Embed Size (px)
Citation preview

SQL Data ServicesUnder The Hood
Gopal KakivayaPartner ArchitectMicrosoft Corporation
BP03
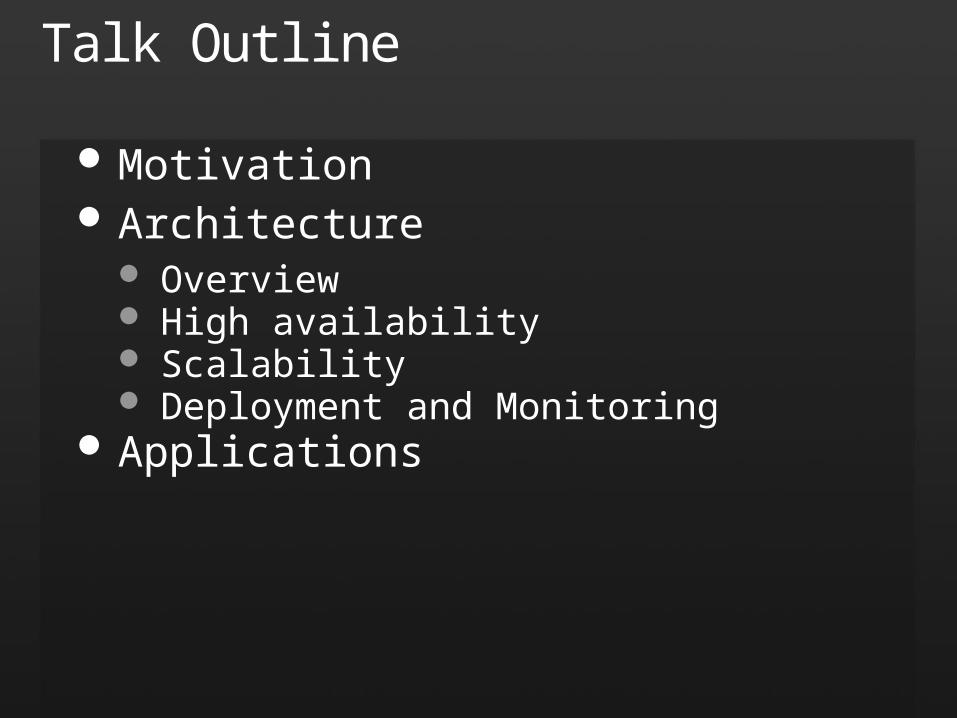
Motivation Architecture
Overview High availability Scalability Deployment and Monitoring
Applications
Talk Outline

Motivation
Azure™ Services Platform

Comprehensive Database Services
Mission critical service Scalable, reliable, available, ubiquitous,
and cost-effective
Data storage
• Blobs• Flexible• Structured• Birth to Archival• Multiple
consistency levels
Data Processing
• Filters• Aggregates• User-defined
logic• Online-Offline
Indexing• Reliable
Data Delivery
• Network proximity aware
• Locate closest static-content copies
• Spanning trees for live-content
• Failure resiliency

Scale Millions of geo-distributed machines, peta-bytes of storage, peta-
flops of computational power, geo-scale content delivery Reduced capital cost
Previous generation processors, IDE/SATA drives Reduced operational cost
Self-monitoring, self-adjusting, and self-healing Predictable, deterministic, and consistent behavior
Not affected by hardware, software, and communications failures Best performance
Innovative algorithms
Requirements

Architecture
Overview Concepts Major subsystems Components
High availability Failure Detection Replication Reconfiguration
Scalability Partition management Operation
Deployment and Monitoring

