Embed Size (px)
Citation preview

1
A Conceptual Framework of Data Mining
Yiyu Yao1, Ning Zhong2 and Yan Zhao1
1 Department of Computer Science, University of ReginaRegina, Saskatchewan, Canada S4S 0A2E-mail: {yyao, yanzhao}@cs.uregina.ca2 Department of Information Engineering, Maebashi Institute of Technology460-1, Kamisadori-Cho, Maebashi 371, JapanE-mail: [email protected]
Summary. The study of foundations of data mining may be viewed as a scientificinquiry into the nature of data mining and the scope of data mining methods.There is not enough attention paid to the study of the nature of data mining, or itsphilosophical foundations. It is evident that the conceptual studies of data mining asa scientific research field, instead of as a collection of isolated algorithms, are neededfor a further development of the complete field. A three-layer conceptual frameworkis thus proposed, consisting of the philosophy layer, the technique layer and theapplication layer. Each layer focuses on different types of fundamental questionsregarding data mining, and they jointly form a complete characterization of thefield. The layered framework is demonstrated by applying it to three sub-fields ofdata mining, classification, measurements, and explanation-oriented data mining.They exemplify three popular views of data mining, i.e., function-oriented, theory-oriented and procedure-oriented, respectively.
1.1 Introduction
With the development and success of data mining, many researchers becameinterested in the fundamental issues, namely, the foundations of data min-ing [2, 8, 9, 23]. It is arguable that the relationship between data mining andfoundations of data mining is equivalent to the relationship between comput-ers and computer science. The study of foundations of data mining should beviewed as a scientific inquiry into the nature of data mining and the scope ofdata mining methods. This simple view separates two important issues. Thestudy of the nature of data mining concerns the philosophical, theoreticaland mathematical foundations of data mining, and looks at it as a subjectof study; while the study of data mining methods concerns its technologicalfoundations by focusing on the algorithms and tools, and looks at it as asubject of practice.
A review of the existing studies show that not enough attention has beenpaid to the study of the nature of data mining, more specifically, to the philo-
Lin, T.Y., Ohsuga, S., Liau, C.J. and Hu, X. (Eds.), Foundations and Novel Approaches in Data Mining, 75-97, Springer-Verlag, 2005.

sophical foundations of data mining [23]. Although three dedicated interna-tional workshops have been held [7, 8, 9], there still do not exist well-acceptedand non-controversial answers to many basic questions, such as, what is datamining? what makes data mining a distinctive study of artificial intelligence?what are the foundations of data mining? What is the scope of the founda-tions of data mining? What are the differences, if any, between the existingresearches and the research on the foundations of data mining? The study offoundations of data mining should be started by answering these questions.
The foundational study is sometimes ignored or underestimated. In thecontext of data mining, one is more interested in algorithms for finding knowl-edge, but not what is knowledge, and what is the knowledge structure. One isoften more interested in a more implementation-oriented view or frameworkof data mining, rather than a conceptual framework for the understanding ofthe nature of data mining. Same questions are left unsolved in many otherdisciplines. For example, the following problem quoted from Salthe [17] aboutstudies of ecosystem is equally applicable to the studies of data mining:
“The question typically is not what is an ecosystem, but how do wemeasure certain relationships between populations, how do some vari-ables correlate with other variables, and how can we use this knowl-edge to extend our domain. The question is not what is mitochon-drion, but what processes tend to be restricted to certain region of acell.”[page 3]
The lack of the study of the nature does possible harms to the recognition ofits philosophical significance.
There are many reasons accounting for such unbalanced research efforts.The problems of data mining are first raised by very practical needs for find-ing useful knowledge. One inevitably focuses on the detailed algorithms andtools, without carefully considering the problem itself. A workable programor software system is more easily acceptable by, and at the same time is moreconcrete and more easily achievable by, many computer scientists than anin-depth understanding of the problem itself. Furthermore, the fundamentalquestions regarding the nature of the field, the inherent structure of the fieldand its related fields, are normally not asked at its formation stage. This isespecially true when the initial studies produce useful results [17].
