Embed Size (px)
Citation preview

11
ECE-517 Reinforcement LearningECE-517 Reinforcement Learningin Artificial Intelligence in Artificial Intelligence
Lecture 11: Temporal Difference Learning (cont.),Lecture 11: Temporal Difference Learning (cont.),Eligibility TracesEligibility Traces
Dr. Itamar ArelDr. Itamar Arel
College of EngineeringCollege of EngineeringDepartment of Electrical Engineering and Computer ScienceDepartment of Electrical Engineering and Computer Science
The University of TennesseeThe University of TennesseeFall 2010Fall 2010
October 11, 2010October 11, 2010

ECE 517: Reinforcement Learning in AI 22
OutlineOutline
Actor-Critic Model (TD)Actor-Critic Model (TD)
Eligibility TracesEligibility Traces
ECE 517: Reinforcement Learning in AI 33
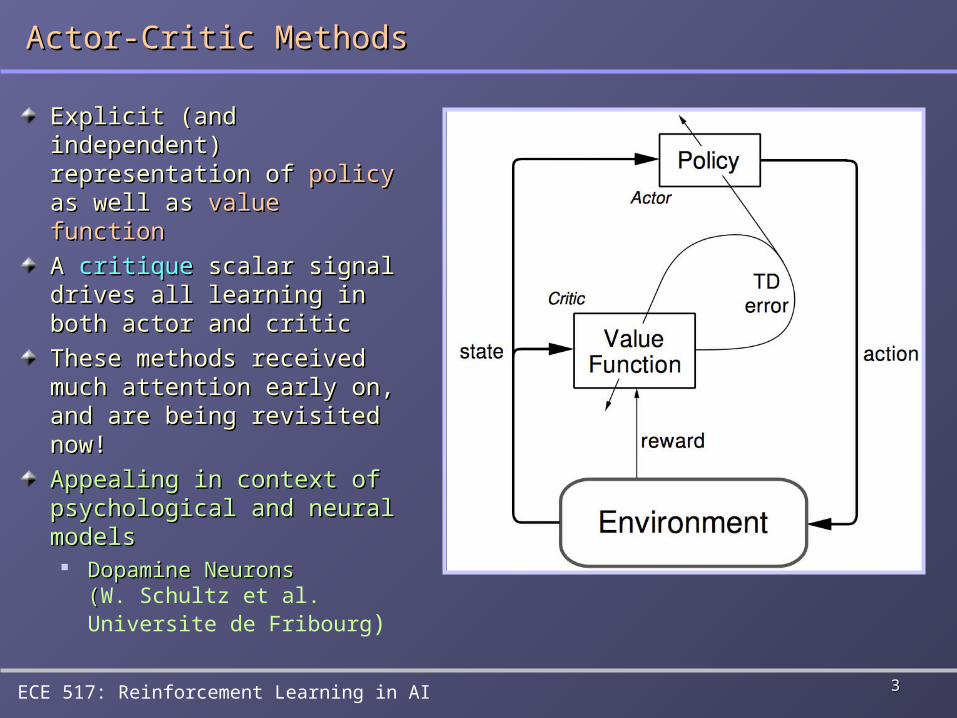
Actor-Critic MethodsActor-Critic Methods
Explicit (and Explicit (and independent) independent) representation of representation of policypolicy as well as as well as value functionvalue function
A A critiquecritique scalar signal scalar signal drives all learning in both drives all learning in both actor and criticactor and critic
These methods received These methods received much attention early on, much attention early on, and are being revisited and are being revisited now!now!
Appealing in context of Appealing in context of psychological and neural psychological and neural models models Dopamine Neurons Dopamine Neurons
((W. Schultz et al. Universite de Fribourg)

