Embed Size (px)
Citation preview

1
A Hybrid Deep Learning Architecture forPrivacy-Preserving Mobile Analytics
Seyed Ali Osia, Ali Shahin Shamsabadi, Sina Sajadmanesh, Ali Taheri,Kleomenis Katevas, Hamid R. Rabiee, Nicholas D. Lane, Hamed Haddadi
Abstract—nternet of Things (IoT) devices and applications are being deployed in our homes and workplaces. These devices often relyon continuous data collection to feed machine learning models. However, this approach introduces several privacy and efficiencychallenges, as the service operator can perform unwanted inferences on the available data.nternet of Things (IoT) devices andapplications are being deployed in our homes and workplaces. These devices often rely on continuous data collection to feed machinelearning models. However, this approach introduces several privacy and efficiency challenges, as the service operator can performunwanted inferences on the available data.I Recently, advances in edge processing have paved the way for more efficient, and private,data processing at the source for simple tasks and lighter models, though they remain a challenge for larger, and more complicatedmodels. In this paper, we present a hybrid approach for breaking down large, complex deep neural networks for cooperative,privacy-preserving analytics. To this end, instead of performing the whole operation on the cloud, we let an IoT device to run the initiallayers of the neural network, and then send the output to the cloud to feed the remaining layers and produce the final result. In order toensure that the user’s device contains no extra information except what is necessary for the main task and preventing any secondaryinference on the data, we introduce Siamese fine-tuning. We evaluate the privacy benefits of this approach based on the informationexposed to the cloud service. We also assess the local inference cost of different layers on a modern handset. Our evaluations showthat by using Siamese fine-tuning and at a small processing cost, we can greatly reduce the level of unnecessary, potentially sensitiveinformation in the personal data, and thus achieving the desired trade-off between utility, privacy and performance.
Index Terms—Machine Learning, Deep Learning, Privacy, Cloud Computing, Internet of Things
F
1 INTRODUCTION
The increasing availability of connected IoT devices such assmartphones and cameras has made them an essential and insepa-rable part of our daily lives. The majority of these devices collectvarious forms of data and transfer it to the cloud in order to benefitfrom cloud-based data mining services such as recommendationsystems, targeted advertising, security surveillance, health moni-toring, and urban planning. Many of these devices are subsidized,and their applications are free, relying on information harvestedfrom the users’ data. This practice has several privacy concernsand resource impacts for the users [1], [2], [3], [4]. For example, acloud-based IoT application that offers emotion detection serviceon the user’s camera as its primary task, may use this data forother tasks such as occupancy analysis, face recognition or sceneunderstanding, which may not be desired for the user, putting herprivacy at risk. Preserving individuals’ privacy versus providingdetailed data analytics faces a dichotomy in this space. Cloud-based machine learning algorithms can provide beneficial services(e.g., video editing tools or health apps), but the redundant datacollected from the users could be used for unwanted purposes(e.g., face recognition for targeted social advertising).
• Seyed Ali Osia, Ali Taheri and Hamid R. Rabiee are with the Departmentof Computer Engineering, Sharif University of Technology, Iran.
• Ali Shahin Shamsabadi is with the School of Electronic Engineering andComputer Science, Queen Mary University of London.
• Sina Sajadmanesh is with Idiap Research Institute and Ecole Polytech-nique Federale de Lausanne (EPFL).
• Hamed Haddadi and Kleomenis Katevas are with the Faculty of Engineer-ing, Imperial College London.
• Nicholas D. Lane is with the Samsung AI Center & University of Oxford.
Motivation. While complete data offloading to a cloud providercan have immediate or future potential privacy risks [5], [6],techniques relying on performing complete analytics at the userend (on-premise solution) or encryption-based methods also comewith their resource limitations and user experience penalties (seeSection 6 for a detailed discussion). Apart from resource consid-erations, an analytics service or an app provider might not be keenon sharing its valuable and highly tuned model. Therefore, it isnot always possible to assume local processing is a viable solutioneven if the task duration, memory, and processing requirementsare not crucial for the user, or the task can be performed whenusers are not actively using their devices (e.g., when the device isbeing charged overnight).
In this paper, we focus on achieving an optimization trade-off between resource-hungry, on-device analytics, versus privacy-invasive cloud-based services. We design and evaluate a hybridarchitecture where the local device and the cloud system collabo-rate on running a complex neural network that has previously beentrained and fine-tuned on the cloud. The proposed framework isbased on the idea that the end-user does not need to upload her rawdata to the cloud (which can put her privacy at risk), nor to hide allthe information employing cryptographic methods (which can beresource-hungry or overly complicated for the end-user’s device).Instead, it is sufficient to preserve the necessary information forthe service provider’s main task and discard any other irrelevantinformation which could be used for unwanted inferences frompersonal data as much as possible. In this way, we can augmentthe local device to benefit from the cloud processing efficiencyand effectively addressing the privacy concerns.
Fig 1 depicts an overview of the proposed hybrid framework,in which the user and the cloud collaborate to process the user’s
arX
iv:1
703.
0295
2v7
[cs
.LG
] 2
7 D
ec 2
019

2
data privately and efficiently. Our work relies on the assumptionthat the service provider releases a feature extractor module that ispublicly verifiable in terms of privacy. Using this feature extractor,instead of sending personal data, the user performs a minimalisticanalysis and extracts an exclusive feature from her data and sendsit to the service provider for subsequent analysis. The exclusivefeature is then processed in the cloud, and the result yields backto the user. The fundamental challenge in using this framework isthe design of the feature extractor module that removes irrelevantinformation to achieve an acceptable trade-off among the privacy,utility, and scalability.
Overview & Contributions. We begin by introducing the pro-posed hybrid framework, which addresses the problem of “userdata privacy in interaction with cloud services”. In this paper, wefocus on those services that utilize deep neural networks (DNNs)aiming to solve classification problems as their main task. Bydecoupling layers of a pre-trained DNN into two parts, we shiftinitial layers of the network that act as the feature extractor moduleto the user’s device, while keeping the remaining layers on thecloud. We demonstrate that the proposed solution does not havethe overhead of running the whole deep model on the user’sdevice, and it can be used effectively to preserve the privacyof users by preventing exposure of irrelevant information to thecloud.
In order to evaluate our hybrid privacy-preserving framework,we consider two different main tasks: gender classification on faceimages and activity recognition on mobile sensor data. First, weuse activity recognition as the main task and consider genderrecognition as the privacy-invasive secondary task. Then we setgender recognition as the main task, and we use face recognition,which tries to reveal the identity of individuals in the images, as asensitive secondary task. We use Convolutional Neural Networks(CNNs) as one of the most widely used DNN architectures [7], [8],[9] to build accurate models for gender and activity recognition.Then we fine-tune these models with our suggested Siamese ar-chitecture to preserve the privacy of users’ data while maintainingan acceptable level of accuracy. To verify the proposed featureextractor, measure its privacy, and evaluate the efficiency of themodel in removing irrelevant information, we introduce a newmeasure for privacy measurement that is an extension of the zero-one loss for classification. Besides, we use transfer learning [10],which proves that secondary inferences are not feasible. To givemore insight into the performance of our framework, we use deepvisualization, which tries to reconstruct the input image using theexclusive feature [11]. We also implement the gender classificationmodel on a modern smartphone device and compare the completeon-premise solution with our hybrid architecture. Even though wereport the evaluation results for a typical smartphone device, thisframework can be extended to other devices with limited memoryand processing capabilities, such as Raspberry Pi and similar IoTdevices. Our main contributions in this paper include:
• Introducing a hybrid user-cloud framework for the privacypreservation problem which utilizes a novel feature extrac-tor as its core component.
• Proposing a novel technique for building the feature ex-tractor based on Siamese architecture that enables privacyat the point of offloading to the cloud.
• Proposing a new measure to evaluate the privacy and verifythe feature extractor module.
User’s Device Cloud Service
Feature Extractor ClassifierExclusive
Feature
Result
Raw Data
Fig. 1: Hybrid privacy-preserving framework: The cloud serviceprovides the feature extractor to the user’s device, by which thedevice extracts an exclusive feature from the data and uploads itto the cloud for the rest of the process. The cloud runs a classifieron the exclusive feature and sends the result back to the user.
• Evaluating the framework across two deep learning archi-tectures for gender classification and activity recognition,based on the proposed privacy measure, transfer learning,and deep visualization.
Paper Organization. The rest of this paper is organized asfollows. In the next section, we present a thorough overview ofthe proposed hybrid architecture. In Section 3, we describe how todeploy a pre-trained model to build the feature extractor moduleusing Siamese fine-tuning, dimensionality reduction and noiseaddition mechanisms. Next, we introduce different methodologieswe employed to measure the privacy of the proposed frameworkin Section 4. Extensive evaluations and experimental results aredescribed in Section 5. After reviewing related works in Section6, we finally conclude the paper in Section 7.
