Embed Size (px)
Citation preview

1
Our Expertise and Commitment – Driving your Success
Data Modeling OverviewDecember 11, 2012
Offices in Boston, New York and Northern VA

2
Table of Contents
Data Modeling Overview
Artifacts
Data Architecture
Data Lineage
Data Dictionary
Tools
Modeling
Extract, Transform and Load
Data Governance
Data Stewardship

3
Data Modeling OverviewA proper data management programs is a corporate wide strategy and process for
building decision support systems and a knowledge-based applications architecture
and environment that supports everyday decision making and long-term business
strategy.
The data management environment positions a business to utilize enterprise-wide
operational and historical data to link information from various sources and make
the data accessible for a variety of corporate wide user purposes.
The data management and business intelligence (BI) applications are designed to
support executives, senior managers, and business analysts for regular reporting to
making complex business decisions.
The applications provide the business community with access to integrated and
consolidated information from internal and external sources. All of these items
start with quality requirements and a solid data model.

4
Data Modeling Overview (Continued)Requirements for a Data Model
Establish the scope of the data store and its intended use.
Define and prioritize the business requirements and the subsequent data needs the data store will address
Identify the business directions & objectives that may influence the data & application architectures.
Determine which business subject areas provide the most needed information.
Data ArchitectureThe Data Architecture organizes the sources and stores of business information and defines the quality
and management standards for data and metadata.
The Data Architecture is the logical and physical foundation on which the data store will be built.
The logical architecture is a configuration map (picture) of the necessary source data stores including but
not limited to a central Enterprise Data Store, an optional Operational Data Store, one or more individual
business area Data Marts, and one or more Metadata stores.
Once the logical configuration is defined, the physical Data Architecture is designed to implement it. The
physical architecture is the actual database design and data definition language (DDL) that is used to
define and create the data structures in the database.
Requirements of these architectures are carefully analyzed so that the data store can be optimized to
serve the users while achieving a “single point of truth” for each business data element.

5
Data Modeling Overview (Continued)Analysis
Top Down
Data is perceived to flow downhill or from its initial source
or creation point to the final data store destination. Analysis
of this flow is called “Top-Down” analysis. For example, a
piece of data could begin at an user making a transaction on a
website. This data is sent to an Operational Data Store
(ODS) in real time. This data will flow into a Corporate Data
Warehouse with the nightly batch cycle and into Data Marts.
This flow of Source -> ODS -> CDW -> Data Mart is a Top
Down view.
This analysis is primarily done at the creation of the data
model to ensure straight thru processing and eliminating
duplication of the same data (aka single point of truth).
ODS
CDW
Marts

6
Data Modeling Overview (Continued)Analysis
Bottom Up
The inverse of Top Down analysis is Bottom Up or
Data Lineage. This is where you start at the final
destination point of the data element and trace it
backwards to its initial source. Using the example
about, the Bottom Up view would be Datamart <-
CDW <- ODS <- Source.
This analysis is normally performed after
implementation to resolve data quality or load issues
or for future enhancements.
ODS
CDW
Marts
77
Artifacts - Data Architecture
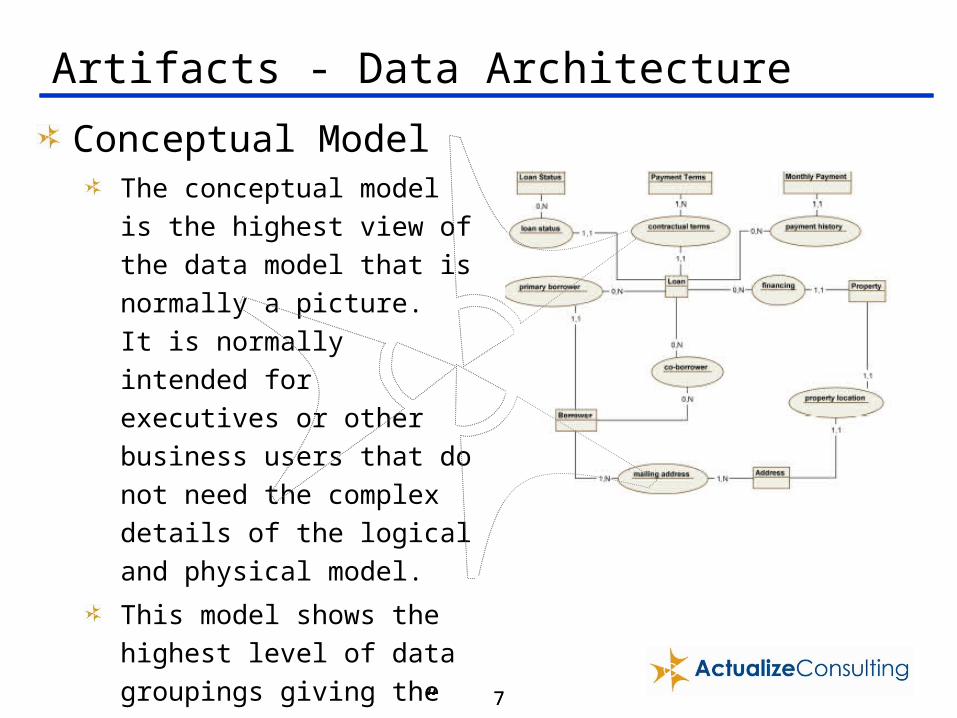
Conceptual ModelThe conceptual model is the
highest view of the data model
that is normally a picture. It is
normally intended for executives
or other business users that do not
need the complex details of the
logical and physical model.
This model shows the highest
level of data groupings giving the
users the “concept” of the data
structure without extraneous
details.

