Embed Size (px)
Citation preview

1
PART-OF-SPEECH TAGGING

2
Topics of the next three lectures
Tagsets Rule-based tagging Brill tagger Tagging with Markov models The Viterbi algorithm

3
POS tagging: the problem
People/NNS continue/VBP to/TO inquire/VB the/DT reason/NN for/IN the/DT race/NN for/IN outer/JJ space/NN
Problem: assign a tag to race Requires: tagged corpus

4
Why is POS tagging useful?
Makes search of patterns of interest to linguists in a corpus much easier (original motivation!)
Useful as a basis for parsing For applications such as IR, provides some
degree of meaning distinction In ASR, helps selection of next word

5
Ambiguity in POS tagging
The ATman NN VBstill NN VB RBsaw NN VBDher PPO PP$

6
How hard is POS tagging?
Number of tags 1 2 3 4 5 6 7
Number of words types
35340 3760 264 61 12 2 1
In the Brown corpus,- 11.5% of word types ambiguous- 40% of word TOKENS

7
Frequency + Context
Both the Brill tagger and HMM-based taggers achieve good results by combining– FREQUENCY
I poured FLOUR/NN into the bowl. Peter should FLOUR/VB the baking tray
– Information about CONTEXT I saw the new/JJ PLAY/NN in the theater. The boy will/MD PLAY/VBP in the garden.

8
The importance of context
Secretariat/NNP is/VBZ expected/VBN to/TO race/VB tomorrow/NN
People/NNS continue/VBP to/TO inquire/VB the/DT reason/NN for/IN the/DT race/NN for/IN outer/JJ space/NN

9
Choosing a tagset
The choice of tagset greatly affects the difficulty of the problem
Need to strike a balance between– Getting better information about context (best:
introduce more distinctions)– Make it possible for classifiers to do their job (need
to minimize distinctions)

10
Some of the best-known Tagsets
Brown corpus: 87 tags Penn Treebank: 45 tags Lancaster UCREL C5 (used to tag the BNC):
61 tags Lancaster C7: 145 tags

11
Important Penn Treebank tags

12
Verb inflection tags
13
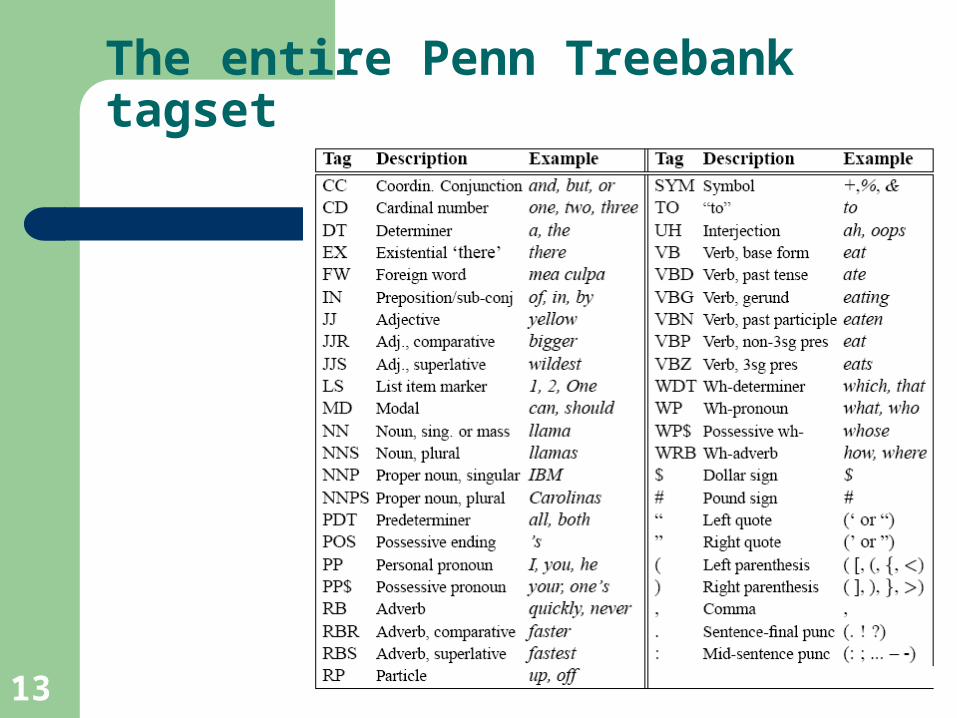
The entire Penn Treebank tagset

14
UCREL C5

16
Il tagset di SI-TAL

17
POS tags in the Brown corpus
Television/NN has/HVZ yet/RB to/TO work/VB out/RP a/AT living/RBG arrangement/NN with/IN jazz/NN ,/, which/VDT comes/VBZ to/IN the/AT medium/NN more/QL as/CS an/AT uneasy/JJ guest/NN than/CS as/CS a/AT relaxed/VBN member/NN of/IN the/AT family/NN ./.