ECE 517: Reinforcement Learning in AI 44
Actor-Critic DetailsActor-Critic Details
Typically, the Typically, the criticcritic is a state-value function is a state-value function After each action selection, an evaluation error is obtained in After each action selection, an evaluation error is obtained in
the formthe form
where where VV is the critic’s current value function is the critic’s current value function
Positive error Positive error action action aatt should be strengthened for the should be strengthened for the
futurefuture
Typical actor is a Typical actor is a parameterizedparameterized mapping of states to actions mapping of states to actions
Suppose actions are generated by Gibbs softmaxSuppose actions are generated by Gibbs softmax
then the agent can update the preferences asthen the agent can update the preferences as
)()( 11 tttt sVsVr
b
bsp
asp
ttt e
essaaas
),(
),(
Pr),(
ttttt aspasp ),(),(

ECE 517: Reinforcement Learning in AI 55
Actor Critic Models (cont.)Actor Critic Models (cont.)
Actor-Critic methods offer a powerful Actor-Critic methods offer a powerful framework for scalable RL systems (as will be framework for scalable RL systems (as will be shown later)shown later)
They are particular interesting since they …They are particular interesting since they … Operate inherently onlineOperate inherently online Require minimal computation in order to select Require minimal computation in order to select
actionsactionse.g. Draw a number from a given distributione.g. Draw a number from a given distribution
In Neural Networks it will be equivalent to a single In Neural Networks it will be equivalent to a single feed-forward passfeed-forward pass
Can cope with non-Markovian environmentsCan cope with non-Markovian environments

ECE 517: Reinforcement Learning in AI 66
Summary of TDSummary of TD
TD is based on prediction (and associated error)TD is based on prediction (and associated error)
Introduced Introduced one-step tabular model-free TD one-step tabular model-free TD methodsmethods
Extended prediction to control by employing Extended prediction to control by employing some form of GPIsome form of GPI On-policy control: On-policy control: SarsaSarsa Off-policy control: Off-policy control: Q-learningQ-learning
These methods bootstrap and sample, These methods bootstrap and sample, combining aspects of DP and MC methodscombining aspects of DP and MC methods
Have shown to have some correlation with Have shown to have some correlation with biological systemsbiological systems

ECE 517: Reinforcement Learning in AI 77
Unified View of RL methods (so far)Unified View of RL methods (so far)

ECE 517: Reinforcement Learning in AI 88
Eligibility TracesEligibility Traces
ET are one of the basic practical mechanisms in RLET are one of the basic practical mechanisms in RL
Almost any TD methods can be combined with ET to Almost any TD methods can be combined with ET to obtain a more efficient learning engineobtain a more efficient learning engine Combine TD concepts with Monte Carlo ideasCombine TD concepts with Monte Carlo ideas
Addresses the gap between events and training dataAddresses the gap between events and training data Temporary record of occurrence of an eventTemporary record of occurrence of an event Trace marks memory parameters associated with the Trace marks memory parameters associated with the
event as eligible for undergoing learning changesevent as eligible for undergoing learning changes
When TD error is recorded – eligible states or actions When TD error is recorded – eligible states or actions are assigned are assigned creditcredit or or “blame”“blame” for the error for the error
There will be two views of ETThere will be two views of ET Forward viewForward view – more theoretic – more theoretic Backward viewBackward view – more mechanistic – more mechanistic

ECE 517: Reinforcement Learning in AI 99
nn-step TD Prediction-step TD Prediction
Idea:Idea: Look farther into the future when you do TD Look farther into the future when you do TD backup (1, 2, 3, …, backup (1, 2, 3, …, nn steps) steps)

ECE 517: Reinforcement Learning in AI 1010
Mathematics of Mathematics of nn-step TD Prediction-step TD Prediction
Monte Carlo:Monte Carlo:
TD:TD: Use Use VV((ss)) to estimate remaining return to estimate remaining return
nn--step TD:step TD: 2-step return:2-step return:
nn--step return at time step return at time tt::
Rt rt1 rt2 2rt3 T t 1rT
Rt(1) rt1 Vt (st1)
Rt(2) rt1 rt2 2Vt (st2)
Rt(n ) rt1 rt2 2rt3 n 1rtn nVt (stn )

