Embed Size (px)
Citation preview

© 2005 IBM Corporation
IBM Systems and Technology Group
Practical Experiences from theBlue Gene Project
Manish GuptaIBM Research

IBM Systems and Technology Group
© 2005 IBM Corporation
Outline
Overview of Blue Gene Practical experiences and lessons learned

3
IBM Research
Blue Gene/L © 2004 IBM Corporation
What is Blue Gene/L?
The world’s fastest supercomputer http://www.top500.org
A different approach to design of scalable parallel systems The popular approach to large systems is to build clusters of large SMPs
(NEC Earth Simulator, ASCI machines, Linux clusters) High electrical power consumption: low computing power density Expensive switches for high performance Significant amount of resources devoted to improving single-thread
performance Blue Gene follows a more modular approach, with a simple building block
(or cell) that can be replicated ad infinitum as necessary Low power processors – allowing higher aggregate performance System-on-a-chip offers cost/performance advantages Integrated networks for scalability Familiar software environment, simplified for HPC
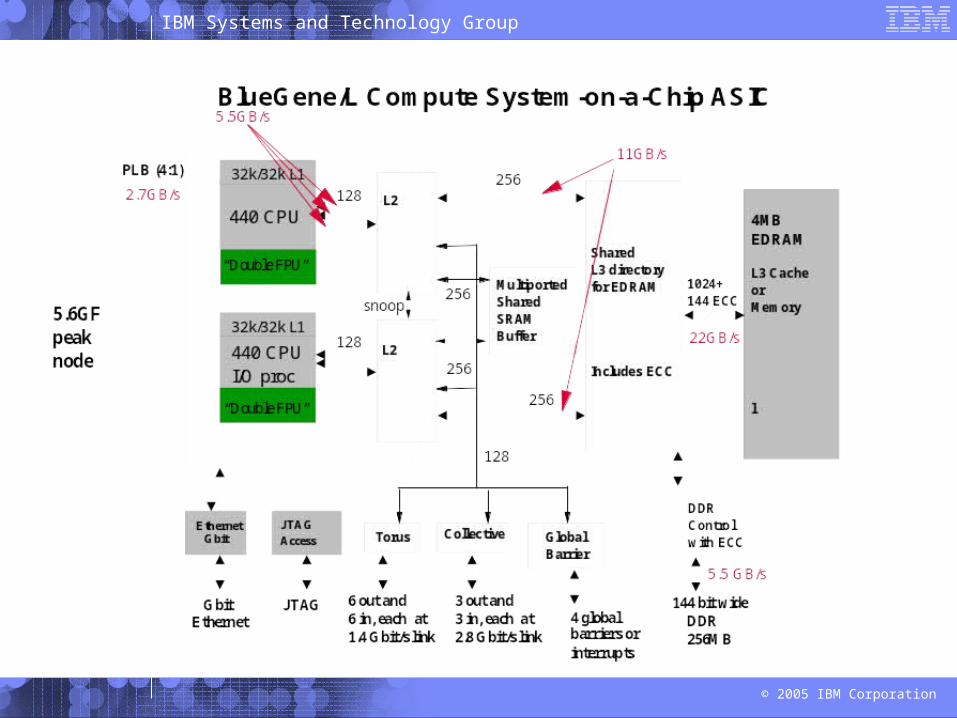
IBM Systems and Technology Group
