Embed Size (px)
Citation preview

1 KontingenstabellerKrydstabellerForventede under nulhypotesenKi-kvadrat testResidualanalyseEksakt test
2 Logaritme- og eksponentialfunktion
3 Logistisk regressionSammenligning af odds for 2 grupperKonfidensinterval for effektTest for effektBeregninger i StataMultiple prediktorerEffektmodifikationSammenligning af flere grupperRegression pa intervalvariabelEffektmodifikation af intervalvariabel
PSE (I17) FSV1 Statistik - 4. lektion 1 / 34

Kontingenstabeller Krydstabeller
2 dikotome variableVi skal studere sammenhænge mellem kategoriske variable, hvor vi førstbetragter situationen med dikotome variable.Aktuelt kigger vi pa eksemplet med placebo/vaccine og influenza(ja/nej).
Data er indtastet i Stata, hvor vi forhver kombination af faktorerne(fluog vac) angiver, hvor mange(ant) viobserverer for denne kombination.
PSE (I17) FSV1 Statistik - 4. lektion 2 / 34
Kontingenstabeller Krydstabeller
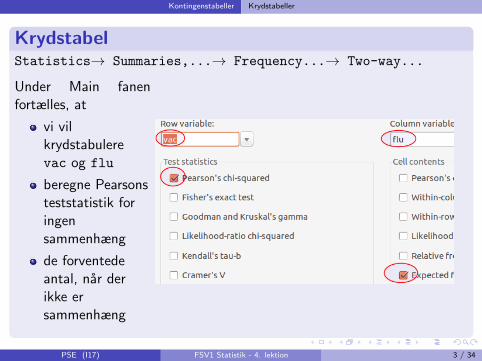
KrydstabelStatistics→ Summaries,...→ Frequency...→ Two-way...
Under Main fanenfortælles, at
vi vilkrydstabulerevac og flu
beregne Pearsonsteststatistik foringensammenhæng
de forventedeantal, nar derikke ersammenhæng
PSE (I17) FSV1 Statistik - 4. lektion 3 / 34
Kontingenstabeller Krydstabeller
Krydstabel
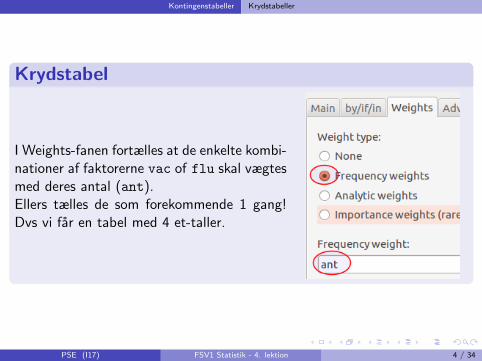
I Weights-fanen fortælles at de enkelte kombi-nationer af faktorerne vac of flu skal vægtesmed deres antal (ant).Ellers tælles de som forekommende 1 gang!Dvs vi far en tabel med 4 et-taller.
PSE (I17) FSV1 Statistik - 4. lektion 4 / 34
Kontingenstabeller Krydstabeller
Krydstabel
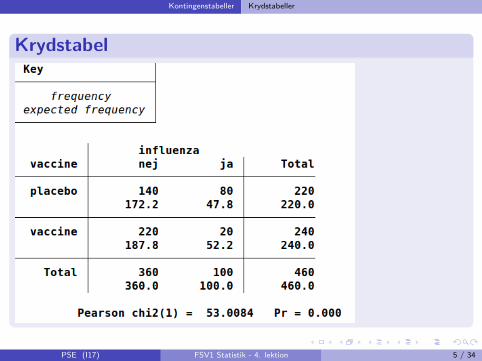
PSE (I17) FSV1 Statistik - 4. lektion 5 / 34
Kontingenstabeller Forventede under nulhypotesen
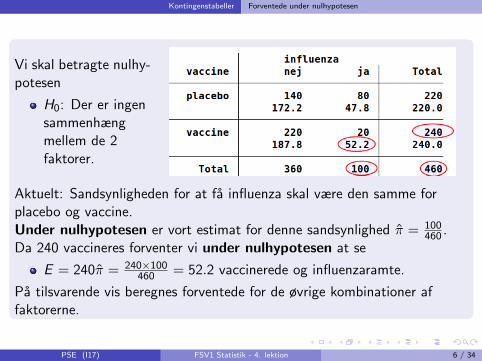
Vi skal betragte nulhy-potesen
H0: Der er ingensammenhængmellem de 2faktorer.
Aktuelt: Sandsynligheden for at fa influenza skal være den samme forplacebo og vaccine.Under nulhypotesen er vort estimat for denne sandsynlighed π = 100
460 .Da 240 vaccineres forventer vi under nulhypotesen at se
E = 240π = 240×100460 = 52.2 vaccinerede og influenzaramte.
Pa tilsvarende vis beregnes forventede for de øvrige kombinationer affaktorerne.
PSE (I17) FSV1 Statistik - 4. lektion 6 / 34

