Embed Size (px)
Citation preview

1
Design & Analysis of Multistratum Randomized Experiments
Ching-Shui Cheng
Nov. 30, 2006
National Tsing Hua University

2
Schedule
Nov. 30Introduction, treatment and block structures, examples
Dec. 1Randomization models, null ANOVA, orthogonal designs
Dec. 7More on orthogonal designs, non-orthogonal designs
Dec. 8More complex treatment and block structures, factorial experiments

3
Nelder (1965a, b)
The analysis of randomized experiments with
orthogonal block structure, Proceedings of the
Royal Society of London, Series A
Fundamental work on the analysis of randomized experiments with orthogonal block structures

4
Bailey (1981) JRSS, Ser. A
“Although Nelder (1965a, b) gave a unified treatment of what he called ‘simple’ block structures over ten years ago, his ideas do not seem to have gained wide acceptance. It is a pity, because they are useful and, I believe, simplifying. However, there seems to be a widespread belief that his ideas are too difficult to be understood or used by practical statisticians or students.”

5
Experimental Design
Planning of experiments to produce valid information as efficiently as possible

6
Comparative Experiments
Treatments 處理 Varieties of grain, fertilizers, drugs, ….
Experimental Units
Plots, patients, ….

7
Design: How to assign the treatments to the experimental units
Fundamental difficulty: variability among the units; no two units are exactly the same.
Different responses may be observed even if the same
treatment is assigned to the units.
Systematic assignments may lead to bias.

8
Suppose is an observation on the th unit, and is the treatment assigned to that unit. Assume treatment-unit additivity:

9
R. A. Fisher worked at the Rothamsted Experimental Station in the United Kingdom to evaluate the success of various fertilizer treatments.

10
Fisher found the data from experiments going on for decades to be basically worthless because of poor experimental design.
Fertilizer had been applied to a field one year and not in another in order to compare the yield of grain produced in the two years. BUT
It may have rained more, or been sunnier, in different years. The seeds used may have differed between years as well.
Or fertilizer was applied to one field and not to a nearby field in the same year. BUT
The fields might have different soil, water, drainage, and history of previous use.
Too many factors affecting the results were “uncontrolled.”

11
Fisher’s solution: Randomization 隨機化 In the same field and same year,
apply fertilizer to randomly spaced
plots within the field.
This averages out the effect of
variation within the field in
drainage and soil composition on
yield, as well as controlling for
weather, etc.
F F F F F F
F F F F F F F F
F F F F F
F F F F F F F F
F F F F F
F F F F

12
Randomization prevents any particular treatment from
receiving more than its fair share of better units, thereby
eliminating potential systematic bias. Some treatments may
still get lucky, but if we assign many units to each treatment,
then the effects of chance will average out.
In addition to guarding against potential systematic biases,
randomization also provides a basis for doing statistical
inference.
(Randomization model)

13
F F F F F F F F F F F F
F F F F F F F F F F F F
F F F F F F F F F F F F
Start with an initial design
Randomly permute (labels of) the experimental units
Complete randomization: Pick one of the 72! Permutationsrandomly

14
1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2
3 3 3 3 3 3 3 3 3 3 3 3
3 3 3 3 3 3 4 4 4 4 4 4
4 4 4 4 4 4 4 4 4 4 4 4
Pick one of the 72! Permutations randomly
4 treatments
Completely randomized design

15
Assume treatment-unit additivity

16
Randomization model for a completely randomized design
The ’s are identically distributed
is a constant for all

17

18
Blocking: an effective method for
improving precision
Randomized complete block design
After randomization:
完全區集設計
區集化

