Embed Size (px)
Citation preview

1 Introduction
LASI (Linguistic Analysis for Subject Identification) is a natural language processing
engine that will combine raw lexical analysis heuristics with sophisticated syntax aware
heuristics and thereby form a basis to extrapolate, determine ways to interrelate, and abstract
statistically derived semantic content over an input domain containing multiple English written
works. The process of linguistic analysis, defined herein as the procedural study of how the
words and phrases within a written work compose to form emergent meanings, is the central
concept behind the LASI project. The use of language is a constantly evolving, self-describing
process which complexifies on the composition of syntactic rules to express complex, emergent
ideas, which in turn compose together to form themes: the distillation of the relationships
literally described by the document.
1.1 Purpose
LASI is a software package which aims to provide decision support and validation by
pairing a set of high performance, context-sensitive heuristics with a graphical frontend in order
to assist researchers in quickly gleaning meaningful content from written sources of information.
Additionally, by pairing these algorithms with a graphical user interface (GUI) it will be able to
assist a broad range of individuals with widely varying and areas of research and levels of
technical proficiency. Furthermore, because of the broad societal significance of the problem it
approaches, there are many potential applications which go beyond the domain of pure research.
For example, its pattern recognition and synonym generalization features could assist professors
in identifying non verbatim plagiarism, such as in the case of content which has been wrapped in
a thin veneer by basic paraphrasing. In terms of students, its contextual awareness capabilities

could be of assistance to students by helping them to quickly find relevant sources to cite for
written assignments. In more in depth contexts, advanced users, such as Researchers like the
progenitor of the LASI project Dr. Patrick T. Hester, could reap the benefits of the algorithms’
inferential capabilities to provide their clients with more specialized, quantitatively verifiable
assessments of the complex systems. Broadly speaking, any individual needing to quickly
become familiar with a single specific area of broad topic could employ LASI’s unique
functionality to quickly hone in on increasingly relevant written resources.
Essentially, linguistic analysis in this context aims to, at least conceptually, to sufficiently
quantify qualitative information, thereby reducing trivial disagreements to be dispelled
potentially allowing for faster and more effective decision making. Such analysis tools can
provide key services in role as decision support tools. LASI is such a tool.
The notion of theme refers to emergent, overlapping, intra and inter-textually derived,
mental constructs which represent one of the key bases for human communication. In a sense,
themes provide an abstraction interface which allows for the expression of linguistic ideas.
However, as much as communicating via thematic abstraction is something without
which humans would be unable to express complex ideas to one another; interpreting and
expressing themes is often fraught with misunderstandings, conflation, and subject-arbitrary
emotional associations. Any of these pitfalls can impede and stifle linguistic communication. For
example, consider the case of an author who, while he genuinely expresses a certain theme with
eloquence and brevity, is criticized for stating something he did not in fact assert, but the
reference frame of the reader unpredictably clashed with that of the author in a way neither of
them were capable of predicting, and perhaps resulted in a mutual perception of disagreement
over a subject on which, had the authors words been parameterized differently, they might have

wholeheartedly agreed. Thus, in spite of or perhaps because of the critical role which themes
play in communication and expression, a multitude of potentially baseless or conflated concepts
are communicated between authors and readers as well as between individual readers. In the case
of readers, small differences in their respective interpretations of some works can compose into
serious disagreement over what a given author is trying to express. While this has many powerful
and sometimes even positive implications, and while it forms one of the key underpinnings for
meta-explorative disciplines such epistemology and philosophy, discord over needless
misunderstanding can have very harmful effects in areas where justifiable, imperative decisions
must made based solely on textual perusal. For example, consider a situation is when time
critical decisions must be made by government agencies or large corporations who must
carefully determine how to allocate of scarce resources, or make time-critical financial or
military decisions. As these situations involve multiple individuals doing independent research
and then pooling their knowledge, and since some such degree of semantic disagreement is
inevitable in a relatively democratic environment, serious problems such as needless delays,
resource misappropriations, or outright inaction may result and cause severe damage.
1.2 Scope
The prototype version of LASI, while it retains and implements much of the real world
product’s proposed functionality, nevertheless suffers from some significant cutbacks. These
cutbacks have been instigated to cope with the time and manpower constraints imposed by the
undergraduate academic schedule on the software development process. Pronoun binding
algorithms, PDF input file parsing, and session suspension are all among the key features which
will not be part of the prototype package.