Distributed systems challenges Scale (storage, processing, and delivery) Consistency (transactions, replication, failure
detection, and failover) Manageability (ease of deployment, self-adjusting
and self-healing) Our approach
Use proven SQL Server database technology as the node storage solution
Use distributed fabric to make the system self-heal and support extreme scale
Automatic bare metal provisioning and bits deployment
Challenges And Our Approach
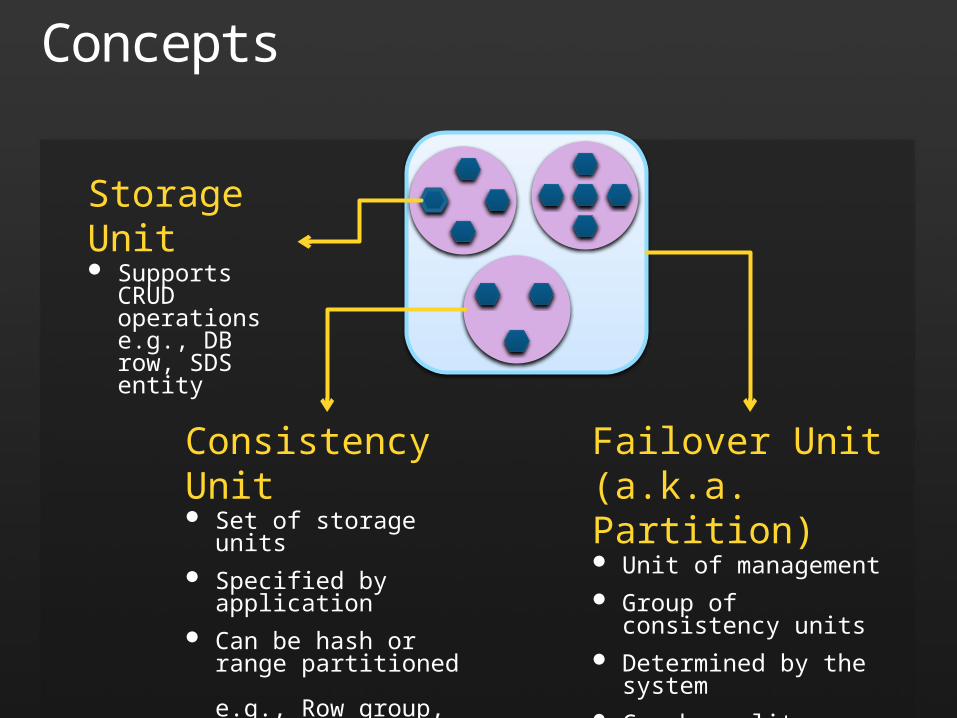
Concepts
Storage Unit Supports CRUD
operations e.g., DB row, SDS entity
Consistency Unit Set of storage units Specified by application Can be hash or
range partitioned e.g., Row group, Database, SDS Container
Failover Unit (a.k.a. Partition) Unit of management Group of consistency units Determined by the system Can be split or merged at
consistency unit boundaries
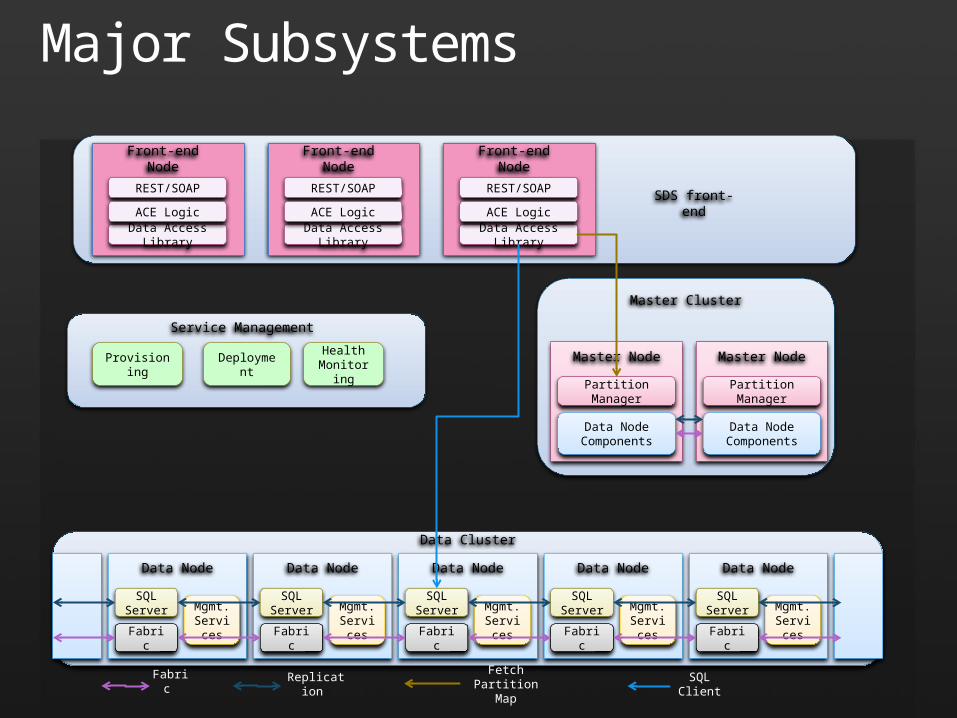
Major Subsystems