Kontingenstabeller Forventede under nulhypotesen
Forventede under nulhypotesenHvis E angiver det forventede antal i en indgang i tabellen kan detteberegnes via formlen
E =rækkeTotal× søjleTotal
tabelTotal
Vi skal sammenligne dette forventede billede med værdierne O i denobserverede tabel.Dette gøres ved at beregne Ki-kvadrat afstanden mellem de 2 tabeller
X 2 =∑ (O − E )2
E
Aktuelt
(20−52.2)2
52.2 + (80−47.8)2
47.8 + (220−187.8)2
187.8 + (140−172.2)2
172.2 = 53.09
Er denne afstand stor?
PSE (I17) FSV1 Statistik - 4. lektion 7 / 34
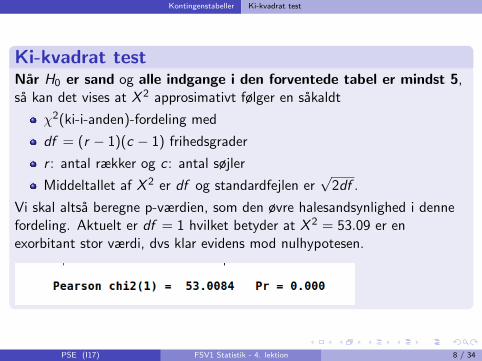
Kontingenstabeller Ki-kvadrat test
Ki-kvadrat testNar H0 er sand og alle indgange i den forventede tabel er mindst 5,sa kan det vises at X 2 approsimativt følger en sakaldt
χ2(ki-i-anden)-fordeling med
df = (r − 1)(c − 1) frihedsgrader
r : antal rækker og c : antal søjler
Middeltallet af X 2 er df og standardfejlen er√
2df .
Vi skal altsa beregne p-værdien, som den øvre halesandsynlighed i dennefordeling. Aktuelt er df = 1 hvilket betyder at X 2 = 53.09 er enexorbitant stor værdi, dvs klar evidens mod nulhypotesen.
PSE (I17) FSV1 Statistik - 4. lektion 8 / 34

