Embed Size (px)
Citation preview

Снежана Георгиева Гочева-Илиева
МАРКЕТИНГОВИ ИЗСЛЕДВАНИЯ
Факултет по математика, информатика и информационни технологии
Пловдивски университет „Паисий Хилендарски“
Пловдив, 2013

2
Съдържание
ЛЕКЦИЯ 7. Класификационни и регресионни дървета. Построяване на класификационни и регресионни дървета с метода CART. Процедури с SPSS. ......................................................................... 3 Въведение в методите на класификационните и регресионни дървета - (CART) методи ............................................................................................ 3 Приложения на CART методите ................................................................ 6 Алгоритъм на метода на класификационните и регресионни дървета .. 8 Регресионно CART дърво с 1 зависима и 1 независима променлива .. 10 Регресионно дърво с повече от един предиктор .................................... 13 Кросвалидация ........................................................................................... 15 Класификация и регресия с дървета с SPSS ........................................... 17 Построяване на дървета в SPSS ............................................................... 19

3
ЛЕКЦИЯ 7. Класификационни и регресионни дървета. Построяване на класификационни и регресионни дървета с метода CART. Процедури с SPSS. Въведение в методите на класификационните и регресионни дървета - (CART) методи
Методът на класификационните и регресионни дървета CART е предложен през 1984 г. от Л. Бреймън, Дж. Фрийдмън, Р. Олшен и С. Стоун. Съществуват различни варианти на CART, напр. CHAID, ExhaustiveCHAID и др.
Като регресионна техника CART методът се определя като рекурсивно-разделяща регресия. Целта е разделяне на данните в относително хомогенни (с ниско стандартно отклонение или с минимална обща грешка по метода на най-малките квадрати) крайни

4
възли и получаване на средна наблюдавана стойност при всеки краен възел като прогнозна стойност.
За зададена обучителна извадка моделната функция в CART има вида
X X1
ˆ ˆˆm
Y I Y I
X
(1)
където XI
е равно на 1, ако X и 0 в противен случай, m - брой крайни възли. Нека грешката на предсказване (loss function) от дървото T е:
2
1
1ˆ ˆn
i ii
L y yn
, (2)

5
където ˆ ˆi iy X e предсказаната стойност за наблюдението iX . Грешката ˆL има минимална стойност при ˆiy Y , където
Y е средната стойност на iy за всички наблюдения, принадлежащи на възел , т.е.
1ˆ
i
iY Y yn
X
, (3)
за n - брой на наблюденията във възел . По този начин, дървото може да се разглежда и като p-мерна хистограма на данните, където p е броят на входните променливи 1 2, ,..., pX X X .

6
Приложения на CART методите
Сегментиране: Позволява автоматично разпределяне на наблюденията по групи, например разделяне на клиентите на фирма на групи по най-съществените им предпочитания.
Класификация в степувани групи: Разделяне на наблюденията в категории чрез степенуване, напр. висока категория, средна, ниска
Предсказване: Създаване на правила и използването им за предсказване на бъдещи събития, напр. доколко някой се очаква да изпадне в неплатежноспособност, или е готов да рискува да продаде имота си или леката си кола.
Намаляване на размерността на задачата (броя на променливите и/или случаите): Подбор на подмножество от

7
предиктори като най-полезни за анализа и създаване на модел, описващ достатъчно добре цялия обем от данни.
Разкриване на взаимодействия: Отделяне на специфични подгрупи в извадката, които си взаимодействат.
Сливане на категории и дискретизиране на непрекъснати променливи: Преподреждане на групови предиктори и непрекъснати променливи с минимална загуба на информация.
Пример: Банка иска да класифицира кандидатите за кредит, доколко са податливи на риск – слаборискови или силнорискови за изплащане на кредита им, което може да зависи от много фактори. За целта се използват известни данни за стари клиенти на банката.

8
Алгоритъм на метода на класификационните и регресионни дървета
Метод CART. Изгражда се двоично дърво, което започва от възел-родител, съдържащ всички наблюдения от обучителната извадка. На всяка стъпка от построяване на дървото на решенията (за всеки текущ възел) се използва правило, което дели съвкупността от наблюдения във възела на две подсъвкупности, съгласно условиe за минимизиране на грешката от тип (2) за текущото подмножество наблюдения относно някой от предикторите, напр. kX . Условието има вида k jX или k jX , (4) където j е търсена прагова стойност измежду стойностите на kX във възела. Ако за дадено наблюдение от текущия възел това условие е

9
изпълнено, той преминава към група на левия наследствен възел, в противен случай – преминава към десния наследствен възел. Така разделянето по възли се повтаря многократно до достигане на краен възел tR . Поставят се и други условия за растеж на дървото като минимален брой наблюдения в краен възел, дълбочина и др. Като резултат се получава т. нар. максимално дърво maxT .
На втора стъпка полученото максимално дърво се редуцира (свива) с
помощта на някакъв допълнителен критерий и се получава редица от дървета:
max 0 1 2 3 ... MT T T T T T , (5)
с MT - оптимално дърво. Обикновено , 1,2,...,qT q M се оценява с помощта на независима тестова извадка чрез крос-валидация. Грешката на моделирането с V-разделна крос-валидация (V-fold CV).