2 HYBRID USER-CLOUD FRAMEWORK
In this section, we present our hybrid framework for cloud-basedprivacy-preserving analytics. Suppose the scenario in which theuser would like to interact with a cloud-based service that makesuse of a classification model for inferring a primary measure ofinterest from the user’s data as its main task. However, the end-user wants to prevent the exposure of her sensitive information tothe service provider that could potentially put her privacy at risk.An example of this scenario can be seen when the end-user hasan application on her phone, which sends sensor data to a cloud-based service provider for activity recognition (the main task) toreact to her activities (the primary measure) differently (e.g., makethe phone silent when sleeping). However, the end-user wouldnot like the service provider to be able to infer other potentiallysensitive information, such as her identity or gender, from her data.Note that in this case, the end-user does not choose to train herclassification model, but in fact, she wants to use a provided pre-trained cloud-based service in a safe, privacy-preserving manner.
While uploading the raw data to the cloud has the potential riskof revealing sensitive information, using cryptographic methods toencrypt personal data has its potential drawbacks, as discussed inSection 6. Instead, an intermediary solution to this problem is toperform a minimal process on user’s raw data in the client-side toextract a specially crafted feature, which we refer to as exclusivefeature, and then upload this feature instead of the raw data tothe cloud for further processing. In this case, the exclusive featureshould have the following properties:
• The exclusive feature must keep as much informationrelative to the primary measure as possible to prevent theperformance drop of the main task.

3
Input
User’s Device
Feature Extractor
Output
Cloud Service
Classifier
… …
Layer1 Layeri
(Intermediate)LayerN
W1 Wi-1 Wi WN-1
Input Output
Pre
-tra
ined
N
etw
ork
Lay
er-S
epar
ated
N
etw
ork
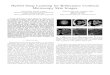
Fig. 2: Simple Embedding of a DNN. The above network is a pre-trained DNN before applying layer separation, entirely resided inthe cloud. After layer separation, the beginning part of the DNNforms the feature extractor and will be sent to the user’s device foroperation. The second part will remain and operate in the cloud.
• It must hide or discard all the other unnecessary informa-tion to prevent the inference of any sensitive measure.
As a result, according to Fig 1, the user and the serviceprovider collaborate in the following steps:
1) The service provider determines how to extract the ex-clusive feature on the client-side by providing a featureextractor module to the user.
2) Using the provided feature extractor, the user extracts theexclusive feature from her data on the client-side anduploads it to the cloud for further processing.
3) The service provider’s classifier module receives andprocesses the exclusive feature to yield and return theexpected result to the user.
Any classifier which can be separated to feature extractor andclassier modules can be embedded in this framework. The mainchallenge of this work is to properly design the feature extractormodule to output the exclusive feature constrained to keepingthe primary information, while discarding any other irrelevantinformation to the main task. Usually, these two objectives arecontradictory because information removal may adversely affectthe performance of the main task. Besides, due to the limitationsof client-side processing, feature extraction needs to have minimaloverhead on the user’s device. Therefore, designing the featureextractor is the most challenging issue to address.
In order to narrow down the scope of this paper, in the rest,we will focus on feed-forward neural networks (e.g., CNN orMLP) and address how to build and train the feature extractormodule for them. By considering the accuracy of the classifier, wecan guarantee the preservation of the primary information in theexclusive feature. The privacy preservation of the feature extractorcan also be verified (either by the end-user or by a third party)using different methods, which will be discussed in Section 4.
3 DEEP PRIVACY EMBEDDING
In this section, we address how to embed a pre-trained deep neuralnetwork (DNN), which classifies the primary measure (e.g., forgender recognition), into the proposed framework. We chooseDNNs as the core learning method for our framework due totheir increasing popularity in machine learning and data mining
applications. Complex DNNs consist of many layers that canbe embedded in this framework following the layer separationmechanism. In this approach, we choose an intermediate layerof the DNN as a pivot, based on which we split the wholenetwork into two parts. The first part that forms the featureextractor module includes the input layer of the DNN up tothe intermediate layer (inclusive). We refer to the output of theintermediate layer as the intermediate feature. The second part,which contains the remaining layers of the network, forms theclassifier module. This way, using the layer separation mechanism,we achieve two essential objectives simultaneously: (i) obtainingthe desired feature extractor, and (ii) benefiting from the intrinsiccharacteristics of DNNs: The output of higher layers are morespecific to the main task, containing less irrelevant information.
If we just rely on the layer separation mechanism, we will endup with an embedding method, which we call Simple Embedding,as illustrated in Fig 2. In this embedding method, the featureextractor module that is sent to the user’s device is just the initiallayers of the network up to the intermediate layer with no changes,with the exclusive feature being the same as the intermediatefeature.
Choosing the intermediate layer from lower layers of thenetwork intrinsically results in privacy compromises. As we pro-ceed through the deep network layers, the feature becomes morespecific to the main task, and irrelevant information (includingsensitive information) will be gradually lost [10]. Meanwhile,the more privacy we gain by choosing higher layers as theintermediate one, the more processing overhead we impose onthe user’s device. Therefore, for the sake of scalability, it isbetter to select the intermediate layer from the lower layers of thenetwork. However, lower layers of a DNN learn general invariantfeatures that are not specific to the main task [12]. This willbring privacy concerns with the simple embedding approach. Thesolution is to manipulate the intermediate feature coming from alower intermediate layer and try to adjust it only for the desiredprimary measure so that all the other sensitive measures becomeunpredictable. To this end, we employ three different techniques:dimensionality reduction, noise addition, and Siamese fine-tuning,which are discussed accordingly.
3.1 Dimensionality Reduction
The first approach to increase the privacy of the intermediatefeature is to reduce its dimensionality using Principle ComponentAnalysis (PCA) or autoencoder-based solutions [13], as thesemethods try to preserve the primary structure of the input signalas much as possible, and remove all the other unnecessary de-tails. This mechanism also reduces the communication overheadbetween the user and the cloud. We only intended to show theeffect of reducing dimensionality on the privacy of the exclusivefeatures, so we simply used the popular PCA as a proof of concept.In this approach, a dense reduction matrix is added as the last layerof the feature extractor module, and a dense reconstruction matrixis attached before the first layer of the classification module. Werefer to this embedding (with PCA applied) as reduced embedding.In this method, the exclusive feature is obtained by reducing thedimensionality of the intermediate feature. As will be shown inSection 5, this procedure does not significantly affect the accuracyof the main task.

4
Input Is Similar Input
F(Input) F(Input)Distance
Contrastive LossF F
(a) Traditional Siamese
Input
Softmax
Intermediate
…
CN
N
Is Similar Input
Softmax
…
CN
N
Distance
Contrastive Loss
Classification Loss
Classification Loss
… …
Intermediate
(b) Privacy-preserving Siamese
Fig. 3: The figure on the left shows the traditional Siamesearchitecture used for some applications like face verification. Theone on the right shows the privacy-preserving Siamese architectureused to fine-tune a pre-trained DNN on the cloud.
3.2 Siamese Fine-tunning
A more complicated approach to craft the exclusive feature is toutilize a many to one mapping for any sensitive variable. Thisis similar to the main idea behind k-anonymity [14], when theidentities are assumed to be sensitive variables. As an example,consider the problem of gender classification using a featureextractor that maps input images to a feature space. If we havek images of the “male” class mapped to k distinct points, anadversary may be able to reconstruct the original images if hecould discover the reverse mapping function. Conversely, if all ofthe k different male images map to a single point in the featurespace, the adversary will experience confusion to select the correctidentity between k possible ones. Therefore, if we fine-tune thefeature extractor in such a way that the features of the same classfall within a very small neighborhood of each other, the privacyof the input data will be better preserved. To accomplish this task,we use the Siamese architecture [15] to fine-tune the pre-trainedmodel on the cloud, before applying the layer separation.
The Siamese architecture presented in Fig 3 has previouslybeen used in verification applications [15]. It provides a fea-ture space where the similarity between data points is definedby their Euclidean distance. The main idea of fine-tuning withSiamese architecture is making the representation of semanticallysimilar points become as close as possible to each other, whilethe representation of dissimilar points fall far from each other.For example, in face verification problem, where the goal is todetermine whether two images belong to the same person or not,the Siamese fine-tuning can make any two images that belong tothe same person fall within a local neighborhood in the featurespace, and the features of any two images having mismatchingfaces become far from each other.
To fine-tune with Siamese architecture, the training datasetmust comprise pairs of samples labeled as similar/dissimilar. Acontrastive loss function is applied to each pair, such that thedistance between two points gets minimized if they are similar andmaximized otherwise. Here, we use the one introduced in [16]:
L(f1, f2) =
{‖f1 − f2‖22 similar
max(0,margin− ‖f1 − f2‖2)2 dissimilar(1)
where f1 and f2 are the mappings of data points, and margin isa hyper parameter controlling the variance of the feature space.