Kontingenstabeller Residualanalyse
ResidualerForskellen O − E mellem det observerede og det forventede kaldesresidualet.Nar denne divideres med
√E fas Pearson residualet
pRes =O − E√
E
Hvis nulhypotesen er sand kan vi tænke pa pRes som en z-værdi, dvshovedparten af disse skal ligge mellem ±2.Desværre er disse ikke umiddelbart tilgængelige i Stata. Men de kan opnasved at installere tabchi som beskrevet nedenfor.
PSE (I17) FSV1 Statistik - 4. lektion 9 / 34
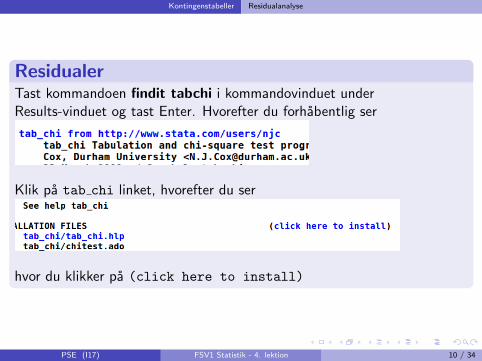
Kontingenstabeller Residualanalyse
ResidualerTast kommandoen findit tabchi i kommandovinduet underResults-vinduet og tast Enter. Hvorefter du forhabentlig ser
Klik pa tab chi linket, hvorefter du ser
hvor du klikker pa (click here to install)
PSE (I17) FSV1 Statistik - 4. lektion 10 / 34

Kontingenstabeller Residualanalyse
Residualer
I kommandovinduet taster dutabchi vac flu [fw=ant] , pefterfulgt af Enter.Det observerede antal med influenza iplacebogruppen ligger 4.7 standardfejlover det forventede. Altsa signifikant formange.
Vi kan konkludere at vaccine har en signifikant positiv effekt.
PSE (I17) FSV1 Statistik - 4. lektion 11 / 34

Kontingenstabeller Eksakt test
Eksakt testHvis ikke alle indgange i den forventede tabel er mindst 5, sa er χ2-testetdubiøst.I dette tilfælde kan man i stedet bruge Fisher’s eksakte test.Dette aktiveres i Stata ved i Main-fanen at vælge Fisher’s exact test
i stedet for Pearson’s chi-squared.
PSE (I17) FSV1 Statistik - 4. lektion 12 / 34

Logaritme- og eksponentialfunktion
EksponentialfunktionenEksponentialfunktionen defineres ud fra tallet
e = 2.7182818
eu betyder e multipliceret med sig selv u gange
Eksempelvis e3 = e × e × e = 20.09.Der gælder at
e(u+v) = eu × ev
Højresiden af lighedstegnet fortæller at vi multiplicerer e med sig selv hhvu og v gange og nar disse multipliceres far vi et produkt, hvor e ermultipliceret med sig selv u + v gange.Eksempelvis
e2 × e3 = (e × e)× (e × e × e) = e5
PSE (I17) FSV1 Statistik - 4. lektion 13 / 34

Logaritme- og eksponentialfunktion
EksponentialfunktionenEksponentialfunktion defineres ogsa for negative potenser via
e−u =1
eu
Eksempelvis e−3 = 1e3 = 1
20.09 = 0.05.
Eksponentialfunktionen kan udvides til ogsa at gælde for ”skæve” potenserved at vedtage at e(u+v) = eu × ev skal gælde for alle tal.Eksempelvis ser vi sa at
e0.5 × e0.5 = e(0.5+0.5) = e
hvorfor der ma gælde at e0.5 =√e = 1.65
Endvidere følger at
e0 = e(1−1) = e × e−1 =e
e= 1
PSE (I17) FSV1 Statistik - 4. lektion 14 / 34

Logaritme- og eksponentialfunktion
LogaritmefunktionFundamentale egenskaber ved eksponentialfunktionen:
eu > 0
e(u+v) = eu × ev
e0 = 1
Hvis x = eu sa kaldes u for logaritmen til x og betegnes log(x). Sa dergælder eksempelvis log(1) = 0.Fundamentale egenskaber ved logaritmefunktionen:
log(x) er kun defineret for x > 0.
log(x × y) = log(x) + log(y)
log(xn) = n × log(x)
log(1) = 0
Eksempelvis log(10n) = n × log(10) = n × 2.3, dvs hver gang vi 10-doblerforøges logaritmen blot med 2.3.Fex log(1000)− log(100) = log(10)− log(1) = 2.3
PSE (I17) FSV1 Statistik - 4. lektion 15 / 34