ECE 517: Reinforcement Learning in AI 1111
Learning with Learning with nn-step Backups-step Backups
Backup (on-line or off-line):Backup (on-line or off-line):
Error reduction propertyError reduction property of of nn-step returns-step returns
Using this, one can show that Using this, one can show that nn-step methods -step methods convergeconverge
Yields a family of methods, of which Yields a family of methods, of which TDTD and and MCMC are are membersmembers
Vt (st ) Rt(n ) Vt (st )
maxs
E{Rt(n ) | st s} V (s) n max
sV (s) V (s)
Maximum error using n-step return Maximum error using V(s)

ECE 517: Reinforcement Learning in AI 1212
On-line vs. Off-line UpdatingOn-line vs. Off-line Updating
In In on-line updatingon-line updating – updates are done during the – updates are done during the episode, as soon as the increment is computedepisode, as soon as the increment is computed
In that case we haveIn that case we have
In In off-line updatingoff-line updating – we update the value of each – we update the value of each state at the end of the episodestate at the end of the episode Increments are accumulated and calculated “on the Increments are accumulated and calculated “on the
side”side” Values are constant throughout the episodeValues are constant throughout the episode Given a value V(s), the new value (in the next episode) Given a value V(s), the new value (in the next episode)
will bewill be
)()()(1 sVsVsV ttt
1
0
)()(T
tt sVsV

ECE 517: Reinforcement Learning in AI 1313
Random Walk Revisited: e.g. for 19-Step Random WalkRandom Walk Revisited: e.g. for 19-Step Random Walk

ECE 517: Reinforcement Learning in AI 1414
Averaging Averaging nn-step Returns-step Returns
nn-step methods were introduced to help with -step methods were introduced to help with TD(TD() understanding) understanding
Idea:Idea: backup an average of several returns backup an average of several returns e.g. backup half of 2-step and half ofe.g. backup half of 2-step and half of
4-step4-step
The above is called a The above is called a complex backupcomplex backup Draw each componentDraw each component Label with the weights for that componentLabel with the weights for that component TD(TD() can be viewed as one way of averaging) can be viewed as one way of averaging
nn--stepstep backupsbackups
)4()2(
2
1
2
1tt
avgt RRR
One backup

ECE 517: Reinforcement Learning in AI 1515
Forward View of TD(Forward View of TD())
TD(TD() is a method for ) is a method for averaging all averaging all n-n-step step backups backups weight by weight by n-1n-1 (time (time
since visitation)since visitation) -return: -return:
Backup using Backup using -return:-return:
Rt (1 ) n 1
n1
Rt(n )
Vt (st ) Rt Vt (st )

ECE 517: Reinforcement Learning in AI 1616
-Return Weighting Function for episodic tasks-Return Weighting Function for episodic tasks
Rt (1 ) n 1
n1
T t 1
Rt(n ) T t 1Rt
Until termination
After termination

ECE 517: Reinforcement Learning in AI 1717
Relation of Relation of -Return to TD(0) and Monte Carlo-Return to TD(0) and Monte Carlo
-return can be rewritten as:-return can be rewritten as:
If If = 1, you get Monte Carlo: = 1, you get Monte Carlo:
If If = 0, you get TD(0) = 0, you get TD(0)
Rt (1 ) n 1
n1
T t 1
Rt(n ) T t 1Rt
Rt (1 1) 1n 1
n1
T t 1
Rt(n ) 1T t 1Rt Rt
)( :reminder
00)01(
11)1(
)1(1)(1
1
1
tttt
tttTn
t
tT
n
nt
sVrR
RRRR

ECE 517: Reinforcement Learning in AI 1818
Forward View of TD(Forward View of TD())
Look forward from each state to determine update Look forward from each state to determine update from future states and rewardsfrom future states and rewards
Q: Can this be practically implemented? Q: Can this be practically implemented?

ECE 517: Reinforcement Learning in AI 1919
-Return on the Random Walk-Return on the Random Walk
Same 19 state random walk as beforeSame 19 state random walk as before
Q: Why do you think intermediate values of Q: Why do you think intermediate values of are best?are best?

