Embed Size (px)
Citation preview

1
Multimodal Input Analysis
Making Computers More Humane
Shubha Tandon Youlan Hu
TJ Thinakaran

2
Roadmap
Basis for Multimodal interfaces and media. Differences between Multimodal and
conventional interfaces. Multimedia input analysis Cognitive basis to Multimodal Interfaces Architectures for information processing

3
Multimodal Fundamentals

4
What is a Multimodal System?
Multimodal systems process two or more combined user input modes – such as speech, pen, touch, manual gestures, gaze, and head and body movements – in a coordinated manner with multimedia system output.
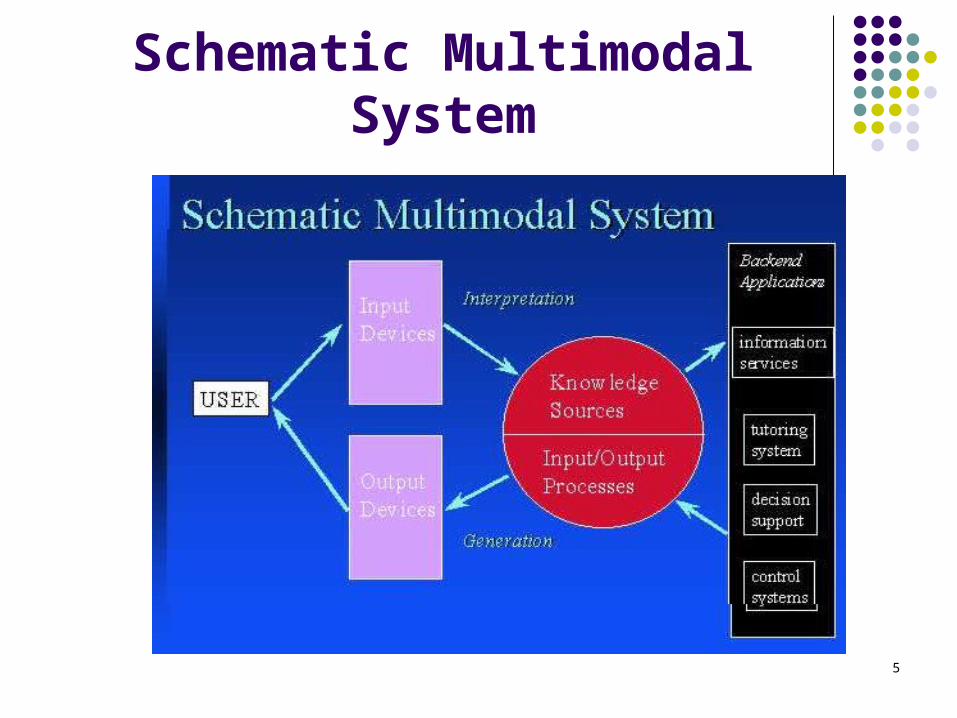
5
Schematic Multimodal System

6
Multimodal Systems – Why?
Provide transparent, flexible, and powerfully expressive means of HCI.
Easier to learn and use. Robustness and Stability. If used as front-ends to sophisticated application
systems, conducting HCI in modes all users are familiar with, then the cost of training users would be reduced.
Potentially user, task and environment adaptive.

7
Multimodal Interface TerminologyMultimodal interfaces process two or more combined user input modes— such as
speech, pen, touch, manual gestures, gaze, and head and body movements— in a coordinated manner with multimedia system output. They are a new class of interfaces that aim to recognize naturally occurring forms of human language and behavior, and which incorporate one or more recognition-based technologies (e.g., speech, pen, vision).
Active input modes are ones that are deployed by the user intentionally as an explicit command to a computer system (e.g., speech).
Passive input modes refer to naturally occurring user behavior or actions that are recognized by a computer (e.g., facial expressions, manual gestures). They involve user input that is unobtrusively and passively monitored, without requiring any explicit command to a computer.
Blended multimodal interfaces are ones that incorporate system recognition of at least one passive and one active input mode. (e.g., speech and lip movement systems).
Temporally-cascaded multimodal interfaces are ones that process two or more user modalities that tend to be sequenced in a particular temporal order (e.g., gaze, gesture, speech), such that partial information supplied by recognition of an earlier mode (e.g., gaze) is available to constrain interpretation of a later mode (e.g., speech). Such interfaces may combine only active input modes, only passive ones, or they may be blended.

8
Multimodal Interface TerminologyMutual disambiguation involves disambiguation of signal or semantic-level
information in one error-prone input mode from partial information supplied by another. Mutual disambiguation can occur in a multimodal architecture with two or more semantically rich recognition-based input modes. It leads to recovery from unimodal recognition errors within a multimodal architecture, with the net effect of suppressing errors experienced by the user.
Visemes refers to the detailed classification of visible lip movements that correspond with consonants and vowels during articulated speech. A viseme-phoneme mapping refers to the correspondence between visible lip movements and audible phonemes during continuous speech.
Feature-level fusion is a method for fusing low-level feature information from parallel input signals within a multimodal architecture, which has been applied to processing closely synchronized input such as speech and lip movements.
Semantic-level fusion is a method for integrating semantic information derived from parallel input modes in a multimodal architecture, which has been used for processing speech and gesture input.

9
Multimodal Interface Terminology
Frame-based integration is a pattern matching technique for merging attribute-value data structures to fuse semantic information derived from two input modes into a common meaning representation during multimodal language processing.
Unification-based integration is a logic-based method for integrating partial meaning fragments derived from two input modes into a common meaning representation during multimodal language processing. Compared with frame-based integration, unification derives from logic programming, and has been more precisely analyzed and widely adopted within computational linguistics.

10
Trends…
Hardware, software and integration technology advances have fueled research in this area.
Research Trends: Earliest systems: supported speech input along with keyboard or
mouse GUI interfaces. In ’80s and ’90s systems were developed to use spoken input as an
alternative to text via keyboard. E.g.: CUBRICON, XTRA, Galaxy, Shoptalk and others.
Most recent system designs are based on two parallel input steams both capable of conveying rich semantic information.
The most advanced systems have been produced using speech and pen input, and speech and lip movement.
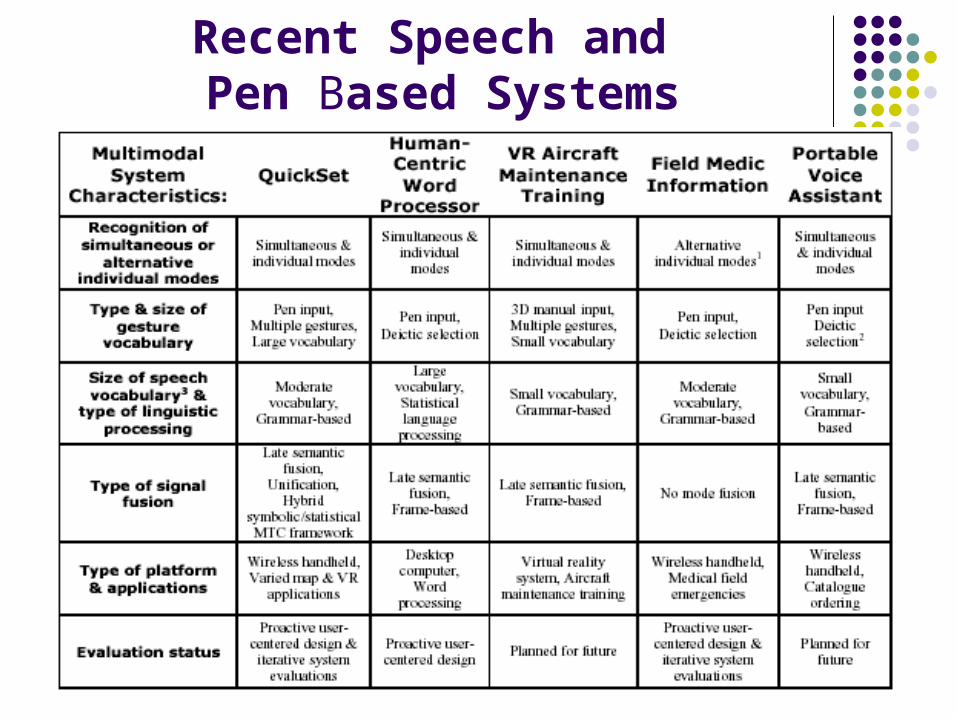
11
Recent Speech and Pen Based Systems

12
Other Systems and Future Directions
Speech and Lip movement systems used to build animated characters used as interface design vehicles.
Use of vision based technologies, such as interpretation of gaze, facial expressions etc – passive vs. active modes.
Blended multimodal interfaces with temporal cascading
New pervasive and mobile interfaces, capable of adapting processing to user and environmental context.