10
Регресионно CART дърво с 1 зависима и 1 независима променлива
Най-напред ще даден прост пример за построяване на двоично дърво по данните от таблицата с едно разделяне (само 2 поддървета).
Пример 1. Нека са дадени независима променлива (предиктор) x и зависима променлива y с 10 наблюдения.
i xi yi 1 1 10 2 1 12 3 1 11 4 1 10 5 2 12 6 2 14 7 2 13 8 3 15 9 3 16
10 3 16
В случая имаме 3 различни възможни стойности за прагова стойност j от формула (4) по предиктора x.
1j , с първите 4 стойности; средна стойност ymean=10.8 2j , със средните 3 стойности; ymean=11.7; 3j , с последните 3 стойности; ymean=12.9.
Тези средни са и предсказванията ˆiy за всяко наблюдение.
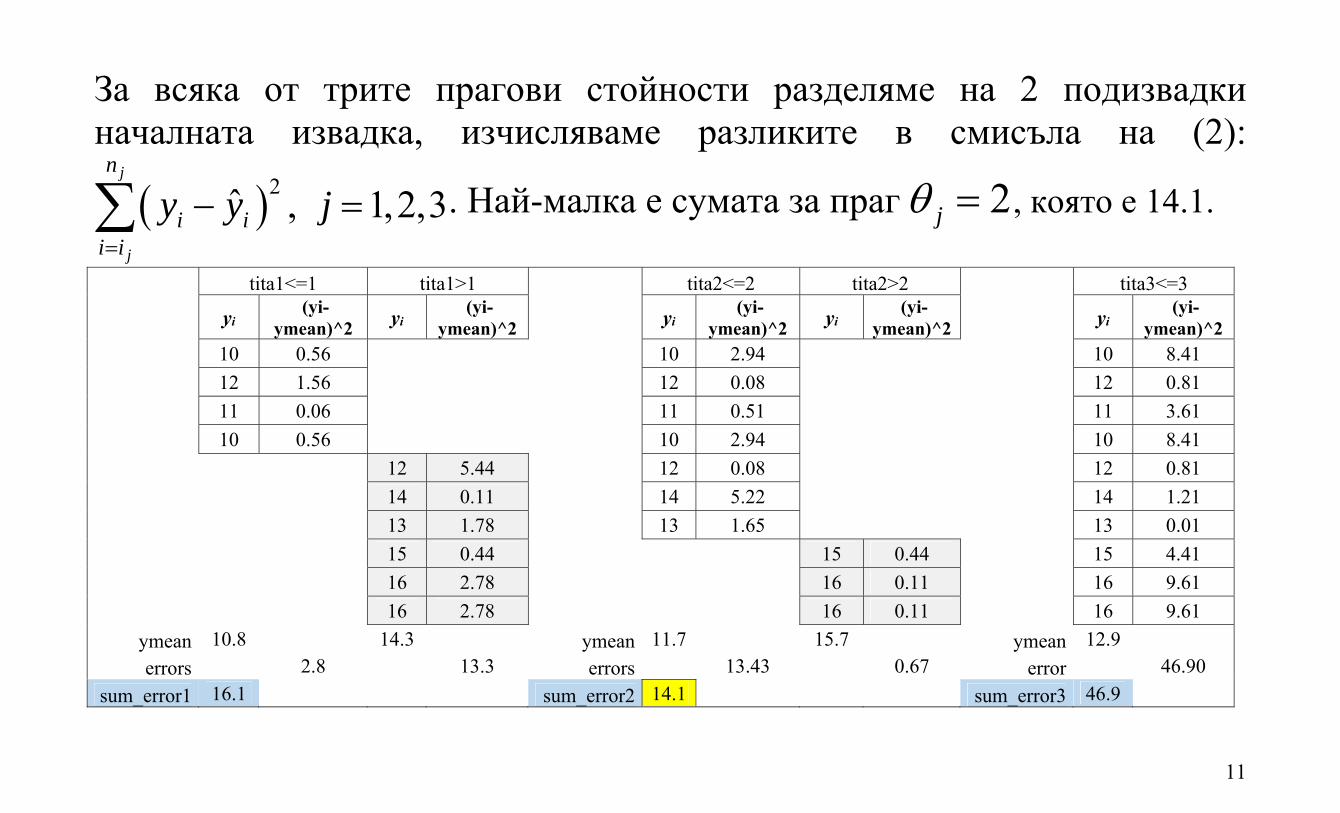
11
За всяка от трите прагови стойности разделяме на 2 подизвадки началната извадка, изчисляваме разликите в смисъла на (2):
2ˆ , 1,2,3j
j
n
i ii i
y y j
. Най-малка е сумата за праг 2j , която е 14.1.
tita1<=1 tita1>1 tita2<=2 tita2>2 tita3<=3
yi (yi-ymean)^2 yi (yi-
ymean)^2 yi (yi-ymean)^2 yi (yi-
ymean)^2 yi (yi-ymean)^2
10 0.56 10 2.94 10 8.41 12 1.56 12 0.08 12 0.81
11 0.06 11 0.51 11 3.61 10 0.56 10 2.94 10 8.41 12 5.44 12 0.08 12 0.81 14 0.11 14 5.22 14 1.21 13 1.78 13 1.65 13 0.01 15 0.44 15 0.44 15 4.41 16 2.78 16 0.11 16 9.61 16 2.78 16 0.11 16 9.61 ymean 10.8 14.3 ymean 11.7 15.7 ymean 12.9 errors 2.8 13.3 errors 13.43 0.67 error 46.90
sum_error1 16.1 sum_error2 14.1 sum_error3 46.9
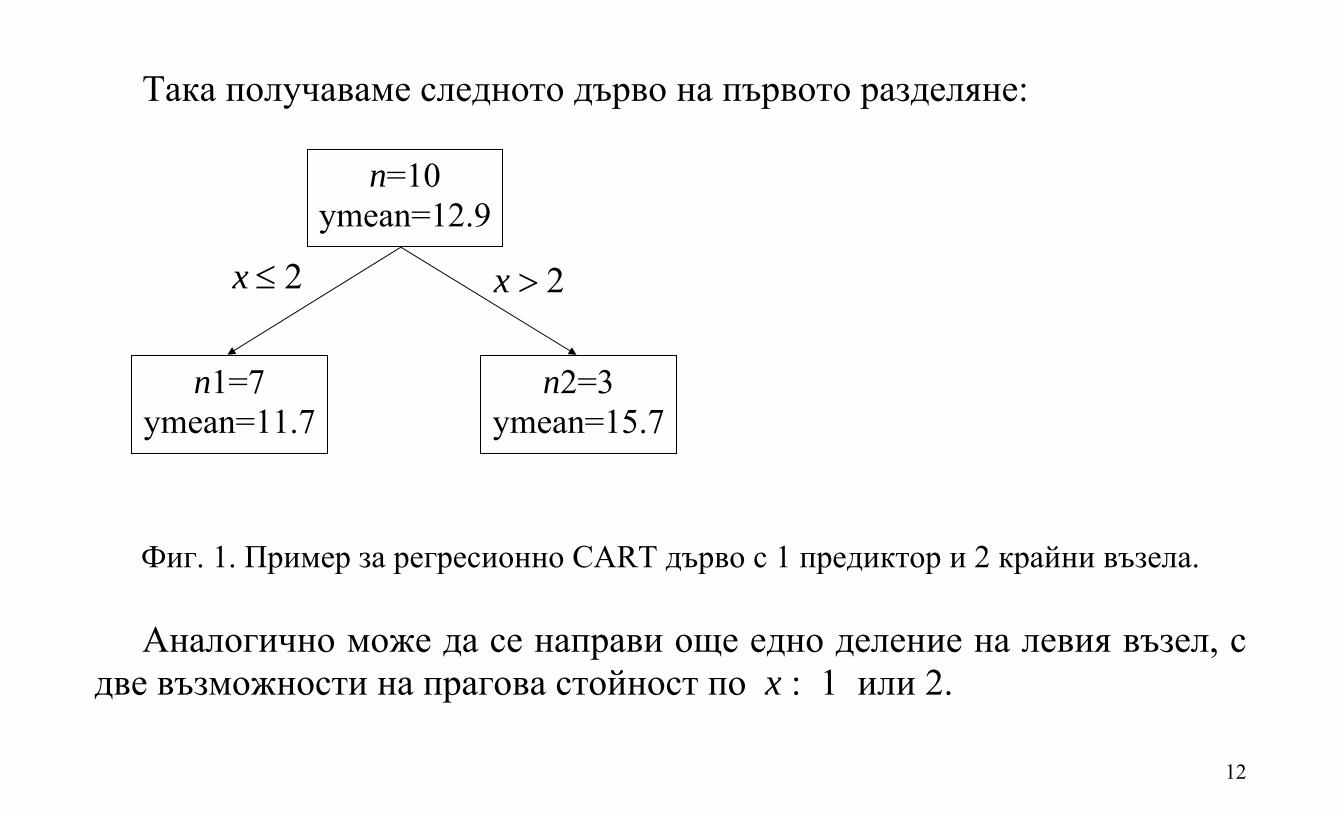
12
Така получаваме следното дърво на първото разделяне: Фиг. 1. Пример за регресионно CART дърво с 1 предиктор и 2 крайни възела. Аналогично може да се направи още едно деление на левия възел, с
две възможности на прагова стойност по x : 1 или 2.
2x 2x
n=10 ymean=12.9
n1=7 ymean=11.7
n2=3 ymean=15.7