ECE 517: Reinforcement Learning in AI 2020
Backward ViewBackward View
The forward view was theoreticalThe forward view was theoretical
The backward view is for practical mechanismThe backward view is for practical mechanism ““Shout” Shout” tt backwards over time backwards over time
The strength of your voice decreases with temporal distance The strength of your voice decreases with temporal distance by by
t rt1 Vt (st1) Vt (st )

ECE 517: Reinforcement Learning in AI 2121
Backward View of TD(Backward View of TD())
TD(TD() parametrically shifts from TD to MC) parametrically shifts from TD to MC
New variable called New variable called eligibility traceeligibility trace On each step, decay all traces by On each step, decay all traces by
is the discount rate and is the discount rate and is the Return weighting is the Return weighting coefficientcoefficient
Increment the trace for the current state by 1Increment the trace for the current state by 1 Accumulating trace is thusAccumulating trace is thus
et (s) et 1(s) if s st
et 1(s)1 if s st
et (s)

ECE 517: Reinforcement Learning in AI 2222
0
On-line Tabular TD(On-line Tabular TD())
terminalis Until
)()(
)()()(
:s allFor
1)()(
)()(
statenext and , reward, observe , action Take
for by given action
:episode) of step each(for t Repea
allfor ,0)(
Initialize
:episode) each(for Repeat
yarbitraril )( Initialize
s
ss
sese
sesVsV
sese
sVsVr
sra
sa
Ssse
s
sV

ECE 517: Reinforcement Learning in AI 2323
Relation of Backwards View to MC & TD(0)Relation of Backwards View to MC & TD(0)
Using the update rule: Using the update rule:
As before, if you set As before, if you set to 0, you get to TD(0) to 0, you get to TD(0)
If you set If you set 1 (no decay), you get MC but in a 1 (no decay), you get MC but in a better waybetter way Can apply TD(1) to continuing tasksCan apply TD(1) to continuing tasks Works incrementally and on-line (instead of waiting Works incrementally and on-line (instead of waiting
to the end of the episode)to the end of the episode)
In between – In between – earlier states are given less credit for the earlier states are given less credit for the TD ErrorTD Error
Vt (s) tet (s)

ECE 517: Reinforcement Learning in AI 2424
Forward View = Backward ViewForward View = Backward View
The forward (theoretical) view of TD(The forward (theoretical) view of TD() is equivalent to ) is equivalent to the backward (mechanistic) view for off-line updatingthe backward (mechanistic) view for off-line updatingThe book shows (pp. 176-178):The book shows (pp. 176-178):
On-line updating with small On-line updating with small is similar is similar
VtTD (s)
t0
T 1
t0
T 1
Isst()k tk
kt
T 1
Vt(st )Isst
t0
T 1
t0
T 1
Isst()k tk
kt
T 1
VtTD (s)
t0
T 1
Vt(st )
t0
T 1
Isst
Backward updates Forward updates
algebra shown in book

ECE 517: Reinforcement Learning in AI 2525
On-line versus Off-line on Random WalkOn-line versus Off-line on Random Walk
Same 19 state random walkSame 19 state random walk
On-line performs better over a broader range of On-line performs better over a broader range of parametersparameters

ECE 517: Reinforcement Learning in AI 2626
Control: Sarsa(Control: Sarsa())
Next we want to use ET for control, not just prediction Next we want to use ET for control, not just prediction (i.e. estimation of value functions)(i.e. estimation of value functions)
IdeaIdea: we save eligibility for state-action pairs instead : we save eligibility for state-action pairs instead of just statesof just states
otherwisease
aassasease
t
ttt ),(
& if1),(),(
1
1
),(),(
),(),(),(
111
1
tttttttt
tttt
asQasQr
aseasQasQ

