Embed Size (px)
Citation preview

А вы готовы к новым архитектурам Intel?
Анатолий Звездин, Вячеслав Шакин

Готовы ли ваши приложения?
Чем может помочь Intel?

MIC архитектура
• Больше ядер – больше задач выполняется параллельно (масштабирование)
• Шире вектор – больше данных вычисляется одновременно (векторизация)
Параллелизм – ключ к успеху
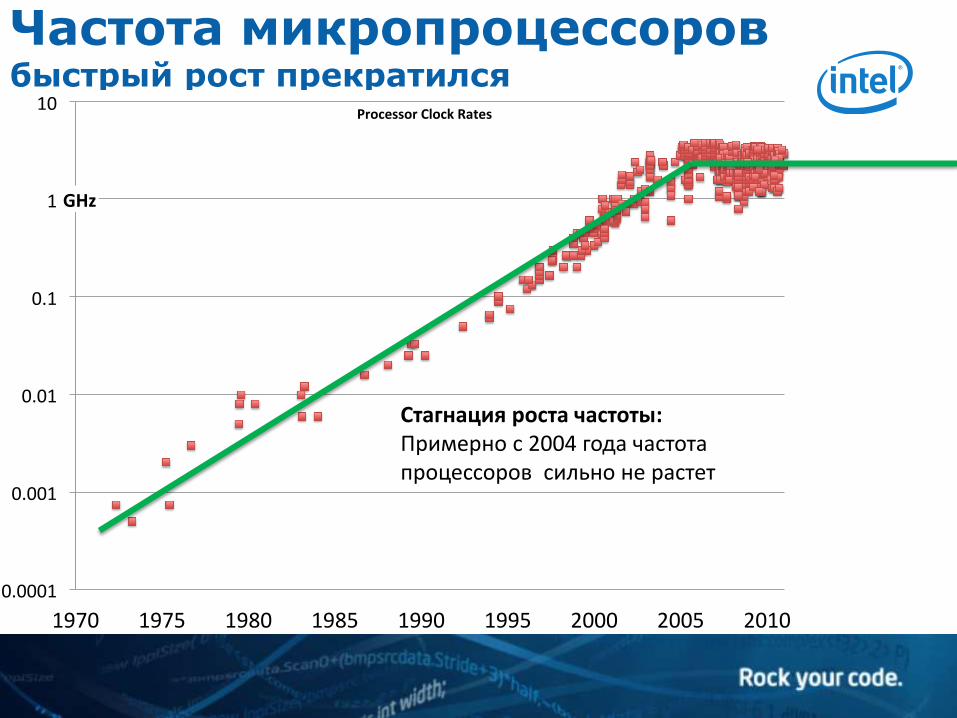
Частота микропроцессоров быстрый рост прекратился
0.0001
0.001
0.01
0.1
1
10
1970 1975 1980 1985 1990 1995 2000 2005 2010
GHz
ProcessorClockRates
Стагнация роста частоты: Примерно с 2004 года частота процессоров сильно не растет
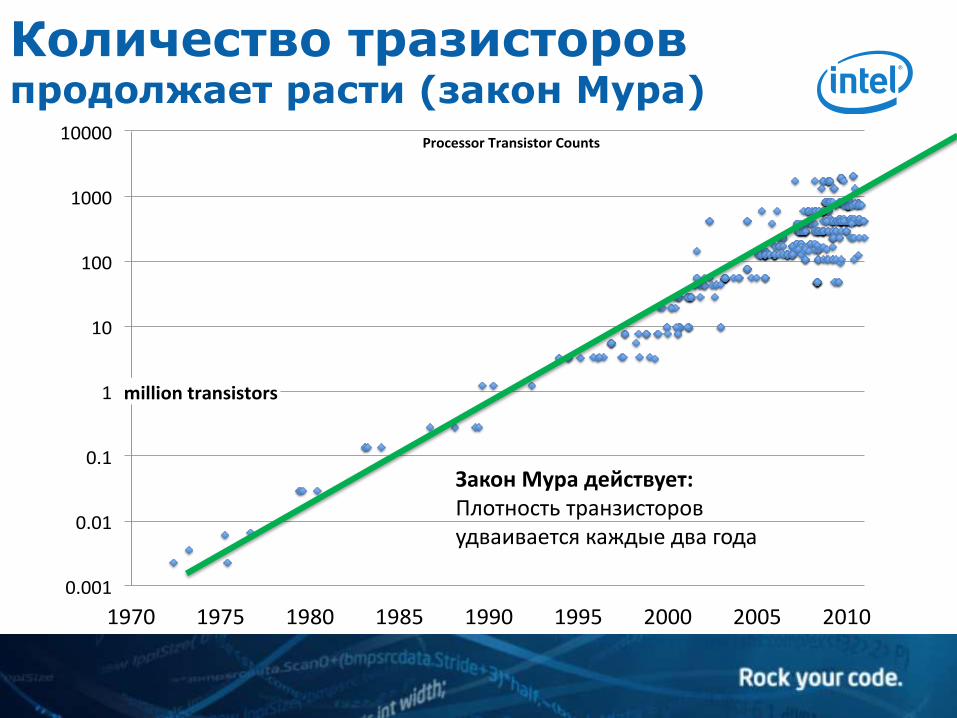
Количество тразисторов продолжает расти (закон Мура)
0.001
0.01
0.1
1
10
100
1000
10000
1970 1975 1980 1985 1990 1995 2000 2005 2010
milliontransistors
ProcessorTransistorCounts
Закон Мура действует: Плотность транзисторов удваивается каждые два года

