When one looks into the satisfactionsurveys that have been done with regard to information tech-nology products4, one notes that people are satisfied withrespect to the computer itself but not with the after-salesservice, especially with software programs. The basic ten-dency shown by the 01 Informatique survey is that the cli-
4 This is not new, see for instance the satisfaction survey which has beencarried out over three years by "01 informatique" weekly magazine forlarge French organizations (issue no.. 1521 in 1998, 1566 in 1999, and1612 in 2000). Other inquiries exist which are sometimes even harsher,like those of De Bandt [9], or Dréan [11] (pp. 276 and following).

UPGRADE Vol. VI, No. 3, June 2005 9© Novática
Libre Software as A Field of Study
ent seeks a better before and after-sales support. He/she alsowants to be helped to solve his/her difficulties and wantshis/her needs to be satisfied.
We have found all the elements present on the eve of anew period of IT organization: some technical evolutions,corresponding to some evolutions of demand, for which thepresent industrial organization appears relatively inefficient.
If we admit that we are at the beginning of a new indus-trial organization, or "regime of competition", one can askwhat could be the characteristics of such a regime.
3.2 Can Libre Be The Next Industrial Organization?We will defend the idea that the innovation of Libre con-
cerns the software development process. It provides the in-dustry with two linked 'tools': a system to produce whatRomer [32] has called "public industrial goods" in order toorganize norm development and implementation5, both ofwhich the software industry lacked.
This should make it possible to redefine service rela-tions, and, in that way, causing the industrial organizationto evolve.
3.2.1 Libre Production: A Way to Organize A PublicIndustrial Goods Production, Respecting Norms ...
More than mere public research products, libre programswere, first and foremost, tools developed by user-experts,to meet their own needs. The low quality of closed softwarepackages and, especially, the difficulty of making themevolve was one of the fundamental reasons for RichardStallman’s initiative6. These user-experts are behind manylibre software development initiatives (among which areLinux, Apache or Samba) and have improved them. Onemust also note that, concerning these flagship software pro-grams, this organization has obtained remarkable results interm of quality and quick improvements7.
This is undoubtedly due to the free availability of thesources which allowed skilled users to test the software pro-grams, to study their code and correct it if they found er-
rors. The higher the number of contributors, the greater thechance that one of these contributors will find an error, andwill know how to correct it. But libre programs are alsotools (languages) and programming rules that make thisreading possible. All this contributes to guarantee minimumthresholds of robustness for the software. Other libre pro-grams largely distributed are program development tools(compilers, such as GCC C/C++ compiler, developmentenvironment, such as Emacs or Eclipse). The reasons aretwofold: they are tools used by computer professional, who are
able and interested by developing or adapting their work-ing tools; they are the first tools you need to develop software
programs, and their efficiency is very important for pro-gram efficiency. That is why FSF’s first products were suchprograms, and particularly the GCC compiler.
Co-operative work, the fact that the software programsare often a collection of simultaneously evolving small-scaleprojects, also requires that the communication interfaceshould be made public and 'normalized'8. Open codes dofacilitate the checking of this compatibility and, if need be,the modification of the software programs. It is also remark-able to note that, in order to avoid the reproduction of di-verging versions of Unix, computer firms have set up or-ganizations which must guarantee the compatibility of thevarious versions and distribution of Linux. They must alsopublish technical recommendations on how to program theapplications so that they can work with this system in thesame spirit as the POSIX standard9.
The fact that firms use libre programs can be seen as thecreation of professional tools to collectively coordinate tocreate components and software program bricks which areboth reliable and, especially, 'normalized'. Up to now, thiscollective, normalized base has been lacking within the in-formation technology industry [11].
This normalization of the components used to build"mass custom-made products" helps to improve the qualityof this production because the services based on them maybe of better quality.
3.2.2 ... Allowing The Development of A More EfficientService Industry10
To prove that a more efficient, perennial service indus-try can be built on libre products, we have to analyze twopoints: from the firms’ perspective 1) that these offers aremore interesting than the existing ones and that there is somebusiness, 1.bis) that this business is financially sustainable;and from a global perspective 2) that in the long run it pro-
5 Still understood as economics theory defines it, meaning an open systemallowing actors to negotiate the characteristics of a component/product/interface and guarantying that product design would respect these char-acteristics.
6 Stallman ‘’invented’ the concept of libre program, with the creation ofthe GNU/GPL license and of the Free Software Foundation, the organi-zation which produces them; see <http://www.fsf.org/gnu/thegnuproject.html>. See also <http://www.gnu.org/prep/standards.html> fortechnical recommendations on how to program GNU software.
7 About the way libre development is structured, besides Raymond[28][29[30], one can also refer to Lakhani and von Hippel [24] and Jullien[21]. See Tzu-Ying and Jen-Fang [33] for a survey and an analysis ofon-line user community involvement efficiency, Bessen [4] and Baldwinand Clark [3] for a theoretical analysis of the impact of libre code archi-tecture on the efficiency of libre development. The latter argue that libremay be seen as a new development ‘institution’ (p. 35 and later). As toperformance tests, one can refer to <http://gnet.dhs.org/stories/bloor.php3> for operating systems. The results for numerous compara-tive evaluations are available on the following sites : <http://www.spec.org> and <http://www.kegel.com/nt-linux-benchmarks.html>(the latter mainly deals with NT/Linux).
8 In the sense that they respect public formats whose evolution is decidedcollectively.
9 It is the Free Standard Group, <http://www.freestandards.org/>. Amongothers, members of this committee are: Red Hat, Mandriva, SuSE/Novell,VA Software, Turbo Linux, and also IBM, SUN or Dell, etc.
10 This theoretical analysis is based on an study of the commercial strate-gies of companies saying they sell Libre software based services or prod-ucts in France (see Jullien [22]).

10 UPGRADE Vol. VI, No. 3, June 2005 © Novática
Libre Software as A Field of Study
vides actors with enough incentives to contribute to thedevelopment of such public goods to maintain the dyna-mism of innovation.
The BusinessThere is a business based on libre software. As with clas-
sical 'private'11 programs, when using libre ones, it is neces-sary to define one’s needs, to find a/the software programthat answers them, to install it and, sometimes, to adapt itby developing complementary modules. Once installed, itis necessary to follow its evolution (security upgrade, newfunctionalities...). It should be taken into account that users(firms, administrations or even single users) are not alwayscompetent enough to evaluate, install or follow the evolu-tion of these software programs. They do not always knowhow to adapt them to their own needs.
All this requires the presence of specialists of these soft-ware programs in the firm, which is not always easy. Andmost of the business users do not need them on a full-timebasis. That is why, for a long time, some agents from thelibre movement argue that "companies should be createdand that this activity should be profitable" (Ousterhout [27]).
Of course, the absence of license fees definitely bestowsa competitive advantage on the libre solution. But this alonedoes not justify its adoption: over the long term, this solu-tion must prove to be less expensive and yet offer the samequality standards. Proprietary solution manufacturers usethis indicator to defend their offers12.
Let’s consider now the specific advantages of libresoftware.
We have already said that the most mature libre pro-grams were of very high quality. This facilitates the rela-tionships between the producers of a software-based solu-tion and those who use this solution. Producers can moreeasily guarantee, through a contract, the reliability of thelibre programs they use, because they are able to evaluatetheir quality thanks to the norm they have set up during thedevelopment phase. An assistance network is available tothem and they can also intervene by themselves in thesesoftware programs. In addition, the fact that the softwareprogram sources are accessible and that the evolution ofthese programs is not controlled by a firm can reassure theadopter: the solution respects and will continue to respectthe standards. It will thus remain inter-operable with theother programs he/she uses.
The pooling of software bricks should also change thecompetition among service firms towards long-term rela-tionships and maintenance of software programs. It would
become more difficult for them to pretend that the malfunc-tioning of a software program they have installed andparameterized is due to a program error. This can encour-age firms to improve customer services and allows us tosay that, in this field, libre solutions can be competitive.
Does that 'theoretical' organization provide libre servicecompanies with profitable business models? This is undoubt-edly the most delicate point to defend today. There are fewexamples of profitable firms and many, still, have not reacheda balance. However, we can point the following points: with regard to production costs, thanks to construction
modules, the cost for developing software programs is morebroadly spread over time, thus resembling a service pro-duction structure whereby the missing functionality is de-veloped only when necessary. The contribution of the serv-ice firms does not relate to the entire production of a soft-ware program but to the production of these componentsfor clients who prefer libre programs so as not to depend ontheir supplier. Moreover, a component that has been devel-oped for one client can be re-used to meet the needs of an-other client. A "security hole" that has been detected forone client can be corrected for all the clients of the firm. Asa consequence, firms monopolize part of the economies ofscale generated by the collective use of a software program.In exchange, they guarantee the distribution of their inno-vations and corrections, which is one of the software edi-tors’ traditional roles. But traditionally, they finance thisactivity by producing and selling new versions of the soft-ware program. One may say that service firms which base their offers
on libre programs propose free 'codified' knowledge, thatis, software programs in order to sell the 'tacit' knowledgethey possess: the way software programs intimately func-tion, the capabilities of their developers to produce contri-butions that work, to have those who control the evolutionof software programs accept these contributions, etc. Thesefirms are the most competent to take advantage of the ben-efits linked to the apprenticeship generated by the develop-ment and improvement of software programs. because of these learning effects and because it is diffi-
cult to diffuse the tacit knowledge one needs to master inorder to follow and influence the evolution of a libre pro-gram, this role will inevitably be limited to a small numberof firms. They will bring together specialists in softwareprograms and will place them at the disposal of client-firms.They will have created strong trademarks, recognized bythe users-developers of software programs and known byother clients. This will make it possible to diminish the pres-sure of competition, thus ensuring their profit margins.
If it is hard to measure the incentives to innovate butsuch competition should also encourage these producers tocontribute to the development of the software programs theyuse.
The Contribution to Software DevelopmentFirst of all, it is a way to make themselves known and
demonstrate their competence as developers to their clients.
11 We prefer this term to proprietary, as all programs have an owner. Here"private" means that the owner do not share the program with others, asit in a classical software distribution.
12 This is called TCO, for "Total Cost of Ownership". Today, Microsoftdefends the idea that, if its software programs are more expensive thanlibre programs, they have a lower TCO, because it is easier to find firmsthat install them, given that their evolution is guaranteed, controlled bya firm, etc.

UPGRADE Vol. VI, No. 3, June 2005 11© Novática
Libre Software as A Field of Study
Because every client has different needs, it is importantfor the firms to master a vast portfolio of software programsas well as to contribute to the development of standard soft-ware programs which are used in most offers. They must beable to present their clients with realizations that are linkedto their problems. It is not so much the question of master-ing technical products as to be able to follow, even controltheir evolution, to guarantee the client, in the long run, thatit will meet his/her needs. And it is easier to follow the evo-lution of these software programs if one takes part in theinnovation process as it easier to understand other people’sinnovations (Cohen and Levinthal [6]).
In a market based on the increase in value of technicalexpertise, this contribution activities reinforce the image ofa firm with regard to its expertise and capacities to be reac-tive, two qualities which allow it to highlight a special offeras well as to improve its reputation (via the trademark) andincrease margins. On the other hand, this once again willreinforce the tendency to concentrate on specific activitiesbecause it is necessary to lower research costs and, there-fore, to increase the number of projects and clients.
A more important source of innovation should be thatcoming from users. As it is important to have the modifica-tions of the program included in the official version (not tohave to redevelop these modifications for each new versionof the program), most of the new functionalities developedby or for a user should be redistributed to all. Incidentally,this will also give incentives for the service companies toparticipate in the development of the most evolving soft-ware. If they want to be able to propose add-ons for theirclients they have to be already known as an ‘authorized’contributor13.
4 Conclusion: Choosing The Right EconomicLandscapeIf the libre movement seems to be the next step in an
historical trend, and the global economic model can be de-scribed, it is rather clear that business models which shouldemerge and structure this new period are not yet well de-fined.
This stresses the necessity for more analysis of thesemodels, an analysis initiated by Dahlander [8] and Jullienet al. [23]. But we have to focus on producer-communityrelationships and the competitive advantage of managing alibre project. This also means better understanding how thelibre organization(s) of production work(s), the incentivefor developers to participate in this production, and to meas-ure the productivity of libre organization.
This is the research agenda of the CALIBRE (Coordi-nation Action for LIBRE Software Engineering) Europeanresearch project14.
AcknowledgementsThis work has been funded by RNTL (Réseau National des Tech-
nologies Logicielles, French National Network for Software Technolo-gies, <http://www.telecom.gouv.fr/rntl/>). The final report of this work isavailable at <http://www-eco.enst-bretagne.fr/Etudes_projets/RNTL/rapport_final/>.
References[1] W. B. Arthur. "Self-reinforcing mechanisms in economics".
En P. W. Anderson, K. J. Arrow, and D. Pines, editors, "TheEconomy as an Evolving Complex System". SFI Studies inthe Sciences of Complexity, Addison-Wesley Publishing Com-pany, Redwood City C.A, 1998.
[2] W. B. Arthur. "Competing technologies, increasing returns andlock-in by historical events: The dynamics of allocations un-der increasing returns to scale". Economic Journal, 99: 116-131, 1999. <http://www.santafe.edu/arthur/Papers/Pdf_files/EJ.pdf>.
[3] C. Y. Baldwin y K. B. Clark. "The architecture of coopera-tion: How code architecture mitigates free riding in the opensource development model". Harvard Business School, 43pages, 2003. <http://opensource.mit.edu/papers/baldwinclark.pdf>.
[4] J. Bessen. "Open source software: Free provision of complex publicgoods". Research on Innovation, 2002. <http://www.researchoninnovation.org/online.htm# oss>.
[5] P. Breton. "Une histoire de l’informatique". Point Sciences,Le Seuil, Paris, 1990.
[6] W. M. Cohen y D. A. Levinthal. "Innovation and learning:The two faces of r&d". Economic Journal, 99: 569-596, 1989.
[7] M. Coris. "Free software service companies: the emergenceof an alternative production system within the software in-dustry?" In [23, pp. 81-98], 2002.
[8] L. Dahlander. "Appropriating returns from open innovationprocesses: A multiple case study of small firms in open sourcesoftware". School of Technology Management and Econom-ics, Chalmers University of Technology, 24 pages, 2004.<http://opensource.mit.edu/papers/dahlander.pdf.>
[9] J. De Bandt. "Services aux entreprises: informations, produits,richesses". Economica, Paris, 1995.
[10] M. Delapierre, L.-A. Gerard-Varet, y J.-B. Zimmermann."Choix publics et normalisation des réseaux informatiques".Technical report, Rapport BNI, Décembre 1980.
[11] G. Dréan. "L’industrie informatique, structure, économie,perspectives". Masson, Paris, 1996.
[12] J. Gadray. "La caractérisation des biens et des services, d’adamsmith à peter hill: une approche alternative". Technical report,IFRESI, Lille. Document de travail, 1998.
[13] C. Genthon. "Croissance et crise de l’industrie informatiquemondiale". Syros, Paris, 1995.
[14] C. Genthon. "Le cas Sun Microsystem". ENST Bretagne,2000. <http://www-eco.enst-bretagne.fr/Enseignement/2A/1999 -2000/EST201/sun/sun00.htm>. Course material.
[15] C. Genthon. "Le libre et l’industrie des services et logicielsinformatique". RNTL, 2001. <http://www-eco.enst-bretagne.fr/Etudes_projets/RNTL/work shop1/genthon.pdf>, workshop.
[16] L.-A. Gérard-Varet y J.-B. Zimmermann. "Concept de produitinformatique et comportement des agents de l’industrie". Inpanel "Structures économiques et économétrie", Mai 1985.
13 Firms such as Easter Eggs in France are today paid by companies tomake a modification of a libre program accepted and integrated into theofficial distribution.
14 <http://www.calibre.ie>.

12 UPGRADE Vol. VI, No. 3, June 2005 © Novática
Libre Software as A Field of Study
[17] F. Horn. "L’économie du logiciel". Tome 1: De l’économiede l’informatique à l’économie du logiciel. Tome 2: Del’économie du logiciel à la socio-économie des "mondes deproduction" des logiciels. PhD, Université de Lille I, men-tion: économie industrielle, 570 pages, 2000. <http://www-e c o . e n s t - b r e t a g n e . f r / E t u d e s _ p r o j e t s / R N T L /documents_universit aires.html>.
[18] F. Horn. "Company strategies for the freeing of a softwaresource code: opportunities and difficulties". In [23, pp. 99-122], 2002.
[19] F. Horn. "L’économie des logiciels". Repères, La Découverte,2004.
[20] N. Jullien. "Linux: la convergence du monde Unix et dumonde PC". Terminal, 80/81: 43-70. Special issue, Lelogiciel libre, 1999
[21] N. Jullien. "Impact du logiciel libre sur l’industrieinformatique". PhD, Université de Bretagne Occidentale /ENST Bretagne, mention: sciences économiques, 307 pages,Novembre 2001. <http://www-eco.enst-bretagne.fr/Etudes_projets/RNTL/documents_universitaires.html>.
[22] N. Jullien. "Le marché francophone du logiciel libre". Systèmesd’Information et Management, 8 (1): 77-100, 2003.
[23] N. Jullien, M. Clément-Fontaine, y J.-M. Dalle. "New economicmodels, new software industry economy". Technical Report,RNTL (French National Network for Software Technologies)project, 202 pages, 2002. <http://www-eco.enst-bretagne.fr/Etudes_ projets/RNTL/>.
[24] K. Lakhani y E. von Hippel. "How open source softwareworks: Free user to user assistance". Research Policy, 32:923-943, 2003. <http://opensource.mit.edu/papers/lakhanivonhippelusersupport.pdf>.
[25] D. C. Mowery, editor. "The International Computer SoftwareIndustry, A comparative Study of Industry Evolution and Struc-ture". Oxford University Press, 1996.
[26] L. Muselli. "Licenses: strategic tools for software publish-ers?", In [23, pp. 129-145], 2002.
[27] J. Ousterhout. "Free software needs profit". Communicationsof the ACM, 42 (4): 44-45, April 1999.
[28] E. S. Raymond. "The Cathedral and the Bazaar", 1998. <http:/
/www.tuxedo.org/~esr/writ ings/cathedral-bazaar/>.[29] E. S. Raymond. "Homesteading the Noosphere", 1998. <http:/
/www.tuxedo.org/~esr/wri tings/homesteading/>.[30] E. S. Raymond. "The Cathedral & the Bazaar; Musing on
Linux and Open Source by Accidental Revolutionary".O’Reilly, Sebastopol, California, 1999.
[31] G. B. Richardson. "Economic analysis, public policy and thesoftware industry". In The Economics of Imperfect Knowl-edge - Collected papers of G.B. Richardson, volumen 97-4.Edward Elgar, DRUID Working Paper, April 1997.
[32] P. Romer. "The economics of new ideas and new goods".Annual Conference on Development Economics, 1992,Banque Mondiale, Banque Mondiale, Washington D. C.,1993.
[33] C. Tzu-Ying y L. Jen-Fang. "A comparative study of onlineuser communities involvement in product innovation anddevelopment". National Cheng Chi University of Technol-ogy and Innovation Management, Taiwan, 29 pages, 2004.<http://opensource.mit.edu/papers/chanlee.pdf>.
[34] J.-B. Zimmermann. "Le concept de grappes technologiques.Un cadre formel". Revue économique, 46 (5): 1263-1295,Septembre 1995.
[35] J.-B. Zimmermann. "Un régime de droit d’auteur: la propriétéintellectuelle du logiciel". Réseaux, 88-89: 91-106, 1998.
[36] J.-B. Zimmermann. "Logiciel et propriété intellectuelle: ducopyright au copyleft". Terminal, 80/81: 95-116. SpecialIssue, Le logiciel libre, 1999.

UPGRADE Vol. VI, No. 3, June 2005 13© Novática
Libre Software as A Field of Study
Keywords: COCOMO, Debian, Libre Software, Libre Soft-ware Engineering, Lines of Code, Linux.
1 IntroductionOn June 6, 2005, the Debian Project announced the of-
ficial release of the Debian GNU/Linux version 3.1,codenamed "Sarge", after almost three years of develop-ment [6]. The Debian distribution is produced by the Debianproject, a group of nearly 1,400 volunteers (a.k.a.maintainers) whose main task is to adapt and package allthe software included in the distribution [11]. Debianmaintainers package software which they obtain from theoriginal (upstream) authors, ensuring that it works smoothlywith the rest of the programs in the Debian system. To en-sure this, there is a set of rules that a package should com-ply with, known as the Debian Policy Manual [5].
Debian 3.1 includes all the major libre software pack-ages available at the time of its release. In its main distribu-tion alone, composed entirely of libre software (accordingto Debian Free Software Guidelines), there are more than8,600 source packages. The whole release comprises almost15,300 binary packages, which users can install easily fromvarious media or via the Internet.
In this paper we analyse the system, showing its sizeand comparing it to other contemporary GNU/Linux sys-tems1. We decided to write this paper as an update of Count-ing Potatoes (see [8]), and Measuring Woody (see [1]) whichwere prompted by previous Debian releases. The paper isstructured as follows. The first section briefly presents themethods we used for collecting the data used in this paper.Later, we present the results of our Debian 3.1 count (in-cluding total counts, counts by language, counts for the larg-est packages, etc.). The following section provides somecomments on these figures and how they should be inter-preted and some comparisons with Red Hat Linux distribu-tions and other free and proprietary operating systems. Weclose with some conclusions and references.
2 Collecting The DataIn this work we have considered only the main distri-
bution, which is the most important and by far the largest
Measuring Libre Software Using Debian 3.1 (Sarge)as A Case Study: Preliminary Results
Juan-José Amor-Iglesias, Jesús M. González-Barahona, Gregorio Robles-Martínez, and Israel Herráiz-Tabernero
This paper is copyrighted under the CreativeCommons Attribution-NonCommercial-NoDerivs 2.5 license available at <http://creativecommons.org/licenses/by-nc-nd/2.5/>
The Debian operating system is one of the most popular GNU/Linux distributions, not only among end users but also asa basis for other systems. Besides being popular, it is also one of the largest software compilations and thus a goodstarting point from which to analyse the current state of libre (free, open source) software. This work is a preliminary studyof the new Debian GNU/Linux release (3.1, codenamed Sarge) which was officially announced recently. In it we show thesize of Debian in terms of lines of code (close to 230 million source lines of code), the use of the various programminglanguages in which the software has been written, and the size of the packages included within the distribution. We alsoapply a ‘classical’ and well-known cost estimation method which gives an idea of how much it would cost to createsomething on the scale of Debian from scratch (over 8 billion USD).
Juan-José Amor-Iglesias has an MSc in Computer Science fromthe Universidad Politecnica de Madrid, Spain, and he is currentlypursuing a PhD at the Universidad Rey Juan Carlos in Madrid,Spain. Since 1995 he has collaborated in several free softwarerelated organizations: he is a a co-founder of LuCAS, the bestknown free documentation portal in Spanish, and Hispalinux,and collaborates with Barrapunto.com. <[email protected]>
Jesús M. González-Barahona teaches and researches at theUniversidad Rey Juan Carlos, Madrid, Spain. He started workingin the promotion of libre software in the early 1990s. Since thenhe has been involved in several activities in this area, such asthe organization of seminars and courses, and the participationin working groups on libre software. He currently collaboratesin several libre software projects (including Debian), andparticipates in or collaborates with associations related to libresoftware. He writes in several media about topics related to li-bre software, and consults for companies on matters related totheir strategy regarding these issues. His research interestsinclude libre software engineering and, in particular, quantitativemeasures of libre software development and distributed toolsfor collaboration in libre software projects. He is editor of theFree Software section of Novática since 1997 and has been guesteditor of several monographs of Novática and UPGRADE onthe subject. <[email protected]>
Gregorio Robles-Martínez is a PhD candidate at the Universi-dad Rey Juan Carlos in Madrid, Spain. His main research interestlies in libre software engineering, focusing on acquiringknowledge of libre software and its development through thestudy of quantitative data. He was formerly involved in theFLOSS project and now participates in the CALIBREcoordinated action and the FLOSSWorld project, all EuropeanCommission IST-program sponsored projects. <[email protected]>
Israel Herráiz-Tabernero has an MSc in Chemical andMechanical Engineering, a BSc in Chemical Engineering andhe is currently pursuing his PhD in Computer Science at theUniversidad Rey Juan Carlos in Madrid, Spain. He ‘discovered’free software in 2000, and has since developed several free toolsfor chemical engineering. <[email protected]>1 GNU/Linux systems are also known as 'distributions'.
part of any Debian release. It is composed exclusively offree software (according to Debian Free Software Guide-lines, DFSG [7]). Other sections, such as non-free or

14 UPGRADE Vol. VI, No. 3, June 2005 © Novática
Libre Software as A Field of Study
contrib, are not covered here. The approach used for col-lecting the data is as follows: first, the sources for the distribu-tion are retrieved from the public archives on the Internet,through archive.debian.org <ftp://archive.debian.org> and itsmirrors, on a per-package basis. Debian provides source codepackages and binary packages. We have used the former inthis study, although the latter are what tend to be downloadedby users as they are pre-compiled. For each source code pack-age there may be one or many binary packages.
Our second step was to analyse the packages and extractthe information that we were looking for using SLOCCount2
[12]. The lines of code count is only an estimate due to somepeculiarities of the tool (basically based on source code andprogramming language identification heuristics) and the crite-ria chosen for the selection of packages [8].
The final step was to identify and remove packages thatappear several times in different versions (for instance, thishappens with the GCC compiler) so as not to count the samecode more than once. This may lead to an underestimationas in some cases the source code base may not be that simi-lar (in the case of PHP, we have left the PHP4 version butremoved PHP3), so we have kept some cases where we knowthat at least significant amounts of common code (for in-stance for xemacs and emacs or for gcc and gnat) are present.The final step is to draw up a set of reports and statisticalanalyses using the data gathered in the previous step andconsidering it from various points of view. These resultsare presented in the following section.
3 Results of Debian 3.1 CountAfter applying the methodology described we calculated
that the total source lines of code count for Debian 3.1 is229,496,000 SLOC (Source Lines Of Code). Results by cat-egory are presented in the following subsections (all num-bers are approximate, see [4] for details).
3.1 Programming LanguagesThe number of physical SLOC and percentages, broken
down by programming language, are shown in Table 1.Below 0.5% there are some other languages such as
Objective C (0.37%), ML (0.31%), Yacc (0.29%), Ruby(0.26%), C# (0.23%) or Lex (0.10%). A number of otherlanguages score less than 0.1%.
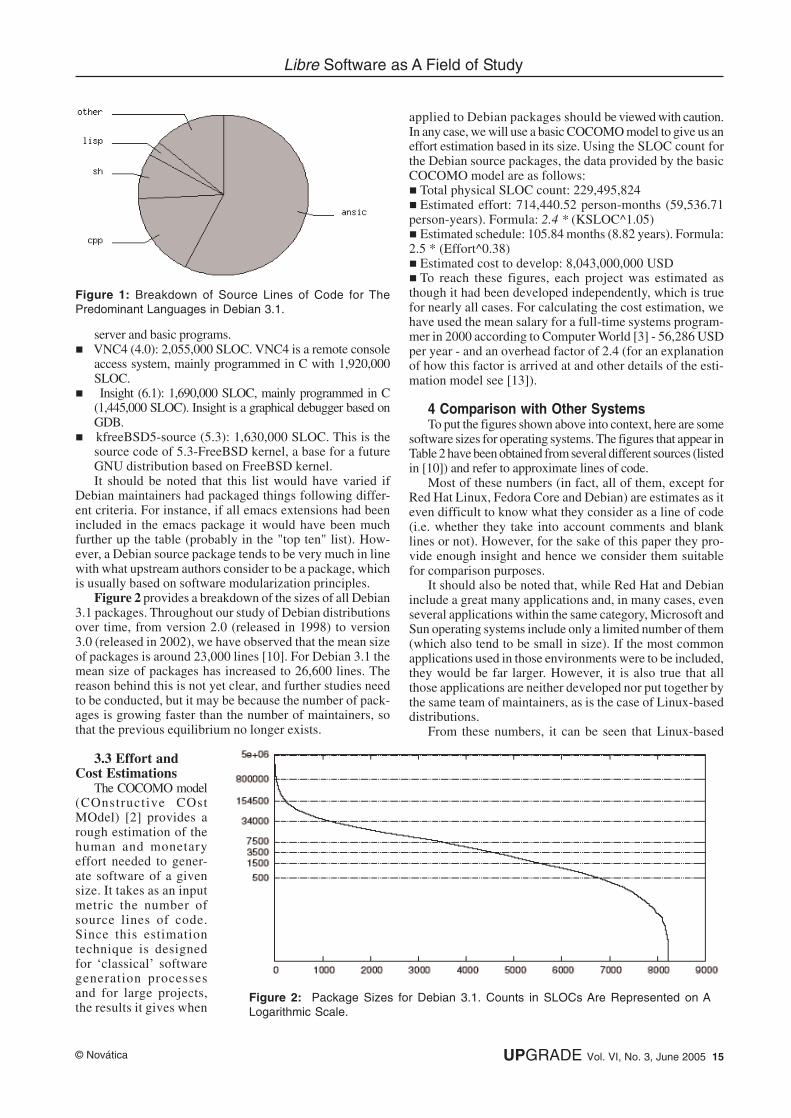
The pie chart in Figure 1 shows the relative importanceof the main languages in the distribution. Most Debian pack-ages are written in C, but C++ is also to be found in manypackages, being the main language in some of the most im-portant ones (such as OpenOffice.org or Mozilla). Next upcomes Shell, which is mainly used by scripts supportingconfiguration and other auxiliary tasks in most packages.Surprisingly LISP is one of the top languages, although thiscan be explained by the fact that it is the main language inseveral packages (such as emacs) and is used in many oth-ers. While this is not reflected in our results, there is a his-torical trend towards a relative decline of the C program-ming language combined with a growing importance of moremodern languages such as Java, PHP, and Python.
3.2 Largest PackagesThe following list shows the most important Debian 3.1.
packages over 2 MSLOC broken down by size. For eachpackage we give the package name, version, total numberof SLOC, composition of programming languages, and adescription of the purpose of the software. OpenOffice.org (1.1.3): 5,181,000 SLOC. C++ accounts
for 3,547,000 SLOC. C accounts for 1,040,000 SLOC.There is also code written in 15 more languages, eitherscripting languages (such as shell, tcl, python or awk)or non-scripting languages (pascal, java, objective-C,lisp, etc).
Linux kernel (2.6.8): 4,043,000 SLOC. C accounts for3,794,000 SLOC, Makefiles, assembler and scripts inseveral languages accounts for the rest. This is the latestkernel included in the Debian 3.1 release.
NVU (N-View) (0.80): 2,480,000 SLOC. Most of thecode is C++, with more than 1,606,000 SLOC, plus alarge percentage of C (798,000 SLOC). Other languages,mainly scripting languages, are also used. It is a com-plete web authoring system capable of rivalling wellknown proprietary solutions such as MicrosoftFrontPage.
Mozilla (1.7.7): 2,437,000 SLOC. Most of its code isC++, with more than 1,567,000 SLOC plus a large per-centage of C (789,000 SLOC). Mozilla is a well knownopen source Internet suite (WWW browser, mail client,etc). GCC-3.4 (3.4.3): 2,422,000 SLOC. C accounts for
1,031,000 SLOC, Ada for 485,000 SLOC and C++ for244,000 SLOC. Other languages are used minimally.GCC is the popular GNU Compiler Collection.
XFS-XTT (1.4.1): 2,347,000 SLOC. Mainly 2,193,000SLOC of C. Provides an X-TrueType font server.
XFree86 (4.3.0): 2,316,000 SLOC. Mainly 2,177,000 SLOCof C. An X Window implementation, including a graphics
2 We use SLOCCount revision 2.26. It currently recognizes 27 program-ming languages.
Table 1: Count of Source Lines of Code by ProgrammingLanguage in Debian 3.1.
Source Lines
Language of Code (SLOC) %
C 130,847,000 57
C++ 38,602,000 16.8
Shell 20,763,000 9
LISP 6,919,000 3
Perl 6,415,000 2.8
Python 4,129,000 1.8
Java 3,679,000 1.6
FORTRAN 2,724,000 1.2
PHP 2,144,000 0.93
Pascal 1,423,000 0.62
Ada 1,401,000 0.61
TOTALS 229,496,000 100
UPGRADE Vol. VI, No. 3, June 2005 15© Novática
Libre Software as A Field of Study
Figure 1: Breakdown of Source Lines of Code for ThePredominant Languages in Debian 3.1.
server and basic programs. VNC4 (4.0): 2,055,000 SLOC. VNC4 is a remote console
access system, mainly programmed in C with 1,920,000SLOC.
Insight (6.1): 1,690,000 SLOC, mainly programmed in C(1,445,000 SLOC). Insight is a graphical debugger based onGDB.
kfreeBSD5-source (5.3): 1,630,000 SLOC. This is thesource code of 5.3-FreeBSD kernel, a base for a futureGNU distribution based on FreeBSD kernel.It should be noted that this list would have varied if
Debian maintainers had packaged things following differ-ent criteria. For instance, if all emacs extensions had beenincluded in the emacs package it would have been muchfurther up the table (probably in the "top ten" list). How-ever, a Debian source package tends to be very much in linewith what upstream authors consider to be a package, whichis usually based on software modularization principles.
Figure 2 provides a breakdown of the sizes of all Debian3.1 packages. Throughout our study of Debian distributionsover time, from version 2.0 (released in 1998) to version3.0 (released in 2002), we have observed that the mean sizeof packages is around 23,000 lines [10]. For Debian 3.1 themean size of packages has increased to 26,600 lines. Thereason behind this is not yet clear, and further studies needto be conducted, but it may be because the number of pack-ages is growing faster than the number of maintainers, sothat the previous equilibrium no longer exists.
3.3 Effort andCost Estimations
The COCOMO model(COnstructive COstMOdel) [2] provides arough estimation of thehuman and monetaryeffort needed to gener-ate software of a givensize. It takes as an inputmetric the number ofsource lines of code.Since this estimationtechnique is designedfor ‘classical’ softwaregeneration processesand for large projects,the results it gives when
applied to Debian packages should be viewed with caution.In any case, we will use a basic COCOMO model to give us aneffort estimation based in its size. Using the SLOC count forthe Debian source packages, the data provided by the basicCOCOMO model are as follows:
Total physical SLOC count: 229,495,824Estimated effort: 714,440.52 person-months (59,536.71
person-years). Formula: 2.4 * (KSLOC^1.05)Estimated schedule: 105.84 months (8.82 years). Formula:
2.5 * (Effort^0.38)Estimated cost to develop: 8,043,000,000 USDTo reach these figures, each project was estimated as
though it had been developed independently, which is truefor nearly all cases. For calculating the cost estimation, wehave used the mean salary for a full-time systems program-mer in 2000 according to Computer World [3] - 56,286 USDper year - and an overhead factor of 2.4 (for an explanationof how this factor is arrived at and other details of the esti-mation model see [13]).
4 Comparison with Other SystemsTo put the figures shown above into context, here are some
software sizes for operating systems. The figures that appear inTable 2 have been obtained from several different sources (listedin [10]) and refer to approximate lines of code.
Most of these numbers (in fact, all of them, except forRed Hat Linux, Fedora Core and Debian) are estimates as iteven difficult to know what they consider as a line of code(i.e. whether they take into account comments and blanklines or not). However, for the sake of this paper they pro-vide enough insight and hence we consider them suitablefor comparison purposes.
It should also be noted that, while Red Hat and Debianinclude a great many applications and, in many cases, evenseveral applications within the same category, Microsoft andSun operating systems include only a limited number of them(which also tend to be small in size). If the most commonapplications used in those environments were to be included,they would be far larger. However, it is also true that allthose applications are neither developed nor put together bythe same team of maintainers, as is the case of Linux-baseddistributions.
From these numbers, it can be seen that Linux-based
Figure 2: Package Sizes for Debian 3.1. Counts in SLOCs Are Represented on ALogarithmic Scale.