13
Регресионно дърво с повече от един предиктор Когато има 2 и повече предиктора, алгоритъмът работи така. За всеки получен възел се изпробват всички възможни прагови
стойности по първата независима променлива, както в случая на един предиктор. Определя се минималната грешка и съответната прагова стойност. Същото се прави за втората и т.н. за всики други предиктори. От всички минимални грешки, се избира променливата, чиято минимална грешка е май-малка и се прави подразделяне на текущия възел със съответния праг.
За да не се стигне до много малки подизвадки и да се оптимизира дървото, се задават минимален брой наблюдения за родителски и за краен възел, както и други контролни параметри на алгоритъма.
Пример на регресионно дърво с 1 зависима и 2 независими променливи е даден на Фиг. 2.
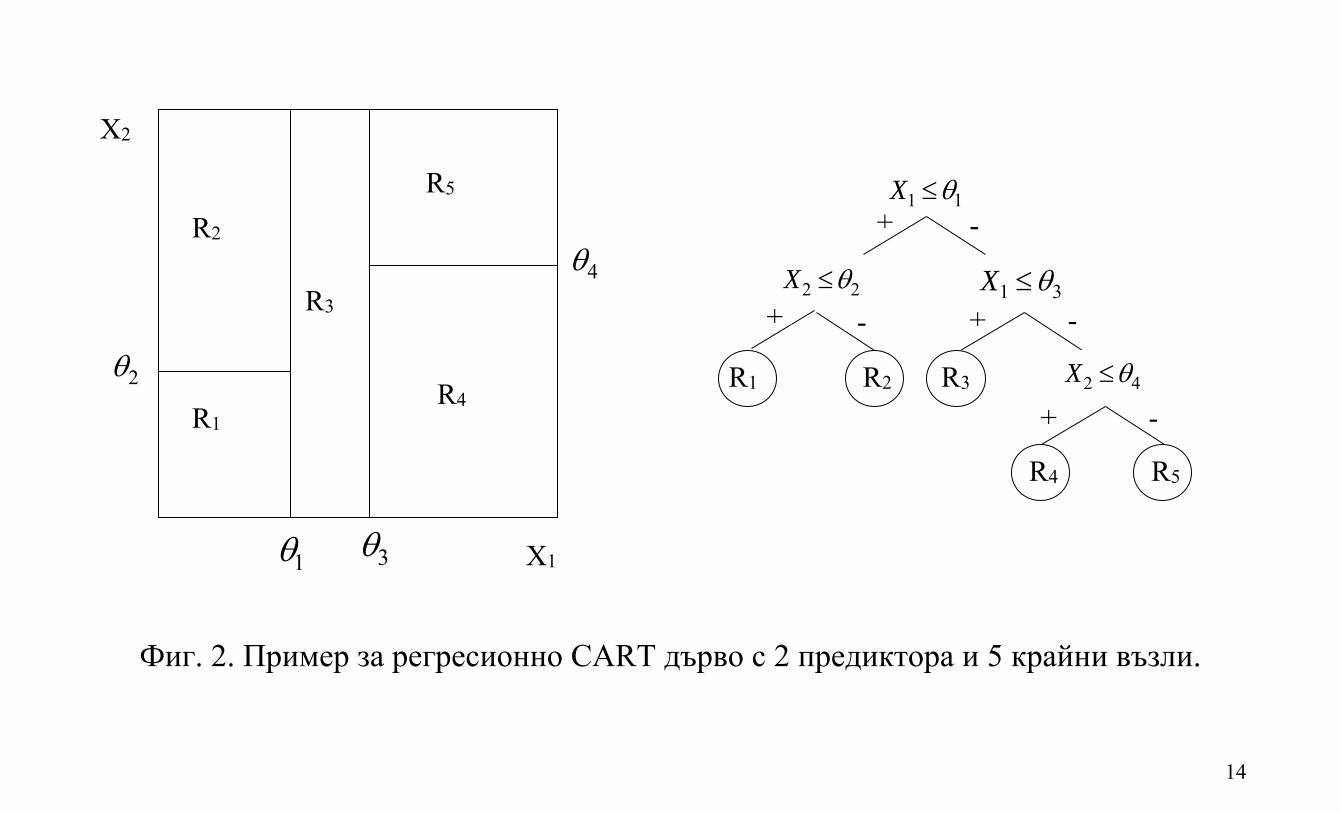
14
Фиг. 2. Пример за регресионно CART дърво с 2 предиктора и 5 крайни възли.
2 2X 1 3X
1 1X
2 4X R1 R2 R3
R4 R5
+
+ +
+
-
- -
-
1
3
R2
R1
R3
R4
R5
4
2
X1
X2

15
Кросвалидация Ако изберем V=10, т.е. 10-разделна крос-валидация, то разделяме по
случаен начин обучаващата извадка на 10 (почти) равни подгрупи. За всяка една подгрупа използваме останалите 9 като обучителна извадка за построяване и редуциране на дърво, с което се предсказват наблюденията от отделената подгрупа (тестова извадка).
Ще използваме основно варианта CART. Алгоритми на различни варианти на метода са реализирани също в пакетите STATISTICA, R и др.
Регресионните дървета са сравнително лесен метод за предсказване на зависимата променлива, но регресионната функция е прекъсната. Освен това не е възможно автоматично включване на локални взаимодействия между предикторните променливи.

16
Полученият модел може да се прилага за оценка и за предсказване на бъдещи наблюдения, които според установените правила ще попаднат в точно един краен възел на дървото и ще получат като предсказана стойност на зависимата променлива средната стойност на този краен възел.

17
Класификация и регресия с дървета с SPSS Цел на анализа. Построяване на аналитично дърво, моделиращо
данните с помощта на правила. Получаване на крайните възли на дървото (Terminal nodes) и изчисляване на средната стойност за всеки краен възел, която да послужи за предсказване на стойност за попадащите в този възел данни.
SPSS методи за нарастване на дървото:
CHAID метод. Автоматично откриване на взаимодействия. Този метод на всяка стъпка избира тази независима променлива, която най-силно влияе на зависимата, например чрез регресия. Категориите на всяка независима променлива (наричана още предиктор) се сливат, ако те не са статистически различни спрямо зависимата променлива.

18
Exhaustive CHAID. Модификация на CHAID, която опитва всички възможни разделяния за всеки предиктор. Дървото не е непременно двоично. CRT. Classification and Regression Trees. CRT e вариантът на CART (двоично дърво), който разделя данните на сегменти (групи) които са колкото е възможно по-хомогенни спрямо зависимата променлива. Краен възел, в който всички случаи (наблюдения, cases) имат една и съща стойност на зависимата променлива е хомогенен и се нарича „чист“ възел. QUEST. Бързо получавано, неизместено, ефективно статистическо дърво (Quick, Unbiased, Efficient Statistical Tree). Може да групира предикторите. QUEST работи само ако зависимата променлива е номинална.

19
Построяване на дървета в SPSS Ще използваме данни от файловете на IBM SPSS от папката : C:\Program Files\IBM\SPSS\Statistics\21\Samples\English Пример 1. За първия пример използваме файла с данни: tree_textdata.sav Той има само 2 променливи: Dependent и Independent, с размер на
извадката n = 1000. Данните са от интервален тип (Scale). Възможно е предефиниране на данните като номинални и
изполването на съответен метод с дървета. Ще направим класификация на случаите (наблюденията) с метода
CRT на SPSS за построяване на разрешаващи дървета (Decision trees).
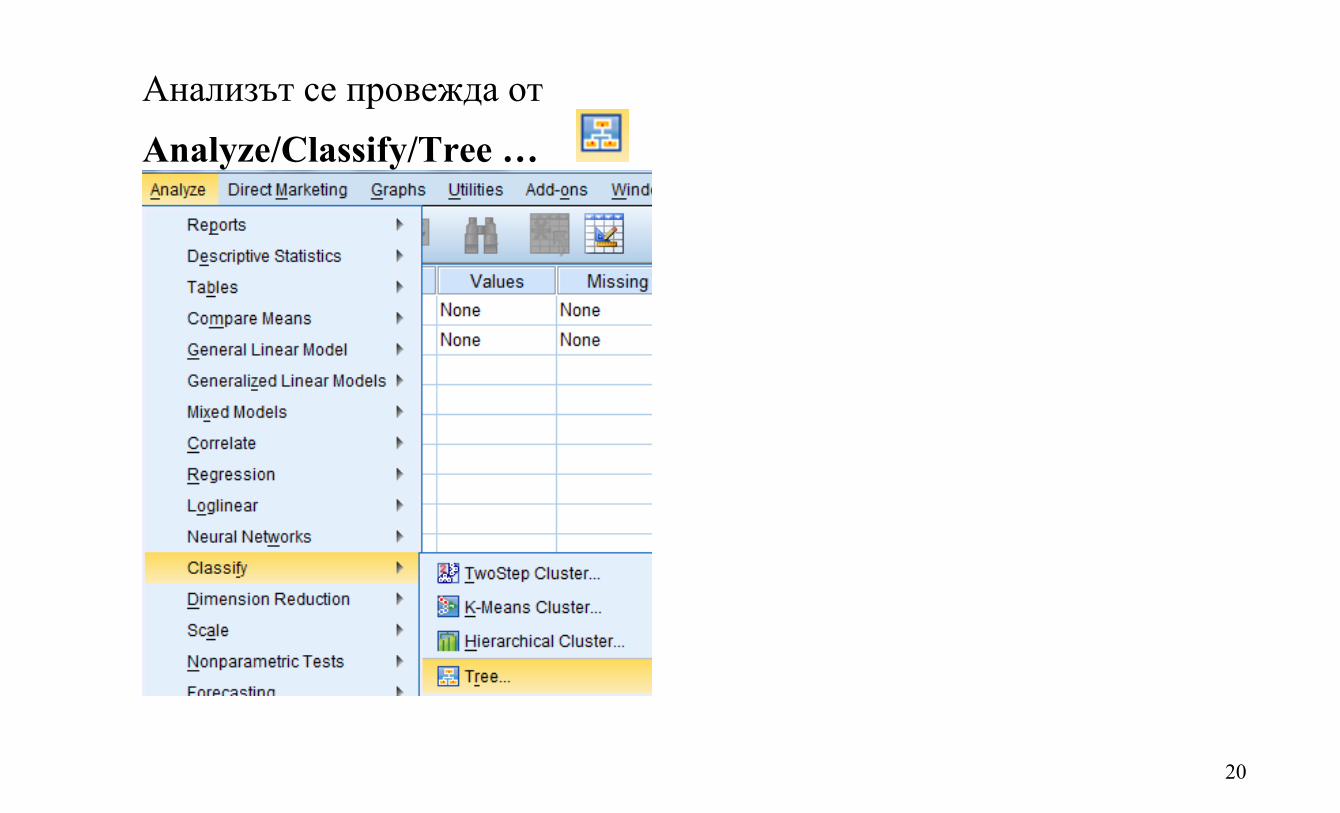
20
Анализът се провежда от Analyze/Classify/Tree …