Mgmt. Services
Data Node
SQL Server
Fabric
Data Node Components
Partition Manager
Master Node
Mgmt. Services
Data Node
SQL Server
Fabric
Mgmt. Services
Data Node
SQL Server
Fabric
Mgmt. Services
Data Node
SQL Server
Fabric
Deployment Health Monitoring
Service Management
Master Cluster
Data Cluster
Fabric Replication Fetch Partition Map
SQL Client
Mgmt. Services
Data Node
SQL Server
Fabric
Data Node Components
Partition Manager
Master NodeProvisioning
SDS front-end
Data Access Library
REST/SOAP
ACE Logic
Front-end Node
Data Access Library
REST/SOAP
ACE Logic
Front-end Node
Data Access Library
REST/SOAP
ACE Logic
Front-end Node
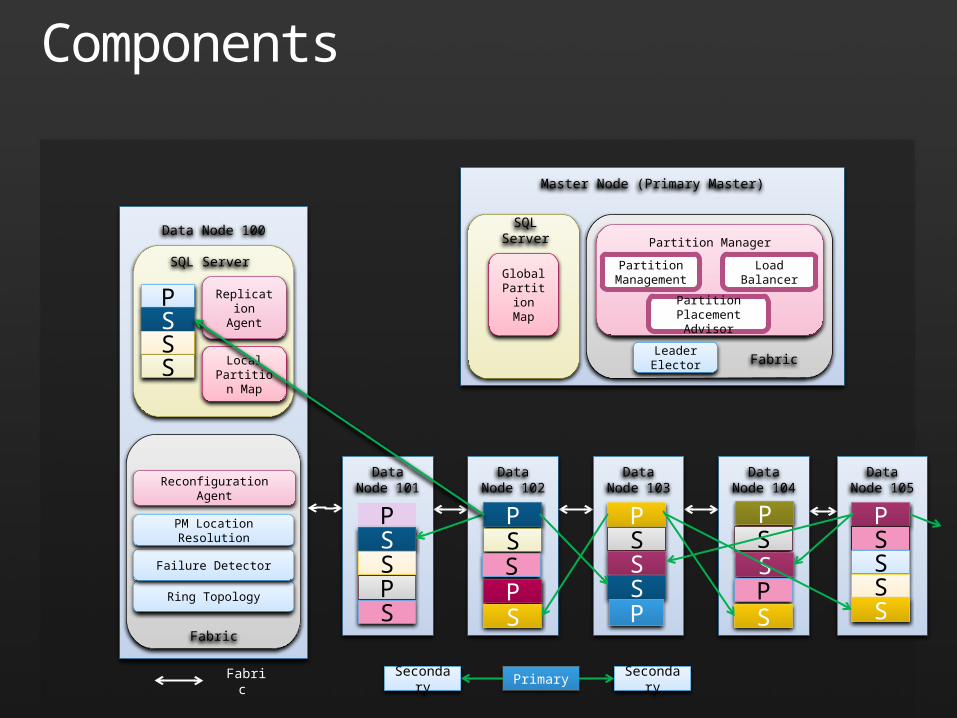
Components
SQL Server
PSSS
Replication Agent
Local Partition
Map
Data Node 100
Master Node (Primary Master)
Primary SecondarySecondary
Fabric
Ring Topology
Failure Detector
PM Location Resolution
Reconfiguration Agent
FabricLeader Elector
Partition Manager
