Embed Size (px)
Citation preview

1
13.2 Fundamentals of Characters and Strings
• Characters: fundamental building blocks of Python programs
• Function ord returns a character’s character code • Function chr returns the character with the given
character code >>> ord('ff')
Traceback (most recent call last):
File "<stdin>", line 1, in ?
TypeError: ord() expected a character, but string of length 2 found
>>> ord('f')
102
>>> ord('.')
46
>>> chr(46)
'.'

2
Characters and Strings
String Method Description
capitalize() Returns a version of the original string in which only the first letter is capitalized. Converts any other capital letters to lowercase.
center( width ) Returns a copy of the original string centered
(using spaces) in a string of width characters.
count( substring[, start[, end]] )
Returns the number of times substring occurs
in the original string. If argument start is specified, searching begins at that index. If
argument end is indicated, searching begins at
start and stops at end.
endswith( substring[, start[, end]] )
Returns 1 if the string ends with substring.
Returns 0 otherwise. If argument start is specified, searching begins at that index. If
argument end is specified, the method searches
through the slice start:end.
expandtabs( [tabsize] ) Returns a new string in which all tabs are
replaced by spaces. Optional argument tabsize specifies the number of space characters that replace a tab character. The default value is 8.
Since characters and strings are fundamental in python, there are a lot of useful methods for dealing with them (fig. 13.2).

3
13.2 Fundamentals of Characters and Strings
find( substring[, start[, end]] )
Returns the lowest index at which substring occurs in the string; returns –1 if the string does
not contain substring. If argument start is specified, searching begins at that index. If
argument end is specified, the method searches
through the slice start:end.
index( substring[, start[, end]] )
Performs the same operation as find, but
raises a ValueError exception if the
string does not contain substring.
isalnum() Returns 1 if the string contains only alphanumeric characters (i.e., numbers and letters); otherwise, returns 0.
isalpha() Returns 1 if the string contains only alphabetic characters (i.e., letters); returns 0 otherwise.
isdigit() Returns 1 if the string contains only numerical characters (e.g., "0", "1", "2"); otherwise, returns 0.
islower() Returns 1 if all alphabetic characters in the string are lower-case characters and at least one exists; otherwise, returns 0.
isspace() Returns 1 if the string contains only whitespace characters; otherwise, returns 0.
istitle() Returns 1 if the first character of each word in the string is the only uppercase character in the word; otherwise, returns 0.
isupper() Returns 1 if all alphabetic characters in the string are uppercase characters and at least one exists; otherwise, returns 0.

4
13.2 Fundamentals of Characters and Strings
join( sequence ) Returns a string that concatenates the strings in
sequence using the original string as the separator between concatenated strings.
ljust( width ) Returns a new string left-aligned in a whitespace
string of width characters.
lower() Returns a new string in which all characters in the original string are lowercase.
lstrip() Returns a new string in which all leading whitespace is removed.
replace( old, new[, maximum ] )
Returns a new string in which all occurrences of
old in the original string are replaced with new.
Optional argument maximum indicates the maximum number of replacements to perform.
rfind( substring[, start[, end]] )
Returns the highest index value in which
substring occurs in the string or –1 if the
string does not contain substring. If argument
start is specified, searching begins at that index.
If argument end is specified, the method
searches the slice start:end.
rindex( substring[, start[, end]] )
Performs the same operation as rfind, but
raises a ValueError exception if the
string does not contain substring.
rjust( width ) Returns a new string right-aligned in a string of
width characters.
rstrip() Returns a new string in which all trailing whitespace is removed.

5
13.2 Fundamentals of Characters and Strings
split( [separator] ) Returns a list of substrings created by splitting
the original string at each separator. If
optional argument separator is omitted or
None, the string is separated by any sequence of whitespace, effectively returning a list of words.
splitlines( [keepbreaks] ) Returns a list of substrings created by splitting the original string at each newline character. If
optional argument keepbreaks is 1, the substrings in the returned list retain the newline character.
startswith( substring[, start[, end]] )
Returns 1 if the string starts with substring;
otherwise, returns 0. If argument start is specified, searching begins at that index. If
argument end is specified, the method searches
through the slice start:end.
strip() Returns a new string in which all leading and trailing whitespace is removed.
swapcase() Returns a new string in which uppercase characters are converted to lowercase characters and lower-case characters are converted to uppercase characters.
title() Returns a new string in which the first character of each word in the string is the only uppercase character in the word.
translate( table[, delete ] ) Translates the original string to a new string. The translation is performed by first deleting any
characters in optional argument delete, then by
replacing each character c in the original string
with the value table[ ord( c ) ].