21
Отваря се прозорецът Decision tree, в който пренасяме променливите от лявото поле, както е показано и избираме CRT в Growing Method:
Настройка на изхода –
показване на дървото, правилата и др.
Настройка на правилата за валидиране на анализа
Задаване на критерии на анализа
Запомняне на предсказаните стойности
Избор на метод
22
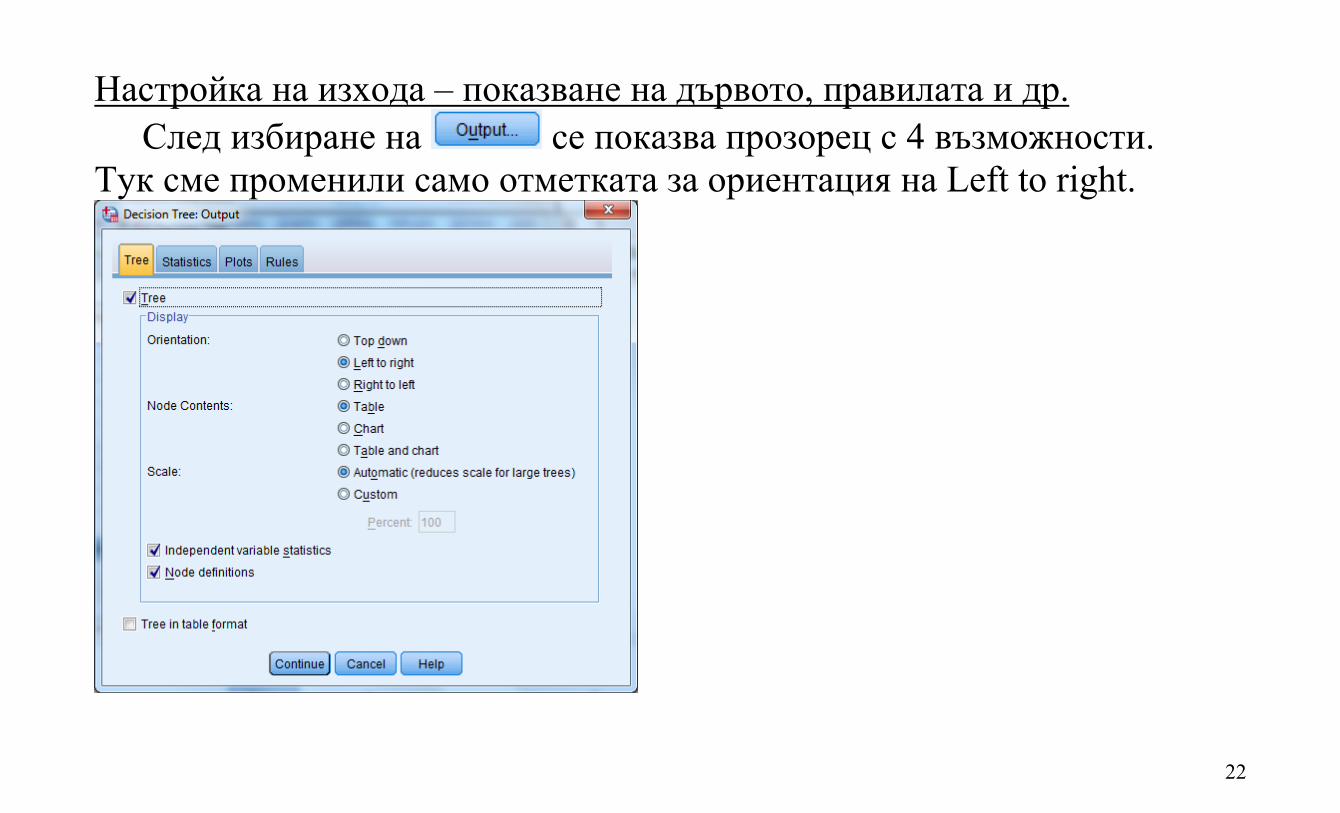
Настройка на изхода – показване на дървото, правилата и др. След избиране на се показва прозорец с 4 възможности.
Тук сме променили само отметката за ориентация на Left to right.
23
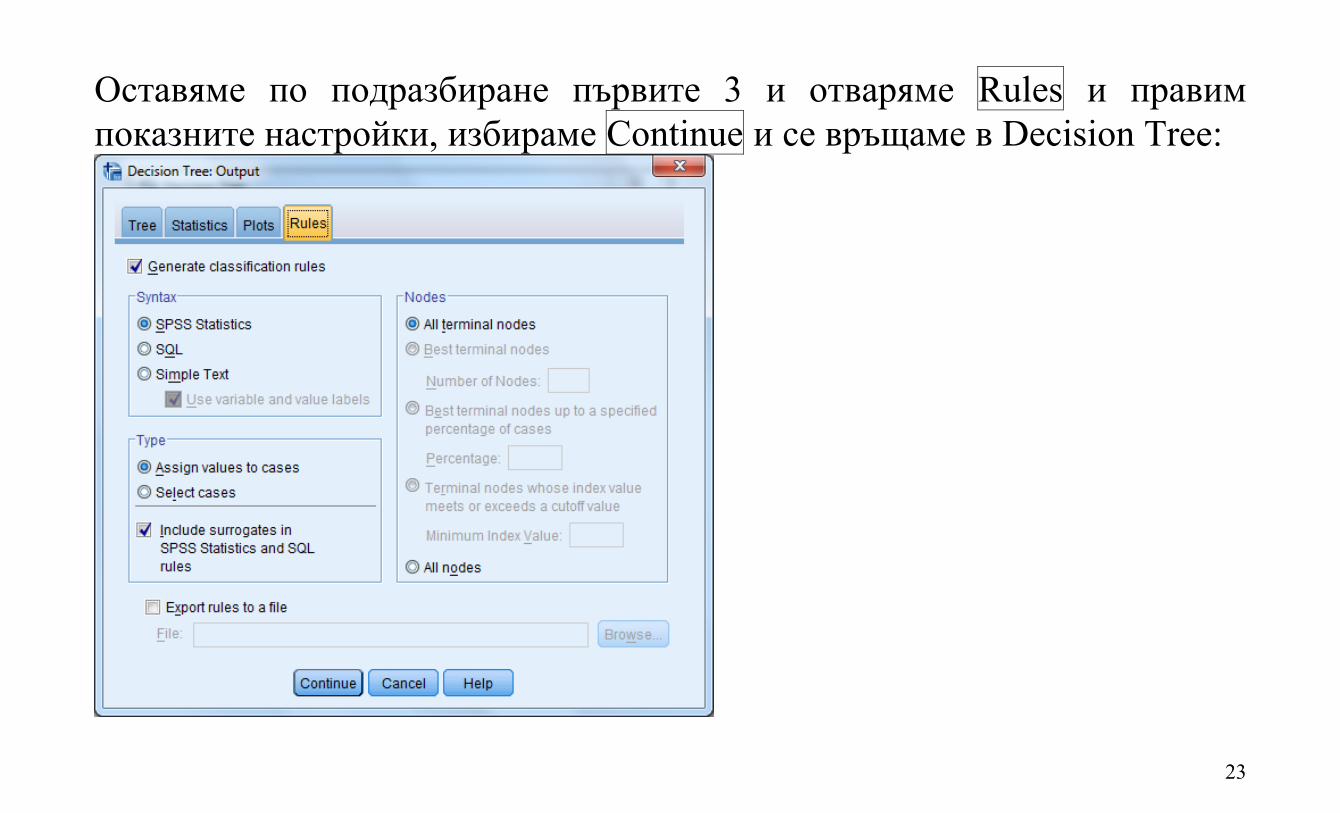
Оставяме по подразбиране първите 3 и отваряме Rules и правим показните настройки, избираме Continue и се връщаме в Decision Tree:
24
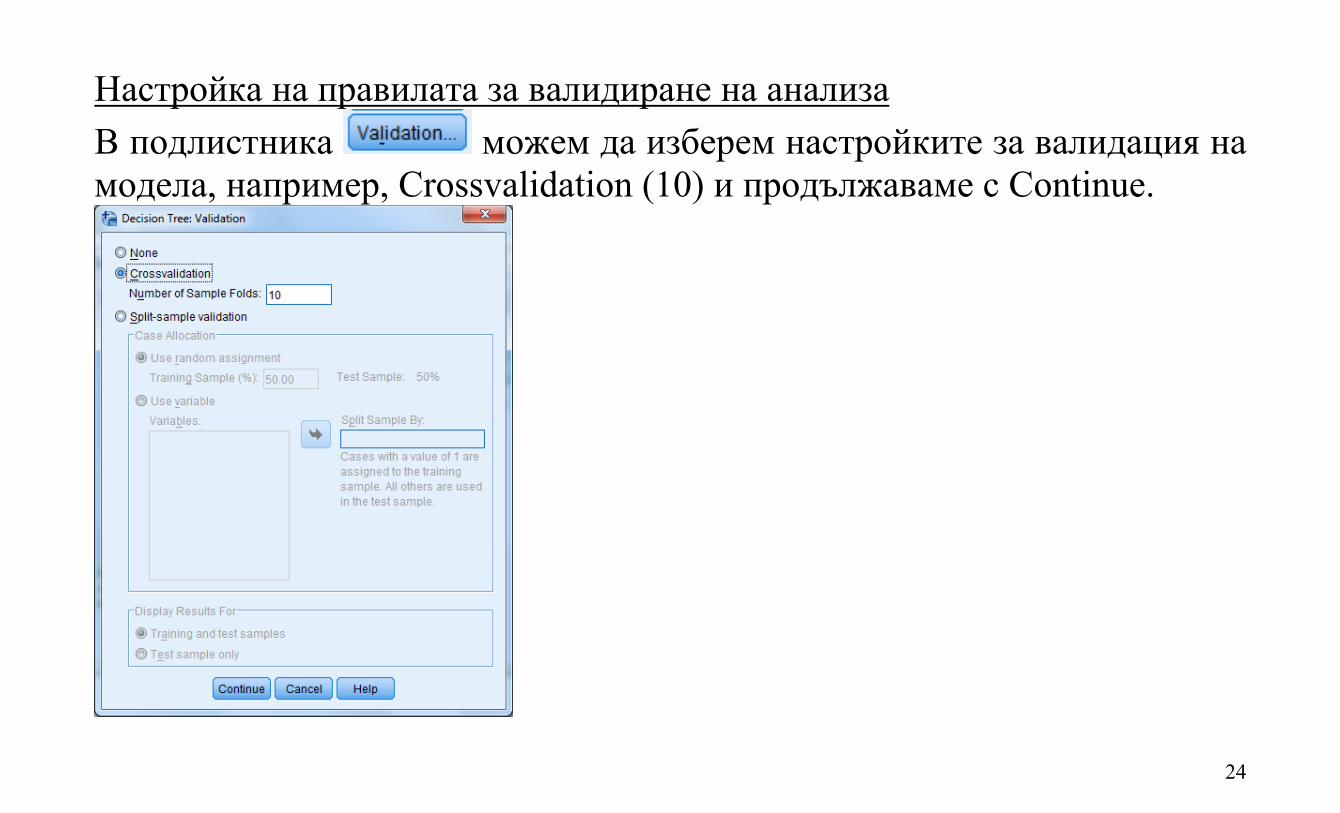
Настройка на правилата за валидиране на анализа В подлистника можем да изберем настройките за валидация на модела, например, Crossvalidation (10) и продължаваме с Continue.
25
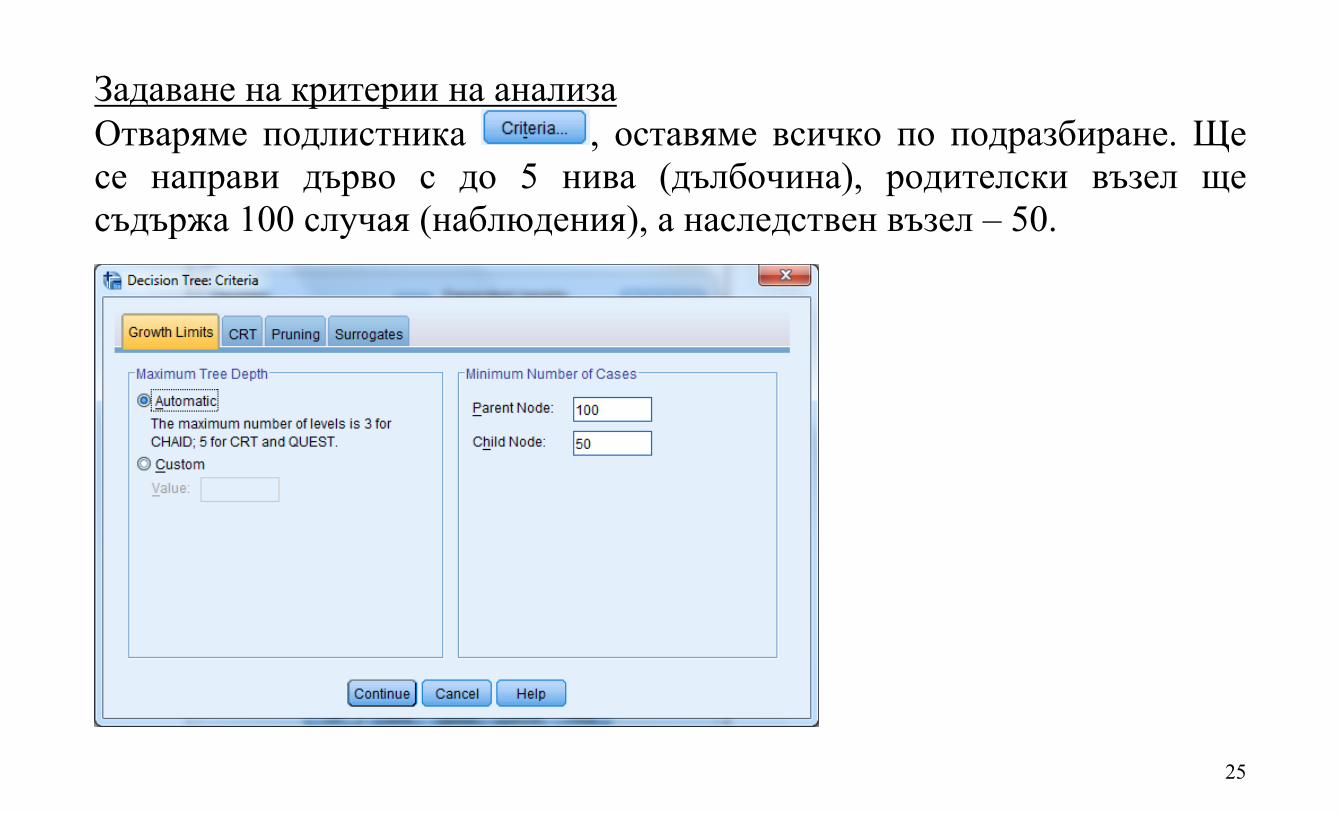
Задаване на критерии на анализа Отваряме подлистника , оставяме всичко по подразбиране. Ще се направи дърво с до 5 нива (дълбочина), родителски възел ще съдържа 100 случая (наблюдения), а наследствен възел – 50.
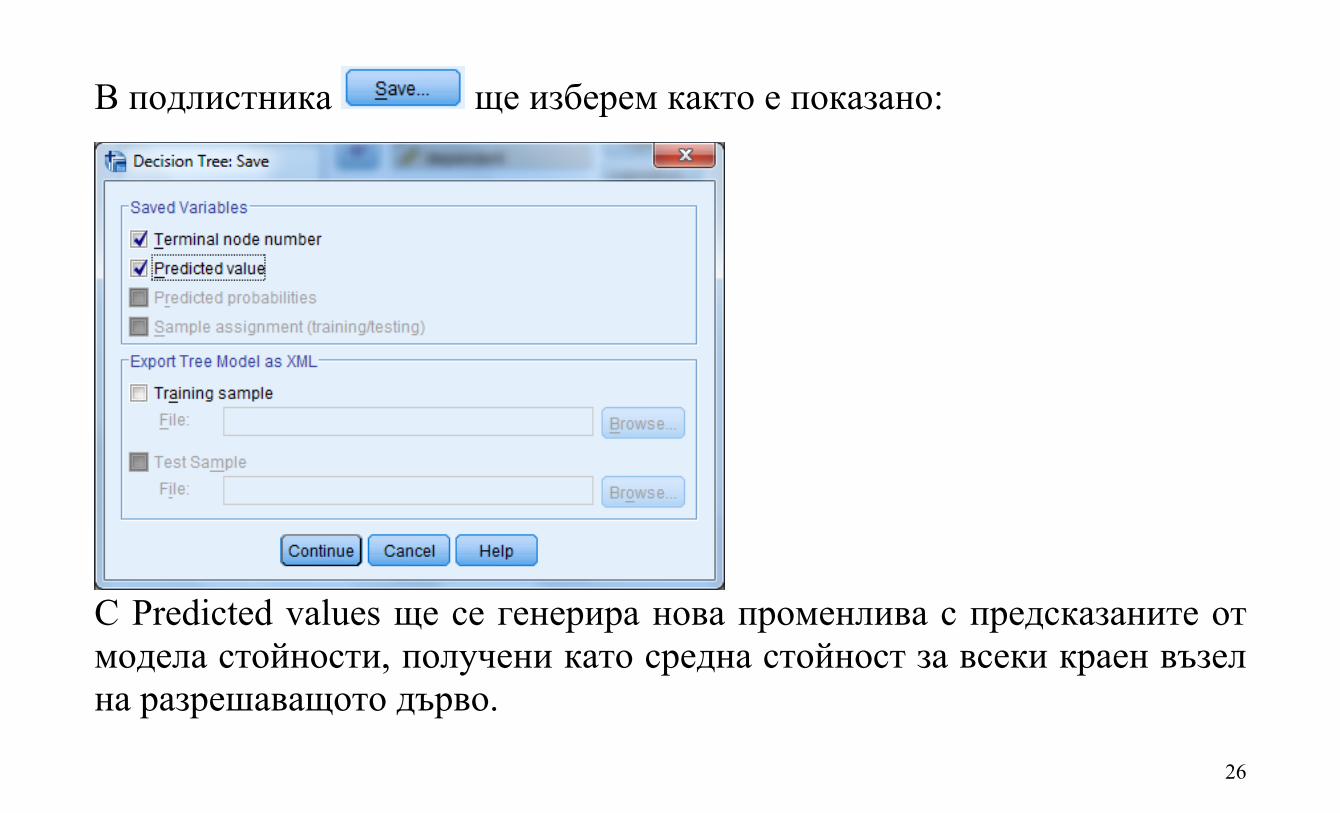
26
В подлистника ще изберем както е показано:
С Predicted values ще се генерира нова променлива с предсказаните от модела стойности, получени като средна стойност за всеки краен възел на разрешаващото дърво.