Logistisk regression Sammenligning af odds for 2 grupper
Sammenligning af odds for 2 grupperVi vender tilbage til eksperimentet, hvor responsen er dikotom(binær), dvsder er 2 mulige udfald.Vi vil kode de 2 mulige udfald med
D: Som kunne betyde syg(desased)
H: Som kunne betyde rask(healthy)
Ud over responsen har vi en dikotom forklarende variabel(fexbehandling/eksponering), som deler populationen i 2 grupper (kaldet 0 og1).Vi er interesseret i at sammenligne sygdomsodds for de 2 delpopulationer
Odds0(D) = π01−π0
, hvor π0 er andelen i gruppe 0, som har status ligmed D.
Odds1(D) = π11−π1
, hvor π1 er andelen i gruppe 1, som har status ligmed D.
PSE (I17) FSV1 Statistik - 4. lektion 16 / 34

Logistisk regression Sammenligning af odds for 2 grupper
Sammenligning af odds for 2 grupperVi skal basere sammenligningen pa odds for gruppe1 relativt til odds fragruppe0, det sakaldte odds ratio
OR1,0(D) =Odds1(D)
Odds0(D)
Hvis eksempelvis OR1,0(D) = 1.5, sa er odds for sygdom 50% større igruppe 1 end i gruppe 0.Ligningen ovenfor kan ogsa skrives
Odds1(D) = Odds0(D)× OR1,0(D)
Hvis gruppe1 svarer til exposure og gruppe0 kaldes baseline, sa kan detudtrykkes som
OddsExposure = OddsBaseline× OR(Exposure)
PSE (I17) FSV1 Statistik - 4. lektion 17 / 34

Logistisk regression Sammenligning af odds for 2 grupper
logOddsVi opnar den mest valide analyse ift konfidensintervaller og hypotesetestved at transformere til log-skala:
log(OddsExposure) = log(OddsBaseline) + log(OR(Exposure))
Vi skal indføre notationen:
β0 = log(OddsBaseline)
β1 = log(OR(Exposure))
Bemærk at
β1 = log(OddsExposure)− log(OddsBaseline)
dvs β1 maler effekten af exposure ift baseline.Hypotesen om ingen effekt undersøges saledes ved at teste H0 : β1 = 0.
PSE (I17) FSV1 Statistik - 4. lektion 18 / 34

Logistisk regression Sammenligning af odds for 2 grupper
Eksempel
Med Savanne som baseline kan vi estimere logOdds for baseline:
β0 = log(281/267) = 0.0511
Effekten pa logOdds ved at flytte til regnskoven estimeres til
β1 = log(541/213)− log(281/267) = 0.881
Er denne effekt signifikant?
PSE (I17) FSV1 Statistik - 4. lektion 19 / 34

Logistisk regression Konfidensinterval for effekt
KonfidensintervalNar vi skal vurdere om β1 er signifikant større end nul, sa har vi brug fordens standardfejl.Vi overlader beregningen til Stata, som rapporterer at
se(β1) = 0.118
Vi kan sa bestemme 95% konfidensintervallet
β1 ± 1.96× se(β1)
som giver grænser 0.650 og 1.112, dvs effekten er tydelig.Effekten pa odds findes via exponentialfunktionen:
Nedre grænse: e0.65 = 1.92, dvs vi forventer at odds forøges medmindst 92%.
Øvre grænse: e1.112 = 3.04, dvs 3-dobling.
PSE (I17) FSV1 Statistik - 4. lektion 20 / 34

