Embed Size (px)
Citation preview

1
Router Construction II
OutlineNetwork ProcessorsAdding ExtensionsScheduling Cycles

2
Observations
• Emerging commodity components can be used to build IP routers– switching fabrics, network processors,
…
• Routers are being asked to support a growing array of services– firewalls, proxies, p2p nets, overlays, ...
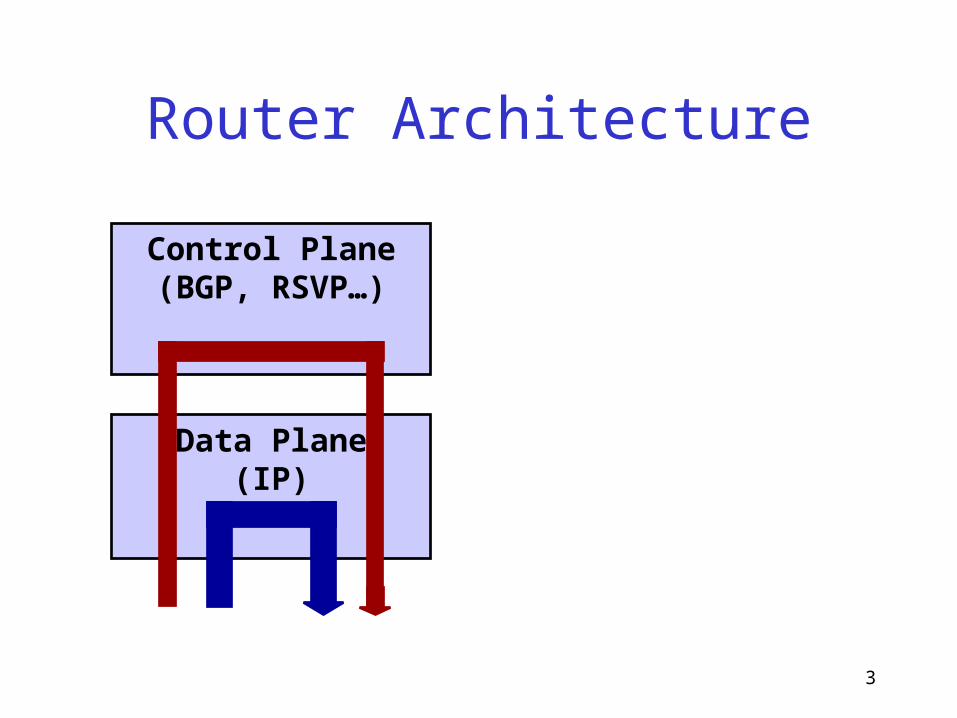
3
Data Plane(IP)
Control Plane(BGP, RSVP…)
Router Architecture
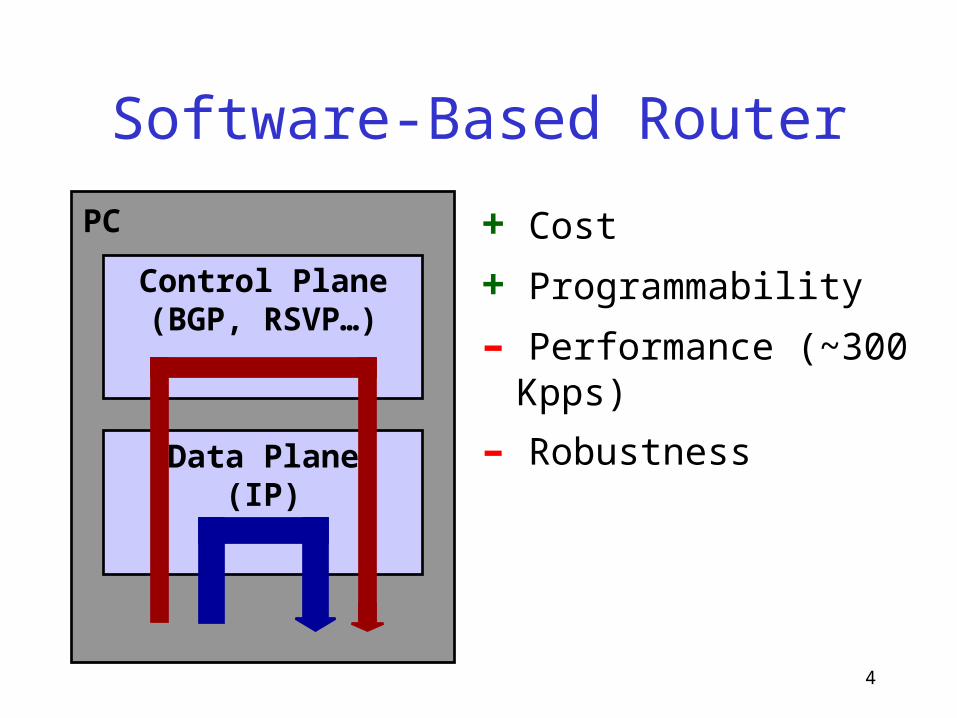
4
Software-Based Router
+ Cost
+ Programmability
– Performance (~300 Kpps)
– RobustnessData Plane(IP)
Control Plane(BGP, RSVP…)
PC