Graph: James Reinders
Количество ядер и потоков
Потоки
Ядра
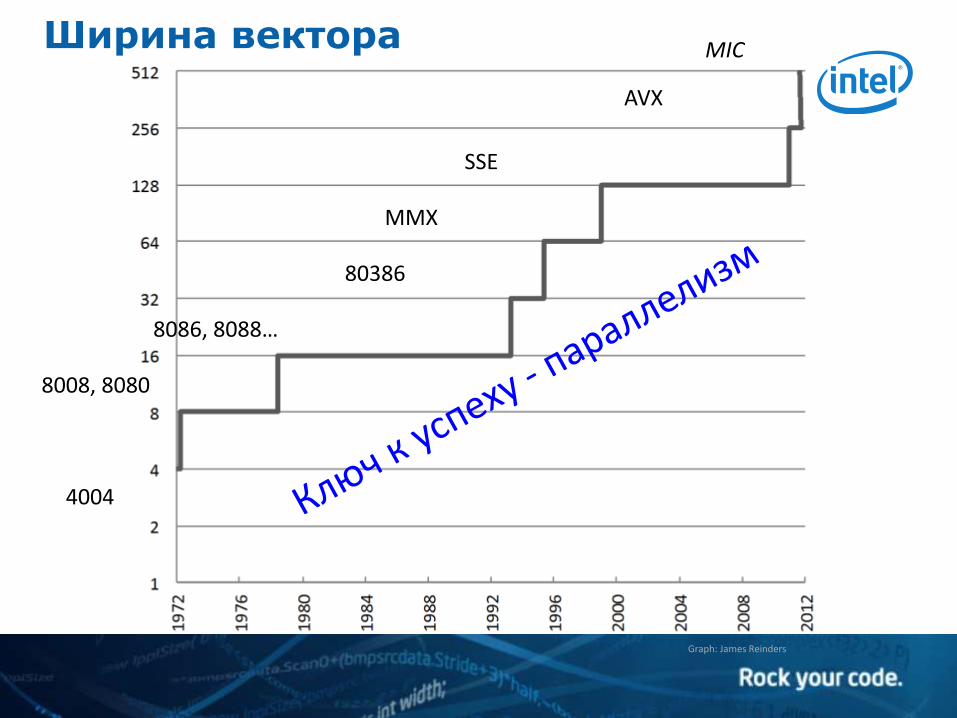
Graph: James Reinders
MMX
SSE
AVX
MIC
4004
8008, 8080
8086, 8088…
80386
Ширина вектора

Knights Corner Терафлоп в одном чипе
1 TFLOPS на операциях двойной точности с плавающей запятой
22-нанометровая технология, 3-D Tri-Gate транзисторы
Более 50 ядер
512-битные вектора и команды (SIMD)
Расширение IA (Intel Architecture) на MIC
PCI express slot
Linux* OS, IP адресация
Привычные современные средства разработки
* Other names and brands may be claimed as the property of others.