Logistisk regression Test for effekt
SignifikanstestVi skal betragte nulhypotesen H0 : β1 = 0.Pa basis af β1 og se(β1) kan vi beregne
z =β1
se(β1)
som approksimativt følger en standard normalfordeling, hvisnulhypotesen er sand.Vi kan sa pa sædvanlig vis beregne den tilhørende p-værdi.
Aktuelt z = 0.8810.118 = 7.5 - langt over 3, sa pVærdi=0.
PSE (I17) FSV1 Statistik - 4. lektion 21 / 34
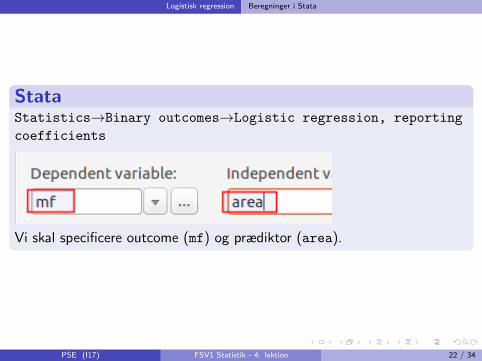
Logistisk regression Beregninger i Stata
StataStatistics→Binary outcomes→Logistic regression, reporting
coefficients
Vi skal specificere outcome (mf) og prædiktor (area).
PSE (I17) FSV1 Statistik - 4. lektion 22 / 34
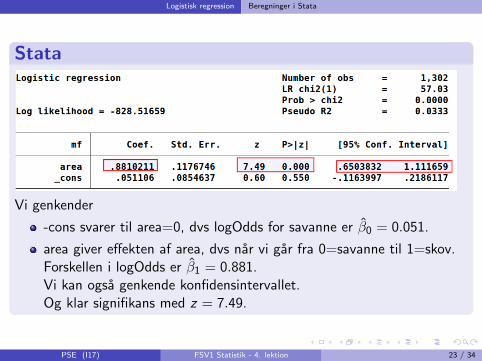
Logistisk regression Beregninger i Stata
Stata
Vi genkender
-cons svarer til area=0, dvs logOdds for savanne er β0 = 0.051.
area giver effekten af area, dvs nar vi gar fra 0=savanne til 1=skov.Forskellen i logOdds er β1 = 0.881.Vi kan ogsa genkende konfidensintervallet.Og klar signifikans med z = 7.49.
PSE (I17) FSV1 Statistik - 4. lektion 23 / 34

Logistisk regression Multiple prediktorer
ModelNar x1 angiver dummykodning af gruppevariablen(eksponering/behandling) kan vi formulere modellen pa denne made
logOdds = β0 + β1x1
som læses
Nar x1 = 0(baseline) er logOdds β0
Nar x1 = 1(exposure) er logOdds β0 + β1
dvs β1 er kontrasten/forskellen i logOdds og maler effekten af eksponering.Pa helt samme made som ved multipel lineær regression kan vi udvidemodellen til at inkludere effekten af flere prediktorer.
logOdds = β0 + β1x1 + β2x2 + β3x3
inkluderer effekt af x1 , x2 og x3.
PSE (I17) FSV1 Statistik - 4. lektion 24 / 34

Logistisk regression Multiple prediktorer
Eksempel
Lad os inkludere køn som prediktor dvs
logOdds = β0 + β1x1 + β2x2
x2 = 0 for mænd og x2 = 1 for kvinder, dvs β2 maler forskellen framænd til kvinder.
I Statas Model-fane:
Independent variables: area sex, dvs hovedvirkning af beggefaktorer.
PSE (I17) FSV1 Statistik - 4. lektion 25 / 34

Logistisk regression Multiple prediktorer
Eksempel
Signifikante effekter af bade sex og area.Vi kan se
Estimeret logOdds for kvinder er β2 = −0.484 lavere end for mænd.
Konfidensintervallet -.717 til -.25 svarer til en faktor melleme−0.717 = 0.49 og e−0.25 = 0.78 pa oddsSkalaen. Vi skønner altsa atodds for kvinderne er mellem 1− 0.78 = 22% og 1− 0.49 = 51%lavere end for mænd.
PSE (I17) FSV1 Statistik - 4. lektion 26 / 34