6
fig13_03.py
1 # Fig. 13.3: fig13_03.py2 # Simple output formatting example.3 4 string1 = "Now I am here."5 6 print string1.center( 50 )7 print string1.rjust( 50 )8 print string1.ljust( 50 )
Now I am here. Now I am here.Now I am here.
Centers calling string in a new string of 50 characters
Right-aligns calling string in new string of 50 characters
Left-aligns calling string in new string of 50 characters
Remember: strings are immutable; a string manipulating function returns a new string
>>> aString = 'gacataggt'>>> >>> aString.upper()'GACATAGGT'>>> >>> aString'gacataggt'
7
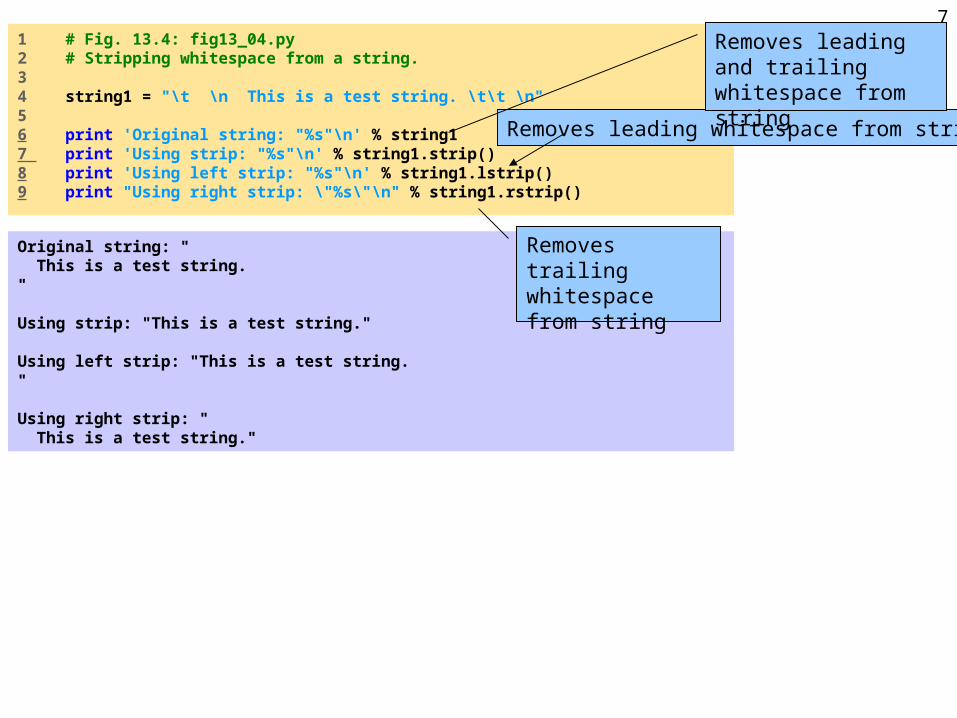
fig13_04.py
1 # Fig. 13.4: fig13_04.py2 # Stripping whitespace from a string.3 4 string1 = "\t \n This is a test string. \t\t \n"5 6 print 'Original string: "%s"\n' % string17 print 'Using strip: "%s"\n' % string1.strip()8 print 'Using left strip: "%s"\n' % string1.lstrip()9 print "Using right strip: \"%s\"\n" % string1.rstrip()
Original string: " This is a test string." Using strip: "This is a test string." Using left strip: "This is a test string." Using right strip: " This is a test string."
Removes leading whitespace from string
Removes trailing whitespace from string
Removes leading and trailing whitespace from string