The study of foundations of data mining therefore needs to adjust thecurrent unbalanced research efforts. We need to focus more on the under-standing of the nature of data mining as a field instead of as a collection ofalgorithms. We need to define precisely the basic notions, concepts, princi-ples, and their interactions in an integrated whole. Many existing studies cancontribute to the foundational study of data mining. Here are two examples:(a.) Results from the studies of cognitive science and education are relevantto such a purpose. Posner suggested that, according to the cognitive scienceapproach, to learn a new field is to build appropriate cognitive structures andto learn to perform computations that will transform what is known into what
Lin, T.Y., Ohsuga, S., Liau, C.J. and Hu, X. (Eds.), Foundations and Novel Approaches in Data Mining, 75-97, Springer-Verlag, 2005.

is not yet known [15]. (b.) Reif and Heller showed that knowledge structureof a domain is very relevant to problem solving[16]. In particular, knowledgeabout a domain, such as mechanics, specifies descriptive concepts and rela-tions described at various levels of abstraction, is organized hierarchically, andis accompanied by explicit guidelines that specify when and how knowledge isto be applied [16]. The knowledge hierarchy is used by Simpson for the studyof foundations of mathematics [20]. It follows that the study of foundationsof data mining should focus on the basic concepts and knowledge of datamining, as well as their inherent connections, at multi-level of abstractions.Without such kind of understanding of data mining, one may fail to makefurther progress.
In summary, in order to study the foundations of data mining, we need tomove beyond the existing studies. More specifically, we need to introduce aconceptual framework, to be complementary to the existing implementationand process-oriented views. The main objective of this chapter is therefore tointroduce such a framework.
The rest of the chapter is organized as follows. In Section 2, we re-examinethe existing studies of data mining. Based on the examination, we can observeseveral problems and see the needs for the study of foundations of data min-ing. More specifically, there is a need for a framework, within which to studythe basic concepts and principles of data mining, and the conceptual struc-tures and characterization of data mining. For this purpose, in Section 3, athree-layer conceptual framework of data mining is discussed, consisting ofthe philosophy layer, the technique layer, and the application layer [23]. Therelationships among the three layers are discussed. The layered framework isdemonstrated in Section 4 by applying it to an example of function-orientedview - classification, an example of theory-oriented view - measurement the-ory, and an example of procedure-oriented view - explanation-oriented datamining. Section 5 draws the conclusion.
1.2 Overview of the Existing Studies and the Problems
Data mining, as a relatively new branch of computer science, has receivedmuch attention. It is motivated by our desire of obtaining knowledge from hugedatabases. Many data mining methods, based on the extensions, combinations,and adaptation of machine learning algorithms, statistical methods, relationaldatabase concepts, and the other data analysis techniques, have been proposedand studied for knowledge extraction and abstraction.
1.2.1 Three views of data mining
The existing studies of data mining can be classified roughly under threeviews.
Lin, T.Y., Ohsuga, S., Liau, C.J. and Hu, X. (Eds.), Foundations and Novel Approaches in Data Mining, 75-97, Springer-Verlag, 2005.

The function-oriented viewThe function-oriented view focuses on the goal or functionality of a data
mining system, namely, the discovery of knowledge from data. In a well-accepted definition, data mining is defined as “the non-trivial process of iden-tifying valid, novel, potentially useful, and ultimately understandable patternsfrom data” [4]. The function-oriented approaches put forth efforts on search-ing, mining and utilizing different patterns embedded in various databases. Apattern is an expression in a language that describes data, and has a repre-sentation simpler than the data. For example, frequent itemsets, associationrules and correlations, as well as clusters of data points, are common classesof patterns. Such goal-driven approaches establish a close link between datamining research and real world applications.
Depending on the data and their properties, one may consider differentdata mining systems with different functionalities and for different purposes,such as text ming, Web mining, sequential mining, and temporal data min-ing. Under the function-oriented view, the objectives of data mining can bedivided into prediction and description. Prediction involves the use of somevariables to predict the values of some other variables, and description focuseson patterns that describe the data [4].
The theory-oriented viewThe theory-oriented approaches concentrate on the theoretical studies of
data mining, and its relationship to the other disciplines. Many models ofdata mining have been proposed, critically investigated and examined fromthe theory-oriented point of view [4, 12, 22, 27].
Conceptually, one can draw a correspondence between scientific researchby scientists and data mining by computers [26, 27]. More specifically, theyshare the same goals and processes. It follows that any theory discoveredand used by scientists can be used by data mining systems. Thus, many fieldscontribute to the theoretical study of data mining. They include statistics, ma-chine learning, databases, pattern recognition, visualization, and many other.There is also a need for the combination of existing theories. For example,some efforts have been made to bring the rough sets theory, fuzzy logic, util-ity and measurement theory, concept lattice and knowledge structure, andother mathematical and logical models into the data mining models.