© 2005 IBM Corporation
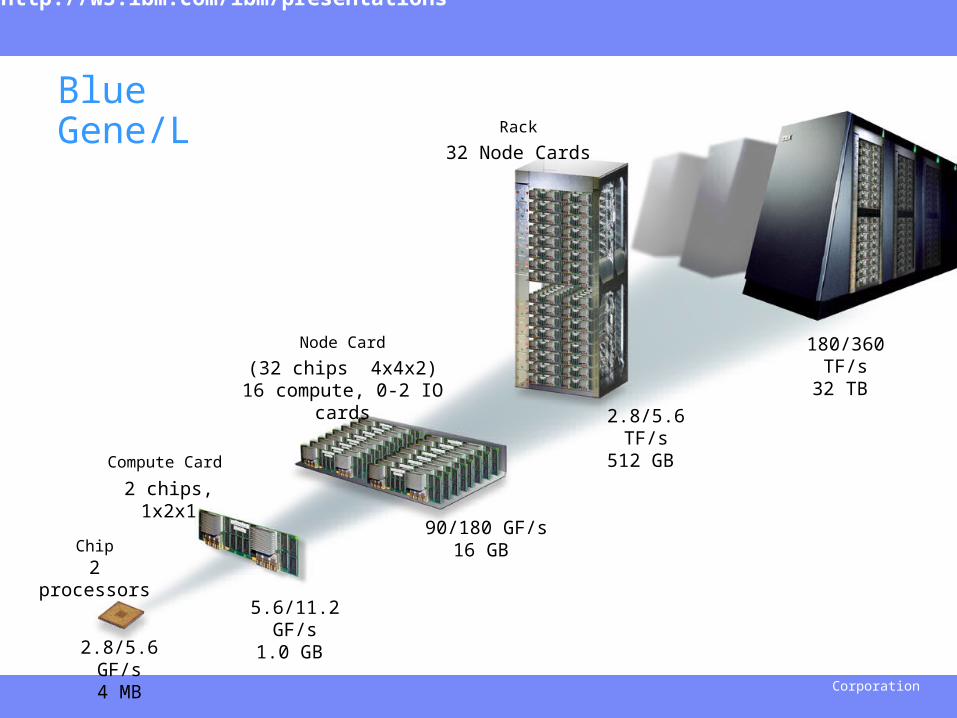
IBM Research
© 2004 IBM Corporation
Blue Gene/L
2.8/5.6 GF/s4 MB
2 processors
2 chips, 1x2x1
5.6/11.2 GF/s1.0 GB
(32 chips 4x4x2)16 compute, 0-2 IO cards
90/180 GF/s16 GB
32 Node Cards
2.8/5.6 TF/s512 GB
64 Racks, 64x32x32
180/360 TF/s32 TB
Rack
System
Node Card
Compute Card
Chip
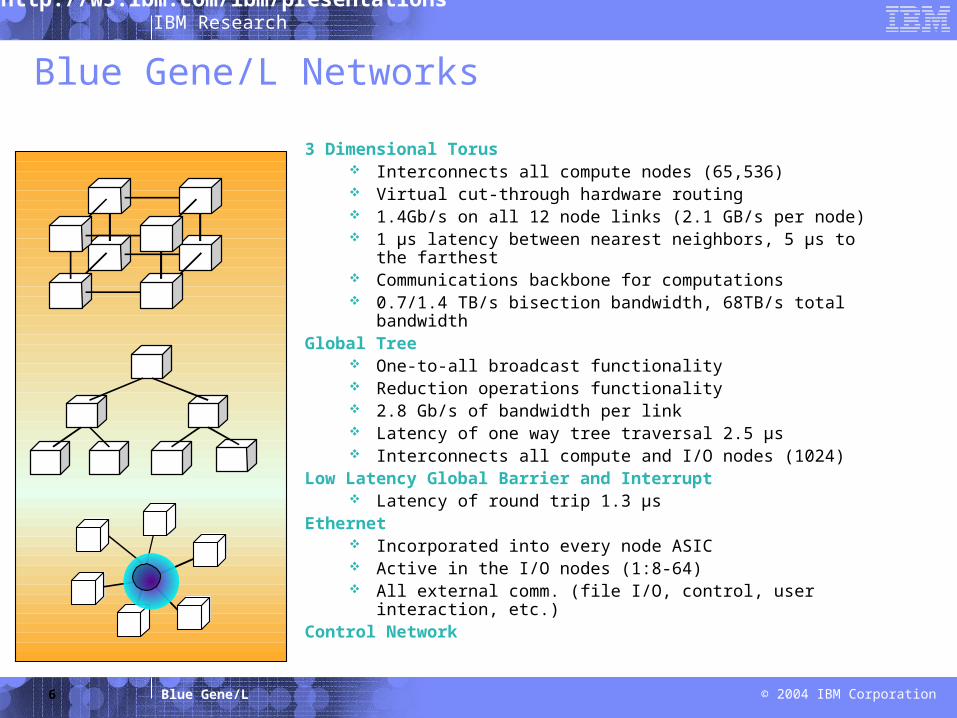
6
IBM Research
Blue Gene/L © 2004 IBM Corporation
Blue Gene/L Networks
3 Dimensional Torus Interconnects all compute nodes (65,536) Virtual cut-through hardware routing 1.4Gb/s on all 12 node links (2.1 GB/s per node) 1 µs latency between nearest neighbors, 5 µs to the
farthest Communications backbone for computations 0.7/1.4 TB/s bisection bandwidth, 68TB/s total bandwidth
Global Tree One-to-all broadcast functionality Reduction operations functionality 2.8 Gb/s of bandwidth per link Latency of one way tree traversal 2.5 µs Interconnects all compute and I/O nodes (1024)
Low Latency Global Barrier and Interrupt Latency of round trip 1.3 µs
Ethernet Incorporated into every node ASIC Active in the I/O nodes (1:8-64) All external comm. (file I/O, control, user interaction, etc.)
Control Network