8
13.4 Searching Strings
• Method find, index, rfind and rindex search for substrings in a calling string
• Methods startswith and endswith return 1 if a calling string begins with or ends with a given string, respectively
• Method count returns number of occurrences of a substring in a calling string
• Method replace substitutes its second argument for its first argument in a calling string
9
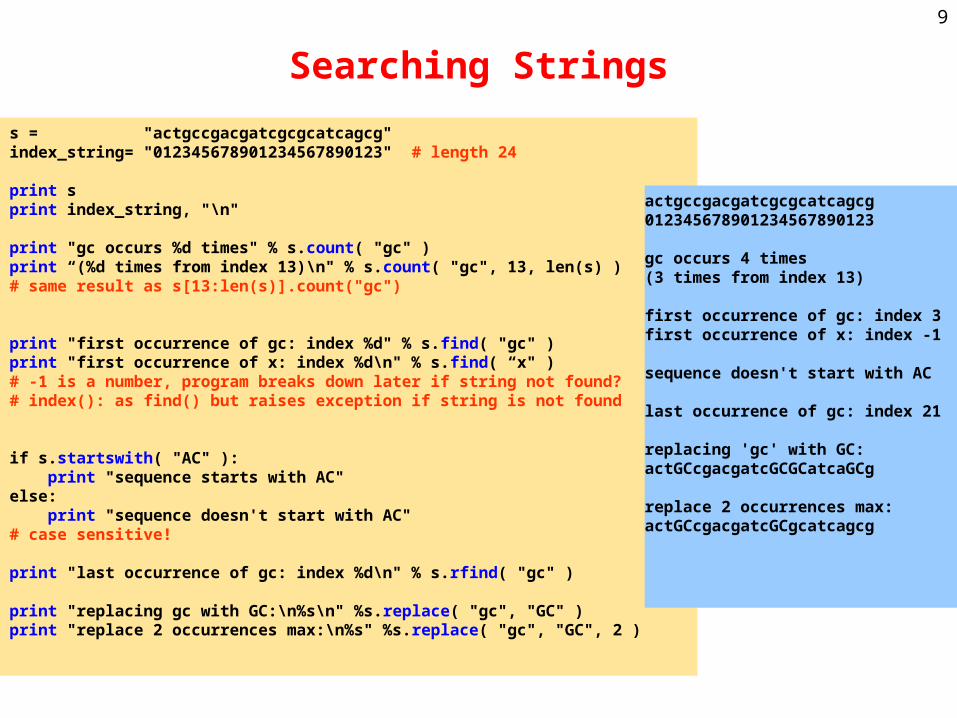
s = "actgccgacgatcgcgcatcagcg"index_string= "012345678901234567890123" # length 24
print sprint index_string, "\n"
print "gc occurs %d times" % s.count( "gc" )print “(%d times from index 13)\n" % s.count( "gc", 13, len(s) )# same result as s[13:len(s)].count("gc")
print "first occurrence of gc: index %d" % s.find( "gc" )print "first occurrence of x: index %d\n" % s.find( “x" )# -1 is a number, program breaks down later if string not found?# index(): as find() but raises exception if string is not found
if s.startswith( "AC" ): print "sequence starts with AC"else: print "sequence doesn't start with AC"# case sensitive!
print "last occurrence of gc: index %d\n" % s.rfind( "gc" )
print "replacing gc with GC:\n%s\n" %s.replace( "gc", "GC" )print "replace 2 occurrences max:\n%s" %s.replace( "gc", "GC", 2 )
actgccgacgatcgcgcatcagcg012345678901234567890123
gc occurs 4 times(3 times from index 13)
first occurrence of gc: index 3first occurrence of x: index -1
sequence doesn't start with AC
last occurrence of gc: index 21
replacing 'gc' with GC:actGCcgacgatcGCGCatcaGCg
replace 2 occurrences max:actGCcgacgatcGCgcatcagcg
Searching Strings

10
13.5 Splitting and Joining Strings
• Tokenization breaks statements into individual components (or tokens)
• Delimiters, typically whitespace characters, separate tokens

11
fig13_06.py1 # Fig. 13.6: fig13_06.py2 # Token splitting and delimiter joining.3 4 # splitting strings5 string1 = "A, B, C, D, E, F"6 7 print "String is:", string18 print "Split string by spaces:", string1.split()9 print "Split string by commas:", string1.split( "," )10 print "Split string by commas, max 2:", string1.split( ",", 2 )11 print12 13 # joining strings14 list1 = [ "A", "B", "C", "D", "E", "F" ]15 string2 = "___"16 17 print "List is:", list118 print 'Joining with ___ : %s' % ( string2.join ( list1 ) )1920 print 'Joining with -.- :', "-.-".join( list1 )
String is: A, B, C, D, E, FSplit string by spaces: ['A,', 'B,', 'C,', 'D,', 'E,', 'F']Split string by commas: ['A', ' B', ' C', ' D', ' E', ' F']Split string by commas, max 2: ['A', ' B', ' C, D, E, F'] List is: ['A', 'B', 'C', 'D', 'E', 'F']Joining with "___": A___B___C___D___E___FJoining with "-.-": A-.-B-.-C-.-D-.-E-.-F
Splits calling string by whitespace characters
Return list of tokens split by first two comma delimiters
Splits calling string by specified character
Joins list elements with calling string as a delimiter to create new string
Joins list elements with calling quoted string as delimiter to create new string

