Embed Size (px)
DESCRIPTION
圖書館推薦系統建置 - 以淡江圖書館資料為例. 指導教授:魏世杰 研究生:陳慶宇. 緒論 文獻探討 研究方法 實驗及評估 結論和未來目標. 緒論 : 研究動機. 圖書館擁有大量資料 搜尋模式單一,只能使用關鍵詞 若遇 書名用詞或語言不同 ,搜尋結果可能遺漏使用者所需 使用推薦系統改善 [13]. 緒論: 推薦系統. 常用技術 [7] 有: 協同過濾 (Collabrative Filtering) : 社群力量 內容為本 (Content-based) : 文字比對 知識為本 (Knowledge-based) :屬性篩選. 緒論: 本文推薦方法. - PowerPoint PPT Presentation
Citation preview

指導教授:魏世杰研究生:陳慶宇
1
+ 緒論+ 文獻探討+ 研究方法+ 實驗及評估+ 結論和未來目標
2

+ 圖書館擁有大量資料+ 搜尋模式單一,只能使用關鍵詞+ 若遇書名用詞或語言不同,搜尋結果可能遺漏使用者所需
+ 使用推薦系統改善 [13]
3

常用技術 [7]有:+協同過濾 (Collabrative Filtering):社群力量+內容為本 (Content-based):文字比對+知識為本 (Knowledge-based):屬性篩選
4

+ 以淡江圖書借閱紀錄及分類號為協同及內容推薦基礎
+ 考量個資問題– 當無法取得借閱者身份
提出物推薦物方法– 當可取得借閱者身份
提出物推薦物內嵌在人推薦物方法下之做法+ 結果與Mahout協同推薦法 [4]互相比較
5

+ 協同推薦 (Collabrative Filtering)– 用戶為本 (User-based)– 物品為本 (Item-based)– 模型為本 (Model-based)
+ 內容為本 (Content-based)+ 知識為本 (Knowledge-based)
6

+ 採物品為本推薦,觀察購物車已有商品進行推薦+ 推薦過程依賴事先建好的相似物品表
– 相似物品表建立演算法如下 [2]:
7
//計算型錄中每樣物品 I1和其餘物品 I2相似度For each item I1 in product catalog //分別統計所有物品和 I1同時購買之次數 For each customer C who purchased I1
For each item I2 purchased by customer C Record that a customer purchased I1 and I2
//利用和 I1同時購買之次數高低計算所有物品和 I1相似度
For each item I2
Compute the similarity between I1 and I2
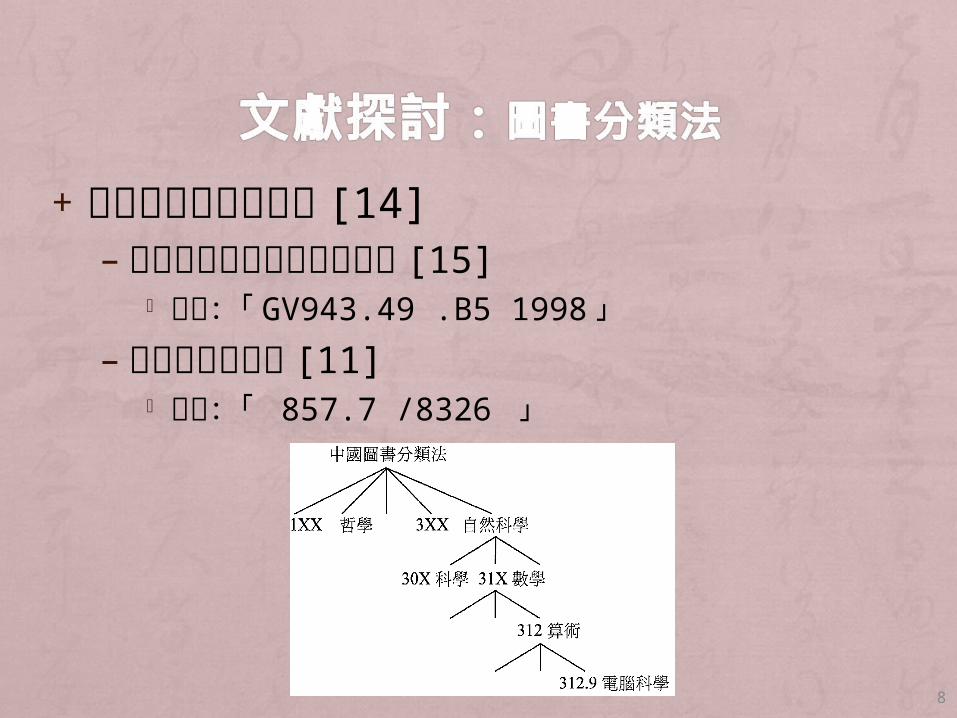
+ 杜威十進圖書分類法 [14]– 美國國會圖書館圖書分類法 [15]
例如:「 GV943.49 .B5 1998」– 中國圖書分類法 [11]
例如:「 857.7 /8326 」
8