Intel® Xeon® + Intel® Xeon Phi™ Дополнительные решения для параллельных приложений
Основа высокопроизводительных вычислений
Наилучшее решение для большинства последовательных и параллельных задач
Небольшое количество мощных ядер
Энергоэффективность, безопасность и надежность
Оптимальная производительность для задач с высокой степенью параллелизма, требующих
больших вычислительных мощностей
Intel® MIC архитектура – большое количество ядер/потоков, «широкие» вектора;
Синергическое дополнение Intel® Xeon® процессора
Продуктивность – те же программные модели и средства разработки

Технологии ✓
Программирование✓
Intel® Xeon® Processor
Intel® Xeon® PhiTM
Coprocessor
Единый набор инструментов Признанная операционная
система для HPC
* Other names and brands may be claimed as the property of others.

Пример
#pragma offload target (mic)
#pragma omp parallel for reduction(+:pi)
for (i=0; i<count; i++) {
float t = (float) ((i + 0.5) / count);
pi += 4.0 / (1.0 + t * t);
}
pi = pi / count;
Сначала делаем код параллельным
“Отдаем” параллельный
код на сопроцессор
Просто и эффективно!

Программирование для Intel® Xeon® PhiTM
Языки программирования
C/C++/Fortran
Модели параллелизации
Оптимизированные библиотеки (MKL, IPP)
OpenMP, MPI
Intel® Cilk™ Plus, Intel® Thread Building Blocks
Любые комбинации в одном приложении

Программирование для Intel® Xeon® PhiTM
Программные модели
Неявное использование - библиотеки (MKL, IPP)
Offload – добавление директив в исходный код
Intel® Cilk™ Plus – расширение языка
Самостоятельное исполнение на MIC
С использованием MPI

Offload
• Offload директива
• Доступна в C/C++ и Fortran
• #pragma offload - для указания того, что конструкция может исполняться на Intel® Xeon® PhiTM сопроцессоре
• Позволяет программисту управлять передачей данных между CPU и сопроцессором
• Intel® Cilk™ Plus – расширение языка
• Доступна в C/C++
• _Cilk_shared – общая доступность данных
• _Cilk_offload – исполнение кода на сопроцессоре
• Возможности асинхронного исполнения