12
Intermezzo 1
www.daimi.au.dk/~chili/CSS/Intermezzi/2.10.1.html
1. Copy and run this program: /users/chili/CSS.E03/ExamplePrograms/random_text.py What does it do?
2. Extend the program: search the text string it produces and print out the index of the first occurrence of 11 (you might look at Figure 13.2 at page 438ff to find a suitable string method). Tell the user if there is no '11'.
3. Split the text into a list of substrings using '11' as a delimiter, print out the list.

13
Solutionfrom random import randrange
text = ""
for i in range(150): next_char = chr( randrange(48, 58) ) text = "".join( [text, next_char] )
print text
i = text.find( "11" )
if i>=0: print "'11' found at index", i
splittext = text.split( "11" )print "text split in %d pieces" %len(splittext)
for piece in splittext: print piece
126011248464036361812051952665405020454120395337118715150931373046328653809239514732592664241323032411475077087579523798182173083754226565772851806864'11' found at index 4text split in 4 pieces126024846403636181205195266540502045412039533787151509313730463286538092395147325926642413230324475077087579523798182173083754226565772851806864

14
Regular Expressions – Motivation
import re
text1 = "No Danish email address here [email protected] *@[email protected]! fj3a"text2 = "But here: [email protected] what a *(.@#$ nice @#*.( email address"
regularExpression = "\w+@[\w.]+\.dk"compiledRE = re.compile( regularExpression)
SRE_Match1 = compiledRE.search( text1)SRE_Match2 = compiledRE.search( text2)
if SRE_Match1: print "Text1 contains this Danish email address:", SRE_Match1.group()else: print "Text1 contains no Danish email address" if SRE_Match2: print "Text2 contains this Danish email address:", SRE_Match2.group()else: print "Text2 contains no Danish email address"
Problem: search a text for any Danish email address: <something>@<something>.dk
Text1 contains no Danish email addressText2 contains this Danish email address: [email protected]

15
13.6 Regular Expressions
• Provide more efficient and powerful alternative to string search methods
• Instead of searching for a specific string we can search for a text pattern– Don’t have to search explicitly for ‘Monday’, ‘Tuesday’,
‘Wednesday’.. : there is a pattern in these search strings.
– A regular expression is a text pattern
• In Python, regular expression processing capabilities provided by module re

16
Example
Simple regular expression: regExp = “football”
- matches only the string “football”
To search a text for regExp, we can use
re.search( regExp, text )

17
Compiling Regular Expressions
re.search( regExp, text )1. Compile regExp to a special format (an SRE_Pattern object)
2. Search for this SRE_Pattern in text
3. Result is an SRE_Match object
If we need to search for regExp several times, it is
more efficient to compile it once and for all:
compiledRE = re.compile( regExp)1. Now compiledRE is an SRE_Pattern object
compiledRE.search( text )2. Use search method in this SRE_Pattern to search text
3. Result is same SRE_Match object

18
Searching for ‘football’import re
text1 = "Here are the football results: Bosnia - Denmark 0-7"
text2 = "We will now give a complete list of python keywords."
regularExpression = "football"
compiledRE = re.compile( regularExpression)
SRE_Match1 = compiledRE.search( text1 )
SRE_Match2 = compiledRE.search( text2 )
if SRE_Match1:
print "Text1 contains the substring ‘football’"
if SRE_Match2:
print "Text2 contains the substring ‘football’"
Text1 contains the substring 'football'
Compile regular expression and get the SRE_Pattern object
Use the same SRE_Pattern object to search both texts and get two SRE_Match objects
(or none if the search was unsuccesful)

19
Building more sophisticated patterns
Metacharacters: regular-expression syntax element
?: matches zero or one occurrences of the expression it follows
+: matches one or more occurrences of the expression it follows
*: matches zero or more occurrences of the expression it follows
# search for zero or one t, followed by two a’s:
regExp1 = “t?aa“
# search for g followed by one or more c’s followed by a:
regExp1 = “gc+a“
#search for ct followed by zero or more g’s followed by a:
regExp1 = “ctg*a“