+ Mahout [4]為一 JAVA寫成具有運算可分散能力 (scalable)的機器學習套件,能和 Apache Hadoop 分散式架構相結合,有效使用分散式系統來實現高性能計算。– 提供協同推薦、分類和分群演算法
協同推薦包含用戶為本、物品為本和斜率 1 推薦法
9

//計算用戶 u 尚未評價過的所有物品 i 之可能評價,回傳前面名次物品for every item i that u has no preference for yet
//計算其餘用戶 v對物品 i之評價,依照 v,u相似度 s加權,結合到 u 對 i之評價
for every other user v that has a preference for icompute a similarity s between u and vincorporate v’s preference for i, weighted by s, into
running average return the top items, ranked by weighted average
GenericUserBasedRecommender類別 [4]
10

GenericItemBasedRecommender類別 [4]
//計算用戶 u 尚未評價過的所有物品 i 之可能評價,回傳前面名次物品for every item i that u has no preference for yet
//計算用戶 u 對其餘物品 j之評價,依照 i,j相似度 s加權,結合到 u 對 i之評價 for every item j that u has a preference for
compute a similarity s between i and jadd u’s preference for j, weighted by s, to running
average return the top items, ranked by weighted average
11

SlopeOneRecommender類別 [4]
//計算用戶 u 尚未評價過的所有物品 j 之可能評價,回傳前面名次物品for every item i the user u expresses no preference for
//計算用戶 u 對其餘物品 j之評價,依照 i,j平均喜好差 d ,結合到 u 對 i之評價 for every item j that user u expresses a preference for
find the average preference difference between j and iadd this diff to u’s preference value for jadd this to a running average
return the top items, ranked by these averages
12

+ 不可取得借閱者身份時– 給定書代碼 bid,推薦書本個數 n,輸出是一群和 bid相關的書集合bid_set={bid1,bid2,...,bidn}。目標是找出一般使用者在借過 bid之後將來最可能借的書集合
+ 可取得借閱者身份時– 給定用戶代碼 uid,推薦書本個數 n,輸出是一群和 uid相關的書集合bid_set={bid1,bid2,...,bidn}。目標是找出該使用者將來最可能借的書集合
13

第一層是從給定的書 bid,找到同樣有借過此書的使用者 u ,第二層是從使用者 u找出過去所有借過的書 b ,最後將所有書集合做成聯集 bid_mset,回傳重複次數最多的前 n 名集合 bid_set,當作推薦
for every user u who has borrowed book bidfor every book b that user u has borrowed
add book b into multiset bid_msetconvert multiset bid_mset into set book_setsort book_set by the occurrence count of each bid in decreasing orderbid_set = top n of sorted book_setreturn bid_set
14