13
Advantages and Goals Choice of modality to user for conveying different types
of information, use of combined modes, alternate between modes as required.
Potential to accommodate broader range of users different users like to use different modes to interact.
Prevents overuse and physical damage to any single modality.
Ability to accommodate continuously changing conditions for mobile use.
Efficiency gains especially noticeable in certain domains.
Superior error handling.

14
Error Handling- Reasons for Improved Performance
User centered reasons:• Users intuitively select input mode less error
prone in lexical context.• User language is simpler when interacting
multimodally – reduced complexity.• Users have a tendency to switch modes after
system error recognition – good error recovery. System Centered reasons:
• Multimodal architecture support mutual disambiguation.

15
Differences Between Multimodal Interfaces and GUIs
GUIs1. Assume that there is a single
event stream that controls event loop with processing being sequential.
2. Assume interface actions (e.g. selection of items) are atomic and unambiguous.
3. Built to be separable from application software and reside centrally on one machine.
4. Do not require temporal constraints. Architecture not time sensitive.
Multimodal Interface1. Typically process continuous and
simultaneous input from parallel incoming streams.
2. Process input modes using recognition based technology, good at handling uncertainty.
3. These have large computational and memory requirements and are typically distributed over the network.
4. Require time stamping of input and development of temporal constraints on mode fusion operations.

16
Put-That-There

17
Put-That-There One of the earliest multimodal concept
demonstration using speech and pointing.
Created by Architecture Machine Group at MIT.
Quote from Richard Bolt: “Even after 17 years, looking at the video of the demo, you
sense something special when Chris, seated before our media room screen, raises his hand, points, and says “ Put that (pointing to a blue triangle)…there (pointing to a spot above and to the left),” and lo, the triangle moves to where he told it to. I have yet to see an interface demo that makes its point as cleanly and succinctly as did that very first version of Put-That-There.”

18
Media Room
Size of personal office Walls (not in picture) have
loudspeakers on either side of the wall sized, frosted glass projection screen.
TV monitors on either side of user’s chair.
User Chair – arms have one-inch high joystick sensitive to pressure and direction.
Near each joystick, a square shaped touch sensitive pad.

19
Features of Media Room Two spatial orders: virtual graphical space and
user’s immediate real space. Key Technologies used:
DP -100 Connected Speech recognition System (CSRS) by NEC America, Inc. – capable of limited amount of connected speech recognition.
ROPAMS: Remote Object Position Attitude Measurement System) for space position and orientation sensing – to track where the user is pointing.
Basic Items system recognizes: circles, squares, diamonds etc.
Variable attributes: color and sizes.

20
Commands
“Create”: “Create a blue square there.” Effect of complete utterance is a
“call” to the create routine which needs object to be created (with attributes) as well as x, y pointing input from wrist-borne space sensor.
“Move”: “Move the blue triangle to the right
of the green square” Pronomialized version:
“ Move that there” (User does not even have know what
“that” is.) Note: Pronomialization:
• Makes utterances shorter• No need for reference objects
(Graphic taken from [1])

21
Some more commands
“Make that …”: “Make that blue triangle smaller”“Make that smaller”
“Make that like that” – Internally object indicated by second that is the model, the first object is deleted and replaced by a copy of the second.
“Delete”: “Delete that green circle” “Delete that”

22
Commands…
Command: “Call that …the calendar”
Processing steps involved: On hearing Call that recognizer sends code to host system
indicating a naming command. The x, y coordinates of item signal are noted by host.
Host system directs speech recognition unit to switch from recognition mode to training mode to learn the (possibly new) name to be given to the object.
After completion of naming, recognizer is directed to go back to recognition mode.
Improvement : If recognizer could itself switch from recognition to training mode and back (without direction from the host system)

23
Possible Uses
Moving ships about in a harbor map in planning the harbor facility.
Moving battalion formations
Facilities planning moving rooms and hallways about.

24
CUBRICON

25
CUBRICON
System integrating deictic and graphic gestures with simultaneous NL for both user input and system output.
Unique Interface capabilities: Accept and understand multimedia input – references to
entities in NL can include pointing. Also disambiguate unclear references and infer intended referent.
Dynamically compose and generate multimodal language – synchronously present spoken NL, gestures and graphical expressions in output. Also distinguish between spoken and written NL

26
CUBRICON Dialogue example
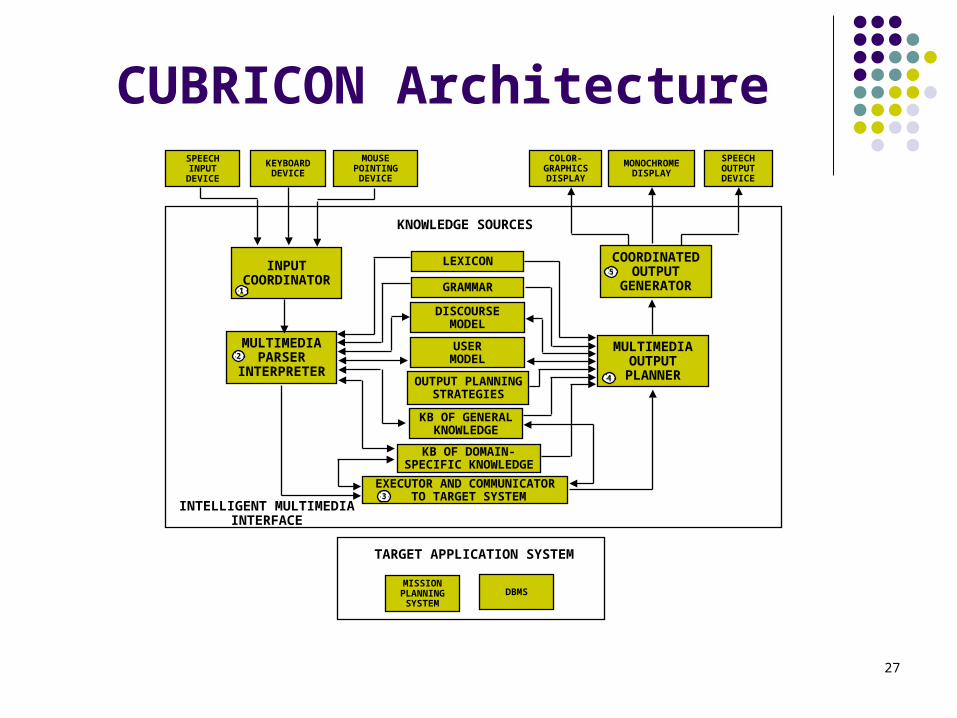
27
CUBRICON ArchitectureSPEECH
INPUTDEVICE
KEYBOARDDEVICE
MOUSEPOINTINGDEVICE
COLOR-GRAPHICSDISPLAY
MONOCHROMEDISPLAY
SPEECHOUTPUTDEVICE
LEXICON
DISCOURSEMODEL
OUTPUT PLANNINGSTRATEGIES
KB OF GENERALKNOWLEDGE
EXECUTOR AND COMMUNICATOR TO TARGET SYSTEM
GRAMMAR
USERMODEL
KB OF DOMAIN-SPECIFIC KNOWLEDGE
TARGET APPLICATION SYSTEM
MISSIONPLANNINGSYSTEM
DBMS
INPUTCOORDINATOR
MULTIMEDIAPARSER
INTERPRETER
COORDINATEDOUTPUT
GENERATOR
MULTIMEDIAOUTPUT
PLANNER
KNOWLEDGE SOURCES
INTELLIGENT MULTIMEDIAINTERFACE
1
2
3
4
5
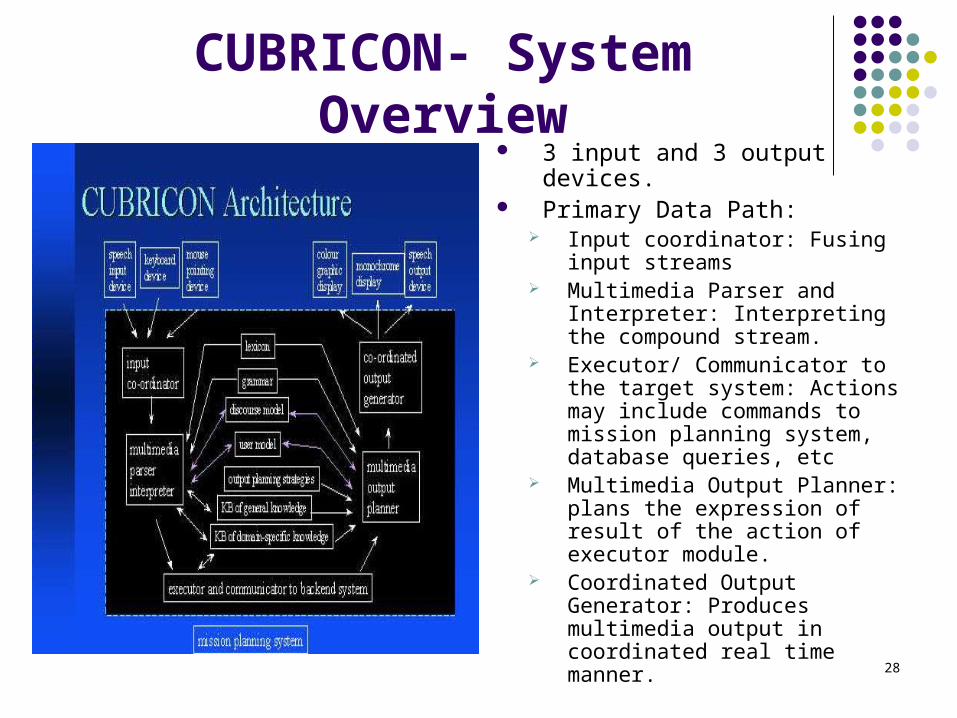
28
CUBRICON- System Overview 3 input and 3 output devices. Primary Data Path:
Input coordinator: Fusing input streams
Multimedia Parser and Interpreter: Interpreting the compound stream.
Executor/ Communicator to the target system: Actions may include commands to mission planning system, database queries, etc
Multimedia Output Planner: plans the expression of result of the action of executor module.
Coordinated Output Generator: Produces multimedia output in coordinated real time manner.

