Embed Size (px)
Citation preview

1
Algorithms for Large Data Sets
Ziv Bar-YossefLecture 3
April 2, 2006
http://www.ee.technion.ac.il/courses/049011

2
Ranking Algorithms

3
Outline
The ranking problem PageRank HITS (Hubs & Authorities) Markov Chains and Random Walks PageRank and HITS computation

4
Input: D: document collection Q: query space
Goal: Find a ranking function rank: D x Q R s.t.
rank and q induce a ranking (partial order) q on D
Same as the “relevance scoring function” from previous lecture
The Ranking Problem

5
Text-based Ranking
Classical ranking functions: Keyword-based boolean ranking Cosine similarity + TF-IDF scores
Limitations in the context of web search: The “abundance problem”
Recall is not important Short queries Web pages are poor in text Synonymy (cars vs. autos) Polysemy (java, “Michael Jordan”) Spam

6
Link-based Ranking
Hyperlinks carry important semantics Recommendation Critique Navigation
Hypertext IR Principle #1
If p q, then q is “relevant” to p
Hypertext IR Principle #2
If p q, then p confers “authority” to q

7
Static Ranking
Static ranking: rank: D R, where rank(d) > rank(d’) implies d is more “authoritative” than d’
Use links to come up with a static ranking of all web pages.
Given a query q, use text-based ranking to identify a set S of candidate relevant pages.
Order S by their static rank.
Advantage: static ranking can be computed at a pre-processing step.
Disadvantage: no use of Hypertext IR Principle #1.

8
Query-Dependent Ranking
Given a query q, use text-based ranking to identify a set S of candidate relevant pages.
Use links within S to come up with a ranking rank: S R, where rank(d) > rank(d’) implies d is more authoritative than d’ with respect to q.
Advantage: both Hypertext IR principles are exploited. Disadvantage: less efficient.

9
The Web as a Graph
V = a set of pages In static ranking, V = web In query dependent ranking, V = S
The Web Graph: G = (V,E), where(p,q) is an edge iff p has a hyperlink to q
A = adjacency matrix of G

10
Popularity Ranking
rank(p) = in-degree(p)
Advantages Most important pages extracted from millions of
matches No need for text rich documents Efficiently computable
Disadvantages Bias towards popular pages, irrespective of query Easily spammable

11
PageRank [Page, Brin, Motwani, Winograd 1998]
Motivating principlesRank of p should be proportional to the rank of
the pages that point to p Recommendations from Bill Gates & Steve Jobs vs.
from Moishale and Ahuva
Rank of p should depend on the number of pages “co-cited” with p
Compare: Bill Gates recommends only me vs. Bill Gates recommends everyone on earth

12
Then: r is a left eigenvector of B with eigenvalue 1
PageRank, Attempt #1
Q1: Is a solution guaranteed to exist? Q2: If a solution exists, how to find it? Q3: If more than one solution exists, which one to pick?
B = normalized adjacency matrix:

13
PageRank, Attempt #1
Solution exists if and only if B has eigenvalue 1 Problem: Solution may not exist
Example:
Note: If r is a solution, then rT = rTBk, for any k ≥ 1 Rank is at “steady state”
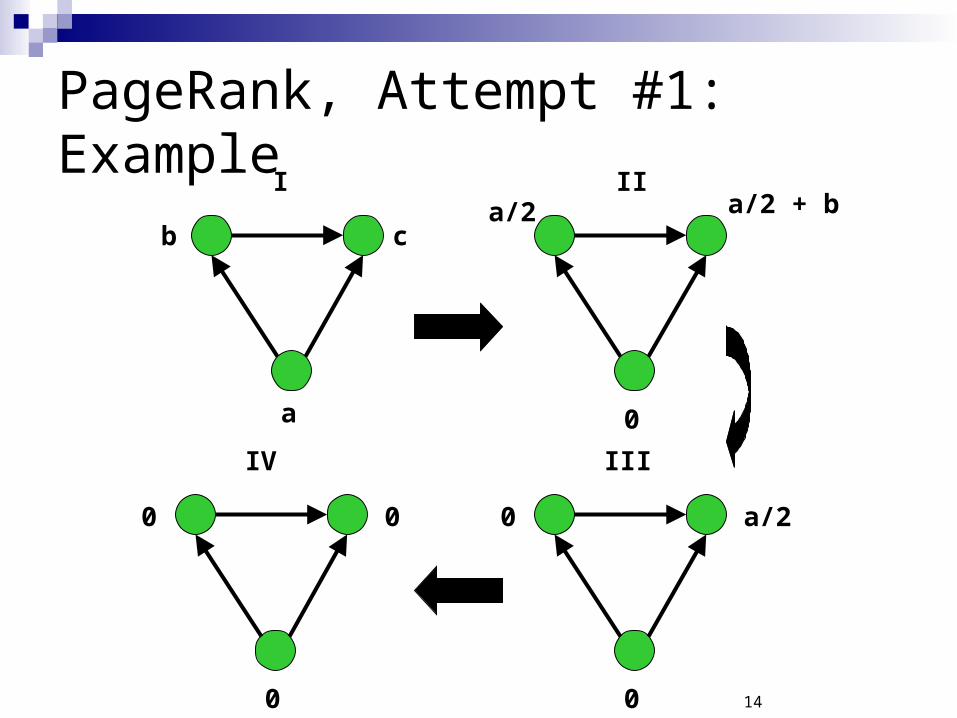
14
PageRank, Attempt #1: Example
a
b c
I
0
a/2 a/2 + bII
0
0 a/2
III
0
0 0
IV