19
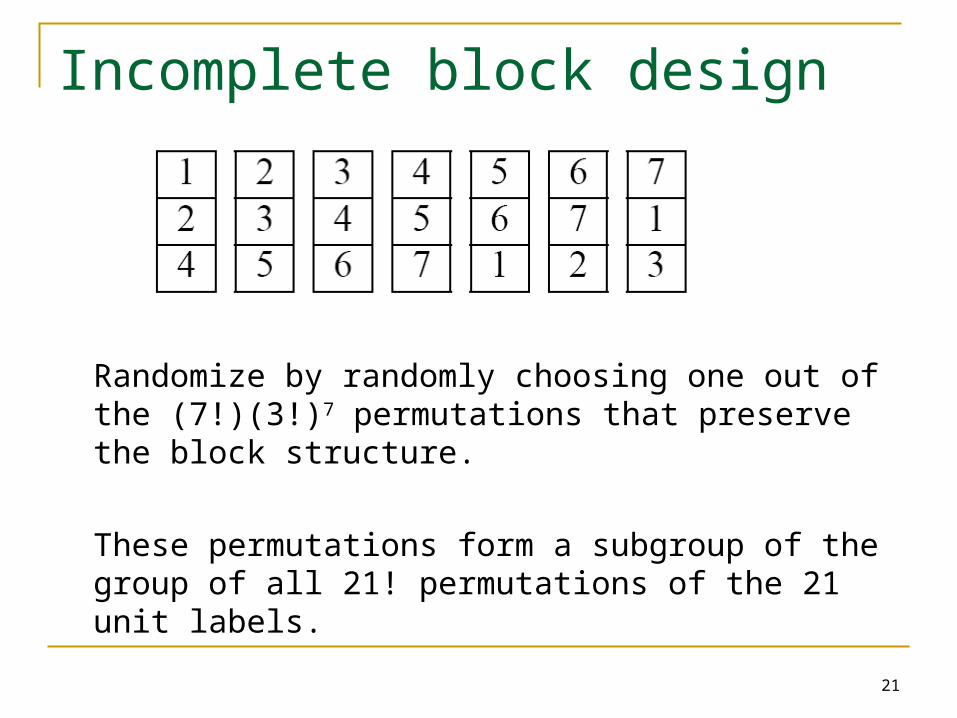
Incomplete block design
7 treatments

20
Incomplete block design
Balanced incomplete block design
Optimality was shown by Kiefer (1958)
Randomization is performed independently within each block, and the block labels are also randomly permuted.
平衡不完全區集設計
21
Incomplete block design
Randomize by randomly choosing one out of the (7!)(3!)7 permutations that preserve the block structure.
These permutations form a subgroup of the group of all 21! permutations of the 21 unit labels.

22
Block what you can and randomize what you cannot.
The purpose of randomization is to average out those nuisance factors that we cannot predict or cannot control, not to destroy the relevant information we have.
Choose a permutation group that preserves any known relevant structure on the units. Usually take the group for randomization to be the largest possible group that preserves the structure to give the greatest possible simplification of the model.

23
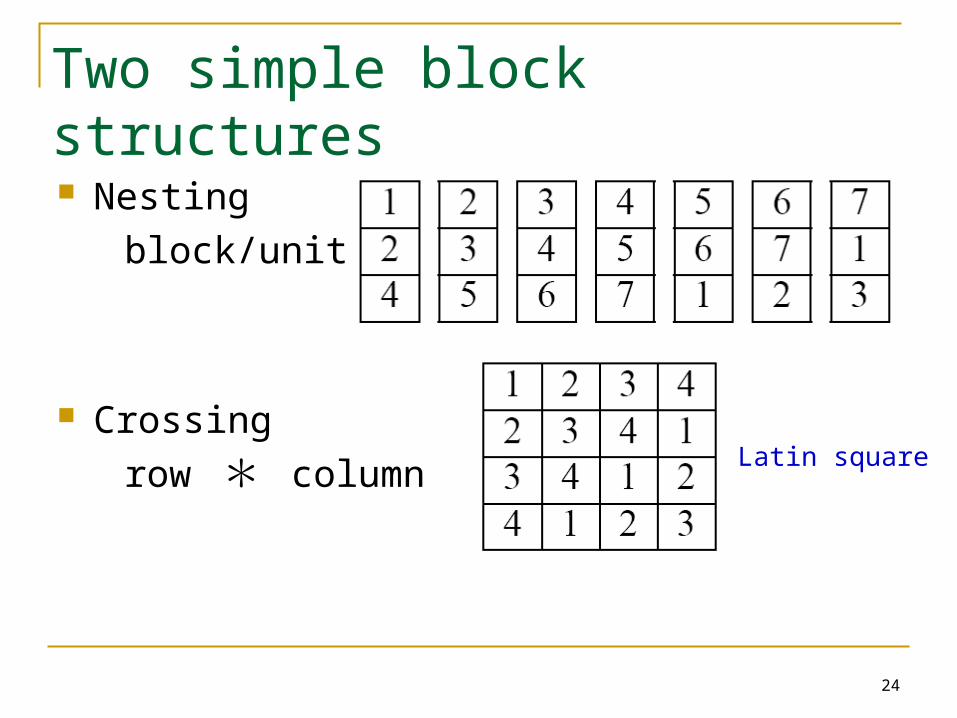
Two simple block (unit) structures Nesting
block/unit
Crossing
row * column
24
Two simple block structures
Nesting
block/unit
Crossing
row * columnLatin square

25

26
Treatment structures
No structure
Treatments vs. control
Factorial structure

27
Unstructured treatments
(Treatment contrast)
The set of all treatment contrasts form a dimensional space (generated by all the pairwisecomparisons.
Might be interested in estimating pairwise comparisons
or