27
С Continue се връщаме в основния прозорец на анализа Decision Tree и можем да го старираме с . Получаваме следните резултати:
Model Summary
Specifications
Growing Method
CRT
Dependent Variable
dependent
Independent Variables
independent
Validation Cross Validation Maximum Tree Depth
5
Minimum Cases in Parent Node
100
Minimum Cases in Child Node
50
Results
Independent Variables Included
independent
Number of Nodes
7
Number of Terminal Nodes
4
Depth 3
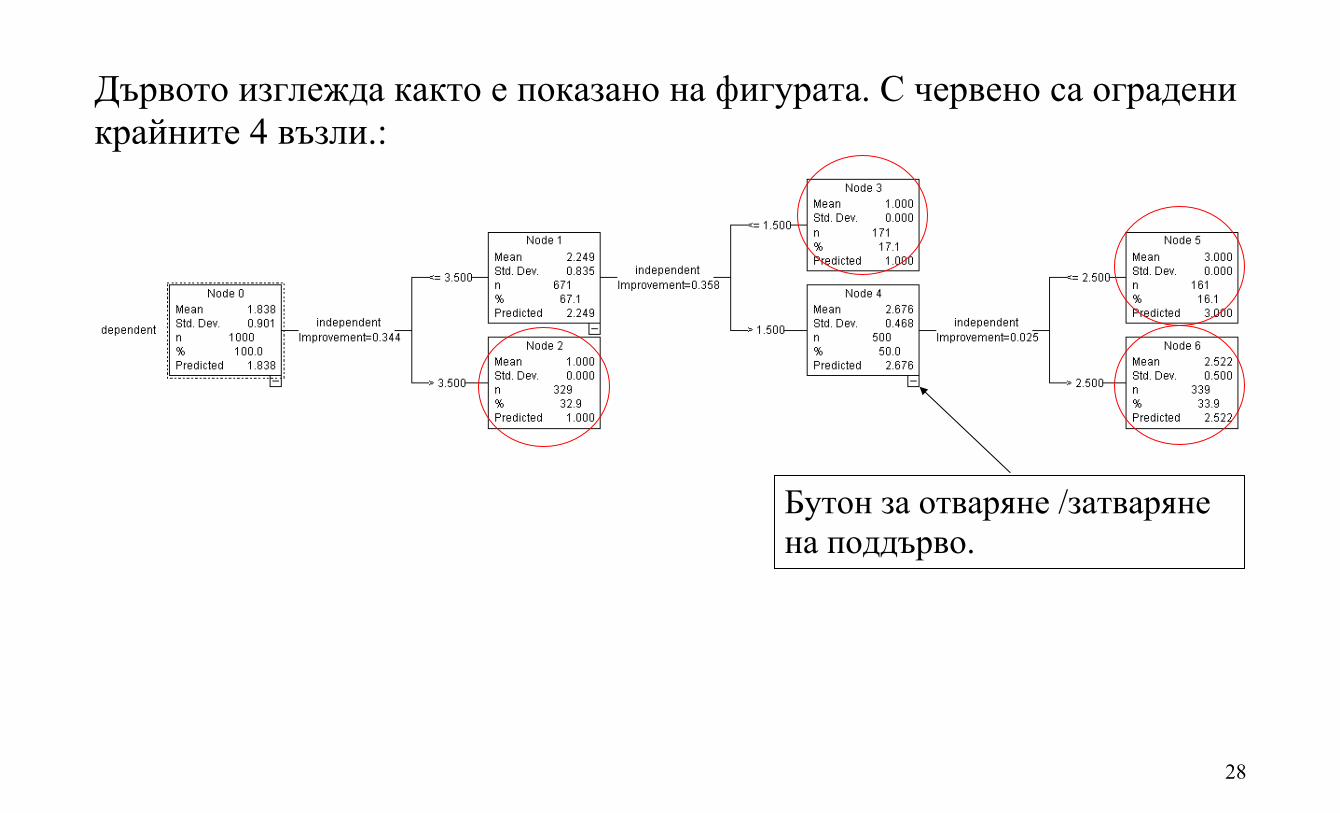
28
Дървото изглежда както е показано на фигурата. С червено са оградени крайните 4 възли.:
Бутон за отваряне /затваряне на поддърво.
29
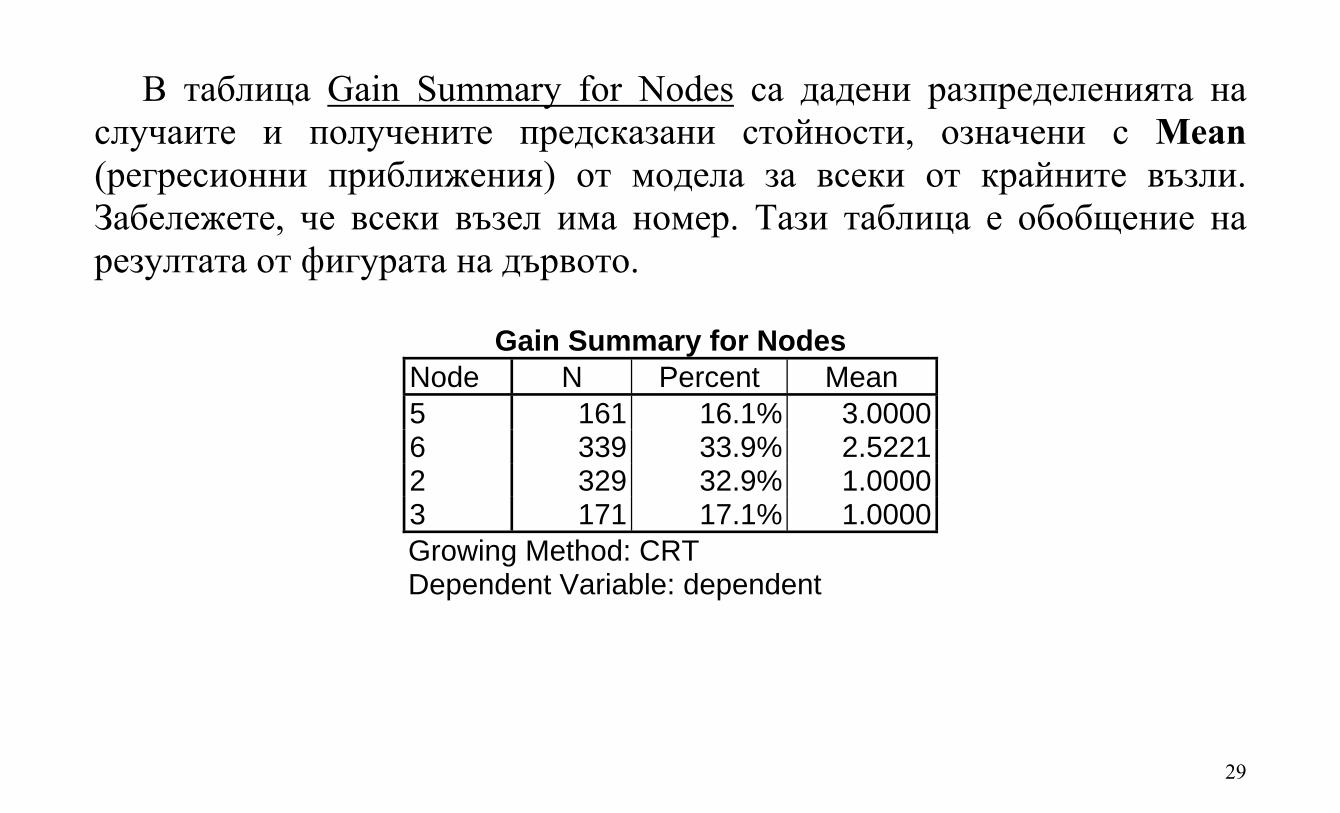
В таблица Gain Summary for Nodes са дадени разпределенията на случаите и получените предсказани стойности, означени с Mean (регресионни приближения) от модела за всеки от крайните възли. Забележете, че всеки възел има номер. Тази таблица е обобщение на резултата от фигурата на дървото.
Gain Summary for Nodes Node N Percent Mean 5 161 16.1% 3.00006 339 33.9% 2.52212 329 32.9% 1.00003 171 17.1% 1.0000Growing Method: CRT Dependent Variable: dependent