88
Artifacts - Data Architecture ContinuedLogical Model
Logical data models represent the abstract
structure of a domain of information. They
are often images and are used to capture data
groupings of importance and more
importantly how they relate to one another.
The data is at both an entity and attribute
level using business terms.
Once validated and approved, the logical data
model will become the basis of a physical
data model and inform the design of a
database.
The example shows more details than the
conceptual model including how structures
are related.

99
Artifacts - Data Architecture ContinuedPhysical Model
A physical data model is a representation of a
data design which takes into account the
facilities and constraints of a given database
management system.
It is typically derived from a logical data
model, though it may be reverse-engineered
from a given database implementation. A
complete physical data model will include all
the database artifacts required to create
relationships between tables or to achieve
performance goals, such as indexes, constraint
definitions, linking tables, partitioned tables or
clusters.
This example shows the same info as the
logical model but also contains more detail
around the data elements in each structure,
primary keys, indices and data types.

1010
Artifacts - Data Architecture ContinuedSummarization of the primary differences between a logical and physical model
Logical Data Model Physical Data Model
Includes entities (tables), attributes (columns/fields) and relationships (keys ), data format type
Includes tables, columns, keys, data types, validation rules, database triggers, stored procedures, domains, and access constraints
Uses business names for entities & attributes Uses more defined and less generic specific names for tables and columns, such as abbreviated column names, limited by the database management system (DBMS) and any company defined standards
Is independent of technology (platform, DBMS)
Includes primary keys and indices for fast data access.
Is normalized to fourth normal form(4NF) May be de-normalized to meet performance requirements based on the nature of the database. If the nature of the database is Online Transaction Processing (OLTP) or Operational Data Store (ODS) it is usually not de-normalized. De-normalization is common in Data warehouses.

1111
Data Lineage
Data lineage tracks the journey a data element travels from either
an internal or external source or internal creation to its final data
storage location.
The lineage should be as short a possible with as few steps as
possible to ensure accuracy, timeliness and non-duplication of
the data element in different states.
Data Lineage documentation is critical for timely resolution of
data quality issues that can cause issues into downstream
databases or for change management purposes for changes to the
source or other upstream databases.