+ 當聯集後的書集合 bid_mset發生有書出現次數相同情形時,會造成許多書排名相同無法區別的缺點
+ 引入分類號,計算兩書分類號的距離,讓比較靠近給定 bid的圖書排名在前做仲裁– 所有書分類號依字典字串順序由小排到大,給予排序編號 1 到 m , m為總書數
– 任一本書 bid的排序編號表示為 rank(bid)– 定義 x 及 y兩書的距離為 dist(x,y)=|rank(x)-rank(y)|– 出現次數相同的兩本書 bid1 、 bid2,將依據
dist(bid1,bid) 及 dist(bid2,bid)兩距離做仲裁,距離短者排名在前
15
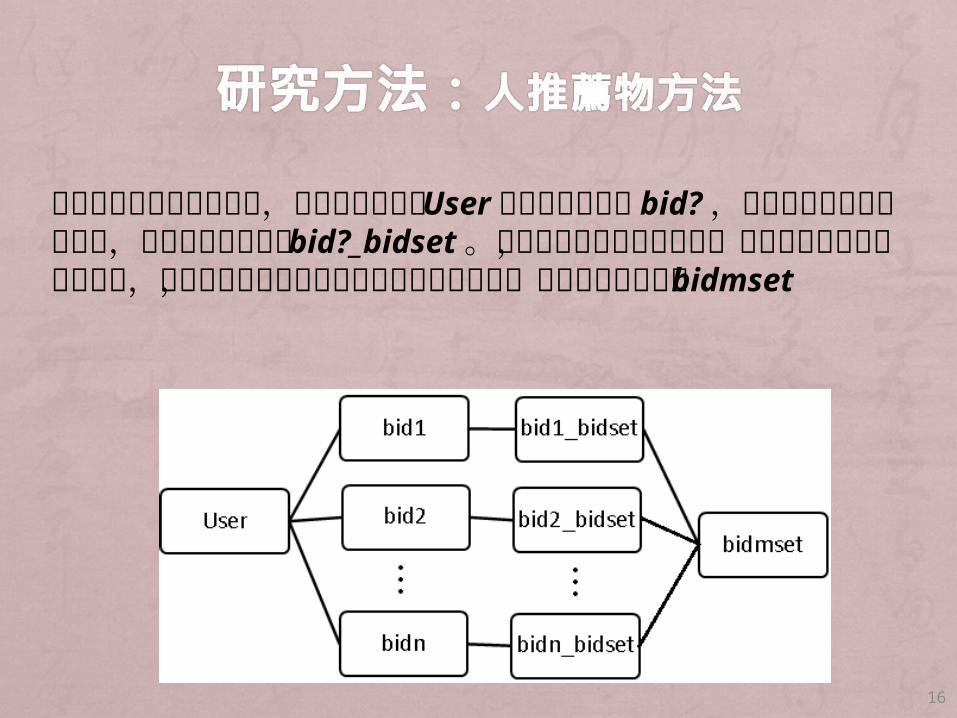
當可以取得借閱者身分時,可以利用借閱者 User過去借過的書籍 bid?,再利用原來物推薦物方法,找出相關書籍集合 bid?_bidset。最後將這些集合聯集起來,再依書籍出現次數多寡排序,若遇次數相同時再利用分類號方法做仲裁,產生最後推薦集合 bidmset
16

淡江大學圖書館 101年度整年份 (2011.8.1~2012.7.31) 的 920172筆流通紀錄每筆紀錄有如下欄位:
TRANSACTION_DATE(借閱日期 ) PATRON_ID(借閱者 ID) BIB_ID(書籍 ID) CALL_NUMBER(分類號 ) TXN_TYPE(借閱情況 )
ckin(還入 ) 、 ckout(借出 ) 、 renewal(續借 )本文只篩選留下 373834筆借出記錄做為資料集
借閱者 18097人圖書 ( 含 CD)103306冊
17

為方便測試,本文將所有借出紀錄依不同月份時間點做分界線,分界線之前當訓練集,之後當測試集,共切割出 11組訓練和測試集
資料集
訓練集 測試集訓練和測試集並存借書人數
起訖月份
借閱筆數
借閱人數
借閱書數
起訖月份
借閱筆數
借閱人數
借閱書數
M1 8 10288 1881 8441 9-7 363546 18526 108199 1676
M2 8-9 48288 8046 32799 10-7 325606 17805 102030 7125
M3 8-10 87744 11264 49822 11-7 286090 16881 95026 9414
M4 8-11 131431 13310 62912 12-7 242403 15845 87160 10424
M5 8-12 172503 14641 73401 1-7 201331 14481 78020 10391
M6 8-1 187037 14884 76844 2-7 186797 14123 74543 10276
M7 8-2 214890 15653 82897 3-7 158944 13337 68161 10259
M8 8-3 261873 16817 91873 4-7 111961 11457 56123 9543
M9 8-4 294353 17541 97230 5-7 79481 9645 45510 8455
M10 8-5 336012 18233 103971 6-7 37822 5792 27343 5294
M11 8-6 362835 18557 108061 7 10999 2037 9064 1863 18