Partition Placement Advisor
SQL Server
Global Partition
Map
Fabric
Data Node 103
PSSSP
Data Node 104
PSSPS
Data Node 102
PSSPS
Data Node 105
PSSSS
Data Node 101
PSSPS
Load BalancerPartition Management
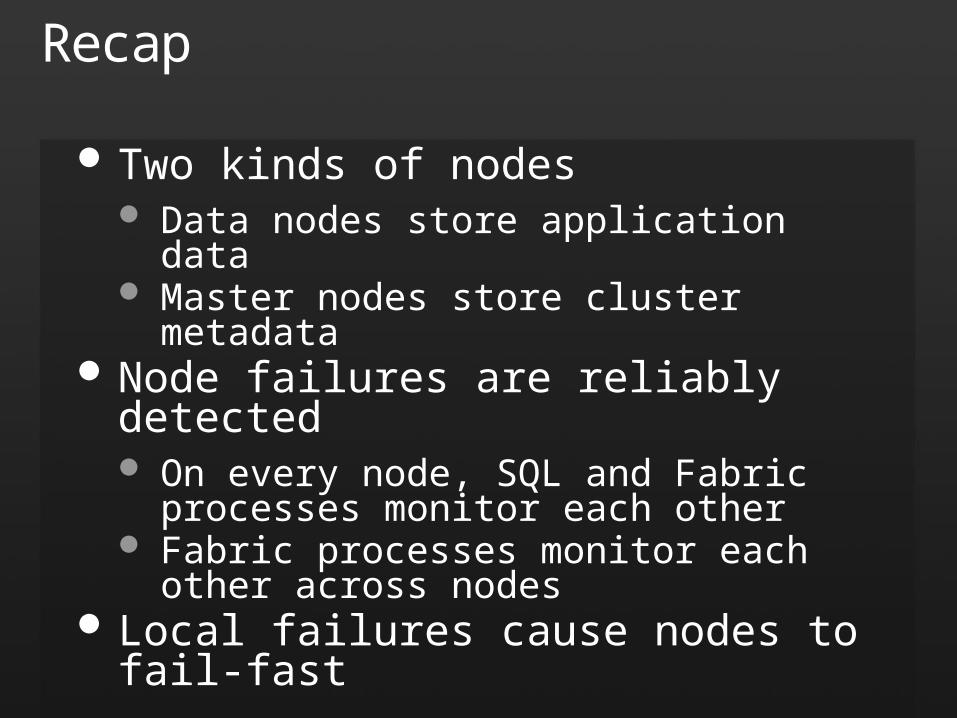
Two kinds of nodes Data nodes store application data Master nodes store cluster metadata
Node failures are reliably detected On every node, SQL and Fabric processes
monitor each other Fabric processes monitor each
other across nodes Local failures cause nodes to fail-fast
Recap
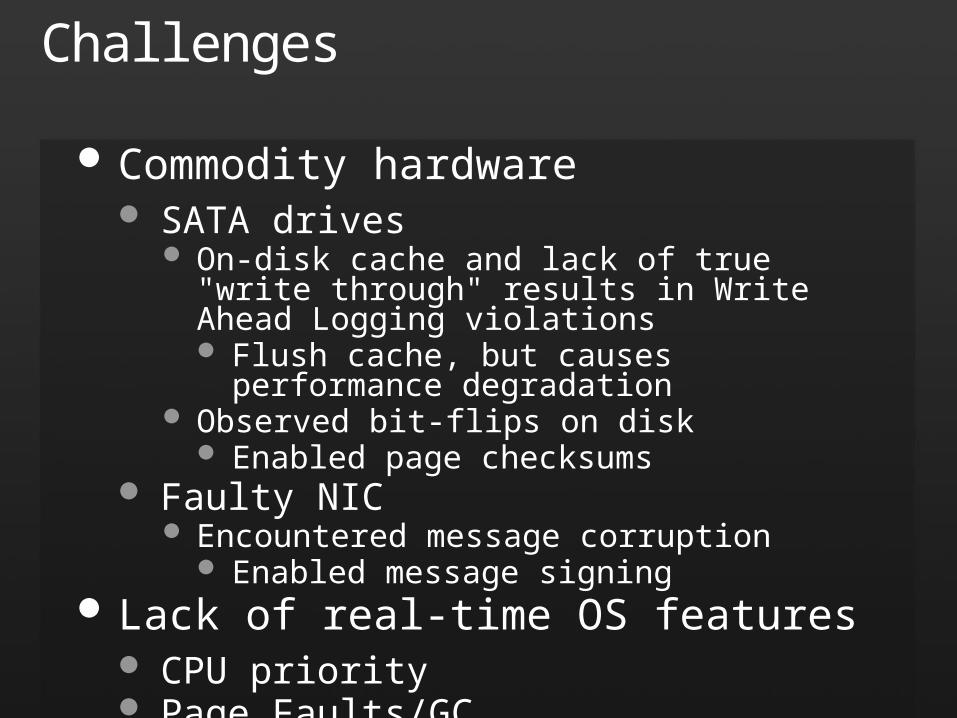
Commodity hardware SATA drives
On-disk cache and lack of true "write through" results in Write Ahead Logging violations Flush cache, but causes performance degradation
Observed bit-flips on disk Enabled page checksums
Faulty NIC Encountered message corruption
Enabled message signing Lack of real-time OS features
CPU priority Page Faults/GC
Challenges