29
CUBRICON Knowledge Sources
Used for understanding input and generating output.
Knowledge Source: Lexicon Grammar: defines multimodal language. Discourse Model: Representation of “attention
focus space” of dialogue. Has a “focus list” and “display model” – tries to retain knowledge pertinent to the dialogue.

30
CUBRICON Knowledge Sources
User Model: Has dynamic “Entity Rating Module” to evaluate relative importance of entities to user dialogue and task – tailors output and responses to user’s plans, goals and ideas.
Knowledge Base: Information about task domain (Air Force mission planning). Concepts like, SAMs, radars, air bases, missions.

31
Multimodal Language – Features in CUBRICON
Multimodal Language: Spoken or written NL and gestures.
Variety in objects that can be pointed to: windows, form slots, table entries, icons, points.
Variety in number of point gestures allowed per phrase.
Variety in number of multimodal phrases allowed per sentence.

32
Examples of referent determination
Example 1: User: “What is the mobility of these <point>, <point>, <point> ?
(Use of more than one point gesture in a phrase). System uses “mobility” to select from candidate
referents of the point gesture (if gestures are ambiguous) – users the display model and knowledge base.
Note: Takes care of pointing ambiguities. Also, takes care of pointing inconsistent with NL by
using information from the sentence as filtering criteria for candidate objects.

33
Examples of Referent Determination
Example 2: User: “Enter this <point-map-icon> here <point-form-slot>.” Uses more than one phrase per sentence. Uses more than one CRTs.
Two feature used to process this: Display model containing semantic information about
all CRTs. All objects and concepts represented in single
knowledge representation language (SNePS knowledge base) – shared by all modules.

34
Multimodal Language Generation
In output NL and gestures are integrated to provide unified multimodal language.
To compose reference for an object: If object is an icon on display: points to icons and
simultaneously generates NL expression. If object is a part of an icon on display, points to
the “parent” icon and generates NL describing the relation of the reference to the “parent” icon.

35
Multimodal Language Generation
Situation: If system wants to point to object which is represented in more than one windows on CRT:
Selects all relevant windows Filters out non- active or non-exposed windows. If some exposed windows contain object, uses weak
gestures (highlighting) for all and select most important window and gestures strongly towards it (blink the icon plus text box)
If no exposed windows, then systems determines most important de-exposed window, exposes it and points to it.

36
When is Graphical Representation Generated?
If information being represented is: Locative Information Path traversal information.
Example (Locative Information): User: “Where is the Fritz Steel Plant?”
CUBRICON: “The Fritz Steel plant (figure object) is located
here <point-highlighting/blinking icon>, 45 miles southwest of Dresden (ground object)<graphical expression – arrow between two icons>.

37
Multimedia Input Analysis

38
Multimedia Analysis
The processing and integration of multiple input modes for the communication between a user and the computer.
Examples: Speech and pointing gestures(Put-That-There,
CUBRICON, XTRA) Eye Movement based Interaction(Jacob, 1990) Speech, gaze and hand gestures (ICONIC) Speech and Lip Movement

39
Eye Movement-Based Interaction
Highly Interactive, Non-WIMP, Non-Command
Benefits Extremely rapid Natural, little conscious effort Implicitly indicate focus of attention WYLAIWYG

40
Issues of Using Eye Movement in HCI
Midas Touch Eyes continually dart from point to point, not like
relatively slow and deliberate operation of manual input devices
People not accustomed to operating devices simply by moving their eyes; if poorly done, could be very annoying
Need to extract useful dialogue information (fixation, intention) from noisy eye data
Need to design and study new interaction techniques
Costs of eye tracking(equipments)

41
Measuring Eye Movement
Electronic Skin electrodes around eye
Mechanical Non-slipping contact lens
Optical/Video - Single Point Track some visible feature on eyeball; head stationary
Optical/Video - Two Point Can distinguish between head and eye movements
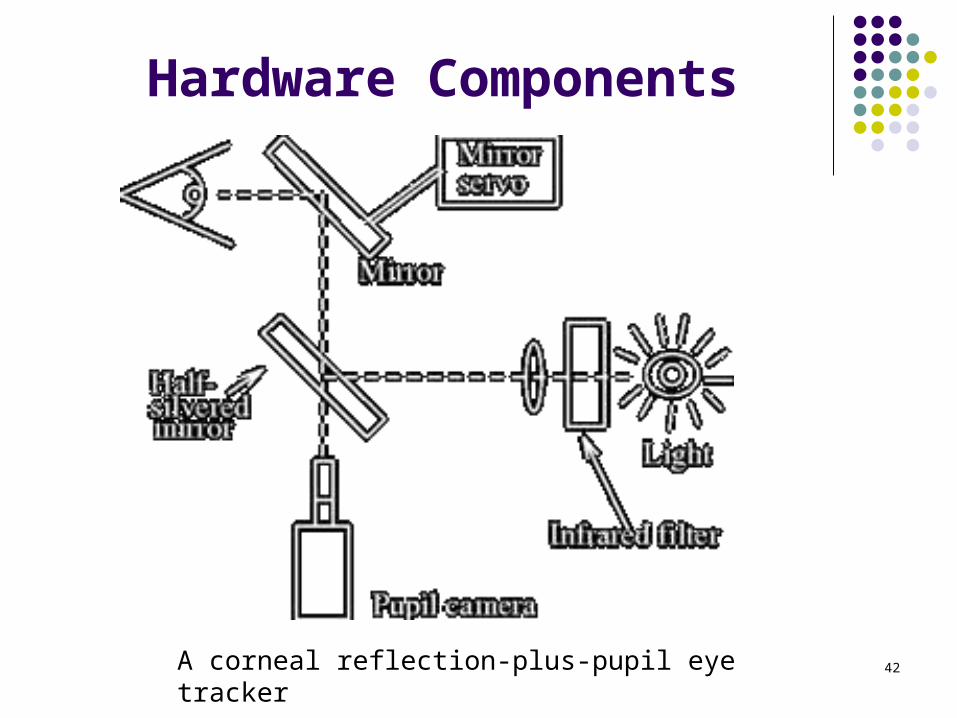
42
Hardware Components
A corneal reflection-plus-pupil eye tracker