+ 假設可取得借閱者身份,故以人推薦物模式進行評估+ 對 Mahout本身已有三種人推薦物方法進行評估+ 針對人推薦物模式評估不同內嵌物推薦物方法的好壞
– m2btop(人推薦物入圍名次門檻 )參數範圍介於 1~10 和10~100(間隔 10)
– b2btop(物推薦物入圍名次門檻 )參數範圍介於 1~10 和10~100(間隔 10)
+ 因為屬布林資料,故Mahout用戶為本和物品為本皆使用 LogLikelihoodSimilarity相似度方法
+ 每組測試集計算平均精確率時皆以訓練測試集交集人數 (介於 1676~10424)當除數,再以平均精確率進行比較
19

對資料集 (M1~M11)進行評估,結果分別是m2btop介於 1~10 和 m2btop介於20~100間隔 10。其精確率表現偏低,介於 0.05%~0.06%
(SlopeOneRecommender)
20
橫軸表人推薦物入圍名次個數
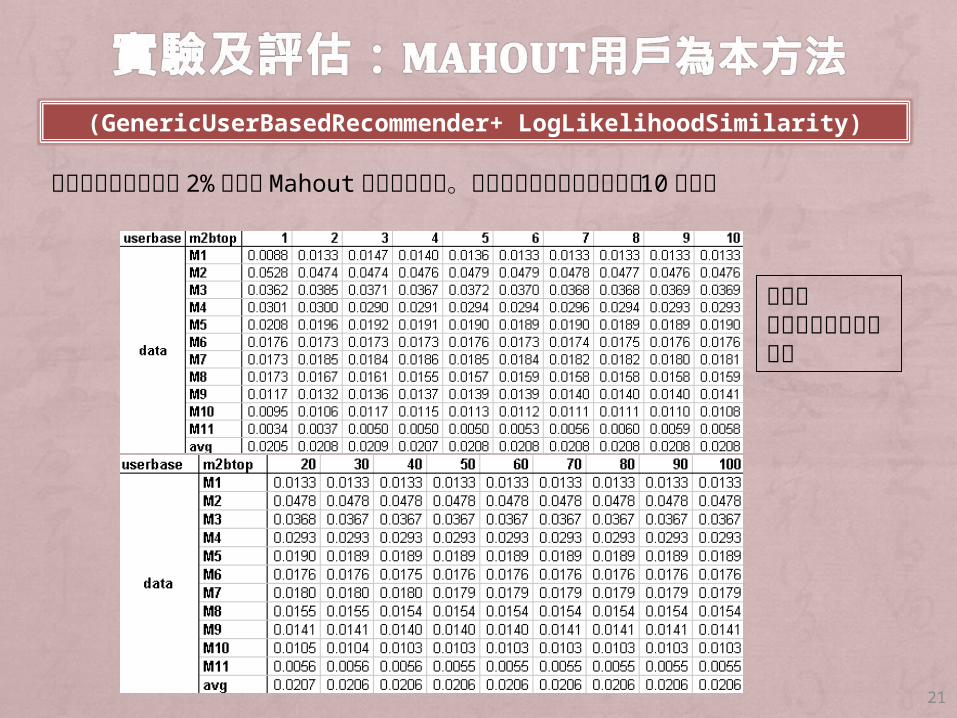
推薦結果,其精確率 2%為三種Mahout方法中最好的。其中近鄰數量本文只固定取 10來使用
(GenericUserBasedRecommender+ LogLikelihoodSimilarity)
21
橫軸表人推薦物入圍名次個數