1.3 Definitions, Acronyms, and Abbreviations
A.I.D.: Assessment Improvement Design
A.I.D. Process: A process that provides quantitative and qualitative basis to identify problems and determine the feasibility of solutions.
Analysis: Detailed examination of the elements or structure of something, typically as a basis for interpretation.
Document: A document herein refers to a formally written, expository paper which expounds, via a declarative approach, on a relatively quantifiable issue, goal, or area of research.
Head word: A locally distinct word within a phrase which, by its syntactic associations, determines the category of the phrase itself.
LASI: Linguistic Analysis for Subject Identification
Linguistic Analysis: The scientific analysis of a language.
Parser: Takes in DOC and DOCX files and converts them to TXT files.
Part of Speech Tagger: Software utility that associates words with the parts-of-speech in a sentence.
Phrase: An instance of the Phrase class.
Phrase: (Linguistically) A group of words standing together as a conceptual unit.
Phrase Class: The root of the class taxonomy whose members correspond to the syntactic roles of phrase level elements. Instances of the types derived from the Phrase class contain a collection of Word instances which together represent a linguistic phrase.
Semantic Analysis: Relating the syntactical structure of words to their language independent meanings.
Sharp NLP: A natural language processing tool used to parse and tag parts-of-speech. It is written in C#.
Strategic Document: Document produced by a client that defines their Goals, Visions and Missions.
Subject Identification: The process by which the subject matter and thematic content of documents is determined.

Syntactic Analysis: Identifies key words based on their location in the sentence, rather than their overall meaning throughout the document.
.TAGGED: The type of file that stores the output of the part-of-speech tagger containing the all of the text of the document with embedded syntactic annotations.
Theme: Subject-object-verb relationships that LASI is attempting to generate from the input set.
Tag: A label, or the act of attaching a label, that specifies the syntactic role of a selected element in a document.
Tagged Set: A group of words, whose part of speech and location in a sentence have been identified by the parser.
WordNet: Compiler and provider of the data files which forms the basis for the LASI thesaurus.
Word Class: The root of the taxonomy of class types which correspond to parts-of-speech at the word level and whose instances encapsulate each occurrence of a textually identified word.
Word Weight: A numeric value, associated with each syntactically and lexically unique word in a written work, indicating its significance.
1.4 References
Haddad, A. (2013). Lab 1 - lasi product description. Unpublished manuscript, Computer Science, Old Dominion University, Norfolk, VA, .
1.5 Overview
The following is a description of the core modules which comprise the LASI software package. It contains an overview of component interactions, conceptual algorithm descriptions, and abstract data type descriptions.
2 General Description
2.1 Prototype Architecture Description
Architecturally, the prototype version of LASI is broken down into three components or modules: the Algorithm, the File System, and the User Interface. The interaction between these components is illustrated by Figure 1. As shown, the modules interact via a constrained set of public interface functions.

Figure 1 Major Functional Component Modules
2.2 Prototype Functional Description
LASI will feature a number of different assessment techniques which will attempt to
extrapolate and construct, from a linear set of words, a reflexive web of syntactic and sematic
associations which will be revised and refined recursively as it continues to infer potential
relationships.

Before attempting any higher level analysis, a set of syntactic parsing libraries will
examine the text and identify, statistically and locally, the likely part of speech of text’s
lexical constructs. The result of this phase is a collection of words and phrases which have
been usage-wise categorized and thus mapped to program constructs which encapsulate their
syntactic roles. After this initial step, which results in a dynamic word and phrase behavior
driven data model, a large number of independent statistical functions and element
association techniques will be applied, their results compared, procedures potentially
reordered and reevaluated, and finally interrelated over multiple sources and representations
in an attempt to find the common thematic ideas and shared concepts of the input domain. A
key technique that allows this to be accomplished is the assignment of a variety of numerical
weights, both to individual word and phrase elements and to sets of potentially associated
constructs which are iteratively modified and scaled by each subsequent metric applied.
2.1.1 Source Document Formats
In terms of common capabilities and user accessibility features, the LASI software
package will accept English textual works in multiple popular file formats. Currently all
Microsoft Word document types as well as raw ASCII text files are fully supported LASI
will also provide native support for adding Adobe Acrobat documents directly to user
projects at some point. Implementing this functionality has been given a relatively low
priority by the team as it requires that an optical character recognition system be
implemented and then integrated such that all potentially erroneous characters parsed from an
Acrobat document containing scanned text must be differentiated and completely dealt with
before the text is passed to the tagging module.