1212
Data Dictionary
A data dictionary is a centralized repository of information about
data in a database such as definition, origin, usage, data type and
relationships to other data.
The information along with a logical data dictionary can be used
to educate both business and technical users about the data stored
in a database.
This information can be housed along with the physical model or
can be created as an output from most data modeling software.
1313
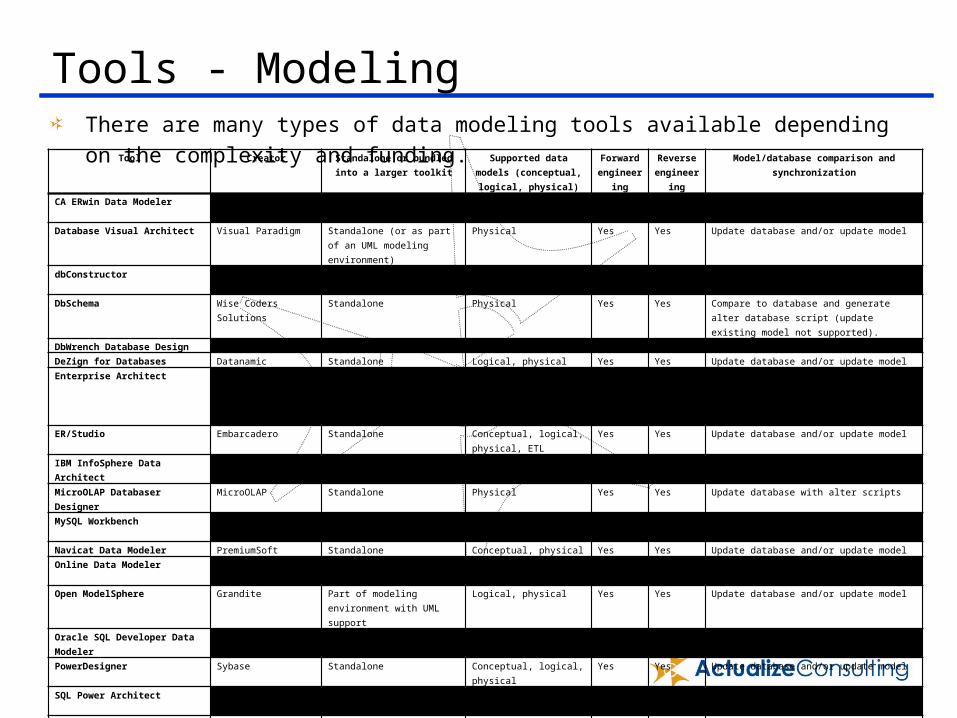
Tools - ModelingThere are many types of data modeling tools available depending on the complexity and funding.
Tool Creator Standalone or bundled into a larger toolkit
Supported data models (conceptual, logical,
physical)
Forward engineerin
g
Reverse engineerin
g
Model/database comparison and synchronization
CA ERwin Data Modeler CA Technologies Standalone Conceptual, logical, physical Yes Yes Update database and/or update model
Database Visual Architect Visual Paradigm Standalone (or as part of an UML modeling environment)
Physical Yes Yes Update database and/or update model
dbConstructor DBDeveloper Solutions Standalone Physical Yes Yes Update database
DbSchema Wise Coders Solutions Standalone Physical Yes Yes Compare to database and generate alter database script (update existing model not supported).
DbWrench Database Design Nizana Systems Standalone Physical Yes Yes Update database and/or update model
DeZign for Databases Datanamic Standalone Logical, physical Yes Yes Update database and/or update model
Enterprise Architect Sparx Systems Data modeling is supported as part of a complete modeling platform.
Conceptual, Logical & Physical + MDA transform of Logical to Physical
Yes Yes Update database and/or update model
ER/Studio Embarcadero Standalone Conceptual, logical, physical, ETL
Yes Yes Update database and/or update model
IBM InfoSphere Data Architect IBM Standalone Conceptual, logical, physical Yes Yes Update database and/or update model
MicroOLAP Databaser Designer MicroOLAP Standalone Physical Yes Yes Update database with alter scripts
MySQL Workbench MySQL (An Oracle Company)
Standalone Physical Yes Yes Update database and/or update model
Navicat Data Modeler PremiumSoft Standalone Conceptual, physical Yes Yes Update database and/or update model
Online Data Modeler JenaSoft Standalone Logical, physical Yes Yes Update database (update model unknown)
Open ModelSphere Grandite Part of modeling environment with UML support
Logical, physical Yes Yes Update database and/or update model
Oracle SQL Developer Data Modeler Oracle Standalone Logical, physical Yes Yes Update database and/or update model
PowerDesigner Sybase Standalone Conceptual, logical, physical Yes Yes Update database and/or update model
SQL Power Architect SQLPower Software Standalone Physical Yes Yes Compare models and generate alter script
Toad Data Modeler Quest Software Standalone Logical, physical Yes Yes Update database and/or update model
XCase Resolution Software Ltd Standalone Physical Yes Yes Update database and/or update model

1414
Tools - Extract Transform and Load (ETL) ETL is the physical code used to extract, transform and load data from its source
location to the database.
All transformation logic gathered during the requirements sessions is stored in the
ETL code.
Example: The source has VA for the State Code but the database is using
enumerated State code and VA = 37. The requirements that would be coded in
the ETL would be to convert State Code VA to 37 in the transformation step of
the ETL.
ETL code should be written to exclude exceptions into an exception handling queue
and continue with the load process. The load job should not cease running due to
incorrect data or mismapped data types.
The technical and business support teams should then review the exceptions, correct
the source and have the corrected data flow back thru the normal ETL process.
Direct changes to the target database are not acceptable as this will cause the source
and targets to be out of synch.

1515
Best Practices and Standards
Modeling/Naming Best Practices
Physical and Business data element naming should be consistent
throughout the organization.
This allows the modelers to easily spot redundancies to prevent duplicate
data from being introduced into the database.
Business users can be confident they are consuming the correct field for
their business decisions.

1616
Best Practices and Standards ContinuedETL Best Practices
The ETL code should encourage straight thru processing. This includes loading the base
tables then the collections then the marts where appropriate.
Timeliness is as important as accuracy so the ETL code should be efficient utilizing the
structure indices to ensure the fastest load possible.
Exceptions should be handled thru an exception process and not impede the load process.
Predecessor & Successor relationships of all ETL code should be maintained and updated
with every implementation. This will ensure new code introduced to the job stream is
kicked off at the correct time and not too early causing it to miss upstream data or too late
causing unnecessary delay in the entire job stream completion.
Changes to the sources for the database should be coordinated and plan in conjunction to the
database loads to prevent unnecessary outages or missed data.
There should be a distinct separation of duties between the requirements, coding, testing and
implementation to ensure there are no compliance issues.