28
Treatments vs control

29
Factorial structureEach treatment is a combination of several factors

30
S=2, n=3:

31
Interested in contrasts representing main
effects and interactions of the factors

32
Here each is coded by 1 and -1.

33

34

35

36
Treatment structure
Block structure (unit structure)
Design
Randomization
Analysis

37
Choice of design
Efficiency Combinatorial considerations Practical considerations

38
Simple orthogonal block structures
Iterated crossing and nesting
cover most, but not all block structures encountered in practice

39
Consumer testing
A consumer organization wishes to compare 8 brands of
vacuum cleaner. There is one sample for each brand.
Each of four housewives tests two cleaners in her home
for a week. To allow for housewife effects, each housewife
tests each cleaner and therefore takes part in the trial for 4
weeks.
8 unstructured treatments
Block structure:

40
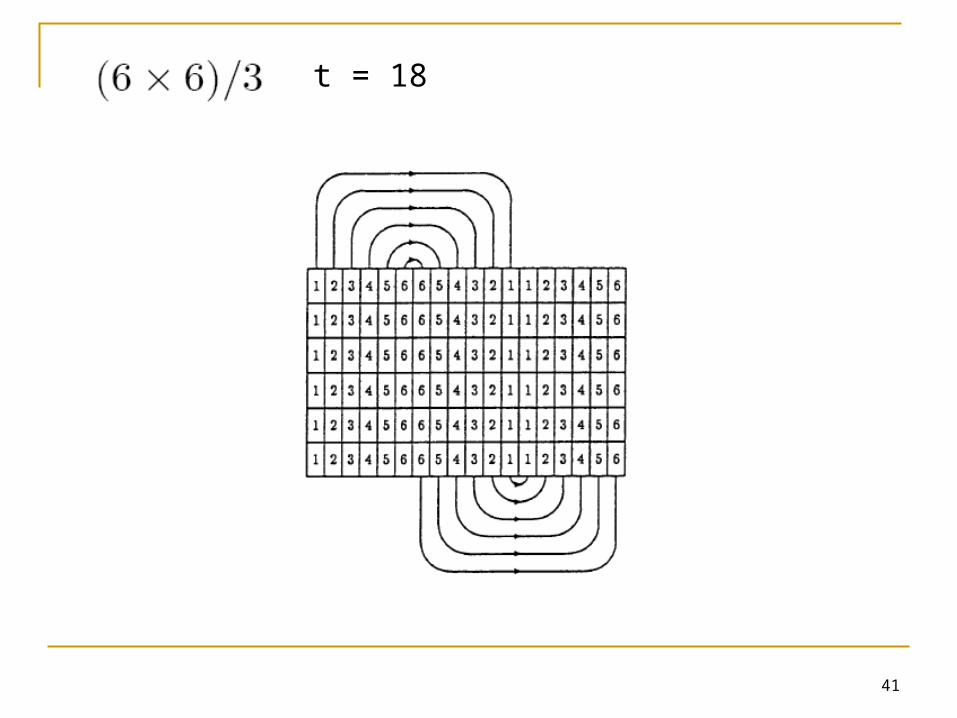
A α B β C γ D δ
B γ A δ D α C β
C δ D γ A β B α
D β C α B δ A γ
Trojan square
Optimality of Trojan squares was shown byCheng and Bailey (1991)
41
t = 18

42
McLeod and Brewster (2004) Technometrics
Blocked split plots (Split-split plots)Chrome-plating process
Block structure: 4 weeks/4 days/2 runs
block/wholeplot/subplot
Treatment structure: A * B * C * p * q * r
Each of the six factors has two levels

43
Hard-to-vary treatment factors
A: chrome concentration B: Chrome to sulfate ratio C: bath temperature
Easy-to-vary treatment factors
p: etching current density q: plating current density r: part geometry

44
Miller (1997) TechnometricsStrip-Plots
Experimental objective: Investigate methods of
reducing the wrinkling of clothes being laundered

45
Miller (1997)
The experiment is run in 2 blocks and employs
4 washers and 4 driers. Sets of cloth samples
are run through the washers and the samples
are divided into groups such that each group
contains exactly one sample from each washer.
Each group of samples is then assigned to one
of the driers. Once dried, the extent of wrinkling
on each sample is evaluated.