推薦結果,其精確率介於 0.7%~1%,在斜率 1和用戶為本之間
(GenericItemBasedRecommender+ LogLikelihoodSimilarity)
22
橫軸表人推薦物入圍名次個數
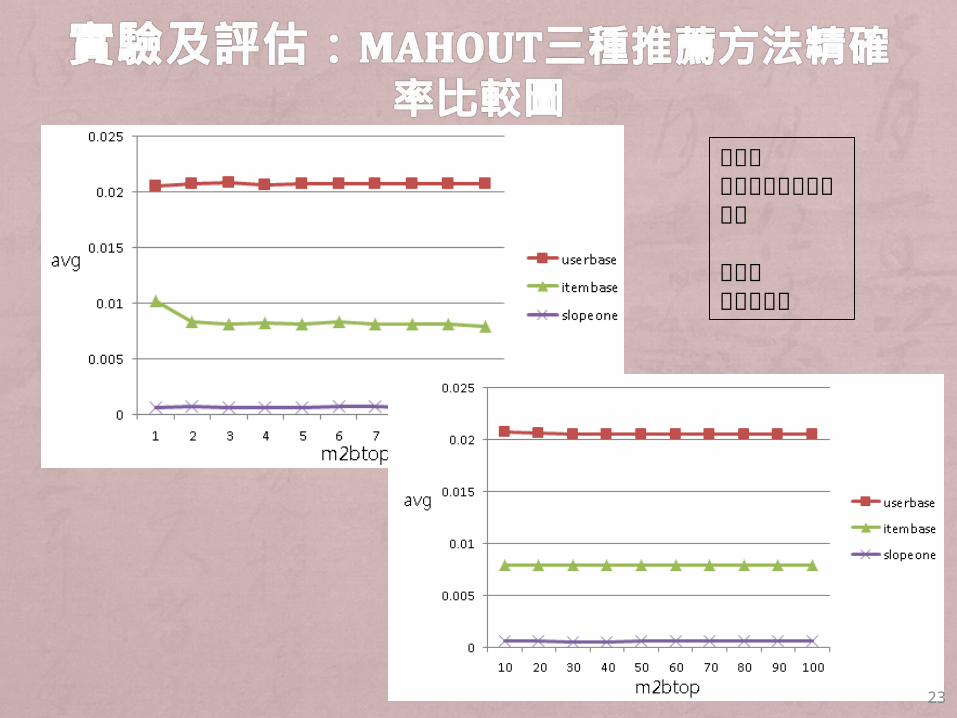
23
橫軸表人推薦物入圍名次個數
縱軸表平均精確率
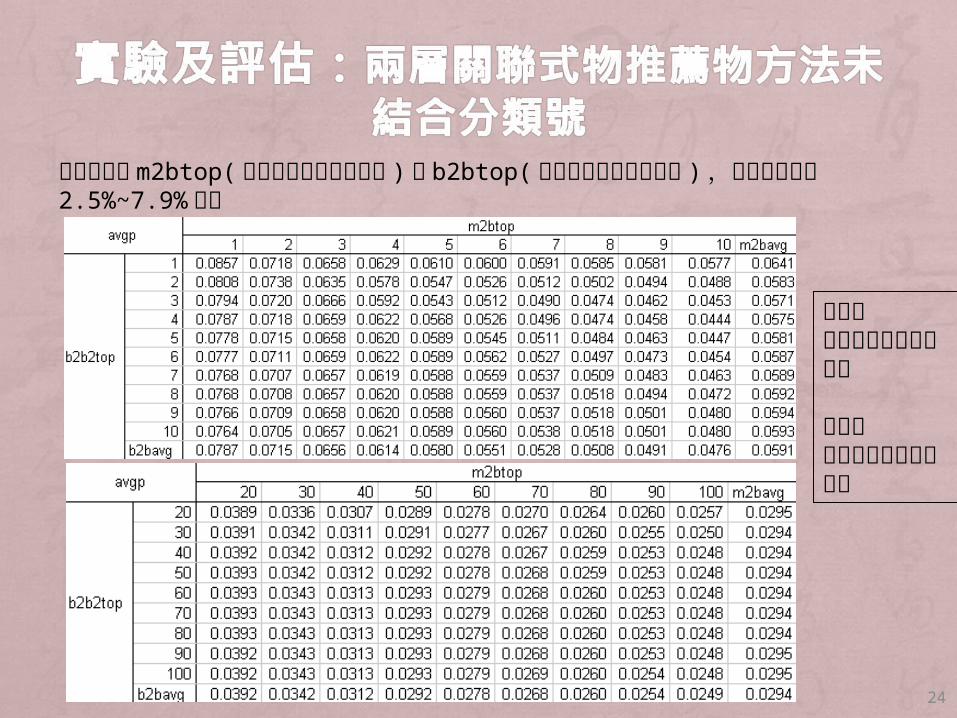
參數使用到m2btop(人推薦物入圍名次門檻 ) 和 b2btop(物推薦物入圍名次門檻 ),其精確率介於 2.5%~7.9%之間