Logistisk regression Effektmodifikation
EksempelLad os udvide modellen til
logOdds = β0 + β1x1 + β2x2 + β3x1x2
LogOdds for mand pa savannen(x1 = x2 = 0): β0.
LogOdds for mand i skoven(x1 = 1,x2 = 0): β0 + β1.
SkovEffekt for mand: β1.
LogOdds for kvinde pa savannen(x1 = 0,x2 = 1): β0 + β2.
LogOdds for kvinde i skoven(x1 = 1,x2 = 1): β0 + β1 + β2 + β3.
SkovEffektfor kvinde: β1 + β3.
Forskel i skovEffekt for mænd og kvinder: β3.
Parameteren β3 fortæller hvordan skovEffekten modificeres, nar vi skifterkøn fra mand til kvinde.
PSE (I17) FSV1 Statistik - 4. lektion 27 / 34
Logistisk regression Effektmodifikation
Eksempel - StataI Statas Model-fane:
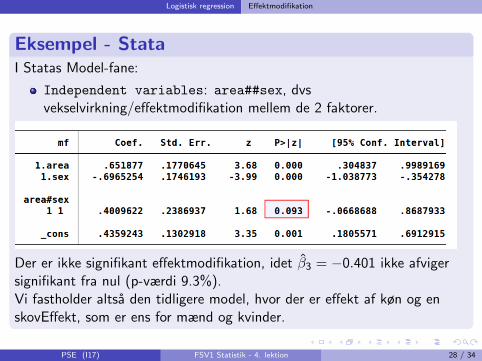
Independent variables: area##sex, dvsvekselvirkning/effektmodifikation mellem de 2 faktorer.
Der er ikke signifikant effektmodifikation, idet β3 = −0.401 ikke afvigersignifikant fra nul (p-værdi 9.3%).Vi fastholder altsa den tidligere model, hvor der er effekt af køn og enskovEffekt, som er ens for mænd og kvinder.
PSE (I17) FSV1 Statistik - 4. lektion 28 / 34

Logistisk regression Sammenligning af flere grupper
EksempelRespondenterne i vores ”flodblindhed” undersøgelse er inddelt ialdersgrupper.
Hvis xi er dummy variabel for aldersgruppe nr i , i = 1, 2, 3 skal vi kigge pamodellen
logOdds = β0 + β1x1 + β2x2 + β3x3
Der gælder altsa at xi = 1 hvis du tilhører aldersgruppe nr i og ellers erxi = 0, hvor i kan være 1, 2, 3.
Vi kan fortolke parametrene:
β1 er kontrast i logOdds mellem aldersgruppe 0 og aldersgruppe 1.
β2 er kontrast i logOdds mellem aldersgruppe 0 og aldersgruppe 2.
β3 er kontrast i logOdds mellem aldersgruppe 0 og aldersgruppe 3.
PSE (I17) FSV1 Statistik - 4. lektion 29 / 34
Logistisk regression Sammenligning af flere grupper
Eksempel
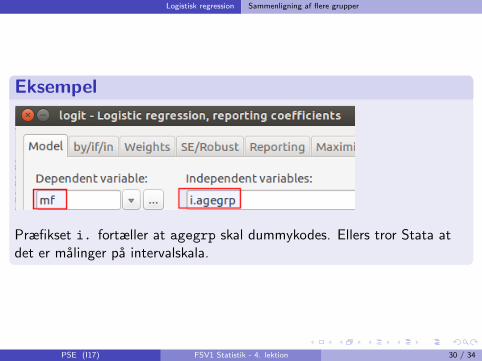
Præfikset i. fortæller at agegrp skal dummykodes. Ellers tror Stata atdet er malinger pa intervalskala.
PSE (I17) FSV1 Statistik - 4. lektion 30 / 34
Logistisk regression Sammenligning af flere grupper
Eksempel
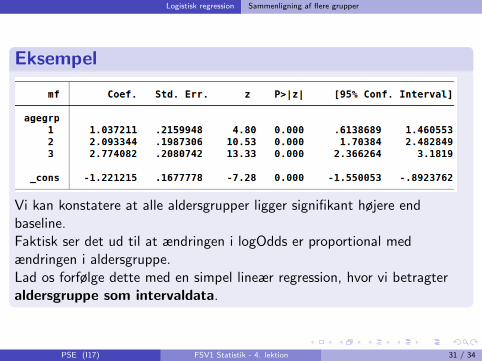
Vi kan konstatere at alle aldersgrupper ligger signifikant højere endbaseline.Faktisk ser det ud til at ændringen i logOdds er proportional medændringen i aldersgruppe.Lad os forfølge dette med en simpel lineær regression, hvor vi betragteraldersgruppe som intervaldata.
PSE (I17) FSV1 Statistik - 4. lektion 31 / 34