20
Metacharacter exampleimport re
text = "gaaagccactgggggggggggggga"
regExp1 = "t?aa"
compiledRE1 = re.compile( regExp1 )
regExp2 = "gc+a"
compiledRE2 = re.compile( regExp2 )
regExp3 = "ctg*a"
compiledRE3 = re.compile( regExp3 )
SRE_Match1 = compiledRE1.search( text )
SRE_Match2 = compiledRE2.search( text )
SRE_Match3 = compiledRE3.search( text )
if SRE_Match1:
print "Text contains the regular expression", regExp1
if SRE_Match2:
print "Text contains the regular expression", regExp2
if SRE_Match3:
print "Text contains the regular expression", regExp3
Text contains the regular expression t?aaText contains the regular expression gc+aText contains the regular expression ctg*a
Compile all three regular expressions into SRE_Pattern objects
Use the three SRE_Pattern objects to search the text and get three SRE_Match objects

21
^: indicates placement at the beginning of the string
$: indicates placement at the end of the string
# search for zero or one t, followed by two a’s
# at the beginning of the string:
regExp1 = “^t?aa“
# search for g followed by one or more c’s followed by a
# at the end of the string:
regExp1 = “gc+a$“
# whole string should match ct followed by zero or more
# g’s followed by a:
regExp1 = “^ctg*a$“
A few more metacharacters

22
Metacharacter exampleimport re
text1 = "aactggagcccca"
text2 = "ctgga"
regExp1 = "^t?aa"
regExp2 = "gc+a$"
regExp3 = "^ctg*a$"
if re.search( regExp1, text1 ):
print "Text1 contains the regular expression", regExp1
if re.search( regExp2, text1 ):
print "Text1 contains the regular expression", regExp2
if re.search( regExp3, text1 ):
print "Text1 contains the regular expression", regExp3
if re.search( regExp3, text2 ):
print "Text2 contains the regular expression", regExp3
Text1 contains the regular expression ^t?aaText1 contains the regular expression gc+a$Text2 contains the regular expression ^ctg*a$
This time we use re.search() to search the text for the regular expressions directly without compiling them in advance

23
{}: indicate repetition| : match either regular expression to the left or to the right(): indicate a group (a part of a regular expression)
# search for four t’s followed by three c’s:regExp1 = “t{4}c{3}“
# search for g followed by 1 to 3 c’s:regExp1 = “gc{1,3}$“
# search for either gg or cc:regExp1 = “gg|cc“
# search for either gg or cc followed by tt:regExp1 = “(gg|cc)tt“
Yet more metacharacters..

24
\: used to escape (to ‘keep’) a metacharacter
# search for x followed by + followed by y:regExp1 = “x\+y“
# search for ( followed by x followed by y:regExp1 = “\(xy“
# search for x followed by ? followed by y:regExp1 = “x\?y“
# search for x followed by at least one ^ followed by 3:regExp1 = “x\^+3“
Escaping metacharacters

25
Intermezzo 2
http://www.daimi.au.dk/~chili/CSS/Intermezzi/2.10.2.html
Copy and run this program:/users/chili/CSS.E03/ExamplePrograms/sequence_searching.pyWhat does it do?
Put in more regular expressions in the list to search for these patterns:
1. 6 c's followed by 3 g's 2. cc, followed by at least one g, followed by cc 3. double triplets (e.g. aaa followed by ccc) 4. any number of a's, followed by either cc or gg, followed by c at
the end of the string

26
Solutionimport re
# this is a dna sequence in fasta format:
seq = """>U03518 Aspergillus awamori\naacctgcggaaggatcattaccgagtgcgggtcctttgggcccaacctcccatccgtgtctattgtaccctgttgcttcggcgggcccgccgcttgtcggccgccgggggggcgcctctgccccccgggcccgtgcccgccggagaccccaacacgaacactgtctgaaagcgtgcagtctgagttgattgaatgcaatcagttaaaactttcaacaatggatctcttggttccggc"""
regular_expressions = [ "a{4}", "c+(t|g)tt", "g*c$", "(gt){2}", "c{6}g{3}", "ccg+cc", "(aaa|ccc|ggg|ttt){2}", "a*(cc|gg)c$" ]
for regExp in regular_expressions: if re.search( regExp, seq ): print "found", regExp
1. 6 c's followed by 3 g's
2. cc, followed by at least one g, followed by cc
3. double triplets (e.g. aaa followed by ccc)
4. any number of a's, followed by either cc or gg, followed by c at the end of the string