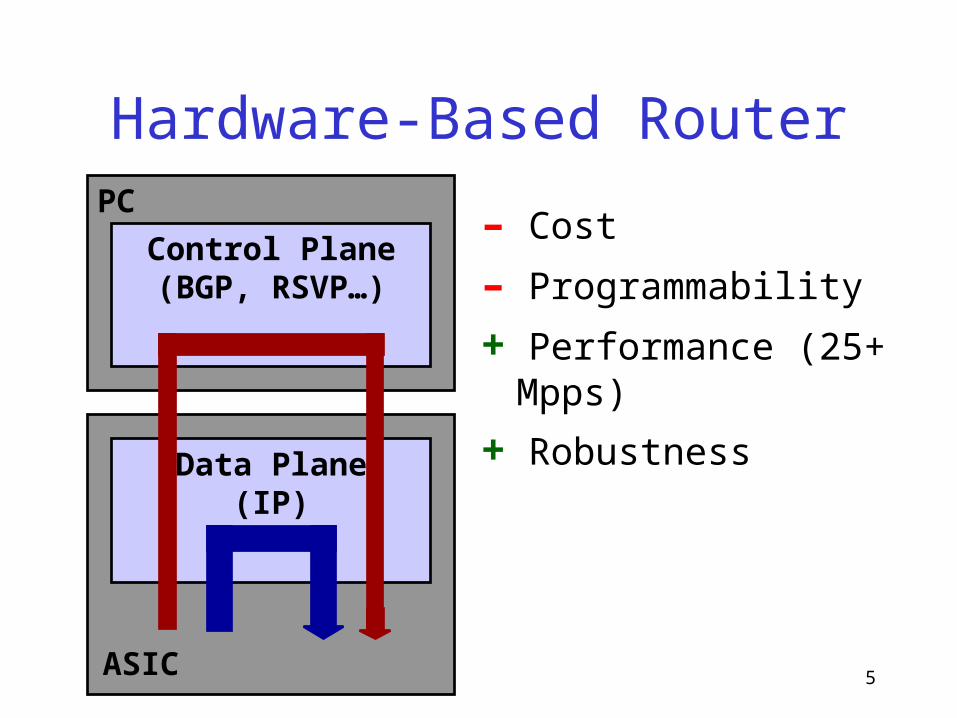
5
Hardware-Based Router
– Cost
– Programmability
+ Performance (25+ Mpps)
+ RobustnessData Plane(IP)
Control Plane(BGP, RSVP…)
ASIC
PC
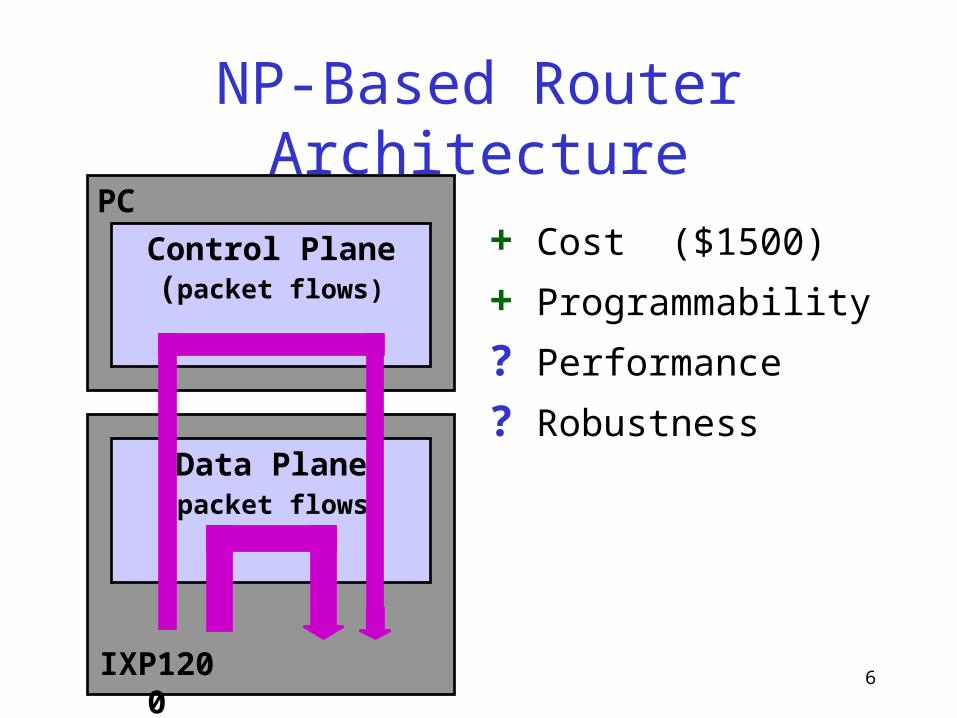
6
NP-Based Router Architecture
+ Cost ($1500)
+ Programmability
? Performance
? RobustnessData Plane(packet flows)
Control Plane(packet flows)
IXP1200
PC
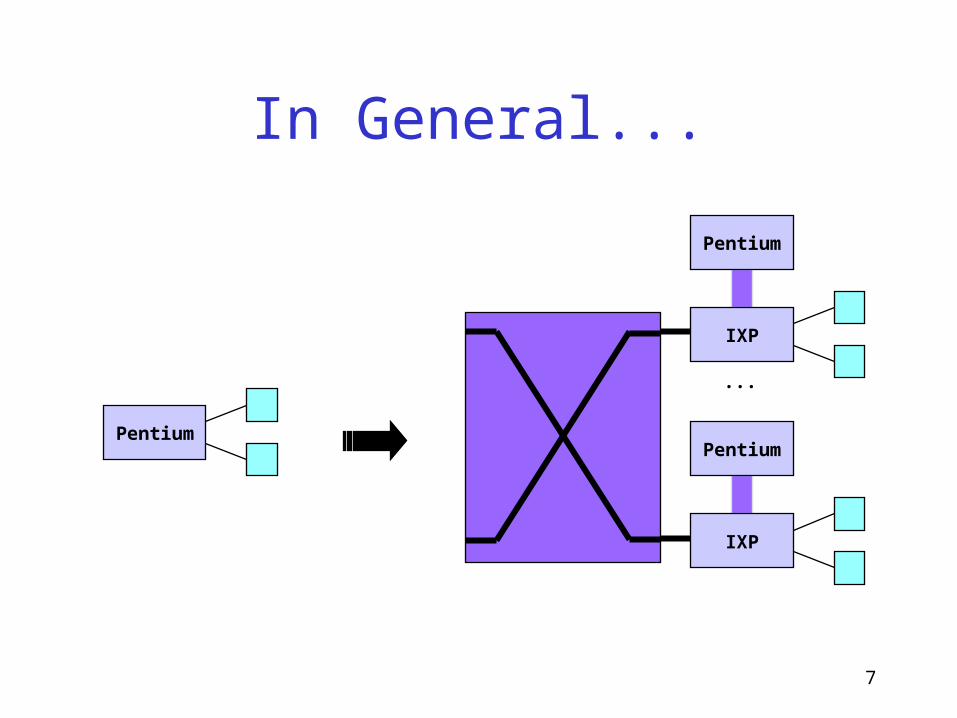
7
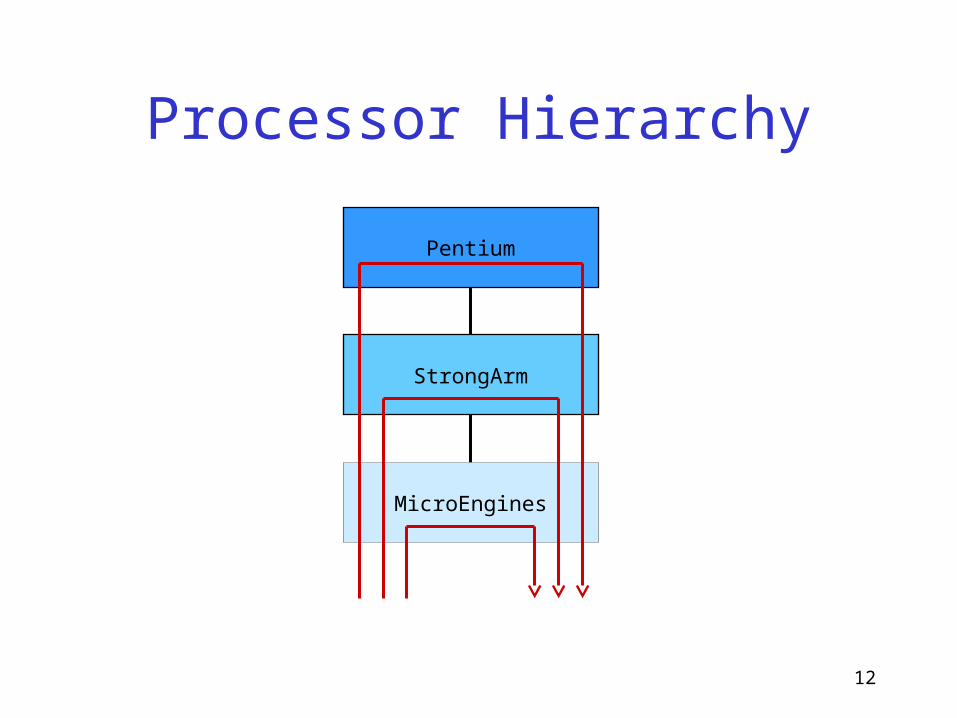
In General...
IXP
Pentium
IXP
Pentium
...
Pentium
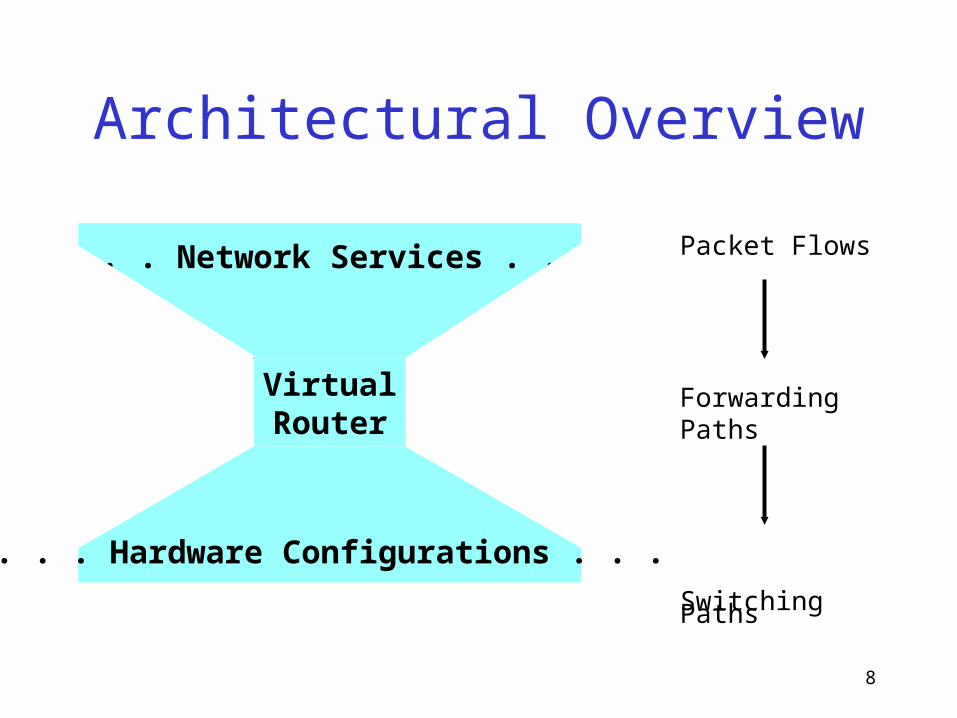
8
Architectural Overview
. . . Network Services . . .
VirtualRouter
. . . Hardware Configurations . . .