IBM Systems and Technology Group
© 2004 IBM Corporation
System designed for reliability from top to bottom System issues
– Redundant bulk supplies, power converters, fans, DRAM bits, cable bits
– Extensive data logging (voltage, temp, recoverable errors … ) for failure forecasting
– Nearly no single points of failure Chip design
– ECC on all SRAMs– All dataflow outside processors is protected by error-detection
mechanisms– Access to all state via noninvasive back door
Low power, simple design leads to higher reliability All interconnects have multiple error detections and correction coverage
– Virtually zero escape probability for link errors
RAS (Reliability, Availability, Serviceability)

IBM Systems and Technology Group
© 2004 IBM Corporation
System Software Design
Goals Scalability
– Performance - scaling to tens of thousands of processors– Reliability – an independent failure on compute node once a month would translate into a failure
every 40 seconds on a 64K node system
Familiarity– Enable familiar programming models and programming environments for end-users
Our approach Simplicity
– Avoid features not absolutely necessary for high performance computing– Using simplicity to achieve both efficiency and reliability
New organization of familiar functionality – Hierarchical organization – Same interface, new implementation– Message passing provides foundation
• Research on higher level programming models using that base

IBM Systems and Technology Group
© 2004 IBM Corporation
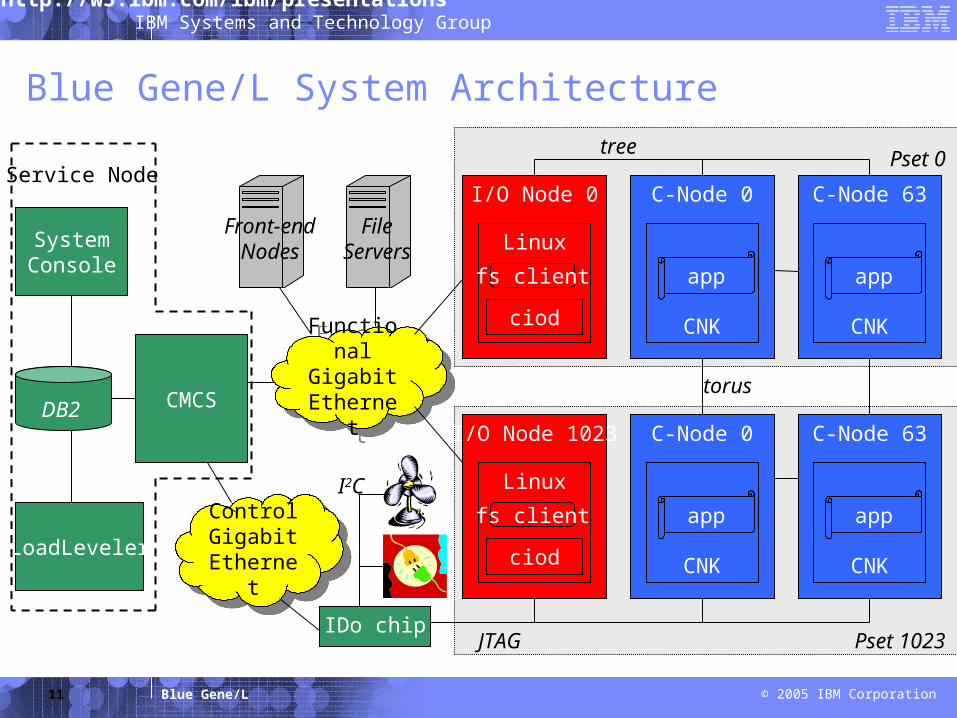
BlueGene/L Software Hierarchical Organization
Compute nodes dedicated to running user application, and almost nothing else - simple compute node kernel (CNK)
I/O nodes run Linux and provide a more complete range of OS services – files, sockets, process launch, signaling, debugging, and termination
Service node performs system management services (e.g., heart beating, monitoring errors) - transparent to application software
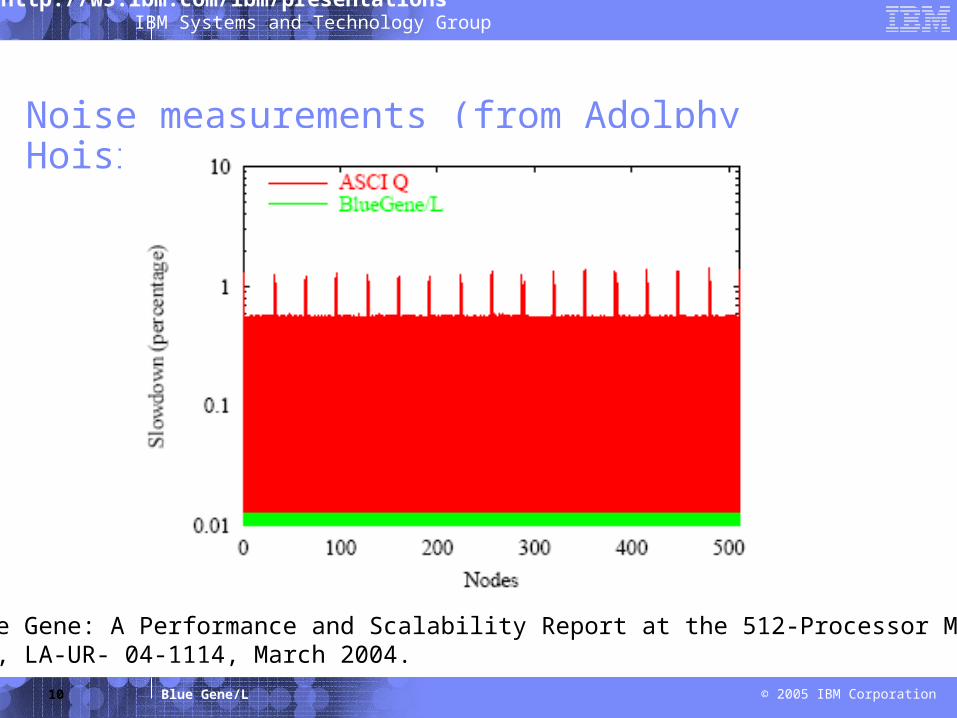
10
IBM Systems and Technology Group
Blue Gene/L © 2005 IBM Corporation
Noise measurements (from Adolphy Hoisie)
