Embed Size (px)
Citation preview

1
CS 430: Information Discovery
Lecture 14
Automatic Extraction of Metadata

2
Course Administration
No Office Hours: Tuesday October 22.
Guest Lecture: Tuesday, October 22. Carl Lagoze, Distributed information retrieval
Midterm Examination: Wednesday, October 23, Upson B17, 7:30 to 9:00. A sample examination and a discussion of the answers is on the web site.
The midterm and final examinations aim to reward regular attendance in class (including guest lectures) and careful reading for the discussion classes.

3
Course Administration
TA Office Hours: Matthew Schultz will hold office hours on Tuesdays 1:30 to 2:30 every week.

4
Automatic extraction of catalog data
Example: Dublin Core records for web pages
Strategies
• Manual by trained cataloguers - high quality records, but expensive and time consuming
• Entirely automatic - fast, almost zero cost, but poor quality
• Automatic followed by human editing - cost and quality depend on the amount of editing
• Manual collection level record, automatic item level record - moderate quality, moderate cost

5
DC-dot
DC-dot is a Dublin Core metadata editor for web pages, created by Andy Powell at UKOLN
http://www.ukoln.ac.uk/metadata/dcdot/
DC-dot has two parts:
(a) A skeleton Dublin Core record is created automatically from clues in the web page
(b) A user interface is provided for cataloguers to edit the record

6

7
Automatic record for CS 430 home page
DC-dot applied to http://www.cs.cornell.edu/courses/cs430/2001sp/
<link rel="schema.DC" href="http://purl.org/dc">
<meta name="DC.Title" content="CS 430: Information Discovery">
<meta name="DC.Subject" content="[email protected]; Course Structure; Readings and references; Slides; Basic Information; William Y. Arms; Information Retrieval Data Structures and Algorithms; [email protected]; Assignments; Syllabus; Text Book; Laptop computers; Assumed Background; Nomadic Computing Experiment; Notices; Course Description; Code of practice; Assignments and Grading; Last changed: February 6, 2001">
continued on next slide
8
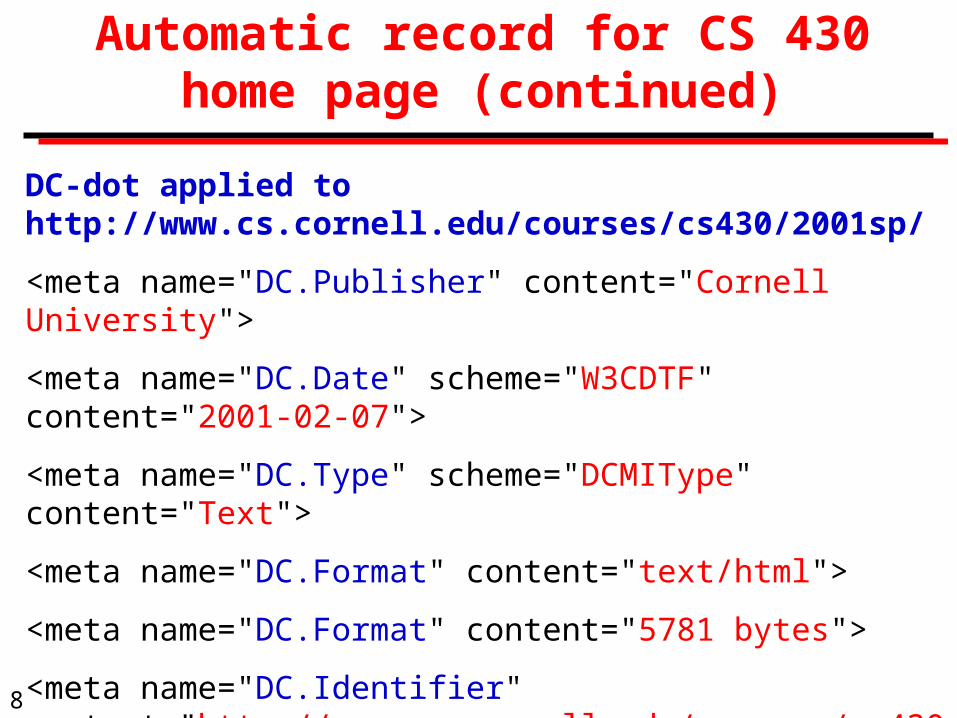
Automatic record for CS 430 home page (continued)
DC-dot applied to http://www.cs.cornell.edu/courses/cs430/2001sp/
<meta name="DC.Publisher" content="Cornell University">
<meta name="DC.Date" scheme="W3CDTF" content="2001-02-07">
<meta name="DC.Type" scheme="DCMIType" content="Text">
<meta name="DC.Format" content="text/html">
<meta name="DC.Format" content="5781 bytes">
<meta name="DC.Identifier" content="http://www.cs.cornell.edu/courses/cs430/2001sp/">