16 UPGRADE Vol. VI, No. 3, June 2005 © Novática
Libre Software as A Field of Study
distributions in general, and Debian 3.1 in particular, aresome of the largest pieces of software ever put together by agroup of maintainers.
5 Conclusions and Related WorkDebian is one of the largest software systems in the world,
probably the largest. Its size has grown with every release,3.1 being twice the size of 3.0. For the last few releases, themain languages used to develop packages included in Debianare C and C++. In fact C, C++ and Shell represent morethan 75% of all source code in Debian. The number ofpackages continues to grow steadily, doubling almost everytwo years.
The Debian GNU/Linux distribution, put together by agroup of volunteers dispersed all over the world, would, at firstsight, appear to show a healthy and fast-growing trend. Despiteits enormous size it continues to deliver stable releases.However, there are some aspects that put into doubt the futuresustainability of this progress. For instance, mean package sizeis showing an unstable behaviour, probably due to the numberof packages growing faster than the number of maintainers.Nor can we forget that we have had to wait almost three yearsfor a new stable release and that the release date has been seri-ously delayed on several occasions.
Regarding other software systems, there are few detailedstudies of the size of modern, complete operating systems.The work by David A. Wheeler, counting the size of RedHat 6.2 and Red Hat 7.1 is perhaps the most comparable.Some other references provide total counts of some Sun andMicrosoft operating systems, but while they do provideestimates for the system as a whole, they are not detailedenough. Debian is by far the largest of them, although thiscomparison has to be taken with a degree of caution.
To conclude, it is important to stress that this paper aimsto provide estimations based only on a preliminary study(since the release is not yet officially published). However,we believe they are accurate enough to allow us to drawsome conclusions and compare them with other systems.
AcknowledgementsThis work has been funded in part by the European Commission,
under the CALIBRE CA, IST program, contract number 004337, in partby the Universidad Rey Juan Carlos under project PPR-2004-42, and inpart by the Spanish CICyT under project TIN2004-07296.
References[1] Juan José Amor, Gregorio Robles y Jesús M. González-Barahona.
Measuring Woody: The size of Debian 3.0 (pending publication).Will be available at <http://people.debian.org/~jgb/debian-counting/>.
[2] Barry W. Boehm. Software Engineering Economics, Prentice Hall,1981.
[3] Computer World, Salary Survey 2000. <http://www.computerworld.com/cwi/careers/surveysandreports>.
[4] Jesús M. González Barahona, Gregorio Robles, and Juan JoséAmor, Debian Counting. <http://libresoft.urjc.es/debian-counting/>.
[5] Debian Project, Debian Policy Manual. <http://www. debian. org/doc/debian-policy/>.
[6] Debian Project, Debian GNU/Linux 3.1 released (June 6th 2005).<http://www.debian.org/News/2005/20050606>.
[7] Debian Project, Debian Free Software Guidelines (part of theDebian Social Contract). <http://www.debian.org/social_contract>.
[8] Jesús M. González Barahona, Miguel A. Ortuño Pérez, Pedro delas Heras Quirós, José Centeno González, and Vicente MatellánOlivera. Counting potatoes: The size of Debian 2.2. UPGRADE,vol. 2, issue 6, December 2001, <http://upgrade-cepis.org/issues/2001/6/up2-6Gonzalez. pdf>; Novática, nº 151 (nov.-dic. 2001),<http://www.ati.es/novatica/2001/154/154-30.pdf> (in Spanish).
[9] Jesús M. González-Barahona, Gregorio Robles, Miguel Ortuño-Pérez, Luis Rodero-Merino, José Centeno-González, VicenteMatellán-Olivera, Eva Castro-Barbero, and Pedro de-las-Heras-Quirós. Anatomy of two GNU/Linux distributions. Chapter inbook "Free/Open Source Software Development" edited byStefan Koch and published by Idea Group, Inc., 2004.
[10] Gregorio Robles, Jesús M. González-Barahona, Luis López, andJuan José Amor, Toy Story: an analysis of the evolution of DebianGNU/Linux, November 2004 (pending publication). Draftavailable at <http://libresoft.urjc.es/debian-counting/>.
[11] Gregorio Robles, Jesús M. González-Barahona, and MartinMichlmayr. Evolution of Volunteer Participation in LibreSoftware Projects: Evidence from Debian, julio 2005, Proceed-ings of the First International Conference on Open SourceSystems. Genova, Italy, pp. 100-107. <http://gsyc.escet.urjc.es/~grex/volunteers-robles-jgb-martin. pdf>.
[12] David Wheeler. SLOCCount. <http://www.dwheeler.com/sloccount/>.
[13] David A. Wheeler. More Than a Gigabuck: Estimating GNU/Linux’s Size. <http://www.dwheeler.com/sloc>.
Table 2: Size Comparison of Several Operating Systems.
Source LinesOperating System of Code
(SLOC)
Microsoft Windows 3.1 (April 1992) 3,000,000
Sun Solaris (October 1998) 7,500,000
Microsoft Windows 95 (August 1995) 15,000,000
Red Hat Linux 6.2 (March 2000) 17,000,000
Microsoft Windows 2000 (February 2000) 29,000,000
Red Hat Linux 7.1 (April 2001) 30,000,000
Microsoft Windows XP (2002) 40,000,000
Red Hat Linux 8.0 (September 2002) 50,000,000
Fedora Core 4 (previous version; May 2005) 76,000,000
Debian 3.0 (July 2002) 105,000,000
Debian 3.1 (June 2005) 229,500,000

UPGRADE Vol. VI, No. 3, June 2005 17© Novática
Libre Software as A Field of Study
Keywords: Common Property, Commons, Institutions,Libre Software.
1 IntroductionSeveral articles in UPGRADE and Novática’s 2001
issue on Open Source/Free Software [1] (referred to fromnow on as simply ‘Libre ’ software) noted that the compo-sition of development teams was changing, from all-volunteer teams to teams with paid participants fromindustry, government or not-for-profit organizations [2].While the Libre collaborative approach is not a panacea,there are enough success stories to conclude that thisdevelopment paradigm is viable and important. At thesame time, a much higher number of Libre projects havebeen abandoned before reaching the goals they set out toachieve at their outset [28]. Therefore, an important ques-tion, recognized by a number of researchers [3-8] is: whatfactors lead to success or failure of Libre projects?
Recently Libre software development projects havebeen recognized as a form of ‘commons’, where sets ofvolunteer and paid professional team members from allover the globe collaborate to produce software that is apublic good [9-13][53]. This recognition provides theopportunity to connect separate streams of research onthe management of natural resource commons ([14][15]provide summaries) with the more traditional informa-tion system research related to the production of soft-ware, and Libre software in particular.
Viewing Libre projects as a commons focuses atten-tion on attributes and issues related to collective action,governance, and the often complex and evolving sys-tem of rules that help to achieve long-enduring com-
mons [16]. Hardin’s famous phrase, "Tragedy of theCommons," [17] describes settings where users whoshare a commons (e.g., a pasture) over-consume theresource, leading to its destruction. For each herdsman,the addition of one more animal to the herd addspositive utility because it is one more animal to sell.The negative is that it is one more animal grazing onthe commons. The rational choice of each herder is toadd more animals, leading eventually to overgrazing ofthe commons.
But because Libre software are digital, over-con-sumption of the commons is not the concern. Sustain-ing (and perhaps growing) a team of developers is. Inthese settings the tragedy to be avoided is the decisionto abandon the project prematurely, not because of anexternal factor (such as a better technology has comealong that is a better solution than what the project willproduce), but because of some kind of problem internalto the project (such as a conflict over project direction,loss of financial support, etc.). (See Endnote 1.)
An Institutional Analysis Approach toStudying Libre Software ‘Commons’
Charles M. Schweik
This paper is copyrighted under the CreativeCommons Attribution-NonCommercial-NoDerivs 2.5 license available at <http:/
/creativecommons.org/licenses/by-nc-nd/2.5/>
Anyone interested in Libre software will be interested in the question of what leads to success and failure of Libreprojects. This paper marks the beginning of a five-year research program, funded by the U.S. National ScienceFoundation, to identify design principles that lead to successful Libre software development efforts. Recently,scholars have noted that Libre software projects can be considered a form of ‘commons’, producing softwarepublic goods. This connection is important, for a large body of theoretical and empirical findings exists relatedto long-enduring environmental commons which could also apply to and inform Libre software projects. Institu-tions – defined here as rules-in-use – are a central set of variables known to influence the ultimate outcome ofcommons settings (e.g., long-enduring commons or ones that succumb to what G. Hardin has called the “Tragedyof the Commons”). To date, we know relatively little about the institutional designs of Libre projects and how theyevolve. This paper presents an oft-used framework for analyzing the institutional designs of environmentalcommons settings that will guide upcoming empirical research on Libre software projects. It presents a trajectoryof these projects and discusses ways to measure their success and failure. The paper closes by presenting examplehypotheses to be tested related to institutional attributes of these projects.
Charles M. Schweik is an Assistant Professor in the Dept.of Natural Resources Conservation and the Center forPublic Policy and Administration at the University ofMassachusetts, Amherst, USA. He has a PhD in PublicPolicy from Indiana University, a Masters in PublicAdministration from Syracuse University, and has anundergraduate degree in Computer Science. A primaryresearch interest is in the use and management of publicinformation technology. For more than six years, betweenhis undergraduate degree and his MPA, he was a programmerwith IBM. <[email protected]>

18 UPGRADE Vol. VI, No. 3, June 2005 © Novática
Libre Software as A Field of Study
Since this is an important point, let me try andanalyze this particular tragedy following Hardin’s logic.In Libre software development settings, developers (andpossibly users, testers, documenters) replace the herds-men as decision-makers. The motivation for these peo-ple to participate is in part the anticipation that thesoftware being produced will fill a personal or organi-zational need. However, research on Libre developermotivations [58] has shown that participants receiveother positive benefits from participating.
From the developer’s perspective, it is worth spend-ing one unit of time contributing to this project becausehe is: (1) getting his name known and thus increasingthe possibility for future job or consulting opportuni-ties, (2) learning new skills through reading source andpeer-review of their code submissions, and/or (3) get-ting paid by his employer to participate.
Alternatively, the logic might be taken to stop con-tributing time because he does not like the direction inwhich the project is going, or that his contributions arenot being accepted and he is not receiving adequatefeedback on why. In these situations, the accumulationof developer dissatisfaction may lead to premature projectabandonment, because of factors internal to the project.
The tragedy of the commons in this context is aboutthe premature loss of a production team, not over-appropriation as in Hardin’s famous pasture example.Consequently, a key concern faced by Information Tech-nology (IT) organizations who are considering Libresoftware as a policy or strategy is how can a vibrantproduction and maintenance effort be sustained overthe longer term and how can the premature abandon-ment of the project be avoided.
In "Governing the Commons" [18], Elinor Ostromemphasized that in some environmental commons set-tings Hardin’s tragedy is avoided – the commons be-comes "long-enduring" – because of the institutionaldesigns created by self-governing communities. Institu-tions, in this context, can be defined as sets of rules –either formal or informal – consisting of monitoring,sanctioning and conflict resolution mechanisms that helpto create appropriate incentive structures to manage the
commons setting. In Libre software commons settings,the evolution of project institutions may help to explainwhy some Libre software projects move more smoothlyfrom alpha to beta to stable and regular release cyclesand grow and maintain larger development teams anduser communities, while other projects become aban-doned before they reach maturity. While research showsthat a vast majority of Libre software projects haveeither one developer or small teams [48-52], I think theinfluence of institutional design will become increas-ingly critical as projects grow (in terms of interestedparties) and mature.
Moreover, the increasing involvement of firms andgovernment agencies in Libre software development willundoubtedly lead to more complex institutional envi-ronments. For this reason, I think attention to the insti-tutional designs of Libre projects is critically importantas Libre software collaborations (and other "open con-tent collaborations", see [13]) become more common-place.
This paper describes some components of a five-year research program just underway which will studythe institutional designs of Libre software developmentprojects from a commons perspective. A primary goalof the research program is to identify design principlesthat contribute to the ultimate success or failure ofthese projects. The paper is organized in the followingmanner.
First, I explain why Libre software developmentprojects are a type of commons, or more specifically, a"common property regime". Next, I define what wemean by institutions and describe a theoretical frame-work utilized by many social scientists to study institu-tional designs of environmental commons settings. Ithen describe the general trajectory of Libre softwaredevelopment projects, and discuss ways to measuresuccess and failure at these stages of this trajectory. Iprovide some examples of hypotheses related to institu-tional designs that, when empirically tested, could helpto identify design principles for Libre software projects.I close with a discussion of why this should matter toIT professionals.
Figure 1: A General Clasification of Goods. (Adapted from [21:7].)

UPGRADE Vol. VI, No. 3, June 2005 19© Novática
Libre Software as A Field of Study
2 Libre Software Are Public Goods Developedby Common Property RegimesIt is possible to view Libre software from two per-
spectives: use and development. I’ll consider the useside first. Social scientists recognize four categories ofgoods, private, public, club and common pool resourcesdistinguished by two properties (Figure 1) [22][21]:first, how easy or difficult is it to exclude others fromusing or accessing the good? second, does the goodexhibit rivalrous properties? That is, if I have one unitof the good, does that prevent others from using it aswell?
Traditional proprietary software can be classified asa club good in Figure 1. The digital nature of software(downloadable over the Internet or copied off of CD-Rom) makes it non-rivalrous. The pricing for access(and the do-not-copy restrictions of the "shrinkwraplicense") make exclusion of non-purchasers possible[53].
But in many cases, this exclusion is not alwayssuccessful. It is widely understood that there illegalcopying of proprietary software occurs, creating a dif-ferent form of club with an entrance to the club basedon the wiliness to risk being caught rather than on aprice for access. But regardless of whether the com-pany can successfully crack down on illegal bootleg-ging of their software, because of its digital nature,proprietary software falls in the club-good category.
Libre software differs from proprietary software inthat Libre licenses (such as the GNU General Public
License) permit users to copy and distribute the soft-ware wherever they please as long as they comply withthe specifications of the license [54]. These licensesprovide a mechanism for acting upon a violation of thespecified rules, so exclusion is theoretically possiblethrough litigation under contract or copyright law [61-62], but in most cases this is unlikely [61].
Since Libre software is also non-rivalrous – it isfreely copied digitally over the Internet or on CD-ROM(such as in the case of a Linux distribution, for exam-ple) – technically, it should be classified as a club good– a club with no "fee" other than license compliance tojoin. But given that Libre software distribution is globalin reach with no monetary cost associated with it,many classify it a public good [23-25][25][55].
Now let me turn to a discussion about the produc-tion of Libre software. I noted earlier that some considerLibre software projects a form of "commons" [25][54].McGowan [53] refers to these commons as "socialspaces" for the production of freely available and modi-fiable software.
While these projects involve collaboration, and con-trary to what some might believe, there are propertyrights (copyright) and ownership issues in these com-mons [53].
Raymond (cited by McGowan) defines owners of aLibre software project as ones who have "exclusiveright, recognized by the community at large, to redis-tribute modified versions" [53: 24]. According toRaymond, one becomes owner of a project by either:
Figure 2: A Framework for Institutional Analyisis of Commons Settings. (Adapted from [21:73].)

20 UPGRADE Vol. VI, No. 3, June 2005 © Novática
Libre Software as A Field of Study
(1) being the person or group who started the projectfrom scratch; (2) being someone who has receivedauthority from the original owner to take the lead infuture maintenance and development efforts; (3) beinga person who takes over a project that is widelyrecognized as abandoned and makes a legitimate effortto locate the original author(s) and gets permission totake over ownership. McGowan adds a fourth option –the "hostile takeover" – where the project can behijacked or "forked" because of the "new derivativeworks" permissions provided by the license. Forkingoften occurs when a project is deemed by some on theteam to be headed technically or functionally in thewrong direction. A kind of mutiny can occur and anew project is created using the existing source fromthe old project. The result is two competing versions[53].
Some readers might find the definition of Libreproject owners by Raymond somewhat troublesome.This definition encapsulates Raymond’s libertarian viewof Libre projects, where the community as a wholesomehow together recognizes ownership rights and col-lectively acts as one to support them. To some, thiscollective recognition and action may appear ratherhard to believe.
An alternative way of identifying or defining anowner in Libre software settings is through a person orteam’s ability to initiate or maintain a coherent collec-tive development process.
From this perspective, ownership is more a result ofthe barriers against expropriation and does not requiresome mystical collective endorsement. The reader shouldnote too that this alternative definition of Libre owner-ship is consistent with Raymond and McGowan’s fourways to become a recognized Libre software ownerlisted above.
Given the ownership aspects above, here is the keypoint: Libre software projects are a form of self-govern-ing "common property regime," with developers work-ing collaboratively to produce a public good[9][11][12][27] [13][25][53][54]. While ‘commons’ is theterm most often used, "common property regime" moreaccurately describes Libre software projects.
The recognition of Libre projects as a form ofcommon property regime provides an opportunity toconnect knowledge amassed over the years on thegovernance and management of natural resource com-mons under common property settings (e.g., [14][15]).
Weber recently noted the importance of governanceand management in Libre software projects when hestated: "The open source process is an ongoing experi-ment. It is testing an imperfect mix of leadership,informal coordination mechanisms, implicit and explicitnorms, along with some formal governance structuresthat are evolving and doing so at a rate that has beensufficient to hold surprisingly complex systems together"[12:189].
3 A Framework for Studying The InstitutionalDesigns of Libre Software ProjectsWeber’s recognition of social norms, informal coor-
dination processes and formal governance structurescoincides with what political scientists and economistsrefer to as "institutions" [18][21][31]. For more than 40years, researchers, including this author [32-34], haveutilized the "Framework for Institutional Analysis" (Fig-ure 2) to organize thinking about environmental com-mons cases [31:8]. This framework has not yet beenapplied to the study of Libre software commons, butthe analytic lens it provides complements other Libresoftware research underway by researchers in moretraditional information systems fields (e.g., [35-38]).
Consider the situation where an analyst is trying tounderstand why a particular Libre software project islively or why it is losing momentum. Figure 2 depictsLibre projects as a dynamic system with feedback. Theanalyst might begin studying the project by first look-ing to elements on the left-hand side: the physical,community and rule attributes.
Physical attributes refers to a variety of variablesrelated to the software itself or to some of the infra-structure to coordinate the team. These include the typeof programming language(s) used, the degree to whichthe software is modular in structure, and the type ofcommunication and content management infrastructureused.
Community attributes refers to a set of variables relat-ing to the people engaged in the Libre software project,such as whether they are volunteer or paid to participate,whether they all speak the same language or not, andaspects that are more difficult to measure related to socialcapital, such as how well team members get along, howwell they trust each other [63], etc. This component alsoincludes other non-physical attributes of the project, suchas its financial situation and the sources that provide thisfunding (e.g., a foundation).
Rules-in-use refers to the types of rules in placethat are intended to guide the behavior of participantsas they engage in their day-to-day activities related todevelopment, maintenance or use of the Libre software.The specific Libre license used is one important compo-nent of the rules-in-use category. But I expect that mostLibre projects – especially more mature ones with largernumbers of participants – will have other sets of formalor informal rules or social norms in place that help tocoordinate and manage the project.
The middle section of Figure 2, Actors and theAction Arena, indicates a moment or a range of timewhere the left side attributes remain relatively constantand actors (e.g., software developers, testers, users)involved in the Libre software project make decisionsand take actions (e.g., programming, reviewing code,deciding to reduce or stop their participation, etc.). Theaggregation of these actors making decisions and takingactions is depicted as Patterns of Interactions in Figure

UPGRADE Vol. VI, No. 3, June 2005 21© Novática
Libre Software as A Field of Study
2. The accumulation of actions results in some Out-come (right side, bottom of Figure 2). An outcomecould be a change in the physical attributes of theLibre software commons (e.g., a new release), a changein the community attributes of the project (e.g., newpeople joining in or people leaving), a change to theexisting rules-in-use (e.g., a new system for resolvingconflicts) or any combination thereof. In Figure 2,these kinds of changes are depicted through the feed-back system from outcome to the three sets of com-mons attributes on the left side of the same figure, anda new time period begins.
Much of what institutional analysis is about is thestudy of rules, from formal laws to informal norms ofbehavior, standard operating procedures, and the like.Embedded in the rules-in-use category of Figure 2 arethree nested levels that, together, influence actions takenand resultant outcomes at these different levels ofanalysis [39]. Operational level rules affect the day-to-day activities made by participants in the Libre softwarecommons. These can be formally written rules, or,perhaps more often in Libre settings, could be commu-nity norms of behavior.
An example of operational rules might be the pro-
cedures for adding new functionality to the next releaseof the software. Another example might be rules onpromoting a particular developer to a position where heor she has more decision-making responsibility in theproject. The Collective-Choice level represents the dis-cussion space where team members with authority de-fine group goals, and create or revise operational rulesto move the team toward these goals. In addition, atthis level there is a system of collective-choice rulesthat define who is eligible to change operational rulesand specify the process for changing these rules [21].Collective-choice rules might, for example, determinehow the team can change the process of code reviewbefore new code can be checked-in or "committed"[40]. Constitutional-Choice level rules specify who iseligible to change collective-choice rules and also de-fine the procedures for making such changes. For ex-ample, if the formally designated leader of a Libreproject has decided to move on to a new opportunity,constitutional-choice rules would outline how a replace-ment is chosen.
At each level, there can be systems for the monitor-ing of rule conformance and systems for sanctioningwhen rules are broken.
Figure 3: Stages of Libre Projects Software and Outcome (Success) Measures. (Adapted from Schweikand Semenov, 2003 [46].)

22 UPGRADE Vol. VI, No. 3, June 2005 © Novática
Libre Software as A Field of Study
In short, at any point in time in the lifecycle of aLibre software project, programmers, users, and testerswill make their decisions on how they participate basedon the existing physical, community and institutionalattributes of the project, as well as their anticipation ofwhere the project is headed and their own personalcircumstances. Participants make decisions and takeactions at three levels: operational, collective-choiceand, less frequently, constitutional-choice.
One hypothesis to be tested in this research is thatthe systems of rules-in-use at any one of these levelswill become more complex as a Libre software projectmatures and gains participants. I also expect the insti-tutional design to become more complex in situationswhere one or more organizations (e.g., firms, non-profits or government agencies) provide resources tosupport the project. This is consistent with McGowan[53:5] when he states: "The social structures necessaryto support production of large, complex projects aredifferent from the structures – if any – necessary tosupport small projects…".
4 The Trajectory of Libre Software ProjectsI now turn to the question of how to evaluate the
"Outcomes" component in this framework. While Fig-ure 2 reveals a feedback loop to draw attention to thedynamic and evolutionary nature of these projects[48][45], it doesn’t depict these longitudinial propertiesvery well. For this reason I include Figure 3.
In earlier work [46] I argued that Libre softwareprojects follow a three-stage trajectory (Figure 3): (1)initiation; (2) a decision to "go open" and license it asLibre software; and (3) a period of growth, stability orabandonment. Most of Libre software research focuseson projects at Stage 3. But some of the decisions madeat the earlier stages may be critical factors leading tothe outcome of growth or abandonment at Stage 3.
Consider Stage 1 in Figure 3. In many cases, Libresoftware projects start with a private consultation ofone or a few programmers working together to developa ‘core’ piece of software.
At this juncture, the software may not yet be placedunder a Libre software license or made available on theInternet, and in some circumstances the team may noteven be planning at the moment to license it as Libresoftware. But critical design decisions may be made atthis stage, such as the modularity of the code, whichmight greatly influence how well the software can bedeveloped in a Libre common property setting in Stage3.
While the "small and private group starting fromscratch" scenario is probably what most might think ofin the initiation phase of a Libre software project, thereis at least one other alternative: "software dumping"[60]. In these situations, the software first is developedunder a more traditional, proprietary, closed-source,software-development model within a firm. At some
point – perhaps after years of work – decision-makersmay make a strategic decision not to support the soft-ware any more, and as a consequence, make the codeavailable and license it as Libre software. This scenariomay become more prominent in future years if softwarefirms continue to consider Libre software as part oftheir business strategy.
The "going open" stage (Figure 3, Stage 2) isprobably brief but perhaps not as simple as it might atfirst appear. In this stage, team members decide on anappropriate Libre software license, and, perhaps moreimportantly, create a public workspace and a collabora-tive infrastructure (e.g., versioning system, methods forpeer review, bug tracking mechanism, etc.) to supportthe project.
Platforms like Sourceforge.net and Freshmeat.net havemade this step fairly easy, but there are some projectsthat utilize web-based platforms that they have imple-mented themselves.
I should note at this juncture that in some Libreprojects, Stages 1 and 2 can be conflated. It may be arelatively common phenomenon where a founding mem-ber has an idea and immediately broadcasts an appealfor other partners to help in the development of theproject.
This appeal may immediately involve the creationof a project page on the web or on a hosting site suchas Sourceforge.net. But regardless of how the projectgets through Stage 2, the next step is Stage 3 of Figure3. This stage describes the period in the project’s lifecycle where the software is actively being developedand used under Libre software licensing and is publiclyavailable on the Internet. Many of the early studies ofLibre software projects focused on cases that fall underthe "high growth" (in terms of market share or numberof developers) success stories such as Linux or ApacheWeb Server. Achieving this stature is often the defaultor assumed measure of success of these projects inLibre software literature.
However, empirical studies of Libre software haveshown that the majority of projects never reach thisstage and many, perhaps most, involve only a smallnumber of individuals [48-52]. Some of these studiesmay be focusing on projects in the early days of theirlife cycle, where people are working to achieve highgrowth. But in other instances, members of a particularproject may be quite satisfied to remain "stable" andactive with a small participant base (Figure 3, Stage 3:Small Group). Some Libre software projects inbioinformatics might provide examples of these kindsof circumstances [47].
The main point regarding Figure 3 is that there areimportant stages in the trajectory of Libre softwareprojects and that the measures for success and failurewill likely change during these stages. Moreover, physi-cal, community and institutional attributes of projectswill evolve as well.

UPGRADE Vol. VI, No. 3, June 2005 23© Novática
Libre Software as A Field of Study
5 Measuring Success or Failure of Libre Soft-ware Projects along This TrajectoryI noted earlier that a goal of this research project is
to define "design principles" that lead to successfulLibre software collaborations. In the empirical work Iam just initiating, success or failure of Libre projects isthe concept I seek to explain. What follows is adescription of one method for measuring success andfailure. Others have undertaken research trying to quan-tify this as well, and I build upon their important work[3][4][8][41].
For my purposes, an initial measure of success orfailure in Libre project collaboration requires askingtwo questions in sequence. First, does the project ex-hibit some degree of development activity or from adevelopment perspective does the project look aban-doned? Second, for projects that appear to be aban-doned, were they abandoned for reasons that wereoutside of the team’s control? Let me elaborate on eachquestion.
5.1 Does The Project Exhibit DeveloperActivity or Does It Look Abandoned?
Several studies have measured whether a Libre soft-ware project is ‘alive’ or ‘dead’ [48], by monitoringchanges in the following physical attribute variables ofthe software (Figure 2) over some period of time:
Release trajectory (e.g., movement from alpha tobeta to stable release) [3].Version number [3][48]. Lines of code [48][43].
Number of ‘commits’ or check-ins to a central stor-age repository [45].Similarly, the analyst could monitor changes in com-
munity attribute variables (Figure 2) such as: The activity or vitality scores as measured on col-
laborative platforms such as Sourceforge.net orFreshmeat.net [3][8][48].
Obviously, if any of these metrics show some changeover a period of time, the project demonstrates somelevel of activity or life. A key issue here will bedeciding what time range will be long enough todetermine a dead or abandoned project. I expect thatsome more mature software projects may show periodsof dormancy in terms of development activity untilsome interesting new idea is suggested by a developeror user. Consequently, the range of time with no signsof activity should be relatively long in order to deter-mine project death, or, better yet, the analyst shouldfind some acknowledgment in project documentation(e.g., website) that the project has been closed down orabandoned.
5.2 If The Project Looks Abandoned, Did TheAbandonment Occur because of Factors Outsideof The Team’s Control?
A classification of a project as dead does not by
itself necessarily mean it was a failed project [63].Some projects may exhibit no activity because theyhave reached full development maturity: the softwareproduced does the job and requires no more improve-ments. In these instances, the project would be classi-fied as a success story, not a failure.
In other instances a project may be classified asdead or abandoned but have become so for reasonsoutside the project team’s control, such as in the casewhere another (rival) technology has come along that istechnologically superior or becomes more accepted (re-call the Gopher versus WWW example in Endnote 1).In these instances, the project should probably not beconsidered a failure from a collaborative point of view(although in some cases they probably could be). Therewere simply rival technologies that were better at doingthe job.
But there will be other cases where the projectshows no signs of development life and yet the soft-ware has not fully matured to its full potential andthere were no apparent external factors that led todevelopers abandoning the project. I would classifythese as premature abandonment cases, for some factorin the internal project led to people abandoning theeffort before it reached maturity.
Consequently, for this research program, I intend touse the questions in Section 5.1 and 5.2 to classifyprojects into success or failed categories. Successfulprojects will either show some level of life or willexhibit no further signs of development because it hasreached development maturity.2 Projects that were aban-doned because of external influences will be droppedout of the population of cases, for they cannot beclassified as either a success story or a failed case.Cases that appear to be abandoned prematurely becauseof some kind of internal issue or issues will be theones classified as failures. These metrics will be fairlyeasy to collect for projects that are in Stage 3 (growth)in Figure 3. It will be more difficult to identify projectsto study that fall in the earlier stages (Stage 1 or 2),but when I do, these same concepts should apply.
6 Toward The Identification of "Design Princi-ples" for Libre Software CommonsUntil now, I have tried to emphasize four points.
First, that Libre software projects are a form of com-mon property regime which have physical, communityand institutional attributes that influence their perform-ance. Second, that there are many ways to measure thesuccess and failure of these projects but an importantone will be a measure of the collaboration being aban-doned prematurely (failure) or remaining until the soft-ware reaches a level of maturity (success). Third, thatthe institutional designs – the rules-in-use – are an areathat has to date been largely neglected in Libre softwarestudies. Fourth, that the identification of "design prin-ciples" which lead to success of these projects at the

24 UPGRADE Vol. VI, No. 3, June 2005 © Novática
Libre Software as A Field of Study
different stages in Figure 3 is desirable as more organi-zations turn to Libre software as an IT strategy.
The identification of design principles will require asystematic study of Libre software projects at differentstages in Figure 3 with attention given to appropriatemeasures of success and failure at each stage. Hypoth-eses will need to be made related to all three sets ofindependent variables – physical, community and insti-tutional attributes in Figure 1 – based upon work intraditional software development, more recent studies ofLibre software projects explicitly, and relevant workrelated to natural resource commons. But because ofspace limitations, I will conclude this paper by provid-ing some hypotheses related to the institutional designsof Libre software projects (rules-in-use in Figure 1) andnoting their relationship to studies of natural resourcecommons.
Libre software projects will be more successful (notbe abandoned prematurely) if they include some degreeof voice by lower level participants in the crafting ofoperational-level rules.
It has been shown that in natural resource commonssettings the resources are better sustained when usershave some rights to make and enforce their own opera-tional-level rules [18][14]. Applying this to Libre soft-ware projects if, for example, operational-level rulesare imposed by some overarching authority without theconsultation of others working "in the trenches," theseworkers may become disenchanted and abandon theproject. Alternatively, if developers and users associatedwith the Libre software project have some say in thecrafting or revising of operational-level rules as theproject progresses, commons theory suggests they willbe more willing to participate over the long run.
Libre software projects will be more successful (notbe abandoned prematurely) if they have establishedcollective-choice arrangements for changing operationalrules when necessary.
It has also been shown that long-enduring naturalresource commons tend to have institutional designsthat allow for rule adaptation when needed. Systemswith fixed rules will more likely fail because theunderstanding at the time they were crafted may be, tosome degree, flawed or the situation they were de-signed to work in will eventually, change [15].
Libre software projects will be more successful (notbe abandoned prematurely) if they have systems estab-lished to handle disputes between group members.
Studies such as Divitni et al. [56] and Shaikh andCornford [57] provide discussions on conflict in Libresoftware settings. The most extreme type of conflict is"forking," described earlier. Commons settings with con-flict management in place often result in early resolu-tion coupled with new learning, and understanding withinthe group [15:1909]. Projects not capable of handlingconflict can lead to dysfunctional situations where co-operation is no longer possible.
Libre software projects will be more successful (notbe abandoned prematurely) if
… they have systems in place that provide for themonitoring of operational rules.
… they have some level of graduated sanctions forpeople who break established rules.
… they have rule enforcers whose judgments aredeemed effective and legitimate.
Operational rules work only if they are enforced.Research in natural resource commons settings has shownthat often systems of low-cost monitoring can be estab-lished by the users themselves, and are most effectivewhen there are (at first) modest sanctions given to offend-ers [15]. Sharma, Sugumaran and Rajgopalan [59] notethat monitoring and sanctioning systems do exist in someform in Libre software projects. However, in current Libresoftware literature little is mentioned on this topic. Com-mons literature suggests that the chance for success willbe higher if there is formal or informal monitoring ofoperational rule conformance as well as a set of tieredsocial sanctions in place to rein in rule-breakers. Forexample, a remonstrance by direct one-to-one email that, ifnot successful, progresses to "flaming" in view of theentire team is one example of a graduated sanction proce-dure in Libre software settings. In addition, commonsstudies have also shown that rule enforcement is more aptto work when the people imposing sanctions are deemedeffective and legitimate [15]. Translated to Libre cases,effective sanctioning of rule breakers requires someonewho possesses formal designation to do this or who isrecognized as a legitimate group authority.
7 ConclusionsThe hypotheses provided in the previous section are
intended to be illustrative of what needs to be done tomove toward the identification of design principles inLibre software commons settings. I have provided ex-amples highlighting institutional (rules-in-use) issues be-cause I think this is an area that has, until now, beenneglected in the Libre software research. However, test-able hypotheses certainly can be generated related toother categories of attributes on the left side of Figure1. For example, an obvious but important one probablyis: Libre software projects will be more successful ifthey have a regular and committed stream of fundingcoming in to support their endeavor.
It may be that, for many Libre projects, attention toinstitutional design is simply not important, because thedevelopment team is comprised of only one or a smallnumber of individuals. More important variables at thatstage may be physical or community attributes. However,I suspect that in the larger (in terms of lines of code)projects, or in Libre projects where more than one firm ororganization is contributing resources to support the project,the institutional design will become a much more impor-tant set of variables. Over the next few years, funded bythe U.S. National Science Foundation, I will be undertak-

UPGRADE Vol. VI, No. 3, June 2005 25© Novática
Libre Software as A Field of Study
ing a systematic study of these projects looking specifi-cally at the design and evolution of their institutionalstructures and these issues.
Why should UPGRADE and Novática readers care?Here I return to where I started. Several papers in their2001 issue emphasized the changing nature of participa-tion in Libre software projects: that increasingly actorsare not volunteers but people paid by their organiza-tions to contribute to the development of the software.It is not difficult to imagine a future where governmentagencies and/or firms devote resources to work on aLibre software project together. (Firms are doing this asright now). A main lesson from natural resource com-mons research is that institutions matter. I expect thatas Libre software and Libre software commons mature,institutional attributes will become increasingly impor-tant and apparent as factors that lead to the success orfailure of these projects.
Endnotes1. I am indebted to an anonymous reviewer for
making the point that some abandoned projects are nottragedies. This reviewer provided the example of theGopher technology being superseded by the World WideWeb technology. This is a case of an external factorleading to the early abandonment of the software projectbut would not be considered a tragedy. I should alsonote that the idea of project cancellation has been usedin more traditional software development in the past[42], but the phrase "premature abandonment" ratherthan "premature cancellation" better fits Libre settingssince in many cases there is no formal organizationmaking the decision to end the project prematurely.
2. An additional analytic part of this project will beto analyze the ‘vibrancy’ of successful projects – cap-turing the degree of life (in terms of developer or useractivity) a project exhibits. In other words, I ultimatelywant to develop a measure of success that movesbeyond the ‘live’ versus ‘dead’ metric. Several studies(e.g., [3][4][8]) have looked at vibrancy metrics, focus-ing in on variables such as the numbers of people inthe formal development team or the extended develop-ment team (e.g., bug reporters), number of commits,number of downloads, etc. Other possible vibrancymetrics might include an examination of the directionof change in numbers of formal or extended developerteams. However, a more thorough examination of thesemetrics is needed – beyond what can be done in thispaper. For it is likely that any vibrancy metric will beclosely tied to the stage of development of the project.For example, Dalle and colleagues [44] note that moreactive, younger projects on Sourceforge.net are likelyto attract developers at a higher rate than older, moremature projects with larger code bases. From this per-spective, vibrancy metrics might look very similar be-tween a project that is being abandoned prematurelyand a project that is reaching maturity. For this reason,
in this paper I only want to point out that I intend toinvestigate further how to conceptualize and put intooperation vibrancy metrics but it is beyond the scopeof this paper to do so.
AcknowledgmentsSupport for this study was provided by a grant from the U.S.
National Science Foundation (NSFIIS 0447623). However, the find-ings, recommendations, and opinions expressed are those of theauthors and do not necessarily reflect the views of the fundingagency.
References[1] UPGRADE, Vol. II, No. 6, December 2001, <http://
www.upgrade-cepis.org/issues/2001/6/upgrade-vII-6.html>;Novática, n. 154 (nov.-dic. 2001), <http://www.ati.es/novatica/2001/154/nv154sum.html> (in Spanish).
[2] R.W. Hahn. "Government Policy Toward Open Source Soft-ware: An Overview." In R. W. Hahn (ed.) Government Policytoward Open Source Software. Washington, D.C.: AEI-Brookings Joint Center for Regulatory Studies, 2002.
[3] K. Crowston, H. Annabi, and J. Howison. "Defining OpenSource Project Success." In Proceedings of the 24th Interna-tional Conference on Information Systems (ICIS 2003).Seattle, WA, 2003.
[4] Crowston, Annabi, Howison, and Masango. "Towards a Port-folio of FLOSS Project Success Measures." In Feller,Fitzgerald, Hissam, and Lakhani (eds.) Collaboration, Con-flict and Control: The Proceedings of the 4th Workshop onOpen Source Software Engineering. Edinburg, Scotland,2004.
[5] K. Crowston and B. Scozzi. "Open Source Software Projectsas Virtual Organizations: Competency Rallying for Soft-ware Development," IEE Proceedings Software (149:1), pp.3-17, 2002.
[6] W. Scacchi. "Understanding the Requirements for DevelopingOpen Source Software Systems." IEE Proceedings Software.149, 1: 24-39, 2002.
[7] W. Scacchi. "Free and Open Source Development Practices inthe Game Community." IEEE Software. January/February,2004.
[8] K.J. Stewart and T. Ammeter. "An Exploratory Study of Fac-tors Influencing the Level of Vitality and Popularity of OpenSource Projects." In L. Applegate, R. Galliers, and J.I.DeGross (eds.) Proceedings of the Twenty-Third InternationalConference on Information Systems, Barcelona. Pp. 853-57,2002.
[9] Y. Benkler. "Coase’s Penguin, or Linux and the Nature of theFirm. Yale Law Journal. 112 (3), 2002.
[10] A. Nuvolari. "Open Source Software Development: SomeHistorical Perspectives." Eindoven Center for InnovationStudies, Working paper 03.01. <http://opensource.mit.edu/nuvolari.pdf>, 2003.
[11] J. Boyle. The second enclosure movement and the construc-tion of the public domain. Law and Contemporary Prob-lems. 66(1-2): 33-75, 2003.
[12] S. Weber. The Success of Open Source. Cambridge, MA:Harvard University Press, 2004.
[13] C.M. Schweik, T. Evans, and J.M. Grove. "Open Sourceand Open Content: A Framework for the Development ofSocial-Ecological Research." Ecology and Society (pendingpublication).
[14] E. Ostrom, J. Burger, C.B. Field, R.B. Norgaard, and D.