18
SGML-based POS in the BNC
<div1 complete=y org=seq> <head> <s n=00040> <w NN2>TROUSERS <w VVB>SUIT </head> <caption> <s n=00041> <w EX0>There <w VBZ>is <w PNI>nothing <w AJ0>masculine <w PRP>about <w DT0>these <w AJ0>new <w NN1>trouser <w NN2-VVZ>suits <w PRP>in <w NN1>summer<w POS>'s <w AJ0>soft <w NN2>pastels<c PUN>. <s n=00042> <w NP0>Smart <w CJC>and <w AJ0>acceptable <w PRP>for <w NN1>city <w NN1-VVB>wear <w CJC>but <w AJ0>soft <w AV0>enough <w PRP>for <w AJ0>relaxed <w NN2>days </caption>

20
Quick test
DoCoMo and Sony are to develop a chip that would let people pay for goods through their mobiles.

21
Tagging methods
Hand-coded Brill tagger Statistical (Markov) taggers

22
Hand-coded POS tagging: the two-stage architecture
Early POS taggers all hand-coded Most of these (Harris, 1962; Greene and
Rubin, 1971) and the best of the recent ones, ENGTWOL (Voutilainen, 1995) based on a two-stage architecture

23
Hand-coded rules (ENGTWOL)
STEP 1: assign to each word a list of potential parts of speech- in ENGTWOL, this done by a two-lever morphological analyzer (a finite state transducer)
STEP 2: use about 1000 hand-coded CONSTRAINTS (if-then rules) to choose a tag using contextual information- the constraints act as FILTERS

24
Example
Pavlov had shown that salivation ….
Pavlov PAVLOV N NOM SG PROPER
had HAVE V PAST VFIN SVO
HAVE PCP2 SVOO
shown SHOW PCP2 SVOO SVO SG
that ADV
PRON DEM SG
DET CENTRAL DEM SG
CS
salivation N NOM SG

25
A constraint
ADVERBIAL-THAT RULE
Given input: “that”if (+1 A/ADV/QUANT); /* next word adj,adv, quant */ (+2 SENT-LIM); /* and following that there is a sentence boundary */ (NOT –1 SVOC/A); /* and previous word is not verb `consider’ */then eliminate non-ADV tagselse eliminate ADV tag.

26
Tagging with lexical frequencies
Secretariat/NNP is/VBZ expected/VBN to/TO race/VB tomorrow/NN
People/NNS continue/VBP to/TO inquire/VB the/DT reason/NN for/IN the/DT race/NN for/IN outer/JJ space/NN
Problem: assign a tag to race given its lexical frequency Solution: we choose the tag that has the greater
– P(race|VB)– P(race|NN)
Actual estimate from the Switchboard corpus:– P(race|NN) = .00041– P(race|VB) = .00003

27
The Brill tagger
An example of TRANSFORMATION-BASED LEARNING
Very popular (freely available, works fairly well) A SUPERVISED method: requires a tagged
corpus Basic idea: do a quick job first (using
frequency), then revise it using contextual rules

28
An example
Examples:– It is expected to race tomorrow.– The race for outer space.
Tagging algorithm:1. Tag all uses of “race” as NN (most likely tag in the Brown
corpus)• It is expected to race/NN tomorrow• the race/NN for outer space
2. Use a transformation rule to replace the tag NN with VB for all uses of “race” preceded by the tag TO:• It is expected to race/VB tomorrow• the race/NN for outer space

29
Transformation-based learning in the Brill tagger
1. Tag the corpus with the most likely tag for each word
2. Choose a TRANSFORMATION that deterministically replaces an existing tag with a new one such that the resulting tagged corpus has the lowest error rate
3. Apply that transformation to the training corpus
4. Repeat
5. Return a tagger thata. first tags using unigrams
b. then applies the learned transformations in order