9
Observations on DC-dot applied to CS430 home page
DC.Title is a copy of the html <title> field
DC.Publisher is the owner of the IP address where the page was stored
DC.Subject is a list of headings and noun phrases presented for editing
DC.Date is taken from the Last-Modified field in the http header
DC.Type and DC.Format are taken from the MIME type of the http response
DC.Identifier was supplied by the user as input

10

11
DC-dot applied to http://www.georgewbush.com/
<link rel="schema.DC" href="http://purl.org/dc">
<meta name="DC.Subject" content="George W. Bush; Bush; George Bush; President; republican; 2000 election; election; presidential election; George; B2K; Bush for President; Junior; Texas; Governor; taxes; technology; education; agriculture; health care; environment; society; social security; medicare; income tax; foreign policy; defense; government">
<meta name="DC.Description" content="George W. Bush is running for President of the United States to keep the country prosperous.">
continued on next slide
Automatic record for George W. Bush home page

12
DC-dot applied to http://www.georgewbush.com/
<meta name="DC.Publisher" content="Concentric Network Corporation">
<meta name="DC.Date" scheme="W3CDTF" content="2001-01-12">
<meta name="DC.Type" scheme="DCMIType" content="Text">
<meta name="DC.Format" content="text/html">
<meta name="DC.Format" content="12223 bytes">
<meta name="DC.Identifier" content="http://www.georgewbush.com/">
Automatic record for George W. Bush home page (continued)

13
Observations on DC-dot applied to George W. Bush home page
The home page has several meta tags:
<META NAME="TITLE" CONTENT="George W. Bush for President"> [The page has no html <title>]
<META NAME="CONTACT" CONTENT="George W Bush Campaign, P. O. Box 1902, Austin, TX 78767, Phone: (512) 637-2000">
<META NAME="DESCRIPTION" CONTENT="George W. Bush is running for President of the United States to keep the country prosperous.">
<META NAME="KEYWORDS" CONTENT="George W. Bush, Bush, George Bush, President, republican, 2000 election and more

14
Collection-level metadata
Several of the most difficult fields to extract automatically are the same across all pages in a web site.
Therefore create a collection record manually and combine it with automatic extraction of other fields at item level.
For the CS 430 home page, collection-level metadata:
<meta name="DC.Publisher" content="Cornell University">
<meta name="DC.Creator" content="William Y. Arms">
<meta name="DC.Rights" content="William Y. Arms, 2001">
See: Jenkins and Inman

15

16
Metadata extracted automatically by DC-dot
D.C. Field Qualifier Content
title Digital Libraries and the Problem of Purpose
subject not included in this slide
publisher Corporation for National Research Initiatives
date W3CDTF 2000-05-11
type DCMIType Text
format text/html
format 27718 bytes
identifier http://www.dlib.org/dlib/january00/01levy.html