26 UPGRADE Vol. VI, No. 3, June 2005 © Novática
Libre Software as A Field of Study
Policansky. "Revisiting the Commons: Local Lessons, Glo-bal Challenges." Science 284. pp. 278-282, 1999.
[15] T. Dietz, E. Ostrom, and P. Stern. "The Struggle to Governthe Commons." Science 302(5652). pp. 1907-1912, 2003.
[16] C. Hess and E. Ostrom. "Ideas, Artifacts and Facilities: In-formation as a Common-Pool Resource. Law and Contem-porary Problems. 66(1&2), 2003.
[17] G. Hardin. "The Tragedy of the Commons." Science.162:1243-48, 1968.
[18] E. Ostrom. Governing the Commons: The Evolution ofInstitutions for Collective Action. New York: CambridgeUniversity Press, 1990.
[19] R. Netting. Balancing on an Alp: Ecological Change andContinuity in a Swiss Mountain Community. Cambridge:Cambridge Uiversity Press, 1981.
[20] J.M. Baland and J.P. Platteau. Halting Degradation ofNatural Resources. Is there a Role for Rural Communities?Oxford University Press, 1996.
[21] E. Ostrom, R. Gardner, and J.K. Walker. Rules, Games, andCommon-Pool Resources, Ann Arbor: University of Michi-gan Press, 1994.
[22] V. Ostrom and E. Ostrom. "Public Goods and PublicChoices." In Alternatives for Delivering Public Services:Toward Improved Performance. E.S. Savas (editor). Boul-der, Colo: Westview Press. pp. 7-49, 1977.
[23] J. Bessen. "Open Source Software: Free Provision of Com-plex Public Goods." <http://www.researchoninnovation.org/opensrc.pdf>, 2001 .
[24] Peter Kollock. "The Economies of Online Cooperation: Giftsand Public Goods in Computer Communities." In Commu-nities in Cyberspace, edited by Marc Smith and PeterKollock. London: Routledge, 1999.
[25] R. van Wendel de Joode, J.A. de Bruijin, and M.J.G. vanEeten. Protecting the Virtual Commons: Self OrganizingOpen Source and Free Software Communities and Innova-tive Intellectual Property Regimes. The Hague: T.M.C. AsserPress, 2003.
[26] S.V. Ciriacy-Wantrup and R.C. Bishop. "’Common Prop-erty’ as a Concept in Natural Resource Policy." Natural Re-sources Journal. 15:713-27, 1975.
[27] A. Nuvolari. "Open Source Software Development: SomeHistorical Perspectives." Eindoven Center for InnovationStudies, Working paper 03.01. <http://opensource.mit.edu/papers/nuvolari.pdf>, 2003.
[28] K. Healy and A. Schussman. "The Ecology of Open-SourceSoftware Development." Available at <http://opensource.mit.edu/papers/ healyschussman.pdf>, 2003.
[29] B.J. McCay and J.M. Acheson. The Question of the Com-mons: The Culture and Ecology of Communal Resources.Tucson: University of Arizona Press, 1987.
[30] D. W. Bromley et al. Making the Commons Work: Theory,Practice, and Policy (ICS Press, San Francisco, 1992.
[31] C. Hess and E. Ostrom. "A Framework for Analyzing Schol-arly Communication as a Commons." Presented at the Work-shop on Scholarly Communication as a Commons, Work-shop in Political Theory and Policy Analysis, Indiana Uni-versity, Bloomington, IN, March 31-April 2, 2004. <http://dlc.dlib. indiana. edu/archive/00001244/>.
[32] C.M. Schweik. The Spatial and Temporal Analysis of ForestResources and Institutions. Tesiks Doctoral. Center for theStudy of Institutions, Population and Environmental Change,Indiana University. Bloomington, IN, 1998.
[33] C.M. Schweik. Optimal Foraging, Institutions and Forest
Change: A Case from Nepal. Environmental Monitoring andAssessment. 62: 231-260, 1999.
[34] Schweik, C.M., Adhikari, K., and Pandit, K.N. 1997. "Land-Cover Change and Forest Institutions: A Comparison of TwoSub-Basins in the Southern Siwalik Hills of Nepal." Moun-tain Research and Development. 17(2): 99-116, 1997.
[35] Institute for Software Research. <http://www.isr.uci.edu/re-search-open-source.html>, 2005.
[36] Libre Software Engineering. <http://libresoft.urjc.es/>, 2005.[37] FLOSS, Free/Libre Open Source Software Research. <http:/
/floss.syr.edu/>, 2005.[38] K. Stewart. Open Source Software Development Research
Project. <http://www.rhsmith.umd.edu/faculty/kstewart/ResearchInfo/KJSResearch.htm>, 2005.
[39] L.L: Kiser and E. Ostrom. "The Three Worlds of Action: AMeta-theoretical Synthesis of Institutional Approaches." InE. Ostrom (ed.) Strategies of Political Inquiry. Beverly Hills,CA: Sage. Pp. 179-222, 1982.
[40] K. Fogel and M. Bar. Open Source Development with CVS.Scottsdale, AZ: Coriolis, 2001.
[41] K. Stewart. "OSS Project Success: From Internal Dynamicsto External Impact." In Proceedings of the 4th Annual Work-shop on Open Source Software Engineering. Edinburgh,Scotland. May 25th , 2004.
[42] Standish Group International, Inc. The CHAOS Report.<http:/ /www.standishgroup.com/sample_research/chaos_1994_1.php>, 1994.
[43] S. Hissam, C.B. Weinstock, D. Plaksoh, and J. Asundi. Per-spectives on Open Source Software. Technical report CMU/SEI-2001-TR-019, Carnegie Mellon University. <http://www.sei.cmu.edu/publications/documents/01.reports/01tr019.html>, 2001.
[44] J-M. Dalle, P.A. David, R.A. Ghosh, and F.A. Wolak. "Free& Open Source Software Developers and ‘the Economy ofRegard’: Participation and Code-Signing in the Modules ofthe Linux Kernel." <http://siepr.stanford.edu/programs/O p e n S o f t w a r e _ D a v i d / E c o n o m y - o f -Regard_8+_OWLS.pdf>, 2004.
[45] G. Robles-Martinez, JM. Gonzalez-Barahona, J. Centeno-Gonzalez, V. Matellan-Olivera, and L. Rodero-Merino."Studying the Evolution of Libre Software Projects UsingPublically Available Data. In J. Feller, B. Fitzgerald, S.Hissam, and K. Lakhani (eds.) Taking Stock of the Bazaar:Proceedings of the 3rd Workshop on Open Source SoftwareEngineering. <http://opensource.ucc.ie/icse2003>, 2003.
[46] C.M. Schweik and A. Semenov. The Institutional Design of"Open Source" Programming: Implications for AddressingComplex Public Policy and Management Problems. FirstMonday 8(1). <http://www.firstmonday.org/issues/issue8_1/schweik/>, 2003.
[47] <http://bioinformatics.org/>.[48] A. Capiluppi, P. Lago, and M. Morisio. "Evidences in the
Evolution of OS projects through Changelog Analyses," InJ. Feller, B. Fitzgerald, S. Hissam, and K. Lakhani (eds.)Taking Stock of the Bazaar: Proceedings of the 3rd Work-shop on Open Source Software Engineering. <http://opensource.ucc.ie/icse2003>, 2003.
[49] R.A. Ghosh and V.V. Prakash. "The Orbiten Free SoftwareSurvey." First Monday (5) 7. <http://firstmonday.org/issues/issue5_7/ghosh/>, 2000.
[50] R.A. Ghosh, G. Robles, and R. Glott. Free/Libre and OpenSource Software: Survey and Study. Technical report. Inter-national Institute of Infonomics. University of Maastricht,

UPGRADE Vol. VI, No. 3, June 2005 27© Novática
Libre Software as A Field of Study
The Netherlands. June. <http://www.infonomics.nl/FLOSS/report/index.htm>, 2002.
[51] K. Healy and A. Schussman. "The Ecology of Open-SourceSoftware Development." Disponible en: <http://opensource.mit.edu/papers/healyschussman.pdf>, 2003.
[52] S. Krishnamurthy. "Cave or Community? An Empirical Ex-amination of 100 Mature Open Source Projects." FirstMonday7, 2002.
[53] D. McGowan. Legal Implications of Open Source Software.University of Illinois Review, 241 (1): 241-304, 2001.
[54] E. Moglen. "Anarchism Triumphant: Free Software and theDeath of Copyright." First Monday, 4. August, 1999.
[55] P. Kollock. The Economies of Online Coorperation: Giftsand Goods in Cyberspace. In M. Smith and P. Kollock (eds.)Communities in Cyberspace. London: Routeldge. Pp. 220-239, 1999.
[56] M. Divitini, L. Jaccheri, E. Monteiro, and H. Traetteberg."Open Source Processes: No Place for Politics?". In J. Fel-ler, B. Fitzgerald, S. Hissam, and K. Lakhani (eds.) TakingStock of the Bazaar: Proceedings of the 3rd Workshop on OpenSource Software Engineering. <http://opensource.ucc.ie/icse2003>, 2003.
[57] M. Shaikh and T. Cornford. "Version Management Tools:CVS to BK in the Linux Kernel." In J. Feller, B. Fitzgerald,S. Hissam, and K. Lakhani (eds.) Taking Stock of the Ba-zaar: Proceedings of the 3rd Workshop on Open Source Soft-ware Engineering. <http://opensource.ucc.ie/icse2003>,2003.
[58] J. Feller and B. Fitzgerald. Understanding Open Source Soft-ware Development. London: Addison Wesley, 2002.
[59] Sharma, Sugmaran, and Rajgopalan. "A Framework for Cre-ating Hybrid-Open Source Software Communities." Infor-mation Systems Journal. 12:7-25, 2002.
[60] A. Wasserman, A. Center for Open Source Innovation,Carnegie Mellon West Coast Campus. Personal conversa-tion.
[61] L. Rosen. Open Source Licensing. Upper Saddle River, NJ:Prentice Hall, 2005.
[62] A.M. St. Laurent. Understanding Open Source and Free Soft-ware Licensing. Sebastopol, CA: O’Reilly, 2004.
[63] J.M. Garcia. "Quantitative Analysis of the Structure and Dy-namics of the Sourceforge Project and Developer Populations:Prospective Research Themes and Methodologies." <http://siepr. stanford.edu/programs/OpenSoftware_David/JuanM-G_FOSS-PopDyn_Report2+.pdf>, 2004.

28 UPGRADE Vol. VI, No. 3, June 2005 © Novática
Libre Software as A Field of Study
Keywords: Cave, Developer Recruitment, Firefox, FLOSS,Group Size, Open Source Software.
I sent the club a wire stating - "PLEASE ACCEPT MY RESIGNA-TION. I DON’T WANT TO BELONG TO ANY CLUB THAT WILL
ACCEPT ME AS A MEMBER."
Groucho Marx,US comedian with Marx Brothers (1890-1977)
1 IntroductionThe vast majority of open source projects are ‘small’,
i.e., have less than five members[3][5][4][11]. Many open source projects are ‘caves’ or
have just one member [7].At the same time, some open source scholars have ar-
gued that the number of developersin a project is a proxyfor the level of that project’s success [9]. In this line ofreasoning, since developers have multiple options and manydemands on their time, merely attracting a large number ofdevelopers to a project is an indication of success. In [12] ithas been argued that projects that do not grow beyond a"strong core of developers ... will fail because of a lack ofresources devoted to finding and repairing defects" (pp. 329,341). However, these "bigger is better" arguments ignoresome of the negatives in attracting a large number ofdevelopers to a project - e.g. coordination costs, conflict,loss in quality.
What we are now learning that is that the edict ofRaymond in "The Cathedral and the Bazaar" [14] - "treat-ing your users as co-developers is your least-hassle routeto rapid code improvement and effective debugging" - doesnot always apply. In some groups, what we observe is notthe promiscuous Raymondian model of "user as co-devel-oper" which allows free access to code and broad check-in
About Closed-door Free/Libre/Open Source (FLOSS) Projects:Lessons from the Mozilla Firefox Developer Recruitment Approach
Sandeep Krishnamurthy
This paper is copyrighted under the CreativeCommons Attribution-NonCommercial-NoDerivs 2.5 license available at <http://
creativecommons.org/licenses/by-nc-nd/2.5/>
In this paper, the notion of a "closed-door open source project" is introduced. In such projects, the most important devel-opment tasks (e.g. code check-in) are controlled by a tight group. I present five new arguments for why groups may wish toorganize this way. The first argument is that developers simply do not have the disposable time to evaluate potentialmembers. The next two arguments are based on self-selection- by setting tough entry requirements the project can ensurethat it gets high quality and highly persistent programmers. The fourth argument is that expanding a group destroys thefun. The fifth argument is that projects requiring diverse inputs require a closed door approach.
privileges. Rather, what we see is that individuals are askednot to apply and a tight group of individuals control the mostpivotal tasks (e.g. code check-in).
Sandeep Krishnamurthy is Associate Professor of E-Commerce and Marketing at the University of Washington,Bothell, USA. Today, he is interested in studying the impact ofthe Internet on businesses, communities and individuals. He isthe author of a successful MBA E-Commerce textbook, "E-Commerce Management: Text and Cases" and has recentlyedited two books, "Contemporary Research in E-Marketing:Volumes I, II". His academic research has been published injournals such as Organizational Behavior and Human DecisionProcesses (OBHDP), Marketing Letters, Journal of ConsumerAffairs, Journal of Computer-Mediated Communication,Quarterly Journal of E-Commerce, Marketing Management,Information Research, Knowledge, Technology & Policy andBusiness Horizons. He is the Associate Book Review Editor ofthe Journal of Marketing Research and a co-editor for a SpecialIssue of the International Marketing Review on E-Marketing.His writings in the business press have appeared on Clickz.com,Digitrends.net and Marketingprofs.com. Sandeep was recentlyfeatured on several major media outlets (TV- MSNBC, CNN,KING5 News; Radio- KOMO 1000, Associated Press RadioNetwork; Print- Seattle Post Intelligencer, The Chronicle ofHigher Education, UW’s The Daily; Web- MSNBC.com,Slashdot.org) recently for pointing out the flaws in MicrosoftWord’s Grammar Check. His comments have been featured inpress articles in outlets such as Marketing Computers, DirectMagazine, Wired.com, Medialifemagazine.com, Oracle’s ProfitMagazine and The Washington Post. Sandeep also works inthe areas of generic advertising and non-profit marketing. Youcan access his web site at <http://faculty.washington.edu/sandeep> and his blog at <http://sandeepworld. blogspot.com>.<sandeep@u. washington.edu>

UPGRADE Vol. VI, No. 3, June 2005 29© Novática
Libre Software as A Field of Study
In this article, using the example of the Mozilla Firefoxbrowser, I argue that some very successful FLOSS (Free/Libre/Open Source) projects are designed to be small. Farfrom seeking a large number of developers, these groupsactively discourage applicants and do not even let interestedindividuals to submit patches. Rather than opening the doorsto all interested individuals, these projects provide the codefor their programs to the world- but do not allow anyone toparticipate in the development of the product. Based onpublic online conversations, I provide five theoretical ex-planations to describe why some open source groups take a"closed-door" approach.
2 Firefox Development TeamThe Mozilla Foundation’s Firefox browser, <http://
www.mozilla.org/products/firefox/>, has done very well. Ithas been downloaded more than 60 million times in a veryshort period. Even though the Firefox browser benefits fromthe vast Netscape code, an extremely small team of com-mitted programmers developed the entire Firefox browser.At this point, six individuals, Blake Ross, David Hyatt, BenGoodger, Brian Ryner, Vladmir Vukicevic and Mike Connor,form the core group. At all points, a small group has had theprivilege of checking in code.
The Firefox project (originally named Phoenix and thenrenamed Firebird) was initiated by Blake who had long fixedbugs on Mozilla browser and was disenchanted with thedirection of the project. David Hyatt was brought in sincehe was an ex-Netscape employee and had an intimate knowl-edge of the code. A significant subset of this core groupwas paid a salary1 by the Mozilla Foundation to work onthis project.
The documents used by members of this team provideus with a rare glimpse of what motivates some groups tokeep out others. Consider these excerpts from the FrequentlyAsked Questions (FAQ) in the team’s original manifesto(source: <http://www.blakeross.com/firefox/README-1.25.html)>:
"- Q2. Why only a small team?- The size of the team working on the trunk is one of the
many reasons that development on the trunk is so slow. Wefeel that fewer dependencies (no marketing constraints),faster innovation (no UI committees), and more freedom toexperiment (no backwards compatibility requirements) willlead to a better end product.
- Q3. Where do I file bugs on this?- We’re still chopping with strong bursts and broad
strokes. There’s plenty that’s obviously broken and we don’tneed bugs on that. If you find a bug (a feature request is nota bug) and you’re sure that it’s specific to Firefox (notpresent in Mozilla) and you’ve read all of the existing Firefoxbugs well enough to know that it’s not already reported thenfeel free report it on the Phoenix product in Bugzilla.
...- Q5: How do I get involved?- By invitation. This is a meritocracy — those who gain
the respect of those in the group will be invited to join thegroup."
The FAQ is very clear. Those who wish to participate inthe process are discouraged from doing so. Potential par-ticipants are told that membership is by invitation only.Clearly, the group has done everything in its power to keepout people rather than encouraging them to participate. Ifattracting developers is the path to success for an open sourceproject [9], this would not be the case.
What this teaches us is that some open source projectsare not "open door" projects. Many can best be describedas "closed-door" projects. Formally, closed-door projectsare defined as those that provide access to the program andsource code to any interested person, but do not provideaccess to core functions of software development (esp. set-ting up roadmaps, checking in code and submitting patches).
Such projects want their target audience to downloadand use their product and tinker with their code. However,they intentionally keep out qualified potential participants.Even developers who work on bugs and submit patches arenot admitted to the team. Firefox has consistently been de-veloped as a closed-door project.
While users can provide feedback through open forums,the actual development is done by a core group.
This approach is controversial and it upsets many mem-bers of the open source community. If open source projectsare about building a community of hackers, the closed-doorapproach seemingly provides a manifestation of this phi-losophy that is built on the standard principles of control.Here is one public reaction to the Firefox developer recruit-ment policy:
"They say loudly that they are only willing to acceptdevelopers to the project that they have vetted themselves,no one need apply. And with this attitude in front of them,they drive away people who want to help but are unsure oftheir abilities.
Then they say that they want people to submit patchesand pitch in to help develop the product. But how is anyonesupposed to do that without being a member? Well, obvi-ously you don’t have to be on the team to work for the team.But who wants to work for someone that isn’t going to treatthem as part of the same team?
…However, the spirit of OSS (at least on the BSD side of
the world) is one of openness and acceptance. Turning peo-ple away or accepting a new member only through invita-tion smacks of elitism. Unfortunately when you deal withhuman beings, you will inevitably end up dealing with somewho think themselves elite and worthy of looking down uponothers from the heights of their snoots." (Source: <http://developers.slashdot.org/comments.pl? sid=137815&cid=11526872>).
Moreover, relying on a small group could potentiallyjeopardize the future of a project as members get other op-
1 Working off public documents, it appears that Blake, David and Benwere paid while Peter was not.

30 UPGRADE Vol. VI, No. 3, June 2005 © Novática
Libre Software as A Field of Study
portunities. Mike Connor, one of Firefox’ main developersvented his frustration in this way:
"This is bugging me, and its been bugging me for a while.In nearly three years, we haven’t built up a community ofhackers (emphasis added) around Firefox, for a myriad ofreasons, and now I think we’re in trouble. Of the six peoplewho can actually review in Firefox, four are AWOL, andone doesn’t do a lot of reviews. And I’m on the verge of justwalking away indefinitely, since it feels like I’m the onlyperson who cares enough to make it an issue." (Source:<http://steelgryphon.com/blog/index.php?p =37>)
3 Onion TheoryAt this point, the onion theory of open source software
development has gained currency (e.g. [13][15][3][10]). Inthis theory, a small group of powerful individuals controlcheck-in privileges while members of outer layers of theonion are assigned routine tasks such as fixing bugs. Thereasons and implications of this organizational structure arestill not fully explicated in the literature.
The most common explanation for restricting group sizeis that increasing the number of developers leads to coordi-nation problems [2]. Some scholars have pointed out ac-cess to the core group in most open source projects is con-trolled by a "joining script".
Those who know how to approach the developers in theproject in a manner that is culturally compatible get in whileothers are denied access [15]. Joining scripts certainly playeda role in the choice of Firefox core group developers - DaveHyatt was employed at Netscape and knew the culture, BenGoodger got in as a result of a thorough critique of theMozilla browser on his website.
In this article, drawing from public conversations onFirefox, I discuss five other explanations for executing aclosed-door approach. It is, of course, not clear if all expla-nations provided here apply to all closed-door projects.Future research should evaluate the relative importance ofeach explanation. These arguments are somewhat new inthe way they are presented and should move the conversa-tion on the recruitment of open source developers forward.
4 Four Explanations
Explanation 1 - Low Disposable TimeEvaluating new members takes time that developers have
very little of. As a result, frequently, leaders who have lim-ited time at their disposal choose to do the work themselvesrather than spending the time trying to identify a potentialcandidate.
Blake Ross has said: "I’m only just now finding time toget back on Firefox, and even then I often have 1-2 hourstops (a day). Ben obviously has his hands full leading andtrying to get all his ducks in a row." (Source: <http://blakeross.com/index.php?p=19>)
Finding new team members is an onerous and a riskytask. The task involves the cost of advertising and screen-ing applicants. If the applicant is not known to a member of
the core group, it may be hard to judge the competence andcapabilities of potential new members.
Moreover, there is the usual agency problem where ap-plicants may hide their abilities or game it in a way to en-sure membership. Therefore, when members are pressed fortime, the incremental benefit from including a new memberis outweighed by the incremental cost of finding that per-son.
Explanation 2 - Meritocracy (Only The Most SkilledWill Get in)
Open source communities compete with corporationsfor developers. Attracting the best developers enhances thecommunity’s chances of competing in a tough marketplace.Setting the highest standards allows them to recruit highlyskilled developers enhancing their chances of corporatesuccess. Closing the door leads to self-selection with themost competent developers applying. It is possible to as-sess the quality of work of an open source developer sincethe record of accomplishment is open and hence, easilyavailable.
This theory is supported by an observation made by,Blake Ross, a key Firefox developer: "We basically wantedto use open source as the world’s best job interview. Ratherthan get people in front of a whiteboard for two hours andask them to move Mount Fuji (Author clarifies- this is areference to a book on Microsoft interview processes), wewanted people to submit patches that would demonstrateexactly what they would bring to the table if they joined theteam." (Source: <http://blakeross.com/index.php?p=19>)
A participant on a Slashdot thread also articulated a simi-lar argument: "Firefox actually want the ‘smartest coders’that work with their codebase. While it is certainly elitist, itmakes sure that only the elite (dedication plus skill) get towork on their branch of the browser. If that ends up makingit work faster, more robustly and more efficiently, then all tothe better. A small team of highly skilled individuals canoften achieve more than a large pool of medium skilled peo-ple, and usually far more than a huge team of mediocrelyskilled people. Everyone they compete with (corporate en-tities, such as MS and Opera) is pretty much guaranteed tobe elitist (they’ll hire the best coders and designers theycan at interview), so why shouldn’t the firefox team? Ofcourse, as has been noted, if you think you can do betterwith your choice of team recruitment, then fork the project,and see which one survives." [Source: <http://developers.slashdot.org/comments.pl?sid= 137815&cid=11527401>]
Explanation 3 - Persistence (Only The Most Persist-ent Will Get in)
Closed-door projects deter people from applying. Ref-erences are frequently made to the amount of work that isinvolved. See, for instance, this post by Ben Goodger ofMozilla Firefox: "Help Wanted We always need HeavyLifters in code. If you’re excited about web browser tech-nology, why not get involved in the premier Open Sourcebrowser project? We’re especially looking for people with

UPGRADE Vol. VI, No. 3, June 2005 31© Novática
Libre Software as A Field of Study
skills in Mac OS X programming and Windows developers.Get started today by finding and fixing something. Instruc-tions are not provided here since figuring out how to do allof this can be considered part of the "entry requirements".;-) [Source: <http://www.mozilla. org/projects/firefox/>]
This has got to be the world’s most intimidating "HelpWanted" advertisement. Ben literally tells people that theywill have to work hard for nothing and if they want to im-press, they should work on low-end work, i.e., fixing bugs.
Blake Ross justifies this approach in this way: "Ben con-cedes that even figuring out how to get noticed is part of therecruitment process, and rightfully so. After all, most of thecurrent Mozilla super reviewers and the people running theproject began as "entry-level" contributors and floated tothe top of the meritocracy. If you aren’t willing to do a littleresearch, observe how the project functions, and figure outhow to make your mark on it, do you really belong on theteam?" (Source: <http://blakeross.com/index.php?p=19>)
This is likely to lead to people with high levels of per-sistence to self-select into the project with positive results.While self-selection based on developer quality is under-standable, self-selection based on persistence may lead tolower quality programmers (e.g. those who have high dis-posable time) being admitted.
While a long-term commitment to the project (e.g. longposts on forums) is a sign of persistence, it may also be anindicator of ideological fervor.
Therefore, enabling self-selection through persistencemay lead to peculiarities in terms of group composition.Other groups have dealt with persistent participants whodo not add much by creating niche developer mailing lists[12].
Explanation 4 - Opening the Door Will Kill The FunScholars who study the motivation of open source de-
velopers tell us that many individuals are motivated by thefun of building something [8][6]. In [1] Bitzer, Schrettl andSchroeder even classify open source developers as homoludens and model the intrinsic motivation of developers.Eric Raymond, an early observer of FLOSS and the authorof the popular "The Cathedral and the Bazaar", has saidthat: "It may well turn out that one of the most importanteffects of open source’s success will be to teach us that playis the most economically efficient mode of creative work." 2
Closed-door projects are frequently started by a smallgroup that is intimately familiar with each other. Admittingoutsiders takes away this cozy feeling and reduces the in-trinsic motivation of current developers.
Blake Ross has noted that Firefox has always been aninformal project: "People sometimes ask why we work onFirefox for free. It gets hard to keep a straight face at "work."Give me another project that touches the lives of millions ofpeople worldwide and still has public codenames like "TheOcho" which get published in the media. ("The Ocho" is
the name of the fictitious ESPN 8 station in Dodgeball; ku-dos to Ben for the flash of v1.5 naming brilliance). The bestpart of Firefox is that even as it’s skyrocketed to the top, it’snever really grown out of its humble roots as a skunkworksproject that was by and large coordinated on caffeine highsat Denny’s. It has, in short, never quite grown up." (Source:<http://blakeross.com/index.php?p=24>)
As one observer on Slashdot put it: "Maybe it is abouthaving fun ...
If you limit the developers to people who actually likeworking together, and have similar ideas of how to behaveand talk to other people, more can often be done than if youalso invite all the socially dysfunct coders, who cannot takea rejection of patch as anything but a personal insult (or, forthe true nutcase, some political game).
There are more than a couple of great coders out therewith zero people skill. They can damage a project because,even though their own contributions are great, they lowerthe fun level and therefore productivity of everybody else.
Some of them make great solo projects ..." (Source:<http://developers. slashdot.org/comments.pl?sid=137815&cid=11527896>)
Similar observations have been made in the entrepre-neurship arena. Frequently, we find that a company is startedby a group of good friends. Over time, as formalization in-creases, the company puts in more processes making it morestructured and bureaucratic reducing the ad-hoc and funnature.
It is not clear if this can only be a partial explanation forthe existence of closed-door projects.
Explanation 5 - Products Requiring Diverse Capa-bilities Require Closed-Door Approach
Firefox is one of the few open source products that tar-gets a general audience, i.e., a consumer market. Unlike thevast majority of open source products that target a generalaudience, Firefox needs to succeed with lay consumers. Thisimplies that for the project to succeed what is needed is anintuitive user interface (UI) along with a sound product.
Therefore, the project team needs to involve people withdiverse capabilities- some that are more adept at UI designand others that have strong programming capabilities.
The original manifesto states that: "We feel that fewerdependencies (no marketing constraints), faster innovation(no UI committees), and more freedom to experiment (nobackwards compatibility requirements) will lead to a betterend product."
In Blake Ross’ words: "Since this audience was primarlynon-technical in character, we felt it necessary to judgepatches not just on technical merit but also on how closelythey adhered to this new vision. Code+UI review, however,took more time than we were willing to spend in our eager-ness to develop Phoenix quickly. So we sought to find thepeople who understood our vision so well that they didn’tneed this additional layer of review, and then bring themonto the team." (Source: <http://blakeross.com/index.php?p=19>)
2 We are grateful to Bitzer, Schrettl and Schroeder [1], page 9, for alertingus to this quote.

32 UPGRADE Vol. VI, No. 3, June 2005 © Novática
Libre Software as A Field of Study
closed-door approach. The group did not want a UI com-mittee and wanted to handle patches differently (i.e.,Code+UI review). Increasing the group size and allowingoutsiders to enter the group would dilute this process.
5 ConclusionIn this paper, I have proposed five new arguments for
organizing an open source project in a closed-door manner.The first argument is that developers simply do not have thedisposable time to evaluate potential members and are likelyto use their time to do the work rather than invest it in evalu-ating new members. The next two arguments are based onself-selection - by setting tough entry requirements theproject can ensure that it gets high quality and highly per-sistent programmers. The fourth argument applies the homoludens fun-driven intrinsic motivation arguments by imply-ing that extending a group beyond a small coterie will ruinthe fun. The fifth argument is that complicated projects (e.g.those requiring input in technical and user interface areas)require a closed-door approach.
Future research must investigate the relative importanceof these arguments. Moreover, we do not know if projectoutcomes are improved or hurt by organizing the project ina closed-door way. An empirical comparison of closed-doorand open-door approaches is needed.
References[1] J. Bitzer, W. Schrettl, and P.J.H. Schroeder. "Intrinsic
Motivation in Open Source Software Development", 2004.Available at <http://econwpa.wustl.edu/eps/dev/papers/0505/0505007.pdf>.
[2] Frederick Brooks. The Mythical Man-Month: Essays onSoftware Engineering, 20th Anniversary Edition, Addison-Wesley Professional, 1995.
[3] K. Crowston and J. Howison "The Social Structure of OpenSource Software Development Teams. Working Paper", 2003.Available at <http://floss.syr.edu/tiki-index.php> [accessed onAugust 22, 2004].
[4] K. Healy and A. Schussman. "The Ecology of Open SourceSoftware Development", 2004. Working paper. Available at<http://www.kieranhealy.org/files/drafts/ossactivity.pdf>[accessed on August 22, 2004].
[5] F. Hunt and P. Johnson. "On the Pareto distribution ofSourceforge projects", in Proceedings of the F/OSS SoftwareDevelopment Workshop. 122-129, Newcastle, UK`, 2002.
[6] S. Krishnamurthy. "On the Intrinsic and Extrinsic Motivationof Open Source Developers", 2005. Forthcoming inKnowledge, Technology & Policy.
[7] S. Krishnamurthy. "Cave or Community?: An EmpiricalExamination of 100 Mature Open Source Projects", in FirstMonday, 7(6), 2002. Available at
<http://firstmonday.org/issues/issue7_6/krishnamurthy/index.html>.
[8] K.R. Lakhani and R. Wolf. "Why Hackers Do What They Do:Understanding Motivation and Effort in Free/Open SourceSoftware Projects", in Perspectives on Free and Open SourceSoftware, edited by J. Feller, B. Fitzgerald, S. Hissam, and K.R. Lakhani. Cambridge, MA: MIT Press, 2005.
[9] J. Lerner and J.Tirole. "Some Simple Economics of OpenSource", in Journal of Industrial Economics, 52, pp. 197-234,2002.
[10] Luis Lopez-Fernandez, Luis, Gregorio Robles, and Jesus M.González-Barahona. "Applying Social Network Analysis toInformation in CVS Repositories", 2005. Available at <http://opensource.mit.edu/papers/llopez-sna-short.pdf>.
[11] G. Madey, V. Freeh, and R. Tynan. "Modeling the F/OSSCommunity: A Quantitative Investigation", in Free/OpenSource Software Development, edited by Stephan Koch,Hershey, PA: Idea Group Publishing, 2004.
[12] A. Mockus, R. T. Fielding, and J. D. Herbsleb. "Two Casesof Open Source Software Development: Apache and Mozilla",in ACM Transactions on Software Engineering andMethodology, 11(3), pp. 309-346, 2002.
[13] K. Nakakoji, Y. Yamamoto, Y. Nishinaka, K. Kishida, and Y.Ye. "Evolution Patterns of Open-Source Software Systems andCommunities", in Proceedings of International Workshop onPrinciples of Software Evolution (IWPSE 2002), pp. 76-85,2002.
[14] E. Raymond. "The Cathedral and the Bazaar", in FirstMonday, Volume 3, Issue 3, 1998. Available at <http://www.firstmonday.org/issues/issue3_3/raymond/>.
[15] G. Von Krogh, S. Haefliger, and S.Spaeth. "Collective Actionand Communal Resources in Open Source SoftwareDevelopment: The Case of Freenet", en Research Policy, 32(7),pp. 1217-1241, 2003.