Class 1
Class 2
(a) Before fine-tuning
Class 1
Class 2
(b) After fine-tuning
Fig. 4: A two-dimensional representation of the feature spacebefore and after Siamese fine-tuning where the main task is a two-class classification. The dashed line shows the border betweenprimary class 1 and 2. The points with the same color have thesame attribute, which is potentially sensitive. Before Siamese fine-tuning, an adversary can discover sensitive information as thereare clear borders between different colors, but after fine-tuning,the sample points with the same primary class will get too close toeach other, making the inference of the sensitive information muchharder. A small perturbation of the data points after the fine-tuningwill totally dispose of the sensitive class borders while maintainingthem on the right-hand side of the primary class border.
We exploit Siamese fine-tuning to increase the privacy of thefeature extractor by forcing it to map the input data to the featurespace in such a way that samples with the same primary classlabel become close to each other, while samples with differentclass labels become far. This is illustrated in Fig. 4. For example,if the main task is gender recognition, with Siamese fine-tuning,all the images of the ”male” class will be mapped to a small localregion in the feature space, and similarly, all the ”female” imageswill be mapped to another region which is far from the male’s.
By defining a contrastive loss on the intermediate layer, weget a multi-objective optimization problem. It tries to increase theaccuracy of the primary variable prediction by minimizing theclassification loss, and at the same time, it increases the privacy ofthe exclusive feature by minimizing the contrastive loss. In fact,we add the contrastive loss as a regularization term to the mainclassification loss (weighted sum) and try to optimize the new lossfunction with gradient descent based algorithms.
We refer to this embedding method as Siamese embedding.Note that the whole process of Siamese fine-tuning is done inthe cloud by the service provider only once, before applying thelayer separation and delivering the feature extractor module toend-users. The exclusive feature, in this case, will be the output ofthe intermediate layer of the fine-tuned DNN.
3.3 Noise AdditionNoise addition is another traditional method for preserving privacy[17], which increases the inference uncertainty of unauthorizedtasks. Apart from Siamese fine-tuning and dimensionality reduc-tion, the feature extractor module can also add multi-dimensionalnoise to the feature vector to further increase the privacy. Werefer to this technique as noisy embedding. Although Siamese fine-tuning tries to map data points with different sensitive classes toa single point, these points may still have small distances fromeach other (Fig 4b). We can highly increase the uncertainty aboutsensitive variables by adding random noise to the feature. As thevariance of the added noise increases, we get more uncertainty inthe sensitive variable, and thus the privacy will be better preserved.However, a high-variance noise could also decrease the predictionaccuracy of the primary variable, as it could cause the data points

5
Input
User’s Device
Feature Extractor
Output
Cloud Service
Classifier
Fig. 5: The noisy reduced embedding of a pre-trained DNN withboth dimensionality reduction and noise addition. If Siamese fine-tuning is also applied to the DNN before layer separation in thecloud, it will be the advanced embedding method. In this case,after cloud-side Siamese fine-tuning, the feature extractor is sentto the user’s device where PCA projection and noise additionare applied to produce the exclusive feature. This feature is thenuploaded to the cloud to proceed with the processing.
to fall out of the right-class region. Therefore, we have a trade-off between privacy and accuracy when increasing the amount ofnoise. A significant benefit of Siamese fine-tuning is that it allowsus to add noise with higher variance, because after the fine-tuning,the intra-class variance of the primary variable decreases, while theinter-class variance gets increased. Therefore, with Siamese fine-tuning, our framework can tolerate higher variance noises withoutnoticeable performance drop in the main task.
Ultimately, we can combine all the embedding methods,namely Siamese fine-tuning with both dimensionality reductionand noise addition, as a method that we call advanced embedding.Fig 5 illustrates an overview of the advanced embedding, in whichSiamese fine-tuning is performed on the cloud before pushing thefeature extractor to the end-users’ devices. When the user attemptsto use the service, the feature extractor module on her deviceextracts a feature vector from the input data at the intermediatelayer. Next, the dimensionality of the obtained feature is reducedby applying a PCA or an Auto-Encoder. Before uploading tothe cloud, the feature extractor adds some noise to the reduced-size feature to obtain the exclusive feature. The classifier moduleresiding in the cloud receives the exclusive feature and performs adecompression operation. Finally, the reconstructed feature is fedinto the neural network to produce the expected result.
4 PRIVACY VERIFICATION
In this section, we introduce three different methods to verify andevaluate the privacy of the exclusive feature. First, we define aprivacy evaluation measure based on a statistical analysis of anarbitrary sensitive variable given the exclusive feature. Next, weuse transfer learning [10] to determine the degree of generalityand particularity of the exclusive feature to the main task, anddeep visualization [11] to evaluate how well we can reconstructinput data from the exclusive feature. In practice, these methodscan be used by the end-user or a third party to verify the privacyof the feature extractor module of a service provider in order todecide if the service provider should be trusted.
4.1 Privacy MeasureHere, we introduce an intuitive method to measure and quantifythe privacy of the feature extractor. We consider the cases wherewe want to verify the privacy of the exclusive feature concerning adiscrete sensitive variable, such as the identity of people. Althoughthere exist various methodologies for this purpose in the literature,
including k-anonymity [14] or differential privacy [18], they cannot be directly applied to our problem, since they are designed fordifferent privacy-preserving scenarios such as dataset and modelpublishing (discussed in Section 6). However, as our methodaddresses the privacy issue in a different context, we have toevaluate the privacy of our framework using a different measure.
The privacy of our framework directly relies on the amount ofsensitive information that exists in the exclusive feature. The reli-able approach to this end is to use information-theoretic conceptssuch as mutual information or conditional entropy to measurethe amount of sensitive information. However, even if we wereable to obtain a reasonable estimate of the joint distribution ofthe sensitive variable and the exclusive feature, calculating thesemeasures would be intractable, especially in the high dimensionalspace [19]. Another approach is to consider the deficiency ofthe classifier trying to discriminate an arbitrary sensitive variable,given the exclusive feature. In this context, less classification ac-curacy implies that the exclusive feature contains less informationabout the sensitive variable, and thus more privacy is preserved.However, classification accuracy by itself is not sufficient to guar-antee privacy because the actual sensitive class might be amongthe most probable candidates. Therefore, we extend this approachto include the rank of the results in the measure. Considering therank of likelihood as the privacy measure makes sense, because itcan be seen as an extension of k-anonymity and top-k accuracy,and also an estimation of guessing entropy [20]. In fact, averagerank is equivalent to the expected k-anonymity, and lower ranksresult in less top-k accuracy and thus more privacy. Moreover, theaverage rank is an empirical estimation of guessing entropy, whichis a well-known measure of uncertainty [20] that can also be usedas a measure of privacy.
Formally speaking, assume that we have a dataset D ={(xi, si)}i=1:N , where xi is an input data and si is a discretesensitive class which can take values from the set {1, 2, . . . ,K}.We apply the feature extractor on D to obtain the set of featuresF = {(fi, si)}i=1:N . Then, by adding noise to F , we build the setof noisy features Z = {(zi, si)}i=1:N . To measure the privacy ofa certain noisy feature zi, we calculate the conditional likelihoodof all the sensitive classes {P (s|zi) | 1 ≤ s ≤ K}. Therefore, wefirst estimate P (zi|s) for an arbitrary sensitive class s as:
P (zi|s) =∫fP (zi, f |s)df =
∫fP (zi|f, s)P (f |s)df (2)
if we condition on f , s becomes independent of zi, and we have:
P (zi|s) =∫fP (zi|f)P (f |s)df = Ef∼P (f |s)[P (zi|f)] (3)
Assuming Fs = {f1, f2, ..., fNs} is the set of extracted featureswith the sensitive class s in our dataset, we can estimate the aboveexpected value with sample mean calculated on Fs:
P (zi|s) =1
Ns
∑fj∈Fs
P (zi|fj) (4)
Now by using the Bayes rule, we have:
P (s|zi) ∝ P (zi|s)P (s) (5)
Then, we can compute the relative likelihood of all sensitiveclasses given a noisy feature zi. As we know the correct sensitiveclass of zi which is si, we find the rank of the likelihood of thetrue class P (si|zi) in the set {P (s|zi)|1 ≤ s ≤ Ns} sorted

6
WMT WMT WMT WMT WMT
MT
WMTWMT WMT WRan WRan
RanMT
WMTWMT WMT WST WST
STMT
WST WST WST WST WST
ST
Fig. 6: The transfer learning procedure from top to bottom: (1)the trained network N1 for the main task; (2) another networkN2 for the secondary task; (3) the weights of the beginning layersare copied from N1 to N2 and frozen, while the remaining layersinitialize with random weights; (4) final trained network for thesecondary task, using transfer learning.
in descending order (lower likelihoods get higher rank), as theprivacy of zi:
Privacy(zi) =Rank(si)
K(6)
where we divide the rank by K (the total number of classes) tonormalize the values between 0 and 1. For all of the members ofZ , we can estimate the total privacy of the transmitted data byaveraging over the individuals privacy values:
Privacy total =1
N
N∑i=1
Privacy(zi) (7)
The utility-privacy trade-off for this measure is addressed in[21] from information-theoretic point of view. In this paper weuse this measure in practice and create the accuracy-privacy trade-off (see Fig 10).