In addition to parsing the data provided by the user, its functionally allows users to
provide custom dictionary-like inputs containing weight adjustments, static associations,
explicit synonym collections, and syntactic-role overrides for lexical entities in order to
facilitate more focused, user-intent-driven results. While his has the advantage of increasing
user control over the process and allowing for more customizable selection of results and
their arrangements, it is inseparably tied to the a loss of a demonstrable validity, detracting
from any assertions developers can make about accuracies and bias likelihoods when
shipping an iteration of LASI which provides such a feature. The most agreeable middle
ground probably is an approach allowing users to make some adjustments, through a properly
abstracted interface, and providing clear, unmistakable warnings regarding the decreasing
verifiability of results. The user interface provides standard, responsive navigation functions
that explicitly provides for all of the possible branches as illustrated by Figure 2.
(This space intentionally left blank.)
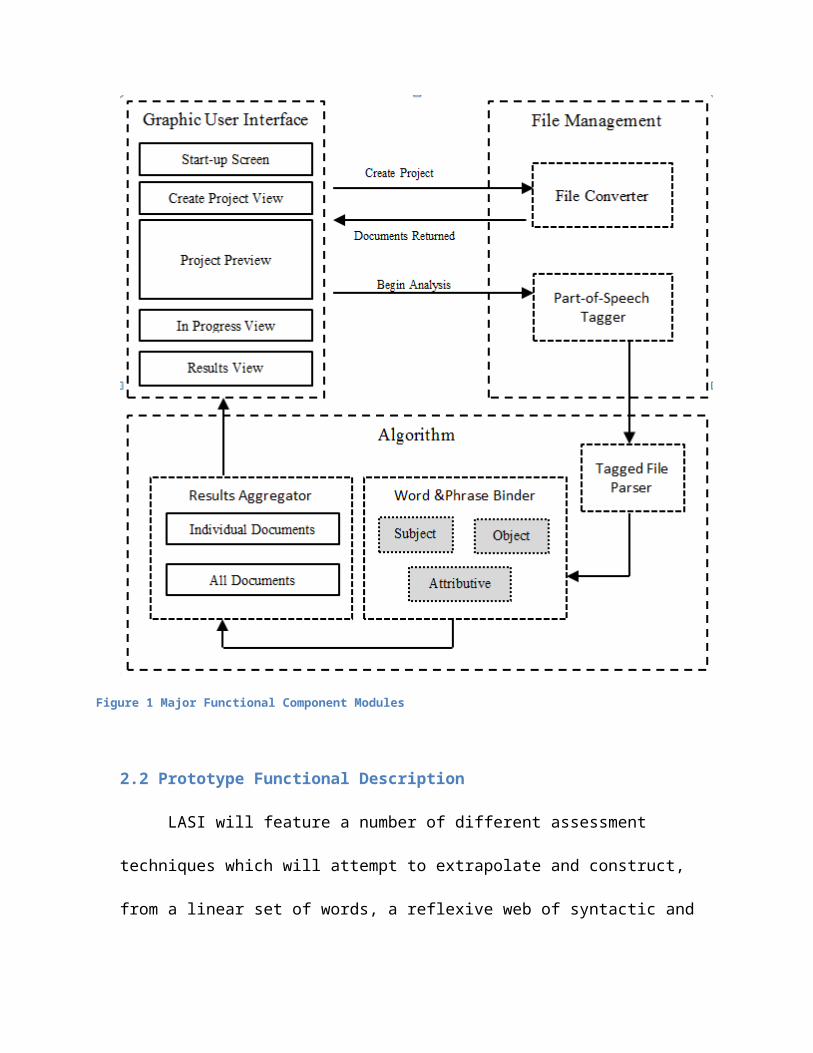
Figure 2 User Interaction Flow through the GUI