UPGRADE Vol. VI, No. 3, June 2005 33© Novática
Libre Software as A Field of Study
Keywords: Agile Methods, Extreme Programming, LibreSoftware.
1 IntroductionAgile Methods (AMs) have grown very popular in the
last few years [3] and so has Libre Software [1][8]. Even ifthese approaches to software development seem very dif-ferent, they present many commonalities, as evidenced byKoch [11].
Both AMs and Libre Software push for a less formaland hierarchical organization of software development anda more human-centric development, with a major empha-sis: in focusing on the ultimate goal of development – pro-
ducing the running system with the correct amount offunctionalities. This means that the final system has to in-clude only the minimum number of features able to satisfycompletely the actual customer. in eliminating activities related to some ‘formal’ specifi-
cation documents that have no clear tie with the final out-come of the product.
This approach is clearly linked with the Lean Manage-ment [16]. AMs acknowledge explicitly their ties with LeanManagement [13], while Libre Software keeps them im-plicit.
Moreover, AMs and Libre Software development looksimilar under several points of view, including:1. Their roots are both fairly old, but now they have been
revamped with a new interest, as it is explicitly acknowl-edged by Beck [4] for AMs (eXtreme Programming, XP,in particular) and evidenced by Fuggetta for Libre Soft-ware [10].
2. They are both disruptive [6], in the sense that they alterestablished values in software production.
3. There are successes of both, whereas more traditionalapproaches have failed (the C3 project for AMs [4] andthe Mozilla/Firefox browser for Libre Software [7][12]).
4. Proposers of AMs are also participating at Libre Soft-ware development (e.g. Beck with JUnit).This paper aims at providing an overview of the
commonalities between Agile Methods (XP in particular)and Libre Software from the point of view of the basic prin-ciples and values these two communities share.
The paper is organized as follows: Section 2 identifiesthe general Agile Principles in Libre Software; Sections 3focuses on specific XP values and principles and identifiesthem in Libre Software; finally, Section 4 draws the con-clusions and proposes further investigation.
2 Agile Principles in Libre SoftwareThe basic principles shared by all AMs are listed in the
so-called Agile Manifesto [2]. Table 1 identifies the princi-ples of the AMs in Libre Software.
Altogether, it is evident that Libre Software adopts mostof the values fostered by supporters of AMs.
Such evidence calls for subsequent analysis to deter-mine the extent and the depth of such adoption. Moreover,AMs and Libre Software are classes of software develop-ment methods, which include a wide number of specificmethods.
Therefore, it is important to consider specific instancesof them to determine how the interactions between AMsand Libre Software really occurs in practice, beyond con-siderations that, left alone, ends up being quite useless.
3 XP Values and Principles in Libre SoftwareBesides the commonalities between Libre Software and
the AMs in general, it is interesting to analyze this relation-ship between Libre Software and one of the most popularAM: Extreme Programming.
Agility and Libre Software Development
Alberto Sillitti and Giancarlo Succi
This paper is copyrighted under the CreativeCommons Attribution-NonCommercial-NoDerivs 2.5 license available at <http://creativecommons.org/licenses/by-nc-nd/2.5/>
Agile Methods and Libre Software Development are both popular approaches to software production. Even if they arevery different, they present many commonalities such as basic principles and values. In particular, there are many analo-gies between Libre Software Development and Extreme Programming (focus on the code and embrace of changes to namea few ones). This paper presents such principles and basic values and identifies the commonalities.
Alberto Sillitti, PhD, PEng, is Assistant Professor at the FreeUniversity of Bozen, Italy. He is involved in several EuropeanUnion funded projects in the software engineering area relatedto agile methods and open source software. His research areasinclude software engineering, component-based softwareengineering, integration and measures of web services, agilemethods, and open source. <[email protected]>
Giancarlo Succi, PhD, PEng, is Professor of SoftwareEngineering and Director of the Center for Applied SoftwareEngineering at the Free University of Bozen, Italy. His researchareas include agile methods, open source development, empiricalsoftware engineering, software product lines, software reuse,and software engineering over the Internet. He is author of morethan 100 papers published in international conferences andjournals, and of one book. <[email protected]>

34 UPGRADE Vol. VI, No. 3, June 2005 © Novática
Libre Software as A Field of Study
XP is centered in four major values (a comprehensivediscussion is in the two editions of Beck’s book [4][5]):1. Communication: developers need to exchange informa-
tion and ideas on the project among each other, to themanagers, and to the customer in an honest, trusted andeasy way. Information must flow seamless and fast.
2. Simplicity: simple solutions have to be chosen whereverpossible. This does not mean to be wrong or to take sim-plistic approaches. Beck often uses the aphorism "sim-ple but not too simple".
3. Feedback: at all levels people should get very fast feed-back on what they do. Customers, managers, and devel-opers have to achieve a common understanding of thegoal of the project, and also about the current status ofthe project, what customers really need first and whatare their priorities, and what developers can do and inwhat time. This is clearly strongly connected with com-munications. There should be immediate feedback alsofrom the work people are doing, that is, from the codebeing produced – this entails frequent tests, integrations,versions, and releases.
4. Courage: every stakeholder involved in the projectshould have the courage (and the right) to present her/his position on the project. Everyone should have thecourage to be open and to let everyone inspect and alsomodify his/her work. Changes should not be viewed withterror and developers should have the courage to findbetter solutions and to modify the code whenever neededand feasible.These values are present in various ways in Raymond’s
description of Open Source (Raymond, 2000) and summa-rized in Table 2.
Moreover, as noted in [9], hidden inside the first ver-sion of Beck’s book [4] there are 15 principles, divided into5 fundamental principles and 10 other principles.
The fundamental principles are:1. Rapid Feedback: going back to the value of feedback,
such feedback should occur as early as possible, to havethe highest impact in the project and limiting to the high-est extent the possible disruptions.
2. Assume Simplicity: As mentioned, simplicity is a ma-jor value. Therefore, simplicity should be assumed eve-rywhere in development.
3. Incremental Change: change (mostly resulting fromfeedback) should not be done all at once. Rather, shouldbe a permanent and incremental project, aimed at creat-ing an evolving system.
4. Embracing Change: change should be handled withcourage and not avoided. The system as a whole, andthe code, should be organized to facilitate change to thelargest possible extent.
5. Quality Work: quality should be the paramount con-cern. Lack of quality generates rework and waste thatshould be avoided to the large degree.Other principles of XP are:
1. Teach Learning: requirement elicitation is an overalllearning process. Therefore, learning is of paramount im-
portance in the system.2. Small Initial Investment: the upfront work should be
kept as minimum as possible, as subsequent changes maydestroy it.
3. Play to Win: all the development should be guided bythe clear consciousness that what we do is effectivelydoable.
4. Concrete Experiments: the ideas should be validatednot though lengthy and theoretical discussions but viaconcrete experimentations on the code base.
5. Open, honest Communication: the communicationshould be kept simple and easy. The customer shouldnot hide his/her priorities nor the developers and themanagers should hide the current status of the work.
6. Work with people’s instincts - not against them: therole of the managers is to get the best out of developers,so their natural inclinations should be exploited. A strongteam spirit should be exploited. Moreover, in the inter-actions between managers, developers, and customers,the fears, anxieties, discomforts should not be ignoredbut properly handled.
7. Accepted Responsibility: all the people in the projectshould voluntary take their own responsibilities, custom-ers, managers, and developers. Such responsibilitiesshould then be assigned with complete trust.
8. Local Adaptation: the methodology should be wiselyadapted to the needs of each development context.
9. Travel Light: in XP projects it is important to keep thelowest amount of documents possible, clearly withoutcompromising the integrity of the project.
10. Honest Measurement: the project should be trackedwith objective and understandable measures. The meas-ures should be collected in a lean way not to alter thenature of XP.In this section we review the application in Open Source
of the fundamental principles: rapid feedback, assume sim-plicity, incremental change, embracing change, quality work.
We have already discussed the issue of feedback andsimplicity from Beck’s point of view. Fowler [9] sharesmost of the Beck’s point of view and he stresses the con-tinuous improvement of the source code making it the sim-plest as possible.
Regarding the incremental changes, Raymond [14] ac-knowledges upfront it as one of its guiding principles sincehis early Unix experience: "I had been preaching the Unixgospel of small tools, rapid prototyping and evolutionaryprogramming for years".
As for embracing changes proposed by others, we havealready mentioned Raymond’s opinion [14] on listening tocustomers even if they do not "pay you in money". He goesfurther and in rule number 12 he states the pivotal role ofembracing the change: "Often, the most striking and inno-vative solutions come from realizing that your concept ofthe problem was wrong".
Raymond [14] goes further than Beck [4] on this sub-ject. Both agree that prototypes (‘spikes’ in Beck jargon)can be instrumental to achieve a better understanding of a
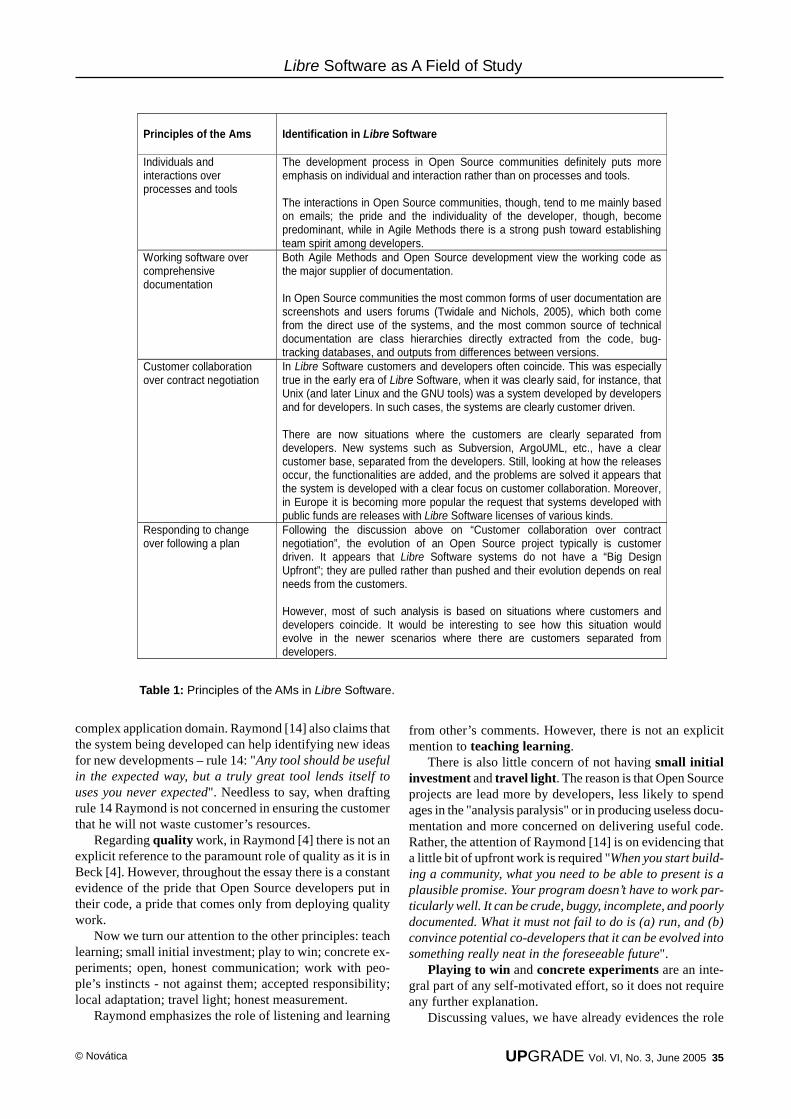
UPGRADE Vol. VI, No. 3, June 2005 35© Novática
Libre Software as A Field of Study
Principles of the Ams
Identification in Libre Software
Individuals and interactions over processes and tools
The development process in Open Source communities definitely puts more emphasis on individual and interaction rather than on processes and tools. The interactions in Open Source communities, though, tend to me mainly based on emails; the pride and the individuality of the developer, though, become predominant, while in Agile Methods there is a strong push toward establishing team spirit among developers.
Working software over comprehensive documentation
Both Agile Methods and Open Source development view the working code as the major supplier of documentation. In Open Source communities the most common forms of user documentation are screenshots and users forums (Twidale and Nichols, 2005), which both come from the direct use of the systems, and the most common source of technical documentation are class hierarchies directly extracted from the code, bug-tracking databases, and outputs from differences between versions.
Customer collaboration over contract negotiation
In Libre Software customers and developers often coincide. This was especially true in the early era of Libre Software, when it was clearly said, for instance, that Unix (and later Linux and the GNU tools) was a system developed by developers and for developers. In such cases, the systems are clearly customer driven. There are now situations where the customers are clearly separated from developers. New systems such as Subversion, ArgoUML, etc., have a clear customer base, separated from the developers. Still, looking at how the releases occur, the functionalities are added, and the problems are solved it appears that the system is developed with a clear focus on customer collaboration. Moreover, in Europe it is becoming more popular the request that systems developed with public funds are releases with Libre Software licenses of various kinds.
Responding to change over following a plan
Following the discussion above on “Customer collaboration over contract negotiation”, the evolution of an Open Source project typically is customer driven. It appears that Libre Software systems do not have a “Big Design Upfront”; they are pulled rather than pushed and their evolution depends on real needs from the customers. However, most of such analysis is based on situations where customers and developers coincide. It would be interesting to see how this situation would evolve in the newer scenarios where there are customers separated from developers.
complex application domain. Raymond [14] also claims thatthe system being developed can help identifying new ideasfor new developments – rule 14: "Any tool should be usefulin the expected way, but a truly great tool lends itself touses you never expected". Needless to say, when draftingrule 14 Raymond is not concerned in ensuring the customerthat he will not waste customer’s resources.
Regarding quality work, in Raymond [4] there is not anexplicit reference to the paramount role of quality as it is inBeck [4]. However, throughout the essay there is a constantevidence of the pride that Open Source developers put intheir code, a pride that comes only from deploying qualitywork.
Now we turn our attention to the other principles: teachlearning; small initial investment; play to win; concrete ex-periments; open, honest communication; work with peo-ple’s instincts - not against them; accepted responsibility;local adaptation; travel light; honest measurement.
Raymond emphasizes the role of listening and learning
from other’s comments. However, there is not an explicitmention to teaching learning.
There is also little concern of not having small initialinvestment and travel light. The reason is that Open Sourceprojects are lead more by developers, less likely to spendages in the "analysis paralysis" or in producing useless docu-mentation and more concerned on delivering useful code.Rather, the attention of Raymond [14] is on evidencing thata little bit of upfront work is required "When you start build-ing a community, what you need to be able to present is aplausible promise. Your program doesn’t have to work par-ticularly well. It can be crude, buggy, incomplete, and poorlydocumented. What it must not fail to do is (a) run, and (b)convince potential co-developers that it can be evolved intosomething really neat in the foreseeable future".
Playing to win and concrete experiments are an inte-gral part of any self-motivated effort, so it does not requireany further explanation.
Discussing values, we have already evidences the role
Table 1: Principles of the AMs in Libre Software.
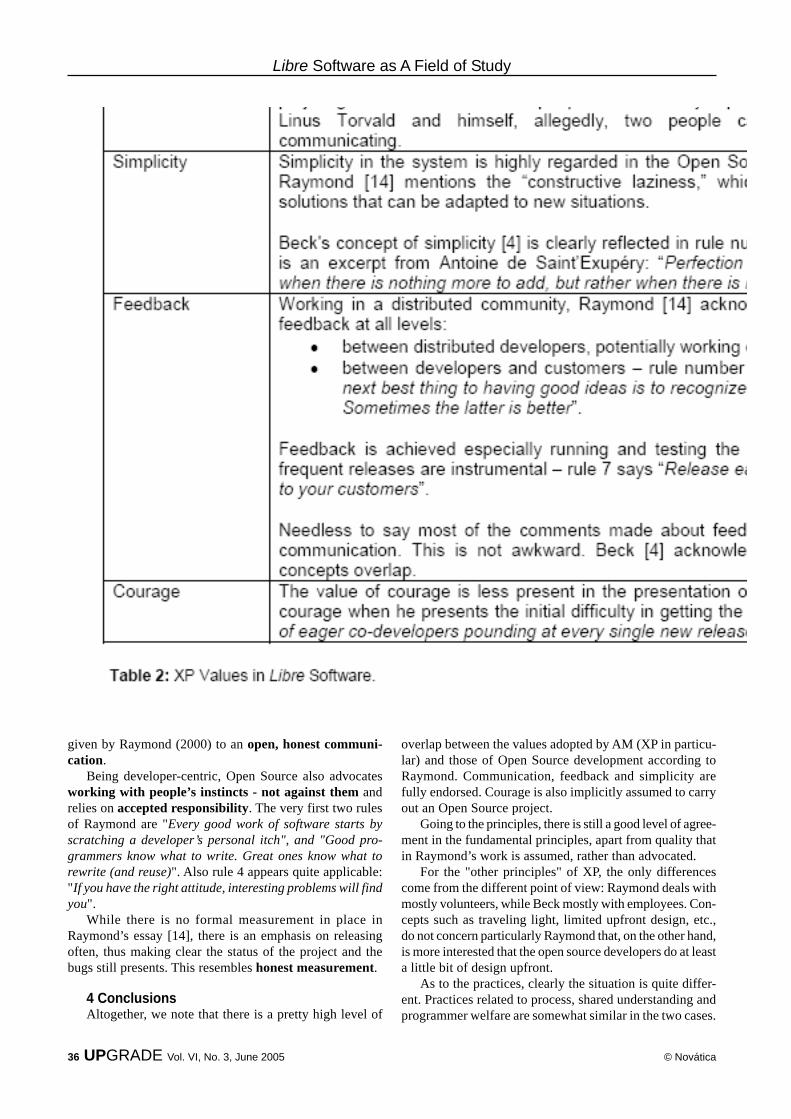
36 UPGRADE Vol. VI, No. 3, June 2005 © Novática
Libre Software as A Field of Study
given by Raymond (2000) to an open, honest communi-cation.
Being developer-centric, Open Source also advocatesworking with people’s instincts - not against them andrelies on accepted responsibility. The very first two rulesof Raymond are "Every good work of software starts byscratching a developer’s personal itch", and "Good pro-grammers know what to write. Great ones know what torewrite (and reuse)". Also rule 4 appears quite applicable:"If you have the right attitude, interesting problems will findyou".
While there is no formal measurement in place inRaymond’s essay [14], there is an emphasis on releasingoften, thus making clear the status of the project and thebugs still presents. This resembles honest measurement.
4 ConclusionsAltogether, we note that there is a pretty high level of
overlap between the values adopted by AM (XP in particu-lar) and those of Open Source development according toRaymond. Communication, feedback and simplicity arefully endorsed. Courage is also implicitly assumed to carryout an Open Source project.
Going to the principles, there is still a good level of agree-ment in the fundamental principles, apart from quality thatin Raymond’s work is assumed, rather than advocated.
For the "other principles" of XP, the only differencescome from the different point of view: Raymond deals withmostly volunteers, while Beck mostly with employees. Con-cepts such as traveling light, limited upfront design, etc.,do not concern particularly Raymond that, on the other hand,is more interested that the open source developers do at leasta little bit of design upfront.
As to the practices, clearly the situation is quite differ-ent. Practices related to process, shared understanding andprogrammer welfare are somewhat similar in the two cases.
XP value
Identification in Libre Software
Communication The very same concept of Open Source is about sharing ideas via the source code, which becomes a propeller for communication. So, with no doubt communication is a major value in the work of Raymond [14]. The role of communications is reinforced by Raymond throughout his essay [14]. He clearly states the paramount importance of listening to customers “But if you are writing for the world, you need to listen to your customers – this does not change just because they’re not paying you in money.” Then, it is evidenced that to lead an Open Source project good communication and people skills are very important: he carries as examples Linus Torvald and himself, allegedly, two people capable of motivating and communicating.
Simplicity Simplicity in the system is highly regarded in the Open Source community. In general, Raymond [14] mentions the “constructive laziness,” which helps in finding existing solutions that can be adapted to new situations. Beck's concept of simplicity [4] is clearly reflected in rule number 13 of Raymond [14]; it is an excerpt from Antoine de Saint’Exupéry: “Perfection (in design) is achieved not when there is nothing more to add, but rather when there is nothing more to take away”.
Feedback Working in a distributed community, Raymond [14] acknowledges the value of a fast feedback at all levels:
• between distributed developers, potentially working on the same fix • between developers and customers – rule number 11 is a clear example: “The
next best thing to having good ideas is to recognize good ideas from your users. Sometimes the latter is better”.
Feedback is achieved especially running and testing the code, this is why early and frequent releases are instrumental – rule 7 says “Release early, release often. And listen to your customers”. Needless to say most of the comments made about feedback could apply as well to communication. This is not awkward. Beck [4] acknowledges explicitly that the two concepts overlap.
Courage The value of courage is less present in the presentation of Raymond [14]. He hints at courage when he presents the initial difficulty in getting the work exposed to “thousands of eager co-developers pounding at every single new release”.
Table 2: XP values in Libre Software.

UPGRADE Vol. VI, No. 3, June 2005 37© Novática
Libre Software as A Field of Study
Practices related to fine-scale feedback are not so widelypresent in the description of Raymond.
As a final note, we would like to evidence that bothBeck’s and Raymond’s experience comes from an early useof very easy to employ, expressive, and powerful program-ming languages: Smalltalk and Lisp respectively. An analysisof the role of programming languages in AMs and in LibreSoftware development could be an interesting subject for afurther study.
References[1] P. Abrahamsson, O. Salo, and J. Ronkainen. Agile software de-
velopment methods, VTT Publications, 2002. <http://www.inf.vtt.fi/pdf/publications/2002/P478.pdf> [accessed onJune 15 2005].
[2] Agile Alliance, Agile Manifesto, 2001. <http://www. agilemanifesto.org/> [accessed on June 15 2005].
[3] L. Barnett. "Teams Begin Adopting Agile Processes". ForresterResearch, November 2004.
[4] K. Beck. Extreme Programming Explained: Embracing Change,Addison Wesley, 1999.
[5] K. Beck. Extreme Programming Explained: Embracing Change,Second Edition, Addison Wesley, 2004.
[6] C.M. Christensen. The Innovator’s Dilemma, Harper Business,2003.
[7] M.A. Cusumano, D.B. Yoffie. Competing on Internet Time:Lessons From Netscape & Its Battle with Microsoft, Free Press,1998.
[8] J. Feller, B. Fitzgerald. Understanding Open Source SoftwareDevelopment, Addison-Wesley, 2002.
[9] M. Fowler. Principles of XP, 2003. <http://www.martinfowler.com/bliki/PrinciplesOfXP.html> [accessed on June 15 2005].
[10] A. Fuggetta. "Open Source Software – an Evaluation", Journalof Systems and Software, 66(1), 2003.
[11] S. Koch. "Agile Principles and Open Source Software Develop-ment: A Theoretical and Empirical Discussion", 5th InternationalConference on eXtreme Programming and Agile Processes inSoftware Engineering (XP2004), Garmisch-Partenkirchen, Ger-many, 6 - 10 June, 2004.
[12] S. Krishnamurthy. "The Launching of Mozilla Firefox - A CaseStudy in Community-Led Marketing", 2005. <http://opensource.mit.edu/papers/sandeep2.pdf> [accessed on June 152005].
[13] M. Poppendieck, T. Poppendieck. Lean Software Development:An Agile Toolkit for Software Development Managers, AddisonWesley, 2003.
[14] E.S. Raymond. The Cathedral and the Bazar, Version 3.0, 2002.<http://www.catb.org/~esr/writings/cathedral-bazaar/cathedral-bazaar/> [accessed on June 15 2005]. Also published by O’Reillyin 2001.
[15] M.B. Twidale, D.M. Nichols. "Exploring Usability Discussionsin Open Source Development", 38th Hawaii International Con-ference on System Sciences, 2005. <http://csdl.computer.org/comp/proceedings/hicss/2005/2268/07/22680198c.pdf>.
[16] J.P. Womack, D.T. Jones. Lean Thinking: Banish Waste andCreate Wealth in Your Corporation, Revised and Updated, FreePress, 2003.

38 UPGRADE Vol. VI, No. 3, June 2005 © Novática
Libre Software as A Field of Study
Keywords: Commercial-Off-The-Shelf, COTS, FOSS, Freeand Open Source Software, Software Engineering, Soft-ware Reuse.
1 IntroductionReusing existing software is an important part of mod-
ern software engineering, promising cost reduction, fastertime to market, and improved quality. One study shows thatproductivity can be increased by up to 113%, the averagefault rate can be lowered by 33% and time to market can beshortened by 25% [11]. Another study reports a 51% defectreduction, a 57% productivity increase, and a 57% fastertime to market [16].
The decision whether or not to introduce reuse into theengineering process depends on two important conditions:components must meet certain technical requirements andtheir usage must be economically viable. This paper de-scribes a technical course of action for choosing the bestalternative out of three rudimentary reuse strategies: thedevelopment and usage of in-house components, the adop-tion of external commercial components (the so Called Com-mercial-Off-The-Shelf, COTS, components), and the inte-gration of Free and Open Source Software, FOSS).
Recent studies have discussed the use of FOSS and itseffect on total cost of ownership and quality. But these stud-ies mainly focus on the use of operating systems such asLinux, or application software like the Apache web server.For example, one study estimates that using FOSS can leadto savings of about 12 million Eur (one fifth of the cost ofusing commercial applications) over a five-year period [7].Another study points to savings of about 33% compared tocommercial software over a two-year period [19].
However, with the exception of these studies, there ishardly any knowledge about the integration of FOSS in thesoftware engineering process. The free concept of FOSSopens the door to new strategies and business models thatcan be executed at almost every phase of the developmentprocess, such as using FOSS as a basis for future productline development or contributing software components tothe FOSS community. The last point is especially interest-ing for companies because it enables the maintenance proc-ess of software artefacts to be outsourced.
This paper focuses on two different business models:system vendors that develop specific software to customerorder, and software companies which develop standard soft-ware.
2 Adapting Reuse StrategiesFigure 1 illustrates the course of action to be taken be-
fore a decision is made. The decision making process isdivided into three phases: sighting, adaptation, and com-parison. In the first two phases, which focus on technicalaspects, the decision is taken as to whether a componentprovides the desired functionality or, if not, whether it canbe extended. In phase three the economic aspects of theremaining candidates are investigated thoroughly and theimplications for different business models are discussed.
2.1 Technical AnalysisFirst of all the technical requirements of the project need
to be specified. This specification is largely deduced fromthe desired functionality and contains the architecture, I/Ofunctionality, and business logic. Based on this specifica-tion, the software developer identifies possible places wherecomponents can be hooked into the architecture of the ap-plication. A good place to start searching is in I/O proce-dures because almost every program uses file operations,
The Challenges of Using Open Source Software as A Reuse StrategyChristian Neumann and Christoph Breidert
This paper is copyrighted under the CreativeCommons Attribution-NonCommercial-NoDerivs 2.5 license available at <http://
creativecommons.org/licenses/by-nc-nd/2.5/>
This paper compares the benefits of adapting open source software to internal and commercial reuse strategies. We propose acourse of action that can be used for technical and economical evaluation. The advantages, disadvantages, and risks of thesebasic strategies are investigated and compared.
Christian Neumann is a PhD student at the Dept. of InformationBusiness at the Vienna University of Economics and BusinessAdministration, Austria. He received his masters degree inEngineering and Management from the University of Karlsruhe,Germany. His research interests include quality of open sourceprojects, usability of frameworks, cost estimation, and softwareinvestment analysis. He worked for several years as a softwareengineer for a major German IT company.<[email protected]>.
Christoph Breidert holds a PhD from the Dept. of InformationBusiness at the Vienna University of Economics and BusinessAdministration, Austria. He received his masters degree inEngineering and Management from the University of Karlsruhe,Germany. He has several years experience in softwaredevelopment of large-scale J2EE projects.<[email protected]. ac.at>.

UPGRADE Vol. VI, No. 3, June 2005 39© Novática
Libre Software as A Field of Study
database access, or a Graphical User Interface (GUI).Phase one of the analysis consists of a sighting in which
possible reusable components are identified. In the case ofinternal components, sources of information for this taskare reuse repositories or implicit knowledge of formerprojects. The search for external components can be per-formed by using the Internet, asking newsgroups, visitingexhibitions, or reading magazines. A good place to start thesearch for FOSS are some of the great online repositoriessuch as sourceforge, <http://www.sourceforge.net>, orApache, <http://www.apache.org>. At these repositoriesFOSS can be searched for by theme, programming language,or keywords. The Apache Foundation in particular hosts awide range of ready to use components, some of which haveevolved into de facto standards (log4j, xerces, xalan, etc.).
The second phase takes a deeper look into the functional-ity provided by the components that were identified in phaseone. Possible sources of information are documentations, speci-fications, and examples. If the provided functionality doesnot comply with the technical requirements we need to checkwhether their components can be extended. Naturally thisis only applicable for FOSS and internal components, be-cause COTS do not provide the source code required formodification. Using the components unchanged is calledblack-box reuse; modifying the components before use iscalled white-box reuse [22].
In the case of FOSS it is very important to address thefollowing issues [28]: future functional upgradability, open-standard compatibility, adaptability and extensibility, andreliability. To address these issues it is necessary to take adeeper look into design and architecture which we wouldhope to be described in the user manual. Unfortunately, manyFOSS projects suffer from bad documentation which makesit very difficult to learn or extend their components, mak-ing their integration, and in particular their extension or ad-aptation, difficult. Therefore the existence of good docu-mentation, examples, articles or newsgroups is indispensa-ble for a fast and cost effective integration. There are sev-eral systematic ways of searching for FOSS components(e.g. <http://www.amosproject.org>) and evaluating FOSS[9].
To ensure the quality of reusable software, especially inlong-term projects such as frameworks in product lines, thesource code must be inspected. This can be done by usingquality indicators such as object-oriented metrics or com-mentaries [4][5][10][18].
All possible candidates that have passed the first twostages are compared in phase three. These two phases mayrequire a great deal of effort, but the information gatheredprovides the basis for our final economic and managerialanalysis.
2.2 Specific SoftwareImagine a system vendor that implements a highly cus-
tomised solution for a client; for example, a monitoring sys-tem for a diversified IT (Information Technology) landscape.The requirements specification forms the basis for the offerand every additional functionality of the customer leads toa change request that has to be renegotiated every time.
The reduction of development effort and the resultingdecrease of costs is the most important managerial aspectto be considered. Time to market may be another constraintthat needs to be kept in mind. The use of existing compo-nents, both internal and external, is therefore extremely ad-visable because it is cheaper to reuse them than to imple-ment the same functionality over and over again, and thedevelopment schedule can also be shortened. Developinginternal reusable components is not cost-efficient becausetheir intended functionality is tailored to just one specificcase and it is highly unlikely that they will be reusable infuture projects.
The integration of COTS or FOSS also enables systemswith highly sophisticated technologies to be produced evenwhen no in-house knowledge is available [2]. Securitymechanisms in particular have proven so difficult to imple-ment correctly that developers should be spared the risk ofproducing major bugs by using suitable COTS [17]. How-ever, the integration of COTS invariably involves licensecosts.
FOSS provides the same advantages as COTS but thereis no license to pay for. The impact of a FOSS componentlicense is not significant in the case of specific software.
Figure 1: Model for Evaluating Reusable Components.

40 UPGRADE Vol. VI, No. 3, June 2005 © Novática
Libre Software as A Field of Study
Even if the application is an extended version of a FOSScomponent covered by a copyleft license, it is of no realsignificance. A copyleft license does not prevent the ven-dor from selling a derived product and the purchaser hasthe right to redistribute the program and obtain its sourcecode. In the case of developing specific applications it iscommon practice to give the source code to the customeranyway. And the customer has nothing to gain from givingits customised solution away to anyone else. But we willlater be pointing out that while FOSS licenses are not sig-nificant in the case of specific software, they do have im-plications on the development of proprietary software.
To sum up, in the case of specific software the overallcosts for the different types of components must be esti-mated and the cheapest alternative should be chosen.
2.3 Proprietary SoftwareNow imagine a software company that has built up ex-
tensive knowledge in a specific field – e.g. document man-agement – and wants to provide a desktop application thatwill help to organise everyday paperwork. The company’smarketing division has spotted additional demands, – e.g.other office work tasks – which should be integrated intothe application. The company wants to extend its marketshare and sell licenses that are valid for one workplace only.This situation is completely different from developing spe-cific software because the time horizon is much longer andthe business model is based on selling licenses.
The tasks for the software engineer are the same as be-fore: To identify the required functionalities, spot possiblecomponents, and investigate the candidates. But in addi-tion it is essential to identify and specify future require-ments very thoroughly, especially if the components are animportant part of the design, such as a framework architec-ture for a product line development. To be open forupcoming features the components must be highlycustomisable, modular and trustworthy.
Developing internal components for reuse is the most flex-ible reuse alternative with regard to reusability and functional-ity. As components can be designed from scratch, their func-tionality is tailored to suit the company’s needs. The greatestdisadvantage of establishing an internal reuse strategy is thevery high initial investment for developing reusable compo-nents. Due to the great need for modularity, software quality,and documentation, the cost of developing reusable softwarecan be significantly higher than if the same functionality isdeveloped for a single application only. One study indicatesthat the break-even point can be reached after just three timesof reusing software components [1]. For a successful reusestrategy a repository for the reusable components is manda-tory and this must be integrated in the development process.This can lead to higher organisational costs.
Choosing COTS does not require any initial investmentapart from purchasing the license. But there are several dis-advantages outweighing this advantage.
Flexibility is limited as components cannot be adaptedto meet special needs. Additional functionality must be re-
alized in wrappers. Development of this glue code can takeup to three times as long as the in-house development ofthe software [24][27].
The fact that COTS are black-boxes gives rise to twoimportant risks: the risk of undetermined interior behav-iour and the risk of interaction with the environment. Thefirst may lead to invalid/wrong results or even to unreliabilityof the whole application. To prevent this from happening, agreat many tests need to be conducted, leading to an in-crease in integration costs. The latter risk gives rise to anumber of security risks such as accessing unauthorisedresources, accessing resources in an unauthorised manner,or abusing authorised privileges [30][17].
Another major problem is maintenance since COTS con-sumers depend on the vendors’ efforts in this regard [2].The frequency and number of updates can be uncertain,making it very difficult for the consumer to maintain theapplication. Therefore it is very important to have an over-view of the development and maintaining cycles of COTSso that they can be synchronised with the actual develop-ment process. For these reasons the additional costs involvedin maintaining COTS-based systems can equal or even ex-ceed those of custom software development [24].
Adapting existing FOSS components can be the basisfor a company’s reuse strategy because FOSS combines theadvantages of an internal reuse and COTS strategy: No ini-tial investment is needed, existing functionalities can beused, and the source code is available.
The free availability of source code is what makes thisstrategy so powerful. On the one hand it provides the nec-essary flexibility to extend or adapt FOSS components andon the other hand it enables inspection and debugging whichreduces the risk of unexpected behaviour. Despite the costof learning and adaptation there is no initial investment neededfor integrating the components into the engineering process.Furthermore, the company can cut its maintenance costs be-cause maintenance is carried out by the community. But thesesteps need to be given careful consideration because any know-how contained in the software may become generally avail-able to the community and other users (see below).
The main drawback of COTS, the unspecified behav-iour, also applies for FOSS. But as the source code is avail-able, bugs and flaws can be fixed immediately.
And even if the community no longer supports the prod-uct, users can extend and maintain it on their own.
Other advantages stem from the FOSS developing proc-ess, which is characterised by the peer-review principal [23].In a peer-review approach the program is reviewed by atleast two experts (in a vivid FOSS community probablymore). This critical judgement helps to improve the design,functionality and quality of the program. Furthermore, open-ness of source code is necessary for security applicationsbecause the user can verify the functionality and reliabilityof the program, such as encrypted data transmission.
But availability of source code does not necessarily meangood programs. A program is only as good as its program-mers. It is therefore necessary to take a close look at the

UPGRADE Vol. VI, No. 3, June 2005 41© Novática
Libre Software as A Field of Study
community’s activities in terms of the number of contribu-tors involved, the project’s maturity (alpha, beta, stable),and the frequency of releases [14][15].
Only projects with several contributors, a high degree ofprogramming activity, and well defined road maps are worthusing in company’s product lines [21]. Projects that only havea handful of contributors or where the contributed work ishighly concentrated may die or remain in an unstable state.
In this case any benefit of using FOSS is lost as there isno community to maintain and evolve the product. The in-tegration of early releases (snapshot release, beta, etc.)should be avoided as these components may be buggy, orfuture changes in design or functionality may require anadditional integration effort.
Other important aspects to be considered are legal is-sues. Usage in commercial applications gives rise to anumber of issues that need to be addressed. Richard Stallmanwas the first person to coin the term "free software" [26]. Inhis view, FOSS software, and especially the programs thatadapt it, should be distributed freely. This idea leads to thewell known GNU General Public License (GPL) whichmeans that the any program using GPL software is coveredunder the same license. As we mentioned above, selling aGPL covered application is not prohibited but the companydoes not hold a copyright preventing the user from redis-tributing the software.
Furthermore the source code of the derived work mustbe available to anyone using this software. This can be ano-go criteria for the usage of GPL products in a propri-etary application. The Library/Lesser GNU Public License(LGPL) is less restrictive and allows closed software usingLGPL products to be distributed, but any changes made tothe FOSS must be contributed to the community. The leastrestrictive one is the Berkeley-license, BSD (and its deriva-tives), which allows the FOSS to be used and modified with-out having to publish the source code of the modification[6][9][8].
In the case of the document management application wementioned above, using a copyleft license could lead to adecrease in market share, because the software can be dis-tributed freely and, even worse, the knowledge containedin the documents managed must be made available to eve-ryone using the program. The matter of whether a programthat uses GPL components is a derived work or not is athorny one and currently the subject of much debate[29][12][25]. The use of GPL should therefore be avoided.The LGPL is less restrictive but the constraint of publish-ing changes to the FOSS community must be carefully con-sidered. Even small changes may reveal insight into the com-pany’s core business. So the adaptation of BSD style FOSSshould be preferred as this is the most flexible license.
3 Conclusion and Further WorkWe have looked into and compared three different reuse
strategies and identified the overall costs for adapting reus-able components as a primary issue, especially for the de-velopment of highly customised specific software. In the
case of proprietary software, additional aspects need to beconsidered. The integration into a product line requires veryflexible, modular, and reliable components. Therefore COTSis not suitable due to the drawbacks of black-box reuse.Using FOSS as white-box reuse is a good alternative to aninternal reuse strategy because it promises savings both formaintenance and for the implementation of upcoming fea-tures. But the impact of the various FOSS licenses must begiven careful consideration.
Unfortunately we are unaware of any empirical studiesthat have compared the overall costs of the three reuse strat-egies. The reason for this lack of knowledge is obvious.The functionality of the applications investigated ideallyneed to be identical and the development effort needs to bemeasured. It is very difficult to find enough comparableprojects and companies that are willing to publish internalmetrics that can be used to determine their productivity ordevelopment methods.
Another way of gathering information is by means of anexperiment. An experiment can be used to compare at leasttwo different settings supervised by an independent scien-tist. The nature of software reuse involves long-term activ-ity which makes it very difficult to conduct such a test in anacademic setting (three groups of students developing thesame application using different reuse strategies). Further-more, any such experiment would produce an indicator ratherthan a substantiated result since the universe is too small.
We suggest comparing the different reuse strategies withexisting models for effort estimation, e.g. the COCOMO II(COnstructive COst MOdel) model [3]. This model is basedon the evaluation of over hundred software projects andcontains a module for software reuse. The impact of severalquality indicators – e.g. documentation and understandability– can be integrated. There is some research currently inprogress into the economic evaluation of FOSS using esti-mation models [13][20].
References[1] T. J. Biggerstaff. "Is technology a second order term in reuse’s
success equation?" In Proceedings of Third International Con-ference on Software Reuse, 1994.
[2] Barry Boehm and Chris Abts. "COTS integration: Plug andpray". IEEE Computer, 32(1):135–138, 1999.
[3] Barry W. Boehm, Chris Abts, A. Windsor Brown, SunitaChulani, Bradford K. Clark, Ellis Horowitz, Ray Madachy,Donald Reifer, and Bert Steece. "Software Cost Estimationwith CoCoMo II". Prentice Hall PTR, Upper Saddle River, 1edition, 2000.
[4] Samuel Daniel Conte, H.E. Dunsmore, and V.Y. Shen. "Soft-ware Engineering Metrics and Models". The Benjamin/Cummings Publishing Company, Menlo Park, CA, 1986.
[5] Norman E. Fenton. "Software Metrics - A Rigorous Approach".Chapman & Hall, London, 1991.
[6] Martin Fink. "The Business and Economics of Linux and OpenSource". Prentice Hall, Upper Saddle River, 2002.
[7] Brian Fitzgerald and Tony Kenny. "Developing an informa-tion systems infrastructure with open source". IEEE Software,21(1):50–55, 2004.
[8] Christina Gacek and Budi Arief. "The many meanings of open

42 UPGRADE Vol. VI, No. 3, June 2005 © Novática
Libre Software as A Field of Study
source". IEEE Software, 21(1):34–40, 2004.[9] Bernard Golden. "Succeeding with Open Source". Addison-
Wesley, Boston, 2005.[10] B. Henderson-Seller. "Object-Oriented Metrics: Measures of
Complexity". Prentice Hall, Upper Saddle River, NJ, 1996.[11] Emmanuel Henry and Benoit Faller. "Large-scale industrial
reuse to reduce cost and cycle time". IEEE Software,12(5):47–53, 1995.
[12] Till Jaeger and Carsten Schulz. "Gutachten zu ausgewähltenrechtlichen aspekten der open source software". Technicalreport, JBB, 2005. <http://opensource.c-lab.de/files/portaldownload/Rechtsgutachten-NOW.pdf>.
[13] S. Koch and C. Neumann. "Evaluierung und aufwandsschätzungbei der integration von open source software-komponenten". InInformatik 2005 -Beiträge der 35. Jahrestagung der Gesellschaftfür Informatik e.V. (GI), Lecture Notes in Informatics (LNI) ,Gesellschaft für Informatik (GI), 2005. (To appear.)
[14] Stefan Koch. "Profiling an open source project ecology andits programmers". Electronic Markets, 14(2):77–88, 2004.
[15] Stefan Koch and Georg Schneider. "Effort, cooperation andcoordination in an open source software project: Gnome".Information Systems Journal, 12(1):27–42, 2002.
[16] Wayne C. Lim. "Effects of reuse on quality, productivity,and economics". IEEE Software, 11(5):23–30, September1994.
[17] Ulf Lindvist and Erland Jonsson. "A map of security risksassociated with using COTS". IEEE Computer, 31(6):60–66,June 1998.
[18] M. Lorenz and J. Kidd. "Object Oriented Metrics". PrenticeHall, Upper Saddle River, N.J., 1995.
[19] T.R. Madanmohan and Rahul De. "Open source reuse in com-mercial firms". IEEE Software, 21(1):62–69, 2004.
[20] C. Neumann. "Bewertung von open source frameworks alsansatz zur wiederverwendung". In Informatik 2005 - Beiträgeder 35. Jahrestagung der Gesellschaft für Informatik e.V. (GI),Lecture Notes in Informatics (LNI) , Gesellschaft fürInformatik (GI), 2005. (To appear.)
[21] Jeffrey S. Norris. "Mission-critical development with opensource software: Lessons learned". IEEE Software, 21(1):42–49, 2004.
[22] Ruben Prieto-Diaz. "Status report: software reusability". IEEESoftware, 10(3):61–66, May 1993.
[23] Eric S. Raymond. "The Cathedral and the Bazaar: Musingson Linux and Open Source by an Accidental Revolutionary".O’Reilly and Associates, Sebastopol, California, 1999.
[24] Donald J. Reifer, Victor R. Basili, Barry W. Boehm, and BetsyClark. "Eight lessons learned during COTS-based systemsmaintenance". IEEE Software, 20(5):94–96, 2003.
[25] Gerald Spindler and Christian Arlt. "Rechtsfragen bei OpenSource". Schmidt, Köln, 2004.
[26] Richard Stallman. "Free Software, Free Society: selected es-says of Richard M. Stallman". GNU Press, Boston, 2002.
[27] Jeffrey M. Voas. "The challenge of using cots software incomponent based development". IEEE Computer, 31(6):44–45, June 1998.
[28]Huaiqing Wang and Chen Wang. "Open source software adop-tion: A status report". IEEE Software, 18(2):90–95, March/April 2001.
[29] Ulrich Wuermerling and Thies Deike. "Open source soft-ware: Eine juristische risikoanalyse". Computer und Recht,(2):87–92, 2003.
[30] Qun Zhong and Nigel Edwards. "Security control for COTScomponents". IEEE Computer, 31(6):67–73, June 1998.