4.2 Transfer Learning
We can also measure the amount of particularity of the extractedfeature to the main task using Transfer Learning [10]. Thisprocedure is depicted in Fig 6. Suppose we have already traineda DNN N1 for primary variable classification. Then, we buildand train another DNN N2 to infer an arbitrary sensitive variableaccording to the following procedure:
1) Copy weights from the first i layers of N1 to the first ilayers of N2.
2) Initialize the remaining layers of N2 randomly.3) Freeze the first i layers of N2 (do not update their
weights).4) Train N2 for sensitive variable inference to learn the rest
of the parameters.
After the training procedure, the accuracy obtained for sen-sitive variable prediction is directly related to the degree ofgenerality of the extracted feature from i’th layer. The loweraccuracy for the sensitive variable prediction means the morespecific is the feature to the main task.
Conv1-1
Relu1-1
Pool1
Conv1-2
Relu1-2
Conv2-1
Relu2-1
Pool2
Conv2-2
Relu2-2
Conv3-2
Relu3-2
Pool3
Conv3-3
Relu3-3
Conv3-1
Relu3-1
Conv4-2
Relu4-2
Pool4
Conv4-3
Relu4-3
Conv4-1
Relu4-1
Conv5-2
Relu5-2
Pool5
Conv5-3
Relu5-3
Conv5-1
Relu5-1
FC6
FC7
Relu7Relu6
FC8
Prob
Fig. 7: VGG-16 architecture for gender classification [22].
4.3 Deep VisualizationVisualization is a method for understanding deep networks. Deepvisualization can give us a fascinating insight into the privacyof the exclusive feature for those tasks in which the input isvisualizable, such as images. In order to obtain an insight into theamount of sensitive information in the exclusive feature, we usean Auto-Encoder visualization technique [11], which is especiallyuseful when working with image datasets. In [11], a decoder isdesigned on the data representation of each layer to reconstruct theoriginal input image from the learned representation. Therefore,we can analyze the preserved sensitive information in each layerby comparing the reconstructed image with the original input.
5 EXPERIMENTS
In this section, we evaluate and analyze the accuracy and privacyof different embedding methods for two widely-used classificationtasks as a case study: activity recognition and gender classification.For activity recognition, we consider gender as a piece of arbitrarysensitive information that the user does not want to be exposed tothe cloud service provider, whereas for gender classification, weset the sensitive variable to identity. In each of these applications,we verify the feature extractor module by using the proposedprivacy measure and transfer learning. We show that among allthe proposed embedding methods, applying Siamese fine-tuningis the most efficient one in preserving privacy, yet it does notdecrease the accuracy of the main classification task. Besides, weshow how deep visualization is not feasible in reconstructing theoriginal data from the exclusive feature. Finally, we evaluate ourhybrid framework on a mobile phone and discuss its advantagescompared to other solutions.
5.1 Experiment SettingsWe embed the proposed framework into the state of the art modelsfor gender classification and activity recognition and evaluate itseffectiveness in preserving users’ data privacy.
5.1.1 Gender ClassificationIn the problem of gender classification, the goal is to classify anindividual’s image to male or female, without disclosing the iden-tity of individuals as an example of sensitive information. This hasvarious applications in different domains such as human-computerinteraction, surveillance, and targeted advertising systems [23].
Datasets. Rothe et al. [24] prepared a large dataset, namedIMDB-Wiki, which is useful for age and gender estimation. Weused the Wiki part of this dataset, containing 62,359 images, to

7
Conv-1
Relu-1
Conv-2
Relu-2
Conv-3
Relu-3
Conv-4
Relu-4
FC-1
FC-2
Pool-1 Pool-3Pool-2 Pool-4
Relu-6Relu-5
Fig. 8: MTCNN architecture for activity recognition [27].
fine-tune the gender classification model with Siamese architec-ture. We used 45,000 images as training data and the rest asvalidation data. We evaluated our privacy measurement techniqueson this dataset, as well. We also used “Labeled Face in the Wild”(LFW) dataset [25] as a benchmark to test the predictive accuracyof different embedding methods. This is an unconstrained facedatabase containing 13,233 images of 5,749 individuals, which isvery popular for evaluating face verification and gender classifi-cation models. For the transfer learning approach, we used theIMDB dataset from [26], containing about 2 million images from2,622 well-known celebrities on the IMDB website, among whichwe selected 100 and divided their images to training and test setsfor evaluating the face recognition model.Setup. We used the pre-trained model proposed in [24] having94% accuracy based on VGG-16 architecture [22], which is shownin Fig 7. We broke it down on Conv5-1, Conv5-2, and Conv5-3as different intermediate layers and evaluated our framework oneach of them. To create reduced embeddings, we applied PCAon the intermediate feature to reduce its dimension to 4, 6, and8 for Conv5-3, Conv5-2, and Conv5-1, respectively. We did nottry to optimize the dimension setting aggressively and just usedcross-validation to select some reasonable dimensions.
5.1.2 Activity RecognitionAnother application we used for evaluating the proposed frame-work is activity recognition, which aims to recognize the activityof a user from the accelerometer and gyroscope data of hersmartphone. In this scenario, we set to prevent the exposure ofthe user’s gender as a piece of arbitrary sensitive information.Dataset. We used the MotionSense dataset [27] for all thestages of Siamese fine-tuning, predictive accuracy assessment, andtransfer learning. This dataset contains time-series data generatedby accelerometer and gyroscope sensors (attitude, gravity, useracceleration, and rotation rate), collected by an iPhone 6s kept inthe 24 participant’s front pocket in 15 trials doing the followingactivities: downstairs, upstairs, walking, and jogging.Setup. The activity recognition model we used in experimentsis the already trained version of a specific implementation of amulti-task convolutional neural network (MTCNN) proposed byMalekzadeh et al. [27]. The overall view of this architecture isdepicted in Fig 8. We decoupled the network on Conv-4, FC-1,and FC-2 as different intermediate layers. Reduced embeddingsof this model were obtained from applying PCA to reduce thedimension of the intermediate feature to 8 for each of the layers.
5.2 Experiment Results
Accuracy of Embedding Methods. In the first step, we assessedhow different embedding methods affect the accuracy of both
TABLE 1: Predictive Accuracy of Different Embedding Methods
Gender Classification Activity Recognition
Method Conv5-1 Conv5-2 Conv5-3 Conv-4 FC-1 FC-2
Simple 94.0% 94.0% 94.0% 93.0% 92.7% 93.2%Reduced 89.7% 87.0% 94.0% 85.3% 92.5% 93.1%Siamese 92.7% 92.7% 93.5% 93.2% 93.3% 94.2%Red. Siam. 91.3% 92.9% 93.3% 90.1% 92.8% 94.2%
Conv5-1 Conv5-2 Conv5-30
5
10
15
20
25
30
Face
Rec
ogni
tion
Acc
urac
y
Simple Reduced Simple Siamese Reduced Siamese
(a) Gender Classification
Conv-4 FC-1 FC-240
50
60
70
80
90
100
Gen
der
Rec
ogni
tion
Acc
urac
y
(b) Activity Recognition
Fig. 9: Transfer learning results for different embeddings acrossdifferent intermediate layers. Less accuracy means more privacy.According to the figure, using higher layers together with Siamesefine-tuning and dimensionality reduction achieves more privacy.
gender classification and activity recognition as two different maintasks. Table 1 reports the accuracy of both tasks under differentembedding methods and intermediate layers (the accuracy ofnoisy version can be seen in Fig 10 for different amounts ofnoise). The obtained results convey two critical messages. First,the predictive accuracy of Siamese and simple embeddings arecomparable, which implies that applying Siamese fine-tuningdoes not necessarily decrease the accuracy of the main task, butsometimes can even result in a slight improvement due to the wayit centralizes same-class data points and separates different-classones. Second, Siamese embedding is more robust to PCA thansimple embedding, again due to the same reason. In other words,the accuracy of Siamese embedding is very close to its reducedcounterpart, while for simple embedding, applying dimensionalityreduction will deteriorate the accuracy. As a result, applying theSiamese embedding with dimensionality reduction leads to betterprivacy with less accuracy degradation of the main task.