43
Types of Eye Movements
Saccade Rapid, ballistic, vision suppressed Interspersed with fixations
Fixation (200-600ms) Steady, but some jitter
Other movements Eyes always moving; stabilized image
disappears

44
Approach to Using EM
Philosophy Use natural eye movements as additional user
input trained movements as explicit commands
Technical approach Process noisy, jittery eye tracker data stream
to filter, recognize fixations, and turn into discrete dialogue tokens that represent user's higher-level intentions
Then, develop generic interaction techniques based on the tokens
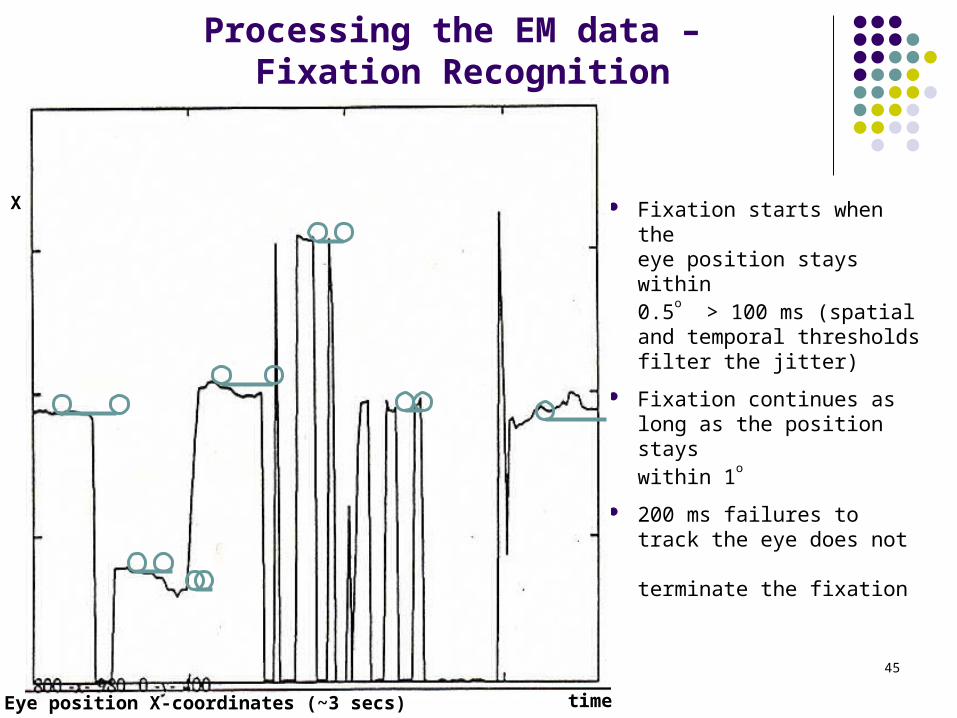
45
Processing the EM data – Fixation Recognition
Fixation starts when theeye position stays within 0.5
o > 100 ms (spatial
and temporal thresholds filter the jitter)
Fixation continues as long as the position stays
within 1o
200 ms failures totrack the eye does not terminate the fixation
Eye position X-coordinates (~3 secs) time
X

46
Processing the EM Data – Input Tokens The fixations are then turned into input tokens
start of fixation continuation of fixation (every 50 ms) end of fixation failure to locate eye position entering monitored regions
The tokens formulate eye events are multiplexed into the event queue stream with other
input events The eye events also carry information of the
fixated screen object

47
Eye as an Input Mode
Faster than manual devices Implicitly indicates focus of attention, not just
a pointing device Less conscious/precise control Eye moves constantly, even when user thinks
he/she is staring at a single object Eye motion is necessary for perception of
stationary objects Eye tracker is always "on" No analogue of mouse buttons Less accurate/reliable than mouse
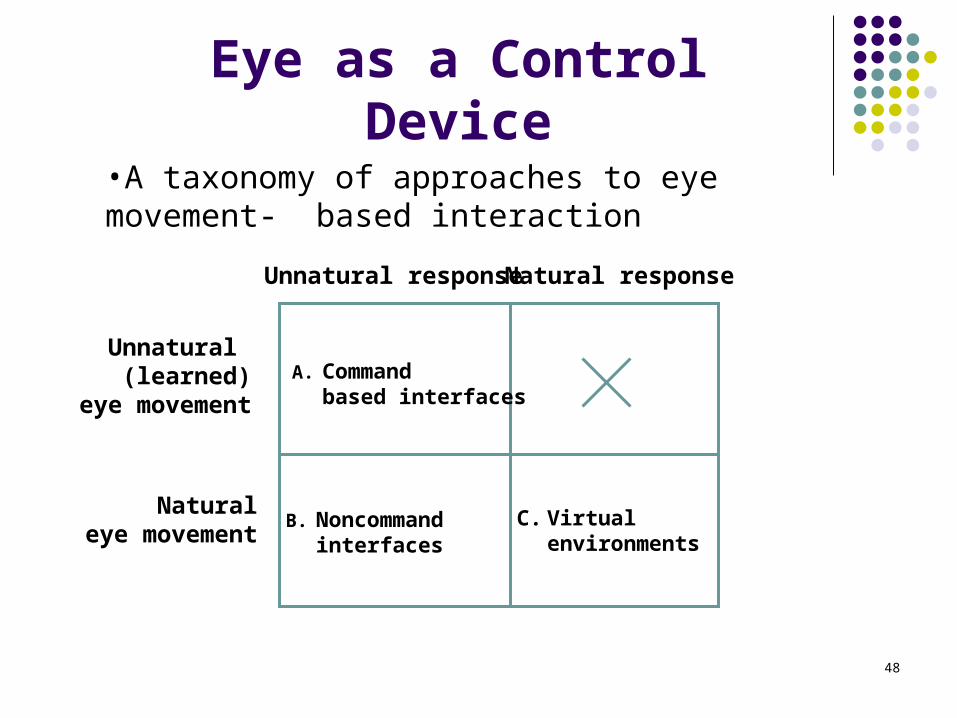
48
Eye as a Control Device
Unnatural response Natural response
Unnatural (learned)
eye movement
Naturaleye movement
A. Commandbased interfaces
B. Noncommandinterfaces
C. Virtual environments
•A taxonomy of approaches to eye movement- based interaction

49
• After user is looking at the desired object, press button to indicate choice
• Alternative = dwell time: if look at object for sufficiently long time, it is selected without further commands
• Poor alternative = blink.
Object Selection•Select object from among several on screen
•Found: 150-250 ms of dwell time feels instantaneous, but provides enough time to accumulate data for accurate fixation recognition •Found:Gaze selection is faster than mouse selection

50
Moving an Object Two methods, both use eye position to
select which object to be moved Hold button down, “drag” object by moving
eyes, release button to stop dragging Eyes select object, but moving is done by
holding button, dragging with mouse, then releasing button
Found: Surprisingly, first works better Use filtered “fixation” tokens, not raw eye
position, for dragging