Architecture
Overview Concepts Major subsystems Components
High availability Failure Detection Replication Reconfiguration
Scalability Partition management Operation
Deployment and Monitoring

Failure Detection

Every node is assigned a unique ID (typically a 128-bit or 160-bit number)
Active member nodes reliably form and maintain themselves in an ordered double-linked structure
The active nodes with the highest ID and lowest ID link to each other
This leads to the formation of a ring of active nodes
Rings are bootstrapped by a seed node
Ring Geometry
64
210
0
30
90
135
180
225
50
76
120151 103
200
83
98
174
218
250
40
46
17
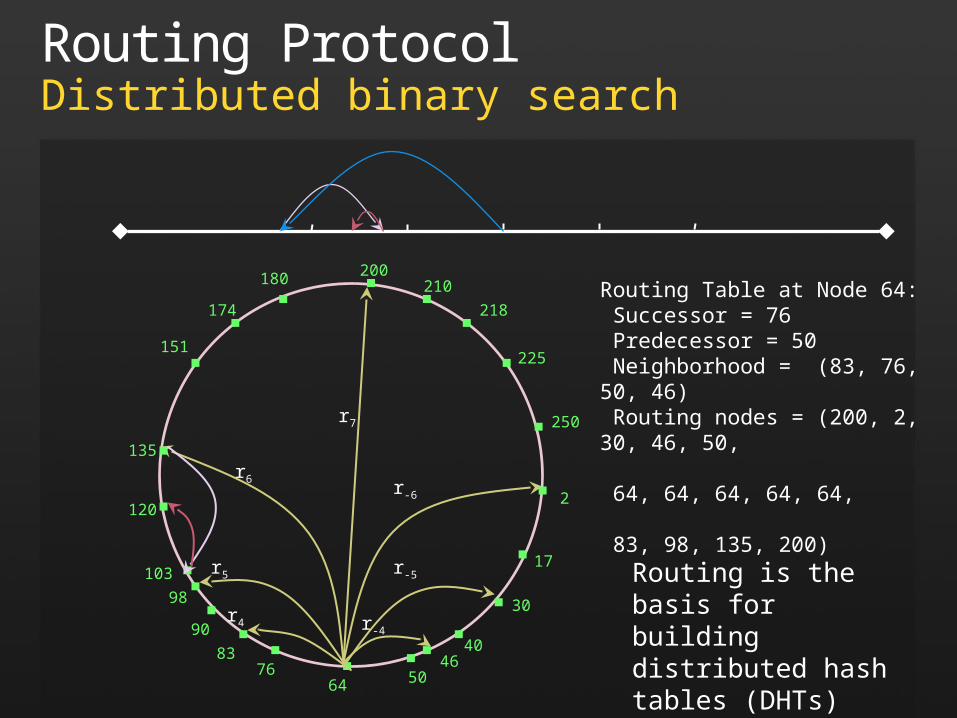
Routing ProtocolDistributed binary search
64
135
120
210
2
3090
180
225
5076
151
103
200
83
98
174 218
250
4046
17
r-6
r-5
r-4
r6
r5
r4
r7
Routing Table at Node 64: Successor = 76 Predecessor = 50 Neighborhood = (83, 76, 50, 46) Routing nodes = (200, 2, 30, 46, 50, 64, 64, 64, 64, 64, 83, 98, 135, 200)
Routing is the basis for building distributed hash tables (DHTs)
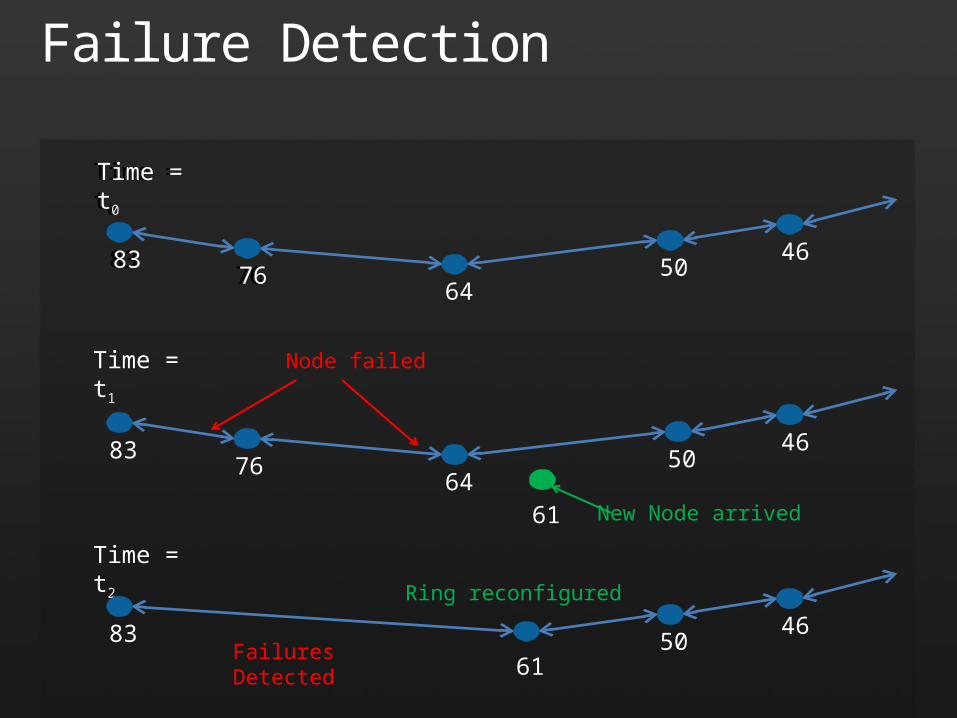
Failure Detection
Time = t1
8376 50
46
64New Node arrived61
Time = t2
8361
5046
Failures Detected
Ring reconfigured
8376
6450
46
Time = t0
8376
Time = t0
Node failed