15
PageRank, Attempt #1
If r has positive “rank mass” at nodes, from which sinks are reachable, the mass “drains” at the sinks
Therefore, only nodes, from which sinks cannot be reached, can have nonzero rank mass. E.g., for DAGs, no non-trivial solution exists
Conclusion: This ranking measure cannot be used for arbitrary graphs.

16
= normalization constant Rank mass is preserved and no longer drains at sinks
r is a left eigenvector of B with eigenvalue 1/
PageRank, Attempt #2
where:

17
Any nonzero eigenvalue of B gives a solution = 1/ r = any left eigenvector of B with eigenvalue
Which solution to pick? Pick a “principal eigenvector” (i.e., corresponding to maximal ) r is normalized to unit L1 norm (i.e., ||r||1 = 1)
How to find a solution? Power iterations
PageRank, Attempt #2

18
Problem #1: Maximal eigenvalue may have multiplicity > 1 Several possible solutions Happens, for example, when graph is disconnected
Problem #2: Rank accumulates at sinks. Only sinks or nodes, from which a sink cannot be reached, can
have nonzero rank mass.
PageRank, Attempt #2
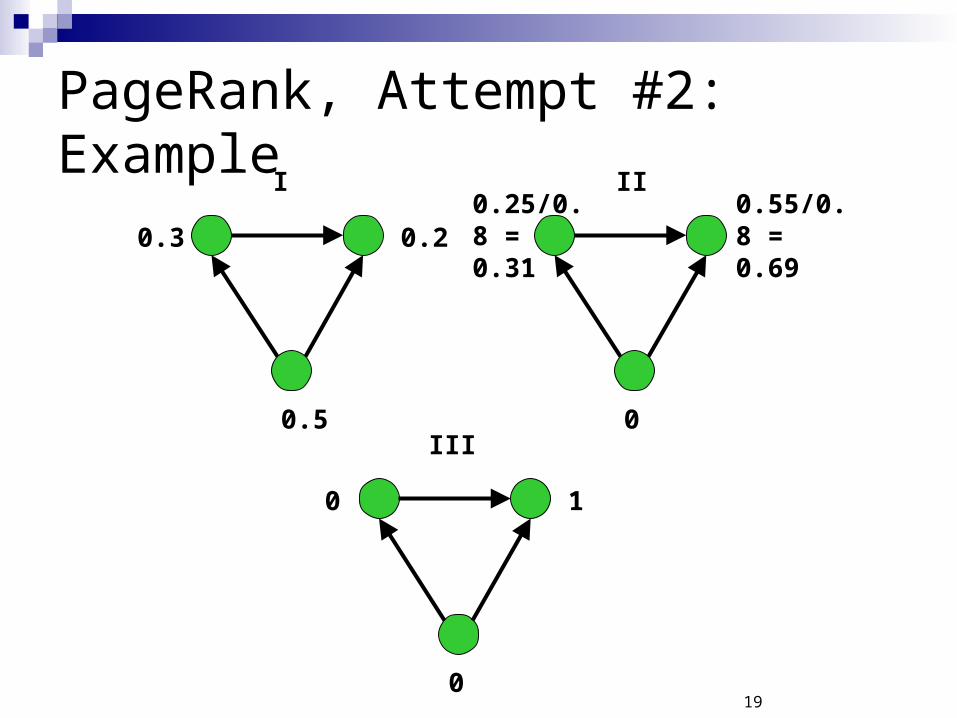
19
PageRank, Attempt #2: Example
0.5
0.3 0.2
I
0
0.25/0.8 = 0.31
0.55/0.8 = 0.69
II
0
0 1
III