51
Pull down menus using dwell time did not work out very well, the time was
either too long or too prone to errors gaze+hardware button worked better
Eye Controlled Menus and Windows04/19/23
Here we have a textwindow. Usually we have to grab the mouseand click in the scroll-bar when we want to read the text on the nextpage, now just look at the arrows
• Listener window control
04/19/23
Scrolling text in a window Indicator appears above or below text If user looks at indicator, text itself
starts to scroll. But it never scrolls while user is looking at text.
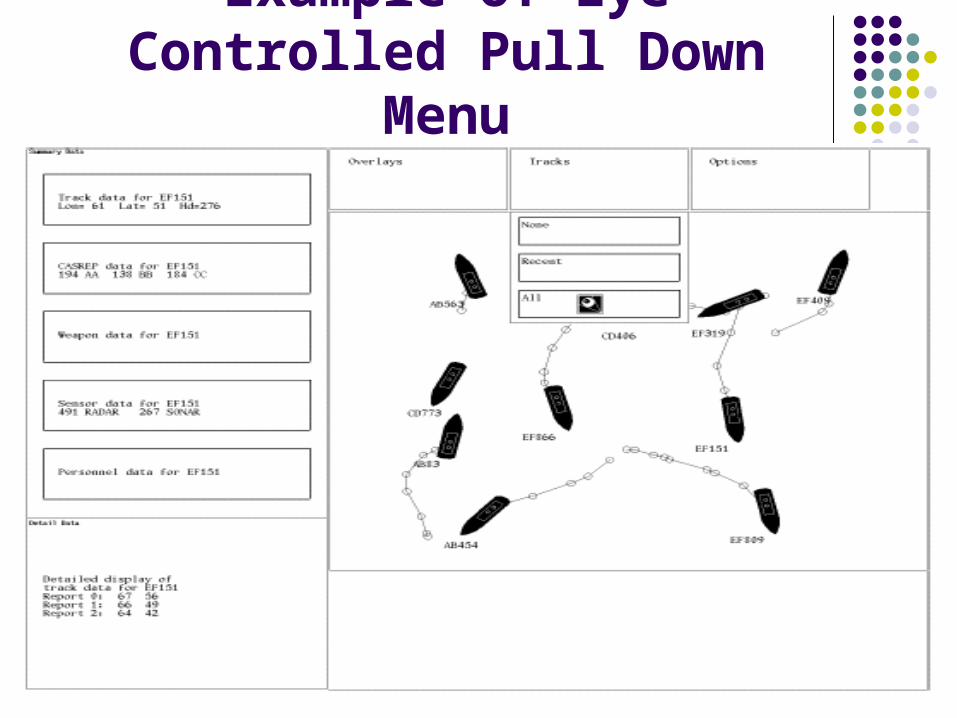
52
Example of Eye Controlled Pull Down Menu

53
Gesture, Speech, and Gaze Integrated Systems

54
Three Modes Multimodal System
Integrating simultaneous speech, gestures, and gaze [Koons et al. 1993]
Purpose reference resolution for map and blocks world
interaction Goal:
Create a multimodal system, which will not require the user to learn new commands.
Intuitive operation (flexibility). Use eye movement in a non-intrusive manner
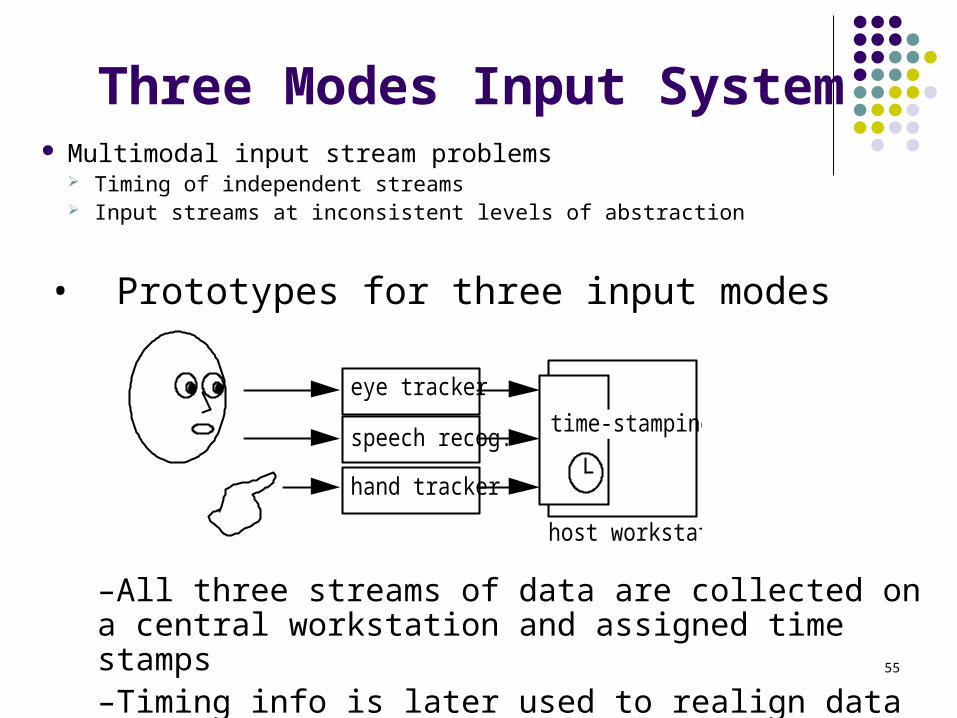
55
Three Modes Input System Multimodal input stream problems
Timing of independent streams Input streams at inconsistent levels of abstraction
eye tracker
speech recog.
hand tracker
host workstation
time-stamping
• Prototypes for three input modes
–All three streams of data are collected on a central workstation and assigned time stamps–Timing info is later used to realign data from different sources

56
Gesture Classification
Symbolic Gestures Can translated to verbal meaning
deictic gestures Actions of the showing on an object or a region
Iconic gestures Describe the object shape, spatial relations, and
actions by hands. Pantomimic gestures
Action of mimicking the interaction with an invisible object with hands
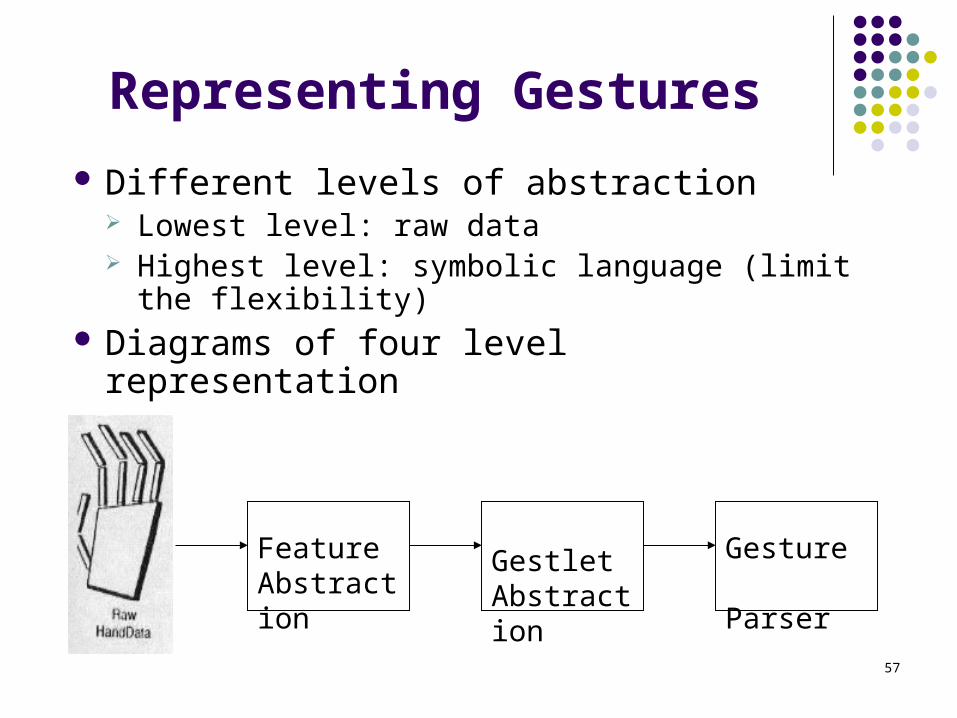
57
Representing Gestures
Different levels of abstraction Lowest level: raw data Highest level: symbolic language (limit the
flexibility) Diagrams of four level representation
Feature Abstraction
GestletAbstraction
Gesture Parser
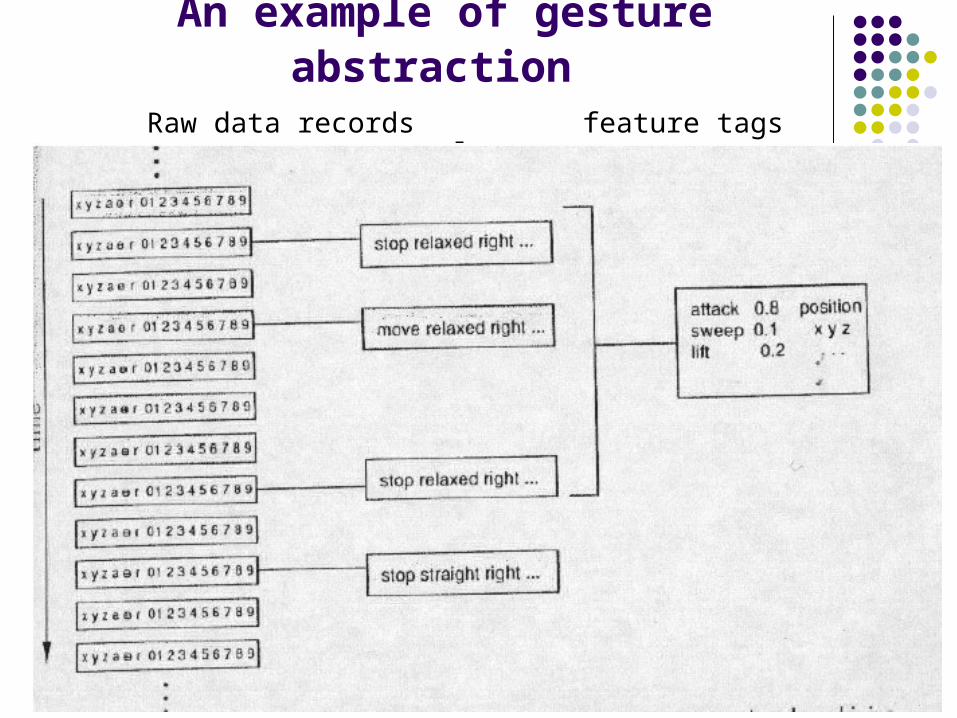
58
An example of gesture abstraction Raw data records feature tags gestlets