The procedure/process-oriented viewFrom the procedure/process-oriented view, data mining deals with a “non-
trivial” process consisting of many steps, such as data selection, data prepro-cessing, data transformation, pattern discovery, pattern evaluation, and resultexplanations [4, 11, 27, 31]. Furthermore, it should be a dynamically organizedprocess.
Under the process-oriented view, data mining studies have been focusedon algorithms and methodologies for different processes, speeding up existingalgorithms, and evaluation of discovered knowledge.
Lin, T.Y., Ohsuga, S., Liau, C.J. and Hu, X. (Eds.), Foundations and Novel Approaches in Data Mining, 75-97, Springer-Verlag, 2005.

1.2.2 Problems and potential solutions
The three views jointly provide a complete description of data mining research.The function-oriented view states the goals of data mining, the theory-orientedview studies the means with which one can carry out the desired targets, andthe process-oriented view deals with how to achieve the goals based on thetheoretical means. The reason that we say they are three views, but not threefoundations, is that these three mainly treat data mining as a technology,instead of a subject of scientific study. The general conceptual framework isstill not proposed and examined.
Intuitively, the terms of technology and science stand for different mean-ings. Science studies the nature of the world. On the other hand, technologystudies the ways that people develop to control or manipulate the world, theman-made world. This is not to say science and technology are unrelated.Science deals with “understanding” while technology deals with “doing”. Thescientific study requires the study of foundations of data mining, so that thefundamental questions of the field itself are asked, examined, explained andformalized.
The foundations of data mining should not be solely mathematics or logic,or any other individual fundamental disciplines. Considering the differenttypes of databases, the diversity of patterns, the ever changing techniques andalgorithms, and the different views, we require a multilevel (or multi-layer)understanding of data mining. By viewing data mining in many layers, one canidentify the inherent structure of the fields, and put fundamental questionsinto their proper perspectives in the conceptual map of data mining.
1.3 A Three-Layer Conceptual Framework
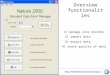
A three-layer conceptual framework is recently proposed by Yao [23], whichconsists of the philosophy layer, the technique layer, and the application layer.The layered framework represents the understanding, discovery, and utiliza-tion of knowledge, and is illustrated in Figure 1.1.
1.3.1 The philosophy layer
The philosophy layer investigates the basic issues of knowledge. One attemptsto answer a fundamental question, namely, what is knowledge? There aremany related issues to this question, such as the representation of knowledge,the expression and communication of knowledge in languages, the relationshipbetween knowledge in mind and in the external real world, and the classifica-tion and organization of knowledge [21]. Philosophical study of data miningserves as a precursor to technology and application, it generates knowledgeand the understanding of our world, with or without establishing the opera-tional boundaries of knowledge. The philosophy layer study is primarily drivenby curiosity, and responds to a certain hypothesis.
Lin, T.Y., Ohsuga, S., Liau, C.J. and Hu, X. (Eds.), Foundations and Novel Approaches in Data Mining, 75-97, Springer-Verlag, 2005.

1.3.2 The technique layer
The technique layer is the study of knowledge discovery in machine. Oneattempts to answer the question, how to discover knowledge? In the contextof computer science, there are many issues related to this question, such asthe implementation of human knowledge discovery methods by programminglanguages, which involves coding, storage and retrieval issues in a computer,and the innovation and evolution of techniques and algorithms in intelligentsystems. The main streams of research in machine learning, data mining,and knowledge discovery have concentrated on the technique layer. Logicalanalysis and mathematical modelling are considered to be the foundations oftechnique layer study of data mining.
1.3.3 The application layer
The ultimate goal of knowledge discovery is to effectively use discovered knowl-edge. The question that needs to be answered is how to utilize the discoveredknowledge. The application layer therefore should focus on the notions of“usefulness” and “meaningfulness” of discovered knowledge for the specificdomain, and aim at many attributes, such as efficiency, optimization, reliabil-ity, cost-effectiveness, and appropriateness. These notions cannot be discussedin total isolation with applications, as knowledge in general is domain specific.The application layer therefore involves the design and development of a so-lution to a target problem that serves a real need.