1717
Best Practices and Standards ContinuedIT Control Framework Best Practices
The ETL code should be stored in a version control system with business and
technical owner’s approval & testing steps before being introduced to production.
No end users or technical staff should have permissions to update the production
databases directly via an update query or access to the job scheduler. A master
update ID should be used and stored in a secure location that can be referenced by
the production code to perform the load jobs.
Database Analysts (DBA’s) should monitor the database to ensure proper tuning
and elimination of rouge queries.
ODS’s should only be accessed by the applications that need the operational data
real time. All other applications should access the data in a CDW or Data Mart.
1818
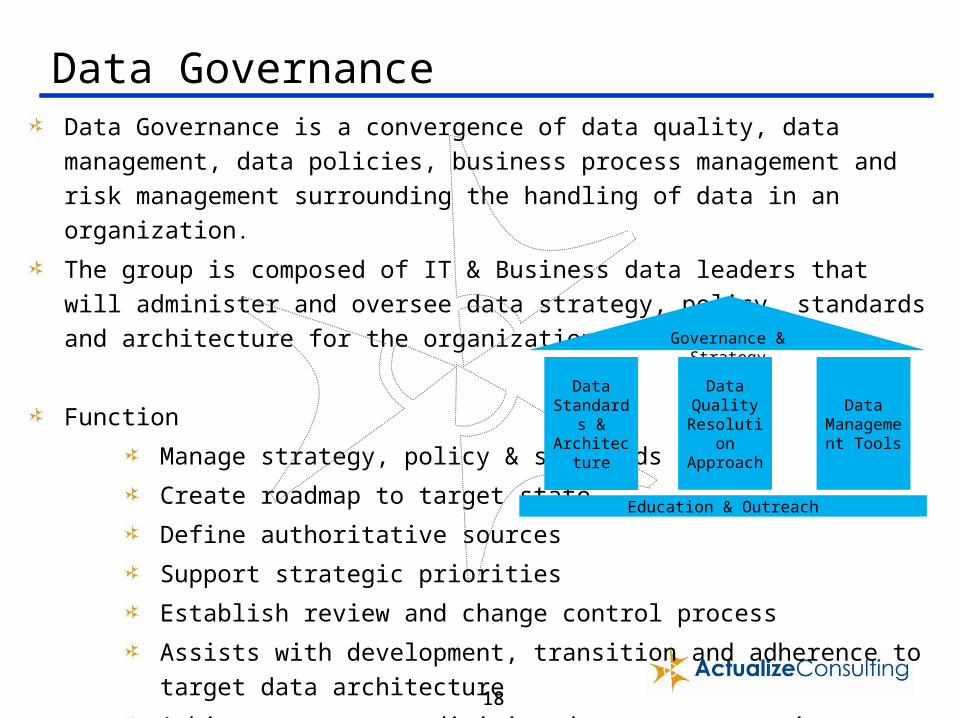
Data GovernanceData Governance is a convergence of data quality, data management, data policies,
business process management and risk management surrounding the handling of data in
an organization.
The group is composed of IT & Business data leaders that will administer and oversee
data strategy, policy, standards and architecture for the organization.
Function
Manage strategy, policy & standards
Create roadmap to target state
Define authoritative sources
Support strategic priorities
Establish review and change control process
Assists with development, transition and adherence to target data architecture
Arbitrators across division data management issues.
Governance & Strategy
Data Standards & Architecture
Data Management
Tools
Data Quality Resolution Approach
Education & Outreach

1919
Data Governance ContinuedBenefits of the Data Governance Function
Improve Business Performance
Accelerated time-to-market for new products
Better understanding of products & customers
Establishes accountability for information quality
Reduce risk
Fewer mistakes, errors, fails, fines
Fewer audit remediation resources
Increased operational efficiency
Better decision support
Improve operating performance
Single, authoritative sources lead to better, faster analytics
Reduce redundancies across systems and functions

2020
Data StewardshipData Stewardship’s is the management of the organization’s data to improve their
reusability, timeliness, accessibility and quality.
A Data Steward is a person assigned to a major subject area that is responsible for
managing the data in an organization for consistency in definitions, data structures,
transformation logic, etc. They should report up to the data governance group.
Data Stewards' responsibilities include
Establishing business naming standards
Developing consistent data definitions
Developing standards for transformation
Documenting the business rules
Reviewing and approving all changes to the data in the subject area
Monitoring and owning the quality of the data
Defining security requirements for who has access to what data
Defining data retention requirements

21
Contact InformationTim McLuckieManaging Director, [email protected]
Heather [email protected]
Geran [email protected]





