UPGRADE Vol. VI, No. 3, June 2005 43© CEPIS
Mosaic
This section includes articles about various ICT (Information and Communication Technologies) matters, as well as news regarding CEPISand its undertakings, and announcements of relevant events. The articles, which are subject to a peer review procedure, complement ourmonographs. For further information see "Structure of Contents and Editorial Policy" at <http://www.upgrade-cepis.org/pages/editinfo.html>.
Computational Linguistics
Juan-José García-Adeva received hisBEng in Computer Engineering degreefrom the Mondragón EngineeringSchool of the University of the BasqueCountry, Spain, and a MSc by researchin Computer Science from the Universityof Essex, UK. He worked for severalyears on different topics of ArtificialIntelligence in research centres of Spain,UK, and USA. He is currently workingtowards his PhD in the School ofElectrical and Information Engineeringof the University of Sydney, Australia.<[email protected]>
Rafael A. Calvo is Senior Lecturer, Di-rector of the Web Engineering Group andAssociate Dean of ICT at the Universityof Sydney - School of Electrical andInformation Engineering. He has a PhDin Artificial Intelligence applied toautomatic document classification. Hehas taught at several Universities, highschools and professional training
institutions. He worked at CarnegieMellon University, USA, and Universi-dad Nacional de Rosario, Argentina, andas an Internet consultant for projects inAustralia, Brazil, USA and Argentina.He is author of a book and over 50 otherpublications in the field, and is also onthe board of the Elearning Network ofAustralasia and the .LRN Consortium.<[email protected]>
Diego López de Ipiña has a BSc inComputer Science from University ofDeusto, Spain, a MSc in DistributedSystem from the University of Essex,UK, and a PhD in Engineering from theUniversity of Cambridge, UK.Currently, he works as a lecturer in theFaculty of Engineering of the Universityof Deusto. His main research interestsare middleware for mobile systems andubiquitous computing. <dipina@ eside.deusto.es>
Multilingual Approaches to Text Categorisation
Juan-José García-Adeva, Rafael A. Calvo, and Diego López de Ipiña
In this article we examine three different approaches to categorising documents from multilingual corpora using machinelearning algorithms. These approaches satisfy two main conditions: there may be an unlimited number of different lan-guages in the corpus and it is unnecessary to previously identify each document’s language. The approaches differ in twomain aspects: how documents are pre-processed (using either language-neutral or language-specific techniques) andhow many classifiers are employed (either one global or one for each existing language). These approaches were testedon a bilingual corpus provided by a Spanish newspaper that contains articles written in Spanish and Basque. The empiri-cal findings were studied from the point of view of classification accuracy and system performance including executiontime and memory usage.
Keywords: Document Classification,Machine Learning, Multilingual Cor-pus, Neutral Stemming, Text Catego-risation.
1 IntroductionText management techniques are an
important topic in the field of Infor-mation Systems. They have been gain-ing popularity over the last decade withthe increased amount of digital docu-ments available and, thus, the neces-sity of accessing their content in flex-ible ways [15]. From these techniques,one of the most prominent is Text Cat-egorisation using Machine Learning,currently relying on a very active andlarge research community. However,the vast majority of this research isdone using English corpora, with muchless attention paid to other languagesor multilingual environments. Somerecent projects applied cross-lingualapproaches to environments with veryfew or none training documents in alanguage for which documents need beclassified [2][8]. We believe that ap-proaches like the ones presented here
are efficient in multilingual contextswhere for each supported language anadequate number of training instancesexist.
In this work we are interested in thetools for writing, distributing and sell-ing news stories to consumers. Thisindustry is one of those most affected

44 UPGRADE Vol. VI, No. 3, June 2005 © CEPIS
Mosaic
by the Internet revolution and, there-fore, in great need of the ability to proc-ess digital content effectively. Becausethe target audiences are culturally di-verse, there is often a need to expressthe same content in different languageseven within the same context (e.g.country, region, community, etc.). Forexample, in certain multilingual coun-tries, a single newspaper carries newsin several (usually two or three) lan-guages in order to cover the largestnumber of readers. This situation isparticularly common in Europe andpresents an interesting applicationproblem to text categorisation, wherethe documents to be classified are pro-vided in more than one language un-der the same set of categories.
There are several sensible ap-proaches to solving this problem. Theyinclude the possible use of languageidentification, language-dependent orneutral preprocessing of documents,single or multiple classifiers involvingone or more learning algorithms, etc.The configuration strongly depends onthe characteristics of the multilingualcorpus. For example, if the corpusdocuments contain no information onthe language they are written in, a lan-guage identification step might be nec-essary. It is desirable to explore thediverse possible configurations in or-der to learn which one best fits a givendocument corpus to obtain the best re-sults. The system-related performanceof these configuration, includingmemory usage and execution time,may also be considered important inproduction environments.
The structure of this paper is as fol-lows. Section 2 includes some back-ground information on the main algo-rithms and methods used in this work.Section 3 describes the corpus of bi-lingual (Spanish and Basque) newspa-per articles used for experimentation.Section 4 briefly describes the softwareframework employed for performingthe experiments. Section 5 details thethree different approaches we propose.Section 6 contains the configurationused in the experiments, while Sec-tion 7 discusses the corresponding re-sults and some derived ideas on futurework.
2 BackgroundThis section contains the descrip-
tion of the learning algorithms used bythe classifiers as well as the automaticlanguage identification functionality. Italso includes an explanation of theclassification accuracy measures stud-ied in this work.
2.1 Base Learners
2.1.1 Naïve BayesNaïve Bayes [10] is a probabilistic
classification algorithm based on theassumption that any two terms from T= {T1,..., t|T|} representing a docu-ment d and classified under category care statistically independent of eachother. This can be expressed by
All neighbours can be treatedequally or a weight can be assigned tothem according to their distance to thedocument to categorise. We selectedtwo weighting methods: inverse to thedistance (1 / s) and opposite to the dis-tance (1 — s). When several of thesek nearest neighbours have the same cat-egory, their weights are added together,and the final weighted sum is used asthe probability score for that category.Once they have been sorted, a list ofcategory ranks for the document tocategorise is produced.
Building a kNN categoriser alsoincludes experimentally determining athreshold k. The best effectiveness isobtained with 30 ≤ k ≤ 45 [16]. It isalso interesting to note that increasingthe value of k does not degrade the per-formance significantly.
2.1.3 RocchioRocchio is a profile-based classifi-
cation algorithm [13] adapted from theclassical Vector Space model with TF/
(1)
The category predicted for d isbased on the highest probability givenby
(2)
Two commonly used probabilisticmodels for text classification under theNaïve Bayes framework are the multi-variate Bernoulli and the multinomialmodels. These two approaches werecompared in [12] and the multinomialmodel proved to perform significantlybetter than the multi-variate Bernoulli,which motivated us to choose it for thiswork.
2.1.2 k-Nearest Neighboursk-Nearest Neighbours (kNN) is an
example-based classification algo-rithm [17] where an unseen documentis classified with the category of themajority of the k most similar trainingdocuments. The similarity between twodocuments can be measured by theEuclidean distance of the n correspond-ing feature vectors representing thedocuments
(3)
IDF weighting and relevance feedbackto the classification situation. This kindof classifier makes use of a similaritymeasure between a representation (alsocalled profile) pi of each existing cat-egory ci and the unseen document dj toclassify. This similarity is usually esti-mated as the cosine angle between thevector that represents ci and the fea-ture vector obtained from dj. A docu-ment to classify is considered to be-long to a particular category when itsrelated similarity estimation is greaterthan a certain threshold.
First, a feature frequency functionis defined
(4)
Where F is the set of all existingfeatures with f ∈ F,ni expresses in howmany documents fi appears, and r is thefunction of relative relevance of mul-tiple occurrences that can be definedby r(f,d) = max {0,log(0,nf)} .

UPGRADE Vol. VI, No. 3, June 2005 45© CEPIS
Mosaic
The profile pi of a category ci is a vector of weights where one instance iscalculated by
n from 1 to 5 are habitually enough.These n-grams are used to create a dic-tionary with the 400 most frequentwords ranked by frequency. Therefore,for each supported language, a profilepi ∈ P = { pi ,..., pp } is generated.
Comparing two language profilesconsists of calculating (6)
where TPi indicates the number oftrue positives or how many documentswere correctly classified under cat-egory ci. Similarly, FPi indicates thenumber of false positives and FNi cor-responds to false negatives. Table 1provides an overview of these meas-ures.
However, precision and recall aregenerally combined into a single meas-ure called Fβ where 0 ≤ β ≤ ∝. The pa-rameter β serves to balance betweenthe importance of π and ρ, and can beexpressed by (9)
Table 1: Category-specific Contingency Table.
Category Expert decisioncj Yes No
Classifier Yes TPj FPj
decision No FNi TNi
(5)
where Dc is the set of documentsbelonging to c and Dc the set of docu-ments not belonging to c. The param-eters β and γ control the relative im-pact of these positive and negative in-stances to the vector of weights, withstandard values being β =16 and γ =4 [13].
2.2 Language IdentificationThe method we used in this work
is based on computing and comparinglanguage profiles using n-gram fre-quencies. A n-gram is a chunk of con-tiguous characters from a word. Forexample, the word hello contains the3-grams: _he, hel, ell, llo, lo_, and o__, with _ representing a blank. In gen-eral, the number of n-grams that canbe obtained from a word of length w isw+1.
On the one hand, Zipf’s law [18]establishes that in human languagetexts the word ranked in n-th positionaccording to how common it is, alsooccurs with a frequency inversely pro-portional to n. On the other hand, ex-periments performed in [3] determinedthat around the 400 most frequent n-grams in a language are almost alwayshighly correlated to that language. Itis now reasonable to generate a lan-guage profile using an arbitrary collec-tion of documents all in the same lan-guage.
For each document, the punctua-tion and digit characters are removed,while letters and apostrophes are kept.The remaining text is tokenised, andeach token properly padded with pre-vious and posterior blanks. Values of
where Gi is the set of n-gramsin pi and gi the n-gram of pi rankedin k-th position. The function K (g,pi ) returns the rank of g in pi. Ifg∉pi then a very high value is usedso that K (g, pi )>>⏐Gi⏐.
When the language of a new docu-ment d is to be identified, its profile pis calculated and compared to eachexisting language profile in P. The cho-sen language will be that of the profilewhose index is obtained by (7)
argmin { δ (p, p1), δ (p, p2),…, δ (p, pp)}
2.3 Measures of ClassificationAccuracy
Precision (π) and recall (p) are twocommon measures for assessing howsuccessful a text categoriser is. Preci-sion indicates the probability that adocument assigned to a certain cat-egory by the classifier actually belongsto that category. On the contrary, re-call estimates the probability that adocument that actually belongs to acertain category will be correctly as-signed to that category during the cat-egorisation process. These two meas-ures are defined by (8)
Values near 0 give more importanceto π while those closer to ∝ providemore relevance to ρ. The most com-mon applied value is 1 that procuresthe same importance for both π and ρ.Therefore, Equation 9 is transformedinto (10)
Instead of using category-specificvalues of F1, an averaged measure isusually preferred, concretely themacro- and micro-average, identifiedby FM
1 y Fµ1 respectively. Micro-
averaging gives more emphasis on per-formance of categories that are morefrequent (i.e. there are more trainingdocuments for these categories) and isdefined by (11)
where |C| indicates the number ofexisting categories. On the contrary,macro-averaging focuses on uncom-mon categories. Micro-averaged meas-ures will almost always have higherscores than the macro-averaged ones.It can be expressed by (12)

46 UPGRADE Vol. VI, No. 3, June 2005 © CEPIS
Mosaic
which language the article was writtenin.
4 Software FrameworkAll the experiments covered in this
paper were performed on Awacate [1],an object-oriented software frameworkfor Text Categorisation, which is writ-ten in Java and available as opensource.
It was designed with the aim ofbeing mainly used in the context ofweb applications. It offers numerousfeatures to suit both a production en-vironment where performance is cru-cial as well as a research context wherehighly configurable experiments mustbe executed.
Awacate includes several learningalgorithms such as Naïve Bayes,Rocchio, SVM (Support Vector Ma-chines), and kNN. They can also beused as the base binary learners forensembles using the decompositionmethods One-to-All, Pairwise Cou-pling, and ECOC (Error CorrectingOutput Codes) [5]. The documents tocategorise can be provided in English,German, French, Spanish, and Basqueand they may belong to one or severalcategories.
Awacate offers complete evaluationof results including category-specificTPi, FPi, FNi, πi, pi, F1, and averagedπµ, pµ, Fµ
1, πM, pM, FM
1, as well as parti-tioning of the testing space using n-foldCross Validation. Awacate can be usedin production systems due to its highscalability based on a cache system thatallows for precise control of theamount of memory allocated, and its
performance efficiency thanks to acarefully tuned-up code-base.
In this project we have added twonew functionalities to Awacate: auto-matic language identification and lan-guage-neutral stemming.
5 ApproachesIn this sections we propose three
different multilingual approaches totext categorisation. They differ in twomain aspects: whether a single or one-per-language classifier is used and howthe documents are processed accord-ing to their language. By documentprocessing, we refer to the pre-process-ing stage (tokenisation, stop-words re-moval, stemming, etc.) in order to se-lect features as well as the later crea-tion of the feature vectors used by thelearning algorithms.
5.1 Language-neutral DocumentProcessing and A Single Classifier(1P1C)
In this approach, a single classifierlearns from training documents regard-less of which language they are in. Thefeature vectors used by this classifierare built using a language-neutralmethod, meaning that instead of usinga common word stemming approach,we use n-grams. This is possible be-cause some of the n-grams obtainedfrom a word will comprise only partsof a word with no morphological vari-ation [11]. For example, the words run-ner, running, and run share the 3-gramrun.
Selecting the n-grams that will laterbe used as features consists of build-ing a dictionary with all the possiblen-grams found in all the training docu-ments, and then choosing those withthe highest inverse document fre-quency. The reason for choosing thisparticular type of frequency is that af-fixes indicating a particular morpho-logical variation will be found fre-quently in many words, and thereforewill offer a low inverse document fre-quency [11]. The best value of n de-pends on the language(s) of the docu-ments and their context, and hencefinding it demands running severalexperiments for evaluation and con-figuration.
Finally, the whole error measure iscalculated by
in Section 4, that 85% of the articleswere written in Spanish and the re-maining 15% in Basque.
There are two important remarksabout this corpus. The first is that eacharticle has only one category. The sec-ond is the lack of information about
(13)
3 The Corpus of NewspaperArticlesIn this work we contribute with a
new corpus of newspaper articlescalled Diario Vasco, which containsabout 75,000 articles written in eitherSpanish or Basque that were publishedduring the year 2004 in the newspaperDiario Vasco, Gipuzkoa, Spain. Thecorpus is divided into monthly lots,with around 6,500 news articles permonth, November being the month thathad the most news, with 7,121,whereas December had the fewest,with 5,501. Each item of news is em-bodied into an XML (eXtensibleMarkup Language) file that containssome additional information other thanthe article contents and its category.These categories correspond to thenewspaper section where the newswere published.
The 20 different categories of thiscorpus are quite skewed. On average,the category Deportes is the most popu-lar, having some 1,000 on any givenmonth. Other categories with the mostnumber of documents include Tolosaand CostaUrola, each with around 500instances per month. The less popu-lated categories are Gipuzkoa, andContraportada, with little more than100 articles in most months.
As a general case, every categorycontains articles in both languages, al-though it is possible to find exceptionaldays where a particular category con-tains articles in only one language. Forthe current corpus of 2004, we esti-mated, by means of the automatic lan-guage identification technique depicted
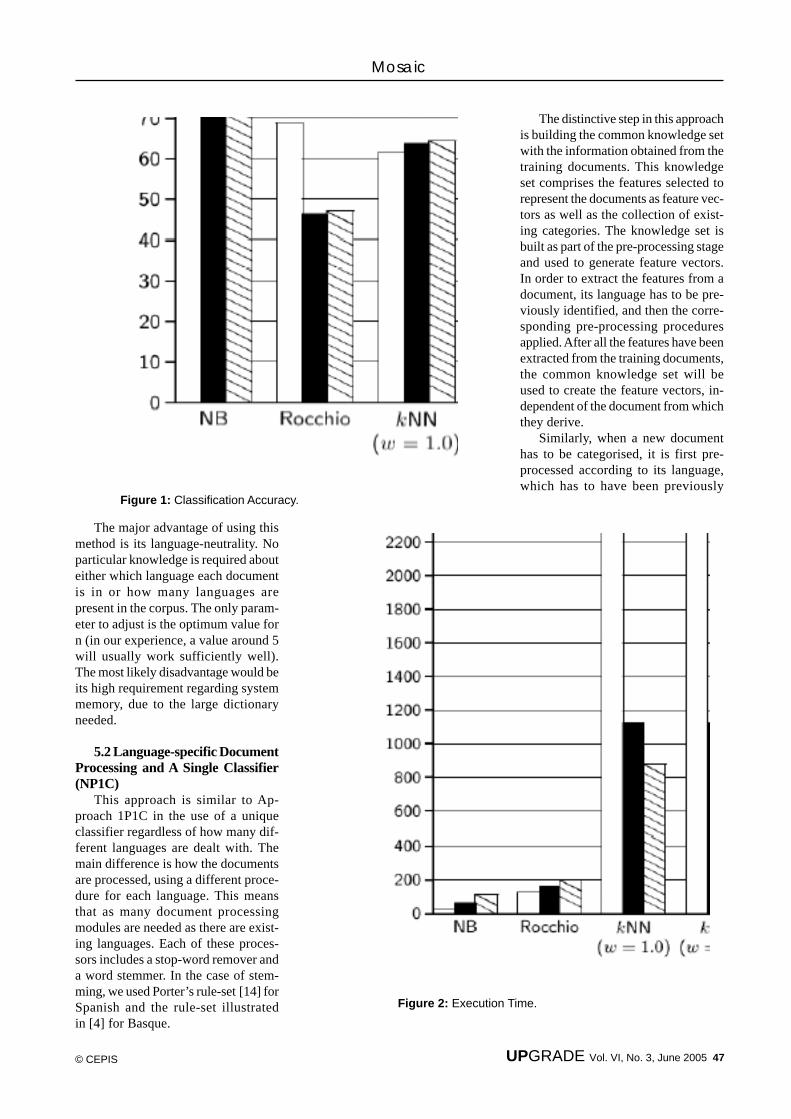
UPGRADE Vol. VI, No. 3, June 2005 47© CEPIS
Mosaic
Figure 1: Classification Accuracy.
The major advantage of using thismethod is its language-neutrality. Noparticular knowledge is required abouteither which language each documentis in or how many languages arepresent in the corpus. The only param-eter to adjust is the optimum value forn (in our experience, a value around 5will usually work sufficiently well).The most likely disadvantage would beits high requirement regarding systemmemory, due to the large dictionaryneeded.
5.2 Language-specific DocumentProcessing and A Single Classifier(NP1C)
This approach is similar to Ap-proach 1P1C in the use of a uniqueclassifier regardless of how many dif-ferent languages are dealt with. Themain difference is how the documentsare processed, using a different proce-dure for each language. This meansthat as many document processingmodules are needed as there are exist-ing languages. Each of these proces-sors includes a stop-word remover anda word stemmer. In the case of stem-ming, we used Porter’s rule-set [14] forSpanish and the rule-set illustratedin [4] for Basque.
The distinctive step in this approachis building the common knowledge setwith the information obtained from thetraining documents. This knowledgeset comprises the features selected torepresent the documents as feature vec-tors as well as the collection of exist-ing categories. The knowledge set isbuilt as part of the pre-processing stageand used to generate feature vectors.In order to extract the features from adocument, its language has to be pre-viously identified, and then the corre-sponding pre-processing proceduresapplied. After all the features have beenextracted from the training documents,the common knowledge set will beused to create the feature vectors, in-dependent of the document from whichthey derive.
Similarly, when a new documenthas to be categorised, it is first pre-processed according to its language,which has to have been previously
Figure 2: Execution Time.
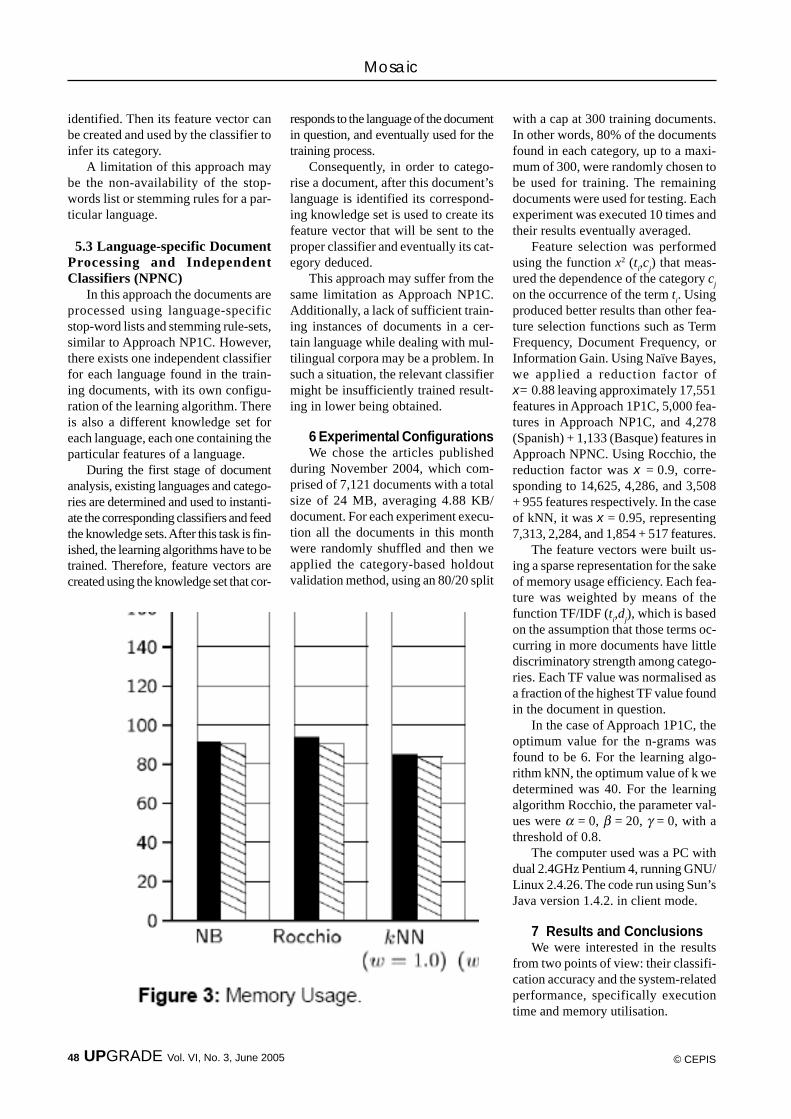
48 UPGRADE Vol. VI, No. 3, June 2005 © CEPIS
Mosaic
identified. Then its feature vector canbe created and used by the classifier toinfer its category.
A limitation of this approach maybe the non-availability of the stop-words list or stemming rules for a par-ticular language.
5.3 Language-specific DocumentProcessing and IndependentClassifiers (NPNC)
In this approach the documents areprocessed using language-specificstop-word lists and stemming rule-sets,similar to Approach NP1C. However,there exists one independent classifierfor each language found in the train-ing documents, with its own configu-ration of the learning algorithm. Thereis also a different knowledge set foreach language, each one containing theparticular features of a language.
During the first stage of documentanalysis, existing languages and catego-ries are determined and used to instanti-ate the corresponding classifiers and feedthe knowledge sets. After this task is fin-ished, the learning algorithms have to betrained. Therefore, feature vectors arecreated using the knowledge set that cor-
responds to the language of the documentin question, and eventually used for thetraining process.
Consequently, in order to catego-rise a document, after this document’slanguage is identified its correspond-ing knowledge set is used to create itsfeature vector that will be sent to theproper classifier and eventually its cat-egory deduced.
This approach may suffer from thesame limitation as Approach NP1C.Additionally, a lack of sufficient train-ing instances of documents in a cer-tain language while dealing with mul-tilingual corpora may be a problem. Insuch a situation, the relevant classifiermight be insufficiently trained result-ing in lower being obtained.
6 Experimental ConfigurationsWe chose the articles published
during November 2004, which com-prised of 7,121 documents with a totalsize of 24 MB, averaging 4.88 KB/document. For each experiment execu-tion all the documents in this monthwere randomly shuffled and then weapplied the category-based holdoutvalidation method, using an 80/20 split
with a cap at 300 training documents.In other words, 80% of the documentsfound in each category, up to a maxi-mum of 300, were randomly chosen tobe used for training. The remainingdocuments were used for testing. Eachexperiment was executed 10 times andtheir results eventually averaged.
Feature selection was performedusing the function x2 (ti,cj) that meas-ured the dependence of the category cjon the occurrence of the term ti. Usingproduced better results than other fea-ture selection functions such as TermFrequency, Document Frequency, orInformation Gain. Using Naïve Bayes,we applied a reduction factor ofx= 0.88 leaving approximately 17,551features in Approach 1P1C, 5,000 fea-tures in Approach NP1C, and 4,278(Spanish) + 1,133 (Basque) features inApproach NPNC. Using Rocchio, thereduction factor was x = 0.9, corre-sponding to 14,625, 4,286, and 3,508+ 955 features respectively. In the caseof kNN, it was x = 0.95, representing7,313, 2,284, and 1,854 + 517 features.
The feature vectors were built us-ing a sparse representation for the sakeof memory usage efficiency. Each fea-ture was weighted by means of thefunction TF/IDF (ti,dj), which is basedon the assumption that those terms oc-curring in more documents have littlediscriminatory strength among catego-ries. Each TF value was normalised asa fraction of the highest TF value foundin the document in question.
In the case of Approach 1P1C, theoptimum value for the n-grams wasfound to be 6. For the learning algo-rithm kNN, the optimum value of k wedetermined was 40. For the learningalgorithm Rocchio, the parameter val-ues were α = 0, β = 20, γ = 0, with athreshold of 0.8.
The computer used was a PC withdual 2.4GHz Pentium 4, running GNU/Linux 2.4.26. The code run using Sun’sJava version 1.4.2. in client mode.
7 Results and ConclusionsWe were interested in the results
from two points of view: their classifi-cation accuracy and the system-relatedperformance, specifically executiontime and memory utilisation.
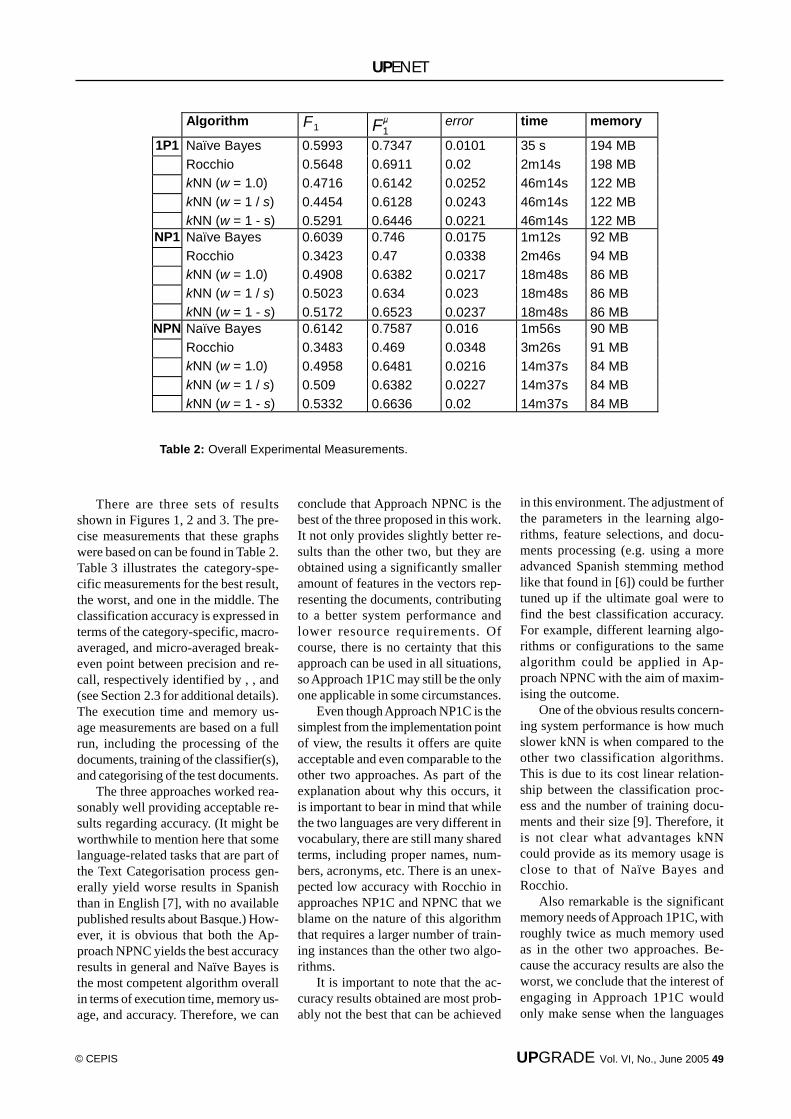
UPGRADE Vol. VI, No., June 2005 49© CEPIS
UPENET
There are three sets of resultsshown in Figures 1, 2 and 3. The pre-cise measurements that these graphswere based on can be found in Table 2.Table 3 illustrates the category-spe-cific measurements for the best result,the worst, and one in the middle. Theclassification accuracy is expressed interms of the category-specific, macro-averaged, and micro-averaged break-even point between precision and re-call, respectively identified by , , and(see Section 2.3 for additional details).The execution time and memory us-age measurements are based on a fullrun, including the processing of thedocuments, training of the classifier(s),and categorising of the test documents.
The three approaches worked rea-sonably well providing acceptable re-sults regarding accuracy. (It might beworthwhile to mention here that somelanguage-related tasks that are part ofthe Text Categorisation process gen-erally yield worse results in Spanishthan in English [7], with no availablepublished results about Basque.) How-ever, it is obvious that both the Ap-proach NPNC yields the best accuracyresults in general and Naïve Bayes isthe most competent algorithm overallin terms of execution time, memory us-age, and accuracy. Therefore, we can
Table 2: Overall Experimental Measurements.
conclude that Approach NPNC is thebest of the three proposed in this work.It not only provides slightly better re-sults than the other two, but they areobtained using a significantly smalleramount of features in the vectors rep-resenting the documents, contributingto a better system performance andlower resource requirements. Ofcourse, there is no certainty that thisapproach can be used in all situations,so Approach 1P1C may still be the onlyone applicable in some circumstances.
Even though Approach NP1C is thesimplest from the implementation pointof view, the results it offers are quiteacceptable and even comparable to theother two approaches. As part of theexplanation about why this occurs, itis important to bear in mind that whilethe two languages are very different invocabulary, there are still many sharedterms, including proper names, num-bers, acronyms, etc. There is an unex-pected low accuracy with Rocchio inapproaches NP1C and NPNC that weblame on the nature of this algorithmthat requires a larger number of train-ing instances than the other two algo-rithms.
It is important to note that the ac-curacy results obtained are most prob-ably not the best that can be achieved
in this environment. The adjustment ofthe parameters in the learning algo-rithms, feature selections, and docu-ments processing (e.g. using a moreadvanced Spanish stemming methodlike that found in [6]) could be furthertuned up if the ultimate goal were tofind the best classification accuracy.For example, different learning algo-rithms or configurations to the samealgorithm could be applied in Ap-proach NPNC with the aim of maxim-ising the outcome.
One of the obvious results concern-ing system performance is how muchslower kNN is when compared to theother two classification algorithms.This is due to its cost linear relation-ship between the classification proc-ess and the number of training docu-ments and their size [9]. Therefore, itis not clear what advantages kNNcould provide as its memory usage isclose to that of Naïve Bayes andRocchio.
Also remarkable is the significantmemory needs of Approach 1P1C, withroughly twice as much memory usedas in the other two approaches. Be-cause the accuracy results are also theworst, we conclude that the interest ofengaging in Approach 1P1C wouldonly make sense when the languages
Algorithm F1 F1 error time memory
1P1 Naïve Bayes 0.5993 0.7347 0.0101 35 s 194 MB Rocchio 0.5648 0.6911 0.02 2m14s 198 MB kNN (w = 1.0) 0.4716 0.6142 0.0252 46m14s 122 MB kNN (w = 1 / s) 0.4454 0.6128 0.0243 46m14s 122 MB kNN (w = 1 - s) 0.5291 0.6446 0.0221 46m14s 122 MB NP1 Naïve Bayes 0.6039 0.746 0.0175 1m12s 92 MB Rocchio 0.3423 0.47 0.0338 2m46s 94 MB kNN (w = 1.0) 0.4908 0.6382 0.0217 18m48s 86 MB kNN (w = 1 / s) 0.5023 0.634 0.023 18m48s 86 MB kNN (w = 1 - s) 0.5172 0.6523 0.0237 18m48s 86 MB NPN Naïve Bayes 0.6142 0.7587 0.016 1m56s 90 MB Rocchio 0.3483 0.469 0.0348 3m26s 91 MB kNN (w = 1.0) 0.4958 0.6481 0.0216 14m37s 84 MB kNN (w = 1 / s) 0.509 0.6382 0.0227 14m37s 84 MB kNN (w = 1 - s) 0.5332 0.6636 0.02 14m37s 84 MB
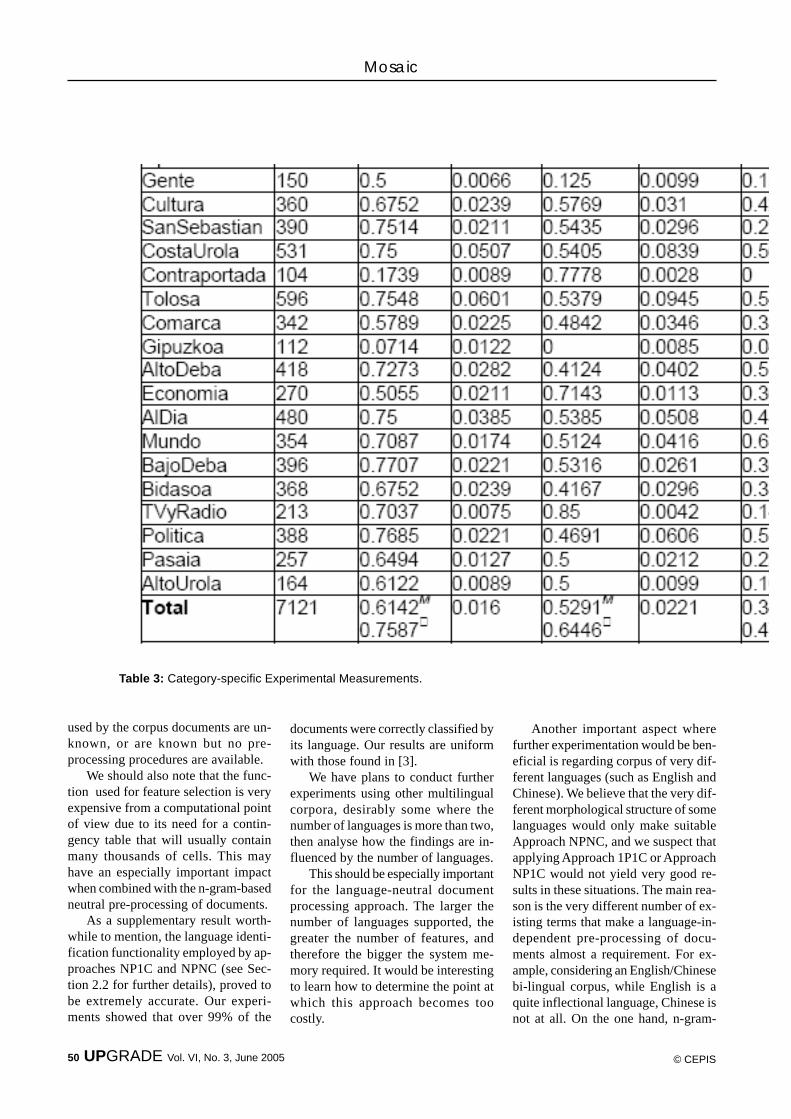
50 UPGRADE Vol. VI, No. 3, June 2005 © CEPIS
Mosaic
used by the corpus documents are un-known, or are known but no pre-processing procedures are available.
We should also note that the func-tion used for feature selection is veryexpensive from a computational pointof view due to its need for a contin-gency table that will usually containmany thousands of cells. This mayhave an especially important impactwhen combined with the n-gram-basedneutral pre-processing of documents.
As a supplementary result worth-while to mention, the language identi-fication functionality employed by ap-proaches NP1C and NPNC (see Sec-tion 2.2 for further details), proved tobe extremely accurate. Our experi-ments showed that over 99% of the
documents were correctly classified byits language. Our results are uniformwith those found in [3].
We have plans to conduct furtherexperiments using other multilingualcorpora, desirably some where thenumber of languages is more than two,then analyse how the findings are in-fluenced by the number of languages.
This should be especially importantfor the language-neutral documentprocessing approach. The larger thenumber of languages supported, thegreater the number of features, andtherefore the bigger the system me-mory required. It would be interestingto learn how to determine the point atwhich this approach becomes toocostly.
Table 3: Category-specific Experimental Measurements.
Another important aspect wherefurther experimentation would be ben-eficial is regarding corpus of very dif-ferent languages (such as English andChinese). We believe that the very dif-ferent morphological structure of somelanguages would only make suitableApproach NPNC, and we suspect thatapplying Approach 1P1C or ApproachNP1C would not yield very good re-sults in these situations. The main rea-son is the very different number of ex-isting terms that make a language-in-dependent pre-processing of docu-ments almost a requirement. For ex-ample, considering an English/Chinesebi-lingual corpus, while English is aquite inflectional language, Chinese isnot at all. On the one hand, n-gram-
C t
Algorithm NPNC
Naïve Bayes 1P1C
kNN (w = 1 – s) NP1C
Rocchio Name Account F
1 error F
1 error F
1 error
Deportes 949 0.894 0.061 0.8352 0.1164 0.6792 0.1596 Opinion 278 0.2632 0.0131 0.5128 0.0268 0.129 0.038 Gente 150 0.5 0.0066 0.125 0.0099 0.1579 0.03 Cultura 360 0.6752 0.0239 0.5769 0.031 0.426 0.0455 SanSebastian 390 0.7514 0.0211 0.5435 0.0296 0.2791 0.0582 CostaUrola 531 0.75 0.0507 0.5405 0.0839 0.5077 0.0901 Contraportada 104 0.1739 0.0089 0.7778 0.0028 0 0.0465 Tolosa 596 0.7548 0.0601 0.5379 0.0945 0.5435 0.0986 Comarca 342 0.5789 0.0225 0.4842 0.0346 0.38 0.0291 Gipuzkoa 112 0.0714 0.0122 0 0.0085 0.0449 0.0399 AltoDeba 418 0.7273 0.0282 0.4124 0.0402 0.5 0.0554 Economia 270 0.5055 0.0211 0.7143 0.0113 0.3056 0.0235 AlDia 480 0.75 0.0385 0.5385 0.0508 0.4841 0.084 Mundo 354 0.7087 0.0174 0.5124 0.0416 0.6557 0.0197 BajoDeba 396 0.7707 0.0221 0.5316 0.0261 0.309 0.0756 Bidasoa 368 0.6752 0.0239 0.4167 0.0296 0.3371 0.0554 TVyRadio 213 0.7037 0.0075 0.85 0.0042 0.1455 0.0221 Politica 388 0.7685 0.0221 0.4691 0.0606 0.5357 0.0366 Pasaia 257 0.6494 0.0127 0.5 0.0212 0.2571 0.0244 AltoUrola 164 0.6122 0.0089 0.5 0.0099 0.169 0.0277 Total 7121 0.6142M
0.7587? 0.016 0.5291M
0.6446? 0.0221 0.3423M
0.47? 0.0338