Philosophy layer
Technique layer Application layer
Fig. 1.1. The three-layer conceptual framework of data mining.
1.3.4 The relationships among the three layers
Two points need to be emphasized about the three-layer conceptual frame-work.
Lin, T.Y., Ohsuga, S., Liau, C.J. and Hu, X. (Eds.), Foundations and Novel Approaches in Data Mining, 75-97, Springer-Verlag, 2005.

First, the three layers are different, relatively independent, and self-contained.
(1.)The philosophical study does not depend on the availability of specifictechniques and applications. In other words, it does not matter whetherknowledge is discovered or not, utilized or not, even if the knowledge struc-ture and expression are recognized or not, it exists. Furthermore, all humanknowledge is conceptual and forms an integrated whole [14]. The output ofthe philosophical study can be expressed as theories, principles, conceptsor other knowledge structures. Knowledge structure is built by connectingnew bits of information to the old. The study of knowledge at the philoso-phy layer has important implications for the human society, even if it is notdiscovered or utilized yet, or it simply provides a general understanding ofthe real world.
(2.)The technical study can carry out part of the philosophic study resultsbut not all, and it is not constrained by applications. The philosophy layerdescribes a very general conceptual scheme. The current techniques, in-cluding hardware and software, may still be insufficient to bring all of itinto reality. On the other hand, the existence of a technique/algorithmdoes not necessarily imply that discovered knowledge is meaningful anduseful. The output of the technical study can be expressed by algorithms,mathematical models, and intelligent systems. The technology can be com-mercialized. The benefits of technological implementation and innovationtend to move the study of technical layer to be more and more profit-driven.
(3.)The applications of data mining is materialized knowledge in specific do-mains. They are related to the evaluation of discovered knowledge, theexplanation and interpretation of discovered knowledge in a particulardomain. The discovered knowledge can be used in many ways. For ex-ample, knowledge from transaction databases can be used for designingnew products, distributing, and marketing. Comparing to the philosoph-ical and technological studies, the applications have more explicit targetsand schedules.
Second, the three layers mutually support each other and jointly form anintegrated whole.
(1.)It is expected that the results from philosophy layer will provide guidelinesand set the stage for the technique and application layers. The technol-ogy development and innovation can not go far without the conceptualguidance.
(2.)The philosophical study cannot be developed without the considerationof reality. Technology development may raise new philosophical questionsand promote the philosophical study. Technique layer is the bridge betweenphilosophical view of knowledge and the application of knowledge.
(3.)The applications of philosophical and technical outcomes give an impe-tus for the re-examination of philosophical and technical studies too. The
Lin, T.Y., Ohsuga, S., Liau, C.J. and Hu, X. (Eds.), Foundations and Novel Approaches in Data Mining, 75-97, Springer-Verlag, 2005.

feedbacks from applications provide evidence for the confirmation, re-examination, and modification of philosophical and technical results.
Three layers of the conceptual framework are tightly integrated, namely,they are mutually connected, supported, promoted, facilitated, conditionedand restricted. The division between the three layers is not a clear cut, andmay overlap and interweave with each other. Any of them is indispensablein the study of intelligence and intelligent systems. They must be consideredtogether in a common framework through multi-disciplinary studies, ratherthan in isolation.
1.4 Enriched Views on the Three-Layered Framework
We believe the three-layer conceptual framework establishes a proper founda-tion of data mining. It can promote the progress of data mining; to advancethe science and technology related to data mining. By putting the three exist-ing views that we have discussed in Section 2 into the conceptual framework,we gain a 3-by-3 table and more insights.
We should study, from the function-oriented view, not only what datamining programs can and cannot do in the technology and application layer,but also in the abstract, what knowledge is possibly stored in the informationsystem, how programs should store and retrieve specific kinds of informationin their specific structure and representation. From the theory-oriented view,the key thing is not only to pile up various theories, algorithms, to beat upthe efficiency, or even worse, to reinvent theories and methodologies that havebeen well-studied in the other domains. It emphasizes the understanding andhuman-computer interaction. From the procedure-oriented view, it should beguided by the procedure of general scientific research too.