Packet Flows
Forwarding Paths
Switching Paths
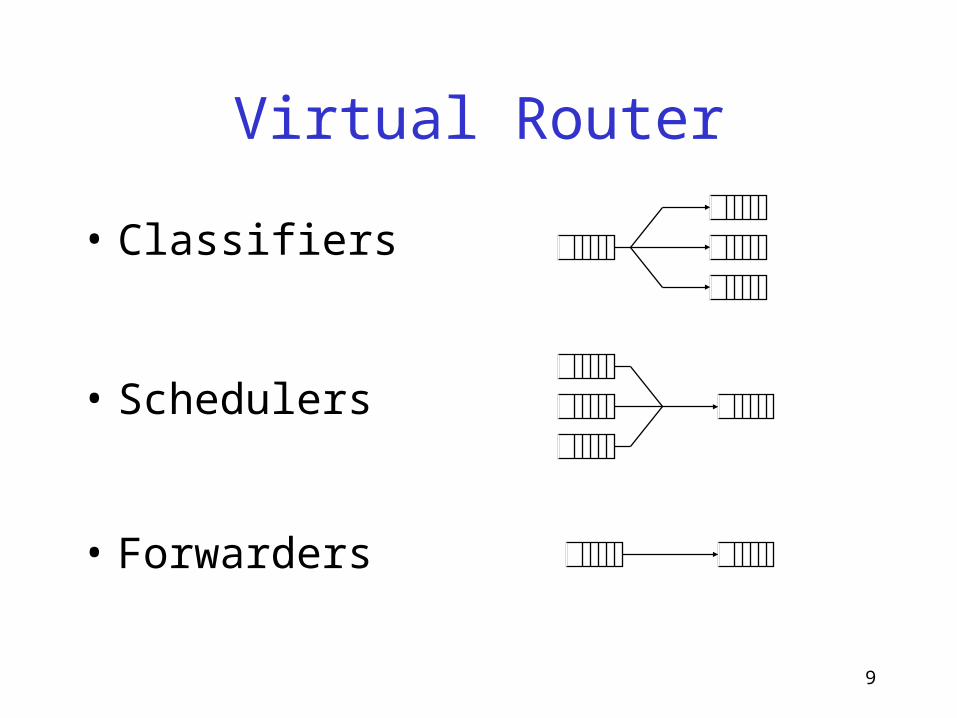
9
Virtual Router
• Classifiers
• Schedulers
• Forwarders
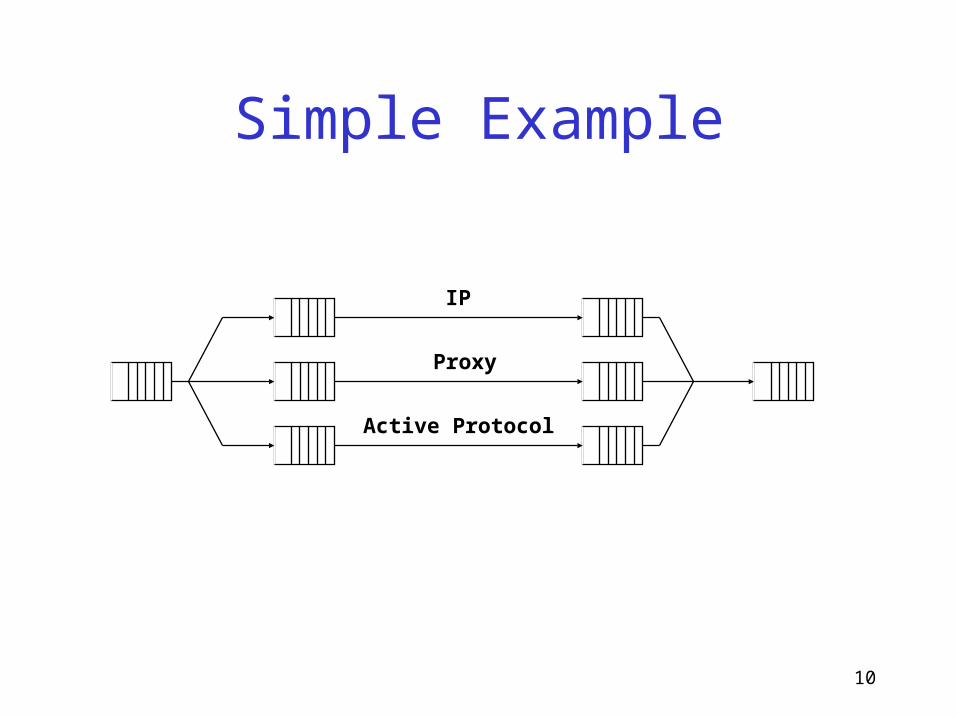
10
Simple Example
IP
Proxy
Active Protocol
11
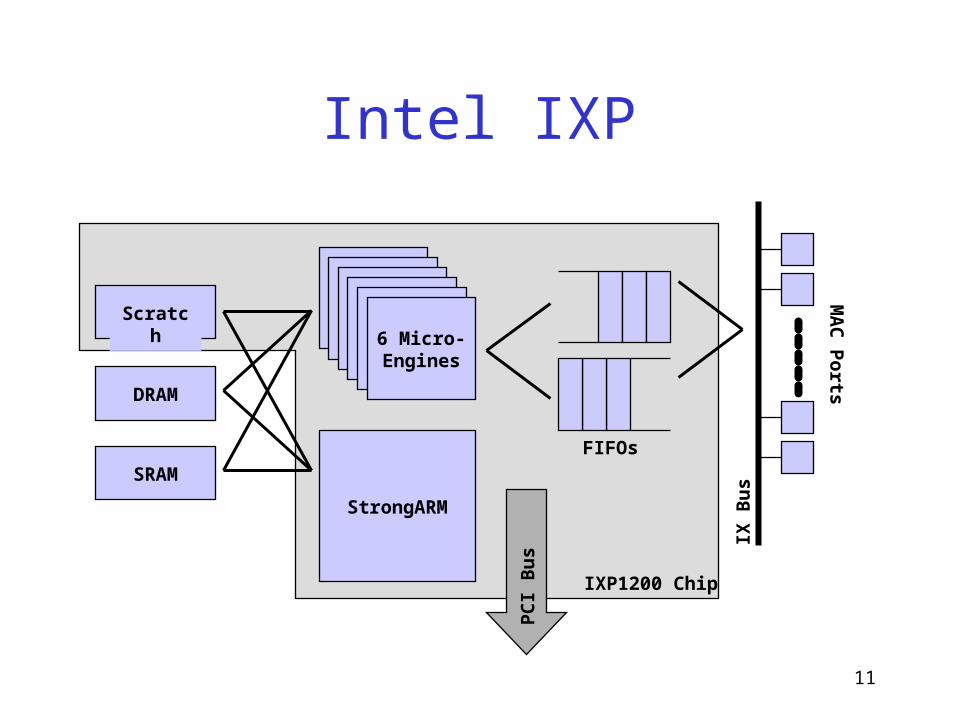
Intel IXP
Scratch
DRAM
SRAM
6 Micro-Engines
StrongARM
FIFOs
IX B
us
MA
C P
orts
IXP1200 Chip
PC
I B
us
12
Processor Hierarchy
MicroEngines
Pentium
StrongArm
13
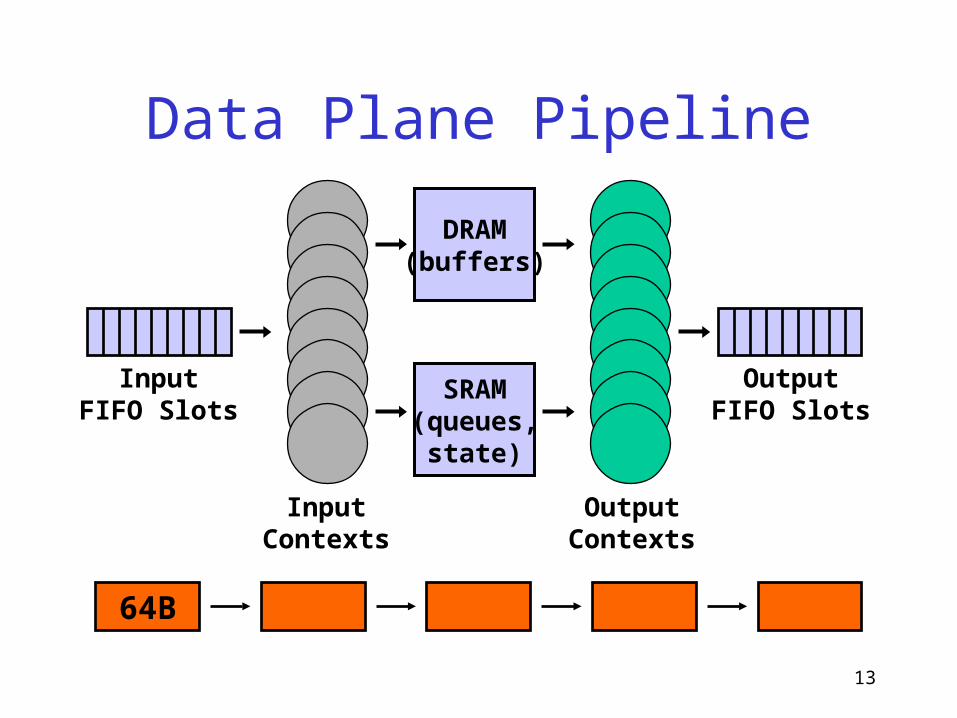
Data Plane Pipeline
DRAM(buffers)
SRAM(queues,
state)
InputFIFO Slots
OutputFIFO Slots
InputContexts
OutputContexts
64B

14
Data Plane Processing
INPUT context loopwait_for_datacopy in_fiforegsBasic_IP_processingcopy regsDRAMif (last_fragment)
enqueueSRAM
OUTPUT context loop
if (need_data)
select_queue
dequeueSRAMcopy DRAMout_fifo
15
0123456789
0 4 8 16 24
MicroEngine Contexts
For
war
ding
Rat
e (M