High Availability

Data needs to be replicated within a replica set for high availability
All clients need to see the same linearized order of read and write operations
Read-Write quorums are supported and are dynamically adjusted
Replica set is dynamically reconfigured to account for member arrivals and departures
Data Consistency
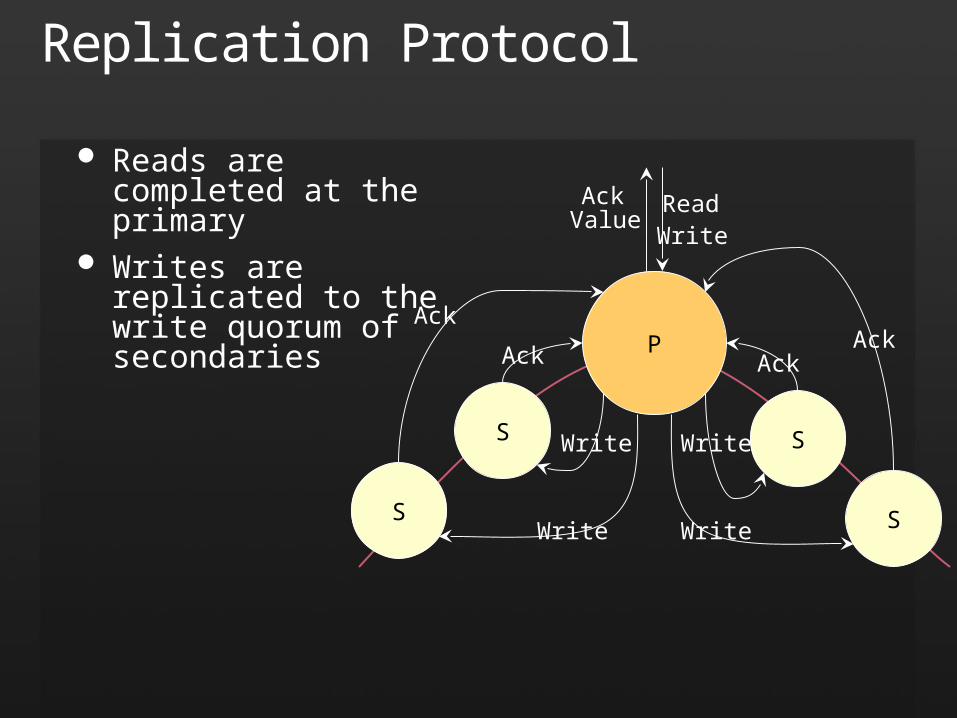
Replication Protocol
Reads are completed at the primary
Writes are replicated to the write quorum of secondaries
P
S
S
S
SWriteWrite
WriteWrite
AckAckAck
Ack
ReadValue
Write
Ack

Reconfiguration
Types of reconfiguration Primary failover Removing a failed secondary Adding recovered replica Building a new secondary
Assumes Failure detector Leader election
P
S
S
S
S
S
Safe in the presence of cascading failures
B PX
Failed
X Failed

Architecture
Overview Concepts Major subsystems Components
High availability Failure Detection Replication Reconfiguration
Scalability Partition management Operation
Deployment and Monitoring

Scalability
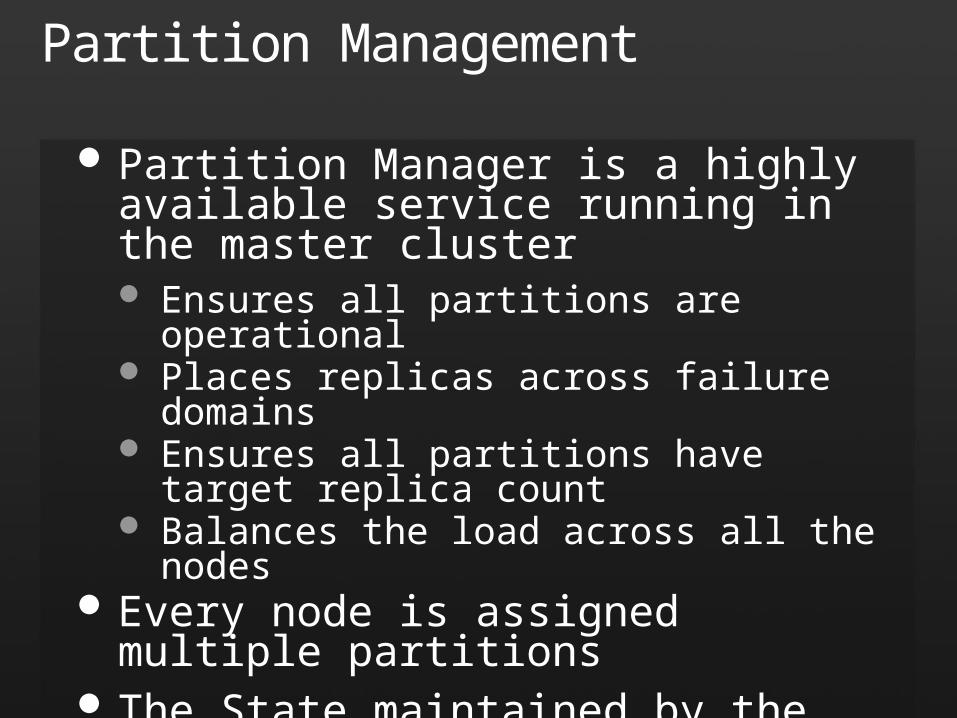
Partition Manager is a highly available service running in the master cluster Ensures all partitions are operational Places replicas across failure domains Ensures all partitions have target replica count Balances the load across all the nodes
Every node is assigned multiple partitions The State maintained by the Partition
Manager can be recreated from the local partition state maintained by the nodes
Partition Management
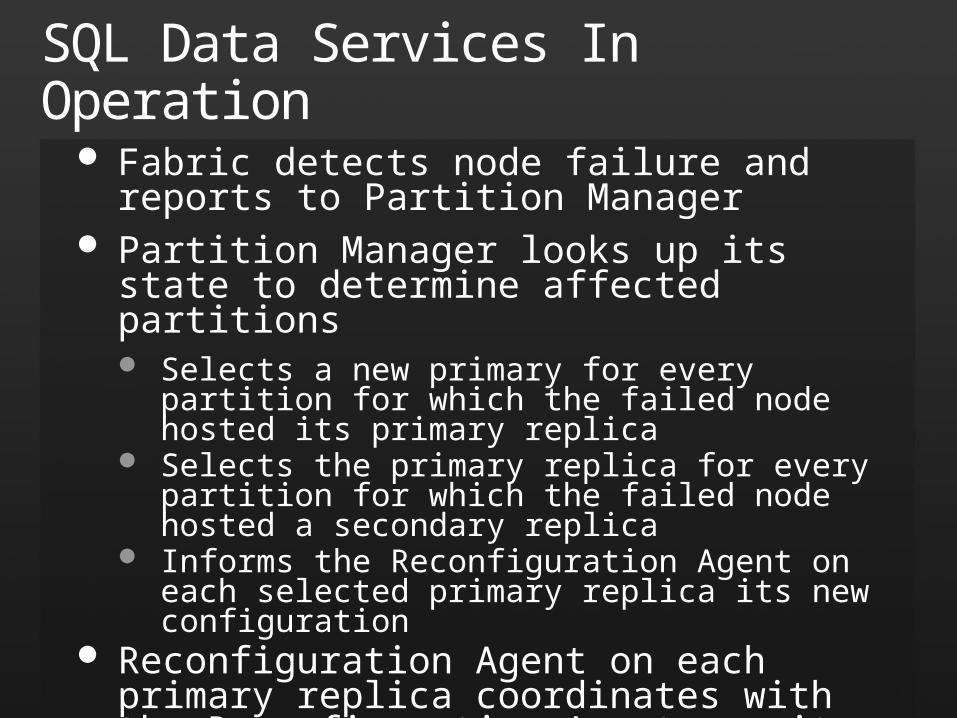
Fabric detects node failure and reports to Partition Manager
Partition Manager looks up its state to determine affected partitions Selects a new primary for every partition for which the
failed node hosted its primary replica Selects the primary replica for every partition for which
the failed node hosted a secondary replica Informs the Reconfiguration Agent on each selected
primary replica its new configuration Reconfiguration Agent on each primary replica
coordinates with the Reconfiguration Agents on its secondary replicas to activate the new configuration
SQL Data Services In Operation
Partition Manager needs to be a highly available service It is hosted in the fabric process of the primary master
node and maintains state in master partition Master nodes fail as well. This implies that master
partition needs to undergo reconfiguration as well. But, there is has no Partition Manager for master cluster…?
Partition Manager plays the role of perfect leader elector for data partitions. In the case of master partition, fabric assumes the perfect leader election role by hosting Partition Manager at Node ID 0 on the ring
The reconfiguration and replications algorithms are the same between data and master partitions and are reused
Reliable Master