In this section, we explain three examples with respect to the three-layerframework. The classification is corresponding to the function-oriented view,evaluation and measurement theory is corresponding to the theory-orientedview, and the explanation-oriented data mining extends the procedure-orientedview. We demonstrate how these three views are enriched by the conceptualframework, especially the philosophy layer study.
1.4.1 Classification on the three-layer framework
Classification is considered as one of the most important tasks of data mining.It is therefore associated with the function-oriented view that we discussedin Section 2. Partitions and coverings are two simple and commonly usedknowledge classifications of the universe. A partition of a finite universe is acollection of non-empty, and pairwise disjoint subsets whose union is the uni-verse. A covering of a finite universe is a collection of non-empty and possiblyoverlapped subsets whose union is the universe. Partitions are a special caseof coverings.
Lin, T.Y., Ohsuga, S., Liau, C.J. and Hu, X. (Eds.), Foundations and Novel Approaches in Data Mining, 75-97, Springer-Verlag, 2005.

Knowledge is organized in a tower (hierarchy) or a partial ordering. Basedon the above discussion, we have partition-based hierarchy and covering-basedhierarchy. Hierarchy means that the base or minimal elements of the order-ing are the most fundamental concepts and higher-level concepts depend onlower-level concepts [20]. Partial ordering means that the concepts in the hi-erarchy are reflexive, anti-symmetric and transitive. The first-level conceptis formed directly from the perceptual data [14]. The higher-level concepts,representing a relatively advanced state of knowledge, are formed by a processof abstracting from abstractions [14]. On the other hand, the series of lower-level concepts, on whom the higher-level concept is formed, are not necessarilyunique in content. Within the requisite overall structure, there may be manyalternatives in detail [14].
The natural process of knowledge cognition follows the hierarchy fromlower-level concepts to higher-level according to the intellectual dependency.The revise process does exist because of impatience, anti-effort, or simpleerror. Peikoff analyzes that the attempt to function on the higher levels ofcomplex structure without having established the requisite base will buildconfusion on confusion, instead of knowledge on knowledge. In such minds,the chain relating higher-level content to perceptual reality is broken [14].
A virtual space that can hold knowledge as concepts is called a conceptspace, namely, it refers to the set or class of the concepts. If we consider thedata mining process as searching for concepts in a particular concept space,we need to study different kinds of concept spaces first. Inside the conceptspace, the concept can be represented and discovered. Generally, a conceptspace S can hold all the concepts, including the ones that can be definedas a formula, and the ones that cannot. A definable concept space DS is asub-space of the concept space S. There are many definable concept spacesin different forms. In most situations, one is only interested in the conceptsin a certain form. Consider the class of conjunctive concepts, that formulaconstructed from atomic formula by only logic connective ∧. A concept spaceCDS is then referred to as the conjunctively definable space, which is a sub-space of the definable space DS. Similarly, a concept space is referred to asa disjunctively definable space if the atomic formulas are connected by logicdisjunctive ∨.
In [30], we discuss the complete concept space for classification tasks us-ing granular network concepts. The immediate result is that a classificationtask can be understood as a search of the distribution of classes in a granulenetwork defined by the descriptive attribute set. The analysis shows that thecomplexity of the search space of a consistent classification task is not poly-nomially bound. This can be extremely complex especially when the numberof possible values of attributes are large, let alone continuous. This forces usto use heuristic algorithms to quickly find solutions in a constrained space.Indeed, the existing heuristic algorithms perform very well. Each of them canbe understood as a particular heuristical search within the granule network.
Lin, T.Y., Ohsuga, S., Liau, C.J. and Hu, X. (Eds.), Foundations and Novel Approaches in Data Mining, 75-97, Springer-Verlag, 2005.

1.4.2 Rule interestingness evaluation on the three-layer framework
Traditionally, when we talk about evaluating the usefulness and interesting-ness of discovered rules and patterns, we talk about many measures, infor-mation theory and measurement theory. Thus, the study of interestingnessevaluation is a theory-oriented study referring to the categories in Section 2.
With respect to the framework, in the philosophical layer, quantitativemeasures can be used to characterize and classify different types of rules. Inthe technique layer, measures can be used to reduce search space. In the appli-cation layer, measures can be used to quantify the utility, profit, effectiveness,or actionability of discovered rules.