Примеры offload кода
• C/C++ Offload Pragma
#pragma offload target (mic)
#pragma omp parallel for reduction(+:pi)
for (i=0; i<count; i++) {
float t = (float)((i+0.5)/count);
pi += 4.0/(1.0+t*t);
}
pi /= count;
• Function Offload Example
#pragma offload target(mic)
in(transa, transb, N, alpha, beta) \
in(A:length(matrix_elements)) \
in(B:length(matrix_elements)) \
inout(C:length(matrix_elements))
sgemm(&transa, &transb, &N, &N, &N, &alpha, A, &N, B, &N, &beta, C, &N);
• Fortran Offload !dir$ offload target(mic) !$omp parallel do do i=1,10 A(i) = B(i) * C(i) enddo
• Расширение C/C++ class _Cilk_shared common {
int data1;
char *data2;
class common *next;
void process();
};
_Cilk_shared common obj1, obj2;
_Cilk_spawn obj1.process();
_Cilk_offload obj2.process();
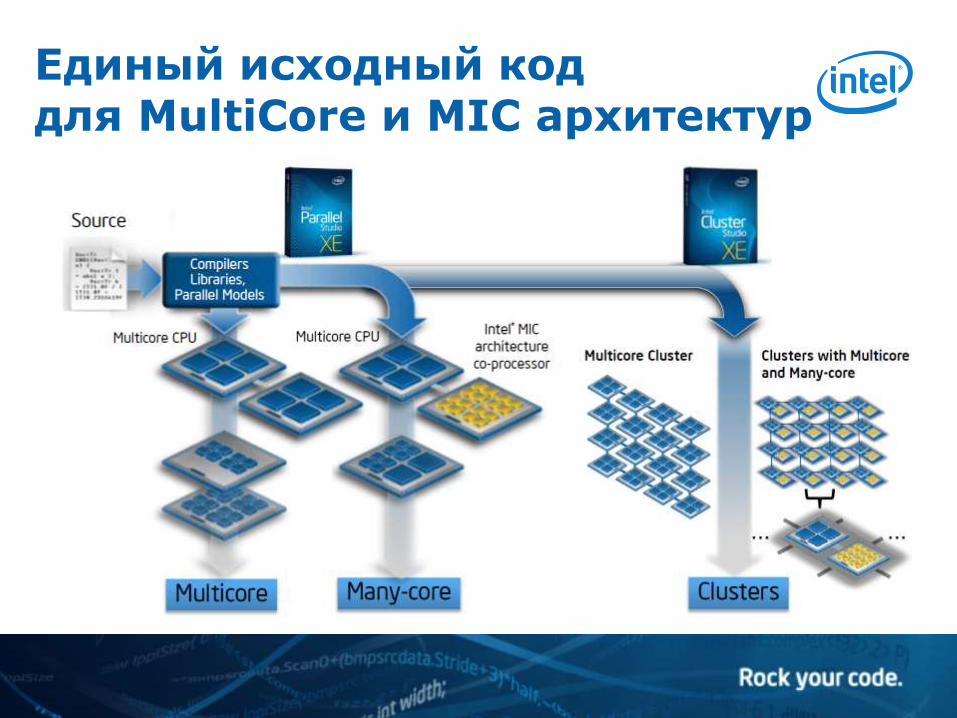
Единый исходный код для MultiCore и MIC архитектур
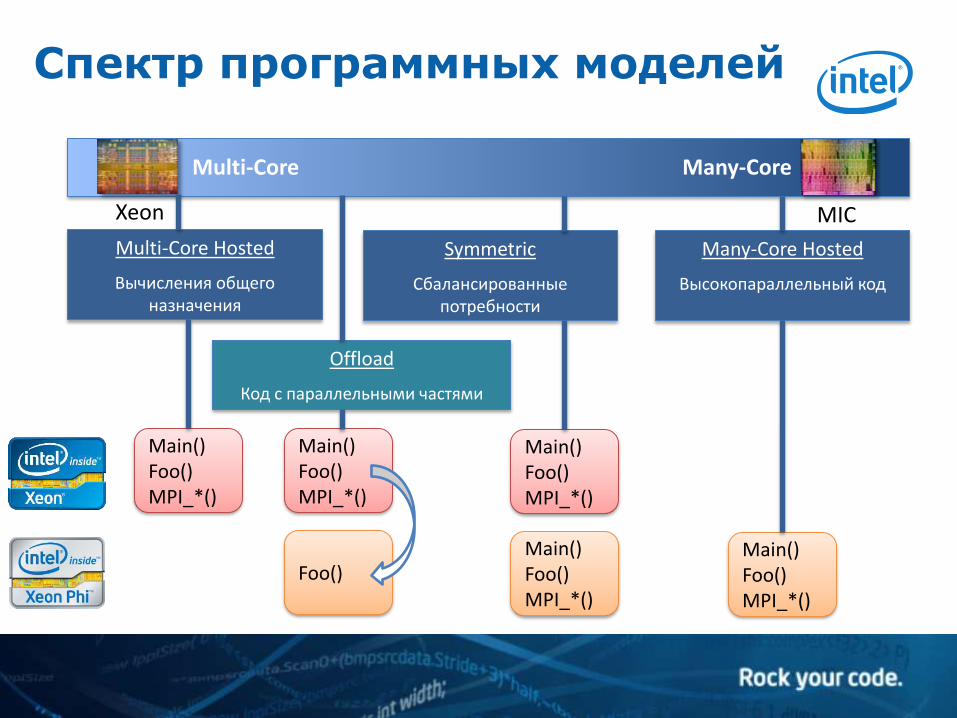
Спектр программных моделей
Xeon MIC
Multi-Core Many-Core
Multi-Core Hosted
Вычисления общего назначения
Symmetric
Сбалансированные потребности
Many-Core Hosted
Высокопараллельный код
Offload
Код с параллельными частями