30
The algorithm

31
Examples of learned transformations

32
Templates

33
An example

34
Markov Model POS tagging
Again, the problem is to find an `explanation’ with the highest probability:
As in yesterday’s case, this can be ‘turned around’ using Bayes’ Rule:
)..|..(argmax 11Tt
nn wwttPi
)..(
)..()..|..(argmax
1
111
n
nnn
wwP
ttPttwwP

35
Combining frequency and contextual information
As in the case of spelling, this equation can be simplified:
As we will see, once further simplifications are applied, this equation will encode both FREQUENCY and CONTEXT INFORMATION
prior
1
likelihood
11 )..()..|..(argmax nnn ttPttwwP

36
Three further assumptions
MARKOV assumption: a tag only depends on a FIXED NUMBER of previous tags (here, assume bigrams)– Simplify second factor
INDEPENDENCE assumption: words are independent from each other.
A word’s identity only depends on its own tag– Simplify first factor

37
The final equations
FREQUENCYCONTEXT

38
Estimating the probabilities
Can be done using Maximum Likelihood Estimation as usual, for BOTH probabilities:

39
An example of tagging with Markov Models :
Secretariat/NNP is/VBZ expected/VBN to/TO race/VB tomorrow/NN
People/NNS continue/VBP to/TO inquire/VB the/DT reason/NN for/IN the/DT race/DT for/IN outer/JJ space/NN
Problem: assign a tag to race given the subsequences– to/TO race/???– the/DT race/???
Solution: we choose the tag that has the greater of these probabilities:
– P(VB|TO) P(race|VB)– P(NN|TO)P(race|NN)

40
Tagging with MMs (2)
Actual estimates from the Switchboard corpus: LEXICAL FREQUENCIES:
– P(race|NN) = .00041– P(race|VB) = .00003
CONTEXT:– P(NN|TO) = .021– P(VB|TO) = .34
The probabilities:– P(VB|TO) P(race|VB) = .00001– P(NN|TO)P(race|NN) = .000007

41
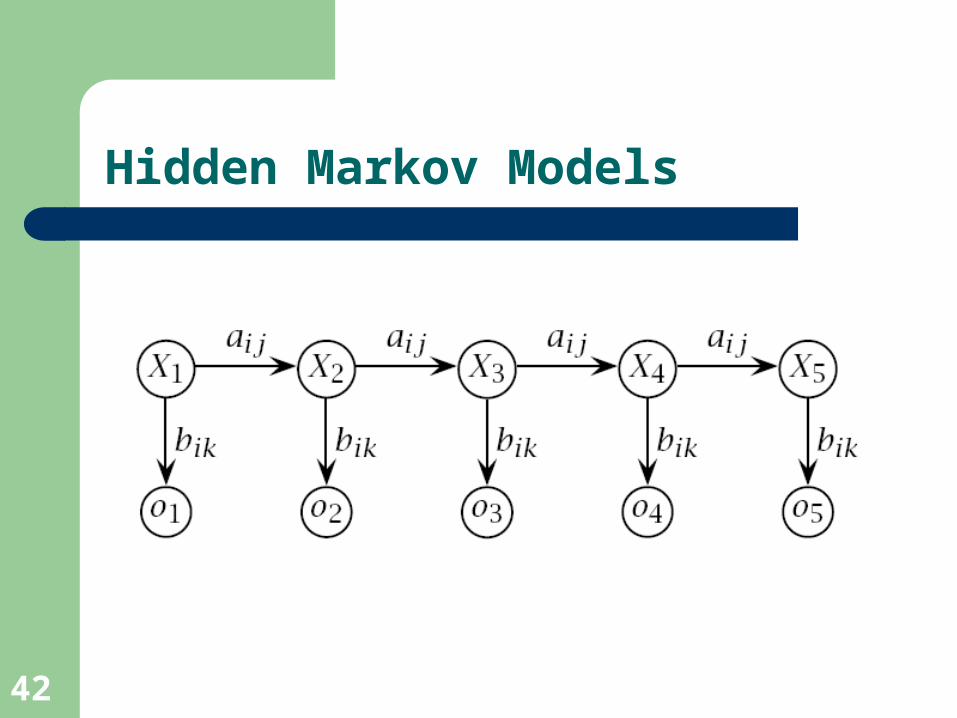
A graphical interpretation of the POS tagging equations
42
Hidden Markov Models