From the existing studies, one can observe that rule evaluation plays atleast three different types of roles:
i. In the data mining phase, quantitative measures can be used to reduce thesize of search space. An example is the use of well-known support measure,which reduces the number of itemsets that need to be examined [1].
ii. In the phase of interpreting mined patterns, rule evaluation plays a role inselecting the useful or interesting rules from the set of discovered rules [18,19]. For example, the confidence measure of association rules is used toselect only strongly associated itemsets [1].
iii. In the phase of consolidating and acting on discovered knowledge, ruleevaluation can be used to quantify the usefulness and effectiveness of dis-covered rules. Many measures such as cost, classification error, and classi-fication accuracy play such a role [5].
To carry out the above three roles, many measures have been proposedand studied. We need to understand that measures can be classified into twocategories consisting of objective measures and subjective measures [18]. Ob-jective measures depend only on the structure of rules and the underlyingdata used in the discovery process. Subjective measures also depend on theuser who examines the rules [18]. In comparison, there are limited studies onsubjective measures. For example, Silberschatz and Tuzhilin proposed a sub-jective measure of rule interestingness based on the notion of unexpectednessand in terms of a user belief system [18, 19].
Also from Yao et al. [24], the rule interestingness measures have threeforms: statistical, structural and semantic. Many measures, such as support,confidence, independence, classification error, etc., are defined based on sta-tistical characteristics of rules. A systematic analysis of such measures is givenby Yao et al. using a 2× 2 contingency table induced by a rule [25, 28]. Thestructural characteristics of rules have been considered in many measures. Forexample, information, such as the disjunct size, attribute interestingness, theasymmetry of classification rules, etc., can be used [5]. These measures reflectthe simplicity, easiness of understanding, or applicability of rules. Althoughstatistical and structural information provides an effective indicator of the
Lin, T.Y., Ohsuga, S., Liau, C.J. and Hu, X. (Eds.), Foundations and Novel Approaches in Data Mining, 75-97, Springer-Verlag, 2005.

potential effectiveness of a rule, its usefulness is limited. One needs to con-sider the semantics aspects of rules or explanations of rules [26]. Semanticscentered approaches are application and user dependent. In addition to sta-tistical information, one incorporates other domain specific knowledge suchas user interest, utility, value, profit, actionability, and so on.
Measures defined by statistical and structural information may be viewedas objective measures. They are user, application and domain independent.For example, a pattern is deemed interesting if it has certain statistical prop-erties. These measures may be useful in philosophy layer of the three-layerframework. Different classes of rules can be identified based on statisticalcharacteristics, such as peculiarity rules (low support and high confidence),exception rules (low support and high confidence, but complement to otherhigh support and high confidence rules), and outlier patterns (far away fromthe statistical mean) [29]. Semantic based measures involve the user interpre-tation of domain specific notions such as profit and actionability. They maybe viewed as subjective measures. Such measures are useful in the applicationlayer of the three-layer framework. The usefulness of rules are measured andinterpreted based on domain specific notions.
1.4.3 Explanation-oriented data mining on the three-layerframework
To complement the extensive studies of various tasks of data mining, the ex-planation task of data mining, more specifically, the concept of explanation-oriented data mining, was first proposed in [27]. It is arguable that someinformation technologies of data mining cannot immediately create knowledgeor guarantee knowledge generation, but only retrieve, sort, quantify, organizeand report information out of data. As we believe, information can turn intoknowledge if and only if it can be rationalized, explained and validated. Sim-ilarly, explanation-oriented data mining can be explored with respect to thethree-layer framework.
To add the explanation task into the existing data mining process is basedon an important observation, that scientific research and data mining havemuch in common in terms of their goals, tasks, processes and methodologies.Scientific research is affected by the perceptions and the purposes of science.Martella et al. summarized the main purposes of science, namely, to describeand predict, to improve or manipulate the world around us, and to explain ourworld [13]. The results of the scientific research process provide a descriptionof an event or a phenomenon. The knowledge obtained from research helps usto make predictions about what will happen in the future. Research findingsare a useful tool for making an improvement in the subject matter. Researchfindings also can be used to determine the best or the most effective waysof bringing about desirable changes. Finally, scientists develop models andtheories to explain why a phenomenon occurs.
Lin, T.Y., Ohsuga, S., Liau, C.J. and Hu, X. (Eds.), Foundations and Novel Approaches in Data Mining, 75-97, Springer-Verlag, 2005.