The User Interface thus provides, for each category of information which the LASI
engine can infer from a document, a human readable view which highlights the relevant
information and provides contextual navigation to other perspectives. However, in addition to in
dynamic result renderings, the LASI UI will facilitate exporting static representations of all
results to common presentational, tabular, and serialization-oriented file formats such as Adobe
Acrobat and Microsoft Excel formats and addition to simple non-proprietary formats such as the
CSV (Separated Value) , XML (Extensible Markup Language) , and JSON(JavaScript Object
Notation) file formats. This allows for results to be flexibly retained, viewed, and shared
indecently of the LASI environment itself.
2.1.1 Host Operating System and Software Platform Description
Due to the both the selection of C# and Dr. Hester’s use of Windows enterprise software,
LASI will initially target Microsoft’s .Net framework. However, due to the availability of
reliable C# framework implementations for non-Windows platforms, the slow but steady
transition Microsoft is making towards and supporting open source programs, and the
conservative selection of core language features used in its implementation, LASI will ultimately
be accessible to users of a wide array of software platforms including Windows 7 and 8, various
iterations of Mac OSX, and a multitude of Linux based platforms including RedHat and BSD.
The requirements for the host operating system are fairly standard, consisting of an up-to-
date, 64 bit build of Microsoft Windows 7 Home Premium or above. The software framework
requirements are equally standard consisting of an up-to-date version of the Microsoft .Net
Framework v4.5 or above. Support for non-Microsoft based platforms, such as a RedHat build

pared with the Mono Framework, is a planned feature. Support for the DotGNU UNIX platform
is also a future possibility.
2.1.2 Hardware Platform Description
The physical hardware requirements being targeted, irrespective of the operating
system hosting LASI, are those of a fast but affordable desktop or notebook computer. While
some requirements are more flexible than others, the absolute minimum system
specifications required are that the Processor must have at least four logical cores (via an
dual core Intel core series processor with hyper-threading support enabled, or a quad core
AMD processor), be clocked at a frequency at or above 2.0GHz, and a minimum of eight
gigabytes of DDR3 (Double Data Rate memory type 3) of total system memory clocked at or
above 1,066MHz.
For an optimal experience, or for an open source developer experimenting with the
code post release, the recommended hardware requirements consist of a processor having at
least eight logical cores (via an quad core Intel core series processor with hyper-threading
support enabled or a eight core AMD processor), of eight gigabytes of low latency DDR3
clocked at or above 1,333MHz with timings memory access latencies not greater than 9-9-9,
a solid state based data storage medium for document retrieval having at least 128 megabytes
of onboard DDR3 cache and a rated random read speed of at least 40 megabytes per second
for arbitrary 512 kilobyte data blocks.
2.2.1 External Interfaces and Third Party Components
The LASI project library contains source and executable code files from two
preexisting open source C# projects. First, LASI incorporates executable code files from

b2xtranslator, an open source binary to XML file format converter. Specifically, LASI
contains two of its child programs, the precompiled executable doc2x which converts Legacy
(1997) Microsoft Word DOC files to DOCX open XML files and the precompiled executable
ppt2x which converts Legacy (1997) Microsoft PowerPoint PPT files to PPTX open XML
files, which are included and used under the FreeBSD open source license.
Secondly, and far more significantly, LASI contains the part-of-speech-tagging
library SharpNLP, an open source C# fork of OpenNLP, which are included and used under
the limited GNU open source license. The methods provided by therein provide critical
support to the LASI project as they are utilized to convert from ASCII text files containing
whitespace delimited word-tokens into TAGGED files wherein these tokens are re-serialized
to incorporate the original lexical string annotated with embedded syntactic role information.
The reasons for returning a constructor to an object instead of the object itself in this
case are twofold. First, the pattern of returning a constructor provides beneficial abstraction
between the Word and Phrase types used by the algorithm, only requiring that instantiated
objects derive from the abstract class Word, and secondly, it allows for deferred execution of
object instantiation which can be used with other patterns, such as monadic function
composition, to provide unique and useful behavior not efficiently achieved otherwise.
An additional third party, but not strictly software, asset used by LASI is Princeton
University’s free, manually compiled set of synonym database files. These files are mapped
at runtime to thesaurus constructs which provide various types of synonym lookup. These
thesauri make it possible for LASI to generalize many patterns that would otherwise rely on
random guessing techniques, thereby providing potentially higher levels of results and
allowing for significant performance increases.