27
Character Classes
A character class matches one of the characters in
the class: [abc] matches either a or b or c.
d[abc]d matches dad and dbd and dcd
[ab]+c matches e.g. ac, abc, bac, bbabaabc, ..
• Metacharacter ^ at beginning negates character class:[^abc] matches any character other than a, b and c
• A class can use – to indicate a range of characters:[a-e] is the same as [abcde]
• Characters except ^ and – are taken literally in a class:[a+b*] matches a or + or b or *

28
Special Sequences
Special Sequence Describes
\d The class of digits ([0-9]).
\D The negation of the class of digits ([^0-9]).
\s The whitespace characters class ([ \n\f\r\t\v]).
\S The negation of the whitespace characters class ([^ \n\f\r\t\v]).
\w The alphanumeric characters class ([a-zA-Z0-9_]).
\W The negation of the alphanumeric characters class ([^a-zA-Z0-9_]).
\\ The backslash (\).
. Any character except a newline
Fig. 13.10 Regular-expression special sequences.
Special sequence: shortcut for a common character class
regExp1 = “\d\d:\d\d:\d\d [AP]M” # (possibly illegal) time stamps like 04:23:19 PM
regExp2 = "\w+@[\w.]+\.dk“ # any Danish email address

29
import re
text = "1a2b3c4d5e6f"
print re.sub( "\d", "*", text ) # substitute * for any digit (i.e. replace digit with *)printprint re.sub( "\d", "*", text, 3 ) # substitute * for any digit, max 3 timesprint
print re.split( "\d", text ) # delimiter: any digitprintprint re.split( "[a-z]", text ) # delimiter: any lower-case letterprint
if re.search( "\db", text ): # the RE of search() can appear anywhere in text print "method search found \db" if re.match( "\db", text ): # the RE of match() must appear in beginning of text print "method match found \db“
if re.match( "\da", text ): print "method match found \da"
Other regular expression functions
*a*b*c*d*e*f
*a*b*c4d5e6f
['', 'a', 'b', 'c', 'd', 'e', 'f']
['1', '2', '3', '4', '5', '6', '']
method search found \dbmethod match found \da

30
Groups
We can extract the actual substring that matched the regular
expression by calling method group() in the SRE_Match object:
text = "But here: [email protected] what a *(.@#$ nice @#*.( email address“
regExp = "\w+@[\w.]+\.dk“ # match Danish email address
compiledRE = re.compile( regExp)
SRE_Match = compiledRE.search( text )
if SRE_Match:
print "Text contains this Danish email address:", SRE_Match.group()

31
13.11 Grouping
• The substring that matches the whole RE called a group
• RE can be subdivided into smaller groups (parts)
• Each group of the matching substring can be extracted
• Metacharacters ( and ) denote a group
text = "But here: [email protected] what a *(.@#$ nice @#*.( email address“
# Match any Danish email address; define two groups: username and domain:
regExp = “(\w+)@([\w.]+\.dk)“
compiledRE = re.compile( regExp )
SRE_Match = compiledRE.search( text )
if SRE_Match:
print "Text contains this Danish email address:", SRE_Match.group()
print “Username:”, SRE_Match.group(1), “\nDomain:”, SRE_Match.group(2)
Text2 contains this Danish email address: [email protected]: chili Domain: daimi.au.dk

32
Greedy vs. non-greedy operators
• + and * are greedy operators– They attempt to match as many characters as possible even if
this is not the desired behavior
• +? and *? are non-greedy operators– They attempt to match as few characters as possible

33
Greedy vs. non-greedy operators
# Task: Find a space-separated list of digits, extract the first number.
import re
text = "1 2 3 4 5 blah blah"
# use greedy operator +
regExp = "(\d )+"
print "Greedy operator:", re.match( regExp, text ).group()
# use non-greedy version instead (by putting a ? after the +)
regExp = "(\d )+?"
print "Non-greedy operator:", re.match( regExp, text ).group()
Greedy operator: 1 2 3 4 5 Non-greedy operator: 1





