Goals similar to those of scientific research have been discussed by many re-searchers in data mining. Guergachi stated that the goal of data mining is whatscience is and has been all about: discovering and identifying relationshipsamong the observations we gather, making sense out of these observations,developing scientific principles, building universal laws from observations andempirical data [6]. Fayyad et al. identified two high-level goals of data miningas prediction and description [4]. Ling et al. studied the issue of manipula-tion and action based on the discovered knowledge [9]. Yao et al. comparedthe research process and data mining process [26, 27]. The comparison led tothe introduction of the notion of the explanation-oriented data mining, whichfocuses on constructing models for the explanation of data mining results [27].
In the philosophy level, we need to understand what kind of pattern needto be explained. A target pattern that arouses user’s interest, hooks up user’sattention and needs to be deep explained resides in the set of discovered pat-terns. In fact, the targets may differ among the views of individuals. One mayquestion the same target at different times based on different considerations,at different cognitive levels. We also need to understand what knowledge canbe applied to explain the target pattern. Explanation-oriented data miningneeds background knowledge to infer features that can possibly explain a dis-covered pattern. We need to note two facts: first, the explanation profiles maynot situate in the original dataset. One needs to collect additional informationthat is characteristically associated with the target pattern, and can be prac-tically transformed to be the explanation context. On the other hand, how oneexplains determines what one may learn. In general, the better one’s back-ground knowledge is, the more accurate the inferred explanations are likelyto be.
The task of explanation construction and evaluation includes five separatephases that need to be undertaken: explanation subject selection, explana-tion profiles proposition, explanation construction, explanation evaluation,and explanation refinement. That is, given a target discovered pattern to beexplained, in order to result an explanatory account one needs to do the fol-lowing: First, propose the heuristic for some explanation profiles, transformand associate them with the environment where the target pattern is located.Then, construct some rules by a particular method in the explanation con-text. After these, the learned results need to be evaluated. According to theevaluation results and the user feedback, the explanation profiles can be sharp-ened and refined, the same or different methods can be applied to the refinedcontext for another plausible explanation construction until it is satisfied.
1.5 Conclusion
A three-layer conceptual framework of data mining is discussed in this chap-ter, consisting of the philosophy layer, the technique layer and the applicationlayer. The philosophy layer deals with the formation, representation, evalua-
Lin, T.Y., Ohsuga, S., Liau, C.J. and Hu, X. (Eds.), Foundations and Novel Approaches in Data Mining, 75-97, Springer-Verlag, 2005.

tion, classification and organization, and explanation of knowledge; the tech-nique layer deals with the technique development and innovation; and theapplication layer emphasizes on the application, utility and explanation ofmined knowledge. The layered framework focuses on the data mining ques-tions and issues in different abstract levels, and thus, offers us opportunitiesand challenges to reconsider the existing three views of data mining. Theframework is aimed at the understanding of the data mining as a field ofstudy, rather than a collection of theories, algorithms and tools.
References
1. Agrawal, R., Imielinski, T. and Swami, A., Mining association rules betweensets of items in large databases, Proceedings of ACM SIGMOD, 207-216, 1993.
2. Chen, Z., The three dimensions of data mining foundation, Proceedings of IEEEICDM’02 Workshop on Foundation of Data Mining and Knowledge Discovery,119-124, 2002.
3. Craik, K., The Nature of Explanation, Cambridge University Press, London,New York, 1943.
4. Fayyad, U.M., Piatetsky-Shapiro, G. and Smyth, P., From data mining to knowl-edge discovery: an overview, in: Advances in Knowledge Discovery and DataMining, Fayyad, U.M., Piatetsky-Shapiro, G., Smyth, P. and Uthurusamy, R.(eds.), AAAI/MIT Press, Menlo Park, CA, 1-34, 1996.
5. Freitas, A.A., On rule interestingness measures, Knowledge-Based Systems, 12,309-315, 1999.
6. Guergachi, A.A., Connecting traditional sciences with the OLAP and data min-ing paradigms, Proceedings of SPIE: Data Mining and Knowledge Discovery:Theory, Tools, and Technology, 5098, 226-234, 2003.
7. Lin, T.Y., Hu, X.H., Ohsuga, S. and Liau, C.J. (eds.), Proceedings of IEEEICDM’03 Workshop on Foundation of New Directions in Data Mining, 2003.