pps)
input output
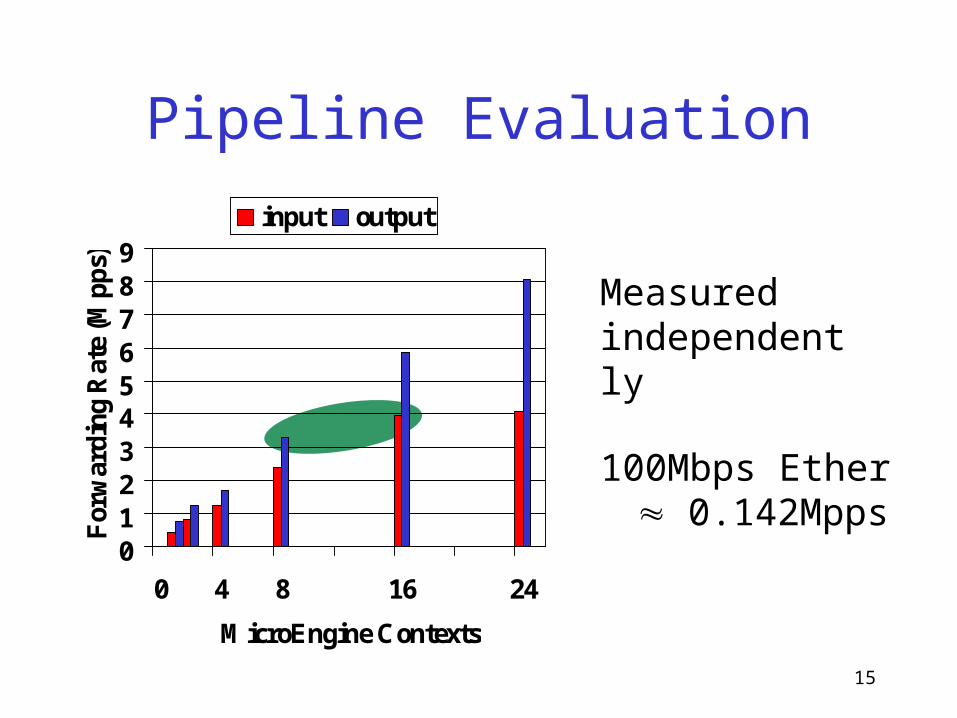
Pipeline Evaluation
100Mbps Ether 0.142Mpps
Measured independently

16
What We Measured
• Static context assignment– 16 input / 8 output
• Infinite offered load• 64-byte (minimum-sized) IP packets• Three different queuing disciplines

17
Single Protected Queue
• Lock synchronization• Max 3.47 Mpps• Contention lower bound 1.67 Mpps
O
I
I
I
Output FIFO
18
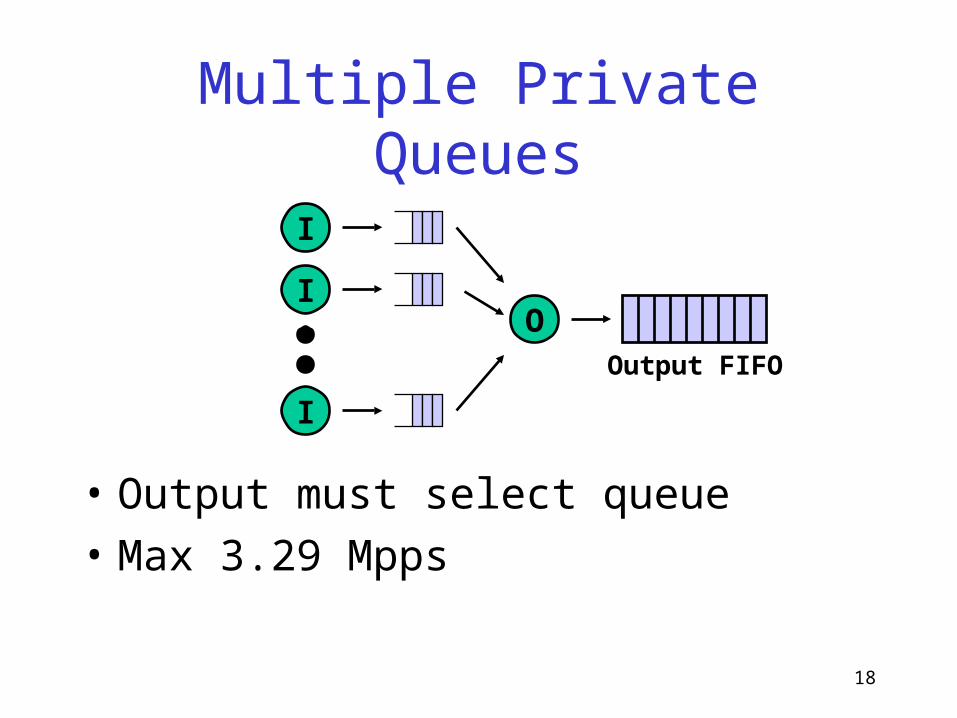
Multiple Private Queues
• Output must select queue• Max 3.29 Mpps
O
I
I
I
Output FIFO
19
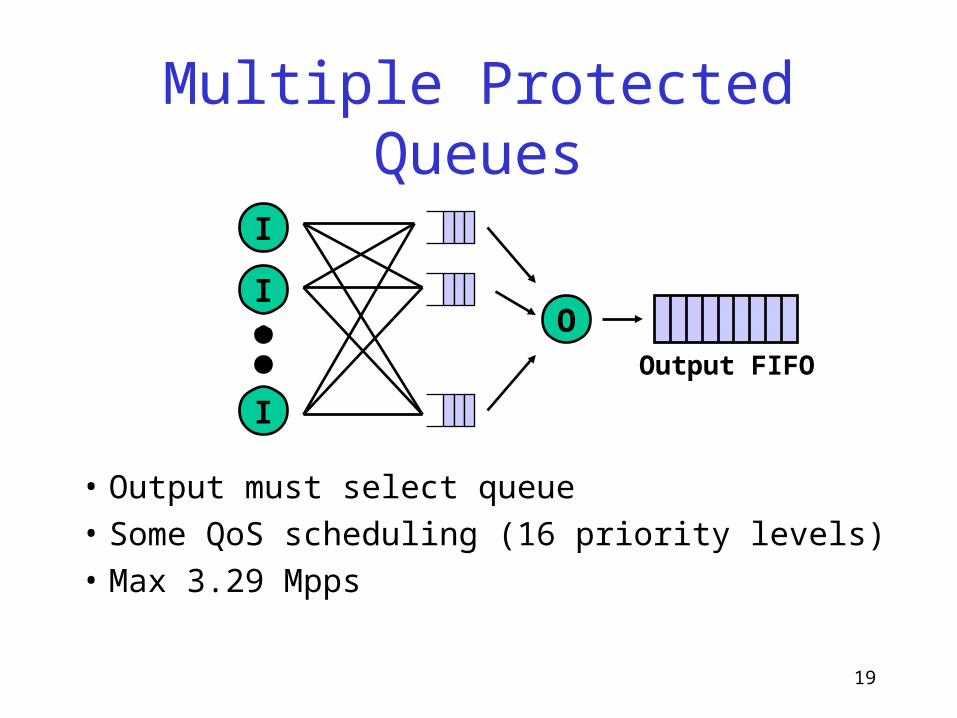
Multiple Protected Queues
• Output must select queue• Some QoS scheduling (16 priority levels)• Max 3.29 Mpps
O
I
I
I
Output FIFO

20
Data Plane ProcessingINPUT context loopwait_for_datacopy in_fiforegsBasic_IP_processingcopy regsDRAMif (last_fragment)
enqueueSRAM
OUTPUT context loop
if (need_data)