UPGRADE Vol. VI, No. 3, June 2005 51© CEPIS
Mosaic
References[1] J. J. García Adeva. "Awacate: Towards
a Framework for Intelligent Text Cat-egorisation in Web Applications".Technical report, University of Sydney,2004.
[2] Nuria Bel, Cornelis H. A. Koster, andMarta Villegas. "Cross-lingual text cat-egorization". In ECDL, pages 126–139, 2003.
[3] William B. Cavnar and John M.Trenkle. "N-Gram-Based Text Catego-rization". In Proceedings of SDAIR-94,3rd Annual Symposium on DocumentAnalysis and Information Retrieval,pages 161–175, Las Vegas, US, 1994.
[4] Ion Errasti. "Snowball-erakoeuskarazko lematizatzailea: sistema etalengoaia orotarako eramangarria".Technical report, Eusko Jaularitza,2004.
[5] J. J. García Adeva and Rafael A. Calvo."A Decomposition Scheme based onError-Correcting Output Codes for En-sembles of Text Categorisers". In Pro-ceedings of the IEEE InternationalConference on Information Technol-ogy and Applications (ICITA), 2005.
[6] A. Honrado, R. Leon, R. O’Donnel,and D. Sinclair. "A word stemming al-gorithm for the spanish language". InSPIRE ’00: Proceedings of the SeventhInternational Symposium on StringProcessing Information Retrieval(SPIRE’00), page 139. IEEE Compu-ter Society, 2000.
[7] J. Kamps, C. Monz, M. de Rijke, andB. Sigurbjörnsson. "Monolingualdocument retrieval: English versusother European languages". In A.P.de Vries, editor, Proceedings DIR2003, 2003.
[8] Victor Lavrenko, Martin Choquette,and W. Bruce Croft. "Cross-lingual rel-evance models". In SIGIR ’02: Pro-ceedings of the 25th annual interna-tional ACM SIGIR conference on Re-search and development in informationretrieval, pages 175–182. ACM.
based stemming is not very effectivein non-inflection languages and actu-ally it can input noise to the feature setinstead of providing any benefit. Onthe other hand, the number of featuresneeded for a non-inflectional languagewith a large vocabulary like Chineseis much larger than English. Therefore,using a common feature set (i.e. 1P1Cand NP1C) would play against Eng-lish for having much fewer features.
AcknowledgementsThe authors would like to thank the
Documentation Chief Editor of the news-paper Diario Vasco, Gipuzkoa, Spain,<http://www.diariovasco.com/>, for kindlyproviding us with the collection of articles.We are also very grateful to the anonymousreviewers for the extremely useful com-ments on the manuscript.

52 UPGRADE Vol. VI, No. 3, June 2005 © CEPIS
Mosaic
Keywords: Error Detection Rate,Estimation of Parameters, Failure In-tensity, Mean Value Function, Predic-tion Deviation.
1 IntroductionA number of reliability growth
models have been developed since1967 to address the need of ensuringsoftware reliability. In 1972, a majorstudy was made by Jelinski andMorando. They applied the MaximumLikelihood Estimation (MLE) tech-nique to determine the total number offaults in the software. This technique,viz., MLE, is even used today to makethe model parameter estimates. In1975, John D Musa presented the Ex-ecution Type model, in which hebrought in the concept of actual proc-essor time utilized in executing a pro-gram instead of calendar time. In 1979,Goel and Okumoto described failuredetection as a Non-HomogenousPoisson Process (NHPP) with anexponentially decaying rate function.The cumulative number of failures de-tected and the distribution of thenumber of remaining failures wasfound to be Poisson. Yamada et al, in1983, came out with another modelwhere the cumulative number of fail-ures detected is described as a SShaped Curve. In 1984, Musa andOkumoto introduced the LogarithmicPoisson Model (LPN) [4]. In recenttimes, we have the Log-Power modelXie 1993 [10] and the PNZ-SRGM(Software Reliability Growth Model)
model, Pham et al 1999 [2], which arevariations of the S-Shaped model.
In the design of the new VPV-SRGM model, the focus has been onfactors such as Simplicity, Capabilityand Applicability. Also, the strategywas to have an existing working modelas the base for developing a new model(thereby taking advantage of the ben-efits already available). After analyzingthe design of a number of models, theLPN model was found to be simple inconcept as compared to other models.It also has an implicit debugging fea-ture One aspect in the design of thismodel was that the failure intensitydecreases exponentially with failuresexperienced. But this capability of themodel will not suffice in the case whenthe testing time increases, i.e., whenfaults get hidden during the earlier testcycle but manifest at a later stage.
A adjustment factor is introducedin the LPN model to balance the nega-tive exponential decrease in the fail-
ure intensity. This paper describes themodification performed on the LPNmodel to achieve better prediction ca-pability without losing out on its sim-plicity. The failure prediction perform-ance capability is analyzed using mul-tiple failure data sets. Also, for a clearunderstanding of the improved capa-bility of the VPV model, a comparisonis made with the existing LPN modelas well with other three parameterSRGM models to present the relativeperformance of the VPV model.
2 Logarithmic Poisson (LPN)SRGMIf we denote N(t) as the number of
software failures that have occurred bytime t, the process {N(t); t>=0} cangenerally be modeled as a Non-homog-enous Poisson process (NHPP) withmean value function m(t) where m(t)= E[N(t)].
The basic assumptions made forthis model are :
Software Engineering
A Two Parameter Software Reliability Growth Model with An Im-plicit Adjustment Factor for Better Software Failure Prediction
S. Venkateswaran, K. Ekambavanan, and P. Vivekanandan
The objective of this paper is to develop a Software Reliability Growth Model (SRGM) with a focus on having a simplemodel with good prediction capability. To keep the model simple, the strategy is to limit the number of parameters wherebyparameter estimation and model implementation becomes easier. Good prediction capability is to be achieved by takingadvantage of the benefits of an existing model instead of developing another from scratch. A new function is introducedinto an existing model to compensate for its current behavior, viz., exponential decrease in the failure intensity rate. Theprediction capability of this new model (that we have called VPV) was then analyzed and also compared with a few wellknown three parameter SRGM’s. The results were found to be good.
S. Venkateswaran received his Master’sDegree in Applied Mathematics from theUniversity of Madras, Chennai, India. Heis currently doing research at AnnaUniversity, India, in the areas of softwarereliability and security. He has over 20years of experience in the IT industry, hasworked on software projects abroad, andalso serves as a visiting faculty at AnnaUniversity. <siva_vkt@ yahoo. co.inz>
K. Ekambavanam received his PhD inMathematics from Anna University, In-dia. He is a Professor in the Dept. ofMathematics of the same university and
has over 25 years of teaching experience.<[email protected]>
P. Vivekanandan received his PhD inMathematics from Madras University andan ME in Computer Science from AnnaUniversity, India. He is a Professor in theDept. of Mathematics in the sameuniversity and has over 24 years ofteaching experience and over fiftyresearch papers to his credit. His researchareas of interest are computer networks,security and software reliability.<[email protected] >

UPGRADE Vol. VI, No. 3, June 2005 53© CEPIS
Mosaic
The software system is subject tofailure at random times caused bysoftware faultsThere are no failures at time t=0Failure intensity is proportional tothe residual fault content (and thisis considered to be decreasing fol-lowing a negative exponential dis-tribution)Faults located are immediately cor-rected and will not appear againThe mean value function of this
model as given by Musa and Okumoto[3], is as follows:
m(t) = a * ln(1 + b * t)where a and b are the model param-
eters and t is the testing timeThe failure intensity function of this
model, obtained by taking the first de-rivative of the MVF, is as follows :
λ(t) = a * b / (1 + b * t)
3 VPV SRGM Model
3.1 FormulationThe LPN model is the basis for the
design of the VPV model. The aim isto take advantage of LPN model’s sim-plicity while introducing a adjustmentfactor for better predictability. Nowconsider the Failure Intensity function(λ(t)) of LPN. It is given as:
d m(t)/dt = λ(t) = a * b / (1 + b * t)
This can be alternately re-writtenas:
d m(t)/dt = λ(t) = a * b * Exp(-m(t)/a) (1)
The above representation clearlyshows the negative exponential de-crease of the failure intensity function.Parameters 'a' and 'b' are constants. Inreality, the deduction rate and expectednumber of errors could increase or de-crease. A decreasing factor is alreadypresent in the equation so the need isto have another factor for providing anincrease. This new factor could be inthe form of another parameter whichwould increase the complexity of theequation. But since the aim is not toincrease the number of parameters inthe equation, the method used in theDuane model is applied. The meanvalue function of the Duane Model,
also called the power-law [1] model,is given below:
m(t) = a * tb
So, the equation, for the new model,can be taken as:
i.e, d m(t) / Exp(-m(t)/a)) = a * tx dt
Now, if we take integration on bothsides, we have
When t = 0, c = a. since m(0) = 0.
Therefore a * Exp(m(t)/a) = a *(tx+1/x+1) + a.
Simplifying the above, we get themean value function of the new VPVmodel as follows (2):
m(t) = a * Ln( (tx+1/x+1) + 1) where x = b2
3.2 Model SimplicityThe new model of Equation 2 is a
simple one with two parameters. Theneed is only to estimate the values ofthese two parameters. Generally, whenthe number of parameters in a modelincreases, estimation of the parametervalues take more time and effort [2].Many of the models that have beendesigned to compensate for factors
such as Imperfect Debugging (viz., K-G Imperfect Debugging Model, YamadaImperfect Mode etc), Learning (K-GLearning Model etc.) and Testing Effort(Raleigh Model, Yamada ExponentialModel etc) have three or four param-eters. These extra parameters help in
fine-tuning the expected number offailures or the deduction rate or both.But the new VPV model uses the basictwo parameters to adjust itself to pro-duce results similar or better than thethree parameter models.
3.3 Model CapabilityThe capability of a model can be
assessed by validating its ability tomake failure predictions, specificallyduring the software development stage.For the new VPV model, a detailedanalysis of its prediction capability hasbeen performed. The results werefound to be good. The specific detailsare provided in Section 4.
Notations
m(t) : Expected number of observed failures during the time interval [0,t)λ (t) ; Failure Intensity FunctionR(x/s) : Software Reliabilityp : Probability of perfect debuggingMVF : Mean Value FunctionMLE : Maximum Likelihood EstimationVPV : VPV ModelLPN : Logarithmic Poisson ModelKGM : Kapur-Garg Imperfect Debugging ModelYIM : Yamada Imperfect Debugging ModelKYL : Kapur-Younes Learning ModelINF : Inflection S Shaped ModelSRGM : Software Reliability Growth Model
d m(t)/dt = λ(t) = a * tx * Exp(-m(t)/a)) where x = b2
i.e. Exp(m(t)/a) d m(t) = a tx d + c where c is a constant
i.e., a * Exp(m(t)/a) = a * (tx+1/x+1) + c

54 UPGRADE Vol. VI, No. 3, June 2005 © CEPIS
Mosaic
3.4 Model ApplicabilityApplicability depends on a model’s
effectiveness across different develop-ment environments, different softwareproducts and sizes, different opera-tional environments and different lifecycle methods. For the VPV model, itsapplicability was measured consider-ing the following:
Failure Data Sets were taken fromdifferent time periods. This accountsfor the different life cycle methods usedduring those periods.
The Software products from whichthe failure data was taken were alsodifferent. Also, the size of these prod-ucts were also different.
Since the software products fromwhich failure data sets were taken weredifferent, their development environ-ment and operational environmentwere also different.
The specific details of the data usedto measure the VPV models applica-bility is given in Section 4.
4. VPV Model Analysis
4.1 IntroductionModel validation is accomplished
by comparing the predicted failure val-ues of the VPV model with that of theobserved failures. A study is also madeto compare its relative performancewith other SRGM’s. The approach con-sists of the following steps: Failure Data Set Compilation
- Three (published) Software FailureData Sets are identified [2][11][12] Parameter Estimation
- The parameters for all Models areestimated using 70% of each of the fail-ure data sets VPV Model Validation
- Remaining 30% of each failure dataset is used for failure prediction vali-dation- Failure prediction analysis with re-spect to 6 time units of the observedfailures (for Data Set 1, 30% of thefailure data amounts to 6 time units.This has been uniformly taken for theremaining two data sets.- Failure prediction analysis in com-parison with the base LPN model- Failure prediction analysis in compari-son with three parameter models
· K-G Imperfect Debugging Model(KGM)· Yamada Imperfect Debugging Model(YIM)· Kapur-Younes Learning Model(KYL)· Inflection S-Shaped Model (INF)- Failure prediction analysis for alonger term prediction (18 time units).
4.2 Failure Data Set CompilationThe failure data sets used for vali-
dating the performance of the VPVmodel have been taken from publisheddata. Three failure data sets were iden-tified on the following basis: Limited number of failure data as
well as large number of failure data- Data set 1 has 20 failure data obser-vations [2]- Data set 2 has 59 failure data obser-vations [11]- Data set 3 has 109 failure data obser-vations [12] Failure data from different periods
- Data sets 2 is from the 1980’s- Data set 1 and 3 are from the 1990’s Failure data from different software
products and sizes- Data set 1 is from a Tandem Comput-ers project (Release #1) [2]- Data set 3 is from a real time controlproject having 870 Kilo steps of For-tran program and a Middle level Lan-guage [12]
4.3 Parameter EstimationThe model parameters are esti-
mated using a well applied methodol-ogy, viz., Maximum Likelihood Esti-mation (MLE) [5][8][9]. The likeli-hood function for a given set of(z1,...,zn) failures , in different time in-terval is given by (3):
The mean value function (Equation 2),of the VPV model, is substituted in theabove equation (Equation 4). The sub-stituted function is then differentiatedwith respect to the parameters (a andb), and equated to zero. These equa-tions are than solved to get the specificvalues of the parameters 'a' and 'b'. Themean value function of the other mod-els are given in Appendix 1. TheMathcad software was used to calcu-late the parameter values. The param-eter values computed for all models,are given in Tables 1 to 6.
4.4 VPV Model ValidationThe aim is to analyze the predic-
tion capability of the VPV model byconsidering its performance against theobserved failures. The aim is to alsosee its relative performance with re-spect to its base model (LPN) as wellas with other well known three param-eter models.
4.4.1 Failure Prediction Analysis(for 6 Time Units)
The prediction analysis has beenperformed by calculating the failureprediction deviation of VPV and othermodels, from actual failure data. Thisprediction deviation is calculated asfollows:
Prediction Variation = (EstimatedFailure Data – Actual Failure Data)/Actual Failure Data
These prediction variations areplotted in the form of a graph. The x-axis shows the time while the y-axisshows the prediction deviation fromthe actual. The closer the generatedcurve is to zero, the closer the predic-
where n is the number of failuresobserved and zi is the actual cumula-tive failure data collected up to time ti.
tion is to the actual.To avoid cluttering in the graph
presentation, the performance of all the
. Taking the natural logarithm of theEquation 3, we get (4):
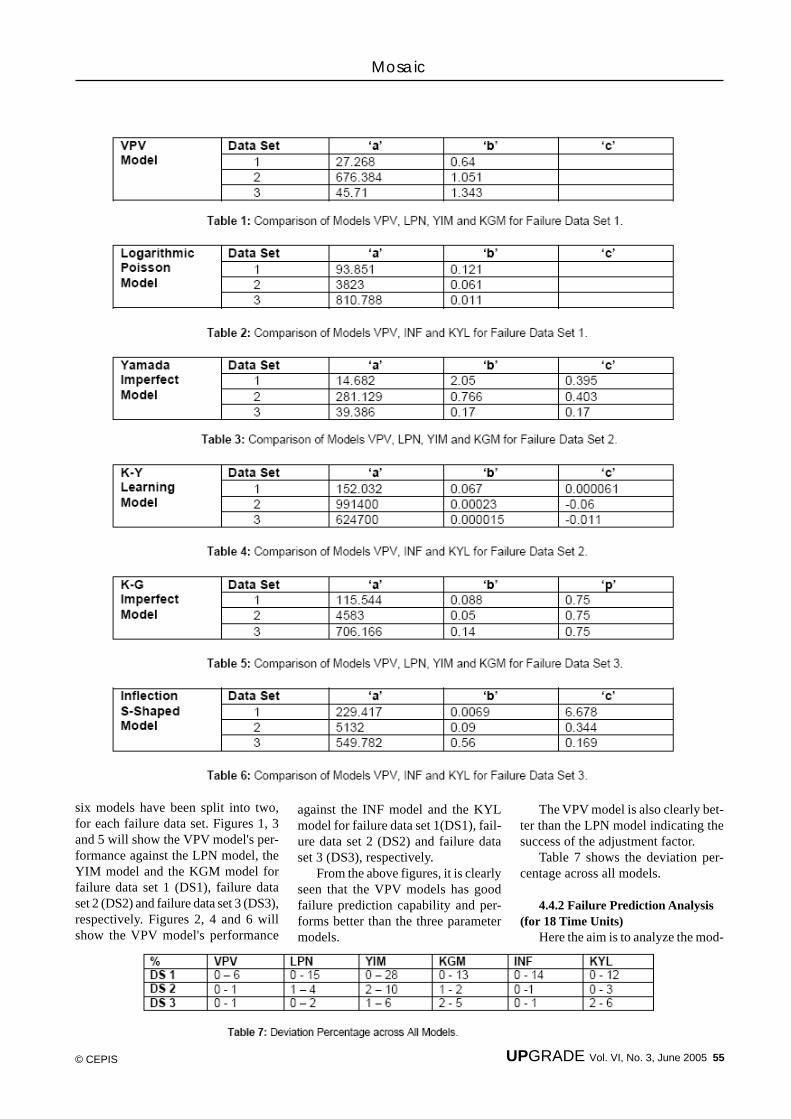
UPGRADE Vol. VI, No. 3, June 2005 55© CEPIS
Mosaic
six models have been split into two,for each failure data set. Figures 1, 3and 5 will show the VPV model's per-formance against the LPN model, theYIM model and the KGM model forfailure data set 1 (DS1), failure dataset 2 (DS2) and failure data set 3 (DS3),respectively. Figures 2, 4 and 6 willshow the VPV model's performance
against the INF model and the KYLmodel for failure data set 1(DS1), fail-ure data set 2 (DS2) and failure dataset 3 (DS3), respectively.
From the above figures, it is clearlyseen that the VPV models has goodfailure prediction capability and per-forms better than the three parametermodels.
The VPV model is also clearly bet-ter than the LPN model indicating thesuccess of the adjustment factor.
Table 7 shows the deviation per-centage across all models.
4.4.2 Failure Prediction Analysis(for 18 Time Units)
Here the aim is to analyze the mod-
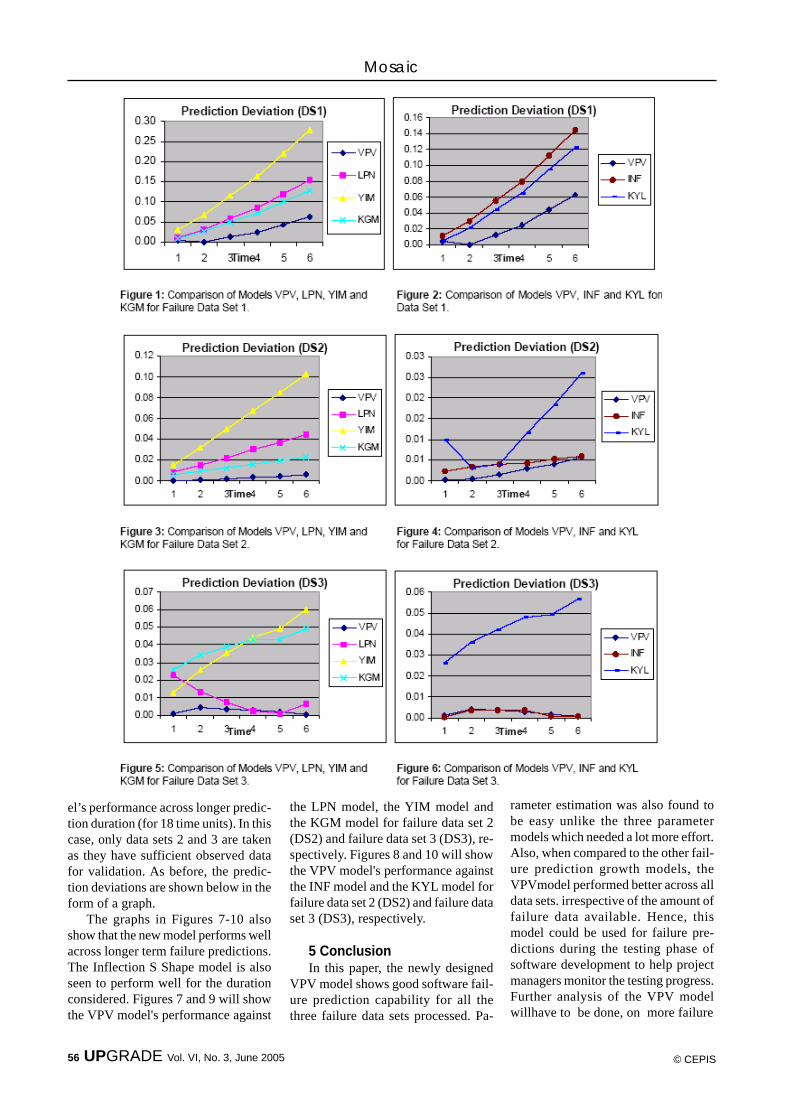
56 UPGRADE Vol. VI, No. 3, June 2005 © CEPIS
Mosaic
el’s performance across longer predic-tion duration (for 18 time units). In thiscase, only data sets 2 and 3 are takenas they have sufficient observed datafor validation. As before, the predic-tion deviations are shown below in theform of a graph.
The graphs in Figures 7-10 alsoshow that the new model performs wellacross longer term failure predictions.The Inflection S Shape model is alsoseen to perform well for the durationconsidered. Figures 7 and 9 will showthe VPV model's performance against
the LPN model, the YIM model andthe KGM model for failure data set 2(DS2) and failure data set 3 (DS3), re-spectively. Figures 8 and 10 will showthe VPV model's performance againstthe INF model and the KYL model forfailure data set 2 (DS2) and failure dataset 3 (DS3), respectively.
5 ConclusionIn this paper, the newly designed
VPV model shows good software fail-ure prediction capability for all thethree failure data sets processed. Pa-
rameter estimation was also found tobe easy unlike the three parametermodels which needed a lot more effort.Also, when compared to the other fail-ure prediction growth models, theVPVmodel performed better across alldata sets. irrespective of the amount offailure data available. Hence, thismodel could be used for failure pre-dictions during the testing phase ofsoftware development to help projectmanagers monitor the testing progress.Further analysis of the VPV modelwillhave to be done, on more failure
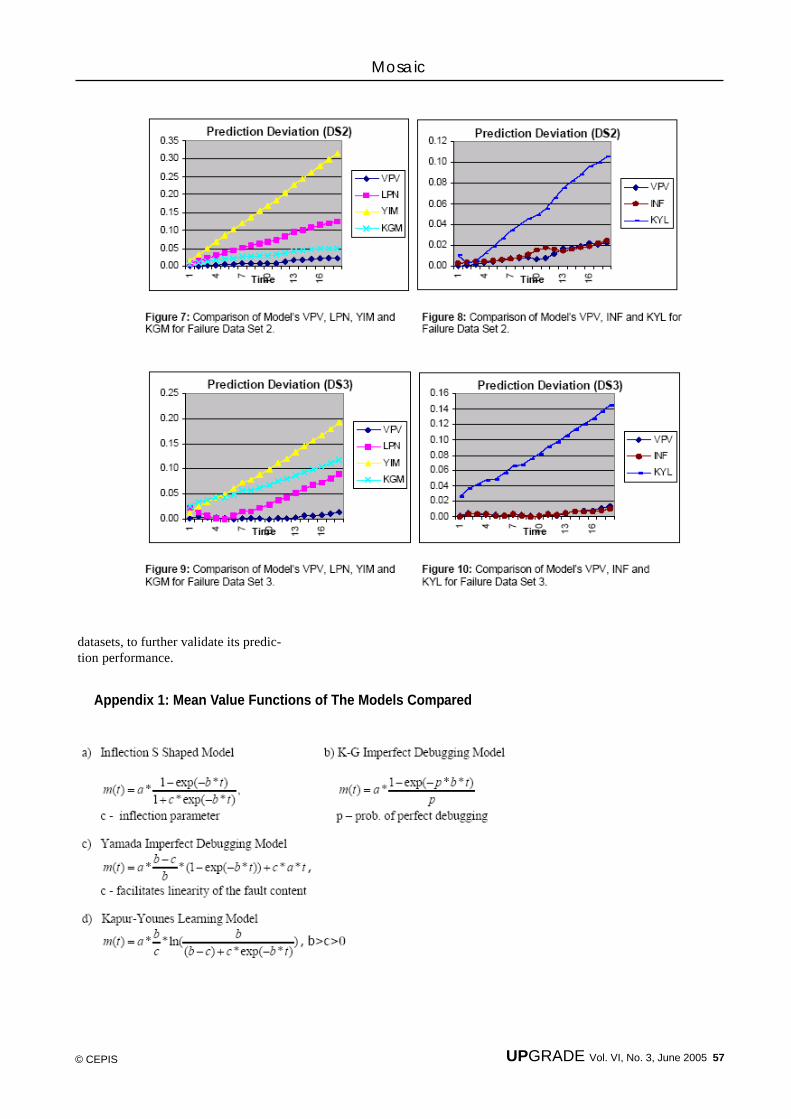
UPGRADE Vol. VI, No. 3, June 2005 57© CEPIS
Mosaic
datasets, to further validate its predic-tion performance.
Appendix 1: Mean Value Functions of The Models Compared

58 UPGRADE Vol. VI, No. 3, June 2005 © CEPIS
Mosaic
References[1] M. Xie. "Software Reliability Models
Past, Present & Future", published inthe book 'Recent Advances in Reliabil-ity Theory', released at the second In-ternational Conference on Mathemati-cal Methods in Reliability held inBordeaux, France, pp. 325-340, 2000.
[2] H. Pham, L. Nordmann, and X Zhang."A General Imperfect-Software-De-bugging Model with S-Shaped Fault-Detection rate", IEEE Transaction onReliability Vol. 48, No.2, 1999.
[3] Kapur and Garg. "Optimal software re-lease policies for software reliabilitygrowth models under imperfect de-bugging", RAIRO:Operations Re-search, Vol 24, pp. 295-305, 1990.
[4] J.D Musa and K. Okumoto. "A loga-rithmic Poisson execution time modelfor software reliability measurement",Proceedings of the 7th InternationalConference on software engineering,pp. 230-238, 1984.
[5] M. Obha. "Software Reliability Analy-sis Models", IBM. J. Res. Develop.Vol. 28, No.4, pp. 428-443, 1984.
[6] A.L Goel and Kune-Zang Yang. "Soft-ware Reliability and Readiness As-sessment based on NHPP", Advancesin Computers, Vol 45, pp. 235, 1997.
[7] D.R. Prince Williams, P. Vivekanandan."Truncated Software ReliabilityGrowth Model, Korean Journal ofComputational and Applied Math-ematics", Vol 9(2) pp. 591-599, 2002.
[8] N. Kareer, P.K Kapur, and P.S. Grover."An S-Shaped Software ReliabilityGrowth Model with two types of er-rors", Microelectron Reliab, Vol 30,No. 6, pp. 1085-1090. 1990.
[9] T. Lynch, H. Pham, and W. Kuo."Modeling Software-Reliability withMultiple Failure-Types and ImperfectDebugging", Proceedings Annual Re-liability and Maintainability Sympo-sium, pp. 235-240, 1994.
[10] M. Xie and M. Zhao. "On some Reli-ability Growth Models with simplegraphical interpretations", Microelec-tronics and Reliability, 33, pp. 149-167, 1993.
[11] P.K Kapur and S. Younes. "Modelingan Imperfect Debugging Phenomenonin Software Reliability",Microelectron Reliab Vol 36, No. 5,pp. 645-650, 1996.
[12] Y.Tohma, H Yamano, M. Obha, and RJacoby. "Parametric Estimation of theHyper-Geometric Distribution Modelfor Real Test/Debug", Data Proceed-ings, 1991, International Symposiumon Software Reliability Engineering,pp. 28-34, 1991.