20
Then: r is a left eigenvector of (B + 1eT) with eigenvalue 1/ r has unit norm
PageRank, Final Definition
e = “rank source” vector Standard setting: e(p) = /n for all p ( < 1)
r is normalized to L1 unit norm 1 = the all 1’s vector

21
Any nonzero eigenvalue of (B + 1eT) gives a solution Pick r to be a normalized principal eigenvector of (B + 1eT) Will show: Principal eigenvalue has multiplicity 1, for any
graph Hence, PageRank always exists and is uniquely defined
Due to rank source vector, rank no longer accumulates at sinks
PageRank, Final Definition

22
An Alternative View of PageRank:The Random Surfer Model When visiting a page p, a “random surfer”:
With probability 1 - d, selects a random outlink p q and goes to visit q. (“focused browsing”)
With probability d, jumps to a random web page q. (“loss of interest”)
If p has no outlinks, assume it has a self loop. P: probability transition matrix:

23
PageRank & Random Surfer Model
Therefore, r is a principal left eigenvector of (B + 1eT) if and only if it is a principal left eigenvector of P.
Suppose:
Then:

24
V = state space P = probability transition matrix
Non-negative. Sum of each row is 1.
q0 = initial distribution on V qt = q0 Pt : distribution on V after t steps P is ergodic if it is:
Irreducible (underlying graph is strongly connected) Aperiodic (for all states u,v, the gcd of the lengths of paths from u
to v is 1) Theorem
If P is ergodic, then it has a “stationary distribution” . Furthermore, for all q0, qt as t tends to infinity.
P = . is a principal left eigenvector of P with e.v. 1.
Markov Chain Primer

25
PageRank & Markov Chains
PageRank vector is normalized principal left eigenvector of (B + 1eT).
Hence, PageRank vector is also a principal left eigenvector of P
Conclusion: PageRank is the unique stationary distribution of the random surfer Markov Chain.
PageRank(p) = r(p) = probability of random surfer visiting page p at the limit.
Note: “Random jump” guarantees Markov Chain is ergodic.

26
PageRank Computation
In practice: about 50 iterations suffices

27
HITS: Hubs and Authorities [Kleinberg, 1997]
HITS: Hyperlink Induced Topic Search Main principle: every page p is associated with
two scores: Authority score: how “authoritative” a page is about the
query’s topic Ex: query: “IR”; authorities: scientific IR papers Ex: query: “automobile manufacturers”; authorities: Mazda,
Toyota, and GM web sites Hub score: how good the page is as a “resource list”
about the query’s topic Ex: query: “IR”; hubs: surveys and books about IR Ex: query: “automobile manufacturers”; hubs: KBB, car link
lists

28
Mutual Reinforcement
HITS principles: p is a good authority, if it is linked by many
good hubs. p is a good hub, if it points to many good
authorities.

29
HITS: Algebraic Form
a: authority vector h: hub vector A: adjacency matrix
Then:
Therefore:
a is principal eigenvector of ATA h is principal eigenvector of AAT
Need to normalize, like in PageRank

30
Co-Citation and Bibilographic Coupling ATA: co-citation matrix
ATAp,q = # of pages that link both to p and to q.
Thus: authority scores propagate through co-citation.
AAT: bibliographic coupling matrix AAT
p,q = # of pages that both p and q link to.
Thus: hub scores propagate through bibliographic coupling.
p
q
p
q

31
HITS Computation

32
Principal Eigenvector Computation
E: n × n matrix |1| > |2| >= |3| … >= |n| : eigenvalues of E v1,…,vn: corresponding eigenvectors Eigenvectors are linearly independent Input:
The matrix E The principal eigenvalue 1
A unit vector u, which is not orthogonal to v1
Goal: compute v1

33
The Power Method

34
Why Does It Work?
Theorem: As t , w/1t c · v1
(c is a constant)
• Convergence rate: Proportional to (2/1)t
• The larger the “spectral gap” 2 - 1, the faster the convergence.

35
End of Lecture 3





























