Embed Size (px)
Citation preview

1
Using Lex
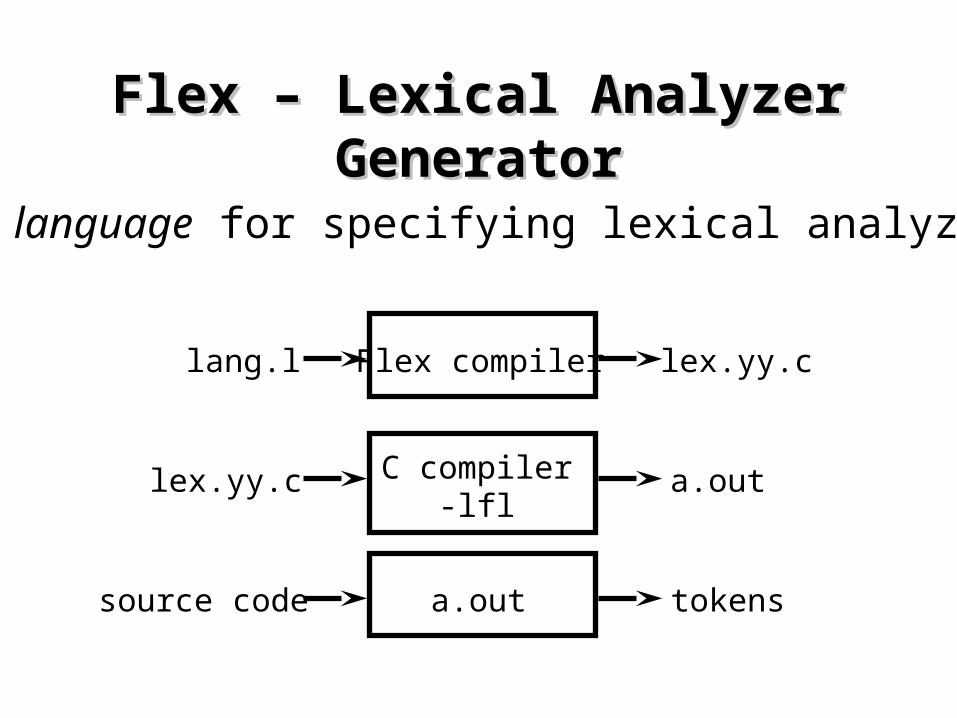
Flex – Lexical Analyzer GeneratorFlex – Lexical Analyzer Generator
A language for specifying lexical analyzers
Flex compiler lex.yy.clang.l
C compiler-lfl
a.outlex.yy.c
a.out tokenssource code

3
The Structure of a Lex Program
(Definition section)%%(Rules section)%%(User subroutines section)

Flex ProgramsFlex Programs
%{auxiliary declarations%}regular definitions%%translation rules%%auxiliary procedures

5
%{/* * this sample demonstrates (very) simple recognition: * a verb/not a verb. */
%}%%
[\t ]+ /* ignore white space */ ;
is |am |are |were |was |be |being |been |do |does |did |
will |would |should |can |could |has |have |had |go { printf("%s: is a verb\n", yytext); }
[a-zA-Z]+ { printf("%s: is not a verb\n", yytext); }
.|\n { ECHO; /* normal default anyway */ }%%
main(){ yylex();}
Example 1-1: Word recognizer ch1-02.l

6
The definition section
• Lex copies the material between “%{“ and “%}” directly to the generated C file, so you may write any valid C codes here

7
Rules section
• Each rule is made up of two parts– A pattern – An action
• E.g.
[\t ]+ /* ignore white space */ ;

8
Rules section (Cont’d)• E.g.is |am |are |were |was |be |being |been |do |does |did |will |would |should |can |could |has |have |had |go { printf("%s: is a verb\n", yytext); }

9
Rules section (Cont’d)• E.g.
[a-zA-Z]+ { printf("%s: is not a verb\n", yytext); }
.|\n { ECHO; /* normal default anyway */ }
• Lex had a set of simple disambiguating rules:1. Lex patterns only match a given input character or
string once2. Lex executes the action for the longest possible
match for the current input

10
User subroutines section• It can consists of any legal C code
• Lex copies it to the C file after the end of the Lex generated code
%%
main(){ yylex();}

11
Regular Expressions• Regular expressions used by Lex
catenation. the class of all characters except newline.* 0 or more[] character class^ not (left most)$ 以 newline 為跟隨字元 ab${} macroexpansion of a symbol ex: {Digit}+\ escape character+ once or more
? Zero time or once| or“…” … to be taken/ 以甚麼為跟隨字元 ab/cd() used for more complex expressions- range