Transfer Learning. The result of transfer learning for differentembeddings on different intermediate layers for both gender clas-sification and activity recognition tasks are presented in Fig 9.For gender classification (Fig 9a), applying (reduced) simple orSiamese embedding results in a considerable decrease in theaccuracy of face recognition (secondary task) from Conv5-1 toConv5-3. The reason for this trend is that as we go up throughthe layers, the features of each layer will be more specific tothe main task. In other words, the feature of each layer willhave less information related to identity (the sensitive information)comparing to the previous ones. In addition, the face recognitionaccuracy of Siamese embedding is by far less than the accuracy ofsimple embedding in all configurations. As it is shown in Fig 9a,when Conv5-3 is chosen as the intermediate layer in Siameseembedding, the accuracy of face recognition is 2.3%. Anotherinteresting point of Fig 9 is the effect of dimensionality reductionon the accuracy of face recognition. Reduced simple and reduced

8
0 5 10 15 20 25 30 35 4084
86
88
90
92
94
96
Identity Privacy (%)
Gen
der
Cla
ssifi
catio
nA
ccur
acy
(%)
Noisy Reduced Advanced
(a) Effect of Siamese fine-tunning on gender classifica-tion using conv5-3 as inter-mediate layer
0 5 10 15 20 25 30 35 4084
86
88
90
92
94
96
Identity Privacy (%)
Gen
der
Cla
ssifi
catio
nA
ccur
acy
(%)
Conv5-1 Conv5-2 Conv5-3
(b) Effect of different in-termediate layers on gen-der classification using ad-vanced embedding
0 5 10 15 20 25 30 35 4084
86
88
90
92
94
96
Gender Privacy (%)
Act
ivity
Rec
ogni
tion
Acc
urac
y(%
)
Noisy Reduced Advanced
(c) Effect of Siamese fine-tunning on activity recogni-tion using FC-2 as interme-diate layer
0 5 10 15 20 25 30 35 4084
86
88
90
92
94
96
Gender Privacy (%)
Act
ivity
Rec
ogni
tion
Acc
urac
y(%
)
Conv-4 FC-1 FC-2
(d) Effect of different in-termediate layers on activityrecognition using advancedembedding
Fig. 10: Accuracy-privacy trade-off. In each plot, y-axis shows accuracy of the main task (gender classification in (a) and (b), andactivity recognition in (c) and (d)), and x-axis shows privacy of the sensitive task (identity recognition in (a) and (b), and genderrecognition in (c) and (d)). For the left-most point in each plot, noise is zero, and it gains the most accuracy with the least privacy. Byincreasing the amount of noise variance, we can obtain more privacy while giving up some accuracy. Each point represents a certainamount of variance for the added noise. We can observe that the advanced embedding (which includes Siamese fine-tuning) achievesbetter trade-off than the noisy reduced embedding (without Siamese fine-tuning) (see (a) and (c)). Also, higher intermediate layers leadto better trade-off (see (b) and (d)).
Siamese embeddings have lower face recognition accuracy thansimple and Siamese embeddings, respectively.
We observe similar trends for the activity recognition taskdepicted in Fig 9b, in which the accuracy of the gender recognitionmodel (secondary task) is decreased in all embedding methodsacross different intermediate layers. Analogous to gender classifi-cation, the Siamese embedding works better than simple embed-ding for activity recognition as well, and applying dimensionalityreduction helps with better privacy protection.Privacy Measure. We used the rank measure proposed in Sec-tion 4.1 to evaluate the privacy of different embedding methodsagainst their achieved accuracy for the gender classification andactivity recognition tasks. We increased the privacy of noisy em-bedding methods by widening the variance of the added symmetricGaussian noise. Fig 10 illustrates the achieved privacy based onthis measure against the predictive accuracy of the main task fordifferent noisy configurations of gender classification and activityrecognition. Each data point in the figures represents a certainamount of variance for the added noise.
In Fig 10a, for the gender classification task, we fixed theintermediate layer on Conv5-3 and evaluated the accuracy-privacytrend of two embedding methods: noisy reduced simple and ad-vanced embeddings in order to evaluate the effect of Siamese fine-tuning. We can see from the figure that as the privacy increases(by adding higher-variance noises), gender classification accuracydecreases more slowly in advanced embedding, where we useSiamese fine-tuning, compared to the other method that doesnot benefit from Siamese fine-tuning. We also assessed the effectof choosing different intermediate layers on the accuracy-privacycurve when using the advanced embedding method. The result ofthis experiment is depicted in Fig 10b, where the accuracy-privacycurve of higher layers are above lower ones, meaning that higherlayers provide more privacy when achieving the same accuracy.This result conforms with that of transfer learning in a way thatchoosing the intermediate layer closer to the output of the networkresults in having a lower face recognition accuracy.
Similar to gender classification, we also evaluated theaccuracy-privacy trade-off for different embedding techniques in
the activity recognition task. The effect of having Siamese fine-tuning is shown in Fig 10c, where we fixed the intermediate layerto FC-2. As expected, the advanced embedding curve is above theone for noisy reduced simple embedding in this task, as well. InFig 10d, we assessed the effect of choosing different intermediatelayers, among Conv-4, FC-1, and FC-2, on the accuracy-privacytrend of the advanced embedding method. Like what we experi-enced for gender classification, in activity recognition, consideringhigher layers as the intermediate results in having more area underthe accuracy-privacy curve.
Visualization. We evaluate the identity privacy of the genderclassification task, whose input is an image and thus visualizable,using deep visualization techniques. In order to visualize theoutput of the feature extractor module, we fed the Alexnet decoder[11] with the exclusive feature of the gender classification modelfor different embeddings. Then we fine-tuned the decoder toreconstruct the input image as much as possible. We can visuallyverify the identity privacy of the feature extractor by looking atthe reconstructed images. The results are illustrated in Fig 11for different embedding methods. It can be observed that underall of the different embedding methods, genders of all imagesremain the same as the original ones. However, we can see that foradvance embedding, it is harder to distinguish identities from thereconstructed images compared to other embeddings. The originalimages are mostly recovered in simple embedding. Therefore, justseparating layers of a deep network can not guarantee the privacyof users’ data. Siamese embedding performs better than simpleembedding by distorting the identity, yet advanced embeddingprovides the best results.
Mobile Evaluation. We evaluated the proposed hybrid frameworkfor both gender classification and activity recognition on a modernhandset device, as shown in Table 2. In order to assess the timeand memory usage of our framework, we evaluated simple andreduced embeddings separately for each of the three intermediatelayers, Conv5-1, Conv5-2, and Conv5-3, of VGG-16 architectureand Conv-4, FC-1, and FC-2 of activity recognition model, andcompared them with the on-premise solution (full model running

9
Original Image
Simple Embedding
Siamese Embedding
Advanced Embedding
Fig. 11: The first row shows the original images and the others show the reconstructed ones from exclusive feature. In all reconstructedimages, the gender of the individuals is recognized to be the same as the originals. In addition, From simple to advanced embedding, theidentity of the individuals is increasingly removed, proving that the advanced embedding has the best privacy preservation performance.
TABLE 2: Device Specification
Apple iPhone Xs
Memory 4GB LPDDR4X RAMStorage 256GBChipset A12 Bionic chip
CPU Hexa-core 64bitOS iOS 12.2
Conv5-1 Conv5-2 Conv5-3 On-Prem.
15
20
25
30
35
40
Run
ning
Tim
e(m
s)
Simple
Reduced
(a) Gender Classification
Conv-4 FC-1 FC-2 On-Prem.2
2.5
3
3.5
4
4.5
5
Run
ning
Tim
e(m
s)
Simple
Reduced
(b) Activity Recognition
Fig. 12: Running time statistics for different embeddings onmobile device over 60 tests per configuration
on device). Note that we omitted Siamese embedding in mobileevaluations, because the Siamese fine-tuning is done entirely onthe cloud, so it does not impact the running time or memoryusage of the mobile device. We used Core ML Tools v2.1.01 toconvert the models into CoreML format that is compatible withiOS platform. Next, we evaluated each model by measuring therunning time (Fig 12), model loading time (Fig 13) and modelmemory usage (Fig 14) of each of the seven configurations.
Most of the variations of trained model architectures underthe proposed embedding approach report the same loading timeand memory usage performance. As the VGG-16 network of thegender classification is too vast compared to the light activityrecognition model, there is a much more significant increase inmemory usage, loading time, and running time when loading theon-premise solution in gender classification, proving the efficiencyof our framework, especially using heavier deep models.
We conclude that our approach is feasible to be implementedin a modern smartphone. By choosing a privacy-complexity trade-off and using different intermediate layers, we were able tosignificantly reduce the cost when running the model on themobile device, while at the same time preserving important userinformation from being uploaded to the cloud.
1. https://pypi.org/project/coremltools/
Conv5-1 Conv5-2 Conv5-3 On-Prem.
1,000
2,000
3,000
4,000
5,000
6,000
7,000
Loa
ding
Tim
e(m
s)
Simple
Reduced
(a) Gender Classification
Conv-4 FC-1 FC-2 On-Prem.
0
100
200
300
400
500
600
700
800
Loa
ding
Tim
e(m
s)
Simple
Reduced
(b) Activity Recognition
Fig. 13: Loading time for different embeddings on mobile device
Conv5-1 Conv5-2 Conv5-3 On-Prem.
0
200
400
600
800
Mem
ory
Usa
ge(M
B)
Simple
Reduced
(a) Gender Classification
Conv-4 FC-1 FC-2 On-Prem.