46
Treatment structure:
A, B, C, D, E, F: configurations of washers
a,b,c,d: configurations of dryers

47
Block structure:2 blocks/(4 washers * 4 dryers)

48
Block 1 Block 2 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 0 1 1 0 0 0 0 0 0 0 0 0 1 1 0 0 0 1 1 1 0 1 0 10 0 0 0 0 0 1 1 0 0 0 0 0 1 1 1 1 0 1 0 0 0 0 0 0 0 1 1 1 1 0 0 0 1 1 1 1 0 0 10 1 1 0 1 1 0 0 0 0 0 1 1 1 0 0 0 1 1 00 1 1 0 1 1 0 0 1 1 0 1 1 1 0 0 0 1 0 10 1 1 0 1 1 1 1 0 0 0 1 1 1 0 0 1 0 1 00 1 1 0 1 1 1 1 1 1 0 1 1 1 0 0 1 0 0 11 0 1 1 0 1 0 0 0 0 1 0 1 0 1 0 0 1 1 01 0 1 1 0 1 0 0 1 1 1 0 1 0 1 0 0 1 0 11 0 1 1 0 1 1 1 0 0 1 0 1 0 1 0 1 0 1 01 0 1 1 0 1 1 1 1 1 1 0 1 0 1 0 1 0 0 11 1 0 1 1 0 0 0 0 0 1 1 0 0 0 1 0 1 1 0 1 1 0 1 1 0 0 0 1 1 1 1 0 0 0 1 0 1 0 1 1 1 0 1 1 0 1 1 0 0 1 1 0 0 0 1 1 0 1 01 1 0 1 1 0 1 1 1 1 1 1 0 0 0 1 1 0 0 1

49
GenStat code
factor [nvalue=32;levels=2] block,A,B,C,D,E,F,a,b,c,d
& [levels=4] wash, dryer
generate block,wash,dryer
blockstructure block/(wash*dryer)
treatmentstructure
(A+B+C+D+E+F)*(A+B+C+D+E+F)
+(a+b+c+d)*(a+b+c+d)
+(A+B+C+D+E+F)*(a+b+c+d)

50
matrix [rows=10; columns=5; values=“ b r1 r2 c1 c2"
0, 0, 1, 0, 0,0, 1, 0, 0, 0, 0, 1, 1, 0, 0, 1, 0, 1, 0, 0,1, 1, 0, 0, 0,1, 1, 1, 0, 0, 0, 0, 0, 0, 1,1, 0, 0, 0, 1, 1, 0, 0, 1, 0,
0, 0, 0, 1, 0] Mkey

51
Akey [blockfactors=block,wash,dryer; Key=Mkey;rowprimes=!(10(2));colprimes=!(5(2)); colmappings
=!(1,2,2,3,3)] Pdesign Arandom [blocks=block/(wash*dryer);seed=12345]PDESIGN ANOVA

52
Source of variation d.f. block stratum
AD=BE=CF=ab=cd 1 block.wash stratum
A=BC=EF 1B=AC=DF 1 C=AB=DF 1D=BF=CE 1E=AF=CD 1F=BD=AE 1

53
block.dryer stratum
a 1b 1c 1d 1ac=bd 1bc=ad 1

54
block.wash.dryer stratum
Aa=Db 1Ba=Eb 1Ca=Fb 1Da=Ab 1Ea=Bb 1Fa=Cb 1Ac=Dd 1Bc=Ed 1Cc=Fd 1Dc=Ad 1Ec=Bd 1Fc=Cd 1Residual 6Total 31

55
Seven Error Terms!! Are you kidding??T. M. Loughin et al.

56

57

58

59

60

61

62

63

64

65
Treatment structure: 3*2*3*7
Block structure: 4/((3/2/3)*7)

66
Factor [nvalues=504;levels=4] Block & [levels=3] Sv, Sr, Var, Rate & [levels=2] St, Time & [levels=7] Sw, WeedGenerate Block, Sv, St, Sr, SwMatrix [rows=4;columns=6; \values="b1 b2 Col St Sr Row"\1, 0, 1, 0, 0, 0,\0, 0, 1, 1, 0, 0,\0, 0, 1, 1, 1, 0,\1, 1, 0, 0, 0, 1] CkeyAkey [blockfactor=Block,Sv,St,Sr,Sw; \Colprimes=!(2,2,3,2,3,7);Colmappings=!(1,1,2,3,4,5);Key=Ckey] Var, Time, Rate, WeedBlocks Block/((Sv/St/Sr)*Sw)Treatments Var*Time*Rate*WeedANOVA

67
Block stratum 3 Block.Sv stratumVar 2Residual 6 Block.Sw stratumWeed 6Residual 18
Block.Sv.St stratumTime 1Var.Time 2Residual 9

68
Block.Sv.Sw stratumVar.Weed 12Residual 36
Block.Sv.St.Sr stratumRate 2Var.Rate 4Time.Rate 2Var.Time.Rate 4Residual 36

69
Block.Sv.St.Sw stratumTime.Weed 6Var.Time.Weed 12Residual 54 Block.Sv.St.Sr.Sw stratumRate.Weed 12Var.Rate.Weed 24Time.Rate.Weed 12Var.Time.Rate. Weed 24Residual 216
Total 503





