Functions and VariablesFunctions and Variables
yylex() a function implementing the lexical analyzer and returning the token matched
yytext a global pointer variable pointing to the lexeme matched
yyleng a global variable giving the length of the lexeme matched
yylval an external global variable storing the attribute of the token

Functions and VariablesFunctions and Variables• yywrap()
– If yywrap() returns false (zero), then it is assumed that the function has gone ahead and set up yyin to point to another input file, and scanning continues. If it returns true (non-zero), then the scanner terminates, returning 0 to its caller.
– If you do not supply your own version of yywrap(), then you must either use % option noyywrap or….
13

14
Examples of Regular Expressions• [0-9]• [0-9]+• [0-9]*• -?[0-9]+• [0-9]*\.[0-9]+• ([0-9]+)|([0-9]*\.[0-9]+)• -?(([0-9]+)|([0-9]*\.[0-9]+))• [eE][-+]?[0-9]+• -?(([0-9]+)|([0-9]*\.[0-9]+))([eE][-+]?[0-9]+)?)

15
Example 2-1
%%[\n\t ] ;
-?(([0-9]+)|([0-9]*\.[0-9]+)([eE][-+]?[0-9]+)?) { printf("number\n"); }
. ECHO;%%main(){ yylex();}

16
A Word Counting Program
• The definition section
%{unsigned charCount = 0, wordCount = 0, lineCount = 0;%}
word [^ \t\n]+eol \n

17
A Word Counting Program (Cont’d)
• The rules section
{word} { wordCount++; charCount += yyleng; }{eol} { charCount++; lineCount++; }. charCount++;

18
A Word Counting Program (Cont’d)• The user subroutines section
main(argc,argv)int argc;char **argv;{
if (argc > 1) { FILE *file;
file = fopen(argv[1], "r"); if (!file) { fprintf(stderr,"could not open %s\n",argv[1]); exit(1); } yyin = file; } yylex(); printf("%d %d %d\n",charCount, wordCount, lineCount); return 0;}

stripquotes• No tossing mechanism provided.• int frompos, topos, numquotes=2;• For (frompos=1;frompos<yyleng;frompos++) {
– yytext[topos++]=yytext[frompos];
– if(yytext[frompos]==‘”’ && yytext[frompos+1]==‘”’)• {frompos++;numqotes++;}}
• yyleng-=numquotes;• yytext[yyleng]=‘\0’;
19

Micro scanner• auxiliary declarations
– %option noyywrap– %{– #ifndef DEFINE– #define DEFINE 1– #include <stdlib.h> – #include "token.h" – #endif – #define YYLMAX 33 – char token_buffer[YYLMAX];– FILE *out_fd, *status_fd;– extern void check_id(char *);– extern void list_token_type(token);– extern void get_file_name(char *, char *, char *);– %}
20

Micro scanner• regular definitions
– letter [a-zA-Z]– digit [0-9]– KEYWORD
"BEGIN"|"begin"|"END"|"end"|"READ"|"read"|"WRITE"|"write"|"SCANEOF"
– literal {digit}+– IDENTIFIER {letter}+[{letter}|{digit}|"_"]*– special_char "+"|"-"|"*"|":="|"("|")"|";"|","– comment “--”.*[\n]
21

Micro scanner• translation rules
– %%
– {KEYWORD} {list_token_type(check_reserved(yytext));}
– {literal} {list_token_type(INTLITERAL)
– {IDENTIFIER} {list_token_type(ID);}
– {special_char}{list_token_type(check_special_char(yytext));}
– [\n]
– [ \t]
– {comment}
– . {lexical_error(yytext);}
22

Micro scanner• auxiliary procedures
– %%
– main(int argc,char *argv[])
– {
– if ((yyin=fopen(argv[1],"r"))==NULL)
– {
– printf("ERROR:file open error!!\n");
– exit(0);
– }
– yylex();
– fclose(yyin);
– } 23

Micro scanner
• check_reserved– 確認是否為保留字
• check_special_char– 確認是否為 +-*(),;:=
• list_token_type– 顯示 token型態
24

Example
• begin
• read (A,B);
• A := (B+3)*A;
• B := A*3-B;
• write (A,B,3*4);
• end SCANEOF
25

Example• BeGIN
• READ
• LPAREN
• ID
• COMMA
• ID
• RPAREN
• SEMICOLON
• ID
• ASSIGNOP
• LPAREN
• ID
• PLUSOP
• INTLITERAL
• RPAREN
• ID
• COMMA
• INTLITERAL
• MULTOP
• INTLITERAL
• RPAREN
• SEMICOLON
• END
• SCANEOF
26
• MULTOP
• ID
• SEMICOLON
• ID
• ASSIGNOP
• ID
• MULTOP
• INTLITERAL
• MINUSOP
• ID
• SEMICOLON
• WRITE
• LPAREN
• ID
• COMMA





