Main() Foo() MPI_*()
Main() Foo() MPI_*()
Foo()
Main() Foo() MPI_*()
Main() Foo() MPI_*()
Main() Foo() MPI_*()
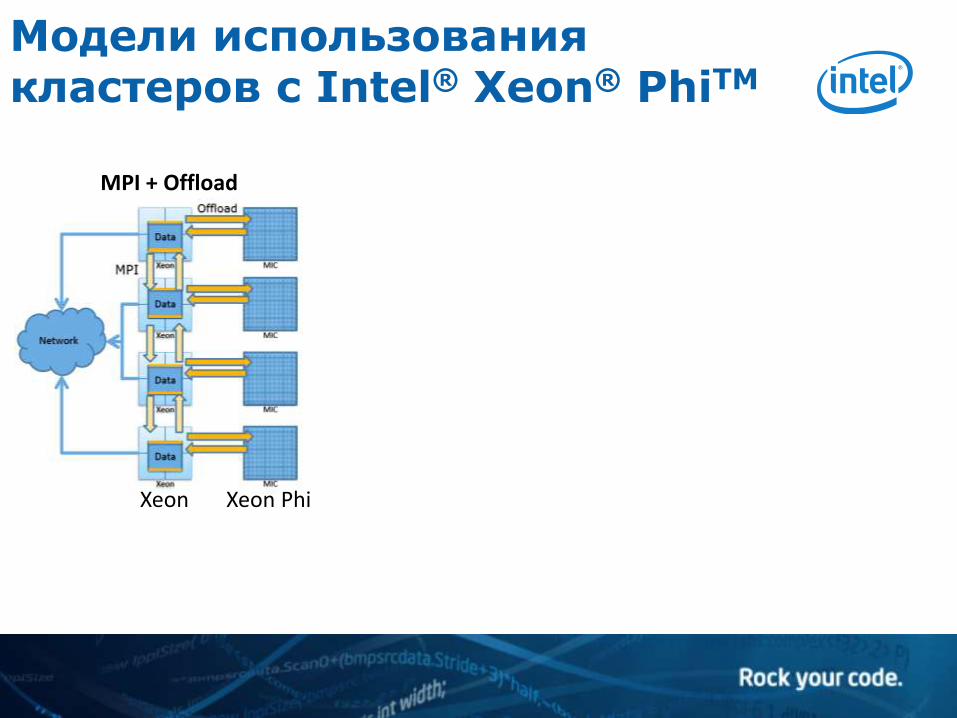
Модели использования кластеров с Intel® Xeon® PhiTM
MPI + Offload
Xeon Xeon Phi
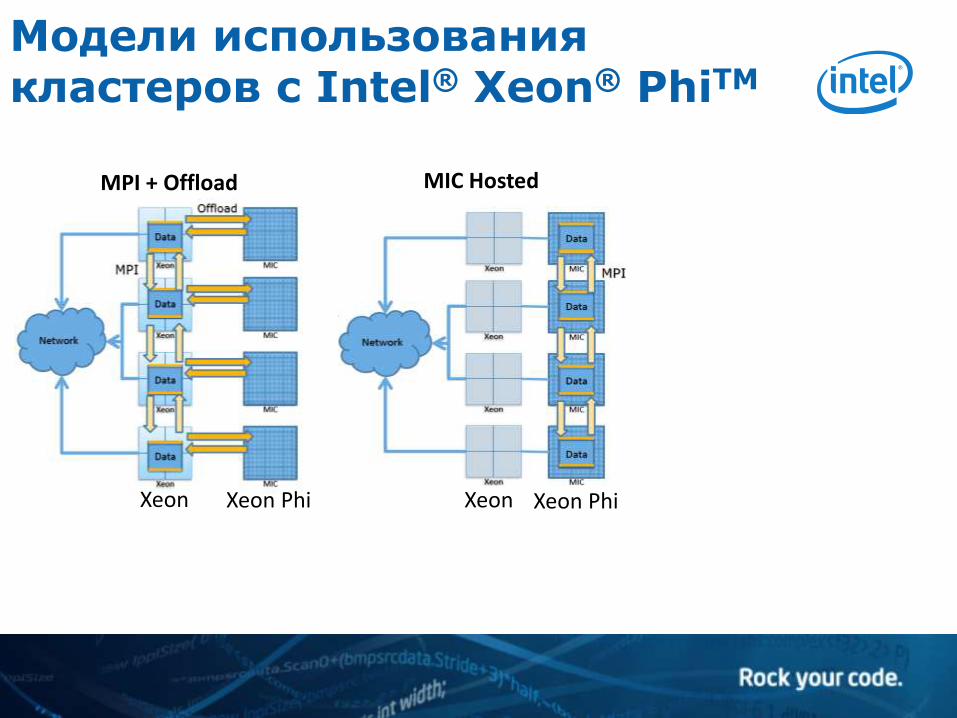
Модели использования кластеров с Intel® Xeon® PhiTM
MPI + Offload MIC Hosted
Xeon Xeon Phi Xeon Xeon Phi
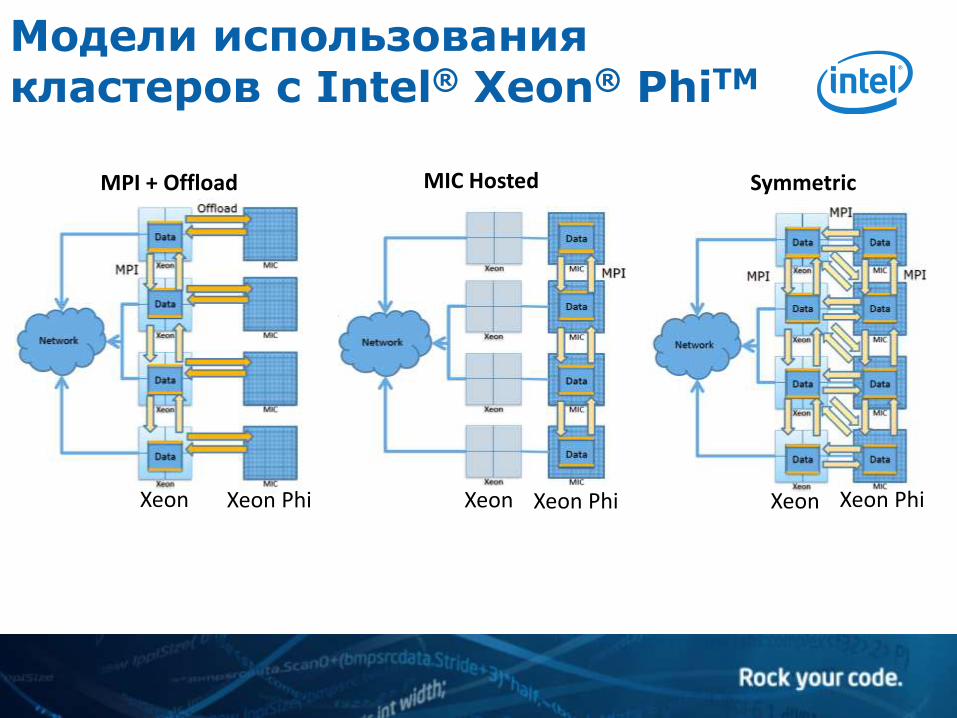
Модели использования кластеров с Intel® Xeon® PhiTM
MPI + Offload MIC Hosted Symmetric
Xeon Xeon Phi Xeon Xeon Phi Xeon Xeon Phi