30
Таблицата Risk показва степента на точност на получените от модела предсказани стойности и стандартната грешка.
Risk Method Estimate Std. Error Resubstitution .085 .004Cross-Validation .086 .004Growing Method: CRT Dependent Variable: dependent
Предсказаното и кросвалидацията трябва да са близки. В нашия случай данните са 1000 и тези показатели, както и малката грешка на модела в последната колона, показват, че моделът е много добър.
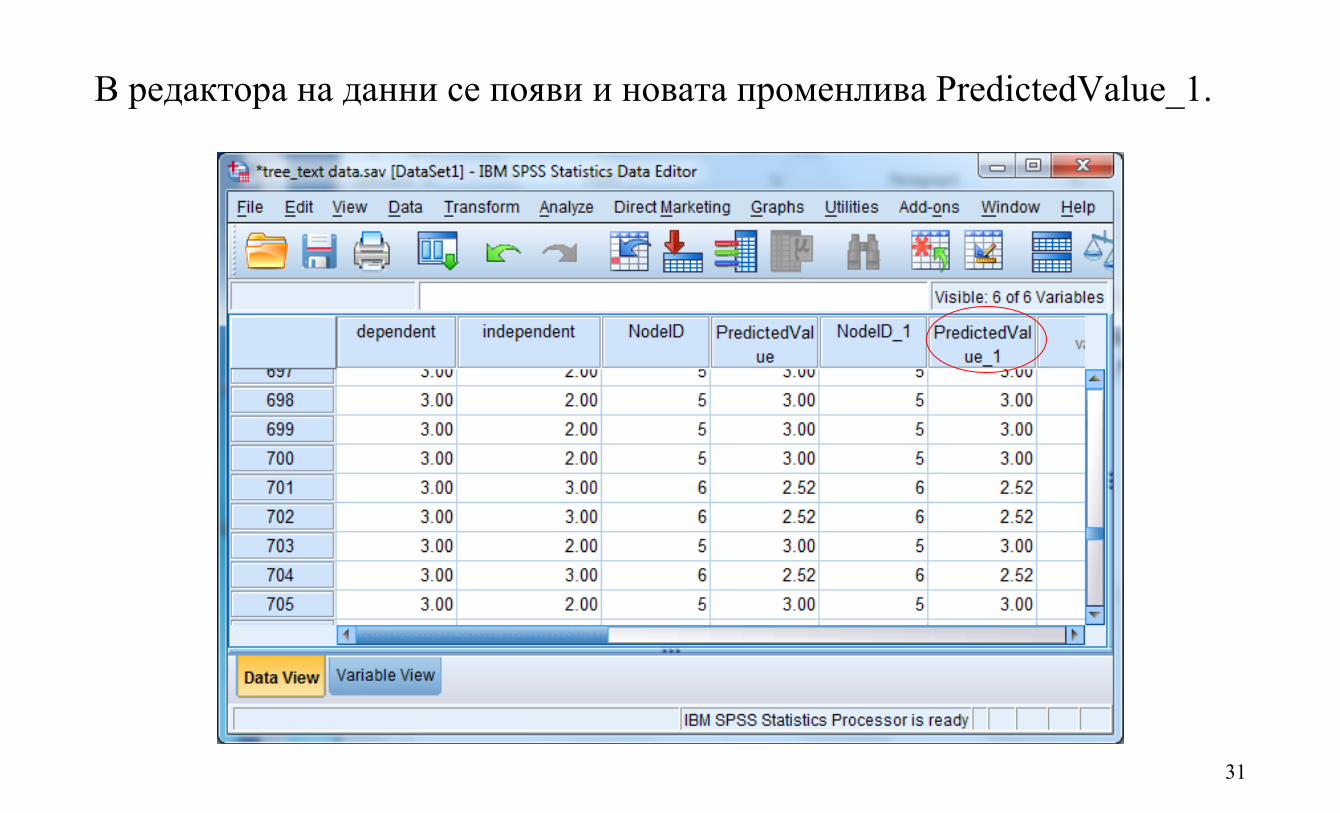
31
В редактора на данни се появи и новата променлива PredictedValue_1.