UPGRADE Vol. VI, No. 3, June 2005 59© CEPIS
Mosaic
The long and heated debate aboutthe implementation in Europa of aUSA-like software patent model cameapparently to an end with the July 6vote of the European Parliamentagainst the Proposal of Directive putforward by the European Commission.
Let’s remark that, motivated by the
(Press release issued by FFII, Foun-dation for a Free Information Infra-structure, <http://www.ffii.org>)
Strasbourg, 6 July 2005 — TheEuropean Parliament today decided bya large majority (729 members (ofwhich 689 signed that day’s attendanceregister), 680 votes, 648 in favour, 14against, 18 abstaining) to reject the di-rective "on the patentability of com-puter implemented inventions", alsoknown as the software patent directive.This rejection was the logical answerto the Commission’s refusal to restartthe legislative process in February andthe Council’s reluctance to take the willof the European Parliament and na-tional parliaments into account. TheFFII congratulates the European Par-liament on its clear "No" to bad legis-lative proposals and procedures.
This is a great victory for those whohave campaigned to ensure that Euro-pean innovation and competitivenessis protected from monopolisation ofsoftware functionalities and businessmethods. It marks the end of an attemptby the European Commission and gov-ernmental patent officials to impose
comments on the outcome of today’svote: "This result clearly shows that thor-ough analysis, genuinely concerned citi-zens and factual information have moreimpact than free ice-cream, boatloads ofhired lobbyists and outsourcing threats.I hope this turn of events can give peo-ple new faith in the European decisionmaking process. I also hope that it willencourage the Council and Commissionto model after the European Parliamentin terms of transparency and the abilityof stakeholders to participate in the de-cision-making process irrespective oftheir size."
Hartmut Pilch, president of FFII,explains why FFII supported the movefor rejection in its voting recommen-dations: “In recent days, the big hold-ers of EPO-granted software patentsand their MEPs, who had previouslybeen campaigning for the Council’s'Common Position', joined the call forrejection of the directive because itbecame clear that the 21 cross-partyamendments championed by Roithová,Buzek, Rocard, Duff and others werevery likely to be adopted by the Par-liament. It was well noticeable that
News & Events
Proposal of Directive on Software Patents Rejectedby The European Parliament
impact of software patents on bothEuropean Information Technology in-dustry and professionals, CEPIS set upin 2004 a Working Group on this mat-ter, led by Juan Antonio Esteban (ATI,Spain). The discussion paper producedby this group is available at <http://www.ati.es/DOCS/>.
We publish the reactions from FFII(Foundation for a Free InformationInfrastructure), EPO (European PatentOffice) and EICTA (European Infor-mation & Communications Technol-ogy Industry Association), after thevoting of the Europarliament.
FFII: European Parliament says No to software patents
detrimental and legally questionablepractises of the European Patent Of-fice (EPO) on the member states. How-ever, the problems created by thesepractices remain unsolved. FFII be-lieves that the Parliament’s work, inparticular the 21 cross-party compro-mise amendments, can provide a goodbasis on which future solutions, bothat the national and European level, canbuild.
Rejection provides breathing spacefor new initiatives based on all theknowledge gained during the last fiveyears. All institutions are now fullyaware of the concerns of allstakeholders. However, the fact that theCouncil Common Position needs 21amendments in order to be transformedinto a coherent piece of legislation in-dicates that the text is simply not readyto enter the Conciliation between Par-liament, Commission and Council. Wehope the Commission and Council willat least respond to the concerns raisedby Parliament the next time, in orderto avoid this sort of backlash in thefuture.
Jonas Maebe, FFII Board Member,

60 UPGRADE Vol. VI, No. 3, June 2005 © CEPIS
Mosaic
support for all most of these amend-ments was becoming the mainstreamopinion in all political groups. Yet therewould not have been much of a pointin such a vote. We rather agree to theassessment of the situation as given byOthmar Karas MEP in the Plenary
yesterday: a No was the only logicalanswer to the unconstructive attitudeand legally questionable maneuvers ofthe Commission and Council, by whichthis so-called Common Position hadcome about in the first place.”
The FFII wishes to thank all those
EPO: European Patent Office continues to advocate harmonisationin the field of CII patents
EICTA: Europe’s High Tech Industry WelcomesEuropean Parliament Decision
people who have taken the time to con-tact their representatives. We also thankthe numerous volunteers who have sogenerously given their time and energy.This is your victory as well as the Par-liament’s.
(Press release issued by EPO, Eu-ropean Patent Office, <http://www.european-patent-office.org/>)
Munich/Strasbourg, 6 July 2005 -The European Patent Office (EPO) hasfollowed with interest the vote of theEuropean Parliament today and hastaken note of the decision of the Euro-pean Parliament not to accept the Di-rective on the patentability of compu-ter-implemented inventions (CII) ac-cording to the Common Position of theCouncil. The proposed Directive istherefore deemed not to have beenadopted. "The objective of the direc-tive would have been to harmonize theunderstanding of what constitutes apatentable invention in the field ofCII", explained the President of theEPO, Professor Alain Pompidou.
The EPO carries out a centralisedpatent granting procedure for the 31
member states of the European PatentOrganisation. "Our Organisation wasfounded by almost the same countries asthose which founded the European Un-ion, and in the same spirit. The purposebehind the creation of the EPO was tomake the patenting process in Europemore efficient by applying a single pro-cedure on the basis of the European Pat-ent Convention (EPC). In its practice, theEPO follows strictly the provisions of theConvention, which has been ratified byall member states of the Organisation",President Pompidou explained.
Under the EPC a well-defined prac-tice on granting patents in the field ofCII has been established: "The EPCprovides the general legal basis for thegrant of European patents, whereas theobjective of the directive would havebeen to harmonise the EU memberstates’ rules on CII and the relevant
provisions of the EPC. The EPC alsogoverns our work in the field of CII,together with the case law of our judi-ciary, the Boards of Appeal of theEPO", Mr Pompidou said.
As with all inventions, CII are onlypatentable if they have technical charac-ter, are new and involve an inventivetechnical contribution to the prior art.Moreover, the EPO does not grant "soft-ware patents": computer programsclaimed as such, algorithms or compu-ter-implemented business methods thatmake no technical contribution are notconsidered patentable inventions underthe EPC. In this respect, the practice ofthe EPO differs significantly from thatof the United States Patent & TrademarkOffice. For more information please con-tact: European Patent Office, MediaRelations Department, 80298 Munich,[email protected]
(Press release issued by EICTA,European Information & Communica-tions Technology Industry Association,<http://www.eicta.org/>)
06 July 2005EICTA, the industry body repre-
senting Europe’s large and small hightech companies, today welcomed theEuropean Parliament decision on theCII Patents Directive. This decisionwill ensure that all high tech compa-nies in Europe continue to benefit froma high level of patent protection.
Commenting on the outcome of to-day’s vote, Mark MacGann, DirectorGeneral of EICTA, said: “This is a wisedecision that has helped industry to avoidlegislation that could have narrowed thescope of patent legislation in Europe.
Parliament has today voted for thestatus quo, which preserves the currentsystem that has served well the inter-ests of our 10, 000 member companies,both large and small.
EICTA will continue to make thecase throughout Europe for the con-tribution that CII patents make to re-
search, innovation and to overall Eu-ropean competitiveness.”
All the European institutions andindustry have worked hard and con-structively on the issue of CII patentsfor some time. Europe’s high tech in-dustry will support the efforts of theEuropean institutions to find broaderimprovements to the European patentsystem that will particularly benefit theinterests of smaller companies. Forfurther information: Mark MacGann,EICTA: +32 473 496 388; RichardJacques, Brunswick: +44 7974 982 557

UPGRADE Vol. VI, No., June 2005 61© CEPIS
UPENET
Informatics Law
Security, Surveillance and Monitoring ofElectronic Communications at The Workplace
Olga Georgiades-Van der Pol
© Pliroforiki 2005This paper was first published, in English, by Pliroforiki (issue no. 11, June 2005, pp. 10-16). Pliroforiki, (“Informatics” in Greek), a founding memberof UPENET (Upgrade European Network), is a journal published, in Greek or English, by the Cyprus CEPIS society CCS (Cyprus Computer Society,<http://www.ccs.org.cy/about/>)
This article, which is an extract from the author’s book "PRIVACY: Processing of Personal Data, Obligations of Compa-nies, Surveillance of Employees, Privacy on the Internet", has as its main objective to offer a first approach to the securityobligations of companies in relation to the personal information they hold about their employees. It also gives an overviewof the rights and obligations of the company when monitoring its employees for the purpose of ensuring the security of itssystems.
This section includes articles published by the journals that make part of UPENET.For further information see <http://www.upgrade-cepis.org/pages/upenet.html>.
Keywords: Electronic Communica-tions, Monitoring, Privacy, Security,Surveillance, Workers’s Rights,Workplace.
1 IntroductionThe vast majority of the population
will either permanently or at varioustimes find itself in an employment re-lationship in the public or private sec-tor. The availability and use of manynew monitoring technical methodsavailable to the company is raising newissues such as the extent of monitor-ing workers’ communications (e-mailand telephone calls), workplace super-
Olga Georgiades-Van der Pol is theholder of a Bachelor of Laws (LLB) inEnglish Law and French Law from theUniversity of East Anglia, UK, and of aMasters’ in Laws (LLM) in EuropeanLaw with Telecommunications Lawfrom the University College London(UCL), UK. She is also a holder of aDiploma of French higher legal studiesfrom the University of RobertSchumann, Strasbourg, France. Olga hastrained in the European Commission, atthe Information Society Directorate.Since she has been admitted as a Lawyer,she has worked as an Advocate at Lellos
P. Demetriades Law Office in Nicosia,Cyprus, heading the European and I.T.Law department, where she specialisesin European Law, Internet Law,Telecommunications Law andCompetition Law. She is the author ofvarious books and reports concentratingon Privacy, Processing of Personal Data,Surveillance of Employees, Privacy onthe Internet & Obligations ofCompanies, Financial Assistance forCyprus under EU programs andCompetition Law in Cyprus especiallyin the field of Telecommunications.<[email protected]>
vision, workers’ data transfer to thirdparties, use of biometric methods forcontrolling access in the workplace,etc.
2 Security Issues in KeepingEmployee Data2.1 Main PrinciplesBy virtue of the Cyprus Data Pro-
tection Law1, the employer must takethe appropriate organizational andtechnical measures for the security ofworker’s personal data and their pro-tection against accidental or unlawfuldestruction, accidental loss, alteration,unauthorised dissemination or accessand any other form of unlawfulprocessing. Such measures must en-
1 S.10 of the Processing of Personal Data (pro-tection of the Person) Law of 2001, LawN.138(I)/2001 as amended. (Available at <http:// w w w. m o h . g o v . c y / m o h / m o h . n s f / 0 /9267FFD2810B177EC2256D49003 E D1FC?OpenDocument>.)
(Keywords and section numbering added by the Editor of UPGRADE.)

62 UPGRADE Vol. VI, No., June 2005 © CEPIS
UPENET
2. Personal data should, in principle,be used only for the purposes for whichthey were originally collected.3. If personal data are to be processedfor purposes other than those for whichthey were collected, the employershould ensure that they are not used ina manner incompatible with the origi-nal purpose, and should take the nec-essary measures to avoid any misinter-pretation caused by a change of con-text.4. Personal data collected in connec-tion with technical or organisationalmeasures to ensure the security andproper operation of automated infor-mation systems should not be used tocontrol the behaviour of workers.5. Decisions concerning a workershould not be based solely on the au-tomated processing of that worker’spersonal data.
3 Security Issues in Monitor-ing Employee Electronic Com-munications
3.1 Main PrinciplesThis issue concerns the question
what are the acceptable limits of moni-toring by the company of e-mail andInternet use by employees and whatconstitutes legitimate monitoring ac-tivities.
The basic principle is that workersdo not abandon their right to privacyand data protection every morning atthe doors of the workplace3. They dohave a legitimate expectation of a cer-tain degree of privacy in the workplaceas they develop a significant part oftheir relationships with other humanbeings within the workplace. Their fun-damental right of privacy is safe-guarded by Article 15 of the Constitu-tion of the Republic of Cyprus, by Ar-ticle 8 of the Convention for the Pro-
tection of Human Rights and Funda-mental Freedoms and by other Euro-pean and international legislative in-struments.
While new technologies constitutea positive development of the resourcesavailable to employers, tools of elec-tronic surveillance present the possi-bility of being used in such a way soas to intrude upon the fundamentalrights and freedoms of workers. Itshould not be forgotten that with thecoming of the information technolo-gies it is vital that workers should en-joy the same rights whether they workon-line or off-line.
However, companies should notpanic. While workers have a right to acertain degree of privacy in the work-place, this right must be balanced withother legitimate rights and interests ofthe company as employer, in particu-lar:
The need to ensure the security ofthe system.
The employer’s right to run and con-trol the functioning of his business ef-ficiently.
The right to protect his legitimateinterests from the liability or the harmthat workers’ actions may create, forexample the employer’s liability for theaction of their workers, i.e. from crimi-nal activities.
The need of the employer to protecthis business from significant threats,such as to prevent transmission of con-fidential information to a competitor.
These rights and interests constitutelegitimate grounds that may justifyappropriate measures to limit the work-er’s right to privacy.4
Nevertheless, balancing differentrights and interests requires taking anumber of principles into account, inparticular proportionality. The simplefact that a monitoring activity or sur-
sure a level of security which is pro-portionate to the risks involved in theprocessing and the nature of the dataprocessed. As a result, employee per-sonal data must remain safe from thecuriosity of other workers or third par-ties not employed by the company.Within this context, employers mustuse appropriate technological meansfor preventing such unauthorised ac-cess or disclosure, allowing in any casethe identification of the staff access-ing the files.
Where an external data processoris used by the company, there must bea contract between him and the em-ployer, providing security guaranteesand ensuring that the processor actsonly according to the employer’s in-structions. The European Union2 rec-ommends that the following securitymeasures be used at the workplace:
Password/identification systems foraccess to computerised employmentrecords;
Login and tracing of access and dis-closures;
Backup copies;Encryption of messages, in particu-
lar when the data is transferred outsidethe company.
2.2 Code of Practice of TheInternational Labour Office on TheProtection of Workers’ PersonalData
In the field of employment, theData Protection Commissioner maytake into account the Code of Practiceof the International Labour Office onthe protection of workers’ personaldata which establishes the followinggeneral principles:1. Personal data should be processedlawfully and fairly, and only for rea-sons directly relevant to the employ-ment of the worker.
2 Article 29 Data Protection Working Party,Opinion 8/2001 on the processing of personaldata in the employment context, 5062/01/EN/Final, WP 48, 13 September 2001. (The Article29 Working Party is an advisory group composedby representatives of the data protection authori-ties of the European Union member States.)
3 Article 29 Data Protection Working Party,Working document on the surveillance of elec-tronic communications in the workplace, 5401/01/EN/Final, WP 55.
4 Article 29 Data Protection Working Party,Working document on the surveillance of elec-tronic communications in the workplace, 5401/01/EN/Final WP 55, 29 May 2002.

UPGRADE Vol. VI, No., June 2005 63© CEPIS
UPENET
veillance is considered convenient toserve the employer’s interest, wouldnot solely justify any intrusion in work-er’s privacy. In this respect, where theobjective identified can be achieved ina less intrusive way, the employershould consider this option. For exam-ple, the employer should avoid systemsthat monitor the worker automaticallyand continuously.
3.2 The Constitution of TheRepublic of Cyprus
The Right of Privacy is safeguardedby Article 15.1 of the Constitution ofCyprus, that reads:
"1. Every person has the right torespect for his private and family life.
2. There shall be no interference withthe exercise of this right except such asis in accordance with the law and is nec-essary only in the interests of the secu-rity of the Republic or the constitutionalorder or the public safety or the publicorder or the public health or the publicmorals or for the protection of the rightsand liberties guaranteed by this Consti-tution to any person."
3.3 The European Convention forThe Protection of Human Rights
Article 15.1 of the Constitution ofCyprus is modelled on Article 8 of theEuropean Convention of HumanRights which has been ratified by theEuropean Convention on HumanRights (Ratification) Law of 19625.Article 8 reads:
"1. Everyone has the right to re-spect for his private and family life, hishome and his correspondence.
2. There shall be no interference bya public authority with the exercise ofthis right except such as is in accord-ance with the law and is necessary ina democratic society in the interests ofnational security, public safety or theeconomic well-being of the country, forthe prevention of disorder or crime, forthe protection of health or morals, orfor the protection of the rights andfreedoms of others."
3.3 Case Law of The EuropeanCourt of Human Rights
The position of the European Courtof Human Rights is that the protectionof "private life" enshrined in Article 8does not exclude the professional lifeas a worker and is not limited to lifewithin home.
In the case of Niemitz v. Germany6
that concerned the search by a govern-ment authority of the complainant’soffice, the Court stated that respect forprivate life must also comprise to acertain degree the right to establish anddevelop relationships with other hu-man beings. There appears, further-more, to be no reason of principle whythis understanding of the notion of "pri-vate life" should be taken to excludeactivities of a professional or businessnature since it is, after all, in the courseof their working lives that the major-ity of people have a significant, if notthe greatest, opportunity of develop-ing relationships with the outsideworld. This view is supported by thefact that it is not always possible to dis-tinguish clearly, which of an individu-al’s activities form part of his profes-sional or business life and which donot.
3.4 Code of Practice of TheInternational Labour Office on TheProtection of Workers’ PersonalData
The Code of Practice of the Inter-national Labour Office (ILO) estab-lishes the following general principleswith regards to monitoring of employ-ees:
"1. If workers are monitored, theyshould be informed in advance of thereasons for monitoring, the time sched-ule, the method and techniques usedand the data to be collected, i.e. byestablishing an e-policy."
2. Secret monitoring should bepermitted only:
(a) if it is in conformity with na-tional legislation, i.e. in accordancewith section 5 of the Data Protection
Law, it is necessary for safeguardingthe legitimate interests pursued by thecompany, on condition that such inter-ests override the rights, interests andfundamental freedoms of the employee.One such legitimate purpose is safe-guarding the security of the company;or
(b) if there is suspicion on reason-able grounds of criminal activity orother serious wrongdoing by the em-ployee.
3. Continuous monitoring shouldbe permitted only if required for healthand security or the protection of prop-erty, i.e. from theft.
4. Workers’ representatives, wherethey exist, and in conformity with na-tional law and practice, should be in-formed and consulted:
(a) concerning the introduction ormodification of automated systems thatprocess worker’s personal data,
(b) before the introduction of anyelectronic monitoring of workers’ be-haviour in the workplace,
(c) about the purpose, contents andthe manner of administering and in-terpreting any questionnaires and testsconcerning the personal data of theworkers."
3.5 Position of The Article 29Data Protection Working Party ofThe European Community
According to the Article 29 DataProtection Working Party of the Euro-pean Community, prevention shouldbe more important than detection.In other words, the interest of the em-ployer is better served in preventingInternet misuse rather than in detect-ing such misuse. In this context, tech-nological solutions are particularly use-ful. A ban on personal use of theInternet by employees does not appearto be reasonable and fails to reflect thedegree to which the Internet can assistemployees in their daily lives.
3.6 Obligation to Inform TheWorker - Transparency
An employer must be clear andopen about his activities and should notengage in covert e-mail monitoringexcept where specific criminal activ-ity or security breach has been identi-
5 Cyprus Law No. 39/1962. 6 23 November 1992, Series A n° 251/B, par.29. Available at <http://www. worldlii. org/eu/cases/ECHR/1992/80.html>.

64 UPGRADE Vol. VI, No., June 2005 © CEPIS
UPENET
fied. The Data Protection Commission-er’s authorisation should be requestedfor this.
The employer has to provide hisworkers with a readily accessible, clearand accurate statement of his policywith regard to e-mail and Internetmonitoring. Elements of this informa-tion should be: E-mail/Internet policy within the
company describing in detail the ex-tent to which communication facilitiesowned by the company may be usedfor personal/private communicationsby the employees (e.g. limitation ontime and duration of use). Reasons and purposes for which
surveillance, if any, is being carriedout. Where the employer has allowedthe use of the company’s communica-tion facilities for express private pur-poses, such private communicationsmay under very limited circumstancesbe subject to surveillance, e.g. to en-sure the security of the informationsystem and virus checking. The details of surveillance meas-
ures taken, i.e. by whom, for what pur-pose, how and when. Details of any enforcement proce-
dures outlining how and when work-ers will be notified of breaches of in-ternal policies and be given the oppor-tunity to respond to any such claimsagainst them.
It is essential that the employer alsoinform the worker of: The presence, use and purpose of
any detection equipment and/or appa-ratus activated with regards to his/herworking station; and Any misuse of the electronic com-
munications detected (e-mail or theInternet), unless important reasons jus-tify the continuation of the secret sur-veillance.
The employer should immediatelyinform the worker of any misuse of theelectronic communications detected,unless important reasons justify thecontinuation of the surveillance.Prompt information can be easily de-livered by software such as warningwindows, which pop up and alert theworker that the system has detectedand/or has taken steps to prevent anunauthorised use of the network.
3.7 Necessity of MonitoringThe employer must check if any
form of monitoring is absolutely nec-essary for a specified purpose beforeproceeding to engage in any such ac-tivity. Traditional methods of supervi-sion that are less intrusive for the pri-vacy of individuals should be preferredbefore engaging in any monitoring ofelectronic communications.
It would only be in exceptional cir-cumstances that the monitoring of aworkers mail or Internet use would beconsidered necessary. For instance,monitoring of a worker’s e-mail maybecome necessary in order to obtainconfirmation or proof of certain actionson his part.
Such actions would include crimi-nal activity on the part of the workerinsofar as it is necessary for the em-ployer to defend his own interests, forexample, where he is vicariously liablefor the actions of the worker. Theseactivities would also include detectionof viruses and in general terms any ac-tivity carried out by the employer toguarantee the security of the system.
It should be mentioned that open-ing an employee’s e-mail may also benecessary for reasons other than moni-toring or surveillance, for example inorder to maintain correspondence incase the employee is out of office (e.g.sickness or holidays) and correspond-ence cannot be guaranteed otherwise(e.g. via auto reply or automatic for-warding).
3.8 ProportionalityThe monitoring of e-mails should,
if possible, be limited to traffic data onthe participants and time of a commu-nication rather than the contents ofcommunications.
If access to the e-mail’s content isabsolutely necessary, account shouldbe taken of the privacy of those out-side the organisation receiving them aswell as those inside. The employer, forinstance, cannot obtain the consent ofthose outside the company sending e-mails to his workers. The employershould make reasonable efforts to in-form those outside the organisation ofthe existence of monitoring activitiesto the extent that people outside the
organisation could be affected by them.A practical example could be the in-sertion of warning notices regardingthe existence of the monitoring sys-tems, which may be added to all out-bound messages from the company (e-mail notices).
Since technology gives the em-ployer much opportunity to assess theuse of e-mail by his workers by check-ing, for example, the number of mailssent or received or the format of anyattachments, as a result the actual open-ing of mails would be considered dis-proportionate.
Technology can further be used toensure that the measures taken by anemployer to safeguard the Internet ac-cess he provides to his workers fromabuse are proportionate by utilisingblocking, as opposed to monitoring,mechanisms:
(a) In the case of the Internet, com-panies could use, for example, softwaretools that can be configured in orderto block any connection to predeter-mined categories of websites. The em-ployer can, after consultation of theaggregated list of websites visited byhis employees, decide to add somewebsites to the list of those alreadyblocked (possibly after notice to theemployees that connection to such sitewill be blocked except if the need toconnect to that site is demonstrated byan employee).
(b) In the case of e-mail, companiescould use, for example, an automaticredirect facility to an isolated server,for all e-mails exceeding a certain size.The intended recipient is automaticallyinformed that a suspect e-mail has beenredirected to that server and can beconsulted there.
3.9 Two E-mail Accounts /Web-mail
The Article 29 Data ProtectionWorking Party recommends that, as apragmatic solution of the problem atissue and for the purpose of reducingthe possibility of employers invading
7 Webmail is a web e-mail system, which pro-vides web based e-mail from any POP or IMAPserver, which is generally user name and pass-word protected.

UPGRADE Vol. VI, No., June 2005 65© CEPIS
UPENET
their workers’ privacy, employersshould adopt a policy providing work-ers with two e-mail accounts or web-mail:7
one for only professional purposes,in which monitoring within thelimits of this working documentwould be possible,another account only for purelyprivate purposes (or authorisationfor the use of web mail), whichwould only be subject to securitymeasures and would be checkedfor abuse in exceptional cases.If an employer adopts such a policy
then it would be possible, in specificcases where there is a serious suspi-cion about the behaviour of a worker,to monitor the extent to which thatworker is using their PC for personalpurposes by noting the time spent inweb-mail accounts. In this way theemployer’s interests would be servedwithout any possibility of worker’spersonal data being disclosed.
Furthermore such a policy may beof benefit to workers as it would pro-vide certainty for them as to level ofprivacy they can expect which may belacking in more complex and confus-ing codes of conduct.
3.10 Company Internet PoliciesThe employer must set out clearly
to workers the conditions on whichprivate use of the Internet is permittedas well as specifying material, whichcannot be viewed or copied. Theseconditions and limitations have to beexplained to the workers.
In addition, workers need to be in-formed about the systems imple-mented both to prevent access to cer-tain sites and to detect misuse.
The extent of such monitoringshould be specified, for instance,whether such monitoring relates to in-dividuals or particular sections of thecompany or whether the content of thesites visited is viewed or recorded bythe employer in particular circum-stances.
Furthermore, the policy shouldspecify what use, if any, will be madeof any data collected in relation to whovisited what sites.
Employers should finally inform
workers about the involvement of theirrepresentatives, both in the implemen-tation of this policy and in the investi-gation of alleged breaches.
4 Conclusions - Recommenda-tionsSurveillance of workers is not a
new issue. In the past, companies mayhave gone about monitoring their em-ployees without giving much thoughtof the legal implications, mainly be-cause little legislation existed regulat-ing such monitoring.
However, this is not the case today.With the enactment of the Data Pro-tection Law in 2001 for the purpose ofharmonising Cypriot legislation withEuropean Union Directives on the pro-tection of individuals with regard to theprocessing of personal data, specificrules have been imposed on companieswhen monitoring e-mail communica-tions and surveillance of Internet ac-cess of employees.
Companies should not be alarmedby the rules set out in the law and de-scribed in this article. On the contrary,these rules should serve as a guidelinefor the legitimate surveillance of theiremployees and for avoiding any legalliability and fines.
Companies do have a right to moni-tor their employees but this right mustbe exercised with due care and for spe-cific purposes, i.e. for ensuring the se-curity of their systems, for running andcontrolling the functioning of theirbusiness efficiently, for protecting theirbusiness from significant threats, suchas to prevent transmission of confiden-tial information to a competitor or foravoiding liability from their employ-ees criminal activities.
In order to avoid any legal prob-lems, the author strongly recommendsto companies that need to monitor theiremployees to set up an e-policy docu-ment setting out clearly to workers theconditions on which such monitoringor surveillance will be carried out.

66 UPGRADE Vol. VI, No., June 2005 © CEPIS
UPENET
Evolutionary Algorithms: Concepts and Applications
Andrea G. B. Tettamanzi
Evolutionary Computation
© Mondo Digitale, 2005This paper was first published, in its original Italian version, under the title “Algoritmi evolutivi: concetti e applicazioni”, by MondoDigitale (issue no. 3, March 2005, pp. 3-17, available at <http://www.mondodigitale.net/>). Mondo Digitale, a founding member ofUPENET, is the digital journal of the CEPIS Italian society AICA (Associazione Italiana per l’Informatica ed il Calcolo Automatico,<http://www.aicanet.it/>.)
Evolutionary algorithms are a family of stochastic problem-solving techniques, within the broader category of what wemight call “natural-metaphor models”, together with neural networks, ant systems, etc. They find their inspiration inbiology and, in particular, they are based on mimicking the mechanisms of what we know as “natural evolution”. Duringthe last twenty-five years these techniques have been applied to a large number of problems of great practical and eco-nomic importance with excellent results. This paper presents a survey of these techniques and a few sample applications.
Andrea Tettamanzi is an AssociateProfessor at the Information TechnologyDept. of the University of Milan, Italy.He received his M.Sc. in ComputerScience in 1991, and a Ph.D. inComputational Mathematics andOperations Research in 1995. In thesame year he founded Genetica S.r.l., aMilan-based company specialising inindustrial applications for evolutionaryalgorithms and soft computing. He isactive in research into evolutionaryalgorithms and soft computing, where hehas always striven to bridge the gapbetween theoretical aspects and practicaland applicational aspects.<[email protected]>
Keywords: Evolutionary Algorithms,Evolutionary Computation, Natural-metaphor Models.
1 What Are Evolutionary Algo-rithms?If we think about living beings, in-
cluding humans, and their organs, theircomplexity, and their perfection, wecannot help but wonder how it waspossible for such sophisticated solu-tions to have evolved autonomously.Yet there is a theory, initially proposedby Charles Darwin and later refined bymany other natural scientists, biolo-gists and geneticists, which provides asatisfactory explanation for most ofthese biological phenomena by study-ing the mechanisms which enable spe-cies to adapt to mutable and complexenvironments. This theory is supportedby a considerable body of evidence andhas yet to be refuted by any experimen-tal data. According to Darwin’s theory,these wonderful creations are simplythe result of a purposeless evolution-ary process, driven on the one hand byrandomness and on the other hand bythe law of the survival of the fittest.Such is natural evolution.
If such a process has been capableof producing something as sophisti-cated as the eye, the immune system,
and even our brain, it would seem onlylogical to try and do the same by simu-lating the process on computers to at-tempt to solve complicated problemsin the real world. This is the idea be-hind the development of evolutionaryalgorithms (see the box entitled "SomeHistory" for the birth and evolution ofthese algorithms).
1.1 The Underlying MetaphorEvolutionary algorithms are thus
bio-inspired computer-science tech-niques based on a metaphor which isschematically outlined in Table 1. Justas an individual in a population of or-ganisms must adapt to its surroundingenvironment to survive and reproduce,so a candidate solution must be adaptedto solving its particular problem. Theproblem is the environment in which asolution lives within a population ofother candidate solutions. Solutionsdiffer from one another in terms of theirquality, i.e., their cost or merit, re-flected by the evaluation of the objec-tive function, in the same way as theindividuals of a population of organ-isms differ from one another in termsof their degree of adaptation to the en-vironment; what biologists refer to asfitness. If natural selection allows apopulation of organisms to adapt to its
surrounding environment, when ap-plied to a population of solutions to aproblem, it should also be able to bringabout the evolution of better and bet-ter, and eventually, given enough time,optimal solutions.
Based on this metaphor, the com-putational model borrows a number ofconcepts and their relevant terms frombiology: every solution is coded bymeans of one or more chromosomes;the genes are the pieces of encodingresponsible for one or more traits of asolution; the alleles are the possibleconfigurations a gene can take on; the
(Keywords added by the Editor of UPGRADE.)

UPGRADE Vol. VI, No., June 2005 67© CEPIS
UPENET
Some History
The idea of using selection and random mutation for optimisation tasksgoes back to the fifties at least and the work of the statistician George E. P.Box, the man who famously said "all models are wrong, but some are useful".Box, however, did not make use of computers, though he did manage to for-mulate a statistical methodology that would become widely used in industry,which he called evolutionary operation [1]. At around the same time, otherscholars conceived the idea of simulating evolution on computers: Barricelliand Fraser used computer simulations to study the mechanisms of naturalevolution, while the bio-mathematician Hans J. Bremermann is credited asbeing the first person to recognise an optimisation process in biological evolu-tion [2].
As often happens with pioneering ideas, these early efforts met with con-siderable scepticism. Nevertheless, the time was evidently ripe for those ideas,in an embryonic stage at that point, to be developed. A decisive factor behindtheir development was the fact that the computational power available at thattime in major universities broke through a critical threshold, allowing evolu-tionary computation to be put into practice at last. What we recognise today asthe original varieties of evolutionary algorithms were invented independentlyand practically simultaneously in the mid sixties by three separate researchgroups. In America, Lawrence Fogel and colleagues at the University of Cali-fornia in San Diego laid down the foundations of evolutionary programming[3], while at the University of Michigan in Ann Arbor John Holland proposed hisfirst genetic algorithms [4]. In Europe, Ingo Rechenberg and colleagues, thenstudents at the Technical University of Berlin, created what they called "evolutionstrategies" (Evolutionsstrategien) [5]. During the following 25 years, each of thesethree threads developed essentially on its own, until in 1990 there was a con-certed effort to bring about their convergence. The first edition of the PPSN(Parallel Problem Solving from Nature) conference was held that year in Dort-mund. Since then, researchers interested in evolutionary computation form asingle, albeit articulated, scientific
exchange of genetic material betweentwo chromosomes is called crossover,whereas a perturbation to the code ofa solution is termed mutation (see thebox entitled "A Genetic Algorithm atWork" for an example).
Although the computational modelinvolves drastic simpli-fications com-pared to the natural world, evolution-ary algorithms have proved capable ofcausing surprisingly complex and in-teresting structures to emerge. Givenappropriate encoding, any individual
can be the representation of a particu-lar solution to a problem, the strategyfor a game, a plan, a picture, or even asimple computer program.
1.2 The Ingredients of AnEvolutionary Algorithm
Now we have introduced the con-cepts, let us take a look at what an evo-lutionary algorithm consists of in prac-tice.
An evolutionary algorithm is astochastic optimisation technique that
proceeds in an iterative way. An evo-lutionary algorithms maintains a popu-lation (which in this context means amultiset or bag, i.e., a collection of el-ements not necessarily all distinct fromone another) of individuals represent-ing candidate solutions for the prob-lem at hand (the object problem), andmakes it evolve by applying a (usuallyquite small) number of stochastic op-erators: mutation, recombination, andselection.
Mutation can be any operator thatrandomly perturbs a solution. Recom-bination operators decompose two ormore distinct individuals and thencombine their constituent parts to forma number of new individuals. Selectioncreates copies of those individuals thatrepresent the best solutions within thepopulation at a rate proportional totheir fitness.
The initial population may origi-nate from a random sampling of thesolution space or from a set of initialsolutions found by simple local searchprocedures, if available, or determinedby a human expert.
Stochastic operators, applied andcomposed according to the rules de-fining a specific evolutionary algo-rithm, determine a stochastic popula-tion-transforming operator. Based onthat operator, it is possible to model theworkings of an evolutionary algorithmas a Markov chain whose states arepopulations. It is possible to prove that,given some entirely reasonable as-sumptions, such a stochastic processwill converge to the global optimumof the problem [16].
When talking about evolutionaryalgorithms, we often hear the phraseimplicit parallelism. This term refersto the fact that each individual can bethought of as a representative of amultitude of solution schemata, i.e., ofpartially specified solutions, such that,while processing a single individual,the evolutionary algorithm will in factbe implicitly processing at the sametime (i.e., in parallel) all the solutionschemata of which that individual is arepresentative. This concept should notbe confused with the inherent paral-lelism of evolutionary algorithms. Thisrefers to the fact that they carry out a
EVOLUTION PROBLEMSOLVING
Environment Object problemIndividual Candidate solutionFitness Solution quality
Table 1: A Schematic Illustration of The Metaphor UnderlyingEvolutionary Algorithms.
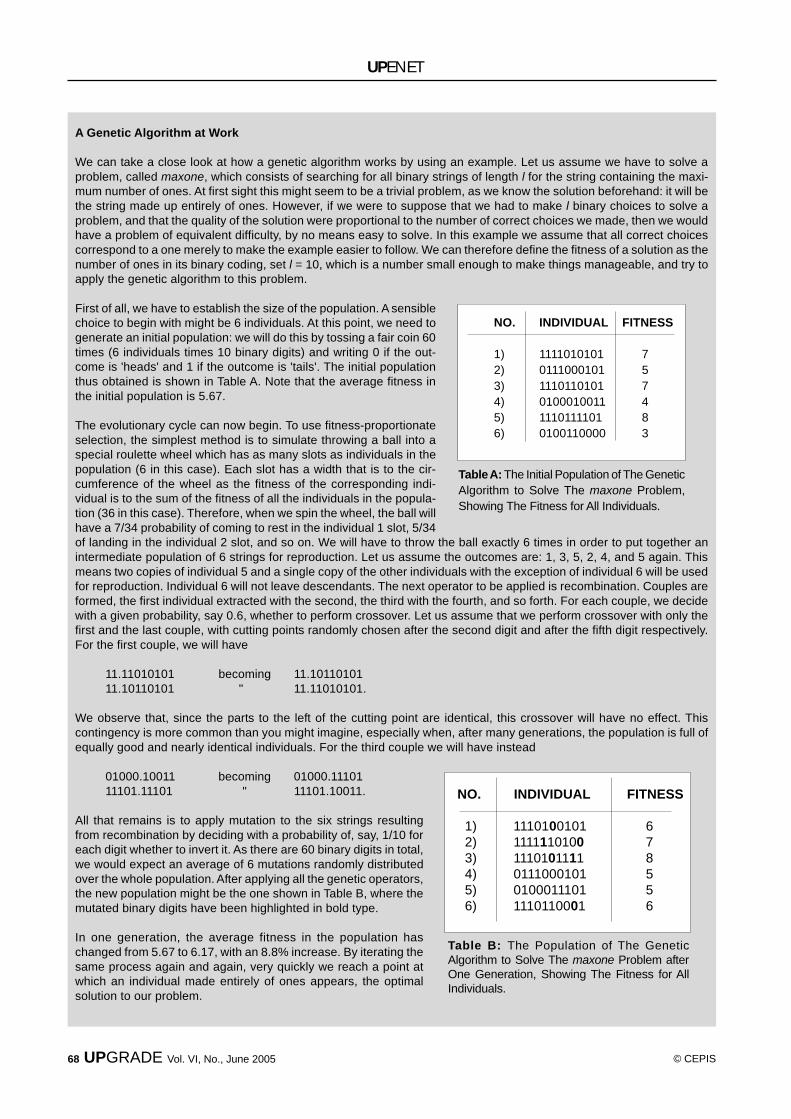
68 UPGRADE Vol. VI, No., June 2005 © CEPIS
UPENET
A Genetic Algorithm at Work
We can take a close look at how a genetic algorithm works by using an example. Let us assume we have to solve aproblem, called maxone, which consists of searching for all binary strings of length l for the string containing the maxi-mum number of ones. At first sight this might seem to be a trivial problem, as we know the solution beforehand: it will bethe string made up entirely of ones. However, if we were to suppose that we had to make l binary choices to solve aproblem, and that the quality of the solution were proportional to the number of correct choices we made, then we wouldhave a problem of equivalent difficulty, by no means easy to solve. In this example we assume that all correct choicescorrespond to a one merely to make the example easier to follow. We can therefore define the fitness of a solution as thenumber of ones in its binary coding, set l = 10, which is a number small enough to make things manageable, and try toapply the genetic algorithm to this problem.
First of all, we have to establish the size of the population. A sensiblechoice to begin with might be 6 individuals. At this point, we need togenerate an initial population: we will do this by tossing a fair coin 60times (6 individuals times 10 binary digits) and writing 0 if the out-come is 'heads' and 1 if the outcome is 'tails'. The initial populationthus obtained is shown in Table A. Note that the average fitness inthe initial population is 5.67.
The evolutionary cycle can now begin. To use fitness-proportionateselection, the simplest method is to simulate throwing a ball into aspecial roulette wheel which has as many slots as individuals in thepopulation (6 in this case). Each slot has a width that is to the cir-cumference of the wheel as the fitness of the corresponding indi-vidual is to the sum of the fitness of all the individuals in the popula-tion (36 in this case). Therefore, when we spin the wheel, the ball willhave a 7/34 probability of coming to rest in the individual 1 slot, 5/34of landing in the individual 2 slot, and so on. We will have to throw the ball exactly 6 times in order to put together anintermediate population of 6 strings for reproduction. Let us assume the outcomes are: 1, 3, 5, 2, 4, and 5 again. Thismeans two copies of individual 5 and a single copy of the other individuals with the exception of individual 6 will be usedfor reproduction. Individual 6 will not leave descendants. The next operator to be applied is recombination. Couples areformed, the first individual extracted with the second, the third with the fourth, and so forth. For each couple, we decidewith a given probability, say 0.6, whether to perform crossover. Let us assume that we perform crossover with only thefirst and the last couple, with cutting points randomly chosen after the second digit and after the fifth digit respectively.For the first couple, we will have
11.11010101 becoming 11.1011010111.10110101 " 11.11010101.
We observe that, since the parts to the left of the cutting point are identical, this crossover will have no effect. Thiscontingency is more common than you might imagine, especially when, after many generations, the population is full ofequally good and nearly identical individuals. For the third couple we will have instead
01000.10011 becoming 01000.1110111101.11101 " 11101.10011.
All that remains is to apply mutation to the six strings resultingfrom recombination by deciding with a probability of, say, 1/10 foreach digit whether to invert it. As there are 60 binary digits in total,we would expect an average of 6 mutations randomly distributedover the whole population. After applying all the genetic operators,the new population might be the one shown in Table B, where themutated binary digits have been highlighted in bold type.
In one generation, the average fitness in the population haschanged from 5.67 to 6.17, with an 8.8% increase. By iterating thesame process again and again, very quickly we reach a point atwhich an individual made entirely of ones appears, the optimalsolution to our problem.
NO. INDIVIDUAL FITNESS
1) 1111010101 72) 0111000101 53) 1110110101 74) 0100010011 45) 1110111101 86) 0100110000 3
Table A: The Initial Population of The GeneticAlgorithm to Solve The maxone Problem,Showing The Fitness for All Individuals.
NO. INDIVIDUAL FITNESS
1) 1110100101 62) 1111110100 73) 1110101111 84) 0111000101 55) 0100011101 56) 1110110001 6
Table B: The Population of The GeneticAlgorithm to Solve The maxone Problem afterOne Generation, Showing The Fitness for AllIndividuals.