Начните сегодня!
• Выбирайте подходящую программную модель для вашего приложения
• Векторизуйте ваше приложение
Intel® компилятор
• Параллелизуйте ваше приложение
Intel® CilkTM Plus, OpenMP*, Intel® TBB, MPI
• Заботьтесь об асинхронности вычислений и коммуникаций
Параллельное программирование для Intel® Xeon® сегодня обеспечит производительность на Intel® Xeon® PhiTM завтра
Подробности на intel.com/software/products

C++ для Intel® Graphics Technology Обзор встроенной графики (pGfx) Ivy Bridge:
• Масштабируемость: до 16 многопоточных SIMD исполнительных устройств на варианте GT2
• pGfx L3$ значительно снижает нагрузку на LL$ и память
• Быстрые gather/scatter
• Большой файл регистров
• Поддержка Microsoft* DirectX* 11
• Массовый рынок: ноутбуки, десктопы
Эффективная платформа для гетерогенных вычислений

__declspec(vector(uniform(m, X, Y, Z, n, impact)))
__declspec(target(gtx))
void accel(TYPE *m, TYPE *X, TYPE *Y, TYPE *X, …){
…
for (int j=0; j<n; j++){…}
…
}
#pragma offload target(gtx) \
pin( m, X, Y, Z, X1, Y1, Z1: length(size))
#pragma loop_nest
for (int i=0; i<n; i++) {
accel(m, X, Y, Z, &X[i], &Y[i], &Z[i], …);
}
Примечание: синтаксис может измениться к выпуску компилятора
Для многих алгоритмов: несколько строк кода для перехода к параллельной гетерогенной версии
Векторизуем всю функцию
Генерируем версии для GPU
и CPU
C++ для Intel® Graphics Technology
Примеры: NBody
Делаем данные доступными
на GPU
Указываем, что цикл
параллельный
Генерируем версии для GPU
и CPU

#pragma offload target(gtx) \
pin(A: length(m*k)), pin(B: length(k*n)), pin(C: length(m*n))
#pragma loop_nest collapse(2)
for (int r = 0; r < m; r += TILE_m) {
for (int c = 0; c < n; c += TILE_n) {
float atile[TILE_m][TILE_k], btile[TILE_n], ctile[TILE_m][TILE_n];
ctile[:][:] = 0.0f;
for (int t = 0; t < k; t += TILE_k) {
atile[:][:] = A[r:TILE_m][t:TILE_k];
for (int rc = 0; rc < TILE_k; rc++) {
btile[:] = B[t+rc][c:TILE_n];
for (int rt = 0; rt < TILE_m; rt++)
ctile[rt][:] += atile[rt][rc] * btile[:];
}
}
C[r:TILE_m][c:TILE_n] = ctile[:][:];
}
}
Примечание: синтаксис может измениться к выпуску компилятора
Компилятор разместит эти
массивы в файле регистов
Векторное чтение из памяти
Векторная запись в память
Векторные операции на данных в
регистрах
Примеры: умножение матриц • Кэширование блоков в быстрой памяти (регистрах) • Параллелизация вложенных циклов
C++ для Intel® Graphics Technology

C++ для Intel® Graphics Technology
Примеры: разделение задачи между CPU и GPU
void execute_part(bool do_offload, float * A, float * B, int N)
{
#pragma offload target(gtx) if (do_offload) \
pin(A, B: length(N))
#pragma loop_nest
B[0:N] = my_kernel(A[0:N], N);
}
{
int split = N/2;
_cilk_spawn execute_part(false, A, B, split);
execute_part(true, A + split, B + split, N – split);
}
Примечание: синтаксис может измениться к выпуску компилятора
Делить задачи между CPU и GPU очень просто

Специфика программной модели:
• Подмножество Cilk Plus и #pragma offload
• Только параллельный код: • Параллелизм начинается с #pragma offload
• #pragma loop_nest [collapse(N)] для указания,
что гнездо циклов параллелизуется
• Общие данные между CPU и GPU: • pin(ptr: length(N)) в #pragma offload
• Основные текущие ограничения • Нет SVM, общих указателей, виртуальных функций,
переходов по динамическому адресу, исключений Примечание: синтаксис может измениться к выпуску компилятора
Совместимость с CPU Тривиальный переход к исполнению на MIC
C++ для Intel® Graphics Technology

Резюме:
• Процессоры на базе архитектуры Ivy Bridge со встроенным графическим ядром являются эффективной плаформой для гетерогенных вычислений
• Intel разрабатывает расширения компилятора C/C++ для существенного облегчения разработки гетерогенных приложений
C++ для Intel® Graphics Technology

Уведомление об оптимизации
Компиляторы Intel могут не обеспечивать для процессоров других производителей такой же уровень
оптимизации для оптимизаций, которые не являются присущими только процессорам Intel. В число этих
оптимизаций входят наборы команд SSE2, SSE3 и SSSE3, а также другие оптимизации. Корпорация Intel не
гарантирует наличие, функциональность или эффективность оптимизаций микропроцессоров других
производителей. Содержащиеся в данной продукции оптимизации, зависящие от микропроцессора,
предназначены для использования с микропроцессорами Intel. Некоторые оптимизации, не характерные для
микроархитектуры Intel, резервируются только для микропроцессоров Intel. Более подробную информацию о
конкретных наборах команд, покрываемых настоящим уведомлением, можно получить в соответствующих
руководствах пользователя и справочниках на продукт.
Уведомление, редакция № 20110804





