59
Processing Input Stream
Step 1 - Parsing Parse input data stream Generate frame-based description of the data
Step 2 - Evaluation Encode and evaluate the frames based on two
interpretation model Combine all the expressions to evaluate the
user’s utterance

60
Interpretation Model
Two interconnected representational system Encode categorical information Encode spatial information
A knowledge base spans the two representational systems. Map objects are represented as Nodes in a semantic network within categorical system Models in the spatial system
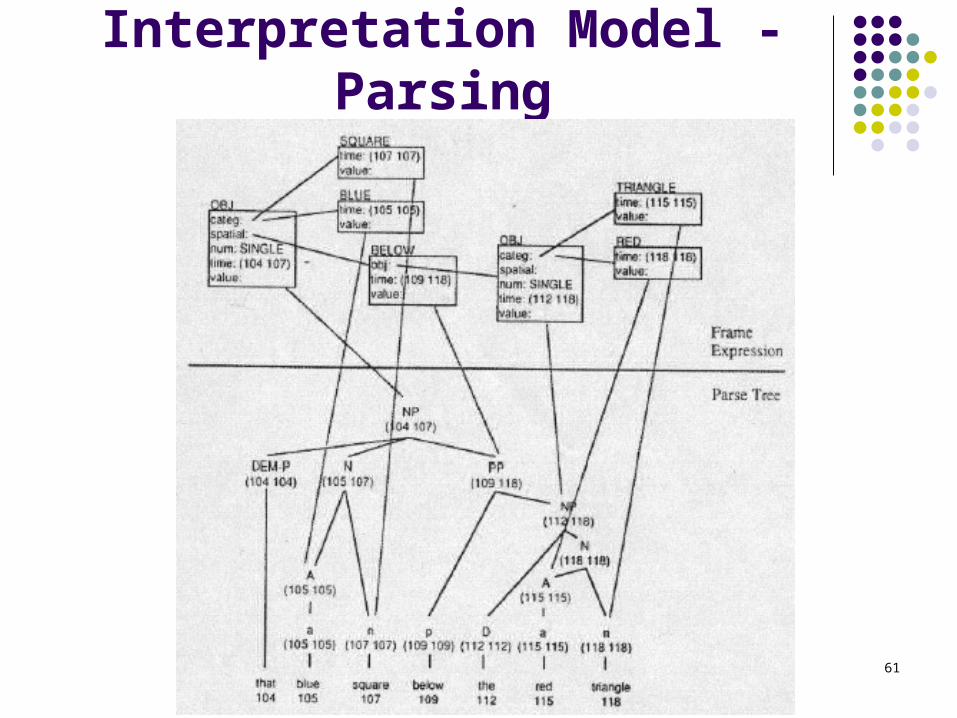
61
Interpretation Model - Parsing
62
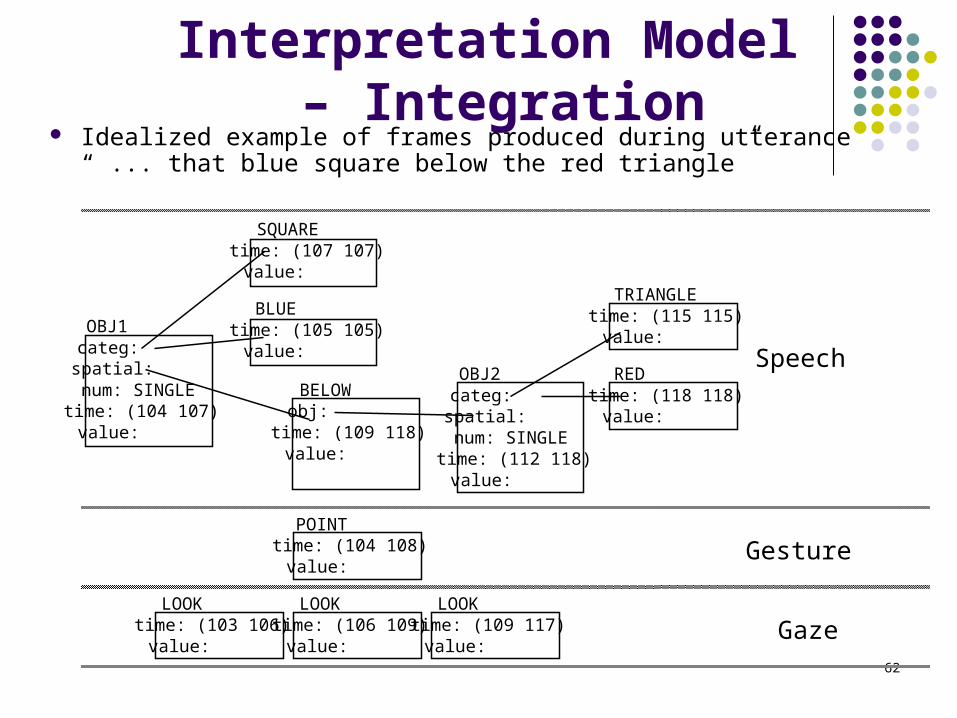
Interpretation Model – Integration
Idealized example of frames produced during utterance “ ... that blue square below the red triangle”
OBJ1categ:spatial:num: SINGLEtime: (104 107)value:
SQUAREtime: (107 107)value:
BLUEtime: (105 105)value:
BELOWobj:time: (109 118)value:
OBJ2categ:spatial:num: SINGLEtime: (112 118)value:
REDtime: (118 118)value:
TRIANGLEtime: (115 115)value:
POINTtime: (104 108)value:
LOOKtime: (106 109)value:
LOOKtime: (103 106)value:
LOOKtime: (109 117)value:
Speech
Gesture
Gaze
63
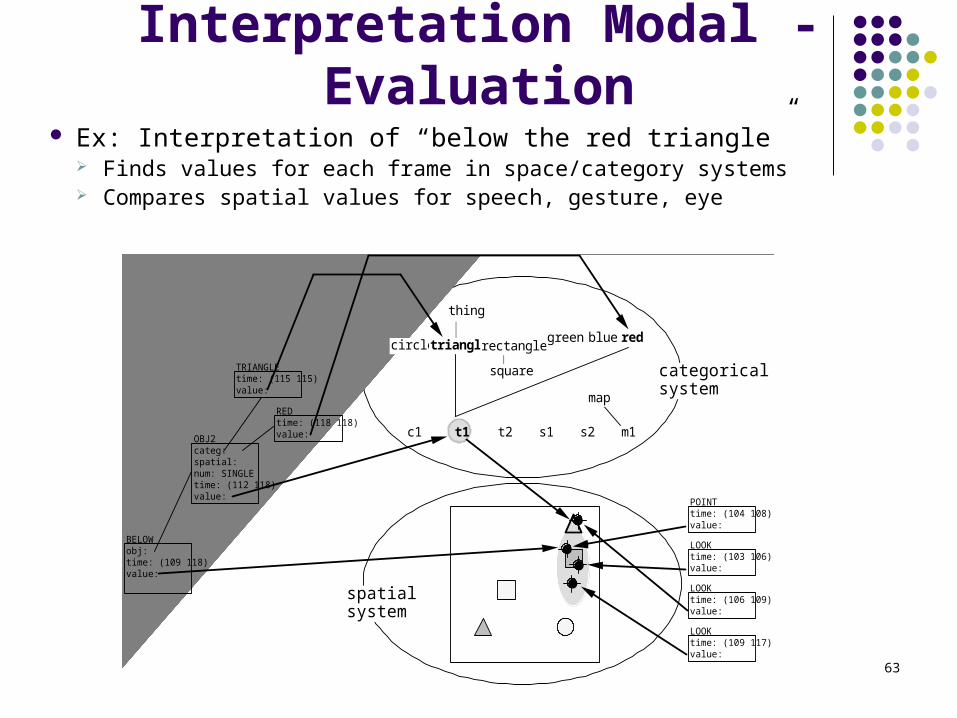
Interpretation Modal - Evaluation
Ex: Interpretation of “below the red triangle” Finds values for each frame in space/category systems Compares spatial values for speech, gesture, eye
c1 t1 t2 s1 s2 m1
BELOWobj:time: (109 118)value:
REDtime: (118 118)value:
TRIANGLEtime: (115 115)value:
categoricalsystem
spatialsystem
OBJ2categ:spatial:num: SINGLEtime: (112 118)value:
thing
circle triangle
square
rectanglegreen blue red
map
POINTtime: (104 108)value:
LOOKtime: (106 109)value:
LOOKtime: (103 106)value:
LOOKtime: (109 117)value:
64
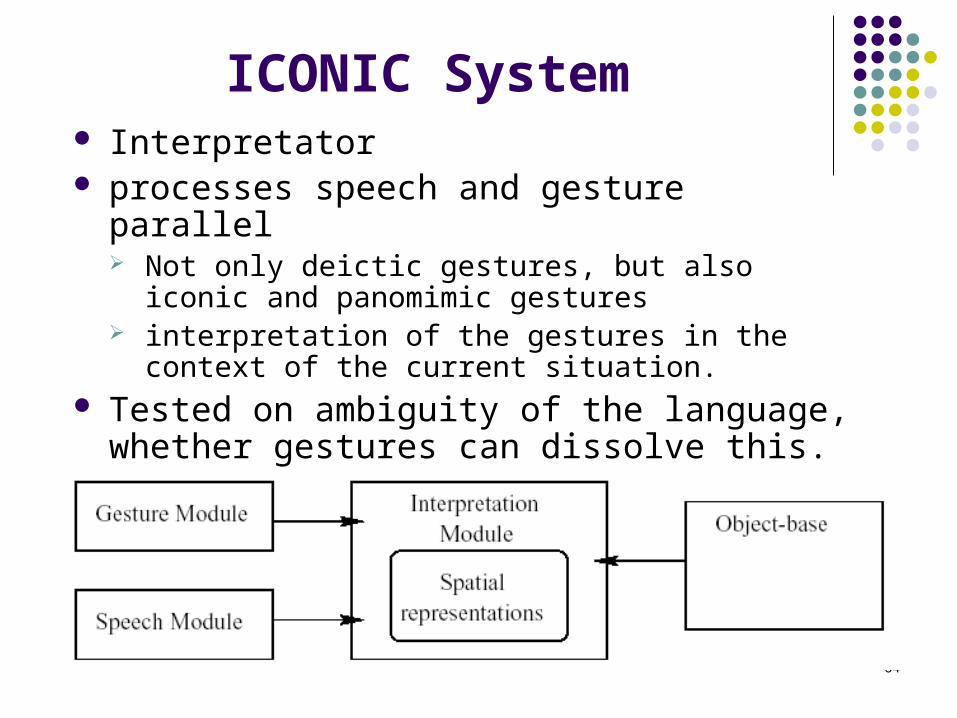
ICONIC System Interpretator processes speech and gesture parallel
Not only deictic gestures, but also iconic and panomimic gestures
interpretation of the gestures in the context of the current situation.
Tested on ambiguity of the language, whether gestures can dissolve this.