select_queue
dequeueSRAMcopy DRAMout_fifo

21
Cycles to WasteINPUT context loopwait_for_datacopy in_fiforegsBasic_IP_processingnopnop…nopcopy regsDRAMif (last_fragment)
enqueueSRAM
OUTPUT context loop
if (need_data)
select_queue
dequeueSRAMcopy DRAMout_fifo
22
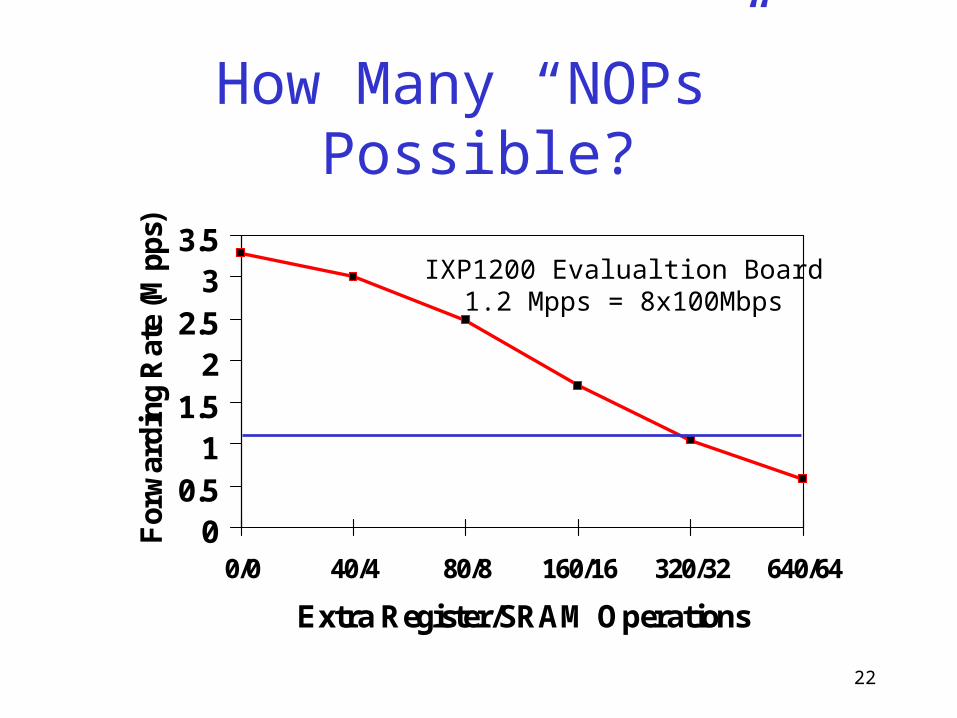
How Many “NOPs” Possible?
00.5
11.5
22.5
33.5
0/0 40/4 80/8 160/16 320/32 640/64
Extra Register/SRAM Operations
For
war
din
g R
ate
(Mp
ps)
IXP1200 Evalualtion Board1.2 Mpps = 8x100Mbps
23
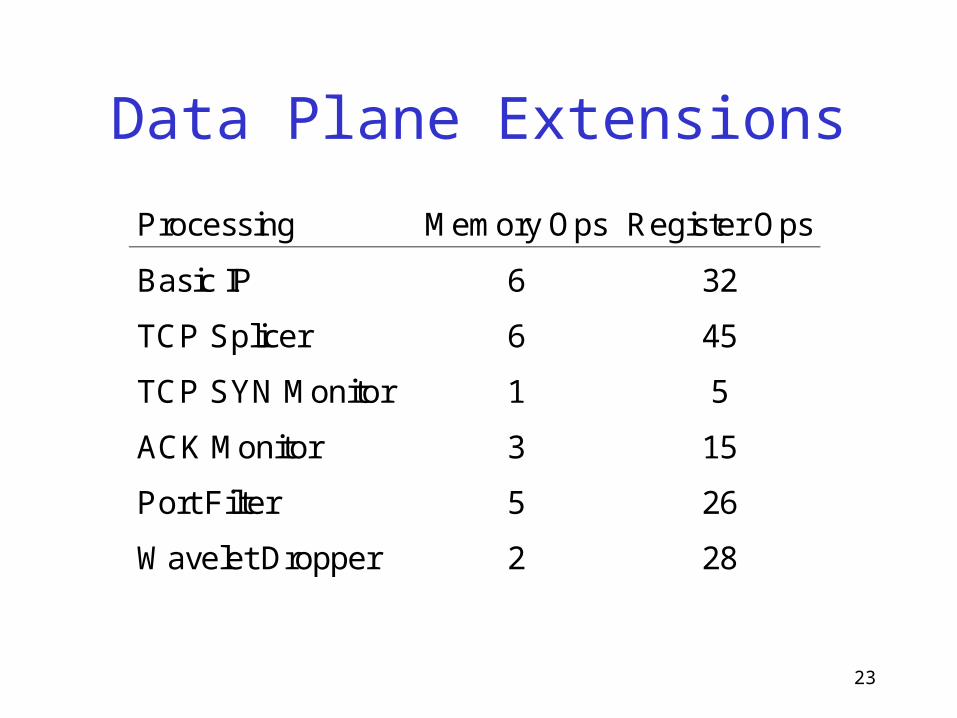
Data Plane Extensions
Processing Memory Ops Register Ops
Basic IP 6 32
TCP Splicer 6 45
TCP SYN Monitor 1 5
ACK Monitor 3 15
Port Filter 5 26
Wavelet Dropper 2 28
24
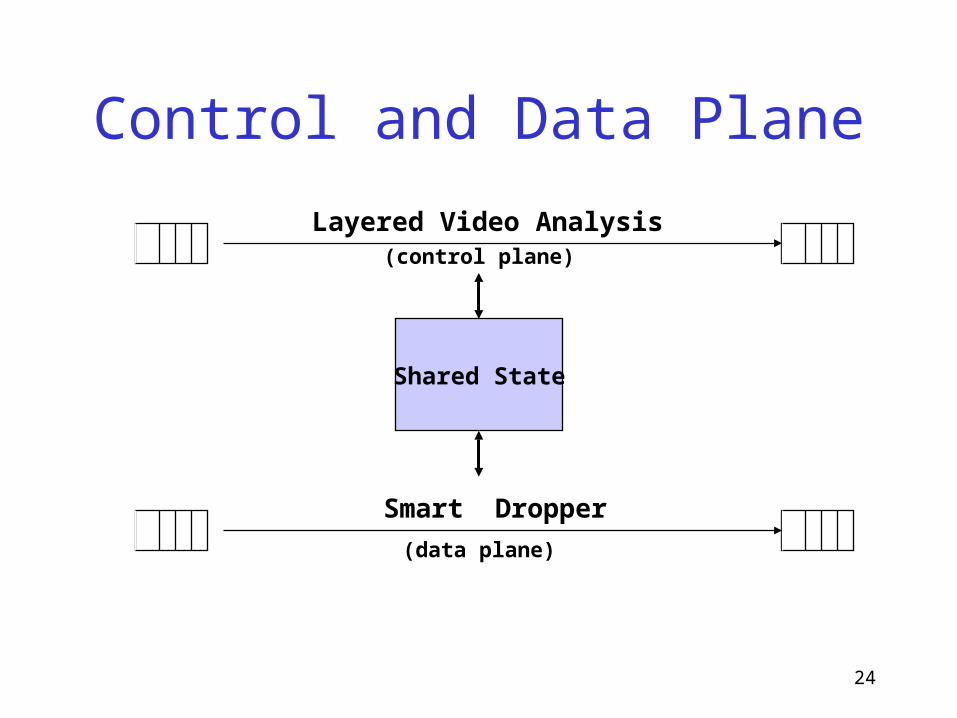
Control and Data Plane
Smart Dropper
Layered Video Analysis(control plane)
(data plane)
Shared State

25
What About the StrongARM?