Ref: Blue Gene: A Performance and Scalability Report at the 512-Processor Milestone, PAL/LANL, LA-UR- 04-1114, March 2004.
11
IBM Systems and Technology Group
Blue Gene/L © 2005 IBM Corporation
Blue Gene/L System Architecture
Functional Gigabit Ethernet
Functional Gigabit Ethernet
I/O Node 0
Linux
ciod
C-Node 0
CNK
I/O Node 1023
Linux
ciod
C-Node 0
CNK
C-Node 63
CNK
C-Node 63
CNK
Control Gigabit
Ethernet
Control Gigabit
Ethernet
IDo chip
LoadLeveler
SystemConsole
CMCS
JTAG
torus
tree
DB2
Front-endNodes
Pset 1023
Pset 0
I2C
FileServers
fs client
fs client
Service Node
app app
appapp

12
IBM Systems and Technology Group
Blue Gene/L © 2005 IBM Corporation
Status Summary
BG/L systems already installed and accepted at 11 external customer locations
32 racks (32,768 nodes; 65,536 processors) at Rochester and LLNL
June 2005 TOP500 list#1 with 136.8 Teraflop/s on LINPACK5 BG/L machines in Top 10
Various applications and benchmarks executed
Highest ever delivered performance on many applications9 submissions to SC 2005 for Gordon Bell prize – 3 accepted

13
IBM Systems and Technology Group
Blue Gene/L © 2005 IBM Corporation
Summary of Applications Issues Functionality/porting issues
Limited memory on compute nodes (512MB, no paging) Read-only tables Sometimes due to serial components in code
Cross-compilation, no dynamic linking Even large MPI applications that meet BG/L restrictions often port within a day
Serial components Graph partitioning in some codes – e.g., UMT2K ran out of memory at 2K nodes Serial I/O – many weather and climate codes (NOAA)
Single node performance Little benefit from SIMD FPU for many codes
Scaling at 16K/32K nodes Load imbalance in application – e.g., ParaDiS (LLNL) Had to tune MPI_Alltoallv to improve scaling for some codes - eg. Miranda Some applications sensitive to mapping to 3D torus toplogy – e.g., QBox Pacing of messages to avoid network overload – e.g., Raptor By and large, excellent results obtained within 2 weeks of availability of 16K/32K
node system for target applications – noise-free environment, balance between compute and communication, low MPI latency, low “half-bandwidth” point
14