17
Collection-level record
D.C. Field Qualifier Content
publisher Corporation for National Research Initiatives
type article
type resource work
relation rel-type InSerial
relation serial-name D-Lib Magazine
relation issn 1082-9873
language English
rights Permission is hereby given for the material in D-Lib Magazine to be used for ...
18
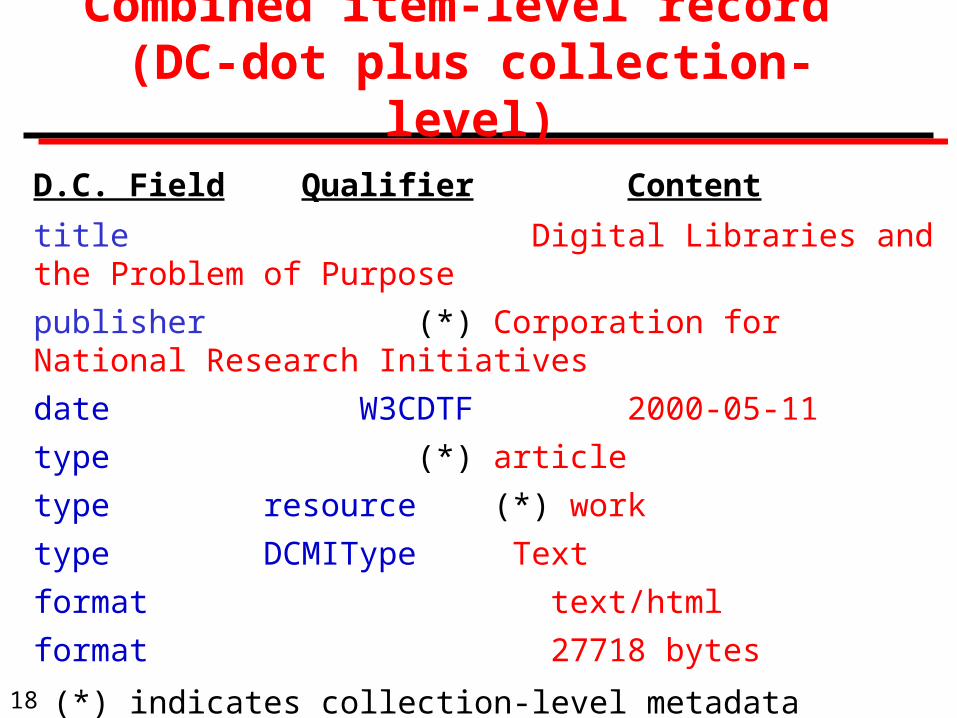
Combined item-level record (DC-dot plus collection-level)
D.C. Field Qualifier Content
title Digital Libraries and the Problem of Purpose
publisher (*) Corporation for National Research Initiatives
date W3CDTF 2000-05-11
type (*) article
type resource (*) work
type DCMIType Text
format text/html
format 27718 bytes
(*) indicates collection-level metadata
continued on next slide

19
Combined item-level record (DC-dot plus collection-level)
D.C. Field Qualifier Content
relation rel-type (*) InSerial
relation serial-name (*) D-Lib Magazine
relation issn (*) 1082-9873
language (*) English
rights (*) Permission is hereby given for the material in D-Lib Magazine to be used for ...
identifier http://www.dlib.org/dlib/january00/01levy.html
(*) indicates collection-level metadata

20
Manually created record
D.C. Field Qualifier Content
title Digital Libraries and the Problem of Purpose
creator (+) David M. Levy
publisher Corporation for National Research Initiatives
date publication January 2000
type article
type resource work
(+) entry that is not in the automatically generated records
continued on next slide

21
Manually created record
D.C. Field Qualifier Content
relation rel-type InSerial
relation serial-name D-Lib Magazine
relation issn 1082-9873
relation volume (+) 6
relation issue (+) 1
identifier DOI (+) 10.1045/january2000-levy
identifier URL http://www.dlib.org/dlib/january00/01levy.html
language English
rights (+) Copyright (c) David M. Levy
(+) entry that is not in the automatically generated records

22
Collection-level metadata
Compare:
(a) Metadata extracted automatically by DC-dot
(b) Collection-level record
(c) Combined item-level record (DC-dot plus collection-level)
(d) Manual record
For web pages information retrieval works better by automatic indexing, rather than automatic extraction of metadata followed by indexing of metadata.
However, we will see later an effective example of automated extraction of metadata from video sequences (Informedia).





