10
20
30
40
50
60
70
80
90
Mem
ory
Usa
ge(M
B)
Simple
Reduced
(b) Activity Recognition
Fig. 14: Memory usage for different embeddings on mobile device
6 RELATED WORK
In this section, we first describe the prior works on privacy-preserving machine learning methods and then focus on the caseof image analytics. Next, we review the works that have used deeplearning on mobile devices.
6.1 Learning with privacy
Prior works have approached the problem of privacy in machinelearning from a different point of view. Some approaches attemptto remove irrelevant information by increasing the amount of un-certainty, while others try to hide information using cryptographictechniques. Earlier works in this area mainly focus on publiclypublishing datasets for machine learning tasks [14], [17], [28],[29]. We categorize these as the Dataset Publishing methods. Theyusually concern about publishing a dataset that consists of high-level features for data mining purposes (e.g., a medical databaseconsisting of patients details), while preserving the individuals’privacy. Solutions such as randomized noise addition [17], [28]

10
and k-anonymity [14] extended by generalization and suppression[30], [31], [32] are proposed and surveyed in [33]. However, thesemethods have some major caveats, as they are just appropriatefor low-dimensional data due to the curse of dimensionality [34].Therefore, they are not suitable for dealing with high-dimensionaldata, such as multimedia. Furthermore, it is shown that a varietyof attacks can make many of these methods unreliable [33].
Differential privacy [35] is another method that provides anexact way to publish statistics of a database while keeping allindividual records of the database private. A learning modeltrained on a dataset can be considered as its high-level statistics.Therefore, considering the training data privacy while publishinga learning model is another important problem, which we callModel Sharing. Many machine learning algorithms were madedifferentially private in the last decade, surveyed in [36]. Recently,Abadi et al. [37] proposed differentially private deep models.
A different but related problem to model sharing is the privacyof training data during the training phase. In this problem, whichwe call it Training Privacy, a machine learning model needs tobe trained on the data which are distributed among individuals.Centralizing the individual’s data may lead to privacy concernsif they contain sensitive information. In this case, the privacy ofindividuals can be preserved using distributed learning [38], [39].In contrast to centralized learning, federated learning methodstrain a machine learning model in a distributed way by aggregatingthe parameters. Papernote et al. [40] introduced a new privacy-preserving framework utilizing differential privacy, which has thestate of the art utility-privacy tradeoff. More specific work hasbeen done by Mao et al. that addresses the privacy of individualswhen outsourcing the training task of deep convolutional neuralnetworks to an untrusted server [41].
All the methods above answer how to train the model suchthat the training data cannot be revealed from the model. On thecontrary, in this paper, we are concerned with the privacy of aservice that is being delivered to the users who want to use a modelin the cloud, and they are concerned about the privacy of theirpersonal data that is being uploaded. Our method lets the usersinput the model in the cloud such that their data cannot be storedand used for unauthorized purposes. Hence, we address the privacyissue of users’ data from a different perspective compared todataset publishing, model sharing, and training privacy, includingdifferential privacy and federated learning.
In our scenario, the focus is on the privacy of users’ datawhen they have to upload their data to use an online machinelearning based service that is already trained. As a result, neitherpublishing a dataset, sharing a learned model, nor participating inthe training phase are directly relevant to the problem addressedin this paper. Traditional approaches to solving this problem arebased on cryptographic methods. In [42], the authors provide asecure protocol for machine learning. In [43], the neural networkis held in the cloud, and the input of the network is encryptedin a way that inference becomes applicable to encrypted data,but this approach requires highly complex operations. The neuralnetwork should be changed in a complicated manner to enablehomomorphic encryption taking 250 seconds on a PC, whichmakes it impractical in terms of usability on mobile devices. Theauthors in [44], [45] tried to improve this work by employinga more advanced encryption setting, but they have used simpledeep models in their experiments. Recently, Sanyal et al. hasfurther decreased the computational complexity of encryption-based methods using parallelization techniques, but their method
still requires more than 100 seconds to be run on a 16-machinecluster [46]. Instead of encryption-based methods, an information-theoretic approach is recently introduced in [47], where the mainfocus is on discarding information related to a single user-definedsensitive variable. However, the end-user may not have a completeunderstanding of what can be inferred from her data to define assensitive variables. Instead, we enforce the exclusive feature tobe specific for the main task of the online service, automaticallydiscarding any other irrelevant information, including those thatmight be sensitive to users. We use the Siamese architectureto obtain the exclusive feature, which is non-informative forsecondary inferences and can be shared with the cloud service.
6.2 Privacy in image analyticsA good survey on visual privacy can be found in [48] that classifiesdifferent works into five categories: intervention, blind vision,secure processing, redaction, and data hiding. Our work is similarto de-identification, a subcategory of redaction methods. The goalof these approaches is to perturb the individuals’ faces in imagesin such a way that a face recognition system can not recognizethem. A fundamental work in this category is presented in [49],which targets privacy issues in video surveillance data. This workaims to publish a transformed dataset, where individuals are notidentifiable. They show that using simple image filtering can notguarantee privacy, and suggest K-same algorithm based on k-anonymity, aiming to create average face images and replacingthem with the original ones. A shortcoming of this work is the lackof protection against future analyses on the dataset. Several worksfollowed this idea and tried to improve it, mainly to publish adataset of face images. However, they have not considered protect-ing the privacy of a new face image, which is one of our primaryconcerns in this paper. Some recent works have tried to transform aface image in a way that it is unrecognizable, while other analyticson the image such as gender classification is possible. Most ofthe works in this area use visual filters or morphing to make theimage unrecognizable [50], [51]. One of the main issues with priorprivacy preservation methods is the lack of a privacy guaranteeagainst new models due to engineering features against specificlearning tasks. In most cases, the learning task is not explicitlydefined. Moreover, many works ignore the accuracy constraints ofthe learning task in their privacy preservation methods.
6.3 Deep learning on mobile phoneIn the last two years, the implementation and inference ability ofdeep neural networks on smartphones has experienced a dramaticincrease. Using pre-trained deep learning models can increase theaccuracy of different sensors. For example, in [52], Lane et al.uses a three layer network that does not overburden the hardware.Complex networks with more layers need more processing power.More complex architectures, such as the 16-layer model (VGG-16) proposed in [22] and the 8-layer model (VGG-S) proposedin [53], are implemented on mobile handsets in [54], and theresource usage, such as time, CPU, and energy overhead, arereported. As most of the state of the art models are large-scale,a full evaluation of all layers on a mobile device results in seriousdrawbacks in processing time and memory requirements. Somemethods are proposed to approximate these complex functionswith simpler ones to reduce the cost of inference. Kim et al.[54] tried to compress deep models, while in [55], the authorsuse sparsification and kernel separation. However, the increase

11
in the efficiency of these methods comes with a decrease in theaccuracy of the model. In order to obtain more efficient results,they also implemented the models on GPU. However, the GPUimplementation is battery-intensive, making it infeasible for somepractical applications that users frequently use or continuouslyrequire for long periods [56]. To tackle these problems, Lane et al.[56] has implemented a software accelerator called DeepX forlarge-scale deep neural networks to reduce the required resourceswhile the mobile is doing inference using different kinds of mobileprocessors. A survey on deep learning on mobile is available in[57].
7 CONCLUSION AND NEXT STEPS
In this paper, we presented a new hybrid framework for efficientprivacy-preserving mobile analytics by breaking down a deepneural network into a feature extractor module, which should bedeployed on the user’s device, and a classifier module, whichoperates in the cloud. We exploited the properties of DNNs,especially convolutional neural networks, to benefit from theiraccuracy and layered architecture. In order to protect the dataprivacy against unauthorized tasks, we used Siamese fine-tuningto prepare an exclusive feature well-suited for the main task, butinappropriate for any other secondary tasks. This is in contrast toordinary deep neural networks in which the features are genericand may be used for various tasks. Removing the undesiredsensitive information from the extracted feature results in theprotection of users’ privacy. We presented three methods to verifythe privacy of the proposed framework and evaluated differentembedding methods on various layers of pre-trained state-of-the-art models for gender classification and activity recognition. Wedemonstrated that our framework could achieve an acceptabletrade-off between accuracy and privacy. Furthermore, by imple-menting the framework on mobile phones, we showed that wecould highly decrease the computational complexity on the userside, as well as the communication cost between the user’s deviceand the cloud.
There are many potential future directions for this work troughdifferent case studies. First, the proposed framework is designedto preserve the privacy of users’ data when the desired serviceis a (multi-class) classification task, such as gender recognitionor emotion detection. A possible extension to our work is toaddress this problem for other supervised or unsupervised machinelearning problems, such as regression. Second, we would like toprovide support for recurrent neural networks to handle time-seriesinput data, such as speech or video. Also, the proposed solution forbalancing the trade-off between accuracy, privacy, and complexityis naive, and the hyper-parameters can be optimized better. Finally,our current framework is designed for learning inferences in thetest phase. In ongoing work, we plan to extend our method bydesigning a framework for Machine Learning as a Service, wherethe users could share their data in a privacy-preserving manner, totrain a new learning model.