Architecture
Overview Concepts Major subsystems Components
High availability Failure Detection Replication Reconfiguration
Scalability Partition management Operation
Deployment and Monitoring
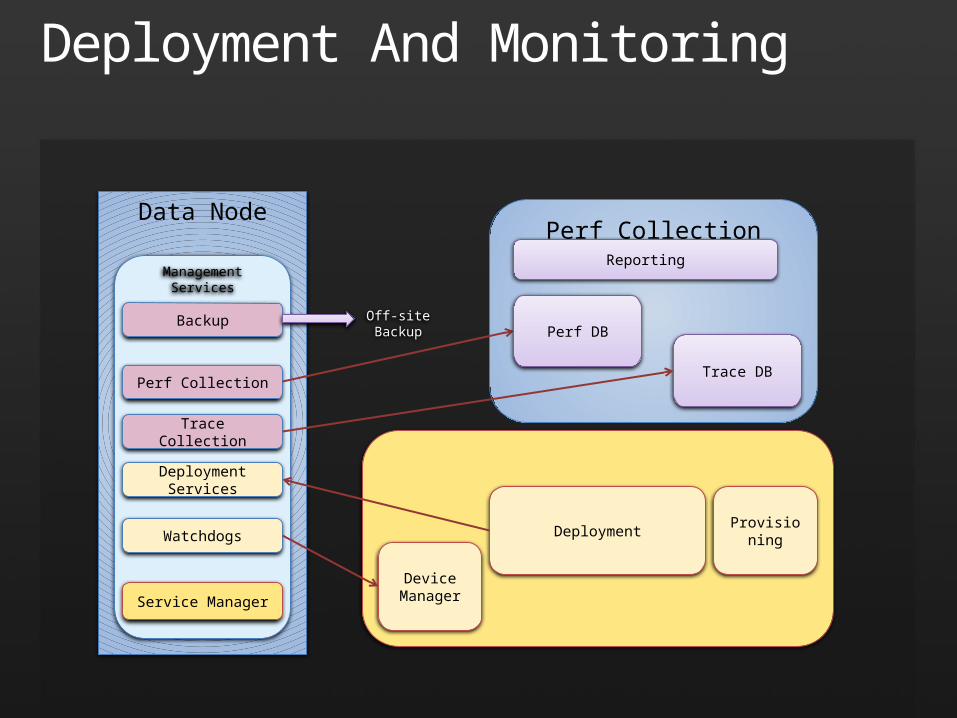
Deployment And Monitoring
Data Node
Device Manager
ProvisioningDeployment
Service Manager
Watchdogs
Management Services
Deployment Services
Perf Collection
Backup
Perf Collection Cluster
Perf DB
Reporting
Off-site Backup
Trace Collection
Trace DB