15
IBM Research
Aug. 22, 2005 © 2005 IBM Corporation
Other APIs supported by new communication library
ARMCI / Global Arrays (GA) Active message library used by GA for point-2-point communications
GA (and NWChem) also use MPI for collectives, some p2p as well
NAMD on Charm++/Conversenew Converse machine layer using commlibConverse microbenchmark performance improvement:
bandwidth increased from 124MB/s (Converse/MPI) to 154MB/s (Converse/commlib) latency down from 10.1us to 6.9us.
NAMD scaling to 4K nodes
UPC (Unified Parallel C) Port of IBM UPC runtime to BG/L Added one-sided communication primitives to commlib: BLRMA_Get, BLRMA_Put (under development)

© 2005 IBM Corporation
IBM Systems and Technology Group
Practical Experiences

IBM Systems and Technology Group
© 2005 IBM Corporation
Don’t be afraid of challenging conventional wisdom
Technological trends can change basis of old assumptions Conventional wisdom:
Better to use fewer, more powerful processors
– Programming• Difficulty in expressing large scale parallelism• Overheads of parallelism – many barriers to scalability
– Reliability• Probability of failure (within system) goes up as the number of
components increase– Management
• Hard to manage larger systems – boot, configure, monitor, launch jobs,…
Embedded processors were more power efficient, allowed system level integration

18
IBM Research
Blue Gene/L © 2004 IBM Corporation
Choose your battles
Multiplicative effect of probabilities of success of critical components – overall probability can rapidly approach zero if not careful
Focus efforts where goals are most aggressive Examples: Battles chosen
Scalability – unprecedented levels (over 100K processors) Packaging – extremely dense packaging, aggressive cooling RAS features
Examples: Battles avoided Circuit speed (technology) – not particularly aggressive, 700 MHz clock Scaling standard OS to over 100K processors Exclusive reliance on higher level programming models Keeping job working in a partition with faulty nodes

19
IBM Research
Blue Gene/L © 2004 IBM Corporation
Prepare, prepare… (simulate, simulate…)
Packaging Thermal mockup to simulate air cooling
Control system Service cards to test control functionality
System simulation for software Complete system software, with applications – 512 node system
simulated ahead of hardware availability Hardware schedule slips expected to be made up by software
schedule Rapid progress with software when first chips arrived
Single node software (Day 1), MPI (Day 2), Linux (Day 3),…

20
IBM Research
Blue Gene/L © 2004 IBM Corporation
Be prepared to deal with failures
When dealing with large systems (in particular), if something can go wrong, it will
Significant emphasis on RAS - redundancy, error detection and correction
Emphasis on reproducibility – helping identify tough problems

21
IBM Research
Blue Gene/L © 2004 IBM Corporation
Simplicity has benefits
Examples Strictly space sharing – single job per partition, single process per processor
Allows user space communication without protection problems or interference
More deterministic performance – real CPU behind each thread of execution
Virtual memory constrained to physical memory size No page faults, TLB misses – lower overhead, more deterministic
performance Has helped with both reliability and performance
System has been much more robust and high performance than we feared Most problems have been with the more complex software components
Bringup and scaling exercises have been remarkably fast

22
IBM Research
Blue Gene/L © 2004 IBM Corporation
“Conflict is good”
Good to bring in diverse opinions from people in early stages of project
Can lead to powerful solutions if “conflicts” are resolved in a co-operative manner
Competitive spirit of individual groups helps As long as overall project interests are kept in mind

23
IBM Systems and Technology Group
Blue Gene/L © 2005 IBM Corporation
Conclusions
Blue Gene/L represents a new level of performance scalability and density for scientific computing
Leverages system-on-a-chip technology and powerful interconnects Judicious use of redundancy leads to high reliability system Low power and floorspace requirements
Blue Gene/L system software stack with Linux-like personality for applications
Custom solution (CNK) on compute nodes for highest performance Linux solution on I/O nodes for flexibility and functionality MPI is the default programming model, others are being investigated Complements the hardware to deliver an extremely scalable system – low
latency, high bandwidth communication, with negligible noise Very encouraging performance results on benchmarks and applications –
people beginning to do real science with BG/L Continued investment in Blue Gene roadmap





