(This space intentionally left blank.)

2.2.4 Fundamental Data Abstractions and Document Representation
The core analysis functionalities LASI implements are built around compositions and
permutations of Enumerable collections of redundantly linked data structures which directly
represent words and phrases as instances of corresponding class types. Figure 4 provides a
detailed view of the static composition of the linear and compositional relationships between the
objects which describe a document at runtime. Of particular importance are the multidirectional
many-to-one and one-to-many aggregation relationships as well as the deliberate multi-parent
and multi-child redundancy relationships which allow for independent iteration over the contents
to begin at any construct. This allows for useful data abstractions such as functions which can
return free words or phrases without the need to store, maintain, and return their indirect lexical
contexts.
Figure 3 Illustrates the Reflexive Links between Lexical Elements

2.2.4.1 Word Level Syntactic Class Types
The class taxonomy which defines lexical elements at the word level consists of classes
which represent the text of individual words together with strongly typed syntactic behaviors
corresponding to their part of speech. Instances of word types serve to wrap and represent
lexically distinct words with the encapsulation of their behavioral capabilities. Figures v and w
illustrate the sets of word classes which represent nouns and verbs.
(This space intentionally left blank.)

Figure 4 Class Hierarchy of Verb Types

Figure 5 Additional Word Types
2.2.4.2 Phrase Level Syntactic Class Types
The class taxonomy which defines lexical elements at the phrase level consists of classes
which represent the aggregate of one or more words together with a parallel, but more
generalized concept of syntactic specializations. Many of the core algorithms within the
LASI prototype operate primarily on instances of these types. Figure x illustrates the set of
phrase classes and their inheritance relationships.

Figure 6 Class Hierarchy of Phrase Types
2.2.4.3 Generalizing Syntactic Interface Types
To represent the fluidity of relationships between constructs within the English
language, it becomes necessary to associate objects which have no direct inheritance suitable
relationships. For example, the object of a transitive verb is a role compatible with both
nouns and noun phrases, but it is conceptually, and here programmatically, incorrect to have
noun and noun phrase share compositional inheritance relationships because phrases are
compositions of words and not words themselves, so to cause noun phrase to derive from
noun would introduce a literal and intellectual circular dependency and additionally lead to
inexpressive, awkwardly written functions. To provide the desired syntax role generalization
between words and phrases which have parallel behaviors but not compositions or

derivations, a number of interface types are defined, which allow for elegant coding patterns
and a level of abstraction which more closely matches one’s mental concept of their parallel
relationships.
Figure 7 Hierarchy of Interface Types
2.2 Prototype Functional Description
2.2.1 Binding Algorithms
The two primary binding algorithms within the LASI prototype operate primarily at the
phrasal level. They are a Subject Binder and an Object Binder. Both of them operate at
similar levels of abstraction and primarily serve to associate nouns, noun phrases, and other
explicitly mentioned entities with the verb phrases which specify their relationships and

behaviors. Together, they comprise the core logic of the analysis process by attempting to
determine, broadly speaking, who does what and to whom.
The core logic of the object binder is most transparently modeled and understood through
the lens of finite state automaton logic. The process illustrated by the state diagram
comprising Figure j identifies and associates the subjects of each verb phrase. The subject
information embedded in the links established by the subject binder comprises the most
significant associations made during analysis.
Figure 8 Subject Binder Logic Staet Diagram

Similarly, the core logic of the object binder is most transparently modeled and
understood through the lens of finite state automaton logic. The process illustrated by the
state diagram comprising Figure k identifies and associates the objects of each verb phrase.
The object binder additionally attempts to distinguish between direct objects, indirect objects,
and prepositional objects.
Figure 9 Object Binder Logic State Diagram





