65
ICONIC – A typical Interaction
Interpreter determines the semantic content of a gesture in the context of the world and the accompanying speech
Example : “place that cylinder next to the red cube”

66
Summary of Current Methods Used in Multimodal Systems
Cognitive science literature Intersensory perception Intermodel coordination
High-fidelity automatic simulations Prototyping multimodel systems Test tool

67
Cognitive Basis for Multimodal Interfaces

68
Agenda
Cognitive Science
The myths of multi-modal interaction
Multimodal language

69
Cognitive Science noun
“The study of the nature of various mental tasks and the processes that enable them to be performed.”
The American Heritage Dictionary of the English Language, Third Edition

70
Multimodal systems depend on natural human integration
patterns.
Knowledge of individual modes
Accurate Prediction of user preference
Integration and synchronization of interaction.

71
If you build a multimodal system, users will interact multimodally.
True only for natural interpersonal communication
Multimodal interaction is highly dependent on the user task at hand. Typically most used for spatial commands (86%). General actions (like printing) need only unimodal
communcation.
Knowledge of type of actions should influence the building of multimodal interfaces

72
Speech & Pointing is the dominant multimodal integration pattern
Made popular by the “Put-it-there” system. Can be used only for selection of objects. Speak-and-point systems fail to provide much
user functionality Only 14% of all multimodal utterances Pen is used more often to create digital content

73
Multimodal input involves simultaneous signals
Lag time between gestures Inputs are often temporally cascaded Often gesture precedes language
Ex: Chinese Leads to the need of mutual disambiguation.
Temporally diverse occurrence of modal events requires mutual disambiguation to ensure
effective error recovery

74
Enhanced efficiency is the main advantage of multimodal systems.
Only proven for spatial domains (10%)
Not proven when task content is quantitative in nature
Allow substantial error avoidance and recovery

75
Some More Myths.
Combination of individual modal technology leads to unreliability.
Speech is the primary input mode for any system that uses it.
Multimodal and unimodal languages are linguistically equipollent.
Multimodal integration involves redundancy. All users’ multimodal commands are
integrated in a uniform way.

76
A Language for Multimodal Communication
A multimodal language consists of many multimodal elements.
Provide a cohesive, coherent syntactical form. Eg: Multimedia ‘language’

77
Features of a Multimodal Language.
Linguistically simpler than spoken language. Briefer sentences and better spatial expressions.
English:
“Add an open space on the north lake to include the north lake part of the road and north.”
Bimodal System: “Open space”
Linguistic indirection replaced with direct commands. 50% reduction in commands.

78
Multimodal languages are not unique to computers.
Cirque du Soleil A circus without animals or death defying acts Themes and motifs that tell a story. Created a multimodal performance language. Communicates through visual and aural signs.
Lighting, costuming, make-up, props, set design, soundscape, choreography and performance style.
Cirque du Soleil used a multimodal language to cross boundaries.