43
An example

44
Computing the most likely sequence of tags
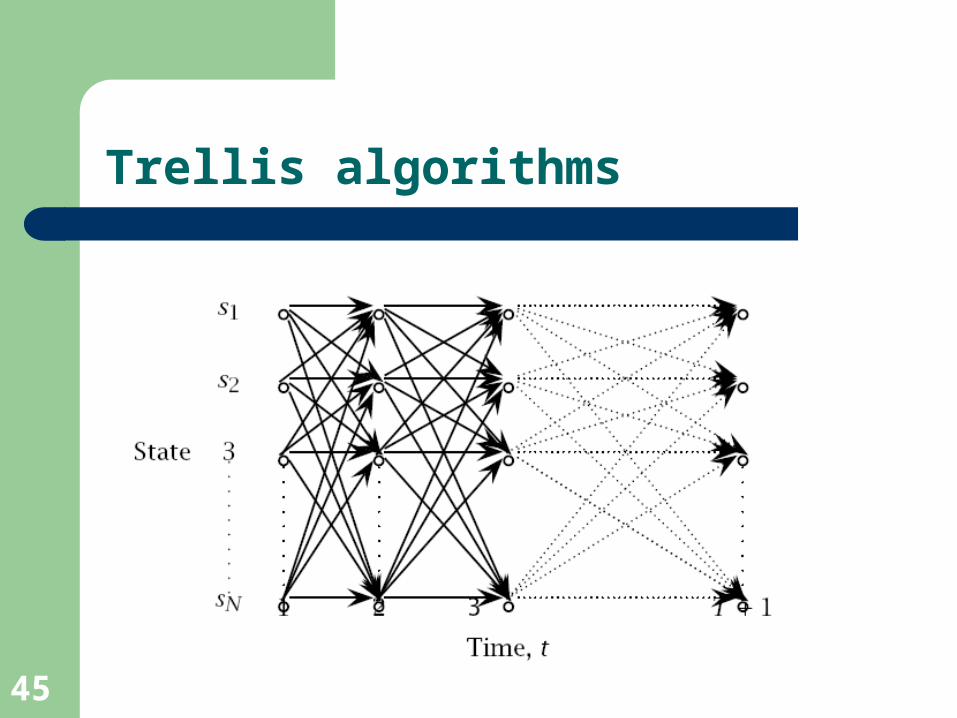
In general, the problem of computing the most likely sequence t1 .. tn could have exponential complexity
It can however be solved in polynomial time using an example of DYNAMIC PROGRAMMING: the VITERBI ALGORITHM (Viterbi, 1967)
(Also called TRELLIS ALGORITHMs)
45
Trellis algorithms

46
The Viterbi algorithm

47
Viterbi (pseudo-code format)

48
Viterbi: an example

49
Markov chains and Hidden Markov Models
Markov chain: only transition probabilities. Each node associated with a single OUTPUT
Hidden Markov Models: nodes may have more than one output; probability P(w|t) of outputting word w from state t.

50
Training HMMs
The reason why HMMS are so popular is because they come with a LEARNING ALGORITHM: the FORWARD-BACKWARD algorithm (an instance of a class of algorithms called EM algorithms)
Basic idea of the forward-backward algorithm: start by assigning random transition and emission probabilities, then iterate

51
Evaluation of POS taggers
Can reach up to 96.7% correct on Penn Treebank (see Brants, 2000)
(But see next lecture)

52
Additional issues
Most of the difference in performance between POS algorithms depends on their treatment of UNKNOWN WORDS
Multiple token words (‘Penn Treebank’)
Class-based N-grams

53
Other techniques
There is a move away from HMMs for this task and towards techniques that make it easier to use multiple features
MAXIMUM ENTROPY taggers among the highest performing at the moment

54
Freely available POS taggers
Quite a few taggers are freely available– Brill (TBL)– QTAG (HMM; can be trained for other languages)– LT POS (part of the Edinburgh LTG suite of tools)– See Chris Manning’s Statistical NLP resources web
page (from the course web page)

56
Other kinds of tagging
Sense tagging (SEMCOR, SENSEVAL) Syntactic tagging (`supertagging’) Dialogue act tagging Semantic tagging (animacy, etc.)

57
Readings
Jurafsky and Martin, chapter 8





