• Shares memory bus with MicroEngines– must respect resource budget
• What we do– control IXP1200 Pentium DMA– control MicroEngines
• What might be possible– anything within budget– exploit instruction and data caches
• We recommend against– running Linux
26
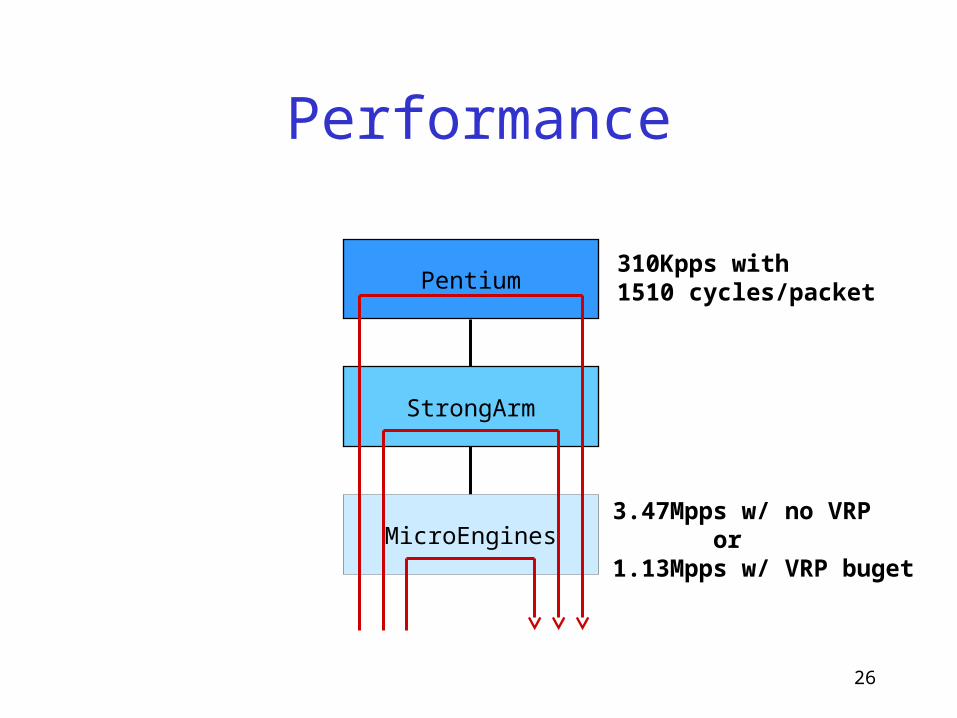
Performance
MicroEngines
Pentium
StrongArm
310Kpps with1510 cycles/packet
3.47Mpps w/ no VRP or1.13Mpps w/ VRP buget

27
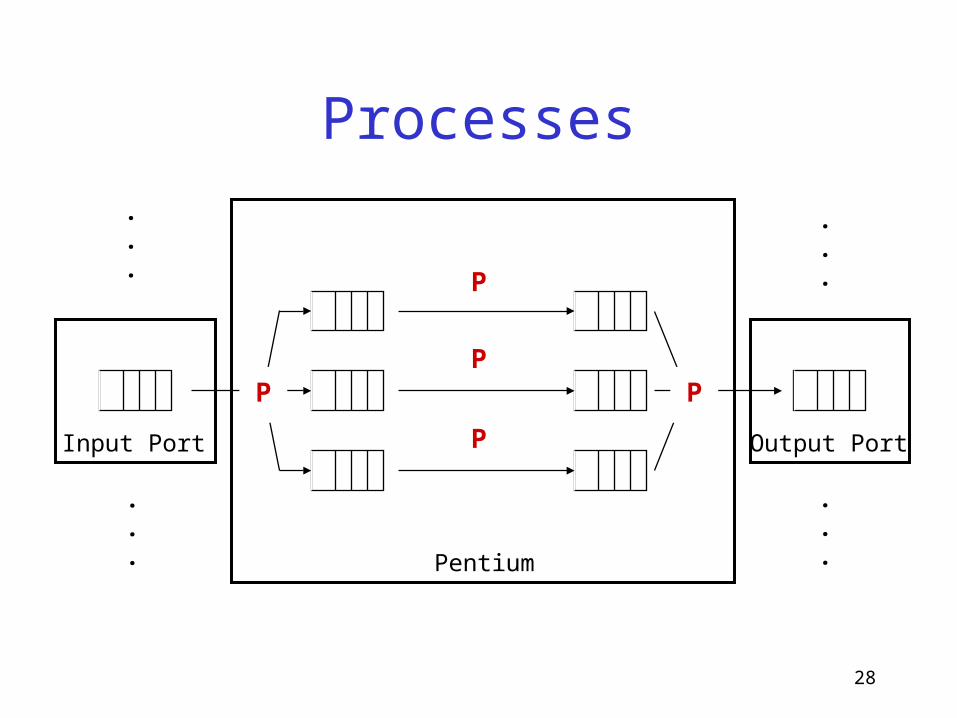
Pentium
• Runs protocols in the control plane– e.g., BGP, OSPF, RSVP
• Run other router extensions– e.g., proxies, active protocols,
overlays
• Implementation– runs Scout OS + Linux IXP driver– CPU scheduler is key
28
Processes...
.
.
.
.
.
.
.
.
.
Input Port
Pentium
Output PortP
P
PPP
29
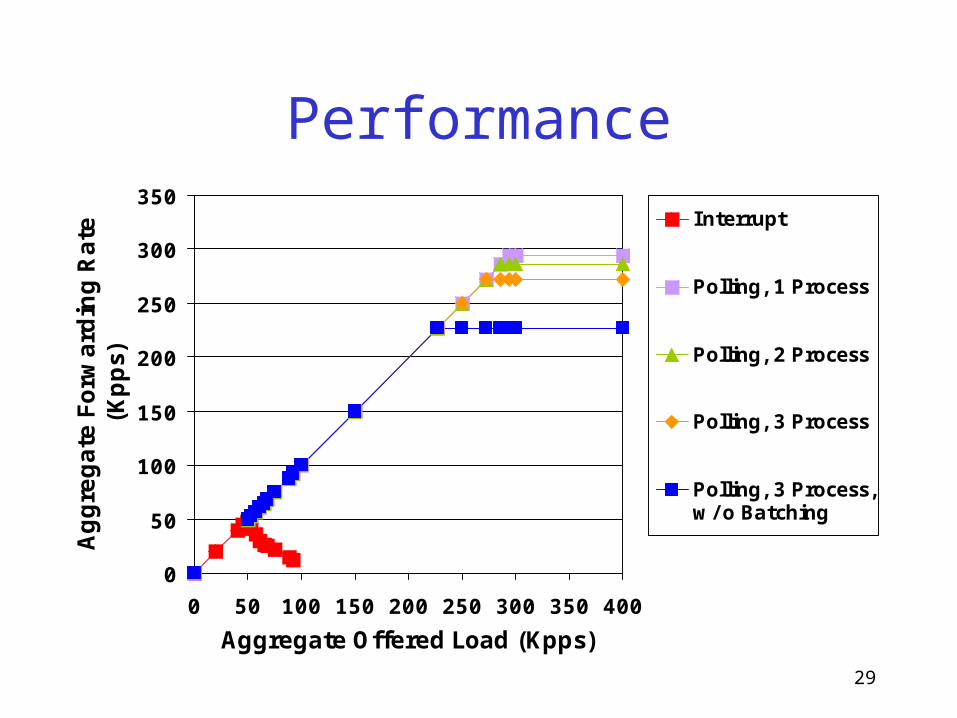
Performance
0
50
100
150
200
250
300
350
0 50 100 150 200 250 300 350 400
Aggregate Offered Load (Kpps)
Aggre
gate
Forw
ard
ing R
ate
(K
pps)
Interrupt
Polling, 1 Process
Polling, 2 Process
Polling, 3 Process
Polling, 3 Process,w/ o Batching
30
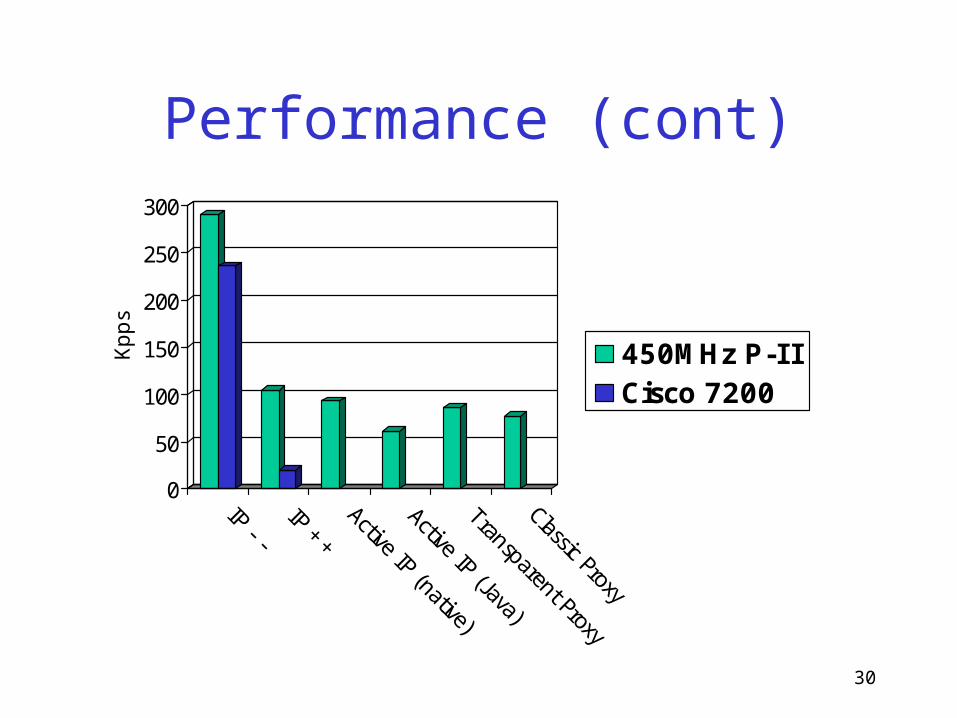
Performance (cont)
0
50
100
150
200
250
300
IP - -IP ++
Active IP (native)
Active IP (Java)
Transparent Proxy
Classic Proxy
450MHz P-I ICisco 7200
Kpps

31