79
Summation
Cognitive Science
The myths of multi-modal interaction
Multimodal language

80
Multimodal Architectures

81
Agenda
Different kinds of architecture
Multi Agent Architecture
XTRA: Referent Identification Techniques

82
Feature Fusion Architecture
Based on ‘early fusion’
Signal-level recognition of one mode affects recognition process of other modes.
Good for temporally synchronized inputs. Ex: Speech & Lip movements.
83
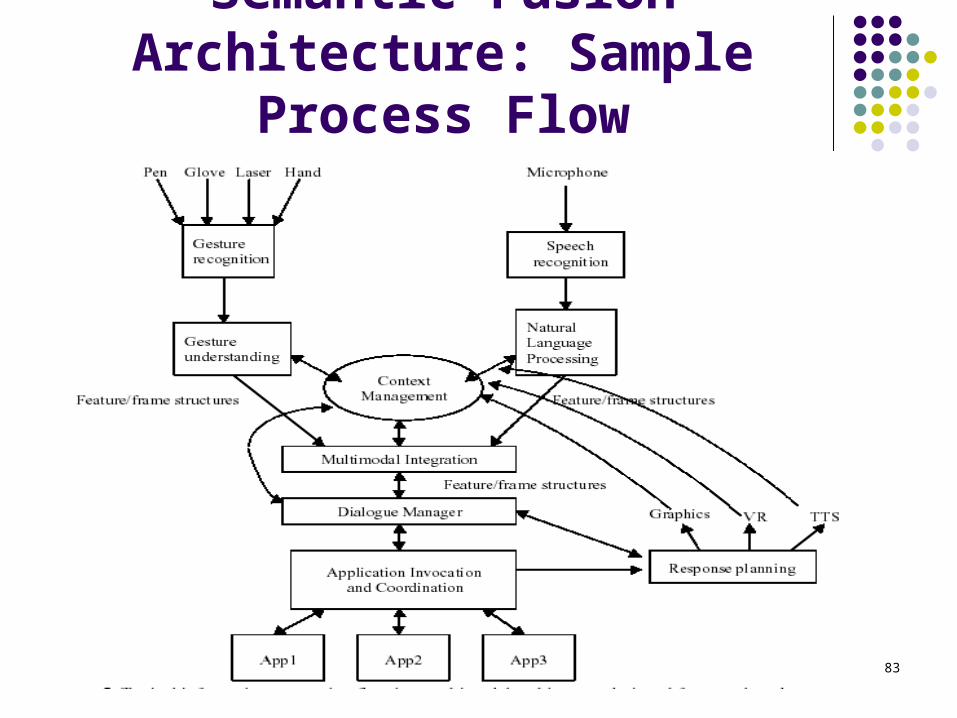
Semantic Fusion Architecture: Sample Process Flow

84
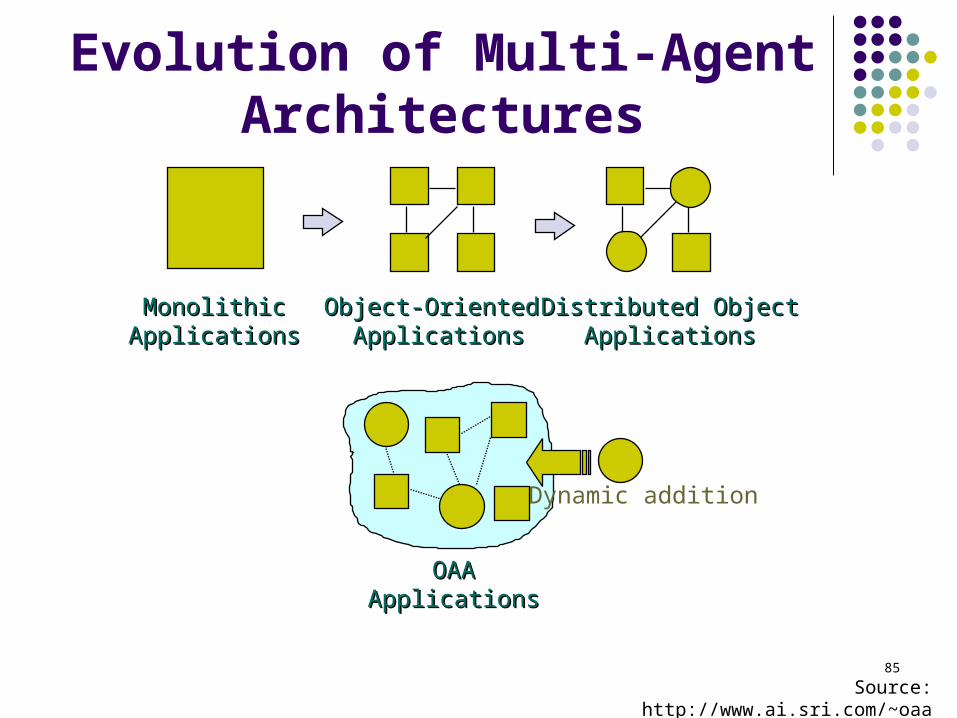
Multi Agent Architecture
Input components written in different programming languages.
Allow for asynchronous delivery, triggers, and provided distributed features.
Extension of the blackboard architecture
85
Evolution of Multi-Agent Architectures
MonolithicMonolithicApplicationsApplications
Object-Oriented Object-Oriented ApplicationsApplications
Distributed ObjectDistributed ObjectApplicationsApplications
OAAOAAApplicationsApplications
Dynamic addition
Source: http://www.ai.sri.com/~oaa
86
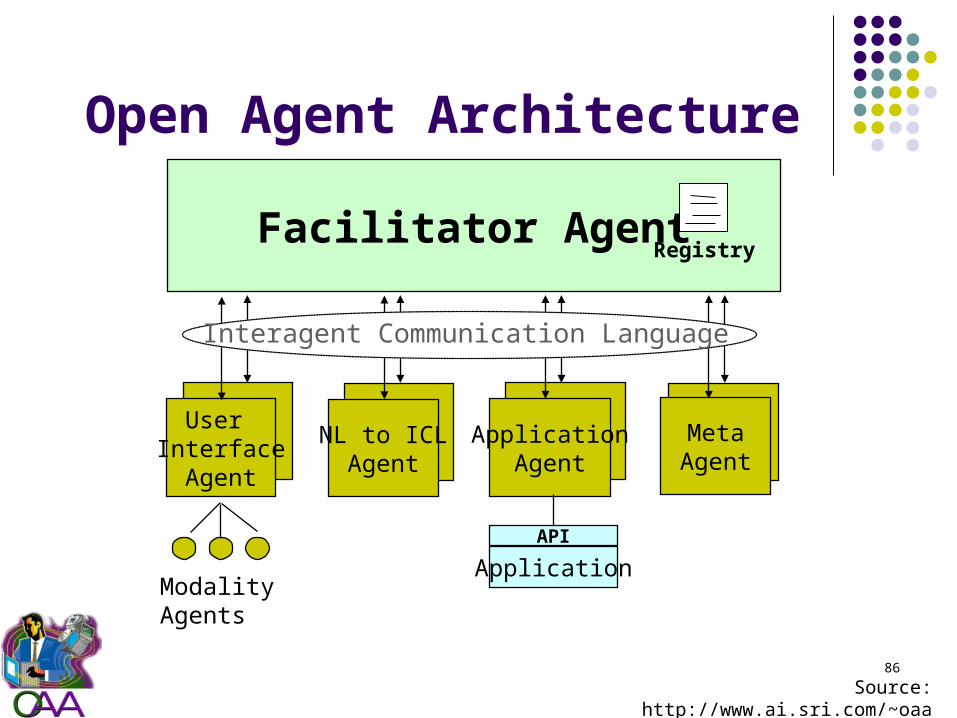
Open Agent Architecture
Facilitator Agent
Modality Agents
ApplicationAgent
Application
API
MetaAgent
Registry
NL to ICLAgent
User Interface
Agent
Interagent Communication Language
Source: http://www.ai.sri.com/~oaa

87
XTRA and Referent Identification
Assist in filling annual tax withholding form
An expert system access program
Translates natural language (NL) and deictic gestures
Incorporates error-resolution in referent Identification

88
Demonstratum and Referent
Pointing Gestures The demonstratum is identical to the referent. The demonstratum is a descendant of the
referent. The demonstratum is adjacent to the referent.
A deictic gesture alone is not enough to identify referent

89
Knowledge Sources of the System.
“Can I add my annual $15.00 ACL dues to these membership fees?”

90
Referent Identification Process
Generation of potential referents Decide on most appropriate knowledge source Use deictic field to generate candidates
Re-evaluating the set of candidates Re-evaluate through deictic, descriptor, case
frame and dialog memory. Overall evaluation using the plausibility
factor.

91
Spatial Deixis is a Valuable Source of Identifying Referents.
Simplify natural-language dialog.
Allow for linguistic inadequacies.
Permit vagueness in commands, hence more user friendly.

92
Summation
Different kinds of architecture
Multi Agent Architecture
XTRA: Referent Identification Techniques

93
Conclusion
Basis for Multimodal interfaces and media. Differences between Multimodal and
conventional interfaces. Multimedia input analysis Cognitive basis to Multimodal Interfaces Architectures for information processing
•What is an Multimodal Interface•Trends in Multimodal interface•Future directions of Multimodal systems
•Eye movement based interaction•Modes•Interpretation model
•Cognitive Science•Multimodal Language•Agent based architectures

94
Final Thoughts

95
References
http://www.sics.se/~jarmo/kurser http://www.mitre.org/resources/ http://www.sics.se/~bylund http://www.cs.uta.fi/hci/ieye/html http://www.techfak.uni-bielefeld.de/~tsowa http://www.ai.sri.com/~oaa





