32
Пример 2. Използваме файла с данни: tree_credit.sav Банка поддържа база данни с историческа информация, т.е. данни за
старите си клиенти, които са получили заеми от банката. Зависимата променлива е Credit Rating: „добрите“ длъжници, които са си изплатили заема без просрочки са маркирани с Good (1), „лошите“ - с Bad (0), ако няма данни са от тип No credit history (9). За всеки клиент на банката има данни за следните 5 независими променливи:
Възраст, интервална променлива Месечен доход на клиента, ординална Брой кредитни карти на клиента Образование на клиента Заем за кола

33
Цел на анализа: да се направи дърво за класификация по групи клиенти, така че банката да може по 5-те независими променливи (предиктора) да преценява кои потенциални клиенти са „добри“ и кои „лоши“. Размерът на извадката е с n = 2464 данни.
Провеждане на анализа:
Повтаряме анализа от предния пример и получаваме дърво с 27 крайни възела, с информация, подобна на тази, която вече видяхме за пример 1.
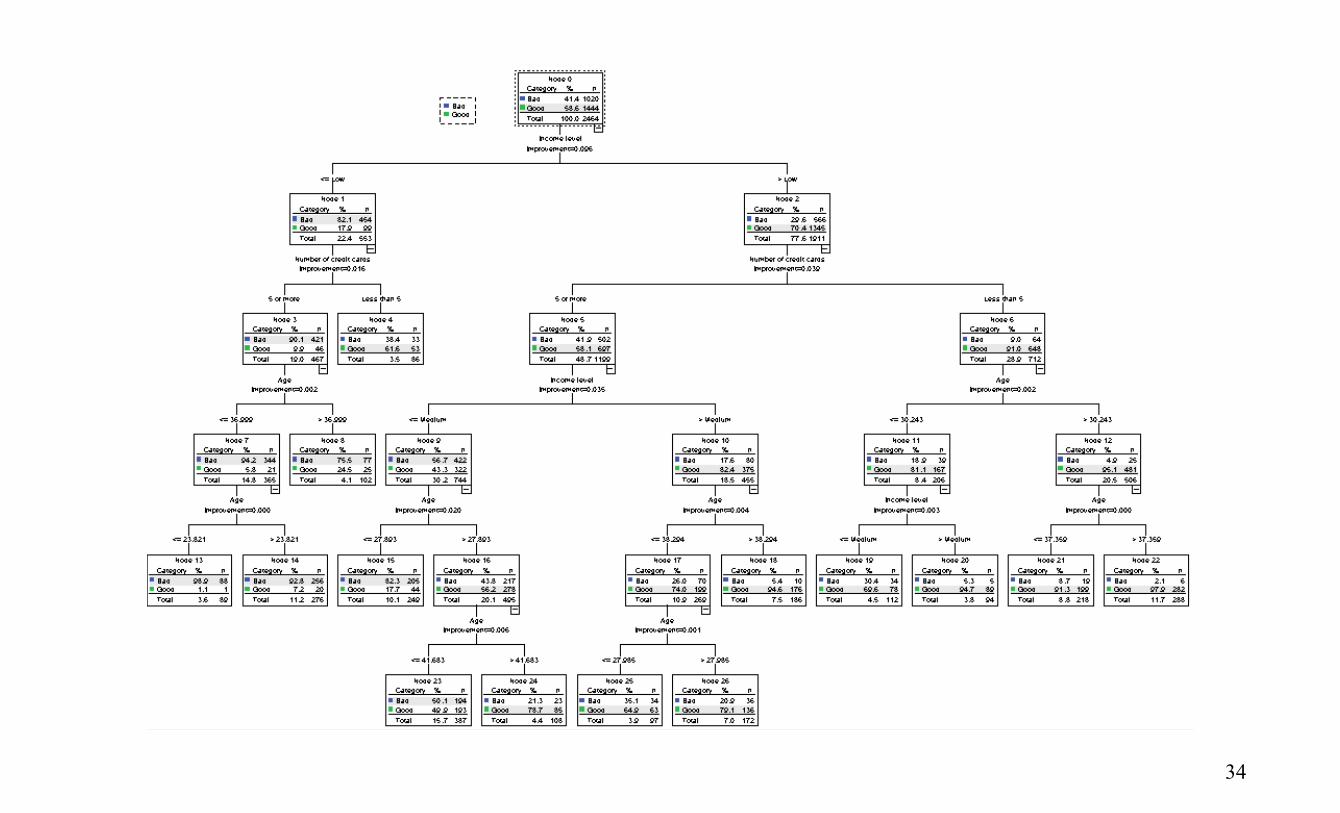
34

35
Node Good 4 53 8 25 13 1 14 20 15 44 18 176 19 78 20 89 21 199 22 282 23 193 24 85 25 63 26 136
1444
Тълкуване на резултата: От табличката виждаме, че най-много „добри“ клиенти
на банката има във възел 22, брой=282. Правилата на класификация последователно от корена
на дървото са следните: Ниво 1: Income (Доход) > Low (Нисък) Ниво 2: Number of credit cards < 5 Ниво 3: Age >30.243 Ниво 4: Age >37.350 От последното правило се вижда, че подобрението на
модела е 0.000. Следователно, можем да заключим, че най-добрите клиенти (общо 506, или 20.5%) нямат нисък доход, имат под 5 кредитни карти и са над 30 годишна възраст – възел 12. Дървото следва да се ограничи до по-малък брой крайни възли.
36
Може да намерите подробни решени примери и в следния източник: IBM_SPSS_Decision_Trees.pdf ftp://public.dhe.ibm.com/software/analytics/spss/documentation/statistics/22.0/en/client/Manuals/IBM_SPSS_Decision_Trees.pdf























![Глава III - uni-sofia.bg · до линейно нарастване на адсорбционния параметър k (вж. ур. 6.4 и 7.1 в тази глава) [34,38]](https://img.pdfslide.net/doc/110x75/5fc458f5ac016462e33220d3/-iii-uni-sofiabg-.jpg)