Scheduling Mechanism• Proportional share forms the base
– each process reserves a cycle rate– provides isolation between processes– unused capacity fairly distributed
• Eligibility– a process receives its share only when its
source queue is not empty and sink queue is not full
• Batching– to minimize context switch overhead

32
Share Assignment
• QoS Flows– assume link rate is given, derive cycle rate– conservative rate to input process– keep batching level low
• Best Effort Flows– may be influenced by admin policy– use shares to balance system (avoid livelock)– keep batching level high
33
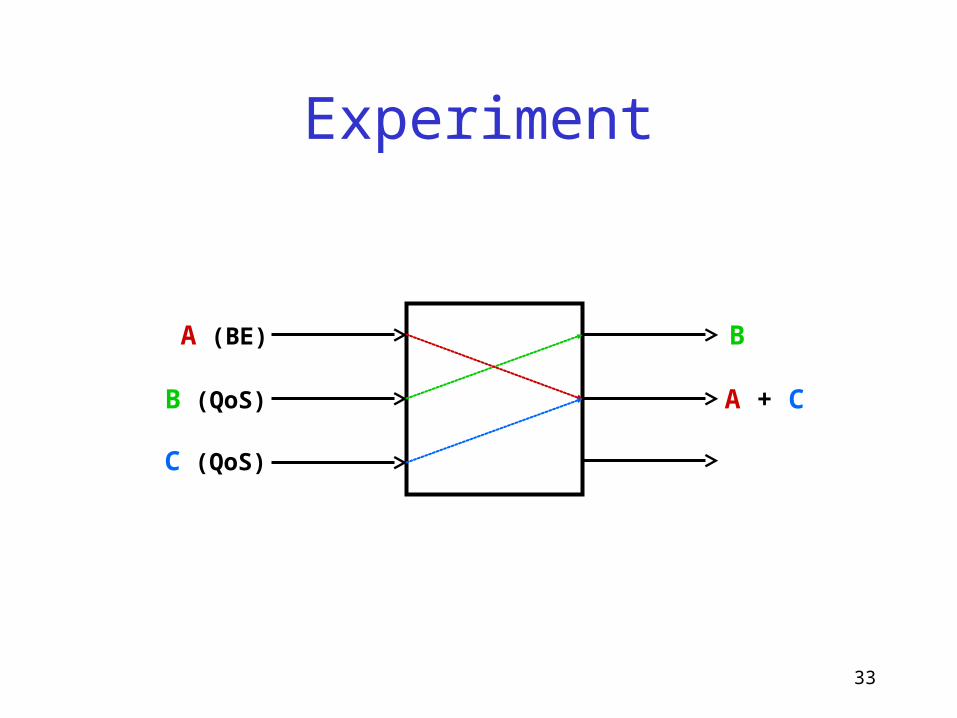
Experiment
A (BE)
B (QoS)
C (QoS)
A + C
B
34
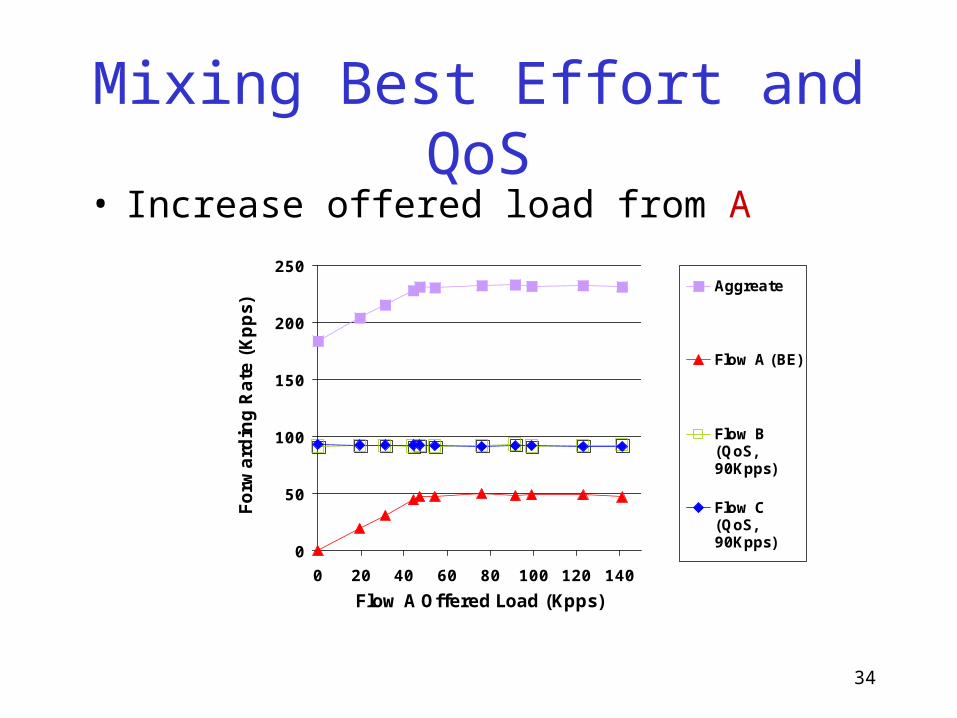
Mixing Best Effort and QoS
0
50
100
150
200
250
0 20 40 60 80 100 120 140
Flow A Offered Load (Kpps)
Forw
ard
ing R
ate
(Kpps)
Aggreate
Flow A (BE)
Flow B(QoS,90Kpps)
Flow C(QoS,90Kpps)
• Increase offered load from A
35
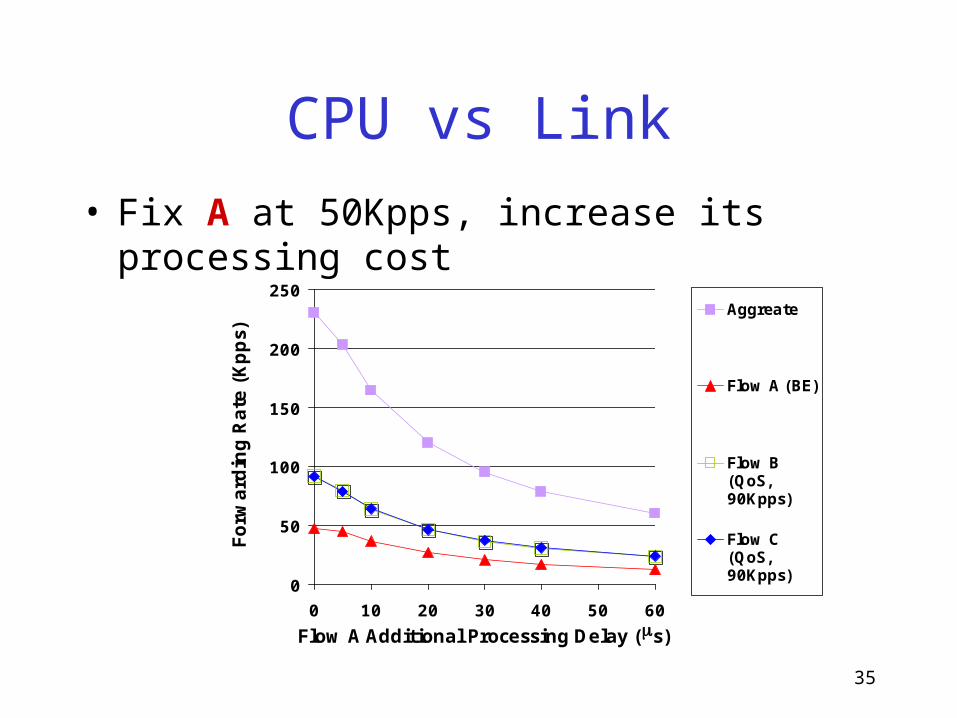
CPU vs Link
0
50
100
150
200
250
0 10 20 30 40 50 60
Flow A Additional Processing Delay (ms)
Forw
ard
ing R
ate
(Kpps)
Aggreate
Flow A (BE)
Flow B(QoS,90Kpps)
Flow C(QoS,90Kpps)
• Fix A at 50Kpps, increase its processing cost
36
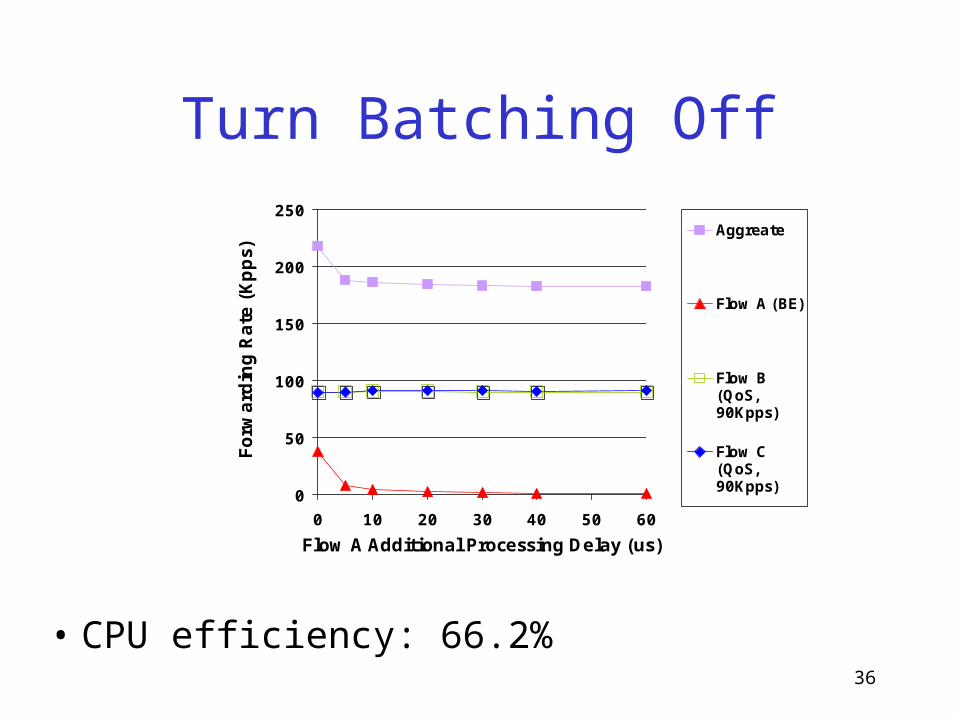
Turn Batching Off
0
50
100
150