Future Work
Delta backup and restore Differential b-trees Distributed transactions Geo-replication
Synchronous – replica set spans datacenters Asynchronous – independent replica sets in
different datacenters Distributed Materialized Views Job framework Distributed query

Applications
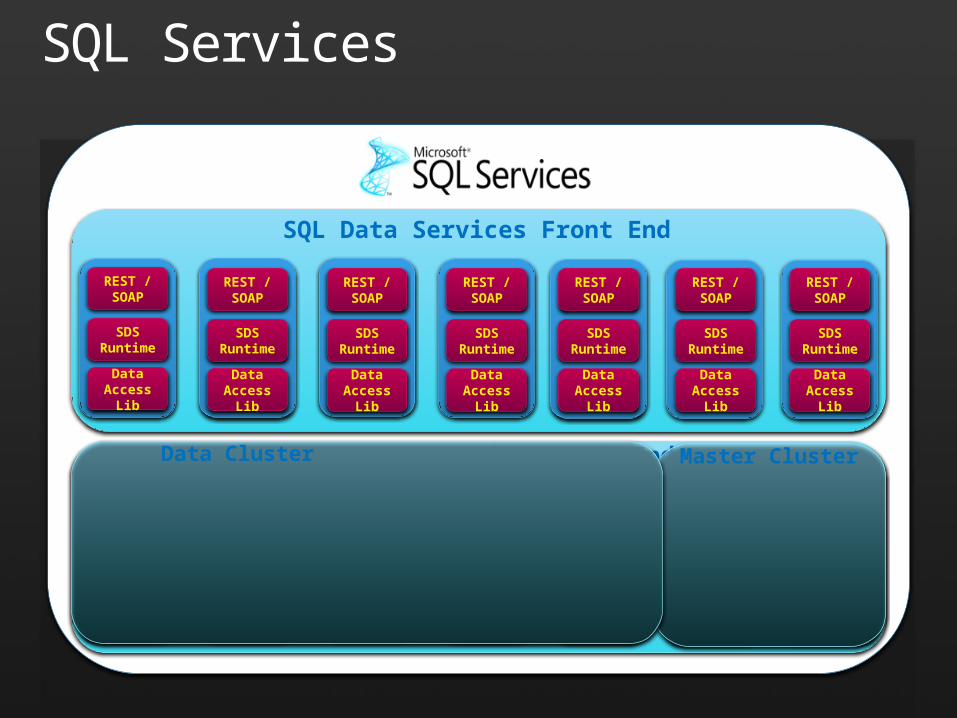
SQL Services
Data Access Lib
SDS Runtime
REST / SOAP
Data Access Lib
SDS Runtime
REST / SOAP
Data Access Lib
SDS Runtime
REST / SOAP
Data Access Lib
SDS Runtime
REST / SOAP
Data Access Lib
SDS Runtime
REST / SOAP
Data Access Lib
SDS Runtime
REST / SOAP
Data Access Lib
SDS Runtime
REST / SOAP
Mgmt. Services
Distributed Data Fabric
SQL Server
Mgmt. Services
Distributed Data Fabric
SQL Server
Mgmt. Services
Distributed Data Fabric
SQL Server
Mgmt. Services
Distributed Data Fabric
SQL Server
Mgmt. Services
Distributed Data Fabric
SQL Server
Mgmt. Services
Distributed Data Fabric
SQL Server
Mgmt. Services
Distributed Data Fabric
SQL Server
SQL Data Services Front End
SQL Data Services Back End Master ClusterData Cluster
Distributed cache for ASP.NET session state SQL server at nodes replaced with a key-
value in-memory store Uses the same distributed fabric algorithms
as SDS for achieving scalability and availability
Velocity
Evals & Recordings
Please fill
out your
evaluation for
this session at:
This session will be available as a recording at:
www.microsoftpdc.com

Please use the microphones provided
Q&A

© 2008 Microsoft Corporation. All rights reserved. Microsoft, Windows, Windows Vista and other product names are or may be registered trademarks and/or trademarks in the U.S. and/or other countries.The information herein is for informational purposes only and represents the current view of Microsoft Corporation as of the date of this presentation. Because Microsoft must respond to changing market
conditions, it should not be interpreted to be a commitment on the part of Microsoft, and Microsoft cannot guarantee the accuracy of any information provided after the date of this presentation. MICROSOFT MAKES NO WARRANTIES, EXPRESS, IMPLIED OR STATUTORY, AS TO THE INFORMATION IN THIS PRESENTATION.






