UPGRADE Vol. VI, No., June 2005 69© CEPIS
UPENET
population-based search, which meansthat, although for the sake of conven-ience they are usually expressed bymeans of a sequential description, theyare particularly useful and easy to im-plement on parallel hardware.
1.3 Genetic AlgorithmsThe best way to understand how
evolutionary algorithms work is to con-sider one of their simplest versions,namely genetic algorithms [6]. In ge-netic algorithms, solutions are repre-sented as fixed-length binary strings.This type of representation is by far themost general, although, as we shall seebelow, not always the most convenient,although the fact is that any data struc-ture, no matter how complex and ar-ticulated, will always be encoded inbinary in a computer’s memory. A se-quence of two symbols, 0 and 1, fromwhich it is possible to reconstruct asolution, is very reminiscent of a DNAthread made up of a sequence of fourbases, A, C, G, and T, from which it ispossible to reconstruct a living organ-ism! In other words, we can consider abinary string as the DNA of a solutionto the object problem.
A genetic algorithm consists of twoparts:1. a routine that generates (randomlyor by using heuristics) the initial popu-lation;2. an evolutionary cycle, which at eachiteration (or generation), creates a newpopulation by applying the geneticoperators to the previous population.
The evolutionary cycle of the ge-netic algorithms can be representedusing the pseudocode in Table 2. Eachindividual is assigned a particular fit-ness value, which depends on the qual-ity of the solution it represents. Thefirst operator to be applied is selection,whose purpose is to simulate the Dar-winian law of the survival of the fit-test. In the original version of geneticalgorithms, that law is implemented bymeans of what is known as the fitness-proportionate selection: to create a newintermediate population of n ‘parent’individuals, n independent extractionsof an individual from the existingpopulation are carried out, where theprobability for each individual to beextracted is directly proportional to its
fitness. As a consequence, above-av-erage individuals will be extractedmore than once on average, whereasbelow-average individuals will faceextinction.
Once n parents are extracted as de-scribed, the individuals of the next gen-eration will be produced by applying anumber of reproduction operators,which may involve one parent only(thus simulating a sort of asexual re-production) in which case we speak ofmutation, or more than one parent, usu-ally two (sexual reproduction), inwhich case we speak of recombination.In genetic algorithms, two reproduc-tion operators are used: crossover andmutation.
To apply crossover, the parent in-dividuals are mated two by two. Then,with a certain probability pcross, calledthe "crossover rate", which is a param-eter of the algorithm, each couple un-dergoes crossover itself. This is doneby lining up the two binary strings,cutting them at a randomly chosenpoint, and swapping the right-handhalves, thus yielding two new individu-als, which inherit part of their charac-ters from one parent and part from theother.
After crossover, all individuals un-dergo mutation, whose purpose is tosimulate the effect of random transcrip-tion errors that can happen with a verylow probability pmut every time a chro-mosome is duplicated. Mutationamounts to deciding whether to inverteach binary digit, independently of theothers, with probability pmut. In otherwords, every zero has probability pmutof becoming a one and vice versa.
The evolutionary cycle, accordingto how it is conceived, could go onforever. In practice, however, one has
to decide when to halt it, based on someuser-specified termination criterion.Examples of termination criteria are:· a fixed number of generations or acertain elapsed time;· a satisfactory solution, according tosome particular criterion, has beenfound;· no improvement has taken place fora given number of generations.
1.4 Evolution StrategiesEvolution strategies approach the
optimisation of a real-valued objectivefunction of real variables in an l-dimen-sional space. The most direct represen-tation is used for the independent vari-ables of the function (the solution),namely a vector of real numbers. Be-sides encoding the independent vari-ables, however, evolution strategiesgive the individual additional informa-tion on the probability distribution tobe used for its perturbation (mutationoperator). Depending on the version,this information may range from justthe variance, valid for all independentvariables, to the entire variance-covariance matrix C of a joint normaldistribution; in other words, the size ofan individual can range from l + 1 tol(l + 1) real numbers.
In its most general form, the muta-tion operator perturbs an individual intwo steps:1. It perturbs the C matrix (or, moreexactly, an equivalent matrix of rota-tion angles from which the C matrixcan be easily calculated) with the sameprobability distribution for all individu-als;2. It perturbs the parameter vector rep-resenting the solution to theoptimisation problem according to ajoint normal probability distribution
generation = 0Initialize populationwhile not <termination condition> do
generation = generation + 1Compute the fitness of all individualsSelectionCrossover(p
cross)
Mutation(pmut)
end while
Table 2: Pseudocode Illustrating A Typical Simple Genetic Algorithm.

70 UPGRADE Vol. VI, No., June 2005 © CEPIS
UPENET
having mean 0 and the perturbed C asits variance-covariance matrix.
This mutation mechanism allowsthe algorithm to evolve the parametersof its search strategy autonomouslywhile it is searching for the optimalsolution. The resulting process, calledself-adaptation, is one of the mostpowerful and interesting features ofthis type of evolutionary algorithm.
Recombination in evolution strat-egies can take different forms. Themost frequently used are discrete andintermediate recombination. In dis-crete recombination, each componentof the offspring individuals is takenfrom one of the parents at random,while in intermediate recombinationeach component is obtained by linearcombination of the correspondingcomponents in the parents with a ran-dom parameter.
There are two alternative selectionschemes defining two classes of evo-lution strategies: (n, m) and (n + m). In(n, m) strategies, starting from a popu-lation of n individuals, m > n offspringare produced and the n best of themare selected to form the population ofthe next generation. In (n + m) strate-gies, on the other hand, the n parentindividuals participate in selection aswell. Of those n + m individuals, onlythe best n make it to the population ofthe next generation. Note that, in bothcases, selection is deterministic andworks "by truncation", i.e., by discard-ing the worst individuals. In this way,it is not necessary to define a non-nega-tive fitness, and optimisation can con-sider the objective function, which canbe maximised or minimised accordingto individual cases, directly.
1.5 Evolutionary ProgrammingEvolution, whether natural or arti-
ficial, has nothing ‘intelligent’ about it,in the literal sense of the term: it doesnot understand what it is doing, nor isit supposed to. Intelligence, assumingsuch a thing can be defined, is ratheran ‘emergent’ phenomenon of evolu-tion, in the sense that evolution maymanage to produce organisms or solu-tions endowed with some form of ‘in-telligence’.
Evolutionary programming is in-tended as an approach to artificial in-
telligence, as an alternative to symbolicreasoning techniques. Its goal is toevolve intelligent behaviours repre-sented through finite-state machinesrather than define them a priori. Inevolutionary programming, therefore,the object problem determines the in-put and output alphabet of a family offinite-state machines, and individualsare appropriate representations of fi-nite-states machines operating on thosealphabets. The natural representationof a finite-state machine is the matrixthat defines its state-transition and out-put functions. The definition of themutation and recombination operatorsis slightly more complex than in thecase of genetic algorithms or evolutionstrategies, as it has to take into accountthe structure of the objects those op-erators have to manipulate. The fitnessof an individual can be computed bytesting the finite-state machine it rep-resents on a set of instances of the prob-lem. For example, if we wish to evolveindividuals capable of modelling a his-torical series, we need to select anumber of pieces from the previousseries and feed them into an individual.We can then interpret the symbols pro-duced by the individual as predictionsand compare them with the actual datato measure their accuracy.
1.6 Genetic ProgrammingGenetic programming [7] is a rela-
tively new branch of evolutionary al-gorithms, whose goal is an old dreamof artificial intelligence: automatic pro-gramming. In a programming problem,a solution is a program in a given pro-
gramming language. In genetic pro-gramming, therefore, individuals rep-resent computer programs.
Any programming language can beused, at least in principle. However, thesyntax of most languages would makethe definition of the genetic operatorsthat preserve it particularly awkwardand burdensome. This is why early ef-forts in that direction found a sort ofrestricted LISP to be an ideal expres-sion medium of expression. LISP hasthe advantage of possessing a particu-larly simple syntax. Furthermore, itallows us to manipulate data and pro-grams in a uniform fashion. In prac-tice, approaching a programming prob-lem calls for the definition of a suit-able set of variables, constants, andprimitive functions, thus limiting thesearch space which would otherwisebe unwieldy. The functions chosen willbe those that a priori are deemed use-ful for the purpose. It is also custom-ary to try and arrange things so that allfunctions accept the results returned byall others as arguments, as well as allvariables and predefined constants. Asa consequence, the space of all possi-ble programs from which the programthat will solve the problem is to befound will contain all possible compo-sitions of functions that can be formedrecursively from the set of primitivefunctions, variables, and predefinedconstants.
For the sake of simplicity, and with-out loss of generality, a genetic pro-gramming individual can be regardedas the parse tree of the correspondingprogram, as illustrated in Figure 1. The
Figure 1: A Sample LISP Program with Its Associated Parse Tree.

UPGRADE Vol. VI, No., June 2005 71© CEPIS
UPENET
recombination of two programs is car-ried out by randomly selecting a nodein the tree of both parents and by swap-ping the subtrees rooted in the selectednodes, as illustrated in Figure 2. Theimportance of the mutation operator islimited in genetic programming, forrecombination alone is capable creat-ing enough diversity to allow evolu-tion to work.
Computing the fitness of an indi-vidual is not so different from testinga program. A set of test cases must begiven as an integral part of the descrip-tion of the object problem. A test caseis a pair (input data, desired output).The test cases are used to test the pro-gram as follows: for each case, the pro-gram is executed with the relevant in-put data; the actual output is comparedwith the desired output; and the erroris measured. Finally, fitness is obtainedas a function of the accumulated totalerror over the whole test set.
An even more recent approach togenetic programming is what is knownas grammatical evolution [8], whosebasic idea is simple but powerful: giventhe grammar of a programming lan-guage (in this case completely arbi-trary, without limitations deriving fromits particular syntax), consisting of anumber of production rules, a programin this language is represented bymeans of a string of binary digits. Thisrepresentation is decoded by startingfrom the target non-terminal symbol ofthe grammar and reading the binarydigits from left to right – enough dig-its each time to be able to decide whichof the applicable production rulesshould actually be applied. The produc-tion rule is then applied and the decod-
ing continues. The string is consideredto be circular, so that the decodingprocess never runs out of digits. Theprocess finishes when no productionrule is applicable and a well-formedprogram has therefore been produced,which can be compiled and executedin a controlled environment.
2 ‘Modern’ Evolutionary Algo-rithmsSince the early eighties, evolution-
ary algorithms have been successfullyapplied to many real-world problemswhich are difficult or impossible tosolve with exact methods and are ofgreat interest to operations researchers.Evolutionary algorithms have gaineda respectable place in the problem solv-er’s toolbox, and this last quarter of acentury has witnessed the coming ofage of the various evolutionary tech-niques and their cross-fertilisation aswell as progressive hybridisation withother technologies.
If there is one major trend line inthis development process, it is the pro-gressive separation from elegant rep-resentations, based on binary strings,of the early genetic algorithms, so sug-gestively close to their biologicalsource of inspiration, and an increas-ing propensity for adopting represen-tations closer to the nature of the ob-ject problem, ones which map moredirectly onto the elements of a solu-tion, thus allowing all available infor-mation to be exploited to ‘help’, as itwere, the evolutionary process to findits way to the optimum [9].
Adopting representations closer tothe problem also necessarily impliesdesigning mutation and recombination
operators that manipulate the elementsof a solution in an explicit, informedmanner. On the one hand, those opera-tors end up being less general, but onthe other hand, the advantages in termsof performance are often remarkableand compensate for the increased de-sign effort.
Clearly, the demand for efficientsolutions has prompted a shift awayfrom the coherence of the geneticmodel.
2.1 Handling ConstraintsReal-world problems, encountered
in industry, business, finance and thepublic sector, whose solution often hasa significant economical impact andwhich constitute the main target ofoperations research, all share a com-mon feature: they have complex andhard to handle constraints. In earlywork on evolutionary computation, thebest way to approach constraint han-dling was not clear. Over time, evolu-tionary algorithms began to be appre-ciated as approximate methods for op-erations research and they have beenable to take advantage of techniquesand expedients devised within theframework of operations research forother approximate methods. Threemain techniques emerged from thiscross-fertilisation, which can be com-bined if needed, that enable nontrivialconstraints to be taken into account inan evolutionary algorithm:· the use of penalty functions;· the use of decoders or repair algo-rithms;· the design of specialised encodingsand genetic operators.
Penalty functions are functions as-sociated with each problem constraintthat measure the degree to which a so-lution violates its relevant constraint.As the name suggests, these functionsare combined with the objective func-tion in order to penalise the fitness ofindividuals that do not respect certainconstraints. Although the penalty func-tion approach is a very general one,easy to apply to all kinds of problems,its use is not without pitfalls. If pen-alty functions are not accuratelyweighted, the algorithm can waste a
Figure 2: Schematic Illustration of Recombination in Genetic Programming.
OROR
ANDANDNOTNOT
d0d0 d0d0 d1d1
OROR
OROR ANDAND
d1d1 NOTNOT NOTNOT NOTNOT
d0d0 d0d0 d1d1
OROR
ANDAND NOTNOT
d0d0d0d0 d1d1
OROR
ORORANDAND
d1d1 NOTNOTNOTNOT NOTNOT
d0d0d0d0 d1d1

72 UPGRADE Vol. VI, No., June 2005 © CEPIS
UPENET
great deal of time processing infeasi-ble solutions, or it might even end upconverging to an apparent optimumwhich is actually impossible to imple-ment. For instance, in a transportationproblem, described by n factories andm customers to which a given quantityof a commodity has to be delivered,where the cost of transporting a unitof the commodity from every factoryto any of the customers, a solutions thatminimises the overall cost in an unbeat-able way is the solution where abso-lutely nothing is transported! If the vio-lation of the constraints imposing thatthe ordered quantity of the commodityis delivered to each customer is notpenalised to a sufficient extent, theabsurd solution of not delivering any-thing could come out as better than anysolution that actually meets customers’orders. For some problems, called fea-sibility problems, finding a solutionthat doe not violate any constraint isalmost as difficult as finding the opti-mum solution. For this kind of prob-lems, penalty functions have to be de-signed with care or else the evolutionmay never succeed in finding any fea-sible solution.
Decoders are algorithms based ona parameterised heuristics, which aimto construct an optimal solution fromscratch by making a number of choices.When such an algorithm is available,the idea is to encode the parameters ofthe heuristics into the individuals proc-essed by the evolutionary algorithms,rather than the solution directly, and touse the decoder to reconstruct the cor-responding solution from the param-eter values. We have thus what wemight call an indirect representation ofsolutions.
Repair algorithms are operatorsthat, based on some heuristics, take aninfeasible solution and ‘repair’ it byenforcing the satisfaction of one vio-lated constraint, then of another, andso on, until they obtain a feasible solu-tion. When applied to the outcome ofgenetic operators of mutation and re-combination, repair algorithms canensure that the evolutionary algorithmis at all times only processing feasiblesolutions. Nevertheless, the applicabil-ity of this technique is limited, sincefor many problems the computational
complexity of the repair algorithm faroutweighs any advantages to be gainedfrom its use.
Designing specialised encodingsand genetic operators would be theideal technique, but also the most com-plicated to apply in all cases. The un-derlying idea is to try and design a so-lutions representation that, by its con-struction, is capable of encoding all andonly feasible solutions, and to designspecific mutation and recombinationoperators alongside it that preserve thefeasibility of the solutions they are ap-plied to. Unsurprisingly, as the com-plexity and number of constraints in-creases, this exercise soon becomesformidable and eventually impossible.However, when possible, this is theoptimal way to go, for it guarantees theevolutionary algorithm processes fea-sible solutions only and therefore re-duces the search space to the absoluteminimum.
2.2 Combinations with OtherSoft-Computing Techniques
Evolutionary algorithms, togetherwith fuzzy logic and neural network,are part of what we might call soft com-puting, as opposed to traditional orhard computing, which is based on cri-teria like precision, determinism, andthe limitation of complexity. Soft com-puting differs from hard computing inthat it is tolerant of imprecision, un-certainty, and partial truth. Its guidingprinciple is to exploit that tolerance toobtain tractability, robustness, andlower solution costs.
Soft computing is not just a mix-ture of its ingredients, but a disciplinein which each constituent contributesa distinct methodology for addressingproblems in its domain, in a comple-mentary rather than competitive way[10]. Thus evolutionary algorithms canbe employed not only to design andoptimise fuzzy systems, such as fuzzyrule bases or fuzzy decision trees, butalso to improve the learning character-istics of neural networks, or even de-termine their optimal topology. Fuzzylogic can also be used to control theevolutionary process by acting dy-namically on the algorithm parameters,to speed up convergence to the globaloptimum and escape from local optima,
and to fuzzify, as it were, some ele-ments of the algorithm, such as the fit-ness of individuals or their encoding.Meanwhile neural networks can helpan evolutionary algorithm obtain anapproximate estimate of the fitness ofindividuals for problems where fitnesscalculation requires computationallyheavy simulations, thus reducing CPUtime and improving overall perform-ance.
The combination of evolutionaryalgorithms with other soft computingtechniques is a fascinating researchfield and one of the most promising ofthis group of computing techniques.
3 ApplicationsEvolutionary algorithms have been
successfully applied to a large numberof domains. For purely illustrative pur-poses, and while this is not intended tobe a meaningful classification, wecould divide the field of application ofthese techniques into five broad do-mains: Planning, including all problems
that require choosing the most eco-nomical and best performing way touse a finite set of resources. Among theproblems in this domain are vehiclerouting, transport problems, robot tra-jectory planning, production schedul-ing in an industrial plant, timetabling,determining the optimal load of a trans-port, etc. Design, including all those prob-
lem that require determining an opti-mal layout of elements (electronic ormechanic components, architectural el-ements, etc.) with the aim of meetinga set of functional, aesthetic, and ro-bustness requirements. Among theproblems in this domain are electroniccircuit design, engineering structuredesign, information system design, etc. Simulation and identification,
which requires determining how agiven design or model of a system willbehave. In some cases this needs to bedone because we are not sure abouthow the system behaves, while in oth-ers its behaviour is known but the ac-curacy of a model has to be assessed.Systems under scrutiny may be chemi-cal (determining the 3D structure of aprotein, the equilibrium of a chemicalreaction), economical (simulating the

UPGRADE Vol. VI, No., June 2005 73© CEPIS
UPENET
dynamics of competition in a marketeconomy), medical, etc. Control, including all problems that
require a control strategy to be estab-lished for a given system; Classification, modelling and ma-
chine learning, whereby a model of theunderlying phenomenon needs to bebuilt based on a set of observations.Depending on the circumstances, sucha model may consist of simply deter-mining which of a number of classesan observation belongs to, or building(or learning) a more or less complexmodel, often used for prediction pur-poses. Among the problems in this do-main is data mining, which consists ofdiscovering regularities in hugeamounts of data that are difficult to spot"with the naked eye".
Of course the boundaries betweenthese five application domains are notclearly defined and the domains them-selves may in some cases overlap tosome extent. However, it is clear thattogether they make up a set of prob-lems of great economic importance andenormous complexity.
In the following sections we willtry to give an idea of what it means toapply evolutionary algorithms to prob-lems of practical importance, by de-scribing three sample applications indomains that differ greatly from oneanother, namely school timetabling,electronic circuit design, and behav-ioural customer modelling.
3.1 School TimetablingThe timetable problem consists of
planning a number of meetings (e.g.,exams, lessons, matches) involving agroup of people (e.g., students, teach-ers, players) for a given period and re-quiring given resources (e.g., rooms,laboratories, sports facilities) accord-ing to their availability and respectingsome other constraints. This problemis known to be NP-complete: that is the
main reason why it cannot be ap-proached in a satisfactory way (fromthe viewpoint of performance) withexact algorithms, and for a long timeit has been a testbed for alternativetechniques, such as evolutionary algo-rithms. The problem of designing time-tables, in particular for Italian highschools, many of which are distributedover several buildings, is further com-plicated by the presence of very strictconstraints, which makes it very mucha feasibility problem.
An instance of this problem con-sists of the following entities and theirrelations: rooms, defined by their type, ca-
pacity, and location; subjects, identified by their required
room type; teachers, characterised by the sub-
jects they teach and their availability; classes, i.e., groups of students fol-
lowing the same curriculum, assignedto a given location, with a timetableduring which they have to be at school; lessons, meaning the relation <t, s,
c, l>, where t is a teacher, s is a sub-ject, c is a class and l is its durationexpressed in periods (for example,hours); in some cases, more than oneteacher and more than one class canparticipate in a lesson, in which casewe speak of grouping.
This problem involves a great manyconstraints, both hard and soft, toomany for us to go into now in this arti-cle. Fortunately, anybody who hasgone to a high school in Europe shouldat least have some idea of what thoseconstraints might be.
This problem has been approachedby means of an evolutionary algorithm,which is the heart of a commercialproduct, EvoSchool [11]. The algo-rithm adopts a ‘direct’ solution repre-sentation, which is a vector whosecomponents correspond to the lessonsthat have to be scheduled, while the(integer) value of a component indi-cates the period in which the corre-sponding lesson is to begin. The func-tion that associates a fitness to eachtimetable, one of the critical points ofthe algorithm, is in practice a combi-nation of penalty functions with theform
where hi is the penalty associatedwith the violation of the ith hard con-straint, sj is the penalty associated withthe violation of the jth soft constraint,and parameters ai and bj are appropri-ate weightings associated with eachconstraint. Finally, g is an indicatorwhose value is 1 when all hard con-
II DD <<2<<2 ++ DD+–+–II DD <<2<<2 ++ DD+–+–
Figure 3: A Schematic Diagram of A Sample Circuit Obtained by Composition of 6 Primitive Operations.
Table 3: Primitive Operations for The Representation of Digital Filters. (The formatof the primitives is fixed, with two operands, of which only the required operandsare used. The integers n and m refer to the inputs at cycles t – n and t – mrespectively.)
Operation Code operand 1 operand 2 Description
Input I not used not used Copy inputDelay D n not used Delay n cyclesLeft shift L n p multiply by 2p
Right shift R n p divide by 2p
Add A n m addSubtract S n m subtractComplement C n not used complement input

74 UPGRADE Vol. VI, No., June 2005 © CEPIS
UPENET
straints are satisfied and zero other-wise. In effect, this means that softconstraints are taken into considerationonly after all hard constraints havebeen satisfied.
All other ingredients of the evolu-tionary algorithm are fairly standard,with the exception of the presence oftwo mutually exclusive perturbationoperators, called by the mutation op-erator, each with its own probability:· intelligent mutation;· improvement.
Intelligent mutation, while preserv-ing its random nature, is aimed at per-forming changes that do not decreasethe fitness of the timetable to which itis applied. In particular, if the operatoraffects the ith lesson, it will propagateits action to all the other lessons involv-ing the same class, teacher or room.The choice of the "action range" of thisoperator is random with any givenprobability distribution. In practice, theeffect of this operator is to randomlymove some interconnected lessons insuch a way as to decrease the numberof constraint violations.
Improvement, in contrast, restruc-tures an individual to a major extent.Restructuring commences by randomlyselecting a lesson and concentrates onthe partial timetables for the relevantclass, teacher, or room. It compacts theexisting lessons to free up enoughspace to arrange the selected lessonwithout conflicts.
A precisely balanced interactionbetween these two operators is the se-cret behind the efficiency of this evo-lutionary algorithm, which has provencapable of generating high qualitytimetables for schools with thousandsof lessons to schedule over differentbuildings scattered over several sites.A typical run takes a few hours on anot so powerful PC of the kind to befound in high schools.
3.2 Digital Electronic CircuitDesign
One of the problems that has re-ceived considerable attention from theinternational evolutionary computationcommunity is the design of finite im-pulse response digital filters. This in-terest is due to their presence in a large
number of electronic devices that formpart of many consumer products, suchas cellular telephones, network de-vices, etc.
The main criterion of traditionalelectronic circuit design methodologiesis minimising the number of transis-tors used and, consequently, produc-tion costs. However, another very sig-nificant criterion is power absorption,which is a function of the number oflogic transitions affecting the nodes ofa circuit. The design of minimumpower absorption digital filters hasbeen successfully approached bymeans of an evolutionary algorithm[12].
A digital filter can be representedas a composition of a very smallnumber of elementary operations, likethe primitives listed in Table 3. Eachelementary operation is encoded bymeans of its own code (one character)and two integers, which represent therelative offset (calculated backwardsfrom the current position) of the twooperands. When all offsets are positive,the circuit does not contain any feed-back and the resulting structure is thatof a finite impulse response filter. Forexample, the individual (I 0 2) (D 1 3) (L 2 2) (A 2 1) (D 1 0) (S 1 5)
corresponds to the schematic dia-gram in Figure 3.
The fitness function has two stages.In the first stage, it penalises violationsof the filter frequency response speci-fications, represented by means of a‘mask’ in the graph of frequency re-sponse. In the second stage, which isactivated when the frequency responseis within the mask, fitness is inverselyproportional to the circuit activity,which in turn is directly proportionalto power absorption.
The evolutionary algorithm whichsolves this problem requires a greatdeal of computing power. For this rea-son, it has been implemented as a dis-tributed system, running on a clusterof computers according to an islandmodel, whereby the population is di-vided into a number of islands, resid-ing on distinct machines, which evolveindependently, except that, every nowand then, they exchange ‘migrant’ in-dividuals, which allow genetic mate-
rial to circulate while at the same timekeeping the required communicationbandwidth as small as we wish.
A surprising result of the aboveevolutionary approach to electroniccircuit design has been that the digitalfilters discovered by evolution, besideshaving a much lower power absorptionin comparison with the correspondingfilters obtained using traditional designtechniques, as was intended, they alsobring about a 40% to 60% reductionin the number of logic elements and,as a consequence, in area and speed aswell. In other words, the decrease inconsumption has not been achieved atthe expense of production cost andspeed. On the contrary, it has broughtabout an overall increase in efficiencyin comparison with traditional designmethods.
3.3 Data MiningA critical success factor for any
business today is its ability to use in-formation (and knowledge that can beextracted from information) effec-tively. This strategic use of data canresult in opportunities presented bydiscovering hidden, previously unde-tected, and frequently extremely valu-able facts about consumers, retailers,and suppliers, and business trends ingeneral. Knowing this information, anorganisation can formulate effectivebusiness, marketing, and sales strate-gies; precisely target promotional ac-tivity; discover and penetrate new mar-kets; and successfully compete in themarketplace from a position of in-formed strength. The task of siftinginformation with the aim of obtainingsuch a competitive advantage is knownas data mining [13]. From a technicalpoint of view, data mining can be de-fined as the search for correlations,trends, and patterns that are difficultto perceive "ith the naked eye" by dig-ging into large amounts of data storedin warehouses and large databases,using statistical, artificial intelligence,machine learning, and soft computingtechniques. Many large companies andorganisations, such as banks, insurancecompanies, large retailers, etc., have ahuge amount of information about theircustomers’ behaviour. The possibility

UPGRADE Vol. VI, No., June 2005 75© CEPIS
UPENET
of exploiting such information to inferbehaviour models of their current andprospective customers with regard tospecific products or classes of productsis a very attractive proposition for or-ganisations. If the models thus obtainedare accurate, intelligible, and informa-tive, they can later be used for deci-sion making and to improve the focusof marketing actions,.
For the last five years the authorhas participated in the design, tuning,and validation of a powerful data min-ing engine, developed by GeneticaS.r.l. and Nomos Sistema S.p.A (nowan Accenture company) in collabora-tion with the University of Milan, aspart of two Eureka projects funded bythe Italian Ministry of Education andUniversity.
The engine is based on a geneticalgorithm for the synthesis of predic-tive models of customer behaviour,expressed by means of sets of fuzzyIF-THEN rules. This approach is aclear example of the advantages thatcan be achieved by combining evolu-tionary algorithms and fuzzy logic.
The approach assumes a data set isavailable: that is, a set as large as welike of records representing observa-tions or recordings of past customerbehaviour. The field of applicabilitycould be even wider: the records couldbe observations of some phenomenon,not necessarily related to economy orbusiness, such as the measurement offree electrons in the ionosphere [14].
A record consists of m attributes,i.e., values of variables describing thecustomer. Among these attributes, weassume that there is an attribute meas-uring the aspect of customer behaviourwe are interested in modelling. With-out loss of generality, we can assumethere is just one attribute of this kind— if we were interested in modellingmore than one aspect of behaviour, wecould develop distinct models for eachaspect. We could call this attribute ‘pre-dictive’, as it is used to predict a cus-tomer’s behaviour. Within this concep-tual framework, a model is a functionof m – 1 variables which returns thevalue of the predictive attribute de-pending on the value of the other at-tributes.
The way we choose to represent
this function is critical. Experienceproves that the usefulness and accept-ability of a model does not derive fromits accuracy alone.
Accuracy is certainly a necessarycondition, but more important is themodel’s intelligibility for the expertwho will have to evaluate it before au-thorising its use. A neural network or aLISP program, to mention just two al-ternative ‘languages’ that others havechosen to express their models, mayprovide killer results when it comes toaccuracy. However, organisations willbe reluctant to ‘trust’ the results of themodel unless they can understand andexplain how the results have been ob-tained.
This is the main reason for usingsets of fuzzy IF-THEN rules as the lan-guage for expressing models. FuzzyIF-THEN rules are probably the near-est thing to the intuitive way expertsexpress their knowledge, due to the useof rules that express relationships be-tween linguistic variables (which takeon linguistic values of the type LOW,MEDIUM, HIGH). Also, fuzzy ruleshave the desirable property of behav-ing in an interpolative way, i.e., theydo not jump from one conclusion to theopposite because of a slight change inthe value of a condition, as is the casewith crisp rules.
The encoding used to represent amodel in the genetic algorithm is quitecomplicated, but it closely reflects thelogical structure of a fuzzy rule base.It allows specific mutation and recom-bination operators to be designedwhich operate in an informed way ontheir constituent blocks. In particular,the recombination operator is designedin such a way as to preserve the syn-tactic correctness of the models. A childmodel is obtained by combining therules of two parent models: every rulein the child model may be inheritedfrom either parent with equal probabil-ity. Once inherited, a rule takes on allthe definitions of the linguistic values(fuzzy sets) of the source parent modelthat contribute to determining its se-mantics.
Models are evaluated by applyingthem to a portion of the data set. Thisyields a fitness value gauging their ac-curacy. As is customary in machine
learning, the remaining portion of thedata set is used to monitor the gener-alisation capability of the models andavoid overfitting, which happens whena model learns one by one the exam-ples it has seen, instead of capturingthe general rules which can be appliedto cases never seen before.
The engine based on this approachhas been successfully applied to creditscoring in the banking environment, toestimating customer lifetime value inthe insurance world [15], and to thecollection of consumer credit receiva-bles.
4 ConclusionsWith this short survey on evolution-
ary algorithms we have tried to pro-vide a complete, if not exhaustive - forobvious reasons of space -, overviewof the various branches into which theyare traditionally divided (genetic algo-rithms, evolution strategies, evolution-ary programming and genetic program-ming). We have gone on to providesome information about the most sig-nificant issues concerning the practi-cal application of evolutionary comput-ing to problems of industrial and eco-nomic importance, such as solutionrepresentation and constraint handling,issues in which research has made sub-stantial progress in the last few years.Finally, we have completed the picturewith a more in-depth, but concise, il-lustration of three sample applicationsto "real-world" problems, chosen forbeing in domains which are as differ-ent from one another as possible, withthe idea of providing three complemen-tary views on the criticalities and theissues that can be encountered whenimplementing a software system thatworks. Readers should appreciate theversatility and the enormous potentialof these techniques which are still com-ing of age almost forty years after theirintroduction. Unfortunately, this sur-vey necessarily lacks an illustration ofthe theoretical foundations of evolu-tionary computing, which includes theschema theorem (with its so-calledbuilding block hypothesis) and the con-vergence theory. These topics havebeen omitted on purpose, since theywould have required a level of formal-ity unsuited to a survey. Interested

76 UPGRADE Vol. VI, No., June 2005 © CEPIS
UPENET
readers can fill this gap by referring tothe bibliography below. Another aspectthat has been overlooked because it isnot really an ‘application’, although itis of great scientific interest, is the im-pact that evolutionary computation hashad on the study of evolution itself andof complex systems in general (for anexample, see the work by Axelrod onspontaneous evolution of co-operativebehaviours in a world of selfish agents[18]).
Readers wishing to look into thefield of evolutionary computation arereferred to some excellent introductorybooks [6][9][17][19] or more in-depthtreatises [20][21], or can browse theInternet sites mentioned in the box"Evolutionary Algorithms on theInternet".
References[1] George E. P. Box, N. R. Draper. Evolu-
tionary Operation: Statistical Methodfor Process Improvement. John Wiley& Sons, 1969.
[2] Hans J. Bremermann. "Optimizationthrough Evolution and Recombina-tion". In M. C. Yovits, G. T. Jacobi andG. D. Goldstein (editors), Self-Organ-izing Systems 1962, Spartan Books,Washington D. C., 1962.
[3] Lawrence J. Fogel, A. J. Owens, M. J.Walsh. Artificial Intelligence throughSimulated Evolution. John Wiley &Sons, New York, 1966.
[4] John H. Holland. Adaptation in Natu-ral and Artificial Systems. Universityof Michigan Press, Ann Arbor, 1975.
[5] Ingo Rechenberg. Evolutions strategie:Optimierung technischer Systemenach Prinzipien der biologischen Evo-lution. Frommann-Holzboog, Stutt-gart, 1973.
[6] David E. Goldberg. Genetic Algorithmsin Search, Optimization, and Machine
Learning. Addison-Wesley, 1989.[7] John R. Koza. Genetic Programming.
MIT Press, Cambridge, Massachu-setts, 1992.
[8] Michael O’Neill, Conor Ryan. Gram-matical Evolution. Evolutionary au-tomatic programming in an arbitrarylanguage. Kluwer, 2003.
[9] Zbigniew Michalewicz. Genetic Algo-rithms + Data Structures = EvolutionPrograms, 3rd Edition. Springer, Ber-lin, 1996.
[10] Andrea G. B. Tettamanzi, MarcoTomassini. Soft Computing. Integrat-ing evolutionary, neural, and fuzzysystems. Springer, Berlin, 2001.
[11] Calogero Di Stefano, Andrea G. B.Tettamanzi. " An Evolutionary Algo-rithm for Solving the School Time-Tabling Problem". In E. Boers et al.,Applications of Evolutionary Comput-ing. EvoWorkshops 2001, Springer,2001. Pages 452–462.
[12] Massimiliano Erba, Roberto Rossi,Valentino Liberali, Andrea G. B.Tettamanzi. "Digital Filter DesignThrough Simulated Evolution". Pro-ceedings of ECCTD’01 - EuropeanConference on Circuit Theory and De-sign, August 28-31, 2001, Espoo, Fin-land.
[13] Alex Berson, Stephen J. Smith. DataWarehousing, Data Mining & OLAP,McGraw Hill, New York, 1997.
[14] Mauro Beretta, Andrea G. B.Tettamanzi. "Learning Fuzzy Classi-fiers with Evolutionary Algorithms".In A. Bonarini, F. Masulli, G. Pasi (edi-tors), Advances in Soft Computing,Physica-Verlag, Heidelberg, 2003.Pagg. 1–10.
[15] Andrea G. B. Tettamanzi et al. "Learn-ing Environment for Life-Time ValueCalculation of Customers in InsuranceDomain". In K. Deb et al. (editors),Proceedings of the Genetic and Evo-lutionary Computation Congress(GECCO 2004), Seattle, June 26–30,
2004. Pages II-1251–1262.[16] Günter Rudolph. Finite Markov Chain
Results in Evolutionary Computation:A Tour d’Horizon . FundamentaInformaticae, vol. 35, 1998. Pages67–89.
[17] Melanie Mitchell. An Introduction toGenetic Algorithms. Bradford, 1996.
[18] Robert Axelrod. The Evolution ofCooperation. Basic Books, 1985.
[19] David B. Fogel. Evolutionary Com-putation: Toward a new philosophy ofmachine intelligence, 2nd Edition.Wiley-IEEE Press, 1999.
[20] Thomas Bäck. Evolutionary Algo-rithms in Theory and Practice: Evo-lution Strategies, Evolutionary Pro-gramming, Genetic Algorithms. Ox-ford University Press, 1996.
[21] Thomas Bäck, David B. Fogel,Zbigniew Michalewicz (editors). Evo-lutionary Computation (2 volumes).IoP, 2000.
Evolutionary Algorithms on The Internet
Below are a few selected websites where the reader can find introductory or ad-vanced information about evolutionary algorithms:· <http://www.isgec.org/>: the portal of the International Society for Genetic and
Evolutionary Computation;· <http://evonet.lri.fr/>: the portal of the European network of excellence on evolu-
tionary algorithms;· <http://www.aic.nrl.navy.mil/galist/>: the GA Archives, originally the "GA-List" mail-
ing list archives, now called the "EC Digest"; it contains up-to-date informationon major events in the field plus links to other related web pages;
· <http://www.fmi.uni-stuttgart.de/fk/evolalg/index.html>: the EC Repository, main-tained at Stuttgart University.





