ECE 517: Reinforcement Learning in AI 2727
0
Sarsa(Sarsa() Algorithm) Algorithm
Initialize Q(s,a) arbitrarily
Repeat (for each episode) :
e(s,a) 0, for all s,a
Initialize s,a
Repeat (for each step of episode) :
Take action a, observe r, s
Choose a from s using policy derived from Q (e.g. - greedy)
r Q( s , a ) Q(s,a)
e(s,a) e(s,a)1
For all s,a :
Q(s,a) Q(s,a)e(s,a)
e(s,a) e(s,a)
s s ;a a
Until s is terminal

ECE 517: Reinforcement Learning in AI 2828
Implementing Q(Implementing Q())
Two methods have been Two methods have been proposed that combine ET proposed that combine ET and Q-Learning: and Q-Learning: Watkins’sWatkins’s Q( Q() and ) and Peng’sPeng’s Q(Q())
Recall that Q-learning is Recall that Q-learning is an off-policy methodan off-policy method Learns about greedy Learns about greedy
policy while follows policy while follows exploratory actionsexploratory actions Suppose the agent followsSuppose the agent follows
the greedy policy for the the greedy policy for the first two steps, but not on first two steps, but not on the third the third
WatkinsWatkins:: Zero out eligibility trace after a non-greedy action. Zero out eligibility trace after a non-greedy action. Do Do maxmax when backing up at first non-greedy choice. when backing up at first non-greedy choice.
),(max13
221 asQrrrr ntt
a
nnt
nttt

ECE 517: Reinforcement Learning in AI 2929
0
Watkins’s Q(Watkins’s Q())
Initialize Q(s,a) arbitrarily
Repeat (for each episode) :
e(s,a) 0, for all s,a
Initialize s,a
Repeat (for each step of episode) :
Take action a, observe r, s
Choose a from s using policy derived from Q (e.g. - greedy)
a* argmaxb Q( s ,b) (if a ties for the max, then a* a )
r Q( s , a ) Q(s,a*)
e(s,a) e(s,a)1
For all s,a :
Q(s,a) Q(s,a)e(s,a)
If a a*, then e(s,a) e(s,a)
else e(s,a) 0
s s ;a a
Until s is terminal

ECE 517: Reinforcement Learning in AI 3030
Peng’s Q(Peng’s Q())
Disadvantage to Disadvantage to Watkins’s method:Watkins’s method: Early in learning, the Early in learning, the
eligibility trace will be eligibility trace will be “cut” (zeroed out), “cut” (zeroed out), frequently resulting in frequently resulting in little advantage to traceslittle advantage to traces
Peng: Peng: Backup max action Backup max action
except at the endexcept at the end Never cut tracesNever cut traces
Disadvantage:Disadvantage: Complicated to Complicated to
implementimplement

ECE 517: Reinforcement Learning in AI 3131
Variable Variable
ET methods can improve by allowing ET methods can improve by allowing to change in time to change in timeCan generalize to variable Can generalize to variable
can be defined, for example, (as a function of time) ascan be defined, for example, (as a function of time) as
States visited with high certainty values States visited with high certainty values Use that value estimate fully and ignore subsequent statesUse that value estimate fully and ignore subsequent states
States visited with uncertainty of values States visited with uncertainty of values Causes their estimated values to have little effect on any Causes their estimated values to have little effect on any
updatesupdates
et (s) tet 1(s) if s st
tet 1(s)1 if s st
t (st ) or t t

ECE 517: Reinforcement Learning in AI 3232
ConclusionsConclusions
Eligibility Traces offer an efficient, Eligibility Traces offer an efficient, incremental way to combine MC and TDincremental way to combine MC and TD Includes advantages of MC Includes advantages of MC
Can deal with lack of Markov propertyCan deal with lack of Markov property
Consider an n-step interval for improved performanceConsider an n-step interval for improved performance Includes advantages of TDIncludes advantages of TD
Using TD errorUsing TD error
BootstrappingBootstrapping
Can significantly speed learningCan significantly speed learning
Does have a cost in computationDoes have a cost in computation





