24
橫軸表人推薦物入圍名次個數
縱軸表物推薦物入圍名次個數
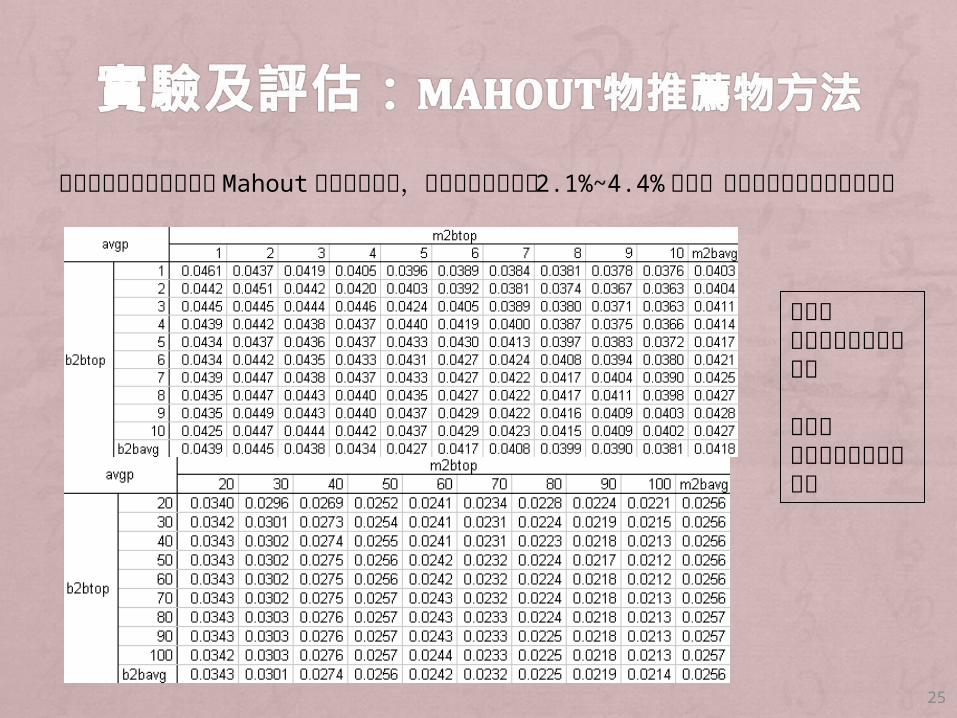
把人推薦物中間部分改成Mahout物推薦物方法,發現其精確率介於 2.1%~4.4%之間,不如內嵌兩層關聯式推薦法
25
橫軸表人推薦物入圍名次個數
縱軸表物推薦物入圍名次個數
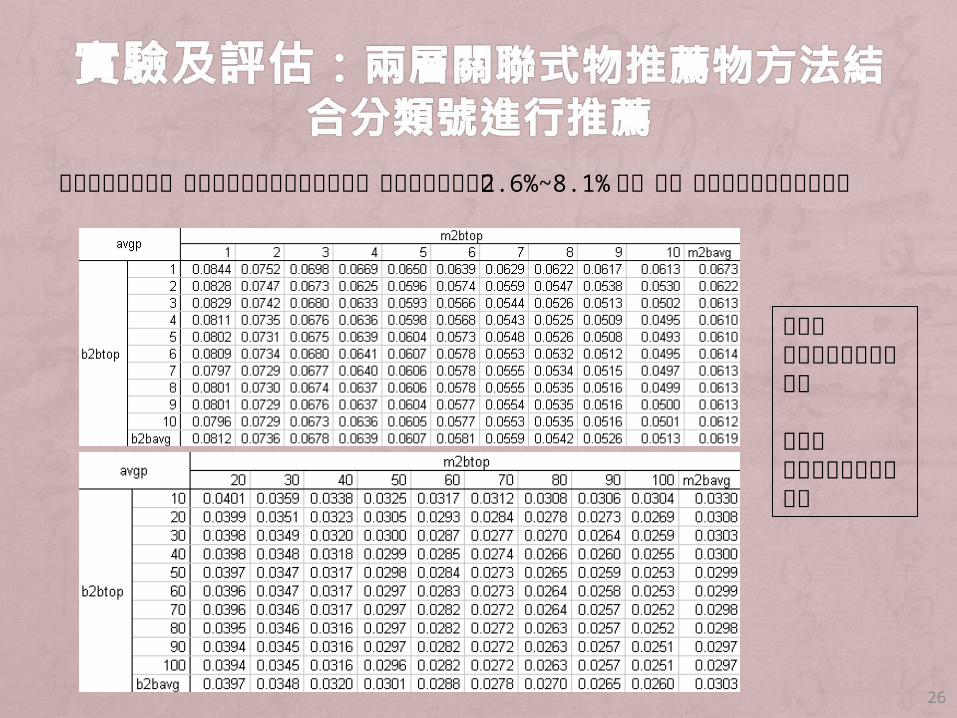
計算分類號距離,找出最相近的來做推薦排名。其精確率結果介於 2.6%~8.1%間,整體而言比未結合分類號稍佳
26
橫軸表人推薦物入圍名次個數