Logistisk regression Regression pa intervalvariabel
Eksempel - StataI Statas Model-fane:
Independent variables: agegrp, der nu opfattes som metrisk.
Stigningen i logOdds nar vi gar en aldersgruppe op er signifikant medkonfidensgrænser 0.805 0g 1.055.
Pa odds skala er dette e0.805 = 2.24 og e1.055 = 2.87 .
Stigningen i odds for flodfeber er saledes mellem 124% og 187%, narvi bliver en aldersgruppe ældre.
PSE (I17) FSV1 Statistik - 4. lektion 32 / 34

Logistisk regression Effektmodifikation af intervalvariabel
EffektmodifikationUd over alderseffekten har vi set en effekt af area, som maske kanbortforklares af alderseffekten, hvis alderssammensætningen erforskellig pa savanne og skov.Hvis skovbefolkningen generelt er ældre, sa vil de have en højeresygelighed.
Lad os kigge pa en model med effekt af begge variable.
Hvis begge variable har effekt er det ogsa interessant at undersøge omaldereffekten er forskellig pa savanne og skov.
I Statas Model-fane:
Independent variables: area##c.agegrp, hvor nu præfix c.
fortæller at variablen er metrisk.
PSE (I17) FSV1 Statistik - 4. lektion 33 / 34

Logistisk regression Effektmodifikation af intervalvariabel
Effektmodifikation
LogOdds for aldersgruppe 0 pa savannen er -1.443.
Pa savannen vokser LogOdds med 0.799, nar aldersgrp gar 1 op.
Skoveffekten i aldersgruppe 0 estimeres til 0.480. Denne er ikkesignifikant.
LogOdds for forskel pa alderseffekten pa skov og savanne er 0.343,hvilket er signifikant.
Konklusion: Skov og savanne har samme odds i aldersgruppe 0. Tilgengæld vokser LogOdds signifikant hurtigere med alderen iskoven(0.799+0.343=1.142) end pa savannen(0.799).
PSE (I17) FSV1 Statistik - 4. lektion 34 / 34














![CONTRIBUTIONS TO DIRECTED ALGEBRAIC …people.math.aau.dk/~raussen/TALKS/diss.pdfrected Algebraic Topology. It is based on seventeen of the author’s published research papers ( [1]](https://img.pdfslide.net/doc/110x75/5fb32665430f821d5c10d81a/contributions-to-directed-algebraic-raussentalksdisspdf-rected-algebraic-topology.jpg)

![Sheet No. I17 COMPREHENSIVE DETAILED AREA PLAN ...ADMINISTRATIVE INDEX SHEET INDEX I17 Grid Values! are! Shown in Meter Detailed Area Plan for DMDP Area [Group-A] Sheet No. COMPREHENSIVE](https://img.pdfslide.net/doc/110x75/5f59fe516f1ec571d10b8375/sheet-no-i17-comprehensive-detailed-area-plan-administrative-index-sheet-index.jpg)