200
250
0 10 20 30 40 50 60
Flow A Additional Processing Delay (us)
Forw
ard
ing R
ate
(Kpps)
Aggreate
Flow A (BE)
Flow B(QoS,90Kpps)
Flow C(QoS,90Kpps)
• CPU efficiency: 66.2%
37
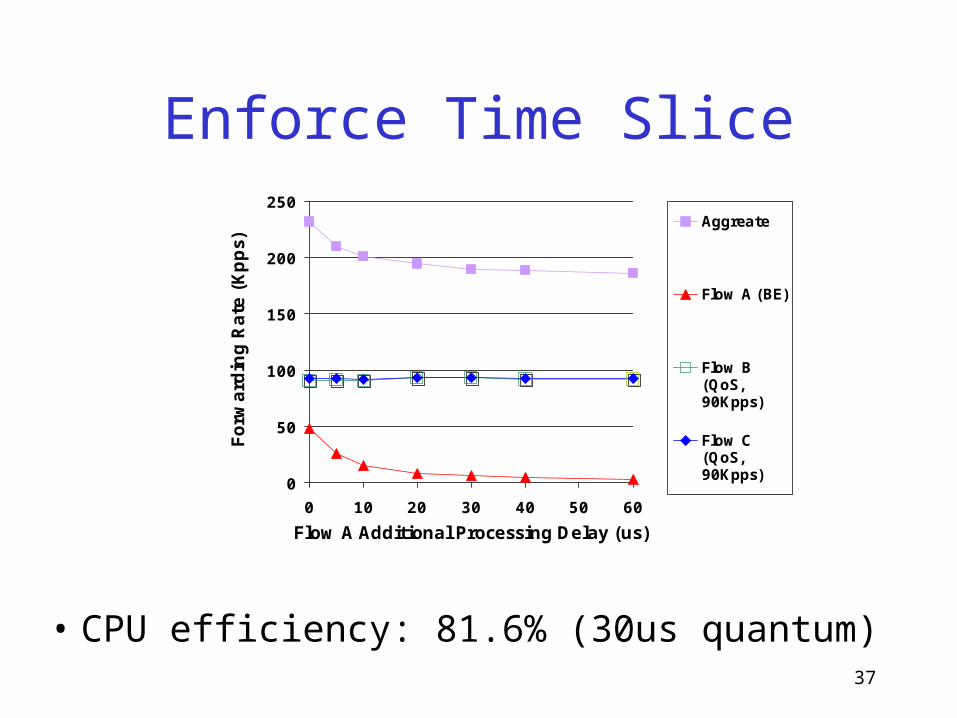
Enforce Time Slice
0
50
100
150
200
250
0 10 20 30 40 50 60
Flow A Additional Processing Delay (us)
Forw
ard
ing R
ate
(Kpps)
Aggreate
Flow A (BE)
Flow B(QoS,90Kpps)
Flow C(QoS,90Kpps)
• CPU efficiency: 81.6% (30us quantum)

38
Batching Throttle• Scheduler Granularity: G
– flow processes as many packets as possible w/in G
• Efficiency Index: E, Overhead Threshold: T– keep the overhead under T%, then 1 / (1+T) < E
• Batch Threshold: Bi– don’t consider Flow i active until it has
accumulated at least Bi packets, where Csw / (Bi x
Ci) < T
• Delay Threshold: Di– consider a flow that has waited Di active

39
Dynamic Control
• Flow specifies delay requirement D• Measure context switch overhead
offline• Record average flow runtime• Set E based on workload• Calculate batch-level B for flow
40
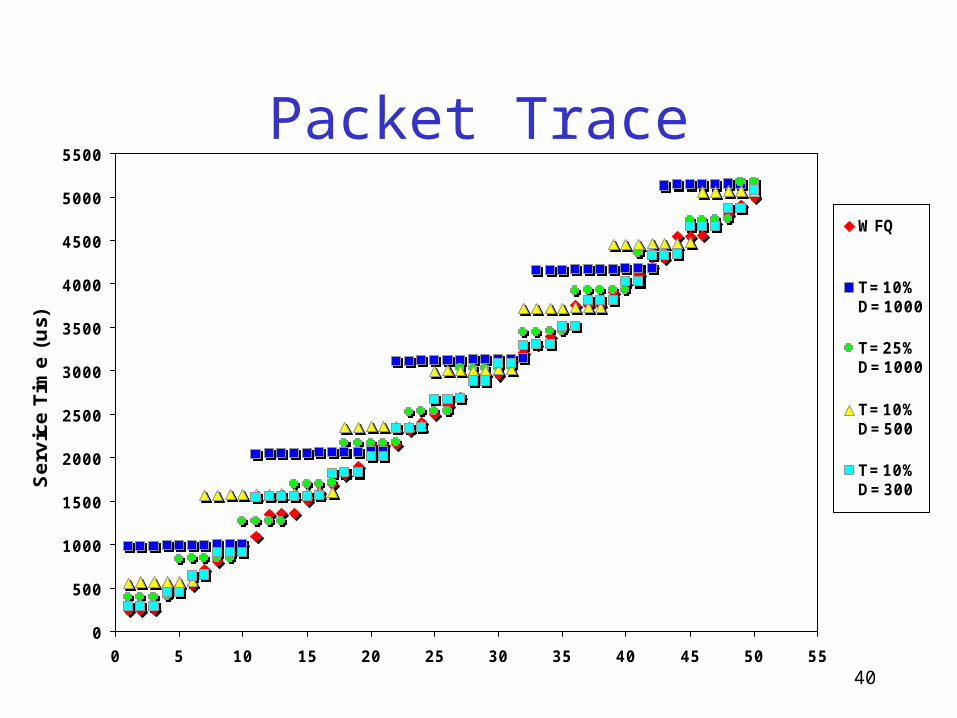
Packet Trace
0
500
1000
1500
2000
2500
3000
3500
4000
4500
5000
5500
0 5 10 15 20 25 30 35 40 45 50 55
Serv
ice T
ime (
us)
WFQ
T=10%D=1000
T=25%D=1000
T=10%D=500
T=10%D=300





