縱軸表物推薦物入圍名次個數
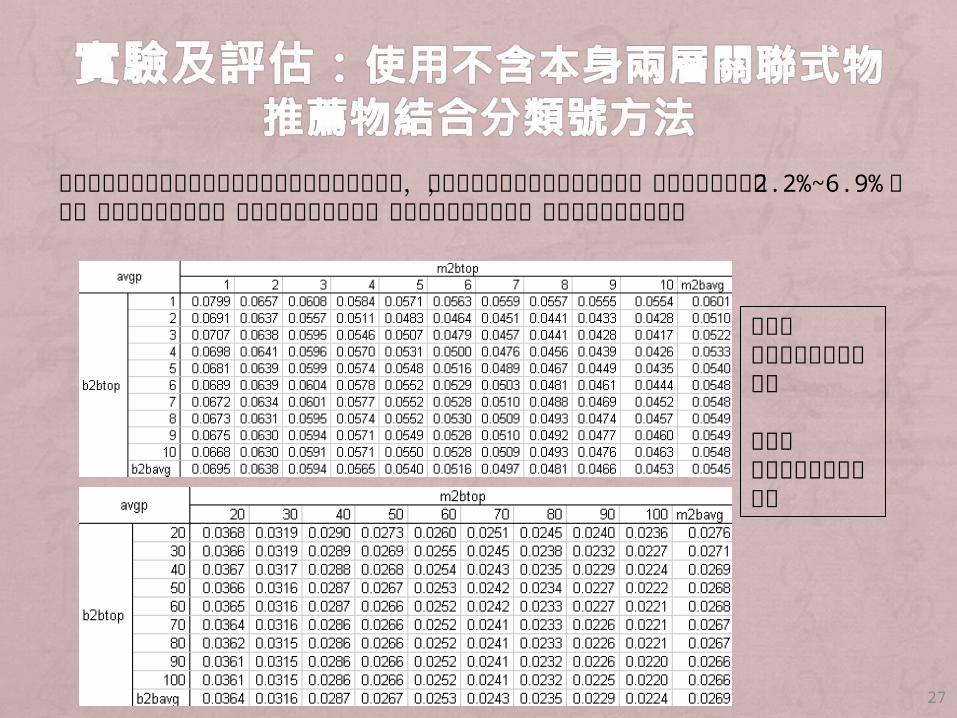
兩層關聯式物推薦物方法會把給定物品本身也加入推薦,所以測試把本身排除的推薦結果,發現其精確率介於 2.2%~6.9%之間,不如包含本身優秀,顯示圖書借閱行為中,重複借閱的可能性高,所以最好推薦包含本身
27
橫軸表人推薦物入圍名次個數
縱軸表物推薦物入圍名次個數
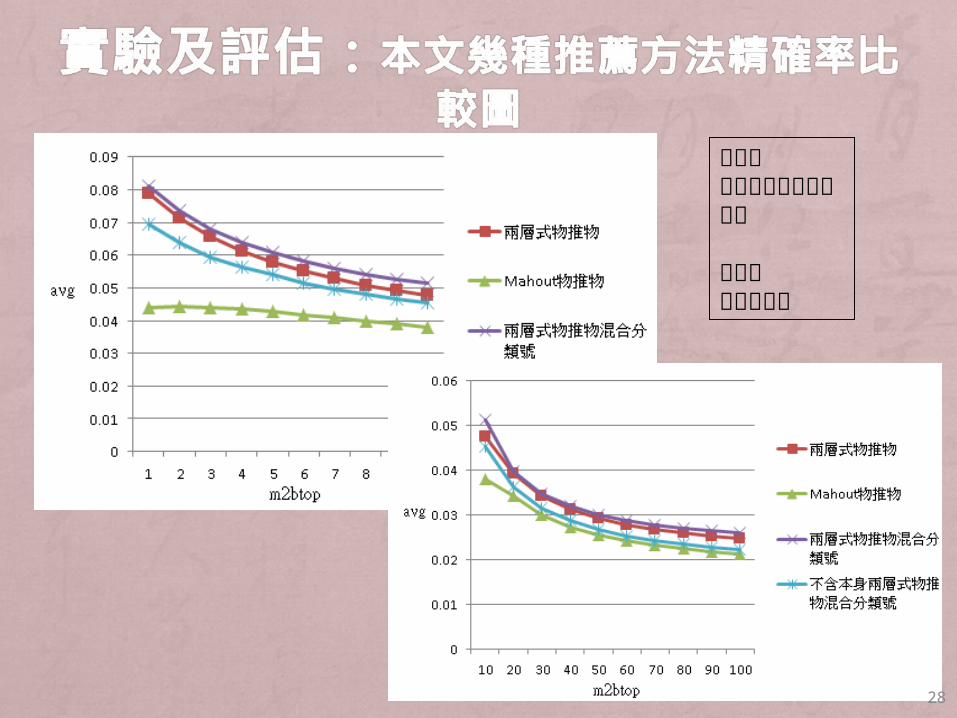
28
橫軸表人推薦物入圍名次個數
縱軸表平均精確率
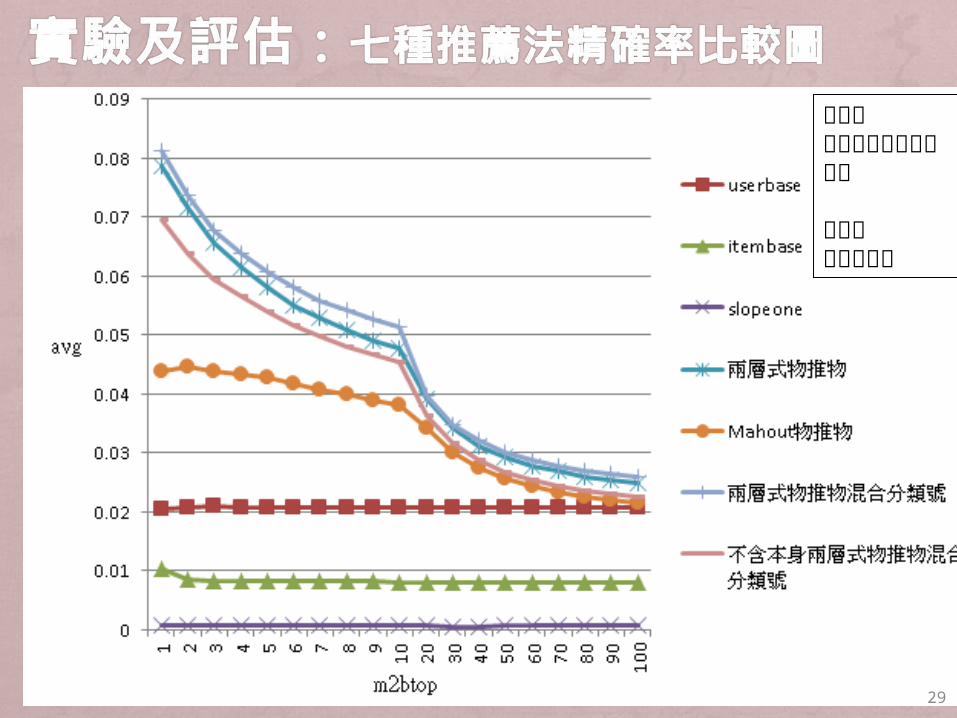
29
橫軸表人推薦物入圍名次個數
縱軸表平均精確率

+ 為了增加借閱者找書效率,本文提出兩層關聯式物推薦物方法,適用於借閱者身份開放與否之場合
+ 兩層關聯式物推薦物方法優於Mahout三種方法,高出 5%以上
+ 兩層關聯式物推薦物方法在結合分類號時效果更好,可提升 3%
+ 利用兩層關聯式物推薦物方法推薦時宜包含給定物品本身,否則表現下降達 14%
+ 未來本推薦系統將做成網站服務 (web service),內嵌在圖書查詢系統網頁上
30

謝謝大家
31





