REFERENCES
[1] N. V. Rodriguez, J. Shah, A. Finamore, Y. Grunenberger, K. Papa-giannaki, H. Haddadi, and J. Crowcroft, “Breaking for commercials:characterizing mobile advertising,” in Proceedings of ACM InternetMeasurement Conference, Nov. 2012, pp. 343–356.
[2] I. Leontiadis, C. Efstratiou, M. Picone, and C. Mascolo, “Don’t killmy ads!: balancing privacy in an ad-supported mobile applicationmarket,” in Proceedings of ACM HotMobile, 2012. [Online]. Available:http://doi.acm.org/10.1145/2162081.2162084
[3] C. Stergiou, K. E. Psannis, A. P. Plageras, Y. Ishibashi, B.-G. Kim et al.,“Algorithms for efficient digital media transmission over iot and cloudnetworking,” Journal of Multimedia Information System, vol. 5, no. 1,pp. 27–34, 2018.
[4] K. E. Psannis, C. Stergiou, and B. B. Gupta, “Advanced media-basedsmart big data on intelligent cloud systems,” IEEE Transactions onSustainable Computing, vol. 4, no. 1, pp. 77–87, 2018.
[5] L. Pournajaf, D. A. Garcia-Ulloa, L. Xiong, and V. Sunderam, “Partic-ipant privacy in mobile crowd sensing task management: A survey ofmethods and challenges,” ACM SIGMOD Record, vol. 44, no. 4, pp.23–34, 2016.
[6] M. Haris, H. Haddadi, and P. Hui, “Privacy leakage in mobile computing:Tools, methods, and characteristics,” arXiv preprint arXiv:1410.4978,2014.
[7] J. Rich, H. Haddadi, and T. M. Hospedales, “Towards bottom-upanalysis of social food,” in Proceedings of the 6th InternationalConference on Digital Health Conference, ser. DH ’16. New York,NY, USA: ACM, 2016, pp. 111–120. [Online]. Available: http://doi.acm.org/10.1145/2896338.2897734
[8] P. N. Druzhkov and V. D. Kustikova, “A survey of deep learning methodsand software tools for image classification and object detection,” PatternRecognition and Image Analysis, vol. 26, no. 1, pp. 9–15, 2016. [Online].Available: http://dx.doi.org/10.1134/S1054661816010065
[9] J. Wan, D. Wang, S. C. H. Hoi, P. Wu, J. Zhu, Y. Zhang, and J. Li, “Deeplearning for content-based image retrieval: A comprehensive study,” inProceedings of the 22nd ACM international conference on Multimedia.ACM, 2014, pp. 157–166.
[10] J. Yosinski, J. Clune, Y. Bengio, and H. Lipson, “How transferable arefeatures in deep neural networks?” in Neural Information ProcessingSystems, 2014, pp. 3320–3328.
[11] A. Dosovitskiy and T. Brox, “Inverting visual representations withconvolutional networks,” in IEEE Conference on Computer Vision andPattern Recognition, 2016, pp. 4829–4837.
[12] Y. Bengio et al., “Deep learning of representations for unsupervised andtransfer learning.” ICML Unsupervised and Transfer Learning, vol. 27,pp. 17–36, 2012.
[13] M. Malekzadeh, R. G. Clegg, and H. Haddadi, “Replacement autoen-coder: A privacy-preserving algorithm for sensory data analysis,” in The3rd ACM/IEEE International Conference of Internet-of-Things Designand Implementation, 2018.
[14] L. Sweeney, “k-anonymity: A model for protecting privacy,” Interna-tional Journal of Uncertainty, Fuzziness and Knowledge-Based Systems,vol. 10, no. 05, pp. 557–570, 2002.
[15] S. Chopra, R. Hadsell, and Y. LeCun, “Learning a similarity metric dis-criminatively, with application to face verification,” in IEEE Conferenceon Computer Vision and Pattern Recognition, 2005, pp. 539–546.
[16] R. Hadsell, S. Chopra, and Y. LeCun, “Dimensionality reduction bylearning an invariant mapping,” in IEEE Conference on Computer Visionand Pattern Recognition, 2006, pp. 1735–1742.
[17] R. Agrawal and R. Srikant, “Privacy-preserving data mining,” in ACMSigmod Record, vol. 29, no. 2. ACM, 2000, pp. 439–450.
[18] C. Dwork, “Differential privacy,” in International Colloquium on Au-tomata, Languages and Programming, 2006, pp. 1–12.
[19] S. S. Haykin, Neural networks and learning machines. Pearson UpperSaddle River, NJ, USA, 2009.
[20] J. L. Massey, “Guessing and entropy,” in Proceedings of 1994 IEEEInternational Symposium on Information Theory. IEEE, 1994, p. 204.
[21] S. A. Osia, B. Rassouli, H. Haddadi, H. R. Rabiee, and D. Gunduz,“Privacy against brute-force inference attacks,” IEEE International Sym-posium on Information Theory, 2019.
[22] K. Simonyan and A. Zisserman, “Very deep convolutional networks forlarge-scale image recognition,” CoRR, vol. abs/1409.1556, 2014.
[23] C. B. Ng, Y. H. Tay, and B. M. Goi, “Vision-based human genderrecognition: A survey,” arXiv preprint arXiv:1204.1611, 2012.
[24] R. Rothe, R. Timofte, and L. Van Gool, “Dex: Deep expectation ofapparent age from a single image,” in IEEE International Conferenceon Computer Vision Workshops, 2015, pp. 10–15.
[25] G. B. Huang, M. Ramesh, T. Berg, and E. Learned-Miller, “Labeled facesin the wild: A database for studying face recognition in unconstrainedenvironments,” University of Massachusetts, Amherst, Tech. Rep. 07-49,October 2007.
[26] O. M. Parkhi, A. Vedaldi, and A. Zisserman, “Deep face recognition,” inBMVC, vol. 1, no. 3, 2015, p. 6.
[27] M. Malekzadeh, R. G. Clegg, A. Cavallaro, and H. Haddadi, “Protectingsensory data against sensitive inferences,” in Proceedings of the 1stWorkshop on Privacy by Design in Distributed Systems. ACM, 2018,p. 2.

12
[28] D. Agrawal and C. C. Aggarwal, “On the design and quantificationof privacy preserving data mining algorithms,” in ACM Symposium onPrinciples of Database Systems, 2001, pp. 247–255.
[29] V. S. Iyengar, “Transforming data to satisfy privacy constraints,” inProceedings of the eighth ACM SIGKDD international conference onKnowledge discovery and data mining. ACM, 2002, pp. 279–288.
[30] K. LeFevre, D. J. DeWitt, and R. Ramakrishnan, “Incognito: Efficientfull-domain k-anonymity,” in Proceedings of the 2005 ACM SIGMODinternational conference on Management of data. ACM, 2005, pp. 49–60.
[31] A. Machanavajjhala, D. Kifer, J. Gehrke, and M. Venkitasubramaniam,“l-diversity: Privacy beyond k-anonymity,” ACM Transactions on Knowl-edge Discovery from Data, vol. 1, no. 1, p. 3, 2007.
[32] N. Li, T. Li, and S. Venkatasubramanian, “t-closeness: Privacy beyondk-anonymity and l-diversity,” in IEEE International Conference on DataEngineering, 2007, pp. 106–115.
[33] C. C. Aggarwal and S. Y. Philip, “A general survey of privacy-preservingdata mining models and algorithms,” in Privacy-preserving Data Mining,2008, pp. 11–52.
[34] C. C. Aggarwal, “On k-anonymity and the curse of dimensionality,” inInternational Conference on Very Large Data Bases, 2005, pp. 901–909.
[35] C. Dwork, “Differential privacy: A survey of results,” in InternationalConference on Theory and Applications of Models of Computation, 2008,pp. 1–19.
[36] Z. Ji, Z. C. Lipton, and C. Elkan, “Differential privacy and machinelearning: A survey and review,” arXiv preprint arXiv:1412.7584, 2014.
[37] M. Abadi, A. Chu, I. Goodfellow, H. B. McMahan, I. Mironov, K. Talwar,and L. Zhang, “Deep learning with differential privacy,” in Proceedingsof the 2016 ACM SIGSAC Conference on Computer and CommunicationsSecurity. ACM, 2016, pp. 308–318.
[38] R. Shokri and V. Shmatikov, “Privacy-preserving deep learning,” in ACMConference on Computer and Communications Security, 2015, pp. 1310–1321.
[39] J. Konecny, H. B. McMahan, F. X. Yu, P. Richtarik, A. T. Suresh, andD. Bacon, “Federated learning: Strategies for improving communicationefficiency,” arXiv preprint arXiv:1610.05492, 2016.