8. Lin, T.Y. and Liau, C.J. (eds.), Proceedings of the PAKDD’02 Workshop onFundation of Data Mining, Communications of Institute of Information andComputing Machinery, 5, 101-106, 2002.
9. Lin, T.Y. and Ohsuga, S. (eds.), Proceedings of IEEE ICDM’02 Workshop onFoundation of Data Mining and Knowledge Discovery, 2002.
10. Lin, T.Y., Yao, Y.Y. and Louie, E., Value added association rules, Proceedingsof PAKDD, 328-333, 2002.
11. Mannila, H., Methods and problems in data mining, Proceedings of InternationalConference on Database Theory, 41-55, 1997.
12. Mannila, H., Theoretical frameworks for data mining, SIGKDD Explorations,1, 30-32, 2000.
13. Martella, R.C., Nelson, R. and Marchand-Martella, N.E., Research Methods:Learning to Become a Critical Research Consumer, Allyn & Bacon, Bosten,1999.
14. Peikoff, L., Objectivism: The Philosophy of Ayn Rand, Dutton, 1991.15. Posner, M.I. (ed.), Foundations of Cognitive Science, Preface: learning cognitive
science, The MIT Press, Cambridge, Massachusetts, 1989.
Lin, T.Y., Ohsuga, S., Liau, C.J. and Hu, X. (Eds.), Foundations and Novel Approaches in Data Mining, 75-97, Springer-Verlag, 2005.

16. Reif, F. and Heller, J.I., Knowledge structure and problem solving in physics,Educational Psychologist, 17, 102-127, 1982.
17. Salthe, S.N., Evolving Hierarchical Systems, their Structure and Representation,Columbia University Press, 1985.
18. Silberschatz, A. and Tuzhilin, A., On subjective measures of interestingness inknowledge discovery, Proceedings of KDD, 275-281, 1995.
19. Silberschatz, A. and Tuzhilin, A., What makes patterns interesting in knowledgediscovery systems? IEEE Transactions on Knowledge and Data Engineering, 8,970-974, 1996.
20. Simpson, S.G., What is foundations of mathematics? 1996.http://www.math.psu.edu/simpson/hierarchy.html, retrieved November 21,2003.
21. Sowa, J.F., Conceptual Structures, Information Processing in Mind and Ma-chine, Addison-Wesley, Reading, Massachusetts, 1984.
22. Yao, Y.Y., Modeling data mining with granular computing, Proceedings ofthe 25th Annual International Computer Software and Applications Conference(COMPSAC 2001), 638-643, 2001.
23. Yao, Y.Y., A step towards the foundations of data mining, Proceedings of theSPIE: Data Mining and Knowledge Discovery: Theory, Tools, and Technology,5098, 254-263, 2003.
24. Yao, Y.Y., Chen, Y.H. and Yang X.D., Measurement-theoretic foundation forrules interestingness, ICDM 2003 Workshop on Foundations of Data Mining,221-227, 2003.
25. Yao, Y.Y. and Liau, C.J., A generalized decision logic language for granularcomputing, FUZZ-IEEE on Computational Intelligence, 1092-1097, 2002.
26. Yao, Y.Y. and Zhao, Y., Explanation-oriented data mining, Manuscript, 2004.27. Yao, Y.Y., Zhao, Y. and Maguire, R.B., Explanation-oriented association mining
using rough set theory, Proceedings of the 9th International Conference of RoughSets, Fuzzy Sets, Data Mining, and Granular Computing, 165-172, 2003.
28. Yao, Y.Y. and Zhong, N., An analysis of quantitative measures associated withrules, Proceedings of PAKDD’99, 479-488, 1999.
29. Yao, Y.Y. and Zhong, N. and Ohshima, M., An analysis of peculiarity orientedmulti-database mining, IEEE Transactions on Knowledge and Data Engineer-ing, 15, 952-960, 2003.
30. Zhao, Y. and Yao, Y.Y., Interactive classification using a granule network, Pro-ceedings of ICCI’05, 2005.
31. Zhong, N., Liu, C. and Ohsuga, S., Dynamically organizing KDD processes,International Journal of Pattern Recognition and Artificial Intelligence, 15, 451-473.
Lin, T.Y., Ohsuga, S., Liau, C.J. and Hu, X. (Eds.), Foundations and Novel Approaches in Data Mining, 75-97, Springer-Verlag, 2005.