[40] N. Papernot, M. Abadi, U. Erlingsson, I. Goodfellow, and K. Talwar,“Semi-supervised Knowledge Transfer for Deep Learning from PrivateTraining Data,” in Proceedings of the International Conference onLearning Representations (ICLR), 2017.
[41] Y. Mao, S. Yi, Q. Li, J. Feng, F. Xu, and S. Zhong, “A privacy-preservingdeep learning approach for face recognition with edge computing,” inUSENIX Workshop on Hot Topics in Edge Computing (HotEdge 18),Boston, MA, 2018.
[42] S. Avidan and M. Butman, “Blind vision,” in European Conference onComputer Vision, 2006, pp. 1–13.
[43] R. Gilad-Bachrach, N. Dowlin, K. Laine, K. Lauter, M. Naehrig, andJ. Wernsing, “Cryptonets: Applying neural networks to encrypted datawith high throughput and accuracy,” in International Conference onMachine Learning, 2016, pp. 201–210.
[44] B. D. Rouhani, M. S. Riazi, and F. Koushanfar, “Deepsecure: Scalableprovably-secure deep learning,” arXiv preprint arXiv:1705.08963, 2017.
[45] P. Mohassel and Y. Zhang, “Secureml: A system for scalable privacy-preserving machine learning,” in IEEE Symposium on Security andPrivacy. IEEE, 2017, pp. 19–38.
[46] A. Sanyal, M. J. Kusner, A. Gascon, and V. Kanade, “Tapas: tricks to ac-celerate (encrypted) prediction as a service,” in International Conferenceon Machine Learning, 2018.
[47] S. A. Osia, A. Taheri, A. S. Shamsabadi, K. Katevas, H. Haddadi, andH. R. Rabiee, “Deep private-feature extraction,” IEEE Transactions onKnowledge and Data Engineering, 2018.
[48] J. R. Padilla-Lopez, A. A. Chaaraoui, and F. Florez-Revuelta, “Visualprivacy protection methods: A survey,” Expert Systems with Applications,vol. 42, no. 9, pp. 4177–4195, 2015.
[49] E. M. Newton, L. Sweeney, and B. Malin, “Preserving privacy by de-identifying face images,” IEEE transactions on Knowledge and DataEngineering, vol. 17, no. 2, pp. 232–243, 2005.
[50] P. Korshunov and T. Ebrahimi, “Using face morphing to protect privacy,”in IEEE International Conference on Advanced Video and Signal BasedSurveillance, 2013, pp. 208–213.
[51] N. Rachaud, G. Antipov, P. Korshunov, J.-L. Dugelay, T. Ebrahimi,and S.-A. Berrani, “The impact of privacy protection filters on genderrecognition,” in SPIE Optical Engineering+ Applications, 2015, pp.959 906–959 906.
[52] N. D. Lane and P. Georgiev, “Can deep learning revolutionize mobilesensing?” in Proceedings of the 16th International Workshop on MobileComputing Systems and Applications. ACM, 2015, pp. 117–122.
[53] K. Chatfield, K. Simonyan, A. Vedaldi, and A. Zisserman, “Return ofthe devil in the details: Delving deep into convolutional nets,” in BritishMachine Vision Conference, 2014.
[54] Y.-D. Kim, E. Park, S. Yoo, T. Choi, L. Yang, and D. Shin, “Compressionof deep convolutional neural networks for fast and low power mobileapplications,” arXiv preprint arXiv:1511.06530, 2015.
[55] S. Bhattacharya and N. D. Lane, “Sparsification and separation of deeplearning layers for constrained resource inference on wearables,” inProceedings of the 14th ACM Conference on Embedded Network SensorSystems CD-ROM. ACM, 2016, pp. 176–189.
[56] N. D. Lane, S. Bhattacharya, P. Georgiev, C. Forlivesi, L. Jiao, L. Qendro,and F. Kawsar, “Deepx: A software accelerator for low-power deeplearning inference on mobile devices,” in 2016 15th ACM/IEEE Interna-tional Conference on Information Processing in Sensor Networks (IPSN).IEEE, 2016, pp. 1–12.
[57] C. Zhang, P. Patras, and H. Haddadi, “Deep learning in mobile andwireless networking: A survey,” arXiv preprint arXiv:1803.04311, 2018.
Seyed Ali Osia received his B.Sc. degree inSoftware Engineering and his Ph.D. degree inArtificial Intelligence from Sharif University ofTechnology in 2014 and 2019, respectively. Hisresearch interests include Statistical MachineLearning, Deep Learning, Privacy and ComputerVision.
Ali Shahin Shamsabadi received his B.S. de-gree in electrical engineering from Shiraz Uni-versity of Technology, in 2014, and the M.Sc.degree in electrical engineering (digital) from theSharif University of Technology, in 2016. Cur-rently, he is a Ph.D. candidate at Queen MaryUniversity of London. His research interests in-clude deep learning and data privacy protectionin distributed and centralized learning.
Sina Sajadmanesh received his B.Sc. degreein Computer Engineering from the University ofIsfahan in 2014, and his M.Sc. degree in In-formation Technology Engineering from SharifUniversity of Technology in 2016. He is currentlya Ph.D. student in the School of Engineeringat EPFL and a research assistant in Idiap Re-search Institute. He is interested in MachineLearning, Data Mining, and Social Computing.
Ali Taheri received his B.Sc. degree in SoftwareEngineering from Shahid Beheshti University in2015. He received his M.Sc. degree in ArtificialIntelligence from Sharif University of Technologyin 2017. He is currently a Ph.D. student of Artifi-cial Intelligence in the Department of ComputerEngineering at Sharif University of Technology.His research interests include Deep Learningand Privacy.
Kleomenis Katevas received his B.Sc. degreein Informatics Engineering from the University ofApplied Sciences of Thessaloniki in 2006, andhis M.Sc. and Ph.D. degrees in Software Engi-neering from Queen Mary University of Londonin 2010 and 2018. He is currently a postdoc-toral researcher at Imperial College London. Hisresearch interests include Mobile & UbiquitousComputing, Applied Machine Learning, CrowdSensing and Human-Computer Interaction.

13
Hamid R. Rabiee (SM ’07) received his BS andMS degrees (with Great Distinction) in Electri-cal Engineering from CSULB, Long Beach, CA(1987, 1989), his EEE degree in Electrical andComputer Engineering from USC, Los Angeles,CA (1993), and his Ph.D. in Electrical and Com-puter Engineering from Purdue University, WestLafayette, IN, in 1996. From 1993 to 1996 hewas a Member of Technical Staff at AT&T BellLaboratories. From 1996 to 1999 he worked asa Senior Software Engineer at Intel Corporation.
He was also with PSU, OGI and OSU universities as an adjunct pro-fessor of Electrical and Computer Engineering from 1996-2000. SinceSeptember 2000, he has joined Sharif University of Technology, Tehran,Iran. He was also a visiting professor at the Imperial College of Londonfor the 2017-2018 academic year. He is the founder of Sharif UniversityAdvanced Information and Communication Technology Research Insti-tute (AICT), ICT Innovation Center, Advanced Technologies Incubator(SATI), Digital Media Laboratory (DML), Mobile Value Added ServicesLaboratory (VASL), Bioinformatics and Computational Biology Labora-tory (BCB) and Cognitive Neuroengineering Research Center. He is alsoa consultant and member of AI in Health Expert Group at WHO. Hehas been the founder of many successful High-Tech start-up companiesin the field of ICT as an entrepreneur. He is currently a Professor ofComputer Engineering at Sharif University of Technology, and Directorof AICT, DML, and VASL. He has received numerous awards andhonors for his Industrial, scientific and academic contributions, andholds three patents. His research interests include statistical machinelearning, Bayesian statistics, data analytics and complex networks withapplications in social networks, multimedia systems, cloud and IoTprivacy, bioinformatics, and brain networks.
Nicholas D. Lane is an Associate Professor inthe Computer Science department at the Uni-versity of Oxford, where he leads the MachineLearning Systems lab (OxMLSys). Alongside hisacademic role, he is also a Program Directorat the Samsung AI Center in Cambridge wherehis teams study on-device and distributed formsof machine learning. To find out more abouthis research please visit http://niclane.org andhttp://mlsys.cs.ox.ac.uk.
Hamed Haddadi received his B.Eng., M.Sc.,and Ph.D. degrees from University College Lon-don. He was a postdoctoral researcher at MaxPlanck Institute for Software Systems in Ger-many, and a postdoctoral research fellow at De-partment of Pharmacology, University of Cam-bridge and The Royal Veterinary College, Uni-versity of London, followed by few years as aLecturer and consequently Senior Lecturer inDigital Media at Queen Mary University of Lon-don. He is currently a Senior Lecturer and the
Deputy Director of Research in the Dyson School of Design Engineeringat The Faculty of Engineering at Imperial College of London. He isinterested in User-Centered Systems, IoT, Applied Machine Learning,and Data Security & Privacy.